
PlantStereo: A High Quality Stereo Matching Dataset for Plant Reconstruction

 ,
,  ,
,
Abstract
1. Introduction
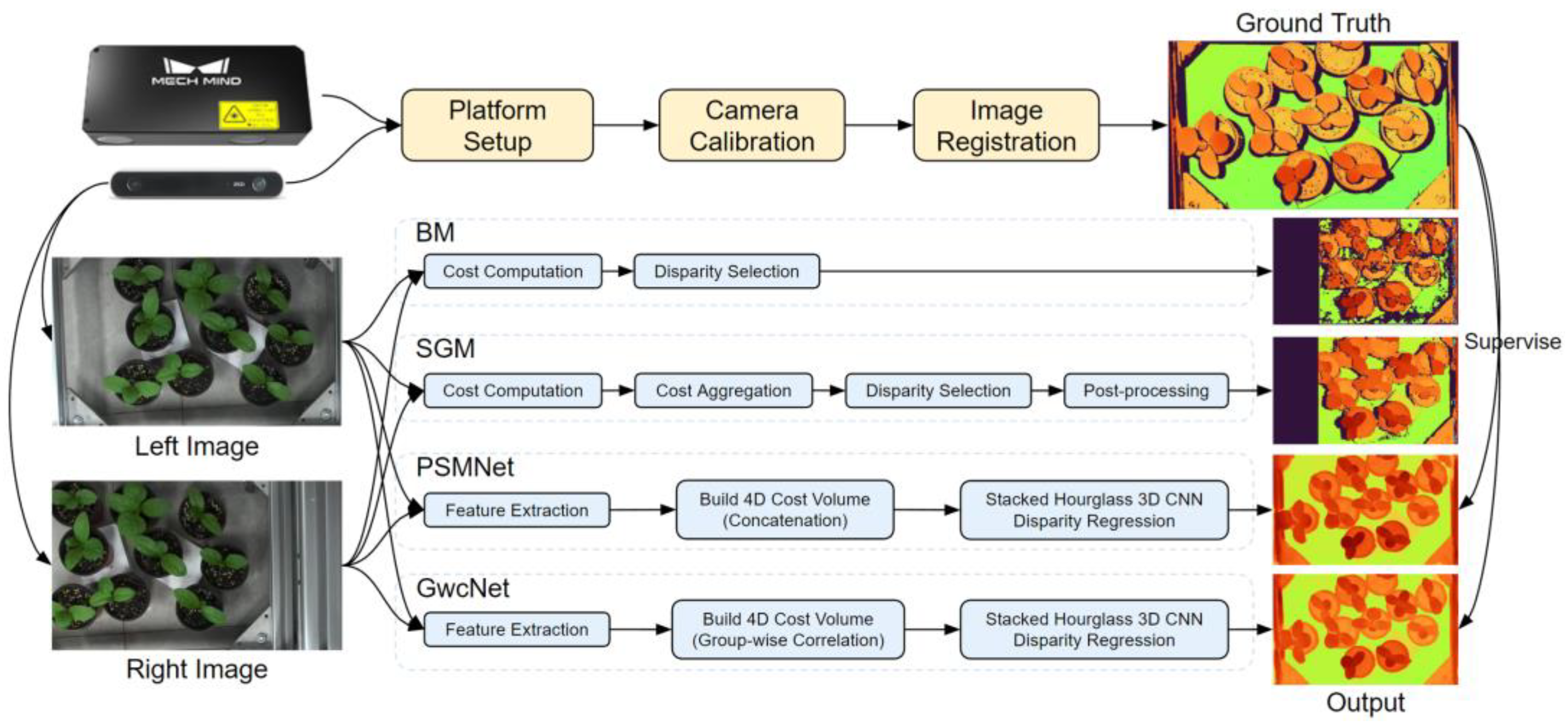
- A data sampling system was set up to build a dataset for stereo matching. The difficulty in obtaining the ground truth can be solved on the basis of the semi-automatic pipeline we propose, including camera calibration, image registration, and disparity image generation.
