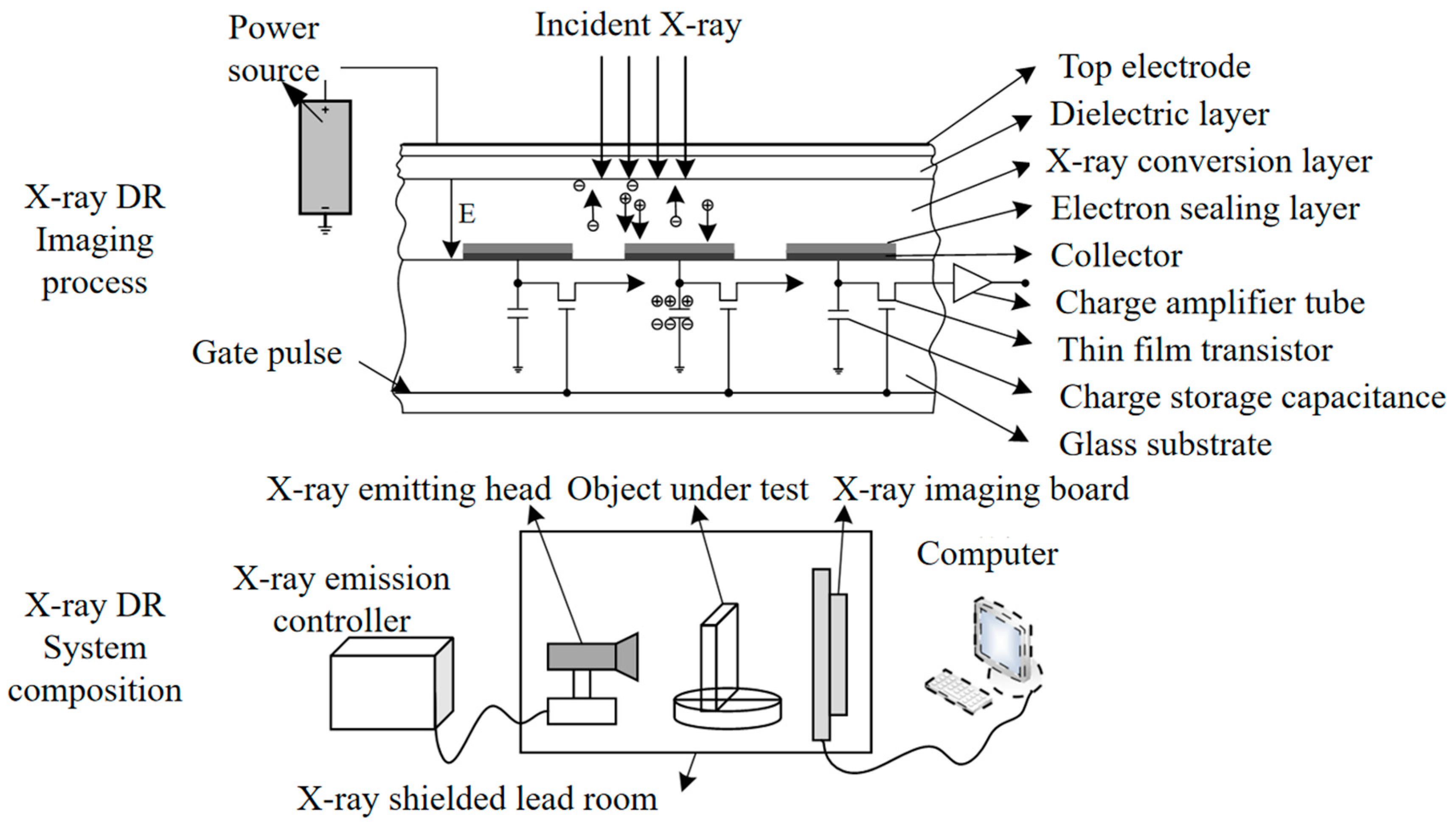
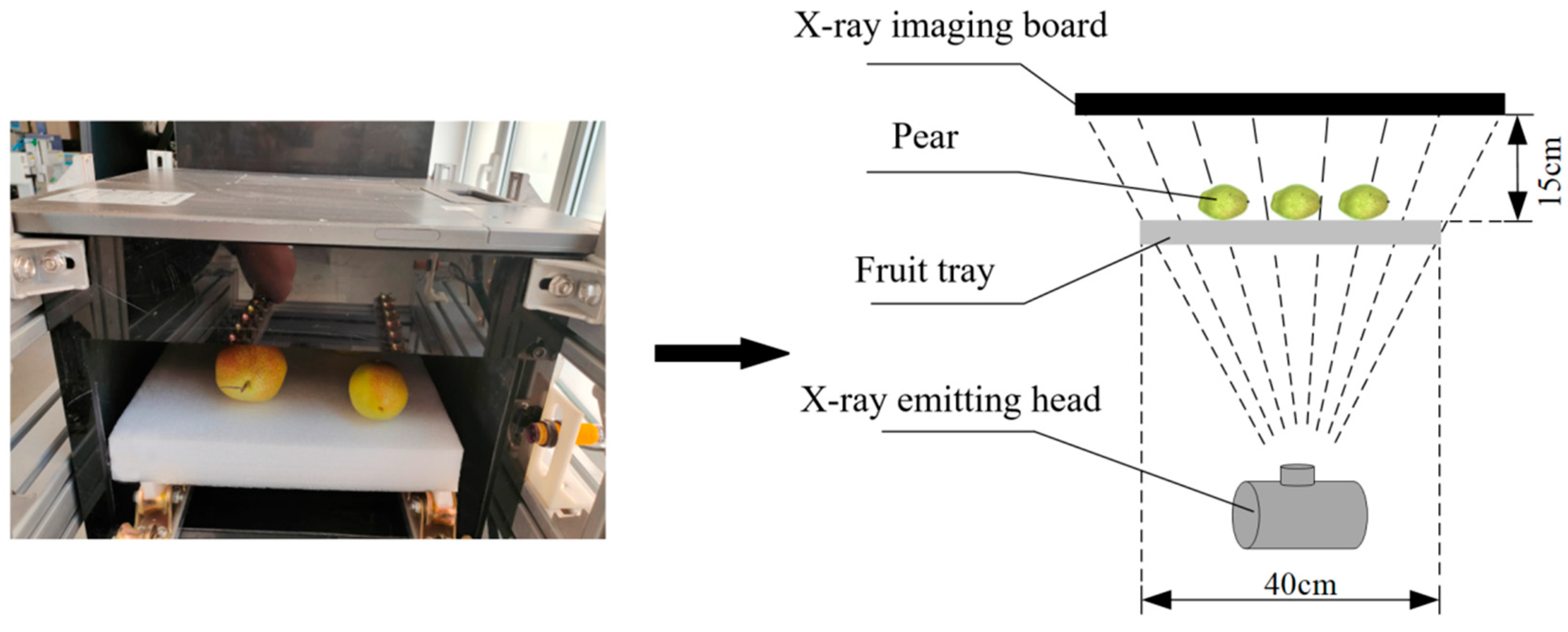
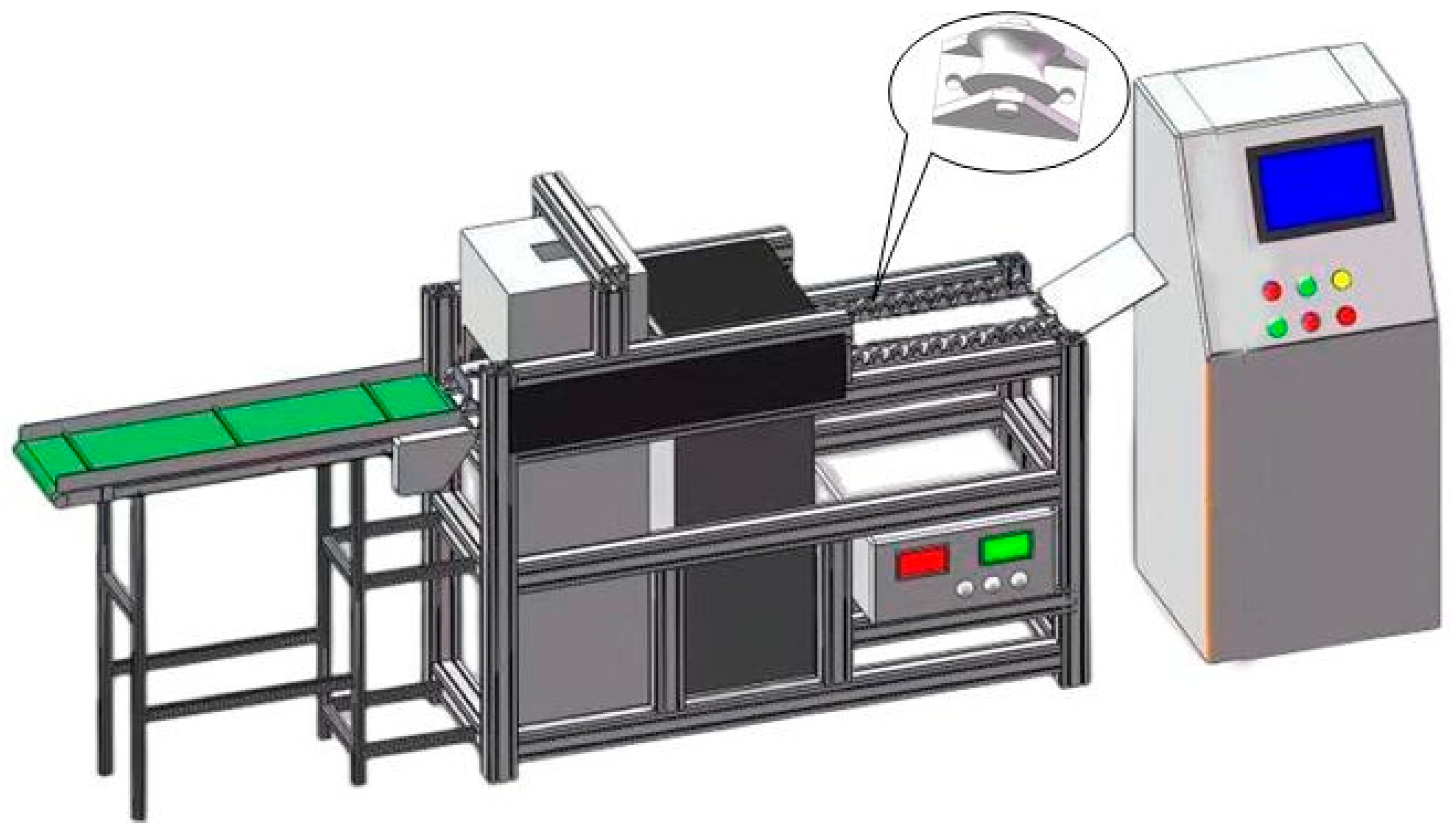
2.1. X-Ray Imaging Detection System
X-ray DR (Direct Radiography) technology uses photoconductive materials for imaging. When X-rays are applied to photoconductive materials, electron-hole pairs are generated. Under the influence of an external electric field, the electron-hole pairs move in opposite directions, creating a current. The magnitude of the current is directly proportional to the number of incident X-ray photons. Thin-film transistors integrate the current into charges for storage. As a result, each thin-film transistor becomes a pixel. Under the action of a field-effect transistor within the pixel, when the electric signal in the pixel unit is read, the charges inside the pixel unit are transferred to the external circuit for release. The read electric signal is amplified and synchronized to be converted into a digital signal, as shown in
Figure 1. X-ray DR imaging provides high resolution, can directly output X-ray images, and offers high work efficiency, enabling online detection. For detecting the internal quality of pears, X-ray DR technology is employed.
Using the strong penetrating ability of X-rays, internal defects in pears can be detected. When incident X-rays penetrate the interior of the object, some of the X-ray photons can pass through the object without interacting with it, while others are absorbed by the object, with their energy being absorbed by the object’s electrons, or scattered. The initial energy of the X-ray photons affects their ability to penetrate the object. The initial energy of the X-ray photons can be calculated using the Planck equation:
where
is the initial energy of the X-ray photons,
is Planck’s constant,
is the speed of light, and
is the wavelength. The shorter the wavelength, the greater the photon energy, and the stronger the penetration ability. X-rays, in particular, have a relatively short wavelength, granting them strong penetration capability. Meanwhile, the density of the object also affects the ability of X-rays to penetrate. The denser the object, the more X-rays it absorbs, and the less it allows penetration. The intensity of monochromatic X-ray transmission through an object follows the formula:
where
is the transmitted intensity of the X-ray after penetrating the object,
is the initial transmitted intensity of the X-ray,
represents the attenuation coefficient, which is related to the density of the object, and
denotes the path length of the X-ray through the object.
