1. Introduction
Accurate crop type classification remains a foundational task in agricultural remote sensing, supporting precision farming, yield estimation, and land-use monitoring [
1,
2,
3]. However, real-world planting systems—with interleaved plots, visually similar crops, and complex backgrounds—have challenged the representational capacity of traditional paradigms, particularly in horticultural and mixed cropping contexts where class boundaries are spectrally ambiguous [
4,
5,
6,
7].
HSI provides such potential, capturing fine spectral signatures across hundreds of contiguous bands to distinguish subtle physiological differences [
8,
9,
10]. However, spectral richness alone is insufficient under spatial irregularity or ambiguous class transitions. This demand is underscored by the growing role of hyperspectral systems in global agricultural monitoring: recent meta-analyses report classification accuracies exceeding 90% across diverse crop types when using HSI-based models, outperforming traditional multispectral methods by up to 15% in complex scenes [
11,
12].
Early deep learning approaches—most notably 3D-CNNs and their spatial–spectral variants—improved over traditional machine learning by jointly encoding spectral and spatial features [
10,
13]. These methods proved effective in structured croplands with clear geometric regularity. However, their fixed receptive fields and limited context-awareness hinder generalization in fields with fragmented planting patterns, non-uniform illumination, or mixed vegetative cover [
14,
15]. Such limitations are amplified in agricultural environments where crop plots are irregularly shaped, interspersed with non-crop elements like mulch, water bodies, or infrastructure, and where class adjacency blurs semantic coherence [
16]. Transformer-based architectures, by contrast, offer the potential to model agricultural scenes as holistic semantic fields [
17,
18]. Their self-attention mechanisms enable each spatial–spectral token to contextualize its identity based on distant dependencies—allowing, for instance, a lettuce patch partially occluded by shade to be aligned with similar instances across the scene. However, most existing transformer models, when directly applied to HSI, inherit limitations from their vision or language origins as follows: token sequences are treated uniformly, spatial hierarchy is flattened, and semantic structure is often diluted [
17,
19]. This is particularly problematic in agricultural settings where semantic function is tied to both local cues and spatial arrangement—for example, when distinguishing between classes that differ more by field layout than by spectral reflectance [
20]. Recent hybrid models have attempted to combine the locality-preserving strengths of CNNs with the global abstraction capacity of transformers [
21,
22,
23]. While such architectures achieve progress in scene-level accuracy, they often do not explicitly address the semantic disambiguation and spatial logic intrinsic to crop distributions. Static fusion schemes, redundant token flows, and uniform projection strategies fall short in maintaining class continuity and field coherence—especially under conditions of low inter-class variance or high structural density [
24,
25].
To address these limitations, we propose UniHSFormer-X, a unified transformer framework specifically tailored for hyperspectral crop classification under real-world agricultural constraints. Unlike traditional models that treat spectral features uniformly or apply static spatial kernels, UniHSFormer-X introduces a prototype-aligned semantic routing mechanism that dynamically guides token propagation based on class-informed cues [
26,
27]. This allows the model to emphasize semantically meaningful structures while suppressing redundant or noisy activations [
28]. By aligning spectral–spatial tokens with learnable semantic anchors (prototypes), the model captures fine-grained agricultural semantics, especially in morphologically irregular or spectrally ambiguous regions. Empirical results across three benchmark scenes demonstrate that this routing strategy not only improves boundary sharpness and inter-class separability but also enhances performance on challenging subclasses with dense spatial entanglement, attributable to the model’s architectural inductive bias as follows: class-conditioned routing, prototype alignment, and multi-scale encoding collectively promote structural generalization across heterogeneous datasets [
29,
30]. Through this design, UniHSFormer-X bridges the gap between global abstraction and local structure, offering a robust, interpretable solution to long-standing challenges in hyperspectral agricultural segmentation. While UniHSFormer-X employs a single prototype per class to anchor semantic alignment, we acknowledge that this inductive bias may be suboptimal for classes with high intra-class variability. To address this, our routing mechanism allows token–prototype interactions to adapt dynamically based on class-conditioned cues during training—thus preserving flexibility while maintaining interpretability. This also opens avenues for future extension toward multi-prototype or instance-aware routing schemes.
2. Related Works
Hyperspectral imaging (HSI) has become increasingly pivotal in agricultural monitoring due to its capacity to capture detailed spectral characteristics across narrow and contiguous bands. This enables fine-grained crop classification, particularly in environments with subtle spectral variability and spatial complexity. Yet, real-world agricultural fields present a number of challenges—such as class adjacency, morphological irregularity, and background interference (e.g., shadows, plastic, bare soil)—that demand not only precise spectral discrimination but also structural resilience across spatial scales [
31,
32]. The transition from shallow statistical models to deep learning frameworks marks a fundamental shift in how such complexity is managed. Early deep models focused predominantly on convolutional neural networks (CNNs), leveraging their capacity to extract spatial context and local spectral patterns. Traditional machine learning classifiers, such as SVM and SAM, have also shown promising performance in hyperspectral vegetation mapping tasks—for instance, Borana et al. achieved over 81% accuracy in arid vegetation species classification using SVM on high-resolution field hyperspectral data [
33]. Approaches such as 1D-CNN and 2D-CNN emphasized either spectral vectorization or spatial neighborhood encoding, but their separation limited comprehensive feature learning [
34,
35,
36]. The introduction of 3D-CNNs bridged this gap by applying spectral–spatial convolutions over data cubes, significantly improving joint feature extraction [
37,
38]. Nonetheless, despite their dense connectivity, these models typically operate within constrained receptive fields and fixed kernel structures, which can be insufficient in modeling remote dependencies and long-range contextual cues—features often critical in heterogeneous croplands where spectrally similar classes are interleaved across irregular field boundaries.
To overcome these limitations, the transformer architecture, originally devised for sequence modeling in language tasks, has been adapted for remote sensing applications [
39,
40]. Its self-attention mechanism enables dynamic weighting of feature contributions across entire sequences, facilitating the learning of global dependencies within high-dimensional hyperspectral cubes. In agricultural contexts, this global capacity is especially valuable [
15]: it allows the model to suppress local spectral noise and integrate class-consistent information across disjoint planting zones, where identical crop types may appear under different lighting, soil, or occlusion conditions. Initial attempts in this direction relied on direct application of vision transformers (ViT), which proved adept at capturing global semantics but often lacked inductive biases for spatial structure, leading to suboptimal performance in scenarios requiring fine boundary delineation [
41,
42]. Subsequent refinements, including spectral tokenization and spatial–spectral fusion, aimed to better align transformer modules with the structural characteristics of HSI data, particularly where agricultural boundaries are implicit or ill-defined [
43].
Hybrid models emerged as a response to the complementary strengths of CNNs and transformers [
44,
45]. These models seek to embed the locality-preserving advantages of convolutional modules within the globally aware context of attention mechanisms. Notably, CMTNet and CTDBNet adopt dual-branch architectures, where convolutional layers capture shallow spatial details while transformer encoders extract long-range spectral dependencies [
46,
47]. Similarly, MST-SSSNet introduces separable convolutional streams coupled with transformer layers to sequentially refine spectral–spatial embeddings [
18]. Such architectures demonstrate improved robustness to class imbalance and inter-class spectral similarity, yet often suffer from rigid fusion schemes and token redundancy during inference—limitations that become particularly pronounced in high-density horticultural fields [
46,
47]. More recent advances emphasize semantic disentanglement, frequency-aware decomposition, and multiscale encoding [
48,
49]. For instance, dual-frequency transformers, octave convolution networks, and frequency-domain filters have been explored to selectively enhance discriminative patterns while suppressing noise [
50]. Although these techniques contribute to improved representation diversity, their reliance on fixed decomposition strategies can limit adaptability across different crop types, maturity stages, or resolution scales. Moreover, many existing methods still employ static projection heads or uniform supervision strategies, which fail to account for the semantic hierarchy inherent in agricultural land cover—where crops may differ more by spatial arrangement than by pure reflectance [
51].
These observations highlight a persistent gap in achieving scale-invariant, class-adaptive, and semantically unified representation learning for agriculture [
52,
53]. Addressing this challenge necessitates a framework that integrates not only flexible attention and spectral–spatial interaction but also dynamic token selection and prototype-guided alignment—while explicitly reflecting the hierarchical, irregular, and high-ambiguity nature of agricultural imagery. It is in this context that UniHSFormer-X is introduced—a unified architecture designed to route informative tokens via learned prototype attention, reinforce discriminability through contrastive semantic projection, and adaptively balance local-global fusion across multi-resolution crop scenes.