- A stereo matching dataset named PlantStereo was published for plant reconstruction and phenotyping. The PlantStereo dataset is promising and has potential compared with other representative stereo matching datasets when considering disparity accuracy, disparity density, and data type.
- The depth perception workflow proposed in this study is competitive in aspects of depth perception error (2.5 mm at 0.7 m), real-time performance (50 fps at 1046 × 606), and cost, compared with depth cameras based on other methods.
2. Materials and Methods
2.1. System Set Up
2.2. Methods
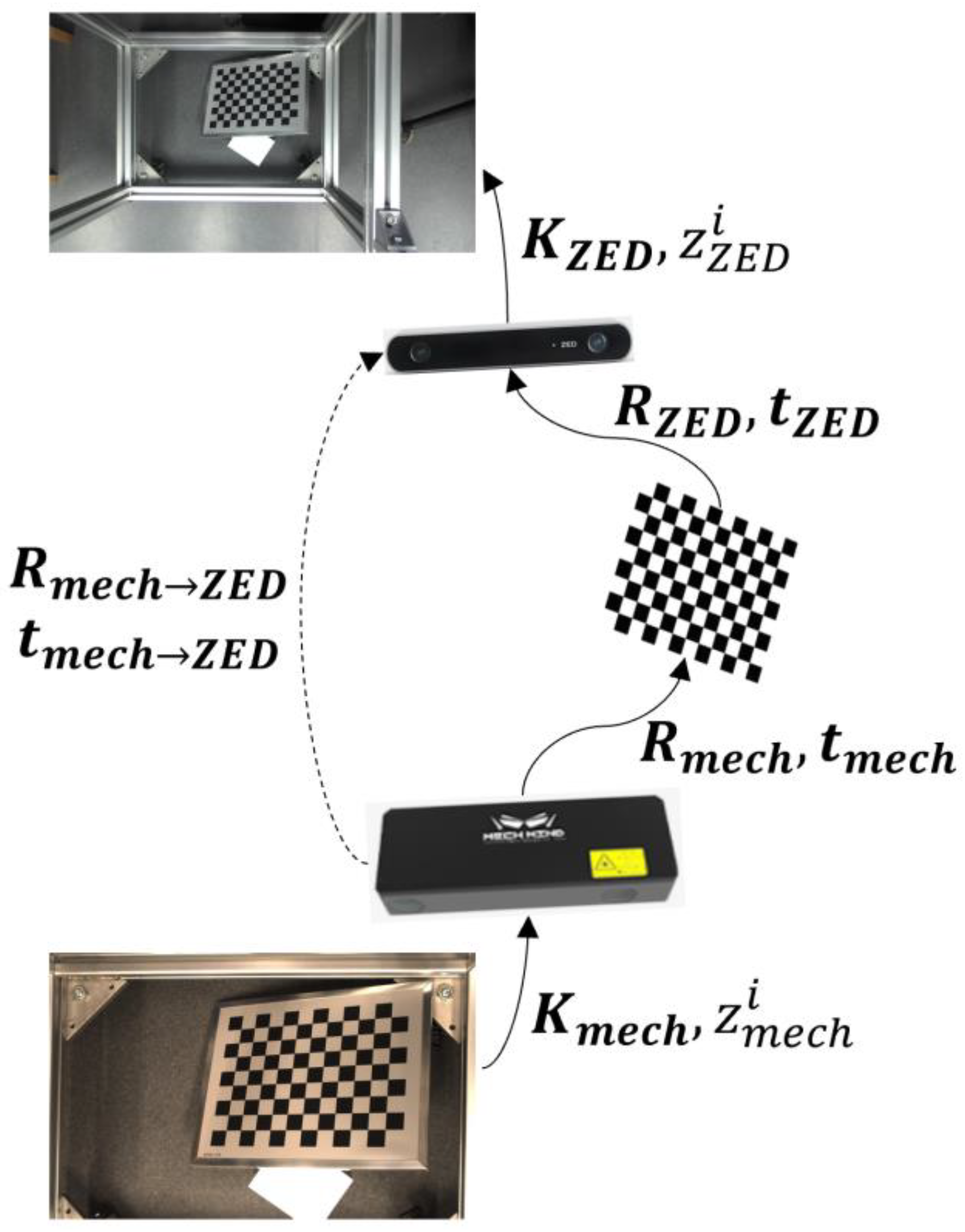
2.2.1. Camera Calibration
2.2.2. Image Registration
2.2.3. Disparity Image Generation
2.2.4. Stereo Matching Methods
2.2.5. Evaluation Metrics
3. Results
3.1. Overview of the PlantStereo Dataset
3.2. Method Comparison
3.3. Ablation Study on Disparity Accuracy
4. Discussion
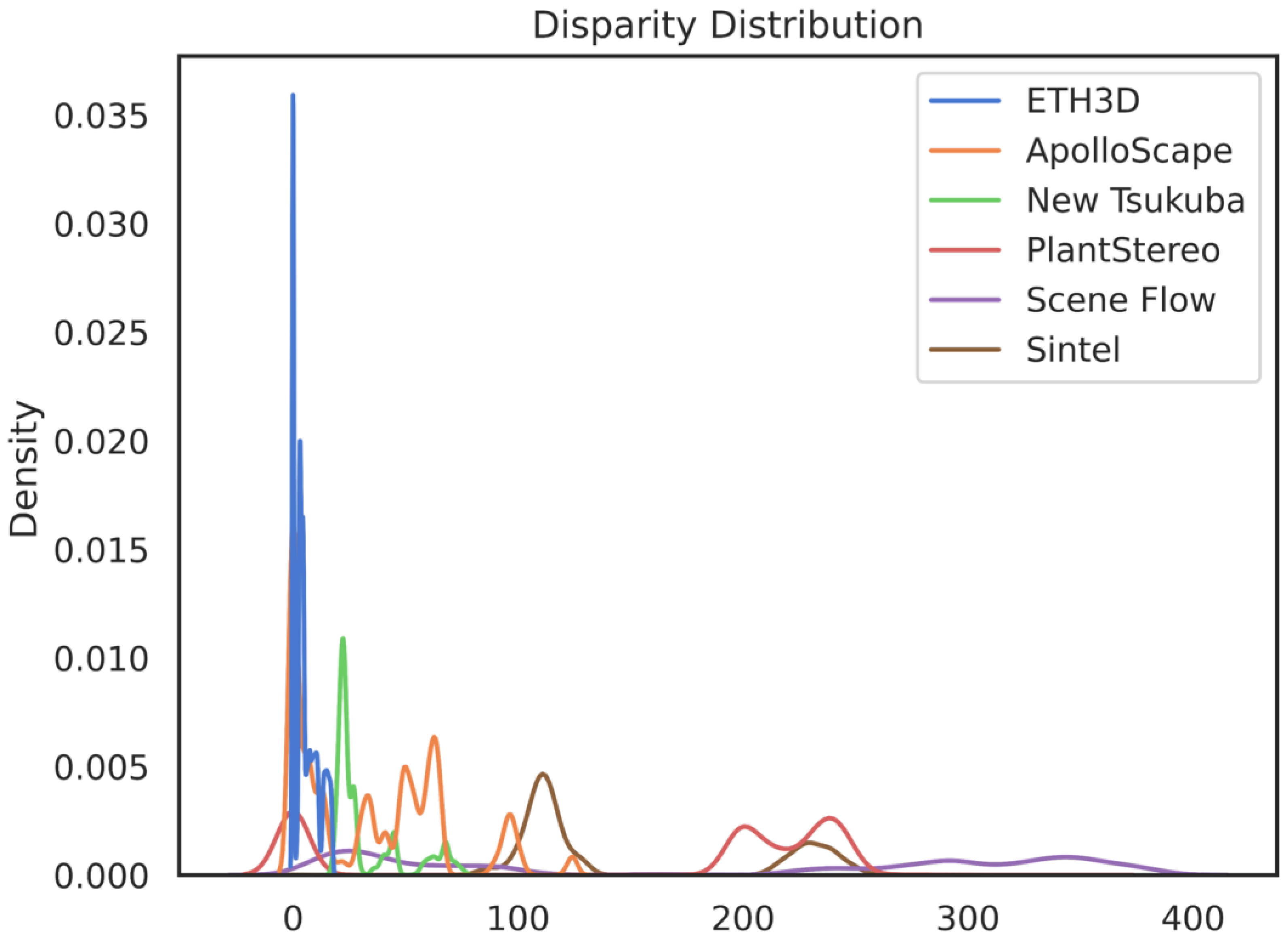
4.1. Comparison with Other Stereo Matching Datasets
4.2. Comparison with Other Depth Cameras Based on Different Depth Perception Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lou, M.; Lu, J.; Wang, L.; Jiang, H.; Zhou, M. Growth parameter acquisition and geometric point cloud completion of lettuce. Front. Plant Sci. 2022, 13, 947690. [Google Scholar] [CrossRef]
- Li, D.; Xu, L.; Tang, X.S.; Sun, S.; Cai, X.; Zhang, P. 3D imaging of greenhouse plants with an inexpensive binocular stereo vision system. Remote Sens. 2017, 9, 508. [Google Scholar] [CrossRef]
- Ni, X.; Li, C.; Jiang, H. Development of a 3D Multispectral Imaging System using Structured Light. In Proceedings of the 2019 ASABE Annual International Meeting, Boston, MA, USA, 7–10 July 2019; American Society of Agricultural and Biological Engineers. p. 1. [Google Scholar] [CrossRef]
- Yang, X.; Xie, H.; Liao, Y.; Dai, N.; Gao, G.; Liu, J. Calibration Method Research of Structured-light Sensor Camera System for Soil Surface Roughness Measurement. In Proceedings of the 2018 ASABE Annual International Meeting, Detroit, MI, USA, 20 July–1 August 2018; American Society of Agricultural and Biological Engineers. p. 1. [Google Scholar] [CrossRef]
- Andujar, D.; Ribeiro, A.; Fernández-Quintanilla, C.; Dorado, J. Using depth cameras to extract structural parameters to assess the growth state and yield of cauliflower crops. Comput. Electron. Agric. 2016, 122, 67–73. [Google Scholar] [CrossRef]
