
Application of Vis/NIR Spectroscopy in the Rapid and Non-Destructive Prediction of Soluble Solid Content in Milk Jujubes


Abstract
1. Introduction
- (1)
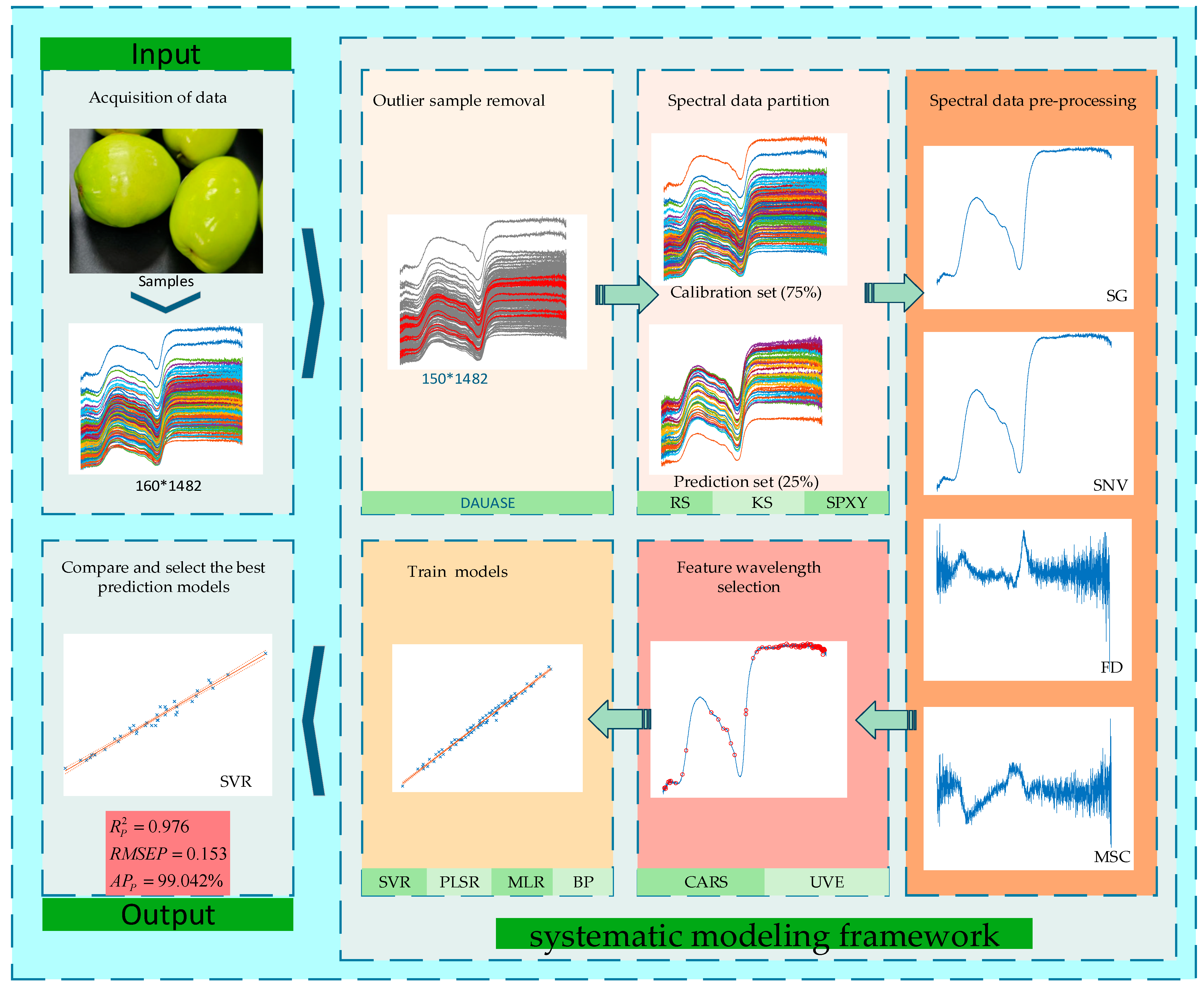
- A systematic modeling framework is established, incorporating outlier removal, dataset partitioning, preprocessing, wavelength selection, and model construction. The impact of outlier detection and partitioning strategies on model performance is analyzed.
- (2)
- A new anomaly sample elimination strategy (DAUASE) is proposed. This approach improves data interpretability and model accuracy.
