1. Introduction
World’s population is projected to reach 9.8 billion in 2050 [
1] and food production needs to increase by 60% to meet the demand [
2,
3]. One reason for that is the developing countries—that have been growing much more rapidly than the industrial countries—are creating implications for world food demand mainly in products such as animal-based, fruits, and vegetables [
4]. However, declining rates of growth in crop yields, slowing investment in agricultural research, and rising commodity prices have raised concerns of a general slowdown in global agricultural harvest area, yield, and production [
5].
The rapid per capita income growth in countries like China and India (40% world population) pressure food supply chains shifting towards animal-based products that require disproportionately more agricultural resources in production [
4,
6] such as land, water, and vegetable protein [
7]. Moreover, there is a concern revolving around big agriculture growers such as Brazil and the US using their agriculture areas to produce biofuels [
6].
It is not only in the economy that this relationship between food demand and income are finding shelter. It is possible to verify in the literature a connection about technology and agricultural production. Crop yield and production, for instance, have been studied in the light of artificial intelligence. Khan et al. [
8] predicted fruit production using deep neural networks. García-Martiínez et al. [
9] estimated corn grain yield with a neural network using multispectral and RGB images acquired with unmanned aerial vehicles. Maimaitijiang et al. [
10] predicted soybean yield using multimodal data fusion and deep learning. These applications are a clear attempt to improve knowledge about food production and provide decision-makers with valuable information to face the challenges of food demand.
