
Research on SPAD Inversion of Rice Leaves at a Field Scale Based on Machine Vision and Leaf Segmentation Techniques

 ,
,
Abstract
1. Introduction
2. Study Area and Data Sources
2.1. Experimental Plots and Data Collection
2.2. Image Segmentation Dataset
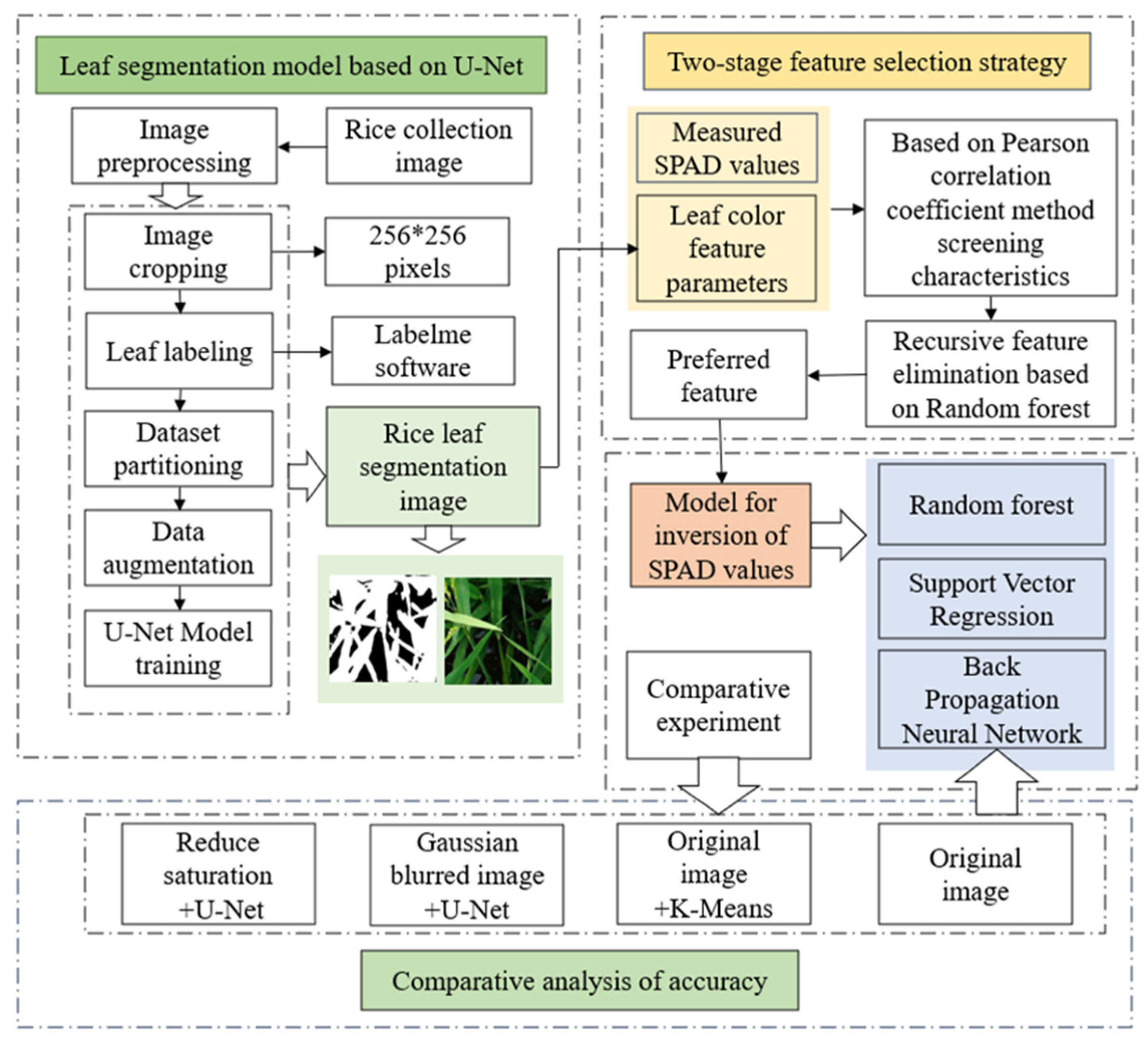
3. Method
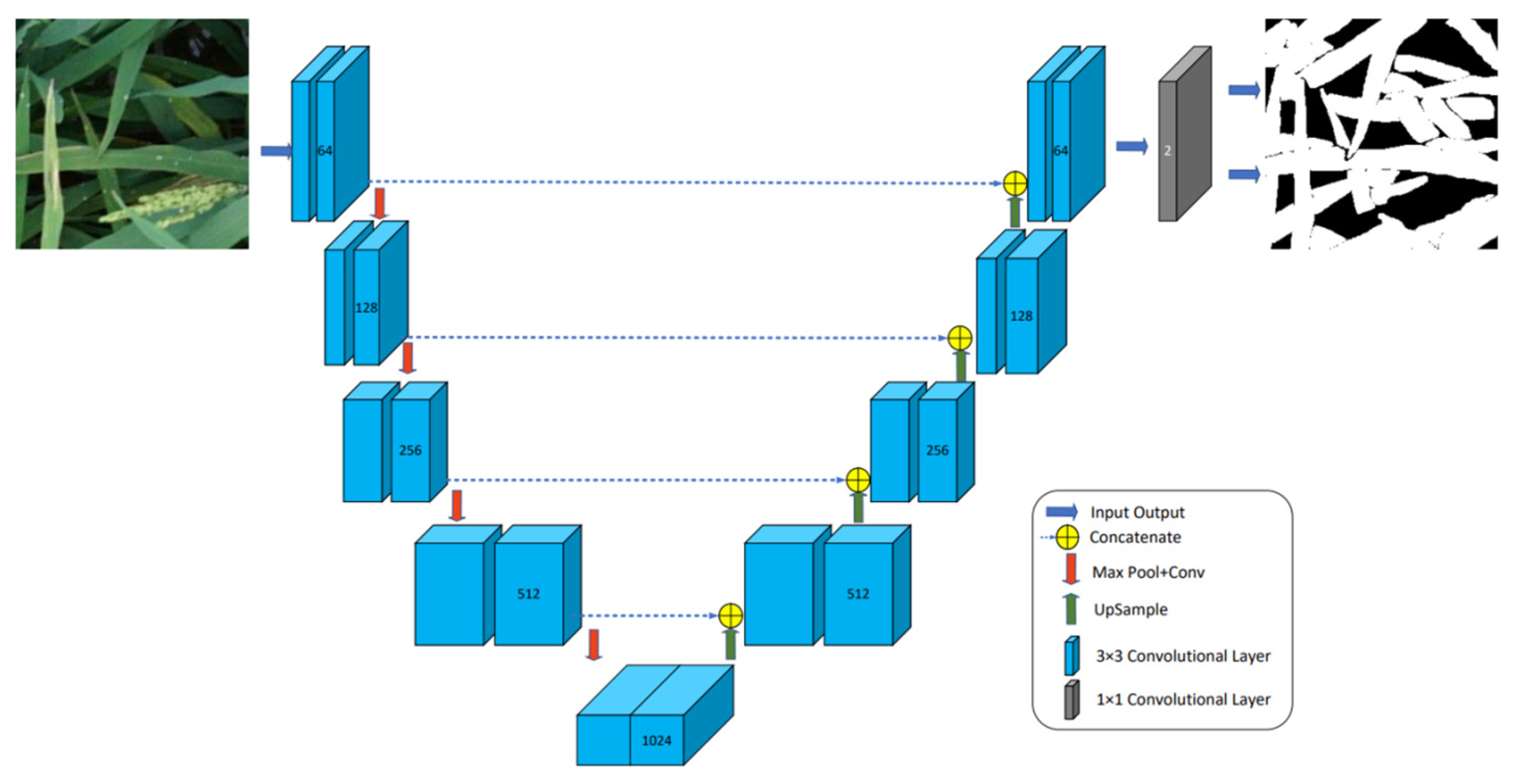
3.1. Rice Leaf Segmentation Model Based on the U-Net Architecture
3.1.1. U-Net Network
3.1.2. Evaluation Indicators
3.2. Two-Phase Leaf Color Feature Optimization Approach
3.2.1. Pearson Correlation Coefficient Method
3.2.2. Recursive Feature Elimination
3.3. Inversion Modeling and Accuracy Evaluation
3.3.1. Random Forest Regression
3.3.2. Support Vector Regression
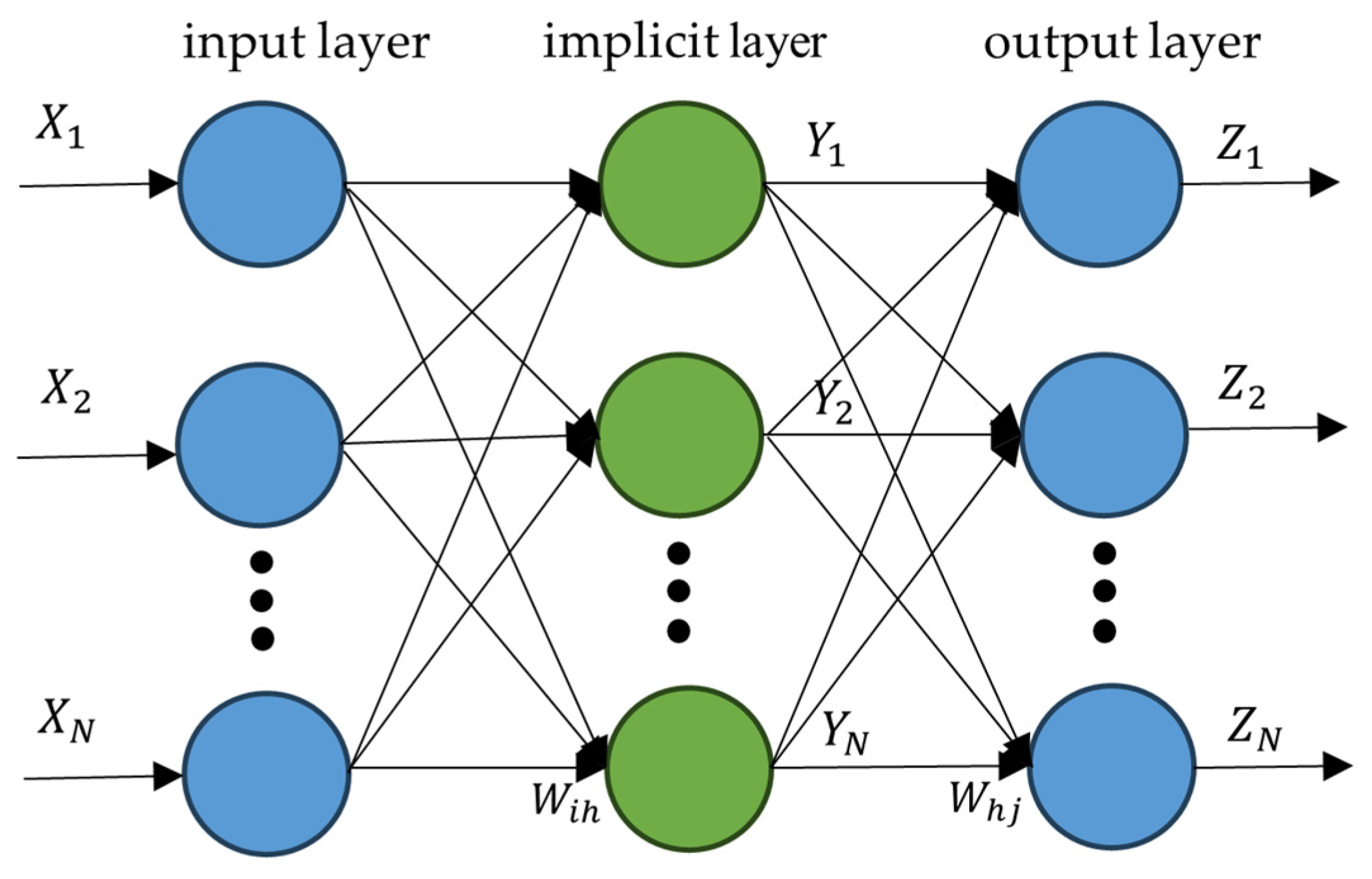
3.3.3. Backpropagation Neural Network
3.3.4. Extreme Gradient Boosting (XGBoost)
3.3.5. Evaluation Indicators
4. Results
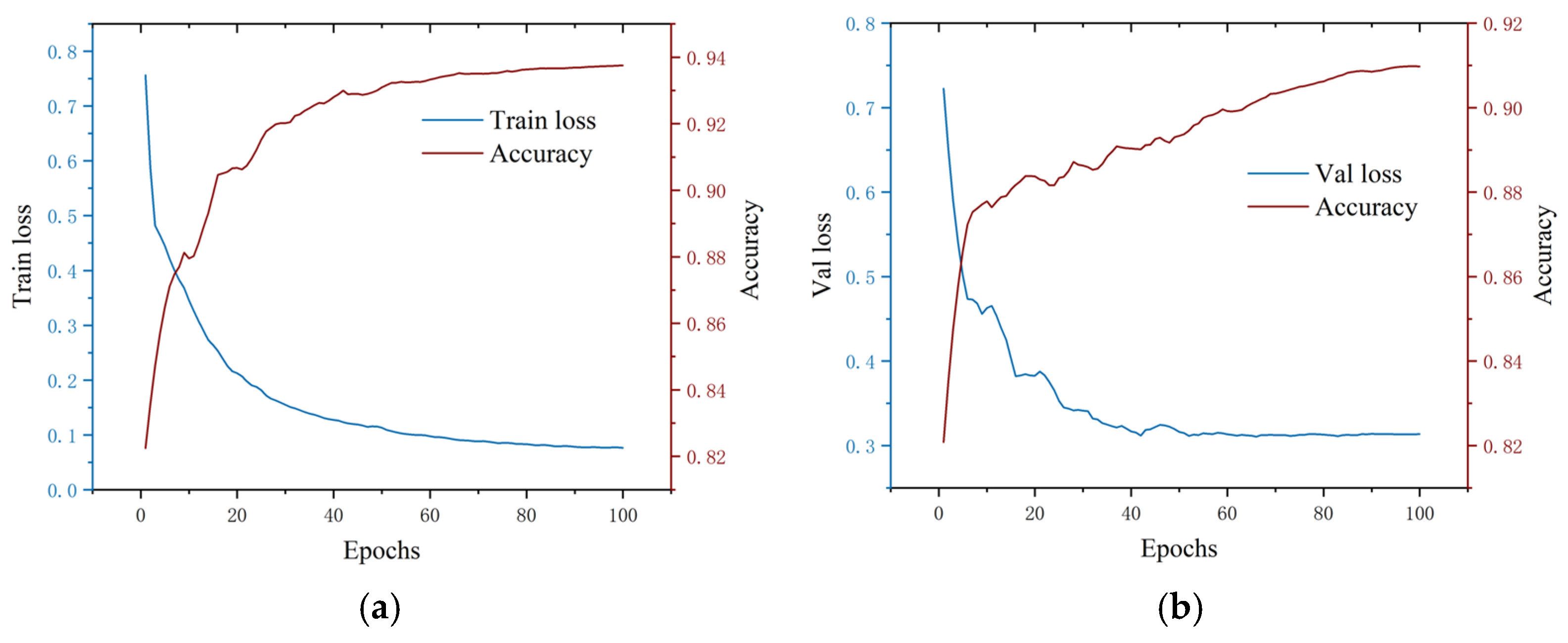
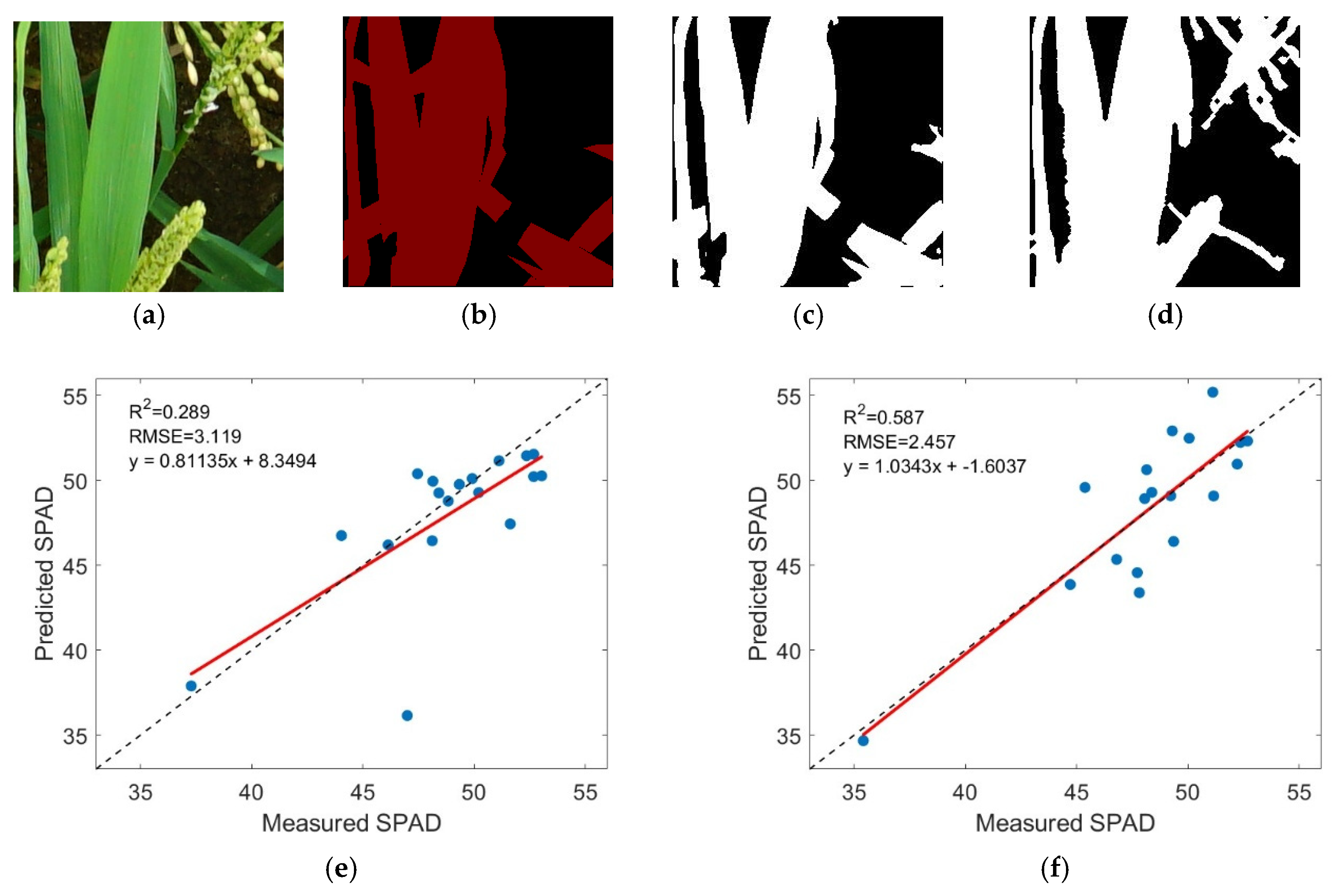
4.1. Rice Leaf Segmentation Model Training and Prediction
4.2. Leaf Color Characteristics
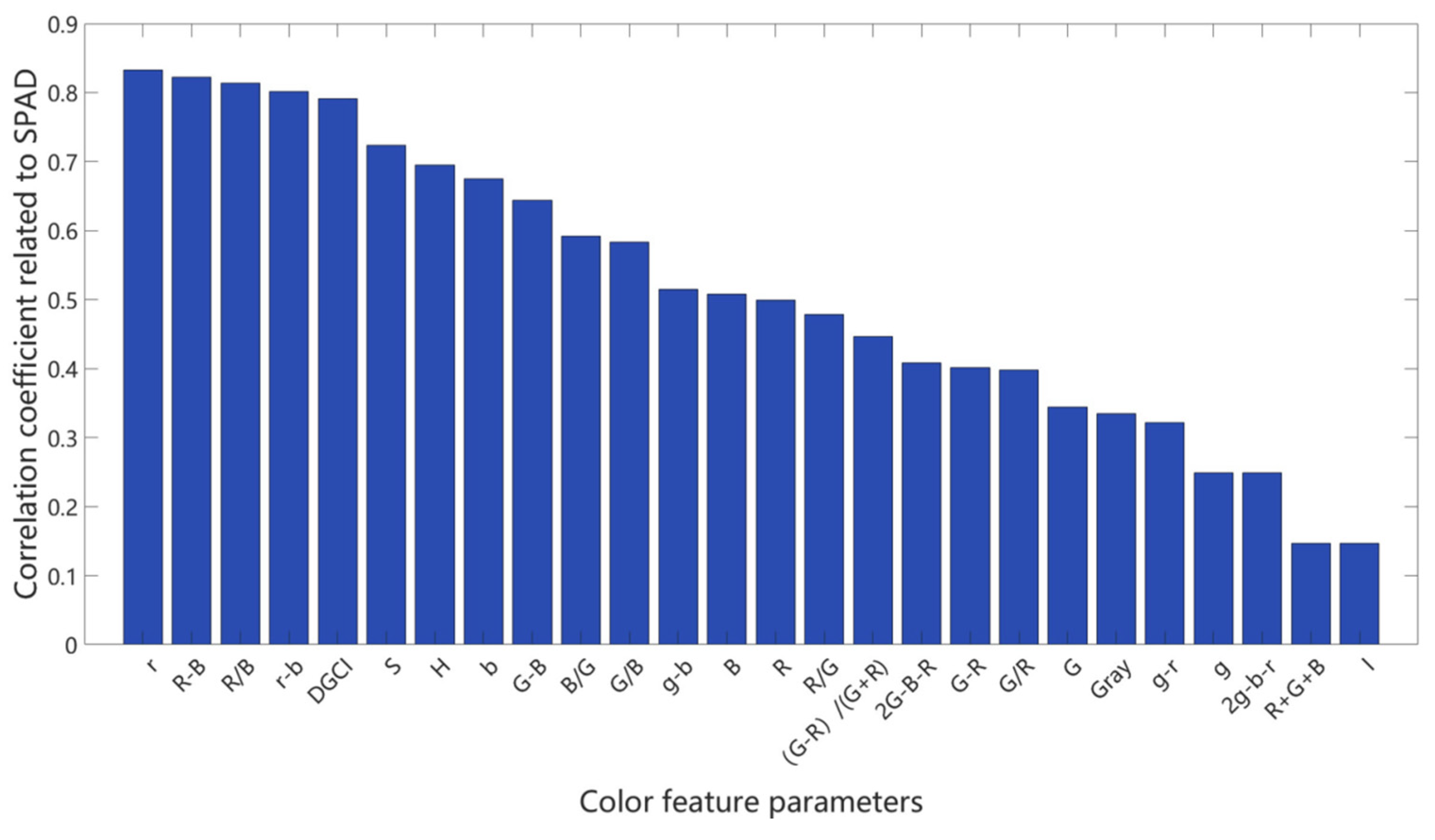
4.2.1. Pearson Coefficient Feature Selection
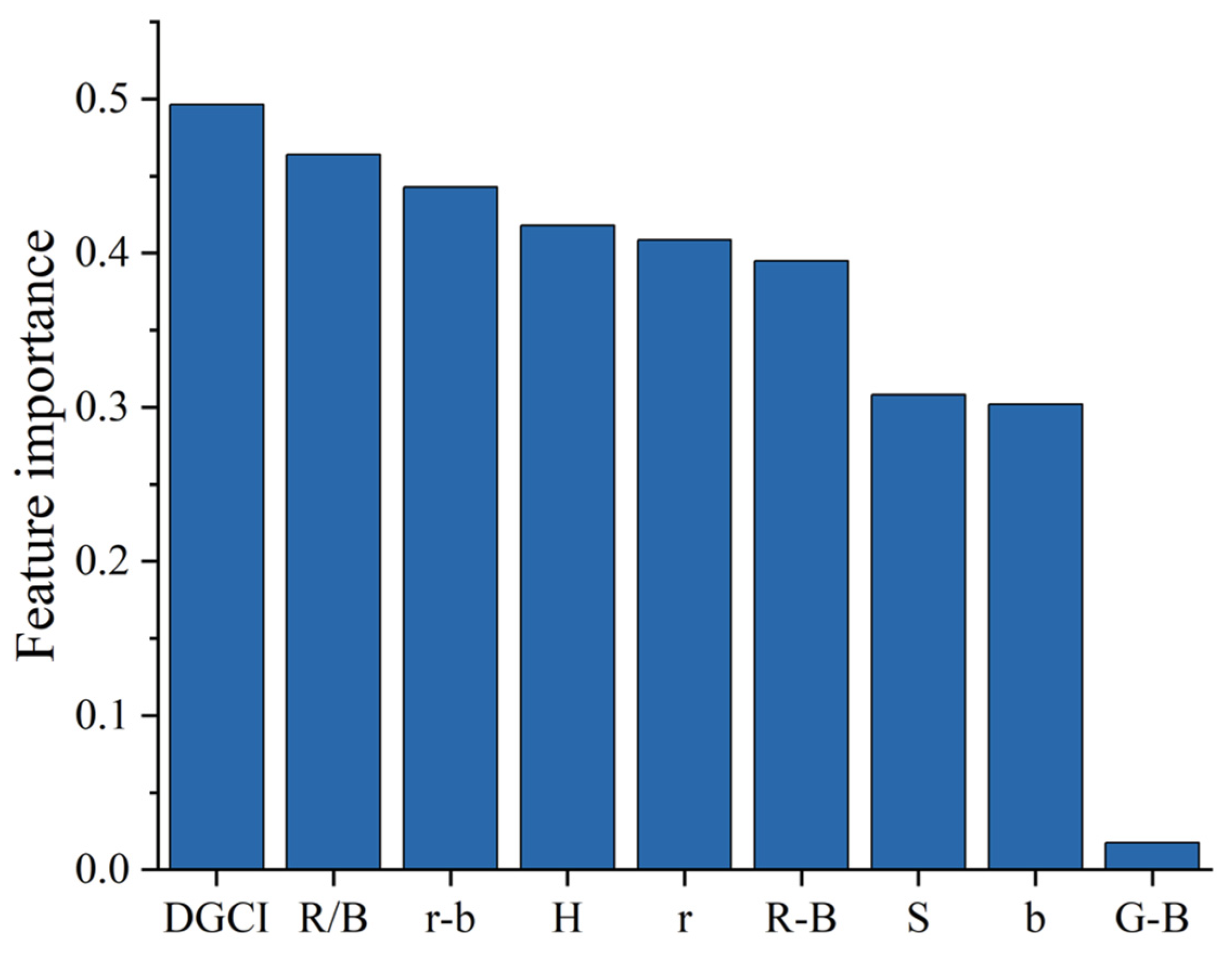
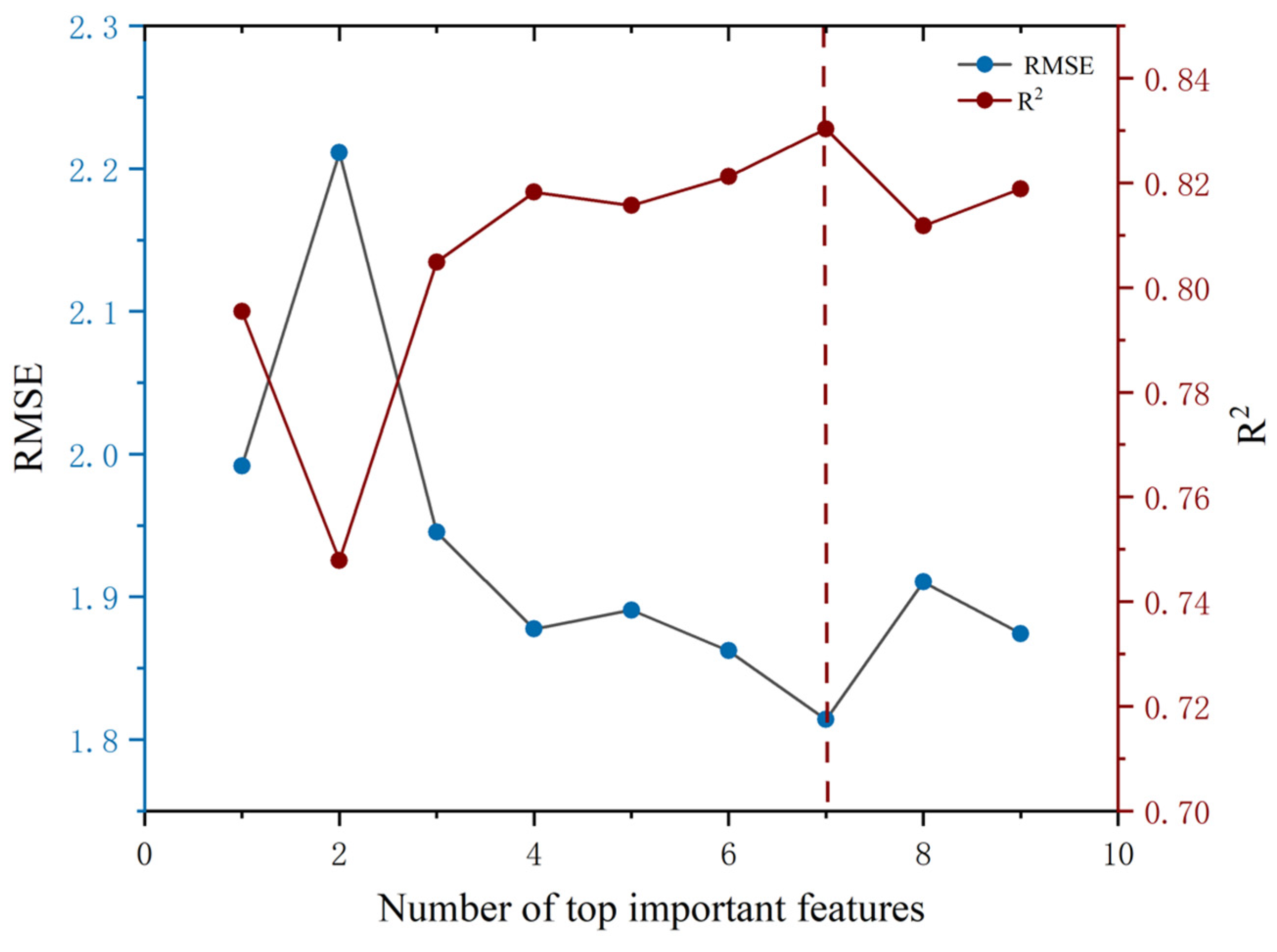
4.2.2. Random Forest-Based Recursive Feature Elimination
4.3. Machine Learning-Based Inversion Model for SPAD Values
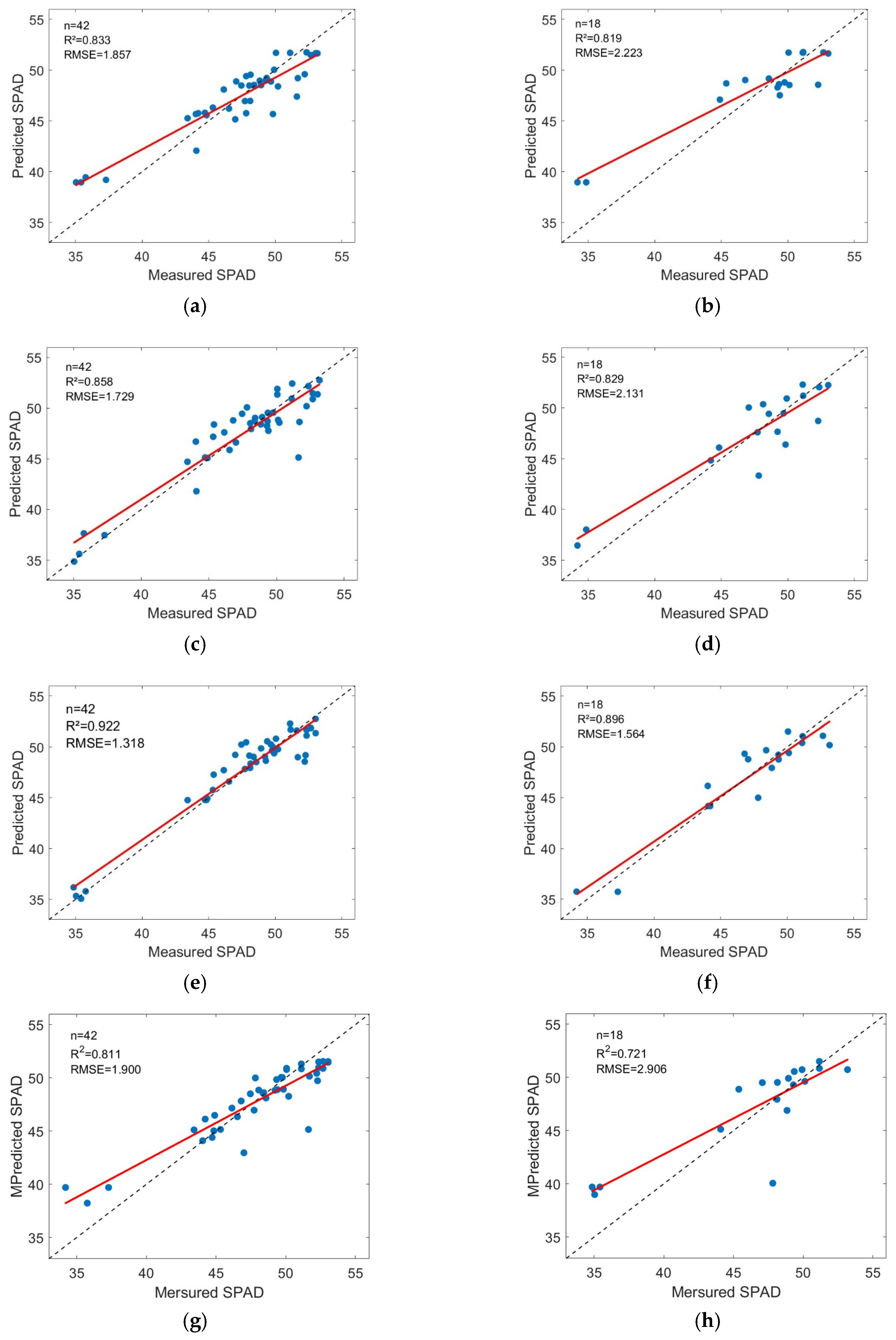
4.3.1. Machine Learning-Based Inversion and Accuracy Verification of SPAD Values
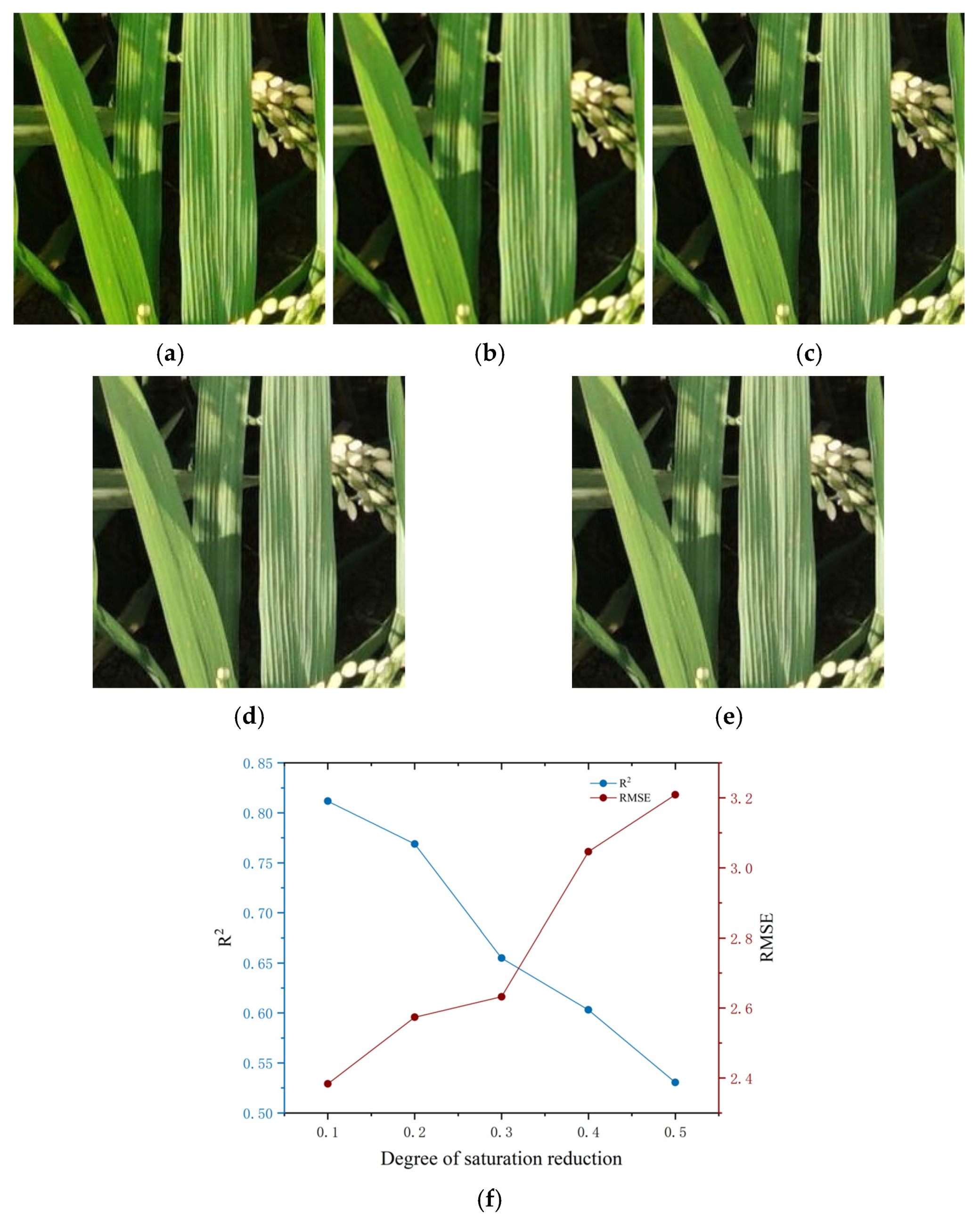
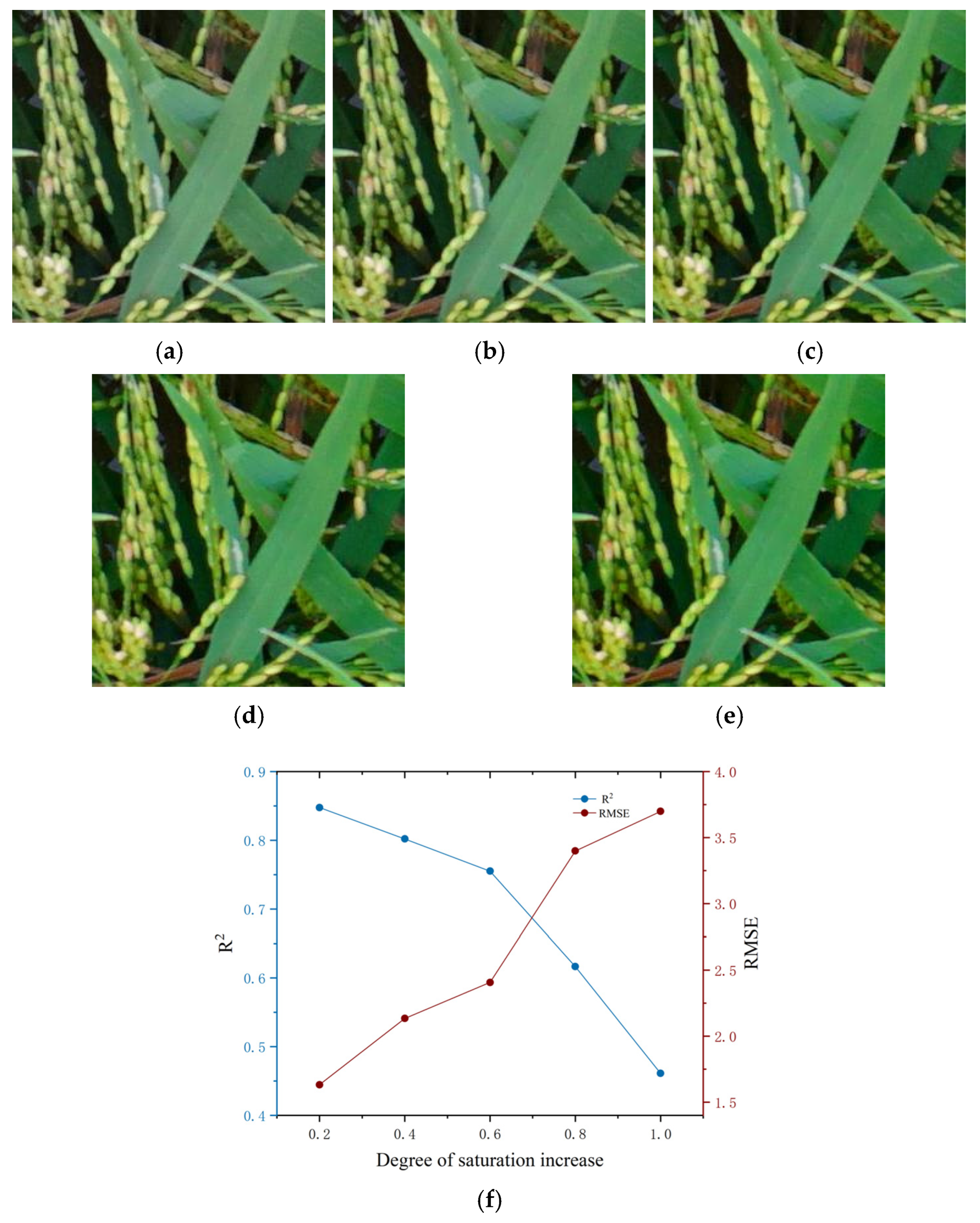
4.3.2. Comparison of the Inversion Accuracy of SPAD Values Under Different Image Qualities
5. Discussion
5.1. Important Role of Rice Leaf Segmentation via the U-Net Network for Accurate SPAD Extraction
