1. Introduction
Chaenomeles japonica, commonly known as Japanese quince or Japanese flowering quince, is native to Japan and eastern China [
1]. It belongs to the genus Chaenomeles within the Rosaceae family [
2]. Typically growing as a shrub or small tree, this species is well recognized for its bright coloration. The fruit of Chaenomeles japonica is characterized by its firm texture, astringent and sour taste, and is valued for its rich nutritional content and health benefits [
3,
4]. Due to these qualities, it has attracted widespread attention in food and pharmaceutical research. As a temperate fruit tree, the cultivation and harvesting of papaya heavily rely on manual operations, particularly in determining the optimal picking time, where accurate assessment of fruit ripeness is essential [
5]. In recent years, with the rapid advancement of computer vision and deep learning technologies, the application of image recognition algorithms has emerged as an effective strategy to improve the efficiency of papaya ripeness detection. These technologies enable real-time analysis of the fruit’s external features—such as color, shape, and texture—facilitating precise identification of typical ripening stages and overall fruit health [
6,
7]. By automating ripeness detection, growers can ensure that papayas are harvested at their optimal maturity, thereby avoiding issues such as reduced quality, inconsistency in ripeness, and increased risks during storage and transportation caused by premature or delayed harvesting. Moreover, automated systems can also detect visual defects such as blemishes and mechanical damage, enhance quality control, and reduce financial losses associated with manual inspection errors. Overall, computer-based papaya ripeness detection technologies offer multiple benefits, including reducing labor costs, lowering physical workload, improving fruit yield and quality, and advancing the level of agricultural automation. Consequently, research focused on the automated detection of Japanese papaya (Japanese quince) [
8] ripeness holds significant practical value and application potential, particularly in promoting the digital transformation of the papaya industry and the development of intelligent agriculture [
9].
To date, extensive research has been conducted on ripeness detection tasks for various agricultural fruits [
10]. Within the field of deep learning-based object detection, two primary categories of network architectures have been widely explored: two-stage and one-stage object detection methods. Two-stage object detection methods typically begin by generating region proposals using modules such as the Region Proposal Network (RPN). In the second stage, these candidate regions are refined through classification and bounding box regression to produce final predictions of object locations and category labels. Although structurally more complex, two-stage approaches demonstrate robust accuracy in scenarios involving complex backgrounds, and fine-grained detection tasks. For instance, Li et al. [
11] proposed an automatic detection method for hydroponic lettuce seedlings based on the Faster R-CNN framework, achieving a mean Average Precision (mAP) of 86.2%. Similarly, Lv et al. [
12] developed two enhanced models—Mask R-CNN-Point and Mask R-CNN-PointKD—targeting the detection of apple growth patterns, which yielded recognition accuracies of 85.65% and 74.13%, respectively, on test datasets. In another study, Cui et al. [
13] constructed a dataset containing 4000 images of soybeans, broadleaf weeds, and other weed types, and proposed a field weed recognition method using low-altitude UAV imagery and the Faster R-CNN, demonstrating comparable performance to traditional models. Moreover, Parvath et al. [
14] designed a modified Faster R-CNN for coconut product detection, capable of identifying two key maturity stages under complex background conditions. Jin et al. [
15] proposed an improved Faster R-CNN model suitable for deployment on a Field Robot Platform (FRP), enabling automatic feature extraction and accurate identification of maize seedlings at different growth stages in complex field environments, thereby offering critical support for standardized intervillage operations.
Compared to two-stage detection methods, one-stage object detection approaches—such as the YOLO series—adopt a more streamlined architectural design. These models formulate object detection as a high-precision regression problem, enabling the simultaneous prediction of object locations and class labels directly from images. YOLO performs both detection and classification within a unified network framework, significantly reducing computational cost compared to traditional two-stage methods, while achieving faster inference speed. This makes it particularly suitable for applications with real-time performance requirements. In recent years, lightweight YOLO-based detection algorithms have been widely applied in the agricultural domain. For example, Sun et al. [
16] proposed a YOLO-FHLD–based method for detecting the ripeness of ‘Huping’ jujubes under natural environmental conditions. Xu et al. [
17] developed a bitter gourd phenotype detection model called CSW-YOLO by integrating the ConvNeXt V2 module to replace the backbone network of YOLOv8. Chen et al. [
18] developed ESP-YOLO, a detection algorithm designed for an embedded platform on grape-picking robots, which maintained high detection accuracy while significantly improving efficiency. Wu et al. [
19] constructed the DNE-APPLE dataset, which includes apple images captured under various natural lighting conditions such as sunny, cloudy, drizzly, and foggy weather. They further proposed DNE-YOLO, a lightweight object detection network tailored to ensure accurate apple detection under challenging environmental conditions. In addition, in Ma et al. [
20] a lightweight model named YOLOv8n-ShuffleNetv2-Ghost-SE was proposed, which can effectively detect multi-stage apple fruits in real time in complex orchard environments. Wei et al. [
21] created a tomato dataset comprising both common and cherry tomato varieties and proposed a lightweight ripeness detection model based on an enhanced YOLOv11, which can adapt to complex field conditions and meet the real-time detection requirements for tomatoes at different ripening stages. Recent studies have explored fruit maturity detection through self-supervised contrastive learning, meta-learning under few-shot settings, attention-enhanced CNNs, and hyperspectral anomaly detection, demonstrating progress in generalization, label efficiency, and fine-grained recognition across various fruit types. Inspired by these advancements, our work incorporates lightweight detection refinement and maturity-specific visual modeling to address challenges in real-world orchard scenarios [
22,
23,
24,
25].
