1. Introduction
Animal husbandry, being a pivotal industry, serves as a primary source of nutrition for people, and its demand is consistently escalating. In recent years, the government has released several policy documents, including the Digital Agriculture and Rural Development Plan (2019–2025) and Opinions on Promoting High-Quality Development of Animal Husbandry. These policies underscore the significance of digital farming in driving high-quality progress within the animal husbandry sector. Presently, the dairy farming industry holds a strategic position within animal husbandry [
1]. It is imperative to intensify research and implementation of advanced technologies like computer vision, big data, and automation in dairy farming. This will elevate the level of intelligence in animal farming, facilitate the advancement of precision animal husbandry, and establish a contemporary animal husbandry farming system [
2].
In the initial phases, cow identification primarily relied on numbered plastic ear tags, neck collars, or leg bands as markers, followed by manual recognition and documentation. However, with the onset of digital farming, farms shifted to electronic ear tags for cow management. Despite its convenience, this method posed issues like easy detachment and the potential to harm the cows. To address these concerns, various non-contact cow identification technologies have surfaced in recent times [
3]. Amongst these, the cow identification technique utilizing two-dimensional images has garnered significant attention and research from scholars globally. This approach not only mitigates the downsides of electronic ear tags but also opens up new avenues for digital farm management. Image-based cow identification can be categorized into four distinct methods [
4,
5]: identification through cow eyes, cow muzzle patterns, cow faces, and cow body patterns. While eye-based and muzzle pattern-based techniques are susceptible to interference from cow movements and demand high-quality images, face-based methods encounter challenges during on-site data collection. Factors like hair, texture variations, and unpredictable image acquisition complicate the process, augmenting the dataset construction workload and hindering real-time identification in farming environments. Alternatively, the body pattern emerges as a distinctive and easily observable identifier for cows [
6,
7].
In 2005, Kim et al. [
8] from Kyoto University captured cow body patterns using a charge-coupled device (CCD). They enhanced recognition accuracy through techniques like edge detection and fine noise component analysis. However, the equipment’s complexity made it impractical for modern cattle farms. A decade later, in 2015, Ahmed [
9] introduced a method that extracted features from cow body images using the Speeded-Up Robust Features (SURF) algorithm, coupled with an SVM for cow classification and recognition. This approach focused on minimal image features, leading to limited recognition performance. That same year, Zhao Kaixuan [
10] developed a Holstein cow identification model based on video analysis and convolutional neural networks. By precisely extracting and analyzing cow body image features and designing a corresponding neural network structure, this method achieved a recognition rate of 90.55% in experiments, with room for further optimization. In 2021, Li S et al. [
11] improved Alexnet by incorporating multiple multiscale convolutions, using a short-circuit connected BasicBlock to maintain desired values and prevent gradient issues. They added an enhanced inception module and attention mechanism to capture features at various scales, boosting feature point detection. That year, Liu J et al. [
12] and colleagues introduced transfer learning, using the AlexNet network to extract blurred contours and side body features. They then employed SVM to identify 35 cows, achieving a data accuracy rate of 98.91%. Also in 2021, Xing Y et al. [
13] proposed an enhanced SSD algorithm that fused features from different images, improving detection efficiency and accuracy, especially for overlapping cows in complex farming environments. In 2023, Zhang Yu [
14] presented a recognition method based on the TLAINS-InceptionV3 model. This approach established an experimental dataset using side body images of 39 beef cattle to capture target features and develop an individual cow identification model.
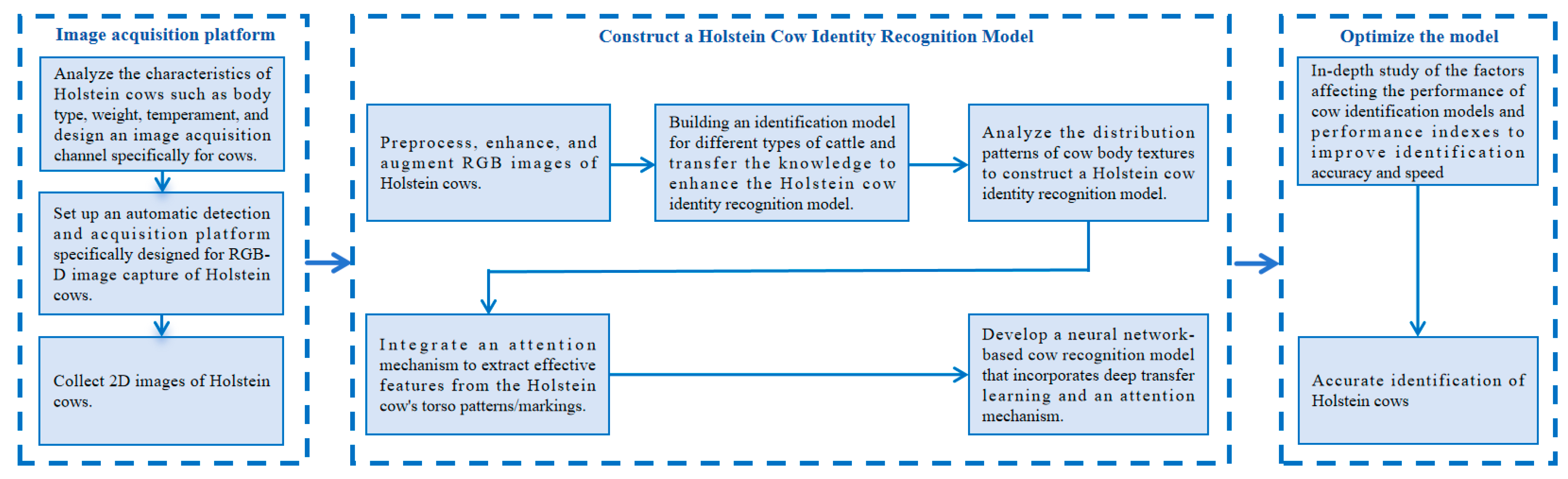
Cow identification serves as the cornerstone for attaining digital and intelligent management in cattle farms. Scholars worldwide have conducted relevant research utilizing computer vision technology. However, there is still room for improvement in recognition accuracy, particularly in scenarios involving complex backgrounds, partial occlusions, and unconstrained environments. Additionally, there is a need to augment data volumes to bolster the generalization capabilities of algorithm models and devise more efficient and precise cow identification algorithms. These advancements will pave the way for intelligent and automated cow farming. The methodology outlined in this paper, and illustrated in
Figure 1, comprises the following steps:
- (1)
Establishing an image preprocessing platform for acquiring Holstein cow side body images
By conducting a comprehensive analysis of cow characteristics, including size, weight, and temperament, as well as fence attributes such as height, strength, and background wall materials, we determine the optimal width of the cow image acquisition channel and the positioning of infrared sensors. Given that cameras are prone to environmental influences, it is imperative to assess factors that impact imaging quality. These factors encompass the relative positioning and height of depth and color cameras, imaging distance, light source distribution and intensity, fence dimensions, and imaging background. The ultimate goal is to construct an image acquisition platform that minimally disrupts the cows while capturing high-quality side body images.
