
A Global Forecasting Approach to Large-Scale Crop Production Prediction with Time Series Transformers


Abstract
:1. Introduction
- To the best of our knowledge, this is the first work that focuses on collectively forecasting large-scale disaggregated crop production across an entire country, comprising of thousands of time series from a diverse group of crops, including fruits, vegetables, cereals, root and tuber crops, non-food crops, and industrial crops.
- We demonstrate that a time series transformer trained via a global approach can achieve superior forecast accuracy when compared against tree-based machine learning models and traditional local forecasting approaches. Empirical results show a significant 84.93%, 80.69%, and 79.54% improvement in normalized root mean squared error (NRMSE), normalized deviation (ND), and modified symmetric mean absolute percentage error (msMAPE), respectively, over the next-best methods.
- Since only a single deep global model is optimized and trained, our proposed method scales more efficiently with respect to the number of time series being predicted and to the number of covariates and exogenous features being included.
- By leveraging cross-series information and learning patterns from a large pool of time series, our proposed method performs well even on time series that exhibit multiplicative seasonality, intermittent behavior, sparsity, or structural breaks/regime shifts.
- While the global transformer model shows impressive performance, our analysis of the model’s errors also reveals insights that can be used to further improve model performance, as well as provide directions for future work.
- Our work also has practical implications beyond academic research, as we envision this framework being used by stakeholders in the agriculture sector that manage crop production at a national scale. Our results suggest that closer collaboration between domain experts (e.g., crop scientists, farmers) and other data-collecting government agencies (e.g., meteorological and climate agencies, statistical agencies) is vital to improving data-driven frameworks such as ours.
2. Materials and Methods
2.1. Study Area
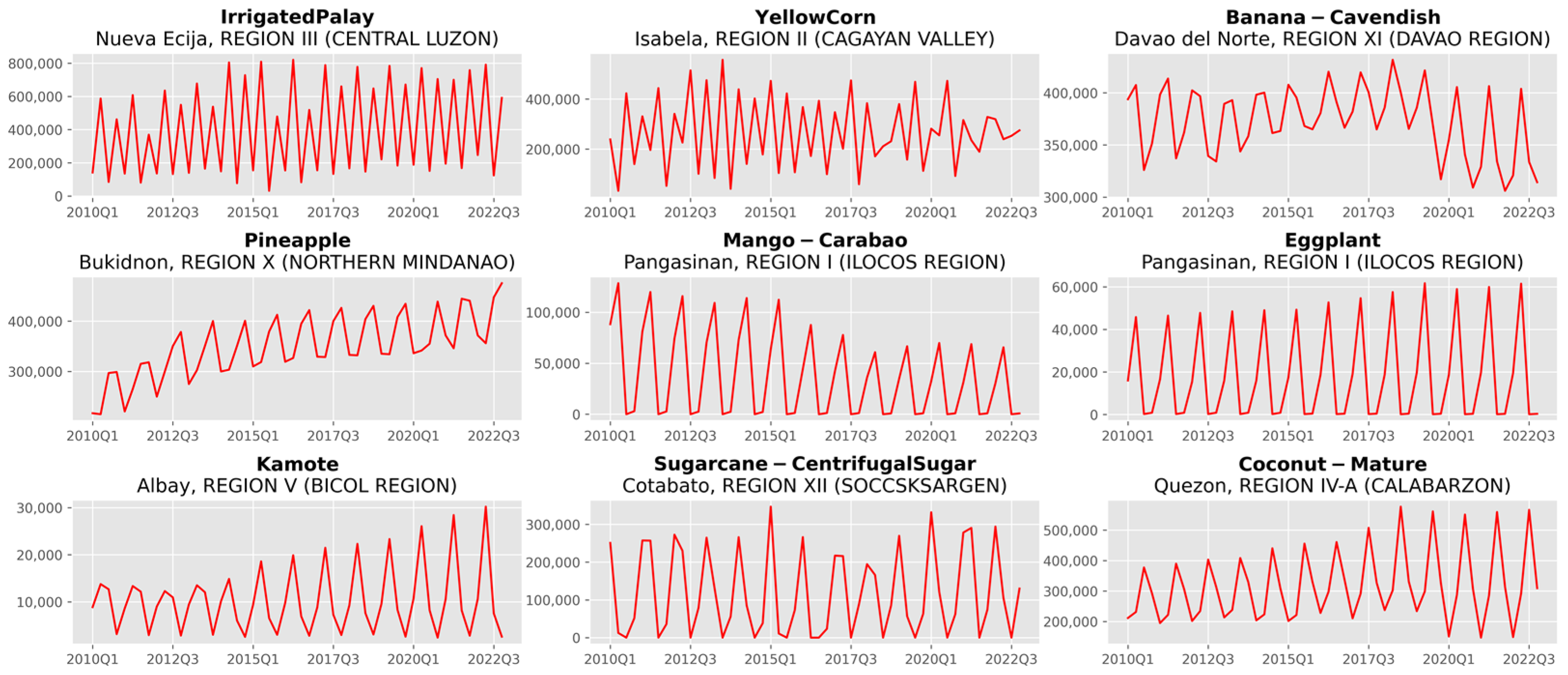
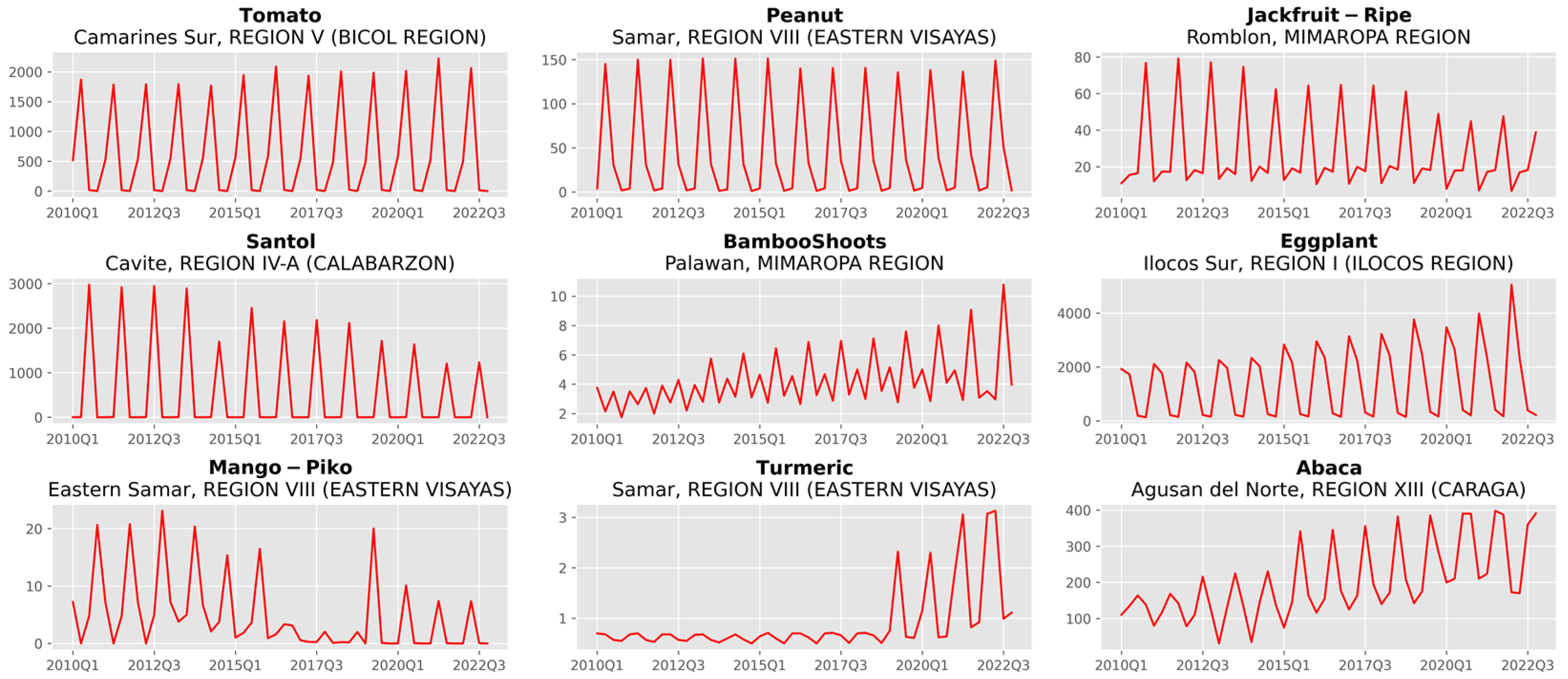
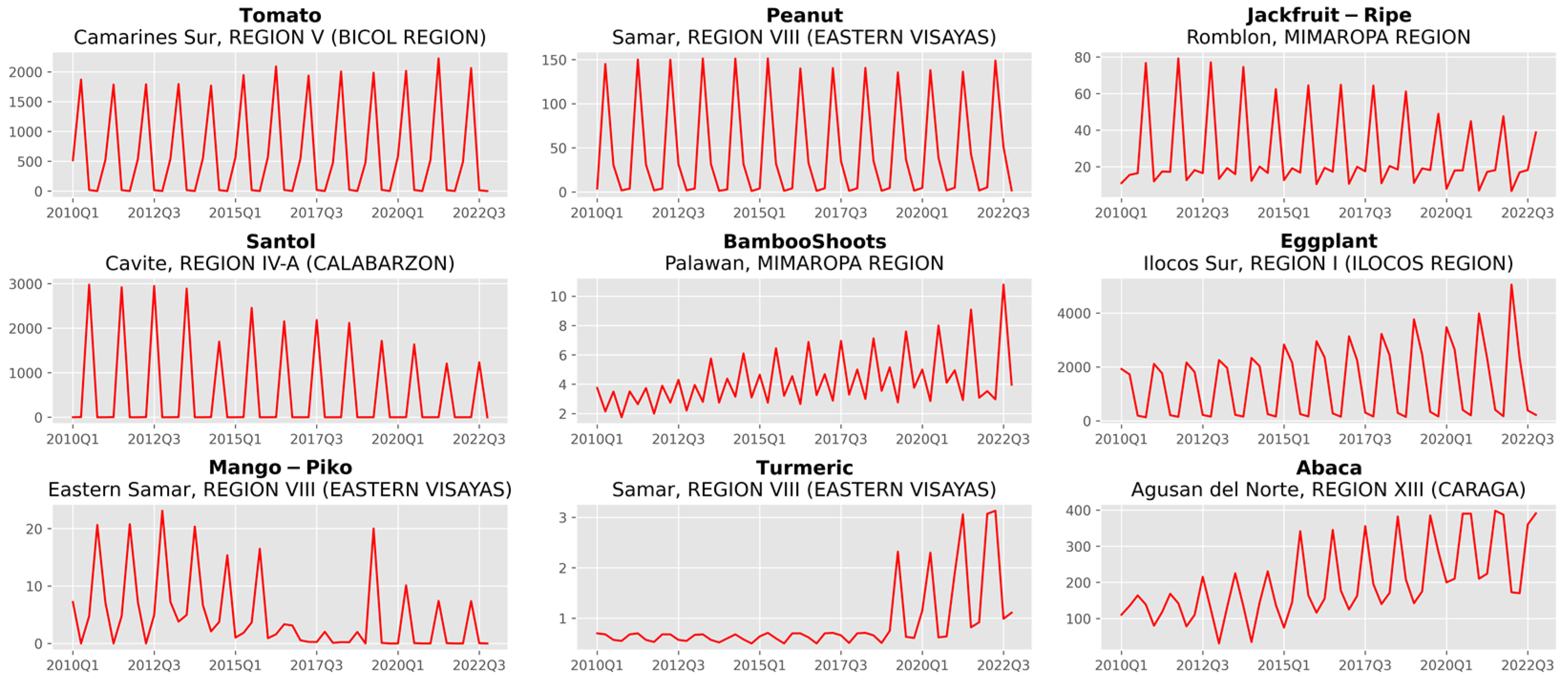
2.2. Data Description
2.3. Forecasting Methods
2.3.1. Baseline and Statistical Methods
2.3.2. Machine Learning Models
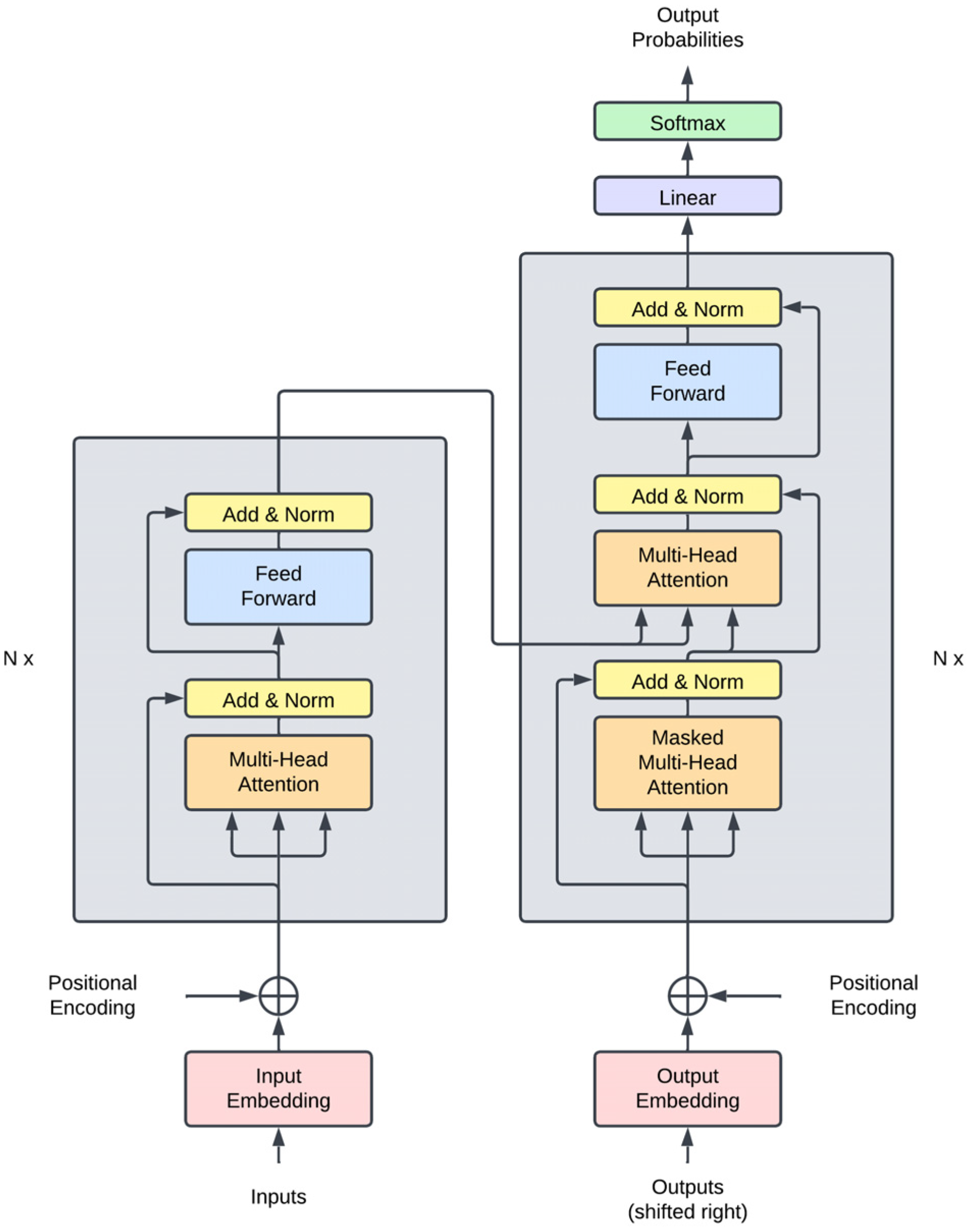
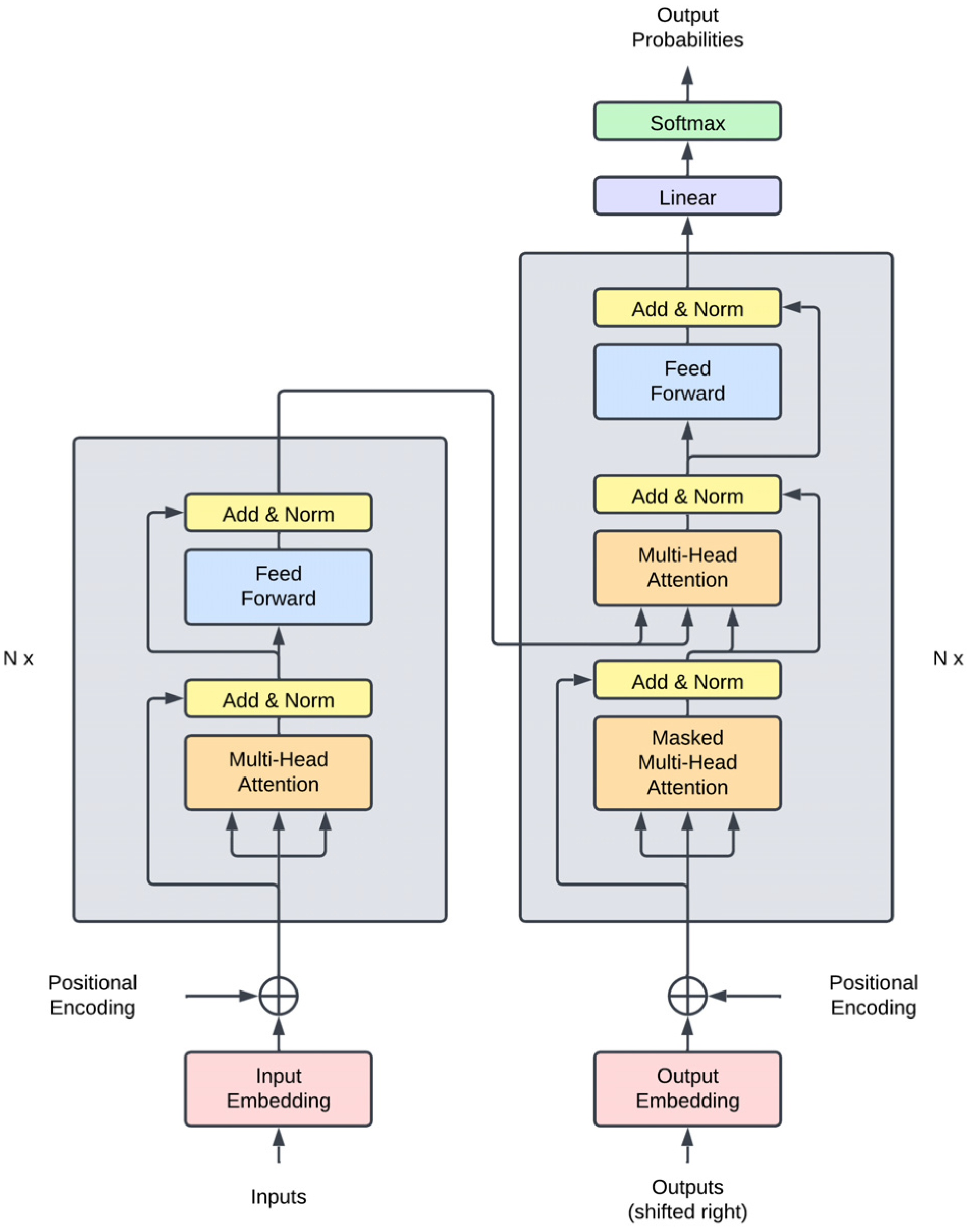
2.3.3. Deep Learning and the Transformer
2.3.4. The Global Forecasting Approach
2.4. Evaluating Model Performance
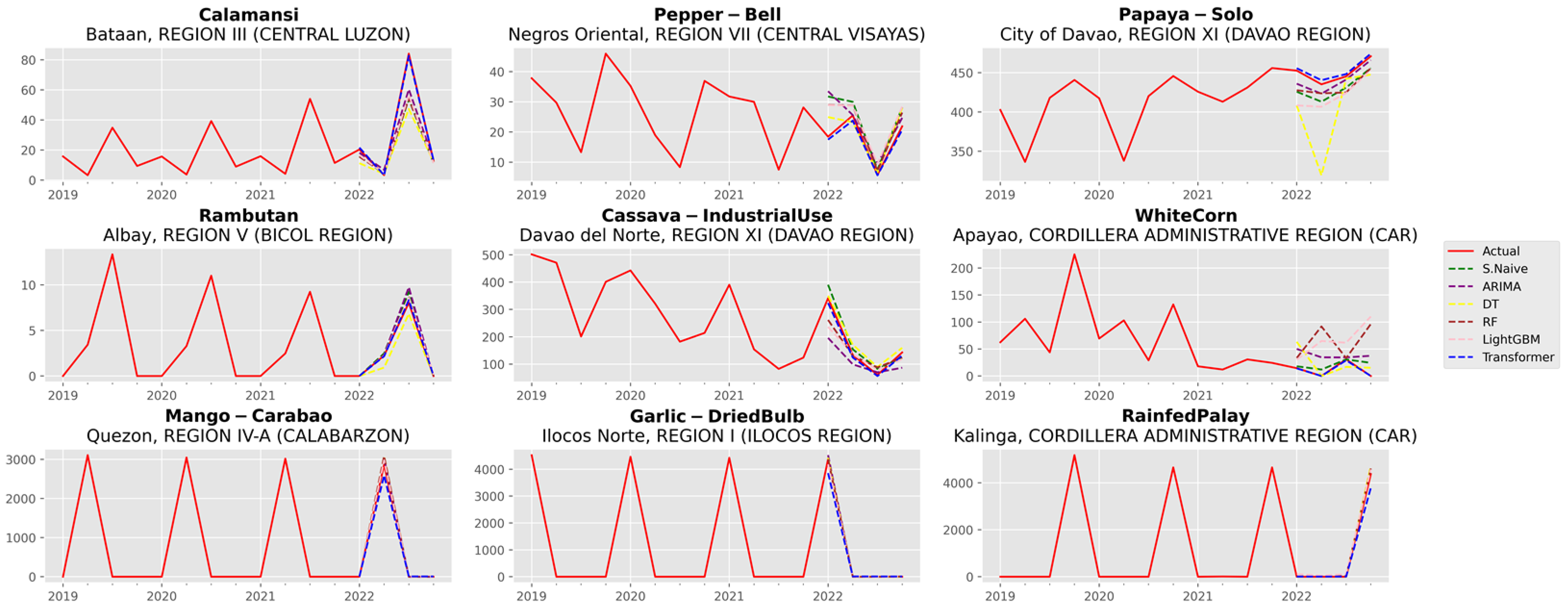
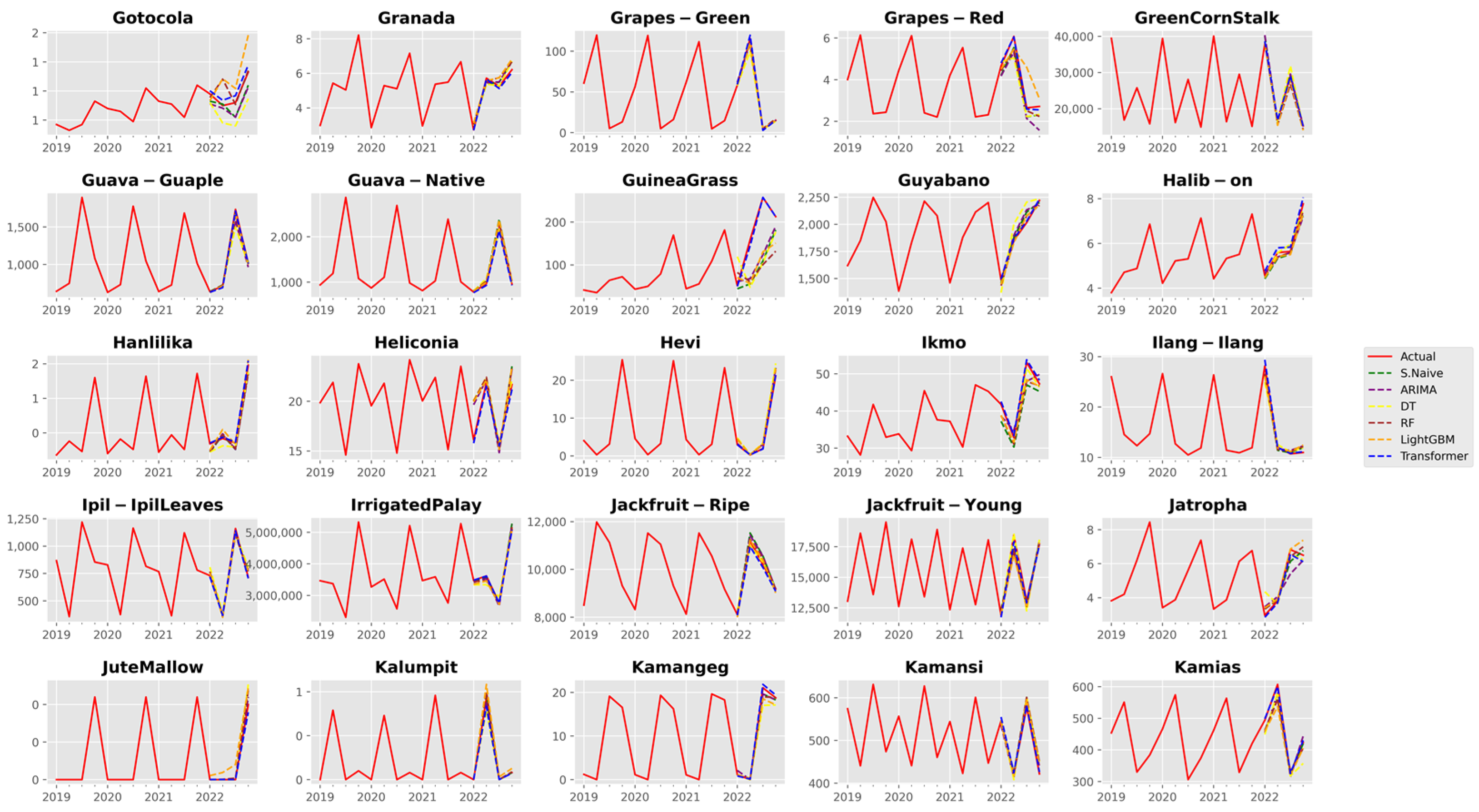
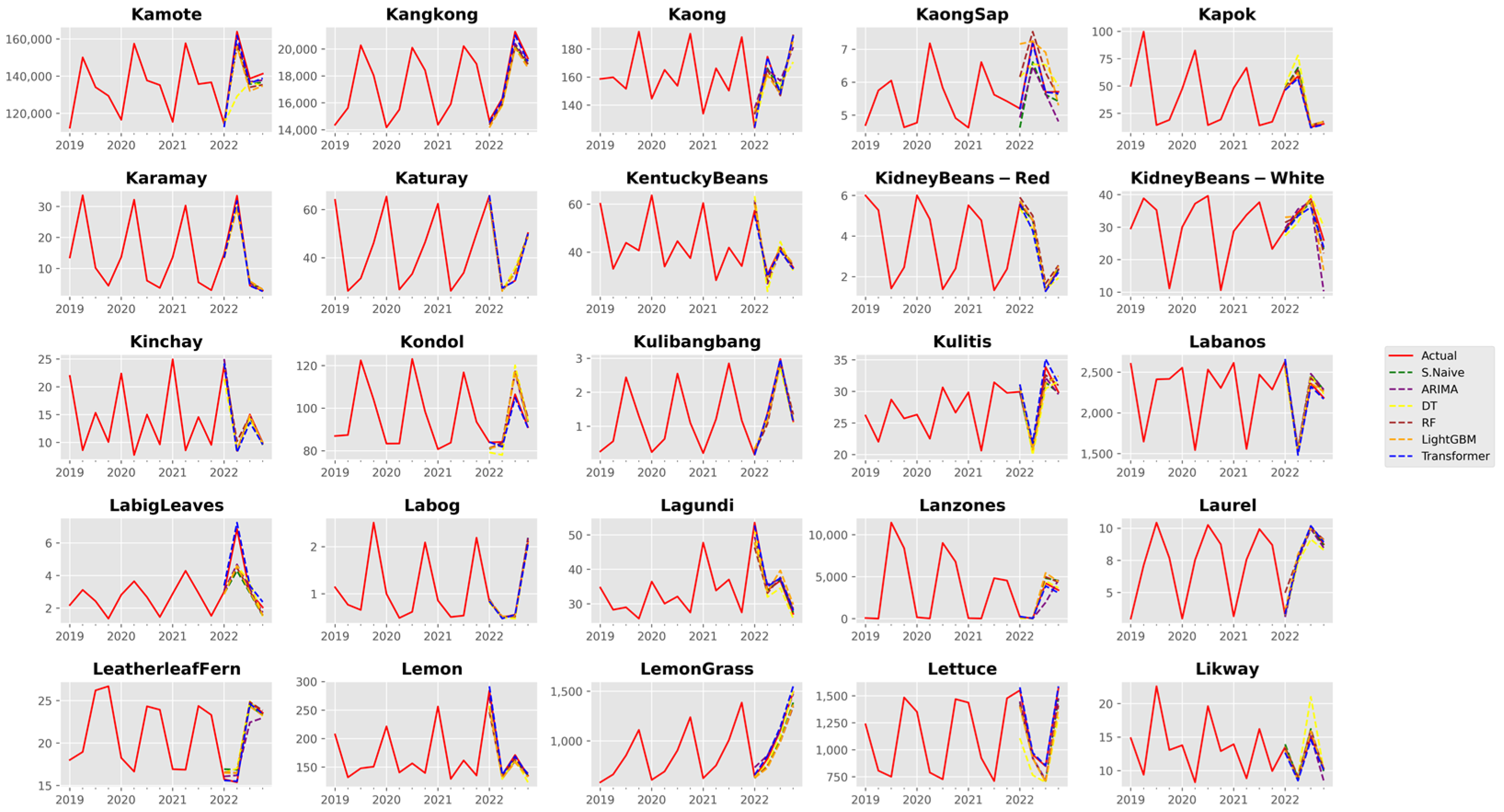
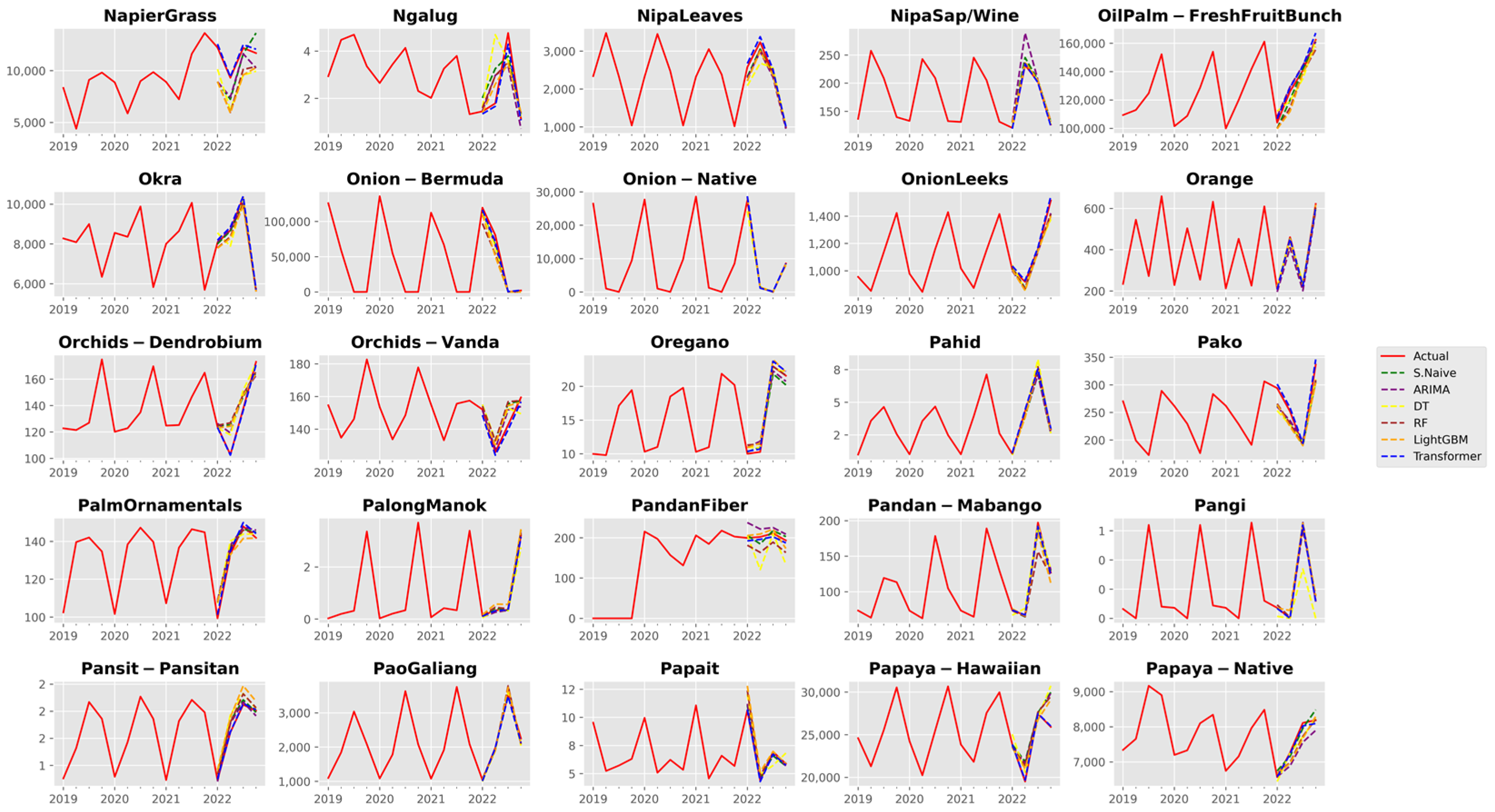
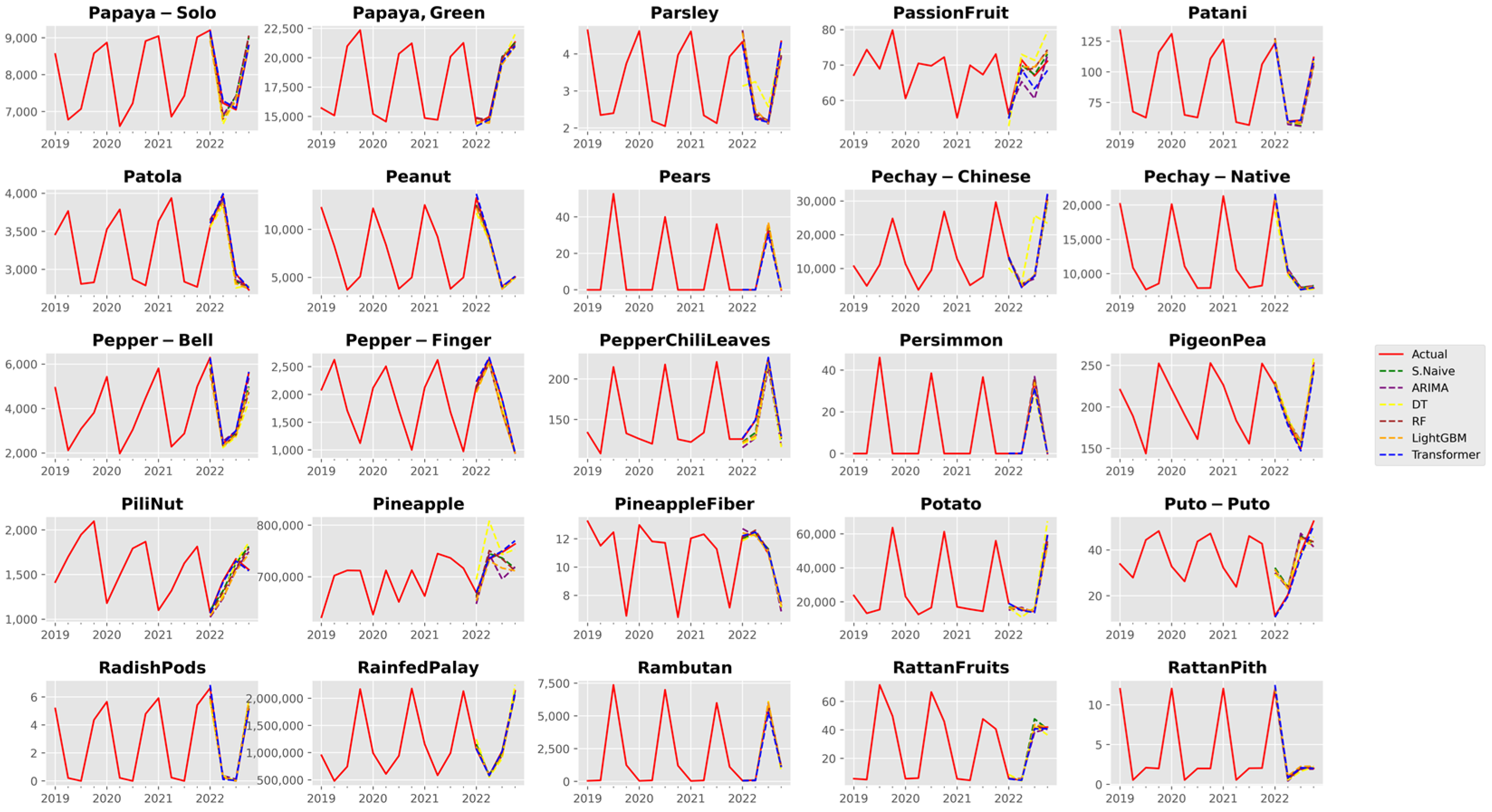
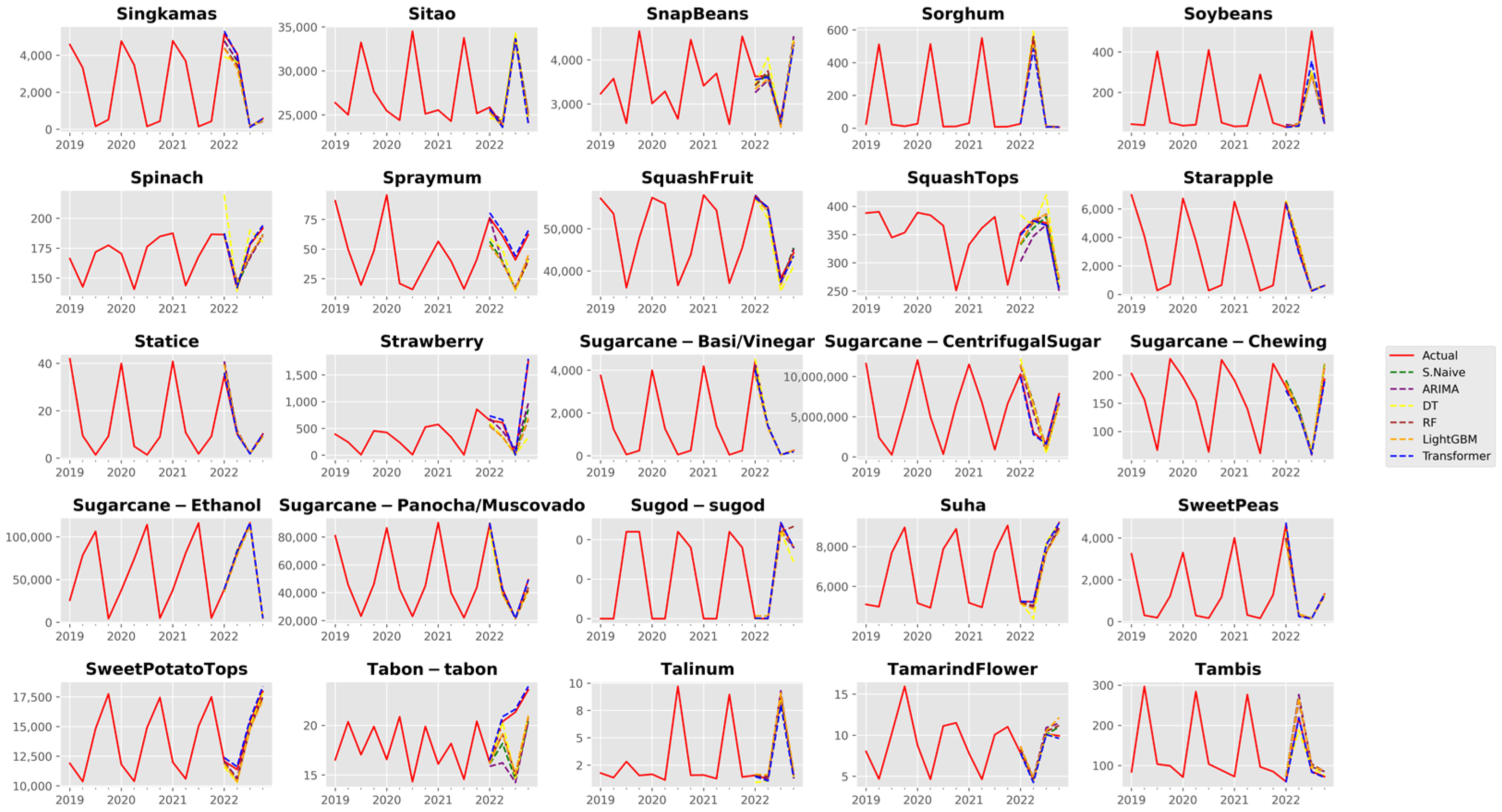
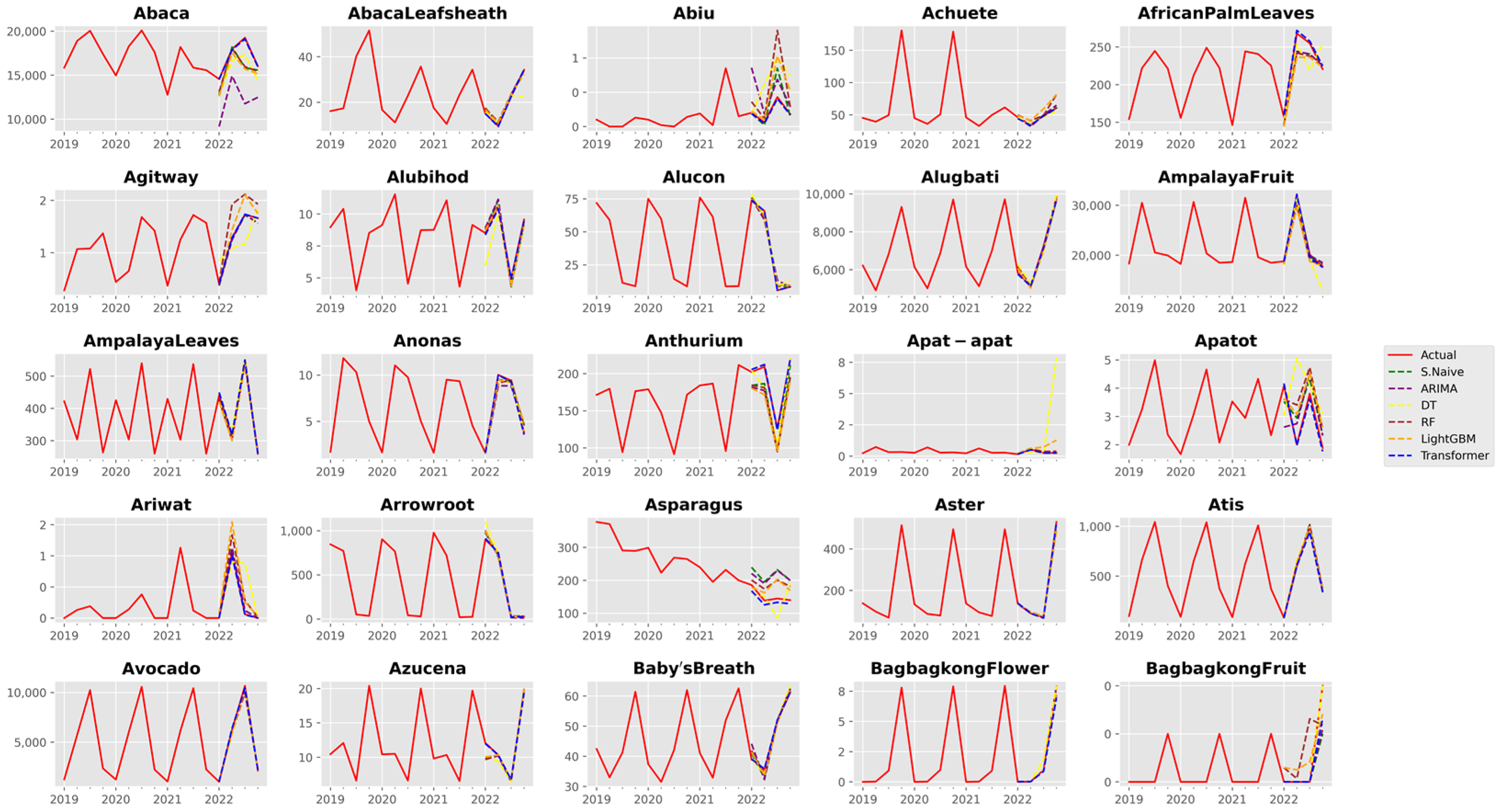
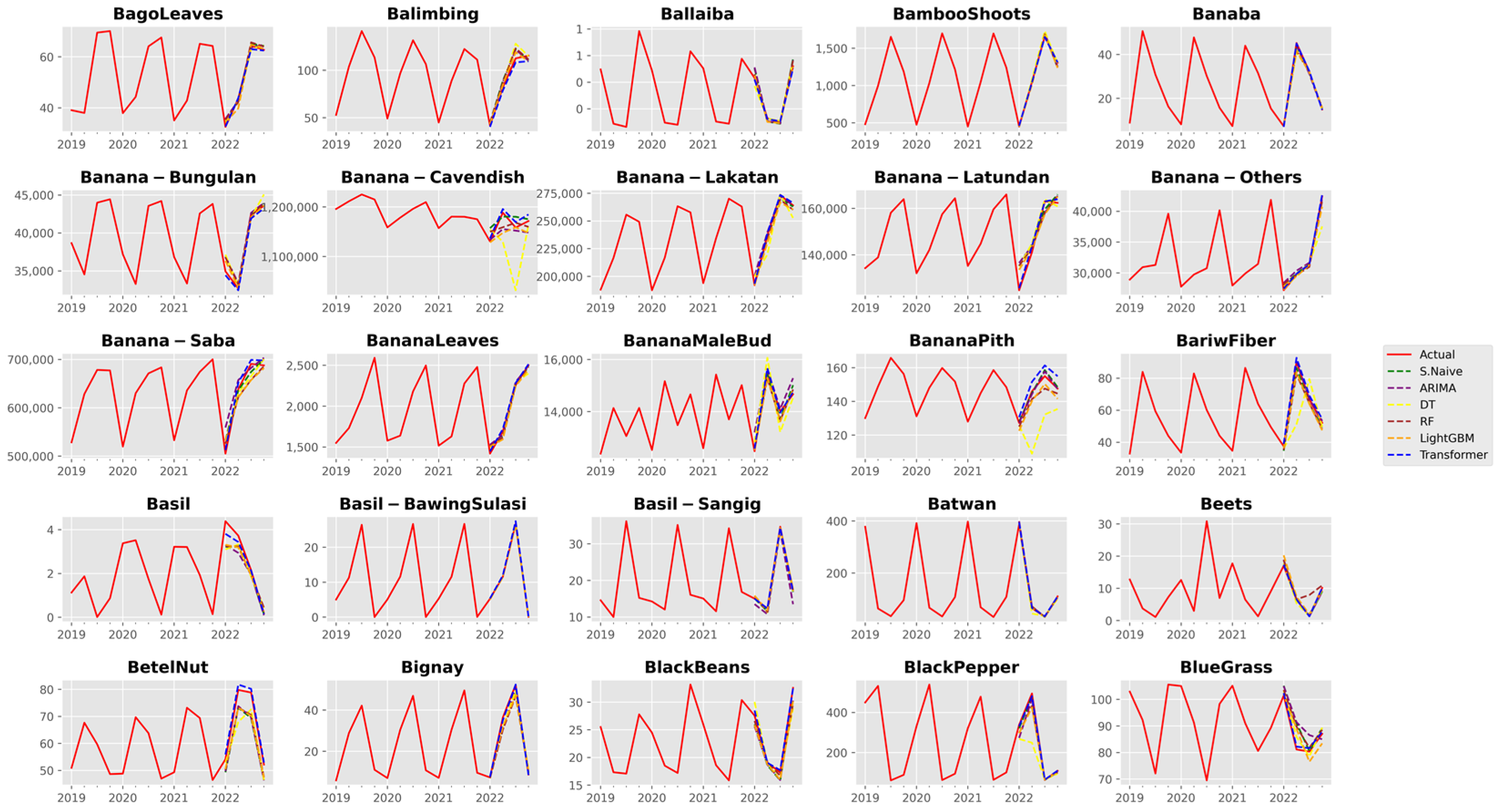
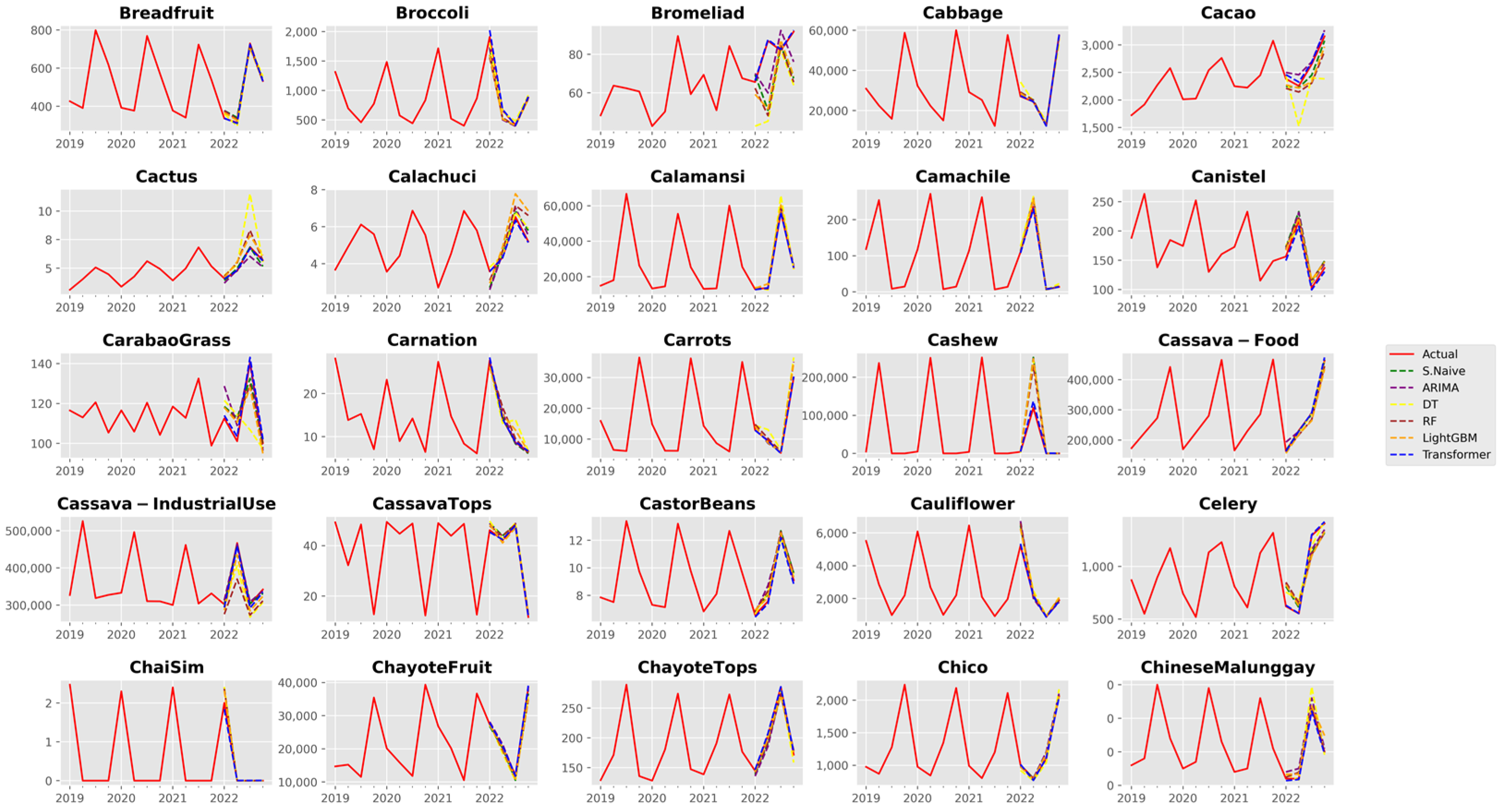
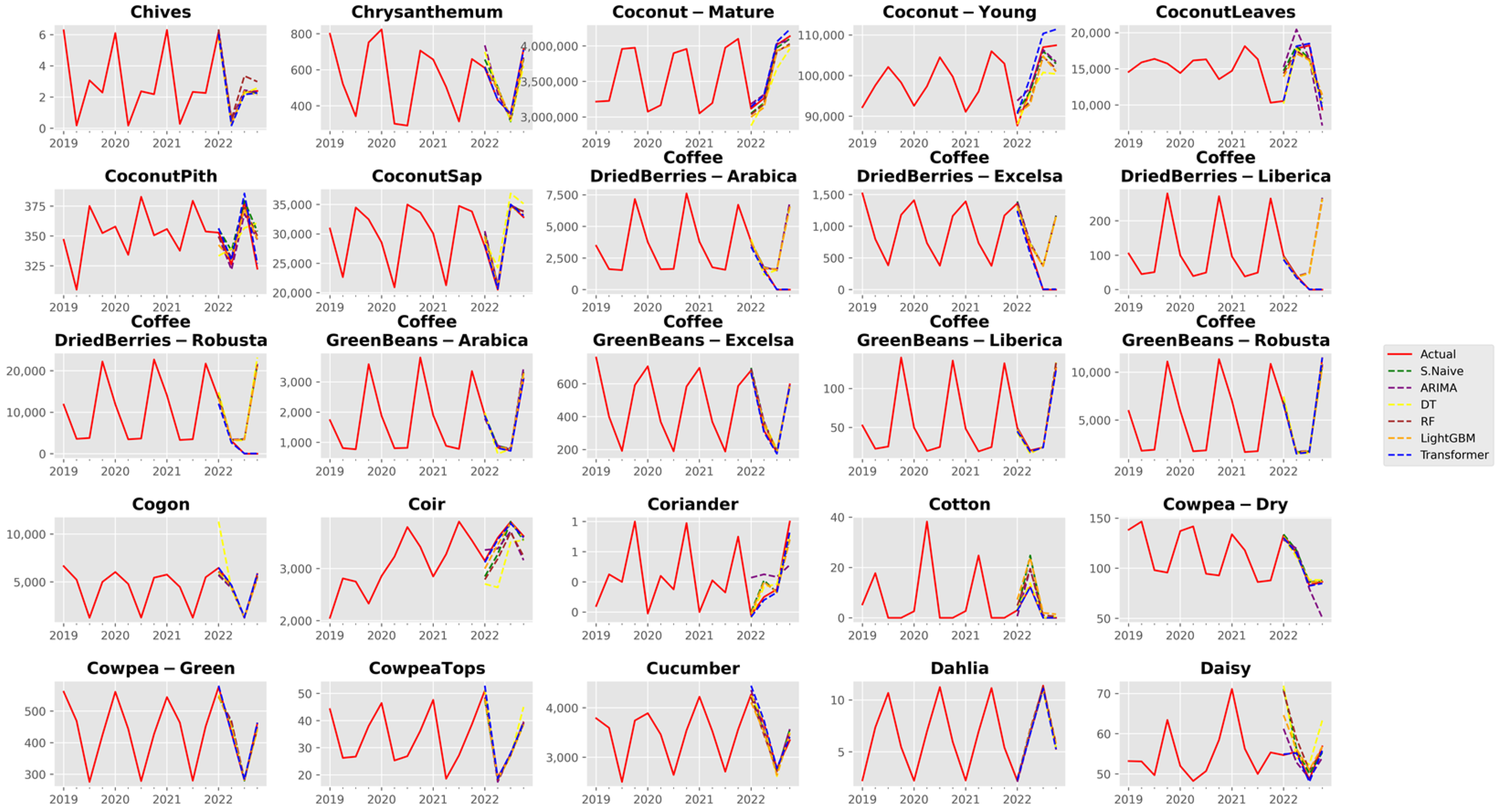
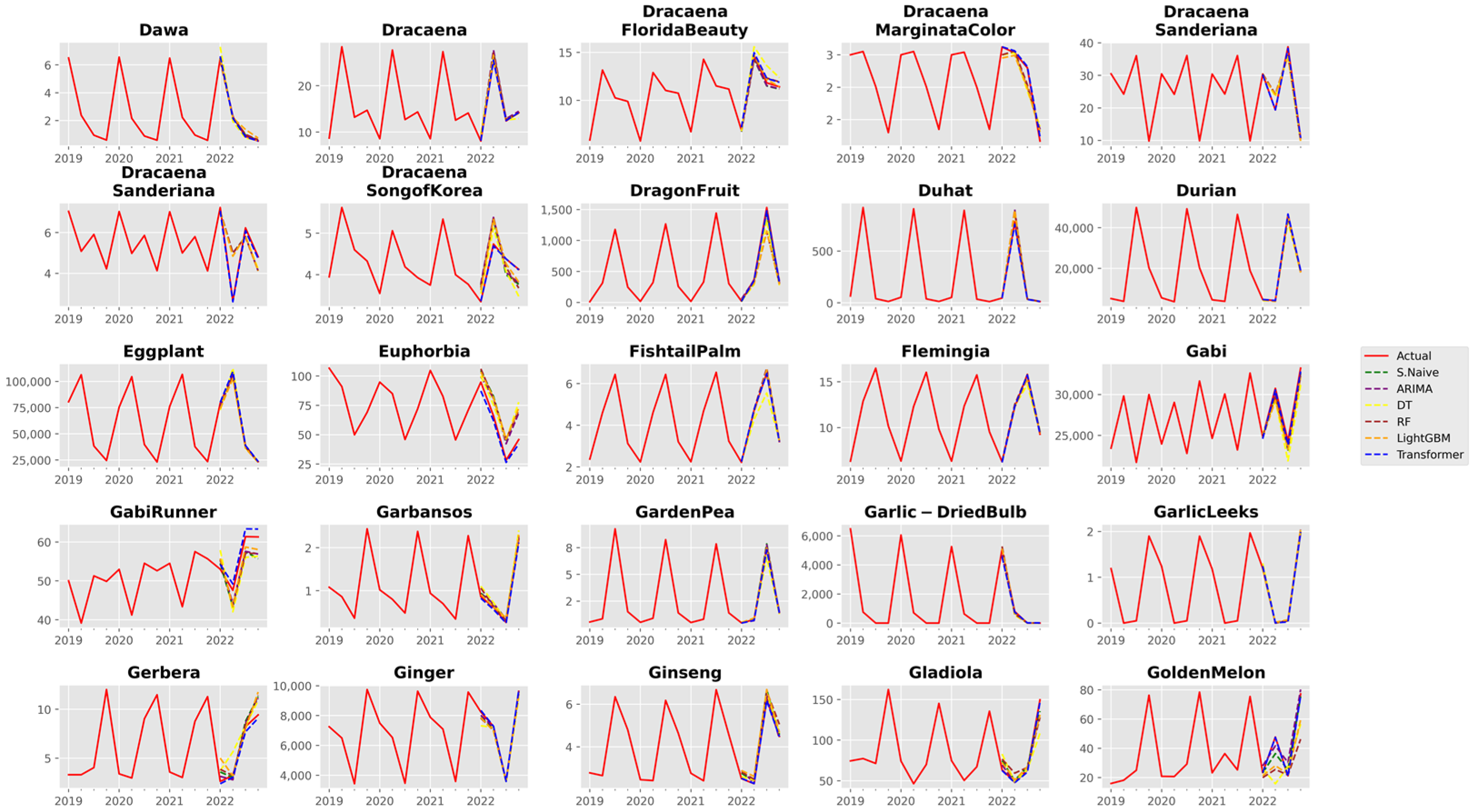
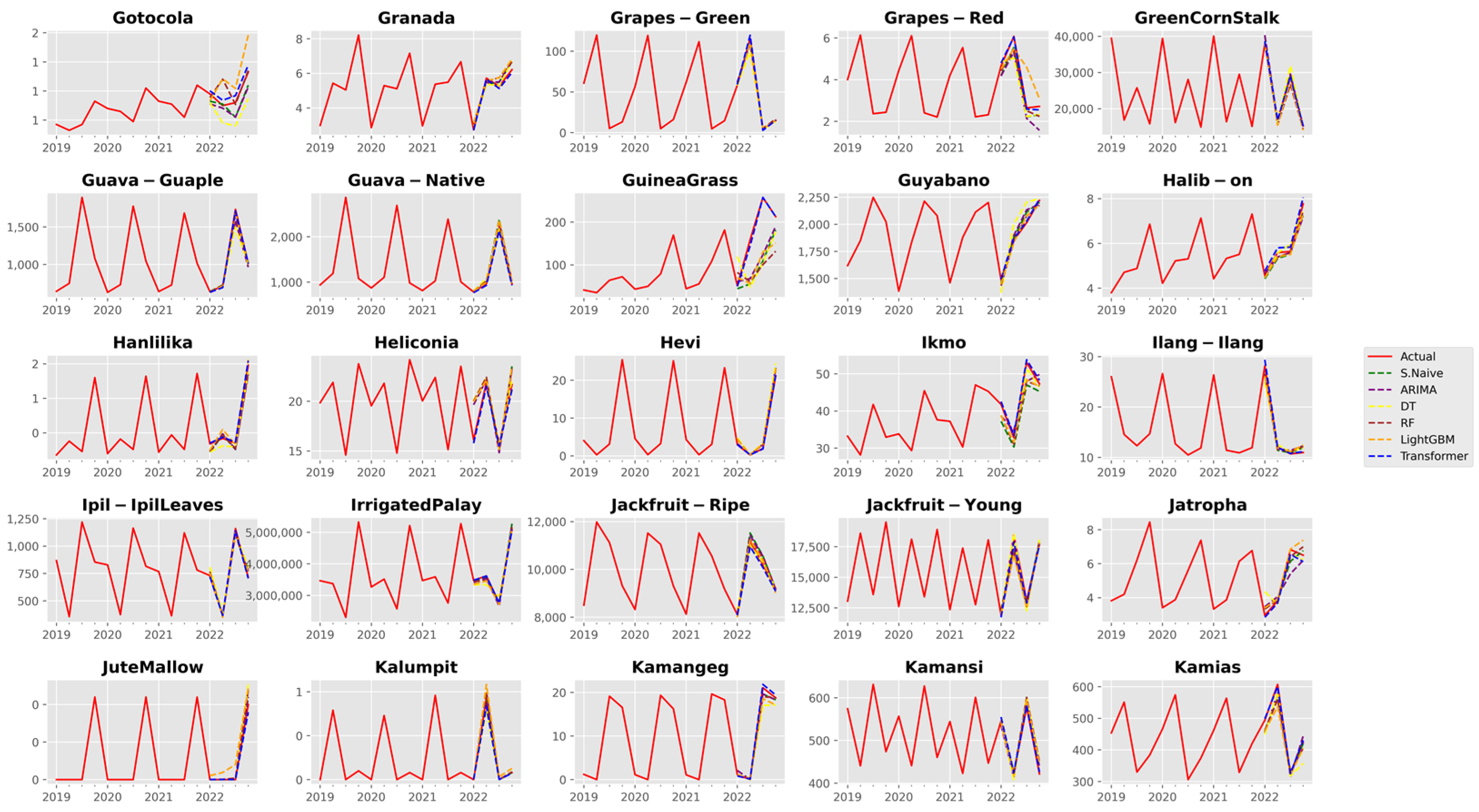
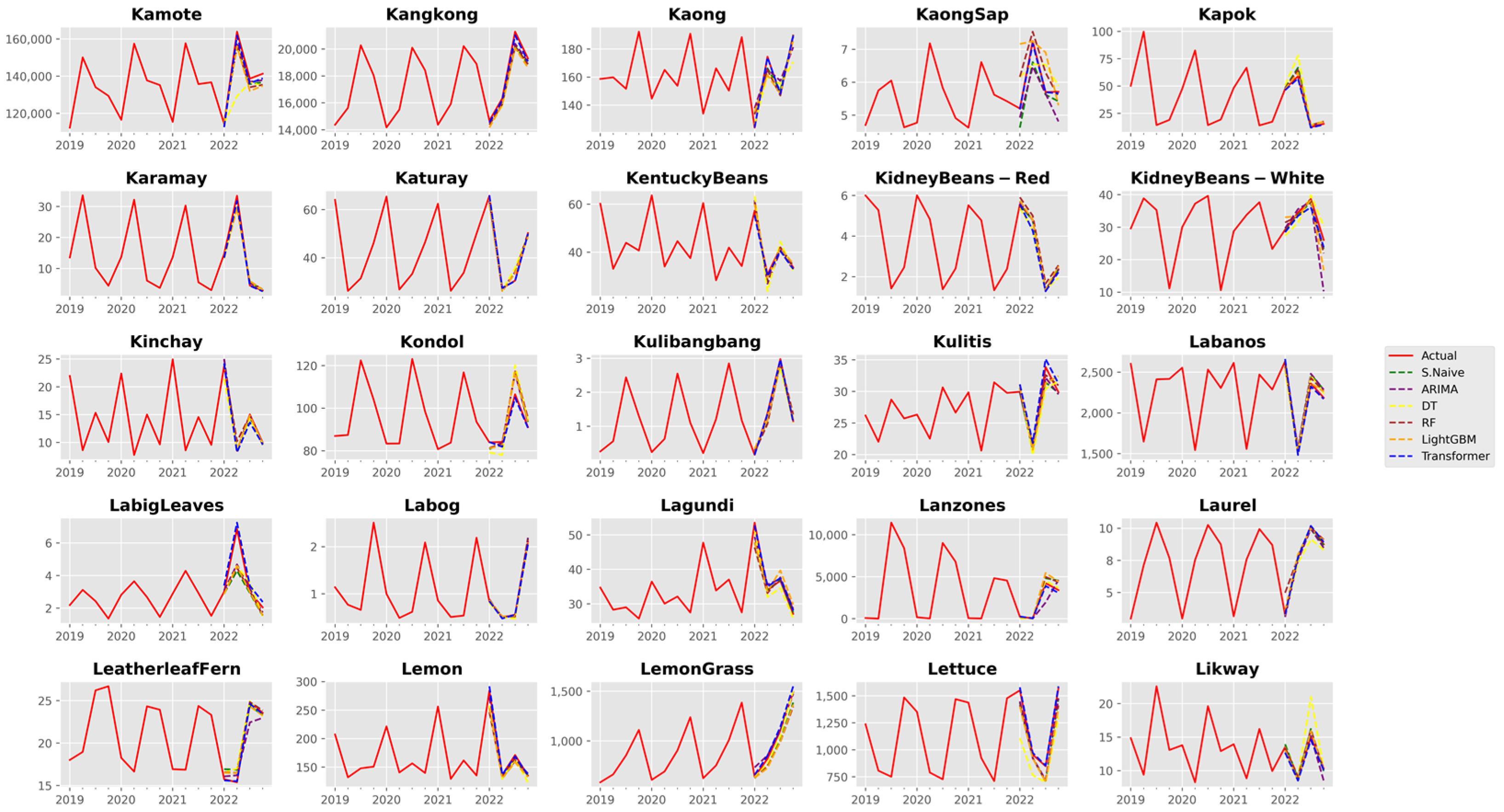
3. Results and Discussion
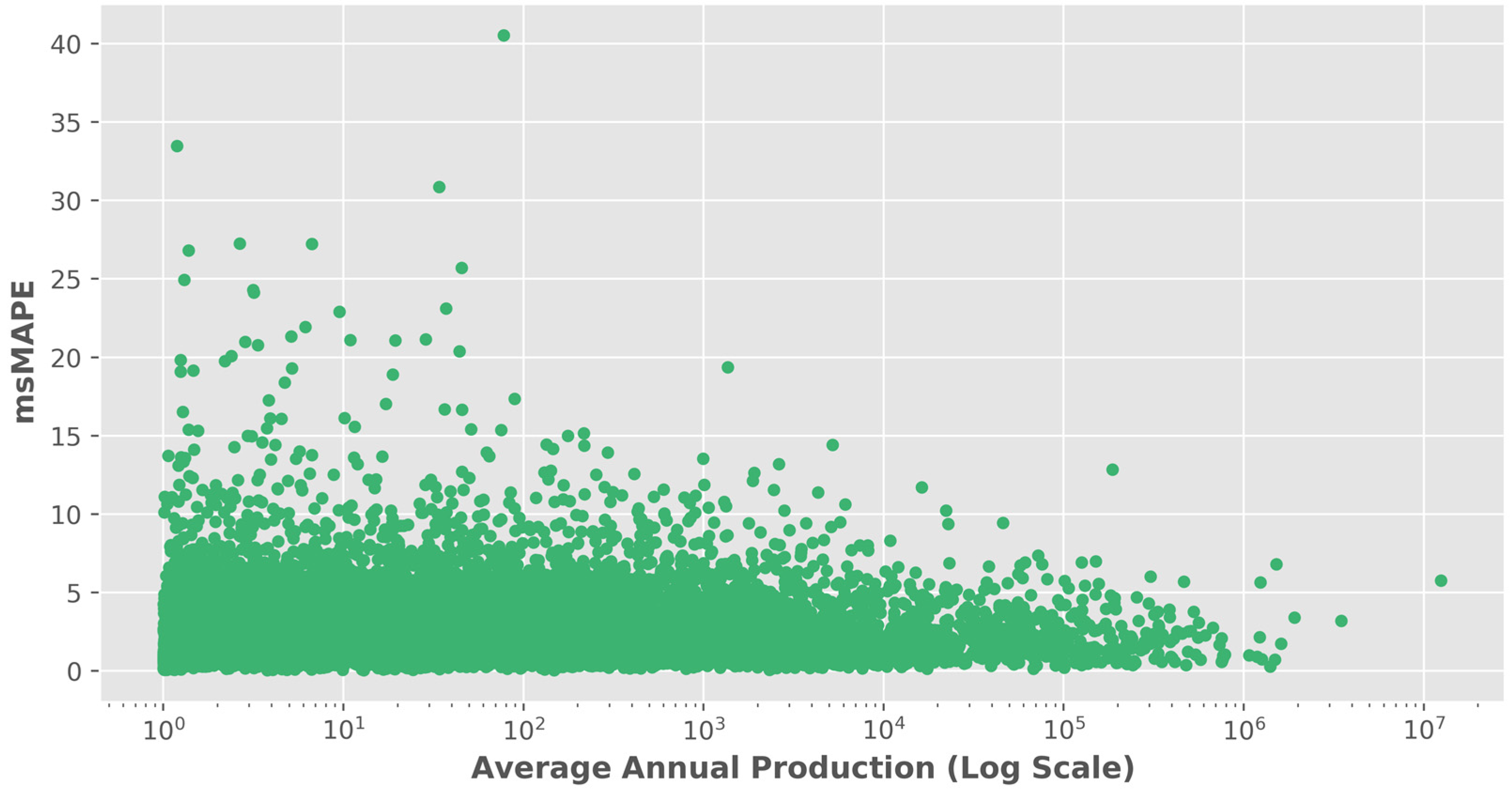
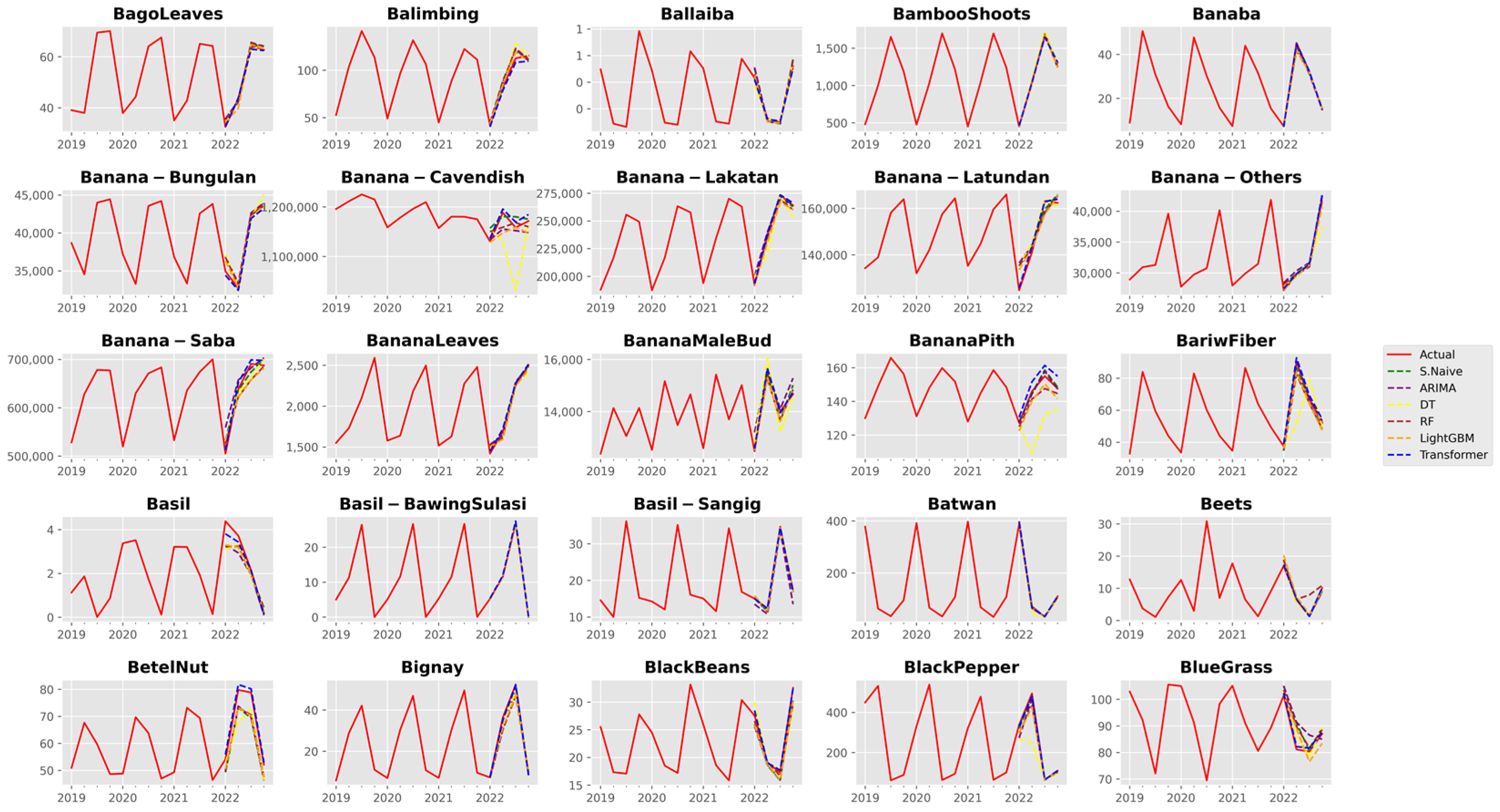
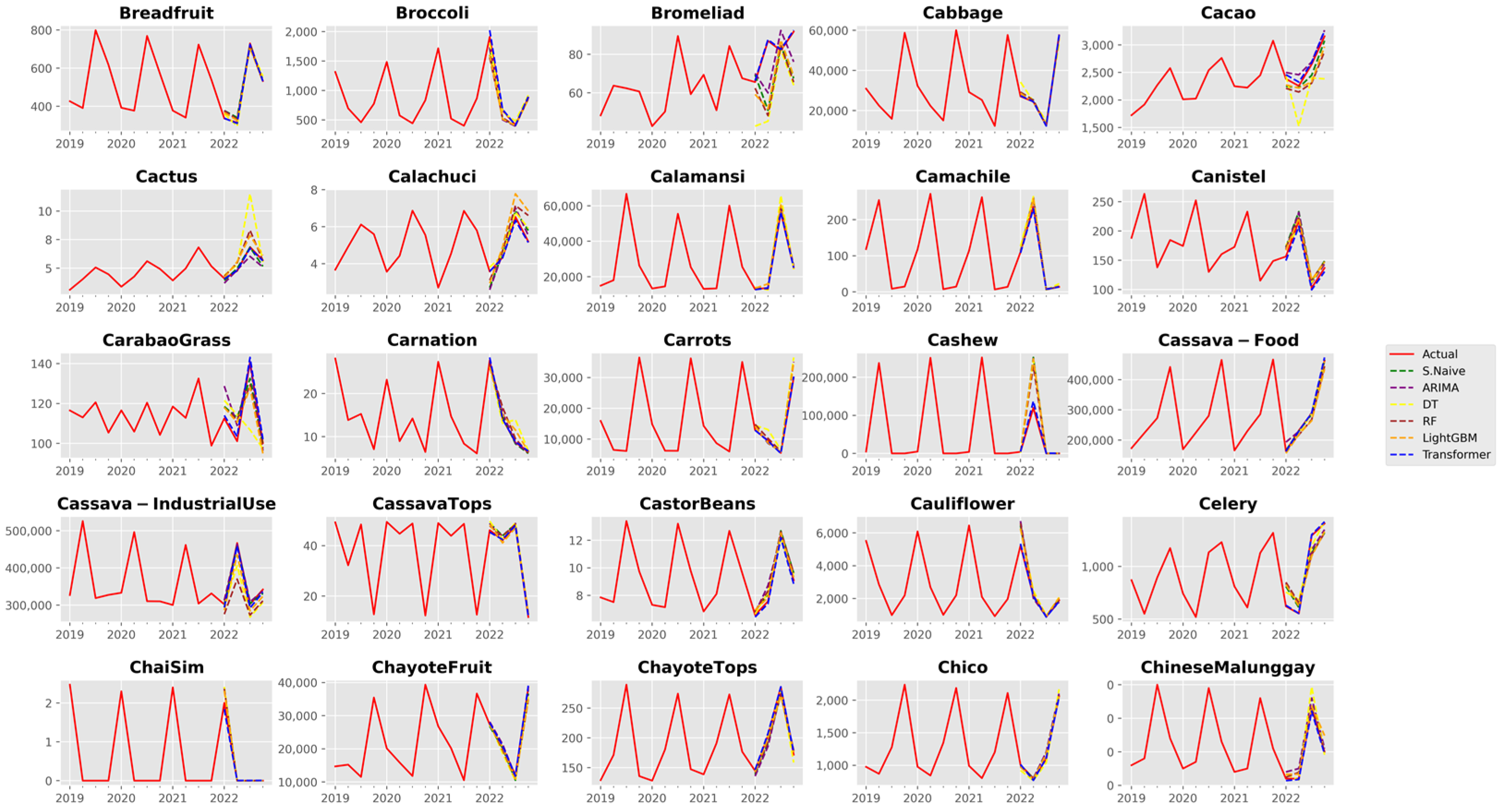
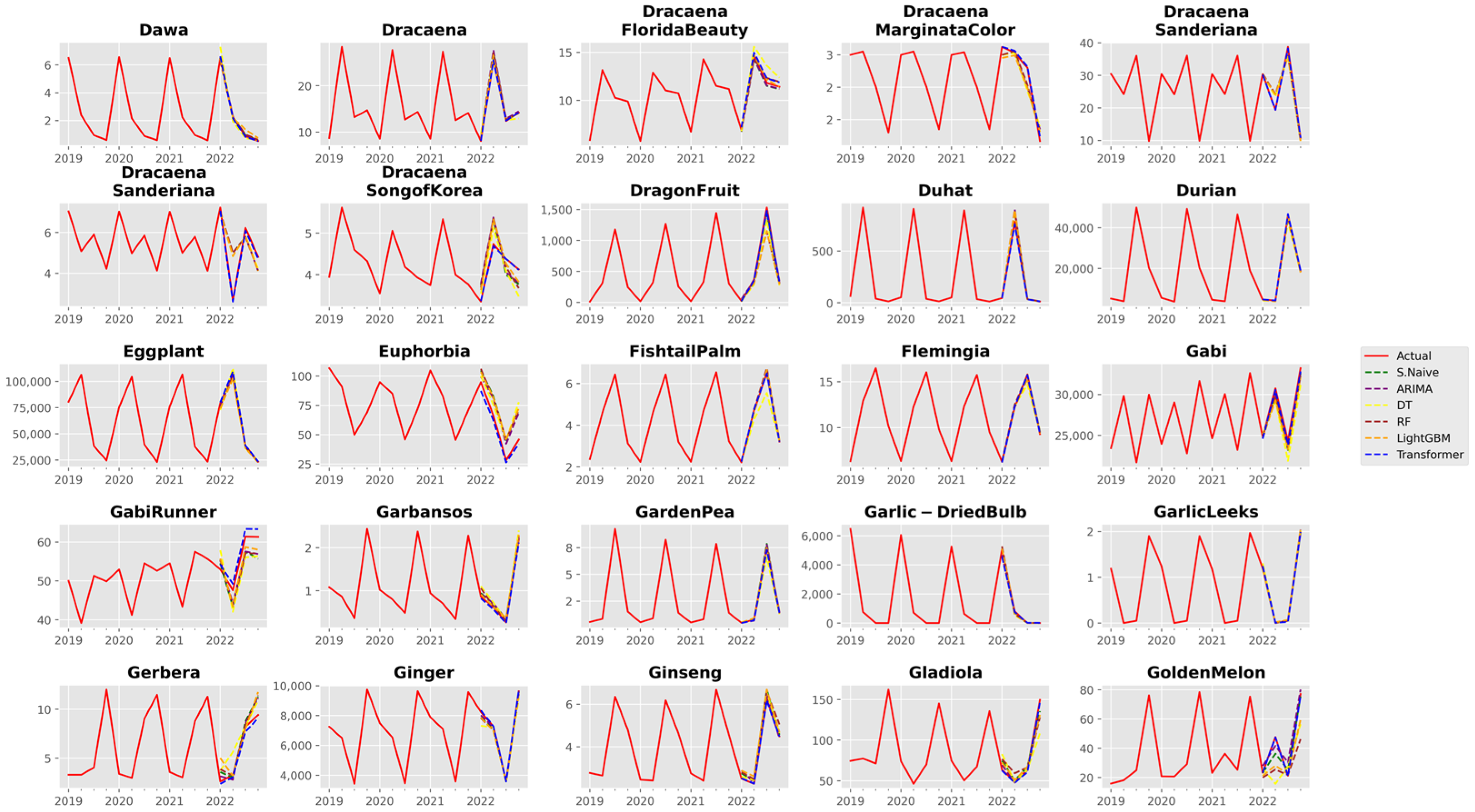
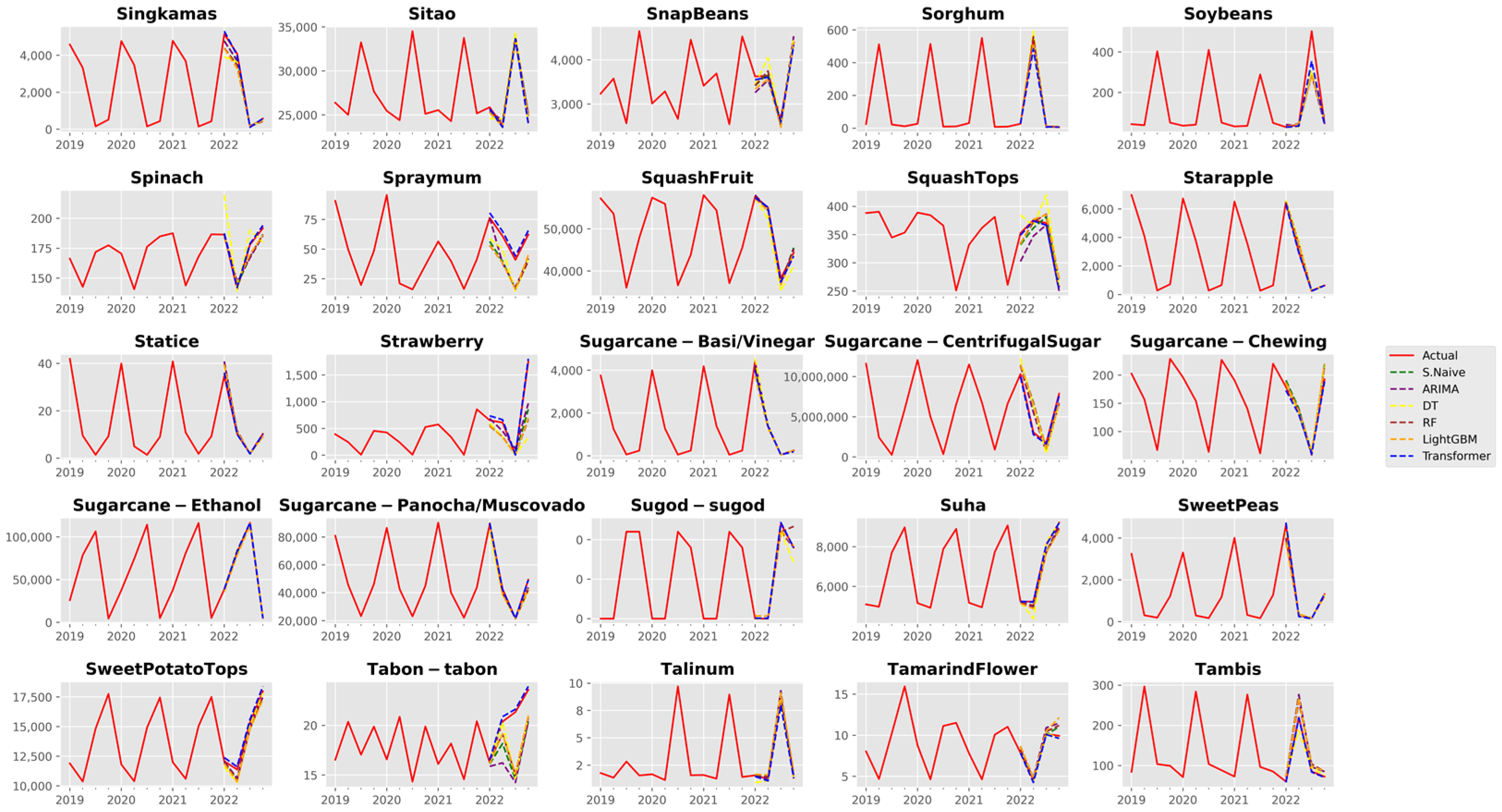
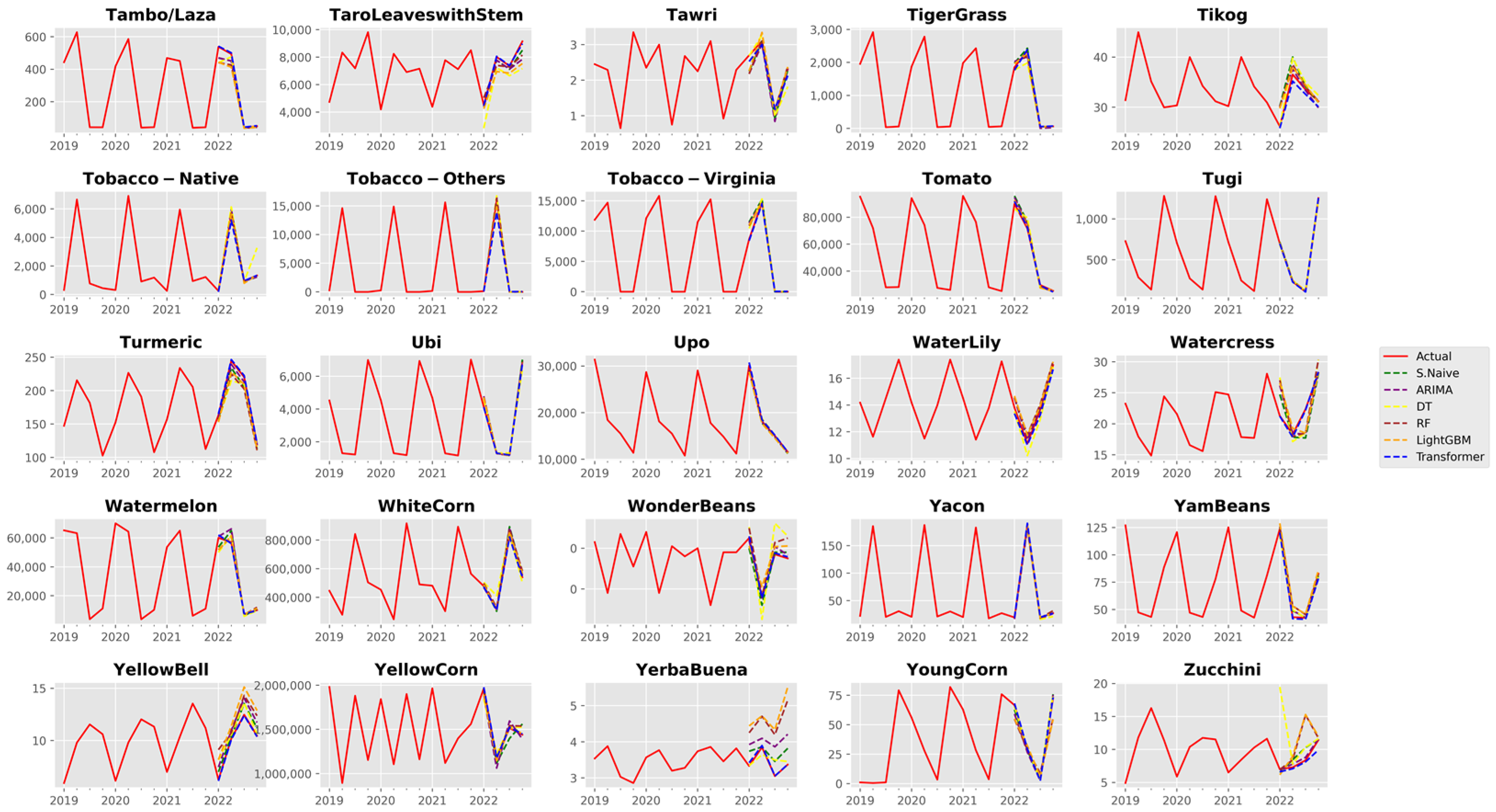
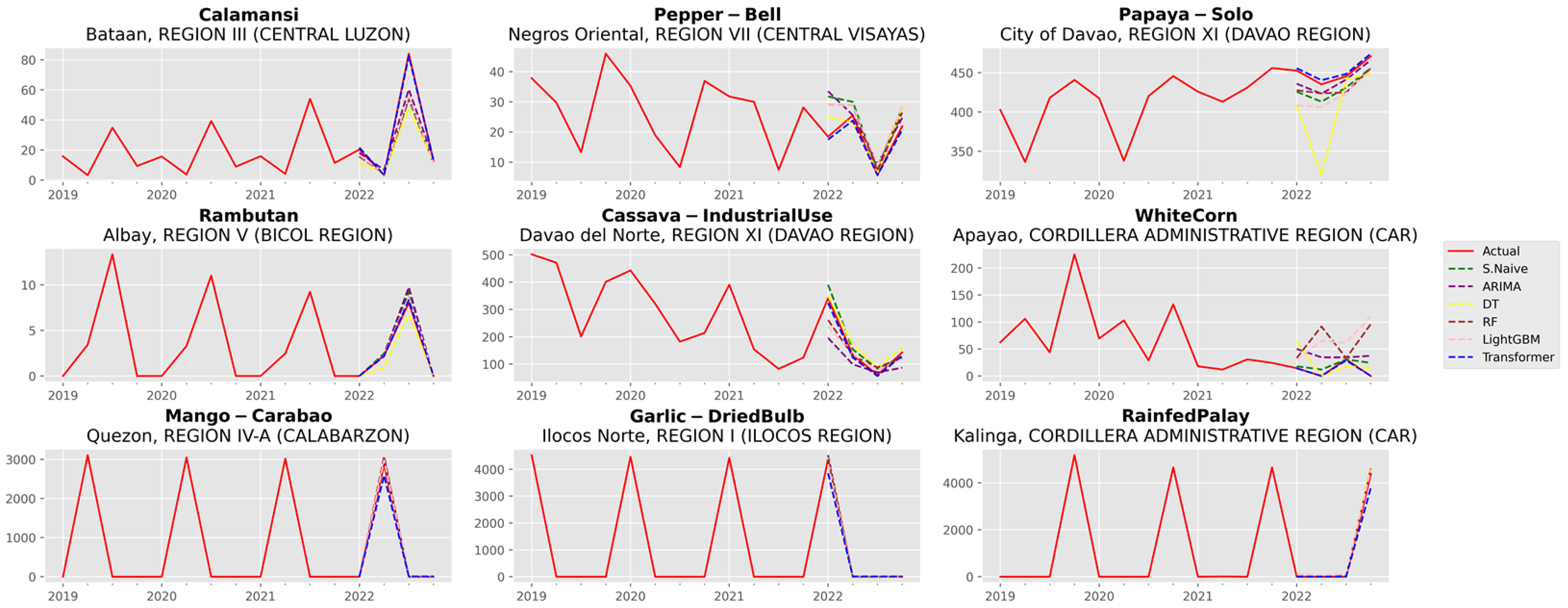
