
Data Classification and Demand Prediction Methods Based on Semi-Supervised Agricultural Machinery Spare Parts Data

Abstract
:1. Introduction
2. Materials and Methods
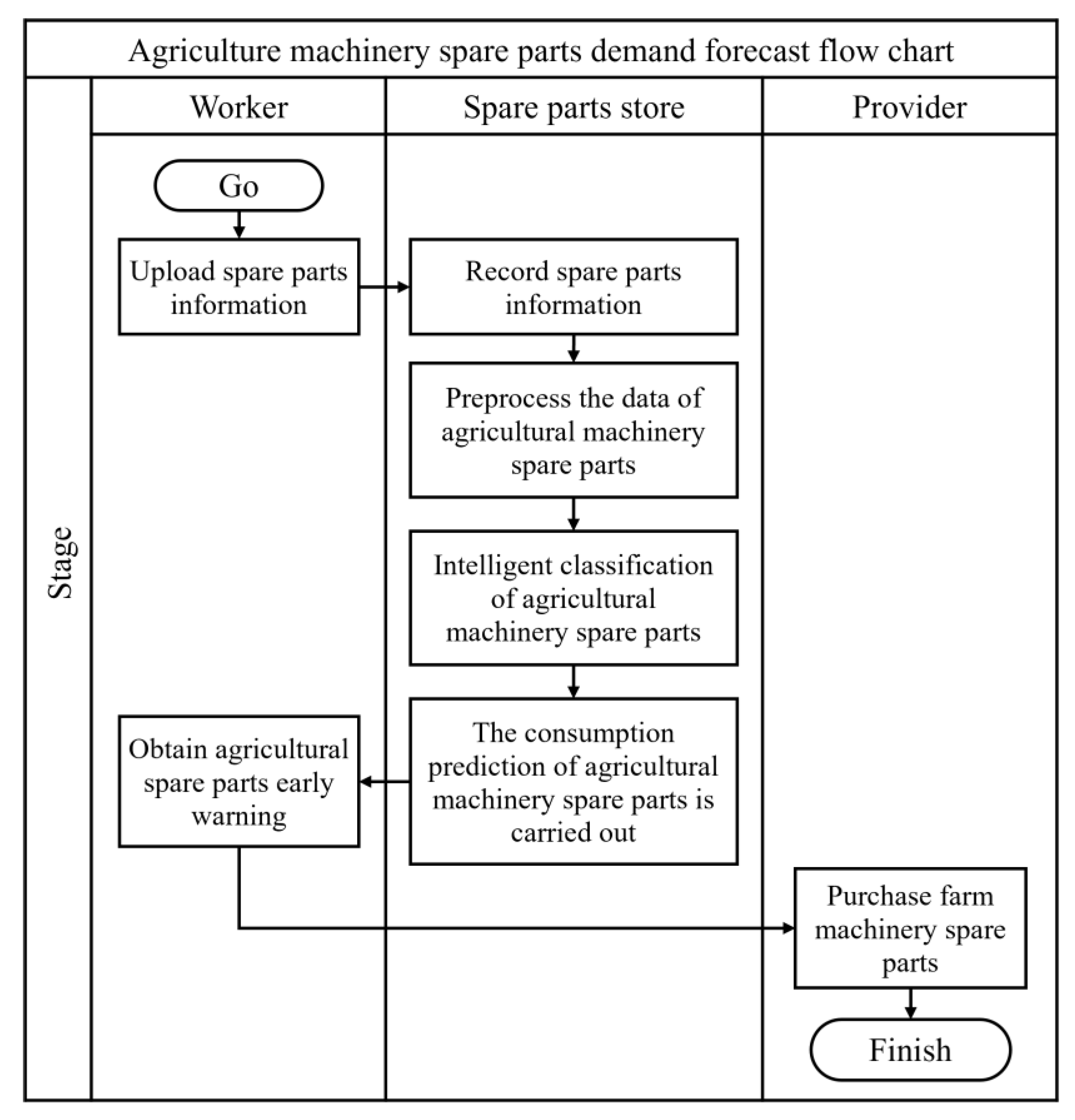
2.1. The Overall Design of the Demand for Spare Parts
2.2. Intelligent Classification Algorithm Based on Semi-Supervision
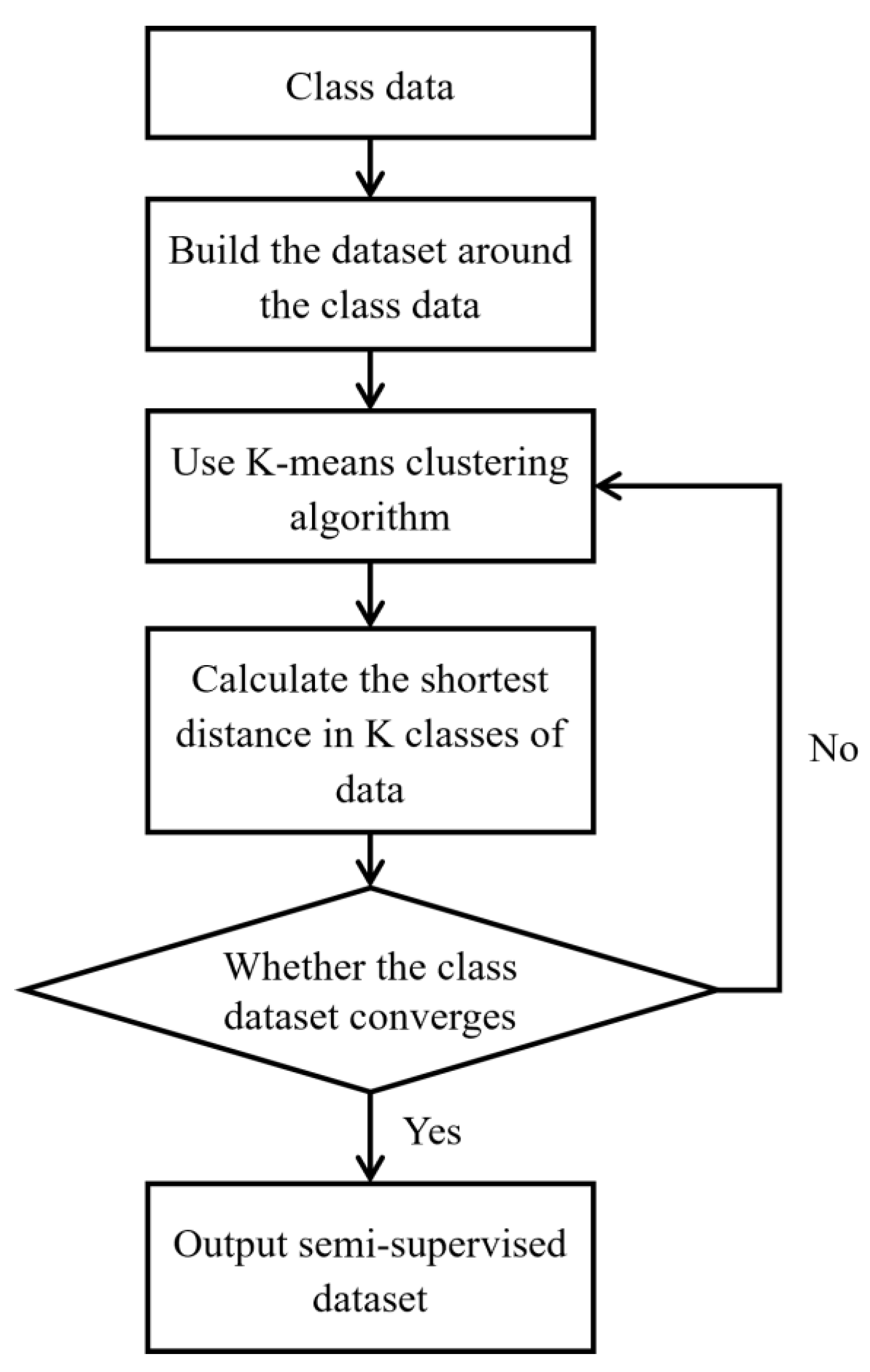
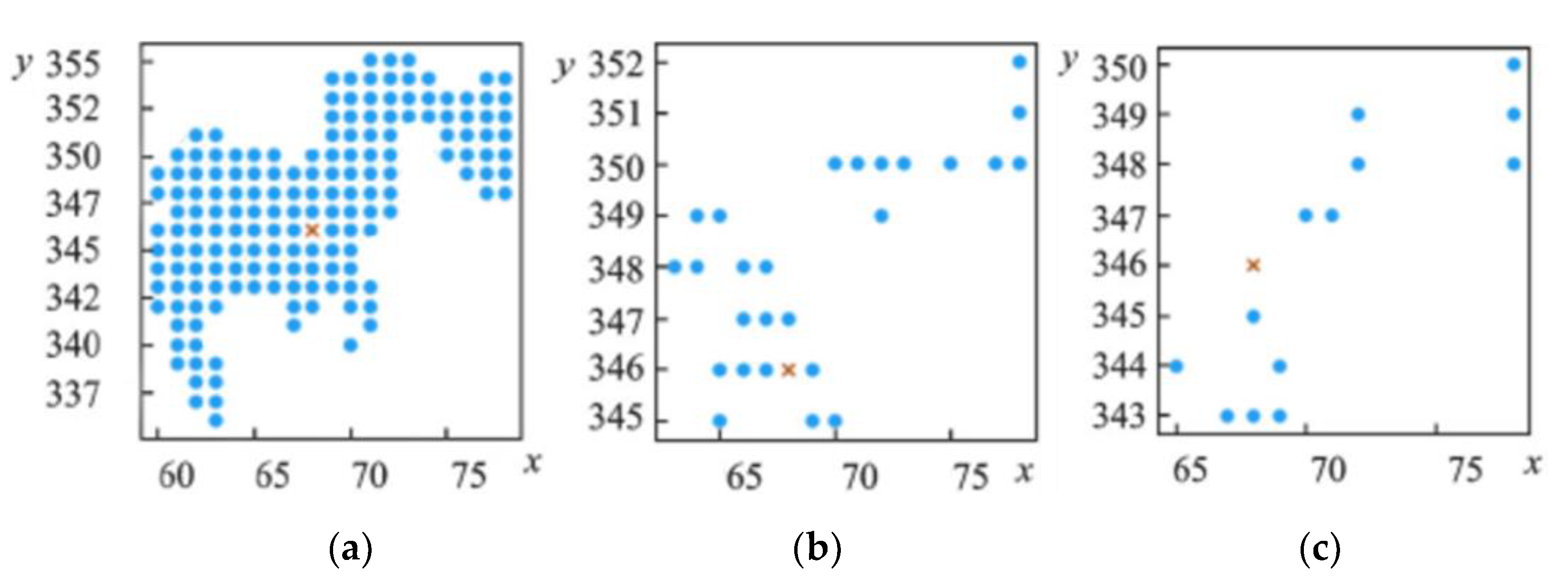
2.3. Similarity Expansion of the Positive Set Based on the K-MEANS Clustering
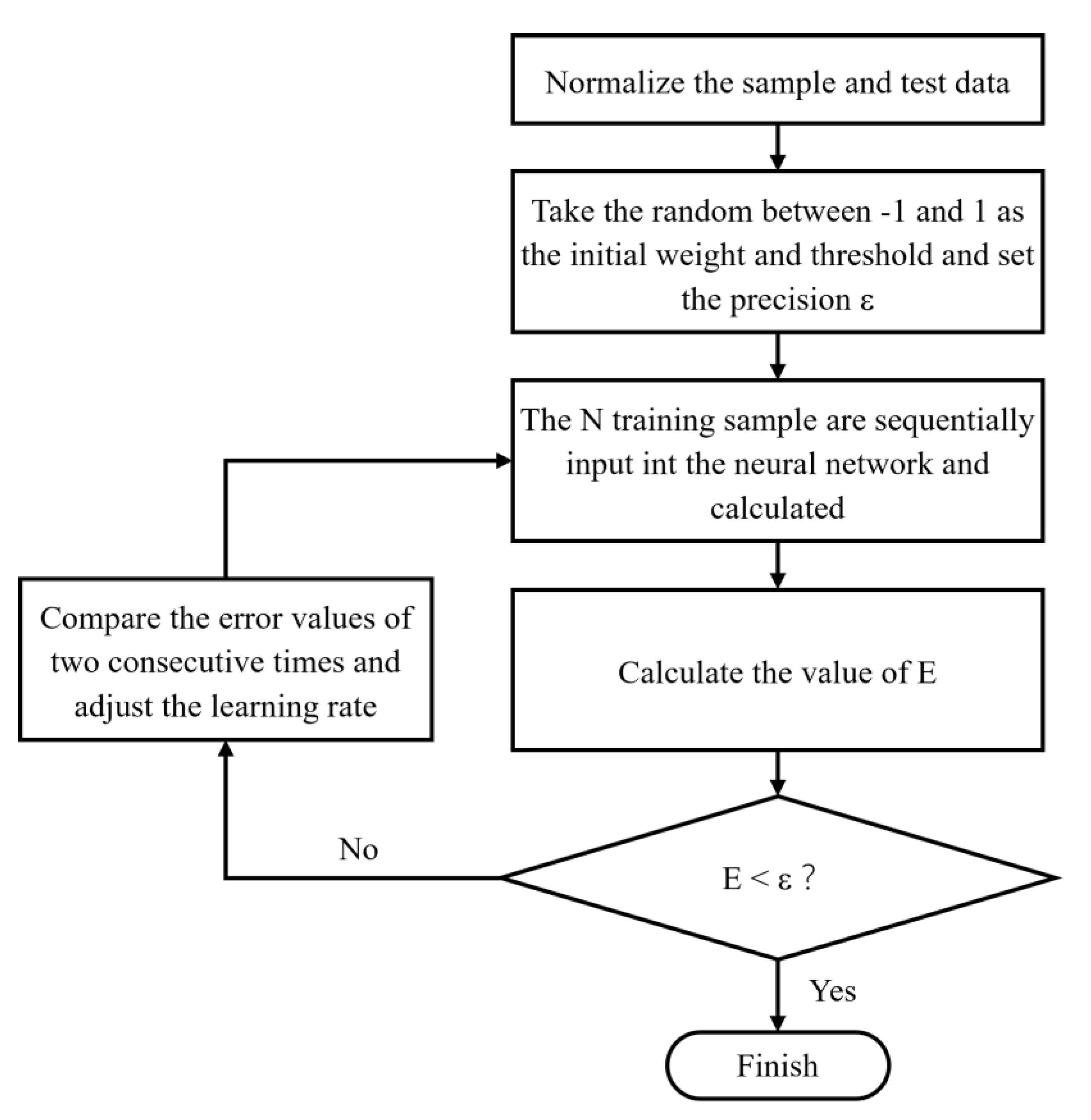
2.4. Prediction Algorithm of Spare Parts Consumption Based on BP Neural Network
3. Results and Discussion
3.1. Performance Evaluation of Classification Algorithm Based on Semi-Supervised Learning
3.2. Performance Evaluation of Prediction Algorithm Based on IPS0-BP Neural Network
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Guimaraes, C.B.; Marques, J.M.; Tortato, U. Demand forecasting for high-turnover spare parts in agricultural and construction machines: A case study. South Afr. J. Ind. Eng. 2020, 31, 116–128. [Google Scholar] [CrossRef]
- Haffar, I. “SPAM”: A computer model for management of spare-parts inventories in agricultural machinery dealerships. Comput. Electron. Agric. 1995, 12, 323–332. [Google Scholar] [CrossRef]
- Hu, Y.G.; Sun, S.; Wen, J.Q. Agricultural Machinery Spare Parts Demand Forecast Based on BP Neural Network. In Applied Mechanics and Materials; Trans Tech Publications Ltd.: Hangzhou, China, 2014; Volume 3485, pp. 635–637. [Google Scholar]
