
A Method for Obtaining the Number of Maize Seedlings Based on the Improved YOLOv4 Lightweight Neural Network


Abstract
1. Introduction
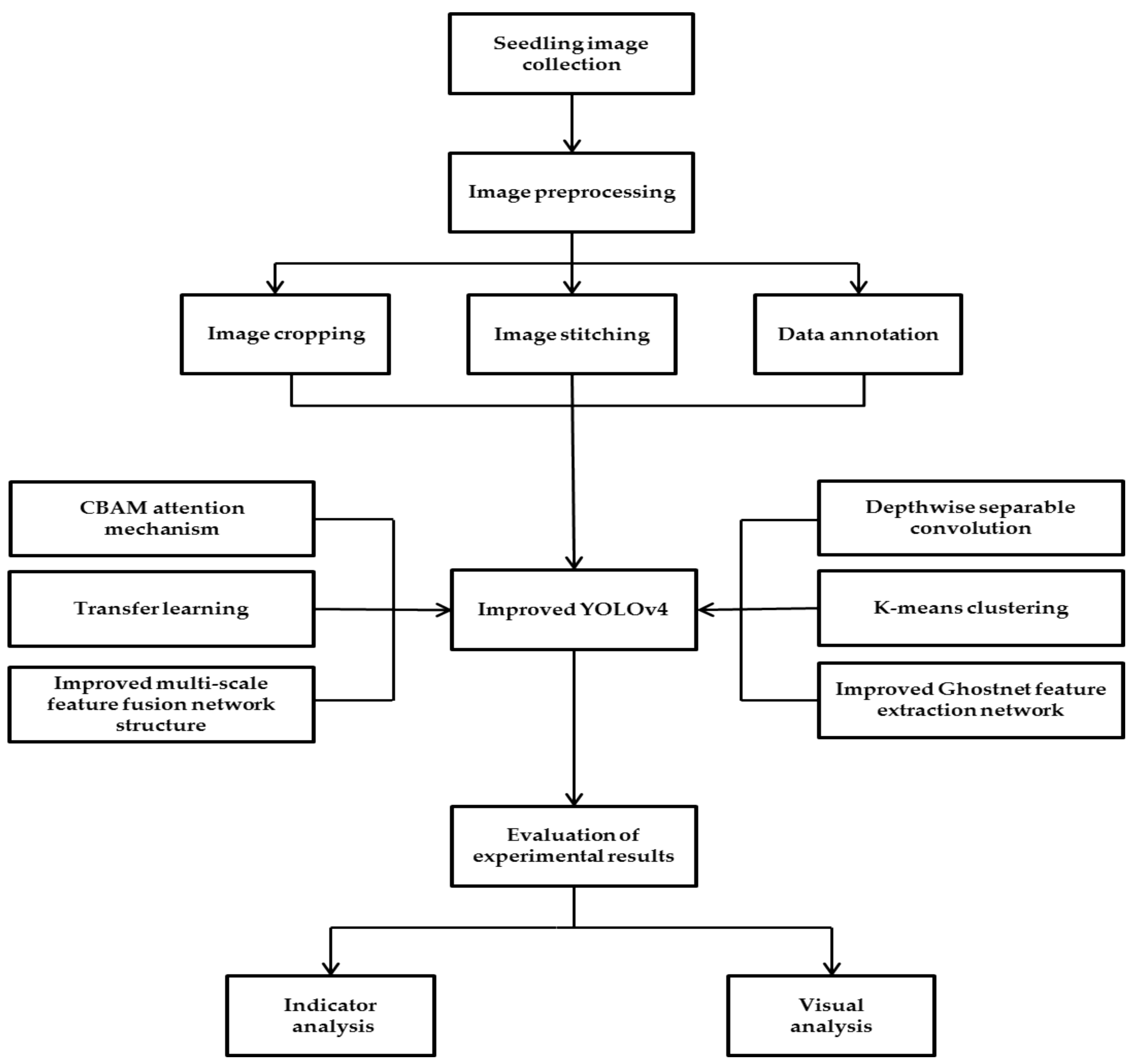
2. Materials and Methods
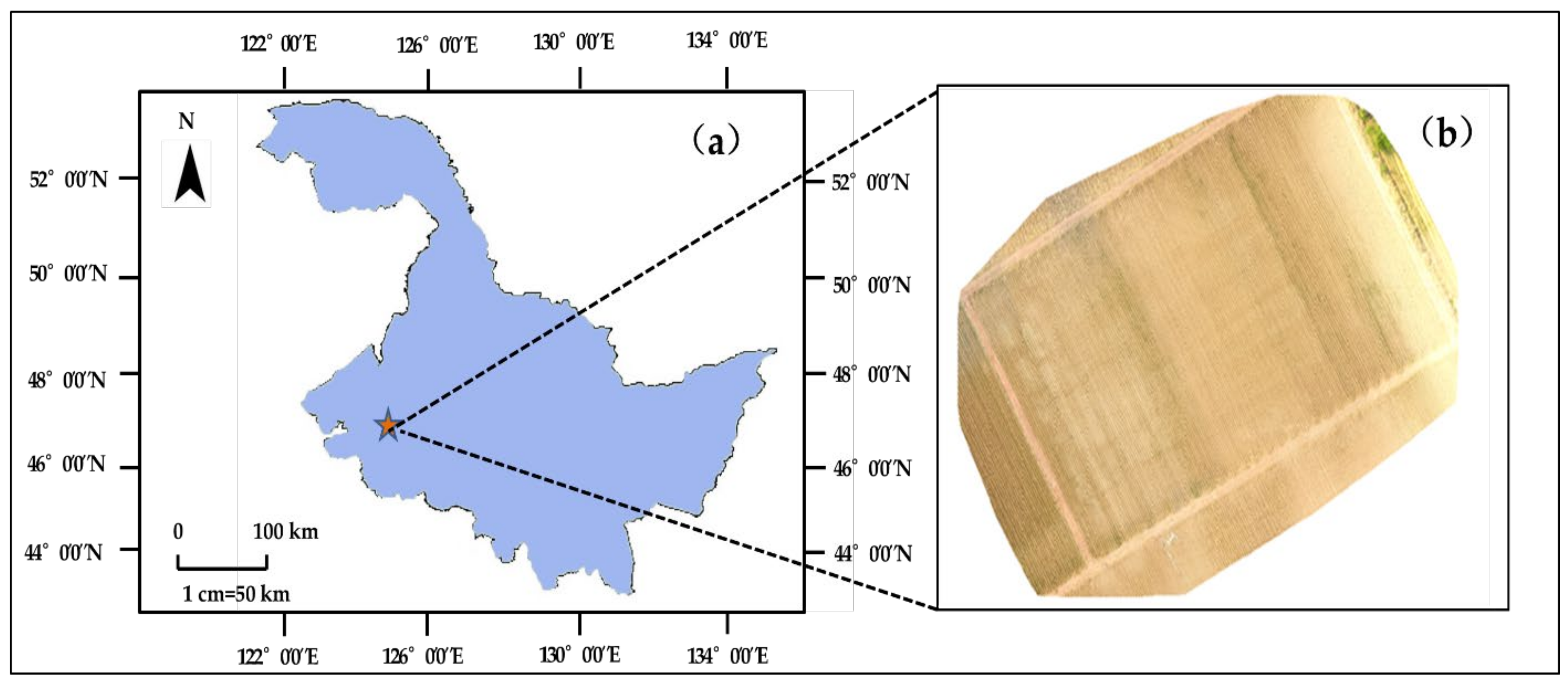
2.1. Overview of Experimental Area
2.2. Image Acquisition
2.3. Data Set Construction and Preprocessing
2.3.1. Image Preprocessing
2.3.2. Data Set Construction
2.4. YOLOv4 Network Model
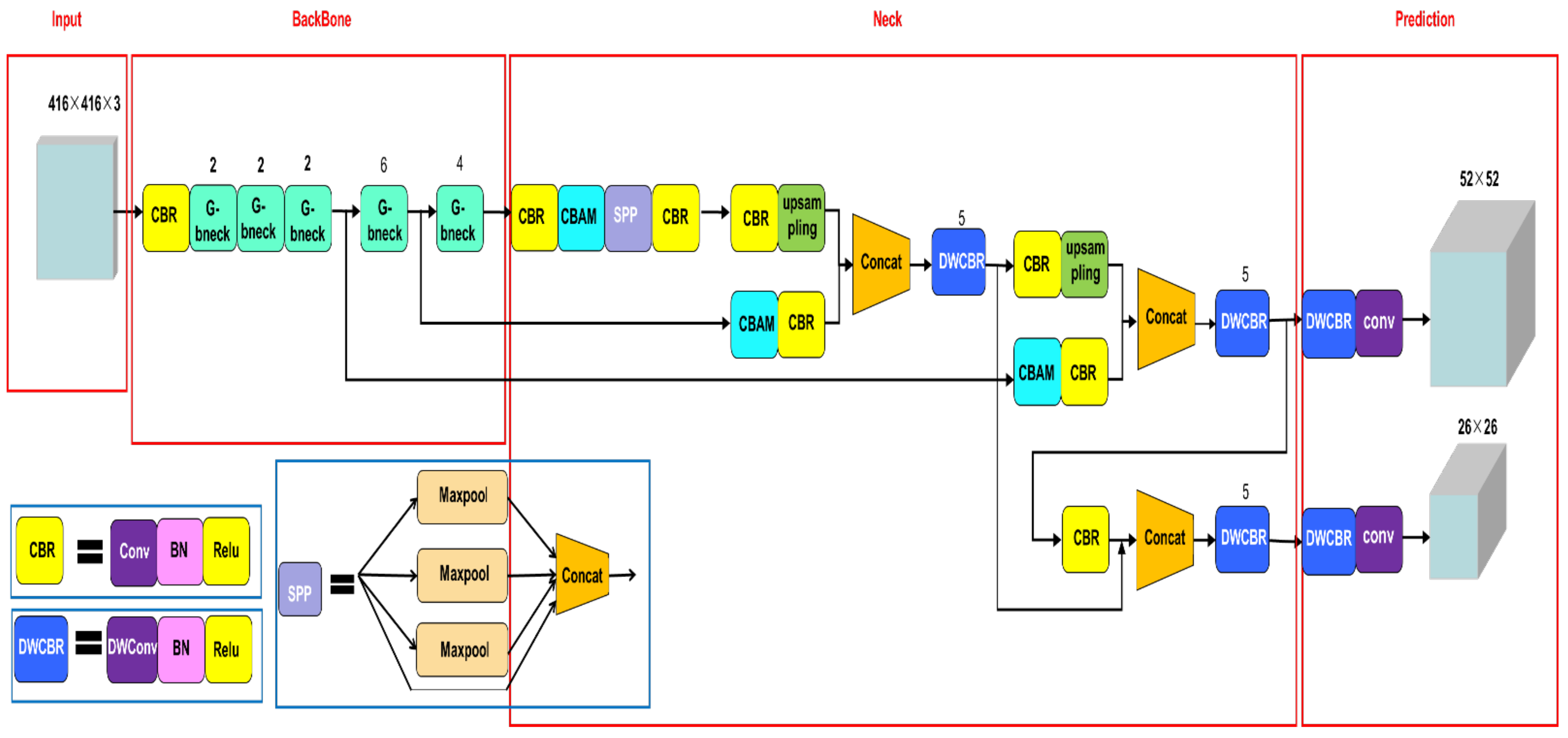
2.5. Improved YOLOv4 Network Model Design
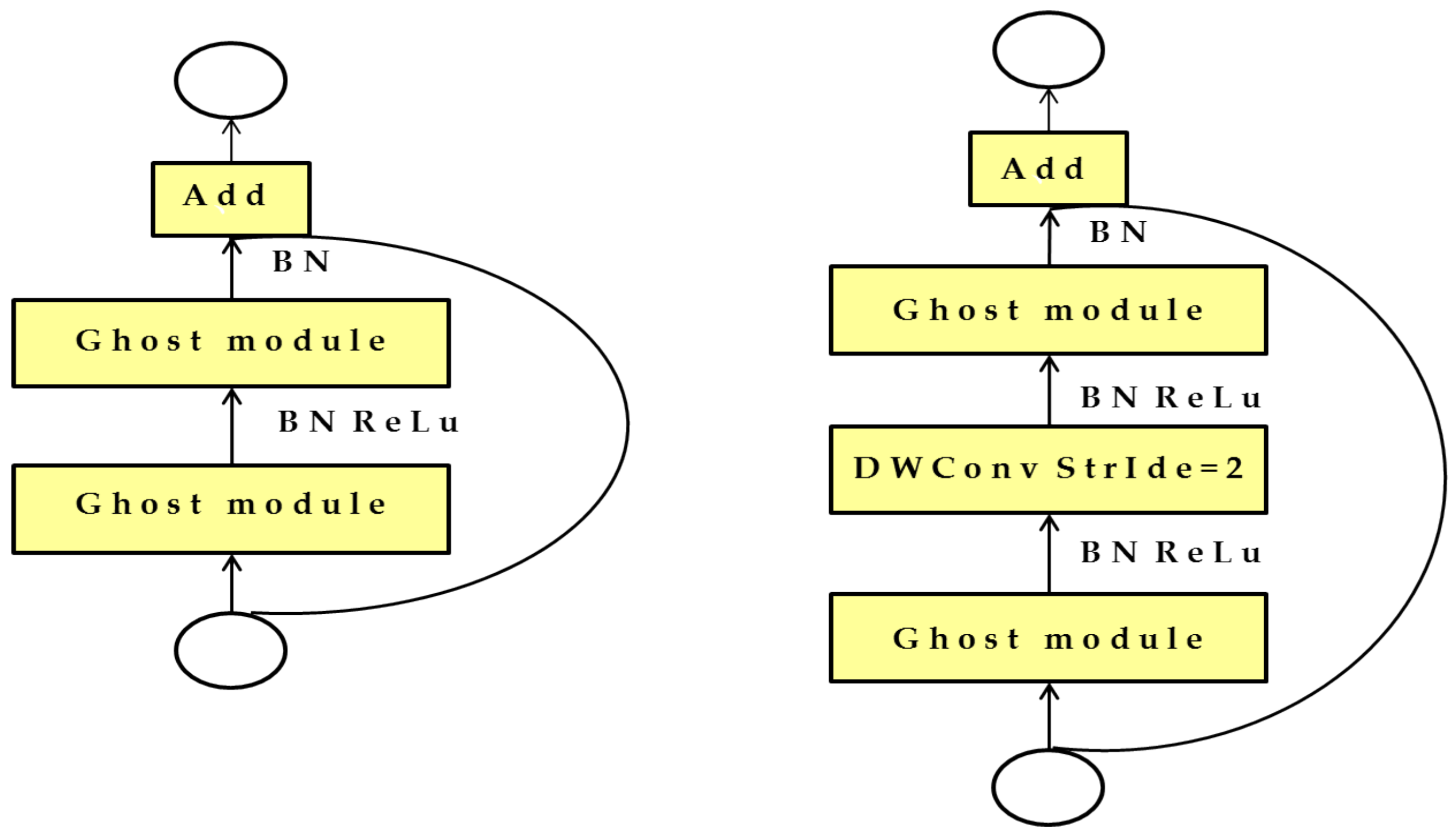
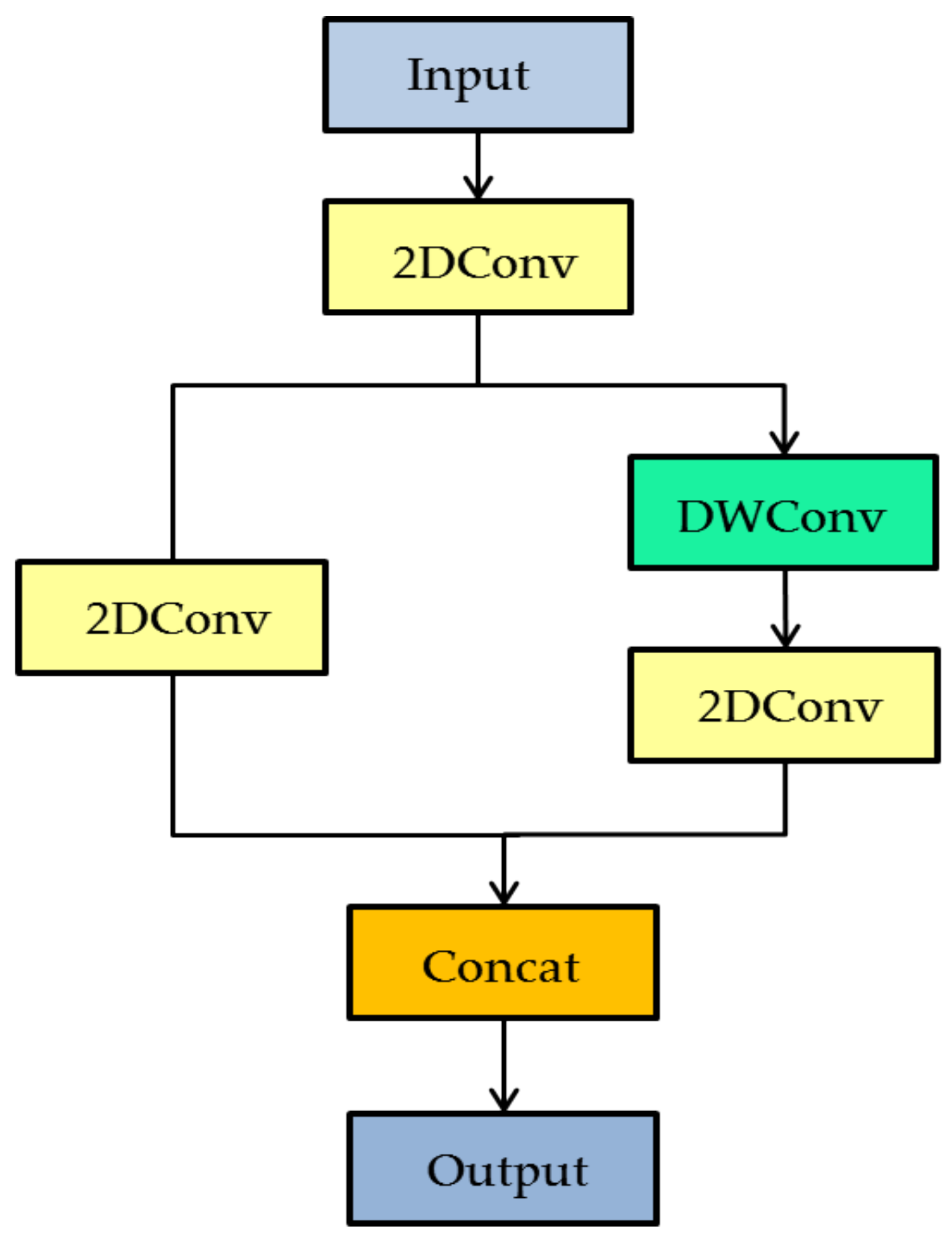
2.5.1. Improved Ghostnet Feature Extraction Network
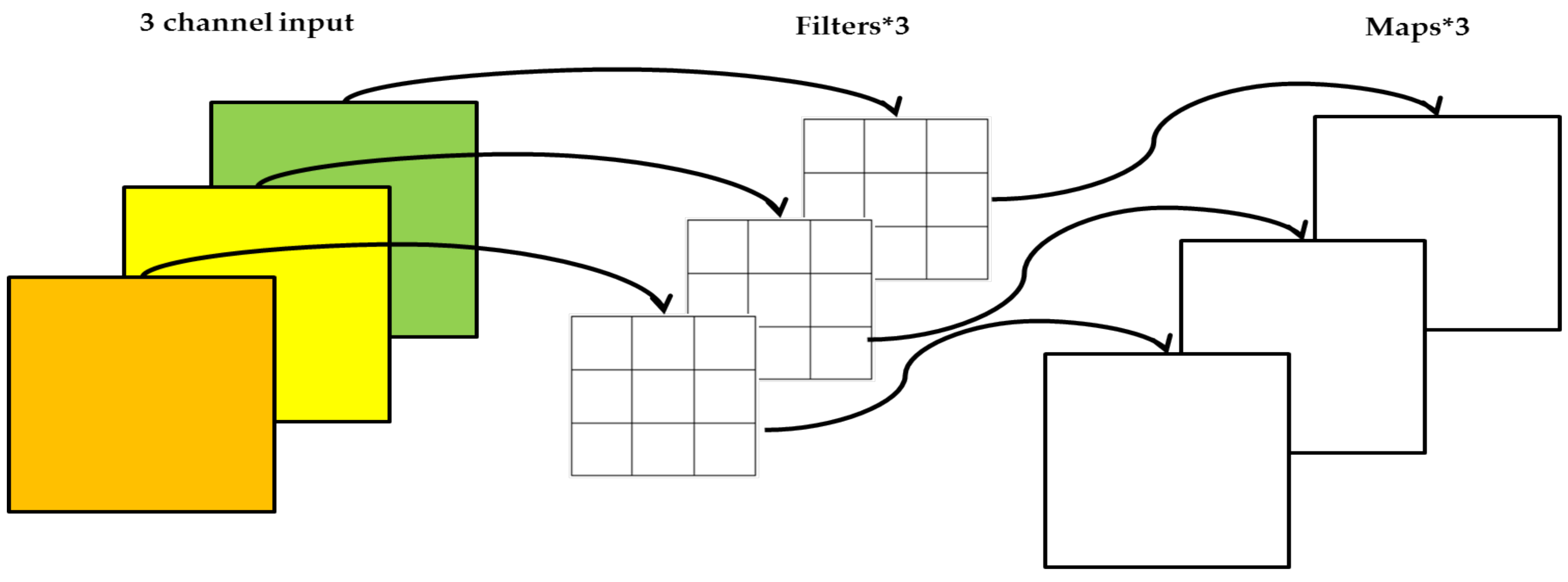
2.5.2. Depthwise Separable Convolution
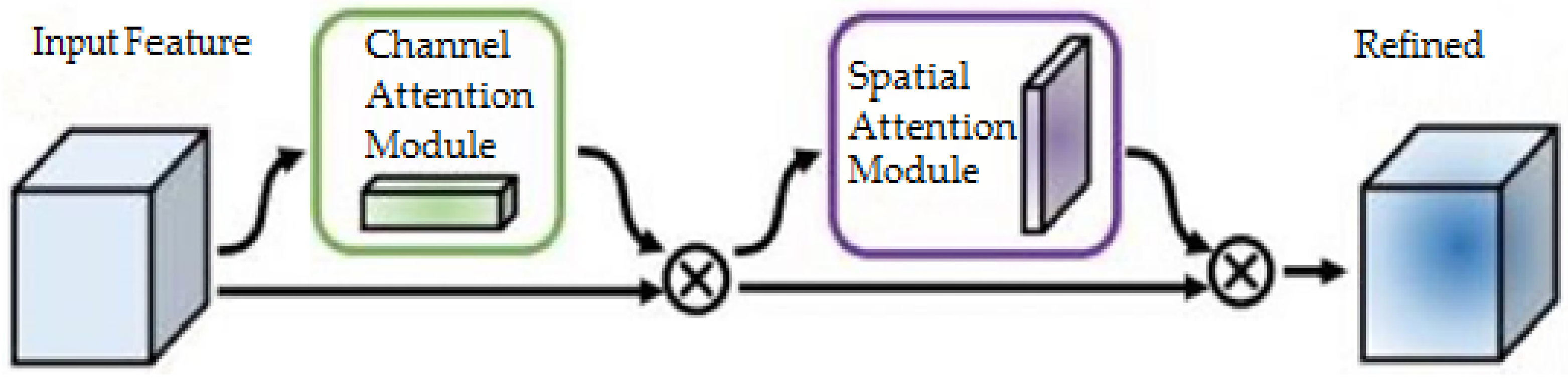
2.5.3. CBAM Attention Mechanism
2.5.4. K-means Clustering Adjusts the Target Prior Box
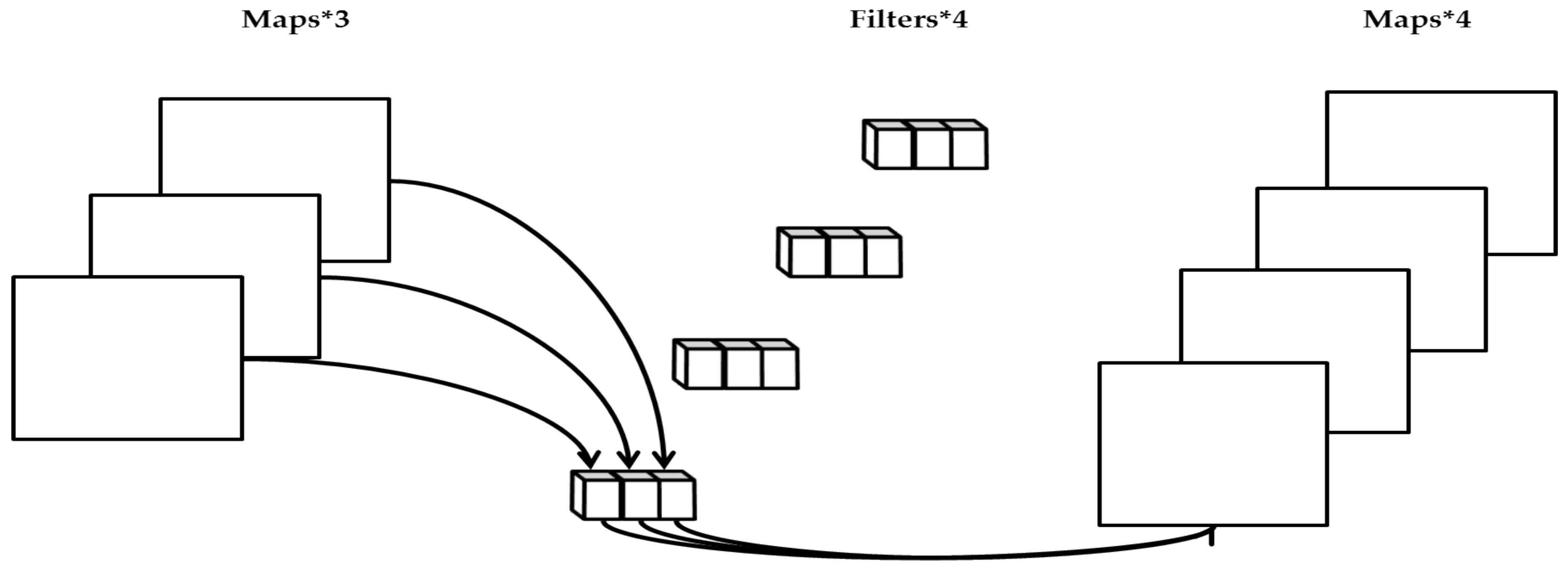
2.5.5. Improved Multi-Scale Feature Fusion Network Structure
2.5.6. Pre-training the Original Network with Transfer Learning
2.6. Test Evaluation Index
3. Results and Analysis
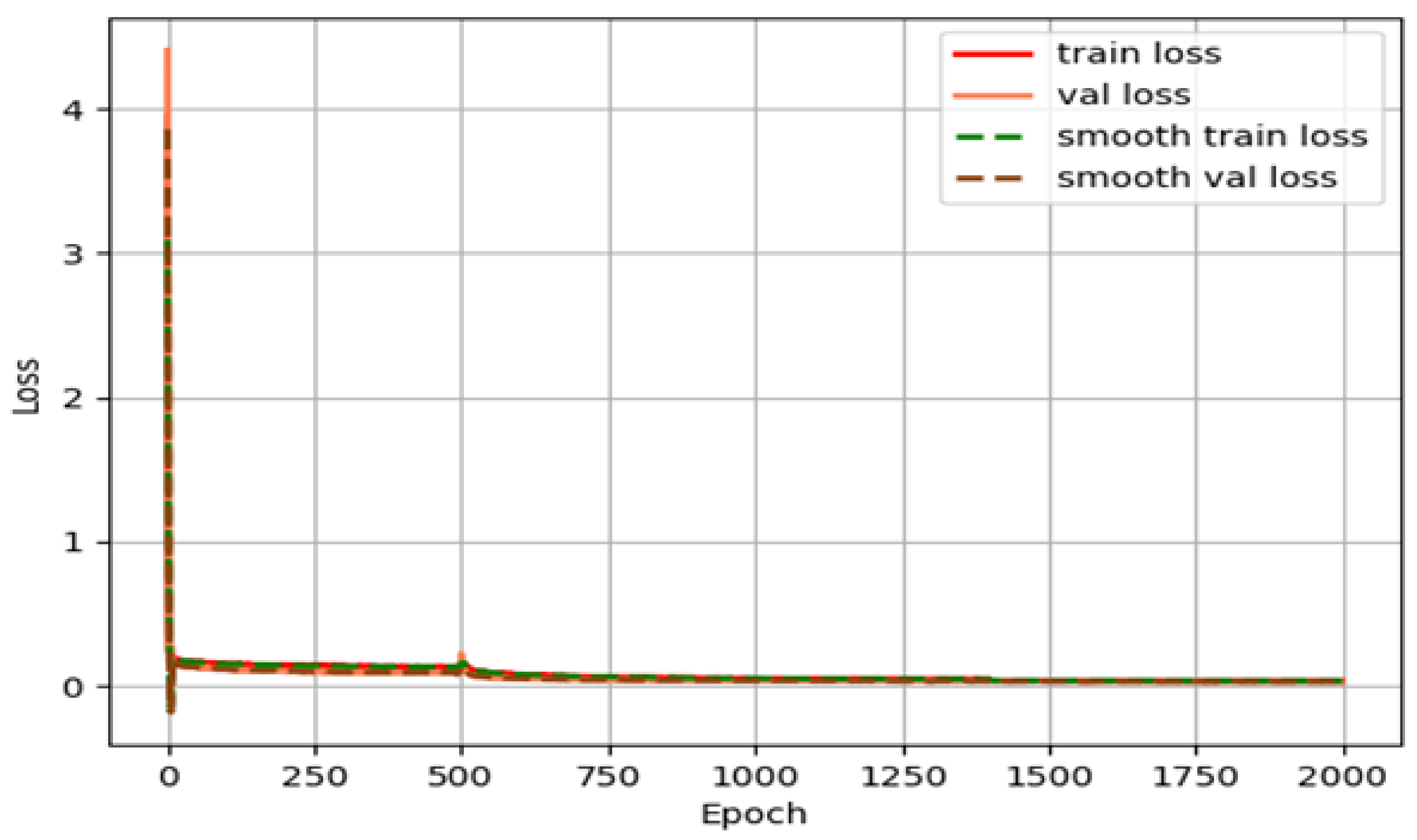
3.1. Test Platform and Training Parameters Setting
3.2. Comparison of Seedling Test Results
3.2.1. Comparison of Different Backbone Feature Extraction Networks
3.2.2. Comparison of Test Results of Different Improved Structures
4. Discussion
5. Conclusions
- (1)
- This study proposes an improved YOLOv4 lightweight neural network algorithm for detecting maize seedlings. We used the improved Ghostnet as the backbone feature extraction network to construct the YOLOv4 lightweight network, improved the multi-scale feature fusion network structure, introduced the k-means