- Vázquez-Arellano, M.; Paraforos, D.S.; Reiser, D.; Garrido-Izard, M.; Griepentrog, H.W. Determination of stem position and height of reconstructed maize plants using a time-of-flight camera. Comput. Electron. Agric. 2018, 154, 276–288. [Google Scholar] [CrossRef]
- Vázquez-Arellano, M.; Reiser, D.; Paraforos, D.S.; Garrido-Izard, M.; Burce, M.E.C.; Griepentrog, H.W. 3-D reconstruction of maize plants using a time-of-flight camera. Comput. Electron. Agric. 2018, 145, 235–247. [Google Scholar] [CrossRef]
- Wang, L.; Hu, Y.; Jiang, H.; Shi, W.; Ni, X. Monitor geomatical information of plant by reconstruction 3D model based on Kinect V2. In Proceedings of the 2018 ASABE Annual International Meeting, Detroit, MI, USA, 20 July–1 August 2018; American Society of Agricultural and Biological Engineers. p. 1. [Google Scholar] [CrossRef]
- Xiang, L.; Bao, Y.; Tang, L.; Ortiz, D.; Salas-Fernandez, M.G. Automated morphological traits extraction for sorghum plants via 3D point cloud data analysis. Comput. Electron. Agric. 2019, 162, 951–961. [Google Scholar] [CrossRef]
- Cuevas-Velasquez, H.; Gallego, A.J.; Fisher, R.B. Segmentation and 3D reconstruction of rose plants from stereoscopic images. Comput. Electron. Agric. 2020, 171, 105296. [Google Scholar] [CrossRef]
- Malekabadi, A.J.; Khojastehpour, M.; Emadi, B. Disparity map computation of tree using stereo vision system and effects of canopy shapes and foliage density. Comput. Electron. Agric. 2019, 156, 627–644. [Google Scholar] [CrossRef]
- Xiang, L.; Tang, L.; Gai, J.; Wang, L. Measuring Stem Diameter of Sorghum Plants in the Field Using a High-Throughput Stereo Vision System. Trans. ASABE 2021, 64, 1999–2010. [Google Scholar] [CrossRef]
- Xiang, R.; Jiang, H.; Ying, Y. Recognition of clustered tomatoes based on binocular stereo vision. Comput. Electron. Agric. 2014, 106, 75–90. [Google Scholar] [CrossRef]
- Laga, H.; Jospin, L.V.; Boussaid, F.; Bennamoun, M. A survey on deep learning techniques for stereo-based depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1738–1764. [Google Scholar] [CrossRef] [PubMed]