- Łukaszewski, K.; Buchwald, T.; Wichniarek, R. The FDM Technique in Processes of Prototyping Spare Parts for Servicing and Repairing Agricultural Machines: A General Outline. Int. J. Appl. Mech. Eng. 2021, 26, 145–155. [Google Scholar] [CrossRef]
- Ziouzios, D.; Baras, N.; Balafas, V.; Dasygenis, M.; Stimoniaris, A. Intelligent and Real-Time Detection and Classification Algorithm for Recycled Materials Using Convolutional Neural Networks. Recycling 2022, 7, 9. [Google Scholar] [CrossRef]
- Yang, H.; Li, X.; Liu, Z.; Wang, L.; Luo, Q. Trajectory time series classification algorithm based on convolutional self-attention mechanism. J. Phys. Conf. Ser. 2021, 1961, 012037. [Google Scholar] [CrossRef]
- Tsai, P.F.; Wang, C.H.; Zhou, Y.; Ren, J.; Jones, A.; Watts, S.O.; Chou, C.; Ku, W.S. A classification algorithm to predict chronic pain using both regression and machine learning—A stepwise approach. Appl. Nurs. Res. 2021, 62, 151504. [Google Scholar] [CrossRef]
- Sun, G.; Wang, Z.; Ding, Z.; Zhao, J. An Ensemble Classification Algorithm for Short Text Data Stream with Concept Drifts. IAENG Int. J. Comput. Sci. 2021, 48, 4. [Google Scholar]
- Chen, Z.; Chen, Y.; Xiao, T.; Wang, H.; Hou, P. A novel short-term load forecasting framework based on time-series clustering and early classification algorithm. Energy Build. 2021, 251, 111375. [Google Scholar] [CrossRef]