clustering algorithm to adjust the target prior box, and added the attention mechanism to the neck network to make it more suitable for seedling detection. By introducing deep separable convolution in PANet and YOLO Head networks instead of traditional convolution, the network is more lightweight and more conducive to deploying mobile terminals. The model’s training speed and average accuracy are improved by loading the pre-trained weights and freezing some layers.
- (2)
- We verify the feasibility and superiority of the proposed method through comparative experiments on the same test set, taking the F1, recall, mAP, precision, number of model parameters, model size, and FPS as the judgment basis. The method F1, recall rate, mAP, and precision rate of this study are 0.95, 94.02%, 97.03%, and 96.25%, respectively, which are 0.13, 19.96%, 8.68%, and 5.38% higher than YOLOv4. The model network parameters are 18.793 M, the model size is 71.69 MB, and the FPS is 22.92. Compared with the YOLOv4 model, the network parameters are reduced by 70.61%, the model size is reduced by 172.21 MB, and the FPS is increased by 3.71. Through comparative experiments, the model in this study has stronger detection performance, a better prediction effect, and lower model complexity, which is suitable for deployment in edge devices and has a certain application value.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, Z.; Liu, X.; Liu, J.; Chen, P. Study on the evolution of drought and flood trend of spring maize in Northeast China in recent 60 years. Chin. J. Eco-Agric. 2020, 28, 179–190. [Google Scholar] [CrossRef]