- (2)
Constructing a deep convolutional neural network model utilizing transfer learning and attention mechanism for cow identification
By analyzing cow body texture distribution patterns, a recognition model is established using a large dataset containing similar texture data. This model acts as a pre-trained foundation for cow identification and is transferred to enhance the cow identification process. Additionally, an attention mechanism is employed to eliminate irrelevant features. Given the intricate nature of the cattle farm environment, it is imperative to accurately capture cow target information and differentiate between cows and background elements. Hence, it is crucial to devise efficient target detection algorithms, assess the evaluation methods and performance metrics of the deep convolutional neural network model, investigate and pinpoint the optimal network configuration and parameters, refine the network structure, and ultimately construct a tailored deep convolutional neural network model for cow identification within this specific background.
2. Materials and Methods
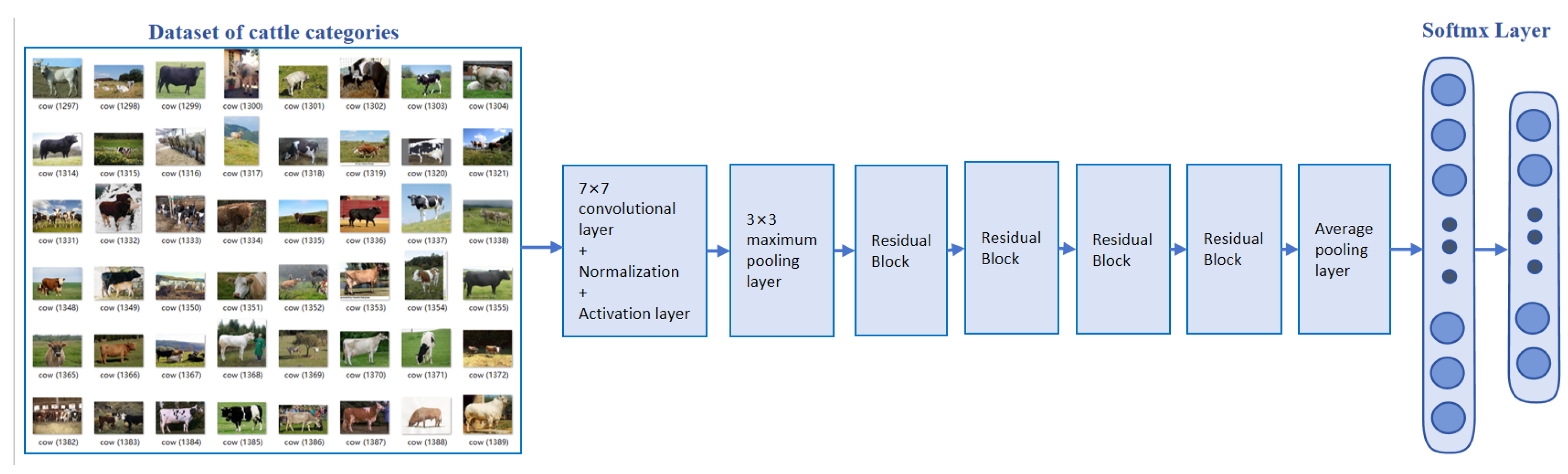
This study aims to establish a comprehensive Holstein cow identification dataset, accompanied by a corresponding 3D point cloud dataset. While existing research primarily focuses on identifying Holstein cows through facial features, there is a notable lack of studies exploring body pattern-based identification. Collecting body images of Holstein cows poses significant challenges, as these animals often exhibit low cooperation, are prone to fright, and tend to gather closely together. To overcome these obstacles, we adopted a non-intrusive and stress-free approach for data collection, successfully compiling a dataset featuring 150 Holstein cows.
Furthermore, we employed advanced image enhancement techniques to enrich the dataset, ensuring it accurately reflects real-world natural conditions. Recognizing the synergy between this study and research on cow body measurements, we will utilize the Helios camera (The Helios camera, manufactured in Canada by the LUCID brand and model HLT0035-001, with version number 204900009.) to develop a cow image acquisition system. This system is designed to efficiently capture two-dimensional body images of cows, providing robust technical support for cow farming and related studies. The resulting two-dimensional image dataset, named “Holstein_cow_RGB-150”, stands as a valuable resource for future research and applications.
