
Automated Speech Intelligibility Assessment Using AI-Based Transcription in Children with Cochlear Implants, Hearing Aids, and Normal Hearing


Abstract
1. Introduction
2. Materials and Methods
2.1. Speech Samples
2.2. Speech Intelligibility Evaluation by Naïve Listeners
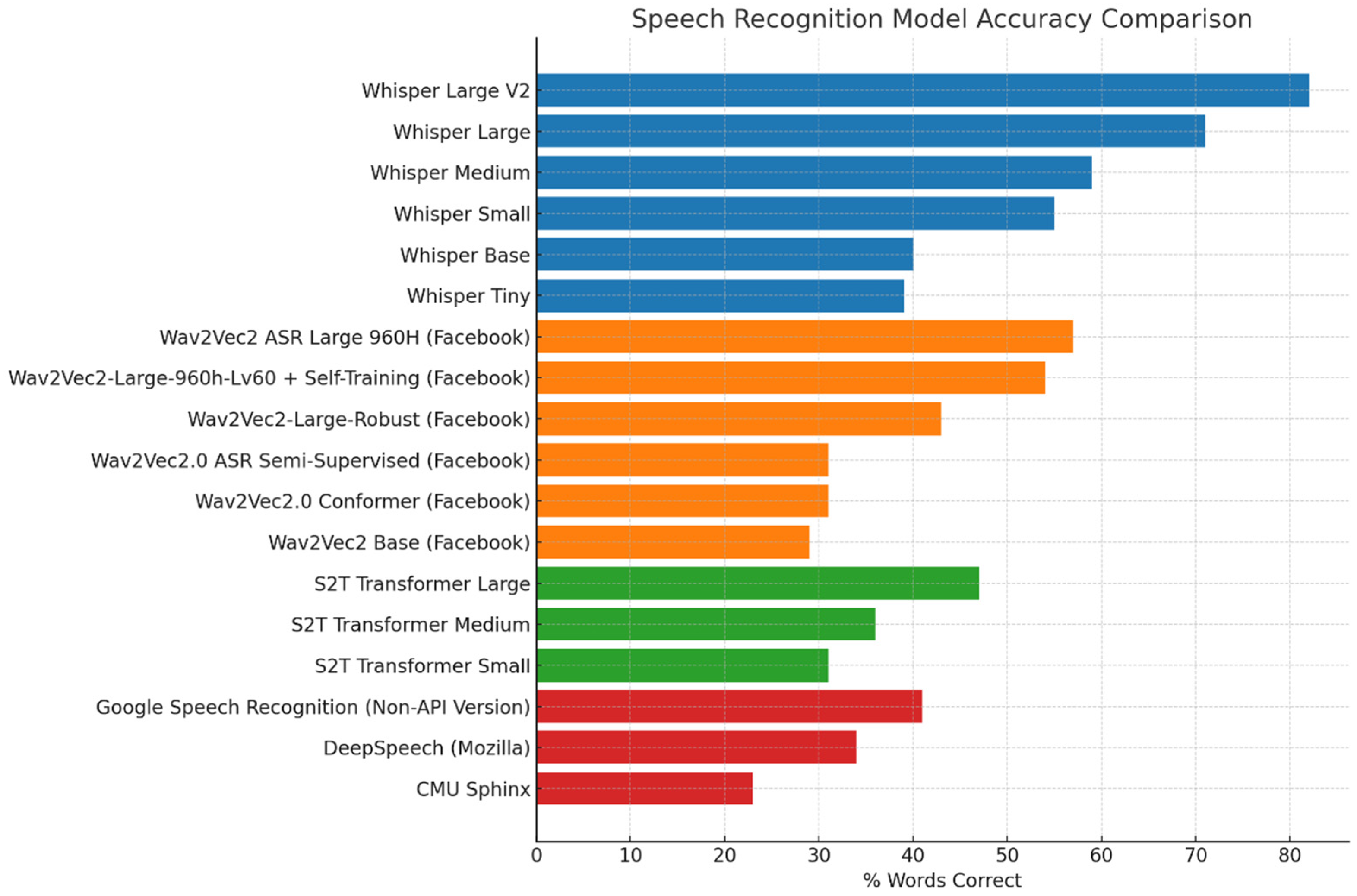
2.3. Selection of AI-Based Speech-to-Text Model
2.4. Data Scoring on the Transcriptions
2.5. Data Analysis
3. Results
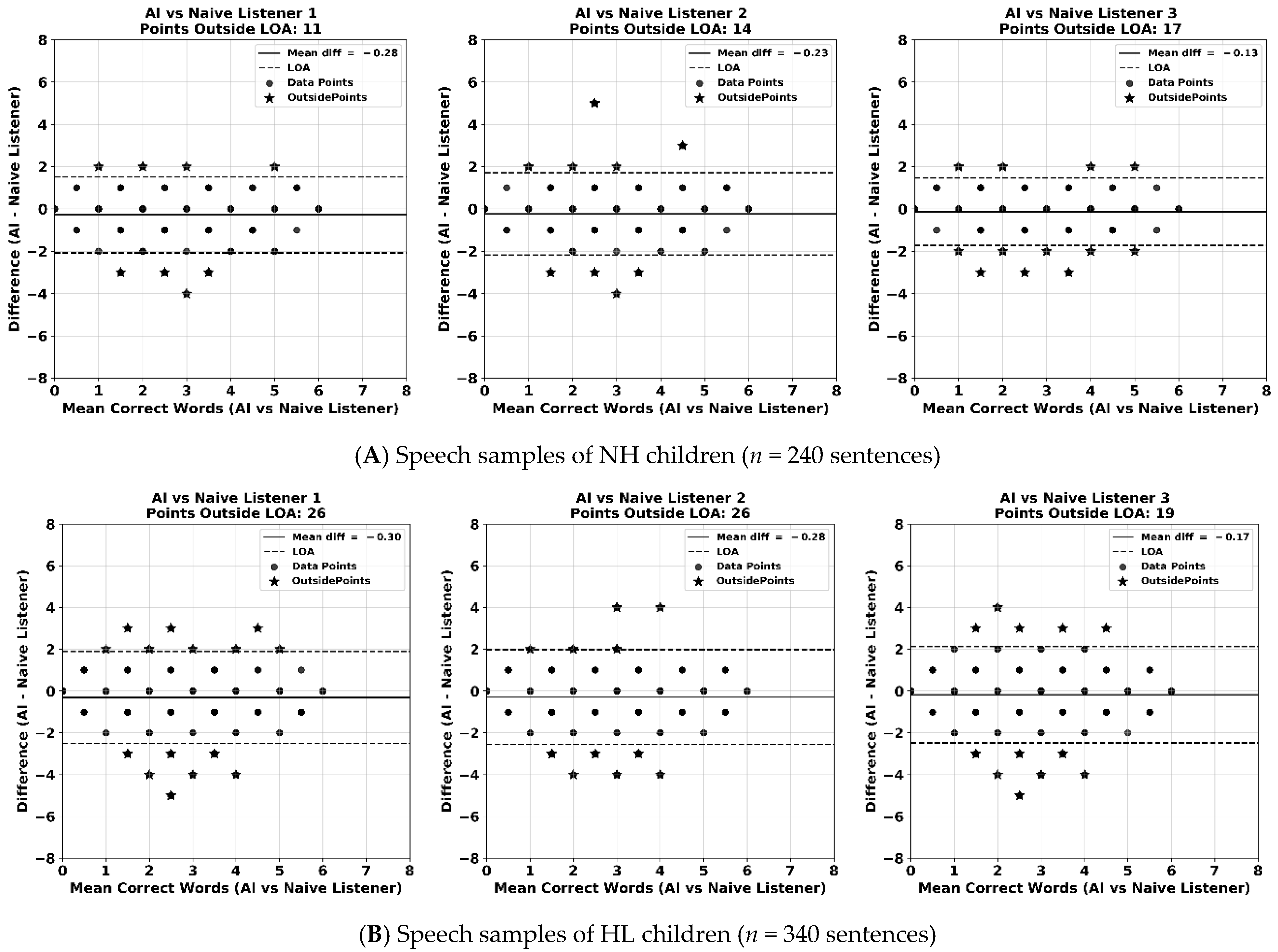
3.1. Comparing Word-Level Transcription: AI vs. Naïve Listeners
3.2. Word-Level Consistency Analysis Between the AI Model and Naive Listeners
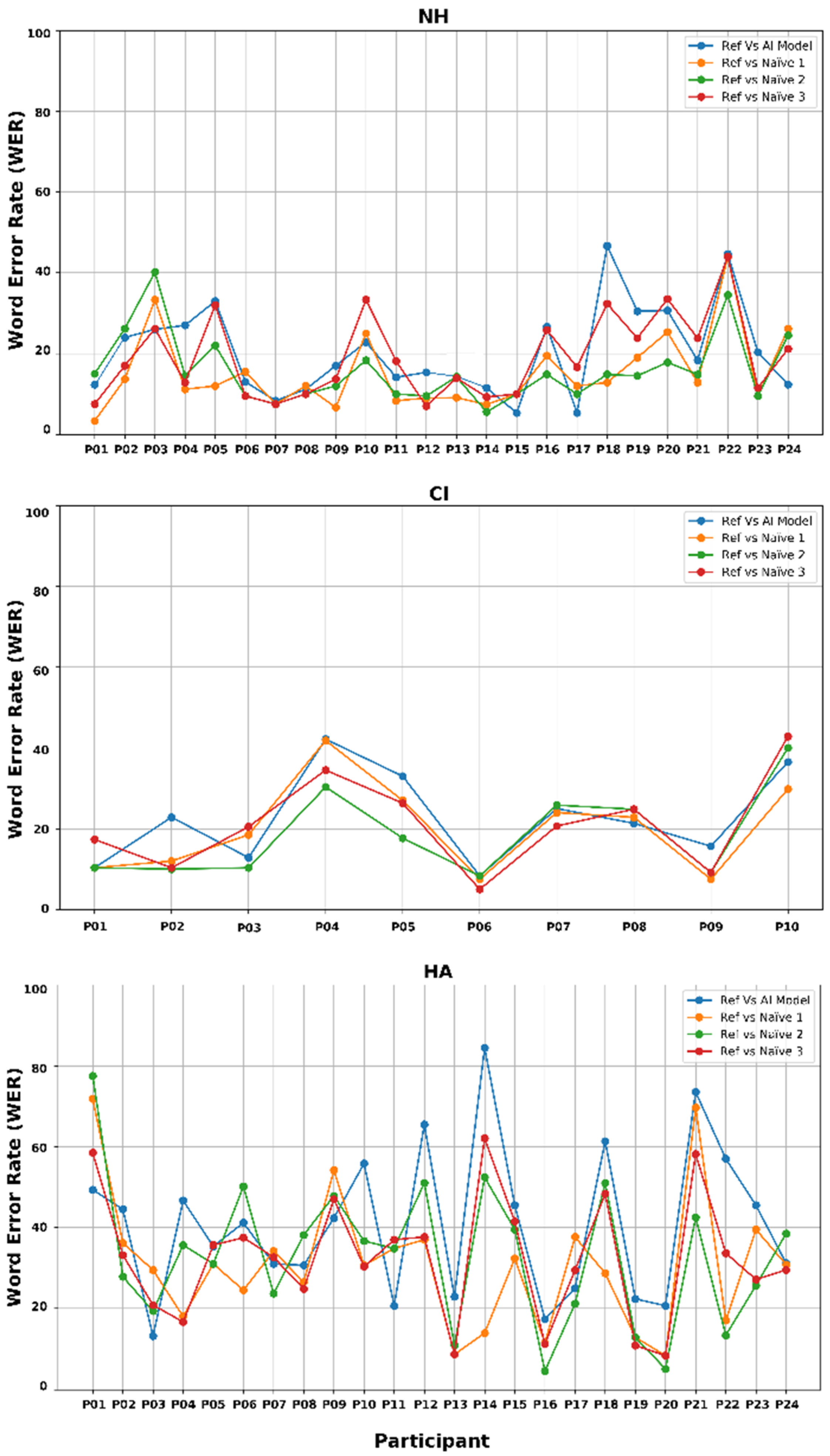
3.3. Word Error Rate Consistency Among AI and Naïve Listener Transcriptions
4. Discussion
4.1. Importance of SI Evaluation for Children with HL
4.2. Summary and Interpretation of Current Findings
4.3. Strengths and Limitations
4.4. Future Clinical Application
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 4FA HL | Four frequency averaged hearing loss at 0.5, 1, 2, and 4 kHz |
| AI | Artificial intelligence |
| ASR | Automatic speech recognition |
| BIT | Beginners Intelligibility Test |
| CIs | Cochlear implants |
| DNN | Deep neural network |
| HAs | Hearing aids |
| HL | Hearing loss |
| ICC | Intraclass correlation coefficient |
| LoA | Limits of agreement |
| NAL | National Acoustic Laboratories |
| NLP | Natural language processing |
| NH | Normal hearing |
| PTA | Pure tone audiometry |
| RMS | Root-mean-square |
| RNN | Recurrent neural network |
| SI | Speech intelligibility |
| SOTA | State-of-the-art |
| STT | Speech-to-text |
| WER | Word Error Rate |
References
- Kent, R.D.; Weismer, G.; Kent, J.F.; Rosenbek, J.C. Toward phonetic intelligibility testing in dysarthria. J. Speech Hear. Disord. 1989, 54, 482–499. [Google Scholar] [CrossRef]
