
LGN-YOLO: A Leaf-Oriented Region-of-Interest Generation Method for Cotton Top Buds in Fields


Abstract
1. Introduction
- 1.
- The LP-Detect module is used to intercept the region of interest of the top bud in the high-resolution image, which eliminates a large amount of redundant information in the original image and saves computational resources for the detection of small-sized top buds.
- 2.
- The CA mechanism is introduced at the end of the backbone to enhance the ability to separate the spatial and channel dimensions of the feature map. A new feature pyramid network (FPN) is constructed to preserve the detailed features of the young leaves. The inner EIoU is introduced as the loss function to further reduce the loss value of the anchor boxes of the young leaves, thus improving the accuracy of linear programming.
- 3.
- Combining the morphological characteristics of cotton plants, a leaf-oriented ROI generation method is proposed, which improves the utilization rate of feature information in the image. The extraction effect of the model under field conditions is verified through experiments, providing technical support for the automatic topping of cotton.
2. Materials and Methods
2.1. Dataset Image Collection
2.2. Dataset Pre-Processing
2.2.1. Dataset Annotation
2.2.2. Data Augmentation and Partitioning
2.3. LGN-YOLO for Generating the Region of Interest of Cotton Top Buds
2.3.1. Baseline Model: YOLOv11n
2.3.2. Structure of the LGN-YOLO Model
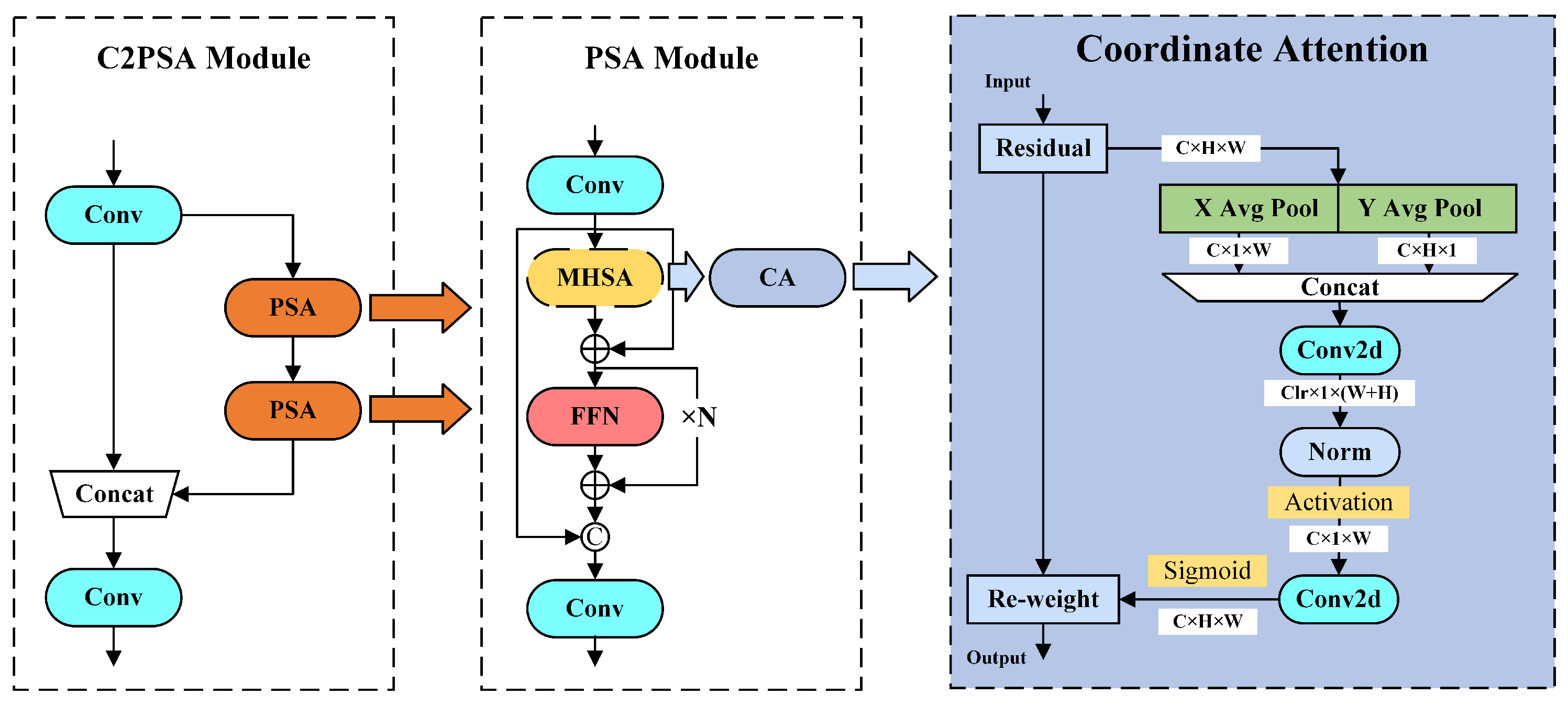
2.3.3. Coordinate Attention Mechanism
2.3.4. LR-FPN
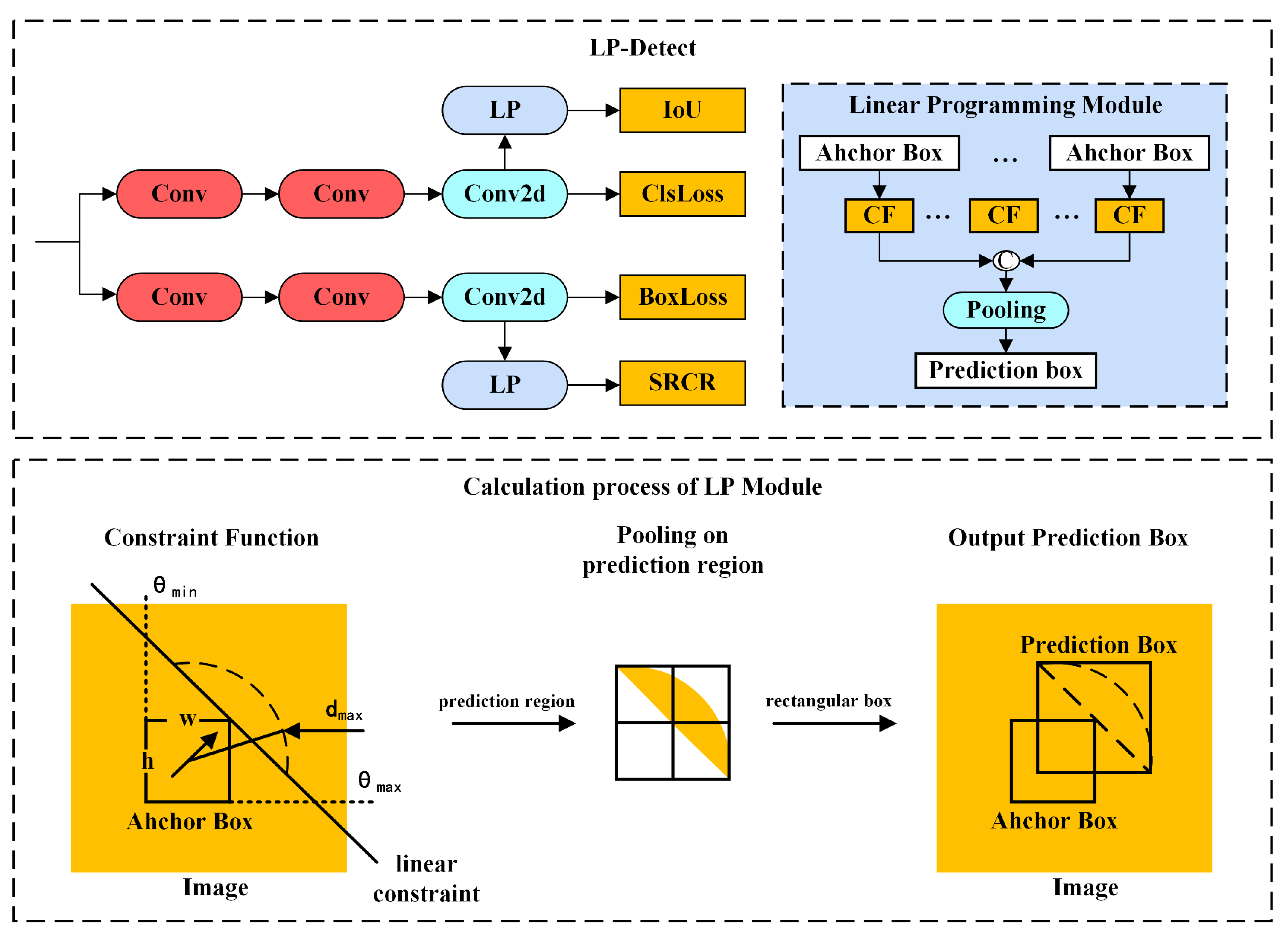
2.3.5. LP-Detect Module
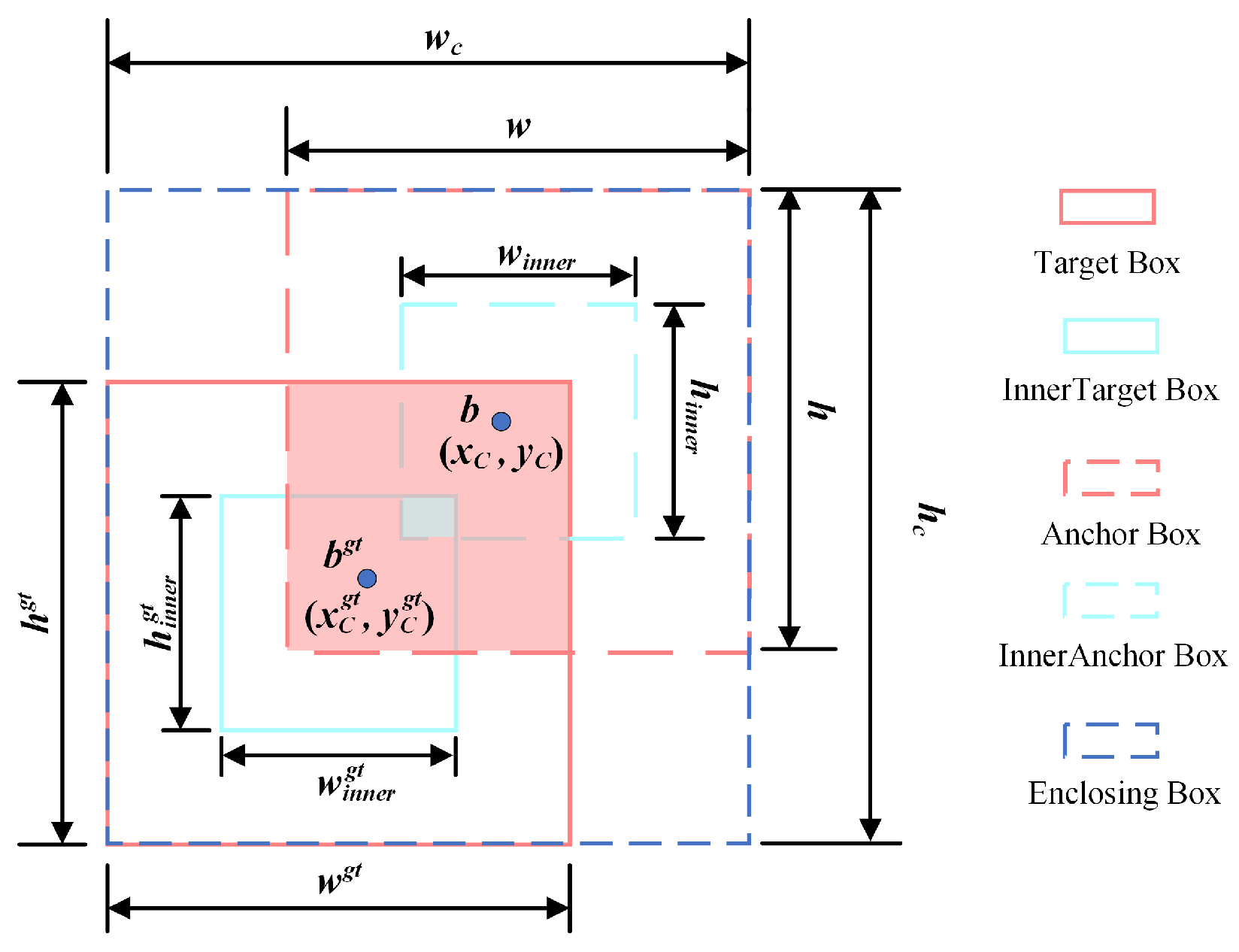
2.3.6. Using the Inner EIoU as the Loss Function
2.4. Performance Metrics
3. Experimental Results and Analysis
3.1. Experimental Environment