Another possible solution discussed is the use of areas in Latin America and the Caribbean to expand agriculture production [
11]. Brazil, for instance, has more than 8 million
of area and uses only 15% of its arable land—approximately 60 of 400 million hectares [
12]. The country is an important global food supplier, and it is estimated that one out of four agribusiness products in circulation around the world came from Brazil [
13]. Despite the concern of biofuel production, sugarcane occupies only 8.9 million hectares of arable land [
14], and the majority is used for sugar production rather than ethanol.
Brazil has more than 300 different crops and exports 350 types of products to 180 countries. The main export products are sugar, coffee, maize, orange juice, cotton, and soybean. Among these products, soybean is the main global source of protein, and the country is the major exporter that corresponded for approximately 29.9% of agribusiness external sales in 2016—USD 25.4 billion [
13]. According to the Department of Agriculture of United States—USDA [
15], Brazilian exports of the soybean complex are 81% grains, 15.7% meal, and 3.3% refined oil.
Soybean production has overspread inside the country from south, through the center-western to the northeast area. These movements are motivated by low land cost, and investments in agriculture inputs, mechanization, and infrastructure [
16,
17,
18]. Other factors contributing to soybean growth in Brazil include the genetic improvement of seeds, increasingly productive planting systems [
19], favourable climatic conditions, predictable precipitation patterns, and public financing policies for soybean plantations [
20].
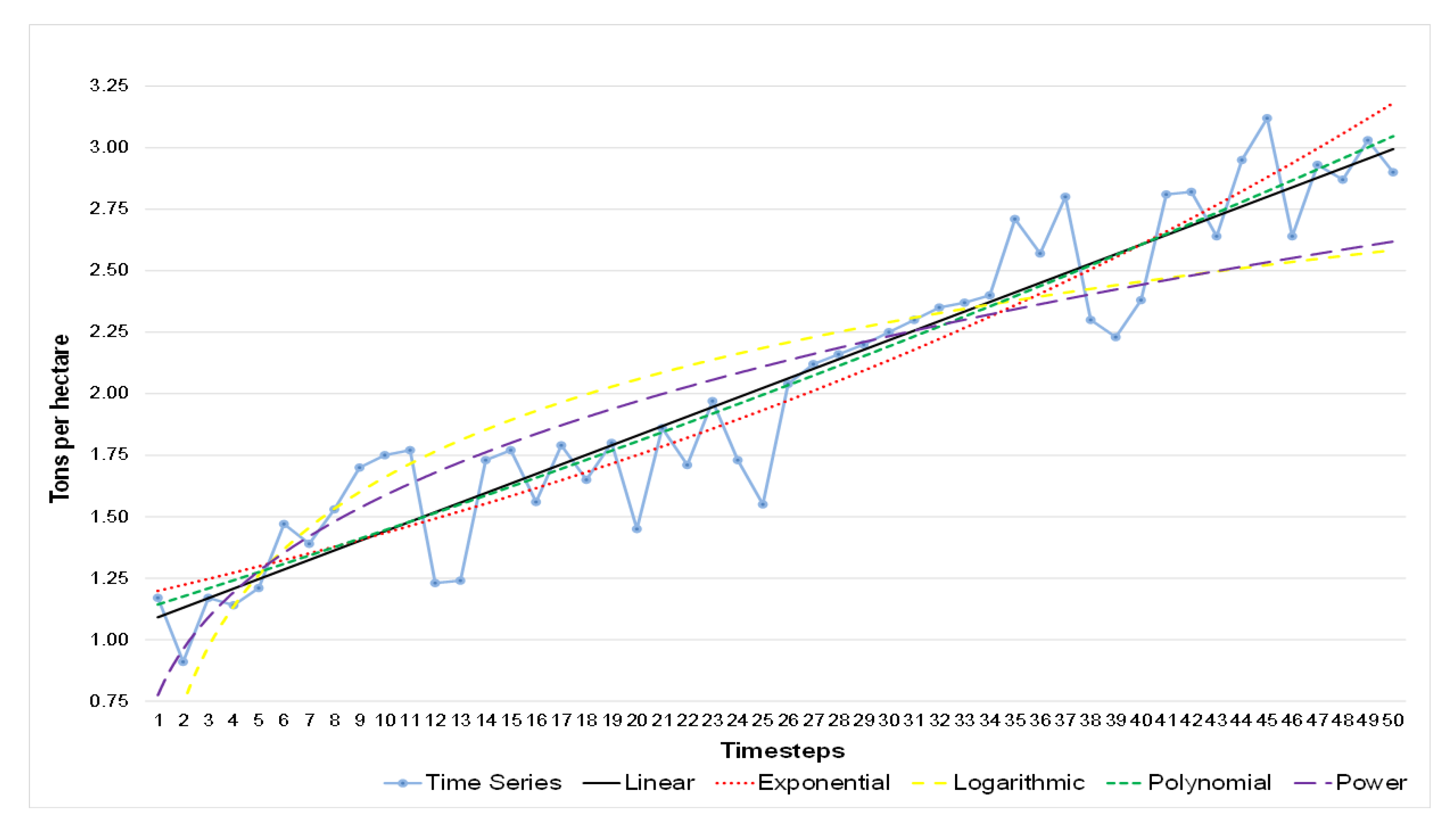