5.2. Construction and Robustness of SPAD Inversion Models
5.3. Limitations of This Study and Future Perspectives
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Jang, Y.H.; Park, J.R.; Kim, E.G.; Kim, K.M. The Basic Helix-Loop-Helix Transcription Factor, Involved in Regulation of Chlorophyll Content in Rice. Biology 2022, 11, 1000. [Google Scholar] [CrossRef]
- Zhai, W.G.; Li, C.C.; Cheng, Q.; Ding, F.; Chen, Z. Exploring Multisource Feature Fusion and Stacking Ensemble Learning for Accurate Estimation of Maize Chlorophyll Content Using Unmanned Aerial Vehicle Remote Sensing. Remote Sens. 2023, 15, 3454. [Google Scholar] [CrossRef]
- Peng, J.; Xu, F.X.; Deng, K.; Wu, J.; Li, W.T.; Wang, N.; Liu, M.S. Spectral Differences of Tree Leaves at Different Chlorophyll Relative Content in Langya Mountain. Spectrosc. Spect. Anal. 2018, 38, 1839–1849. [Google Scholar]
- Liu, H.H.; Lei, X.Q.; Liang, H.; Wang, X. Multi-Model Rice Canopy Chlorophyll Content Inversion Based on UAV Hyperspectral Images. Sustainability 2023, 15, 7038. [Google Scholar] [CrossRef]
- Treder, W.; Klamkowski, K.; Sowik, I.; Maciorowski, R. Possibilities of Using Rgb-Based Image Analysis to Estimate the Chlorophyll Content of Micropropagated Strawberry Plants. Acta Sci. Pol. Hortorum Cultus 2021, 20, 105–115. [Google Scholar] [CrossRef]
- Qin, R.; He, L.; Li, Y.X.; He, J.X.; Gao, J.; Yan, F.F.; Yu, Y.F.; Liao, K.W.; Lu, L.M.; Jian, S.C.; et al. Remote Sensing Inversion of Tobacco Spad Based on Uav Hyperspectral Imagery. In Proceedings of the IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 3478–3481. [Google Scholar] [CrossRef]