- (3)
- Three common dataset partitioning strategies are compared by building identical models on each dataset to evaluate their impact on predictive performance. The optimal partitioning method is identified.
- (4)
- The influence of various preprocessing techniques (SG, SNV, MSC, FD, and their combinations) on model performance is evaluated to determine the best approach.
- (5)
- CARS and UVE are employed to select informative wavelengths.
- (6)
- Several prediction models are compared to identify the most accurate SSC prediction model for milk jujube.
2. Materials and Methods
2.1. Sample Preparation
2.2. Data Acquisition
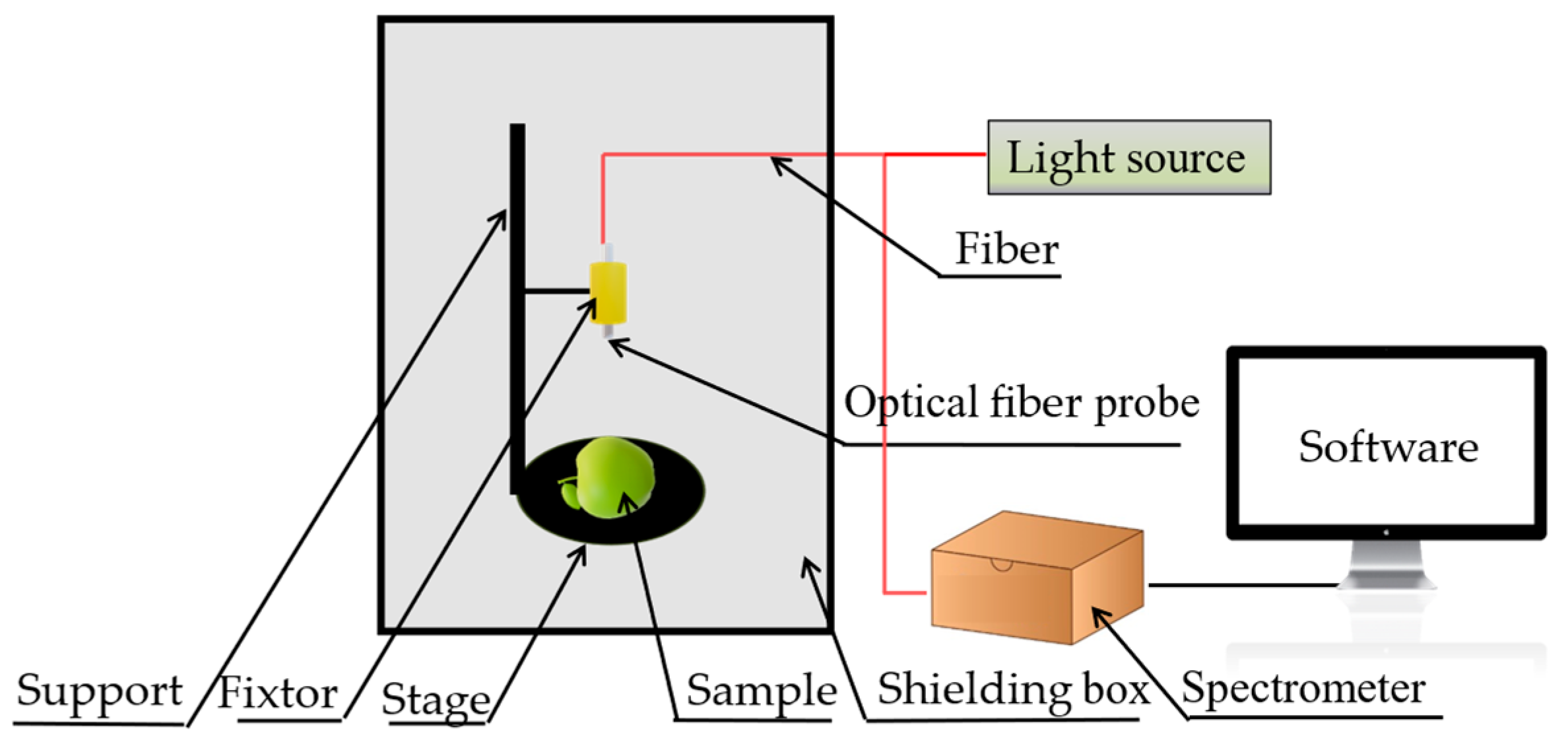
2.2.1. Spectral Data Acquisition
2.2.2. Measurement of SSC
2.3. Spectral Data Processing Methods
2.3.1. Outlier Elimination
- (1)
- Data Augmentation: The input variable matrix and output variable matrix of the original samples are randomly paired to generate the augmented input matrix and output matrix . The augmentation is governed by the following formulation:where (xi, yi) and (xj, yj) are two samples randomly selected from the original dataset. The mixing weight λ is drawn from a beta distribution controlled by the parameter γ. In this study, a beta (1, 1) distribution was selected (i.e., γ = 1), which ensures equal probability distribution between two samples. This configuration achieves a balance between preserving original characteristics and introducing diversity, avoids extreme bias in λ, enhances the representativeness of the generated samples, and improves model stability. Furthermore, this strategy introduces no subjective bias, making it neutral and suitable for unsupervised outlier identification.