With the rapid development of precision agriculture technologies, significant progress has been made in intelligent fruit detection using deep learning. Existing studies, particularly on apples, bananas, and tomatoes, have achieved high detection accuracy by leveraging large-scale public datasets and standardized maturity criteria. These models often demonstrate strong performance under controlled conditions, but they are typically designed without considering practical constraints such as lightweight architecture, computational efficiency, and adaptability to natural field environments. However, few studies have extended these advances to less-studied crops like papaya. While prior research has emphasized detection accuracy, it often overlooks essential factors such as model deployability on edge devices, real-time inference, and the ability to detect fine-grained visual cues—like subtle color transitions and surface texture—which are critical for accurately assessing papaya ripeness [
26,
27]. Moreover, unlike commonly cultivated fruits, papaya lacks well-established benchmarks and suffers from dataset scarcity, making model development more challenging. Given these limitations, there is a clear need for a task-specific, lightweight, and robust detection model for papaya maturity assessment. In response, this study proposes ABD-YOLO-ting, a novel deep learning framework tailored to address the unique challenges of papaya detection. By integrating ADown, BiFPN, and DyHead modules, the model achieves a balance between high accuracy and low computational overhead. When embedded in smart agricultural platforms—such as unmanned aerial vehicles (UAVs) and automated harvesting robots—it enables real-time monitoring across the full growth cycle of papaya, providing actionable insights for irrigation, fertilization, and harvesting decisions. This work thus contributes to bridging the gap between high-precision detection models and real-world deployment in data-scarce, fine-grained agricultural tasks.
The main contributions of this paper are summarized as follows:
- (1)
We propose YOLO-Ting, an optimized lightweight version of YOLOv8n, strategically adjusted scaling factors to significantly reduce parameters and computational complexity. This targeted lightweighting effectively eliminates redundant features unrelated to ripeness, focusing specifically on crucial color and texture visual cues differentiating mature and immature fruits, ensuring efficient deployment in resource-constrained environments like UAVs and mobile devices.
- (2)
We introduced the ADown module, employing a sparse multi-path pooling strategy, specifically designed to preserve critical ripeness-related color and texture details efficiently. Additionally, our enhanced BiFPN employs bidirectional multi-scale feature fusion with dynamic channel-weighting, explicitly emphasizing subtle maturity-specific visual features. These combined innovations significantly enhance accuracy and robustness in discriminating maturity stages, even under challenging field conditions.
- (3)
Recognizing the challenge in visually distinguishing between maturity levels, we integrated DyHead, which dynamically enhances the network’s sensitivity to subtle color and texture differences associated explicitly with papaya maturity stages. Despite a slight increase in computational cost, DyHead substantially improves overall detection accuracy, demonstrating remarkable effectiveness in maturity-level differentiation under realistic field conditions.
2. Materials and Methods
2.1. Image Data Acquisition and Its Division
The image dataset used in this study was collected from a trial orchard at the Dobele Horticultural Institute in southern Latvia (WGS84 coordinates: 56°37′33.5″ N, 23°33′23.3″ E). The orchard spanned approximately 0.3 hectares and included 11 distinct genotypes of
Chaenomeles japonica (Japanese quince). Trees were spaced at intervals ranging from 0.7 to 1.0 m, with crown heights between 0.5 and 0.9 m. Image acquisition was performed using a Samsung Galaxy A8 smartphone equipped with a 16 MP rear camera (f/1.9 aperture, 27 mm equivalent focal length), which captures original images at a resolution of 4608 × 3456 pixels. The images were taken under natural outdoor lighting conditions, with varied weather, light angles, and backgrounds, to simulate real-world orchard environments. To increase generalizability and robustness of the model, each fruit was captured from multiple angles and at different distances: close-up views (15–20 cm), partial plant compositions (20–50 cm), full clusters (50–70 cm), and orchard background scenes (up to 1 m) [
28,
29]. Fruits were captured at two phenological stages—ripe and unripe—identified based on observable external traits such as color, glossiness, and surface texture. To reduce ambiguity, intermediate stages were excluded. Visual examples are provided on
Figure 1.
In this study, fruit ripeness was categorized into two distinct stages—ripe and unripe—based on visual and horticulturally accepted phenotypic traits observable in the orchard environment. Specifically, unripe fruits are characterized by a uniform green peel, firm texture, and undeveloped aroma, indicating that the fruit is still in the early physiological stage of development. Ripe fruits, by contrast, exhibit a fully yellow surface color, slightly softer skin, and visible glossiness, corresponding to the harvest-ready stage typically identified by orchard managers. The color transition from green to yellow serves as a natural and reliable indicator of ripening, consistent with field standards used in Chaenomeles japonica cultivation. This binary classification was verified through expert visual inspection at the Dobel Horticultural Institute and applied consistently throughout the dataset labeling process. Although no instrument-based biochemical assessments (e.g., Brix, firmness, or chlorophyll content) were performed, the criteria aligned with widely accepted visual ripeness indicators in fruit production. Future studies may integrate agronomic scales such as the BBCH growth stage system for enhanced physiological validation.
