
Wheat-Seed Variety Recognition Based on the GC_DRNet Model


Abstract
:1. Introduction
- We collected images of 29 mainstream wheat seeds in Gansu Province and prepared the data by screening and different image-preprocessing techniques to ensure the quality and availability of the data and to provide sufficient training data for the model to learn effectively;
- Since the residual dense network and global context module are less applied in the field of wheat-seed image recognition, we improve the network based on the ResNet18 network by combining the idea of a dense network in the residual module and introducing the global context module and propose the GC_DRNet network model for wheat-seed recognition;
- Comparative experiments and analyses of the proposed GC_DRNet model with other classical networks on the self-constructed wheat-seed dataset and the public dataset CIFAR-100 have fully demonstrated the fast accuracy of the GC_DRNet model, which can successfully identify the varieties of wheat seeds.
2. Materials and Methods
2.1. Data Analysis
2.1.1. Self-Built Dataset
2.1.2. Open Dataset CIFAR-100
2.1.3. Data Processing
2.2. Model Architecture
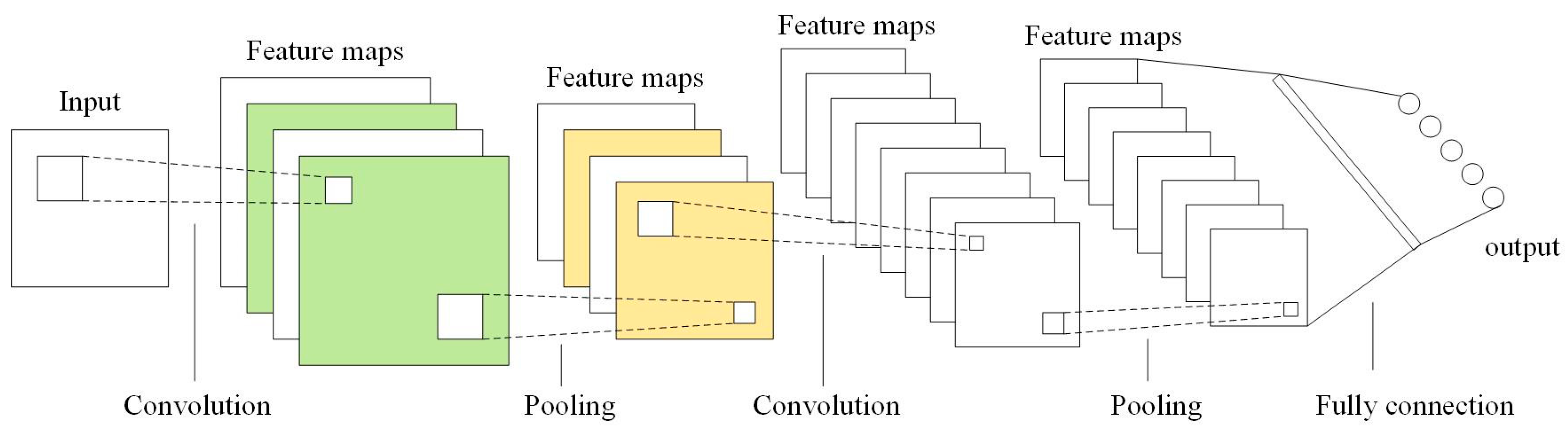
2.2.1. Convolutional Neural Networks
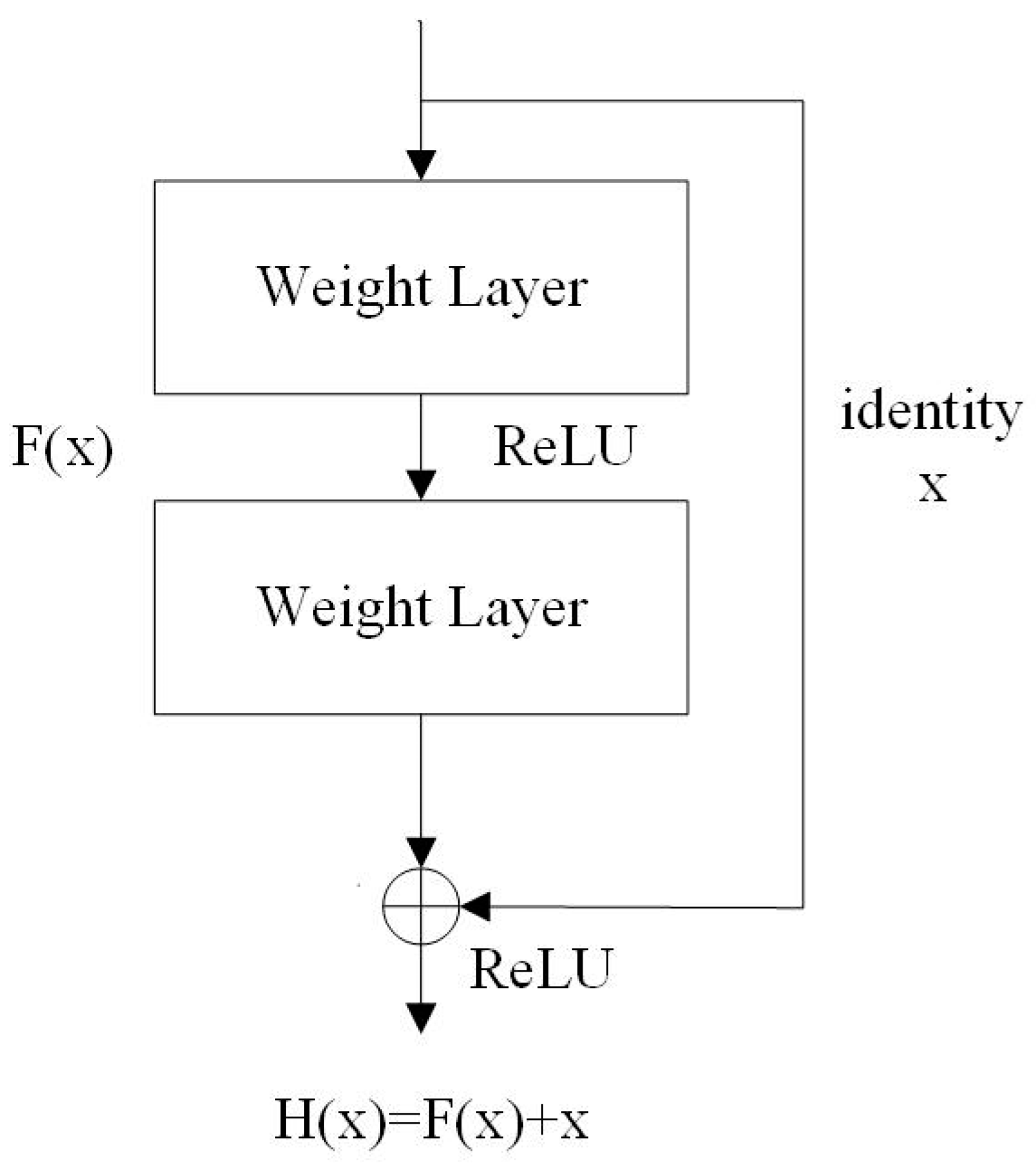
2.2.2. ResNet18
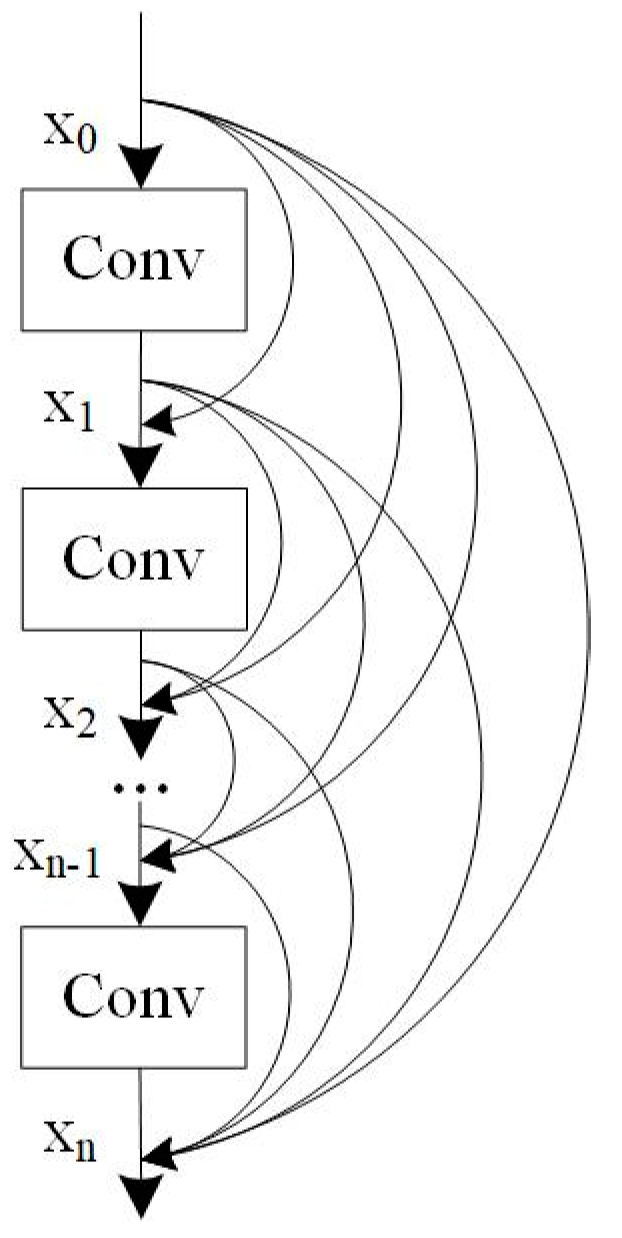
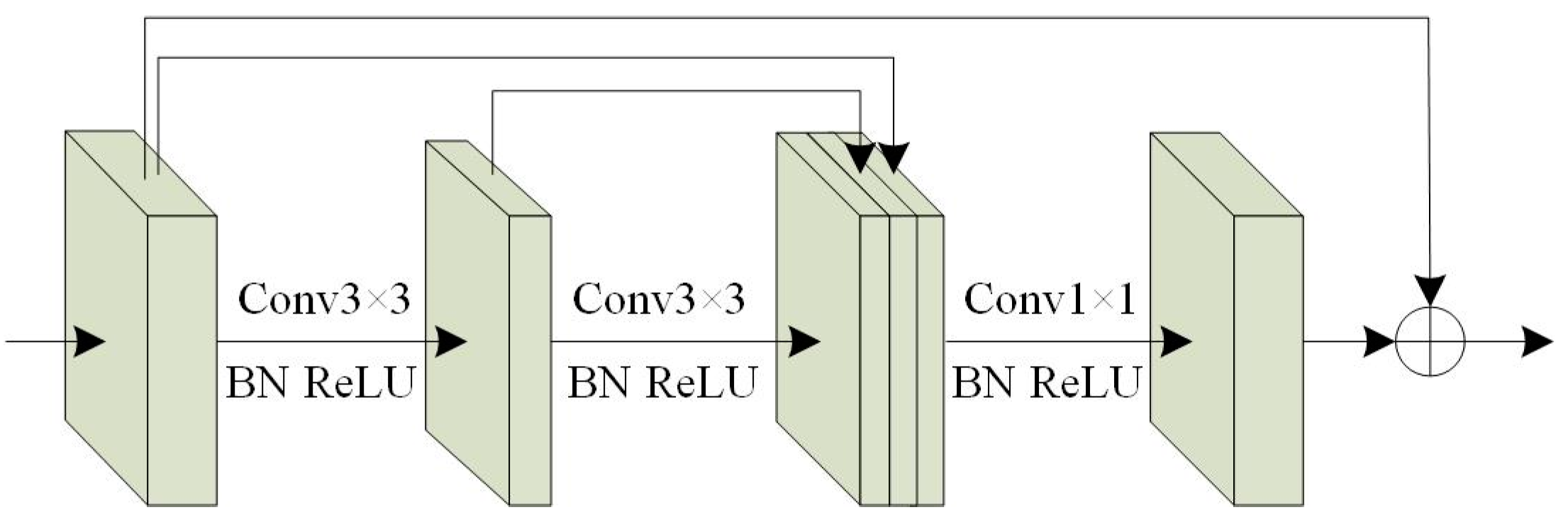
2.2.3. Dense Residual Block
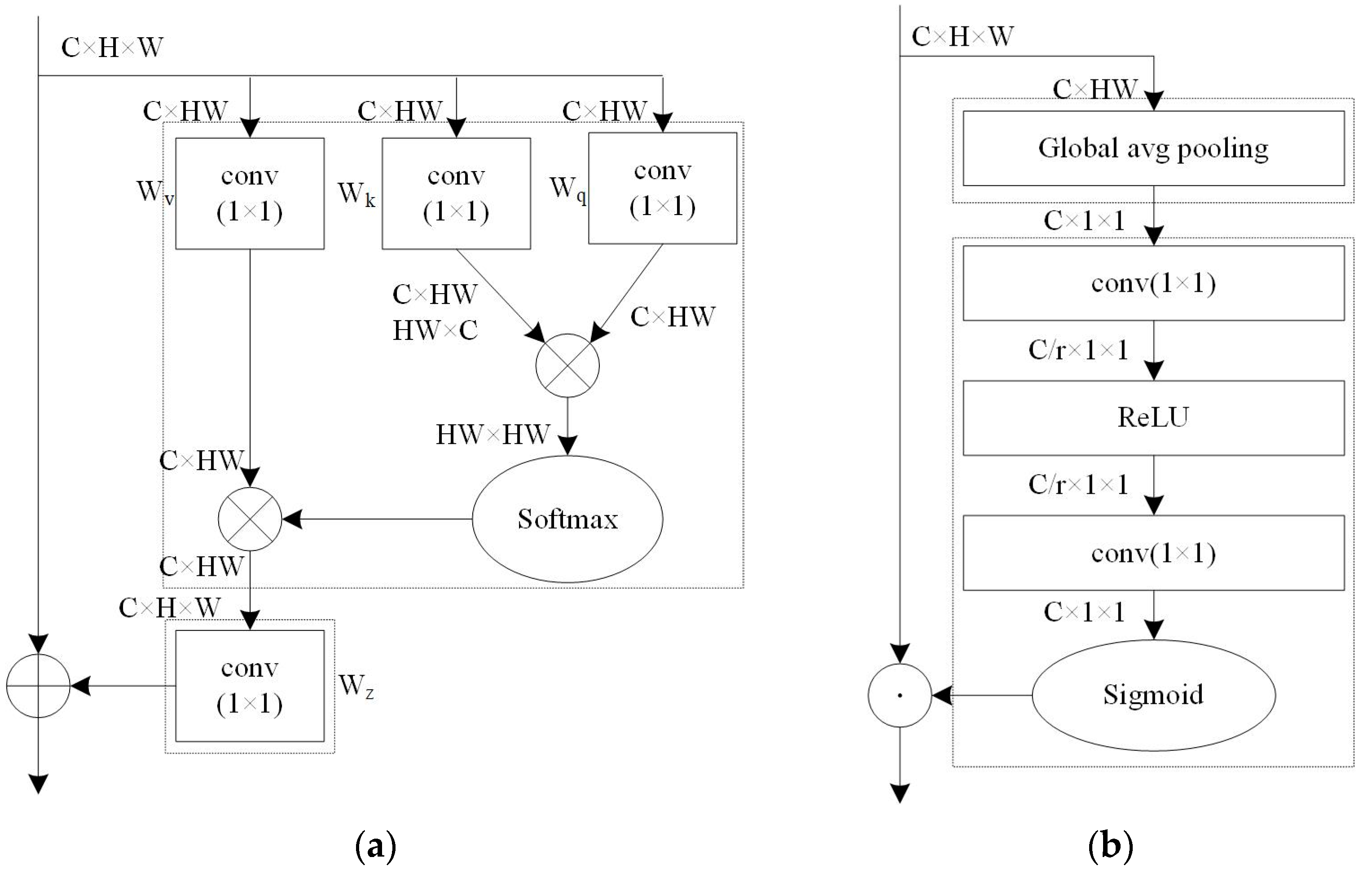
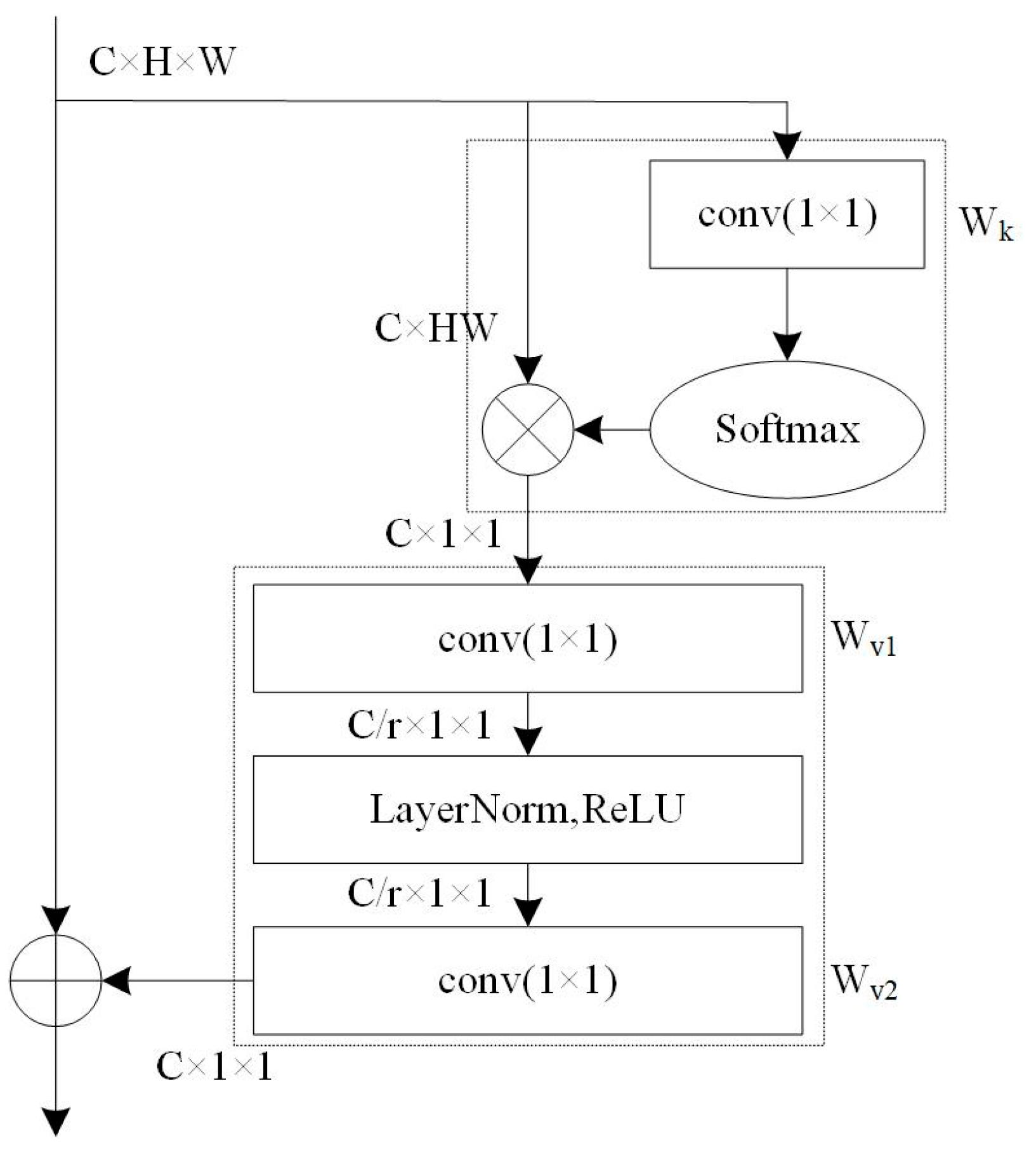
2.2.4. The Global Context Module
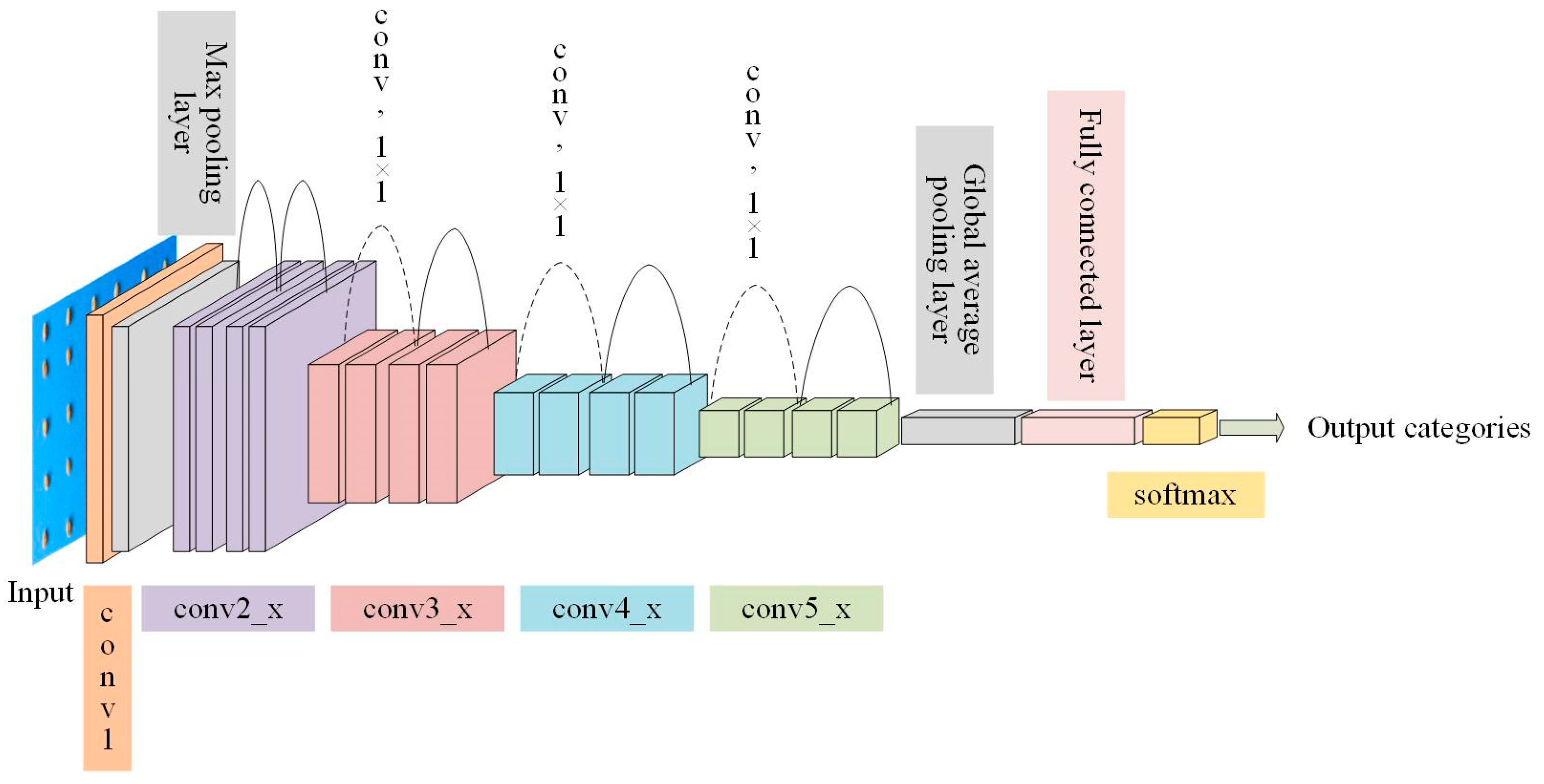
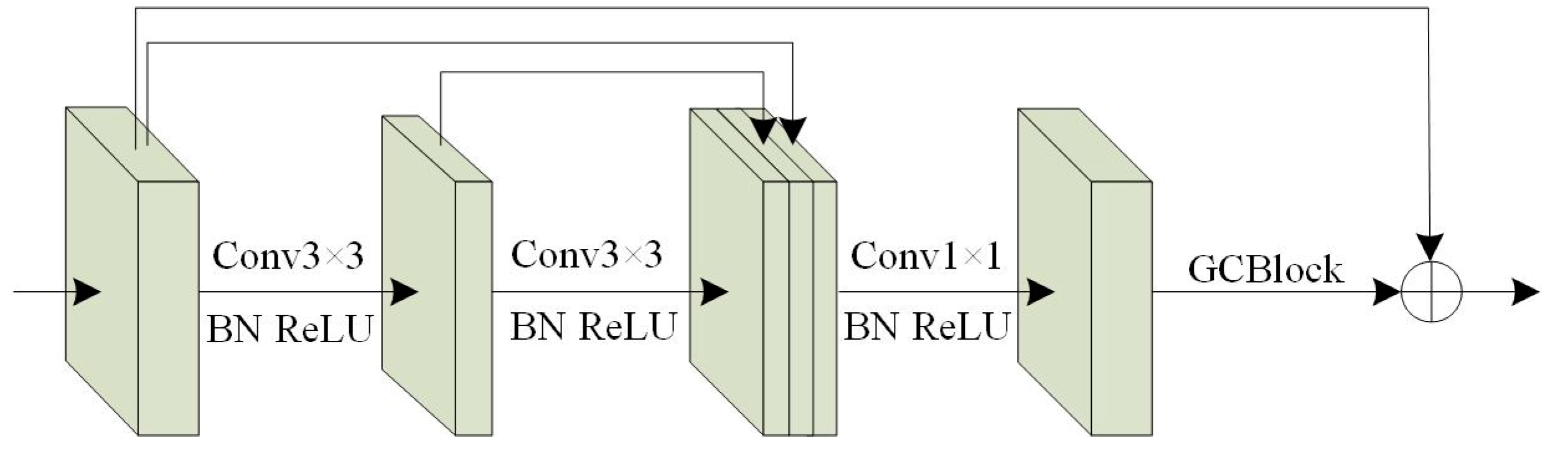
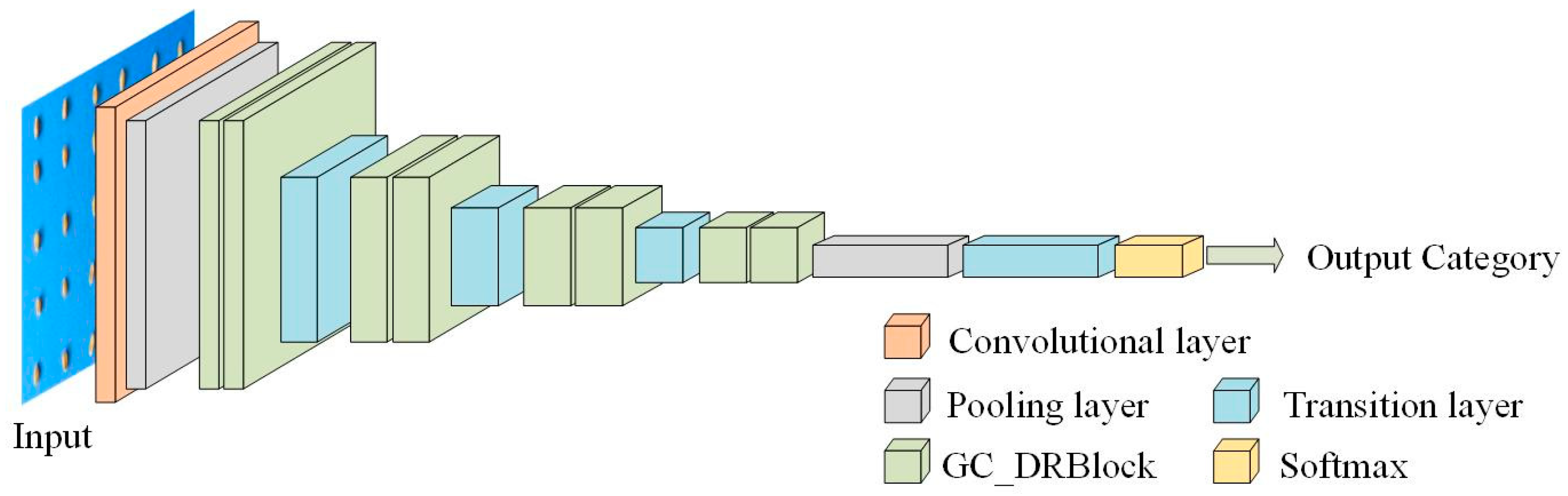
2.2.5. GC_DRNet Model Architecture
3. Experimental Design and Results Analysis