- Zhao, Y.-J.; Xing, S.; Zhang, Q.-S.; Zhang, F.-S.; Ma, W.-Q. Causes of maize density loss in farmers’ fields in Northeast China. J. Integr. Agric. 2019, 18, 1680–1689. [Google Scholar] [CrossRef]
- Chad, L.K.; Susana, G.; Kenneth, J.M. Seed Size, Planting Depth, and a Perennial Groundcover System Effect on Corn Emergence and Grain Yield. Agronomy 2022, 12, 437. [Google Scholar] [CrossRef]
- Maria Victoria, B.; Tomohiro, N.; Satoshi, S.; Itsuki, T.; Nanami, K.; Yusuke, K.; Shun, I.; Kazuyuki, D.; Jun, M.; Shunsaku, N. Estimating Yield-Related Traits Using UAV-Derived Multispectral Images to Improve Rice Grain Yield Prediction. Agriculture 2022, 12, 1141. [Google Scholar] [CrossRef]
- Lu, Z.; Qi, L.; Zhang, H.; Wan, J.; Zhou, J. Image Segmentation of UAV Fruit Tree Canopy in a Natural Illumination Environment. Agriculture 2022, 12, 1039. [Google Scholar] [CrossRef]
- Liu, H.; Qi, Y.; Xiao, W.; Tian, H.; Zhao, D.; Zhang, K.; Xiao, J.; Lu, X.; Lan, Y.; Zhang, Y. Identification of Male and Female Parents for Hybrid Rice Seed Production Using UAV-Based Multispectral Imagery. Agriculture 2022, 12, 1005. [Google Scholar] [CrossRef]
- Zhao, J.; Yan, J.; Xue, T.; Wang, S.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W.; Zhang, X. A deep learning method for oriented and small wheat spike detection (OSWSDet) in UAV images. Comput. Electron. Agric. 2022, 198, 107087. [Google Scholar] [CrossRef]
- Su, W.; Zhang, M.; Bian, D.; Liu, Z.; Huang, J.; Wang, W.; Wu, J.; Guo, H. Phenotyping of Corn Plants Using Unmanned Aerial Vehicle (UAV) Images. Remote Sens. 2019, 11, 2021. [Google Scholar] [CrossRef]
- Lee, D.-H.; Kim, H.-J.; Park, J.-H. UAV, a Farm Map, and Machine Learning Technology Convergence Classification Method of a Corn Cultivation Area. Agronomy 2021, 11, 1554. [Google Scholar] [CrossRef]