3. Materials and Methods
3.1. Benchmark Datasets
To comprehensively evaluate the proposed UniHSFormer-X framework in the context of real-world agricultural scenarios, we adopt the publicly available WHU-Hi benchmark, a UAV-borne hyperspectral image collection curated by the RSIDEA group at Wuhan University. The dataset comprises three distinct scenes—WHU-Hi-LongKou, WHU-Hi-HanChuan, and WHU-Hi-HongHu—captured over representative farmland regions in central China [
54,
55]. These scenes differ significantly in terms of spatial layout, crop diversity, and environmental complexity, offering a robust testbed for validating cross-scale generalization and fine-grained class discrimination, both of which are central to modern hyperspectral crop classification. All data were acquired using Headwall Nano-Hyperspec sensors onboard UAV platforms, covering 270+ contiguous spectral bands in the 400–1000 nm range, with spatial resolutions ranging from 0.043 m to 0.463 m. The combination of high spectral granularity and ultra-fine spatial detail enables pixel-level modeling of crop structure, physiological variation, and inter-class spectral overlap—challenges that UniHSFormer-X is explicitly designed to address via semantic routing and prototype-guided learning (
Figure 1).
WHU-Hi-LongKou depicts a relatively homogeneous agricultural layout, with six dominant crop categories (corn, cotton, sesame, broad-leaf soybean, narrow-leaf soybean, and rice) and a few background classes. The image covers 550 × 400 pixels at a spatial resolution of 0.463 m and was acquired under clear midsummer illumination. As a baseline scene, it enables controlled evaluation of spectral–spatial encoding strategies. WHU-Hi-HanChuan corresponds to a rural-urban fringe region, featuring mixed vegetation, artificial surfaces, and complex shadow interference due to lower solar elevation. This scene comprises 16 annotated land-cover types and offers a higher spatial resolution of ~0.109 m across 274 bands. Its structural heterogeneity and spectral ambiguity provide a compelling test case for UniHSFormer-X’s token routing mechanism.
WHU-Hi-HongHu is the most complex of the three, consisting of 22 crop classes, including multiple cultivars of cabbage, lettuce, and brassica, often exhibiting minimal spectral separation. Captured at a resolution of 0.043 m and spanning 940 × 475 pixels, this scene poses considerable challenges in terms of intra-class variability and shadow-normalization, making it ideal for testing the proposed model’s fine-grained semantic alignment capabilities. All datasets underwent radiometric calibration and geometric correction using Headwall’s proprietary preprocessing pipeline. Ground-truth annotations were manually digitized with field validation by domain experts, while
Table 1 summarizes class-wise label distributions used in our 100-sample-per-class training protocol.
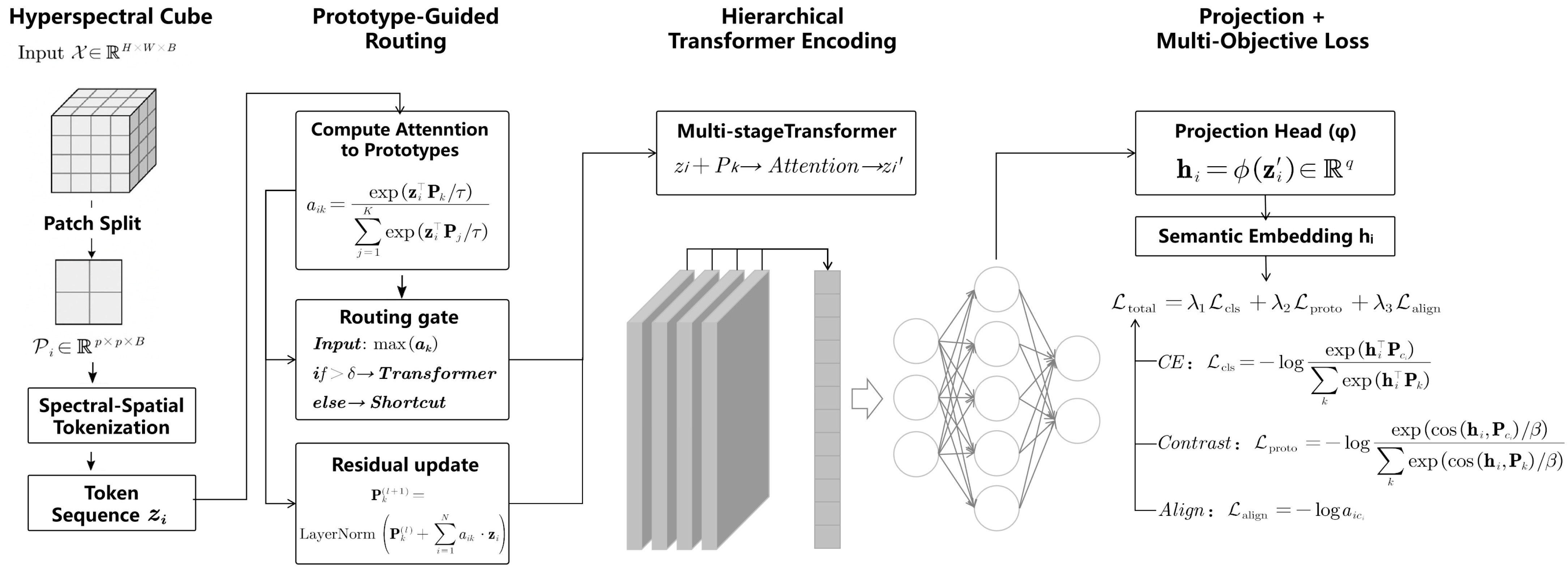
3.2. Proposed Architecture
Despite the remarkable progress in hyperspectral crop classification, most existing frameworks still face challenges in balancing spectral fidelity, spatial context, and semantic alignment. Shallow CNN-based encoders often overlook spectral locality, while purely transformer-based methods may suffer from insufficient class-level structure without explicit inductive guidance. Moreover, token redundancy and inconsistent routing across layers hinder efficiency and generalizability. To address these gaps, we propose UniHSFormer-X, a unified architecture that integrates spectral–spatial tokenization, prototype-guided semantic routing, hierarchical transformer encoding, and multi-objective optimization. As illustrated in
Figure 2, the framework is designed to establish class-aware information flow across the full pipeline, enabling robust, interpretable, and scalable learning from high-dimensional hyperspectral data.
A. Spectral–Spatial Tokenization with Multi-Resolution Patching
Hyperspectral imagery (HSI) is typically modeled as a tensor , where and denote the spatial dimensions, and is the number of spectral bands, typically exceeding 270. Each pixel contains a fine-grained reflectance vector but lacks spatial context when treated independently.
To jointly encode spectral and spatial information, we divide the HSI into non-overlapping patches
, forming the following:
Each patch is embedded into a token
via the following:
Optionally, a spectral attention kernel
is used to reweight band contributions before embedding as follows:
We add relative positional encoding to yield final tokens , forming the input sequence .
To standardize physical coverage, patch size
is adapted to resolution
r by the following:
Compared with CNNs as follows:
we have
, confirming broader representational capacity. This module provides semantically consistent input tokens for downstream modeling, preserving spectral integrity and spatial alignment. The full tokenization process is illustrated in
Figure 3, showing how spectral–spatial patches are converted into learnable tokens compatible with transformer-based modeling. These spectral–spatial tokens form the raw feature basis for semantic structuring via prototype-driven routing.
