
Prediction Model for Tea Polyphenol Content with Deep Features Extracted Using 1D and 2D Convolutional Neural Network


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
2.1.1. Sample Collection
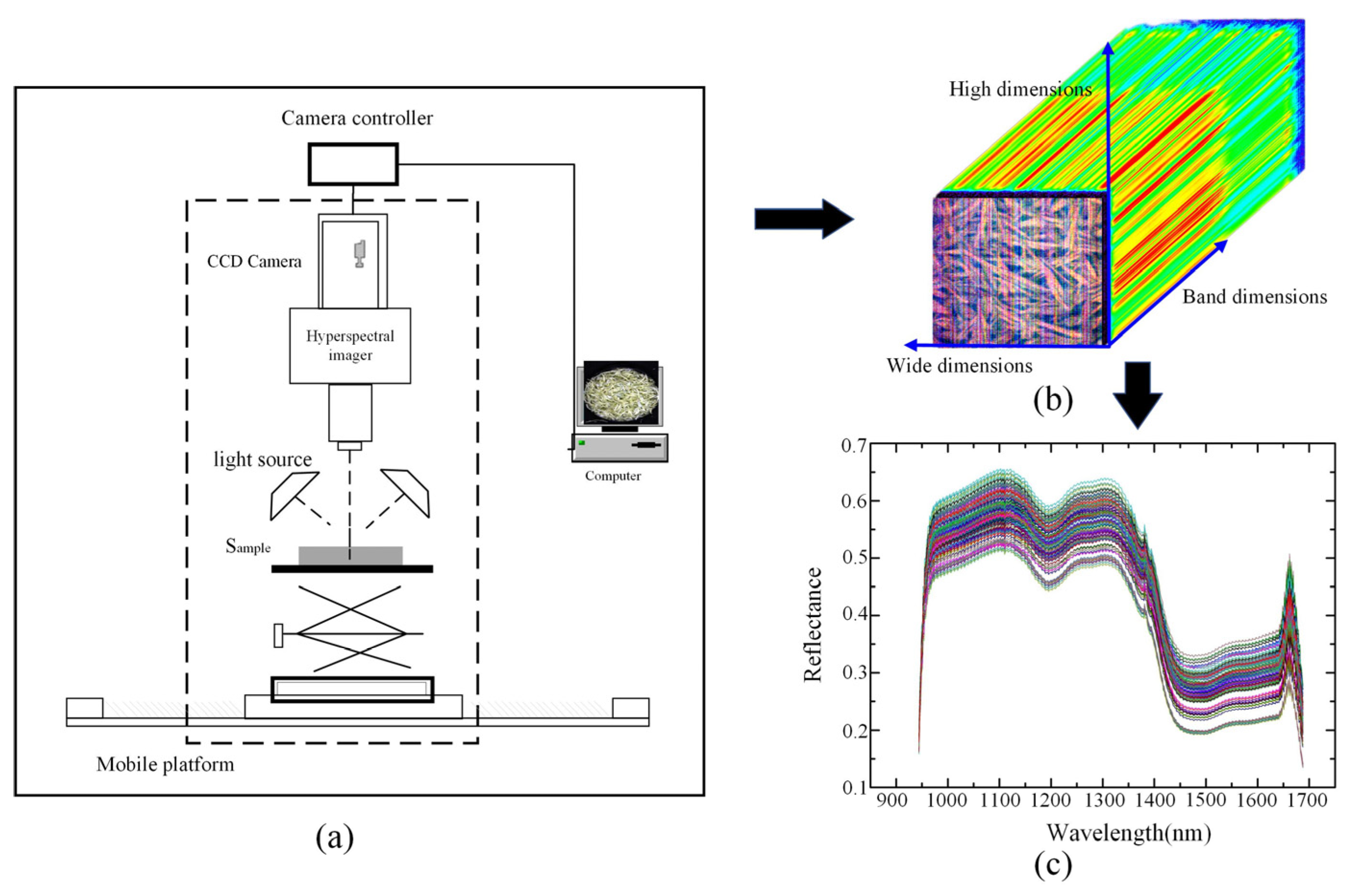
2.1.2. Hyperspectral Images Collection
2.1.3. Tea Polyphenol Content Collection
2.2. Method
2.2.1. Convolutional Neural Network
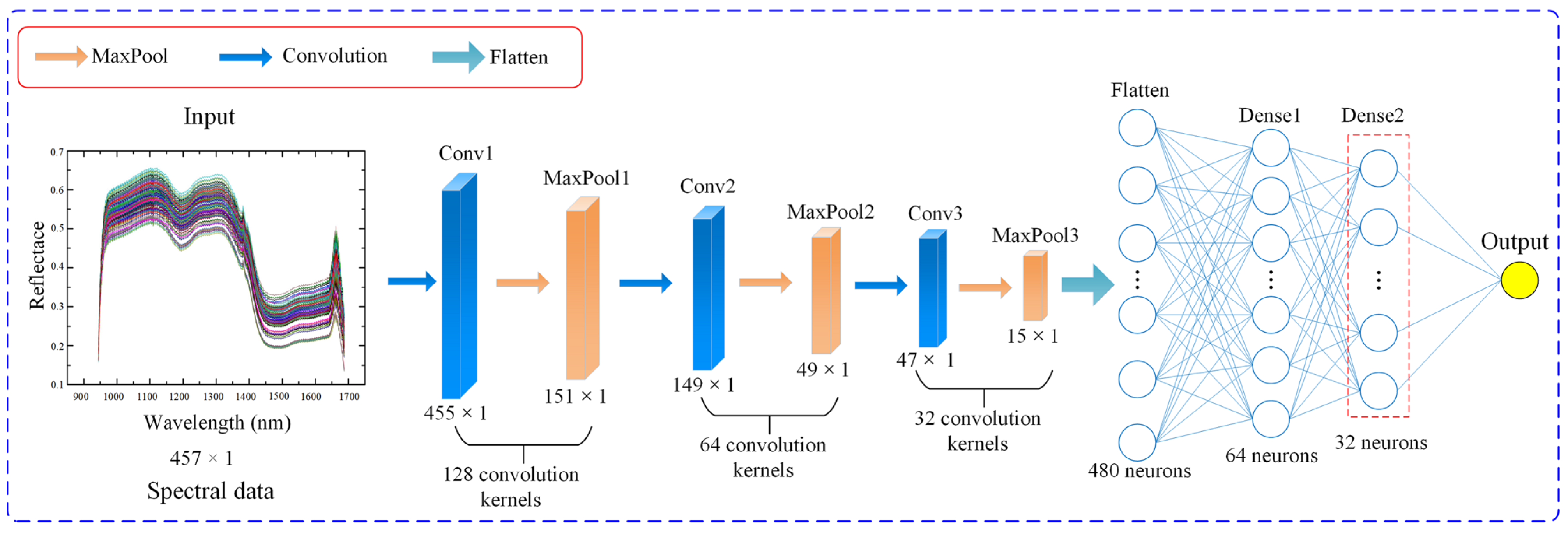
2.2.2. Spectral Deep Feature Extraction Using 1D-CNN
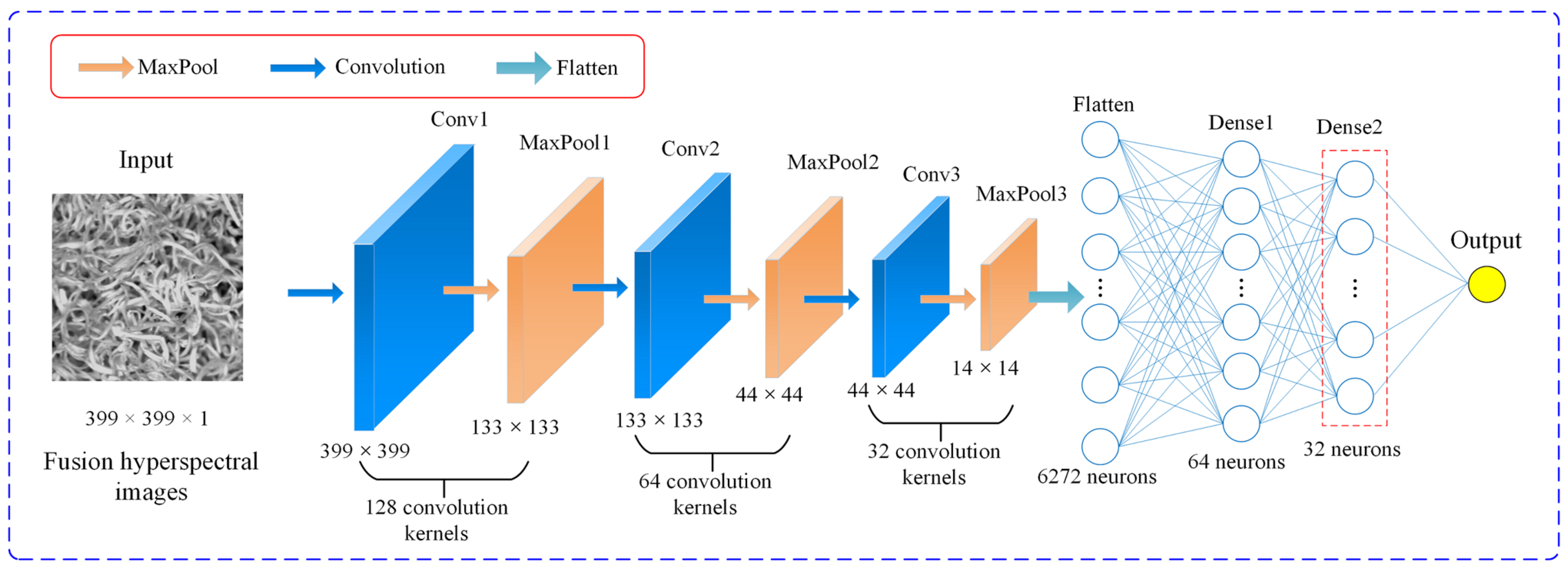
2.2.3. Spatial Deep Feature Extraction Based on 2D-CNN
2.2.4. Estimation of Tea Polyphenol Content Based on Deep Features
3. Results
3.1. Spectral Data and Spatial Deep Features Acquisition
3.2. Hyperspectral Images and Spatial Deep Features Acquisition
3.3. Prediction Model of Tea Polyphenols Content with Spectral-Spatial Deep Features
4. Discussion
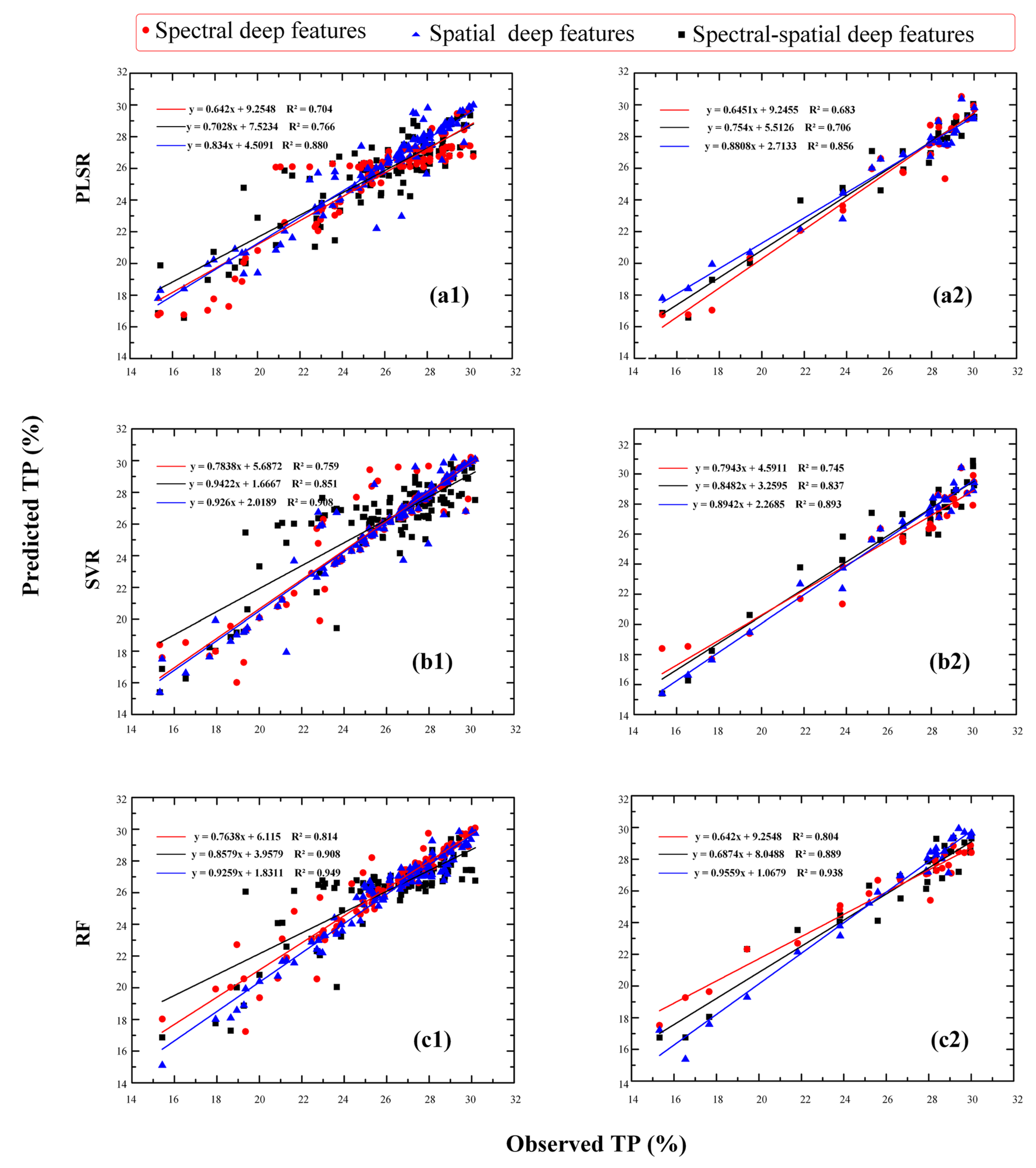
4.1. Comparison Results of Prediction Model for Tea Polyphenols
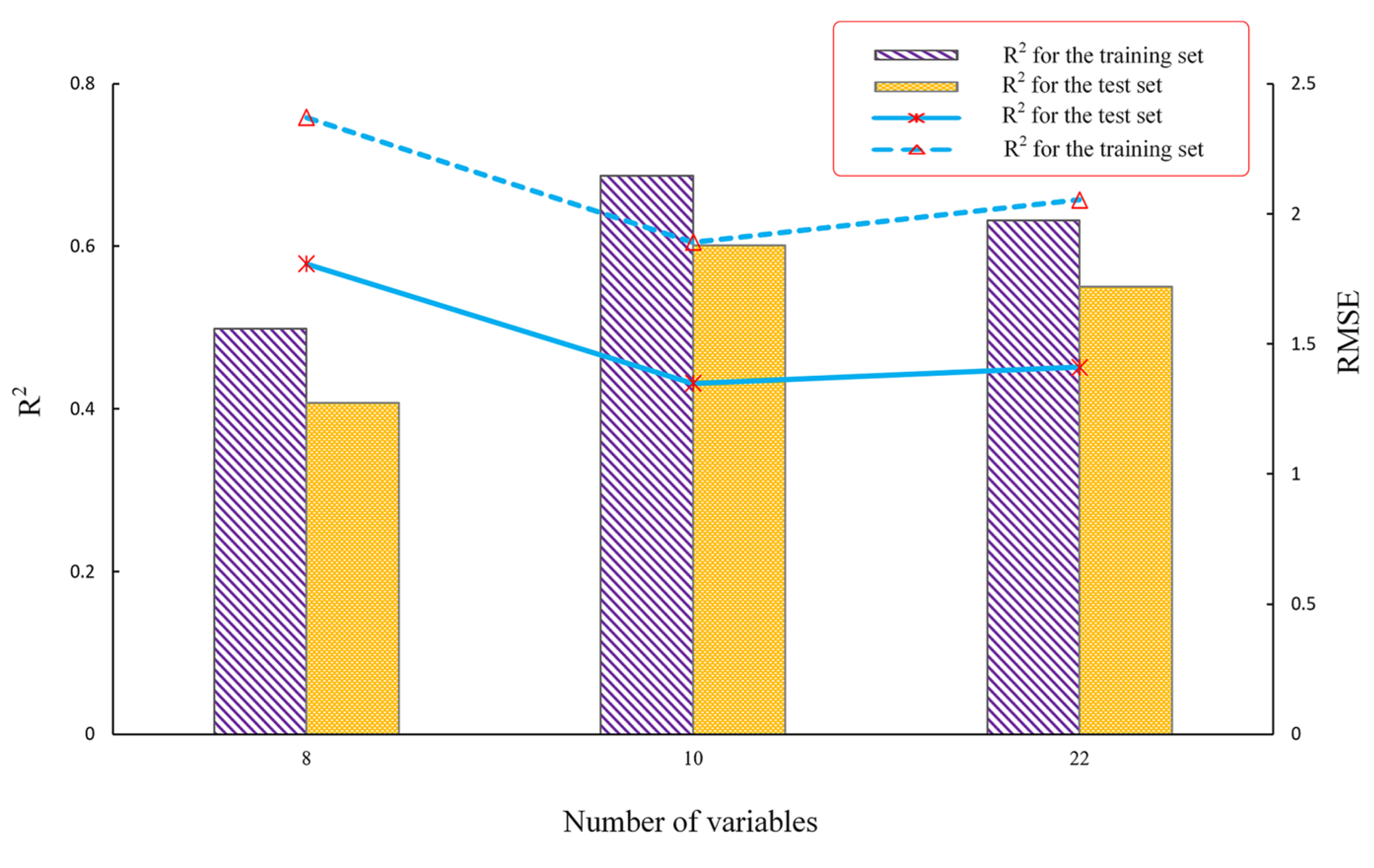
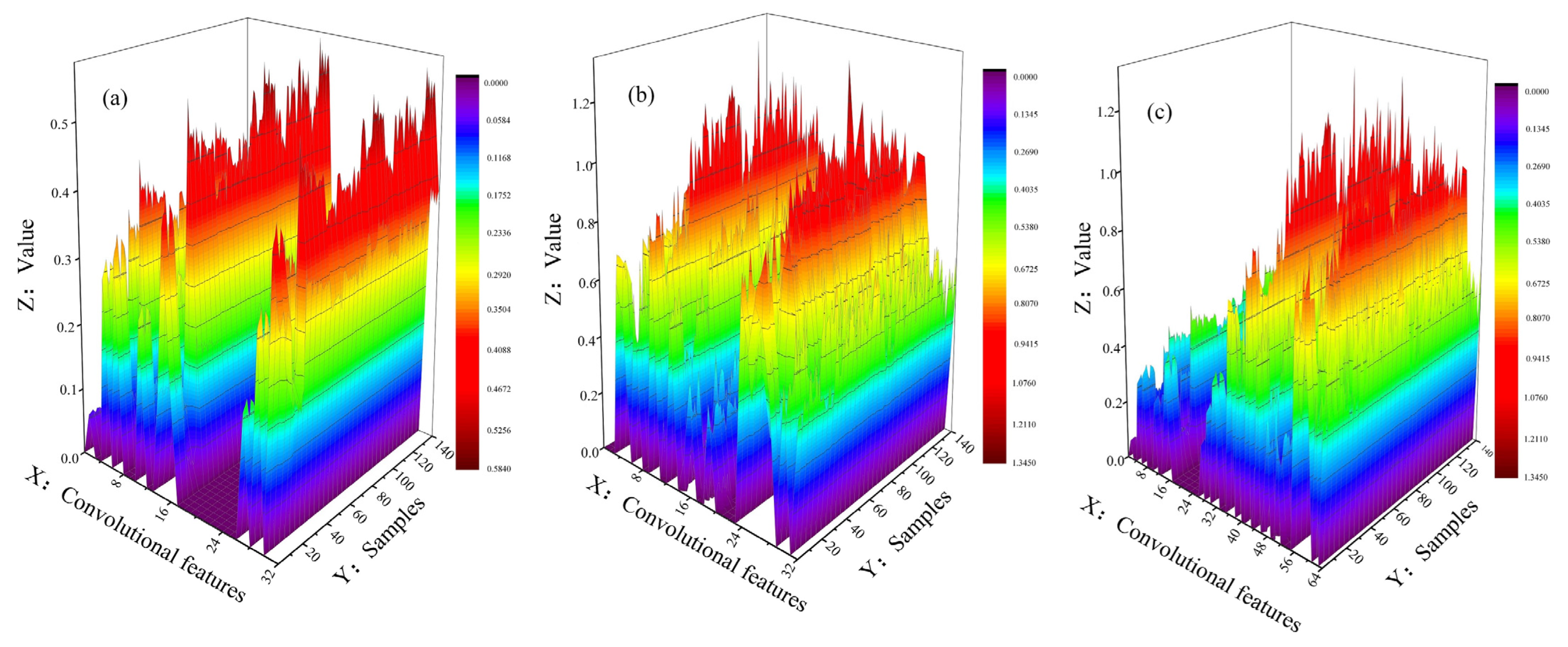
4.2. Comparison of Extraction Results of Different Deep Features
4.3. Visualization of Tea Polyphenol Content Prediction Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Murugesh, C.S.; Rastogi, N.K.; Subramanian, R. Athermal extraction of green tea: Optimisation and kinetics of extraction of polyphenolic compounds. Innov. Food Sci. Emerg. Technol. 2018, 50, 207–2162018. [Google Scholar] [CrossRef]
- Santanu, S.; Bhuyan, L.P.; Goswam, B.C.; Mridul, H. Seasonal and cultivar variation of catechin in north east Indian tea. Sci. Cult. 2011, 77, 406–411. [Google Scholar]
- Zhang, M.; Dai, E.; Zhang, Y.; Yu, Y.; Song, X. Advances in Research of Green Tea Polyphenols in Drug Development. Med. Plant 2020, 11, 10–16. [Google Scholar]