3.2. Model Training and Validation Results
3.3. Comparative Experiment
3.4. Ablation Experiment
3.5. Adjustment of Loss Function
3.6. Experimental Results in a Cotton Field
3.7. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pettigrew, W.; Heitholt, J.; Meredith, W., Jr. Early season floral bud removal and cotton growth, yield, and fiber quality. Agron. J. 1992, 84, 209–214. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, L. Bud-YOLO: A Real-Time Accurate Detection Method of Cotton Top Buds in Cotton Fields. Agriculture 2024, 14, 1651. [Google Scholar] [CrossRef]
- Guangze, X.; Jianping, Z.; Yan, X.; Xuan, P.; Chao, C. Cotton top bud recognition in complex environment based on improved YOLOv5s. J. Chin. Agric. Mech. 2024, 45, 275. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Gao, Y.; Yin, F.; Hong, C.; Chen, X.; Deng, H.; Liu, Y.; Li, Z.; Yao, Q. Intelligent field monitoring system for cruciferous vegetable pests using yellow sticky board images and an improved Cascade R-CNN. J. Integr. Agric. 2025, 24, 220–234. [Google Scholar] [CrossRef]
- Shuang, Z.; Yu, Y.; Miao, Y.; Liu, K. Research of impurity detection of green vegetable based on improved Mask R-CNN. J. Chin. Agric. Mech. 2024, 45, 77–82+140. [Google Scholar] [CrossRef]
- Tu, S.; Pang, J.; Liu, H.; Zhuang, N.; Chen, Y.; Zheng, C.; Wan, H.; Xue, Y. Passion fruit detection and counting based on multiple scale faster R-CNN using RGB-D images. Precis. Agric. 2020, 21, 1072–1091. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3626–3633. [Google Scholar] [CrossRef]
- Feng, H.; Mu, G.; Zhong, S.; Zhang, P.; Yuan, T. Benchmark analysis of yolo performance on edge intelligence devices. Cryptography 2022, 6, 16. [Google Scholar] [CrossRef]