Since the density of the internal defect areas of the object differs from that of the normal parts, the absorption of X-rays also differs, causing a change in the intensity of the X-rays after passing through the object. This change is captured by the X-ray flat panel detector and is ultimately displayed as an image with varying grayscale distribution. The areas with higher density in the object will have lower grayscale values on the corresponding regions of the image, appearing darker to the human eye.
X-ray imaging is a non-destructive testing method that does not alter the chemical composition or nutritional content of fruits, unlike traditional physical and chemical testing methods. By measuring the internal density variations in the fruit, X-ray imaging effectively detects internal defects without affecting its appearance, hardness, sugar content, or other chemical parameters. When using X-rays to detect internal defects in pears, the density of the defect areas differs from that of the normal tissues, leading to variations in X-ray absorption, which are reflected in the resulting image. However, since the internal defects, core, stem, and calyx parts of the pear may be confused in the 2D X-ray image, misjudgments may occur during quality detection. Deep learning technology lays the foundation for high-accuracy detection.
2.2. Internal Quality Detection Evaluation Indicators of Pears
When performing internal quality detection of pears using X-ray imaging technology, the X-ray images of the pears can clearly reflect internal defects. Since the grayscale variations in the regions corresponding to the fruit stem, calyx, and core in the X-ray image are similar to those in the defect areas, traditional machine learning methods often perform poorly when using X-ray images for non-destructive internal defect detection in pears. This section will focus on the X-ray imaging detection system and the application of deep learning in detecting internal defects in pears using X-ray images.
The evaluation of the internal quality of pears is still conducted through manual experiments. First, pears are subjected to X-ray imaging to obtain X-ray images that reflect internal defects. Then, the pears are sliced multiple times after X-ray imaging, and the internal defect information is observed. The internal quality of the pears is evaluated based on this observation, and the X-ray images are annotated accordingly. The annotations are divided into two categories: those with internal defects and those without internal defects, as shown in
Figure 2.
The common internal defects in pear samples discussed in this paper include bruises, russeting, insect infestations, corking, internal rot, etc., as shown in
Figure 3. Different types of internal defects in pears can cause changes in the grayscale distribution in the pear’s X-ray image.