- Yang, B.; Zhu, Y.; Wang, M.; Ning, J. A model for yellow tea polyphenols content estimation based on multi-feature fusion. IEEE Access 2019, 7, 180054–180063. [Google Scholar] [CrossRef]
- Hocker, N.; Wang, C.; Prochotsky, J.; Eppurath, A.; Rudd, L.; Perera, M. Quantification of antioxidant properties in popular leaf and bottled tea by high-performance liquid chromatography (HPLC), spectrophotometry, and voltammetry. Anal. Lett. 2017, 50, 1640–1656. [Google Scholar] [CrossRef]
- Mirasoli, M.; Gotti, R.; di Fusco, M.; Leoni, A.; Colliva, C.; Roda, A. Electronic nose and chiral-capillary electrophoresis in evaluation of the quality changes in commercial green tea leaves during a long-term storage. Talanta 2014, 129, 32–38. [Google Scholar] [CrossRef]
- Lee, M.S.; Hwang, Y.S.; Lee, J.; Choung, M.G. The characterization of caffeine and nine individual catechins in the leaves of green tea (Camellia sinensis L.) by near-infrared reflectance spectroscopy. Food Chem. 2014, 158, 351–357. [Google Scholar] [CrossRef]
- Zhang, S.; Zuo, Y.; Wu, Q.; Wang, J.; Ban, L.; Yang, H.; Bai, Z. Development and Validation of Near-Infrared Methods for the Quantitation of Caffeine, Epigallocatechin-3-gallate, and Moisture in Green Tea Production. J. Anal. Methods Chem. 2021, 2021, 9563162. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, R.; Yang, C.; Hu, B.; Luo, X.; Li, Y.; Dong, C. Research on moisture content detection method during green tea processing based on machine vision and near-infrared spectroscopy technology. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 271, 120921. [Google Scholar] [CrossRef]
- Li, X.; Jin, J.; Sun, C.; Ye, D.; Liu, Y. Simultaneous determination of six main types of lipid-soluble pigments in green tea by visible and near-infrared spectroscopy. Food Chem. 2019, 270, 236–242. [Google Scholar] [CrossRef]
