
The Effect of Antecedence on Empirical Model Forecasts of Crop Yield from Observations of Canopy Properties


Abstract
1. Introduction
2. Materials and Methods
2.1. Trial Design for Fertilisation Experiments
2.2. Field Measurements
2.3. Statistical Analysis and Modelling
2.4. Model Evaluation and Forecasting Approaches
3. Results
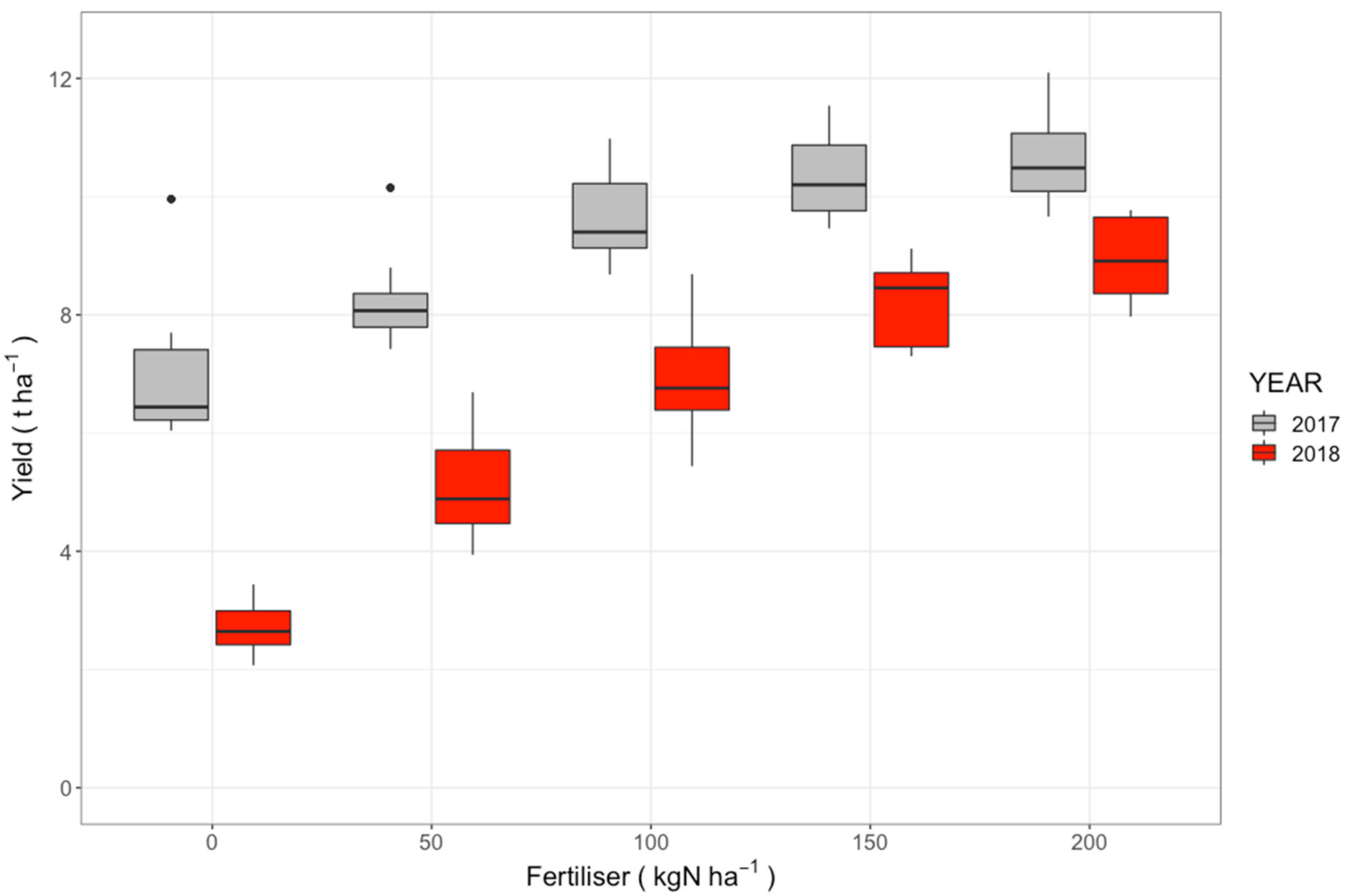
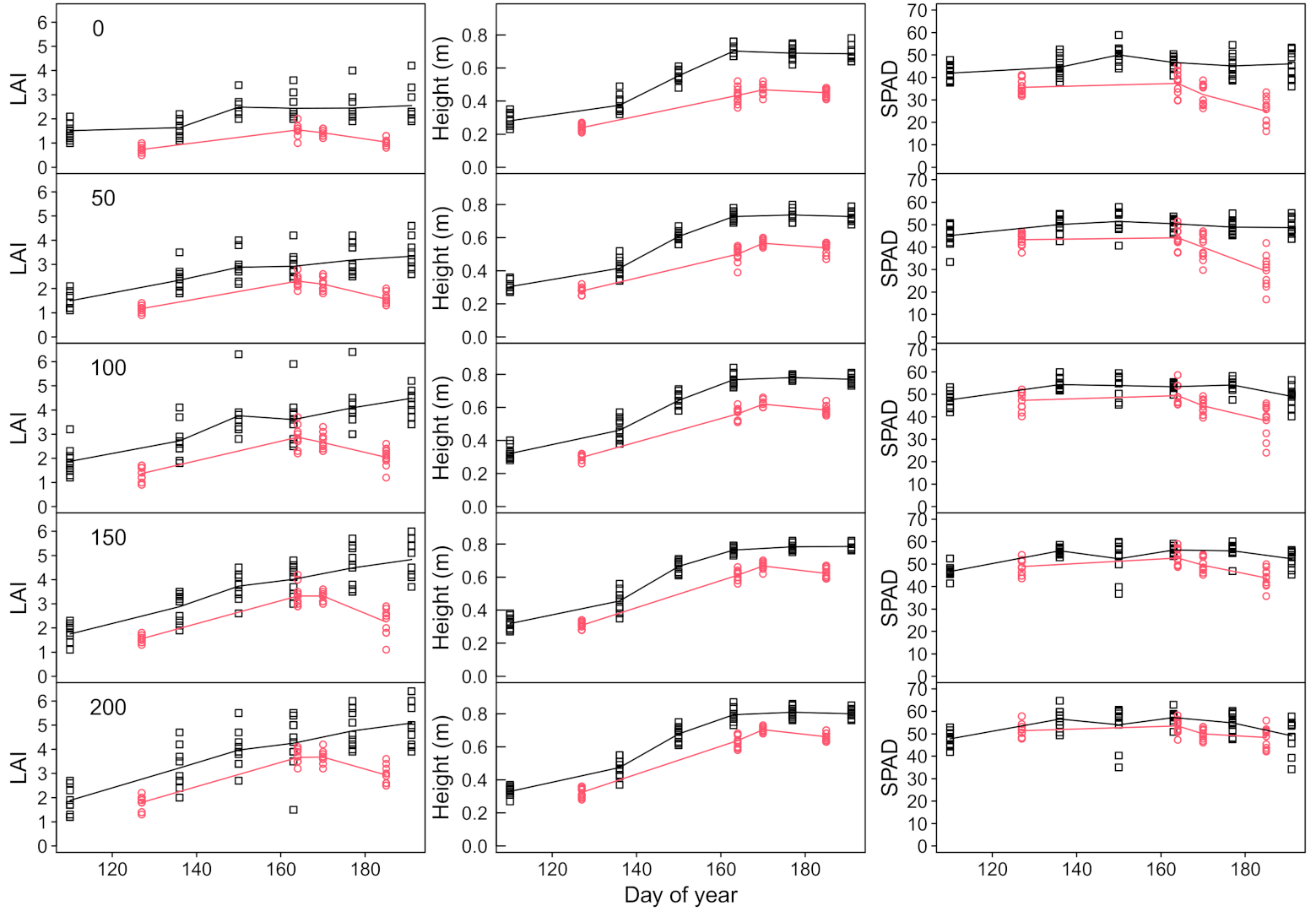
3.1. Variability of Yield and Canopy Development in the Trials
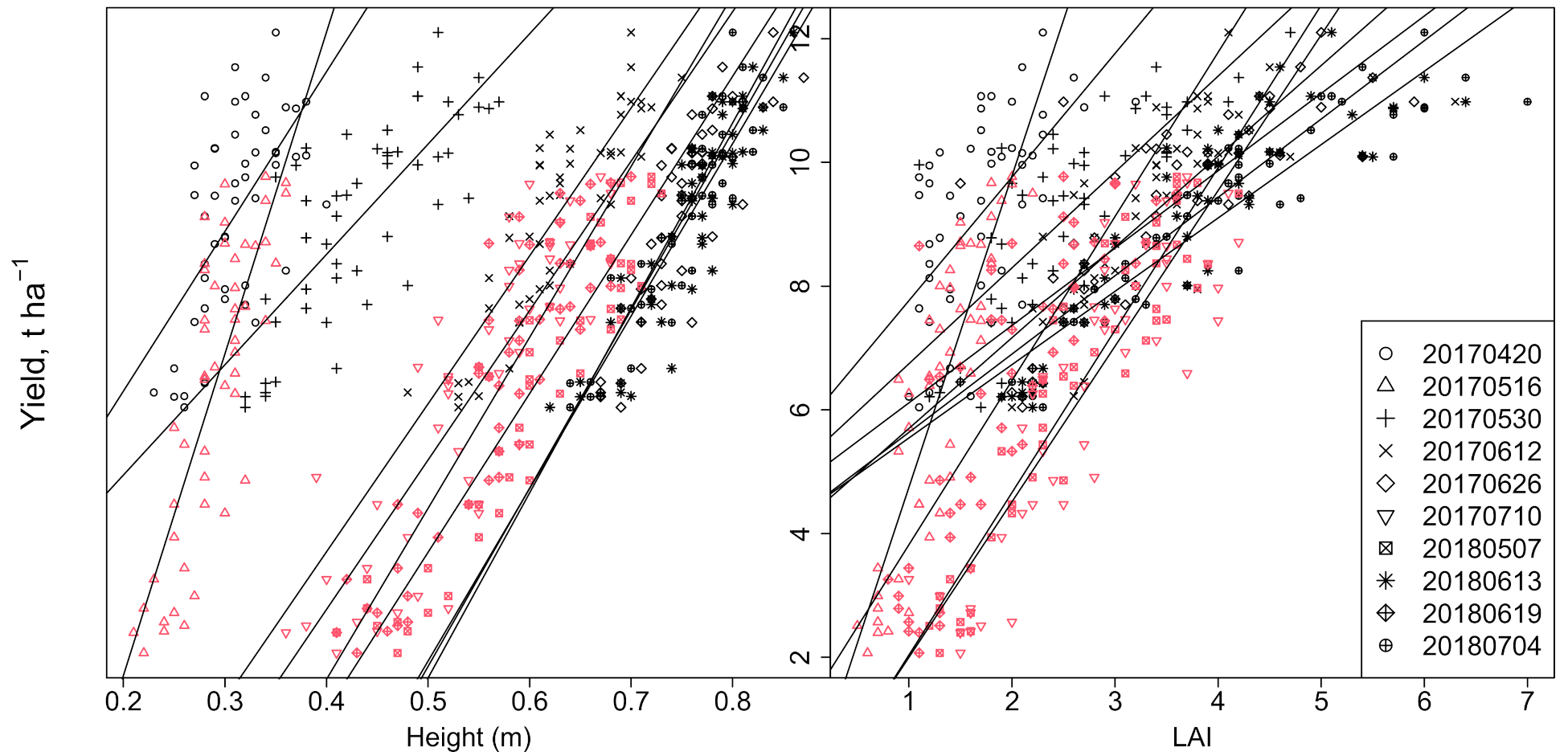
3.2. Canopy Property Relationships with Yield
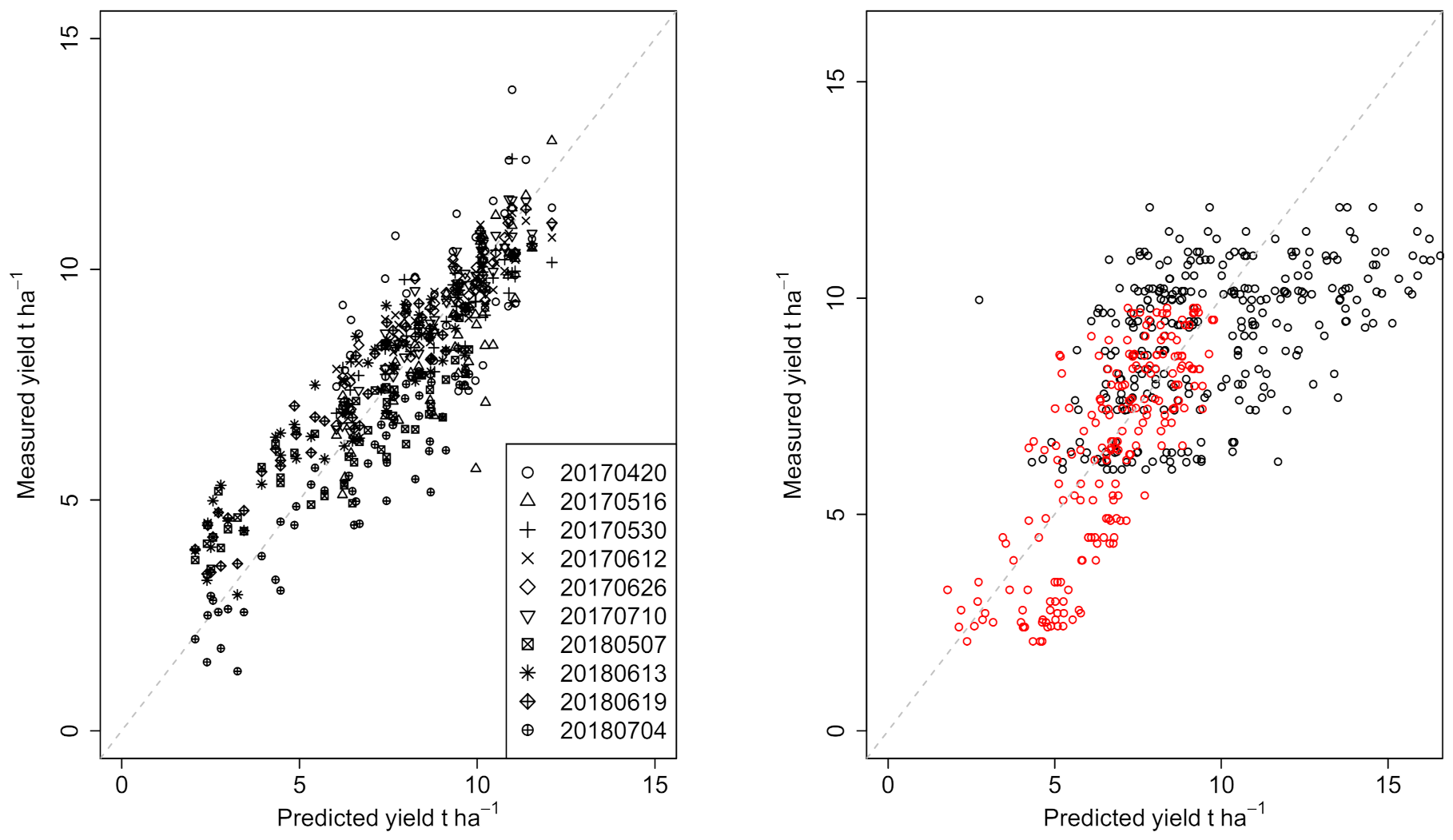
3.3. Predicting Yield Relationships Using Linear Models and Canopy Properties
4. Discussions
4.1. How Accurately can Individual Crop Growth Measures Be Used to Predict Final Yields
4.2. How Does the Accuracy of Prediction Vary through the Growth Season and across Different Seasons?
4.3. The Value of Yield Mapping from Ecological Variables
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Food and Agriculture Organization (FAO). Crop Prospects and Food Situation; Quarterly Global Report; FAO: Rome, Italy, 2020. [Google Scholar]
- Hubert, B.; Rosegrant, M.; Van Boekel, M.A.J.S.; Ortiz, R. The Future of Food: Scenarios for 2050. Crop Sci. 2010, 50, S-33. [Google Scholar] [CrossRef]
- Ray, D.K.; Ramankutty, N.; Mueller, N.D.; West, P.C.; Foley, J.A. Recent patterns of crop yield growth and stagnation. Nat. Commun. 2012, 3, 1293. [Google Scholar] [CrossRef] [PubMed]
- Ray, D.K.; Gerber, J.S.; Macdonald, G.K.; West, P.C. Climate variation explains a third of global crop yield variability. Nat. Commun. 2015, 6, 5989. [Google Scholar] [CrossRef]