All images were manually annotated using the open-source LabelImg software. Each fruit instance was enclosed by a bounding box, and annotation was conducted by trained staff. To ensure annotation quality, we implemented a cross-verification strategy: 10% of the images were randomly selected and independently reviewed by a second annotator. Discrepancies were resolved through consensus to maintain a labeling error rate below 2.5%. The final dataset comprises 1515 annotated images with a total of 17,171 labeled instances. A standard 6:2:2 ratio was applied to divide the dataset into training (909 images, 10,201 instances), validation (303 images, 3366 instances), and test (303 images, 3600 instances) sets. Each subset maintains a consistent distribution of ripeness categories to ensure training stability and evaluation fairness.
Table 1 summarizes the partitioning statistics.
2.2. Papaya Detection Model Construction Based on YOLOv8
The YOLO (You Only Look Once) algorithm is a widely used deep learning framework for real-time object detection and classification. Like YOLOv5, YOLOv8 offers multiple model scales (n/s/m/l/x) to accommodate various deployment requirements [
30]. Notably, YOLOv8 incorporates several architectural advancements, including a redesigned backbone inspired by the E-ELAN structure, a feature pyramid-based neck, and a decoupled detection head that separates classification and localization tasks. It also transitions from an anchor-based to an anchor-free strategy and adopts the Task Aligned Assigner and Distribution Focal Loss to improve positive sample selection and localization precision [
31,
32]. While YOLOv8n delivers competitive performance in general object detection tasks, its computational complexity and resource demands limit its applicability in domain-specific scenarios such as papaya ripeness detection, particularly under edge deployment constraints. To address this, we propose ABD-YOLO-ting, a lightweight model tailored for real-time fruit maturity classification in resource-constrained environments. The model is constructed by optimizing the backbone, neck, and detection head of YOLOv8n to balance detection accuracy and computational efficiency. Specifically, the backbone is compressed through width reduction (YOLO-Ting), which decreases parameter count and FLOPs while preserving network depth. To enhance semantic retention during downsampling, we introduce the ADown module from YOLOv9, improving sensitivity to fine-grained features. A simplified FPN-style neck further reduces intermediate layers while maintaining multi-scale feature fusion. Finally, the detection head is upgraded with DyHead, which leverages dynamic attention mechanisms to better capture subtle differences between ripeness stages. These combined enhancements result in a compact yet high-performing model well-suited for edge deployment. The structure of ABD-YOLO-ting is illustrated in
Figure 2.
2.3. ADown
In the original YOLOv8 architecture, a large number of CBS (Convolution-BatchNorm-SiLU) blocks are utilized as downsampling modules for feature extraction [
33]. Although these blocks effectively reduce the spatial resolution of feature maps and act similarly to pooling layers, they introduce a substantial number of parameters and increase computational burden, which limits their deployment efficiency in real-time applications. Traditional downsampling techniques aim to reduce spatial dimensions while preserving essential semantic and spatial information, thereby improving computational efficiency and reducing memory usage. However, in fruit ripeness detection tasks—where fine-grained visual cues such as subtle color changes and surface texture are critical—conventional downsampling may lose valuable information necessary for distinguishing maturity stages. To address this limitation, we adopt the ADown module, a lightweight downsampling block originally proposed in the YOLOv9 series, as shown in
Figure 3. Unlike standard convolutional blocks, the ADown module employs a multi-path sparse pooling strategy, integrating both average pooling (which captures global color context) and max pooling (which retains local texture details). This dual-path design allows for efficient preservation of spatial structures and maturity-related visual features while substantially reducing the number of parameters and FLOPs. By better maintaining ripeness-specific characteristics during downsampling, ADown improves detection accuracy without compromising inference speed, making it highly suitable for real-time and edge-based maturity classification scenarios.
2.4. Feature Pyramid
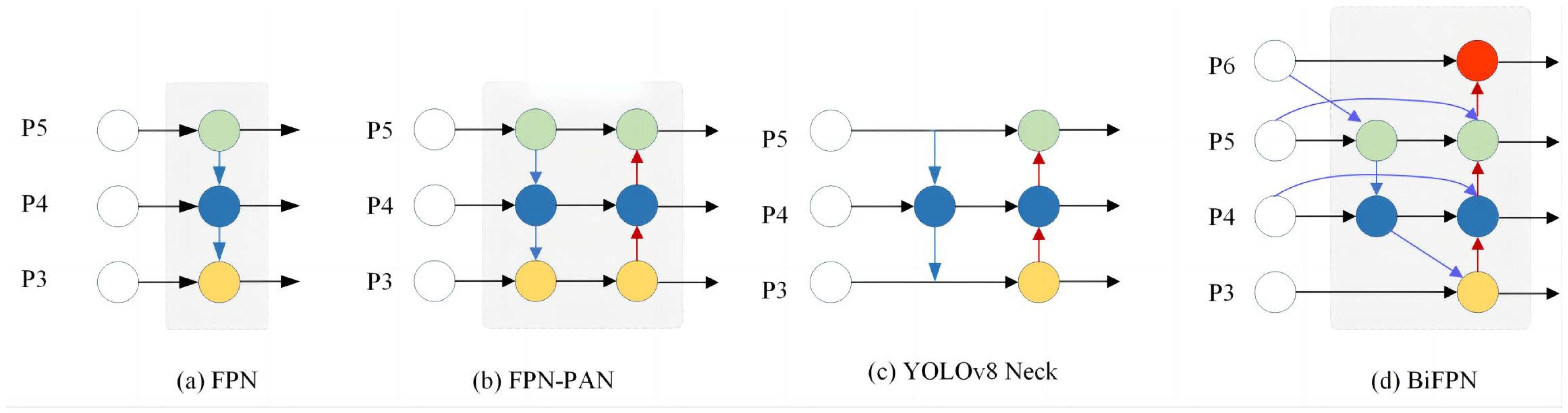
BiFPN (Bidirectional Feature Pyramid Network) is an improved variant of the traditional FPN architecture based on PANet [
34].
