
Feature Wavelength Selection Based on the Combination of Image and Spectrum for Aflatoxin B1 Concentration Classification in Single Maize Kernels


Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
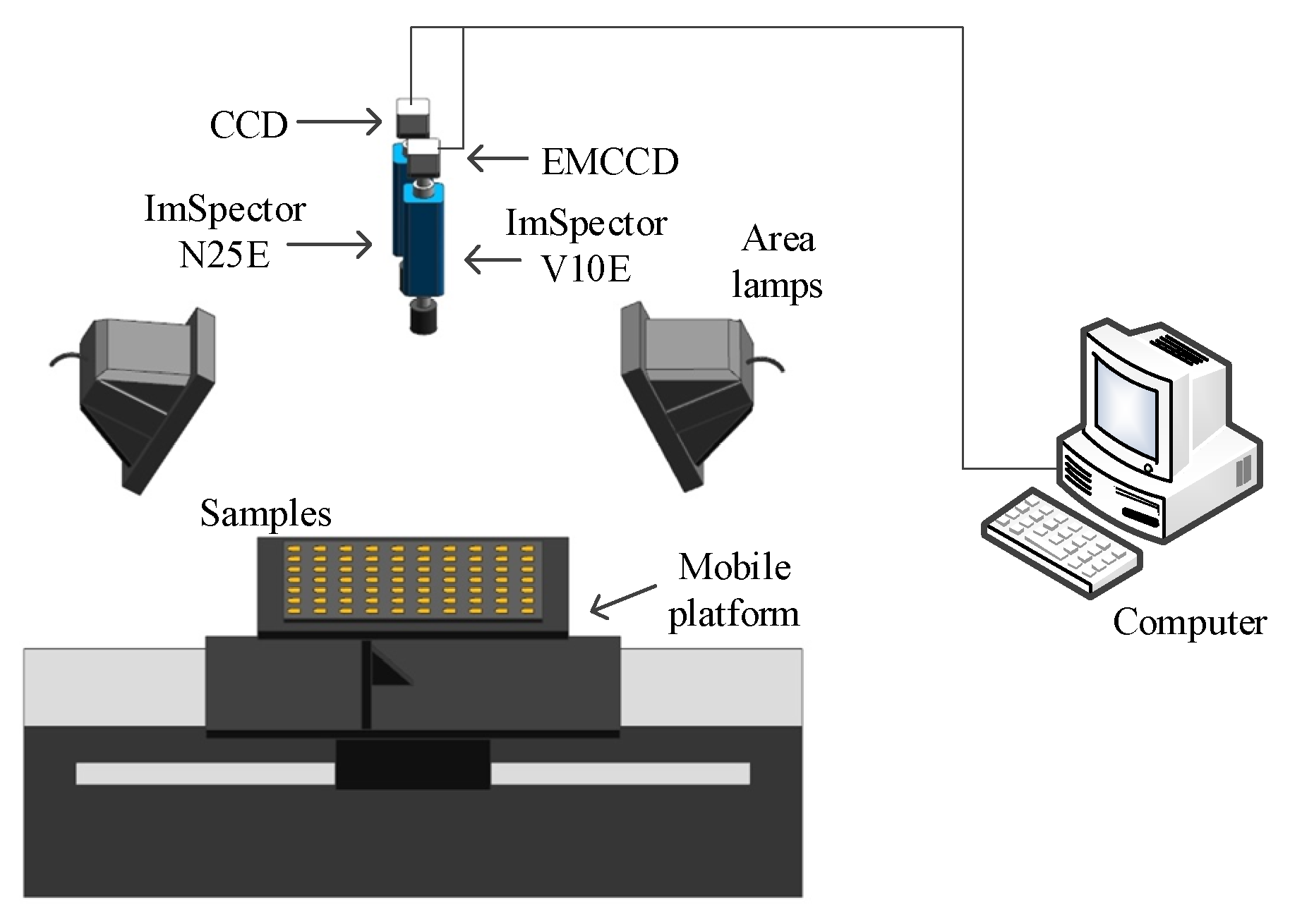
2.2. Hyperspectral Imaging System
2.3. Spectral Extraction of Samples
- Step 1
- Reading of hyperspectral data and convert it into images at different wavelengths, the image (880.3 nm in Vis-LWNIR and 1210.3 nm in LWNIR) with large differences between the background and sample was selected for background segmentation.
- Step 2
- Based on the two selected images, an appropriate threshold was set for binary segmentation of the image to remove the background and to retain the sample area.
- Step 3
- The effective area of sample was retained by morphological filtering method to eliminate the influence of spectral difference in boundary region of the sample.