2.1. Data Acquisition
2.1.1. Collection Equipment
The Helios camera, with its distinctive design and remarkable performance, shines brightly in the realm of visual technology. As illustrated in
Figure 2, the Triton color camera occupies the upper portion of the camera body. This component operates much like standard two-dimensional RGB image collectors, adept at capturing vivid color information and intricate texture details, which offers a valuable reference for subsequent depth image analysis. While the Triton color camera is an integral part of the Helios camera, its true technological masterpiece lies in the TOF (Time of Flight) camera housed in the lower half. By analyzing the phase difference between emitted and reflected light, the TOF camera precisely determines the distance between the camera and its target, subsequently producing depth images of the scene.
2.1.2. Real-Time Data Acquisition
The field test site for this project is situated at the Pasture of Henan Agricultural Science and Technology Co., Ltd. (Xinxiang, China) To facilitate real-time data acquisition, we have established an on-site data collection platform. Before commencing data collection, we gained a comprehensive understanding of the behavioral patterns and time allocation of Holstein cows, as well as the structure of large-scale farms.
Table 1 presents the behavioral characteristics of Holstein cows, and
Table 2 for farming time allocation details.
On large-scale farms, the Helios camera is strategically positioned on the exterior wall adjacent to the milking hall passageway. This placement enables the camera to capture the body posture of cows as they pass through. The decision to install the camera at this location was guided by three key factors: (i) the ability to fully document the cows’ body posture; (ii) the slower gait of the cows, which aids in clearer imaging; and (iii) the prevention of direct contact between the camera and cows, thus preserving equipment integrity. After meticulous on-site measurements, the camera was installed at a precise distance of 2.8 m from the wall and 1.2 m above the ground, which ensures optimal image clarity and accuracy. Prior to installation, simulation tests, and debugging were performed to guarantee comprehensive cow coverage and precise side-image captures. To facilitate automatic real-time photography, a specular reflective infrared sensor is employed, connected to the Helios camera. When a cow enters the milking hall, the infrared beam is interrupted, triggering the sensor to send a signal to the camera, which then captures an image. To accommodate cows of varying sizes, a dual infrared sensor system was implemented, broadening the detection range and ensuring that any interruption prompts the camera to take a picture.
Figure 3 illustrates the conceptual framework and practical application of our experimental data collection setup.
To guarantee the absence of any detrimental impact on the cows and to adhere to the stringent quality standards for image acquisition, we have deliberately selected a specific timeframe spanning from 6 January to 6 February 2024. Specifically, we have captured two-dimensional images of 150 Holstein cows during the milking procedure through the designated platform, with sessions scheduled between 8:30 and 9:30 in the morning and from 11:40 to 12:40 at noon.
The selection of the specific time period from 6 January to 6 February 2024 is based on a series of meticulous considerations. This decision aims to capture a relatively stable physiological state of cows, minimizing behavioral or physical changes caused by natural factors such as seasonal changes and fluctuations in the reproductive cycle, thereby ensuring the consistency and reliability of image data. Meanwhile, during this winter period, the relatively stable environmental conditions, marked by minimal variations in temperature, humidity, and lighting, help reduce potential interference from the external environment on image quality. Furthermore, the choice of this time frame adheres to stringent image acquisition quality standards, simplifying variable control through a fixed timeline and ensuring the uniformity of data quality. The emphasis on the health and safety of cows is also a crucial factor in this decision, ensuring that data collection activities do not adversely affect the animals, reflecting a respect for animal welfare in research. At the level of experimental design, the selection of this specific time period further enhances the precision and scientific rigor of the experiment, contributing to reduced errors and improved accuracy and reliability of research results. Lastly, data collection within a short time frame promotes data consistency and comparability, laying a solid foundation for subsequent data processing and analysis. In summary, the selection of this time period is the result of comprehensive considerations of various factors, aimed at comprehensively enhancing the overall quality and credibility of the research.
2.1.3. Preprocessing of the Holstein_cow_RGB-150 Dataset
Over a 30-day data collection period, we successfully captured 9000 two-dimensional images of 150 Holstein cows. After a careful screening process, we ended up with 8309 high-quality Holstein cow images, as illustrated in
Figure 4a. Training a deep learning model for cow identification demands robust data support. Prior to commencing the training, it is imperative to rigorously screen and evaluate both the quantity and quality of the samples. The quality of the data significantly influences the model’s overall performance. Hence, in deep learning training, the processes of data gathering, preparation, and augmentation are of utmost importance. These vital steps are instrumental in enhancing the model’s recognition accuracy, thereby ensuring precise and reliable model outputs.
This study begins with screening the collected data to eliminate unqualified images, specifically those with blurred bodies or areas with significant overlap or occlusion. To bolster the dataset’s diversity, the compilation from these filtered images incorporates samples featuring single individuals, multiple individuals, various body types, and a wide range of ages. Consequently, random sampling was executed on-site, yielding 500 randomly selected images, as exhibited in
Figure 4b. For the 8809 valid two-dimensional Holstein cow images emerging from the screening, we employed the OpenCV image tool, adhering to a stringent data processing workflow to thoroughly enrich the image data. By implementing image processing algorithms, we accomplished seven data enhancement techniques: brightness enhancement, contrast improvement, rotation angle calibration, image flipping, affine transformation, shear transformation, and HSV data enhancement. These methods guaranteed the precision and completeness of the image data.
