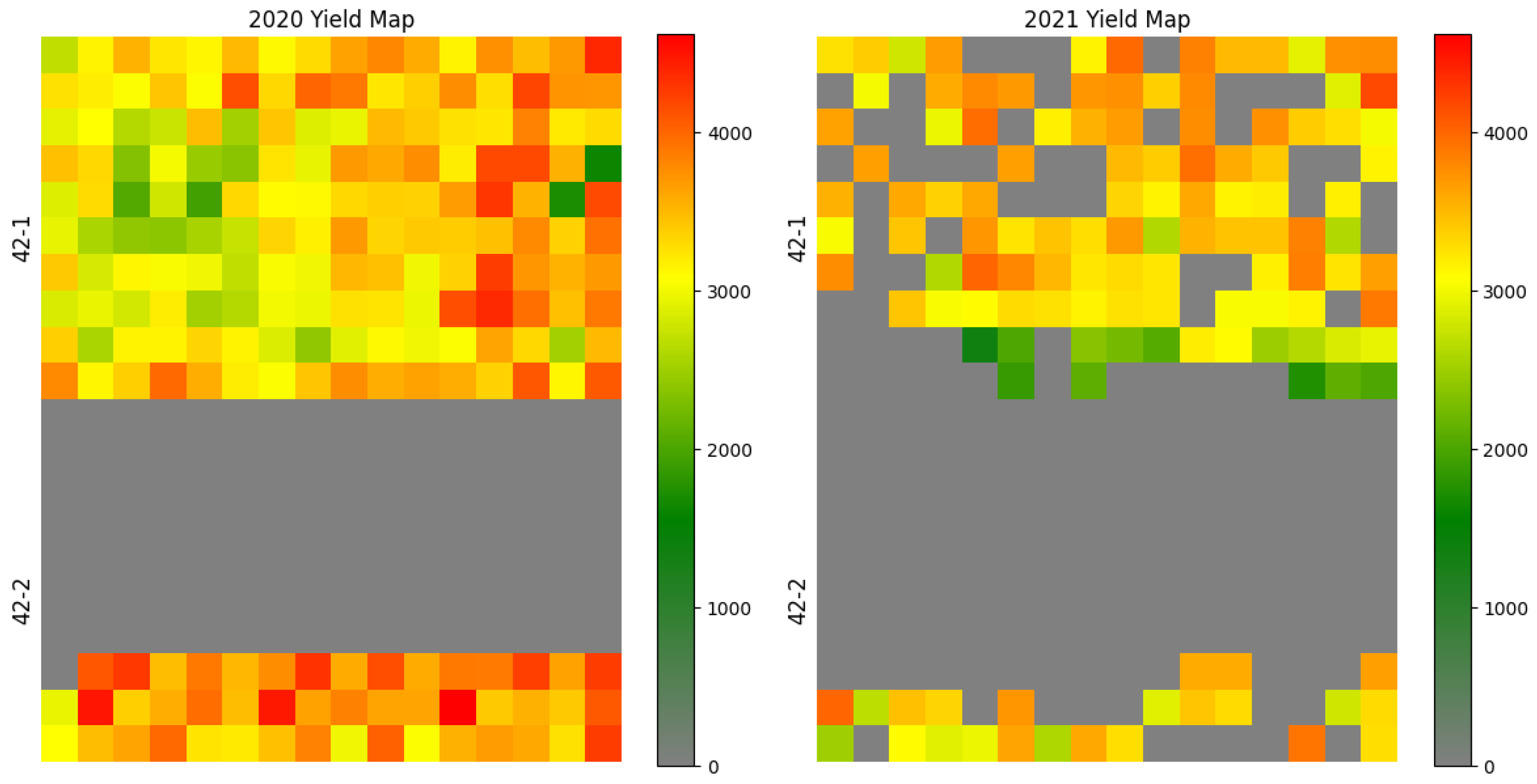
1. Introduction
There are important issues in agriculture, such as crop pest detection, crop symptom detection, and crop yield prediction. However, it is difficult for farmers to manage these problems manually. As data-producing devices have improved in the past decade, these issues have gradually become solvable using artificial intelligence (AI) techniques. Conventional research on crop yield prediction is typically based on farmland yield in the previous year. However, this rule-of-thumb method is not stable and precise because the indirect features such as temperature, rainfall, soil attributes, and sunlight are not in the same conditions yearly. When the environment changes, different crop species have different amplitudes of impact on their yields.
In recent decades, smart farming has become increasingly popular. Remote sensing extracts information from satellites to enable AI models to establish data-driven decisions [
1,
2,
3,
4]. For example, the USGS Global Visualization Viewer (GloVis) is a fast and easy-to-use online satellite and aerial data search tool. Satellite data usually contain predefined wavelength bands in visible and near-infrared (NIR) spectral regions. Unfortunately, satellites face numerous challenges when acquiring remote sensing data. One problem is that it cannot continuously collect data from specific farmlands because of the maintenance of certain orbital positions, periods, and heights. In addition, the spatial resolution is significantly affected by the satellite altitude, which makes it challenging to customize the spatial resolution. Recently, UAVs and drone technologies have become better solutions for obtaining remote sensing data [
5,
6,
7,
8]. With such technologies, users have the flexibility to choose when and where to collect remote sensing data and collect the specific spectral wavelength with an appropriate sensor. However, the problems associated with using UAVs include the management of the collected datasets and extracting relevant information, both of which require domain knowledge. The spectral bands collected from UAVs are ideal for calculating vegetation indices, such as the normalized difference vegetation index (NDVI) [
9].
Predicting the crop yield is a major issue in smart farming. With the advancement of hardware equipment, such as drones and sensors, users can now obtain rich crop features. Data-driven algorithms have gradually acquired the attention of researchers in agriculture [
10]. They have applied data-driven models to improve the performance using available datasets containing crop information, weather, soil conditions, and other environmental features. Data-driven solutions can be classified into machine learning and deep learning. Traditional machine learning has demonstrated good performance in crop yield prediction with classic techniques, such as multiple linear regression, decision tree, random forest, k-nearest neighbor, and support vector machines [
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20]. Despite significant progress in using machine learning techniques for crop yield prediction, the inherent existence of nonlinear reliance between the input and target variables in the datasets is difficult to express using simple linear equations. Hence, these classic machine learning techniques face challenges in improving the next level of performance. Fortunately, the appearance of artificial neural networks (ANNs) has brought the potential to overcome the performance bottlenecks.