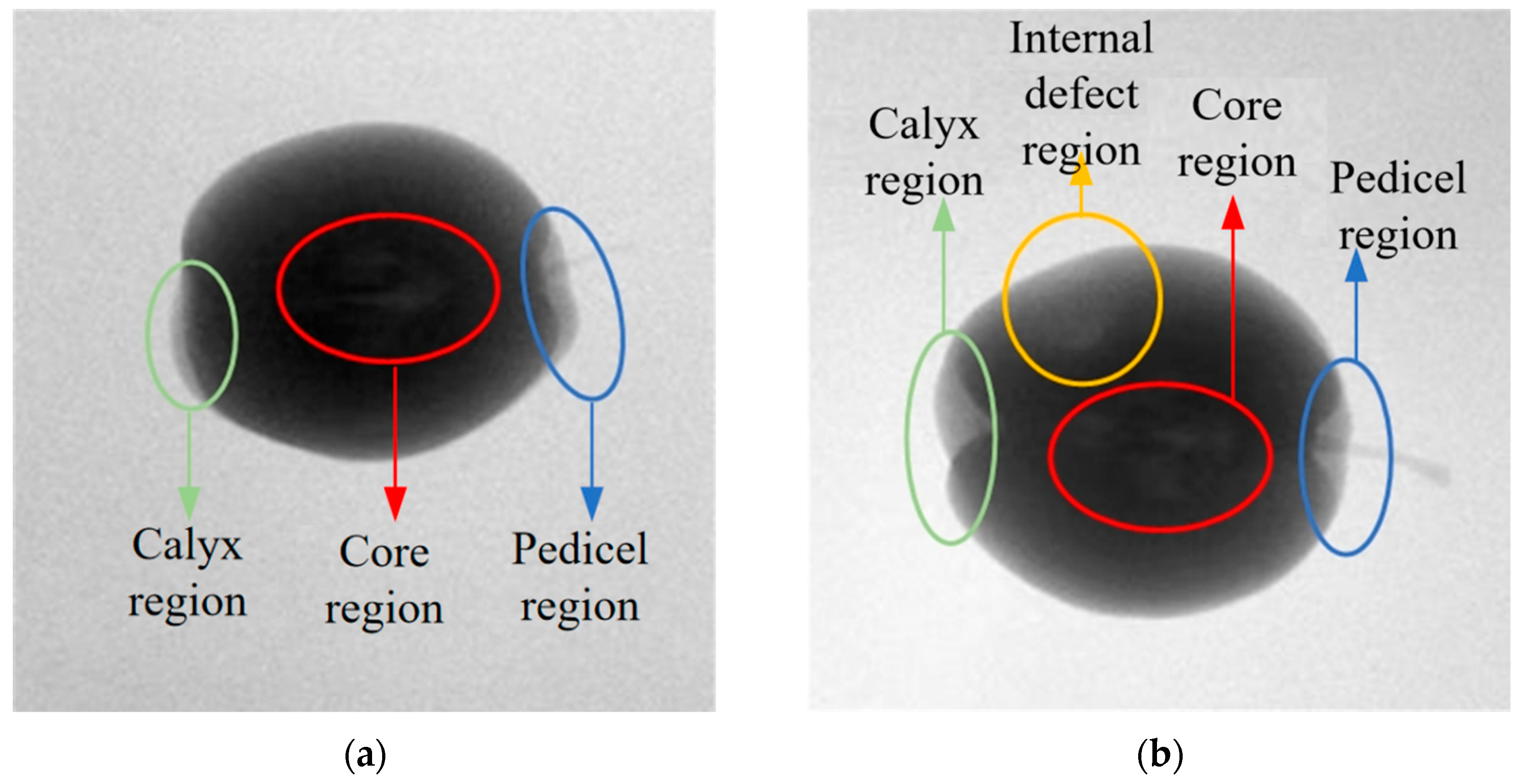
After performing X-ray imaging on the pears, X-ray images are obtained.
Figure 4 shows the X-ray images of pears with no internal defects and pears with internal defects. The red circle marks the core region, the green circle marks the calyx region, the blue circle marks the stem region, and the yellow circle marks the internal defect region. It can be observed that there are grayscale value differences between the defective tissue inside the pear and the surrounding healthy tissue in the corresponding X-ray image. Meanwhile, similar grayscale value differences are also present in the X-ray image regions corresponding to the pear’s stem, calyx, and core. This causes interference when judging the internal quality of the pear based on its X-ray image. However, the regions of the pear’s stem, calyx, and core are relatively fixed in distribution compared to the internal defect regions. Based on this observation, we construct a probabilistic spatial prior map, which reflects the likelihood of these structural regions occurring in normalized image coordinates. For instance, the core generally appears near the center of the image, while the stem and calyx are distributed at the top and bottom ends, respectively.
During the inference phase, the spatial prior map is employed to modulate the classifier’s response. When a suspected defect region overlaps with a high-probability structural zone, the classifier applies a confidence suppression mechanism, such as threshold elevation or Gaussian attenuation, to reduce false positives. This allows the model to diminish spurious activations originating from non-defective anatomical features. Moreover, this prior knowledge can be fused with intermediate feature maps from the deep network, serving as a structural guidance signal during training. It encourages the model to focus on truly anomalous regions while suppressing attention to known non-defect areas. As a result, the approach significantly improves the classifier’s robustness, particularly under challenging conditions such as low contrast or background interference, and effectively reduces the overall false detection rate.
2.3. Artificial Feature Classifier and DCNN Classifier
The combination of an artificial feature classifier and a DCNN (Deep Convolutional Neural Network) classifier may promote the improvement of the detection accuracy for internal quality of pears. This paper considers combining the artificial feature classifier and the DCNN classifier under multi-criteria decision theory to enhance the detection accuracy.
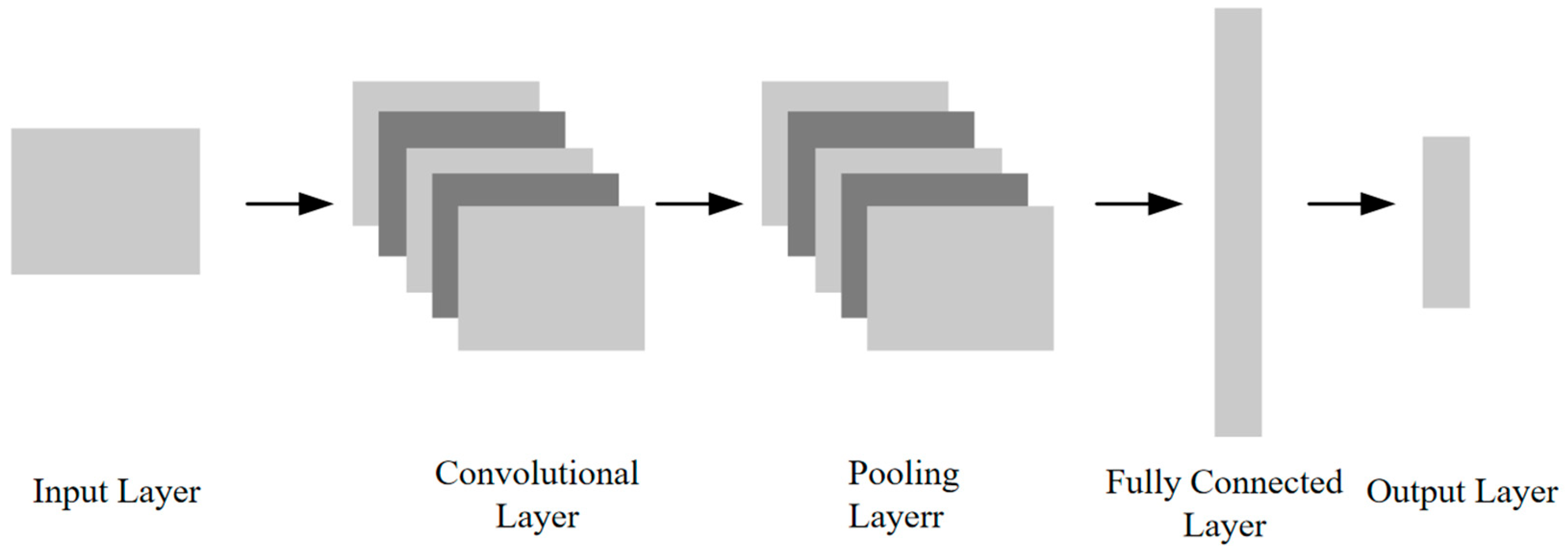
A DCNN is a widely used architecture for object classification, leveraging operations such as feature mapping, weight sharing, local connectivity, and pooling. Typically, a DCNN consists of an input layer, multiple convolutional layers, pooling layers, fully connected layers, and an output layer, as illustrated in
Figure 5.