- Liu, P.; Wen, Y.; Huang, J.; Xiong, A.; Wen, J.; Li, H.; Huang, Y.; Zhu, X.; Ai, S.; Wu, R. A novel strategy of near-infrared spectroscopy dimensionality reduction for discrimination of grades, varieties and origins of green tea. Vib. Spectrosc. 2019, 105, 102984. [Google Scholar] [CrossRef]
- Hazarika, A.K.; Chanda, S.; Sabhapondit, S.; Sanyal, S.; Tamuly, P.; Tasrin, S.; Sing, D.; Tudu, B.; Bandyopadhyay, R. Quality assessment of fresh tea leaves by estimating total polyphenols using near infrared spectroscopy. J. Food Sci. Technol. 2018, 55, 4867–4876. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Zhao, J.; Liu, M.; Cai, J.; Liu, J. Determination of total polyphenols content in green tea using FT-NIR spectroscopy and different PLS algorithms. J. Pharm. Biomed. Anal. 2008, 46, 568–573. [Google Scholar] [CrossRef] [PubMed]
- Bian, M.; Skidmore, A.K.; Schlerf, M.; Wang, T.; Liu, Y.; Zeng, R.; Fei, T. Predicting foliar biochemistry of tea (Camellia sinensis) using reflectance spectra measured at powder, leaf and canopy levels. ISPRS J. Photogramm. Remote Sens. 2013, 78, 148–156. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, Y.; Liu, G.; Fan, N.; Li, Y.; Sun, Y. Rapid evaluation of texture parameters of Tan mutton using hyperspectral imaging with optimization algorithms. Food Control. 2022, 135, 108815. [Google Scholar] [CrossRef]
- Yang, B.; Qi, L.; Wang, M.; Hussain, S.; Wang, H.; Wang, B.; Ning, J. Cross-Category Tea Polyphenols Evaluation Model Based on Feature Fusion of Electronic Nose and Hyperspectral Imagery. Sensors 2020, 20, 50. [Google Scholar] [CrossRef] [PubMed]