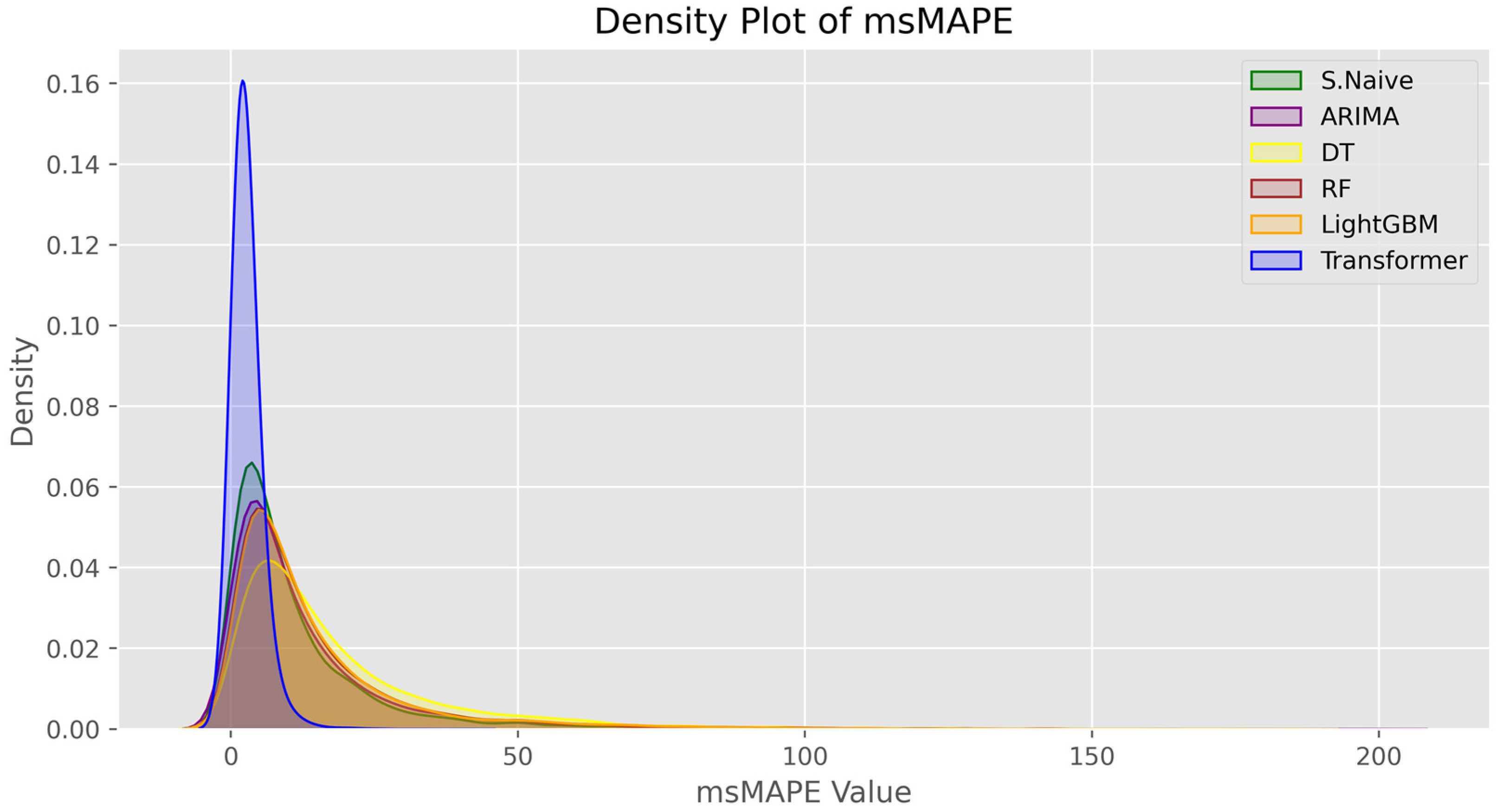
3.1. Analysis of Forecast Accuracy
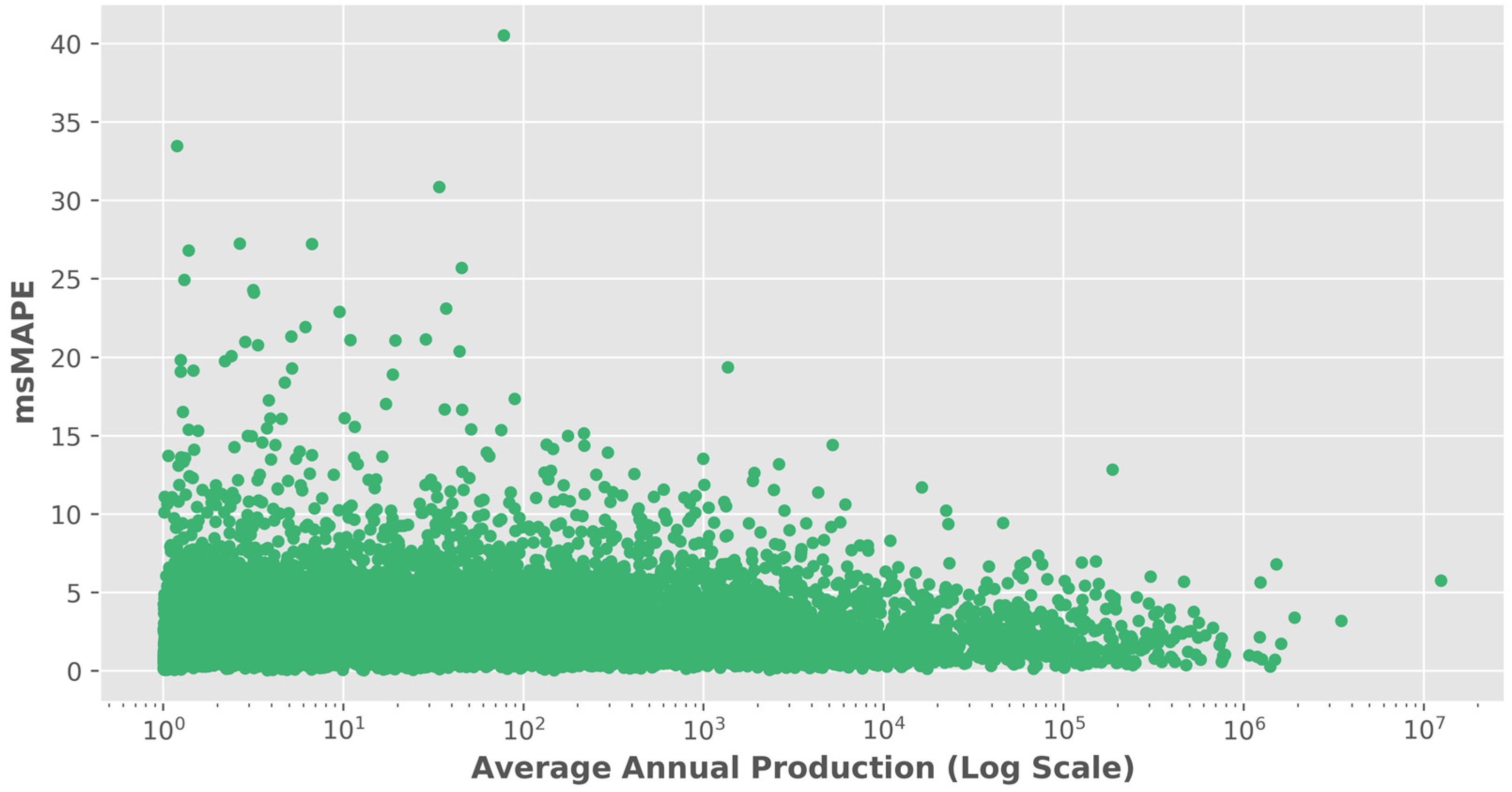
3.2. Performance Analysis of the Time Series Transformer
- Careful attention to data quality becomes paramount. Rigorous data collection efforts should be directed towards crops exhibiting lower production, ensuring the availability of accurate and comprehensive datasets.
- The exploration of data augmentation techniques is one avenue that can be explored to mitigate the scarcity of information for these crops. Some work has been done in exploring data augmentation techniques in the context of global forecasting models, such as GRATIS, moving block bootstrap, and dynamic time-warping barycentric averaging [68].
- Developing and integrating features specific to lower-production crops’ growth patterns and characteristics could yield valuable insights for improved predictions. Closer collaboration with agricultural experts and crop scientists is vital, as their domain knowledge can further inform model refinement strategies and provide insights into the unique challenges faced by crops with lower production.
- Integrating partial pooling and ensemble approaches also hold potential [61,69]. In this case, partial pooling can be achieved by partitioning time series into subgroups (e.g., by crop type, region, or dynamics) and fitting a global model on each subgroup. The criteria and overall methodology for clustering or partitioning groups constitutes its own body of research, which we leave for future work. Additionally, leveraging the predictive power of multiple models via ensembling might alleviate the limitations associated with predicting crops with lower production.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Crops | ||||