The input layer receives the sample image and feeds it into the network in the form of a tensor. The output layer produces the corresponding category label.
The convolutional layer enables DCNNs to effectively learn representative features by applying fixed-size filters across the input image to capture local spatial patterns. Varying kernel sizes allow for multiscale feature extraction. With a defined stride (S) and padding (P), the filter slides over the input, aggregating local information into a feature map that feeds into the next layer. For square inputs and kernels, the output feature map size is given by
where
represents the number of pixels along each edge of the square output feature map after the convolution operation,
denotes the size (width or height) of the input feature map,
is the size of the convolutional kernel,
is the stride with which the kernel slides across the input, and
is the number of zero-padding pixels added to the input along each border. When the result of the calculation is not an integer, the output size is typically rounded down using the floor function. The formula for computing the output feature map size is given by
where
represents the input image and
denotes the convolution kernel. The operation is a two-dimensional discrete convolution, which can be intuitively understood as the kernel sliding across the image. At each spatial position, element-wise multiplication is performed between the overlapping regions of the kernel and the input image, followed by summation to produce a single output value in the corresponding location of the feature map.
The pooling layer, or downsampling layer, reduces the spatial dimensions of feature maps to lower computational complexity while retaining key features. Unlike convolutional layers that learn spatial hierarchies, pooling emphasizes feature presence over exact location, enhancing translational invariance. Common types include max pooling, which selects the highest value in a region, and average pooling, which computes the mean.
The fully connected (FC) layer follows the convolutional and pooling stages. Flattened feature maps are passed through one or more FC layers, where each neuron connects to all previous activations, enabling high-level abstraction and classification. The final layer typically employs a Softmax function to convert raw scores into normalized probabilities summing to one, defined as