- Kang, Y.S.; Ryu, C.; Suguri, M.; Park, S.B.; Kishino, S.; Onoyama, H. Estimating the catechin concentrations of new shoots in green tea fields using ground-based hyperspectral imagery. Food Chem. 2022, 370, 130987. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Gao, Y.; Li, H.; Ye, S.; He, H.; Xie, S. Rapid prediction of yellow tea free amino acids with hyperspectral images. PLoS ONE 2019, 14, e0210084. [Google Scholar] [CrossRef]
- Yang, C.; Zhao, Y.; An, T.; Liu, Z.; Jiang, Y.; Li, Y.; Dong, C. Quantitative prediction and visualization of key physical and chemical components in black tea fermentation using hyperspectral imaging. LWT 2021, 141, 110975. [Google Scholar] [CrossRef]
- Saikrithika, S.; Senthil Kumar, A. Electrochemical detections of tea polyphenols: A review. Electroanalysis 2020, 32, 2343–2360. [Google Scholar] [CrossRef]
- Cui, Q.; Yang, B.; Liu, B.; Li, Y.; Ning, J. Tea Category Identification Using Wavelet Signal Reconstruction of Hyperspectral Imagery and Machine Learning. Agriculture 2022, 12, 1085. [Google Scholar] [CrossRef]
- Yang, B.; Gao, Z.; Gao, Y.; Zhu, Y. Rapid Detection and Counting of Wheat Ears in the Field Using YOLOv4 with Attention Module. Agronomy 2021, 11, 1202. [Google Scholar] [CrossRef]
- Venugopal, N. Automatic semantic segmentation with DeepLab dilated learning network for change detection in remote sensing images. Neural Processing Lett. 2020, 51, 2355–2377. [Google Scholar] [CrossRef]
- Liu, L.; Shi, Z.; Pan, B.; Zhang, N.; Luo, H.; Lan, X. Multiscale deep spatial feature extraction using virtual RGB image for hyperspectral imagery classification. Remote Sens. 2020, 12, 280. [Google Scholar] [CrossRef]
- Diakite, A.; Jiangsheng, G.; Xiaping, F. Hyperspectral image classification using 3D 2D CNN. IET Image Process. 2021, 15, 1083–1092. [Google Scholar] [CrossRef]
