1. Introduction
Corn is one of the most cultivated planted crops worldwide and a crucial source of grain in the world. It was estimated that, by 2020, about a third of global farms were cultivating corn [
1]. Ensuring production is of great importance for world food security. Corn yield is subject to various factors, among which the influence of pests is prominent. For instance, the corn borer, a very menacing pest, first eats the mesophyll during the growth of corn, and then damages the leaves. After being gnawed, the yield of the crop is seriously reduced, and the stalk is easily broken in windy conditions. As a result, early meticulous pest control has great significance. Moreover, a prerequisite for control is accurate monitoring of the degree of pest damage. In traditional agriculture, this monitoring behavior depends on agricultural experts, but manual investigation has many drawbacks: low efficiency, strong subjectivity, and being error prone. Fortunately, the development of information science provides new problem-solving ideas [
2]; for example, precision agriculture combines information technology and agricultural production. In precision agriculture, a crucial issue is that of to accurately detecting pest regions and applying pesticides in a targeted and precise manner according to the degree of damage in different areas. As shown in
Figure 1, crop images are first taken at fixed points according to the flight path planned by the UAV. The images are then preprocessed and the pest regions are detected by computer vision techniques. Finally, the severity of damage to different regions is assessed using clustering algorithms, which produce a heat map of degree of infestation. The key to this entire set of algorithms for automatically assessing the damage degree of the pest regions is the ability to accurately identify targets. Therefore, an automatic pest region detection model with accurate identification and fast localization is required.
In previous studies, computer vision techniques based on machine learning received attention in order to develop accurate and fast methods for pest monitoring. Qin et al. [
3] proposed extracting edge features of stored-grain pests by the spectral residual (SR) method and used this feature to perform saliency edge detection. Camargo et al. [
4] extracted the image features of cotton-crop disease areas, retained the main features and used the features as the input of the Support Vector Machine to identify cotton crop diseases. The above models based on traditional machine learning achieved good results. However, their performance mainly depended on the accuracy of manually extracted target region features and the controllability of the external environment. There are often several problems in the actual farmland, such as a complex environment and the small size of the pest region in the collected image; the detection accuracy of traditional methods are, therefore, adversely affected.
Deep learning technology developed rapidly in recent years, achieving much better performance than traditional machine learning, so it is being widely applied in the agricultural field. As early as 2016, Ding et al. [
5] proposed a sliding-window detection algorithm with a convolutional neural network to automatically detect and count pests. Huang et al. [
6] proposed a Multi-Attention and Multi-Part convolutional neural Network (MAMPNet) for citrus fly identification, combined with electronic traps for monitoring. Wang et al. [
7] proposed a sampling-balanced region proposal network and introduced an attention mechanism into the residual network to enhance the features of small-object pest regions. In addition to the improvement of the network, many scholars discussed the issues from the perspective of data. Li et al. [
8] proposed an effective data augmentation strategy for the CNN-based method, which rotates images to various degrees and crops them to different grids during the training phase to obtain a large number of multi-scale representations. In the final step, the detection results of different scale images are fused. By so doing, they demonstrated the effectiveness of the strategy in four pest datasets. Dai et al. [
9] proposed a generative adversarial network with multiple attention, residual, and dense fusion mechanisms to upscale low-resolution pest images to increase spatial resolution and reconstruct high-frequency details of images, resulting in the recall rate of pest detection being observably improved.
Most pest detection tasks are special subtasks of small-object detection, similar to the study in this paper; small objects are difficult to detect due to low resolution and limited pixels [
10]. The object on the top left of
Figure 2a is hard to identify on its own; however, by considering the surrounding information, such as a row of small holes appearing to its right, the target on the left can be recognized as a pest region. Therefore, we believe that reinforcing the target feature context can alleviate the difficulty of small pest region detection shown in
Figure 2. In the research of small object detection, the context-priming method is the currently popular and is being applied in various fields. Lim et al. [
9] proposed FA-SSD based on SSD [
11]; the model consists of an attention block and a feature-fusion module, introducing high-level context information to improve the accuracy of small target detection. Wang et al. [
12] presented a two-stage, mobile-vision-based cascading pest detection approach (DeepPest), which uses the multi-scale context information of images to build a context-aware attention network, and fuses features from different layers through a multi-projection pest detection model (MDM). Xu et al. [
13] introduced a knowledge graph into object detection, encoded the context by constructing the knowledge graph which enhanced the features with the prior context information, and verified the superiority of the model through experiments. Ilyas et al. [
14] adopted a multi-scale context aggregation approach for strawberry recognition, where the size of the receptive field was dynamically modified by the adaptive receptive field module to aggregate context information at different scales.