Figure 5 illustrates a comparative analysis of data samples pre- and post-data enhancement. Following these enhancement procedures, we successfully amassed a total of 61,663 two-dimensional target images of Holstein cows, offering a comprehensive and varied dataset for subsequent model training.
In the process of image processing and data augmentation, brightness enhancement allows users to adjust based on the original brightness value range of the image (e.g., 0–255), optimizing the image by increasing or decreasing the percentage of each pixel’s brightness value (e.g., ±20%). Contrast improvement, on the other hand, focuses on adjusting the difference between the brightest and darkest pixel values in the image, which can be achieved through methods such as linear stretching or gamma correction. Additionally, rotation angle calibration permits the image to be rotated around its center point by any angle, with the rotation angle being either fixed or randomly set. Image flipping, as a simple enhancement technique, encompasses horizontal and vertical flipping. Affine transformation, a more complex two-dimensional linear transformation combined with translation, enables random adjustments to the image’s rotation, scaling, skewing, and translation parameters. Cropping transformation involves cutting out a rectangular area from the image, with the selection of this area being either random or based on a strategy, and its size and position being flexible and variable. Lastly, HSV data augmentation adjusts the image within the HSV color space, allowing for intuitive control over the image’s color and brightness characteristics by altering hue, saturation, or brightness parameters.
In the realm of image processing, alongside intra-frame algorithms, inter-frame algorithms constitute efficient tools for data augmentation. Both the Mixup method and the Mosaic algorithm belong to image enhancement techniques, aiming to enhance the generalization ability and detection performance of deep learning models through different strategies. Specifically, the Mixup method generates brand-new training samples by randomly mixing two image data, thereby increasing the diversity and complexity of the dataset. In contrast, the Mosaic algorithm adopts a more innovative approach by stitching together different parts of multiple images to create a complex image containing multiple scene elements, further enriching the content of the training data and enabling the model to learn a more comprehensive feature representation. Notably, the Mixup and Mosaic algorithms are two renowned image inter-frame techniques. As depicted in
Figure 6a, the Mixup method enhances the generalization capacity of neural network training by merging two images in equivalent proportions (0.5:0.5). This mixing approach aids the model in better adapting to unseen target data. Conversely, the Mosaic algorithm, as illustrated in
Figure 6b, amplifies image background details and efficiently boosts sample diversity within each training dataset batch through randomized image cropping and splicing. This, in turn, also fosters network generalization. Both approaches are potent methods for enhancing the performance of deep learning models.
2.2. Test Method
2.2.1. Model Evaluation Metrics
Precision: this measures the accuracy of the positive predictions made by the model. It is the ratio of true positive predictions to the total number of positive predictions (both true and false). In other words, it indicates how many of the predicted positive cases were actually correct, as exemplified in Equation (1).
where
TP represents the true positive, and
FP represents the false positive.
Recall, which is defined as the ratio of accurately predicted positive samples to the total number of positive samples, is determined by dividing the count of samples that are correctly predicted as positive by the total count of all positive samples, as demonstrated in Formula (2).
where
FN represents the false negative.
Average Precision (AP) assesses the performance of the algorithm across diverse data types. To compute the Average Precision, the Precision-Recall curve (PR curve) is plotted initially, and subsequently, the area under the curve (AUC) is determined. This area, enclosed by the curve and the axes, represents the Average Precision. The entire calculation procedure is illustrated in Equation (3).
Mean Average Precision (MAP) is obtained by aggregating the mean precision values across multiple category samples and then computing their overall average, as outlined in Formula (4).
where b represents the category of data.
Equation (5) FPS stands for Frames Per Second, an evaluation metric used to measure the speed of object detection. It represents the number of images that can be processed per second. For instance, an FPS of 50 indicates that 50 images can be processed every second, equating to a processing time of 0.02 s per image. The methodology for calculating FPS is exhibited in Formula (5).
where
represents the time required to detect one image.
2.2.2. Training of the Network Model
The optimized and meticulously designed platform seamlessly integrates with the Windows 10 system, ensuring rock-solid stability. It harnesses the exceptional computing and acceleration capabilities of an NVIDIA GeForce RTX 3080 graphics card. Powered by an Intel Core i7-11700KF CPU with a peak frequency of 3.60 GHz, it effortlessly handles a wide range of high-performance demands. A substantial 32 GB of memory guarantees a lag-free and reliable system experience. The software suite boasts features of PyCharm 2021.2, Python 3.9, and the PyTorch 1.9.1 deep learning framework, offering a comprehensive environment for development. Additionally, the CUDA 9.0 programming environment unlocks the full potential of the graphics card’s 10 GB video memory, enabling efficient execution of demanding deep learning workloads. This configuration enables the construction of a robust and high-performance deep learning platform, providing powerful computational support for a variety of experiments [
16].
4. Results and Analysis
4.1. Comparison of Ablation Experiments
The primary aim of this paper is to systematically study, evaluate, and compare various optimization algorithms through rigorous experimental methods. Our goal is to ascertain the practical applicability of these optimization techniques. We are committed to conducting comprehensive research on diverse optimization strategies, aiming to explore their potential to enhance the detection efficiency of algorithms. Taking into account the unique attributes of our research subject and its operational setting, we will thoroughly assess the efficacy of each optimization measure in improving the cow identification algorithm, thereby ensuring its precision and dependability in real-world scenarios. For the purposes of this experiment, YOLOX-S has been chosen as the baseline network. Detailed experimental outcomes are documented in
Table 4.
