1. Introduction
Agriculture is essential for human survival and the development of the national economy [
1]. Fruits represent a key agricultural component, with China leading global apple production and ranking third in citrus production [
2,
3]. Most traditional orchards are transitioning into modern systems, with trellis cultivation emerging as the predominant method due to its numerous advantages. The trellis cultivation model offers strong resistance to adverse conditions, high fruit quality, high unit efficiency, easy field management, and efficient use of land, water, and light resources, making it widely used in the production of kiwifruit, pears, and grapes [
4]. In the trellis orchard cultivation model, fruit trees are planted at fixed intervals, and most branches are tied to supports made of steel pipes and wires through pruning and other horticultural techniques. The tree canopy is concentrated on a horizontal plane at a certain height, creating straight pathways between the trees. This organized structure surpasses that of traditional orchards, providing stronger support for the advancement of orchard mechanization.
Automatic navigation of orchard vehicles is a necessary method for mechanized operations in orchards [
5,
6], and autonomous positioning and navigation technology are the prerequisite for achieving this [
7,
8]. This technology uses satellites, LiDAR, or vision-based systems to enable the robot to sense its surrounding environment, thereby achieving precise self-positioning, target trajectory tracking, and obstacle detection [
9]. However, in trellis orchards, the tree canopies are primarily positioned at the upper level in a horizontal arrangement, with relatively slender trunks, and both the canopies and fruits are mainly distributed in the middle and upper sections. Additionally, there are many weeds on the ground. These characteristics make path recognition in trellis orchards more complex and challenging to study.
With the development of navigation technology, many navigation methods have been created [
10]. Among these methods, satellite-based positioning is the most widely used. For example, Xiong Bin et al. designed an automatic spraying machine using the BeiDou satellite navigation system (N71J-BDS, CTI, Shenzhen, China), which can plan navigation paths based on the terrain characteristics of orchard environments [
11]. Liu Zhaopeng et al. developed a navigation system for a sprayer using RTK-GNSS dual-antenna sensors (BD982, Trimble, Westminster, CO, USA), enabling straight-line driving and headland turns. In trellis orchards, however, satellite navigation is often obstructed by dense tree canopies and branches, leading to signal loss and making it difficult to achieve stable and continuous navigation [
12]. As LiDAR technology has advanced, more researchers have utilized it for navigation. Zhang J et al. designed an automatic orchard vehicle navigation system that generates navigation reference lines using LiDAR (SICK LMS511-20100 PRO
®, Waldkirch, Germany), allowing the vehicle to navigate autonomously at a speed of 0.8 m/s [
13]. Yue Shen et al. developed a posture-adjustable laser scanner to scan artificial trees on uneven road surfaces. However, in trellis orchards, LiDAR is easily affected by weeds and branches, making it difficult to extract accurate navigation lines [
14]. Additionally, the similar morphological characteristics throughout the orchard, without obvious distinguishing features, make precise positioning in point cloud matching challenging. These systems require near-perfect working environments and are relatively expensive, making them unsuitable for agricultural applications.
With the advancement of depth cameras, an increasing number of researchers are using vision-based navigation. Neto proposed a monocular vision-based navigation software that utilizes distributed processing, Sobel operators combined with a region-growing strategy, and the maximum between-class variance method to detect road edges [
15]. Zhang Tiemin et al. used the 2G-R-B color difference method to identify green plants, extract edge information points, and fit the centerline [
16]. They applied the Hough transform to fit multiple lines for path extraction. Cheng HY et al. combined the Mean Shift technique with Bayesian theory to effectively classify irregular road areas and identify suitable road boundaries [
17]. Hong-Kun et al. used a Naive Bayesian classifier to distinguish between tree trunks and the ground in orchards and developed a new algorithm to accurately recognize orchard paths [
18]. Radcliffe designed a vision-based navigation system that captures sky and canopy information by leveraging the clear contrast between the sky and the tree canopy, The root mean square error (RMSE) of this system is 2.13 cm [
19].