- Yu, G.; Ma, B.; Chen, J.; Li, X.; Li, Y.; Li, C. Nondestructive identification of pesticide residues on the Hami melon surface using deep feature fusion by Vis/NIR spectroscopy and 1D-CNN. J. Food Process Eng. 2021, 44, e13602. [Google Scholar] [CrossRef]
- Xu, M.; Sun, J.; Yao, K.; Cai, Q.; Shen, J.; Tian, Y.; Zhou, X. Developing deep learning based regression approaches for prediction of firmness and pH in Kyoho grape using Vis/NIR hyperspectral imaging. Infrared Phys. Technol. 2022, 120, 104003. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Wang, B.; Shao, Q.; Song, D.; Li, Z.; Tang, Y.; Yang, C.; Wang, M. A spectral-spatial features integrated network for hyperspectral detection of marine oil spill. Remote Sens. 2021, 13, 1568. [Google Scholar] [CrossRef]
- Cao, X.; Ge, Y.; Li, R.; Zhao, J.; Jiao, L. Hyperspectral imagery classification with deep metric learning. Neurocomputing 2019, 356, 217–227. [Google Scholar] [CrossRef]
- Guo, A.J.; Zhu, F. A CNN-based spatial feature fusion algorithm for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7170–7181. [Google Scholar] [CrossRef]
- Kavitha, M.; Gayathri, R.; Polat, K.; Alhudhaif, A.; Alenezi, F. Performance evaluation of deep e-CNN with integrated spatial-spectral features in hyperspectral image classification. Measurement 2022, 191, 110760. [Google Scholar] [CrossRef]
- Zhu, S.; Zhou, L.; Gao, P.; Bao, Y.; He, Y.; Feng, L. Near-infrared hyperspectral imaging combined with deep learning to identify cotton seed varieties. Molecules 2019, 24, 3268. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Yang, C.; Hao, Z.; Xie, C.; Li, M. Diagnosis of plant cold damage based on hyperspectral imaging and convolutional neural network. IEEE Access 2019, 7, 118239–118248. [Google Scholar] [CrossRef]