- Asseng, S.; Zhu, Y.; Wang, E.; Zhang, W. Chapter 20—Crop modeling for climate change impact and adaptation. In Crop Physiology, 2nd ed.; Sadras, V.O., Calderini, D.F., Eds.; Academic Press: San Diego, CA, USA, 2015; pp. 505–546. ISBN 978-0-12-417104-6. [Google Scholar]
- Reynolds, M.P.; Quilligan, E.; Aggarwal, P.K.; Bansal, K.C.; Cavalieri, A.J.; Chapman, S.C.; Chapotin, S.M.; Datta, S.K.; Duveiller, E.; Gill, K.S.; et al. An integrated approach to maintaining cereal productivity under climate change. Glob. Food Secur. 2016, 8, 9–18. [Google Scholar] [CrossRef]
- Chen, X.; Cui, Z.; Fan, M.; Vitousek, P.; Zhao, M.; Ma, W.; Wang, Z.; Zhang, W.; Yan, X.; Yang, J.; et al. Producing more grain with lower environmental costs. Nature 2014, 514, 486–489. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine Learning Approaches for Crop Yield Prediction and Nitrogen Status Estimation in Precision Agriculture: A Review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Basso, B.; Fiorentino, C.; Cammarano, D.; Schulthess, U. Variable rate nitrogen fertilizer response in wheat using remote sensing. Precis. Agric. 2016, 17, 168–182. [Google Scholar] [CrossRef]
- Bushong, J.T.; Mullock, J.L.; Miller, E.C.; Raun, W.R.; Brian Arnall, D. Evaluation of mid-season sensor based nitrogen fertilizer recommendations for winter wheat using different estimates of yield potential. Precis. Agric. 2016, 17, 470–487. [Google Scholar] [CrossRef]
- Jin, Z.; Prasad, R.; Shriver, J.; Zhuang, Q. Crop model- and satellite imagery-based recommendation tool for variable rate N fertilizer application for the US Corn system. Precis. Agric. 2017, 18, 779–800. [Google Scholar] [CrossRef]