where
represents
-th element in the one-dimensional feature vector, and
denotes its corresponding probability output.
The architecture of a DCNN inherently includes both feature extraction and classification components, allowing it to autonomously learn from image data and extract hierarchical, deep-level features. However, the learned features are often abstract and not easily interpretable by humans, which has led to DCNNs being commonly referred to as “black-box” models. In this study, we exploit the strong feature learning capability of DCNNs to detect internal defects in pears using X-ray imaging, where conventional manual or shallow-feature approaches fall short in capturing subtle structural differences.
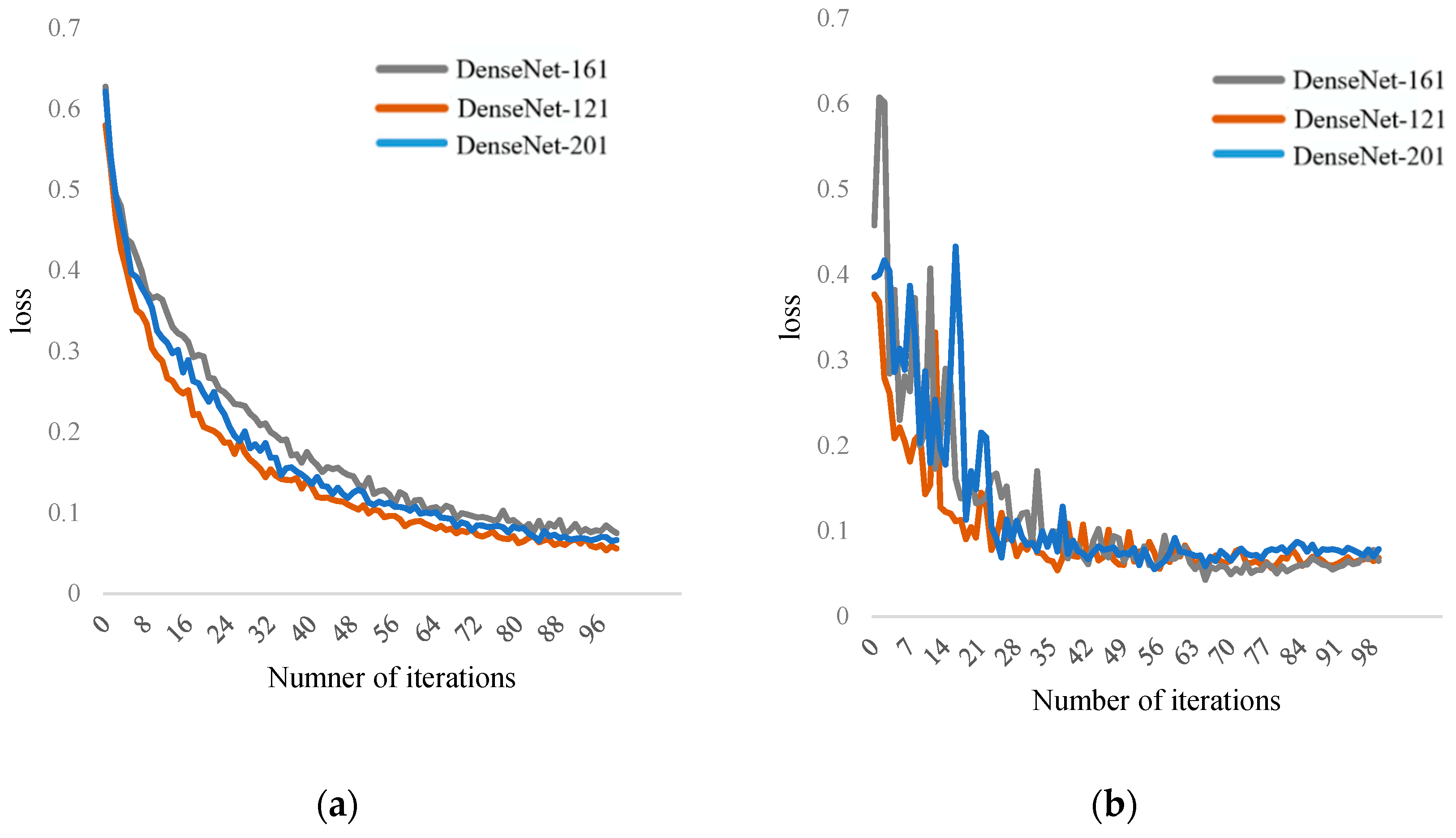
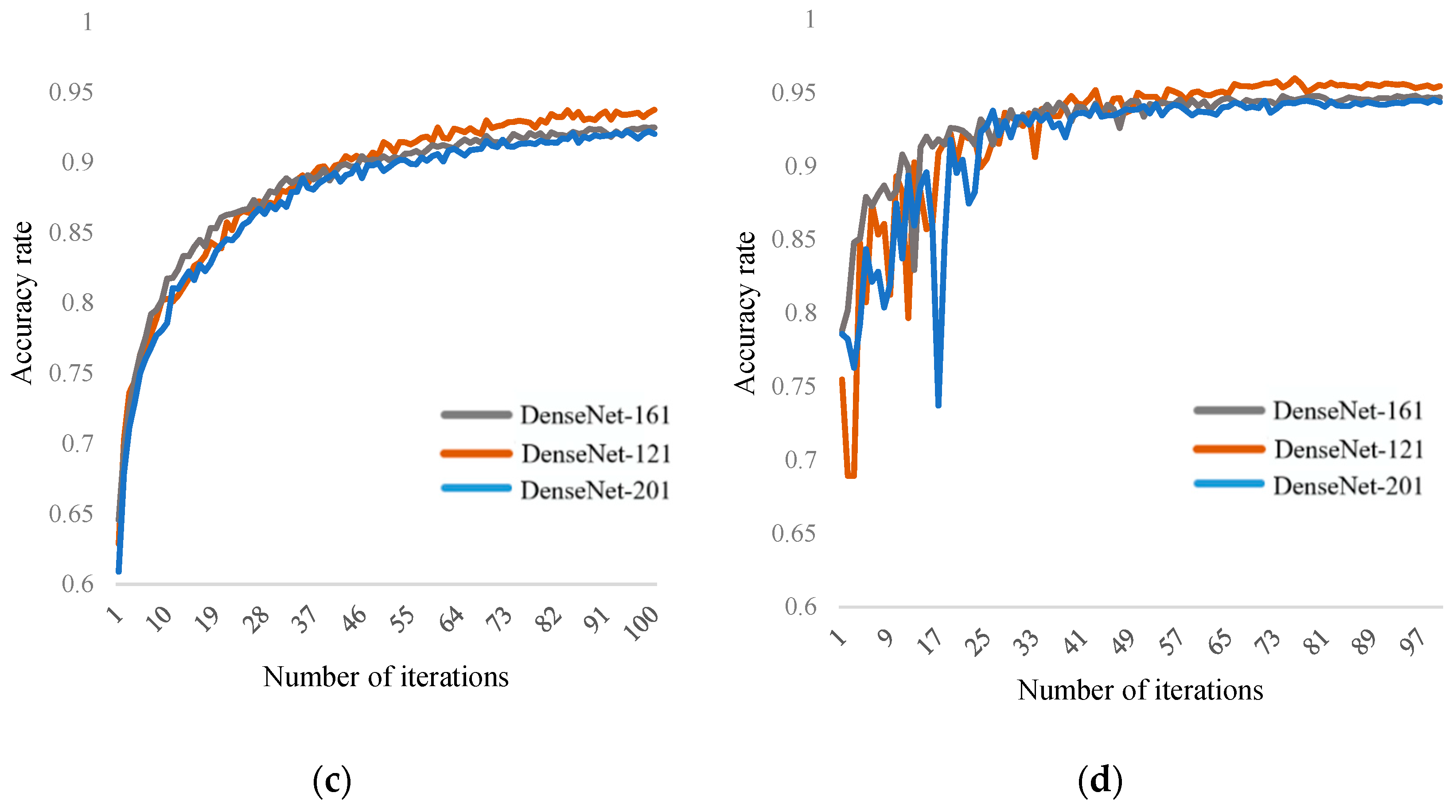
In the process of detecting internal defects in pears using X-ray images, the DCNN channel selects the DenseNet-121 network, which is commonly used in medicine for classifying X-ray images. The network structure is shown in the
Table 1 below.
As can be seen from
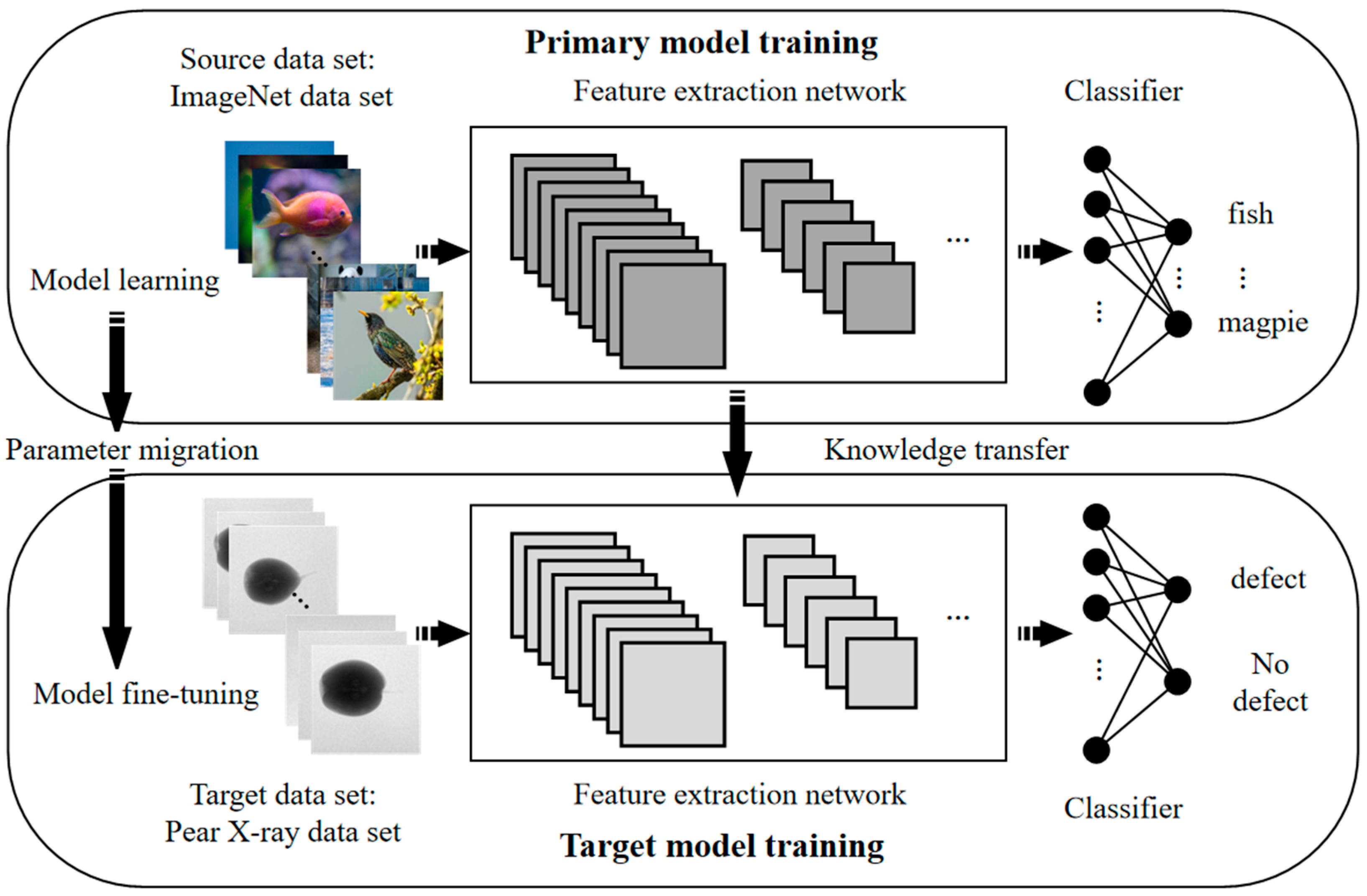
Table 1, the DenseNet-121 network model mainly consists of several Dense blocks and transition blocks. Compared to other DCNN, its advantages lie in reduced parameter quantity and higher computational efficiency. In the final classification, it can utilize both high-level and low-level features, achieving feature reuse and alleviating the problems of gradient vanishing and explosion. Due to the limitations of the dataset, in order to enhance learning efficiency and improve fitting results, although data augmentation was performed, the DCNN still requires large-scale datasets, which are insufficient for this task. Therefore, this paper uses a transfer learning strategy, as shown in
Figure 6. The goal of transfer learning is to apply the knowledge learned from a related domain (source domain) to the target domain (target domain). ImageNet is a large-scale dataset used for image classification tasks, containing over 12 million images from 1000 categories. This dataset can be used for pre-training the DenseNet-121 model. The pre-trained model on the ImageNet dataset is then fine-tuned on the pear X-ray dataset for internal quality evaluation based on pear X-ray images.