- Poggi, M.; Tosi, F.; Batsos, K.; Mordohai, P.; Mattoccia, S. On the synergies between machine learning and binocular stereo for depth estimation from images: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5314–5334. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Liu, Y.; Lv, Y.; Xing, J. LANet: Stereo matching network based on linear-attention mechanism for depth estimation optimization in 3D reconstruction of inter-forest scene. Front. Plant Sci. 2022, 13, 978564. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Zhou, R.; Li, S.; Jiang, S.; Jiang, W. Disparity Estimation of High-Resolution Remote Sensing Images with Dual-Scale Matching Network. Remote Sens. 2021, 13, 5050. [Google Scholar] [CrossRef]
- Yang, G.; Song, X.; Huang, C.; Deng, Z.; Shi, J.; Zhou, B. Drivingstereo: A large-scale dataset for stereo matching in autonomous driving scenarios. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 899–908. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef]
- Yang, W.; Li, X.; Yang, B.; Fu, Y. A novel stereo matching algorithm for digital surface model (DSM) generation in water areas. Remote Sens. 2020, 12, 870. [Google Scholar] [CrossRef]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the 2017 IEEE/CVF International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 66–75. [Google Scholar] [CrossRef]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5410–5418. [Google Scholar] [CrossRef]
- Guo, X.; Yang, K.; Yang, W.; Wang, X.; Li, H. Group-wise correlation stereo network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3273–3282. [Google Scholar] [CrossRef]
- Li, Z.; Liu, X.; Drenkow, N.; Ding, A.; Creighton, F.X.; Taylor, R.H.; Unberath, M. Revisiting stereo depth estimation from a sequence-to-sequence perspective with transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Virtual Conference, 11–17 October 2021; pp. 6197–6206. [Google Scholar] [CrossRef]
- Rao, Z.; Dai, Y.; Shen, Z.; He, R. Rethinking training strategy in stereo matching. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The apolloscape open dataset for autonomous driving and its application. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2702–2719. [Google Scholar] [CrossRef]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3d tracking and forecasting with rich maps. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8748–8757. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar] [CrossRef]