- Tseng, H.-H.; Yang, M.-D.; Saminathan, R.; Hsu, Y.-C.; Yang, C.-Y.; Wu, D.-H. Rice Seedling Detection in UAV Images Using Transfer Learning and Machine Learning. Remote Sens. 2022, 14, 2837. [Google Scholar] [CrossRef]
- Muhammad Nurfaiz Abd, K.; Aimrun, W.; Ahmad Fikri, A.; Abdul Rashid Mohamed, S.; Ezrin Mohd, H.; Muhammad Razif, M. Predictive zoning of pest and disease infestations in rice field based on UAV aerial imagery. Egypt. J. Remote Sens. Space Sci. 2022, 25, 831–840. [Google Scholar] [CrossRef]
- Xu, T.; Wang, F.; Xie, L.; Yao, X.; Zheng, J.; Li, J.; Chen, S. Integrating the Textural and Spectral Information of UAV Hyperspectral Images for the Improved Estimation of Rice Aboveground Biomass. Remote Sens. 2022, 14, 2534. [Google Scholar] [CrossRef]
- Han, W.; Li, G.; Yuan, M.; Zhang, L.; Shi, Z. Research on maize planting information extraction method based on UAV remote sensing technology. Trans. Soc. Agric. Mach. 2017, 48, 139–147. [Google Scholar]
- Gnädinger, F.; Schmidhalter, U. Digital Counts of Maize Plants by Unmanned Aerial Vehicles (UAVs). Remote Sens. 2017, 9, 544. [Google Scholar] [CrossRef]
- Liu, T.; Sun, C.M.; Wang, L.; Zhong, X.C.; Zhu, X.-K.; Guo, W. Field wheat Counting based on image processing technology! Trans. Soc. Agric. Mach. 2014, 45, 282–290. [Google Scholar]
- Jia, H.; Wang, G.; Guo, M.; Shah, D.; Jiang, X.; Zhao, J.L. Method and experiment of maize plant number acquisition based on machine vision. Trans. CSAE 2015, 31, 215–220. [Google Scholar]
- Liu, B.; Yang, G.; Zhou, C.; Jing, H.; Feng, H.; Xu, B.; Yang, H. Information extraction of maize plant number at seedling stage based on UAV remote sensing image. Trans. CSAE 2018, 34, 69–77. [Google Scholar]