When training with transfer learning, it is necessary to fine-tune the original model to adapt it to the target classification task. In this paper, the weights of the network before the fully connected layers are frozen, and the output layer of the fully connected layers is modified to suit the internal quality detection task of pears. Then, the model is retrained using pear X-ray images, focusing primarily on training the parameters of the fully connected layers. Once training is completed, the model can be used for detecting internal quality in pears by determining whether internal defects exist based on the X-ray images.
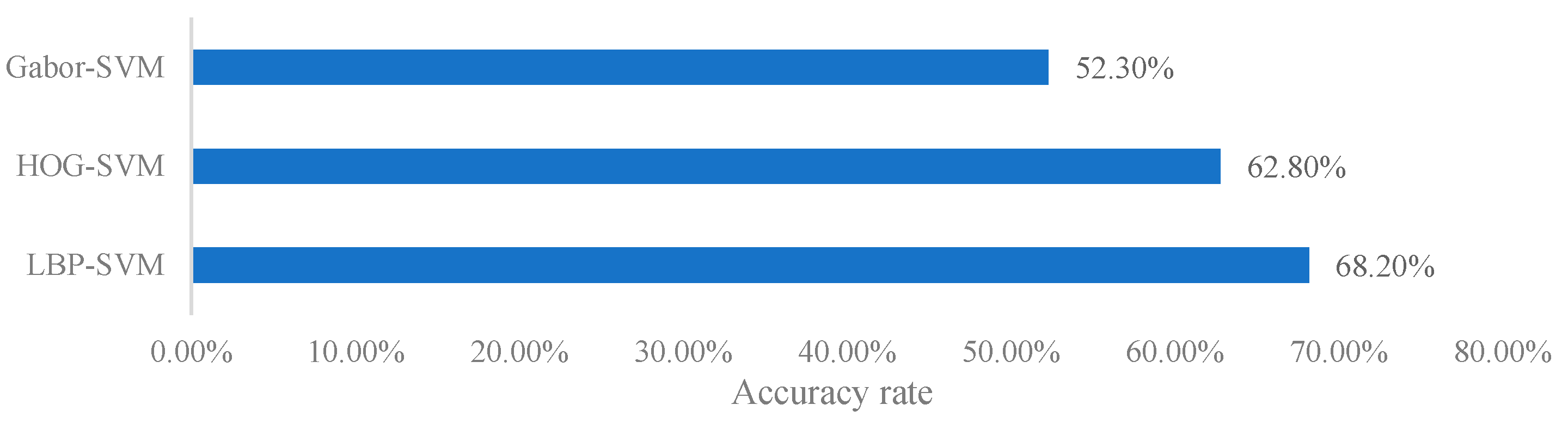
For the artificial feature classifier, commonly used features for X-ray images such as LBP (Local Binary Pattern) and HOG (Histogram of Oriented Gradients) are adopted. In X-ray images of pears, the grayscale variations in the core, stem, and calyx regions are similar to those in defect areas. The use of Local Binary Pattern (LBP) features can effectively prevent confusion between these regions and defect areas, thereby improving detection accuracy. Histogram of Oriented Gradients (HOG) features, on the other hand, are better at capturing edge information in images. When detecting internal grayscale variations in pears, HOG can precisely identify regions associated with internal defects. The integration of these traditional feature extraction methods with deep learning models contributes to enhancing the accuracy of internal quality detection in pears, particularly in the presence of complex image backgrounds and noise interference. Since the detection of internal defects in pears is still a binary classification problem, SVM (Support Vector Machine) is used as the classifier.
LBP is a feature used to describe the local texture of an image. It uses the grayscale value of the specified center pixel as a threshold. The grayscale value of the center pixel is compared with the grayscale values of neighboring pixels at a distance from the center pixel, denoted as . If the grayscale value of a neighboring pixel is greater than the threshold, it is assigned a value of 1; otherwise, it is assigned a value of 0. Starting from the first pixel at the top left, the values of the neighboring pixels are read in a clockwise direction to form a binary number. This binary number is then converted into a decimal value, which becomes the LBP value for the center pixel . By calculating the LBP value for all pixels in the entire image, the LBP image is obtained. The LBP image is then gridded, and the histogram of the LBP values within each grid is calculated to form the feature vector for that grid. The feature vectors of all grids are concatenated to obtain the final feature vector.
LBP features are grayscale-invariant but not rotation-invariant. To achieve rotation invariance, the neighboring pixels surrounding the center pixel are rotated with a radius , and a series of initial LBP values are computed. The minimum value from these values is then taken as the LBP value of the center pixel. This process makes the LBP feature rotation-invariant. However, as the number of sampling points increases, the LBP value increases dramatically, which is not favorable for texture recognition. Therefore, dimensionality reduction in the LBP feature is necessary. The number of times the binary LBP value of the center pixel transitions from 0 to 1 or from 1 to 0 is counted. If this number is less than or equal to two, it is classified as an equivalent pattern class; otherwise, it is classified as a mixed pattern class. This reduces the number of possible LBP values for the center pixel significantly, from to , which greatly reduces the dimensionality of the feature vector. This type of LBP feature is called the LBP equivalent pattern feature, which is one of the features extracted from pear X-ray images in this study.
