1. Introduction
As a tropical fruit, dragon fruit has gained widespread popularity due to its distinctive appearance and rich nutritional content. In recent years, dragon fruit cultivation in China has expanded rapidly, accompanied by a continuous rise in consumer demand [
1]. Currently, dragon fruit harvesting predominantly depends on manual labor, which is not only labor-intensive and costly but also time-consuming. Robots can replace manual labor to automate dragon fruit harvesting, presenting significant implications and broad development prospects in agricultural production [
2]. Fruit target detection is a critical technology for picking robots [
3]. Thus, achieving accurate recognition of dragon fruits in natural orchard environments is essential for advancing automated harvesting.
With advancements in computer technology, deep learning-based neural network target detection methods have been extensively adopted in agriculture [
4,
5,
6]. Compared with traditional target detection algorithms, deep learning employs deeper neural networks capable of extracting both low-dimensional and high-dimensional features, offering greater adaptability and robustness in fruit recognition tasks [
7]. Gui et al. [
8] explored the application of the YOLO-Tea target detection algorithm for detecting tea buds in unstructured environments. By incorporating a Multi-scale Convolutional Block Attention Module (MCBAM) and a multi-scale prediction layer, the detection of small tea buds in dense scenes was significantly improved. Ji et al. [
9] proposed an improved YOLOv4-based apple recognition method that employs a lightweight EfficientNet-B0 network for feature extraction and integrates it with the Path Aggregation Network (PANet). This method achieves an average accuracy of 93.42%. Liu et al. [
10] applied the K-means clustering algorithm within the YOLOv7 framework. By embedding the Coordinate Attention (CA) module into the backbone network, refining the loss function, and incorporating a downsampling P2 module, unripe yellow peach recognition was achieved with an accuracy of 79.3%. Gai et al. [
11] proposed a blueberry recognition algorithm, TL-YOLOv8, which integrates an improved Multidimensional Coordinated Attention (MPCA) module into the backbone network, achieving an accuracy of 84.6% for blueberry recognition in orchards. Jiang et al. [
12] proposed a novel young apple detection algorithm that integrates the YOLOv4 network and visual attention mechanisms, the improved model achieved a detection accuracy of 85.8%. Despite notable advances in detection accuracy, many existing methods entail high computational complexity and exhibit limited robustness in challenging environments—such as occlusion, low light, and cluttered backgrounds—thereby restricting their deployment on embedded platforms.
Currently, numerous researchers have explored various approaches in the field of dragon fruit recognition. Zhou et al. [
13] incorporated RepGhost and a decoupled header into YOLOv7, along with multiple Efficient Channel Attention (ECA) modules strategically placed across the network to enhance feature extraction and prediction accuracy. Nan et al. [
14] enhanced the network backbone by designing the WFE-C4 module, and they utilized a Bi-FPN-structured header network for multi-scale feature fusion and enhancement, achieving an average detection accuracy of 86.0%. Qiu et al. [
15] categorized dragon fruit into four maturity stages—bud, immature, semi-ripe, and ripe—and developed a classification network leveraging the improved YOLOv8n, which achieved an accuracy of 85.2%. Li et al. [
16] additionally categorized and quantified dragon fruit flowers, immature fruits, and ripe fruits, proposing a rapid identification and counting method that achieved an average accuracy of 95.0% in testing. Wang et al. [
17] proposed a real-time detection and tracking method for dragon fruits in orchard environments. By integrating a convolutional attention module, a Transformer self-attention mechanism, and a DeepSORT multi-target tracking algorithm, they developed the YOLOv5s-DFT model, achieving a recognition accuracy of 87.22%. Huang et al. [
18] introduced an improved YOLOv8-G algorithm for detecting dragon fruit stem diseases, achieving an average detection accuracy of 83.1%. While these studies offer diverse approaches to fruit detection and tracking, opportunities remain to improve real-time performance and detection accuracy.
Although considerable research has been conducted on dragon fruit detection, key challenges persist—particularly in achieving real-time performance under complex field conditions. The key challenges are summarized as follows: (1) existing models often possess large parameter sizes and high computational burdens, hindering deployment on resource-limited agricultural robots; (2) complex orchard environments—characterized by cluttered backgrounds, low illumination, and fruit occlusion—severely impair detection accuracy, leading to missed and false detections; (3) the inference speed of current models remains insufficient to meet the rapid response requirements of field operations, limiting real-time performance and reducing picking efficiency.