- Wang, X.; Li, X.; Du, H.; Wang, J. Design of an intelligent disinfection control system based on an STM32 single-chip microprocessor by using the YOLO algorithm. Sci. Rep. 2024, 14, 31686. [Google Scholar] [CrossRef]
- Shu, M.; Li, C.; Xiao, Y.; Deng, J.; Liu, J. Research on items sorting robot based on SSD target detection. In ITM Web of Conferences; EDP Sciences: Les Ulis, France, 2022; Volume 47, p. 01031. [Google Scholar]
- Ramesh, G.; Jeswin, Y.; Divith, R.R.; BR, S.; Daksh, U.; Kiran Raj, K. Real Time Object Detection and Tracking Using SSD Mobilenetv2 on Jetbot GPU. In Proceedings of the 2024 IEEE International Conference on Distributed Computing, VLSI, Electrical Circuits and Robotics (DISCOVER), Mangalore, India, 18–19 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 255–260. [Google Scholar]
- Wang, L.; Shi, W.; Tang, Y.; Liu, Z.; He, X.; Xiao, H.; Yang, Y. Transfer Learning-Based Lightweight SSD Model for Detection of Pests in Citrus. Agronomy 2023, 13, 1710. [Google Scholar] [CrossRef]
- Zoubek, T.; Bumbálek, R.; Ufitikirezi, J.d.D.M.; Strob, M.; Filip, M.; Špalek, F.; Heřmánek, A.; Bartoš, P. Advancing precision agriculture with computer vision: A comparative study of YOLO models for weed and crop recognition. Crop Prot. 2025, 190, 107076. [Google Scholar] [CrossRef]
- Li, T.; Zhang, L.; Lin, J. Precision agriculture with YOLO-Leaf: Advanced methods for detecting apple leaf diseases. Front. Plant Sci. 2024, 15, 1452502. [Google Scholar] [CrossRef]
- Gomez, D.; Selvaraj, M.G.; Casas, J.; Mathiyazhagan, K.; Rodriguez, M.; Assefa, T.; Mlaki, A.; Nyakunga, G.; Kato, F.; Mukankusi, C.; et al. Advancing common bean (Phaseolus vulgaris L.) disease detection with YOLO driven deep learning to enhance agricultural AI. Sci. Rep. 2024, 14, 15596. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Li, J.; Zhao, X.; Su, X.; Wu, W. Lightweight detection networks for tea bud on complex agricultural environment via improved YOLO v4. Comput. Electron. Agric. 2023, 211, 107955. [Google Scholar] [CrossRef]
