1. Introduction
Field weeds compete with crops for water and nutrients, significantly impacting crop growth [
1]. In my country, weed-related yield losses account for approximately 10–15% of total annual grain production. Rapeseed, the nation’s primary oil crop [
2], is especially susceptible to weed damage. In winter rapeseed-growing areas like the Yangtze River Basin, the high temperature and good soil moisture during sowing create favorable conditions for weeds. After rapeseed is sown, weeds rapidly emerge, reaching a peak that intensively competes with rapeseed seedlings and leads to substantial yield reductions. Typical yield losses range from 10–20% [
3], and severe weed infestations can reduce production by over 50%. The National Farmland Weed Investigation Team reports that weed damage affects approximately 46.9% of winter rapeseed fields in the Yangtze River Basin, with 22.3% experiencing moderate to severe damage. Effective weed control during the seedling stage is crucial for minimizing these losses. However, accurately detecting weeds in crops under natural field conditions remains challenging due to factors such as inter- and intraspecies variability in weed characteristics (e.g., shape, size, color, and texture), weed-crop similarity, and changing field conditions (e.g., lighting, and soil background).
Advancements in image acquisition technology, reduced hardware costs, and increased GPU computing power have facilitated deep-learning applications in agriculture. These applications encompass crop classification, pest and disease identification, fruit counting, plant nutrient content estimation, and weed identification, among others. Deep-learning-based methods have demonstrated considerable success in weed detection and classification, with convolutional neural networks (CNNs) supported by large datasets showing robustness to biological variability and diverse imaging conditions, resulting in more accurate and efficient weed control automation.
For instance, Wang et al. [
4] developed a corn weed recognition method using multi-scale hierarchical features in CNNs, which extracts features from Gaussian pyramid layers and connects them to a multi-layer perceptron for pixel-level classification. Peng et al. [
5] optimized the RPN network with a feature pyramid network, enhancing convolutional network performance for cotton and weed detection under natural lighting. Jiang et al. [
6] proposed a Mask R-CNN-based method to address the low segmentation accuracy in complex field conditions, while Fan et al. [
7] combined data augmentation and Faster R-CNN with a VGG16 feature extraction network for improved weed recognition. Other researchers have leveraged lightweight CNN architectures for efficiency. For example, Dyrmann et al. [
8] constructed a CNN with three convolutional layers and residual blocks, achieving an 86.2% classification accuracy on over 10,000 images containing weed and crop species at early growth stages. Potena et al. [
9] applied two CCNs to RGB and NIR images, achieving rapid, accurate weed-crop classification. In drone-based studies, Beeharry and Bassoo [
10] demonstrated AlexNet’s 99.8% classification accuracy compared to less than 50% with standard ANN methods, emphasizing the advantages of deep-layered CNNs like AlexNet in achieving efficient weed detection.
Further innovations include McCool et al.’s [
11] combination of lightweight CNNs, which achieved an over 90% accuracy at speeds exceeding 10.7 FPS, and You et al.’s [
12] hybrid network with a dilated convolutional network and DropBlock, achieving 88% mean intersection over union (mIOU) on Stuttgart and Bonn datasets. Milioto et al. [
13] improved the pixel segmentation accuracy to 98.16% for weeds and 95.17% for crops by enhancing the RGB input with HSV, Laplacian, and Canny edge representations. Graph convolutional networks (GCNs) have also been adapted for weed detection. Jiang et al. [
14] integrated GCNs with ResNet101 features in a semi-supervised learning framework, achieving 96–99% accuracy on various weed species and outperforming AlexNet, VGG16, and ResNet-101. Similarly, Bah et al. [
15] demonstrated the efficiency of CNNs in unsupervised training for spinach and bean weed detection, achieving similar AUC scores to supervised methods. Peng et al. [
16] developed the WeedDet model, an enhanced RetinaNet-based model for rice field weed detection, which improved the detection speed through a lightweight feature pyramid and detection head. Zhang et al. [
17] used the EM-YOLOv4-Tiny model for real-time weed classification in peanut fields, achieving detection in 10.4 ms per image. In order to deal with the situation where the shape and scale attributes of weeds and cotton at the seedling stage are similar in large fields, Fan et al. [
18] use the weighted fusion BiFPN module, CBAM, and bilinear interpolation method based on the Faster RCNN model to deal with the recognition problem in complex environments. The YOLOv8 model is used to design a multi-scale feature fusion architecture at the Neck end [
19], and a dynamic feature aggregation head is designed at the end to solve the problem of the large number of network parameters and being unable to detect dynamically.