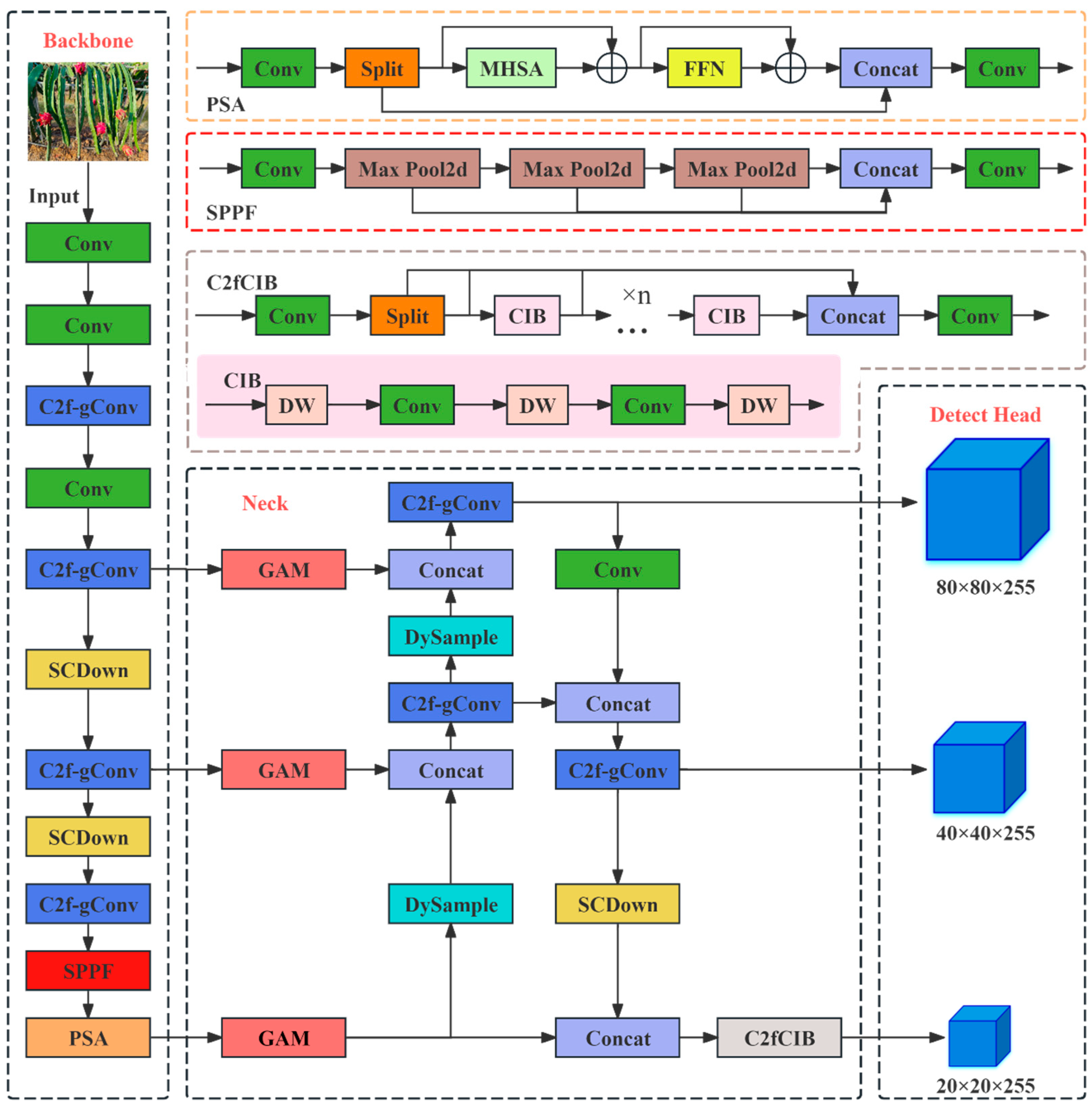
To tackle these challenges, we propose YOLOv10n-CGD—a lightweight and efficient dragon fruit detection method built upon an improved YOLOv10 architecture. The proposed method significantly reduces computational overhead and enhances detection speed while maintaining accuracy, thereby improving deployment efficiency and robustness on embedded platforms to meet the real-time demands of robotic harvesting.
The main contributions of this paper are as follows:
- (1)
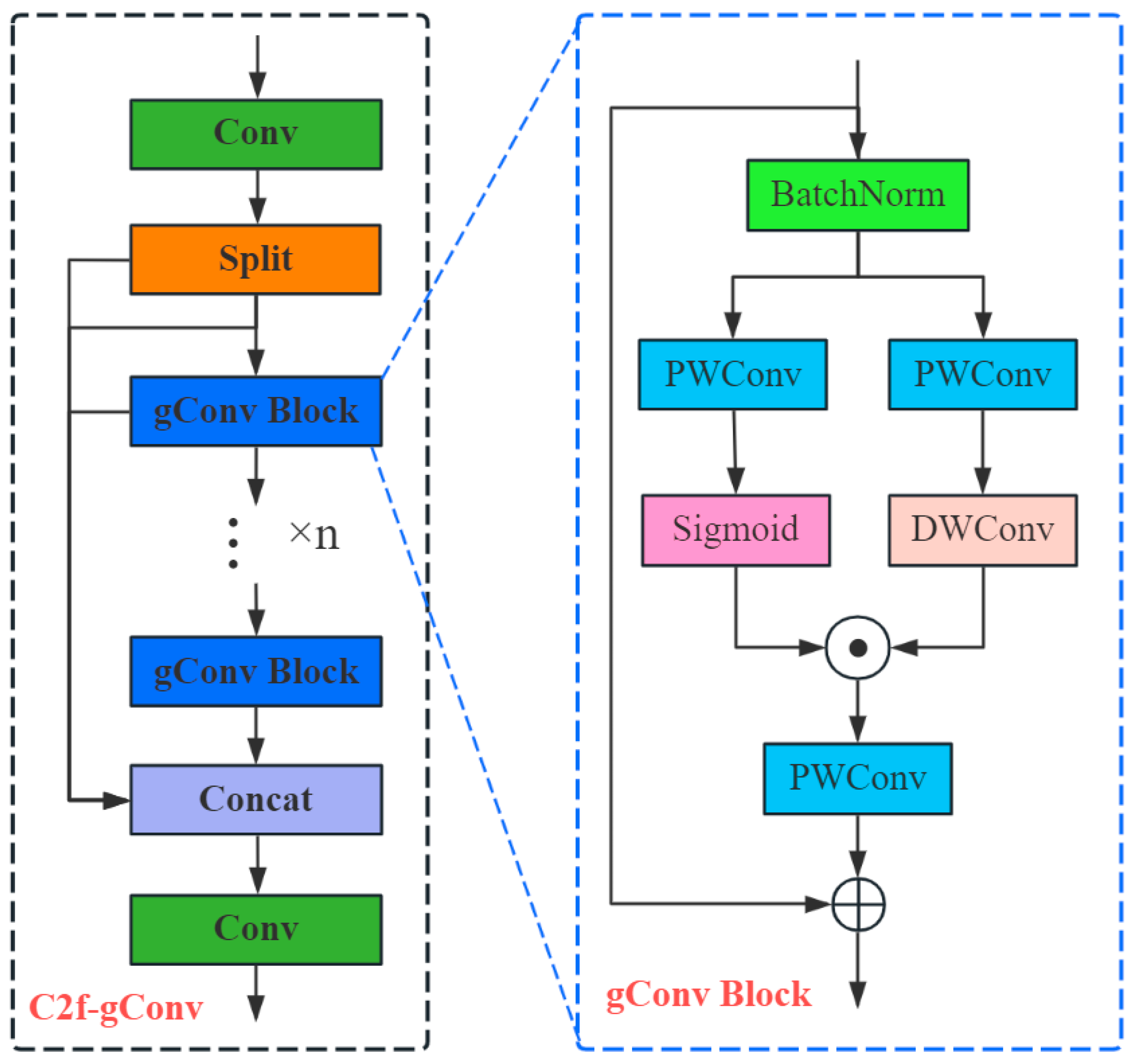
Gated Convolution is integrated into the C2f module to form the C2f-gConv module, which reduces both parameter count and computational cost without compromising detection performance.
- (2)
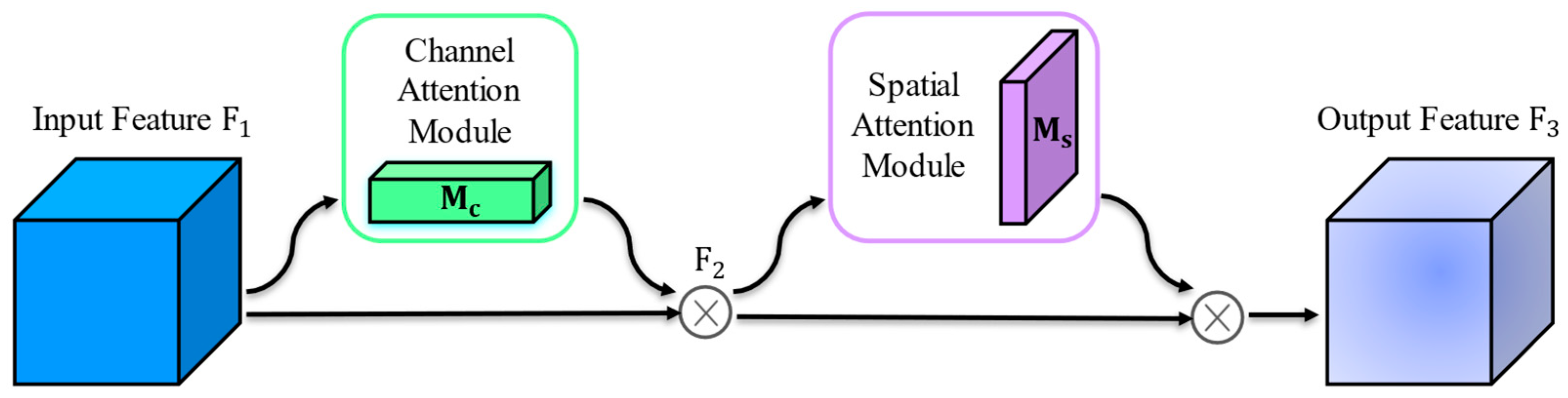
A Global Attention Mechanism is inserted between the backbone and the feature fusion layers to improve the model’s focus on occluded targets and boost detection performance in complex environments.