- Wang, R.F.; Tu, Y.H.; Chen, Z.Q.; Zhao, C.T.; Su, W.H. A Lettpoint-Yolov11l Based Intelligent Robot for Precision Intra-Row Weeds Control in Lettuce. SSRN 2025, 5162748. [Google Scholar]
- Song, K.; Chen, S.; Wang, G.; Qi, J.; Gao, X.; Xiang, M.; Zhou, Z. Research on High-Precision Target Detection Technology for Tomato-Picking Robots in Sustainable Agriculture. Sustainability 2025, 17, 2885. [Google Scholar] [CrossRef]
- Wu, H.; Wang, Y.; Zhao, P.; Qian, M. Small-target weed-detection model based on YOLO-V4 with improved backbone and neck structures. Precis. Agric. 2023, 24, 2149–2170. [Google Scholar] [CrossRef]
- Wang, H.; Feng, J.; Yin, H. Improved method for apple fruit target detection based on YOLOv5s. Agriculture 2023, 13, 2167. [Google Scholar] [CrossRef]
- Jiang, Q.; Huang, Z.; Xu, G.; Su, Y. MIoP-NMS: Perfecting crops target detection and counting in dense occlusion from high-resolution UAV imagery. Smart Agric. Technol. 2023, 4, 100226. [Google Scholar] [CrossRef]
- Li, S.; Zhang, S.; Xue, J.; Sun, H. Lightweight target detection for the field flat jujube based on improved YOLOv5. Comput. Electron. Agric. 2022, 202, 107391. [Google Scholar] [CrossRef]
- Huang, L.; Zhang, X.; Qiang, B.; Yang, H.; Yang, M. Image Clipping Strategy of Object Detection for Super Resolution Image in Low Resource. In Proceedings of the Cognitive Systems and Signal Processing: 5th International Conference, ICCSIP 2020, Zhuhai, China, 25–27 December 2020; Revised Selected Papers; Springer Nature: Berlin/Heidelberg, Germany, 2021; Volume 1397, p. 449. [Google Scholar]