- Peris, M.; Martull, S.; Maki, A.; Ohkawa, Y.; Fukui, K. Towards a simulation driven stereo vision system. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 1038–1042. [Google Scholar]
- Bao, W.; Wang, W.; Xu, Y.; Guo, Y.; Hong, S.; Zhang, X. InStereo2K: A large real dataset for stereo matching in indoor scenes. Sci. China-Inf. Sci. 2020, 63, 1–11. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R. High-accuracy stereo depth maps using structured light. In Proceedings of the 2003 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 16–22 June 2003; Volume 1, p. I-I. [Google Scholar] [CrossRef]
- Scharstein, D.; Pal, C. Learning conditional random fields for stereo. In Proceedings of the 2007 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Hirschmuller, H.; Scharstein, D. Evaluation of cost functions for stereo matching. In Proceedings of the 2007 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA; pp. 1–8. [Google Scholar] [CrossRef]
- Scharstein, D.; Hirschmüller, H.; Kitajima, Y.; Krathwohl, G.; Nešić, N.; Wang, X.; Westling, P. High-resolution stereo datasets with subpixel-accurate ground truth. In Proceedings of the 2014 German Conference on Pattern Recognition, Münster, Germany, 2–5 September 2014; Springer: Cham, Switzerland; pp. 31–42. [Google Scholar] [CrossRef]
- Schops, T.; Schonberger, J.L.; Galliani, S.; Sattler, T.; Schindler, K.; Pollefeys, M.; Geiger, A. A multi-view stereo benchmark with high-resolution images and multi-camera videos. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3260–3269. [Google Scholar] [CrossRef]
- Treible, W.; Saponaro, P.; Sorensen, S.; Kolagunda, A.; O′Neal, M.; Phelan, B.; Sherbondy, K.; Kambhamettu, C. Cats: A color and thermal stereo benchmark. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Ladický, L.; Sturgess, P.; Russell, C.; Sengupta, S.; Bastanlar, Y.; Clocksin, W.; Torr, P.H. Joint optimization for object class segmentation and dense stereo reconstruction. Int. J. Comput. Vis. 2012, 100, 122–133. [Google Scholar] [CrossRef]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 4040–4048. [Google Scholar] [CrossRef]