- Cavallo, D.P.; Cefola, M.; Pace, B.; Logrieco, A.F.; Attolico, G. Contactless and non-destructive chlorophyll content prediction by random forest regression: A case study on fresh-cut rocket leaves. Comput. Electron. Agric. 2017, 140, 303–310. [Google Scholar] [CrossRef]
- Yan, N.; Qin, Y.S.; Wang, H.T.; Wang, Q.; Hu, F.Y.; Wu, Y.W.; Zhang, X.D.; Li, X. The Inversion of SPAD Value in Pear Tree Leaves by Integrating Unmanned Aerial Vehicle Spectral Information and Textural Features. Sensors 2025, 25, 618. [Google Scholar] [CrossRef]
- Lee, G.; Hwang, J.; Cho, S. A Novel Index to Detect Vegetation in Urban Areas Using UAV-Based Multispectral Images. Appl. Sci. 2021, 11, 3472. [Google Scholar] [CrossRef]
- Lu, L.L.; Kuenzer, C.; Wang, C.Z.; Guo, H.D.; Li, Q.T. Evaluation of Three MODIS-Derived Vegetation Index Time Series for Dryland Vegetation Dynamics Monitoring. Remote Sens. 2015, 7, 7597–7614. [Google Scholar] [CrossRef]
- Pradhan, S.; Bandyopadhyay, K.K.; Josh, D.K. Canopy reflectance spectra of wheat as related to crop yield, grain protein under different management practices. J. Agrometeorol. 2012, 14, 21–25. [Google Scholar] [CrossRef]
- Ballester, C.; Brinkhoff, J.; Quayle, W.C.; Hornbuckle, J. Monitoring the Effects of Water Stress in Cotton Using the Green Red Vegetation Index and Red Edge Ratio. Remote Sens. 2019, 11, 873. [Google Scholar] [CrossRef]
- Tian, B.Q.; Yu, H.L.; Zhang, S.L.; Wang, X.L.; Yang, L.; Li, J.Q.; Cui, W.H.; Wang, Z.S.; Lu, L.Q.; Lan, Y.B.; et al. Inversion of Cotton Soil and Plant Analytical Development Based on Unmanned Aerial Vehicle Multispectral Imagery and Mixed Pixel Decomposition. Agriculture 2024, 14, 1452. [Google Scholar] [CrossRef]
- Chen, Z.Q.; Wang, L.; Bai, Y.L.; Yang, L.P.; Lu, Y.L.; Wang, H.; Wang, Z.Y. Hyperspectral Prediction Model for Maize Leaf SPAD in the Whole Growth Period. Spectrosc. Spect. Anal. 2013, 33, 2838–2842. [Google Scholar] [CrossRef]