- Wei, Y.; Hu, H.; Xie, Z.; Liu, Z.; Zhang, Z.; Cao, Y.; Bao, J.; Chen, D.; Guo, B. Improving clip fine-tuning performance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 5439–5449. [Google Scholar]
- Yang, L.; Han, Y.; Chen, X.; Song, S.; Dai, J.; Huang, G. Resolution Adaptive Networks for Efficient Inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, Z.; Cao, L.; Wang, Q. YOLOv5-Based Vehicle Detection Method for High-Resolution UAV Images. Mob. Inf. Syst. 2022, 2022, 1828848. [Google Scholar] [CrossRef]
- Roy, A.M.; Bose, R.; Bhaduri, J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network. Neural Comput. Appl. 2022, 34, 3895–3921. [Google Scholar] [CrossRef]
- Sachar, S.; Kumar, A. Survey of feature extraction and classification techniques to identify plant through leaves. Expert Syst. Appl. 2021, 167, 114181. [Google Scholar] [CrossRef]
- Khakimov, A.; Salakhutdinov, I.; Omolikov, A.; Utaganov, S. Traditional and current-prospective methods of agricultural plant diseases detection: A review. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Bandung, Indonesia, 8–9 November 2022; IOP Publishing: Bristol, UK, 2022; Volume 951, p. 012002. [Google Scholar]
- Srinivas, Y.; Ganivada, A. A modified inter-frame difference method for detection of moving objects in videos. Int. J. Inf. Technol. 2025, 17, 749–754. [Google Scholar] [CrossRef]
- Tzutalin, D. LabelImg. GitHub Repos. 2015, 6, 4. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Li, H.; Zhang, R.; Pan, Y.; Ren, J.; Shen, F. Lr-fpn: Enhancing remote sensing object detection with location refined feature pyramid network. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–8. [Google Scholar]
- Gass, S.I. Linear Programming: Methods and Applications; Courier Corporation: North Chelmsford, MA, USA, 2003. [Google Scholar]