|---|---|---|---|---|
| Abaca | Carnation | Golden Melon | Marang | Samsamping |
| Abaca Leafsheath | Carrots | Gotocola | Mayana | San Francisco |
| Abiu | Cashew | Granada | Melon—Honeydew | Basil—Sangig |
| African Palm Leaves | Cassava—Industrial Use | Grapes—Green | Melon—Muskmelon | Santan |
| Agitway | Cassava—Food | Grapes—Red | Mini Pineapple | Santol |
| Alugbati | Cassava Tops | Ubi | Mint | Sayung-sayong |
| Alubihod | Castor Beans | Green Corn Stalk | Mongo | Serial (Unclear) |
| Alucon | Cauliflower | Papaya, Green | Mushroom | Sesame |
| Ampalaya Fruit | Celery | Guava—Guaple | Mustard | Sineguelas |
| Ampalaya Leaves | Chayote Fruit | Guava—Native | Napier Grass | Sarali (Unclear) |
| Anonas | Chayote Tops | Guinea Grass | Ngalug | Snap Beans |
| Anthurium | Chai Sim | Guyabano | Nipa Leaves | Dracaena—Song of Korea |
| Apat-apat | Garbansos | Halib-on | Nipa Sap/Wine | Sorghum |
| Apatot | Chico | Hanlilika | Oil Palm—Fresh Fruit Bunch | Soybeans |
| Ariwat | Siling Labuyo | Heliconia | Onion Leeks | Spinach |
| Arrowroot | Chinese Malunggay | Hevi | Onion—Bermuda | Spraymum |
| Achuete | Chives | Ikmo | Onion—Native | Sibuyas |
| Asparagus | Chrysanthemum | Ilang-Ilang | Orange | Squash Fruit |
| Aster | Coconut Leaves | Ipil-Ipil Leaves | Oregano | Squash Tops |
| Atis | Coconut—Mature | Jackfruit—Young | Pahid | Starapple |
| Avocado | Coconut Sap | Jackfruit—Ripe | Palm Ornamentals | Statice |
| Azucena | Coconut—Young | Jatropha | Palong Manok | Strawberry |
| Baby’s Breath | Coconut Pith | Jute Mallow | Pandan Fiber | Sitao |
| Bagbagkong Flower | Coffee—Dried Berries—Arabica | Kamias | Pandan-Mabango | Sugarcane—Basi/Vinegar |