- (2)
- Model Construction: In each iteration, a subset of augmented samples is randomly selected as a calibration set to build an SVR model.
- (3)
- Prediction and Accuracy Recording: The constructed model is used to predict all original samples. Prediction accuracy is recorded for each sample.
- (4)
- Preliminary Outlier Detection: Samples with prediction accuracy below a predefined threshold (e.g., 95%) are preliminarily labeled as outliers.
- (5)
- Repetition and Statistical Evaluation: The above process is repeated multiple times. Samples frequently identified as outliers (e.g., more than 10% of iterations) are finally determined as anomalous.
- (6)
- Outlier Removal: All samples identified as final outliers are removed from the original dataset.
2.3.2. Dataset Partitioning
2.3.3. Data Preprocessing
2.3.4. Feature Wavelength Selection
2.3.5. Prediction Model Development
2.4. Model Evaluation Index
3. Results and Discussion
3.1. Analysis of Outlier Elimination Results
3.2. Data Splitting Method
3.3. Optimal Preprocessing Methods
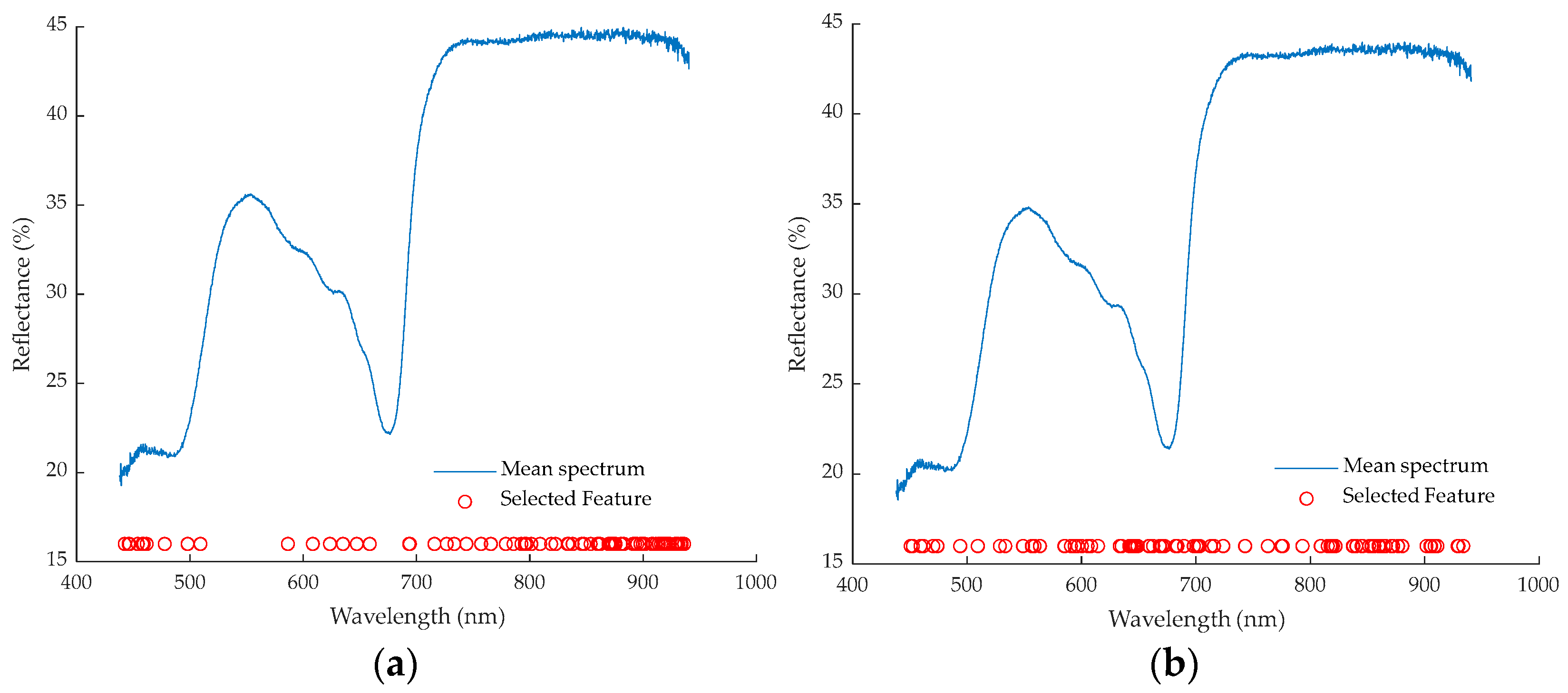
3.4. Feature Wavelength Selection Methods
3.5. Conventional Regression Methods
3.6. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, S.-F. High Yield and High Quality Cultivation Techniques of Indian Jujube. Southeast Hortic. 2015, 47, 12–15. [Google Scholar]
- Xue, P. Influence of different soil moisture conditions in the dry-hot valley of Jinsha River on the fruit quality and yield of Ziziphus mauritiana Lam. Zhejiang Agric. Sci. 2008, 2, 144–148. [Google Scholar]
- Anjum, M.A.; Haram, A.; Ahmad, R.; Bashir, M.A. Physico-chemical attributes of fresh and dried Indian jujube (Zizyphus mauritiana) fruits. Pak. J. Agric. Sci. 2020, 57, 165–176. [Google Scholar]
- Anjum, M.A.; Rauf, A.; Bashir, M.A.; Ahmad, R. The evaluation of biodiversity in some indigenous Indian jujube (Zizyphus mauritiana) germplasm through physico-chemical analysis. Acta Sci. Pol. Hortorum Cultus 2018, 17, 39–52. [Google Scholar] [CrossRef]
- Hussain, S.Z.; Naseer, B.; Qadri, T.; Fatima, T.; Bhat, T.A. Ber/Jujube (Ziziphus mauritiana): Morphology, taxonomy, composition and health benefits. In Fruits Grown in Highland Regions of the Himalayas; Springer: Cham, Switzerland, 2021; pp. 157–168. [Google Scholar]
- Guo, M.; Bi, G.; Wang, H.; Ren, H.; Chen, J.; Lian, Q.; Wang, X.; Fang, W.; Zhang, J.; Dong, Z.; et al. Genomes of autotetraploid wild and cultivated Ziziphus mauritiana reveal polyploid evolution and crop domestication. Plant Physiol. 2024, 196, 2701–2720. [Google Scholar] [CrossRef]