ANNs are groundbreaking machine learning algorithms that have garnered remarkable success in enhancing the performance of data-driven models. They can approximate any nonlinear relationship between the input and target variables [
21]. Numerous studies have implemented ANN models in agricultural fields [
22,
23,
24,
25]. In 2007, Ji et al. [
22] developed an ANN model to predict Fujian rice yield for a typical mountainous climate and compared its performance with that of a linear regression model. The experimental results indicated that the ANN model demonstrated better performance (R-squared = 0.67) than the traditional models (R-squared = 0.52). Subsequently, Baral et al. (2011) [
23] developed an ANN model and particle swarm optimization to predict the rice yield in three different areas using nearly ten years of historical data, including daily mean and maximum temperatures and rainfall. Significant research has been conducted on crop growth in various regions. Çakır et al. (2014) [
24] applied an ANN model to predict wheat yield in the southeast region of Turkey using crop and weather conditions. They evaluated the model’s performance by varying the number of neurons and inputs to determine the optimal combination to improve results. Bhojani et al. (2020) [
25] implemented an ANN to predict wheat yield. The study utilized different meteorological parameter datasets as training data and improved the neural network by incorporating three simple activation functions. In addition, they proposed three new activation functions and tested various configurations of hidden layers and neurons. The results demonstrated that the newly created activation functions outperformed the sigmoid function. Although ANN has delivered better performance in crop yield prediction than other traditional methods, such as regression models, it has to spend much more time training the model without a GPU. In addition, the situation worsens when the predetermined numbers of neurons and hidden layers are large because the model becomes more susceptible to overfitting.
As more crop features can be collected, researchers are attempting to enhance the model complexity by increasing the model depth or width. The primary objective is to equip the model with stronger learning capabilities. Such a complex model is called deep learning. It is considered a subset of machine learning and AI, involving the use of ANNs with multiple layers (deep neural networks, DNNs) to learn and make decisions from data. This approach is powerful within the broader field of AI. Various types of deep learning models have emerged across different domains. One of the earliest deep learning algorithms was the convolutional neural network (CNN). It has demonstrated high efficiency among numerous deep learning algorithms for computer vision tasks, such as image classification and object detection [
26]. The key characteristic of CNN for improving training efficiency is weight sharing. The model can automatically learn image patterns by taking advantage of the kernel. With spatial location information, adjacent pixels have a certain correlation degree. Several studies have used CNN models to address crop-prediction issues in smart farming. Villanueva et al. (2018) [
27] defined six bitter melon yield ranges and implemented a CNN model with three convolution layers to predict bitter melon crop yields using the leaf veins of the bitter melon. Monga et al. (2018) [
28] conducted experiments on grape images using image processing techniques such as scale normalization and contrast enhancement. They then implemented a CNN model with five convolutions and dropout layers to forecast the Pinot Noir grape yield. Recent studies on crop yield prediction have applied distinctive deep learning approaches rather than conditional machine learning approaches. Khaki and Wang (2019) [
29] proposed two DNNs, one for yield prediction and the other for validating yield prediction. The utilization of the validation DNN model indirectly fine-tuned the prediction DNN model, enhancing overall performance. Chu and Yu (2020) [
30] subsequently proposed another deep learning approach that fused two back-propagation neural networks (BPNNs) and an independent recurrent neural network (IndRNN) to forecast summer and winter rice yields. These studies demonstrated that deep learning models outperformed machine learning models. In a recent study, Kalaiarasi and Anbarasi (2021) [
31] introduced the growing-degree day (GDD) as a measure of the effect of weather conditions on crop yield and built a multiparametric deep neural network (MDNN) containing a residual block to predict crop yield. The research findings substantiate that MDNN surpasses DNN in achieving superior performance for crop yield prediction. However, as the learning process involves building representations through a hierarchical structure with increasing complexity, there is no assurance regarding the quality of the final hidden representation.
Regarding crop characteristics, crop growth can be considered a time series containing several time points, each representing the crop’s status at different times. The entire time-series record contains all information about the crop. Researchers have applied time-series models to address yield-prediction issues. One of the most famous and earliest time-series models is the recurrent neural network (RNN). One advantage of an RNN is its hidden state, which allows it to store historical information. This information is shared between the neurons in the same layer for more flexible calculations. You et al. (2017) [
32] implemented a CNN and LSTM to predict soybean yield using sequential remotely sensed images. They also included a Gaussian process unit to improve the model accuracy, which potentially serve as inspiration for applications in remote sensing and computational sustainability. Khaki et al. (2020) [
33] proposed a hybrid model that combines a CNN and an RNN to forecast corn yields. The data used were from the entire Corn Belt in the U.S. three years ago. Although the RNN is a powerful and useful sequential model, it still suffers from issues such as vanishing and exploding gradients [
34]. When the time series becomes too long, RNNs may struggle to optimize and adjust effectively. To address this problem, one type of RNN that has been developed is the long short-term memory (LSTM) network. Rußwurm and Korner (2017) [
35] applied LSTM to extract dynamic temporal features for classifying crop types using a long-sequence image dataset. The results showed that the LSTM-based model outperformed the single-temporal model. The overall accuracy of the multitemporal LSTM model was reported to be 90.6%, which is higher than that of the single-temporal CNN model (89.2%) and the baseline SVM model (40.9%). Zhong et al. (2019) [
36] developed a hybrid deep neural network that combined two different networks–one based on LSTM and the other based on a one-dimensional convolutional neural network (1D-CNN)–to classify summer crops. An improved model based on an LSTM model called the GRU was developed recently. The experiment showed that the performance of the GRU was similar to that of the LSTM but with a faster training time. Yu et al. (2021) [
37] proposed a hybrid CNN-GRU model to predict soil water content. The hybrid model combined a CNN with significant feature extraction and a GRU with strong memory capacity, and the experiment showed that the hybrid model outperformed the independent CNN or GRU. Hence, RNN, LSTM, and GRU are widely used to implement different solutions in smart farming. From the above related studies, hybrid models have become a major trend in solving agricultural issues by combining the advantages of different deep neural networks to improve performance.
In this study, we propose an architecture consisting of two deep neural network models: a multi-kernel convolutional neural network (MKCNN) and bidirectional long short-term memory (Bi-LSTM) [
38]. We employed multitask learning to train both models interactively, and the proposed hybrid model was utilized to predict rice yield. Van Klompenburg et al. (2020) [
39] discovered that some researchers conducted experiments using NDVI and other crop-relevant features. In addition to NDVI, several other useful features have been applied to crop yield prediction. However, researchers must possess domain knowledge to identify the necessary features. Therefore, before training the rice yield prediction model, we proposed a combination of several feature analysis approaches to deal with the Hughes phenomenon, including Pearson correlation coefficients (PCC), SHapley additive extensions (SHAP), and recursive feature elimination with cross-validation (RFECV), to select highly relevant features for training an optimal predictive model.
The remainder of this paper is organized as follows:
Section 2 presents the materials used and explains the variety of crop features. It also describes the approaches used for feature analysis and selection.
Section 3 describes the preprocessing of features and then describes the proposed model, which consists of MKCNNs and Bi-LSTM.
Section 4 illustrates the experimental results with a confusion matrix and uses various evaluation indicators to estimate the model’s performance. Finally,
Section 5 presents the conclusions of the study.