| Bagbagkong Fruit | Coffee—Green Beans—Arabica | Kaong | Pangi | Sugarcane—Centrifugal Sugar |
| Bago Leaves | Coffee—Dried Berries—Excelsa | Kaong Sap | Pansit-Pansitan | Sugarcane—Chewing |
| Balimbing | Coffee—Green Beans—Excelsa | Kapok | Pao Galiang | Sugarcane—Ethanol |
| Ballaiba | Coffee—Dried Berries—Liberica | Karamay | Papait | Sugarcane—Panocha/Muscovado |
| Bamboo Shoots | Coffee—Green Beans—Liberica | Katuray | Papaya—Hawaiian | Sugod-sugod |
| Banaba | Coffee—Dried Berries—Robusta | Kentucky Beans | Papaya—Native | Kangkong |
| Banana Male Bud | Coffee—Green Beans—Robusta | Kidney Beans—Red | Papaya—Solo | Sweet Peas |
| Banana—Bungulan | Cogon | Kidney Beans—White | Parsley | Kamote |
| Banana—Cavendish | Coir | Kinchay | Passion Fruit | Tabon-tabon |
| Banana—Lakatan | Coriander | Kondol | Patola | Talinum |
| Banana—Latundan | Cotton | Kulibangbang | Peanut | Sampalok |
| Banana Leaves | Cowpea—Dry | Kulitis | Pears | Tamarind Flower |
| Banana—Others | Cowpea—Green | Labig Leaves | Pechay—Chinese | Tambis |
| Banana—Saba | Cowpea Tops | Okra | Pechay—Native | Gabi |
| Banana Pith | Cucumber | Lagundi | Pepper Chili Leaves | Tawri |
| Bariw Fiber | Dracaena—Marginata Color | Lanzones | Pepper—Bell | Tiger Grass |
| Basil | Dracaena—Sanderiana—White | Laurel | Pepper—Finger | Tikog |
| Batwan | Dracaena—Sanderiana—Yellow | Tambo/Laza | Persimmon | Tobacco—Native |
| Basil—Bawing Sulasi | Dahlia | Leatherleaf Fern | Pigeon Pea | Tobacco—Others |
| Beets | Daisy | Lemon | Pili Nut | Tobacco—Virginia |
| Betel Nut | Dawa | Lemon Grass | Pineapple | Tomato |
| Bignay | Orchids—Dendrobium | Lipote | Pineapple Fiber | Tugi |