- Liang, T.; Sun, W.; Ren, H.; Ahmad, I.; Vu, N.; Maryam; Huang, J. Genetic diversity of Ziziphus mauritiana germplasm based on SSR markers and ploidy level estimation. Planta 2019, 249, 1875–1887. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.; Zheng, Y.; Tian, H.; Xu, H.; Xie, L. Enhancing fruit SSC detection accuracy via a light attenuation theory-based correction method to mitigate measurement orientation variability. Food Res. Int. 2024, 196, 115024. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhou, L.; Wang, W.; Zhang, X.; Gu, Q.; Zhu, Y.; Chen, R.; Zhang, C. Visible/near-infrared spectroscopy and hyperspectral imaging facilitate the rapid determination of soluble solids content in fruits. Food Eng. Rev. 2024, 16, 470. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, X.; Yu, X.; Li, Y.; Han, S. Research progress of nondestructive testing techniques for fruit and vegetable quality. J. Zhejiang Univ. Agric. Life Sci. 2020, 46, 27–37. [Google Scholar] [CrossRef]
- Cheng, L.; Liu, G.; Wan, G.; He, J. Non-destructive detection of glucose content in Lingwu jujube by visible/near-infrared hyperspectral imaging. Chin. J. Luminesc. 2019, 40, 1055–1063. [Google Scholar] [CrossRef]
- Ma, J.; Wang, K. Research Progress of Optical Nondestructive Testing Technology for Fruit Quality. Food Ind. Sci. Technol. 2021, 42, 427–437. [Google Scholar]
- Chen, B.; Wu, Z.; Li, H.; Wang, J. Research of machine vision technology in agricultural application: Today and the future. Sci. Technol. Rev. 2018, 36, 54–65. [Google Scholar] [CrossRef]
- Liu, J.X.; Yin, X.H.; Han, S.H.; Li, X.; Xu, B.C.; Li, P.Y.; Luo, D.L. Review of Portable Near-infrared Spectrometers. J. Henan Agric. Univ. 2022, 56, 102–110. [Google Scholar]
- Guo, Y.; Zhang, L.; Li, Z.; He, Y.; Lv, C.; Chen, Y.; Lv, H.; Du, Z. Online Detection of Dry Matter in Potatoes Based on Visible Near-Infrared Transmission Spectroscopy Combined with 1D-CNN. Agriculture 2024, 14, 787. [Google Scholar] [CrossRef]
- Yakubu, A.B.; Shaibu, A.S.; Mohammed, S.G.; Ibrahim, H.; Mohammed, I.B. NIRS-based prediction for protein, oil, and fatty acids in soybean (Glycine max (L.) Merrill) seeds. Food Anal. Methods 2024, 17, 1592–1600. [Google Scholar]
- Mundi, H.K.; Sharma, S.; Kaur, H.; Devi, J.; Atri, C.; Gupta, M. Using near-infrared reflectance spectroscopy (NIRS) and chemometrics for non-destructive estimation of the amount and composition of seed tocopherols in Brassica juncea (Indian mustard). J. Food Sci. Technol. 2025, in press. [Google Scholar] [CrossRef]
- Zaukuu, J.-L.Z.; Attipoe, N.Q.; Korneh, P.B.; Mensah, E.T.; Bimpong, D.; Amponsah, L.A. Detection of bissap calyces and bissap juices adulteration with sorghum leaves using NIR spectroscopy and VIS/NIR spectroscopy. J. Food Compos. Anal. 2025, 141, 107358. [Google Scholar] [CrossRef]
- Zhao, X.; Zheng, N.; Wang, J.; Zhang, Y. Application of Near-Infrared Spectroscopy in Quality Detection of Milk and Dairy Products. Anim. Nutr. J. 2024, 36, 5451–5459. [Google Scholar]
- Bao, L.; Du, B.; Liu, F.; Ding, C.; Li, Q.; Shi, Y.; Huang, X.; Li, K. Development of near-infrared spectroscopy and its application in petrochemical industry. China Metrol. 2024, 7, 69–73. [Google Scholar]