3. Methodology
In this section, we divide the proposed model into two main processes: (1) preprocessing the data of the selected features; and (2) the architecture of the hybrid model, which consists of MKCNN and Bi-LSTM, to predict crop yield.
3.1. Preprocessing
Since the collected dataset was noisy and unstructured, preprocessing and reconstruction were inevitable steps before implementing the proposed hybrid model. Hence, this study applies the max normalization to each feature, as follows:
where
is the normalized value,
is the original value, and
and
are the minimum and maximum values of feature
, respectively. All the feature values were projected into the range
. The reason for normalization is that the target was predicted based on different feature scales. They do not contribute equally to the model fitting and learned functions, which indirectly decreases model performance.
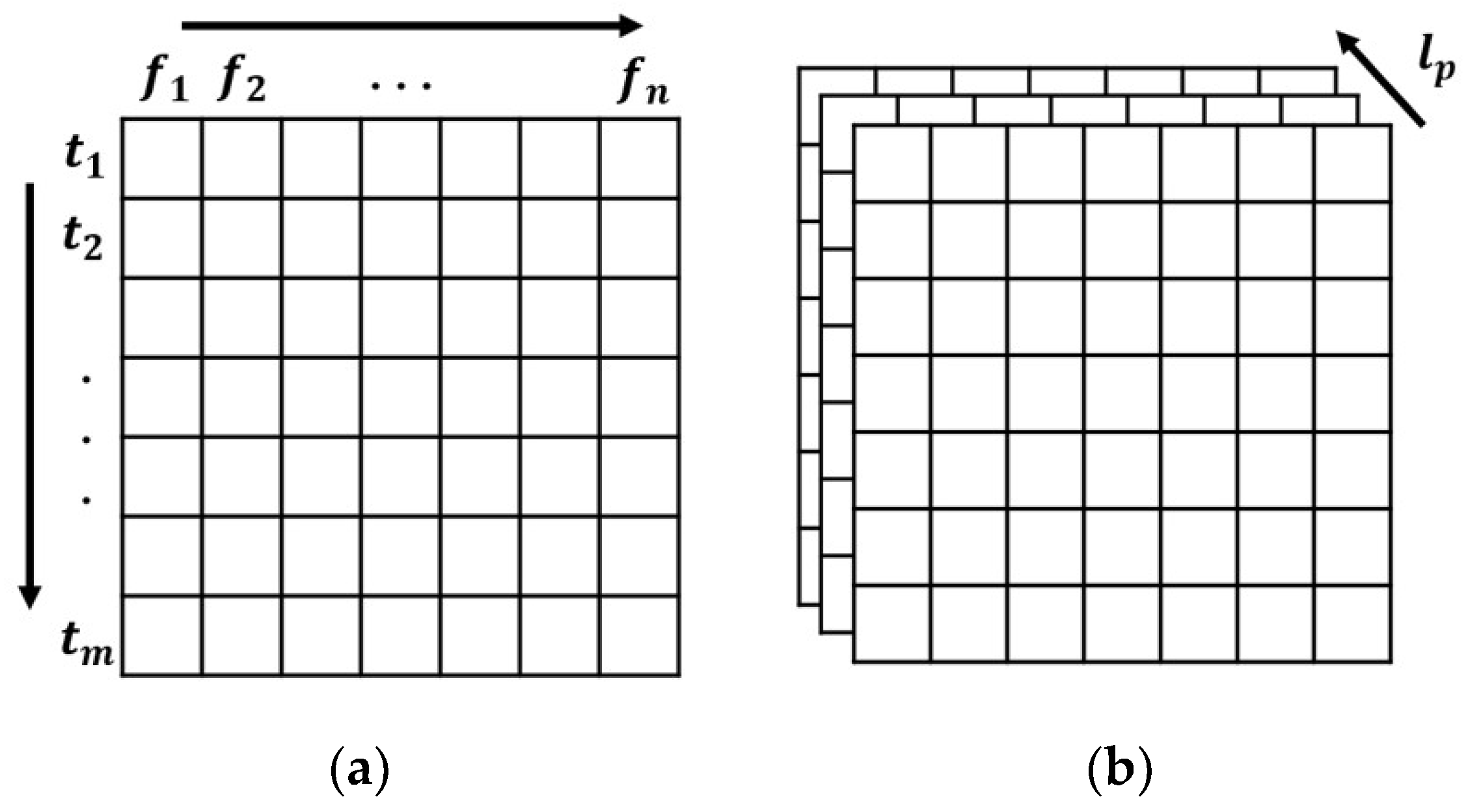
However, since the MKCNN cannot utilize digital data as an input source, we reconstructed the collected data into a three-dimensional matrix. Each remote sensing feature is defined as
, the time stamps are defined as
, and each farmland is defined as
. The remote-sensing features and time series were set as columns and rows, respectively. Hence, the size of the three-dimensional matrix was
.
Figure 5 shows a general view of the reconstructed data collected from the farmland, where each block line is reconstructed as a two-dimensional matrix, and the entire farmland is integrated into a three-dimensional matrix.
For the Bi-LSTM, the time stamps are split into separate segments, with each segment containing all the remote sensing features . Each timestamp is sequentially fed into a hybrid model.
3.2. Proposed Model
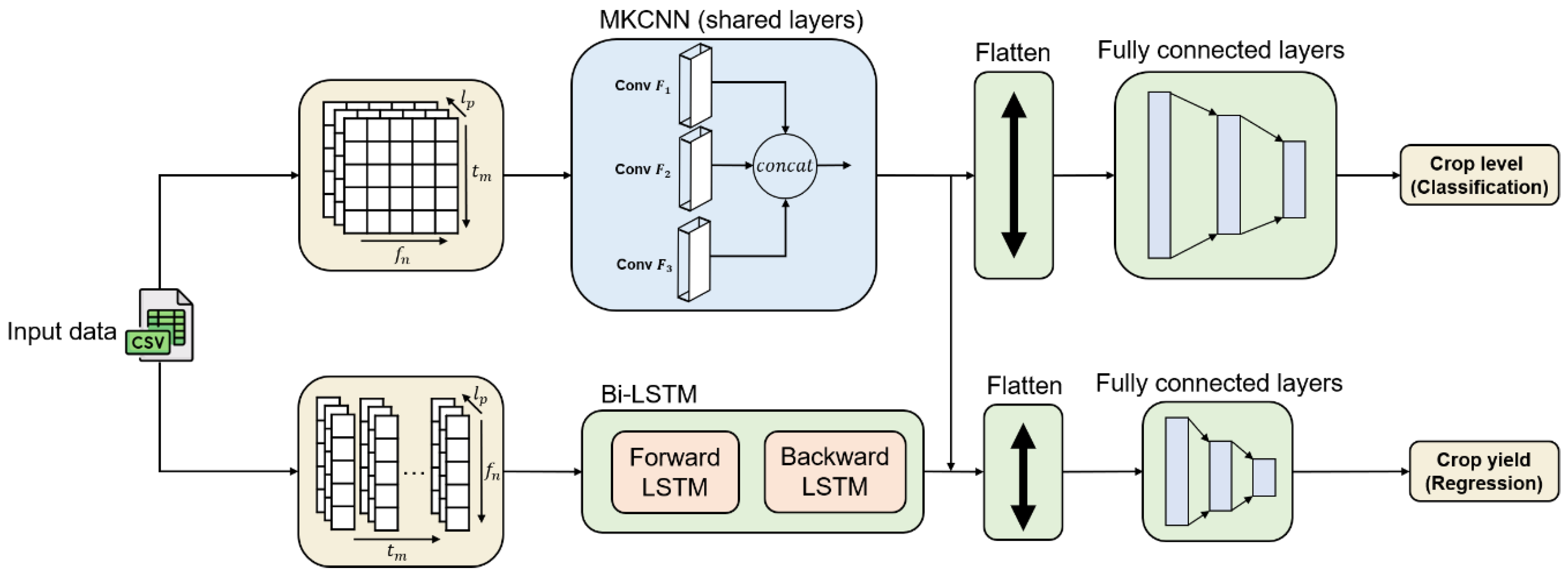
The proposed hybrid model integrates two different classes of deep learning models to analyze the data in block and stream modes, which enriches feature learning.