In the trellis orchard environment, the presence of shadows, light spots, and varying light intensities complicates vision-based navigation [
20]. The performance of these methods is influenced by several factors, such as the distribution of weeds, different lighting conditions, and the overlap or obstruction between crops and weeds. These factors make the real-world environment highly complex, and there is an urgent need for an automated and efficient algorithm that can function under such challenging conditions. In recent years, significant improvements in computing power and advances in deep learning frameworks have driven innovations in many fields. Semantic segmentation techniques based on convolutional neural networks (CNNs) have enabled efficient feature extraction from regions of interest, significantly enhancing the accuracy of object–background separation in complex environments [
21]. However, deep neural network structures are complex, making it difficult to identify an effective semantic segmentation network. In trellis orchards, light variations further impact performance, requiring a lightweight network structure for accurate path and tree row segmentation.
Most research in this field has focused on relatively simple road environments, while trellis orchards present a more complex scenario. This paper proposes a deep network model tailored to navigate complex environments in trellis orchards, achieving accurate path segmentation. To validate the proposed model, a comparative study of three network models was conducted. Additionally, a trellis orchard path recognition method based on attention mechanisms was introduced, combining the actual needs of orchard environment recognition to build an orchard environment model.
2. Material and Methods
2.1. Data Acquisition
This study focuses on a standard pear orchard in Jurong, Jiangsu Province. The photos were taken in June 2023. The distance between rows is 4 m, the distance between trees is 3 m, and the trellis height is 1.8 m. The trunk height of the pear trees is between 0.9 and 1.0 m. A camera with a resolution of 1920 × 1080 was used to capture the orchard paths, and the photos were taken between 8 a.m. and 6 p.m. to include images with different light intensities for diversity. A total of 400 images were selected after excluding blurred ones. Data augmentation techniques were applied to increase diversity and improve the model’s generalization ability and robustness. The images were rotated clockwise and counterclockwise by 10°, 20°, and 30°, as shown in
Figure 1. This increased the number of images from 400 to 2400. The dataset was then divided into training and test sets in a 3:1 ratio.
Figure 1 shows the images after data augmentation. The camera used in this study was the Kinect V2, with a resolution of 1920 × 1080 and a frame rate of 30 fps. Path labeling was conducted using the “Labelme” tool (CSAIL, MIT, Cambridge, MA, USA), with the designated label being “road”.
2.2. Convolutional Neural Network
The U-Net (UNet), Fully Convolutional Network (FCN), and Segmentation Network (SegNet) algorithms are generally based on an encoder–decoder architecture. Both UNet and FCN incorporate skip connections, while SegNet employs unpooling for upsampling, relying heavily on unpooling layers and stepwise reconstruction within the decoder. The input image first passes through the encoder module, which consists of multiple convolutional layers and pooling layers that progressively extract features and reduce spatial resolution. The encoder output is then connected to a bottleneck layer to further compress feature information. Subsequently, in the decoder module, a series of deconvolutional layers and upsampling layers restore the spatial resolution, generating an output image that matches the input size. Each convolutional and deconvolutional operation is followed by a ReLU activation function to introduce non-linearity. The final output image retains the same size as the input image, as shown in
Figure 2.
The UNet architecture is a symmetric encoder–decoder structure designed for image segmentation tasks [
22]. The encoder part consists of multiple convolutional layers and max-pooling operations, which extract features at different scales while progressively reducing the resolution of the feature maps. The decoder part uses transposed convolutions (upsampling) to gradually restore the spatial resolution of the image. Additionally, skip connections are employed at each layer to fuse the features from the corresponding encoder layers, preserving detailed information. This structure enables precise localization and segmentation of targets within the image, making it especially effective for tasks requiring fine-grained segmentation.