However, the above approaches either tend to build complicated models to learn contextual information, or when learning the information at different scales, the feature fusion methods adopted are not sufficient to fully utilize the features to overcome semantic gap. This paper, therefore, proposes a context-priming module with a simple structure, which introduces additional contextual information to augment the features of a corn-borer pest region. On the other hand, to suppress the interference similar to the complex background shown in
Figure 2, a multi-scale mixed attention mechanism (MSMAM) is developed to strengthen the representation ability of effective features and reduce interference. Finally, fusing the additional contextual information at different scales by simple operations, such as add or concatenation, only provides fixed linear aggregation of feature maps, and often fails to take full advantage of these features [
15,
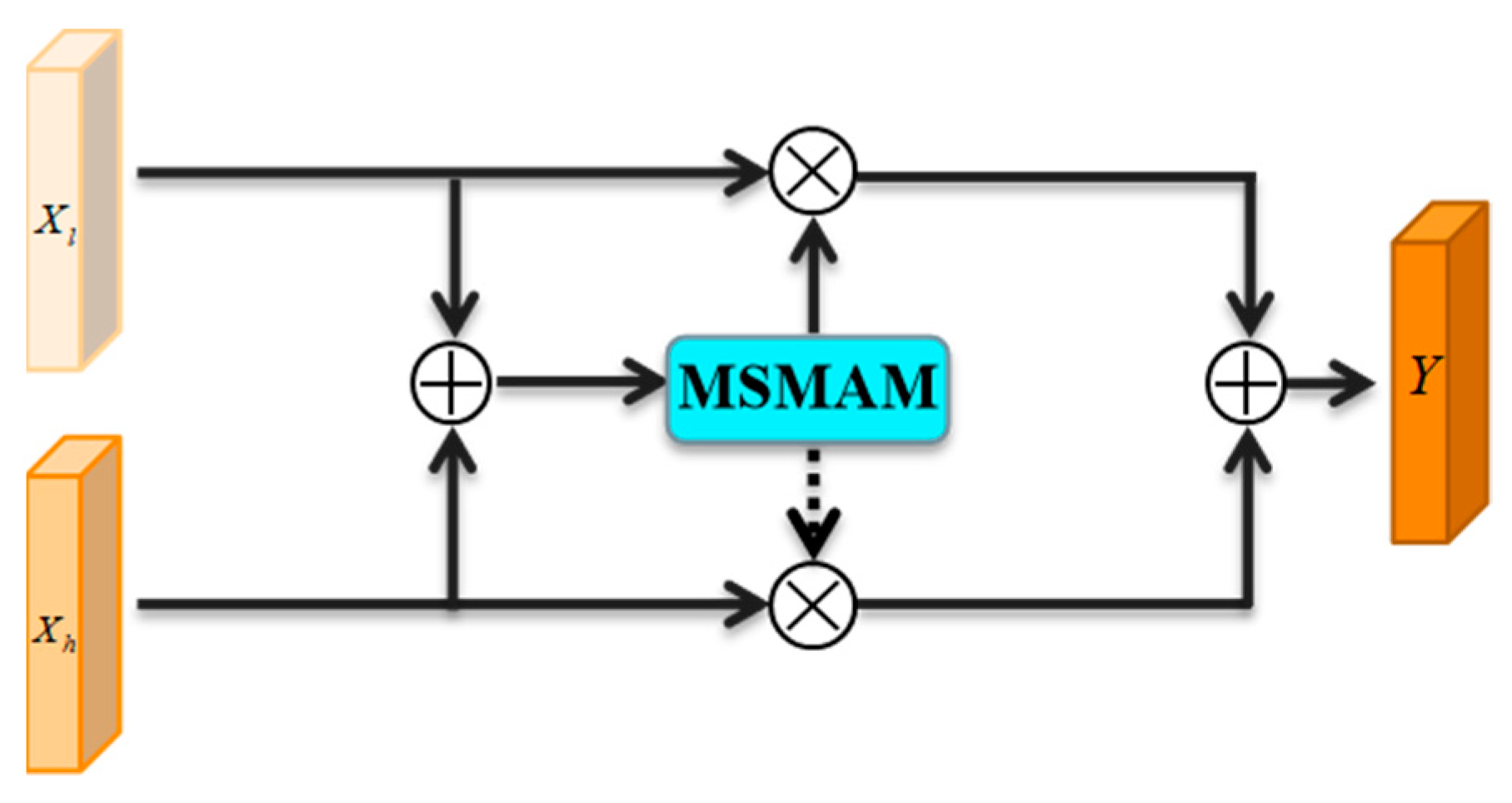
16], so a non-linear fusion method based on MSMAM, mixed attention feature fusion (MAFF) is adopted, to fully fuse effective multi-scale features and mitigate their inconsistency.