From the experimental results of the ablation comparison in
Table 4, we can draw the following conclusions:
The YOLOX-S cow identification model, enhanced with transfer learning (dubbed YOLOX-S-Transfer), demonstrates a notable 2.56% boost in MAP value and a 7-frame elevation in FPS. This result clearly demonstrates that utilizing the cattle species transfer model can effectively accelerate the improvement of accuracy in cow identification and significantly reduce the model training time, showcasing the efficiency of migration learning in cross-domain tasks.
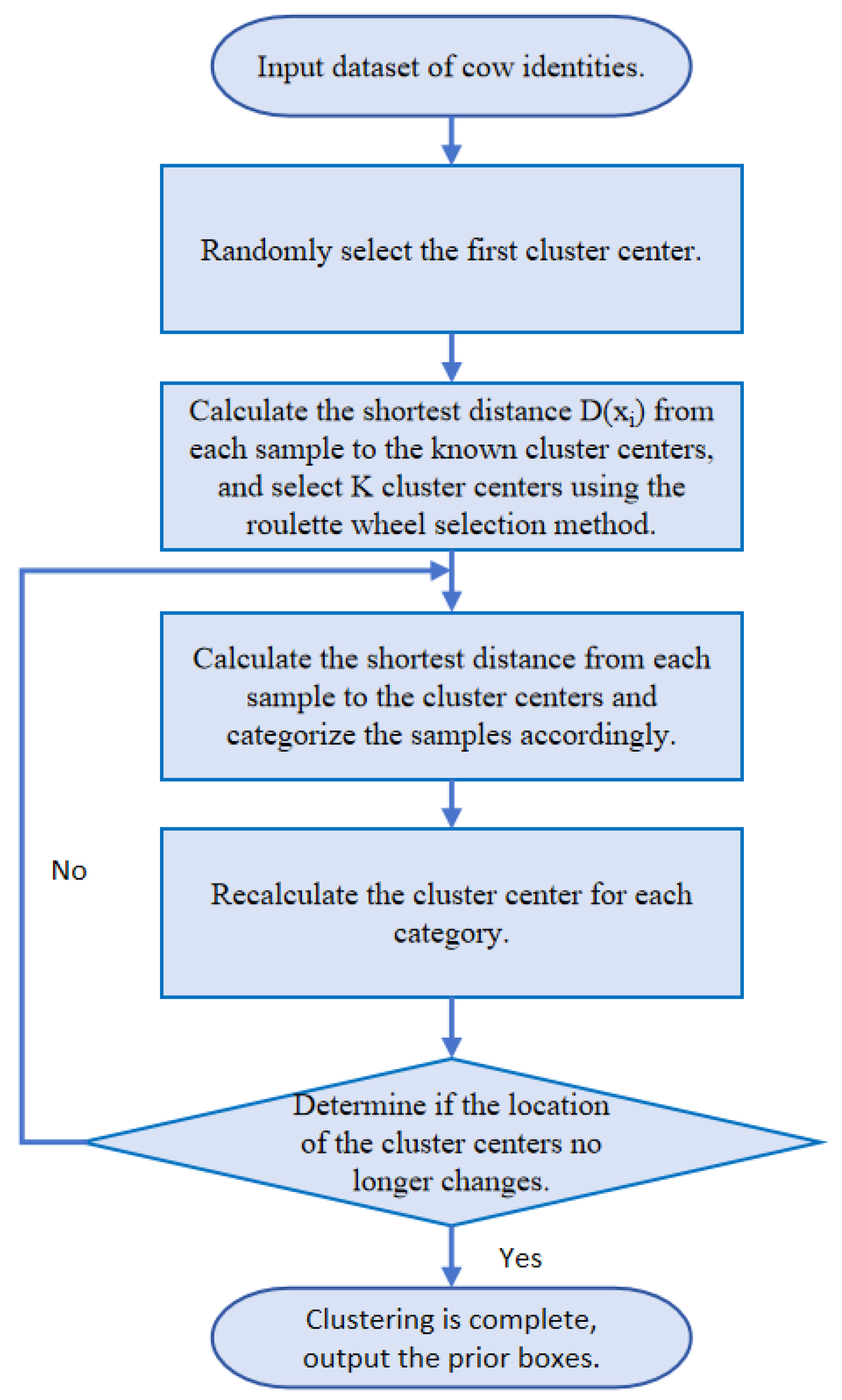
The YOLOX-S cow identification model, combined with the K_means++ algorithm (dubbed YOLOX-S-K_means++), exhibits notable advancements across all metrics when compared to the original clustering approach in target detection box clustering on the Holstein_cow_RGB-150 dataset. Specifically, it achieves a 5.16% boost in MAP value and a 9-frame FPS increase. When benchmarked against the YOLOX-S-Transfer model, the YOLOX-S-TK variant outperforms the YOLOX-S-Transfer model by a 6.14% increase in accuracy and a 5-frame boost in FPS. The K_means++ algorithm effectively avoids the local optimum problem by optimizing the selection of clustering centers and, consequently, significantly enhances the detection performance of the model, thereby demonstrating its positive contribution to clustering optimization for the task of cow identification. Consequently, the integration of K_means++ significantly elevates the cow identification model’s performance.
After substituting the original loss function of the YOLOX-S cow identification model with F_EIOU_Loss, the updated YOLOX-S-F_EIOU_Loss model exhibited a notable 4.76% boost in MAP value and a 10-frame gain in FPS. In comparison to the YOLOX-S-TK model, the YOLOX-S-TKE variant showcased a 2.95% MAP value increase and a 9-frame FPS improvement. The introduction of F_EIOU_Loss demonstrates its effectiveness in mitigating the adverse effects of low-quality data, thereby strengthening the stability and precision of cow identification across diverse real-world applications.