| Black Beans | Dracaena | Lettuce | Suha | Turmeric |
| Black Pepper | Dragon Fruit | Likway | Potato | Singkamas |
| Blue Grass | Duhat | Patani | Puto-Puto | Orchids—Vanda |
| Upo | Durian | Lime | Labanos | Water Lily |
| Breadfruit | Pako | Longans | Radish Pods | Watercress |
| Broccoli | Eggplant | Sago Palm Pith | Rambutan | Watermelon |
| Bromeliad | Euphorbia | Lumbia Leaves | Rattan Fruits | Sigarilyas |
| Cabbage | Fishtail Palm | Lupo | Rattan Pith | Wonder Beans |
| Cacao | Flemingia | Mabolo | Red Beans | Yacon |
| Cactus | Dracaena—Florida Beauty | Maguey | Rensoni | Yam Beans |
| Calachuci | Taro Leaves with Stem | Makopa | Rice Hay | Yellow Bell |
| Calamansi | Gabi Runner | Malunggay Fruit | Romblon | Yerba Buena |
| Kalumpit | Garden Pea | Malunggay Leaves | Roses | Young Corn |
| Kamangeg | Garlic—Dried Bulb | Mandarin | Labog | Sapote |
| Kamansi | Garlic Leeks | Mango—Carabao | Rubber | Zucchini |
| Camachile | Gerbera | Mango—Others | Sabidokong | Irrigated Palay |
| Sweet Potato Tops | Ginger | Mango—Piko | Salago | Rainfed Palay |
| Canistel | Ginseng | Mangosteen | Saluyot | White Corn |
| Carabao Grass | Gladiola | Manzanita | Sampaguita | Yellow Corn |
| Region | Province |
|---|---|
| REGION I (ILOCOS REGION) | Ilocos Norte |
| Pangasinan | |
| Ilocos Sur | |
| La Union | |
| REGION II (CAGAYAN VALLEY) | Batanes |
| Cagayan | |
| Isabela | |
| Nueva Vizcaya | |
| Quirino | |
| REGION III (CENTRAL LUZON) | Aurora |
| Nueva Ecija | |
| Pampanga | |
| Zambales | |
| Bulacan | |
| Bataan | |
| Tarlac | |
| REGION IV-A (CALABARZON) | Rizal |
| Quezon | |
| Laguna | |
| Batangas | |
| Cavite | |
| REGION IX (ZAMBOANGA PENINSULA) | Zamboanga Sibugay |
| Zamboanga del Sur | |
| City of Zamboanga | |