3.1. Experimental Environment
3.2. Parameter Setting
3.3. Evaluation Metrics
3.4. Results and Analysis
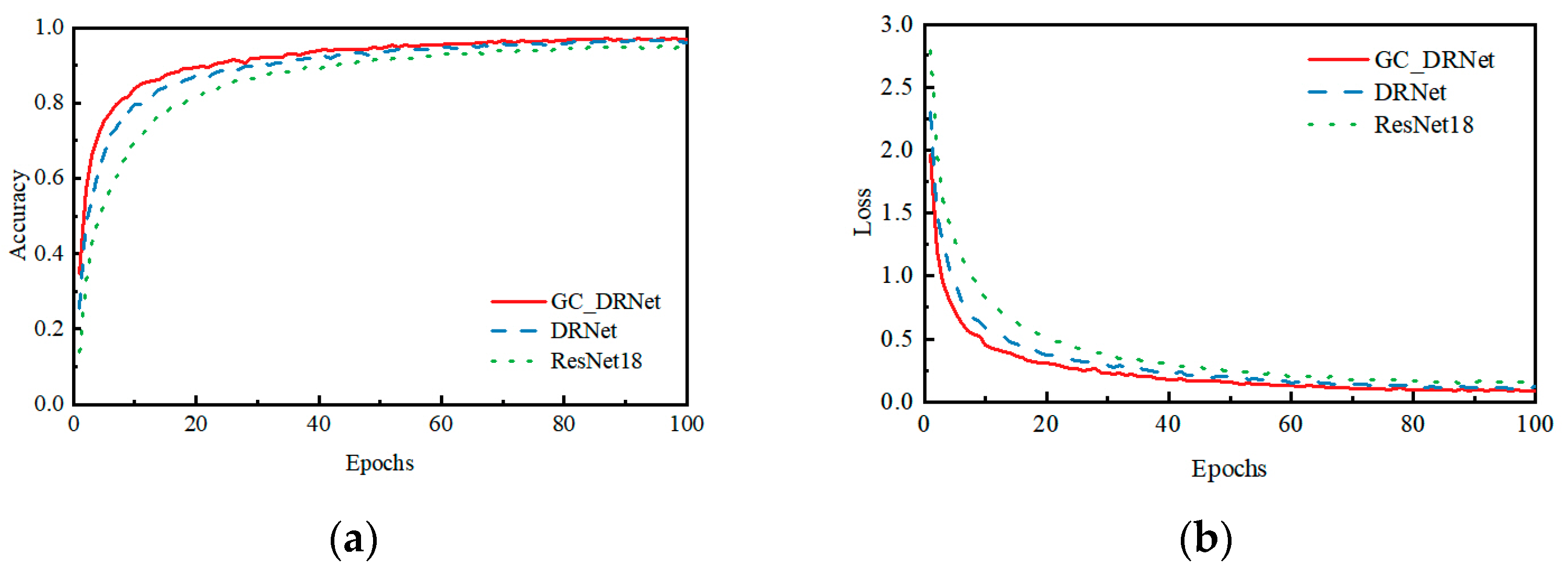
3.4.1. Analysis of Wheat-Seed Dataset Ablation Experiment Results
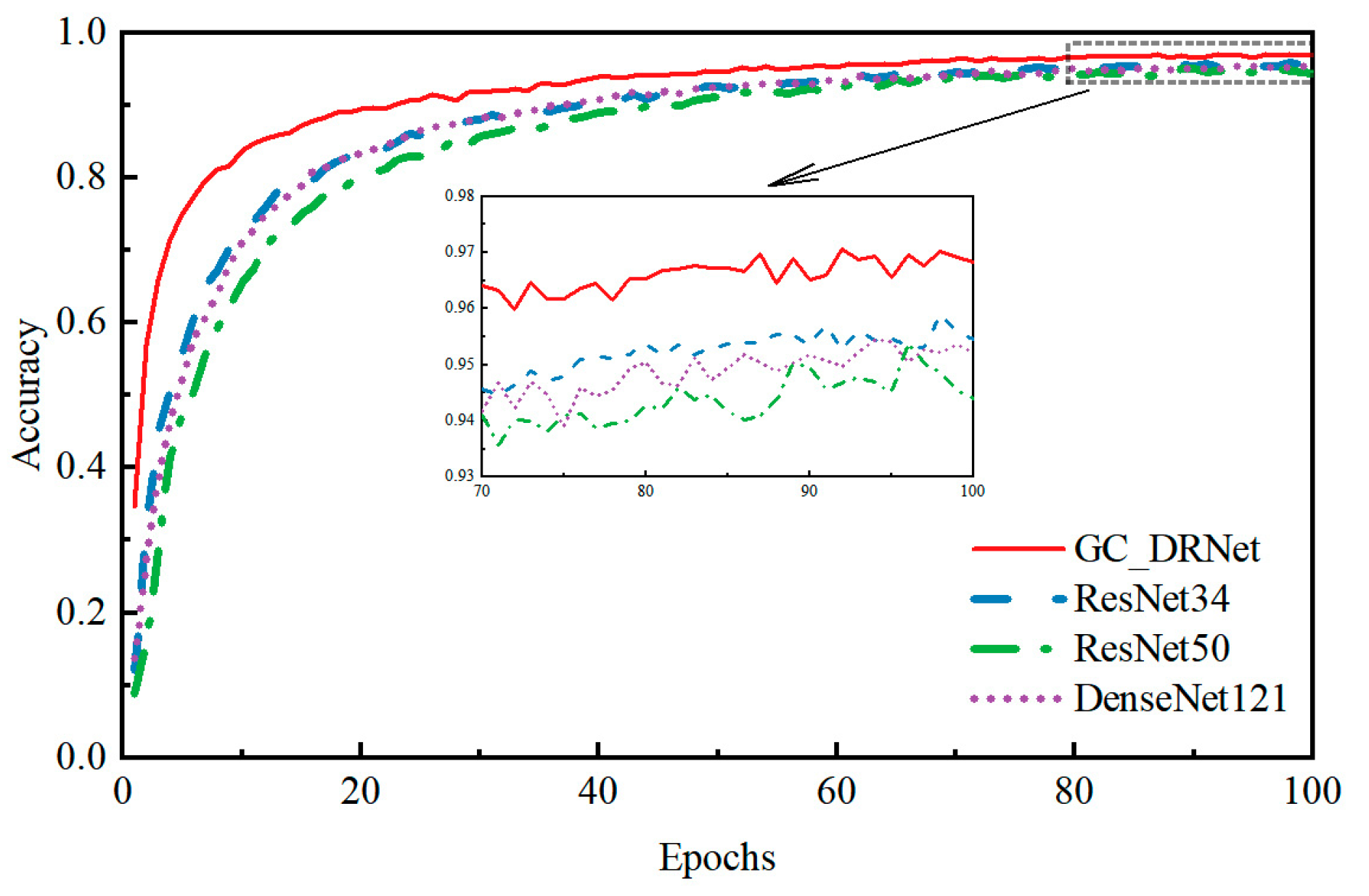
3.4.2. Comparison and Analysis of Different Convolutional Neural Network Models
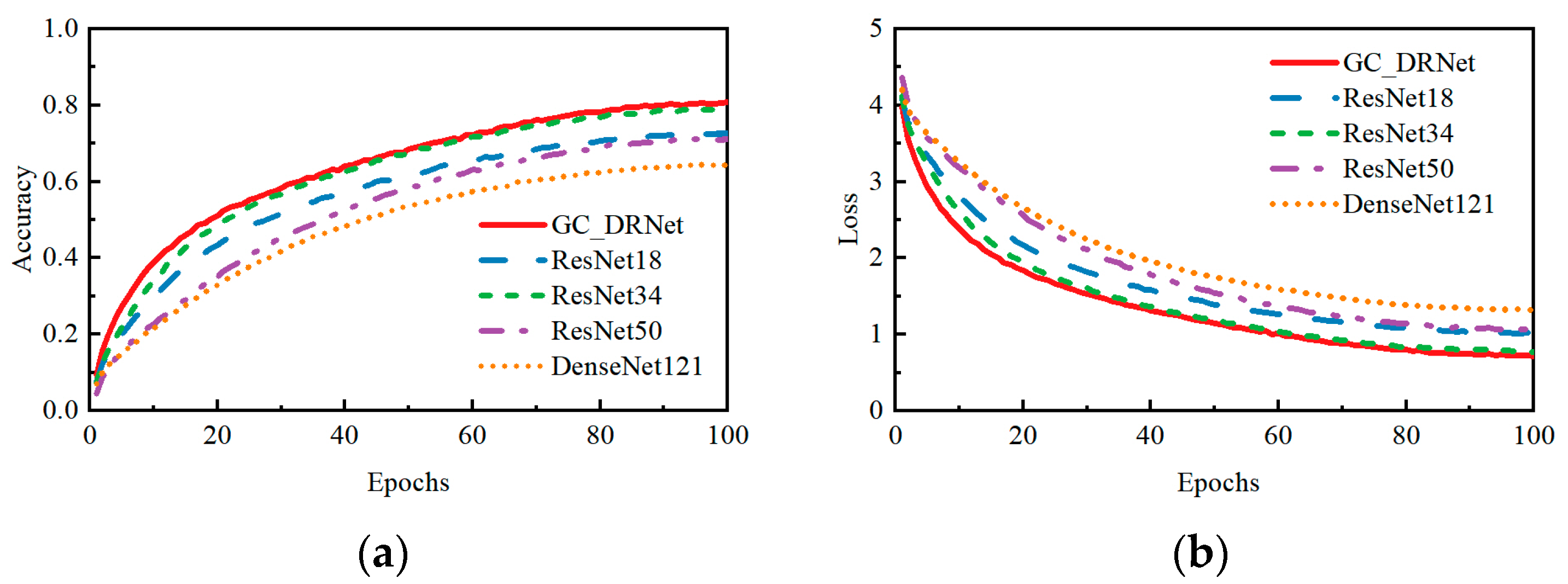
3.4.3. Analysis of Experimental Results on Public Dataset CIFAR-100
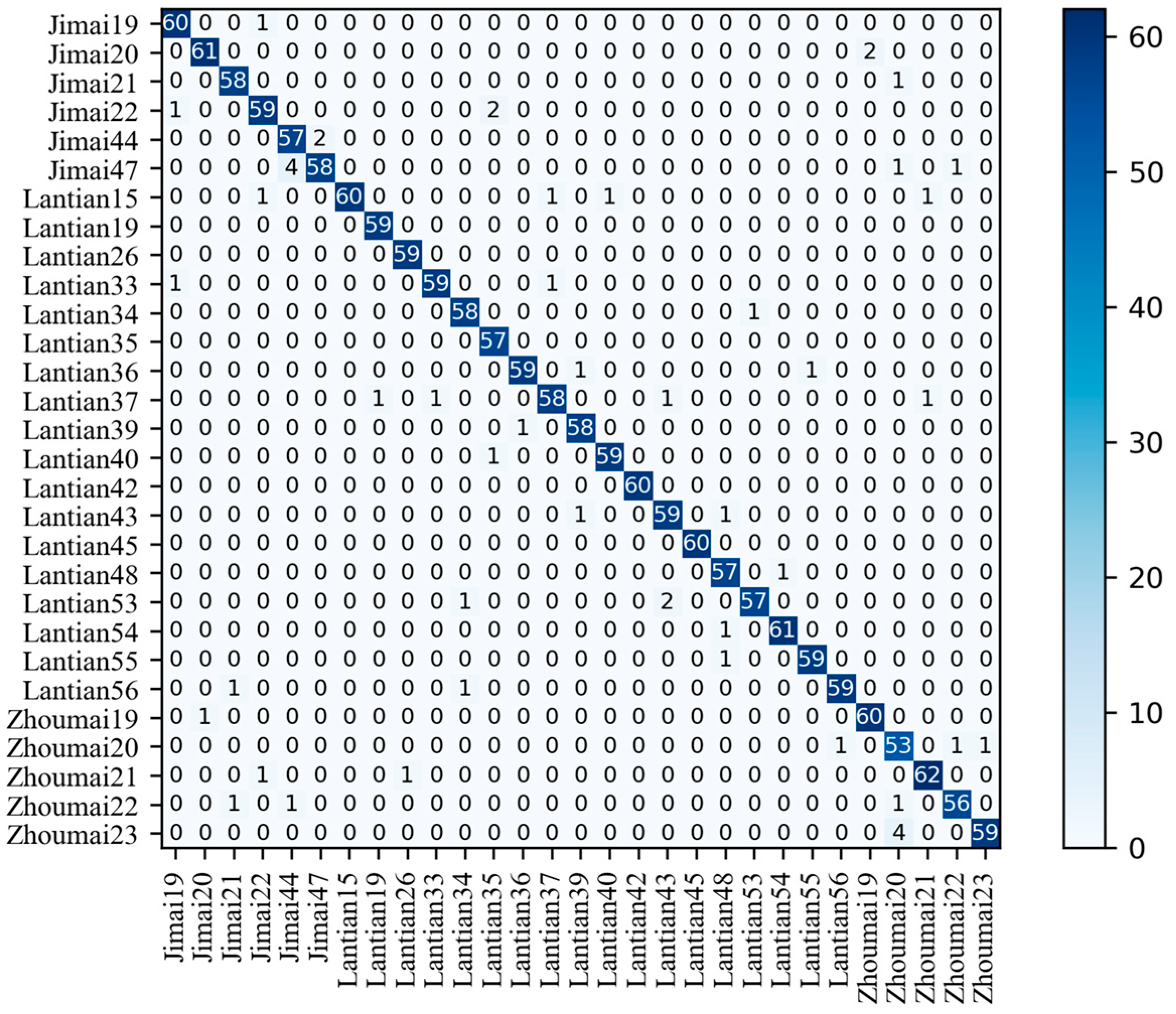
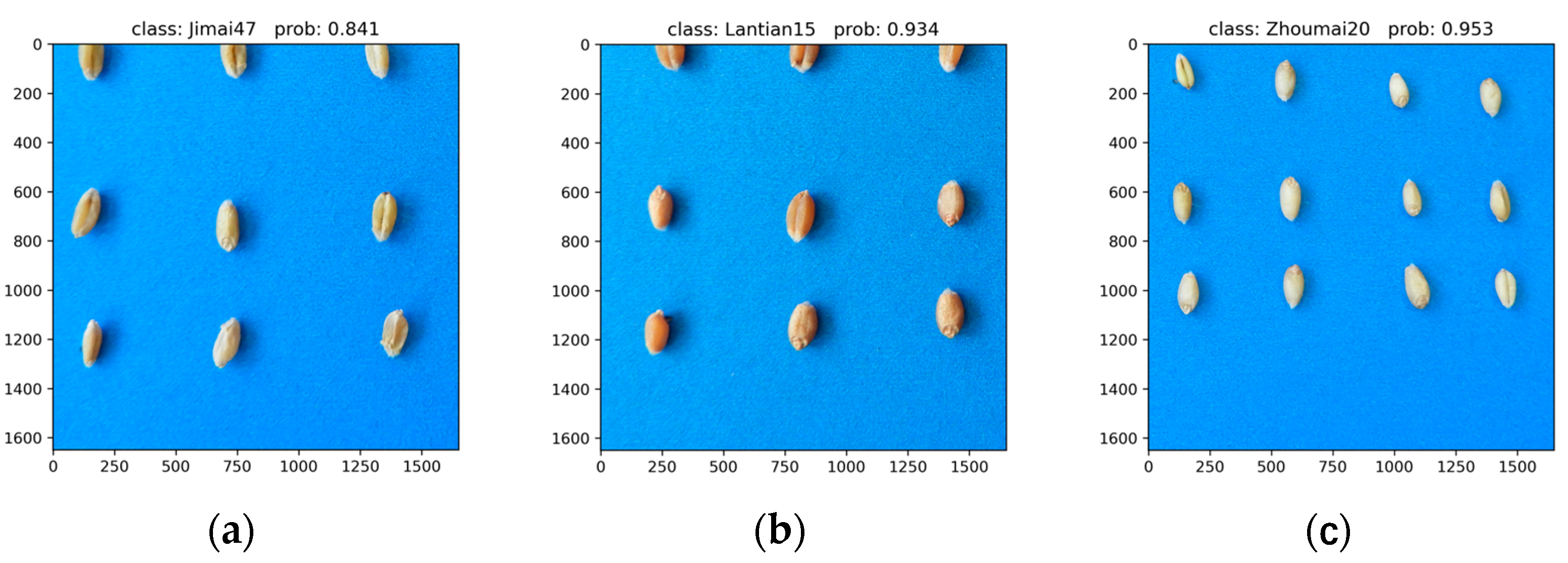
3.4.4. Performance Evaluation of GC_DRNet Model
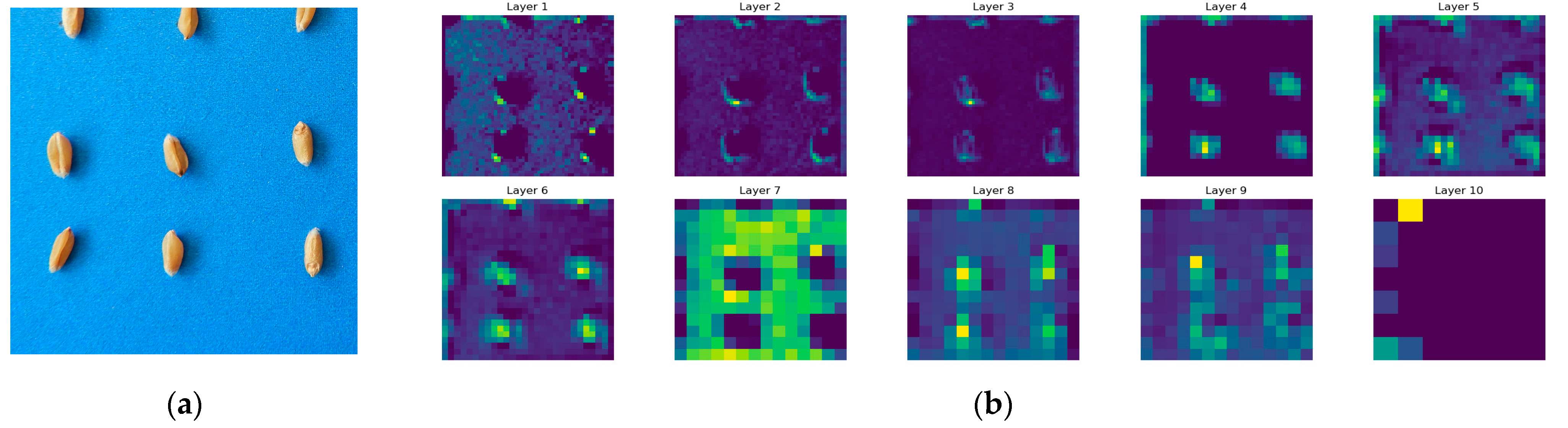
3.4.5. Feature-Map Visualisation
4. Conclusions
- (1)
- On the self-constructed wheat-seed dataset, the recognition accuracy of this model is improved by 2.34% and the amount of parameters is reduced by 73.87%, compared with the original ResNet18 network model. By comparing the ResNet34, ResNet50, and DenseNet121 networks, the GC_DRNet model has more significant advantages in terms of recognition accuracy and parameter quantity, with 1.43%, 2.05%, and 1.77% improvement in recognition accuracy and 85.98% and 88.05% reduction in parameter quantity, respectively, on the test set, 61.73%. It indicates that the introduction of the dense network idea in the residual block of the ResNet18 network model to achieve feature reuse can effectively reduce the network parameters and computational cost, and improve the recognition accuracy of the network model; the introduction of global context information in the improved dense residual module fully extracts the global information, increases the differences between different wheat-seed varieties, and can effectively