- Ruben, R.J. Redefining the survival of the fittest: Communication disorders in the 21st century. Laryngoscope 2000, 110 Pt 1, 241–245. [Google Scholar] [CrossRef]
- Monsen, R.B. Toward measuring how well hearing-impaired children speak. J. Speech Lang. Hear. Res. 1978, 21, 197–219. [Google Scholar] [CrossRef]
- MacNeilage, P.F. The Production of Speech; MacNeilage, P.F., Ed.; Springer: New York, NY, USA, 2012. [Google Scholar]
- Montag, J.L.; AuBuchon, A.M.; Pisoni, D.B.; Kronenberger, W.G. Speech intelligibility in deaf children after long-term cochlear implant use. J. Speech Lang. Hear. Res. 2014, 57, 2332–2343. [Google Scholar] [CrossRef]
- Weiss, C.E. Weiss Intelligibility Test; C.C. Publications: Tigard, OR, USA, 1982. [Google Scholar]
- Coplan, J.; Gleason, J.R. Unclear speech: Recognition and significance of unintelligible speech in preschool children. Pediatrics 1988, 82 Pt 2, 447–452. [Google Scholar]
- Gordon-Brannan, M.; Hodson, B.W. Intelligibility/severity measurements of prekindergarten children’s speech. Am. J. Speech Lang. Pathol. 2000, 9, 141–150. [Google Scholar] [CrossRef]
- Carney, A.E. Understanding speech intelligibility in the hearing impaired. Top. Lang. Disord. 1986, 6, 47–59. [Google Scholar] [CrossRef]
- Osberger, M.J.; Robbins, A.M.; Todd, S.I.; Riley, A.I. Speech intelligibility of children with cochlear implants. Volta Rev. 1994, 96, 12. [Google Scholar] [CrossRef]
- Osberger, M.J. Speech intelligibility in the hearing impaired: Research and clinical implications. In Intelligibility in Speech Disorders: Theory, Measurement and Management; Kent, R.D., Ed.; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2011; pp. 233–264. [Google Scholar]
- Brannon, J.B., Jr. Visual Feedback of Glossal Motions and Its Influence upon the Speech of Deaf Children; Northwestern University: Evanston, IL, USA, 1964. [Google Scholar]