- Step 4
- Each independent region after filtering was the ROI of sample. The original hyperspectral image was masked by the ROI and the effective hyperspectral data of the samples was extracted.
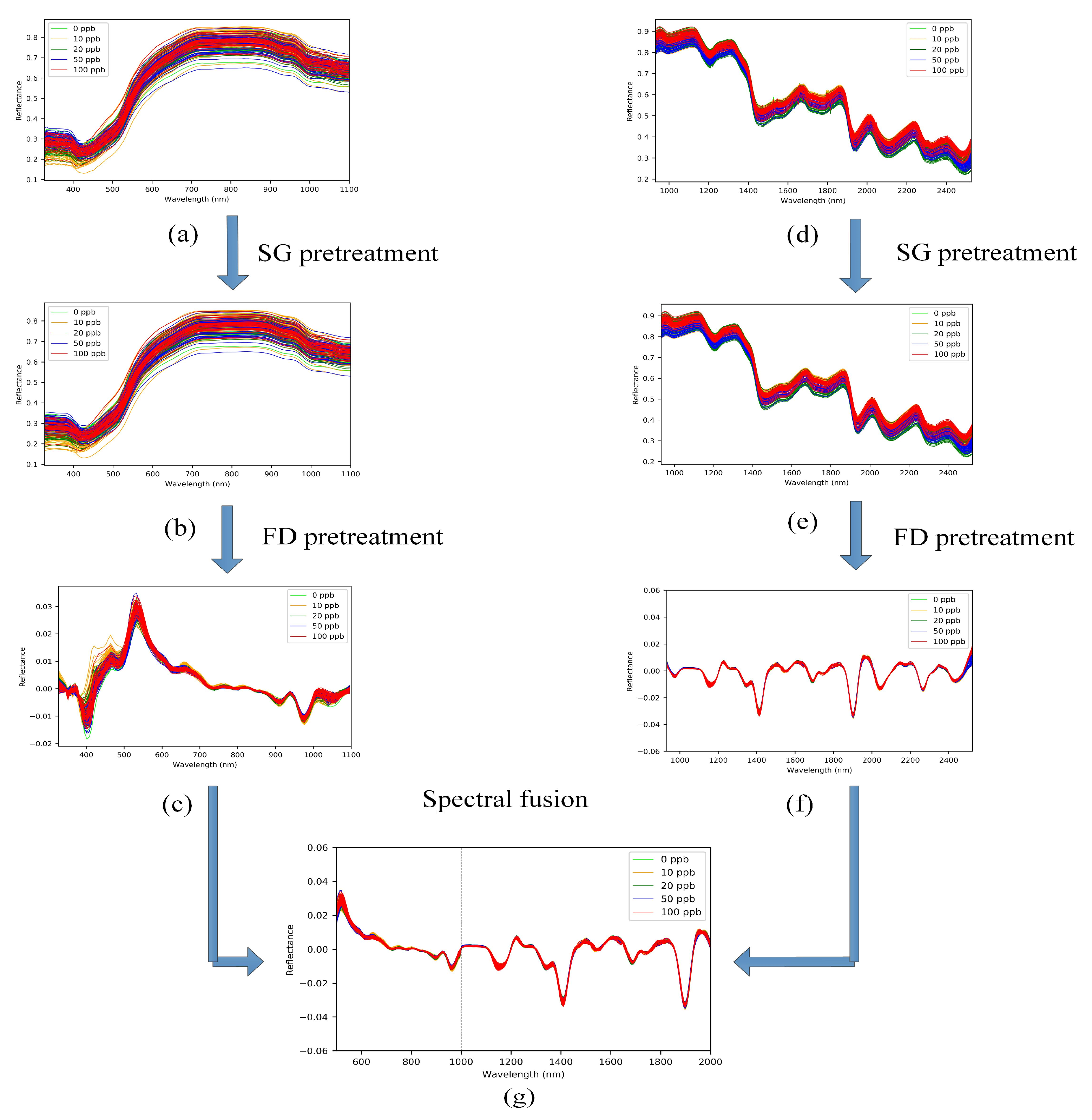
2.4. Spectral Pretreatment
2.5. Characteristic Wavelengths Selection Methods
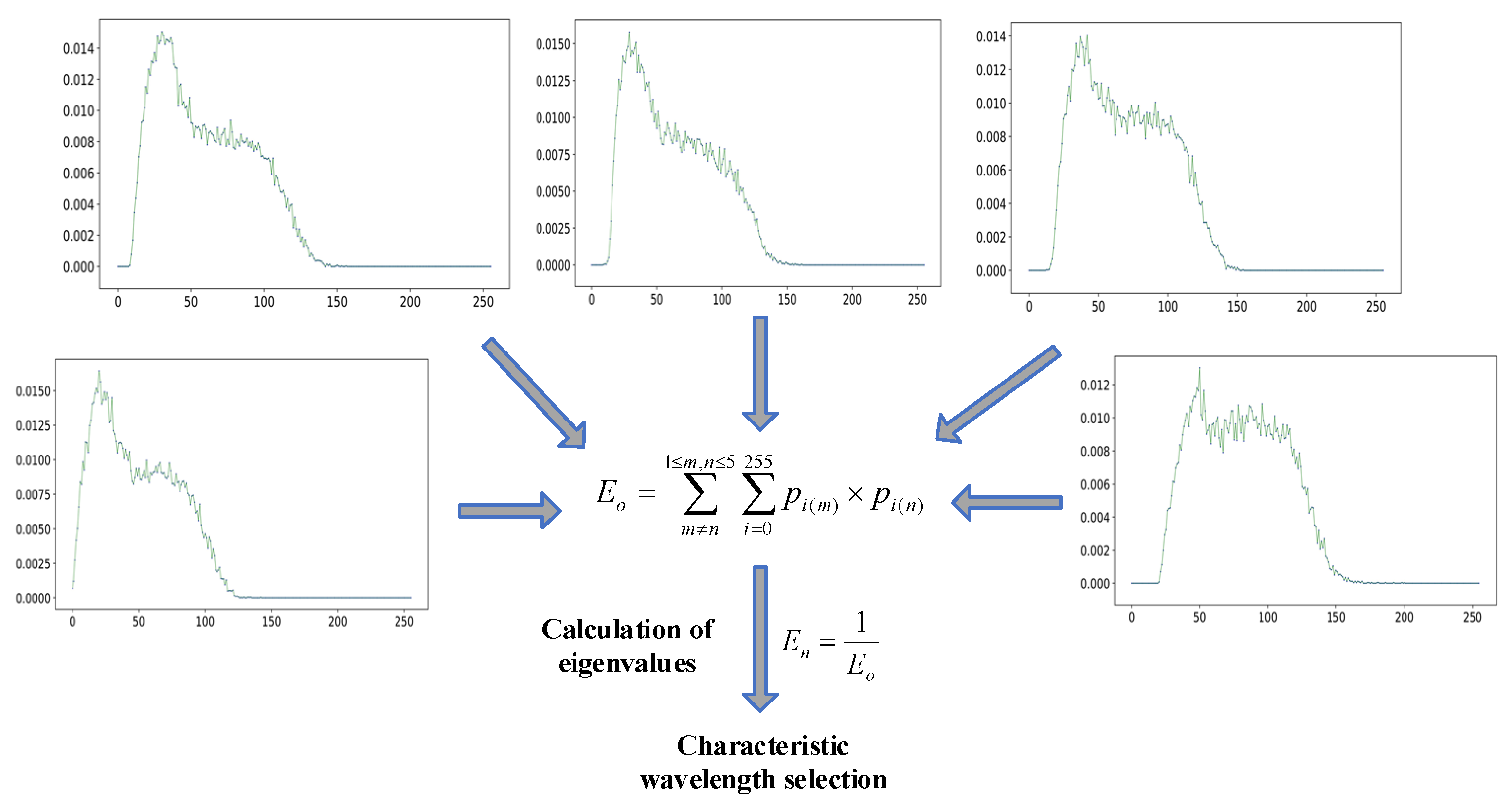
2.5.1. Rough Selection Method of Characteristic Wavelength
2.5.2. Fine Selection Method of Characteristic Wavelength
2.6. Model Construction
3. Results and Discussion
3.1. Spectral Pretreatment
3.2. Rough Characteristic Wavelength Selection
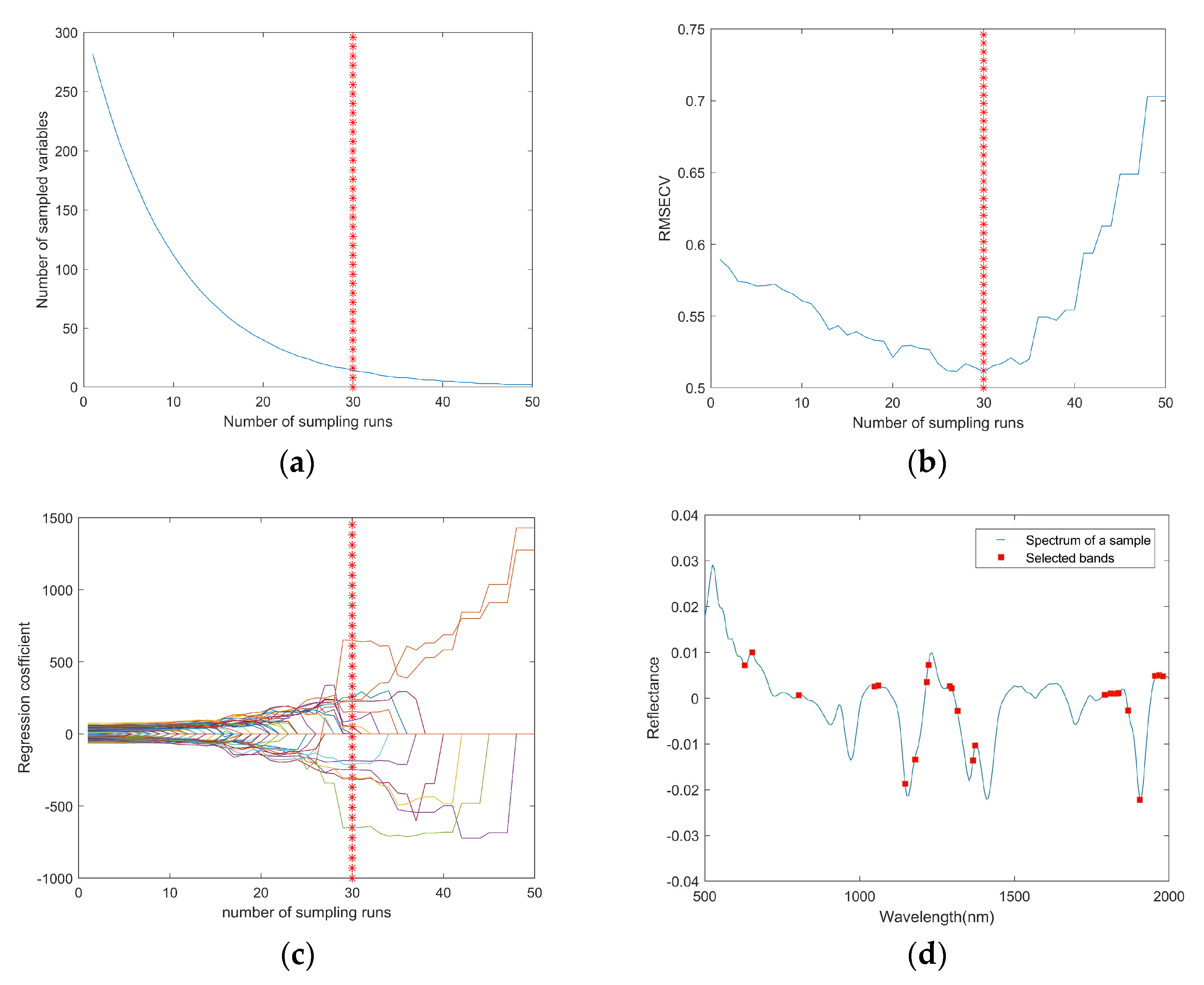
3.2.1. Characteristic Wavelength Selection by CARS
3.2.2. Characteristic Wavelength Selection by SPA
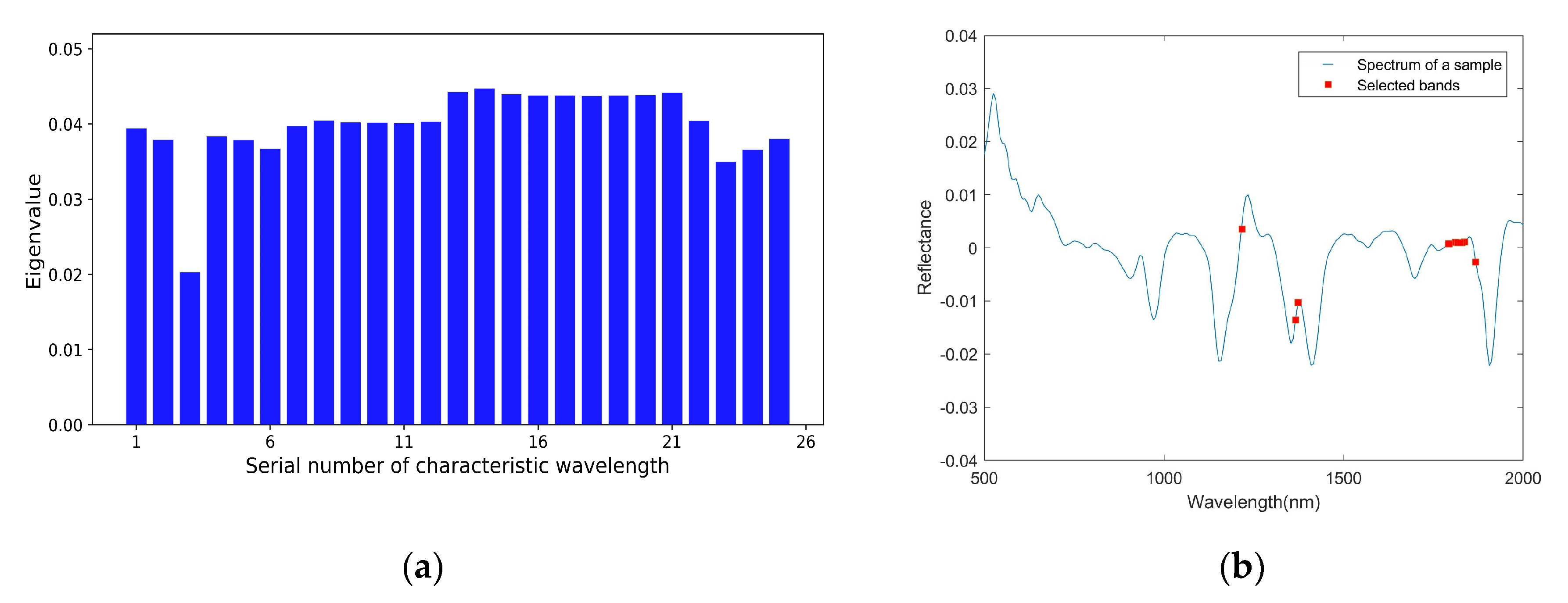
3.3. Fine Characteristic Wavelength Selection by GDI
3.3.1. Fine Wavelength Selection after CARS
3.3.2. Fine Wavelength Selection after SPA
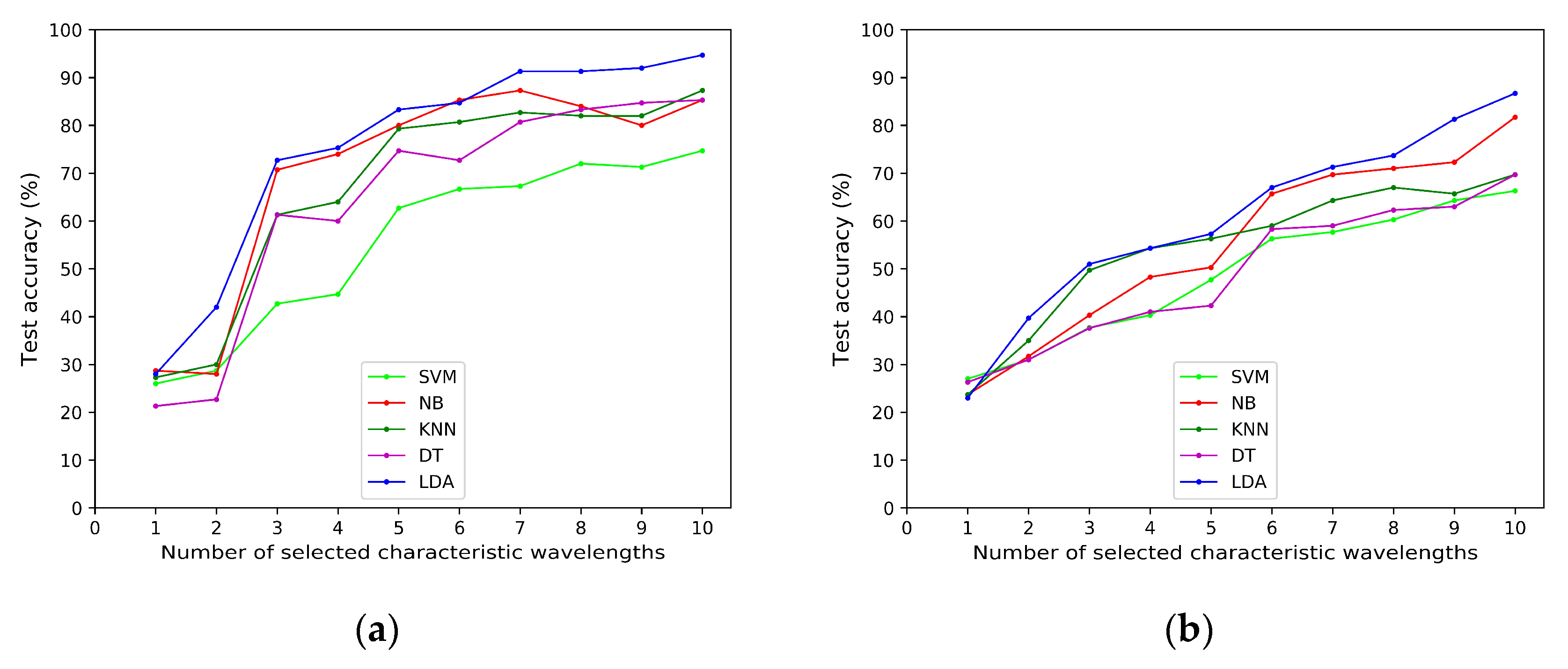
3.4. Classification Results under Different Models
3.5. The Influence of Different Wavelength Selection Methods on the Results
3.6. Test Results of Independent Verification Samples
3.7. Comparison of Results with Other Papers
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hesseltine, C.W. Natural occurrence of mycotoxins in cereals. Mycopathol. Mycol. Appl. 1974, 53, 141–153. [Google Scholar] [CrossRef] [PubMed]
- Kelly, J.D.; Eaton, D.L.; Guengerich, F.P.; Coulombe, R.A. Aflatoxin B1 activation in human lung. Toxicol. Appl. Pharmacol. 1997, 144, 88–95. [Google Scholar] [CrossRef] [PubMed]