Figure 4 illustrates the architectural differences between traditional feature pyramid designs and BiFPN. As shown in (a), FPN supports only top-down fusion, which limits the network’s ability to recover fine-grained low-level details. FPN-PAN (b) incorporates bottom-up connections, but the fusion remains confined to adjacent scales. The YOLOv8 neck (c) improves path layout but still lacks flexibility in inter-scale communication. In contrast, BiFPN (d) adopts a more flexible and hierarchical bidirectional fusion strategy. Information from lower layers (e.g., P3) can be directly propagated to multiple upper layers (P4, P5), and higher-level features like P6 are constructed by aggregating cues from multiple resolutions. Each connection is weighed up by learnable parameters, allowing the network to selectively emphasize the most informative features at different levels. This design enhances semantic consistency across scales while significantly reducing redundant computations, resulting in stronger detection performance for maturity-related subtle features.
In the maturity detection task, the model must capture subtle visual differences such as gradual color changes, variations in surface texture, and fine edge details. These critical features are often distributed across multiple scales and influenced by factors like fruit orientation, occlusion, and camera angle, making it difficult for single-scale representations to capture them comprehensively. BiFPN addresses this limitation by enabling richer cross-scale interactions and incorporating dynamic weighting strategies, which help retain fine-grained features closely associated with ripeness—particularly those prone to being lost during conventional downsampling or deep-layer compression.
Moreover, BiFPN automatically removes redundant nodes that receive only single-source inputs, thereby optimizing the flow of information and reducing unnecessary computation. This design not only ensures semantic consistency across different scales but also effectively controls network complexity, enhancing the model’s robustness in detecting maturity differences under real-world conditions. On this basis, BiFPN achieves a significant reduction in both parameter count and computational cost without compromising classification accuracy.
2.5. Dynamic Detection Heads
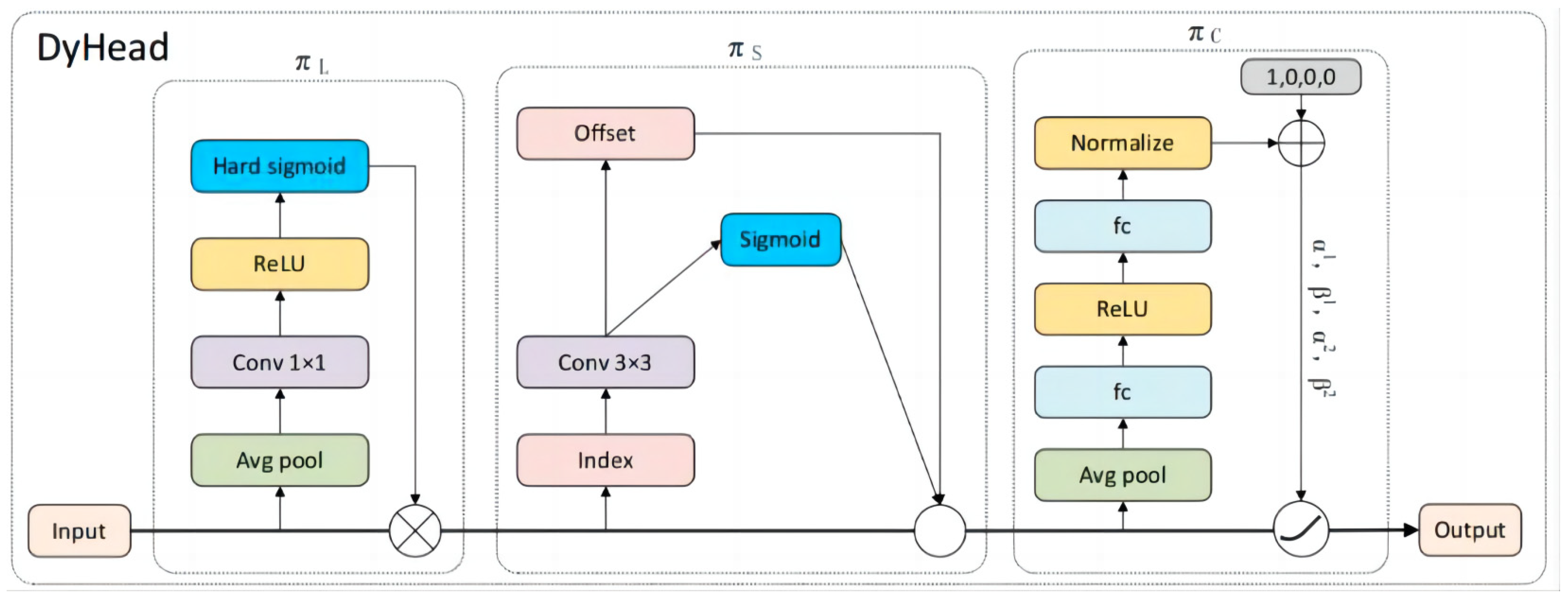
To further enhance the model’s ability to detect ripeness-related visual differences, we integrated the Dynamic Head (DyHead) module into the detection head [
35]. As shown in
Figure 5, DyHead consists of three parallel attention branches: level-wise attention (π
L), spatial attention (π
s), and channel attention (π
c). Each branch independently captures specific aspects of the feature space and contributes to refining the final representation. The level-wise attention branch applies 1 × 1 convolution and hard sigmoid weighting across feature pyramid levels, allowing the model to selectively emphasize maturity-related information at different scales. This is especially important when ripeness features—such as skin color or surface texture—appear prominently at a specific resolution level.