Figure 6 shows a general view of the proposed model architecture. The implementation of MKCNNs was inspired by MS-Blocks [
47]. In the following subsections, we comprehensively introduce each part of the proposed hybrid model.
The proposed model can be divided into two main modules: MKCNNs and Bi-LSTM. First, the input data are converted into the corresponding input structure based on the module. For example, the input structure required for an MKCNN is a three-dimensional matrix obtained through a preprocessing operation. Next, the hybrid model received the input data, processed through various operations and flattened into a one-dimensional vector. Subsequently, it passes through the fully connected layers, resulting in the calculation of two values: the predicted crop yield (regression task) and the classification of high or low yield (classification task). The hybrid model also incorporates shared layers from multi-task learning techniques. In this study, the shared layers were integrated into the MKCNN, enabling the model to indirectly improve the prediction results of the regression task while optimizing the classification task. This enhances the overall accuracy of the model. The internal architecture of the proposed model is described in detail in the following sections.
CNN is a major component of MKCNNs, a deep learning model that handles grid-like data, such as images or rows of multi-column data. It consists of four major operations: a convolution layer, padding, an activation function, and a fully connected layer. The convolutional operation is the first operation generally used in CNN models. This can be regarded as calculating the sum of the products of a block of input values and the values of a convolutional kernel, also called a filter. Kernel was applied to input image using a sliding window. For each pixel in , the sum of the element-wise products was calculated using and stored in the corresponding pixel in . Once convolves the entire image, the resulting feature map is produced. To prevent loss of information at the image’s borders, additional pixels are added to the periphery of the image during convolution. The padding operation has two benefits: it allows border patterns to be captured and prevents the image from being continuously compressed, resulting in the loss of block patterns. All the pixels of the image are subjected to an activation function that transforms the output and input into a nonlinear relationship, thereby enabling the deep learning model to have a more expressive meaning. Finally, the high-dimensional data are flattened into a one-dimensional array and imported into the fully connected layer, where the previously extracted features are classified or regressed after weight calculation in the final stage.
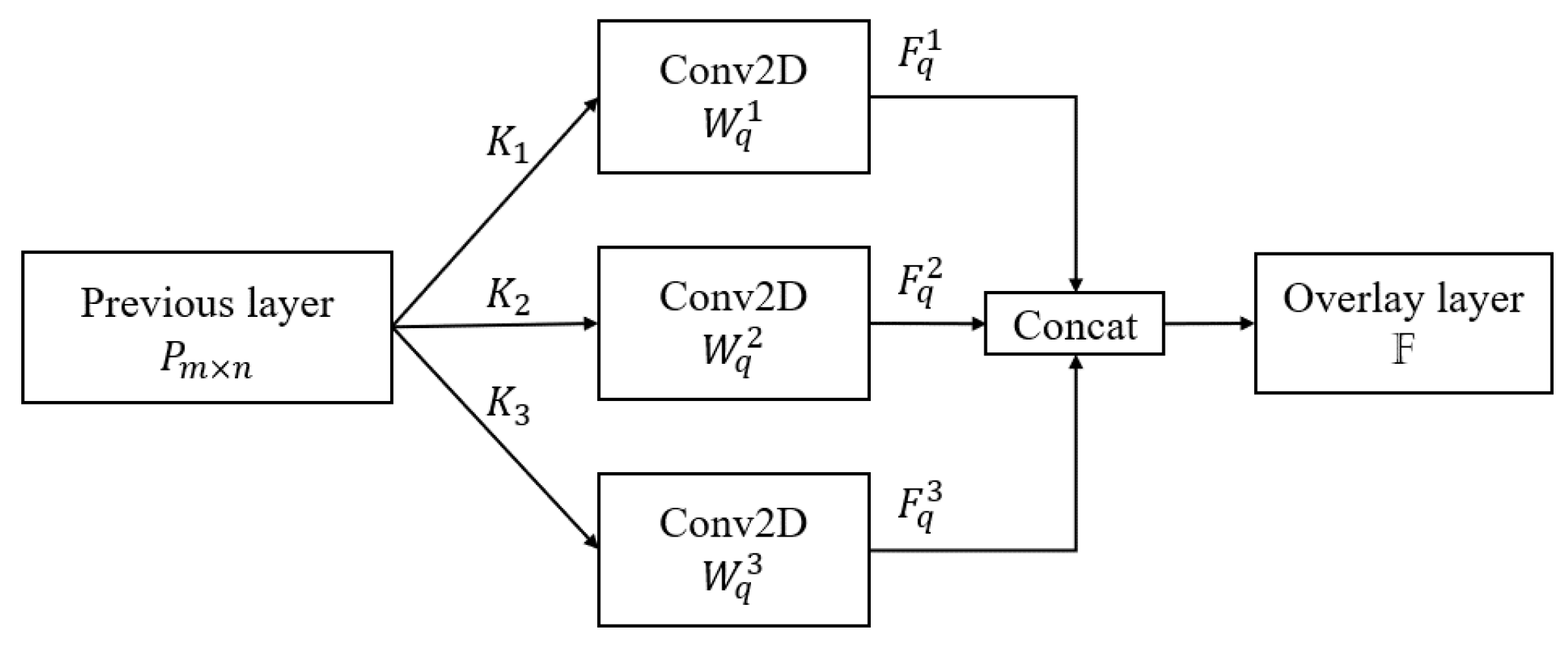
The core of MKCNNs is a multi-kernel block, which applies several kernels of different sizes to perform convolution. We believe implementing filters with the same kernel but different sizes can result in different meanings for the collected feature maps. For instance, the Sobel operation for edge detection in an image with filters of varying sizes, such as
,
, and
, produces feature maps with different meanings. These distinct feature maps enable the model to learn from a wider range of features. A schematic of the multi-kernel block is shown in
Figure 7.
