
YOLOv8n-SSDW: A Lightweight and Accurate Model for Barnyard Grass Detection in Fields

Abstract
1. Introduction
- (1)
- A novel module, SRCConv, was developed to decrease the parameter count; an enhanced SEAM attention mechanism was incorporated to boost feature sensitivity; and the Dysample dynamic upsampling module was integrated to enhance feature map resolution. Consequently, the lightweight YOLOv8n-SSDW model was introduced for barnyard grass detection, offering a fresh method for developing lightweight weed detection models.
- (2)
- Images of barnyard grass in rice experimental fields were collected, and a barnyard grass detection dataset was established through processing, labeling, and augmentation. A redesigned loss function using WIoU was employed to train the YOLOv8n-SSDW model, effectively improving its ability to distinguish barnyard grass.
- (3)
- Validation of the proposed model’s efficacy was confirmed via various experiments. YOLOv8n-SSDW outperformed other models in comparative evaluations, exhibiting higher precision, recall, and mAP scores, alongside reduced loss values. Ablation studies elucidated the functions of individual modules, emphasizing the model’s superiority over alternative approaches.
- (4)
- The model was deployed on a drone for practical field testing. Although accuracy experienced a slight decline due to vibrations and airflow, the overall precision met the required standards, thereby validating the model’s feasibility.
2. Materials and Methods
2.1. Data Acquisition and Processing
2.2. Baseline Model Selection
2.3. Proposed YOLOv8n-SSDW
2.3.1. The Newly Designed SRCConv
2.3.2. Improved SEAM Attention Mechanism
2.3.3. Lightweight Dysample Upsampling
2.3.4. Loss Function Design
2.4. Experimental Environment and Evaluation Metrics
3. Experimental Results and Analysis
3.1. Training Curve Comparative Analysis
3.2. Loss Curve Comparative Analysis
3.3. Ablation Study of YOLOv8n-SSDW
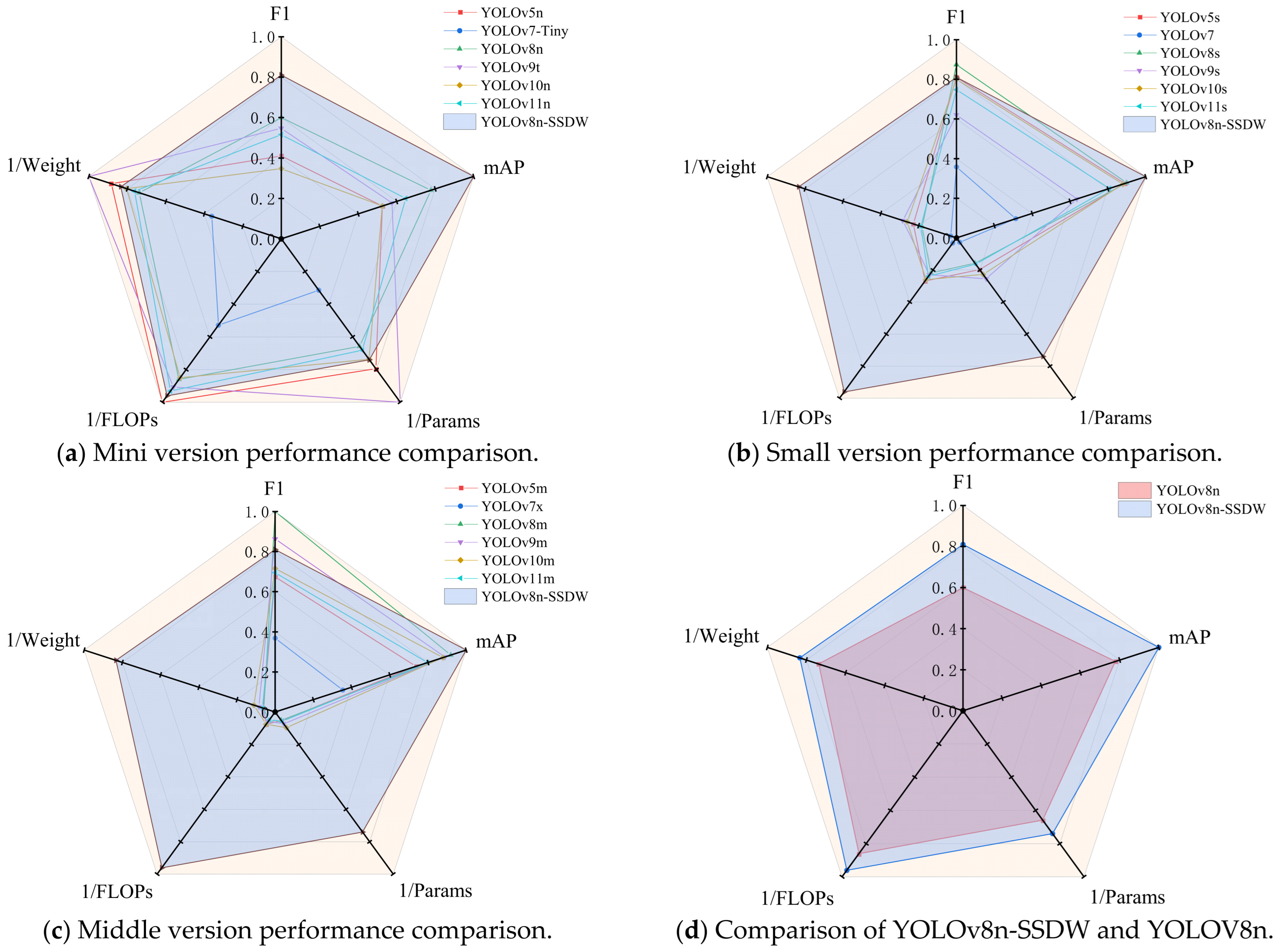
3.4. Quantitative Comparison of Various Object Detection Models
3.5. Qualitative Comparison of Various Object Detection Models
3.6. Evaluation of Detection Outcomes
3.7. Heatmap Analysis of Different Detection Layers
3.8. Field Counting Test
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alagbo, O.O.; Akinyemiju, O.A.; Chauhan, B.S. Weed Management in Rainfed Upland Rice Fields under Varied Agro-Ecologies in Nigeria. Rice Sci. 2022, 29, 328–339. [Google Scholar] [CrossRef]
- Yuan, Q.; Tian, Z.; Lv, W.; Huang, W.; Sun, X.; Lv, W.; Bi, Y.; Shen, G.; Zhou, W. Effects of common rice field weeds on the survival, feeding rate and feeding behaviour of the crayfish Procambarus clarkii. Sci. Rep. 2021, 11, 19327. [Google Scholar] [CrossRef]
- Singh, M.; Bhullar, M.S.; Gill, G. Integrated weed management in dry-seeded rice using stale seedbeds and post sowing herbicides. Field Crops Res. 2018, 224, 182–191. [Google Scholar] [CrossRef]