- Lu, Y.; Yang, H.Y.; Sun, A.Z. The Research of SPAD in Rice Leaves Based on Machine Learning. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 2163–2167. [Google Scholar] [CrossRef]
- Song, J. Bias corrections for Random Forest in regression using residual rotation. J. Korean Stat. Soc. 2015, 44, 321–326. [Google Scholar] [CrossRef]
- Guerrero, J.M.; Pajares, G.; Montalvo, M.; Romeo, J.; Guijarro, M. Support Vector Machines for crop/weeds identification in maize fields. Expert. Syst. Appl. 2012, 39, 11149–11155. [Google Scholar] [CrossRef]
- Sun, B.; Sun, T.; Jiao, P.P. Spatio-Temporal Segmented Traffic Flow Prediction with ANPRS Data Based on Improved XGBoost. J. Adv. Transp. 2021, 2021, 5559562. [Google Scholar] [CrossRef]
- Moghaddam, P.A.; Derafshi, M.H.; Shirzad, V. Estimation of single leaf chlorophyll content in sugar beet using machine vision. Turk. J. Agric. For. 2011, 35, 563–568. [Google Scholar] [CrossRef]
- Sikakollu, P.; Dash, R. Ensemble of multiple CNN classifiers for HSI classification with Superpixel Smoothing. Comput. Geosci. 2021, 154, 104806. [Google Scholar] [CrossRef]
- He, X.F.; Lv, X.G. From the color composition to the color psychology: Soft drink packaging in warm colors, and spirits packaging in dark colors. Color. Res. Appl. 2022, 47, 758–770. [Google Scholar] [CrossRef]
- Hassanijalilian, O.; Igathinathane, C.; Doetkott, C.; Bajwa, S.; Nowatzki, J.; Esmaeili, S.A.H. Chlorophyll estimation in soybean leaves infield with smartphone digital imaging and machine learning. Comput. Electron. Agric. 2020, 174, 105433. [Google Scholar] [CrossRef]