- Filippi, P.; Jones, E.J.; Wimalathunge, N.S.; Somarathna, P.D.S.N.; Pozza, L.E.; Ugbaje, S.U.; Jephcott, T.G.; Paterson, S.E.; Whelan, B.M.; Bishop, T.F.A. An approach to forecast grain crop yield using multi-layered, multi-farm data sets and machine learning. Precis. Agric. 2019, 20, 1015–1029. [Google Scholar] [CrossRef]
- Kantanantha, N.; Serban, N.; Griffin, P. Yield and Price Forecasting for Stochastic Crop Decision Planning. J. Agric. Biol. Environ. Stat. 2010, 15, 362–380. [Google Scholar] [CrossRef]
- Chen, K.; O’Leary, R.A.; Evans, F.H. A simple and parsimonious generalised additive model for predicting wheat yield in a decision support tool. Agric. Syst. 2019, 173, 140–150. [Google Scholar] [CrossRef]
- Wattenbach, M.; Sus, O.; Vuichard, N.; Lehuger, S.; Gottschalk, P.; Li, L.; Leip, A.; Williams, M.; Tomelleri, E.; Kutsch, W.L.; et al. The carbon balance of European croplands: A cross-site comparison of simulation models. Agric. Ecosyst. Environ. 2010, 139, 419–453. [Google Scholar] [CrossRef]
- Valade, A.; Vuichard, N.; Ciais, P.; Ruget, F.; Viovy, N.; Gabrielle, B.; Huth, N.; Martiné, J.F. ORCHIDEE-STICS, a process-based model of sugarcane biomass production: Calibration of model parameters governing phenology. GCB Bioenergy 2014, 6, 606–620. [Google Scholar] [CrossRef]
- Di Paola, A.; Valentini, R.; Santini, M. An overview of available crop growth and yield models for studies and assessments in agriculture. J. Sci. Food Agric. 2016, 96, 709–714. [Google Scholar] [CrossRef]