- Fu, Y.; Yan, M.; Zhang, X.; Xu, L.; Yang, D.; Kymer, J.D. Automated classification of software change messages by semi-supervised Latent Dirichlet Allocation. Inf. Softw. Technol. 2015, 57, 369–377. [Google Scholar] [CrossRef]
- Pang, T.; Wong, J.H.D.; Ng, W.L.; Chan, C.S. Semi-supervised GAN-based Radiomics Model for Data Augmentation in Breast Ultrasound Mass Classification. Comput. Methods Programs Biomed. 2021, 203, 106018. [Google Scholar] [CrossRef]
- Xing, X.; Yu, Y.; Jiang, H.; Du, S. A multi-manifold semi-supervised Gaussian mixture model for pattern classification. Pattern Recognit. Lett. 2013, 34, 2118–2125. [Google Scholar] [CrossRef]
- Piroonsup, N.; Sinthupinyo, S. Semi-supervised cluster-and-label with feature based re-clustering to reduce noise in Thai document images. Knowl.-Based Syst. 2015, 90, 58–69. [Google Scholar] [CrossRef]
- Jing-Yu, C.; Ya-Jun, W. Semi-Supervised Fake Reviews Detection based on AspamGAN. J. Artif. Intell. 2022, 4, 17–36. [Google Scholar] [CrossRef]
- Hore, U.W.; Wakde, D.G. An Effective Approach of IIoT for Anomaly Detection Using Unsupervised Machine Learning Approach. J. IoT Soc. Mob. Anal. Cloud 2022, 4, 184–197. [Google Scholar]
- Lutkoski, S. Neural Network Numerosity. Am. Sci. 2019, 107, 207. [Google Scholar]