- Yoshinaga-Itano, C. From screening to early identification and intervention: Discovering predictors to successful outcomes for children with significant hearing loss. J. Deaf Stud. Deaf Educ. 2003, 8, 11–30. [Google Scholar] [CrossRef]
- Most, T.; Weisel, A.; Lev-Matezky, A. Speech intelligibility and the evaluation of personal qualities by experienced and inexperienced listeners. Volta Rev. 1996, 98, 181–190. [Google Scholar]
- Most, T. Speech intelligibility, loneliness, and sense of coherence among deaf and hard-of-hearing children in individual inclusion and group inclusion. J. Deaf Stud. Deaf Educ. 2007, 12, 495–503. [Google Scholar] [CrossRef] [PubMed]
- Most, T.; Ingber, S.; Heled-Ariam, E. Social competence, sense of loneliness, and speech intelligibility of young children with hearing loss in individual inclusion and group inclusion. J. Deaf Stud. Deaf Educ. 2012, 17, 259–272. [Google Scholar] [CrossRef]
- Most, T.; Weisel, A.; Tur-Kaspa, H. Contact with students with hearing impairments and the evaluation of speech intelligibility and personal qualities. J. Spec. Educ. 1999, 33, 103–111. [Google Scholar] [CrossRef]
- Barker, D.H.; Quittner, A.L.; Fink, N.E.; Eisenberg, L.S.; Tobey, E.A.; Niparko, J.K.; Team, C.D.I. Predicting behavior problems in deaf and hearing children: The influences of language, attention, and parent-child communication. Dev. Psychopathol. 2009, 21, 373–392. [Google Scholar] [CrossRef]
- Hoffman, M.F.; Quittner, A.L.; Cejas, I. Comparisons of social competence in young children with and without hearing loss: A dynamic systems framework. J. Deaf Stud. Deaf Educ. 2015, 20, 115–124. [Google Scholar] [CrossRef]
- Ertmer, D.J. Assessing speech intelligibility in children with hearing loss: Toward revitalizing a valuable clinical tool. Lang. Speech Hear. Serv. Sch. 2011, 42, 52–58. [Google Scholar] [CrossRef]