increase the network model’s wheat-seed recognition accuracy. In addition, the recognition accuracy of the model is 96.98%, the number of references is only 11.65 MB, and the floating-point operation is 8.67 × 108, which indicates that the model in this paper can be embedded in smart terminals;
- (2)
- On the publicly available dataset CIFAR-100, the recognition accuracy of the GC_DRNet network model is 80.77%, which is 8.19%, 1.6%, 9.59%, and 16.29% higher than that of the ResNet18, ResNet34, ResNet50, and DenseNet121 models, respectively. It indicates that features such as blue background and seed spacing have no effect on model robustness.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, G.; Zhao, G.; Li, B.; You, Y.; Zhou, D. Current Situation and Development Countermeasures of the Wheat Industry in Gansu Province; Gansu Agricultural Science and Technology: Lanzhou, China, 2020; pp. 70–75. [Google Scholar]
- Lu, Q.; Ma, Z.; Yang, W.; Zhang, K.; Zhang, L.; Cao, S.; Zhang, W.; Zhou, G. Current Status and Countermeasures of Wheat Breeding in Gansu; Gansu Agricultural Science and Technology: Lanzhou, China, 2022; Volume 53, pp. 1–5. [Google Scholar]
- Yang, S.; Feng, Q.; Zhang, J.; Wang, G.; Zhang, P.; Yan, H. Non-destructive grading of potato external defects based on a lightweight convolutional network. Food Sci. 2020, 42, 284–289. [Google Scholar]
- Liu, C.; Han, J.; Chen, B.; Mao, J.; Xue, Z.; Li, S. A Novel Identification Method for Apple (Malus domestica Borkh.) Cultivars Based on a Deep Convolutional Neural Network with Leaf Image Input. Symmetry 2020, 12, 217. [Google Scholar] [CrossRef]