- Piva, G.; Galvano, F.; Pietri, A.; Piva, A. Detoxification methods of aflatoxins. A review. Nutr. Res. 1995, 15, 767–776. [Google Scholar] [CrossRef]
- GB 2761-2011; The National Food Safety Standards of Mycotoxins in Food Limited. China Food and Drug Administration: Beijing, China, 2011.
- Pearson, T.C.; Wicklow, D.T.; Pasikatan, M.C. Reduction of aflatoxin and fumonisin contamination in yellow corn by high-speed dual-wavelength sorting. Cereal Chem. 2004, 81, 490–498. [Google Scholar] [CrossRef] [Green Version]
- Teena, M.; Manickavasagan, A.; Mothershaw, A.; El Hadi, S.; Jayas, D.S. Potential of Machine Vision Techniques for Detecting Fecal and Microbial Contamination of Food Products: A Review. Food Bioprocess Technol. 2013, 6, 1621–1634. [Google Scholar] [CrossRef]
- Han, Z.; Deng, L. Aflatoxin contaminated degree detection by hyperspectral data using band index. Food Chem. Toxicol. 2020, 137, 111159. [Google Scholar]
- Chu, X.; Wang, W.; Yoon, S.C.; Ni, X.; Heitschmidt, G.W. Detection of aflatoxin B-1 (AFB (1)) in individual maize kernels using short wave infrared (SWIR) hyperspectral imaging. Biosyst. Eng. 2017, 157, 13–23. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Liu, F.; He, Y.; Li, X. Application of Hyperspectral Imaging and Chemometric Calibrations for Variety Discrimination of Maize Seeds. Sensors 2012, 12, 17234–17246. [Google Scholar] [CrossRef]
- Tao, F.; Yao, H.; Hruska, Z.; Kincaid, R.; Rajasekaran, K.; Bhatnagar, D. A novel hyperspectral-based approach for identification of maize kernels infected with diverse Aspergillus flavus fungi. Biosyst. Eng. 2020, 200, 415–430. [Google Scholar] [CrossRef]