- Zhao, B.; Zhang, J.; Yang, C.; Zhou, G.; Ding, Y.; Shi, Y.; Zhang, D.; Xie, J.; Liao, Q. Rapeseed Seedling Stand Counting and Seeding Performance Evaluation at Two Early Growth Stages Based on Unmanned Aerial Vehicle Imagery. Front. Plant Sci. 2018, 9, 1362. [Google Scholar] [CrossRef]
- Vong, C.N.; Conway, L.S.; Zhou, J.; Kitchen, N.R.; Sudduth, K.A. Early corn stand count of different cropping systems using UAV-imagery and deep learning. Comput. Electron. Agric. 2021, 186, 106214. [Google Scholar] [CrossRef]
- Karami, A.; Crawford, M.; Delp, E.J. Automatic Plant Counting and Location Based on a Few-Shot Learning Technique. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5872–5886. [Google Scholar] [CrossRef]
- Yang, B.; Gao, Z.; Gao, Y.; Zhu, Y. Rapid Detection and Counting of Wheat Ears in the Field Using YOLOv4 with Attention Module. Agronomy 2021, 11, 1202. [Google Scholar] [CrossRef]
- Guo, R.; Yu, C.; He, H.; Yu, H.; Feng, X.Z. Detection method of soybean pod number per plant using improved YOLOv4 algorithm. Trans. CSAE 2021, 37, 179–187. [Google Scholar]
- Zhang, H.; Yu, F.; Han, W.; Yang, G.; Niu, D.; Zhou, X.Y. A method to obtain maize seedling number based on improved YOLO. Trans. Soc. Agric. Mach. 2021, 52, 221–229. [Google Scholar]
- Song, H.; Yang, C.; Zhang, J.; Hoffmann, W.C.; He, D.; Thomasson, J.A. Comparison of mosaicking techniques for airborne images from consumer-grade cameras. J. Appl. Remote Sens. 2016, 10, 16030. [Google Scholar] [CrossRef]
- Zhao, R.; Zhu, Y.; Li, Y. An end-to-end lightweight model for grape and picking point simultaneous detection. Biosyst. Eng. 2022, 223, 174–188. [Google Scholar] [CrossRef]