- Jeyaraj, P.R.; Asokan, S.P.; Samuel Nadar, E.R. Computer-Assisted Real-Time Rice Variety Learning Using Deep Learning Network. Rice Sci. 2022, 29, 489–498. [Google Scholar] [CrossRef]
- Du, G.; Lu, M.; Ji, Z.; Liu, J. Research on Apple Defect Detection Method Based on Improved CNN. Food Mach. 2023, 39, 155–160. [Google Scholar]
- Altuntas, Y.; Comert, Z.; Kocamaz, A.F. Identification of haploid and diploid maize seeds using convolutional neural networks and a transfer learning approach. Comput. Electron. Agric. 2019, 163, 104874. [Google Scholar] [CrossRef]
- Javanmardi, S.; Ashtiani, S.H.M.; Verbeek, F.J.; Martynenko, A. Computer-vision classification of corn seed varieties using deep convolutional neural network. J. Stored Prod. Res. 2021, 92, 101800. [Google Scholar] [CrossRef]
- Niu, X.; Gao, B.; Nan, X.; Shi, Y. Tomato Leaf Disease Detection Based on Improved DenseNet Convolutional Neural Network. Jiangsu J. Agric. Sci. 2022, 38, 129–134. [Google Scholar]
- Zhang, R.; Li, Z.; Hao, J.; Sun, L.; Li, H.; Han, P. Convolutional Neural Network Peanut Pod Rank Image Recognition Based on Migration Learning. Trans. Chin. Soc. Agric. Eng. 2020, 36, 171–180. [Google Scholar]
- Yang, H.; Ni, J.; Gao, J.; Han, Z.; Luan, T. A novel method for peanut variety identification and classification by Improved VGG16. Sci. Rep. 2021, 11, 15756. [Google Scholar] [CrossRef]
- Lu, Y.; Chen, B. Identification of hops pests and diseases in small samples based on attentional mechanisms. J. Chin. Agric. Mech. 2020, 42, 189–196. [Google Scholar]
- Lingwal, S.; Bhatia, K.K.; Tomer, M.S. Image-based wheat grain classification using convolutional neural network. Multimed. Tools Appl. 2021, 80, 35441–35465. [Google Scholar] [CrossRef]