- Del Fiore, A.; Reverberi, M.; Ricelli, A.; Pinzari, F.; Serranti, S.; Fabbri, A.A.; Bonifazi, G.; Fanelli, C. Early detection of toxigenic fungi on maize by hyperspectral imaging analysis. Int. J. Food Microbiol. 2010, 144, 64–71. [Google Scholar] [CrossRef]
- Bayman, P.; Baker, J.L.; Mahoney, N.E. Aspergillus on tree nuts: Incidence and associations. Mycopathologia 2002, 155, 161–169. [Google Scholar] [CrossRef] [PubMed]
- Wei, W.; Zhang, J.; Zhang, L.; Tian, C.; Zhang, Y. Deep Cube-Pair Network for Hyperspectral Imagery Classification. Remote Sens. 2018, 10, 783. [Google Scholar] [CrossRef] [Green Version]
- Ramamurthy, M.; Robinson, Y.H.; Vimal, S.; Suresh, A. Auto encoder based dimensionality reduction and classification using convolutional neural networks for hyperspectral images. Microprocess. Microsyst. 2020, 79, 103280. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef]
- Kumar, K. Competitive adaptive reweighted sampling assisted partial least square analysis of excitation-emission matrix fluorescence spectroscopic data sets of certain polycyclic aromatic hydrocarbons. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 244, 118874. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Chen, X.; Li, L.; Chen, H.; Ruan, X.; Liu, W. A consensus successive projections algorithm-multiple linear regression method for analyzing near infrared spectra. Anal. Chim. Acta 2015, 858, 16–23. [Google Scholar] [CrossRef] [PubMed]
- Ji, W.; Qian, Z.; Xu, B.; Tao, Y.; Zhao, D.; Ding, S. Apple tree branch segmentation from images with small gray-level difference for agricultural harvesting robot. Optik 2016, 127, 11173–11182. [Google Scholar] [CrossRef]