- Ding, S.; Su, C.; Yu, J. An optimizing BP neural network algorithm based on genetic algorithm. Artif. Intell. Rev. 2011, 36, 153–162. [Google Scholar] [CrossRef]
- Li, G.; Deng, L.; Chua, Y.; Li, P.; Neftci, E.O.; Li, H. Editorial: Spiking Neural Network Learning, Benchmarking, Programming and Executing. Front. Neurosci. 2020, 14, 276. [Google Scholar] [CrossRef]
- Han, J.-B.; Kim, S.-H.; Jang, M.-H.; Ri, K.S. Using Genetic Algorithm and NARX Neural Network to Forecast Daily Bitcoin Price. Comput. Econ. 2019, 2, 337–353. [Google Scholar] [CrossRef]
- Jain, A.K.; Goel, D.; Agarwal, S.; Singh, Y.; Bajaj, G. Predicting Spam Messages Using Back Propagation Neural Network. Wirel. Pers. Commun. 2020, 110, 403–422. [Google Scholar] [CrossRef]
- Zhang, S.; Hu, Y.; Wang, C. Evaluation of borrower’s credit of P2P loan based on adaptive particle swarm optimisation BP neural network. Int. J. Comput. Sci. Eng. 2019, 19, 197–205. [Google Scholar] [CrossRef]
- Hong, Y.; Liao, H.; Jiang, Y. Construction Engineering Cost Evaluation Model and Application Based on RS-IPSO-BP Neural Network. J. Comput. 2014, 9, 1020–1025. [Google Scholar] [CrossRef]
- Jiang, J. BP Neural Network Algorithm Optimized by Genetic Algorithm and Its Simulation. Int. J. Comput. Sci. Issues 2013, 10, 516–519. [Google Scholar]
- Liu, K. The Prediction Model and System of Stock Rise and Fall Based on BP Neural Network. Acad. J. Bus. Manag. 2022, 4, 67–72. [Google Scholar]