As shown in
Figure 7, the inputs are sent to three different convolutional kernels, denoted as
,
, and
for feature extraction. The previous layer is denoted as
. The convolutional operation is defined as the product of
and the input layer
as in (4), where
represents the convolution using
kernel with
convolutional operations, and the bias of the
kernel is denoted as
. Each feature map is defined as
, where
indicates one of the convolved feature maps using
kernel. Each entire convolved feature map
with
kernel is concatenated to form
, as shown in Equation (5).
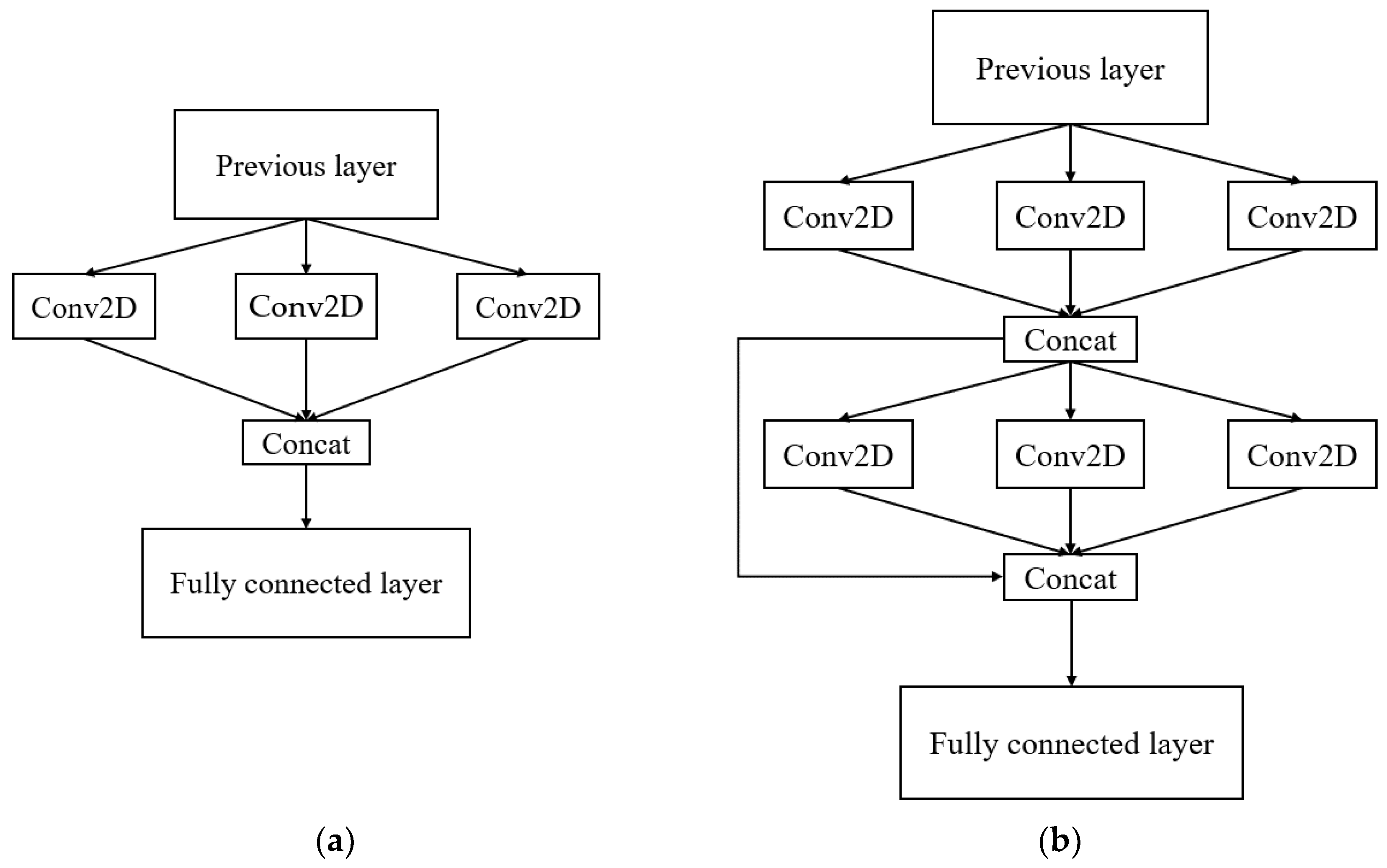
On the other hand, we aim to retain more detailed feature maps, but using more convolutional operations can result in a lack of fidelity in the feature maps. Thus, we applied a forward mechanism in which each multi-kernel block result was passed to the fully connected layers. For instance, if we implement three multi-kernel blocks, we obtain three status forms: , , and . Next, we concatenate these forms into a one-dimensional matrix and feed them into the fully connected layers. This mechanism can also save more features for training predictive models without sacrificing the fidelity of feature maps with more multi-kernel blocks.
MKCNNs determine high-yield versus low-yield patterns based on a data block area of multiple times and features. However, the original data were in a time series. The feature value at a specific time can relate to either the previous or the latter values. Therefore, we applied Bi-LSTM as another model to analyze the data sequentially. The LSTM is a variant of the RNN that overcomes the problem of gradient vanishing or explosion by integrating a gradient superhighway in the form of a cell state
, in addition to the hidden state
[
48]. Given a sequence of data
,
, …,
for
times with output
and hidden state
, the forget gate that decides to discard information can be defined as follows:
where
is sigmoid function, and
is the weight matrix for the forget gate. The input gate can control whether the input value
at time step
is calculated using the previous hidden state
, which is defined in (7). Similarly, the hidden state
and output state
of the LSTM are defined in Equations (8) and (9), respectively, where the cell
at time step
can be taken as an intermediate variable.
LSTM is more efficient and performs better than a simple RNN in building long-term time sequences. However, LSTM applies only previously learned information without considering subsequent information in the time series. In practical scenarios, predictions may require information from the entire input sequence. The model training of Bi-LSTM requires the use of all information from the input sequence. This combines forward and backward information from the input sequence. The output vector contains information from both directions using concatenation operations.