- He, W.; He, H.; Wang, F.; Wang, S.; Lyu, R. Non-destructive detection and recognition of pesticide residues on garlic chive (Allium tuberosum) leaves based on short wave infrared hyperspectral imaging and one-dimensional convolutional neural network. J. Food Meas. Charact. 2021, 15, 4497–4507. [Google Scholar] [CrossRef]
- Rehman, T.U.; Ma, D.; Wang, L.; Zhang, L.; Jin, J. Predictive spectral analysis using an end-to-end deep model from hyperspectral images for high-throughput plant phenotyping. Comput. Electron. Agric. 2020, 177, 105713. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, W.; Zhou, L.; Cheng, H.; Ye, X.; He, Y. Developing deep learning based regression approaches for determination of chemical compositions in dry black goji berries (Lycium ruthenicum Murr.) using near-infrared hyperspectral imaging. Food Chem. 2020, 319, 126536. [Google Scholar] [CrossRef]
- Park, K.; Ki Hong, Y.; Hwan Kim, G.; Lee, J. Classification of apple leaf conditions in hyper-spectral images for diagnosis of Marssonina blotch using mRMR and deep neural network. Comput. Electron. Agric. 2018, 148, 179–187. [Google Scholar] [CrossRef]
- Pang, L.; Men, S.; Yan, L.; Xiao, J. Rapid vitality estimation and prediction of corn seeds based on spectra and images using deep learning and hyperspectral imaging techniques. IEEE Access 2020, 8, 123026–123036. [Google Scholar] [CrossRef]
- Polder, G.; Blok, P.M.; de Villiers, H.A.; van der Wolf, J.M.; Kamp, J. Potato virus Y detection in seed potatoes using deep learning on hyperspectral images. Front. Plant Sci. 2019, 10, 209. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, Y.; Feng, X.; Xu, H.; Chen, J.; He, Y. Identification of bacterial blight resistant rice seeds using terahertz imaging and hyperspectral imaging combined with convolutional neural network. Front. Plant Sci. 2020, 11, 821. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Gao, Y.; Yan, Q.; Qi, L.; Zhu, Y.; Wang, B. Estimation Method of Soluble Solid Content in Peach Based on Deep Features of Hyperspectral Imagery. Sensors 2020, 20, 5021. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Varieties | Level | Manufacturer | Named | Sample |
|---|---|---|---|---|
| Huangshan Maofeng | L1 | GM | L1-GM | 10 |
| ZX | L1-ZX | 10 | ||
| ZYY | L1-ZYY | 10 | ||
| HS | L1-HS | 10 | ||
| ZW | L1-ZW | 10 | ||
| FS | L1-FS | 10 | ||
| YHT | L1-YHT | 10 | ||
| L2 | ZW | L2-ZW | 10 | |
| GM | L2-GM | 10 | ||
| YHT | L2-YHT | 10 | ||
| ZYY | L2-ZYY | 10 | ||
| YJY | L2-YJY | 10 | ||
| WXS | L2-WXS | 10 | ||
| FS | L2-FS | 10 |
| Layer | Kernel | Number Kernels | Stride | Output |
|---|---|---|---|---|
| Input | — | — | — | 457 × 1 |
| Conv1 | 3 × 1 | 128 | 1 | 455 × 1 × 128 |
| Pool1 | 3 × 1 | 128 | 1 | 151 × 1 × 128 |
| Conv2 | 3 × 1 | 64 | 1 | 149 × 1 × 64 |
| Pool2 | 3 × 1 | 64 | 1 | 49 × 1 × 64 |
| Conv3 | 3 × 1 | 32 | 1 | 47 × 1 × 32 |
| Pool3 | 3 × 1 | 32 | 1 | 15 × 1 × 32 |
| Flatten | – | – | – | 480 |
| Dense1 | – | – | – | 64 |
| Dense2 | – | – | – | 32 |
| Layer | Kernel | Number Kernels | Stride | Output |
|---|---|---|---|---|
| Input | —— | —— | —— | 399 × 399 |
| Conv1 | 3 × 3 | 128 | 1 | 399 × 399 × 128 |
| Pool1 | 3 × 3 | 128 | 3 | 133 × 133 × 128 |
| Conv2 | 3 × 3 | 64 | 1 | 133 × 133 × 64 |
| Pool2 | 3 × 3 | 64 | 3 | 44 × 44 × 64 |
| Conv3 | 3 × 3 | 32 | 1 | 44 × 44 × 32 |
| Pool3 | 3 × 3 | 32 | 3 | 14 × 14 × 32 |
| Flatten | – | – | – | 6272 |
| Dense1 | – | – | – | 64 |