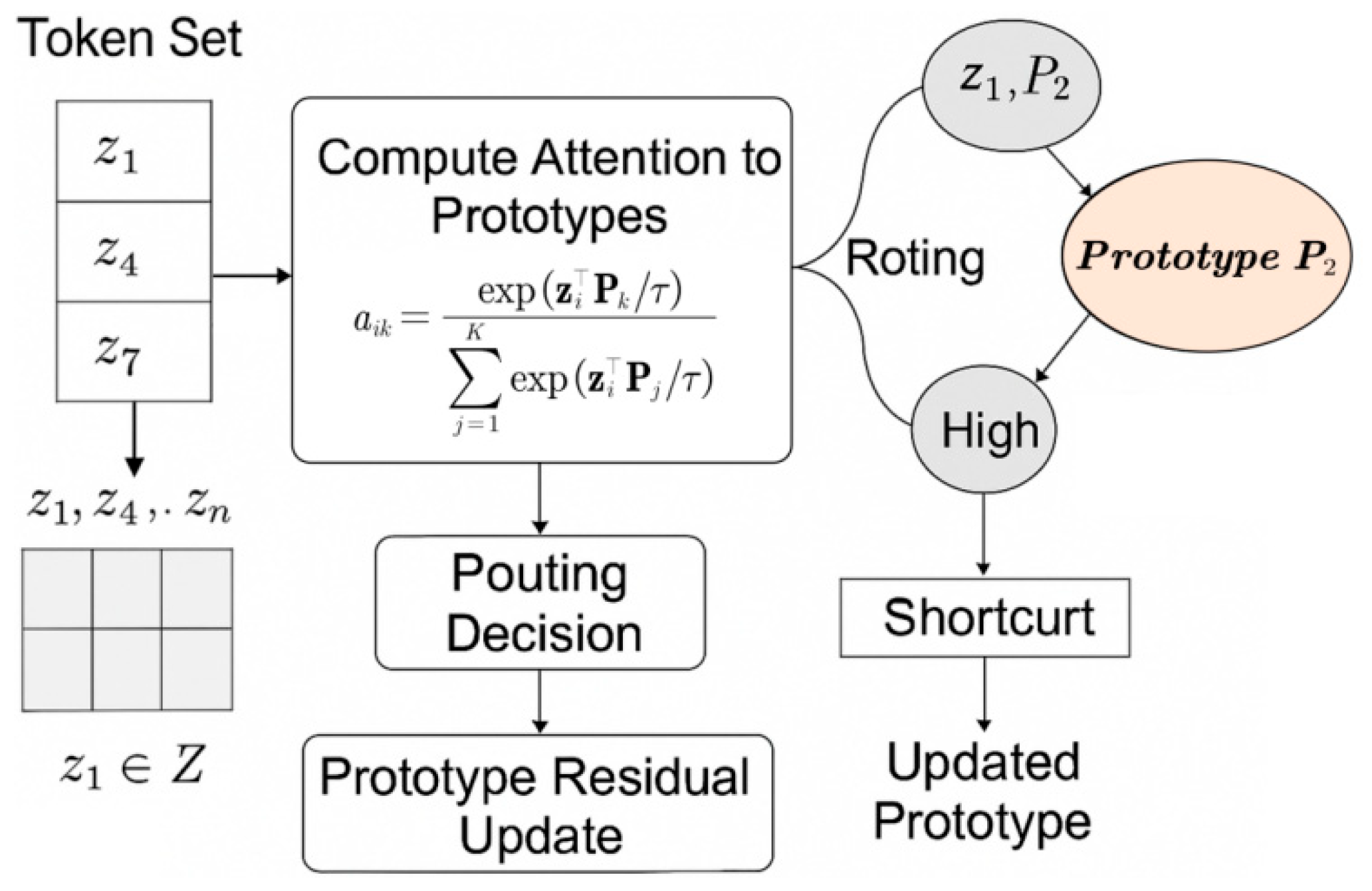
B. Prototype-Guided Semantic Routing Mechanism
To impose semantic regularity on these tokens and guide their downstream processing, we introduce a learnable prototype set of learnable class prototypes
, each representing a spectral–spatial class centroid in
. For each token
, its similarity to each prototype is computed via scaled dot-product attention as follows:
These weights serve the following two roles: (1) soft assignment of tokens to semantic classes, and (2) routing gate controlling participation in deeper encoding. High-confidence tokens are retained, while uncertain ones may shortcut or be downweighted. The semantic routing process is illustrated in
Figure 4. Each token
computes attention scores to all prototypes
, forming soft assignments via a scaled dot-product mechanism. High-confidence tokens contribute to prototype refinement, while low-confidence tokens may be bypassed. The prototypes are updated using weighted residual aggregation, enabling class-level alignment across layers. To enable prototype adaptation, we apply a gated residual update as follows:
This allows prototypes to evolve toward their semantic centers across layers. Semantic routing constrains token dynamics, reduces distraction from background pixels, and provides inductive guidance for class-aware representation learning. It also lays the groundwork for downstream attention integration in the transformer backbone.
C. Hierarchical Transformer with Prototype-Aware Attention
After routing, the selected tokens undergo layered refinement within a hierarchical transformer, where semantic alignment and contextual reasoning co-evolve. To enhance the representation capacity of routed tokens, we adopt a multi-stage transformer encoder, where each stage performs multi-head self-attention (MHSA) followed by feedforward layers. Tokens interact not only with other tokens but also with semantic prototypes, forming a joint attention space as follows:
This allows token updates to incorporate both spatial–spectral context and class-level semantics. After each stage, spatial resolution is reduced via token merging (e.g., 2 × 2 pooling), while the full spectral dimension is retained. Prototypes are refined layer-wise through gated aggregation of token features as follows:
This bidirectional flow enables the encoder to maintain semantic consistency across depth. The hierarchical structure enlarges receptive fields, reduces computational complexity, and regularizes learning by reinforcing class-aware attention. In effect, the transformer backbone becomes both a spectral–spatial encoder and a semantic alignment mechanism.
D. Unified Semantic Projection and Multi-Objective Optimization
Following hierarchical refinement, each token encodes class-relevant spectral–spatial information aligned with learned prototypes. To finalize classification, we map token features into a unified semantic space where similarity to class prototypes directly informs the prediction.
Let
be the projection head. The embedded token is transformed as
, and compared with projected class prototypes
to compute logits. Classification is supervised via cross-entropy loss as follows:
To further enhance feature discriminability, we impose a prototype-based contrastive loss as follows:
where cos (
hi,
Pci) denotes cosine similarity and
is a temperature factor. This encourages same-class tokens to concentrate around their respective prototype and repels them from others. To ensure semantic routing consistency, we introduce an alignment loss between the prototype attention weights
and the ground-truth label
as follows:
We also apply a diversity regularizer to encourage prototype separation as follows:
The total training objective is a weighted combination:
During inference, we exploit routing scores as semantic confidence indicators. Tokens with maximum affinity exceeding a threshold are retained for final prediction; others may be pruned to accelerate computation. This final module unifies the model’s predictions under a semantically interpretable embedding, while contrastive and routing-aligned objectives reinforce the geometry and robustness of the feature space. Together, they ensure that UniHSFormer-X produces accurate, explainable, and generalizable outputs for hyperspectral crop classification.
4. Experiment and Analysis
4.1. Experimental Setup
To validate the effectiveness of UniHSFormer-X across varying spectral resolutions and agricultural structures, we conduct extensive experiments on the WHU-Hi benchmark. This benchmark comprises three UAV-based hyperspectral scenes—LongKou, HanChuan, and HongHu—each characterized by distinct crop types, acquisition resolutions, and label granularity. These heterogeneous conditions provide a challenging and diverse testbed for evaluating both discriminative capacity and generalizability. Following the Train100 protocol, 100 pixels per class are randomly selected for training, while all remaining labeled pixels are used exclusively for testing. This strict, class-balanced sampling ensures that the evaluation focuses on semantic learning rather than data volume. To improve robustness under local appearance shifts, standard augmentations including random flips and rotations are applied.
The UniHSFormer-X model is implemented in PyTorch and trained on a single NVIDIA RTX 4090 GPU (NVIDIA Corporation, headquartered in Santa Clara, CA, USA). Patch sizes are adaptively selected to maintain spatial comparability across datasets of different resolutions, ensuring that each patch encodes a consistent physical footprint. Unlike conventional CNN pipelines, our spectral–spatial tokenization module preserves the full spectral fidelity of each patch and transforms it into a semantically enriched token set via lightweight 3D projections. The number of semantic prototypes is matched to the number of valid classes and remains fixed during training.
We design our optimization schedule to reflect the staged information flow of the network. In early epochs, lower routing thresholds and soft gate margins encourage broader token participation, allowing the model to stabilize its prototype attention patterns. As training proceeds, the gate hardness is gradually increased, effectively pruning noisy or low-contribution tokens and promoting high-confidence semantic routing. The model is trained for 300 epochs using the AdamW optimizer with a warm-start schedule and implicit annealing. Token dropout and token-prototype alignment regularization are applied throughout to enhance stability. Training supervision is composed of three loss components: categorical cross-entropy for basic class discrimination, a prototype-level contrastive loss that introduces semantic margin among classes, and a routing-alignment loss that encourages consistency between attention scores and prototype assignments. These losses jointly drive the semantic calibration of both token and prototype representations.
To assess performance, we adopt Overall Accuracy (OA), Average Accuracy (AA), per-class accuracy, and the Kappa Coefficient (κ). We further report Kappa@100 (K@100), a variant that isolates agreement under fixed-sample constraints and is particularly sensitive to small-class misalignment. Inference efficiency and token retention ratios are also measured to quantify the impact of routing and pruning under real-time constraints. The formal definitions of these metrics are given as follows:
Overall Accuracy (OA) evaluates the proportion of correctly classified pixels across the entire dataset:
where
denotes the number of pixels correctly predicted as class i, and N is the total number of labeled pixels. Average Accuracy (AA) reflects the mean class-wise recall, emphasizing balance across categories:
Kappa Coefficient (κ) measures agreement between predicted and ground-truth labels, normalized by expected agreement by chance:
Kappa@100 (K@100) computes the same κ metric under the Train100 constraint, i.e., using only 100 labeled pixels per class for training, to reflect model agreement under minimal supervision. We compare UniHSFormer-X against a comprehensive set of baselines, spanning classical classifiers (RF, SVM), spectral–spatial CNNs (3D-CNN, ResNet), vision transformer variants (ViT, SSFTT), and state-of-the-art hybrid architectures (CTMixer, CTDBNet). All models are re-trained using identical Train100 splits and evaluation metrics for fair benchmarking.