The spatial attention branch extracts spatial offsets via 3 × 3 convolutions, enabling the model to capture geometric cues and positional variations caused by occlusion, deformation, or imaging angle. The channel attention branch performs global average pooling and learns the inter-channel dependencies, dynamically enhancing semantically relevant dimensions such as pigmentation and surface softness cues. Importantly, although ripe and unripe papayas exhibit distinct visual features, the detection task remains challenging due to variable lighting conditions, background clutter, and diverse growth orientations. DyHead’s multi-dimensional attention structure significantly strengthens the model’s robustness to such variations. Ablation experiments confirm that the inclusion of DyHead improves detection accuracy (mAP50) while maintaining acceptable computational cost, making it highly effective for fine-grained maturity classification.
2.6. Evaluation Indicators
Evaluation metrics are key tools for measuring model performance. To more rigorously assess the accuracy of the model, we used mAP@.50:95, which is a metric based on IoU thresholds between 0.50 and 0.95 at intervals of 0.05, to calculate the average mAP, which is the average precision (AP), as given in the following formula:
In this study, the following metrics were adopted to evaluate the performance of the proposed model in detecting papaya ripeness: mAP50, mAP50:95, Parameters, and Weights. mAP50 refers to the mean Average Precision calculated at an Intersection over Union (IoU) threshold of 0.5. mAP50:95 represents the mean Average Precision averaged across multiple IoU thresholds, ranging from 0.5 to 0.95 in increments of 0.05.hese indicators provide a comprehensive assessment of the model’s detection accuracy and computational efficiency in real-world scenarios. The detailed formulations are presented in Equations (1)–(3).
2.7. Experimental Environment
We performed all experiments on a platform with the following specifications: CPU: Intel(R) Xeon(R) Platinum 8358P, RAM: 30 GB, GPU: RTX A5000 with 24 GB memory, the Ubuntu version 20.04 operating system, CUDA version 11.3, Python version 3.8, and PyTorch version 1.10. Furthermore, we conducted subsequent comparative experiments on the same platform. For repeating this experiment, this paper recommends using a TITAN Xp and the above graphics card with 6 GB of graphics memory, CUDA version 11.0 and above, and a PyTorch version no less than 1.70. The detailed hyperparameters of the experiment are shown in
Table 2.
3. Experimental Sections
3.1. Comparative Tests
To assess the robustness and statistical significance of the improvement of performance, we conducted five independent training and evaluation runs under the same data splits. The proposed ABD-YOLO-ting achieved an average mAP50 of 94.68% ± 0.084% and mAP50–95 of 77.38% ± 0.084%, while YOLOv8n achieved 94.10% ± 0.10% and 76.48% ± 0.13%, respectively. Paired t-tests conducted on the mAP50 and mAP50–95 values yielded p-values of 0.003 and 0.005, indicating statistically significant differences. For clarity, the best-performing results (mAP50 = 94.8%, mAP50–95 = 77.5%) are used as the primary reference throughout this paper.
To comprehensively evaluate the advantages of the proposed ABD-YOLO-ting model, we conducted comparative experiments with a series of representative object detection models, including SSD, RT-DETR, YOLOv5n, YOLOv5s, YOLOv7, YOLOv8n, YOLOv9t, YOLOv10n, and YOLOv11n. As shown in
Table 2, all models were assessed in terms of detection accuracy (mAP50 and mAP50–95), model complexity (parameters and FLOPs), and storage cost (model size). The results demonstrate that while high-accuracy models like YOLOv9t and YOLOv11n [
36] achieve competitive detection performance (mAP50: 94.6–94.7%, mAP50–95: 77.3–77.6%), their parameter counts and computational costs remain relatively high (FLOPs > 6.3 G), posing challenges for real-time or edge deployment. In contrast, our proposed ABD-YOLO-ting achieves equivalent accuracy (94.7% mAP50, 77.4% mAP50–95) with only 1.47 M parameters and 5.4 GFLOPs, achieving a significant 34.1% reduction in computational complexity compared to YOLOv8n and an even greater margin relative to YOLOv7 (over 90% reduction in parameters and FLOPs). RT-DETR achieves the highest accuracy, but its large model size and computational cost (19.9 M parameters, 56.9 GFLOPs) make it unsuitable for lightweight deployment, as summarized in
Table 2.