- Challinor, A.J.; Watson, J.C.; Lobell, D.B.; Howden, S.M.; Smith, D.R.; Chhetri, N. A meta-analysis of crop yield under climate change and adaptation. Nat. Clim. Chang. 2014, 4, 287–291. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L.; et al. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Burke, M.; Lobell, D.B. Satellite-Based Assessment of Yield Variation and Its Determinants in Smallholder African Systems. Proc. Natl. Acad. Sci. USA 2017, 114, 2189–2194. [Google Scholar] [CrossRef]
- Gallagher, J.N.; Biscoe, P.V. Radiation absorption, growth and yield of cereals. J. Agric. Sci. 1978, 91, 47–60. [Google Scholar] [CrossRef]
- Erten, E.; Sanchez, L.J.M.; Yuzugullu, O.; Hajnsek, I. Retrieval of agricultural crop height from space: A comparison of SAR techniques. Remote Sens. Environ. 2016, 187, 130–144. [Google Scholar] [CrossRef]
- Hoffmeister, D.; Waldhoff, G.; Korres, W.; Curdt, C.; Bareth, G. Crop Height Variability Detection in a Single Field by Multi-Temporal Terrestrial Laser Scanning. Precis. Agric. 2016, 17, 296–312. [Google Scholar] [CrossRef]
- Xie, Q.; Wang, J.; Sanchez, L.J.M.; Peng, X.; Liao, C.; Shang, J.; Zhu, J.; Fu, H.; Berman, B.J.D. Crop Height Estimation of Corn from Multi-Year RADARSAT-2 Polarimetric Observables Using Machine Learning. Remote Sens. 2021, 13, 392. [Google Scholar] [CrossRef]
- Revill, A.; Florence, A.; MacArthur, A.; Hoad, S.; Rees, R.; Williams, M. Quantifying Uncertainty and Bridging the Scaling Gap in the Retrieval of Leaf Area Index by Coupling Sentinel-2 and UAV Observations. Remote Sens. 2020, 12, 1843. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, P.; Jia, J.Z.; Zhou, R.H. Quantitative Trait Loci for Leaf Chlorophyll Fluorescence Traits in Wheat. Aust. J. Crop Sci. 2010, 4, 571–579. [Google Scholar]