The Fully Convolutional Network (FCN) is another type of CNN used for image segmentation [
23]. It replaces the fully connected layers of a traditional CNN with convolutional layers, allowing pixel-level predictions for input images of any size. The FCN extracts features using convolution and pooling layers, and then up-samples the feature maps through transposed convolutions to restore the original resolution. Skip connections merge spatial information from shallow layers with semantic information from deeper layers, enhancing segmentation accuracy. As an innovative model in image segmentation, FCN enables efficient, end-to-end processing.
SegNet is a convolutional neural network specifically designed for semantic segmentation, featuring an encoder–decoder architecture [
24]. The encoder part consists of multiple convolutional layers and max-pooling layers, progressively extracting image features and reducing feature maps resolution, similar to the VGG16 network. In the decoder part, transposed convolutions are used for upsampling, restoring the feature maps to the original image resolution. During the decoding process, SegNet leverages max-pooling indices from the encoder to retain spatial information, allowing for better detail recovery during upsampling. This design enables SegNet to achieve high-precision pixel-level segmentation while maintaining robustness and flexibility, making it widely applicable in fields such as autonomous driving.
2.3. Attention Mechanism
Accurate recognition of edge information is essential for effective orchard navigation. The attention mechanism enhances this process by continuously focusing on critical areas, capturing relevant information while filtering out irrelevant details. This visual attention mechanism significantly enhances our efficiency and accuracy in processing information. There are three types of attention mechanisms: channel attention mechanism, spatial attention mechanism, and combined attention mechanism. By focusing on both spatial and channel dimensions, these mechanisms can better capture important information within the features.
The Channel Attention Mechanism (CAM) enhances the performance of convolutional neural networks by adaptively adjusting the weights of features in each channel, thereby emphasizing important features and suppressing less significant ones [
25]. This mechanism typically uses global average pooling or global max pooling to compress the spatial information of the feature map into channel descriptors. These descriptors are then processed through a series of fully connected layers to generate attention weights for each channel. These weights are multiplied element-wise with the original feature map, achieving a weighted adjustment of the feature map, ultimately increasing the model’s focus on key features and enhancing its expressiveness. First, the input feature map
(where
C is the number of channels, and
H and
W are the height and width of the feature map) is processed. A global average pooling operation is performed to generate the channel descriptor vector
, which represents the global features of each channel. The channel descriptor vector
Z is then input into a small fully connected neural network, and an activation function is applied to generate the channel attention weights
, representing the importance of each channel. The generated attention map is multiplied element-wise with the original feature map to obtain the weighted feature map
, where
denotes element-wise multiplication. The feature map processed by the spatial attention mechanism can then serve as input for subsequent layers of the network, improving the final classification, detection, or segmentation results.
where
is the compressed value of the c-th channel;
and
are learnable weight matrices;
is the ReLU activation function;
is the Sigmoid activation function;
is the generated attention map; and
is the original feature map.
The Spatial Attention Mechanism (SAM) is a technique in deep learning used to process spatial information, commonly applied in image processing, computer vision, and natural language processing [
26]. The primary goal of this mechanism is to allow the model to allocate different levels of attention to different positions in the input data, enabling more flexible handling of local information. The input feature map is represented as
(where
C is the number of channels, and
H and
W are the height and width of the feature map). The spatial attention map
is computed using convolution operations (typically 1 × 1 convolution), capturing the importance of various spatial locations.
where
F represents the input feature map;
denotes the spatial attention map;
is the Sigmoid activation function; and
is the generated attention map.
The Combined Attention Mechanism (CBAM) is designed to enhance the neural network’s focus on both spatial and channel information [
27]. This mechanism enables the network to selectively concentrate on specific regions and channels of the input data, improving the model’s ability to extract important features. The CBAM network consists of two main modules, the channel attention module and the spatial attention module. First, global pooling is applied to the feature map to obtain the channel descriptor, and a feedforward neural network generates the channel attention weights
which emphasize the important channels. The spatial attention
is applied to the feature map
F, resulting in the weighted feature map
. The channel attention
is then applied to
, yielding the final feature map
. The resulting weighted feature map
can be used as input for subsequent layers of the network [
28].
where
represents the average pooling operation;
denotes the maximum pooling operation;
refers to the feature map in the third dimension; and
signifies the attention features.