For classical machine learning baselines such as SVM and RF, input features were constructed as raw per-pixel spectral vectors, comprising reflectance values across all available hyperspectral bands. No spatial features or handcrafted descriptors were used, and no feature fusion or augmentation was applied. This ensures consistency with canonical use of these models in hyperspectral classification, and it allows for direct performance comparison with spectral–spatial deep learning models. All models were optimized under consistent strategies and bounded hyperparameter ranges, ensuring fairness without exhaustive tuning. Core settings such as optimizer, batch size, and training epochs are described in later sections alongside model complexity metrics.
4.2. Model Performance Across Different Agricultural Scenarios
Across varied agricultural terrains, the interplay between spatial composition, class diversity, and spectral ambiguity generates markedly different pressures on classification systems. As scene structure shifts from monoculture regularity to horticultural density, the assumptions embedded in traditional spatial–spectral modeling begin to erode. Architectures optimized for uniformity may find themselves mismatched with fragmentation; models trained to emphasize global coherence may overlook small, semantically critical fluctuations. In such settings, the ability to modulate attention—not merely expand it—becomes central. The question is no longer whether global or local modeling prevails, but how representation is routed, pruned, or withheld in response to complexity that resists uniform encoding.
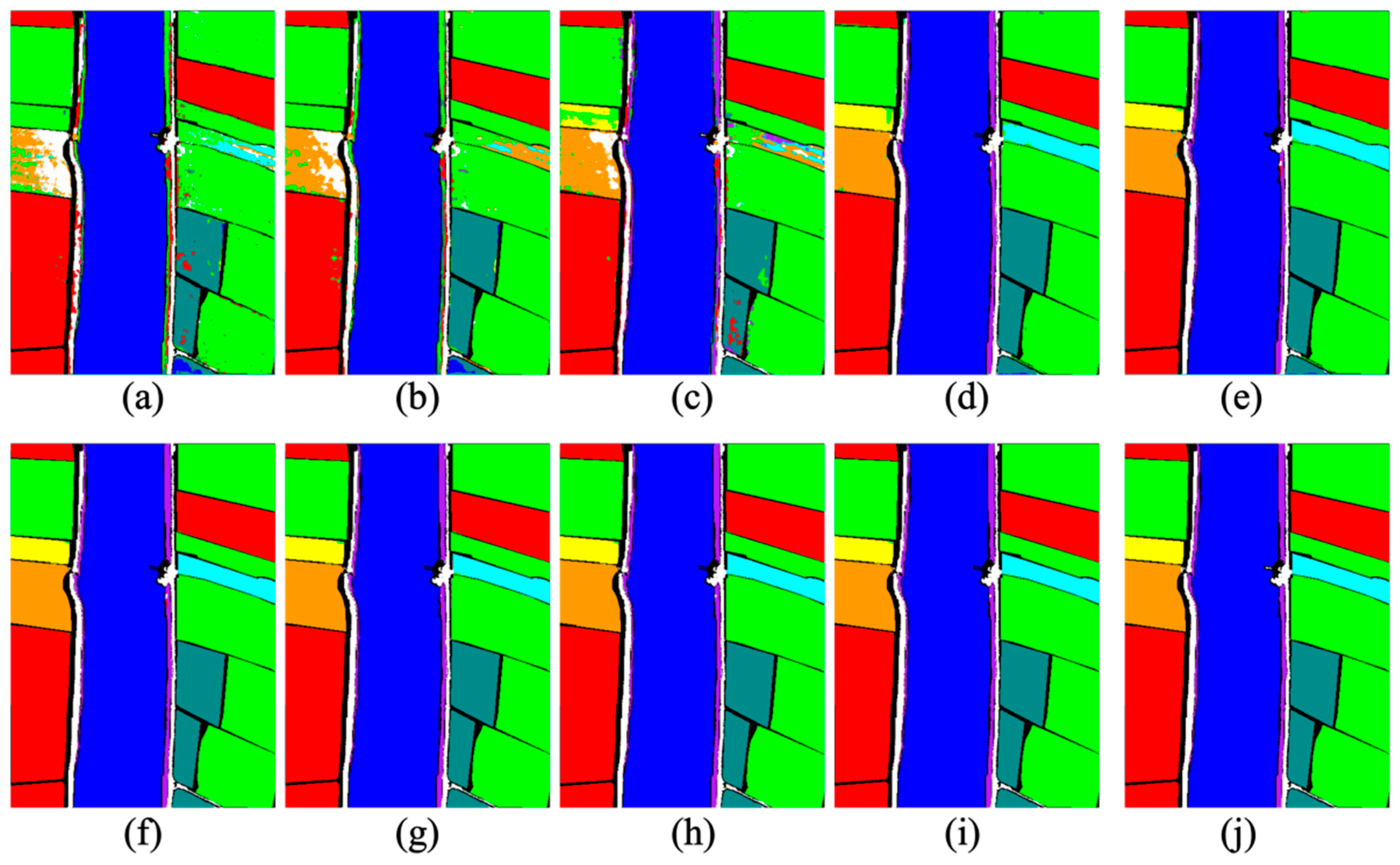
The WHU-Hi-LongKou dataset offers a clean and structured agricultural landscape, composed of well-separated crop bands and minimal background interference. This setting allows for a focused evaluation of models’ ability to preserve field geometry, distinguish spectrally similar crops, and maintain classification stability across large homogeneous zones and sparse minor classes. The outputs shown in
Figure 5 reveal the segmentation behaviors across nine representative models. At first glance, differences in spatial coherence and class boundary precision are apparent. Traditional methods such as RF and SVM (
Figure 5a,b) generate overly fragmented predictions, particularly within narrow-leaf soybean (C5), mixed weed (C9), and transitional zones between roads and crops. This outcome is expected, given their reliance on isolated spectral signatures and lack of spatial encoding. CNN-based architectures (
Figure 5c,d) introduce substantial improvements in intra-field continuity. The 3D-CNN, benefiting from joint spectral–spatial convolution, achieves stable segmentation within dominant crops like corn (C1) and sesame (C3), though its performance remains uneven on low-sample or morphologically irregular classes. ResNet sharpens field edges but shows inconsistencies near class boundaries—especially where texture and structure subtly vary, as seen in the C2–C5 transitions.
Vision Transformer models (ViT, SSFTT;
Figure 5e,f) further enhance inter-class separation by capturing long-range dependencies. ViT suppresses small-scale noise but occasionally oversmooths fine-grained boundaries, especially in the presence of spectral redundancy. SSFTT, which augments attention with spectral–spatial fusion modules, performs more reliably across both major and minor classes, particularly in structurally ambiguous regions such as roads (C8) and weed (C9), where context-based reasoning proves beneficial. Hybrid models (
Figure 5g,h) such as CTMixer and CTDBNet display even more stable behavior, especially in spatially intricate regions. CTMixer balances local and global features through depth-wise mixing, whereas CTDBNet introduces multi-depth supervision to reinforce semantic consistency. Both models maintain strong coherence across broad crop zones, though occasional fluctuations in small, spectrally entangled classes still emerge—suggesting limits in static fusion and token uniformity.
Against this backdrop, the predictions shown in
Figure 5i offer a subtly different impression. Without explicit emphasis, one notices that class boundaries are tightly aligned to field edges, that transitional zones show minimal confusion, and that small, spectrally ambiguous categories—such as narrow-leaf soybean and mixed weed—appear unusually well resolved. These visual outcomes are mirrored in the quantitative results of
Table 2, where the final model achieves 99.80% OA, 99.28% AA, and 99.49 Kappa—all metrics surpassing competing baselines, yet without dramatic deviation from the upper-tier performers. The underlying design may offer some insight into this behavior. Unlike other models that treat all tokens or patches uniformly, UniHSFormer-X introduces a semantic routing mechanism that gates feature propagation through learned class prototypes. This has the effect of selectively amplifying tokens that carry structurally or semantically relevant information, while attenuating background noise or class-ambiguous cues. When combined with a hierarchical transformer backbone that preserves spatial resolution while refining context layer-by-layer, the model seems to naturally align its attention with field structure and class boundaries, even in challenging regions.
Interestingly, the model does not outperform its competitors through brute-force overfitting or spatial over-smoothing. On the contrary, its strength lies in balanced precision across the class spectrum—as evidenced by the uniformly high per-class accuracies, including in traditionally unstable categories such as C2 (cotton, 99.93%), C5 (narrow-leaf soybean, 99.40%), and C9 (mixed weed, 96.18%). This consistency suggests that the model’s improvements are less about peak values and more about structural robustness and semantic alignment.