The proposed hybrid model introduced a multi-tasking technique [
49] to enhance model performance. Many studies have used the root-mean-square error (RMSE) as a loss function for crop yield prediction. RMSE calculates the distance between the ground truth and the predicted value. In this study, we used the predicted value with the RMSE to determine whether the crop yield was high or low. Our main goal was to achieve greater accuracy in the regression task for predicting the rice yield. We found that simply applying the RMSE did not accurately determine the correct predicted value. Therefore, we attempted to incorporate classification to adjust the predicted value. We introduced a multitasking technique to increase the regression accuracy and prevent overfitting of the proposed model. The shared layers facilitate the coordination of relationships between multiple tasks. By sharing layers, adjustments made to one task can affect the performance of other tasks. Given several tasks,
for
tasks. The loss function is defined as follows:
where
is the learning weights of
,
is the loss function in
, and the
, is the proportion of loss in
[
50].
4. Experimental Results
In this section, five indicators were employed to assess the performance of the proposed model. To illustrate the performance of the model, we conducted several experiments, including an ablation experiment. In addition, various hybrid model parameters were evaluated to determine the optimal configuration.
The origin dataset comprises a total of 405 entries. Due to the presence of some data errors, such as missing values, the dataset was cleaned, resulting in a final usable count of 333 entries. The dataset was then divided into training, validation, and testing sets in proportions of 80%, 10%, and 10%, respectively. The validation set was used with an early stopping technique, with the parameter patient set to 100 to avoid overfitting during model training. We collected rice yield data from the past five years and calculated the average value to set the decision boundary. In this study, the decision boundary was set at 3032. Based on this boundary, the positive class was assigned a high yield, and the negative class was assigned a low yield. Five metrics were applied to evaluate the model’s performance: accuracy, recall, precision,
-squared
, and F1 score. These metrics are defined by Equations (11)–(15):
where
is the true value,
is the predict value, and
is the average value of
variable.
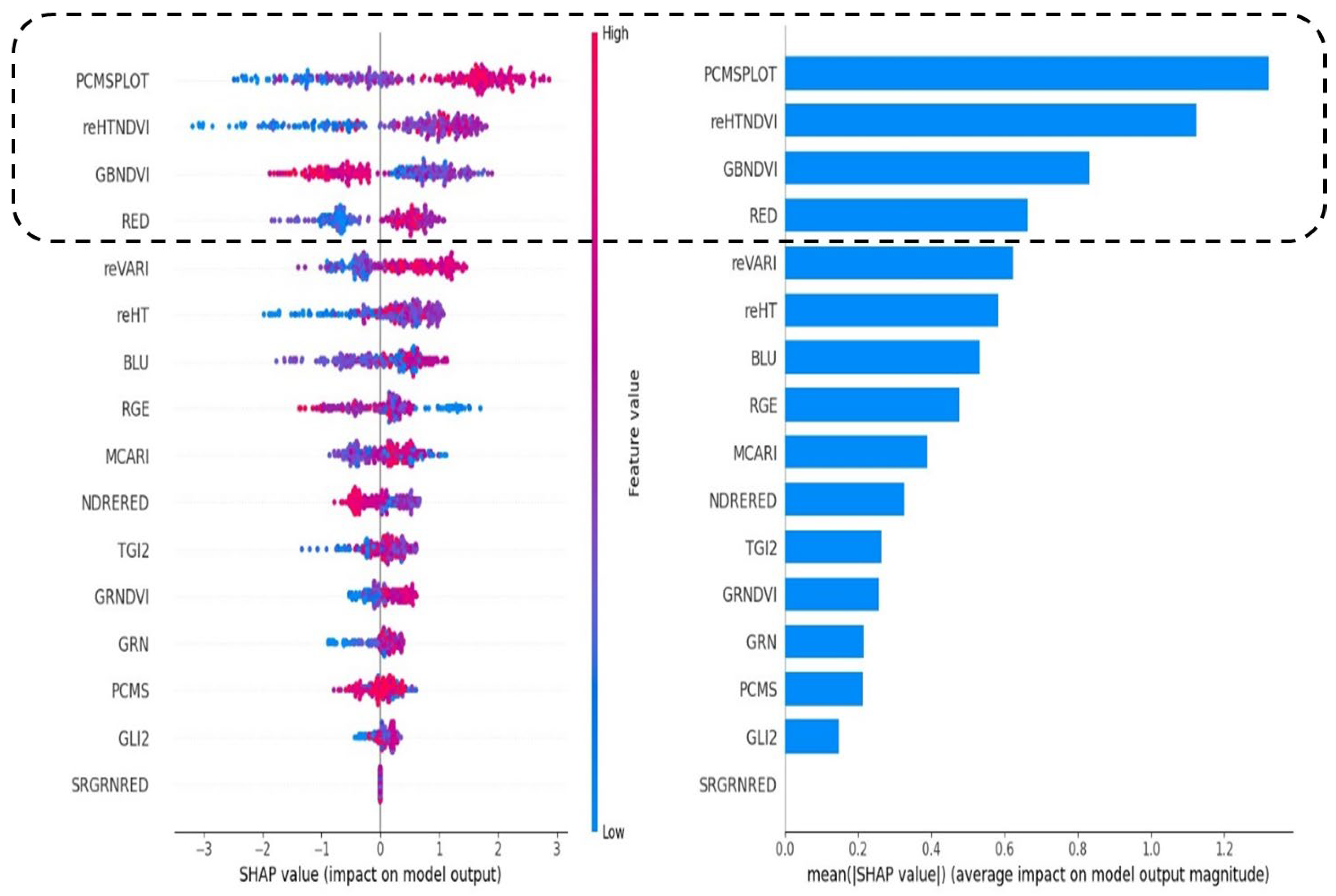
It is necessary to demonstrate that the seven features extracted using the three analytical algorithms benefit model training. The experimental results, depicted in
Table 4, with the best results highlighted in bold, indicate that training the model using 33 features does not yield superior results compared to using only seven features. The experimental results suggest that employing all the features for training inevitably leads to the Hughes phenomenon. Hence, the extraction of the most relevant features of rice yield is an indispensable step.
The proposed hybrid model sets up shared layers to coordinate the prediction results of MKCNN and Bi-LSTM, in which the task of crop yield prediction is split into two subtasks: regression and classification. The regression subtask provided a scalar output for prediction, whereas the classification subtask provided a discrete result (i.e., high versus low yield). Two loss functions, RMSE and cross-entropy, were used in the regression and classification tasks, respectively. It is important to demonstrate that the hybrid model performs better than a single model. Therefore, an ablation experiment was conducted to test this hypothesis. The results of the ablation experiments are presented in
Table 5, with the best results highlighted in bold. The experiment involved implementing single models for crop yield prediction, showcasing the superior performance of the hybrid Bi-LSTM and MKCNN models. The models were constructed both with and without specific components to determine their necessity. As a result, the proposed model, combining MKCNN and Bi-LSTM, achieved the best performance in all aspects except recall. One reason is that the collected data have an imbalanced amount of high-yield versus low-yield data, with more high-yield data than low-yield data. Since the ANN model accurately predicts a high yield for almost all data, it results in the highest recall among the prediction models.