- Thani, J.; Eran, E.; Ali, E. Deep neural network based date palm tree detection in drone imagery. Comput. Electron. Agric. 2021, 192, 106560. [Google Scholar] [CrossRef]
- Wei, L.; Luo, Y.; Xu, L.; Zhang, Q.; Cai, Q.; Shen, M. Deep Convolutional Neural Network for Rice Density Prescription Map at Ripening Stage Using Unmanned Aerial Vehicle-Based Remotely Sensed Images. Remote Sens. 2021, 14, 46. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Ross, G.; Jeff, D.; Trevor, D.; Jitendra, M. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ross, G. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Wei, L.; Dragomir, A.; Dumitru, E.; Christian, S.; Scott, R.; Cheng-Yang, F.; Alexander, C.B. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Alexey, B.; Chien-Yao, W.; Hong-Yuan Mark, L. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Joseph, R.; Santosh, D.; Ross, G.; Ali, F. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Diganta, M. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Kai, H.; Yunhe, W.; Qi, T.; Jianyuan, G.; Chunjing, X.; Chang, X. GhostNet: More Features from Cheap Operations. arXiv 2019, arXiv:1911.11907. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. arXiv 2017, arXiv:1707.01083. [Google Scholar]
- Andrew, H.; Mark, S.; Grace, C.; Liang-Chieh, C.; Bo, C.; Mingxing, T.; Weijun, W.; Yukun, Z.; Ruoming, P.; Vijay, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1345–1459. [Google Scholar] [CrossRef]
- Gao, J.; Dai, S.; Huang, J.; Xiao, X.; Liu, L.; Wang, L.; Sun, X.; Guo, Y.; Li, M. Kiwifruit Detection Method in Orchard via an Improved Light-Weight YOLOv4. Agronomy 2022, 12, 2081. [Google Scholar] [CrossRef]