2.4. Improved UNet Model
The UNet network was selected as the primary model for this study due to its accuracy to boundary information and superior performance in target recognition under low-light conditions, making it particularly suitable for orchard path recognition tasks. Furthermore, compared to Fully Convolutional Networks (FCNs) and SegNet, UNet’s symmetric encoding–decoding architecture and skip connection mechanism more effectively preserve and utilize multi-scale feature information, thereby enhancing robustness in complex environments.
In the improved UNet model, attention mechanisms are introduced at the end of each downsampling module, as shown in
Figure 3. The input images of trellis orchard paths have a resolution of 512 × 512. These images pass through five effective feature layers in the main feature extraction part, where each layer applies two 3 × 3 convolutions and one 2 × 2 max-pooling operation. After each max-pooling operation, an attention mechanism is added. The images are downsampled four times, extracting detailed feature information. In the enhanced feature decoding section, the five decoded effective feature layers undergo upsampling, and feature fusion techniques are applied to merge all features into a single effective feature layer. Each layer in the decoding process first uses bilinear interpolation for upsampling, followed by concatenation with the corresponding shallow feature layer through convolution. This process continues until the final layer, which applies a 1 × 1 convolution for channel adjustment, producing the final segmentation output.
2.5. Evaluating the Model’s Performance
Different network architecture models are primarily evaluated using three parameters: accuracy, recall, and Intersection over Union (IoU). These metrics ensure the model’s generalization ability and aid in adjusting its structure. Accuracy is a metric used to evaluate classification models, representing the ratio of correctly predicted instances to the total number of instances. Recall is the proportion of true positive samples that are correctly identified among all positive samples. Intersection over Union (IoU) is a fundamental metric used to quantify the overlap between predicted regions and ground truth regions in object detection and segmentation tasks. A higher IoU value indicates better alignment between the predicted and actual regions, reflecting greater accuracy of the model.
The number of true positive samples (labeled as positive and classified as positive) is referred to as True Positive (
TP). The number of false negative samples (labeled as positive but classified as negative) is referred to as False Negative (
FN). The number of false positive samples (labeled as negative but classified as positive) is referred to as False Positive (
FP). The number of true negative samples (labeled as negative and classified as negative) is referred to as True Negative (
TN).
2.6. Model Training Platform and Experimental Conditions
In our experiments, all models were trained using Anaconda (Python 3.7) and PyCharm (PyCharm2023, JetBrains, Prague, Czech Republic). GPU acceleration was utilized during both the training and testing phases. The experimental hardware environment included an Intel® Core™ i7-7700T (1.3 GHz base frequency, up to 3.9 GHz with Intel® Turbo Boost technology, 8 MB cache, and 4 cores) (Intel, Santa Clara, CA, USA). Since the images were captured at different sizes, all images were resized to 1920 × 1080 pixels. Three models were trained using the training and testing datasets. The entire dataset was divided into 70%, 10%, and 20% for training, validation, and testing, respectively. The Adam optimizer was utilized to enhance efficiency and minimize the loss function.
3. Results
3.1. Overall Model Performance for Different Combination of Dataset
In the experiments, the UNet, FCN, and SegNet models were trained using a consistent input image size of 512 × 512, a convolution kernel size of 3 × 3, and a pooling window size of 2 × 2. The initial channel count was set to 64, with a learning rate of 0.001 and a batch size of 4. The Adam optimizer was used, and skip connections were implemented in the decoding stage to link corresponding encoding layers, enhancing feature recovery. To expand the training dataset, data augmentation techniques were applied, including angle rotation (±30°) and resizing, which were implemented via Python scripts. This enriched our dataset, enabling the training of the UNet, FCN, and SegNet models using the training data, followed by validation testing on 10% of the dataset. The accuracy of the three models after 250 epochs of training is presented in this study. The UNet model performed the best, achieving an accuracy of 97.32% and a recall of 94.49%.