- Kent, R.D.; Miolo, G.; Bloedel, S. The intelligibility of children’s speech: A review of evaluation procedures. Am. J. Speech Lang. Pathol. 1994, 3, 81–95. [Google Scholar] [CrossRef]
- McGarr, N. The intelligibility of deaf speech to experienced and inexperienced listeners. J. Speech Lang. Hear. Res. 1983, 26, 8. [Google Scholar] [CrossRef]
- Chin, S.B.; Tsai, P.L.; Gao, S. Connected speech intelligibility of children with cochlear implants and children with normal hearing. Am. J. Speech Lang. Pathol. 2003, 12, 12. [Google Scholar] [CrossRef]
- Flipsen, P., Jr.; Colvard, L.G. Intelligibility of conversational speech produced by children with cochlear implants. J. Commun. Disord. 2006, 39, 93–108. [Google Scholar] [CrossRef] [PubMed]
- Nikolopoulos, T.P.; Archbold, S.M.; Gregory, S. Young deaf children with hearing aids or cochlear implants: Early assessment package for monitoring progress. Int. J. Pediatr. Otorhinolaryngol. 2005, 69, 175–186. [Google Scholar] [CrossRef]
- Samar, V.J.; Metz, D.E. Criterion validity of speech intelligibility rating-scale procedures for the hearing-impaired population. J. Speech Hear. Res. 1988, 31, 307–316. [Google Scholar] [CrossRef]
- Allen, M.C.; Nikolopoulos, T.P.; O’donoghue, G.M. Speech intelligibility in children after cochlear implantation. Am. J. Otol. 1988, 19, 742–746. [Google Scholar]
- Beadle, E.A.; McKinley, D.J.; Nikolopoulos, T.P.; Brough, J.; O’Donoghue, G.M.; Archbold, S.M. Long-term functional outcomes and academic-occupational status in implanted children after 10 to 14 years of cochlear implant use. Otol. Neurotol. 2005, 26, 1152–1160. [Google Scholar] [CrossRef] [PubMed]
- Chin, S.B.; Bergeson, T.R.; Phan, J. Speech intelligibility and prosody production in children with cochlear implants. J. Commun. Disord. 2012, 45, 355–366. [Google Scholar] [CrossRef] [PubMed]