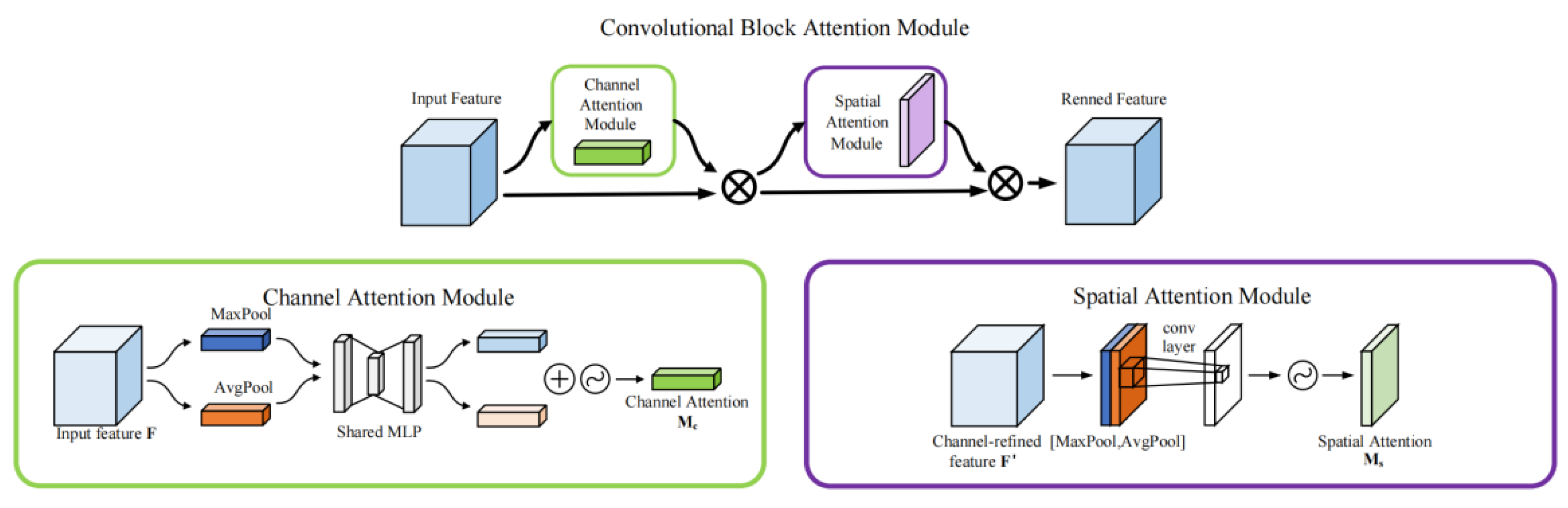
The integration of the hybrid attention mechanism module (CBAM) has led to a notable enhancement in the performance of the YOLOX-S cow identification model, now known as YOLOX-S-CBAM. Specifically, the Mean Average Precision (MAP) value has increased by 2.13%, and the Frames Per Second (FPS) has improved by 4 frames. Furthermore, this integration enhances the feature extraction capabilities of the YOLOX-S-TKE model, resulting in the YOLOX-S-TKEC model with further improvements. As a result, the YOLOX-S-TKEC model demonstrates a 1.25% boost in recognition accuracy, accompanied by a 4-frame increase in FPS. This indicates that CBAM plays a key role in enhancing the feature extraction capability of the model, which enhances the model’s ability to capture and process complex feature information.
The YOLOX-S cow identification model, enhanced with the BiFPN feature fusion pyramid structure (referred to as YOLOX-S-BiFPN), shows significant improvements. Specifically, it boasts a 2.56% increase in MAP value and a 7-frame boost in FPS. Furthermore, when compared to the YOLOX-S-TKEC model, it elevates the MAP value by 2.43% and FPS by 7 frames. These results suggest that the integration of the BiFPN feature fusion module into the YOLOX-S-TKECB algorithm not only strengthens the feature fusion ability of the model, but also improves the system efficiency and performance by optimizing the feature fusion path, which showcases the significant advantage of an efficient feature fusion strategy in enhancing the model’s inference speed.
4.2. Analysis of Results
Through ablation experiments, we have drawn the following conclusions: After implementing all the optimization measures outlined in this paper on YOLOX-S, we observed notable enhancements in terms of the overall MAP value and FPS (Frames Per Second). Specifically, the YOLOX-S-TKECB model pushes the overall MAP value to 97.87%, an improvement of 15.31% over the original YOLOX-S model, and achieves a high frame rate of 108 frames per second, an increase of 32 frames compared to the original. This significant improvement fully validates the effectiveness and efficiency of the optimization measures implemented. In practical application scenarios, the optimized cow identification model demonstrates high accuracy and real-time performance, providing strong technical support for related tasks. In particular, the model exhibits excellent generalization ability and robust performance when dealing with diverse cow identification datasets.