- Feng, T.; Sun, W.; Wang, J.; Lei, T.; Wang, L.; Xie, Y.; Zhou, H.; Zhu, F.; Ma, H. Susceptibility monitoring and metabolic resistance study of Echinochloa crus-galli to three common herbicides in rice regions of the Mid-Lower Yangtze, China. Crop Prot. 2025, 191, 107108. [Google Scholar] [CrossRef]
- Dass, A.; Shekhawat, K.; Choudhary, A.K.; Sepat, S.; Rathore, S.S.; Mahajan, G.; Chauhan, B.S. Weed management in rice using crop competition-a review. Crop Prot. 2017, 95, 45–52. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, R.; Zhao, C.; Qiang, S. Reduction in weed infestation through integrated depletion of the weed seed bank in a rice-wheat cropping system. Agron. Sustain. Dev. 2021, 41, 10. [Google Scholar] [CrossRef]
- Ju, J.; Chen, G.; Lv, Z.; Zhao, M.; Sun, L.; Wang, Z.; Wang, J. Design and experiment of an adaptive cruise weeding robot for paddy fields based on improved YOLOv5. Comput. Electron. Agric. 2024, 219, 108824. [Google Scholar] [CrossRef]
- Hadayat, A.; Zahir, Z.A.; Cai, P.; Gao, C. Integrated application of synthetic community reduces consumption of herbicide in field Phalaris minor control. Soil Ecol. Lett. 2024, 6, 230207. [Google Scholar] [CrossRef]
- Rai, N.; Zhang, Y.; Ram, B.G.; Schumacher, L.; Yellavajjala, R.K.; Bajwa, S.; Sun, X. Applications of deep learning in precision weed management: A review. Comput. Electron. Agric. 2023, 206, 107698. [Google Scholar] [CrossRef]
- Sun, Y.; Li, M.; Liu, M.; Zhang, J.; Cao, Y.; Ao, X. A statistical method for high-throughput emergence rate calculation for soybean breeding plots based on field phenotypic characteristics. Plant Methods 2025, 21, 40. [Google Scholar] [CrossRef]
- Ur Rehman, M.; Eesaar, H.; Abbas, Z.; Seneviratne, L.; Hussain, I.; Chong, K.T. Advanced drone-based weed detection using feature-enriched deep learning approach. Knowl. Based Syst. 2024, 305, 112655. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Varghese, R.; Sambath, M. YOLOv8: A novel object detection algorithm with enhanced performance and robustness. In Proceedings of the International Conference on Advances in Data Engineering and Intelligent Computing Systems, Chennai, India, 18–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Guo, Z.; Cai, D.; Zhou, Y.; Xu, T.; Yu, F. Identifying rice field weeds from unmanned aerial vehicle remote sensing imagery using deep learning. Plant Methods 2024, 20, 105. [Google Scholar] [CrossRef]
- Farooq, U.; Rehman, A.; Khanam, T.; Amtullah, A.; Bou-rabee, M.A.; Tariq, M. Lightweight deep learning model for weed detection for IoT devices. In Proceedings of the 2022 2nd International Conference on Emerging Frontiers in Electrical and Electronic Technologies, Patna, India, 24–25 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Prasad, D. Real-time weed detection and classification using deep learning models and IoT-based edge computing for social learning applications. In Augmented and Virtual Reality in Social Learning: Technological Impacts and Challenges; De Gruyter: Berlin, Germany; Boston, MA, USA, 2024; pp. 241–268. [Google Scholar] [CrossRef]