This efficiency gain is primarily attributed to three lightweight improvements: (1) scaling factor optimization, which compresses the model without undermining key features; (2) the ADown module, which enhances spatial encoding via sparse pooling while reducing redundancy; and (3) BiFPN and DyHead integration, which jointly improve multi-scale feature fusion and maturity-sensitive attention. More importantly, unlike many conventional models, ABD-YOLO-ting is tailored for detecting subtle visual cues related to fruit ripeness—such as hue transitions, texture changes, and edge clarity—under varying field conditions. Its compact architecture and robust performance under occlusion, non-uniform lighting, and complex backgrounds make it especially suitable for real-world agricultural scenarios.
In summary, ABD-YOLO-ting delivers a favorable balance between precision and efficiency. Its design enables practical deployment in resource-constrained settings such as embedded orchard systems and UAV platforms. Future extensions will focus on adapting the model to different fruit types and incorporating more nuanced maturity stages to further enhance its applicability in intelligent agricultural management. The specific data can be found in
Table 3.
3.2. Training Results
Figure 6 presents the loss curves for both the training and validation sets. Overall, the training process demonstrates good convergence behavior, and the stability of the loss curves further underscores the robustness and reliability of the proposed model. The figure highlights three key loss components: bounding box regression loss (train/val box loss), classification loss (train/val cls loss), and Distribution Focal Loss (DFL) (train/val DFL loss). From the training loss curves, it is evident that all loss components progressively decreased as the number of training epochs increases, with convergence occurring around epoch 150. This indicates that the model effectively captures the feature patterns relevant to papaya ripeness detection. Notably, both the classification and box regression losses decline rapidly within the first 50 epochs and then transition into a steady downward phase, reflecting efficient early-stage learning. Although the DFL loss also shows a clear decreasing trend, its convergence is relatively slower. This can likely be attributed to the more intricate nature of refining bounding box distributions, which requires more nuanced adjustments during training. The validation loss curves closely mirror the training loss curves, suggesting consistent model behavior on unseen data and no signs of overfitting. Additionally, the relatively narrow gap between the training and validation losses further indicates that the model exhibits strong generalization capability across different data subsets.
Figure 7 presents the confusion matrices of YOLOv8n and ABD-YOLO-ting, focusing on two primary detection classes: ripe papaya and unripe papaya. The background class is included in representing non-target regions (e.g., leaves, soil, sky) and plays an essential role in identifying false positives and false negatives. Although background is not the primary focus of ripeness classification, it is fully involved in both training and evaluation as part of the detection task. Its presence in the confusion matrix is standard in object detection, enabling a more complete assessment of model performance.
Overall, both models demonstrate similar effectiveness in distinguishing papaya ripeness, with most ripe and unripe samples accurately identified. Compared to YOLOv8n, ABD-YOLO-ting achieves a slightly higher correct prediction rate for ripe papayas, while its performance for unripe papayas remains nearly the same. In both cases, confusion between the two ripeness categories is minimal, reflecting the models’ strong ability to differentiate subtle visual features. Misclassifications involving the background class are rare and have a negligible impact on overall detection accuracy.
3.3. Comparison of Different Detection Heads
In this study, we evaluated the performance of different detection head structures on the papaya ripeness detection task, as summarized in
Table 4. A comprehensive comparison was conducted in terms of detection accuracy (mAP50, mAP50:95), parameter count, model size, and computational complexity (FLOPs). The detection heads differ in their design philosophies for feature extraction, information aggregation, and computational efficiency. According to the experimental results, DyHead demonstrated the best overall performance among all candidates, achieving 94.7% mAP50 and 77.4% mAP50:95. Compared to the original detection head (mAP50 = 94.0%, mAP50:95 = 76.1%), this represents an improvement of 0.7% and 1.3%, respectively. Despite DyHead’s relatively higher parameter count (1.47 M) and 5.4 GFLOPs, its dynamic feature learning mechanism effectively leverages input features, significantly enhancing detection accuracy for ripeness classification. The FRMH-Head, which utilizes a Feature Rearrangement Mechanism (FRMH) to enhance feature expressiveness, achieved 76.8% mAP50:95 with only 1.13 M parameters. However, its improvements in accuracy were limited, falling short of the requirements for high-precision detection applications. SEAM-Head, incorporating both channel and spatial attention mechanisms, strengthens local–global information interactions and optimizes the feature extraction process. With only 0.66 M parameters and 1.5 MB in model size, SEAM-Head achieved 94.4% mAP50 and 76.19% mAP50:95, highlighting its high degree of model compactness. Nonetheless, it still underperformed compared to DyHead in terms of detection precision. MultiSEAM, built upon SEAM-Head, further integrates multi-scale features to improve generalization. It maintains a relatively low computational cost (2.8 GFLOPs) while achieving 94.5% mAP50 and 76.37% mAP50:95. Despite these improvements, MultiSEAM still lags behind DyHead in overall accuracy. Finally, SA-Head applies spatial attention mechanisms to enhance focus on target regions. Although it maintains low computational overhead (0.90 M parameters), it reached only 76.52% mAP50:95, indicating that its contribution to accuracy remains limited compared to other detection heads.