First, we implemented a single model to predict crop yield. The results in the first four rows show that the Bi-LSTM model performed better than the LSTM model and that the MKCNN model performed the best. This is because the Bi-LSTM model incorporates both forward and backward information from the input sequence, resulting in better accuracy than the LSTM model. The single MKCNN model outperformed the other models because it first applied multi-kernel block operations, extracting more useful feature maps that were fed to the fully connected layers. However, LSTM-based models are not inherently poor for crop prediction. Their poor performance is owing to the short input sequence length of only seven units, which does not fully leverage the advantages of the LSTM-based model. The hybrid models without the MTL technique perform similarly to a single MKCNN, as shown in
Table 5. The model without the MTL used two models that made separate crop predictions and averaged the results for the final prediction. The model proposed in the final row fuses the MKCNN and Bi-LSTM models by exploiting their advantages. The proposed model performed best in the ablation experiment. The MKCNN perfectly extracts feature maps, and Bi-LSTM extracts forward and backward information from the input sequence. Finally, applying shared layers to connect the two models yielded the best performance.
Moreover, we attempt to determine the optimal distribution of the two models. The results are listed in
Table 6. We tested various distribution ratios between the regression and classification subtasks, respectively. The model achieved the best performance with a distribution ratio of 3 to 7 compared to other distributions. Therefore, a distribution ratio of 3:7 was identified as optimal for the two models.
Table 7 shows the overall performance of the proposed model compared to other deep learning models [
29,
31,
47]. The best results are highlighted in bold. The proposed model outperformed the other deep learning approaches in all metrics except recall.
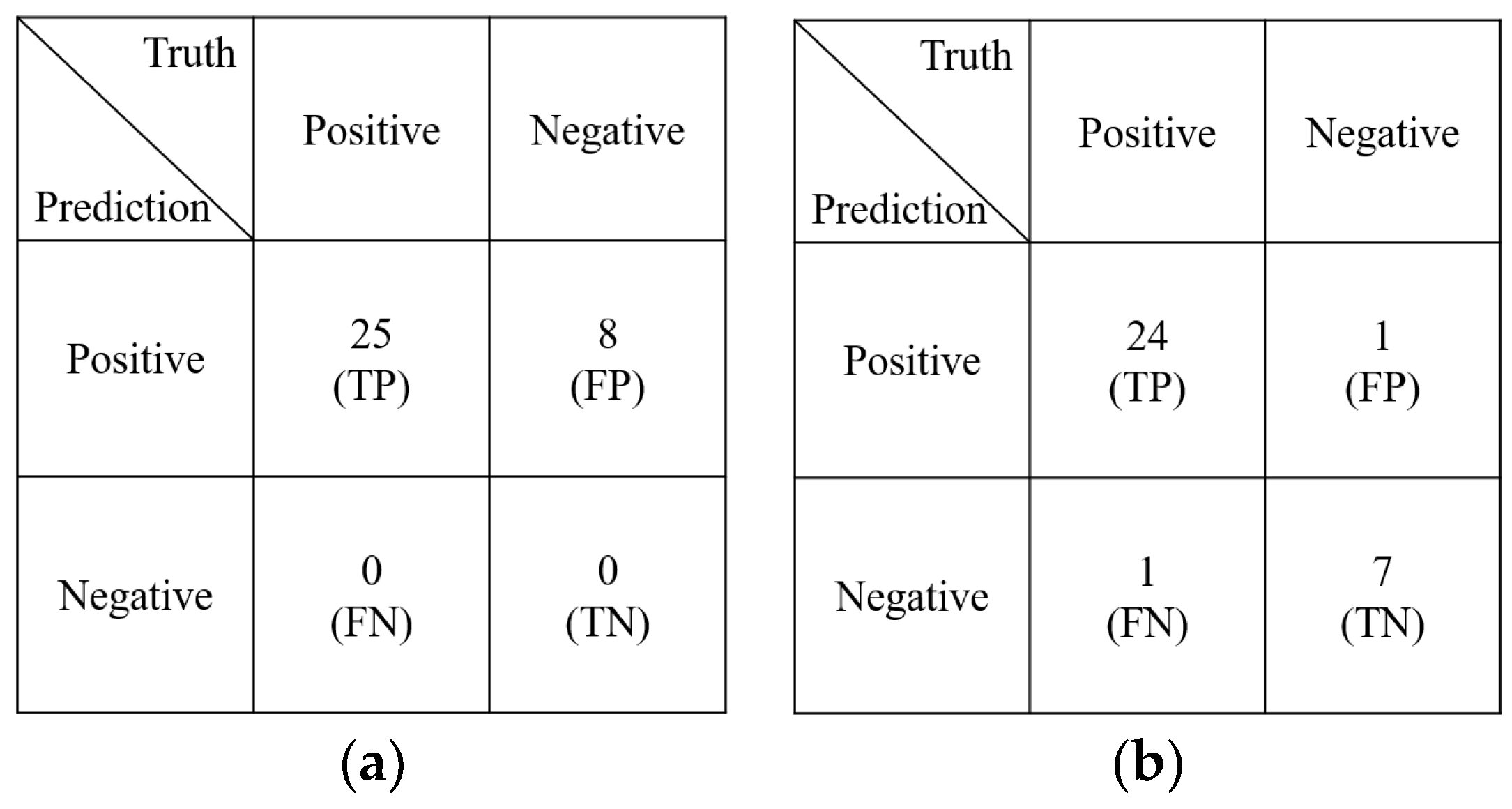
Detailed information is shown in
Figure 8, where we use a confusion matrix to illustrate the performance of the proposed models. The left plot (a) shows the results of the ANN model, and the right plot (b) shows the results of the proposed model. Four parameters were calculated: the true positives (TP), false positives (FP), false negatives (FN), and true negatives (TN). As shown in
Figure 8, although the ANN model achieved a perfect recall result of 100%, it failed to predict low-yield instances. This indicates that the ANN model was biased towards predicting high yields even when the ground truth had a low yield. However, the proposed model could forecast both high and low yields accurately. This is because the dataset was imbalanced, and the proposed model was able to handle such imbalanced datasets effectively. However, the accuracy of the ANN model is 14% lower than that of the proposed model. This means that a high false-positive rate for the ANN in predicting high yield led to poor prediction of low yield.
Next, we discuss the impact of the different parameters used in the proposed model, with a focus on rice yield prediction. To evaluate their effects, we compared loss values, R-squared values, and training times across different settings. The discussion is organized into several subsections, each addressing a specific parameter.
Table 8 lists the performance of the proposed model with different numbers of layers in a fully connected layer. There was a strong relationship between the number of layers and model accuracy. As the number of layers increased, the loss decreased. Although the optimal number of layers is four, as shown in
Table 8, the loss almost reaches a convergent state when the number of layers is three. The reason why the loss of four layers is better than three layers is due to slight fluctuations in the hybrid model, resulting in the losses for three layers to five layers being close to each other (≤1.2%). Therefore, we considered the optimal number of layers to be three for a fully connected layer.