- (3)
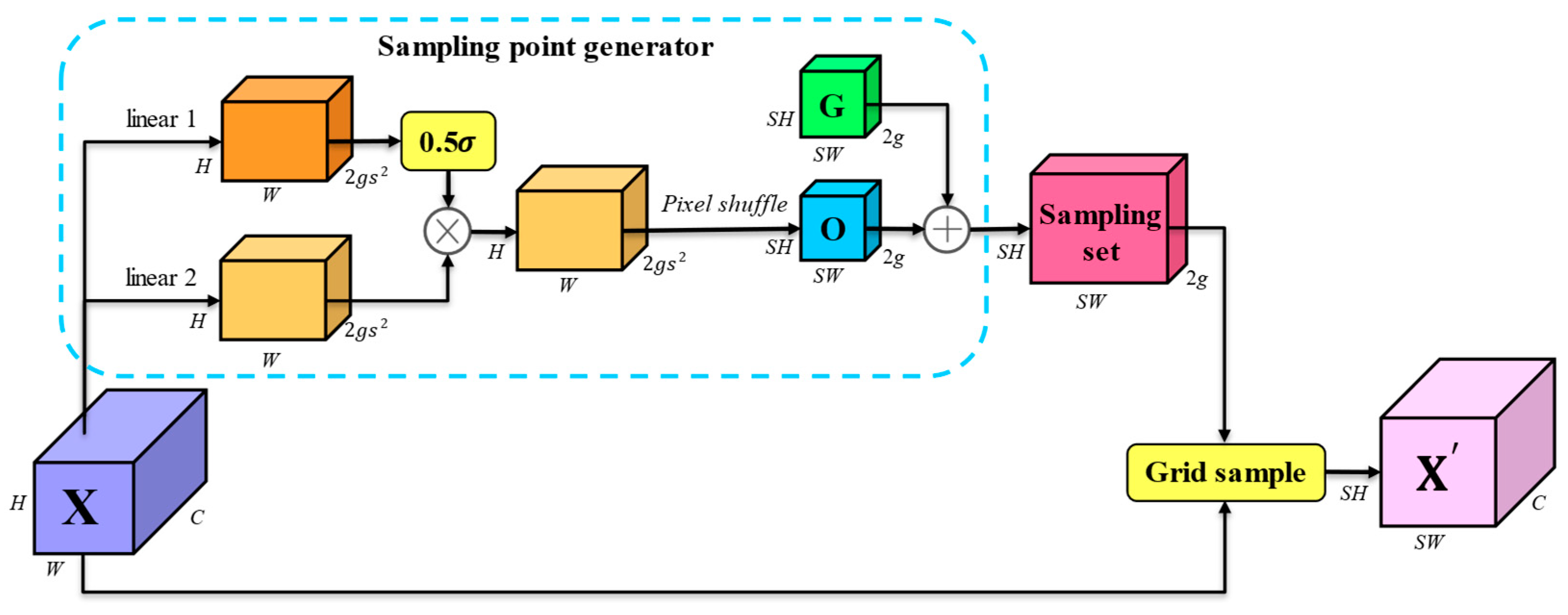
A Dynamic Sampling strategy is applied in the neck to adaptively enhance feature representation while preserving the model’s lightweight structure.
- (4)
The improved model is deployed on embedded devices for testing, showing faster detection speeds than the baseline and demonstrating strong potential for deployment on field harvesting robots.
3. Results and Analysis
3.1. Lightweight Network Design
To verify the effectiveness of the lightweight network used in this study, improvements were made to the backbone network of YOLOv10n using c2f-gConv and the current mainstream lightweight feature extraction backbone networks MobileNetV4 [
24], StarNet [
25], Fasternet [
26], and EfficientViT [
27], comparing the training effects of different backbone networks on the target, as shown in
Table 3.
As shown in
Table 3, while StarNet exhibits the smallest parameter count and floating-point operations, its precision, recall, and mAP decline by 3.4, 1.5, and 1.6 percentage points, respectively, compared to YOLOv10n. In contrast, MobileNetV4 and EfficientViT, despite their larger parameter counts and floating-point operations, do not significantly enhance the model’s mAP, precision, or recall. Fasternet improves precision, recall, and mAP by 0.9, 0.8, and 1.5 percentage points relative to YOLOv10n; however, it requires substantially more parameters and floating-point operations, resulting in an overly large model size. Conversely, the C2f-gConv model, with a compact size of only 4.5 MB, enables rapid deployment on mobile platforms. Additionally, it improves precision, recall, and mAP by 1.2, 0.7, and 1.7 percentage points compared to YOLOv10n, effectively enhancing dragon fruit detection accuracy while reducing parameters and computational complexity. Hence, adopting C2f-gConv is a practical and effective solution for achieving a lightweight model.
3.2. Comparison of Detection Performance of Different Attention Mechanisms
To verify the impact of the attention mechanism GAM added in this study on the YOLOv10n model, the CBAM [
28], EMA [
29], and ECA [
30] attention mechanisms were added at the same position, and a performance comparison was made with the attention mechanism in this paper, as shown in
Table 4.
As illustrated in
Table 4, the YOLOv10n+GAM model, after incorporating the attention mechanism, achieves the highest precision and mAP, with only a marginal decrease in recall compared to the YOLOv10n+CBAM model. Compared to YOLOv10n, the precision, recall, and mAP of YOLOv10n+GAM improve by 2.8, 1.9, and 1.9 percentage points, respectively, albeit with a slight reduction in detection speed. Compared to the YOLOv10n+EMA model, the YOLOv10n+GAM model improves precision, recall, and mAP by 3.1, 2.7, and 2.6 percentage points, respectively. Similarly, compared to the YOLOv10n+ECA model, it achieves improvements of 1.4, 1.4, and 0.8 percentage points, respectively. In summary, the incorporation of the GAM attention mechanism significantly enhances the YOLOv10n+GAM model’s feature extraction capabilities, improving its ability to recognize dragon fruits partially obscured by branches. The results demonstrate that introducing the GAM attention mechanism effectively improves the model’s accuracy in detecting dragon fruits.
3.3. Ablation Experiment
This study extends the original YOLOv10n model by incorporating the C2f-gConv module, a Global Attention Mechanism, and a DySample upsampling operator to improve object detection performance under complex environmental conditions. To evaluate the individual contribution of each module to overall performance, systematic ablation experiments were conducted. Each configuration was trained independently five times using distinct random seeds, with all other training settings held constant. The mAP was used as the primary evaluation metric, and paired t-tests were conducted to assess the statistical significance of performance differences between the baseline and enhanced models. The results of the ablation experiments are summarized in
Table 5.