- Habib, M.G.; Waltzman, S.B.; Tajudeen, B.; Svirsky, M.A. Speech production intelligibility of early implanted pediatric cochlear implant users. Int. J. Pediatr. Otorhinolaryngol. 2010, 74, 855–859. [Google Scholar] [CrossRef]
- Tobey, E.A.; Geers, A.E.; Brenner, C.; Altuna, D.; Gabbert, G. Factors associated with development of speech production skills in children implanted by age five. Ear Hear. 2003, 24, 36S–45S. [Google Scholar] [CrossRef]
- Halpern, B.M.; Feng, S.; van Son, R.; van den Brekel, M.; Scharenborg, O. Automatic evaluation of spontaneous oral cancer speech using ratings from naive listeners. Speech Commun. 2023, 149, 84–97. [Google Scholar] [CrossRef]
- Martinez, A.M.C.; Spille, C.; Roßbach, J.; Kollmeier, B.; Meyer, B.T. Prediction of speech intelligibility with DNN-based performance measures. Comput. Speech Lang. 2022, 74, 34. [Google Scholar] [CrossRef]
- Araiza-Illan, G.; Meyer, L.; Truong, K.P.; Başkent, D. Automated speech audiometry: Can it work using open-source pre-trained Kaldi-NL automatic speech recognition? Trends Hear. 2024, 28, 13. [Google Scholar] [CrossRef]
- Le, D.; Licata, K.; Persad, C.; Provost, E.M. Automatic assessment of speech intelligibility for individuals with Aphasia. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2187–2199. [Google Scholar] [CrossRef]
- Herrmann, B. The perception of artificial-intelligence (AI) based synthesized speech in younger and older adults. Int. J. Speech Technol. 2023, 26, 395–415. [Google Scholar] [CrossRef]
- Herrmann, B. Leveraging natural language processing models to automate speech-intelligibility scoring. Speech Lang. Hear. 2025, 28, 2374160. [Google Scholar] [CrossRef]
- Ali, R.; Hussain, J.; Lee, S.W. Multilayer perceptron-based self-care early prediction of children with disabilities. Digit. Health 2023, 9, 20552076231184054. [Google Scholar] [CrossRef]
- Miyamoto, R.T.; Svirsky, M.; Kirk, K.I.; Robbins, A.M.; Todd, S.; Riley, A. Speech intelligibility of children with multichannel cochlear implants. Ann. Otol. Rhinol. Laryngol. Suppl. 1997, 168, 35–36. [Google Scholar]