| Zamboanga del Norte | |
| REGION V (BICOL REGION) | Masbate |
| Sorsogon | |
| Albay | |
| Catanduanes | |
| Camarines Sur | |
| Camarines Norte | |
| REGION VI (WESTERN VISAYAS) | Aklan |
| Antique | |
| Capiz | |
| Negros Occidental | |
| Iloilo | |
| Guimaras | |
| REGION VII (CENTRAL VISAYAS) | Cebu |
| Negros Oriental | |
| Bohol | |
| Siquijor | |
| REGION VIII (EASTERN VISAYAS) | Eastern Samar |
| Southern Leyte | |
| Northern Samar | |
| Samar | |
| Biliran | |
| Leyte | |
| REGION X (NORTHERN MINDANAO) | Lanao del Norte |
| Misamis Occidental | |
| Misamis Oriental | |
| Camiguin | |
| Bukidnon | |
| REGION XI (DAVAO REGION) | Davao del Norte |
| Davao Occidental | |
| Davao Oriental | |
| Davao de Oro | |
| Davao del Sur | |
| City of Davao | |
| REGION XII (SOCCSKSARGEN) | Cotabato |
| South Cotabato | |
| Sarangani | |
| Sultan Kudarat | |
| REGION XIII (CARAGA) | Dinagat Islands |
| Surigao del Sur | |
| Surigao del Norte | |
| Agusan del Sur | |
| Agusan del Norte | |
| BANGSAMORO AUTONOMOUS REGION IN MUSLIM MINDANAO (BARMM) | Tawi-tawi |
| Maguindanao | |
| Lanao del Sur | |
| Sulu | |
| Basilan | |
| CORDILLERA ADMINISTRATIVE REGION (CAR) | Benguet |
| Kalinga | |
| Abra | |
| Apayao | |
| Mountain Province | |
| Ifugao | |
| MIMAROPA REGION | Occidental Mindoro |
| Palawan | |
| Oriental Mindoro | |
| Romblon | |
| Marinduque |
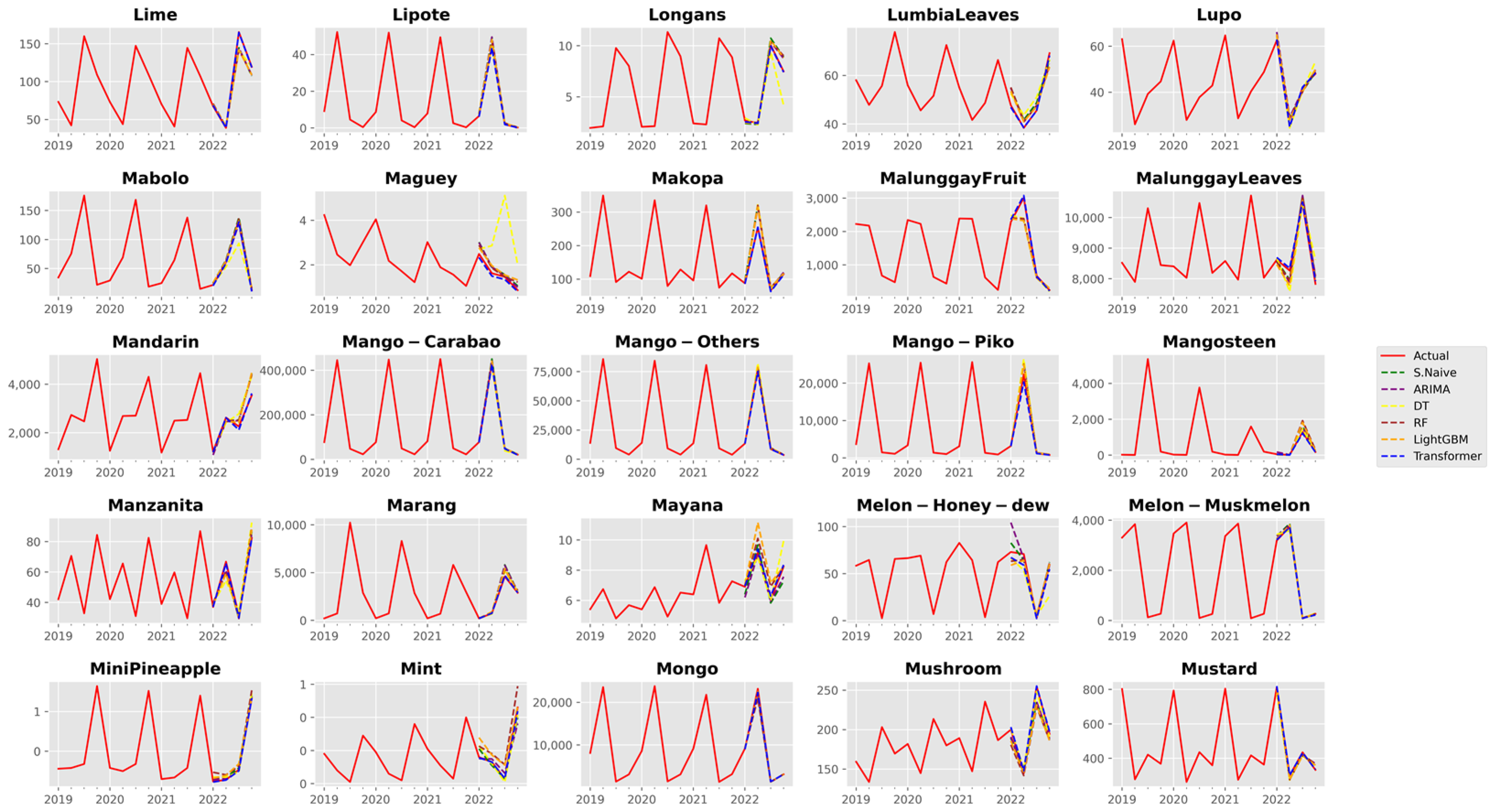
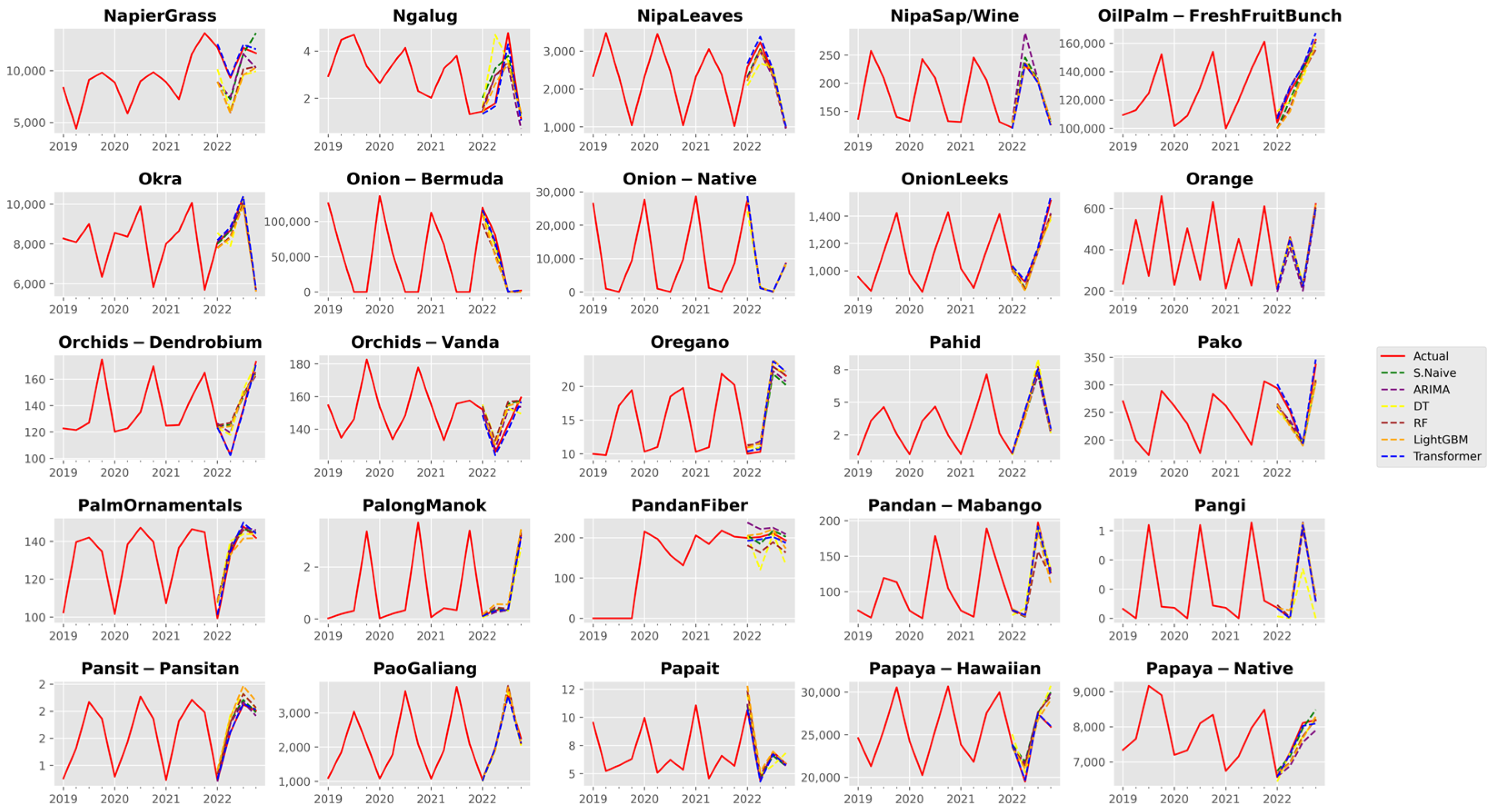
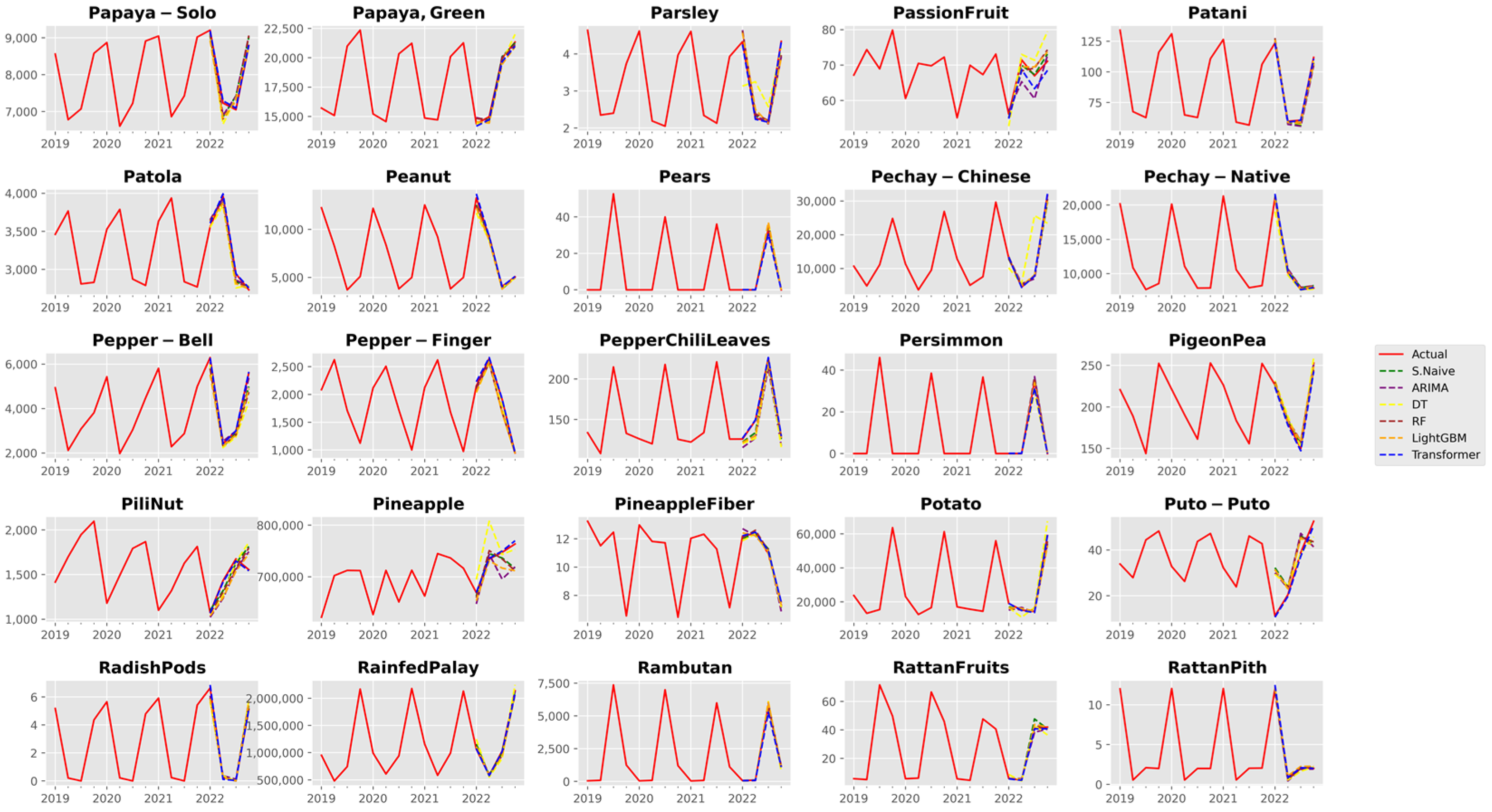
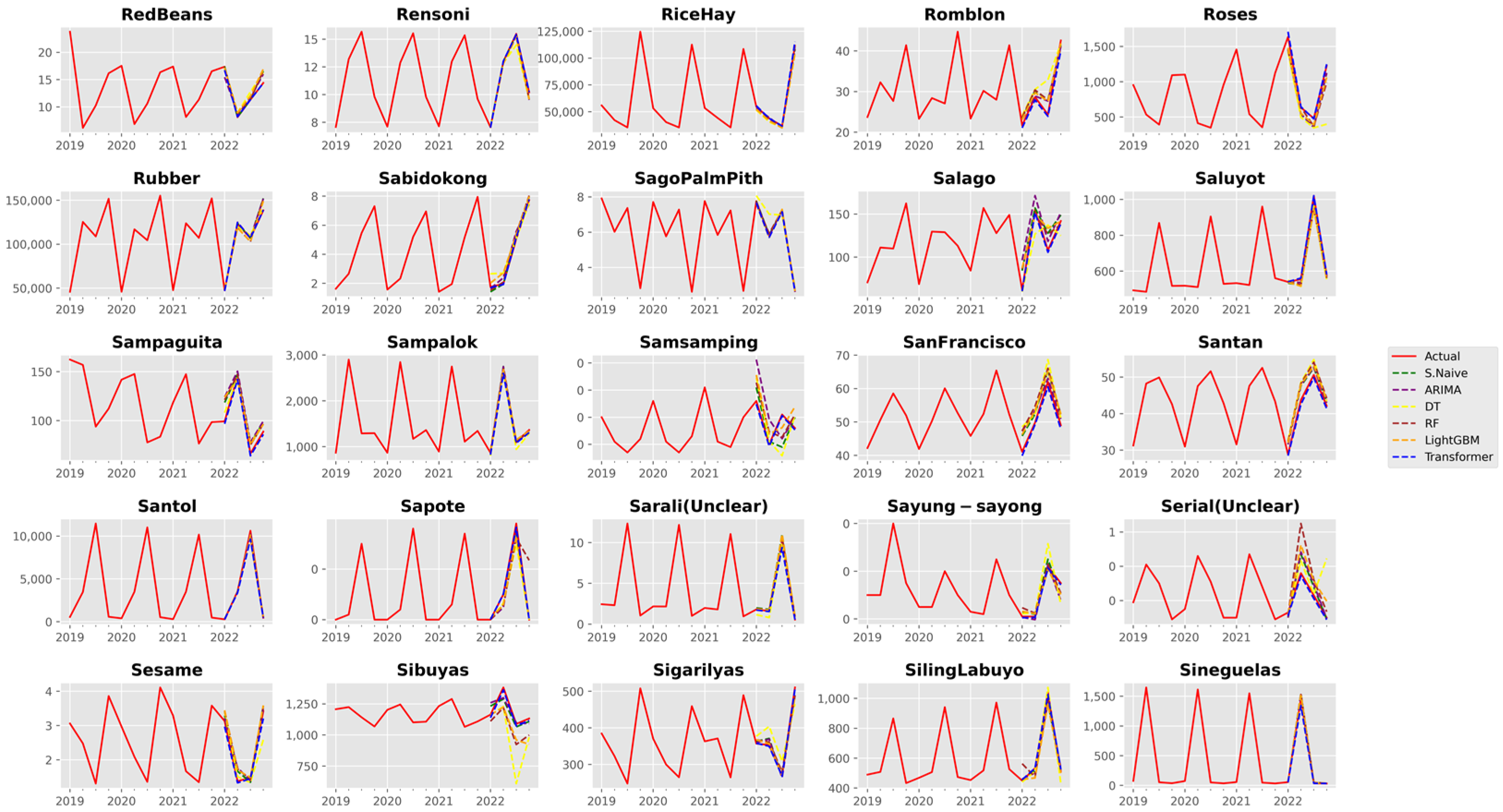
References
- Philippine Statistics Authority Gross National Income & Gross Domestic Product. Available online: http://web.archive.org/web/20230405042721/ (accessed on 12 September 2023).