- Hong, S.L.; Jiang, Z.H.; Liu, L.Z.; Wang, J.; Zhou, L.Y.; Xu, J.P. Improved Mask R-CNN Combined with Otsu Preprocessing for Rice Panicle Detection and Segmentation. Appl. Sci. 2022, 12, 11701. [Google Scholar] [CrossRef]
- Liao, J.; Wang, Y.; Yin, J.N.; Liu, L.; Zhang, S.; Zhu, D.Q. Segmentation of Rice Seedlings Using the YCrCb Color Space and an Improved Otsu Method. Agronomy 2018, 8, 269. [Google Scholar] [CrossRef]
- Zhang, Y.Q.; Xiao, D.Q.; Liu, Y.F. Automatic Identification Algorithm of the Rice Tiller Period Based on PCA and SVM. IEEE Access 2021, 9, 86843–86854. [Google Scholar] [CrossRef]
- Singh, S.; Mittal, N.; Singh, H.; Oliva, D. Improving the segmentation of digital images by using a modified Otsu’s between-class variance. Multimed. Tools Appl. 2023, 82, 40701–40743. [Google Scholar] [CrossRef]
- Han, C.Y. Improved SLIC imagine segmentation algorithm based on K-means. Cluster Comput. 2017, 20, 1017–1023. [Google Scholar] [CrossRef]
- Miao, Y.L.; Li, S.; Wang, L.Y.; Li, H.; Qiu, R.C.; Zhang, M. A single plant segmentation method of maize point cloud based on Euclidean clustering and K-means clustering. Comput. Electron. Agric. 2023, 210, 107951. [Google Scholar] [CrossRef]
- Zhang, J.H.; Gong, J.L.; Zhang, Y.F.; Mostafa, K.; Yuan, G.Y. Weed Identification in Maize Fields Based on Improved Swin-Unet. Agronomy 2023, 13, 1846. [Google Scholar] [CrossRef]
- Zunair, H.; Ben Hamza, A. Sharp U-Net: Depthwise convolutional network for biomedical image segmentation. Comput. Biol. Med. 2021, 136, 104699. [Google Scholar] [CrossRef]
- Wu, W.B.; Liu, G.J.; Liang, K.Y.; Zhou, H. Inner Cascaded U2-Net: An Improvement to Plain Cascaded U-Net. Cmes-Comp. Model. Eng. 2023, 134, 1323–1335. [Google Scholar] [CrossRef]