- Ospina, A.L.; Marmagne, A.; Talbotec, J.; Krupinska, K.; Daubresse, M.C. The identification of new cytosolic glutamine synthetase and asparagine synthetase genes in barley (Hordeum vulgare L.), and their expression during leaf senescence. J. Exp. Bot. 2015, 66, 2013–2026. [Google Scholar] [CrossRef]
- Zadoks, J.C.; Chang, T.T.; Konzak, C.F. A decimal code for the growth stages of cereals. Weed Res. 1974, 14, 415–421. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Han, J.; Zhang, Z.; Cao, J.; Luo, Y.; Zhang, L.; Li, Z.; Zhang, J. Prediction of Winter Wheat Yield Based on Multi-Source Data and Machine Learning in China. Remote Sens. 2020, 12, 236. [Google Scholar] [CrossRef]
- Rivera, J.P.; Verrelst, J.; Marí, M.J.; Moreno, J.; Valls, C.G. Toward a Semiautomatic Machine Learning Retrieval of Biophysical Parameters. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1249–1259. [Google Scholar] [CrossRef]
- Verrelst, J.; Muñoz, J.; Alonso, L.; Delegido, J.; Rivera, J.P.; Valls, C.G.; Moreno, J. Machine learning regression algorithms for biophysical parameter retrieval: Opportunities for Sentinel-2 and -3. Remote Sens. Environ. 2012, 118, 127–139. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing: Vienna, Austria. 2018. Available online: https://www.R-project.org (accessed on 16 December 2019).