- Akbulut, N.K.; Celik, H.A. Differences in mean grey levels of uterine ultrasonographic images between non-pregnant and pregnant ewes may serve as a tool for early pregnancy diagnosis. Anim. Reprod. Sci. 2021, 226, 106716. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.Y.; Ni, J.G.; Wang, D.W.; Deng, L.M.; Li, J.; Han, Z.Z. Pixel-level aflatoxin detecting in maize based on feature selection and hyperspectral imaging. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 234, 118269. [Google Scholar] [CrossRef]
- Kimuli, D.; Wang, W.; Lawrence, K.C.; Yoon, S.-C.; Ni, X.; Heitschmidt, G.W. Utilisation of visible/near-infrared hyperspectral images to classify aflatoxin B1 contaminated maize kernels. Biosyst. Eng. 2018, 166, 150–160. [Google Scholar] [CrossRef]
- Li, J.; Chen, L.; Huang, W. Detection of early bruises on peaches (Amygdalus persica L.) using hyperspectral imaging coupled with improved watershed segmentation algorithm. Postharvest Biol. Technol. 2018, 135, 104–113. [Google Scholar] [CrossRef]
- Zhou, Q.; Huang, W.; Tian, X.; Yang, Y.; Liang, D. Identification of the variety of maize seeds based on hyperspectral images coupled with convolutional neural networks and subregional voting. J. Sci. Food Agric. 2021, 101, 4532–4542. [Google Scholar] [CrossRef] [PubMed]
- Jardim, R.; Morgado-Dias, F. Savitzky-Golay filtering as image noise reduction with sharp color reset. Microprocess. Microsyst. 2020, 74, 74103006. [Google Scholar] [CrossRef]