- Zhang, J.H.; You, S.C.; Liu, A.X.; Xie, L.J.; Huang, C.H.; Han, X.; Li, P.H.; Wu, Y.X.; Deng, J.S. Winter Wheat Mapping Method Based on Pseudo-Labels and U-Net Model for Training Sample Shortage. Remote Sens. 2024, 16, 2553. [Google Scholar] [CrossRef]
- Liu, G.Q.; Bai, L.; Zhao, M.Q.; Zang, H.C.; Zheng, G.Q. Segmentation of wheat farmland with improved U-Net on drone images. J. Appl. Remote Sens. 2022, 16, 034511. [Google Scholar] [CrossRef]
- Zhang, S.W.; Zhang, C.L. Modified U-Net for plant diseased leaf image segmentation. Comput. Electron. Agric. 2023, 204, 107511. [Google Scholar] [CrossRef]
- Kolhar, S.; Jagtap, J. Convolutional neural network based encoder-decoder architectures for semantic segmentation of plants. Ecol. Inform. 2021, 64, 101373. [Google Scholar] [CrossRef]
- Boston, T.; Van Dijk, A.; Larraondo, P.R.; Thackway, R. Comparing CNNs and Random Forests for Landsat Image Segmentation Trained on a Large Proxy Land Cover Dataset. Remote Sens. 2022, 14, 3396. [Google Scholar] [CrossRef]
- Yu, X.; Yin, D.M.; Nie, C.W.; Ming, B.; Xu, H.G.; Liu, Y.; Bai, Y.; Shao, M.C.; Cheng, M.H.; Liu, Y.D.; et al. Maize tassel area dynamic monitoring based on near-ground and UAV RGB images by U-Net model. Comput. Electron. Agric. 2022, 203, 107477. [Google Scholar] [CrossRef]
- Yang, H.B.; Hu, Y.H.; Zheng, Z.Z.; Qiao, Y.C.; Zhang, K.L.; Guo, T.F.; Chen, J. Estimation of Potato Chlorophyll Content from UAV Multispectral Images with Stacking Ensemble Algorithm. Agronomy 2022, 12, 2318. [Google Scholar] [CrossRef]
- Zhang, A.W.; Yin, S.N.; Wang, J.; He, N.P.; Chai, S.T.; Pang, H.Y. Grassland Chlorophyll Content Estimation from Drone Hyperspectral Images Combined with Fractional-Order Derivative. Remote Sens. 2023, 15, 5623. [Google Scholar] [CrossRef]