- Vidyarthi, S.K.; Singh, S.K.; Tiwari, R.; Xiao, H.W.; Rai, R. Classification of first quality fancy cashew kernels using four deep convolutional neural network models. J. Food Process Eng. 2020, 43, e13552. [Google Scholar] [CrossRef]
- Wang, C.; Zhou, J.; Wu, H.; Teng, G.; Zhao, C.; Li, J. Identification of vegetable leaf diseases based on improved Multi-scale ResNet. Trans. Chin. Soc. Agric. Eng. 2020, 36, 209–217. [Google Scholar]
- Zhang, F. Research on Peach Variety Recognition Technology Based on Machine Vision; Hebei Agricultural University: Baoding, China, 2021. [Google Scholar]
- Li, L.; Zhang, S.; Wang, B. Apple Leaf Disease Identification with a Small and Imbalanced Dataset Based on Lightweight Convolutional Networks. Sensors 2021, 22, 173. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.v.d.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Gao, X. A Study on the Improvement of Convolutional Neural Networks and Their Application in Image Classification; Yanshan University: Qinhuangdao, China, 2022. [Google Scholar]
- Xu, X. Quality Classification and Lesion Discrimination of DR Fundus Images Based on Residual-Dense Networks; Tianjin University of Technology: Tianjin, China, 2021. [Google Scholar]
- Wei, X.; Yu, X.; Tan, X.; Liu, B. Hyperspectral Image Classification Using Residual Dense Networks. Laser Optoelectron. Prog. 2019, 56, 95–103. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yan, Z. Research on Identification Technology of Tea Pests Based on Deep Learning; Chongqing University of Technology: Chongqing, China, 2022. [Google Scholar]
- Zhang, G. Arrhythmia Classification System Based on ResGC-Net; Jilin University: Changchun, China, 2022. [Google Scholar]