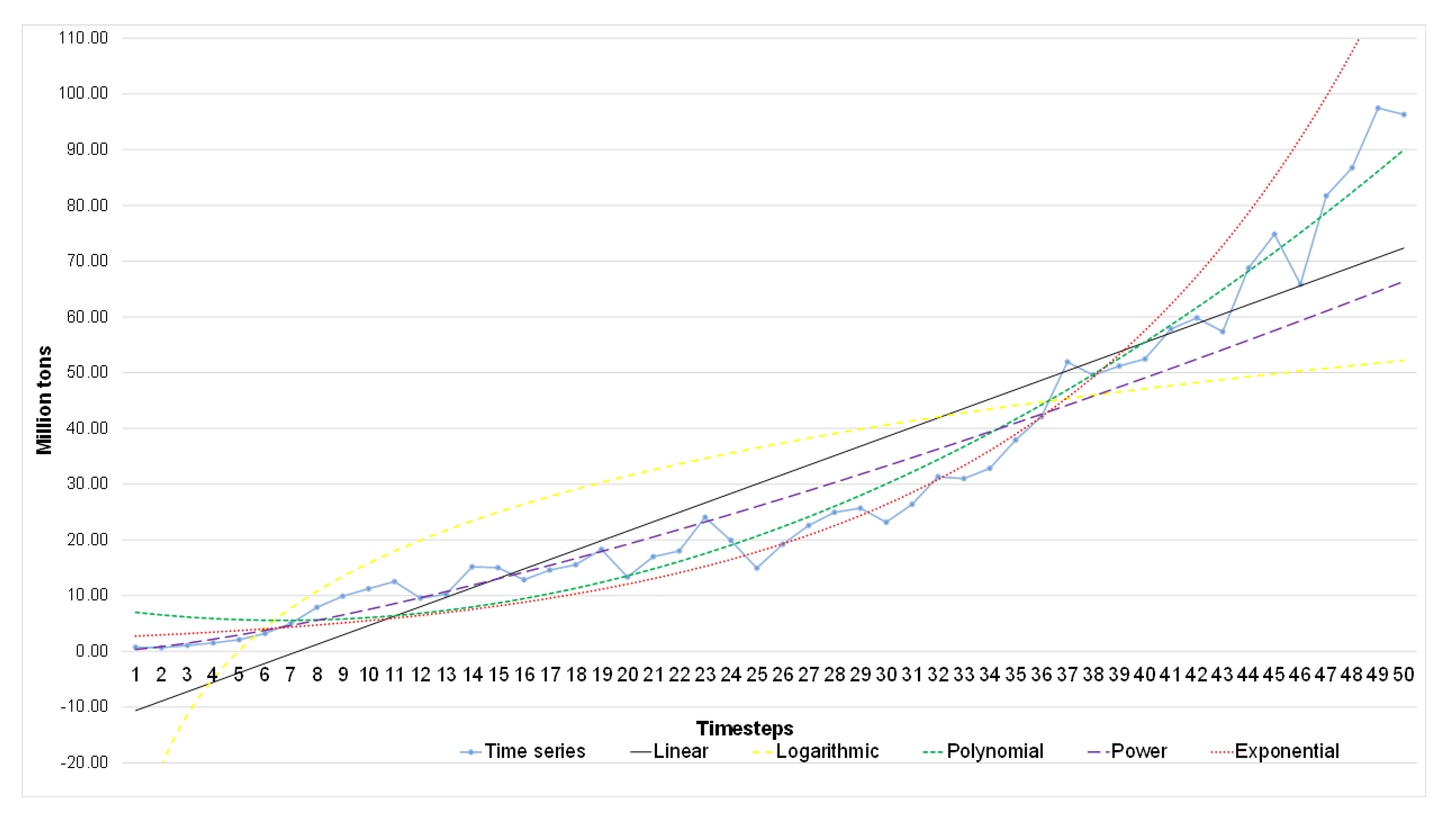
The soybean production is evaluated considering three categories: harvest area, yield, and production. The two main players are Brazil and the US, the former planted a harvest area of 36.9 million of hectares that produced 120.9 million of tones with a yield of 3.3 tones per hectare [
21] and the latter planted a harvest area around 30.8 million of hectares with a production of 96.8 million tons and a yield of 3.1 tones per hectare [
22]. These values are constantly predicted using classical methods and presented to stakeholders by government agencies. However, the respective literature is sparse and relates to agronomy aspects of soybean yield [
10,
23,
24]. In this paper, we focus on the prediction of these soybean indicators based on the previous crop data.
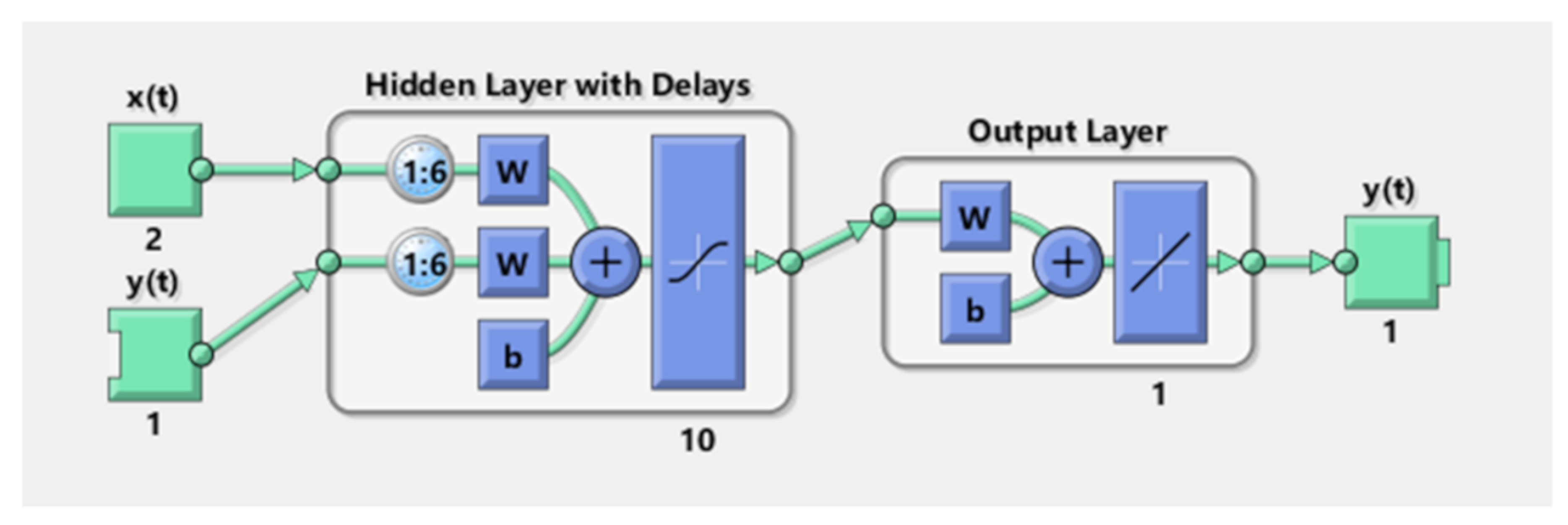
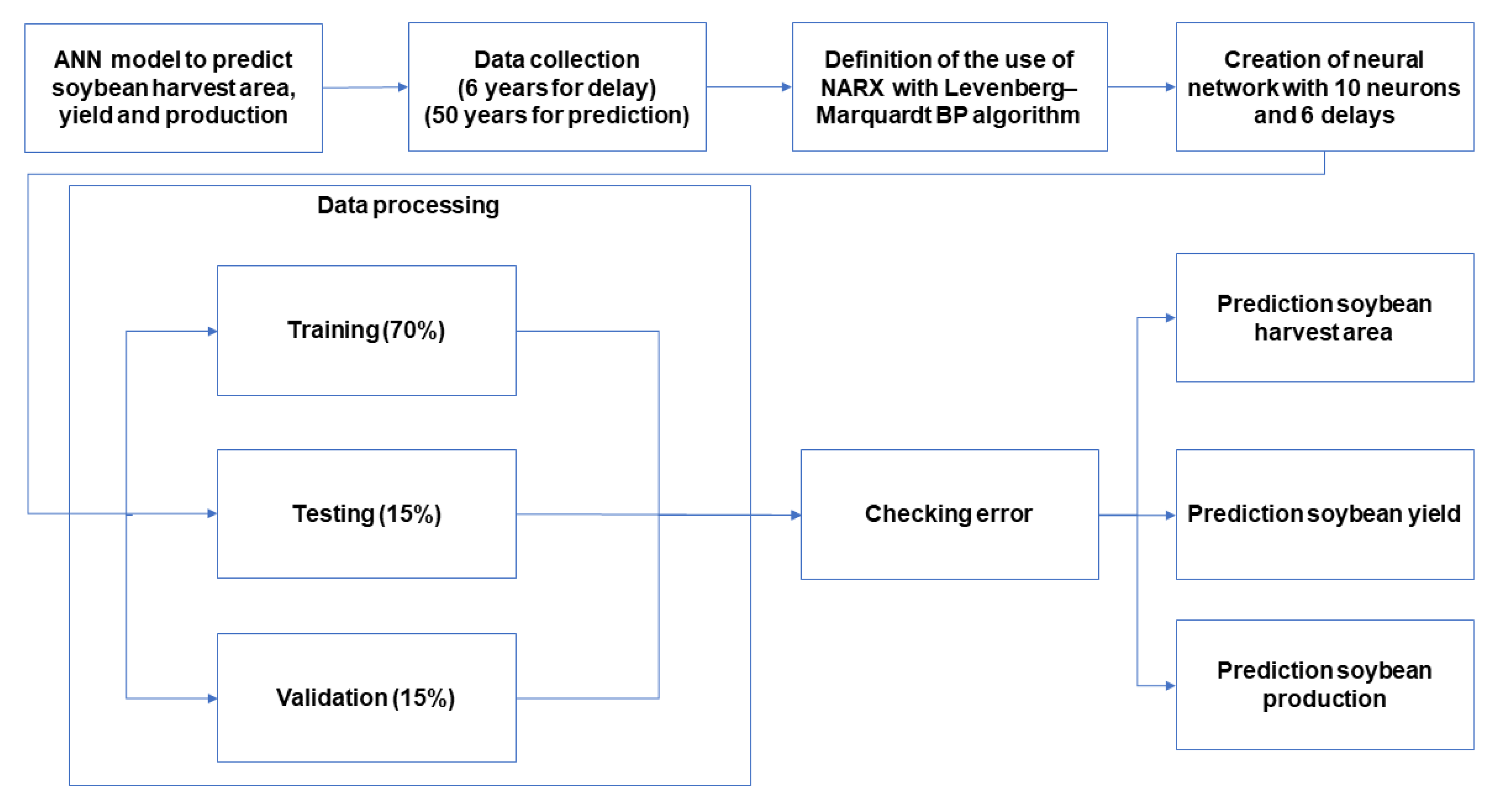