Table 9 lists the performance of the proposed model for different batch sizes. Batch size refers to the number of training samples used in each iteration during training. The batch size has a significant impact on the accuracy of the model as well as its optimization degree and speed. The advantage of a small batch size is that it introduces more randomness during training, which can improve the model’s generalization ability. However, using a small batch size may make converging difficult for the models. Similarly, increasing the batch size is not recommended because it may cause the model to fall into local optima. Implementing a larger batch size can decrease the training time and improve convergence but may affect the model’s accuracy. Therefore, selecting an optimal batch size is an important issue that must be carefully considered.
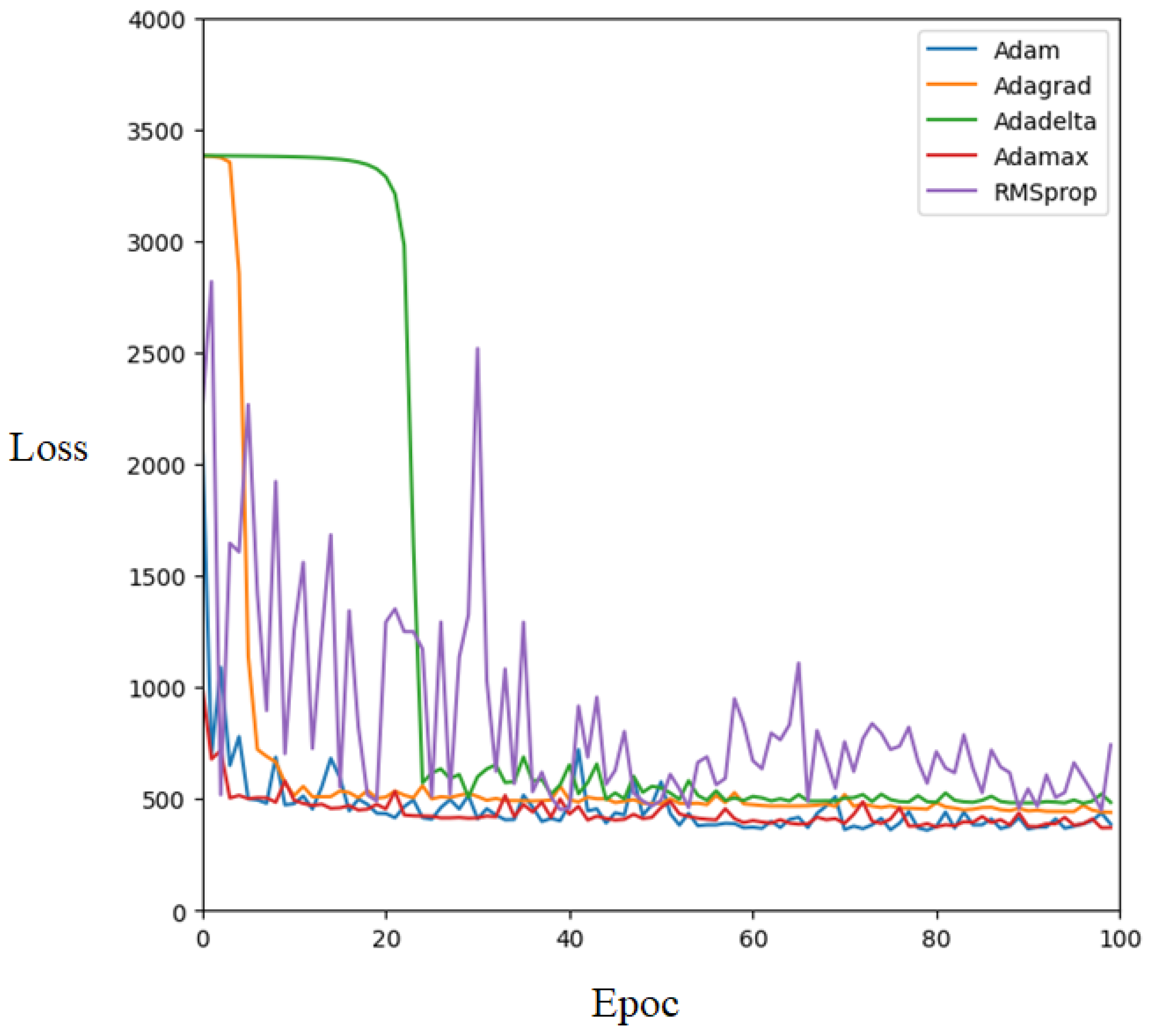
We also tested five network optimizers: Adam, Adagrad, Adadelta, Adamax, and RMSProp.
Table 10 displays the best performance achieved by the different network optimizers, whereas
Figure 9 shows the detailed loss values observed during the training process using various network optimizers.
The number of epochs was not consistent due to the application of an early stopping technique. Therefore, the first 100 training epochs are selected to represent the training steps of the model.
Figure 9 illustrates that Adam was the fastest converging optimizer during training. Interestingly, the Adam optimizer yields the lowest loss in the hybrid model. The reason behind this is Adam combines the advantages of both AdaGrad and RMSProp. It utilizes the same learning rate for each parameter and adapts them independently as the learning progresses. According to the
values in
Table 10, the two worst-performing optimizers were Adadelta and RMSprop. The RMSprop alone may not effectively converge to a stable state, leading to significant fluctuations during training. Although Adadelta appeared to converge after 60 epochs, it became trapped in the local optima. However, the choice of a suitable optimizer depends on the model and problem definition.
The experiments show that the depth of the multi-kernel blocks affects the predictive performance. This is illustrated in
Figure 10, which shows the effect of the depth of the multi-kernel blocks. The experiment used three different sizes of kernels to extract the feature maps.
Table 11 describes the results for different depths of the multi-kernel blocks. The results indicated that the optimal depth was 3. We can also see that as the depth of the multi-kernel blocks increases, the model performance also improves. However, if the depth of a multi-kernel block exceeds a certain threshold, the overall performance decreases. As shown in
Table 11, an infinite increase in the depth of the multi-kernel block leads to overfitting problems rather than the extraction of more useful feature maps. This can result in high accuracy in the training set but poor performance in the testing and validation sets. In addition, as the depth increased, the model training time increased.
As a part of the hybrid model, it is necessary to determine the optimal number of Bi-LSTM neurons. We experimented with five different numbers of neurons in the Bi-LSTM and set up only one Bi-LSTM layer. The results are listed in
Table 12. As a result, the loss value gradually decreases with neurons in the Bi-LSTM. However, increasing the number of neurons beyond 64 did not effectively improve the model performance (i.e., the improvement range was less than 1%), and the training time increased. Therefore, this study set the optimal number of neurons to 64.



 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}