In contrast to the ordered agricultural geometry of LongKou, the WHU-Hi-HanChuan dataset features a spatial composition shaped by mixed-function landscapes—urban edges, orchards, vegetable plots, and various artificial surfaces—interlaced with cast shadows and irregular textures. With 16 annotated classes, including multiple legumes, synthetic coverings, and background structures, HanChuan presents a more demanding test for models aiming to balance spectral discrimination with structural generalization. Displayed in
Figure 6 are the predicted maps from all models, exposing divergences in handling spatial complexity. While most models are able to maintain the overall layout of the scene, notable differences emerge in how they handle spatial irregularity, spectral redundancy, and class imbalance. These discrepancies underscore a broader observation: high performance in highly structured environments does not necessarily translate to consistency under spatial or material complexity.
Among the traditional methods, RF and SVM (
Figure 6a,b) show difficulties in preserving semantic continuity. Their predictions fragment notably in mid-density classes such as soybean (C2), grass (C8), and plastic (C12), where similar spectral responses intersect with blurred boundaries. The absence of spatial reasoning mechanisms leads to scattered predictions even in prominent regions like strawberry fields (C1). CNN-based approaches (3D-CNN and ResNet;
Figure 6c,d) improve upon this, especially in dominant crop regions. 3D-CNN effectively captures compact zones such as C1 and C10, supported by its spectral–spatial feature stacking. However, its outputs begin to soften near occluded or edge-blurred objects like watermelon (C6), while cowpea (C7) and tree crowns (C11) remain inconsistently segmented. ResNet shows improved balance on flat classes like bare soil and plastic but exhibits occasional class bleeding where vegetation interfaces are ambiguous. Transformer-based architectures (ViT and SSFTT;
Figure 6e,f) demonstrate stronger contextual awareness, helping recover fragmented classes and sharpen semantic clusters. ViT’s self-attention offers a broader spatial lens but occasionally smooths over localized transitions—noticeable in interwoven classes such as narrow-leaf legumes (C5) and cabbage variants (C13). SSFTT, with its integrated spectral–spatial attention, mitigates this effect and shows more stable behavior in tree-grass and road-vegetation junctions. However, both models remain sensitive to token redundancy when local patterns lack contrast.
Hybrid models (CTMixer and CTDBNet;
Figure 6g,h) aim to reconcile local detail with global abstraction. CTMixer, through depth-wise mixing, enhances class separation in synthetic materials (e.g., C12), while CTDBNet benefits from hierarchical supervision, improving minority-class reliability. Both handle fringe cases better than their predecessors, though they occasionally inherit the instability of either branch when confronting structurally ambiguous zones. By comparison, the map in
Figure 6i offers a more controlled reconstruction of the scene. Tree outlines are retained with minimal bleed, road segments remain continuous across gaps, and marginal categories such as plastic and grass show fewer outliers. The difference is not radical in form but rather subtle in distribution: fewer misclassifications at boundaries, less class drift in occluded areas, and more regular transitions in spatially tangled zones. The model appears to maintain focus where structure is sparse, and restraint where tokens might otherwise overwhelm the representation.
As reported in
Table 3, this behavioral distinction corresponds with measurable consistency across classes. With 97.50% OA, 94.36% AA, and 95.23 Kappa, the model avoids the typical trade-offs between dominant and fringe classes, performing robustly not only on high-frequency crops like C1 (99.84%) but also on structurally complex or low-sample categories such as plastic (C12: 91.03%) and watermelon (C6: 88.94%). This suggests a capacity for stable representation under both spatial disorder and spectral similarity. Rather than relying on depth or scale alone, the model’s architectural decisions—particularly in the use of class-informed token filtering and guided projection—may help mitigate the kind of over-aggregation often seen in standard attention blocks. Such mechanisms seem to discourage indiscriminate feature propagation and instead favor structured alignment, especially where material heterogeneity and occlusion complicate the classification landscape.
Compared with the structured field layout of LongKou and the spatial heterogeneity of HanChuan, WHU-Hi-HongHu introduces a new level of complexity. It is not merely a matter of spatial irregularity or spectral overlap—but of semantic granularity. The dataset comprises 22 annotated classes, many of which represent subtle botanical variants (e.g., different Brassica species, lettuce types, or hybrid vegetable rows) distributed within dense and spectrally entangled plots. In this context, models are challenged to demonstrate not only class-level discrimination, but also continuity in spatially narrow, interleaved planting regimes.
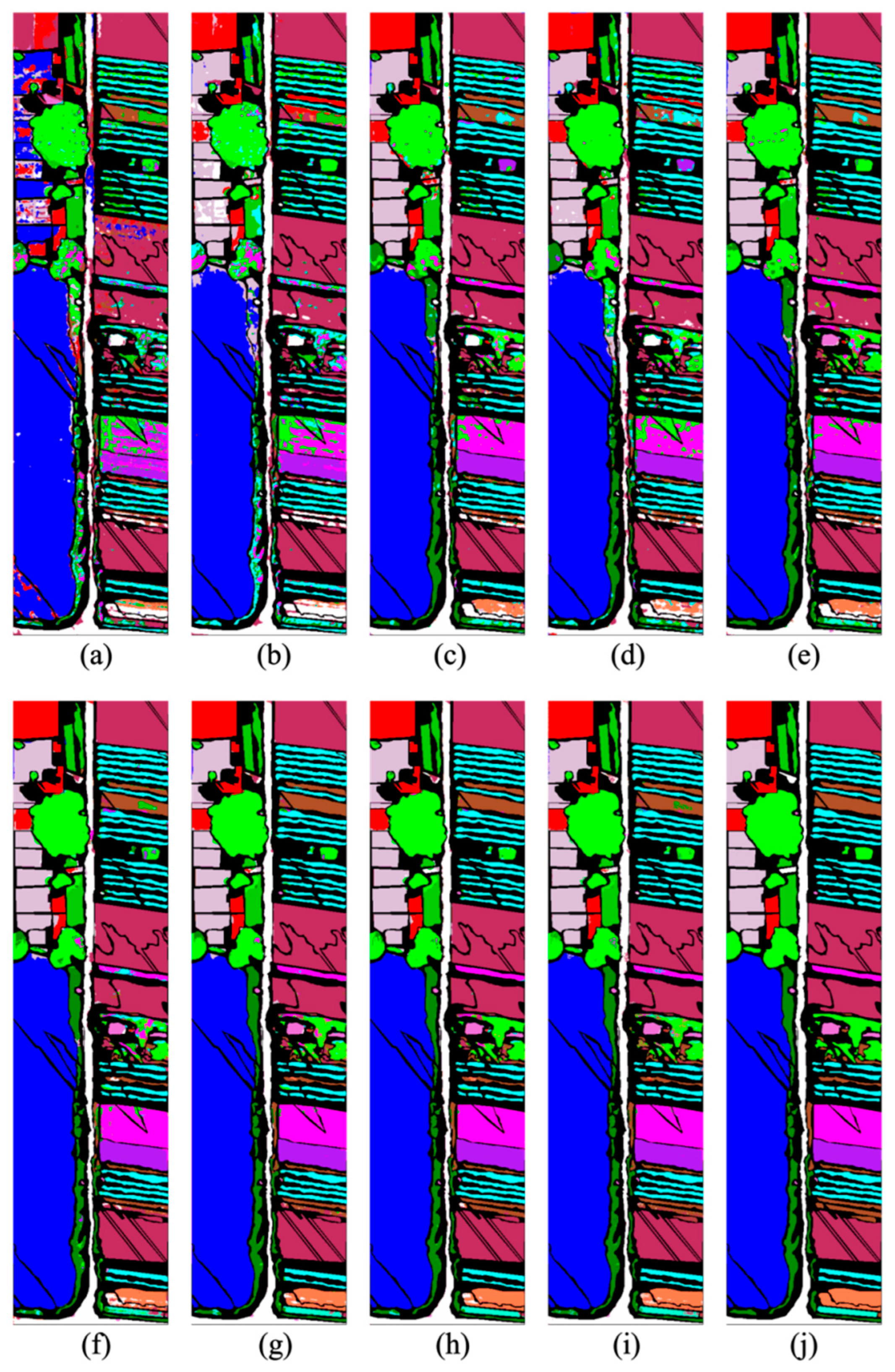
Figure 7 reveals how different models respond to this heightened semantic density. For most models, structural segmentation deteriorates noticeably when transitioning from broadfield crops to fragmented horticultural zones. RF and SVM (
Figure 7a,b) produce scattered outputs with substantial class bleeding, particularly in the lower half of the scene where visually similar crops are densely interleaved. These methods—lacking spatial regularization—are quickly overwhelmed by the subtle variation in reflectance and spatial adjacency.