- Jin, Z.; Zhuang, Q.; Tan, Z.; Dukes, J.S.; Zheng, B.; Melillo, J.M. Do maize models capture the impacts of heat and drought stresses on yield? Using algorithm ensembles to identify successful approaches. Glob. Chang. Biol. 2016, 22, 3112–3126. [Google Scholar] [CrossRef]
- Wu, A.; Hammer, G.L.; Doherty, A.; Von Caemmerer, S.; Farquhar, G.D. Quantifying impacts of enhancing photosynthesis on crop yield. Nat. Plants 2019, 5, 380–388. [Google Scholar] [CrossRef]
- Sus, O.; Williams, M.; Bernhofer, C.; Béziat, P.; Buchmann, N.; Ceschia, E.; Doherty, R.; Eugster, W.; Grünwald, T.; Kutsch, W.; et al. A linked carbon cycle and crop developmental model: Description and evaluation against measurements of carbon fluxes and carbon stocks at several European agricultural sites. Agric. Ecosyst. Environ. 2010, 139, 402–418. [Google Scholar] [CrossRef]
- Revill, A.; Myrgiotis, V.; Florence, A.; Hoad, S.; Rees, R.; MacArthur, A.; Williams, M. Combining Process Modelling and LAI Observations to Diagnose Winter Wheat Nitrogen Status and Forecast Yield. Agronomy 2021, 11, 314. [Google Scholar] [CrossRef]
- Revill, A.; Florence, A.; MacArthur, A.; Hoad, S.P.; Rees, R.M.; Williams, M. The Value of Sentinel-2 Spectral Bands for the Assessment of Winter Wheat Growth and Development. Remote Sens. 2019, 11, 2050. [Google Scholar] [CrossRef]
- Martins, M.A.; Tomasella, J.; Rodriguez, D.A.; Alvalá, R.C.S.; Giarolla, A.; Garofolo, L.L.; Júnior, J.L.S.; Paolicchi, L.T.L.C.; Pinto, G.L.N. Improving Drought Management in the Brazilian Semiarid through Crop Forecasting. Agric. Syst. 2018, 160, 21–30. [Google Scholar] [CrossRef]