- Fu, L.; Yang, Z.; Wu, F.; Zou, X.; Lin, J.; Cao, Y.; Duan, J. YOLO-Banana: A Lightweight Neural Network for Rapid Detection of Banana Bunches and Stalks in the Natural Environment. Agronomy 2022, 12, 391. [Google Scholar] [CrossRef]
- Zhang, C.; Kang, F.; Wang, Y. An Improved Apple Object Detection Method Based on Lightweight YOLOv4 in Complex Backgrounds. Remote Sens. 2022, 14, 4150. [Google Scholar] [CrossRef]
- Gao, J.; French, A.P.; Pound, M.P.; He, Y.; Pridmore, T.P.; Pieters, J.G. Deep convolutional neural networks for image-based Convolvulus sepium detection in sugar beet fields. Plant Methods 2020, 16, 29. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhou, J.; Yang, Y.; Liu, L.; Liu, F.; Kong, W. Rapid Target Detection of Fruit Trees Using UAV Imaging and Improved Light YOLOv4 Algorithm. Remote Sens. 2022, 14, 4324. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configure | Parameter |
|---|---|
| CPU | Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40 GHz |
| GPU Operating System | NVIDIA GeForce RTX 3060 16 G Windows10 |
| Acceleration Environment Development Platform | Cuda 11.3 PyCharm |
| Others | Numpy1.17.0 Opencv4.1.0 |
| Model | P (%) | R (%) | mAP (%) | F1 | Model Size (MB) | Parameters (M) | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv4 | 90.87 | 74.06 | 88.35 | 0.82 | 243.90 | 63.938 | 19.21 |
| Vgg-YOLOv4 | 92.65 | 90.87 | 94.32 | 0.92 | 197.50 | 51.773 | 26.18 |
| Densenet121-YOLOv4 | 94.16 | 87.74 | 95.10 | 0.94 | 168.89 | 44.274 | 23.89 |
| Mobilenetv1-YOLOv4 | 94.04 | 89.06 | 94.54 | 0.91 | 154.60 | 40.527 | 29.46 |