3.2. Model Performance with Different Combinations of Attention Mechanisms
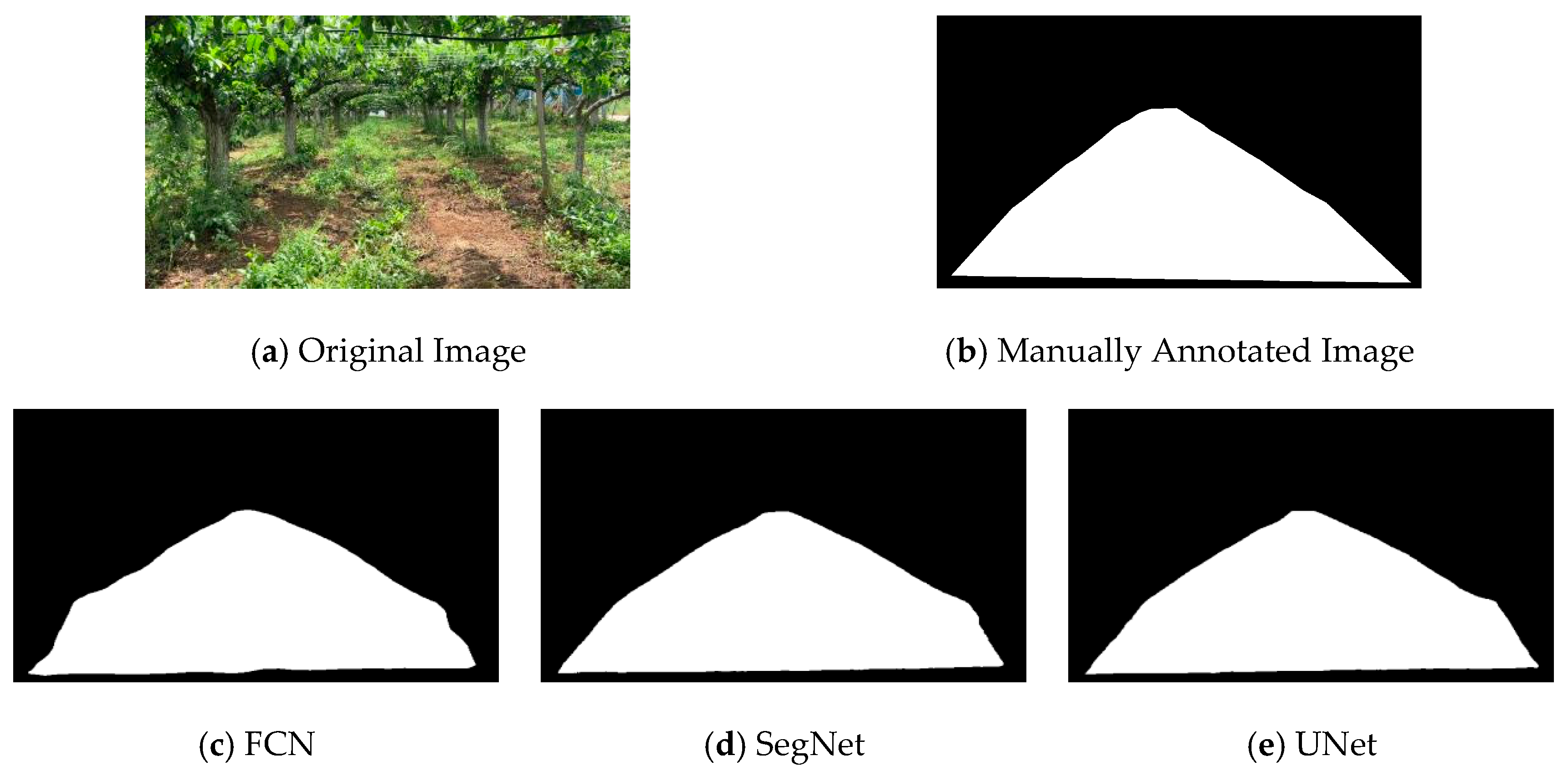
As shown in
Figure 4, all three models effectively recognize the features of the pear orchard pathways under varying lighting conditions, demonstrating strong segmentation performance. The UNet model yields smoother results, particularly excelling in accurately fitting the edges of the pathways.