- Zeng, W.; Chen, Y.; Hu, G.; Bao, W.; Liang, D. Detection of Citrus Huanglongbing in Natural Background by SMS and Two-way Feature Fusion. Trans. Chin. Soc. Agric. Mach. 2022, 53, 280–287. [Google Scholar]
- Gai, L.; Cai, J.; Wang, S.; Cang, Y.; Chen, N. Research review on the application of convolutional neural network in image recognition. J. Chin. Comput. Syst. 2021, 42, 1980–1984. [Google Scholar]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Chen, J.K.; Han, J.Y.; Liu, C.Z.; Wang, Y.F.; Shen, H.C.; Li, L. A Deep-Learning Method for the Classification of Apple Varieties via Leaf Images from Different Growth Periods in Natural Environment. Symmetry 2022, 14, 1671. [Google Scholar] [CrossRef]
- Lee, Y.; Hwang, J.-W.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | ResNet18 | Output Size |
|---|---|---|
| conv1 | 7 × 7, 64, stride 2 | 112 × 112 |
| conv2_x | 3 × 3 max pool stride 2 | 56 × 56 |
| × 2 | ||
| conv3_x | × 2 | 28 × 28 |
| conv4_x | × 2 | 14 × 14 |
| conv5_x | × 2 | 7 × 7 |
| Average pool, fc, softmax | 1 × 1 |
| Layer Name | GC_DRNet | Output Size |
|---|---|---|
| convolution | 7 × 7, 64, stride 2 | 112 × 112 |
| pooling | 3 × 3 max pool, stride 2 | 56 × 56 |
| GC_DRBlock (1) | × 2 | 56 × 56 |
| Transition Layer (1) | 1 × 1 conv | 28 × 28 |
| 2 × 2 avgpool, stride 2 | ||
| GC_DRBlock (2) | × 2 | 28 × 28 |
| Transition Layer (2) | 1×1 conv | 14 × 14 |
| 2 × 2 avgpool, stride 2 | ||
| GC_DRBlock (3) | × 2 | 14 × 14 |
| Transition Layer (3) | 1 × 1 conv | 7 × 7 |
| 2 × 2 avgpool, stride 2 | ||
| GC_DRBlock (4) | × 2 | 7 × 7 |
| Average pool, fc, softmax | 1 × 1 |
| Experimental Environment | Configuration Parameters |
|---|---|
| Operating system | Windows 11 |
| Processor | AMD Ryzen 7 5800H |