Utilizing drone imagery for weed detection presents a compelling advantage over other on-field or alternative imaging methods [
20]. Drones, with their ability to hover at low altitudes, provide a unique perspective that captures high-resolution images with enhanced spatial detail [
21]. The real-time data acquisition capabilities of drones facilitate more frequent monitoring, allowing for the timely identification of emerging weed threats. Additionally, drones are cost-effective and can be deployed rapidly, enabling swift responses to evolving weed dynamics. The comprehensive coverage, agility, and timely data acquisition make drone imagery a superior option for weed detection, contributing to the efficiency and precision of modern agricultural practices.
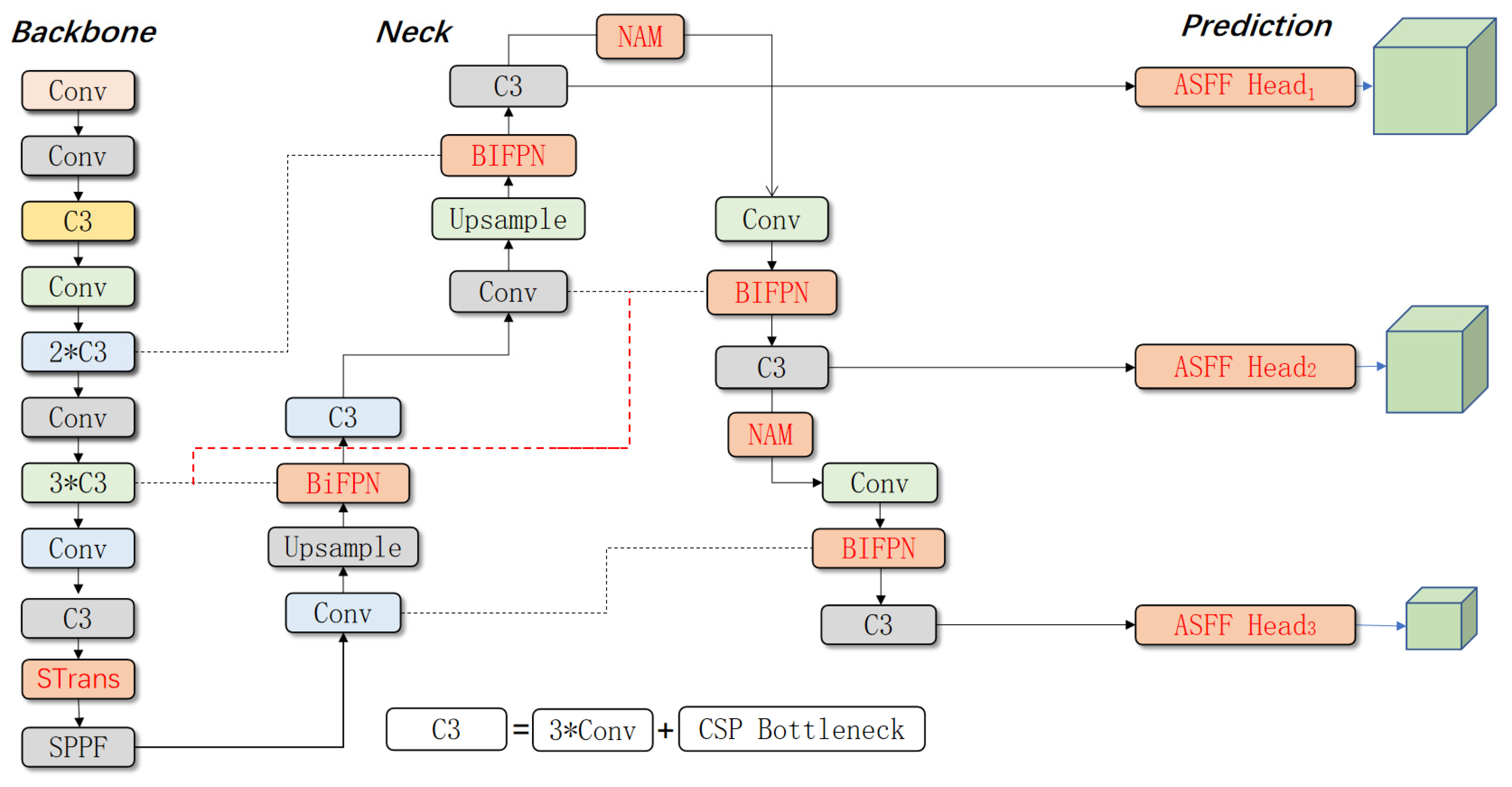
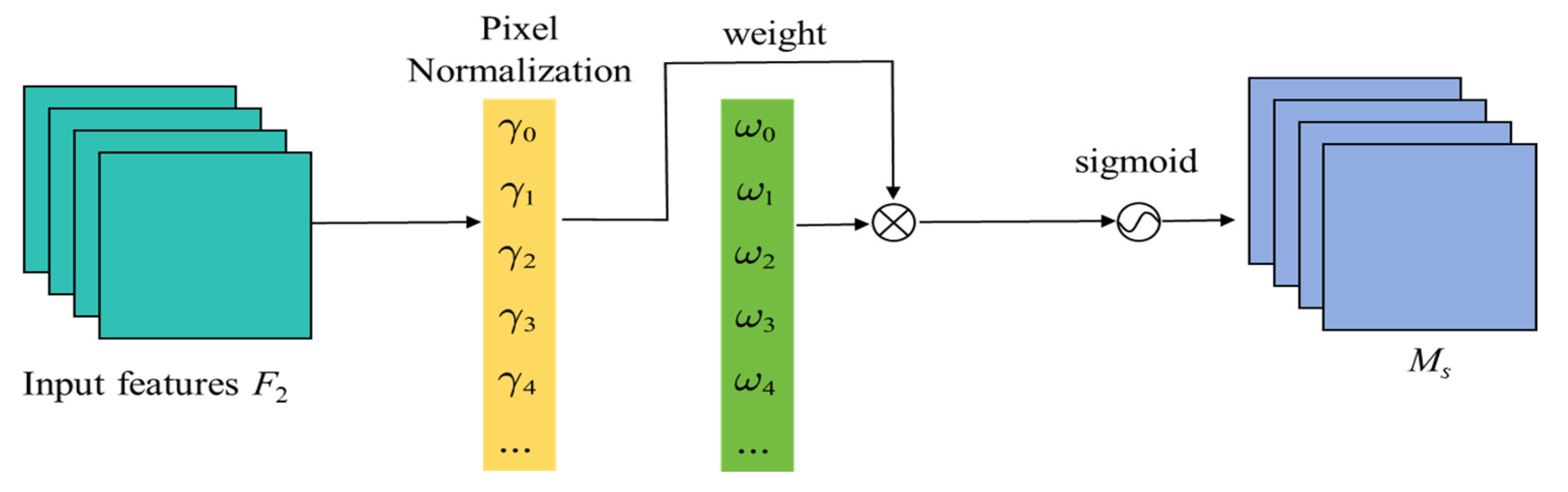
This study focuses on weed detection in winter rapeseed fields during the seedling stage, targeting four common weeds. To address challenges such as high weed density, occlusion, and size variability, we propose the STBNA-YOLOv5 weed detection model. In order to increase the feature extraction ability of the backbone network, the Swin Transformer encoder module is added. In order to make full use of the rich feature information extracted by the backbone network, the BiFPN structure is used and the NAM attention mechanism module is embedded to provide a reliable front-end information source for the Prediction stage. In order to enhance the sensitivity of the detection head to crops and weeds, the Adaptively Spatial Feature Fusion module is introduced into the detection head.
3. Results and Discussion
3.1. Performance of Dataset Augmentation
To verify the actual effectiveness of the random occlusion method based on image pixels and the data augmentation method specific to weed classes in this model, comparative experiments were conducted using the original YOLOv5 model. These methods were evaluated alongside traditional data augmentation techniques (including horizontal translation, vertical rotation, and brightness enhancement). Since the canola recognition accuracy remains above 90% across all models, this study does not discuss canola-specific metrics. Instead, the performance indicators used focus on weed detection, specifically Recall