As shown in
Table 5, the integration of the gConv enhancement into the C2f module of YOLOv10n resulted in a marked reduction in both model parameters and computational overhead, while the mAP increased by an average of 1.3%. This improvement is attributed to gConv’s ability to combine the benefits of standard convolution and depthwise separable convolution, thereby enhancing inter-channel interactions and improving feature modeling efficiency at low computational cost. In orchard environments, small distant targets often become indistinct within deeper feature maps; however, gConv’s enhanced perceptual capability aids in preserving such crucial information, thereby mitigating feature degradation. The addition of the GAM to the backbone network slightly increased model size but led to notable improvements in precision, recall, and mAP—by 3.4, 1.5, and 2.6 percentage points on average, respectively. These performance gains are primarily due to GAM’s global modeling through spatial–channel fusion, which enhances the network’s attention to semantically rich regions such as fruit edges and crowns, thereby improving the detection of partially occluded fruits and reducing the impact of branch interference. Finally, replacing the conventional upsampling module with DySample yielded further gains in precision, recall, and mAP—by 3.8, 2.7, and 3.0 percentage points on average, respectively. This improvement is attributed to DySample’s ability to more accurately reconstruct object boundary details via dynamic weight learning, thereby enhancing detection performance for irregularly shaped dragon fruits. Furthermore, all improved variants demonstrated statistically significant gains in mAP (
p < 0.05) relative to the baseline YOLOv10n, confirming the effectiveness and robustness of the proposed modifications in enhancing detection performance.
Upon the simultaneous integration of gConv, GAM, and DySample, the model’s parameter count was reduced to just 1.7 M, with a computational load of 4.8 GFLOPs. The model size was compressed to 4.5 MB, while the detection frame rate improved to 125.6 FPS, achieving an mAP of 98.1%. These results ensure high detection precision while further optimizing real-time performance and computational efficiency. While all pairwise combinations of the three enhancements improved the network to varying extents, none matched the comprehensive detection performance of YOLOv10n-CGD. Although the GAM + DySample configuration yielded a marginally higher mAP (98.3%), it incurred significantly greater parameter count, model size, and computational complexity than the proposed YOLOv10n-CGD. Furthermore, YOLOv10n-CGD outperformed the GAM + DySample configuration in both precision and recall, reflecting superior robustness and generalization capacity. Therefore, considering multiple metrics including accuracy, inference speed, model compactness, and operational stability, YOLOv10n-CGD delivers the most balanced overall performance in complex field environments, rendering it particularly well-suited for meeting the dual demands of rapid detection and efficient deployment in practical agricultural applications.
3.4. Comparison Test of Different Target Detection Models
The improved YOLOv10n-CGD model based on YOLOv10n is compared with mainstream object detection network models such as SSD, Faster R-CNN, YOLOv5s, YOLOv7-tiny, and YOLOv8n. It is important to note that for the YOLO series models, the training was conducted using the parameter settings specified in
Table 2. In contrast, for SSD and Faster R-CNN, the default official training configurations were adopted due to framework constraints. Nevertheless, to ensure fair comparisons, all models were trained for the same number of epochs and evaluated on the same dataset, thereby maintaining a consistent experimental foundation. The corresponding results are summarized in
Table 6.
As shown in
Table 6, the improved YOLOv10n-CGD model achieves precision, recall, and mean average precision of 97.1%, 95.7%, and 98.1%, respectively, outperforming other models. Its mean average precision exceeds that of SSD, Faster R-CNN, YOLOv5s, YOLOv7-tiny, YOLOv8n, YOLOv9-C, and YOLOv10n by 14.2, 12.9, 4.9, 5.4, 2.5, 6.7, and 3.0 percentage points, respectively. Regarding detection speed, the YOLOv10n-CGD model achieves a frame rate of 125.6 FPS, representing a significant advantage over other models. Moreover, the YOLOv10n-CGD model’s weight is only 4.5 MB, smaller than that of all other models, making it highly suitable for mobile deployment. In summary, the YOLOv10n-CGD model proposed in this study demonstrates superior performance in terms of size, detection accuracy, and speed compared to other mainstream networks, enabling fast and accurate dragon fruit detection in natural environments.