- Tang, G.; Hu, J.; Yan, H.; Zhao, Y.; Xiong, Y.; Min, S. Determination of active ingredients in matrine aqueous solutions by mid-infrared spectroscopy and competitive adaptive reweighted sampling. Optik 2016, 127, 1405–1407. [Google Scholar] [CrossRef]
- Tian, X.; Fan, S.; Li, J.; Xia, Y.; Huang, W.; Zhao, C. Comparison and optimization of models for SSC on-line determination of intact apple using efficient spectrum optimization and variable selection algorithm. Infrared Phys. Technol. 2019, 102, 102979. [Google Scholar] [CrossRef]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvão, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Liu, M.Z.; Shao, Y.H.; Li, C.N.; Chen, W.J. Smooth pinball loss nonparallel support vector machine for robust classification. Appl. Soft Comput. 2021, 98, 106840. [Google Scholar] [CrossRef]
- Alizadeh, S.H.; Hediehloo, A.; Harzevili, N.S. Multi independent latent component extension of naive Bayes classifier. Knowl. Based Syst. 2021, 213, 106646. [Google Scholar] [CrossRef]
- Kumbure, M.M.; Luukka, P.; Collan, M. A new fuzzy k-nearest neighbor classifier based on the Bonferroni mean. Pattern Recognit. Lett. 2020, 140, 172–178. [Google Scholar] [CrossRef]
- Tao, Q.; Li, Z.; Xu, J.; Xie, N.; Wang, S.; Suykens, J.A.K. Learning with continuous piecewise linear decision trees. Expert Syst. Appl. 2021, 168, 114214. [Google Scholar] [CrossRef]
- Sun, P.; Bao, K.; Li, H.; Li, F.; Wang, X.; Cao, L.; Li, G.; Zhou, Q.; Tang, H.; Bao, M. An efficient classification method for fuel and crude oil types based on m/z 256 mass chromatography by COW-PCA-LDA. Fuel 2018, 222, 416–423. [Google Scholar] [CrossRef]