- Kanungo, D.P.; Naik, B.; Nayak, J.; Baboo, S.; Behera, H.S. An Improved Pso Based Back Propagation Learning-MLP (IPSO-BP-MLP) for Classification. In Computational Intelligence in Data Mining-Volume 1; Springer: Berlin/Heidelberg, Germany, 2015; pp. 333–344. [Google Scholar]
- Li, S.; Quan, Y. Financial risk prediction for listed companies using IPSO-BP neural network. Int. J. Perform. Eng. 2019, 15, 1209. [Google Scholar] [CrossRef]
- Wen, L.; Liu, Y. A research about Beijing’s carbon emissions based on the IPSO-BP model. Environ. Prog. Sustain. Energy 2017, 36, 428–434. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, B.; Zhao, Y.; Pan, G. Wind Speed Prediction of IPSO-BP Neural Network Based on Lorenz Disturbance; IEEE Access: Piscataway, NJ, USA, 2018; Volume 6. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classify | Accuracy | Recall Rate | F1 |
|---|---|---|---|
| Traditional method | 0.84 | 0.00 | 0.00 |
| Semi-supervised method | 0.39 | 0.41 | 0.18 |
| Time | Real Value | Predicted Value | Absolute Error | Relative Error |
|---|---|---|---|---|
| 9.15 | 800 | 797 | 3 | 0.375 |
| 9.17 | 813 | 811 | 2 | 0.246 |
| 9.20 | 885 | 889 | −4 | 0.453 |
| 9.25 | 892 | 893 | −1 | 0.112 |
| 9.30 | 921 | 917 | 4 | 0.434 |
| 10.01 | 942 | 940 | 2 | 0.212 |
| Time | Real Value | BP Predicted Value | IPSO-BP Predicted Value | BP Relative Error | IPSO-BP Relative Error |