| Dense2 | – | – | – | 32 |
| Features | Model | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | R2 | RMSE | MAE | ||
| Spectral deep features | PLSR | 0.704 | 1.595 | 1.240 | 0.683 | 2.366 | 1.866 |
| SVR | 0.759 | 1.425 | 1.048 | 0.745 | 2.271 | 2.021 | |
| RF | 0.814 | 1.261 | 1.017 | 0.804 | 1.901 | 1.762 | |
| Spatial deep features | PLSR | 0.766 | 1.437 | 1.031 | 0.706 | 2.462 | 1.957 |
| SVR | 0.851 | 1.167 | 0.613 | 0.837 | 1.831 | 1.596 | |
| RF | 0.908 | 0.924 | 0.552 | 0.889 | 1.661 | 1.514 | |
| Spectral-spatial Deep features | PLSR | 0.880 | 1.029 | 0.626 | 0.856 | 1.642 | 1.123 |
| SVR | 0.908 | 0.885 | 0.427 | 0.893 | 1.456 | 1.279 | |
| RF | 0.949 | 0.665 | 0.533 | 0.938 | 1.043 | 0.799 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, N.; Li, Y.; Yang, B.; Liu, B.; Dai, Q. Prediction Model for Tea Polyphenol Content with Deep Features Extracted Using 1D and 2D Convolutional Neural Network. Agriculture 2022, 12, 1299. https://doi.org/10.3390/agriculture12091299
Luo N, Li Y, Yang B, Liu B, Dai Q. Prediction Model for Tea Polyphenol Content with Deep Features Extracted Using 1D and 2D Convolutional Neural Network. Agriculture. 2022; 12(9):1299. https://doi.org/10.3390/agriculture12091299
Chicago/Turabian StyleLuo, Na, Yunlong Li, Baohua Yang, Biyun Liu, and Qianying Dai. 2022. "Prediction Model for Tea Polyphenol Content with Deep Features Extracted Using 1D and 2D Convolutional Neural Network" Agriculture 12, no. 9: 1299. https://doi.org/10.3390/agriculture12091299
APA StyleLuo, N., Li, Y., Yang, B., Liu, B., & Dai, Q. (2022). Prediction Model for Tea Polyphenol Content with Deep Features Extracted Using 1D and 2D Convolutional Neural Network. Agriculture, 12(9), 1299. https://doi.org/10.3390/agriculture12091299