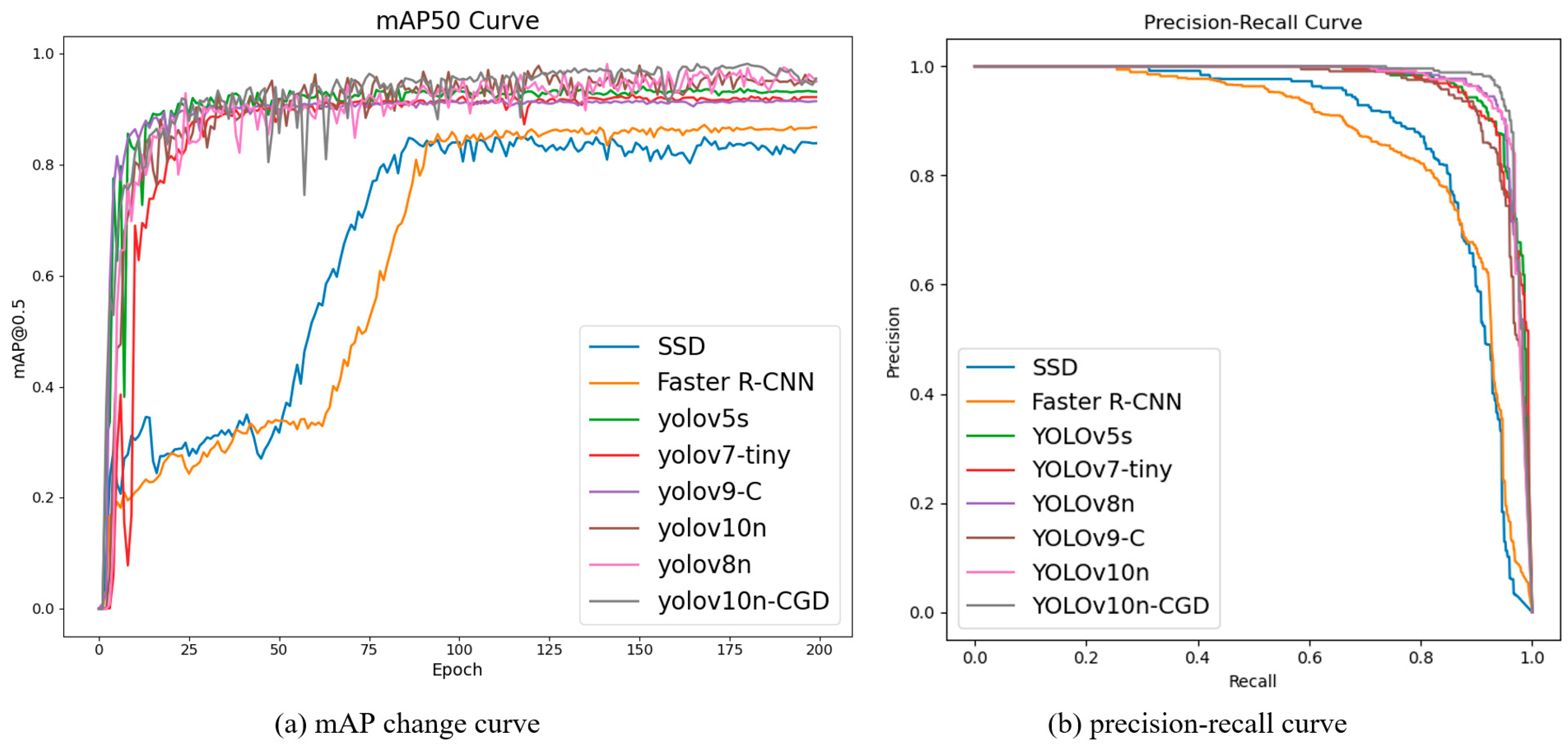
Figure 9 presents the mAP change curves and the P-R curve visualizations for each model during training.
Figure 9a shows that the YOLOv10n-CGD model gradually stabilizes and surpasses other detection models at around 125 iterations, with no signs of overfitting or underfitting. As illustrated in
Figure 9b, the area under the P-R curve for the YOLOv10n-CGD model is closest to 1, demonstrating its superior detection performance.
3.5. Visualization Results of Different Target Detection Models
To further validate the detection performance of the YOLOv10n-CGD model for dragon fruit, this study compares and analyzes the target detection networks discussed in
Section 3.4 under varying lighting conditions and occlusion scenarios.
Figure 10 illustrates the detection results of each algorithm under varying lighting conditions. Under uniform lighting conditions, SSD, Faster R-CNN, and YOLOv9-C miss detecting small target fruits at longer distances. While other networks successfully detect dragon fruits, their accuracy is slightly inferior to YOLOv10n-CGD. Under backlit conditions, the low brightness reduces the color distinction between dragon fruits and the background. Consequently, networks like Faster R-CNN, YOLOv5s, YOLOv8n, and YOLOv10n experience varying levels of missed detections and false positives. In contrast, the YOLOv10n-CGD model maintains robust performance and demonstrates consistent accuracy under diverse lighting conditions.
Figure 11 depicts the detection results for each network when fruits are partially occluded by branches, as illustrated in
Figure 11(a2,b2,d2,f2). SSD, Faster R-CNN, YOLOv7-tiny, and YOLOv9-C each miss detecting two fruits, while YOLOv5s, YOLOv8n, and YOLOv10n miss one fruit each, as illustrated in
Figure 11(c2,e2,g2). In contrast, the proposed YOLOv10n-CGD model demonstrates superior detection performance under occlusion conditions and maintains consistent accuracy across diverse environments.
3.6. Robustness Evaluation of the Model in Complex Environments
To comprehensively assess the robustness of the proposed YOLOv10n-CGD model in real-world complex environments, we constructed test subsets under varying lighting conditions and occlusion scenarios and conducted comparative experiments to verify its adaptability for practical applications.
3.6.1. Robustness Under Varying Lighting Conditions
To evaluate the model’s robustness under complex lighting scenarios, the test dataset was manually annotated and categorized based on lighting direction during image acquisition. Two representative subsets were created: a frontlight subset and a backlight subset, each consisting of 100 representative images for performance evaluation.
Both the baseline YOLOv10n and the improved YOLOv10n-CGD models were evaluated on these two subsets using three standard metrics: Precision, Recall, and mAP. To ensure the reliability of comparative results, five independent training and testing sessions were conducted for each model on both subsets using different random seeds. A paired t-test was performed on the mAP results to determine the statistical significance of the performance differences. The results are presented in
Table 7.