weed, Precision
weed, F1-score
weed, and mAP@0.5. To ensure consistency in data quantity after augmentation, each data augmentation method was adjusted to produce 5000 images for the training set only, without affecting the validation or test sets. During model training, data were divided into training, validation, and test sets at a 7:2:1 ratio. The Precision–Recall (PR) curves and augmentation performance results across various metrics for both the original YOLOv5 with traditional data augmentation and the proposed random occlusion and weed-specific augmentation methods are shown in
Figure 11 and
Figure 12.
Based on the experimental results, as shown in the figures, the proposed random occlusion method based on image pixels and the weed-specific data augmentation technique outperform traditional data augmentation methods in terms of weed detection metrics. Specifically, the proposed methods achieved a Recallweed of 51.3%, Precisionweed of 76%, F1-scoreweed of 61.2%, and mAP@0.5 of 84.7%. Compared to traditional data augmentation, these methods showed improvements in Precisionweed, F1-scoreweed, and mAP@0.5 by 2%, 1.4%, and 1.9%, respectively. While traditional data augmentation effectively increases the weed sample size, it also proportionally increases crop samples. This approach fails to address the deep network’s bias toward high-proportion target objects. In contrast, the proposed random occlusion and weed-specific augmentation methods focus specifically on expanding weed samples without increasing canola samples, thereby balancing the dataset. Additionally, random occlusion forces the network to extract deeper feature information from the target objects. These factors contribute to the superior performance of the proposed methods over traditional augmentation techniques in this model.