In terms of baseline models, the YOLO [
17,
18,
19,
20] series is an advanced single-stage object-detection algorithm. Lippi et al. [
21] used YOLOv4 to detect pests collected by traps arranged in orchards; Liu et al. [
22] improved YOLOv3 based on the idea of feature fusion for the detection of tomato diseases and pests in the natural environment; Fang et al. [
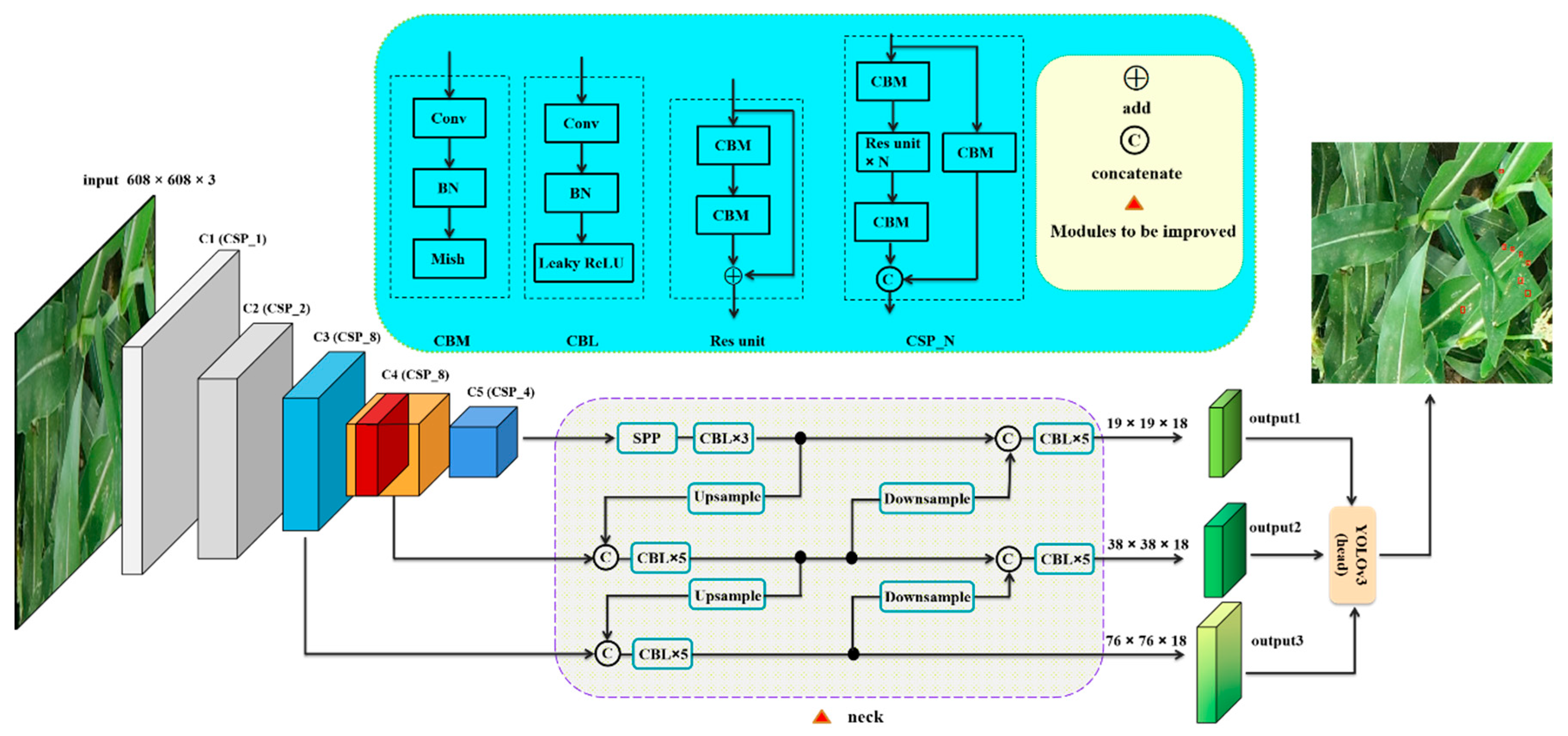
23] proposed an improved YOLOv3 network and improved the detection speed by a pruning operation for fast and accurate detection of ginger images. The above research results demonstrate that the YOLO series of algorithms produce good results in the agricultural field, so we selected YOLOv4 as the baseline model, and our proposed methods were incorporated to improve the original network.
The main contributions of this paper are as follows:
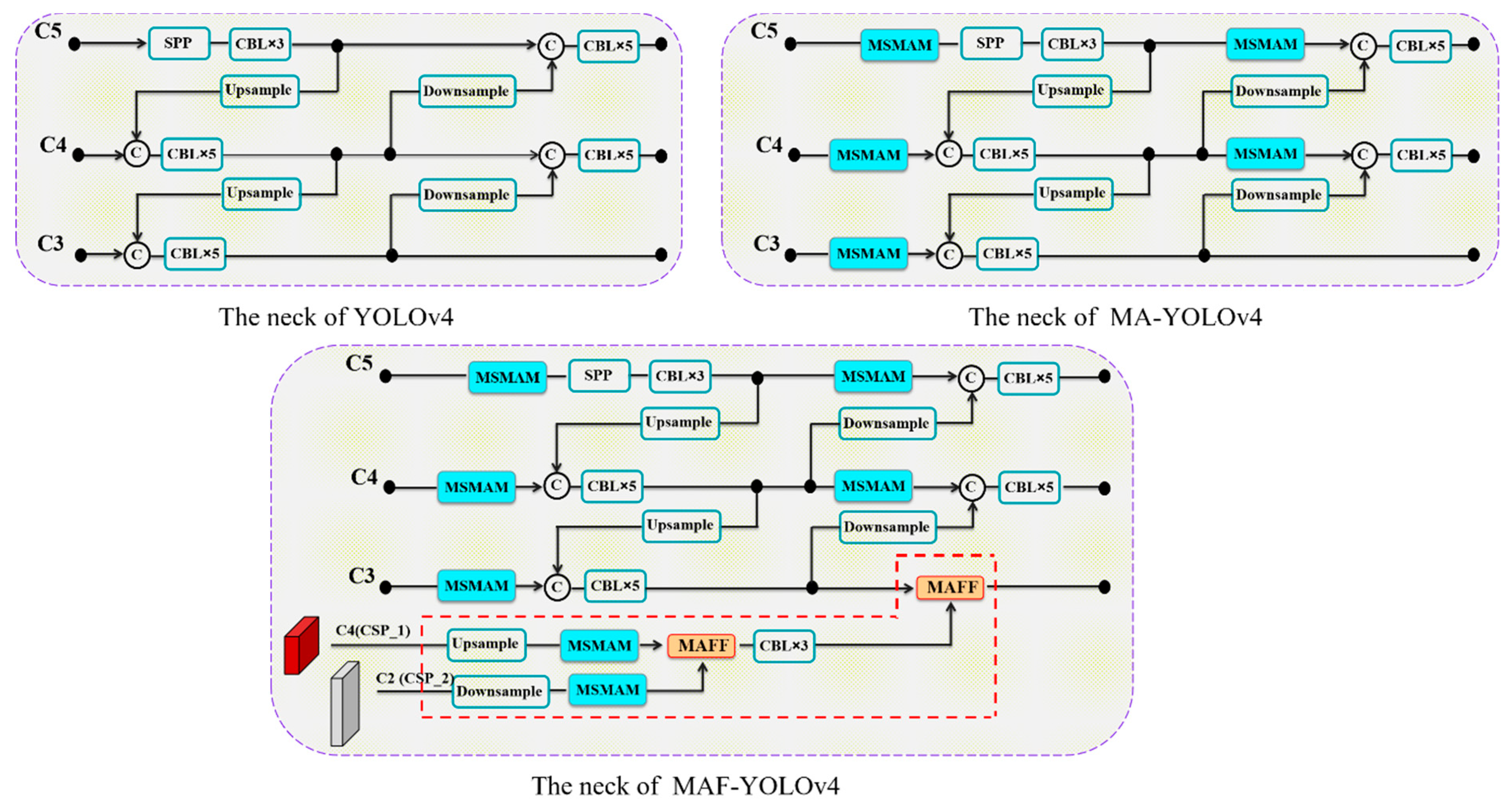
A simple yet effective context-priming module is proposed for intensifying pest region feature representation by fusing shallow fine-grained features with deep semantic features as additional contextual information.