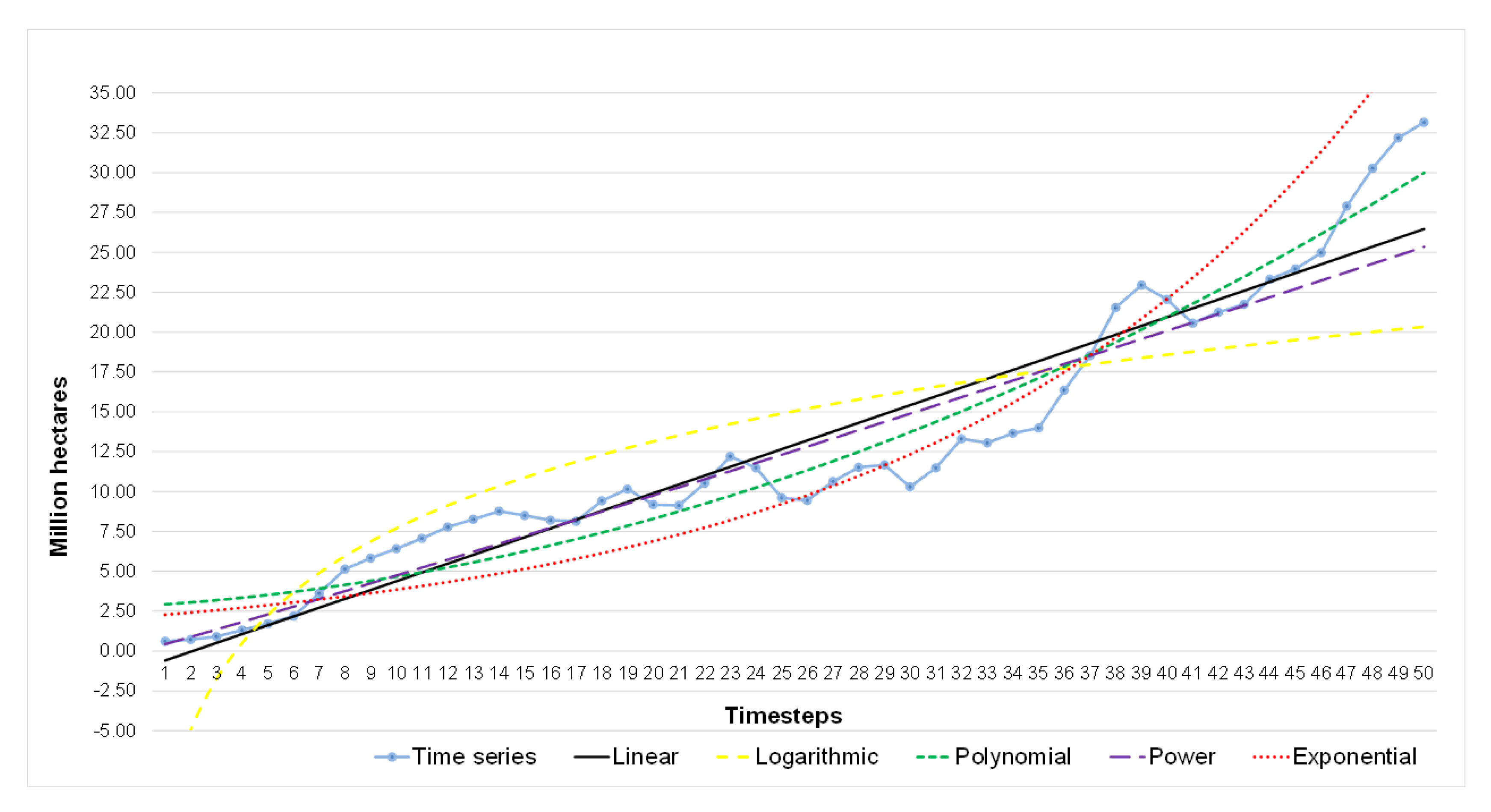
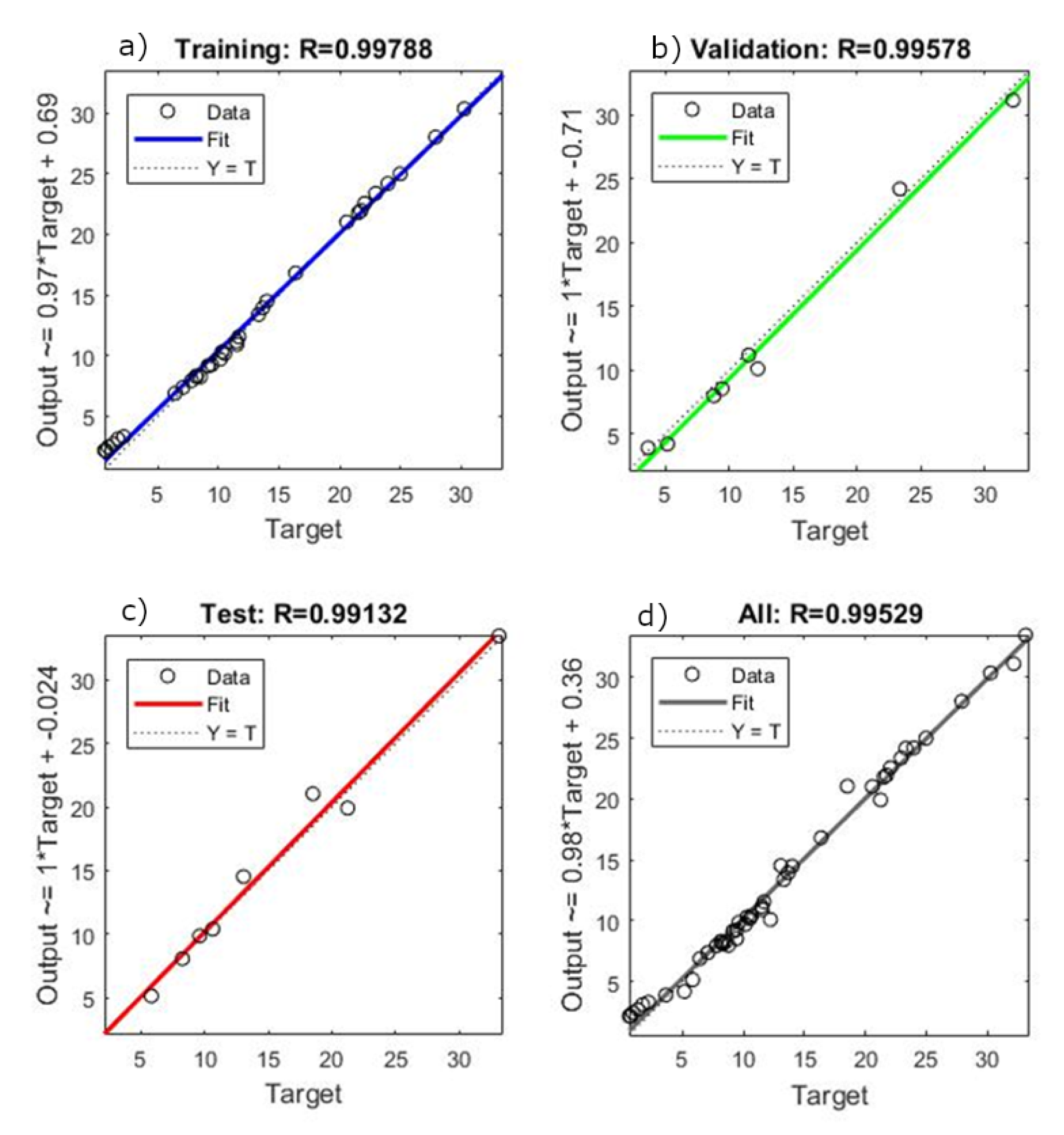
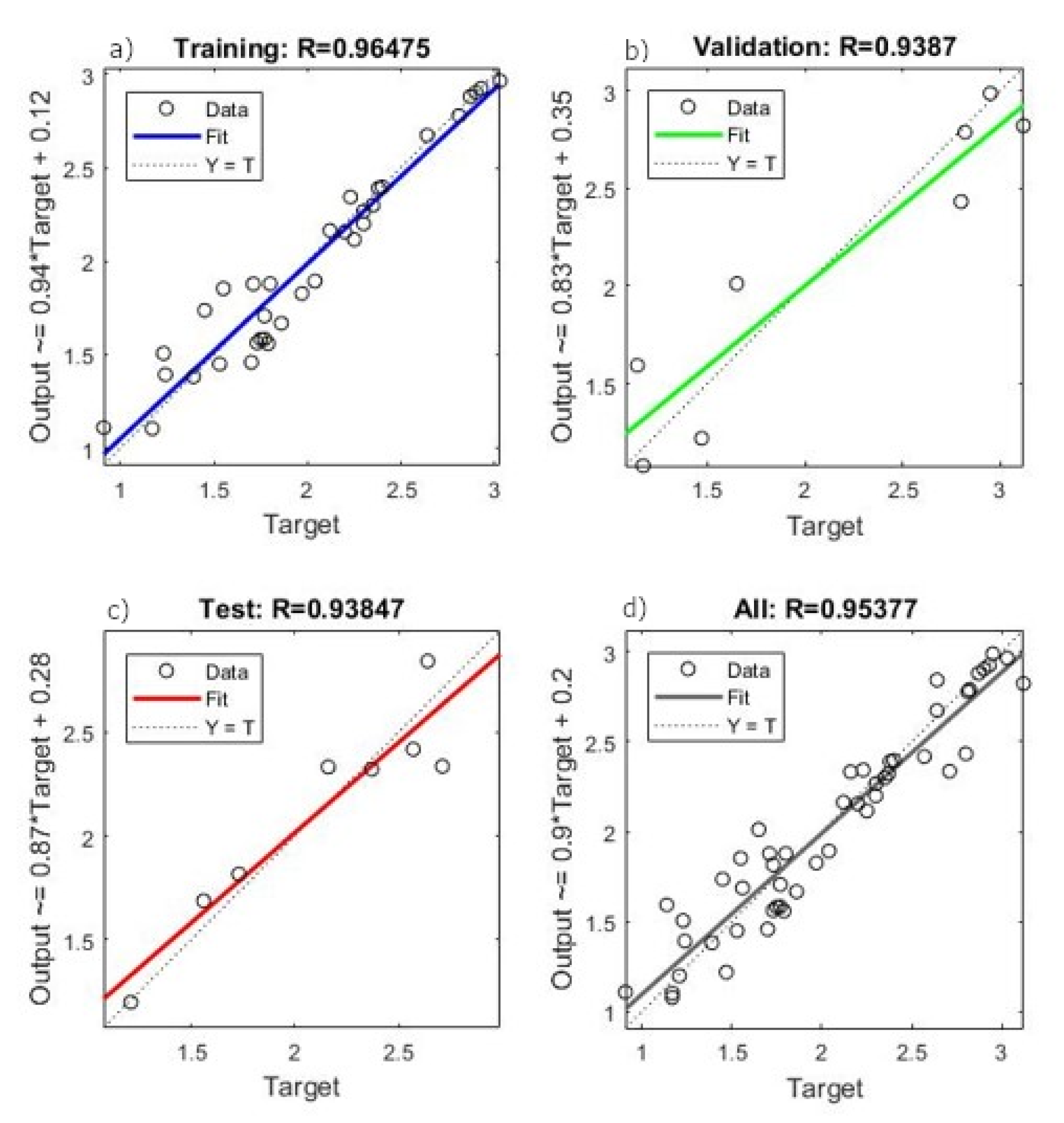
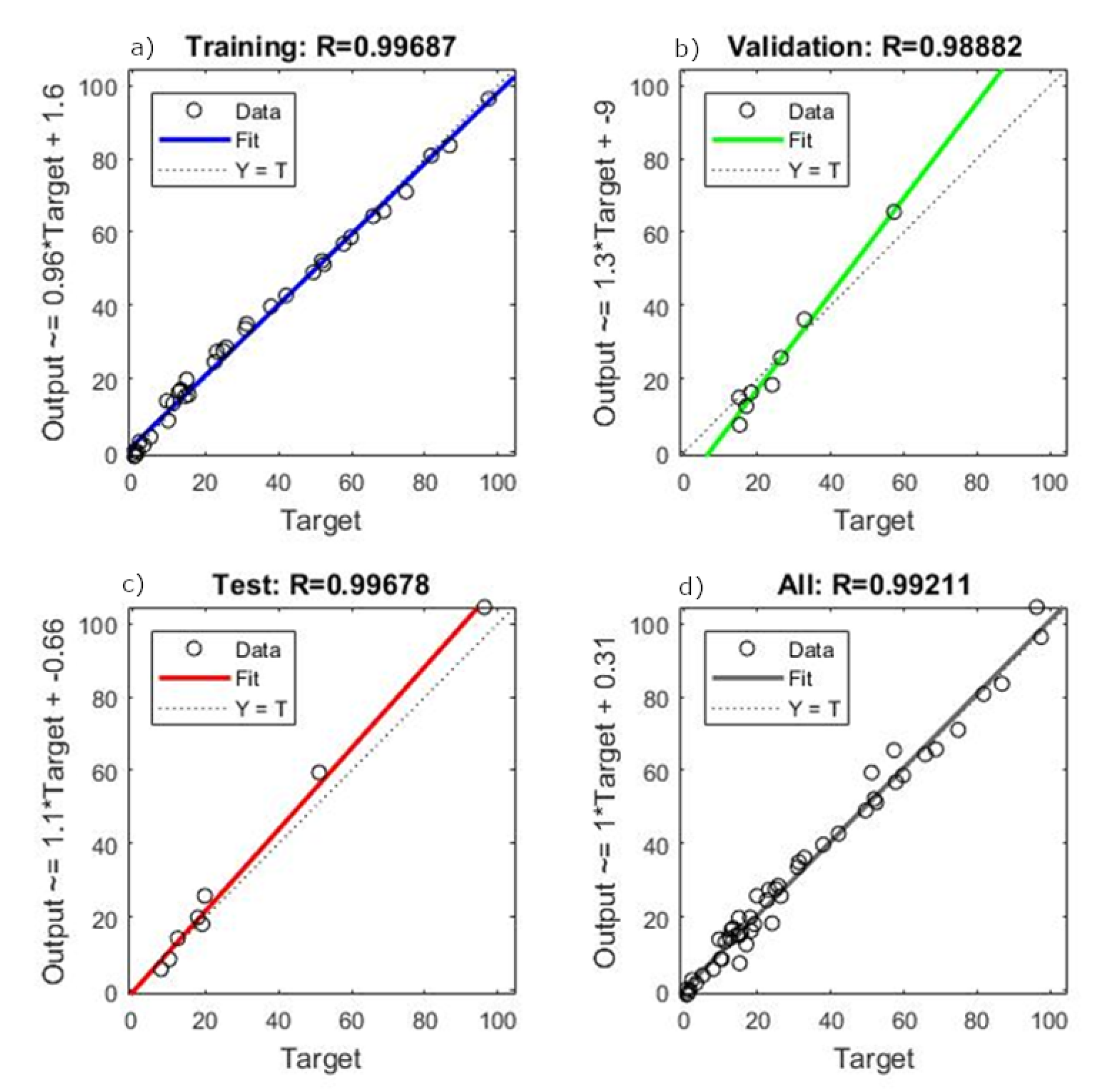
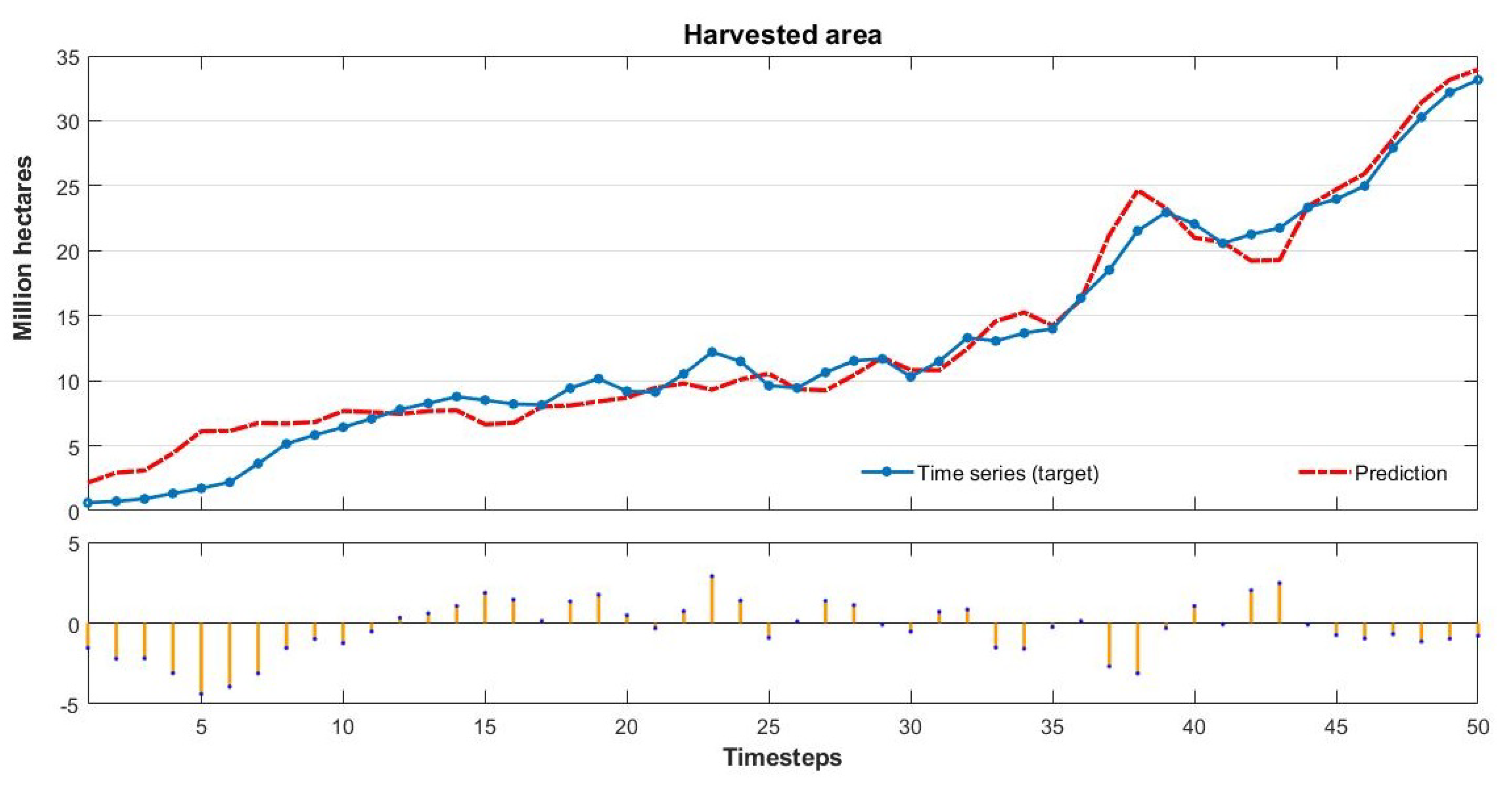
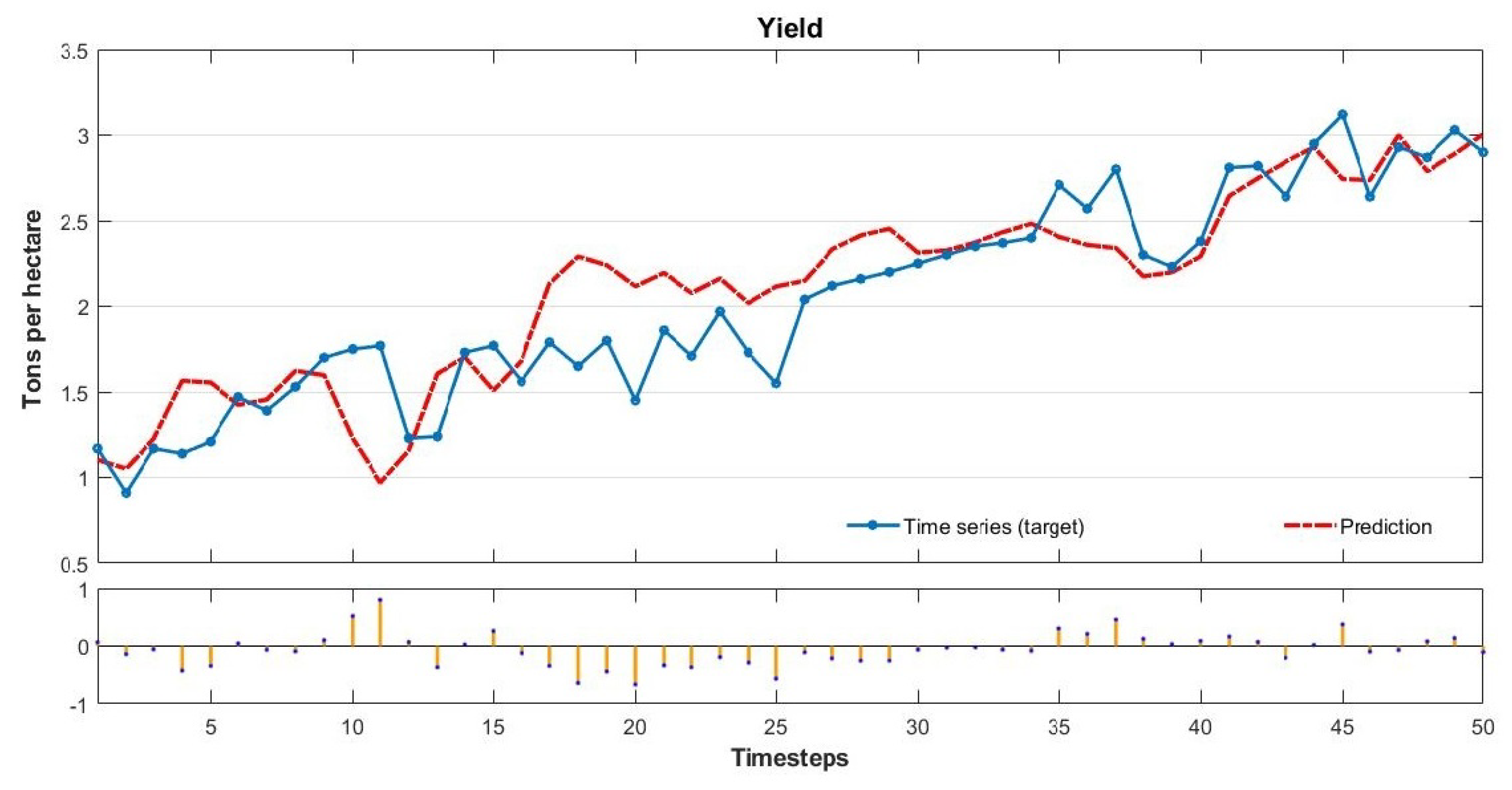
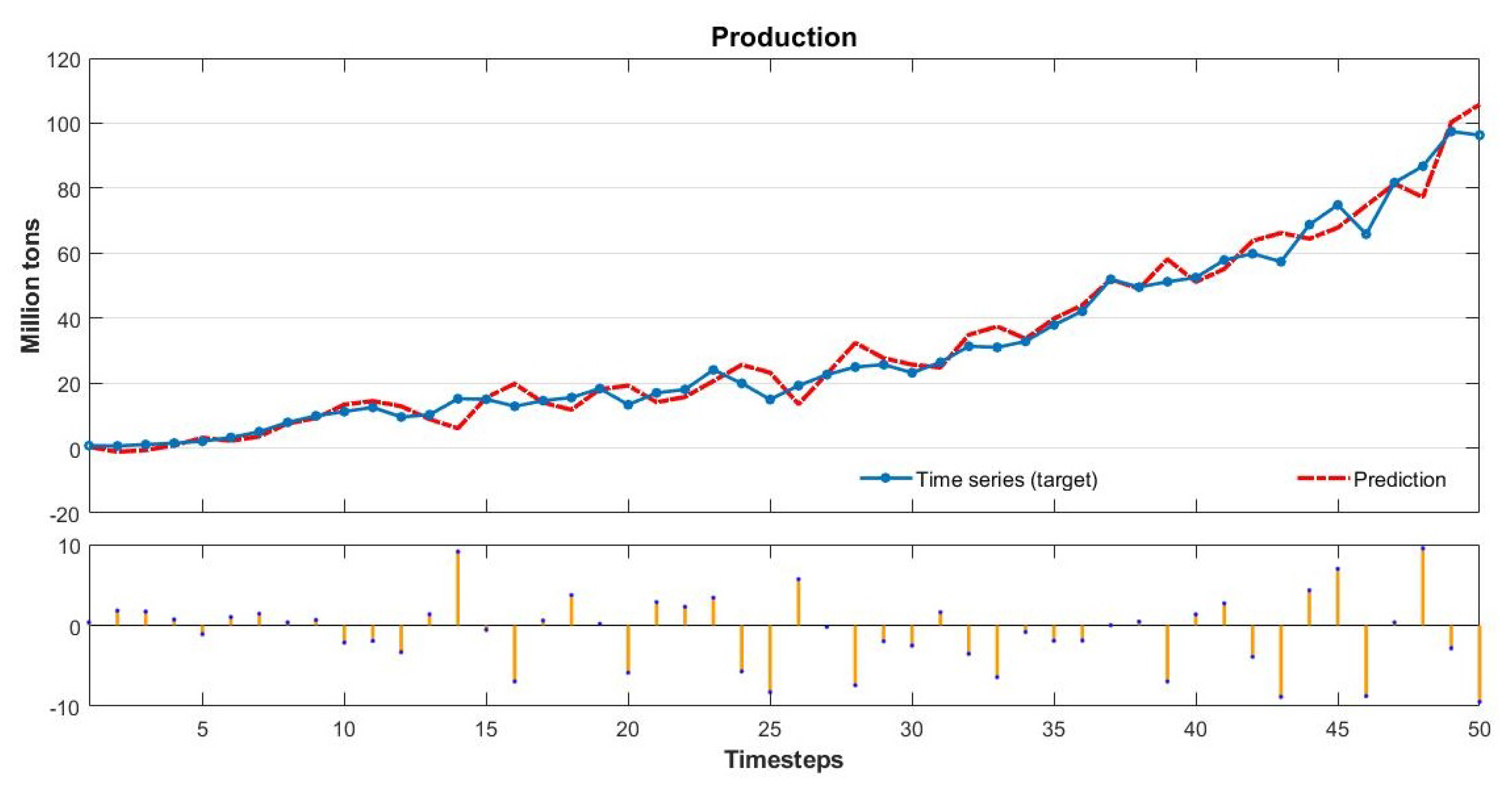
Therefore, our study aims to estimate Brazilian soybean harvest area, yield, and production adopting Artificial Neural Networks (ANN) and comparing with classical methods of Time Series Analysis. To this end, we collected the values of harvest area, production, and yield over a period of 56 years (1961–2016). We established the trend lines for five functions: Linear, Exponential, Logarithmic, Polynomial, and Power, and compared these results with an ANN model with 10 neurons and six delays computed using a Nonlinear Autoregressive Network with External Input-NARX with Levenberg—Marquardt backpropagation for training the network.