- Zhang, H.; Xu, C.; Zhang, S. Inner-iou: More effective intersection over union loss with auxiliary bounding box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Lv, W.; Zhao, Y.; Chang, Q.; Huang, K.; Wang, G.; Liu, Y. Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer. arXiv 2024, arXiv:2407.17140. [Google Scholar]
- Wang, S.; Xia, C.; Lv, F.; Shi, Y. RT-DETRv3: Real-time end-to-end object detection with hierarchical dense positive supervision. In Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, AZ, USA, 26 February–6 March 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 1628–1636. [Google Scholar]
- Qin, Y.M.; Tu, Y.H.; Li, T.; Ni, Y.; Wang, R.F.; Wang, H. Deep Learning for Sustainable Agriculture: A Systematic Review on Applications in Lettuce Cultivation. Sustainability 2025, 17, 3190. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Images | Number of Labels | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Top | TR | Right | BR | Bottom | BL | Left | TL | ||
| Train | 3360 | 674 | 650 | 618 | 602 | 582 | 567 | 553 | 538 |
| Validation | 420 | 85 | 81 | 78 | 75 | 73 | 71 | 69 | 67 |
| Test | 420 | 84 | 81 | 77 | 75 | 73 | 71 | 69 | 67 |
| Total | 4200 | 843 | 812 | 773 | 752 | 728 | 709 | 691 | 672 |
| Hyperparameter | Value |
|---|---|
| epochs | 150 |
| patience | 10 |
| batch size | 32 |
| img size | 640 |
| lr0 | |
| lrf | |
| momentum | 0.937 |
| Model | P | R | mAP50 | mIoU | SRCR | FPS |
|---|---|---|---|---|---|---|
| YOLOv5n | 0.874 | 0.884 | 0.851 | 0.452 | 0.855 | 108.1 |
| YOLOv8n | 0.898 | 0.866 | 0.872 | 0.494 | 0.914 | 121.4 |
| YOLOv9t | 0.874 | 0.865 | 0.881 | 0.493 | 0.901 | 115.6 |
| RT-DETRv2 | 0.924 | 0.905 | 0.922 | 0.556 | 0.927 | 72.3 |
| RT-DETRv3 | 0.940 | 0.954 | 0.945 | 0.634 | 0.938 | 84.5 |
| YOLOv10n | 0.991 | 0.898 | 0.916 | 0.497 | 0.923 | 148.9 |
| YOLOv10s | 0.904 | 0.901 | 0.927 | 0.509 | 0.928 | 99.4 |