- Ching, T.Y.; Leigh, G.; Dillon, H. Introduction to the longitudinal outcomes of children with hearing impairment (LOCHI) study: Background, design, sample characteristics. Int. J. Audiol. 2013, 52 (Suppl. S2), S4–S9. [Google Scholar] [CrossRef]
- Wechsler, D.; Naglieri, J.A. Wechsler Nonverbal Scale of Ability; Harcourt Assessment: San Antonio, TX, USA, 2006. [Google Scholar]
- Zimmerman, I.; Steiner, V.G.; Pond, R.E. Preschool Language Scale, 4th ed.; The Psychological Corporation: San Antonio, TX, USA, 2002. [Google Scholar]
- Ching, T.Y.; Zhang, V.W.; Flynn, C.; Burns, L.; Button, L.; Hou, S.; McGhie, K.; Van Buynder, P. Factors influencing speech perception in noise for 5-year-old children using hearing aids or cochlear implants. Int. J. Audiol. 2018, 57, S70–S80. [Google Scholar] [CrossRef]
- Lai, W.K.; Dillier, N. MACarena: A flexible computer-based speech testing environment. In Proceedings of the 7th International Cochlear Implant Conference, Manchester, UK, 4–6 September 2002. [Google Scholar]
- Yeung, G.; Alwan, A. On the difficulties of automatic speech recognition for kindergarten-aged children. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 1661–1665. [Google Scholar]
- Miller, J.F.; Andriacchi, K.; Nockerts, A. Using language sample analysis to assess spoken language production in adolescents. Lang. Speech Hear. Serv. Sch. 2016, 47, 99–112. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Upervision. arXiv 2022. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural. Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Wang, C.; Tang, Y.; Ma, X.; Wu, A.; Popuri, S.; Okhonko, D.; Pino, J. Fairseq S2T: Fast Speech-to-Text Modeling with Fairseq. Available online: https://arxiv.org/pdf/2010.05171 (accessed on 18 July 2025).