Due to variations in the dataset, quality, and model architecture, the loss rates of the models were compared over 250 epochs, as shown in
Figure 5. Additionally, the training accuracy of the models decreased as the number of epochs increased. The UNet model stabilized after 120 iterations, indicating that it reached a steady state, with the loss value converging to 0.0094, the lowest among the three models. The SegNet model also stabilized after 130 iterations, with its loss value converging to 0.0098, reflecting stability in its performance. In contrast, the FCN model exhibited significant oscillations after a rapid decrease in loss, suggesting difficulties in handling the complex dataset. Even after 200 iterations, oscillations persisted, with the loss value ultimately converging to 0.019.
In comparing the three networks in terms of accuracy, recall, and Intersection over Union (IoU), the UNet model outperforms the others across all metrics. Specifically, UNet’s accuracy is 0.7% higher than that of the FCN and 0.4% higher than that of SegNet. In terms of recall, UNet improves upon the FCN by 1.2% and SegNet by 2.2%. Furthermore, UNet’s IoU is 0.7% higher than that of the FCN and 1.3% higher than that of SegNet, as shown in
Figure 6.
This study selects the UNet convolutional neural network as the overall network architecture, incorporating attention mechanisms at the end of each downsampling module. The input images of the pear orchard pathways are sized at 512 × 512 pixels and pass through five effective feature layers in the backbone feature extraction part. Each feature layer performs two 3 × 3 convolutions and one 2 × 2 max pooling operation, followed by the addition of the attention mechanism after max pooling. This process is followed by four downsampling steps to capture detailed feature information from the images. In the enhanced feature decoding section, the five decoded effective feature layers undergo upsampling, and feature fusion techniques are employed to combine all features into a single effective feature layer. Each layer in the decoding part first performs bilinear interpolation for upsampling, then concatenates the result with the corresponding shallow feature layer through convolution. This process continues, and the final layer undergoes convolution with a 1 × 1 kernel for channel adjustment, resulting in the output segmentation. The experimental parameters were set with an initial learning rate of 0.0001, a total of 250 epochs, a batch size of 2, and two segmentation classes.
Based on the experimental results, the UNet model demonstrates strong performance in accuracy, recall, and Intersection over Union (IoU). Further optimizations were made to the UNet model by adding three types of attention mechanisms at the end of each encoding stage, focusing on key areas of the images during the downsampling process. These enhanced models are named UNet_CAM, UNet_SAM, and UNet_CBAM.
As shown in
Figure 7, the UNet_CBAM model demonstrates superior performance in terms of accuracy, recall, and Intersection over Union (IoU). Specifically, its accuracy is higher by 0.8% and 1.22% compared to the UNet_CAM and UNet_SAM models, respectively. Additionally, the recall for UNet_CAM is greater by 2.14% and 3.18% compared to the other two models, while the IoU is higher by 1.3% and 2.49%, respectively.
Among the three network architectures, the UNet model outperforms the others in accuracy and has been retained for predicting orchard field data. After training, the addition of spatial and channel attention mechanisms resulted in high accuracy in path recognition. The model exhibits high confidence in predicting both fruit trees and pathways.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}