- Ma, C.; Chi, G.; Ju, X.; Zhang, J.; Yan, C. YOLO-CWD: A novel model for crop and weed detection based on improved YOLOv8. Crop Prot. 2025, 192, 107169. [Google Scholar] [CrossRef]
- Tang, B.; Zhou, J.; Pan, Y.; Qu, X.; Cui, Y.; Liu, C.; Li, X.; Zhao, C.; Gu, X. Recognition of maize seedling under weed disturbance using improved YOLOv5 algorithm. Measurement 2025, 242 Pt B, 115938. [Google Scholar] [CrossRef]
- Fan, X.; Sun, T.; Chai, X.; Zhou, J. YOLO-WDNet: A lightweight and accurate model for weeds detection in cotton field. Comput. Electron. Agric. 2024, 225, 109317. [Google Scholar] [CrossRef]
- Saleem, M.H.; Potgieter, J.; Arif, K.M. Weed Detection by Faster RCNN Model: An Enhanced Anchor Box Approach. Agronomy 2022, 12, 1580. [Google Scholar] [CrossRef]
- Peng, H.; Li, Z.; Zhou, Z.; Shao, Y. Weed detection in paddy field using an improved RetinaNet network. Comput. Electron. Agric. 2022, 199, 107179. [Google Scholar] [CrossRef]
- Liu, T.; Zhao, Y.; Wang, H.; Wu, W.; Yang, T.; Zhang, W.; Zhu, S.; Sun, C.; Yao, Z. Harnessing UAVs and deep learning for accurate grass weed detection in wheat fields: A study on biomass and yield implications. Plant Methods 2024, 20, 144. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, Y.; He, C.; Chen, C.; Zhang, Y.; Chen, Z.; Jiang, Y.; Lin, C.; Ma, R.; Qi, L. PIS-Net: Efficient weakly supervised instance segmentation network based on annotated points for rice field weed identification. Smart Agric. Technol. 2024, 9, 100557. [Google Scholar] [CrossRef]
- Dang, F.; Chen, D.; Lu, Y.; Li, Z. YOLOWeeds: A novel benchmark of YOLO object detectors for multi-class weed detection in cotton production systems. Comput. Electron. Agric. 2023, 205, 107655. [Google Scholar] [CrossRef]
- Liu, R.; Lehman, J.; Molino, P.; Petroski Such, F.; Frank, E.; Sergeev, A.; Yosinski, J. An intriguing failing of convolutional neural networks and the CoordConv solution. arXiv 2018, arXiv:1807.03247. [Google Scholar]
- Wang, Y.; Zhang, J.; Kan, M.; Shan, S.; Chen, X. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 12235–12244. [Google Scholar] [CrossRef]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 6004–6014. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Access 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Du, S.; Zhang, B.; Zhang, P. Scale-Sensitive IoU Loss: An Improved Regression Loss Function in Remote Sensing Object Detection. IEEE Access 2021, 9, 141258–141272. [Google Scholar] [CrossRef]
- Jin, S.; Cao, Q.; Li, J.; Wang, X.; Li, J.; Feng, S.; Xu, T. Study on lightweight rice blast detection method based on improved YOLOv8. Pest Manag. Sci. 2025. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar] [CrossRef]
- San, K.H.; Kondo, T.; Maruka Tat, S.; Hara-Azumi, Y. A Comparative Study of Loss Functions for Arbitrary-Oriented Object Detection in Aerial Images. In Proceedings of the 2024 21st International Joint Conference on Computer Science and Software Engineering (JCSSE), Phuket, Thailand, 19–22 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, J.; Tan, D.; Sui, L.; Guo, J.; Wang, R. Wolfberry recognition and picking-point localization technology in natural environments based on improved Yolov8n-Pose-LBD. Comput. Electron. Agric. 2024, 227 Pt 1, 109551. [Google Scholar] [CrossRef]