|---|---|---|---|---|---|
| 9.15 | 800 | 793 | 797 | 0.875 | 0.375 |
| 9.17 | 813 | 808 | 811 | 0.615 | 0.246 |
| 9.20 | 885 | 882 | 889 | 0.339 | 0.452 |
| 9.25 | 892 | 895 | 893 | 0.336 | 0.112 |
| 9.30 | 921 | 910 | 917 | 1.194 | 0.434 |
| 10.01 | 942 | 941 | 940 | 0.106 | 0.212 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, C.; Zhao, B.; Liu, S.; Zhang, W.; Zhou, L.; Li, Y.; Guo, R. Data Classification and Demand Prediction Methods Based on Semi-Supervised Agricultural Machinery Spare Parts Data. Agriculture 2023, 13, 49. https://doi.org/10.3390/agriculture13010049
Qiu C, Zhao B, Liu S, Zhang W, Zhou L, Li Y, Guo R. Data Classification and Demand Prediction Methods Based on Semi-Supervised Agricultural Machinery Spare Parts Data. Agriculture. 2023; 13(1):49. https://doi.org/10.3390/agriculture13010049
Chicago/Turabian StyleQiu, Conghui, Bo Zhao, Suchun Liu, Weipeng Zhang, Liming Zhou, Yashuo Li, and Ruoyu Guo. 2023. "Data Classification and Demand Prediction Methods Based on Semi-Supervised Agricultural Machinery Spare Parts Data" Agriculture 13, no. 1: 49. https://doi.org/10.3390/agriculture13010049
APA StyleQiu, C., Zhao, B., Liu, S., Zhang, W., Zhou, L., Li, Y., & Guo, R. (2023). Data Classification and Demand Prediction Methods Based on Semi-Supervised Agricultural Machinery Spare Parts Data. Agriculture, 13(1), 49. https://doi.org/10.3390/agriculture13010049