As shown in
Table 7, under front-light conditions, YOLOv10n-CGD achieved an average improvement of 2.7 percentage points in mAP compared to the baseline model. Under backlight conditions, the improvement was even more pronounced, reaching 3.5 percentage points. In both scenarios, the improvements were statistically significant (
p < 0.05), indicating that the proposed enhancements effectively improve the model’s feature extraction capability and robustness against illumination variability in complex environments.
3.6.2. Performance Evaluation on the Occlusion Subset
To assess the robustness of the improved model in scenarios involving complex occlusions, an occlusion subset was constructed from the test dataset. This subset comprises samples in which the dragon fruit target is partially obscured by foreground branches. The selection criterion was as follows: if, based on manual assessment, the area of the fruit occluded by branches exceeded 30% of its bounding box area—approximately corresponding to an IoU > 0.3 between the target and occlusion region—the image was considered severely occluded and included in the subset. In total, 100 representative occlusion images were selected for performance evaluation.
On this subset, we evaluated and compared the detection performance of the baseline YOLOv10n model and the improved YOLOv10n-CGD model. To verify the statistical significance of the observed performance differences, a paired t-test was conducted on the key metric, mAP. The evaluation results are summarized in
Table 8.
As shown in
Table 8, YOLOv10n-CGD consistently outperformed the baseline across all evaluated metrics, achieving average improvements of 2.8, 3.8, and 3.9 percentage points in Precision, Recall, and mAP, respectively. Notably, the improvement in mAP was statistically significant (
p < 0.01), confirming that the observed gain is unlikely due to random variation. These results clearly demonstrate that the integration of the GAM attention mechanism enhances the model’s responsiveness to partially occluded targets, substantially alleviates performance degradation caused by branch occlusion, and significantly improves the model’s robustness in real-world orchard environments.
3.7. Model Deployment on Mobile Devices and System Integration Analysis
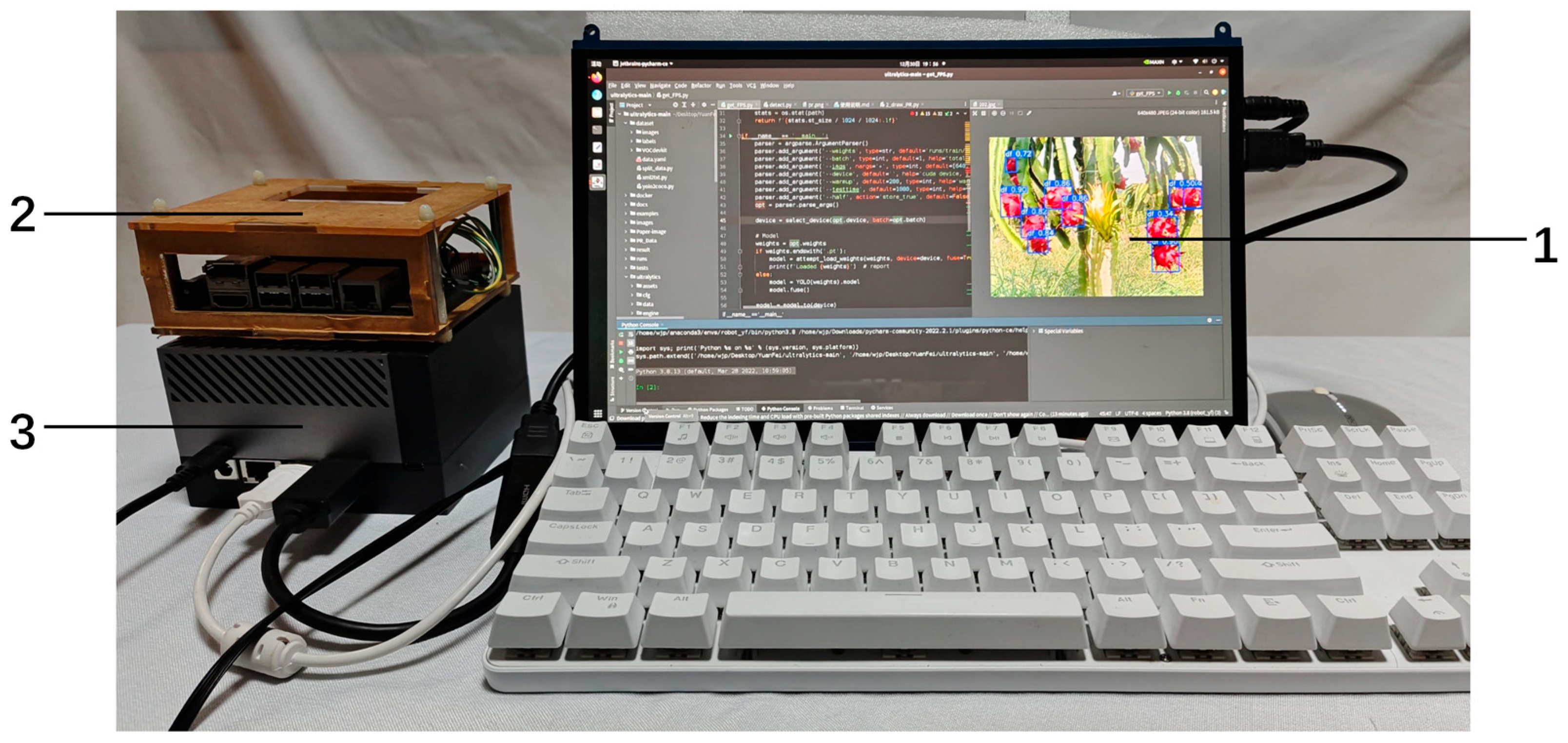
To validate the actual deployment performance of the improved YOLOv10n-CGD model on embedded mobile devices and to evaluate the impact of each enhancement module on model efficiency, this study tested the detection frame rates of various models on edge computing devices Jetson AGX Orin and Jetson Nano. The test platform is shown in
Figure 12.