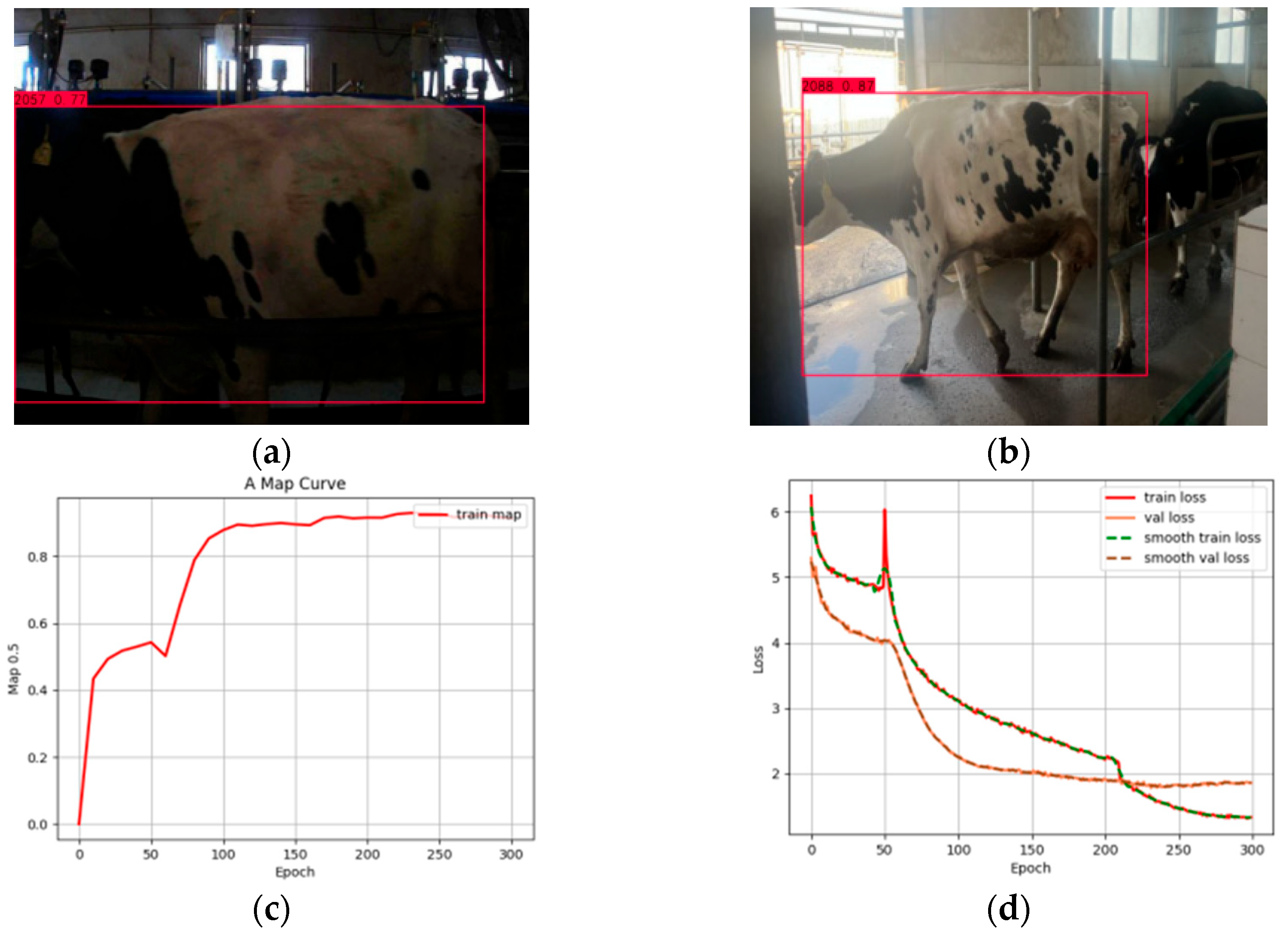
As shown in
Figure 13 and
Figure 14, these two sets of comparison graphs visually reflect the great difference in model performance before and after optimization.
Figure 13a,b reveal the limitations of the original model in single-target and multi-target recognition, such as low detection accuracy, inaccurate positioning of bounding boxes, and recognition failure due to target occlusion. Meanwhile,
Figure 13c,d show changes in the average MAP value and loss value of the original model during the training process, respectively, indicating that the average MAP value of the original model is only 82.56%, and the loss function appears to be significantly increasing during the fitting process. This reflects the instability and inefficiency of the original model during the training process.
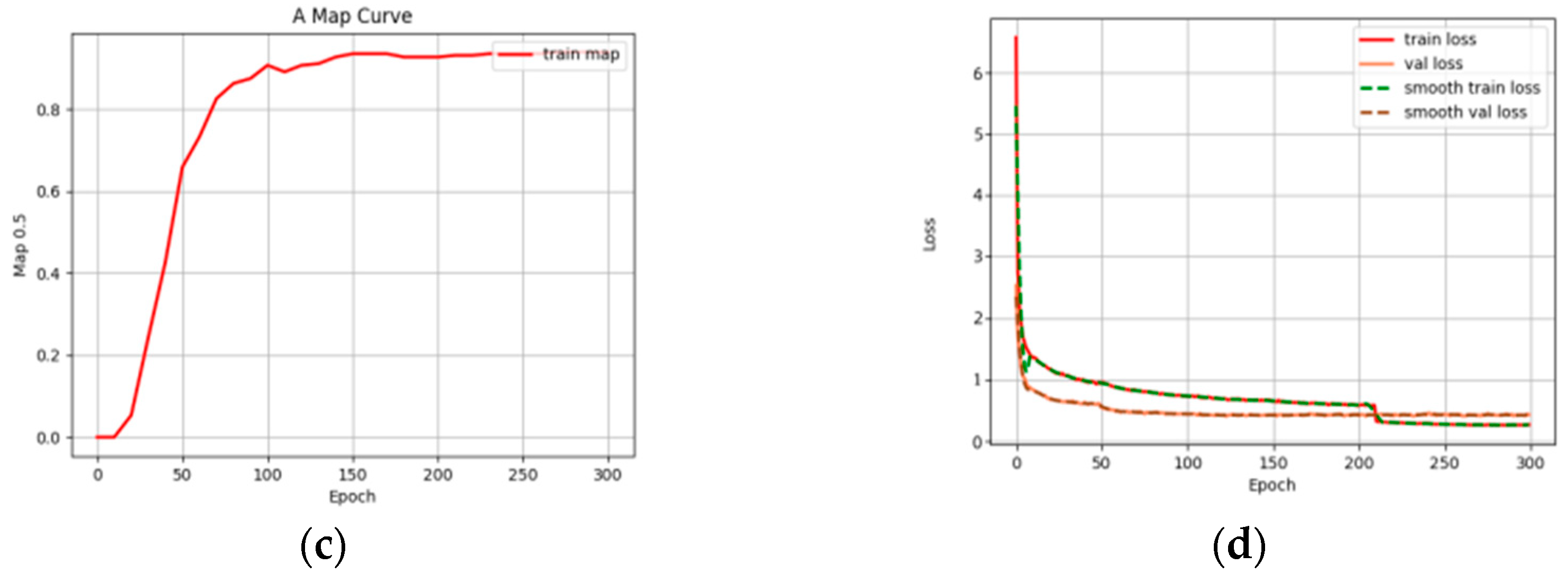
In contrast,
Figure 14a,b demonstrate the excellent performance of the optimized model in single- and multi-target recognition, which not only dramatically improves the detection accuracy, but also effectively deals with complex situations such as target occlusion.