- Hunt, E.R.; Daughtry, C.S.T. Chlorophyll Meter Calibrations for Chlorophyll Content Using Measured and Simulated Leaf Transmittances. Agron. J. 2014, 106, 931–939. [Google Scholar] [CrossRef]
- dos Santos, C.L.; Roberts, T.L.; Purcell, L.C. Canopy greenness as a midseason nitrogen management tool in corn production. Agron. J. 2020, 112, 5279–5287. [Google Scholar] [CrossRef]
- Zhao, X.; Zhao, Z.Y.; Zhao, F.N.; Liu, J.F.; Li, Z.Y.; Wang, X.P.; Gao, Y. An Estimation of the Leaf Nitrogen Content of Apple Tree Canopies Based on Multispectral Unmanned Aerial Vehicle Imagery and Machine Learning Methods. Agronomy 2024, 14, 552. [Google Scholar] [CrossRef]
- Chen, H.Z.; Zhang, Z.J.; Yin, W.L.; Zhao, C.Y.; Wang, F.X.; Li, Y.F. A study on depth classification of defects by machine learning based on hyper-parameter search. Measurement 2022, 189, 110660. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Color Feature | Feature Names |
|---|---|
| R | Mean value of red in RGB color space |
| G | Mean value of green in RGB color space |
| B | Mean value of blue in RGB color space |
| H | Average color tone in HSI space |
| S | Average saturation of HSI space |
| I | Average brightness of the HSI space |
| r = R/(R + G + B) | Red standardized value |
| g = G/(R + G + B) | Green standardized value |
| b = B/(R + G + B) | Blue standardized value |
| g − b | Difference between green and blue standard values |
| g − r | Difference between green and red standard values |
| r − b | Difference between red and blue standard values |
| 2 g − b − r | Normalized super green value |
| EXG = 2G − B − R | Ultra green indicator |
| (G − R)/(G+R) | The ratio of the green–red difference to the green–red sum |
| R/G | Red to green ratio |
| G/R | Green to red ratio |
| R/B | Red to blue ratio |