3.2. Ablation Experiment
To validate and assess the effectiveness of the proposed Swin Transformer module, BiFPN feature fusion module, NAM attention mechanism, and Adaptively Spatial Feature Fusion (ASFF) module on YOLOv5, ablation experiments were conducted for each module. To ensure thorough validation, all models in the ablation experiments were trained using the dataset enhanced by the proposed data augmentation methods, with a total sample size of 5000 images. The dataset was divided into training, validation, and testing sets at a ratio of 7:2:1. The ablation experiment results are shown in
Table 1. ① includes only the Swin Transformer module; ② adds the BiFPN module to ①; ③ further includes the NAM attention mechanism based on ②; and ④ incorporates the ASFF module in addition to ③. Each experiment was evaluated based on the Recall
weed, F1-score
weed, AP
weed, mAP@0.5, and FPS metrics.
Table 1 shows that adding the “YOLOv5 + Swin Transformer” configuration improved the original YOLOv5 network in terms of Recall
weed, F1-score
weed, AP
weed, mAP@0.5, and FPS by 1%, 2.8%, 1.5%, and 0.7 FPS, respectively. These improvements in Recall
weed, F1-score
weed, AP
weed, and mAP@0.5 indicate that the Swin Transformer encoder block enhances YOLOv5’s contextual sensitivity, especially for detecting small weed targets, effectively narrowing the recognition gap between weeds and crops. This module also aids in capturing targets in complex field environments. Additionally, the increase in FPS suggests that the Swin Transformer encoder block has a lower computational burden than YOLOv5’s original CSP module, which is advantageous for field deployment. Comparing the “YOLOv5 + Swin Transformer + BiFPN” model with the original YOLOv5 network on Recall
weed, F1-score
weed, AP
weed, and mAP@0.5 metrics, the configuration achieved respective increases of 4%, 5.4%, and 3%. By reusing the rich feature information extracted from the Backbone network and placing the Swin Transformer module within it, the BiFPN module gains access to more comprehensive information. The feature weight parameters introduced here allow the network to automatically learn the importance of different input features, suppressing irrelevant features to achieve multi-level feature fusion.
Moreover, with the addition of the NAM attention mechanism, which functions similarly to the weight factors in BiFPN, the spatial and semantic information for both weeds and crops is further enriched. The configuration “YOLOv5 + Swin Transformer + BiFPN + NAM” demonstrated improvements over the original model in Recallweed, F1-scoreweed, APweed, and mAP@0.5, with respective gains of 11%, 1.1%, 10.9%, and 5.2%, with only a slight decrease in FPS. Together, the Swin Transformer, BiFPN, and NAM modules provide a wealth of front-end information to the Prediction stage. Finally, after incorporating the ASFF module, the model achieved values of 88.1% Recallweed, 64.4% F1-scoreweed, 82.5% APweed, and 90.8% mAP@0.5 compared to the baseline YOLOv5. Although mAP@0.5 improved by about 6%, this metric is influenced by the high recognition rate of crops, which remained over 90% across both the baseline and improved YOLOv5 models. However, APweed showed a substantial increase of nearly 12%. The added modules bring significant gains in recognition accuracy with minimal sacrifices in detection efficiency, proving beneficial for field operations.
3.3. Comparative Experiment
To further validate the effectiveness of the proposed STBNA-YOLOv5 model, a comparative experiment was conducted using several object detection models: EfficientDet, SSD, Faster R-CNN, DETR, YOLOv3, and the proposed model itself. These models were evaluated on a data-augmented dataset, and split into training, validation, and test sets with a 7:2:1 ratio, using five metrics: Recall, Precision, F1-score, mAP@0.5, and FPS. The comparison results are presented in
Table 2. To ensure fairness, all models were tested on the same dataset with identical conditions. This setup allows a direct and unbiased performance comparison across models, highlighting the specific advantages of STBNA-YOLOv5 in terms of detection accuracy, recall precision, and processing speed, confirming its suitability and robustness in handling complex agricultural field scenarios.
SSD, as a single-stage object detector, achieves a high FPS but underperforms in small object detection. In our experiments, SSD’s Recallweed and Precisionweed were 8.1% and 13.4% lower than those of the proposed model, and its mAP was 7.1% lower than our improved YOLOv5. This is likely because SSD relies on lower-level feature maps, which limits its small object detection capability.