- Yan, Y.; Liang, X.; Qin, B.; Zhuang, Y.; Chen, J.; Yin, G. Nondestructive identification and content prediction of anticancer active ingredient in sorafenib tosylate tablets based on near-infrared spectroscopy. Guangzhou Chem. 2022, 50, 45–52. [Google Scholar]
- Hao, Y.; Du, J.; Zhang, S.; Wang, Q. Research on construction of visible-near infrared spectroscopy analysis model for soluble solid content in different colors of jujube. Spectrosc. Spectr. Anal. 2021, 41, 3385–3391. [Google Scholar]
- Wang, B.; Li, L. Online detection of soluble solid content in fresh jujube based on visible/near-infrared spectroscopy. INMATEH Agric. Eng. 2024, 72, 291–298. [Google Scholar] [CrossRef]
- Fan, C.; Liu, Y.; Cui, T.; Qiao, M.; Yu, Y.; Xie, W.; Huang, Y. Quantitative prediction of protein content in corn kernel based on near-infrared spectroscopy. Foods 2024, 13, 4173. [Google Scholar] [CrossRef] [PubMed]
- Ji, Q.; Li, C.; Fu, X.; Liao, J.; Hong, X.; Yu, X.; Ye, Z.; Zhang, M.; Qiu, Y. Protected geographical indication discrimination of Zhejiang and non-Zhejiang Ophiopogonis japonicus by near-infrared (NIR) spectroscopy combined with chemometrics: The influence of different stoichiometric and spectrogram pretreatment methods. Molecules 2023, 28, 2803. [Google Scholar] [CrossRef]
- Höpker, C.; Dittert, K.; Olfs, H.-W. On-Farm Application of Near-Infrared Spectroscopy for the Determination of Nutrients in Liquid Organic Manures: Challenges and Opportunities. Agriculture 2025, 15, 185. [Google Scholar] [CrossRef]
- Bian, X.; Zhang, R.; Liu, P.; Xiang, Y.; Wang, S.; Tan, X. Near infrared spectroscopic variable selection by a novel swarm intelligence algorithm for rapid quantification of high order edible blend oil. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2023, 284, 121788. [Google Scholar] [CrossRef]
- Li, H.; Li, M.; Tang, H.; Li, H.; Zhang, T.; Yang, X.F. Quantitative analysis of phenanthrene in soil by fluorescence spectroscopy coupled with the CARS-PLS model. RSC Adv. 2023, 13, 9353–9360. [Google Scholar] [CrossRef]
- Zhang, Z.S.; Zhang, R.J.; Gu, H.W.; Xie, Q.; Zhang, X.; Sa, J.; Liu, Y. Research on the twin check abnormal sample detection method of mid-infrared spectroscopy. Spectrosc. Spectr. Anal. 2024, 44, 1546–1552. [Google Scholar]
- Liu, Z.; Cai, W.; Shao, X. Outlier detection in near-infrared spectroscopic analysis by using Monte Carlo cross-validation. Sci. China Ser. B Chem. 2008, 51, 751–759. [Google Scholar] [CrossRef]
- Liu, J.; Fan, S.; Cheng, W.; Yang, Y.; Li, X.; Wang, Q.; Liu, B.; Xu, Z.; Wu, Y. Non-destructive discrimination of sunflower seeds with different internal mildew grades by fusion of near-infrared diffuse reflectance and transmittance spectra combined with 1D-CNN. Foods 2023, 12, 295. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, L.; Wei, W.; Zhang, Y. Hyperspectral image classification with data augmentation and classifier fusion. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1420–1424. [Google Scholar] [CrossRef]