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A naturalistic open source movie for optical flow evaluation. In Proceedings of the 2012 European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany; pp. 611–625. [Google Scholar] [CrossRef]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.; Manela, J.; Happold, M.; Ramanan, D. Hierarchical deep stereo matching on high-resolution images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5515–5524. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Keselman, L.; Iselin Woodfill, J.; Grunnet-Jepsen, A.; Bhowmik, A. Intel realsense stereoscopic depth cameras. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–10. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera | Mech-Mind Pro S Enhanced | Stereolabs ZED 2 |
|---|---|---|
| Principles and Techniques | Structured light depth camera | Passive stereo depth camera |
| Focal Length (mm) | 7.90 | 4.00 |
| FoV (°) | 40.61 × 26.99 at 0.5 m 43.60 × 25.36 at 1.0 m | 110 × 70 |
| Resolution (pixel) | 1920 × 1200 | 2208 × 1242 |
| Range (m) | 0.5–1.0 | 0.2–20 |
| Depth Accuracy | 0.1 mm at 0.6 m | / |
| Size (mm) | 265 × 57 × 100 | 175 × 30 × 33 |
| Cost (USD) | 8000 | 500 |
| Mass (g) | 1600 | 124 |
| Subset | Train | Validation | Test | All | Resolution |
|---|---|---|---|---|---|
| Spinach | 160 | 40 | 100 | 300 | 1046 × 606 |
| Tomato | 80 | 20 | 50 | 150 | 1040 × 603 |
| Pepper | 150 | 30 | 32 | 212 | 1024 × 571 |
| Pumpkin | 80 | 20 | 50 | 150 | 1024 × 571 |
| All | 470 | 110 | 232 | 812 |
| Method | # Param. (M) | GFLOPs | Inference Time (s) |
|---|---|---|---|
| BM | / | / | 0.02 |
| SGM | / | / | 0.19 |
| PSMNet | 5.36 | 29.22 | 1.05 |
| GwcNet | 6.43 | 26.13 | 0.02 |
| Method | (%) | (%) | (%) | ||
|---|---|---|---|---|---|
| BM | 85.83 | 50.12 | 49.57 | 102.79 | 147.90 |
| SGM | 71.55 | 37.08 | 36.21 | 71.48 | 122.30 |
| PSMNet | 29.81 | 4.88 | 3.17 | 1.21 | 3.20 |
| GwcNet | 18.11 | 2.9 | 1.77 | 0.84 | 2.56 |
| Method | Subset | (%) | (%) | (%) | ||
|---|---|---|---|---|---|---|
| PSMNet | Spinach | 13.50 | 5.37 | 3.32 | 0.43 | 0.43 |
| Tomato | 3.41 | 1.13 | 1.19 | 0.16 | 0.22 | |
| Pepper | 7.63 | 0.98 | 0.72 | 0.23 | 0.68 | |
| Pumpkin | 8.66 | 1.02 | 0.70 | 0.28 | 0.75 | |
| GwcNet | Spinach | 0.08 | 0.10 | 0.07 | 0.01 | |
| Tomato | 3.16 | 0.66 | 0.31 | 0.15 | 0.28 | |
| Pepper | 1.79 | 0.86 | 0.95 | 0.06 | 0.22 | |
| Pumpkin | 0.88 | 0.04 | 0.25 | 0.11 | 0.29 |
| Dataset | Tools | Scene | Data Size | Disparity Accuracy | Disparity Density | Data Type |
|---|---|---|---|---|---|---|