| GPU | NVIDIA GeForce RTX 3060 |
| Code-management software | Pycharm 2020.1.3 |
| Programming language | Python 3.8 |
| Deep-learning framework | Pytorch 1.12.1 |
| GPU-acceleration library | CUDA 11.6.134 |
| Model | Training Set Highest Accuracy/% | Accuracy of Test Set/% | Parameter/MB | Flops/109 |
|---|---|---|---|---|
| ResNet18 | 94.97 | 94.64 | 44.59 | 1.82 |
| DRNet | 96.64 | 96.52 | 10.30 | 0.87 |
| GC_DRNet | 97.07 | 96.98 | 11.65 | 0.87 |
| Model | Training Set Highest Accuracy/% | Accuracy of Test Set/% | Parameter/MB | Flops/109 |
|---|---|---|---|---|
| ResNet34 | 95.90 | 95.55 | 83.15 | 3.67 |
| ResNet50 | 95.37 | 94.93 | 97.49 | 4.12 |
| DenseNet121 | 95.44 | 95.21 | 30.44 | 2.88 |
| GC_DRNet | 97.07 | 96.98 | 11.65 | 0.87 |
| Wheat-Seed Variety | TP | FP | FN | TN | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|---|
| Jimai19 | 60 | 1 | 2 | 1691 | 98.36 | 96.77 | 97.56 |
| Jimai20 | 61 | 2 | 1 | 1690 | 96.83 | 98.39 | 97.60 |
| Jimai21 | 58 | 1 | 2 | 1693 | 98.31 | 96.67 | 97.48 |
| Jimai22 | 59 | 3 | 3 | 1689 | 95.16 | 95.16 | 95.16 |
| Jimai44 | 57 | 2 | 5 | 1690 | 96.61 | 91.94 | 94.22 |
| Jimai47 | 58 | 6 | 2 | 1688 | 90.62 | 96.67 | 93.55 |
| Lantian15 | 60 | 4 | 0 | 1690 | 93.75 | 100.00 | 96.77 |
| Lantian19 | 59 | 0 | 1 | 1694 | 100.00 | 98.33 | 99.16 |
| Lantian26 | 59 | 0 | 1 | 1694 | 100.00 | 98.33 | 99.16 |
| Lantian33 | 59 | 2 | 1 | 1692 | 96.72 | 98.33 | 97.52 |
| Lantian34 | 58 | 1 | 2 | 1693 | 98.31 | 96.67 | 97.48 |
| Lantian35 | 57 | 0 | 3 | 1694 | 100.00 | 95.00 | 97.44 |
| Lantian36 | 59 | 2 | 1 | 1692 | 96.72 | 98.33 | 97.52 |
| Lantian37 | 58 | 4 | 2 | 1690 | 93.55 | 96.67 | 95.08 |
| Lantian39 | 58 | 1 | 2 | 1693 | 98.31 | 96.67 | 97.48 |