- Hunt, M.L.; Blackburn, G.A.; Carrasco, L.; Redhead, J.W.; Rowland, C.S. High resolution wheat yield mapping using Sentinel-2. Remote Sens. Environ. 2019, 233, 111410. [Google Scholar] [CrossRef]
- Revill, A.; Sus, O.; Barrett, B.; Williams, M. Carbon cycling of European croplands: A framework for the assimilation of optical and microwave Earth observation data. Remote Sens. Environ. 2013, 137, 84–93. [Google Scholar] [CrossRef]
- Sus, O.; Heuer, M.W.; Meyers, T.P.; Williams, M. A data assimilation framework for constraining upscaled cropland carbon flux seasonality and biometry with MODIS. Biogeosciences 2013, 10, 2451–2466. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
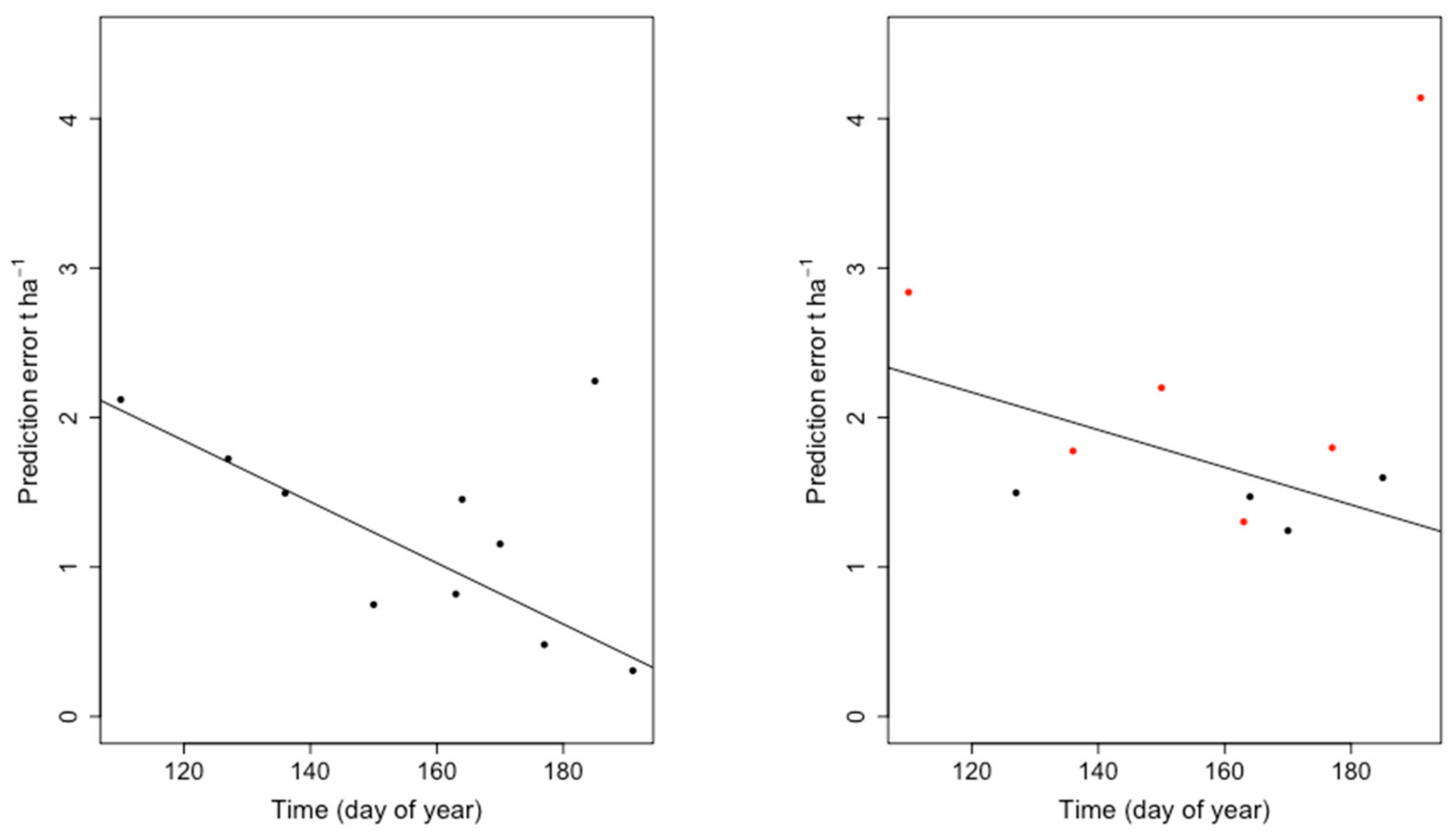{kind=link}
| Date | Growth Stage | SPAD | HEIGHT | LAI | |||
|---|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | R2 | RMSE | ||
| 2017/04/20 | 31 | 0.12 | 1.51 | 0.37 | 1.28 | 0.35 | 1.29 |
| 2017/05/16 | 32 | 0.48 | 1.16 | 0.59 | 1.03 | 0.61 | 1.01 |
| 2017/05/30 | 50 | 0.00 | 1.61 | 0.78 | 0.76 | 0.63 | 0.98 |
| 2017/06/12 | 59 | 0.57 | 1.06 | 0.73 | 0.83 | 0.63 | 0.98 |
| 2017/06/26 | 71 | 0.48 | 1.16 | 0.80 | 0.73 | 0.79 | 0.74 |
| 2017/07/10 | 78 | 0.03 | 1.59 | 0.83 | 0.66 | 0.84 | 0.64 |
| 2018/05/07 | 31 | 0.66 | 1.37 | 0.65 | 1.39 | 0.78 | 1.09 |
| 2018/06/13 | 62 | 0.66 | 1.36 | 0.74 | 1.19 | 0.78 | 1.11 |
| 2018/06/19 | 68 | 0.70 | 1.28 | 0.87 | 0.86 | 0.88 | 0.81 |
| 2018/07/04 | 79 | 0.63 | 1.42 | 0.83 | 0.97 | 0.68 | 1.33 |
| Mean | - | 0.43 | 1.35 | 0.72 | 0.97 | 0.70 | 1.00 |
| Factors | 10-Fold Cross-Validation R2 | 10-Fold Cross-Validation RMSE (t ha−1) | Validation R2 between Years | Validation RMSE (t ha−1) between Years | ||||