Figure 14c,d detail the changes in average MAP value and loss value during the improved model’s training. Notably, after approximately 60 training rounds, the improved model maintains its accuracy without significant decreases or increases in the loss rate, showcasing remarkable stability. This underscores that the optimized algorithm significantly boosts recognition accuracy and speed while also excelling in training stability and efficiency.
5. Discussion
In this paper, a cow identification algorithm based on YOLOX-S-TKECB is proposed, aiming to achieve high-precision identification of Holstein cows in an efficient and interference-free manner. The core of the research encompasses the construction of a data acquisition platform, image preprocessing techniques, and the development and optimization of a convolutional neural network model that integrates transfer learning and attention mechanisms.
5.1. Developing a Platform for Real-Time RGB-D Image Acquisition and Cow-Specific Preprocessing
Based on our in-depth understanding of Holstein cows’ living habits, we designed and implemented a customized RGB-D image real-time acquisition and preprocessing platform. This platform leverages the high performance of the Helios camera to accurately capture 2D images of cows within their feeding environment. After 30 days of continuous data acquisition, we successfully constructed the Holstein_cow_RGB-150 dataset, which comprises images of 150 Holstein cows. To enhance the generalization ability of our model, we employed a diversified data enhancement strategy to effectively expand the diversity of the dataset.
5.2. Establishing a Holstein Cow Identification Model with the YOLOX-S-TKECB Framework
In light of the YOLO algorithm’s strengths in balancing efficient real-time performance with accuracy, this study introduces several innovations to the YOLOX-S model. By incorporating migration learning techniques and leveraging pre-training weights, we accelerate model convergence and enhance generalization capabilities. Optimizing the clustering algorithm ensures that the anchor frames better align with the varying body sizes of cows, thereby improving the detection of targets of different sizes. The introduction of the EIOU and Focal Loss functions significantly improves the accuracy of detecting small and occluded targets. Integrating a hybrid attention mechanism module sharpens the model’s focus on processing key information. Additionally, adopting a multi-scale feature fusion strategy ensures comprehensive detection capabilities for both large and small targets. These optimization measures result in notable improvements in the YOLOX-S-TKECB model during ablation experiments and interpretability analyses, with a 15.31% increase in the mAP value and a 32 frames-per-second (FPS) boost, fully validating its feasibility and application potential in cow identity recognition.
Although the YOLOX-S-TKECB algorithm has made significant progress in cow identification, it still faces several challenges and limitations. Firstly, expanding the scale and diversity of the dataset is necessary. Although the current Holstein_cow_RGB-150 dataset provides a preliminary foundation, it still struggles to comprehensively cover all characteristics of dairy cows and complex environmental backgrounds, limiting the model’s wide adaptability and ability to recognize new images. Secondly, the stability and recognition accuracy of the model in complex agricultural environments, particularly under varying light conditions and heavy occlusions, need to be further improved to ensure high performance in actual feeding environments. Additionally, the trade-off between real-time performance and accuracy remains challenging. Although existing optimizations have significantly improved this, the extreme demand for real-time processing is still not fully met, limiting potential applications in large-scale ranching and automated breeding systems. Finally, considering technology diffusion, reducing the cost of high-end equipment will also be a focus of subsequent work.
In view of these limitations, this study will focus on the following aspects in the future: first, continue to expand the scale and diversity of the dataset by integrating and enhancing multi-source data to construct a more comprehensive and representative dairy cow image dataset; second, deeply optimize the model architecture and explore more efficient network structures and feature extraction methods to further improve recognition accuracy and real-time performance; third, develop a version of the algorithm suitable for low-cost hardware to lower the threshold of technology application and promote the popularization and wide adoption of cow recognition technology; fourth, strengthen research on the model’s adaptability in complex environments and improve its robustness and stability in actual feeding environments through simulation training and adaptive adjustment.
Through these efforts, it is expected that the YOLOX-S-TKECB cow recognition algorithm will play a greater role in the intelligentization of dairy farming and promote technological progress, transformation, and upgrading of the industry.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}