| Lantian40 | 59 | 1 | 1 | 1693 | 98.33 | 98.33 | 98.33 |
| Lantian42 | 60 | 0 | 0 | 1694 | 100.00 | 100.00 | 100.00 |
| Lantian43 | 59 | 2 | 3 | 1690 | 96.72 | 95.16 | 95.93 |
| Lantian45 | 60 | 0 | 0 | 1694 | 100.00 | 100.00 | 100.00 |
| Lantian48 | 57 | 1 | 3 | 1693 | 98.28 | 95.00 | 96.61 |
| Lantian53 | 57 | 3 | 1 | 1693 | 95.00 | 98.28 | 96.61 |
| Lantian54 | 61 | 1 | 1 | 1691 | 98.39 | 98.39 | 98.39 |
| Lantian55 | 59 | 1 | 1 | 1693 | 98.33 | 98.33 | 98.33 |
| Zhoumai56 | 59 | 2 | 1 | 1692 | 96.72 | 98.33 | 97.52 |
| Zhoumai19 | 60 | 1 | 2 | 1691 | 98.36 | 96.77 | 97.56 |
| Zhoumai20 | 53 | 3 | 7 | 1691 | 94.64 | 88.33 | 91.38 |
| Zhoumai21 | 62 | 2 | 2 | 1688 | 96.88 | 96.88 | 96.88 |
| Zhoumai22 | 56 | 3 | 2 | 1693 | 94.92 | 96.55 | 95.73 |
| Zhoumai23 | 59 | 4 | 1 | 1690 | 93.65 | 98.33 | 95.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, X.; Liu, C.; Han, J.; Feng, Q.; Lu, Q.; Feng, Y. Wheat-Seed Variety Recognition Based on the GC_DRNet Model. Agriculture 2023, 13, 2056. https://doi.org/10.3390/agriculture13112056
Xing X, Liu C, Han J, Feng Q, Lu Q, Feng Y. Wheat-Seed Variety Recognition Based on the GC_DRNet Model. Agriculture. 2023; 13(11):2056. https://doi.org/10.3390/agriculture13112056
Chicago/Turabian StyleXing, Xue, Chengzhong Liu, Junying Han, Quan Feng, Qinglin Lu, and Yongqiang Feng. 2023. "Wheat-Seed Variety Recognition Based on the GC_DRNet Model" Agriculture 13, no. 11: 2056. https://doi.org/10.3390/agriculture13112056
APA StyleXing, X., Liu, C., Han, J., Feng, Q., Lu, Q., & Feng, Y. (2023). Wheat-Seed Variety Recognition Based on the GC_DRNet Model. Agriculture, 13(11), 2056. https://doi.org/10.3390/agriculture13112056