3.4. Ablation Experiment
To systematically evaluate the contribution of each optimization module in papaya ripeness detection, we conducted a stepwise ablation study, as summarized in
Table 5. The modules tested include Scaling Factors, ADown, BiFPN, and DyHead. These components were progressively integrated into the YOLOv8n baseline to analyze their individual and combined effects. Each configuration is named directly by its included modules for clarity. The baseline YOLOv8n achieved 94.7% mAP50 and 77.4% mAP50:95, with 3.01 million parameters, 6.3 MB model weight, and 8.2 GFLOPs, as shown in
Table 5.
Adding Scaling Factors resulted in the YOLO-Ting configuration. This module applies learnable multipliers to dynamically adjust feature dimensions, compressing redundant channels while retaining important visual cues such as contour shapes and maturity-related color gradients. This reduced parameters to 1.14 million and FLOPs to 3.8 G, with a slight drop in mAP50 to 94.0%. Integrating ADown, which uses a stride-2 depthwise separable convolution followed by a pointwise convolution, formed the YOLO-Ting + ADown setup. This design preserves spatial detail during downsampling, especially beneficial for small or partially occluded fruits. It further reduced parameters to 1.05 million and FLOPs to 3.6 G, with mAP50 increasing slightly to 94.1%. The next configuration added BiFPN, forming YOLO-Ting + ADown + BiFPN. BiFPN enhances multi-scale feature fusion using bidirectional connections and learnable attention weights, improving the integration of features at different resolutions. This setup lowered the parameter count to 0.71 million and FLOPs to 3.4 G, though mAP50 remained at 94.0%, suggesting fusion alone was not sufficient to recover accuracy.
Finally, the inclusion of DyHead led to the full configuration YOLO-Ting + ADown + BiFPN + DyHead, also referred to as ABD-YOLO-Ting. DyHead employs scale-aware attention and dynamic convolution kernels to enhance semantic representation and better distinguish fine-grained maturity levels. This configuration restored accuracy to 94.7% mAP50 and 77.4% mAP50:95, with 1.47 million parameters and 5.4 GFLOPs—achieving a 34.1% reduction in computational complexity compared to YOLOv8n.
3.5. Detection Effect
This study compares the performance of YOLOv8n and ABD-YOLO-ting in detecting ripe and unripe quince fruits (papayas). As shown in
Figure 8, both models accurately identify ripe fruits in most cases, with high confidence scores.
However, YOLOv8n exhibits a higher tendency toward false positives, whereas ABD-YOLO-ting demonstrates greater stability in detection. Specifically, YOLOv8n occasionally misclassifies leaf or background regions as “unripe papayas,” resulting in unnecessary bounding boxes. This may be attributed to visual similarities in color or texture between certain leaves and fruit regions. Additionally, YOLOv8n occasionally produces overlapping bounding boxes, which may affect overall precision and recall. In contrast, ABD-YOLO-ting achieves fewer false detections in similar scenarios. Although some bounding boxes have relatively lower confidence scores (e.g., as low as 0.73), the model overall delivers more accurate and reliable detection results.
Figure 8 shows the comparison between the YOLOv8n model and ABD-YOLO-ting’s detection of ripe fruit.
In the detection of unripe quince fruits, a comparative analysis was also performed. Both models demonstrated comparable accuracy and produced high-confidence predictions, indicating strong reliability in identifying unripe fruit. Confidence scores for both models primarily ranged between 0.90 and 0.96, suggesting a high level of confidence across predictions. However, YOLOv8n exhibited lower-confidence detections in some regions (e.g., 0.56), particularly under heavy leaf occlusion, indicating reduced stability in complex environments. By contrast, ABD-YOLO-ting maintained higher consistency, with minimum confidence scores remaining above 0.91, even under the same occlusion conditions. These results demonstrate that ABD-YOLO-ting not only reduces false positives but also provides more stable confidence outputs, enhancing its applicability in challenging field scenarios.
Although the two models exhibit comparable detection performance, ABD-YOLO-ting demonstrates a clear advantage in computational efficiency. With its lightweight architectural design, the model requires significantly fewer computational resources while maintaining similar levels of accuracy. This makes ABD-YOLO-ting a more practical and deployable solution, particularly for resource-constrained environments, such as edge devices or field-based intelligent agricultural systems.
Figure 9 shows a comparison between the YOLOv8n model and ABD-YOLO-ting’s detection of immature fruit.
To evaluate the generalization ability of the proposed ABD-YOLO-ting model, we conducted qualitative tests on two unseen fruit types—citrus and strawberries—without any fine-tuning. Both fruits were selected due to their similar ripening process to Japanese quince, with a clear color transition from green (unripe) to yellow or red (ripe). As shown in
Figure 10a, the model accurately detected ripe citrus fruits, demonstrating good transferability to similar shapes and color features. However, some green leaves were mistakenly identified as unripe fruits, likely due to visual similarities in color and texture under natural occlusion. In the strawberry test (
Figure 10b), the model successfully detected the most unripe strawberries, with one instance of missed detection. For partially ripened fruits with mixed red and green areas, the model primarily localized the green (unripe) regions, showing a certain degree of color differentiation. These results suggest that the model’s learned color-based ripeness features can generalize across different fruit types, providing a promising foundation for cross-species maturity detection in data-scarce scenarios.