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep Speech: Scaling Up End-to-End Speech Recognition. Available online: https://arxiv.org/pdf/1412.5567 (accessed on 18 July 2025).
- Lamere, P.; Kwok, P.; Gouvea, E.; Raj, B.; Singh, R.; Walker, W.; Warmuth, M.; Wolf, P. The CMU SPHINX-4 Speech Recognition System. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hong Kong, China, 6–10 April 2003. [Google Scholar]
- Poursoroush, S.; Ghorbani, A.; Soleymani, Z.; Kamali, M.; Yousefi, N.; Poursoroush, Z. Speech intelligibility of cochlear-implanted and normal-hearing children. Iran. J. Otorhinolaryngol. 2015, 27, 361–367. [Google Scholar]
- IBM Corp. IBM SPSS Statistics for Windows, version 29.0; IBM Corp.: Armonk, NY, USA, 2022. [Google Scholar]
- Bland, J.M.; Altman, D.G. Statistical methods for assessing agreement between two methods of clinical measurement. Lancet 1986, 1, 307–310. [Google Scholar] [CrossRef]
- Koo, T.K.; Li, M.Y. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J. Chiropr. Med. 2016, 15, 155–163. [Google Scholar] [CrossRef]
- Spille, C.; Kollmeier, B.; Meyer, B.T. Comparing human and automatic speech recognition in simple and complex acoustic scene. Comput. Speech Lang. 2018, 52, 123–140. [Google Scholar] [CrossRef]
- Way with Words. Word Error Rate: Assessing Transcription Service Accuracy. Available online: https://waywithwords.net/resource/word-error-rate-transcription-accuracy/ (accessed on 18 June 2025).
- Geers, A.E. Factors affecting the development of speech, language, and literacy in children with early cochlear implantation. Lang. Speech Hear. Serv. Sch. 2002, 33, 172–183. [Google Scholar] [CrossRef]
- Geers, A.; Brenner, C.; Nicholas, J.; Tye-Murray, N.; Tobey, E. Educational factors contributing to cochlear implant benefit in children. Int. Congr. Ser. 2003, 154, 6. [Google Scholar] [CrossRef]
- Tobey, E.A.; Geers, A.E.; Sundarrajan, M.; Shin, S. Factors influencing speech production in elementary and high school-aged cochlear implant users. Ear Hear. 2011, 32, 27S–38S. [Google Scholar] [CrossRef]
- Zhang, V.W.; Ching, T.Y.C.; Button, L.; Louise, M.; Marnane, V. Speech intelligibility outcome of 5-year-old children with severe to profound hearing loss. In Proceedings of the 12th Asia Pacific Symposium on Cochlear Implants and Related Sciences (APSCI), Tokyo, Japan, 27–30 November 2019. [Google Scholar]
- Wang, C. Whisper Precision: A Comprehensive Guide to Fine-Tuning and Hyperparameter Tuning. Available online: https://medium.com/@chris.xg.wang/a-guide-to-fine-tune-whisper-model-with-hyper-parameter-tuning-c13645ba2dba (accessed on 30 June 2025).