- Philippine Statistics Authority Unemployment Rate in December 2022 Is Estimated at 4.3 Percent. Available online: https://psa.gov.ph/content/unemployment-rate-december-2022-estimated-43-percent (accessed on 14 July 2023).
- Alliance of Bioversity International and CIAT & World Food Programme. Philippine Climate Change and Food Security Analysis; Alliance of Bioversity International and CIAT & World Food Programme: Manila, Philippines, 2021. [Google Scholar]
- Liu, C.; Yang, H.; Gongadze, K.; Harris, P.; Huang, M.; Wu, L. Climate Change Impacts on Crop Yield of Winter Wheat (Triticum aestivum) and Maize (Zea mays) and Soil Organic Carbon Stocks in Northern China. Agriculture 2022, 12, 614. [Google Scholar] [CrossRef]
- Nazir, A.; Ullah, S.; Saqib, Z.A.; Abbas, A.; Ali, A.; Iqbal, M.S.; Hussain, K.; Shakir, M.; Shah, M.; Butt, M.U. Estimation and Forecasting of Rice Yield Using Phenology-Based Algorithm and Linear Regression Model on Sentinel-II Satellite Data. Agriculture 2021, 11, 1026. [Google Scholar] [CrossRef]
- Florence, A.; Revill, A.; Hoad, S.; Rees, R.; Williams, M. The Effect of Antecedence on Empirical Model Forecasts of Crop Yield from Observations of Canopy Properties. Agriculture 2021, 11, 258. [Google Scholar] [CrossRef]
- Quartey-Papafio, T.K.; Javed, S.A.; Liu, S. Forecasting Cocoa Production of Six Major Producers through ARIMA and Grey Models. Grey Syst. Theory Appl. 2021, 11, 434–462. [Google Scholar] [CrossRef]
- Chen, Y.; Nu, L.; Wu, L. Forecasting the Agriculture Output Values in China Based on Grey Seasonal Model. Math. Probl. Eng. 2020, 2020, 3151048. [Google Scholar] [CrossRef]
- Antonopoulos, I.; Robu, V.; Couraud, B.; Kirli, D.; Norbu, S.; Kiprakis, A.; Flynn, D.; Elizondo-Gonzalez, S.; Wattam, S. Artificial Intelligence and Machine Learning Approaches to Energy Demand-Side Response: A Systematic Review. Renew. Sustain. Energy Rev. 2020, 130, 109899. [Google Scholar] [CrossRef]
- Le, T.; Vo, M.T.; Vo, B.; Hwang, E.; Rho, S.; Baik, S.W. Improving Electric Energy Consumption Prediction Using CNN and Bi-LSTM. Appl. Sci. 2019, 9, 4237. [Google Scholar] [CrossRef]
- Ibañez, S.C.; Dajac, C.V.G.; Liponhay, M.P.; Legara, E.F.T.; Esteban, J.M.H.; Monterola, C.P. Forecasting Reservoir Water Levels Using Deep Neural Networks: A Case Study of Angat Dam in the Philippines. Water 2021, 14, 34. [Google Scholar] [CrossRef]
- Dailisan, D.; Liponhay, M.; Alis, C.; Monterola, C. Amenity Counts Significantly Improve Water Consumption Predictions. PLoS ONE 2022, 17, e0265771. [Google Scholar] [CrossRef]
- Javier, P.J.E.A.; Liponhay, M.P.; Dajac, C.V.G.; Monterola, C.P. Causal Network Inference in a Dam System and Its Implications on Feature Selection for Machine Learning Forecasting. Phys. A Stat. Mech. Its Appl. 2022, 604, 127893. [Google Scholar] [CrossRef]
- Shen, M.-L.; Lee, C.-F.; Liu, H.-H.; Chang, P.-Y.; Yang, C.-H. Effective Multinational Trade Forecasting Using LSTM Recurrent Neural Network. Expert Syst. Appl. 2021, 182, 115199. [Google Scholar] [CrossRef]
- Yang, C.-H.; Lee, C.-F.; Chang, P.-Y. Export- and Import-Based Economic Models for Predicting Global Trade Using Deep Learning. Expert Syst. Appl. 2023, 218, 119590. [Google Scholar] [CrossRef]
- Nosratabadi, S.; Ardabili, S.; Lakner, Z.; Mako, C.; Mosavi, A. Prediction of Food Production Using Machine Learning Algorithms of Multilayer Perceptron and ANFIS. Agriculture 2021, 11, 408. [Google Scholar] [CrossRef]
- Kamath, P.; Patil, P.; Shrilatha, S.; Sowmya, S. Crop Yield Forecasting Using Data Mining. Glob. Transit. Proc. 2021, 2, 402–407. [Google Scholar] [CrossRef]
- Das, P.; Jha, G.K.; Lama, A.; Parsad, R. Crop Yield Prediction Using Hybrid Machine Learning Approach: A Case Study of Lentil (Lens culinaris Medik.). Agriculture 2023, 13, 596. [Google Scholar] [CrossRef]
- Sadenova, M.; Beisekenov, N.; Varbanov, P.S.; Pan, T. Application of Machine Learning and Neural Networks to Predict the Yield of Cereals, Legumes, Oilseeds and Forage Crops in Kazakhstan. Agriculture 2023, 13, 1195. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, S.; Tao, F.; Aboelenein, R.; Amer, A. Improving Winter Wheat Yield Forecasting Based on Multi-Source Data and Machine Learning. Agriculture 2022, 12, 571. [Google Scholar] [CrossRef]
- Onwuchekwa-Henry, C.B.; Ogtrop, F.V.; Roche, R.; Tan, D.K.Y. Model for Predicting Rice Yield from Reflectance Index and Weather Variables in Lowland Rice Fields. Agriculture 2022, 12, 130. [Google Scholar] [CrossRef]
- Godahewa, R.; Bergmeir, C.; Webb, G.I.; Hyndman, R.J.; Montero-Manso, P. Monash Time Series Forecasting Archive. arXiv 2021, arXiv:2105.06643. [Google Scholar]
- Tende, I.G.; Aburada, K.; Yamaba, H.; Katayama, T.; Okazaki, N. Development and Evaluation of a Deep Learning Based System to Predict District-Level Maize Yields in Tanzania. Agriculture 2023, 13, 627. [Google Scholar] [CrossRef]
- Wang, J.; Si, H.; Gao, Z.; Shi, L. Winter Wheat Yield Prediction Using an LSTM Model from MODIS LAI Products. Agriculture 2022, 12, 1707. [Google Scholar] [CrossRef]
- Wolanin, A.; Mateo-García, G.; Camps-Valls, G.; Gómez-Chova, L.; Meroni, M.; Duveiller, G.; Liangzhi, Y.; Guanter, L. Estimating and Understanding Crop Yields with Explainable Deep Learning in the Indian Wheat Belt. Environ. Res. Lett. 2020, 15, 024019. [Google Scholar] [CrossRef]
- Bharadiya, J.P.; Tzenios, N.T.; Reddy, M. Forecasting of Crop Yield Using Remote Sensing Data, Agrarian Factors and Machine Learning Approaches. JERR 2023, 24, 29–44. [Google Scholar] [CrossRef]
- Gavahi, K.; Abbaszadeh, P.; Moradkhani, H. DeepYield: A Combined Convolutional Neural Network with Long Short-Term Memory for Crop Yield Forecasting. Expert Syst. Appl. 2021, 184, 115511. [Google Scholar] [CrossRef]
- Kujawa, S.; Niedbała, G. Artificial Neural Networks in Agriculture. Agriculture 2021, 11, 497. [Google Scholar] [CrossRef]
- Paudel, D.; Boogaard, H.; De Wit, A.; Janssen, S.; Osinga, S.; Pylianidis, C.; Athanasiadis, I.N. Machine Learning for Large-Scale Crop Yield Forecasting. Agric. Syst. 2021, 187, 103016. [Google Scholar] [CrossRef]
- Paudel, D.; Boogaard, H.; De Wit, A.; Van Der Velde, M.; Claverie, M.; Nisini, L.; Janssen, S.; Osinga, S.; Athanasiadis, I.N. Machine Learning for Regional Crop Yield Forecasting in Europe. Field Crops Res. 2022, 276, 108377. [Google Scholar] [CrossRef]
- World Bank Agricultural Land (% of Land Area)-Philippines. Available online: https://data.worldbank.org/indicator/AG.LND.AGRI.ZS?locations=PH (accessed on 15 July 2023).
- Philippine Atmospheric, Geophysical and Astronomical Services Administration Climate of the Philippines. Available online: https://www.pagasa.dost.gov.ph/information/climate-philippines (accessed on 15 July 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 38–45. [Google Scholar]
- Alexandrov, A.; Benidis, K.; Bohlke-Schneider, M.; Flunkert, V.; Gasthaus, J.; Januschowski, T.; Maddix, D.C.; Rangapuram, S.; Salinas, D.; Schulz, J.; et al. Gluonts: Probabilistic and Neural Time Series Modeling in Python. J. Mach. Learn. Res. 2020, 21, 4629–4634. [Google Scholar]
- Nixtla. MLForecast: Scalable Machine Learning for Time Series Forecasting 2022. Available online: https://github.com/Nixtla/mlforecast (accessed on 14 September 2023).
- Garza, F.; Mergenthaler, M.; Challú, C.; Olivares, K.G. StatsForecast: Lightning Fast Forecasting with Statistical and Econometric Models; PyCon: Salt Lake City, UT, USA, 2022. [Google Scholar]
- Hyndman, R.; Athanasopoulos, G. Forecasting: Principles and Practice 2021; OTexts: Melbourne, Australia, 2021. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 Time Series and 61 Forecasting Methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. M5 Accuracy Competition: Results, Findings, and Conclusions. Int. J. Forecast. 2022, 38, 1346–1364. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Khandakar, Y. Automatic Time Series Forecasting: The Forecast Package for R. J. Stat. Soft. 2008, 27, 1–22. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3149–3157. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 14 September 2023).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv 2020, arXiv:2006.11477. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv 2022, arXiv:2212.04356. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.-X.; Yan, X. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting. arXiv 2019, arXiv:1907.00235. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. AAAI 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting. arXiv 2021, arXiv:2106.13008. [Google Scholar]
- Lim, B.; Arık, S.Ö.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for Interpretable Multi-Horizon Time Series Forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Smyl, S. A Hybrid Method of Exponential Smoothing and Recurrent Neural Networks for Time Series Forecasting. Int. J. Forecast. 2020, 36, 75–85. [Google Scholar] [CrossRef]
- Montero-Manso, P.; Athanasopoulos, G.; Hyndman, R.J.; Talagala, T.S. FFORMA: Feature-Based Forecast Model Averaging. Int. J. Forecast. 2020, 36, 86–92. [Google Scholar] [CrossRef]
- Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural Basis Expansion Analysis for Interpretable Time Series Forecasting. arxiv 2020, arXiv:1905.10437. [Google Scholar]
- In, Y.J.; Jung, J.Y. Simple Averaging of Direct and Recursive Forecasts via Partial Pooling Using Machine Learning. Int. J. Forecast. 2022, 38, 1386–1399. [Google Scholar] [CrossRef]
- Jeon, Y.; Seong, S. Robust Recurrent Network Model for Intermittent Time-Series Forecasting. Int. J. Forecast. 2022, 38, 1415–1425. [Google Scholar] [CrossRef]
- Montero-Manso, P.; Hyndman, R.J. Principles and Algorithms for Forecasting Groups of Time Series: Locality and Globality. Int. J. Forecast. 2021, 37, 1632–1653. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Global Models for Time Series Forecasting: A Simulation Study. Pattern Recognit. 2021, 124, 108441. [Google Scholar] [CrossRef]
- Hewamalage, H.; Ackermann, K.; Bergmeir, C. Forecast Evaluation for Data Scientists: Common Pitfalls and Best Practices. Data Min. Knowl. Discov. 2023, 37, 788–832. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.-F.; Rao, N.; Dhillon, I.S. Temporal Regularized Matrix Factorization for High-Dimensional Time Series Prediction. In Proceedings of the NIPS’16: 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- National Economic and Development Authority Statement on the 2022 Economic Performance of the Caraga Region. Available online: https://nro13.neda.gov.ph/statement-on-the-2022-economic-performance-of-the-caraga-region/ (accessed on 28 July 2023).
- World Food Programme. Typhoon Odette–Visayas & MIMAROPA: WFP Rapid Needs Assessment Findings and Programme Recommendations (Abridged); World Food Programme: Manila, Philippines, 2022. [Google Scholar]
- Bandara, K.; Hewamalage, H.; Liu, Y.-H.; Kang, Y.; Bergmeir, C. Improving the Accuracy of Global Forecasting Models Using Time Series Data Augmentation. Pattern Recognit. 2021, 120, 108148. [Google Scholar] [CrossRef]
- Bandara, K.; Hewamalage, H.; Godahewa, R.; Gamakumara, P. A Fast and Scalable Ensemble of Global Models with Long Memory and Data Partitioning for the M5 Forecasting Competition. Int. J. Forecast. 2022, 38, 1400–1404. [Google Scholar] [CrossRef]

| Feature | Type | Training Period | Test Period |
|---|---|---|---|
| Volume | target | Q1 2010 to Q4 2021 | Q1 2022 to Q4 2022 |
| Crop ID | static covariate | ||
| Province ID | static covariate | ||
| Region ID | static covariate | ||
| Quarter | time feature | ||
| Age | time feature |
| Hyperparameter | Value |
|---|---|
| Forecast Horizon | 4 |
| Lookback Window | 12 |
| Embedding Dimension | [4, 4, 4] |
| Transformer Layer Size | 32 |
| No. Transformer Layers | 4 |
| Attention Heads | 2 |
| Transformer Activation | GELU |
| Dropout | 0.1 |
| Distribution Output | Student’s t |
| Loss | Negative log-likelihood |
| Optimizer | AdamW |
| Learning Rate | 1 × 10−4 |
| Batch Size | 256 |
| Epochs | 500 |
| Model | msMAPE | NRMSE | ND | Training Time |
|---|---|---|---|---|
| Seasonal Naïve | 13.5092 | 5.7848 | 0.1480 | - |
| ARIMA | 17.5130 | 4.8592 | 0.1450 | 280 s |
| DT | 18.3116 | 7.6188 | 0.2235 | 21 s |
| RF | 14.7366 | 5.7692 | 0.1598 | 182 s |
| LightGBM | 15.1735 | 5.7227 | 0.1562 | 320 s |
| Transformer | 2.7639 | 0.7325 | 0.0280 | 1529 s |
| Model | Mean | Stdev | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|
| Seasonal Naïve | 11.66 | 15.35 | 0.00 | 2.94 | 6.83 | 14.13 | 181.07 |
| ARIMA | 13.91 | 18.25 | 0.00 | 3.51 | 7.88 | 16.55 | 199.95 |
| DT | 18.31 | 18.95 | 0.00 | 6.06 | 12.27 | 23.40 | 163.16 |
| RF | 14.74 | 17.88 | 0.00 | 4.31 | 9.04 | 17.82 | 180.17 |
| LightGBM | 15.17 | 18.29 | 0.19 | 4.50 | 9.18 | 18.08 | 184.31 |
| Transformer | 2.76 | 2.38 | 0.05 | 1.25 | 2.14 | 3.56 | 40.53 |
| Region | Seasonal Naïve | Transformer | Number of Time Series |
|---|---|---|---|
| REGION I (ILOCOS REGION) | 6.0892 | 2.7566 | 574 |
| REGION II (CAGAYAN VALLEY) | 9.1292 | 2.8928 | 759 |
| REGION III (CENTRAL LUZON) | 10.8197 | 2.9276 | 730 |
| REGION IV-A (CALABARZON) | 10.5602 | 2.9033 | 596 |
| REGION V (BICOL REGION) | 15.6347 | 2.9834 | 641 |
| REGION VI (WESTERN VISAYAS) | 9.8261 | 2.4728 | 938 |
| REGION VII (CENTRAL VISAYAS) | 19.9428 | 2.8230 | 582 |
| REGION VIII (EASTERN VISAYAS) | 14.1325 | 2.5938 | 852 |
| REGION IX (ZAMBOANGA PENINSULA) | 9.2573 | 2.3377 | 603 |
| REGION X (NORTHERN MINDANAO) | 10.3724 | 2.6443 | 888 |
| REGION XI (DAVAO REGION) | 6.3099 | 2.5301 | 909 |
| REGION XII (SOCCSKSARGEN) | 13.5562 | 2.6834 | 763 |
| REGION XIII (CARAGA) | 20.1935 | 3.4582 | 625 |
| BANGSAMORO AUTONOMOUS REGION IN MUSLIM MINDANAO (BARMM) | 6.3572 | 2.4596 | 424 |
| CORDILLERA ADMINISTRATIVE REGION (CAR) | 9.5863 | 2.8841 | 520 |
| MIMAROPA REGION | 16.4558 | 3.1619 | 545 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibañez, S.C.; Monterola, C.P. A Global Forecasting Approach to Large-Scale Crop Production Prediction with Time Series Transformers. Agriculture 2023, 13, 1855. https://doi.org/10.3390/agriculture13091855
Ibañez SC, Monterola CP. A Global Forecasting Approach to Large-Scale Crop Production Prediction with Time Series Transformers. Agriculture. 2023; 13(9):1855. https://doi.org/10.3390/agriculture13091855
Chicago/Turabian StyleIbañez, Sebastian C., and Christopher P. Monterola. 2023. "A Global Forecasting Approach to Large-Scale Crop Production Prediction with Time Series Transformers" Agriculture 13, no. 9: 1855. https://doi.org/10.3390/agriculture13091855
APA StyleIbañez, S. C., & Monterola, C. P. (2023). A Global Forecasting Approach to Large-Scale Crop Production Prediction with Time Series Transformers. Agriculture, 13(9), 1855. https://doi.org/10.3390/agriculture13091855