- Zhu, S.; Gao, X.; Zhang, Z.; Cao, H.; Zheng, D.; Zhang, L.; Xie, Q.; Sa, J. Partitioning proportion and pretreatment method of infrared spectral dataset. Chin. J. Anal. Chem. 2022, 50, 1415–1429. [Google Scholar] [CrossRef]
- She, X.; Huang, J.; Cao, X.; Wu, M.; Yang, Y. Rapid measurement of total saponins, mannitol, and naringenin in Dendrobium officinale by near-infrared spectroscopy and chemometrics. Foods 2024, 13, 1199. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Han, P.; Cui, G.; Wang, D.; Liu, S.; Zhao, Y. The NIR detection research of soluble Solid contentin watermelon based on SPXY algorithm. Spectrosc. Spect. Anal. 2019, 39, 738–742. [Google Scholar] [CrossRef]
- Araújo dos Santos, J.V.; Lopes, H. Savitzky-Golay smoothing and differentiation filters for damage identification in plates. Procedia Struct. Integr. 2024, 54, 575–584. [Google Scholar] [CrossRef]
- Mishra, P.; Biancolillo, A.; Roger, J.M.; Marini, F.; Rutledge, D.N. New data preprocessing trends based on ensemble of multiple preprocessing techniques. TrAC Trends Anal. Chem. 2020, 132, 116045. [Google Scholar] [CrossRef]
- Mishra, P.; Lohumi, S. Improved prediction of protein content in wheat kernels with a fusion of scatter correction methods in NIR data modelling. Biosyst. Eng. 2021, 23, 93–97. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, S.; Zhang, Y. Non-Destructive Detection of Water Content in Pork Based on NIR Spatially Resolved Spectroscopy. Agriculture 2023, 13, 2114. [Google Scholar] [CrossRef]
- Lotfi, M.; Arab Chamjangali, M.; Mozafari, Z. Ridge regression coupled with a new uninformative variable elimination algorithm as a new descriptor screening method: Application of data reduction in QSAR study of some sulfonated derivatives as c-Met inhibitors. Chemom. Intell. Lab. Syst. 2023, 232, 104714. [Google Scholar] [CrossRef]
- Han, J.; Guo, J.; Zhang, Z.; Yang, X.; Shi, Y.; Zhou, J. The Rapid Detection of Trash Content in Seed Cotton Using Near-Infrared Spectroscopy Combined with Characteristic Wavelength Selection. Agriculture 2023, 13, 1928. [Google Scholar] [CrossRef]
- Wang, J.; Lu, S.; Wang, S.H.; Zhang, Y.D. A review on extreme learning machine. Multimed Tools Appl. 2022, 81, 41611–41660. [Google Scholar] [CrossRef]
- Ma, J.; Sun, D.-W.; Pu, H.; Wei, Q.; Wang, X. Protein content evaluation of processed pork meats based on a novel single shot (snapshot) hyperspectral imaging sensor. J. Food Eng. 2019, 240, 207–213. [Google Scholar] [CrossRef]
- Peña, D.; Yohai, V.J. A review of outlier detection and robust estimation methods for high dimensional time series data. Econom. Stat. 2023, in press. [Google Scholar] [CrossRef]