| G/B | Green to blue ratio |
| B/G | Blue to green ratio |
| G − B | The difference between green and blue |
| R − B | The difference between red and blue |
| G − R | The difference between green and red |
| R + G + B | The sum of red and green and blue |
| DGCI | Dark green color index |
| Gray | Grayscale average |
| Absolute Value of Correlation Coefficient | Relevancy |
|---|---|
| 0.8~1.0 | High correlation |
| 0.6~0.8 | Strongly correlation |
| 0.4~0.6 | Moderate intensity correlation |
| 0.2~0.4 | Weak correlation |
| 0.0~0.2 | Minimally correlation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, B.; Jin, Y.; Wu, S.; Tan, J.; Chen, Y.; Zhong, H.; Chen, G.; Deng, Y. Research on SPAD Inversion of Rice Leaves at a Field Scale Based on Machine Vision and Leaf Segmentation Techniques. Agriculture 2025, 15, 1270. https://doi.org/10.3390/agriculture15121270
Yue B, Jin Y, Wu S, Tan J, Chen Y, Zhong H, Chen G, Deng Y. Research on SPAD Inversion of Rice Leaves at a Field Scale Based on Machine Vision and Leaf Segmentation Techniques. Agriculture. 2025; 15(12):1270. https://doi.org/10.3390/agriculture15121270
Chicago/Turabian StyleYue, Bailin, Yong Jin, Shangrong Wu, Jieyang Tan, Youxing Chen, Hu Zhong, Guipeng Chen, and Yingbin Deng. 2025. "Research on SPAD Inversion of Rice Leaves at a Field Scale Based on Machine Vision and Leaf Segmentation Techniques" Agriculture 15, no. 12: 1270. https://doi.org/10.3390/agriculture15121270
APA StyleYue, B., Jin, Y., Wu, S., Tan, J., Chen, Y., Zhong, H., Chen, G., & Deng, Y. (2025). Research on SPAD Inversion of Rice Leaves at a Field Scale Based on Machine Vision and Leaf Segmentation Techniques. Agriculture, 15(12), 1270. https://doi.org/10.3390/agriculture15121270