HOG features can effectively describe the density distribution of local pixel gradient or edge direction in an image. The internal defect regions of pears in X-ray images are presented as variations in grayscale, so HOG features can be used to distinguish whether there are defects inside the pear in X-ray images. The HOG feature vector is generated by concatenating the directional gradient histograms of the local regions in the original image. To suppress noise interference, gamma correction is applied to normalize the color space of the grayscale image. Afterward, the image is processed, and the gradient magnitude and direction of each pixel are calculated. The gradient direction is the object of interest for counting, and the gradient magnitude serves as the weight for the corresponding direction. The grayscale image is gridded, with grid size set as
. The feature vector for each grid is generated by calculating the gradient histogram of the grid. Adjacent grids form a region block, with block size set as
. The number of gradient directions
, grid size, and block size determine the dimensionality
of the feature vector, with the following formula:
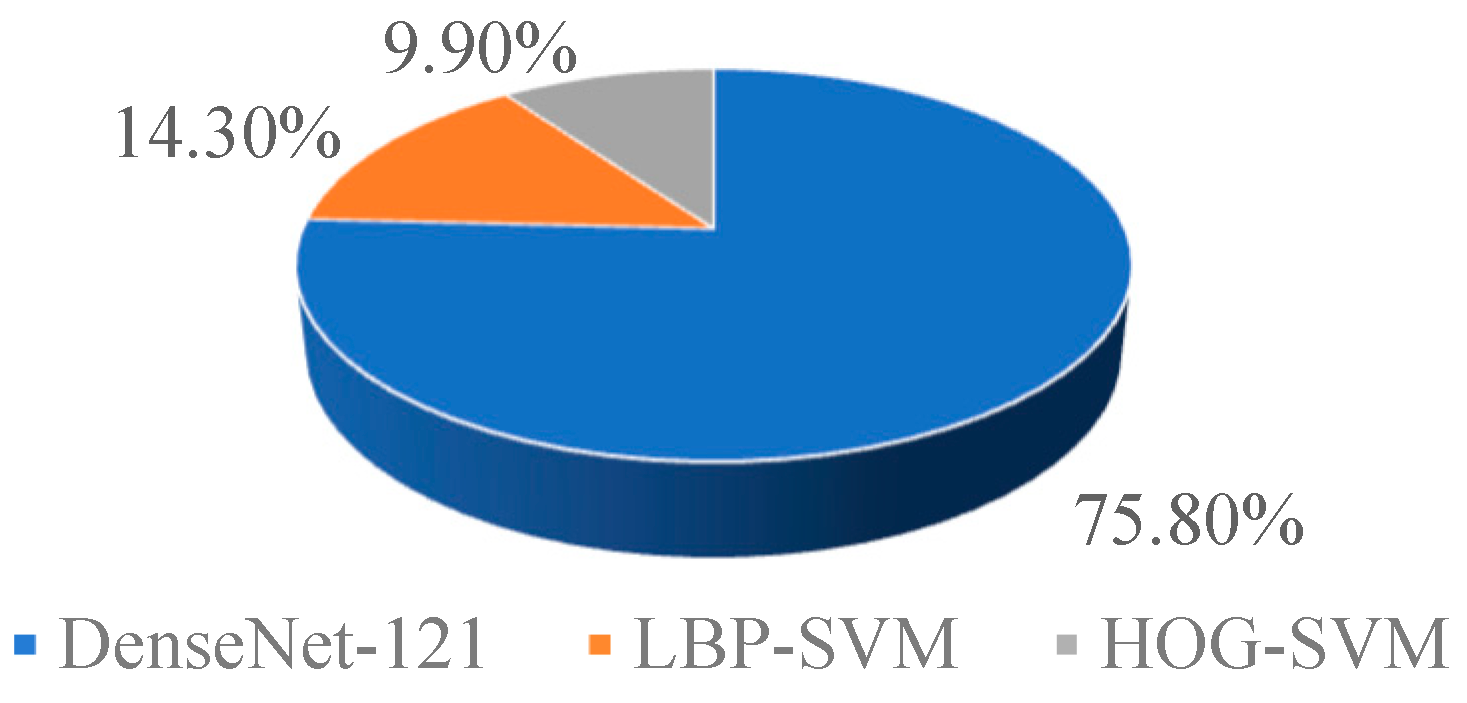
By combining DCNN (Deep Convolutional Neural Network) and the artificial feature classifier, the advantages of both methods can be leveraged. DCNN has a stronger ability to learn features and offers advantages in terms of recognition accuracy and generalization ability. Compared to DCNN, the artificial feature classifier still needs improvement in overall recognition accuracy. However, for this study, the artificial feature classifier shows different tendencies in recognizing samples from different categories. The integration of DCNN and the artificial feature classifier under multi-criteria decision theory enhances the recognition ability of the classification model even further. The following section will present experimental verification and result analysis of the internal quality detection method for pears based on multi-criteria decision theory.
2.4. Multi-Criteria Decision Theory
The method of combining multiple classifiers under multi-criteria decision theory includes the construction of an evaluation matrix, normalization and weighting of the evaluation matrix, calculation of the weights of the classifiers in the combination process, and the classification decision process.
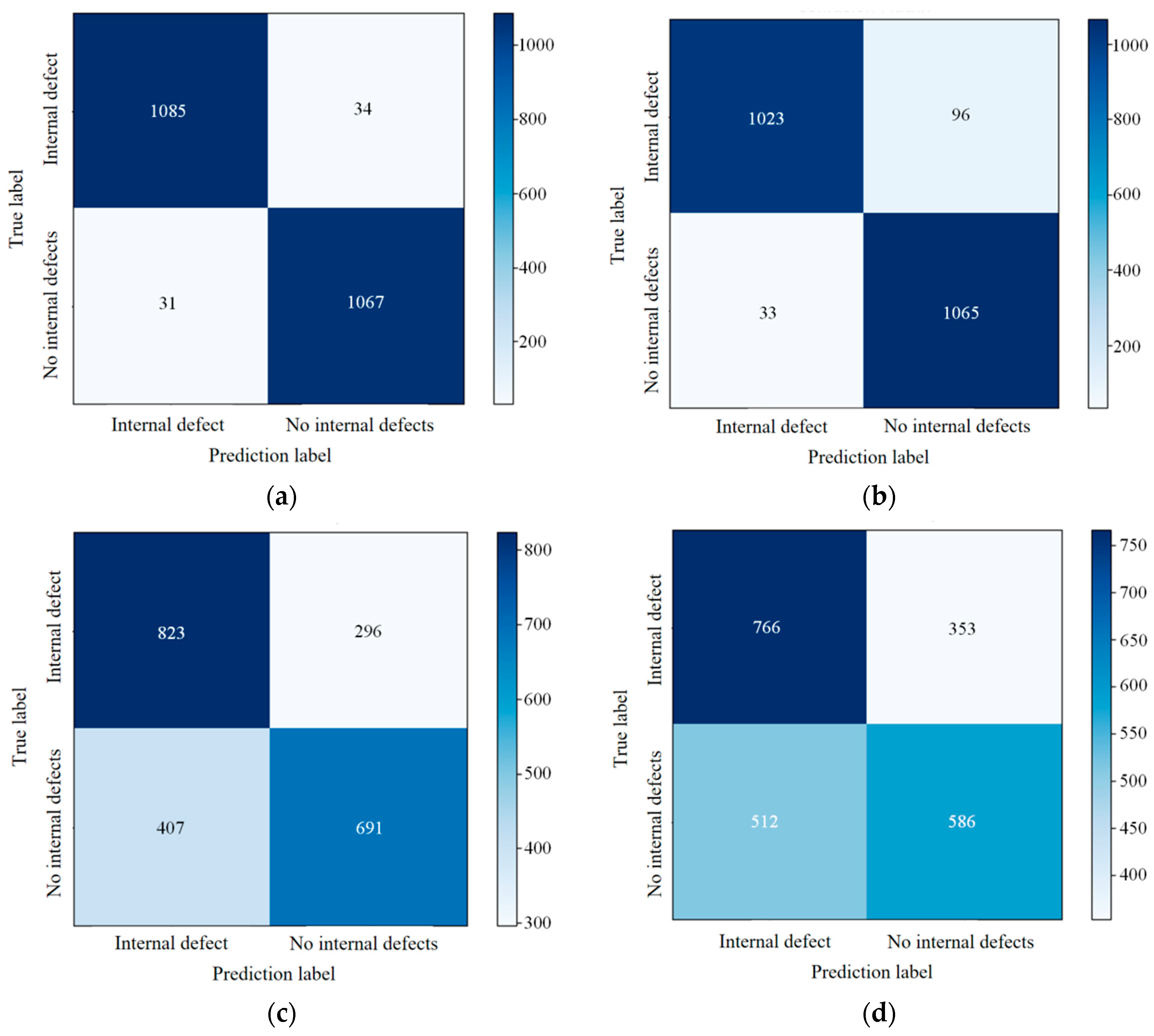
The evaluation matrix is established based on the classification performance metrics of each classifier, including weighted average recall, weighted average precision, weighted average
F1 score, accuracy, and Cohen’s Kappa. The above performance metrics are calculated based on the confusion matrix of each classifier. The formulas for calculating the recall, precision, and
F1 score for each class are as follows:
where
represents the number of samples that actually belong to category
and are predicted as category
,
represents the number of samples that actually belong to category
but are not predicted as category
, and
represents the number of samples that do not belong to class category
but are predicted as category
.