- Andries, J.P.M.; Vander Heyden, Y. Calibration set reduction by the selection of a subset containing the best fitting samples showing optimally predictive ability. Talanta 2024, 266, 124943. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Yan, Z.; Zhang, L. A comparative study of 11 non-linear regression models highlighting autoencoder, DBN, and SVR, enhanced by SHAP importance analysis in soybean branching prediction. Sci. Rep. 2024, 14, 5905. [Google Scholar] [CrossRef]
- Jiao, Y.; Li, Z.; Chen, X.; Fei, S. Preprocessing methods for near-infrared spectrum calibration. J. Chemom. 2020, 34, e3306. [Google Scholar] [CrossRef]
- Robert, G.; Gosselin, R. Evaluating the impact of NIR pre-processing methods via multiblock partial least-squares. Anal. Chim. Acta 2022, 1189, 339255. [Google Scholar] [CrossRef]
- Wang, H.; Huang, W.; Cai, Z.; Yan, Z.; Li, S.; Li, J. Online detection of soluble solid content in watermelon based on full-transmission visible and near-infrared spectroscopy. Spectrosc. Spect. Anal. 2024, 44, 1710–1717. [Google Scholar]
- Li, X.; Fu, X.; Li, H. A CARS-SPA-GA feature wavelength selection method based on hyperspectral imaging with potato leaf disease classification. Sensors 2024, 24, 6566. [Google Scholar] [CrossRef]
- Cui, T.; Lu, Z.; Xue, L.; Wan, S.; Zhao, X.; Wang, H. Research on Research on the rapid detection model of tomato sugar based on near-infrared reflectance spectroscopy. Spectrosc. Spect. Anal. 2023, 43, 1218–1224. [Google Scholar]
- Fu, G.; Gao, Z.; Yang, J.; Li, H.; Luo, F.; Liang, Y.; Yan, D.; Wei, F.; Chang, J.; Ji, X. NIR-based identification of flue-cured tobacco oil grades. J. Henan Agric. Univ. 2024, 58, 583–591. [Google Scholar]
- Sun, H.; Zhang, S.; Ren, R.; Xue, J.; Zhao, H. Detection of soluble solids content in different cultivated fresh jujubes based on variable optimization and model update. Foods 2022, 11, 2522. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.; Meng, Q.; Wu, Z.; Chang, H.; Ni, C.; Qiu, Z.; Li, H.; Huang, Y. Fruit soluble solids content non-destructive detection based on visible/near-infrared hyperspectral imaging in mango. J. Fruit Sci. 2024, 41, 122–132. [Google Scholar]
- Su, Y.; He, K.; Liu, W.; Li, J.; Hou, K.; Lv, S.; He, X. Detection of soluble solid content in table grapes during storage based on visible-near-infrared spectroscopy. Food Innov. Adv. 2025, 4, 10–18. [Google Scholar] [CrossRef]
- Hina, A.; Saadeh, W. Noninvasive blood glucose monitoring systems using near-infrared technology—A review. Sensors 2022, 22, 4855. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Partitioning Method | Sample Size | APC(%) | RC2 | RMSEC (°Brix) | APP(%) | RP2 | RMSEP (°Brix) |
|---|---|---|---|---|---|---|---|
| RS | 150 | 99.239 | 0.990 | 0.101 | 98.716 | 0.957 | 0.209 |
| 150 | 99.284 | 0.990 | 0.098 | 98.834 | 0.971 | 0.184 | |
| 150 | 99.316 | 0.992 | 0.087 | 98.654 | 0.971 | 0.200 | |
| 150 | 99.243 | 0.991 | 0.095 | 98.727 | 0.967 | 0.192 | |
| 150 | 99.308 | 0.992 | 0.091 | 98.610 | 0.956 | 0.201 | |
| 160 | 98.945 | 0.985 | 0.170 | 97.999 | 0.922 | 0.258 | |
| 160 | 99.200 | 0.992 | 0.107 | 98.115 | 0.960 | 0.289 | |