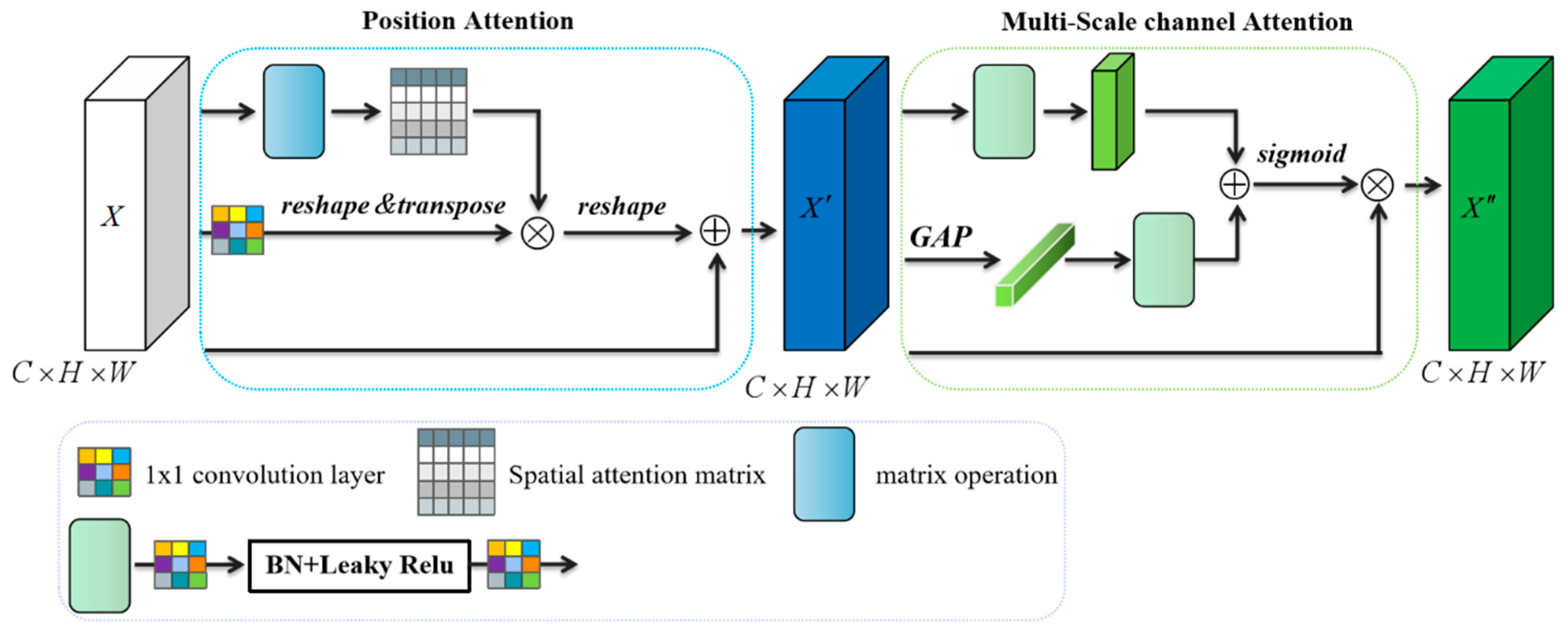
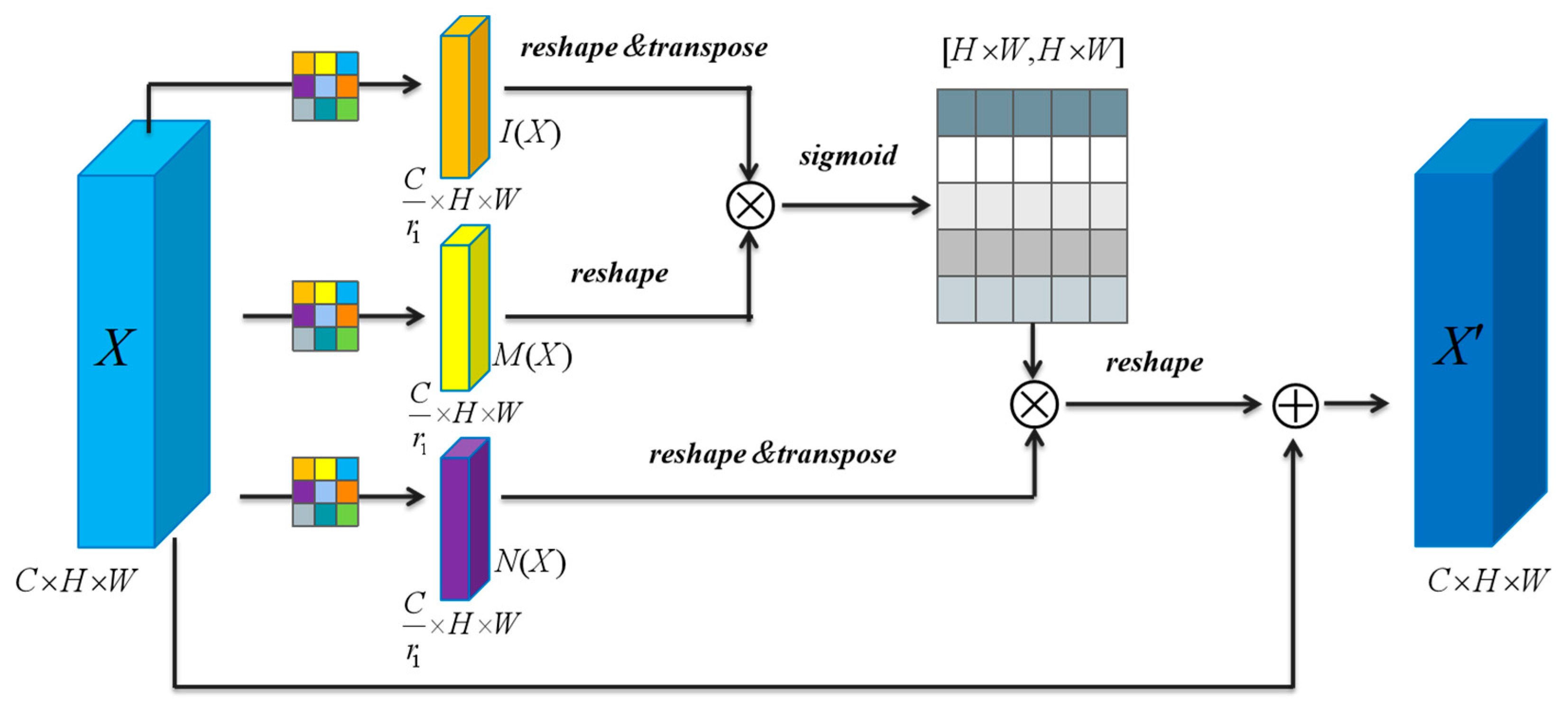
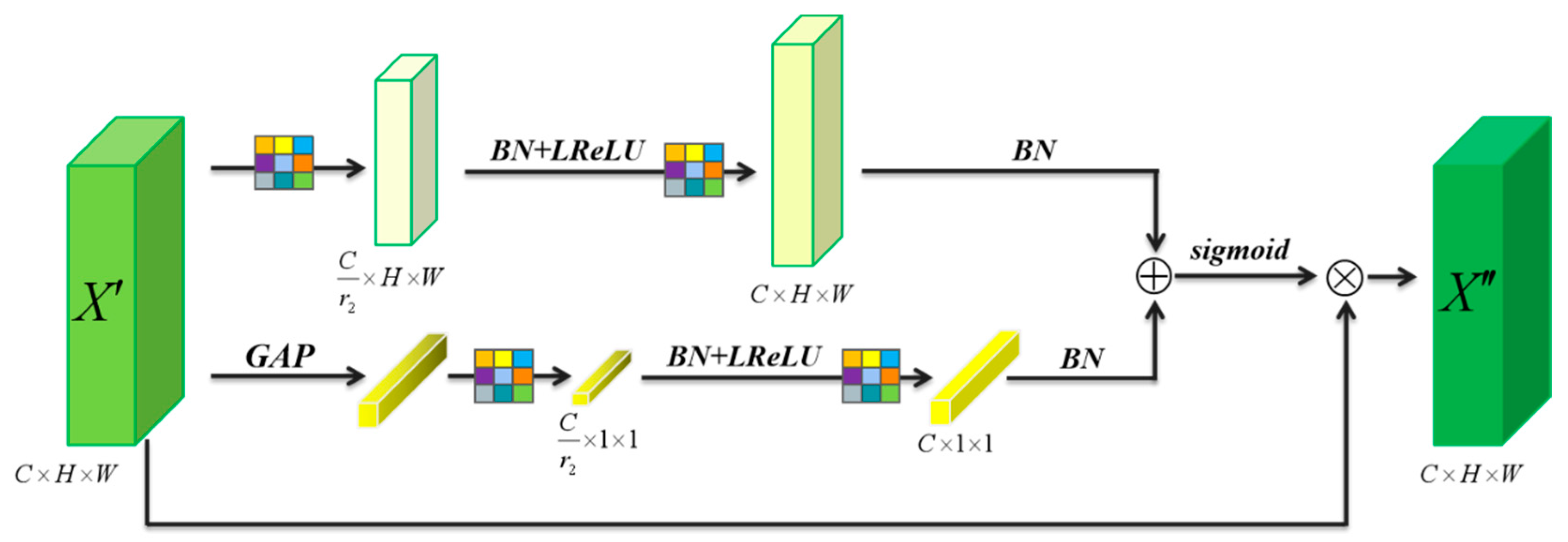
MSMAM further improves the feature representation of a pest region through spatial dependence of different locations and channel dimensions of different scales. Based on this, MAFF is proposed to alleviate the inconsistencies in the context feature fusion of different scales by learning fusion weights and retaining useful features for fusion, these methods being applied to improve YOLOv4.