| Mobilenetv3-YOLOv4 | 93.66 | 90.62 | 94.87 | 0.92 | 150.93 | 39.565 | 28.90 |
| Ghostnet-YOLOv4 | 93.24 | 89.54 | 94.07 | 0.91 | 149.78 | 39.264 | 32.77 |
| Model | P (%) | R (%) | mAP (%) | F1 | Model Size (MB) | Parameters (M) | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv4 | 90.87 | 74.06 | 88.35 | 0.82 | 243.90 | 63.938 | 19.21 |
| YOLOv4 + ① | 92.12 | 77.50 | 90.75 | 0.84 | 179.29 | 47.001 | 31.94 |
| YOLOv4 + ① + ② | 93.61 | 87.98 | 94.25 | 0.91 | 127.49 | 33.422 | 26.89 |
| YOLOv4 + ① + ② + ③ | 94.69 | 90.02 | 94.93 | 0.92 | 71.61 | 18.772 | 24.89 |
| YOLOv4 + ① + ② + ③ + ④ | 97.28 | 91.82 | 96.91 | 0.94 | 71.61 | 18.772 | 24.87 |
| YOLOv4 + ① + ② + ③ + ④ + ⑤ | 96.25 | 94.02 | 97.03 | 0.95 | 71.69 | 18.793 | 22.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, J.; Tan, F.; Cui, J.; Ma, B. A Method for Obtaining the Number of Maize Seedlings Based on the Improved YOLOv4 Lightweight Neural Network. Agriculture 2022, 12, 1679. https://doi.org/10.3390/agriculture12101679
Gao J, Tan F, Cui J, Ma B. A Method for Obtaining the Number of Maize Seedlings Based on the Improved YOLOv4 Lightweight Neural Network. Agriculture. 2022; 12(10):1679. https://doi.org/10.3390/agriculture12101679
Chicago/Turabian StyleGao, Jiaxin, Feng Tan, Jiapeng Cui, and Bo Ma. 2022. "A Method for Obtaining the Number of Maize Seedlings Based on the Improved YOLOv4 Lightweight Neural Network" Agriculture 12, no. 10: 1679. https://doi.org/10.3390/agriculture12101679
APA StyleGao, J., Tan, F., Cui, J., & Ma, B. (2022). A Method for Obtaining the Number of Maize Seedlings Based on the Improved YOLOv4 Lightweight Neural Network. Agriculture, 12(10), 1679. https://doi.org/10.3390/agriculture12101679