|---|---|---|---|---|---|---|---|---|
| LM | GPR | LM | GPR | LM | GPR | LM | GPR | |
| Height*DOY | 0.64 | 0.66 | 1.44 | 1.54 | 0.51, 0.19 | 0.16, 0.36 | 1.78, 1.91 | 1.59, 2.00 |
| SPAD*DOY | 0.48 | 0.95 | 1.73 | 1.16 | 0.13, 0.47 | 0.06, 0.04 | 2.27, 2.64 | 2.30, 3.29 |
| LAI*DOY | 0.65 | 0.91 | 1.42 | 0.83 | 0.53, 0.48 | 0.29, 0.38 | 1.55, 2.16 | 2.13, 2.42 |
| LAI*Height*DOY | 0.78 | 0.93 | 1.12 | 0.63 | 0.63, 0.25 | 0.19, 0.48 | 1.46, 2.52 | 1.55, 1.81 |
| LAI*Height* DOY*SPAD | 0.83 | 0.96 | 1.00 | 0.65 | 0.63, 0.19 | 0.33, 0.59 | 1.46, 2.11 | 1.33, 1.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Florence, A.; Revill, A.; Hoad, S.; Rees, R.; Williams, M. The Effect of Antecedence on Empirical Model Forecasts of Crop Yield from Observations of Canopy Properties. Agriculture 2021, 11, 258. https://doi.org/10.3390/agriculture11030258
Florence A, Revill A, Hoad S, Rees R, Williams M. The Effect of Antecedence on Empirical Model Forecasts of Crop Yield from Observations of Canopy Properties. Agriculture. 2021; 11(3):258. https://doi.org/10.3390/agriculture11030258
Chicago/Turabian StyleFlorence, Anna, Andrew Revill, Stephen Hoad, Robert Rees, and Mathew Williams. 2021. "The Effect of Antecedence on Empirical Model Forecasts of Crop Yield from Observations of Canopy Properties" Agriculture 11, no. 3: 258. https://doi.org/10.3390/agriculture11030258
APA StyleFlorence, A., Revill, A., Hoad, S., Rees, R., & Williams, M. (2021). The Effect of Antecedence on Empirical Model Forecasts of Crop Yield from Observations of Canopy Properties. Agriculture, 11(3), 258. https://doi.org/10.3390/agriculture11030258