To comprehensively evaluate the improved model, we conducted extensive experiments on data from a variety of corn growth cycles. The experimental results show that our approach achieves better performance and robustness. It can provide a technical reference for future pest monitoring projects in precision agriculture.
3. Results and Discussion
In this section, we verify and analyze the method proposed in this paper through different combined comparative experiments on different growth cycle data; the experimental datasets are DV12, DVT, and DV12&DVT—a combination of the former two. The specific experimental environment is shown in
Table 1.
Due to limited GPU resources, we set the batch-size to eight and the initial learning rate to 0.001, which gradually decays according to the initial settings. Parameters, such as momentum and weight decay, refer to the initial parameters in YOLOv4; the number of training iterations was 50,000. For the sample size, resolution which is more difficult to detect was selected for experiments to verify the effect of the model on small pest region detection.
To accurately evaluate the detection performance of a model, the following evaluation metrics are usually adopted in object detection:
precision,
recall, F1-score, and average precision (
AP); accordingly, we used these to evaluate the performance of our proposed model. The specific calculation method was as follows:
where
TP is true positive samples,
FP is false positive samples,
TN is the true negative samples,
FN is false negative samples, and
AP is the area under the PR curve. The
precision rate and
recall rate obtain different values due to different
thresholds; we set the threshold to 0.5 in this paper. In the evaluation index, the
AP or F1-score is usually used to comprehensively evaluate the detection performance of an algorithm. In this paper, we considered
AP as the reference metric in order to evaluate model performance more comprehensively and fairly.
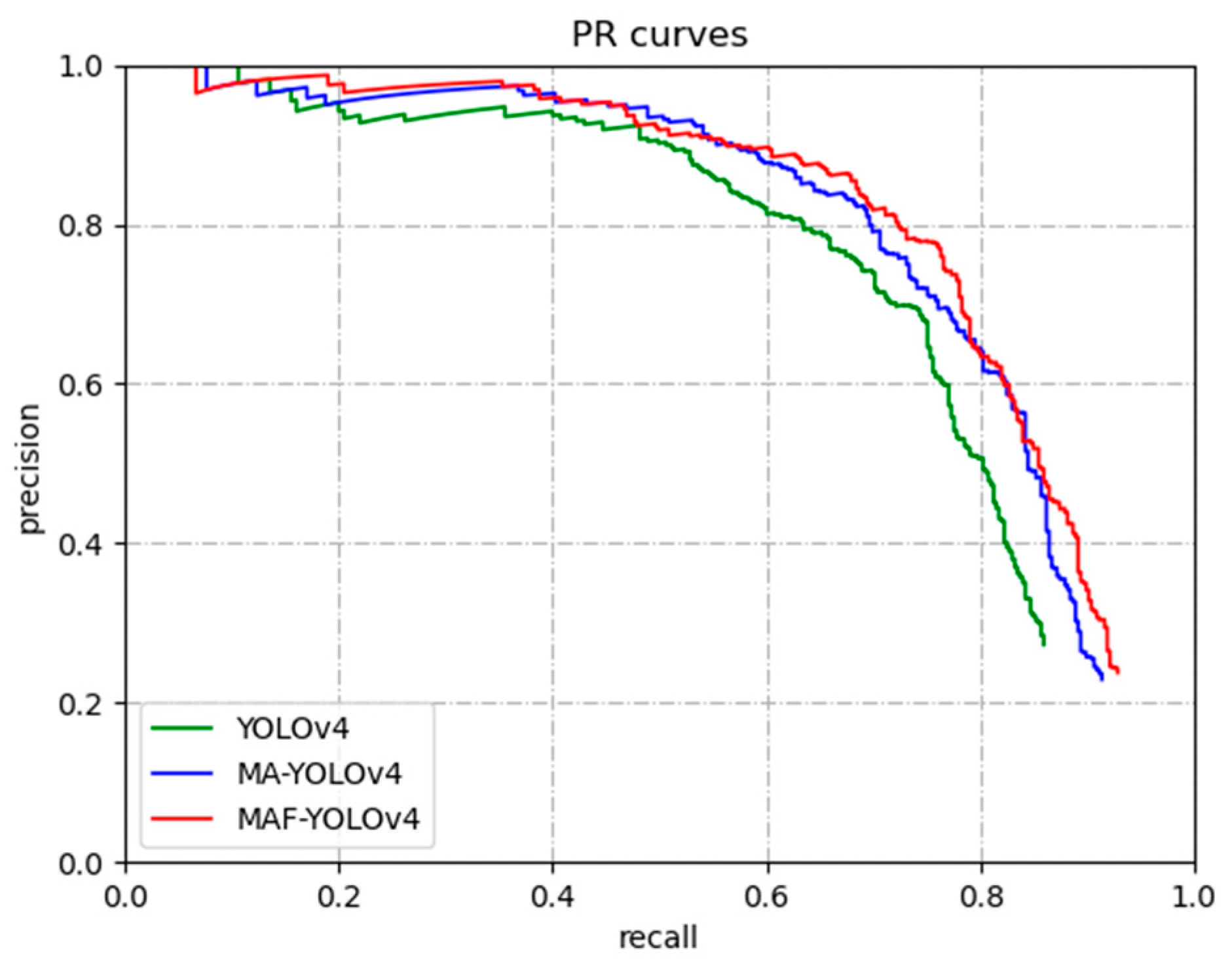
The PR curves for YOLOv4, MA–YOLOv4 and MAF–YOLOv4 are shown in
Figure 11. The area under the PR curve represents the AP. It can be seen from
Figure 11 that the area of MAF–YOLOv4 is the largest, which represents the improved model with better performance.