Table 9 presents the frame rate results of the model tests.
Table 9 reveals that the C2f-gConv module is the primary contributor to the improvement in detection frame rates, yielding performance gains of 14.1 FPS on the Jetson AGX Orin and 6.5 FPS on the Jetson Nano. This underscores its substantial role in enhancing the model’s operational efficiency and reducing computational resource consumption. In contrast, the DySample module has a relatively minor effect on inference speed. The GAM attention mechanism, while beneficial for accuracy enhancement, introduces a slight reduction in frame rate due to its additional computational overhead. The integrated YOLOv10n-CGD model achieves detection frame rates of 44.9 FPS and 17.2 FPS on the Jetson AGX Orin and Jetson Nano, respectively—representing improvements of 12.2 FPS and 5.6 FPS compared to the baseline YOLOv10n. These results highlight the strong adaptability and synergistic optimization effect of the multi-module design in embedded deployment scenarios. Moreover, the deployed model runs stably on both devices, with memory usage remaining well within hardware limits. On the Jetson Nano, the average single-frame inference latency is approximately 58.1 milliseconds (derived from the frame rate), significantly below the 200-millisecond threshold required for real-time robotic control. These findings demonstrate that the improved YOLOv10n-CGD model not only maintains high detection performance on edge devices but also exhibits excellent real-time processing capability and deployment robustness. This provides strong technical support for the development of efficient intelligent perception and robotic harvesting systems for dragon fruit in practical agricultural applications.
Although the proposed YOLOv10n-CGD model demonstrates strong detection performance on embedded mobile devices, practical deployment in agricultural scenarios requires integration with additional functional modules, including 3D localization and robotic arm control. Within the complete automated harvesting pipeline, the detection model first outputs 2D bounding box information, which is then fused with depth image data based on camera calibration principles to estimate the 3D spatial coordinates of the target fruit. These coordinates serve as inputs for the robotic arm control module, enabling accurate path planning and grasp execution. The entire harvesting system adopts a modular architecture that supports closed-loop processing on edge computing platforms. This includes image acquisition, target detection, 3D localization, and transmission of control commands. The system is capable of handling simultaneous multi-fruit detection and planning sequential harvesting actions, thereby meeting the real-time and coordination requirements of automated agricultural operations. These results demonstrate that the improved YOLOv10n-CGD model provides a reliable perceptual foundation for intelligent harvesting systems, particularly for high-value crops such as dragon fruit.
4. Conclusions
This study proposes a lightweight and rapid dragon fruit detection method for harvesting robots under natural environments. The conclusions derived from the ablation experiments and comparative analyses with other target detection models are as follows:
(1) The proposed YOLOv10n-CGD model demonstrates significant performance improvements, with mean precision, recall, and average precision values of 97.3%, 95.8%, and 98.2%, respectively, surpassing the original YOLOv10n model by 4.1, 2.9, and 3.1 percentage points. This highlights its superior detection performance.
(2) The enhanced model exhibits superior detection performance under varying lighting and shading conditions. Compared to SSD, Faster R-CNN, YOLOv5S, YOLOv8n, and other algorithms, it demonstrates clear advantages in model size, detection accuracy, and speed, enabling efficient and accurate dragon fruit detection in natural environments.
(3) The improved model achieves a 22.4% reduction in weight size, with detection frame rates of 44.9 and 17.2 FPS on the Jetson AGX Orin and Jetson Nano edge computing devices, respectively. Its deployment performance surpasses the YOLOv10n baseline, effectively meeting the requirements for lightweight embedded deployment.
The proposed YOLOv10n-CGD model achieves high-precision and real-time detection of dragon fruit in complex orchard environments and demonstrates strong potential for deployment on embedded mobile platforms. However, the model still faces several limitations. The dataset used in this study was collected from specific regions and time periods, lacking diversity in terms of seasons, orchard conditions, and fruit varieties, which limits the generalization capability of the model. Moreover, since all images were acquired using the same type of camera, the model may have implicitly learned sensor-specific imaging characteristics, potentially impacting its performance when deployed across different devices.
To address these limitations, future research will focus on collecting multi-temporal and multi-regional datasets using various camera types in orchards across different geographic locations. We will also explore domain adaptation strategies—such as unsupervised feature alignment—to mitigate performance degradation under cross-orchard and cross-device scenarios, thereby enhancing the model’s cross-domain robustness. In addition, we plan to incorporate active learning techniques to iteratively select and annotate challenging samples, further improving the model’s performance in scenarios with severe occlusion or suboptimal lighting conditions. Finally, efforts will be made to realize end-to-end deployment of the model on agricultural robotic platforms and conduct extensive field validation to support real-world applications in intelligent harvesting systems.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}