- Alirezazadeh, P.; Schirrmann, M.; Stolzenburg, F. Improving Deep Learning-based Plant Disease Classification with Attention Mechanism. Gesunde Pflanz. 2023, 75, 49–59. [Google Scholar] [CrossRef]
- Hu, Y.; Huang, Y.; Zhang, K. Multi-scale information distillation network for efficient image super-resolution. Knowl. Based Syst. 2023, 275, 110718. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, H.; Xu, C.; Wu, X.C.; Liang, B.; Cao, J.; Chen, D. Modeling vegetation greenness and its climate sensitivity with deep-learning technology. Ecol. Evol. 2021, 11, 7335–7345. [Google Scholar] [CrossRef] [PubMed]
- Xia, X.; Wang, M.; Shi, Y.; Huang, Z.; Liu, J.; Men, H.; Fang, H. Identification of white degradable and non-degradable plastics in food field: A dynamic residual network coupled with hyperspectral technology. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2023, 296, 122686. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, M.; Chen, Z. JPEG Quantized Coefficient Recovery via DCT Domain Spatial-Frequential Transformer. IEEE Trans. Image Process. 2024, 33, 3385–3398. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Kang, S.; Chung, K. Robust Data Augmentation Generative Adversarial Network for Object Detection. Sensors 2023, 23, 157. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, J.; Cen, H.; Lu, Y.; Yu, X.; He, Y.; Pieters, J.G. Automated spectral feature extraction from hyperspectral images to differentiate weedy rice and barnyard grass from a rice crop. Comput. Electron. Agric. 2019, 159, 42–49. [Google Scholar] [CrossRef]
- Boursianis, A.D.; Papadopoulou, M.S.; Diamantoulakis, P.; Liopa-Tsakalidi, A.; Barouchas, P.; Salahas, G.; Karagiannidis, G.; Wan, S.; Goudos, S.K. Internet of Things (IoT) and Agricultural Unmanned Aerial Vehicles (UAVs) in smart farming: A comprehensive review. Internet Things 2022, 18, 100187. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baseline Model | Precision | Recall | F1 | mAP_50 | Parameters (M) | FLOPs (G) | Model Size (MB) | Inference Time (ms) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 0.769 | 0.769 | 0.769 | 0.804 | 2.51 | 7.1 | 5.3 | 14.6 |
| YOLOv7-Tiny | 0.752 | 0.709 | 0.730 | 0.752 | 6.01 | 13.0 | 12.3 | 12.7 |
| YOLOv8n | 0.829 | 0.749 | 0.787 | 0.829 | 3.01 | 8.2 | 6.3 | 13.6 |
| YOLOv9-Tiny | 0.806 | 0.760 | 0.782 | 0.809 | 2.01 | 7.8 | 4.7 | 37.2 |
| YOLOv10n | 0.781 | 0.745 | 0.763 | 0.804 | 2.70 | 8.3 | 5.8 | 18.7 |
| YOLOv11n | 0.803 | 0.756 | 0.779 | 0.816 | 2.91 | 7.6 | 6.1 | 15.4 |
| Baseline Model | P | R | mAP_50 | Params (M) | FLOPs (G) | Weight (MB) |
|---|---|---|---|---|---|---|
| YOLOv8n | 0.829 | 0.749 | 0.829 | 3.01 | 8.2 | 6.3 |
| YOLOv8n-Dysample | 0.826 | 0.748 | 0.834 | 3.02 | 8.2 | 6.3 |
| YOLOv8n-Dysample-WIoU | 0.873 | 0.760 | 0.841 | 3.02 | 8.2 | 6.3 |