3.1. Performance Comparison of the Improved Model
The main defect of YOLOv4 in detection of corn-borer pest regions was the omission of small target pest regions or difficult regions, as mentioned in
Section 2.1; the examination results are shown in
Figure 12. The most intuitive performance in the evaluation metric was the low recall rate. The fundamental reason for this phenomenon is the limited information for the small target and interference from complex backgrounds; it was difficult for the original network to obtain sufficient and effective features in this case. To solve this problem, we proposed MSMAM and contextual information to improve YOLOv4, and obtained MA–YOLOv4 and MAF–YOLOv4. The performance of different models was verified on DV12&DVT; to assess, comprehensively, the performance of the improved models, the state-of-the-art detection models currently widely applied in agriculture were chosen for comparison experiments. These included the one-stage algorithms, SSD, YOLOv3, and YOLOv4; the two-stage algorithms, Faster-rcnn, Cascade-rcnn [
34], and Dynamic-rcnn [
35]. The algorithms were run in the same experimental environment, the parameters being consistent with the original models. The quantitative comparison results are reported in
Table 2. It can be seen that the improved models significantly improved the performance of pest region detection. Moreover, for the main shortcoming, the lower recall rate, the model with additional contextual information, MAF–YOLOv4 outperformed MA–YOLOv4 by 9.88% with only the attention mechanism, compared with the original model. Compared to the two-stage algorithm, the recall is only lower than Dynamic-rcnn with the ResNet50 backbone. The detection speed (FPS), computational complexity (GFLOPS), and average precision (AP) of each model were analyzed in parallel: our model showed a significant advantage in all aspects compared with the two-stage algorithms. Compared with the one-stage algorithm, MA–YOLOv4 demonstrated an increase of 0.55 GFLOPS over YOLOv4, with a slight decrease in detection speed, but an improvement of 5.53% in AP over YOLOv4, achieving a balance of speed, computational complexity, and performance; thus the proposed model has a better overall performance.
Influence of Different Growth Cycle Data
Data from different corn growth cycles have different backgrounds and pose different challenges. To analyze the influence of these data on model performance, models were first trained with DV12&DVT; these were then used to detect different cycles of the test set (DV12_test, DVT_test). Next, the models were trained with DV12 and DVT, separately; these were then used to detect the same cycle of the test set.
Table 3 presents the experimental results: it can be seen that different growth cycle data have a strong influence on the model detection. The main challenge arises from the effect of the natural environment and the various physiological phenomena of corn, leading to low accuracy in detecting DVT; DV12 has a minimal effect on improving the detection accuracy of DVT. For MAF–YOLOv4, it performs better in both the DV12_test with a relatively pure background and the DVT_test with a complex background and more interference, whether trained uniformly or separately.
3.2. Visualization
In this paper, a number of test samples was selected as input to visualize the detection results and feature activation. The former is shown in
Figure 12; it can be seen that the improved model can accurately detect more complex pest regions in different corn growth cycles. The latter adopted the feature visualization method, Class Activation Mapping (CAM) [
36], to improve model interpretability and qualitative analysis. The importance of different regions of input image is determined through CAM, which is displayed in the form of a heat map. Owing to the working mechanism of the baseline model, CAM was introduced into output3 and the results are shown in
Figure 13. From the heat maps, we observe that the improved model covers target regions more comprehensively than does the original model. Furthermore, in the same mask areas, such as the dense pest region in
Figure 13, they are more highlighted in the MAF–YOLOv4 CAM, which means that the network is more sensitive to such features and can extract more effective features from them. Thus, with the two visual analysis methods, for the pest region detection task, adopting the attention mechanism to refine the features, and introducing additional contextual information to enhance the pest region features using the nonlinear feature fusion method, can make the model better aggregate effective information and improve detection performance.
3.3. Influence of Attention Mechanism on Detection Performance
To ensure the integrity of comparative experiments, we considered the effectiveness and optimal combination of the various components of MSMAM. First, the effects of PAB and MS-CAB on the overall model performance were verified under the same experimental conditions for different growth cycle data; the results are shown in
Table 4. Both make beneficial contributions to the model for each growth cycle data. Due to different learned emphases, MS-CAB, which aggregates information at different scales along channel dimension through different branches, outperforms PAB, which captures long-distance information by computing arbitrary-position responses, the former focusing more on ‘what’ and the latter on ‘where’.
Second, to make MSMAM work more effectively, we explored the channel reduction rates
and
mentioned in
Section 3.2, and which affect the number of parameters and the feature extraction capacity of MSMAM. We set
and
to 2, 4, 8, and 16, respectively, to determine the optimal channel reduction rate. The experimental results are shown in
Table 5 and take into account the computational costs. The
and
were set to 4 and 16, respectively, for better robustness and performance.
Finally, we considered the critical factor affecting performance in MSMAM and how to combine different components to better capture information. There were three main arrangements, sequential PAB+MS-CAB, sequential MS-CAB+PAB, and a parallel combination of the two, PAB&MS-CAB. Different blocks performed different functions, so various arrangements had different effects on overall performance.
Table 6 summarizes the impact of different arrangements, with sequential PAB+MS-CAB having the best performance. By analyzing the functions of the two modules and results, we found that although PAB can capture long-distance information, due to the complexity of data and inability of PAB to refine the captured features, there may be more redundant contexts that overwhelm truly effective features. While MS-CAB is limited by locality of convolution, it captures context features through global and local branches to refine features more effectively. Therefore, sequential PAB+MS-CAB can generate finer features.