The formulas for calculating the weighted average recall, weighted average precision, and weighted average
F1 score are as follows:
where
is the number of classes. The formula for calculating accuracy is as follows:
where
is the total number of samples in the validation set. The formula for calculating Cohen’s Kappa is as follows:
where
represents the chance agreement. The formula for calculating it is as follows:
where
represents the number of samples in the validation set that actually belong to category
, and
represents the number of samples in the validation set predicted as category
.
The classification performance metrics calculated above are used to construct an evaluation matrix, , where , , , , represents the number of classifiers, andrepresents the number of performance evaluation indicators . corresponds to the classification performance evaluation metric for each classifier.
The performance evaluation metrics of each classifier are combined with weights
, which are calculated using the following formula:
where
represents the relative importance of each classification performance evaluation metric in the multi-classifier combination. The formula for calculating it is as follows:
where
represents the standard deviation of a classification performance evaluation metric corresponding to all classifiers. The formula for calculating it is as follows:
where
represents the elements in the correlation coefficient matrix. The formula for calculating it is as follows:
In Equation (18), represents the average value of the classification performance evaluation metric across all classifiers. Similarly, in Equation (19), the meaning is the same.
The evaluation matrix
is normalized and weighted to obtain
, and the calculation formula is as follows:
Above is the method for constructing and normalizing the evaluation matrix with weighting. Additionally, the weight
of each classifier in the process of combining multiple classifiers is also evaluated. The calculation formula is as follows:
where
and
represent the Euclidean distances between the vector
(Equation (22)), the vector
(Equation (23)), and the vector
(Equation (22)). The calculation formulas for
and
are as follows:
In Formulas (25) and (26),
and
represent the minimum and maximum values of each classification performance evaluation metric across all classifiers, respectively. The calculation formulas for
and
are as follows:
After obtaining the weights of each classifier in the combination process, the next step is to combine the classification decisions from multiple classifiers. As shown in
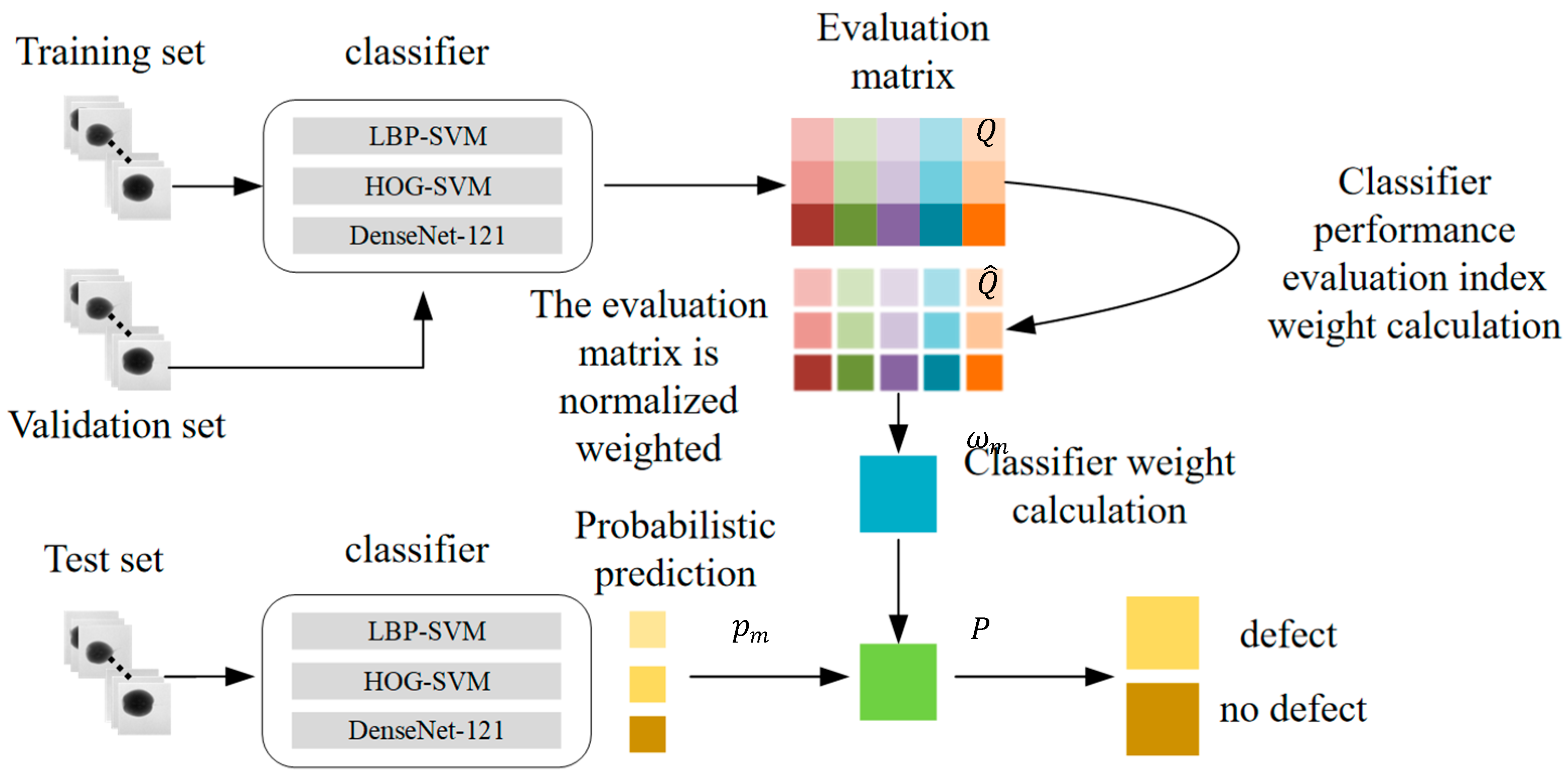
Figure 7, the artificial feature classifier and DCNN classifier are trained using the training set. The validation set is then input into the trained classifiers, and the classification performance evaluation metrics of each classifier are calculated. This completes the establishment and normalization weighting of the evaluation matrix, and the weights of each classifier in the combination process are computed. During the testing phase, the test set is input into each of the trained classifiers to obtain the probability of each sample belonging to the corresponding class. The formula for calculating the probability of each sample in the test set belonging to the corresponding class is as follows:
After the above process, the probabilities are converted into classification labels to obtain the final classification result, determining whether there are internal defects in the pear.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}