| YOLOv11n | 0.923 | 0.953 | 0.924 | 0.612 | 0.931 | 133.5 |
| YOLOv11s | 0.933 | 0.957 | 0.944 | 0.627 | 0.933 | 93.7 |
| YOLOv12n | 0.905 | 0.913 | 0.892 | 0.503 | 0.898 | 110.0 |
| Group | CA | LR-FPN | Inner EIoU | P | R | mAP50 | mIoU | SRCR | FPS |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.923 | 0.953 | 0.924 | 0.612 | 0.931 | 133.5 | |||
| 2 | ✓ | 0.942 | 0.955 | 0.940 | 0.618 | 0.933 | 135.7 | ||
| 3 | ✓ | 0.937 | 0.961 | 0.949 | 0.621 | 0.937 | 140.0 | ||
| 4 | ✓ | ✓ | 0.958 | 0.969 | 0.960 | 0.633 | 0.940 | 144.2 | |
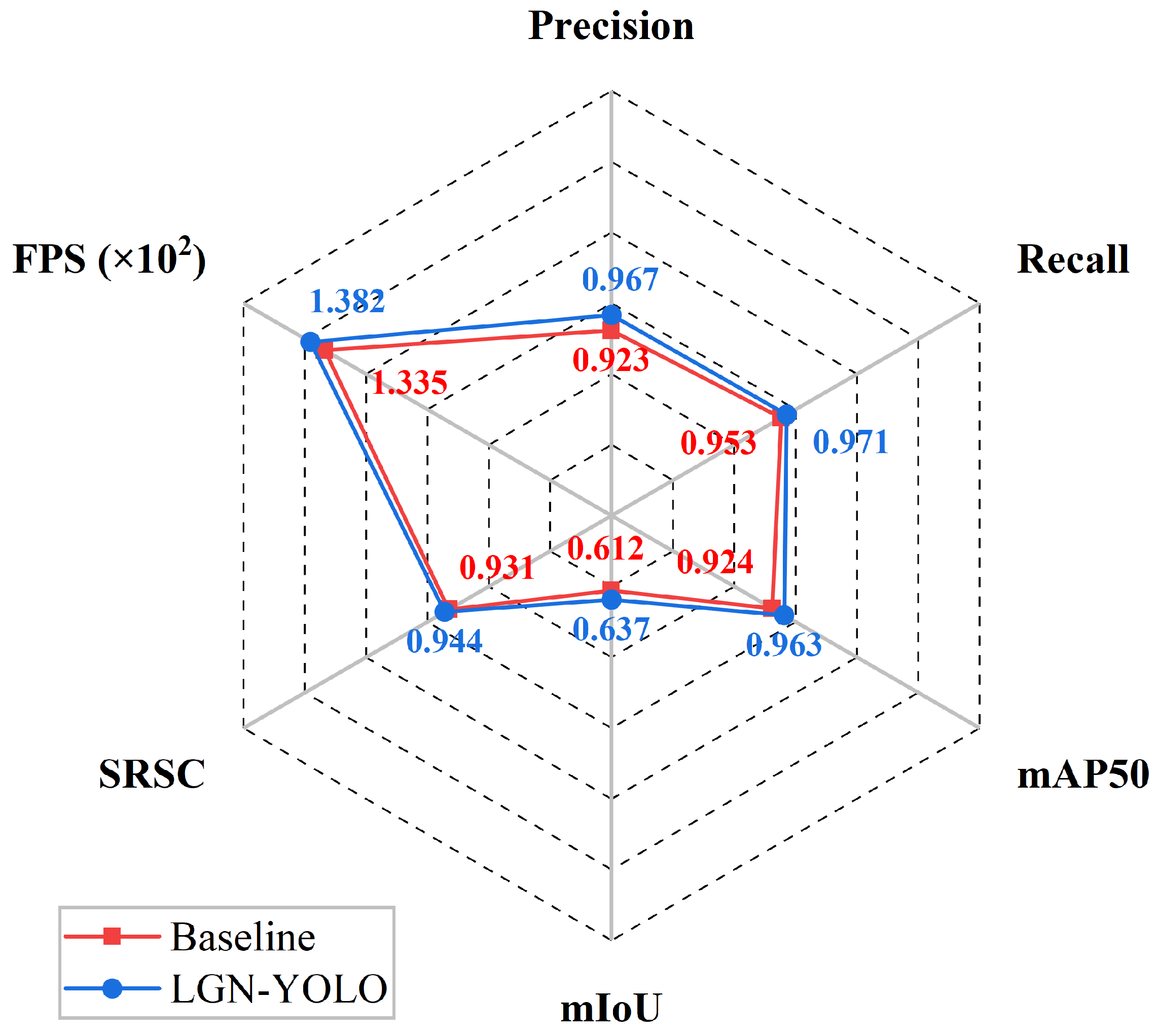
| 5 (Ours) | ✓ | ✓ | ✓ | 0.967 | 0.971 | 0.963 | 0.637 | 0.944 | 138.2 |
| Ratio | P | R | mAP50 | mIoU | SRCR | FPS |
|---|---|---|---|---|---|---|
| 0 (CIoU) | 0.958 | 0.969 | 0.960 | 0.633 | 0.940 | 144.2 |
| 0.5 | 0.955 | 0.970 | 0.962 | 0.633 | 0.941 | 138.1 |
| 1 | 0.963 | 0.971 | 0.963 | 0.635 | 0.943 | 136.4 |
| 1.5 | 0.967 | 0.971 | 0.963 | 0.637 | 0.944 | 138.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, Y.; Chen, L. LGN-YOLO: A Leaf-Oriented Region-of-Interest Generation Method for Cotton Top Buds in Fields. Agriculture 2025, 15, 1254. https://doi.org/10.3390/agriculture15121254
Xie Y, Chen L. LGN-YOLO: A Leaf-Oriented Region-of-Interest Generation Method for Cotton Top Buds in Fields. Agriculture. 2025; 15(12):1254. https://doi.org/10.3390/agriculture15121254
Chicago/Turabian StyleXie, Yufei, and Liping Chen. 2025. "LGN-YOLO: A Leaf-Oriented Region-of-Interest Generation Method for Cotton Top Buds in Fields" Agriculture 15, no. 12: 1254. https://doi.org/10.3390/agriculture15121254
APA StyleXie, Y., & Chen, L. (2025). LGN-YOLO: A Leaf-Oriented Region-of-Interest Generation Method for Cotton Top Buds in Fields. Agriculture, 15(12), 1254. https://doi.org/10.3390/agriculture15121254