| Middlebury [26,33,34,35,36] | Structured light | Indoor | 95 | Sub-pixel | ≈94% | Real |
| KITTI [29,30] | LiDAR | Driving | 789 | Pixel | ≈19% | Real |
| Scene Flow [40] | Software | Animation | 39,049 | Pixel | 100% | Synthetic |
| HR-VS [43] | Software | Driving | 780 | Sub-pixel | 100% | Synthetic |
| ETH3D [37] | Scanner | In/out door | 47 | Pixel | ≈69% | Real |
| DrivingStereo [18] | LiDAR | Driving | 182,188 | Pixel | ≈4% | Real |
| InStereo2K [32] | Structured light | Indoor | 2060 | Pixel | ≈87% | Real |
| Argoverse [28] | LiDAR | Driving | 6624 | Pixel | ≈0.86% | Real |
| Sintel [41] | Software | Animation | 1064 | Pixel | 100% | Synthetic |
| CATS [38] | LiDAR | In/out door | 1372 | Pixel | ≈8% | Real |
| Ladicky [39] | Annotation | Driving | 70 | Pixel | ≈60% | Real |
| Cityscapes [19] | SGM | Driving | 3475 | Pixel | ≈38% | Real |
| PlantStereo | Depth camera | Plant | 812 | Sub-pixel | ≈88% | Real |
| Camera | Principle | Error | Frame Rate (fps) or Time per Frame (s) |
|---|---|---|---|
| RealSense D435 [45] | Active Stereo | 14 mm at 0.7 m | 30 fps at 1280 × 800 90 fps at 848 × 480 |
| Azure Kinect | ToF | 11.7 mm at 0.7 m | 30 fps at 640 × 576 with 0.5–3.86 m 30 fps at 320 × 288 with 0.5–5.46 m |
| Mech-Mind Pro S Enhanced | Structured Light | 0.1 mm at 0.7 m | 3–5 s per frame at 1920 × 1200 |
| Our Workflow | Passive Stereo | 2.5 mm at 0.7 m | 50 fps at 1046 × 606 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Wu, D.; Liu, W.; Lou, M.; Jiang, H.; Ying, Y.; Zhou, M. PlantStereo: A High Quality Stereo Matching Dataset for Plant Reconstruction. Agriculture 2023, 13, 330. https://doi.org/10.3390/agriculture13020330
Wang Q, Wu D, Liu W, Lou M, Jiang H, Ying Y, Zhou M. PlantStereo: A High Quality Stereo Matching Dataset for Plant Reconstruction. Agriculture. 2023; 13(2):330. https://doi.org/10.3390/agriculture13020330
Chicago/Turabian StyleWang, Qingyu, Dihua Wu, Wei Liu, Mingzhao Lou, Huanyu Jiang, Yibin Ying, and Mingchuan Zhou. 2023. "PlantStereo: A High Quality Stereo Matching Dataset for Plant Reconstruction" Agriculture 13, no. 2: 330. https://doi.org/10.3390/agriculture13020330
APA StyleWang, Q., Wu, D., Liu, W., Lou, M., Jiang, H., Ying, Y., & Zhou, M. (2023). PlantStereo: A High Quality Stereo Matching Dataset for Plant Reconstruction. Agriculture, 13(2), 330. https://doi.org/10.3390/agriculture13020330