CNN-based models (
Figure 7c,d) attempt to enforce local coherence. 3D-CNN preserves the general contour of fields and suppresses pixel-level noise, reaching 85.14% OA and 82.12% AA, yet still suffers in micro-structured categories such as Class 13 and 22, where field boundaries are both spectrally and spatially ambiguous. ResNet improves local smoothness in some dominant classes but shows inconsistency in capturing fine spatial rhythms, likely due to its fixed-size receptive field. ViT (
Figure 7e) introduces global receptive awareness and recovers large-area coherence, especially in monoculture zones. However, it appears less confident in discriminating visually close varieties—e.g., Classes 5 through 7, or Classes 12 through 15—frequently merging semantically distinct crops under similar spectral expressions. SSFTT corrects part of this tendency by integrating spatial information into the attention mechanism, showing improved edge discipline and better recovery of tree cover and bare soil. Still, both methods tend to blur boundaries in areas where class separability is not strictly driven by colorimetric cues.
CTMixer and CTDBNet (
Figure 7f–h) continue the trend toward structured outputs, with clearer delineation of elongated field blocks and a marked reduction in speckle noise. CTMixer maintains clean segmentation for dominant crops while CTDBNet, aided by multi-scale fusion, demonstrates an ability to recover thin classes and background boundaries. Nonetheless, even these models occasionally falter under extreme inter-class proximity—where neither pixel distance nor global context is sufficient to resolve the ambiguity. In this highly entangled context, the output of
Figure 7i stands out in its restraint rather than overreach. The transitions are sharper but not exaggerated; class boundaries are aligned to planting structure without artificial smoothing; and confusion between subclasses of leafy vegetables is significantly suppressed. Notably, the model does not erase class boundaries in the name of regularity, it retains complexity where necessary and abstains from oversimplification.
This balance is mirrored in
Table 4. UniHSFormer-X attains 98.42% OA, 97.06% AA, and a Kappa score of 98.02, leading across all metrics. More importantly, it demonstrates reliable per-class accuracy even in traditionally unstable classes: Class 5 (98.24%), Class 13 (97.86%), and Class 22 (98.58%)—all of which have historically challenged both CNNs and Transformers due to their visual similarity and narrow margins. The model’s architecture may help explain this stability. The semantic routing mechanism limits token redundancy while preserving task-relevant features—an advantage in settings where spatial density and spectral proximity co-occur. Meanwhile, hierarchical attention layers allow it to reconcile global field layout with class-local detail. But perhaps the more significant outcome lies in what is not observed: the absence of category collapse, the rarity of excessive smoothing, and the steady confidence across all tiers of class frequency.
To complement the region-wise analysis, we computed cross-region averages of OA, AA, and Kappa for each model, as presented in
Table 5. This unified perspective enables a fairer assessment of generalization across heterogeneous scenes. UniHSFormer-X remains consistently top-ranked, achieving average OA, AA, and Kappa values of 98.57%, 96.90%, and 97.58%, respectively. The performance advantage also extends to minor classes and ambiguous regions, indicating a robustness that transcends specific landscapes. Such cross-region synthesis not only reinforces the model’s superiority but also provides context for interpreting localized inconsistencies observed in individual benchmarks.
What emerges is not always best captured in numerical precision. Some models resist local distortion but falter when confronted with near-class redundancy; others respond well to spatial heterogeneity yet overcommit in zones of weak semantic contrast. The most telling behaviors are not those that dominate a metric, but those that sustain structure without imposing artificial order, as follows: where transitions are managed without erasure, and where ambiguity is acknowledged but not propagated. Here, consistency becomes less about convergence and more about restraint—about how selectively a model aligns features to meaning. Architectures that embed this restraint not as post-processing but as structural grammar may begin to demonstrate not just better results, but more appropriate errors.
4.3. Architectural Dissection and the Structural Grammar of Robustness
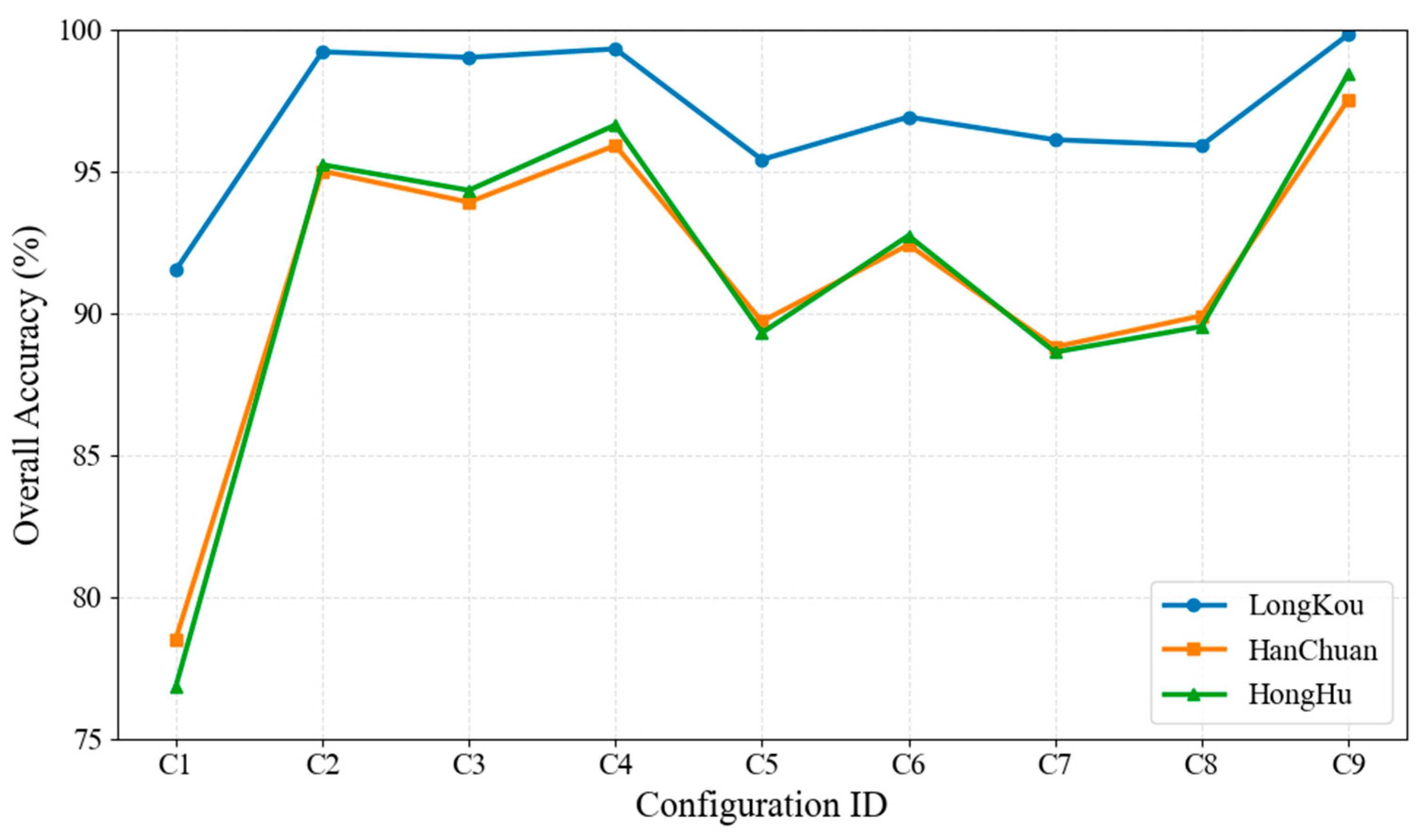
To disentangle the contribution of architectural components to model stability, we designed a series of controlled structure variants by selectively disabling key modules in UniHSFormer-X. Specifically, the following five core components were considered: (1) the semantic routing mechanism, which regulates token propagation through class-aware paths; (2) prototype projection, responsible for aligning features to learned semantic anchors; (3) multi-scale supervision, providing auxiliary gradient signals from different encoder depths; (4) the transformer backbone, enabling global spatial abstraction; and (5) encoder depth, controlling the vertical capacity for hierarchical representation. This structural dissection not only validates the resilience of UniHSFormer-X against modular perturbation but also reveals an underlying architectural grammar, wherein each component operates in a semantically coordinated role—balancing model complexity with robustness.
By systematically toggling these modules, we constructed eleven representative configurations (C1–C11), ranging from a fully disabled scaffold (C1) to the complete UniHSFormer-X model (C9). Single-module ablations (e.g., C2, C3, C4) isolate the effect of core components—routing, projection, and supervision—while C5 and C6 evaluate the influence of architectural backbone and encoder depth. Dual-removal configurations (C7 and C8) further examine how inter-module dependencies shape representational robustness. To extend this dissection, two additional combinations (C10 and C11) were included as follows: C10 preserves supervision and backbone while removing both semantic routing and projection, revealing how loss of semantic anchoring affects residual convergence; C11, by contrast, disables routing and the Transformer backbone together, simulating a low-capacity and low-context regime. Each configuration was evaluated on three structurally diverse datasets—LongKou, HanChuan, and HongHu—with overall accuracy (OA) results reported in
Table 6 and visualized in
Figure 8.