The results show that the ANN model is the most efficient method to predict soybean harvest area and production. The novelty of this paper is to obtain a reliable prediction for soybean production measures using an ANN model and dealing with a short data period time series (50 years) [
25]. The period of 1961–1966 was used only for ANN model delay.
This paper is divided into sections:
Section 1 presents this introduction and literature review,
Section 2 shows the methodological procedures,
Section 3 deal with results and discussion, and
Section 4 presents the conclusions of the study.
1.1. Artificial Neural Networks
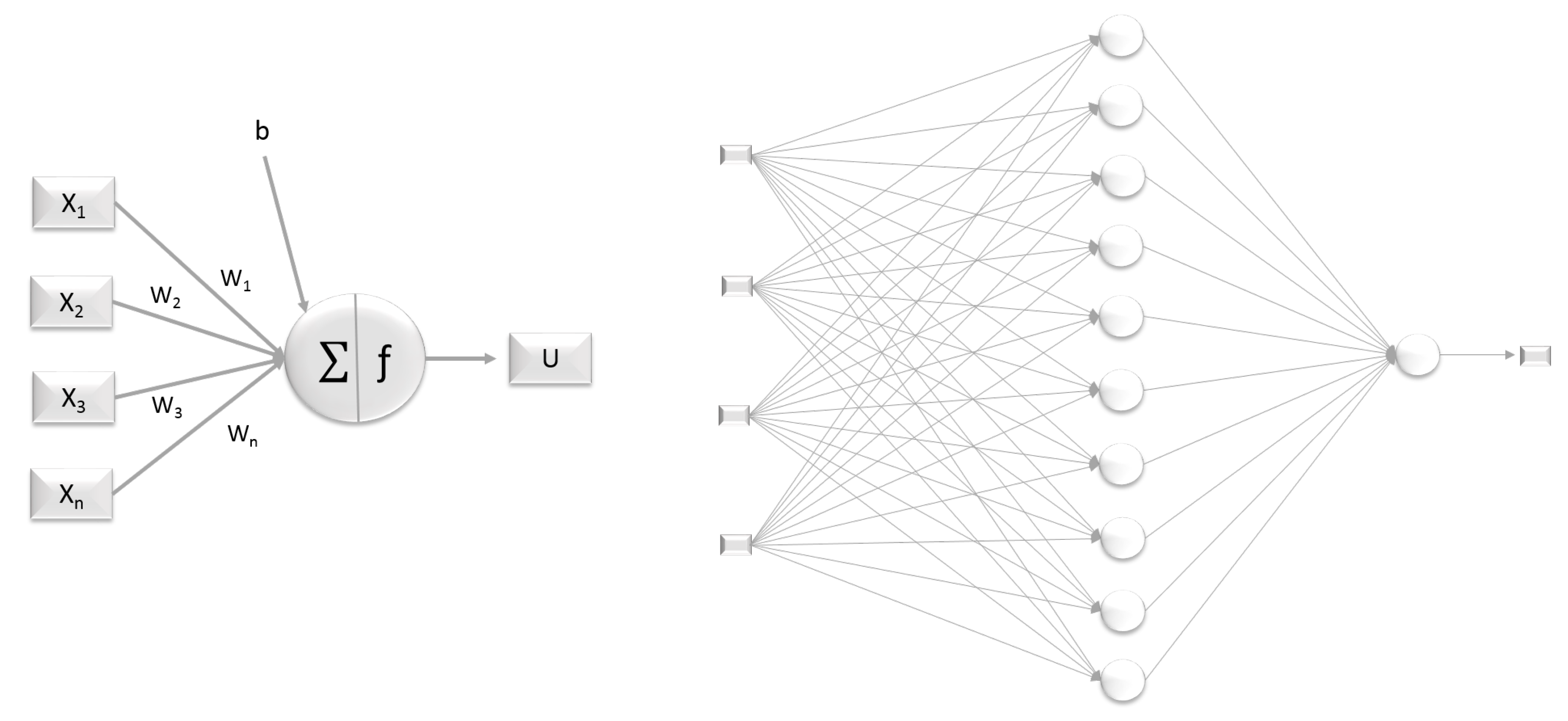
Artificial Neural Networks, as the name proposed, use artificial neurons connected in layers to simulate human synapse (
Figure 1). A mathematical model mimics the neural structure to learn and to acquire knowledge via experiences (Equations (1) and (2)). This technology is effective to solve problems—dynamic and nonlinear—such as pattern recognition and prediction [
25,
26,
27,
28,
29,
30].
where
are the input values (data set),
are the weights, and
b is the activation threshold (bias) in the neuron potential
[
25,
26,
31].
Among several types of neuron activation functions, the most common are: hyperbolic tangent (Equation (
3)), hidden layer, and linear. The last one always assumes values identical to the activation potential
n [
25,
26,
31]:
where
is the constant associated with the slope of the hyperbolic tangent function and the output values assume numbers between −1 and 1.
ANN uses previous data for training the network and minimizes errors between the insertion and the estimation. This process adjusts the weights and possible bias for each neuron interaction. The training usually stops when finding out the optimal learning rate [
25,
26,
27,
28,
29,
30].