| 160 | 99.068 | 0.989 | 0.134 | 97.683 | 0.927 | 0.330 | |
| 160 | 99.246 | 0.994 | 0.102 | 97.931 | 0.926 | 0.311 | |
| 160 | 99.207 | 0.989 | 0.109 | 98.011 | 0.969 | 0.319 | |
| KS | 150 | 99.196 | 0.989 | 0.106 | 98.612 | 0.953 | 0.215 |
| 150 | 99.132 | 0.987 | 0.118 | 99.042 | 0.976 | 0.153 | |
| 160 | 99.199 | 0.993 | 0.108 | 98.151 | 0.948 | 0.288 | |
| 160 | 99.205 | 0.993 | 0.106 | 98.448 | 0.959 | 0.257 | |
| SPXY | 150 | 99.129 | 0.989 | 0.111 | 98.660 | 0.888 | 0.198 |
| 150 | 99.114 | 0.988 | 0.124 | 98.496 | 0.876 | 0.208 | |
| 160 | 99.085 | 0.993 | 0.122 | 98.260 | 0.857 | 0.259 | |
| 160 | 99.109 | 0.993 | 0.120 | 98.232 | 0.864 | 0.253 |
| Preprocessing | Number of Features | APC(%) | RC2 | RMSEC (°Brix) | APP(%) | RP2 | RMSEP (°Brix) |
|---|---|---|---|---|---|---|---|
| Raw | 146 | 95.663 | 0.519 | 0.710 | 95.472 | 0.439 | 0.744 |
| SG | 4 | 93.495 | 0.014 | 1.020 | 94.143 | 0.145 | 0.918 |
| FD | 87 | 99.180 | 0.99 | 0.101 | 98.632 | 0.953 | 0.216 |
| MSC | 169 | 95.801 | 0.567 | 0.673 | 95.610 | 0.331 | 0.812 |
| SNV | 82 | 99.141 | 0.987 | 0.116 | 98.598 | 0.950 | 0.221 |
| SG + SNV | 81 | 99.132 | 0.987 | 0.118 | 99.042 | 0.976 | 0.153 |
| FD + SG | 96 | 99.195 | 0.992 | 0.094 | 98.499 | 0.958 | 0.203 |
| SG + MSC | 266 | 96.155 | 0.675 | 0.583 | 95.714 | 0.368 | 0.790 |
| SNV + FD | 112 | 99.162 | 0.991 | 0.099 | 98.529 | 0.952 | 0.217 |
| FD + SNV | 122 | 99.113 | 0.989 | 0.108 | 98.668 | 0.961 | 0.195 |
| FD + MSC | 70 | 98.952 | 0.973 | 0.167 | 97.690 | 0.918 | 0.285 |
| SNV + MSC | 62 | 98.993 | 0.977 | 0.156 | 98.242 | 0.941 | 0.242 |
| SG + SNV + FD | 83 | 99.153 | 0.989 | 0.110 | 98.569 | 0.955 | 0.211 |
| SG + SNV + MSC | 76 | 99.198 | 0.989 | 0.108 | 97.712 | 0.880 | 0.344 |
| SG + FD + MSC | 214 | 99.113 | 0.992 | 0.093 | 97.588 | 0.898 | 0.317 |
| SNV + FD + MSC | 146 | 99.110 | 0.990 | 0.103 | 98.171 | 0.937 | 0.249 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Ma, S.; Qi, F.; Wang, F.; Xu, H. Application of Vis/NIR Spectroscopy in the Rapid and Non-Destructive Prediction of Soluble Solid Content in Milk Jujubes. Agriculture 2025, 15, 1382. https://doi.org/10.3390/agriculture15131382
Yang Y, Ma S, Qi F, Wang F, Xu H. Application of Vis/NIR Spectroscopy in the Rapid and Non-Destructive Prediction of Soluble Solid Content in Milk Jujubes. Agriculture. 2025; 15(13):1382. https://doi.org/10.3390/agriculture15131382
Chicago/Turabian StyleYang, Yinhai, Shibang Ma, Feiyang Qi, Feiyue Wang, and Hubo Xu. 2025. "Application of Vis/NIR Spectroscopy in the Rapid and Non-Destructive Prediction of Soluble Solid Content in Milk Jujubes" Agriculture 15, no. 13: 1382. https://doi.org/10.3390/agriculture15131382
APA StyleYang, Y., Ma, S., Qi, F., Wang, F., & Xu, H. (2025). Application of Vis/NIR Spectroscopy in the Rapid and Non-Destructive Prediction of Soluble Solid Content in Milk Jujubes. Agriculture, 15(13), 1382. https://doi.org/10.3390/agriculture15131382