The degradation trends are notably non-uniform. In C1, where all higher-level modules are absent, OA drops to 91.5% in LongKou, 78.5% in HanChuan, and 76.82% in HongHu, marking a collapse in spatial coherence and semantic alignment. Importantly, recovery from such collapse is nonlinear. For instance, activating projection alone (C3) elevates performance in LongKou to 99.0% but still leaves fragmentation in HongHu (94.32%), where categories are narrow, spectrally entangled, and spatially nested. Conversely, C2 enables routing but omits projection, yielding asymmetric gains—suggesting that directional flow without semantic anchoring struggles to stabilize higher-entropy scenes. Multi-scale supervision, removed in C4, shows moderate standalone impact, implying a regularization rather than foundational role.
Backbone-related ablations (C5 and C6) show that structural abstraction and vertical depth remain indispensable in complex scenarios. C5, without a Transformer backbone, suffers notable OA drops—particularly in HanChuan and HongHu—highlighting the central role of global attention in resolving spatial fragmentation. C6, with reduced encoder depth, exhibits subtler yet consistent degradation, especially in fine-scale boundary classes, revealing that shallow hierarchies limit vertical expressiveness. In C7 and C8, which simultaneously remove routing and encoder depth or projection, respectively, performance collapses accelerate. These cases suggest that robustness is not merely additive but highly interaction-dependent as follows: the absence of both directional semantics and deep representation in C7 causes compounding ambiguity, while the absence of projection in C8 destabilizes feature anchoring under shallow encoding.
C10 and C11 further validate these dependencies. C10 preserves global structure and multi-scale gradients but lacks any semantic scaffolding; its performance lags behind single-module ablations, implying that even strong backbone and supervision cannot fully compensate for missing semantic anchors. C11, lacking both routing and global abstraction, suffers the sharpest decline outside of C1, confirming the synergy between spatial semantics and context-aware modeling.
As visualized in
Figure 8, robustness in UniHSFormer-X emerges not from any single component but from their negotiated interdependence. Routing informs where features matter; projection aligns how they are represented; supervision regulates how fast they converge. Backbone and depth, in turn, determine how far and how deep that information propagates. Remove one, and the system bends; remove several, and it fractures—especially under complex visual entanglement. Generalization, then, is less about adding capacity than about distributing functional logic across architecture.
While overall accuracy provides a broad assessment of model performance, it often masks the uneven sensitivities that different categories exhibit under structural ablations. To uncover how architectural modules influence specific class behaviors, we performed a focused comparison across three representative datasets—LongKou, HanChuan, and HongHu—each featuring distinct landscape regularity, object density, and inter-class ambiguity. Four critical categories were selected from each dataset, reflecting small-sample instability, semantic overlap, structural fragmentation, and non-agricultural interference.
Table 7 summarizes the per-class accuracy across three structural variants as follows: the full UniHSFormer-X model, and two reduced versions (C7 and C8) lacking combinations of semantic routing, prototype projection, and hierarchical encoder depth. As expected, the complete model achieves consistently high accuracy across all categories, serving as the structural baseline. In contrast, C7 and C8 introduce varying levels of performance degradation, but not uniformly so—each class responds differently depending on its semantic properties and structural context. In LongKou, narrow-leaf soybean (C5) and mixed weed (C9) show the most pronounced decline under structural removal. These classes are both morphologically irregular and spectrally ambiguous, relying heavily on the model’s ability to distinguish subtle spatial cues. The removal of routing and hierarchical refinement (C7) reduces their precision by over 5%, while the absence of prototype projection (C8) amplifies this decline further. Roads and houses (C8), a background class often misclassified as crop margins, also exhibits sensitivity to attention degradation, though its structured layout still provides spatial anchors that mitigate complete collapse.
The HanChuan dataset presents a more fragmented environment, with categories such as grass (C9) and plastic (C12) displaying higher dependence on context-aware attention. Without hierarchical encoding, the model fails to consolidate long-range coherence, resulting in scattered predictions. Interestingly, cowpea (C2) and water spinach (C5)—both mid-frequency crops—also exhibit notable accuracy drops, suggesting that in disordered scenes, even dominant crops require feature routing to resist background drift. In HongHu, where visual similarity between horticultural crops is particularly high, the distinction becomes even sharper. Brassica chinensis (C12) and Celtuce (C15), both nested within dense planting grids, show marked declines under C7/C8, with accuracy falling below 90% in C8. The Tree class (C22), often located at plot boundaries, remains relatively stable, but even here, minor precision losses reveal how background structures benefit from depth-enhanced alignment. Most telling is Lactuca sativa (C14), whose boundaries are consistently preserved under the full model but become blurred as projection modules are removed. These results suggest that the benefits of structural components do not distribute evenly across the class space. Semantic routing and prototype projection not only enhance global modeling, but also act as class-specific filters, modulating attention in semantically ambiguous or spatially irregular regions. Their removal disproportionately affects classes that depend on local structure, class context, or spatial continuity. In contrast, dominant or spectrally isolated classes exhibit resilience, though not immunity. Taken together, this analysis reinforces the need to evaluate structural robustness not solely by aggregate scores, but also by its ability to preserve semantic fidelity under complexity. As datasets grow more heterogeneous, architectural design must shift from uniform modeling toward class-aware mechanisms that respond adaptively to variability in both space and semantics.
Patterns observed across datasets and configurations reveal that robustness in structured semantic modeling is not a consequence of scale or resolution, but of how architectural elements negotiate ambiguity. The capacity to preserve spatial regularity, to suppress class interference, and to recover fine-grained categories appears less tied to individual modules than to the relationships they encode. Where these relationships weaken, so too does the model’s sense of structure—not catastrophically, but perceptibly. The challenge is not just architectural adequacy, but compositional fitness.
4.4. Parameter Configuration and Behavioral Stability
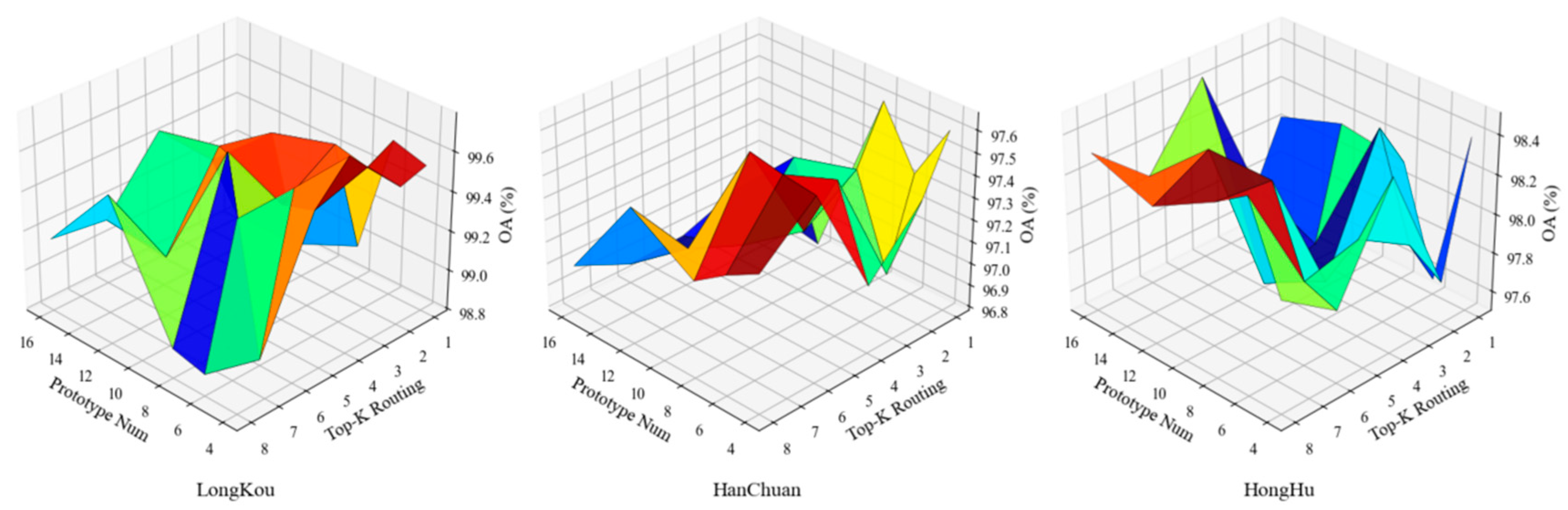
While architectural design fundamentally shapes a model’s capacity to extract semantic structure, the role of parameter configuration in stabilizing this capacity is often overlooked. In UniHSFormer-X, two hyperparameters play a uniquely structural role: the number of semantic prototypes (P), which determines the resolution of concept-space anchoring; and the Top-K routing size (K), which controls the selectivity of attention propagation. Together, these parameters govern how features are filtered, grouped, and relayed through the network—imposing a latent grammar on information flow.