The Faster R-CNN, a two-stage detector, has been applied in agricultural object detection and includes both a region proposal stage and a feature extraction stage. In our tests, the Faster R-CNN achieved an mAP@0.5 of 81.9%. However, due to its separate regression and classification steps, its FPS performance was lower than that of other algorithms, which makes it less suitable for real-time field deployment.
DETR, a recent end-to-end model, shows promise but has a large architecture and slow convergence, requiring extended training time. It underperformed our model in Recall, Precision, and mAP@0.5, suggesting it may not be ideal for real-time applications in our field scenarios.
YOLOv3, the classic YOLO model from which YOLOv5 evolved, uses a simple FPN structure. While YOLOv3 balances an acceptable detection accuracy with fast inference speed, its single FPN architecture limits cross-scale feature fusion. Our model’s BiFPN structure, which enhances multi-scale feature fusion, demonstrates an improved mAP by nearly 7%, although with a slight trade-off in real-time performance.
In comparison with SSD, Faster R-CNN, YOLOv3, and DETR, STBNA-YOLOv5 excels in Precisionweed, F1-scoreweed, and mAP@0.5, proving the effectiveness of our proposed modifications on the rapeseed-weed dataset. This makes our approach the most effective model in accurately detecting rapeseed and weeds among the models tested.
3.4. Experiments on Weed Multi-Class Detection
To better demonstrate the superiority of the proposed algorithm, we selected several test images from the test set to visually showcase the performance of the STBNA-YOLOv5 network in the multi-class detection of weeds in canola fields. As shown in
Figure 13, the detection results under various field conditions—sunny, cloudy, unobstructed, and obstructed—are presented. The model clearly identifies both canola and weed species. The confidence levels for canola consistently exceed 0.7, while those for small nettle and purslane are above 0.8. In unobstructed scenarios, the confidence level for lamb’s quarters exceeds 0.8; even when partially obstructed, the confidence level remains at 0.66, with correct detection results. Additionally, in obstructed conditions, the barnyard grass is accurately detected, achieving a confidence level of 0.86. By incorporating four enhancement methods—the Swin Transformer encoder block, BiFPN, NAM, and ASFF—the STBNA-YOLOv5 model exhibits improved object perception capabilities. This advancement effectively reduces the likelihood of false negatives, false positives, and duplicate detections, making the model well-suited for the real-time detection of weeds and canola during the winter canola seedling stage.
Figure 14 and
Figure 15 illustrate the weed detection results obtained using the YOLOv5 and STBNA-YOLOv5 models, respectively. As shown in
Figure 14a, the YOLOv5 model failed to detect purslane, resulting in a missed detection. In contrast, the STBNA-YOLOv5 model successfully identified all instances of purslane. Additionally,
Figure 14a reveals that the YOLOv5 model incorrectly classified a specimen of nutsedge as barnyard grass, leading to a false positive detection. However, the STBNA-YOLOv5 model correctly identified nutsedge.
4. Conclusions
This study established a dataset containing both weeds and rapeseed. While rapeseed samples are relatively easy to obtain, the diversity of weed species can lead to a significant data imbalance. To address this issue, we introduced a random occlusion method based on image pixel points, along with an image data augmentation technique specifically for weed categories. Building on the original YOLOv5 algorithm, we improved the Backbone, Neck, and Prediction components of the model. To enhance the feature extraction capability of the Backbone, we incorporated a Swin Transformer encoder block. We utilized a BiFPN structure at the Neck to fully leverage the rich feature information extracted by the Backbone, embedding a NAM attention mechanism to further enhance performance. Additionally, we designed a channel feature fusion module with involution for the Prediction component. The modified YOLOv5 algorithm underwent ablation experiments to analyze the impact of various modules, including image augmentation strategies, the Swin Transformer encoder block, the BiFPN module, the NAM module, and the ASFF module. The results indicated that the STBNA-YOLOv5 model excelled in the Recallweed, APweed, and mAP@0.5 metrics. When compared with models such as SDD, Faster-RCNN, YOLOv3, DETR, and EfficientDet, the STBNA-YOLOv5 model demonstrated a superior Precisionweed, F1-scoreweed, and mAP@0.5, with values of 0.644, 0.825, and 0.908, respectively. Furthermore, we presented detection results under various field conditions, including sunny and overcast weather, as well as scenarios with and without occlusions. The model consistently demonstrated its ability to accurately identify specific types of rapeseed and weeds. Future work will be focused on developing a system incorporating the trained weed detection model.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}