3.4. Influence of Attention Mechanism in Context Priming Module
MAF–YOLOv4 is an improved version of YOLOv4 that integrates the MSMAM with the context-priming module. MSMAM optimizes the feature map before additional multi-scale contextual features are fused, reducing invalid information and preventing additional information from overwhelming the target features. To analyze the performance influence of MSMAM on MAF–YOLOv4, the model with and without the integrated attention mechanism were compared in different growth cycle data.
Table 7 presents the experimental results, and combined with the results in
Table 3, it can be seen that MSMAM is essential in the context-priming module. MAF–YOLOv4 without the attention mechanism still outperforms the other models on DV12 because DV12 has less noise interference. On DVT, MAF–YOLOv4 without the attention mechanism performs worse than MA–YOLOv4 due to its inability to reduce noise and unnecessary information. Although the integration of MSMAM increases the computational cost, it is able to effectively improve the detection accuracy of DVT with complex backgrounds.
3.6. Generalizability and Robustness of the Improved Model in Different Growth Cycle Data
Although the backgrounds and detection difficulties of data on pest regions that are in different corn growth cycles are different, they have similar features. To verify the generalizability and robustness of the improved model for different growth cycle data, we conducted cross-tests using DV12 and DVT, with the model trained by DV12 for detecting DVT_test and the model trained by DVT for detecting DV12_test.
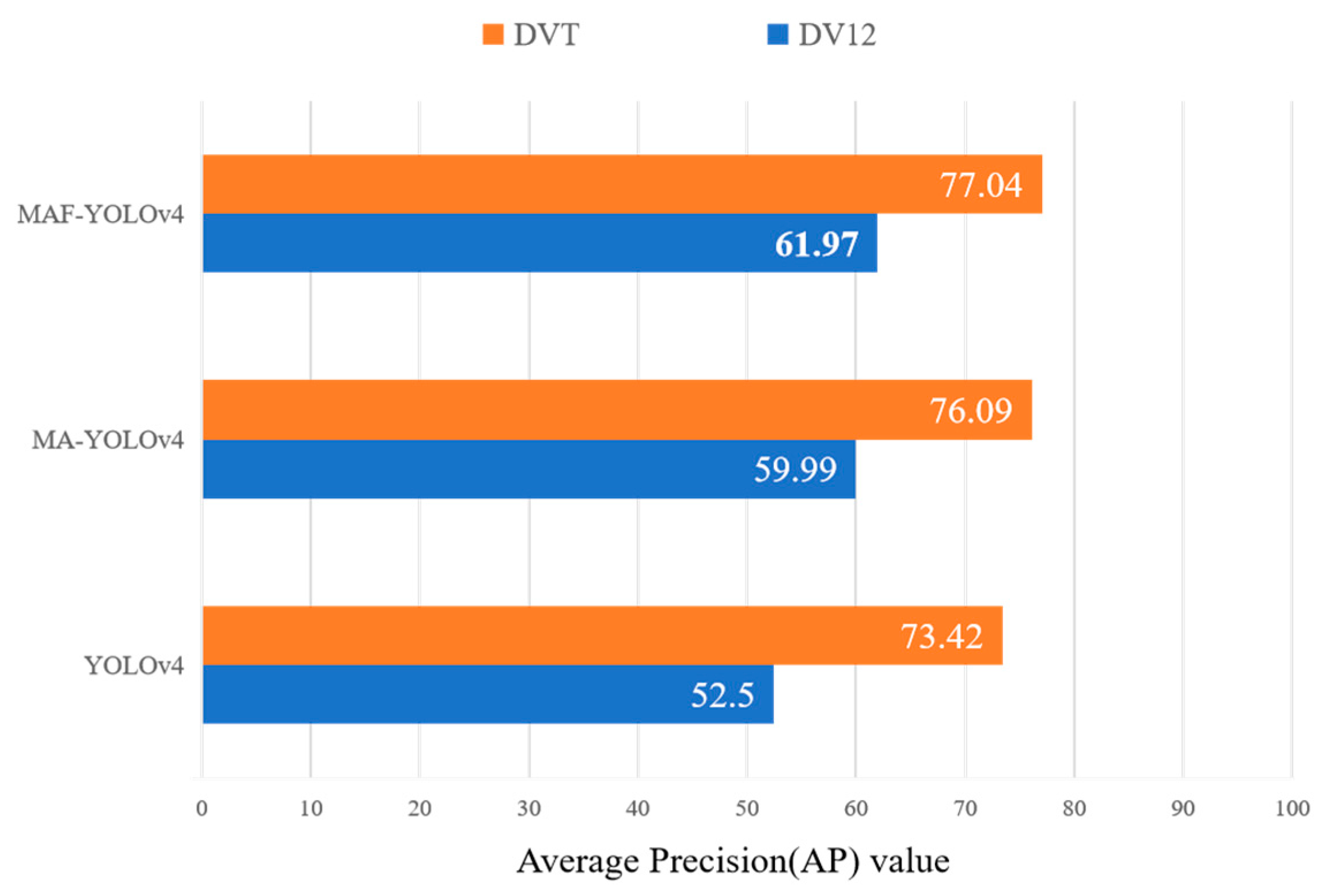
Figure 15 presents the results, and combined with the results of MAF–YOLOv4 in
Table 3, it can be seen that it has better generalizability and robustness compared with YOLOv4 in different corn growth cycle data because of its stronger feature-extraction capability. After training with DV12, it still performed well on the DVT_test, with a 9.47% improvement in AP compared with YOLOv4 under the same conditions. Combined with the above experiments, it illustrates the practical significance of the improved model, which is able to obtain a unified model for detecting pest regions in corn with different growth cycles and backgrounds.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}