To investigate their joint influence, we conducted a grid-based analysis over
P and
K, fixing the token dimension to 128. Prototype numbers were varied from 4 to 16 in steps of 2, and routing sizes from
K = 1 to
K = 8. Each (
P,
K) configuration was independently trained and evaluated on three datasets—LongKou, HanChuan, and HongHu—covering structured, fragmented, and entangled spectral–spatial landscapes. The resulting OA surfaces are shown in
Figure 9. The effects of these parameters are neither monotonic nor dataset-invariant. Across all three datasets, two behavioral patterns emerge as follows: (1) extremely low routing sizes (
K ≤ 2) consistently lead to performance instability, suggesting that insufficient spatial aggregation prevents effective structural alignment; (2) overly dense prototype sets (
P ≥ 14) tend to introduce semantic redundancy, increasing confusion in fine-grained class regions. In contrast, a mid-range prototype count (
P = 8–12) and moderate routing (
K = 3–6) define a stability basin, where classification accuracy remains both high and robust to minor parameter variation.
This basin is the most expansive in LongKou, where field structure is regular, margins are clean, and class boundaries exhibit low entropy. Under such conditions, the model displays graceful degradation even under suboptimal settings. In HanChuan and HongHu, however, the margin for error narrows: structural clutter and spectral overlap amplify the cost of poor routing or excessive semantic partitioning. For instance, at K = 1 with P = 16, OA in HongHu drops by over 2% relative to its local optimum, indicating that excessive semantic fragmentation cannot compensate for the absence of contextual guidance. What these surfaces reveal is that parameter selection does not merely optimize performance—it conditions representational behavior. Prototype granularity defines the semantic resolution at which features are interpreted, while routing determines the structural scope over which relevance is computed. Misaligning these elements can induce failure modes that are not reflected in aggregate metrics alone—such as over-smoothing, class coalescence, or loss of boundary fidelity.
More fundamentally, these results suggest that parameter tuning in semantically modular architectures like UniHSFormer-X should move beyond grid search. The presence of dataset-dependent basins indicates that optimal values are not universal, but emergent from the interplay between model logic and landscape structure. Designing routing strategies or prototype sets that adapt to visual density, class topology, or contextual noise may therefore prove more effective than fixed settings alone. The question is not whether a model works under ideal settings, but whether it remains intelligible and stable as its semantic and structural parameters are perturbed. This view reframes parameter tuning not as a peripheral task, but as a lens into model generalization and the latent structure of semantic encoding.
4.5. Complexity and Runtime Analysis
In real-world agricultural deployments, particularly under constrained hardware or real-time demands, model accuracy alone is insufficient. It must be accompanied by efficient computational performance, compact design, and manageable configuration overheads. Beyond classification accuracy, practical deployment depends on the complexity of model design, the computational cost of inference, and the flexibility or overhead introduced by hyperparameter configurations. To this end, we conducted a tri-dimensional evaluation across representative models, encompassing (1) the number of critical hyperparameters, (2) theoretical computational complexity per inference, and (3) the empirical runtime per image.
We emphasize that a higher hyperparameter count does not necessarily imply higher practical burden. Many parameters—such as learning rate, dropout, or patch size—are typically initialized with standard values and seldom tuned beyond default. What hyperparameter count instead reflects is the potential for architectural flexibility and task adaptability. For example, while our UniHSFormer-X exposes nine configurable options, including spectral and token dimensions, routing structure, and optimization variables, all were bounded within interpretable ranges, requiring no exhaustive search and enabling stable convergence without manual tuning.
Theoretical complexity is expressed using symbolic notation, allowing for model-agnostic comparison across diverse architectural families. Convolutional models (e.g., 3D-CNN, ResNet) scale with local kernel operations, while transformer-based architectures (e.g., ViT, SSFTT, CTDBNet) scale quadratically with token length. Our method, in contrast, replaces global attention with a prototype-guided routing mechanism, achieving linear complexity with respect to token count and spectral prototype size, thus ensuring scalability without sacrificing semantic depth.
To complement theoretical analysis, we measured per-image inference latency on a NVIDIA RTX 4090 GPU, under PyTorch 2.1.0 and CUDA 12.1, using 7 × 7 × 30 input blocks and FP32 precision. All methods were benchmarked in isolation, excluding data I/O or augmentation steps, to ensure forward-pass comparability. To ensure clarity and reproducibility, we summarize the definitions of key variables used in the complexity formulas as follows:
: number of patches/sequence length;
: embedding dimension or input feature dimension;
: mixing kernel size (specific to CTMixer);
: number of channels;
: number of voxels in layer lll (3D-CNN only);
: input/output channels per convolution layer;
: number of support vectors (SVM);
: number of trees (Random Forest);
: number of routing prototypes (UniHSFormer-X).
Table 8 summarizes the results. As expected, SVM and RF incur the lowest computational cost but lack capacity for high-dimensional representation. Convolution-based methods offer a moderate balance. Among transformer models, UniHSFormer-X achieves a competitive latency (~20.3 ms/image) while maintaining structured modularity and interpretability. This balance is rooted in its token-semantic decoupling and prototype-routed attention, which avoids costly full self-attention while preserving context-aware encoding. The results demonstrate that our model is not only accurate and generalizable but also computationally efficient and modularly tunable—qualities crucial for agricultural deployments under resource constraints.
While inference efficiency is crucial for real-time tasks, training cost and scalability are equally important in large-scale deployments.
Table 9 further extends the comparison along these dimensions.
Beyond inference-time efficiency, practical deployment in large-scale agricultural scenarios requires consideration of training overhead, model scalability, and parameter footprint.
Table 9 presents a comprehensive comparison of training time, test time, theoretical FLOPs, and parameter count across three datasets—LongKou (LK), HanChuan (HC), and HongHu (HH).
Our UniHSFormer-X exhibits consistently low training and test latency across datasets. Compared to the transformer baselines, it achieves a 17.2–30.4% reduction in training time and a 15.5–21.3% reduction in testing time versus ViT, SSFTT, and CTDBNet. The streamlined token-prototype routing and modular block composition contribute to this acceleration, avoiding costly full-attention computation while maintaining representational flexibility.
In terms of FLOPs, UniHSFormer-X requires 962.84 M operations, ranking among the most efficient in the transformer group and notably outperforming ViT (1462.44 M) and CTDBNet (1482.7 M). Despite having 9 tunable hyperparameters (see
Table 8), its parameter count remains at 0.48 M, lower than most Transformer variants and only moderately above shallow models like 3D-CNN (0.16 M) or SSFTT (0.16 M). This reflects a balanced architectural compactness, where semantic expressiveness is achieved without redundancy.
Classical machine learning models such as RF and SVM offer minimal training/testing time and negligible parameter size, but lack the expressive capacity required for fine-grained spectral–spatial classification, as shown in previous sections. CNN-based backbones like ResNet and 3D-CNN strike a moderate balance but incur significantly higher FLOPs due to stacked convolutional operations and volumetric encoding.
Collectively, these results affirm that UniHSFormer-X not only achieves high accuracy and generalization, but also demonstrates efficient training, moderate memory demands, and scalable inference, positioning UniHSFormer-X as a scalable, deployable, and semantically robust solution for hyperspectral agricultural monitoring under practical constraints.
6. Conclusions
The classification of crops in hyperspectral imagery is not merely an exercise in pattern recognition, it is a semantic task shaped by the spatial grammar of agriculture. Through this study, we proposed UniHSFormer-X, a unified transformer-based framework designed to align hyperspectral tokens with structurally meaningful semantics across diverse cropland settings. By integrating semantic routing, prototype-guided projection, and a hierarchical transformer encoder, the model moves beyond conventional spatial–spectral fusion, establishing a dynamic mechanism for information flow that mirrors the organizational logics of field planting and phenotypic structure. Comprehensive experiments across the WHU-Hi benchmark demonstrate the model’s superiority in both overall accuracy and class-wise fidelity, particularly in challenging horticultural environments where conventional models tend to degrade. Ablation studies reveal that no single module suffices—robustness stems from the interaction between routing, supervision, and depth-aware abstraction. Moreover, the parameter stability analysis highlights the following critical insight: model behavior is conditioned not only by internal architecture but also by the external structure of the landscape itself.
These findings point to a broader paradigm shift: from fixed, generic pipelines to semantically modular, context-adaptive systems capable of reasoning within the constraints of real-world agriculture. In this view, a model’s strength is not defined by its peak performance, but by its ability to maintain structure under uncertainty, to disambiguate meaning where boundaries blur, and to adapt gracefully to variation across time, region, and crop taxonomy. What emerges is not a finished solution, but a template—an architectural grammar for agricultural AI. Future work may refine this blueprint through self-adaptive routing, continual learning under seasonal dynamics, or cross-modal integration with soil, weather, and management data. The direction, however, is clear; from classification to interpretation, from segmentation to semantics, from pixels to patterns of agriculture.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}