There are various ANN techniques such as General Regression Neural Network (GRNN), Backpropagation Neural Network (BNN), Radial Base Function Neural Network (RBFNN), and Adaptive Neuro-Fuzzy Inference System (ANFIS) [
32]. Backpropagation (BP) is a learning algorithm widely used in forecasting problems with ANN, and the networks [
30]. The weights between the different layers may be updated using the BP algorithm, with momentum and learning rate. Moreover, the weights between the different layers may be updated where the error is then propagated backward from the output to the input layer [
33].
Some studies have been using ANN to study the agricultural environment. Garg et al. [
30] compare the performance between different training methods using an ANN model to forecast wheat production in India. The data contain 95 years of wheat production (1919–2013), and the results revealed that the algorithms most effective in training methods are Bayesian regularization and Levenberg–Marquardt.
Almomani [
34] adopted artificial neural networks to predict the biofuel production from agricultural wastes and cow manure at high accuracy. The training and testing of the ANN used to predict the cumulative methane production was assessed by using the root mean square method. The study confirms the capacity of the ANN model to predict the behavior of biofuel production and to identify the optimum conditions in a short time.
Sankhadeep et al. [
35] use an ANN model for soil moisture quantity prediction for sustainable agricultural applications. They study soil moisture prediction in terms of soil temperature, air temperature, and relative humidity. The nonlinear relation between soil moisture and the features is realized using a hybrid modified flower pollination algorithm supported by the ANN model. They conclude that for sustainable agricultural application the model is highly suitable.
Khan et al. [
8] use deep neural networks to fruit production prediction. They considered different types of fruit production such as apples, bananas, citrus, pears, and grapes with data from the National Bureau of Statistics of Pakistan. They adopted Levenberg–Marquardt optimization, backpropagation, and Bayesian regularization backpropagation. The results reveal that the government of Pakistan needs to further increase fruit production and create better policies for farmers to improve their production.
Wang and Xiao [
36] studied recycle agriculture in West China to make a prediction on the comprehensive development status applying a neural network model with the application of backpropagation through the MATLAB program. They conclude that China needs to take measures to promote resources’ decrement input and resource reuse efficiency, protect the forest resources, and reinforce harnessing of water loss and soil erosion.
Liu et al. [
37] create an artificial neural network model for crop yield responding to soil parameters. The model was established by training a backpropagation neural network with 58 samples and tested with other 14 samples. They conclude that the model can precisely describe crop yield responding to soil parameters.
Fegade and Pawar [
38] describe that, in India, farmers have difficulties to select proper crop for farming due to factors such as rainfall, temperature humidity, soil, and so on. Therefore, they used support vector machine and artificial neural networks to predict crop with 86.80% of accuracy.
Regarding grains, Maimaitijiang et al. [
10] evaluate the power of an unmanned aerial vehicle (UAV) to estimate soybean grain yield within the framework of deep neural networks (DNN). Thermal images were collected using a low-cost multi-sensory UAV. The results propose that multimodal data fusion improves the yield prediction accuracy and is more adaptable to spatial variations; DNN-based models improve yield prediction model accuracy and were less prone to saturation effects.
Zhang et al. [
39] establish a model for forecasting soybean price in China using quantile regression models to describe the distribution of the soybean price range, and using regression-radial basis function neural networks to approximate the nonlinear component of the soybean price. They collected the monthly domestic soybean price in China, and the results of the model indicate that the proposed model is effective.
García-Martínez et al. [
9] analyze different multispectral and red-green-blue vegetation indices, canopy cover, and plant density in order to estimate corn grain yield using a neural network model. The neural network model provided a high correlation coefficient between the estimated and the observed corn grain yield with acceptable errors in the yield estimation.
Abraham et al. [
40] propose to design, train, and simulate an ANN on to forecast the demand of soybean production in Mato Grosso state, Brazil that is exported by the port of Santos. A nonlinear autoregressive solution was adopted considering 80% of data for training, 5% to validation, and 15% for testing the network—a value of 9.0 million tons for 2017 as an increase of about 26.5% compared with the 2016.
Eventually, Abraham et al. [
41] also analyze the relationship between soybean supply (production) and soybean demand (export) using artificial intelligence in a hybrid model neuro-fuzzy. Data from 20 years of soybean production and exportation were used, and the results indicate that the supply tends to be low when the demands of the ports are overloaded.
Specifically, in the present article, we raised two questions regarding ANN in soybean production:
Can soybean harvest area, yield, and production be predicted efficiently using Artificial Neural Networks?
If so, are Artificial Neural Networks more effective than classical methods of Time Series Analysis to predict soybean production measures?
To answer these two questions, we develop an ANN model using NARX with the Levenberg– Marquardt algorithm for backpropagation and data of Brazilian soybean production.
1.2. Time Series and Classical Methods
Time series analysis studies the past behavior of historical series using different methods (
Table 1). It verifies trends, seasonality, and randomness in a dataset in two ways: stationary, when observations oscillate around a central horizontal axis; and non-stationary when oscillates around changing values [
42,
43]. The most appropriate model for a specific dataset is the coefficient of determination (R), the mean absolute error (MAE), and the mean squared error (MSE) [
42,
43].
The coefficient of determination (Equation (
4)) measures the linear regression adjustment, which aims to explain the relationship of the variables. The closer this number is to one, the more fitted is the model. However, a measure higher than 0.7 is satisfactory [
25,
42,
43]:
The coefficient of determination is calculated based on the ratio between the explained and the total variance where y represents the real value of the series, is the expected value (value of the regression line approaching the actual value), and is the average value of the series.
Note that the variance is the difference between the expected value and the mean, and the total variance is the difference between the original and mean value [
25,
42,
43]. The MAE and MSE are calculated according to Equations (2) and (3), where
n is the number of elements in the series.
Finally, functions with error values close to 0 are the most effective in predicting future values. These time series applications are described in the Results and Discussion section.
4. Conclusions
This study compares classical methods of time series prediction with Artificial Neural Networks using Brazilian soybean harvest area, yield and production from 1961–2016. The results indicate that ANN is the best approach to predict soybean harvest area and production while classical linear function remains more effective to predict soybean yield. However, ANN is a reliable model to predict using time series and can help farmers, government, and trading companies anticipate the soybean world offer to organize efficiently logistics resources and public policies.
Our results confirm the important role of neural networks in dealing with agriculture issues as showed in previous studies in the literature [
8,
10,
35,
39]. The R value above 0.9 confirms the high performance of the model. Nevertheless, regarding the agriculture concerns about low availability for planting areas, yield, and production [
4,
5,
6], your results demonstrated that, at least in case of the soybean, this is not a concern.
Furthermore, we can conclude that the ANN model can be effective even using a short time series—that, in our case, was 50 years. This fact reveals a robustness of the model. However, despite the advantages of the ANN model, classical methods also can produce very good models. A comparison in other agriculture commodities can be made to confirm or refuse the behavior presented in a soybean case.
Finally, we also suggest for further studies to combine neural networks in hybrid systems using, for example, ANN and Fuzzy Logic, similar to that proposed by [
41]. Literature has shown that hybrid systems are more efficient. The goal is to achieve a synergy between hybrid systems to compensate for the disadvantage of one by the advantage of another [
55,
56,
57].

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}