- Wang, W.; Heitschmidt, G.W.; Ni, X.; Windham, W.R.; Hawkins, S.; Chu, X. Identification of aflatoxin B-1 on maize kernel surfaces using hyperspectral imaging. Food Control 2014, 42, 78–86. [Google Scholar] [CrossRef]
- Chakraborty, S.K.; Mahanti, N.K.; Mansuri, S.M.; Tripathi, M.K.; Kotwaliwale, N.; Jayas, D.S. Non-destructive classification and pre-diction of aflatoxin-B1 concentration in maize kernels using Vis–NIR (400–1000 nm) hyperspectral imaging. J. Food Sci. Technol. 2021, 58, 437–450. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Real AFB1 Contents | Predicted Results | ||||||
|---|---|---|---|---|---|---|---|---|
| 0 ppb | 10 ppb | 20 ppb | 50 ppb | 100 ppb | Accuracy | Overall Accuracy | ||
| Calibration set | 0 ppb | 40 | 0 | 0 | 0 | 0 | 100.00% | 97.00% |
| 10 ppb | 0 | 40 | 0 | 0 | 0 | 100.00% | ||
| 20 ppb | 0 | 1 | 37 | 2 | 0 | 92.50% | ||
| 50 ppb | 0 | 0 | 1 | 39 | 0 | 97.50% | ||
| 100 ppb | 0 | 0 | 1 | 1 | 38 | 95.00% | ||
| Prediction set | 0 ppb | 30 | 0 | 0 | 0 | 0 | 100.00% | 94.67% |
| 10 ppb | 0 | 30 | 0 | 0 | 0 | 100.00% | ||
| 20 ppb | 0 | 0 | 26 | 4 | 0 | 86.67% | ||
| 50 ppb | 0 | 0 | 1 | 29 | 0 | 96.67% | ||
| 100 ppb | 0 | 0 | 0 | 3 | 27 | 90.00% | ||
| Model | Number of Wavelengths | Calibration Set | Prediction Set | ||
|---|---|---|---|---|---|
| Corrected/All | Accuracy | Corrected/All | Accuracy | ||
| FW-LDA | 240 | 200/200 | 100.00% | 144/150 | 96.00% |
| CARS-LDA | 25 | 200/200 | 100.00% | 145/150 | 96.67% |
| SPA-LDA | 26 | 200/200 | 100.00% | 142/150 | 94.67% |