| YOLOv8n-Dysample-WIoU-SRCConv | 0.872 | 0.767 | 0.837 | 2.58 | 7.2 | 5.4 |
| YOLOv8n-Dysample-WIoU-SRCConv-SEAM | 0.867 | 0.755 | 0.851 | 2.69 | 7.4 | 5.6 |
| Model | Precision | Recall | F1 | mAP_50 | Parameters (M) | FLOPs (G) | Model Size (MB) | Infer Time (ms) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 0.769 | 0.769 | 0.769 | 0.804 | 2.51 | 7.1 | 5.3 | 14.6 |
| YOLOv5s | 0.824 | 0.791 | 0.807 | 0.840 | 9.12 | 24.0 | 18.5 | 15.6 |
| YOLOv5m | 0.817 | 0.773 | 0.794 | 0.825 | 25.1 | 64.2 | 50.5 | 17.1 |
| YOLOv7-Tiny | 0.752 | 0.709 | 0.730 | 0.752 | 6.01 | 13.0 | 12.3 | 12.7 |
| YOLOv7 | 0.771 | 0.757 | 0.764 | 0.783 | 36.5 | 103.2 | 74.8 | 14.5 |
| YOLOv7x | 0.83 | 0.709 | 0.765 | 0.787 | 70.8 | 188.0 | 142.1 | 17.5 |
| YOLOv8n | 0.829 | 0.749 | 0.787 | 0.829 | 3.01 | 8.2 | 6.3 | 13.6 |
| YOLOv8s | 0.841 | 0.786 | 0.813 | 0.841 | 11.1 | 28.6 | 22.5 | 14.8 |
| YOLOv8m | 0.861 | 0.791 | 0.825 | 0.843 | 25.9 | 79.0 | 52.0 | 17.6 |
| YOLOv9t | 0.806 | 0.760 | 0.782 | 0.809 | 2.01 | 7.8 | 4.7 | 37.2 |
| YOLOv9s | 0.823 | 0.757 | 0.789 | 0.815 | 7.29 | 27.4 | 15.3 | 39.6 |
| YOLOv9m | 0.841 | 0.784 | 0.812 | 0.840 | 20.2 | 77.5 | 40.9 | 41.3 |
| YOLOv10n | 0.781 | 0.745 | 0.763 | 0.804 | 2.70 | 8.3 | 5.8 | 18.7 |
| YOLOv10s | 0.849 | 0.768 | 0.806 | 0.839 | 8.05 | 24.6 | 16.5 | 19.1 |
| YOLOv10m | 0.833 | 0.765 | 0.798 | 0.839 | 16.5 | 63.8 | 33.5 | 21.8 |
| YOLOv11n | 0.803 | 0.756 | 0.779 | 0.816 | 2.91 | 7.6 | 6.1 | 15.4 |
| YOLOv11s | 0.869 | 0.742 | 0.801 | 0.832 | 10.7 | 26.5 | 21.8 | 16.9 |
| YOLOv11m | 0.819 | 0.775 | 0.796 | 0.831 | 23.9 | 85.4 | 48.1 | 18.5 |
| YOLOv8n-SSDW | 0.867 | 0.755 | 0.807 | 0.851 | 2.69 | 7.4 | 5.6 | 15.3 |
| Devices | Related Description |
|---|---|
| Camera lens | Zenmuse P1 lens for field barnyard grass images |
| Image processor | Jetson nano B01 used to detect barnyard grass in the field |
| 4G/5G network connection end point | Based on DJI airborne SDK development, real-time transmission of collected image data to the ground |
| Power supply | TB60 smart flight battery for UAV power supply |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Guo, H.; Chen, X.; Li, M.; Fang, B.; Cao, Y. YOLOv8n-SSDW: A Lightweight and Accurate Model for Barnyard Grass Detection in Fields. Agriculture 2025, 15, 1510. https://doi.org/10.3390/agriculture15141510
Sun Y, Guo H, Chen X, Li M, Fang B, Cao Y. YOLOv8n-SSDW: A Lightweight and Accurate Model for Barnyard Grass Detection in Fields. Agriculture. 2025; 15(14):1510. https://doi.org/10.3390/agriculture15141510
Chicago/Turabian StyleSun, Yan, Hanrui Guo, Xiaoan Chen, Mengqi Li, Bing Fang, and Yingli Cao. 2025. "YOLOv8n-SSDW: A Lightweight and Accurate Model for Barnyard Grass Detection in Fields" Agriculture 15, no. 14: 1510. https://doi.org/10.3390/agriculture15141510
APA StyleSun, Y., Guo, H., Chen, X., Li, M., Fang, B., & Cao, Y. (2025). YOLOv8n-SSDW: A Lightweight and Accurate Model for Barnyard Grass Detection in Fields. Agriculture, 15(14), 1510. https://doi.org/10.3390/agriculture15141510