4. Discussion
The accurate assessment of papaya ripeness is critical for ensuring harvest quality, minimizing post-harvest losses, and enabling intelligent agricultural management. Despite the increasing adoption of deep learning in crop monitoring, existing studies have largely focused on common fruits such as apples, grapes, and tomatoes. In contrast, Japanese quince—a fruit of both economic and medicinal value—remains underexplored in the computer vision community. This study addresses this gap by introducing a lightweight, task-specific detection model and a field-validated dataset for ripeness classification, thereby offering new directions for intelligent orchard systems.
A key strength of this work lies in its architectural integration of efficiency and fine-grained detection sensitivity. While prior YOLO-based models often prioritize speed at the cost of precision in subtle classification tasks, ABD-YOLO-ting adopts a bottom-up design strategy: the use of scaling factors compresses the backbone while retaining sufficient feature depth, the ADown module preserves spatial information during downsampling, BiFPN enables effective bidirectional multi-scale feature fusion, and the DyHead module enhances the model’s responsiveness to small visual cues associated with ripeness. This coordinated design is not merely an engineering trade-off, but a methodological response to the specific challenges of fruit maturity detection in outdoor conditions—such as varying lighting, partial occlusion, and low inter-class visual variance.
Compared with existing studies using two-stage detectors (e.g., Faster R-CNN variants), which offer high precision but suffer from large parameter sizes and inference delays, ABD-YOLO-ting achieves competitive accuracy (94.7% mAP50, 77.4% mAP50–95) with a significantly reduced model size (1.47 M parameters, 5.4 GFLOPs). This establishes the model not only as a methodological innovation but also as a practically deployable solution for real-time, resource-constrained agricultural environments.
Another contribution is the careful curation and annotation of a domain-specific dataset, captured in real orchard conditions across diverse lighting and perspective settings. Unlike many existing datasets focused on lab or controlled environments, this dataset reflects real-world deployment challenges and supports robust model generalization. Such datasets are essential to validate whether high-performing models in benchmark environments can truly scale to practical agricultural use cases. Nevertheless, several limitations remain. The dataset focuses on a single papaya species with relatively uniform growth conditions. Future work should consider broader environmental variability and cultivar diversity to assess model robustness at scale. Additionally, although the model is designed for edge deployment, its real-time performance in embedded hardware systems (e.g., NVIDIA Jetson or mobile SoCs) needs to be validated through field experiments. In conclusion, this study proposes a scientifically grounded and practically oriented framework for lightweight papaya ripeness detection. It offers methodological innovations, contributes to the underexplored domain of Japanese quince monitoring, and lays the foundation for scalable, low-cost deployment in smart agriculture systems. The presented architecture, dataset, and evaluation provide a reference point for future research targeting fine-grained fruit classification tasks under real-world conditions.
From an application perspective, the proposed ripeness detection framework not only improves classification accuracy but also provides tangible benefits for smart agriculture. By accurately identifying maturity stages, it supports selective harvesting, thereby reducing postharvest losses and enhancing fruit quality [
37]. Its lightweight architecture and high efficiency make it well-suited for deployment on edge devices such as UAVs, mobile robots, and orchard-based terminals. Moreover, the maturity classification results can be integrated into broader orchard operations including grading, inventory tracking, packaging, and harvest scheduling—fostering a more intelligent, data-driven orchard management system [
38]. To further improve scalability and generalization, future research may focus on three directions. First, automatic annotation techniques—such as integrating the Segment Anything Model (SAM) with object detectors like YOLOv8—can be used to automatically generate high-fidelity training labels from multi-date aerial images [
39]. This approach significantly reduces manual labeling workload while maintaining annotation precision, making it highly applicable in large-scale agricultural scenarios. Second, transfer learning with pre-trained models may boost performance on small agricultural datasets. Third, incorporating time-series images could enable tracking of fruit ripening dynamics, thus supporting more accurate maturity forecasting. These strategies will collectively enhance the adaptability of the framework and facilitate its large-scale deployment in real orchard environments.
5. Conclusions
To overcome limitations of conventional object detection in natural papaya ripeness recognition—such as inefficiency, incomplete classification, and deployment challenges—this paper proposes ABD-YOLO-ting, a lightweight detection algorithm integrating deep learning with an optimized YOLOv8n framework. Key improvements include a compact backbone (YOLO-ting) via redefined scaling, efficient downsampling with the ADown module, enhanced multi-scale feature fusion in the neck, and a dynamic detection head (DyHead) for improved semantic understanding. While DyHead slightly increases computation, it significantly boosts accuracy. Experiments show that ABD-YOLO-ting halves the parameter count and FLOPs of baseline YOLOv8n while maintaining comparable detection performance (mAP50 94.7%, mAP50:95 77.4%). Compared to models like YOLOv5n, YOLOv10n, and YOLOv11n, ABD-YOLO-ting offers superior efficiency with equal or better accuracy. Although YOLOv9t achieves marginally higher accuracy, it requires substantially more resources, highlighting ABD-YOLO-ting’s efficiency. Future work includes cross-variety validation and fine-grained maturity classification, cross-species generalization to other horticultural crops, edge deployment optimization for low-power devices, and integration with agricultural IoT systems for real-time monitoring and precision management.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}