| CARS-GDI-LDA | 10 | 197/200 | 98.50% | 142/150 | 94.67% |
| SPA-GDI-LDA | 10 | 181/200 | 90.50% | 130/150 | 86.67% |
| Data Set | Real AFB1 Contents | Predicted Results | ||||||
|---|---|---|---|---|---|---|---|---|
| 0 ppb | 10 ppb | 20 ppb | 50 ppb | 100 ppb | Accuracy | Overall Accuracy | ||
| New samples | 0 ppb | 18 | 0 | 0 | 0 | 0 | 100.00% | 91.11% |
| 10 ppb | 0 | 17 | 0 | 1 | 0 | 94.44% | ||
| 20 ppb | 0 | 1 | 15 | 2 | 0 | 83.33% | ||
| 50 ppb | 0 | 0 | 1 | 16 | 1 | 88.89% | ||
| 100 ppb | 0 | 0 | 0 | 2 | 16 | 88.89% | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Q.; Huang, W.; Tian, X. Feature Wavelength Selection Based on the Combination of Image and Spectrum for Aflatoxin B1 Concentration Classification in Single Maize Kernels. Agriculture 2022, 12, 385. https://doi.org/10.3390/agriculture12030385
Zhou Q, Huang W, Tian X. Feature Wavelength Selection Based on the Combination of Image and Spectrum for Aflatoxin B1 Concentration Classification in Single Maize Kernels. Agriculture. 2022; 12(3):385. https://doi.org/10.3390/agriculture12030385
Chicago/Turabian StyleZhou, Quan, Wenqian Huang, and Xi Tian. 2022. "Feature Wavelength Selection Based on the Combination of Image and Spectrum for Aflatoxin B1 Concentration Classification in Single Maize Kernels" Agriculture 12, no. 3: 385. https://doi.org/10.3390/agriculture12030385
APA StyleZhou, Q., Huang, W., & Tian, X. (2022). Feature Wavelength Selection Based on the Combination of Image and Spectrum for Aflatoxin B1 Concentration Classification in Single Maize Kernels. Agriculture, 12(3), 385. https://doi.org/10.3390/agriculture12030385