- Abbas, S.R.; Abbas, Z.; Zahir, A.; Lee, S.W. Federated learning in smart healthcare: A comprehensive review on privacy, security, and predictive analytics with IoT integration. Healthcare 2024, 12, 2587. [Google Scholar] [CrossRef]
- Monaghan, J.; Sebastian, A.; Chong-White, N.; Zhang, V.W.; Easwar, V.; Kitterick, P. Automatic detection of hearing loss from children’s speech using wav2vec 2.0 features. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH) of the 2024, Koslsland, Greece, 1–5 September 2024; pp. 892–896. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Characters | Cochlear Implant (CI) (n = 10) | Hearing Aid (HA) (n = 24) | Normal Hearing (NH) (n = 24) |
|---|---|---|---|
| Age at BIT assessment (months), Mean (SD) | 61.4 (1.6) | 61.4 (1.4) | 61.5 (1.5) |
| Gender (Male), n (%) | 3 (30.0%) | 10 (41.7%) | 10 (41.7%) |
| Degree of hearing loss at BIT assessment (4FA HL in better ear), Mean (SD) | 109 (18.4) | 52 (15.1) | na |
| Age at hearing aids fitting (months), Mean (SD) | 5.3 (5.3) | 5.2 (6.0) | na |
| Age at cochlear implantation (months), Mean (SD) | 21.8 (16.5) | na | na |
| Nonverbal cognitive ability *, Mean (SD) | 102.2 (14.7) | 92 (13.5) | 103.9 (15.8) |
| Language score *, Mean (SD) | 104.7 (9.7) | 110.2 (11.9) | 104.6 (9.8) |
| Hearing Group | Comparison | ICC Value | 95% Confidence Interval | F (df1, df2) | p-Value |
|---|---|---|---|---|---|
| NH group (n = 240 sentences) | Within naïve listeners only | 0.95 | [0.94, 0.96] | F (239, 478) = 20.8 | <0.001 |
| AI model vs. naïve listeners | 0.96 | [0.95, 0.96] | F (239, 717) = 22.4 | ||
| HL group (CI and HA) (n = 340 sentences) | Within naïve listeners only | 0.92 | [0.90, 0.93] | F (339, 678) = 11.7 | |
| AI model vs. naïve listeners | 0.93 | [0.91, 0.94] | F (339, 1017) = 13.8 | ||
| CIs group only (n = 100 sentences) | Within naïve listeners only | 0.96 | [0.94, 0.97] | F (99, 198) = 20.8 | |
| AI model vs. naïve listeners | 0.96 | [0.94, 0.97] | F (99, 297) = 22.1 | ||
| HAs group only (n = 240 sentences) | Within naïve listeners only | 0.90 | [0.87, 0.92] | F (239, 478) = 9.6 | |
| AI model vs. naïve listeners | 0.91 | [0.89, 0.93] | F (239, 717) = 11.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, V.W.; Sebastian, A.; Monaghan, J.J.M. Automated Speech Intelligibility Assessment Using AI-Based Transcription in Children with Cochlear Implants, Hearing Aids, and Normal Hearing. J. Clin. Med. 2025, 14, 5280. https://doi.org/10.3390/jcm14155280
Zhang VW, Sebastian A, Monaghan JJM. Automated Speech Intelligibility Assessment Using AI-Based Transcription in Children with Cochlear Implants, Hearing Aids, and Normal Hearing. Journal of Clinical Medicine. 2025; 14(15):5280. https://doi.org/10.3390/jcm14155280
Chicago/Turabian StyleZhang, Vicky W., Arun Sebastian, and Jessica J. M. Monaghan. 2025. "Automated Speech Intelligibility Assessment Using AI-Based Transcription in Children with Cochlear Implants, Hearing Aids, and Normal Hearing" Journal of Clinical Medicine 14, no. 15: 5280. https://doi.org/10.3390/jcm14155280
APA StyleZhang, V. W., Sebastian, A., & Monaghan, J. J. M. (2025). Automated Speech Intelligibility Assessment Using AI-Based Transcription in Children with Cochlear Implants, Hearing Aids, and Normal Hearing. Journal of Clinical Medicine, 14(15), 5280. https://doi.org/10.3390/jcm14155280