1. Introduction
The rapid advancement of artificial intelligence has brought large language models (LLMs) to the forefront of clinical research and medical decision support. These models are being integrated into healthcare workflows due to their ability to synthesize complex information and provide on-demand guidance in time-sensitive environments. LLMs are already being widely used as ancillary tools in domains such as medical imaging analysis, patient triaging, and research support. In ophthalmology, recent studies have evaluated large language models across various areas of ophthalmology using standardized question banks such as the AAO BCSC, OphthoQuestions, and FRCOphth exam materials, StatPearls, as well as author-curated question banks. While ChatGPT-4 has consistently outperformed earlier versions like ChatGPT-3.5 and other models such as Bing AI and Google Bard (now called Gemini), these evaluations have focused on general ophthalmology [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11] or select subspecialties like age-related macular degeneration [
12], myopia care [
13], choroidal melanoma [
14], or retinopathy of prematurity [
15]. The reliability of LLMs in the highly specialized subdiscipline of refractive surgery has limited investigation. Yet refractive surgeries are performed on millions of eyes each year, ranging from otherwise healthy corneas seeking refractive freedom to pathologic cases such as cataracts, post-LASIK ectasia, or keratoconus that require visual rehabilitation. Any decision support tool that sharpens preoperative planning can directly lower complication rates, reduce postoperative refractive surprises, and enhance patient satisfaction and outcomes.
Refractive surgery is a uniquely demanding subspecialty that blends optical physics, corneal biomechanics, and patient-specific visual goals. Clinical decision making requires integrating biometric data, topographic interpretation, risk stratification for postoperative complications, and a nuanced understanding of evolving surgical technologies. These include corneal procedures such as LASIK, PRK, and SMILE, as well as intraocular procedures like phakic intraocular lenses (PIOLs), refractive lens exchange, and cataract surgery with premium intraocular lens (IOL) implantation. Surgeons must also weigh patient-specific factors such as pupil size, corneal irregularity and dry eye risk, while counseling patients on visual quality expectations, glare, halos, and long-term stability. Because many refractive interventions (e.g., LASIK, PIOLs, refractive lens exchange) are elective and expectation-sensitive, whereas cataract surgery is medically indicated yet still outcome-sensitive, even modest improvements in planning or counseling translate into tangible clinical value for any patient groups. These multifactorial considerations make refractive surgery an ideal domain to assess whether large language models can simulate real-world ophthalmic reasoning sufficiently well to support clinicians at the point of care.
Our group recently conducted the first study evaluating LLM performance in the subspecialty of refractive surgery, using 100 standardized questions from the AAO BCSC Self-Assessment Program [
16]. Five widely used models were compared, namely ChatGPT-4, ChatGPT-4o, Gemini, Gemini Advanced, and Copilot. ChatGPT-4o consistently outperformed all other models, including its predecessor, and was the only LLM to statistically surpass the average performance of ophthalmology residents. On 5 December 2024, OpenAI released OpenAI-o1, a new model claiming enhanced “advanced reasoning” capabilities over previous iterations, including ChatGPT-4o [
17]. Whether those upgrades cross a threshold at which model guidance could safely inform surgical planning, however, remains unknown.
Building on our prior findings [
16], the present study investigates whether OpenAI-o1 represents a measurable advancement over ChatGPT-4o in the subspecialty of refractive surgery, a complex and data-intensive domain within ophthalmology. Using a larger dataset of 228 questions from the Refractive Surgery section of the AAO BCSC Self-Assessment Program, we directly compared the performance of both models and benchmarked their accuracy against the scores of 1983 ophthalmology residents and clinicians who previously completed the same questions on the platform. Our primary aim was to determine whether any observed performance gain is clinically meaningful, defined as a statistically and practically significant margin over resident performance that could justify integrating the model as a decision support aid during patient work-up and surgical counseling. This study not only evaluates whether recent architectural improvements in OpenAI-o1 translate into statistically significant gains over its predecessor but also contributes to defining the role of LLMs as reliable tools for subspecialty-level clinical decision support with clear, actionable implications for real-world refractive-surgery practice.
2. Materials and Methods
2.1. Compared Large Language Models
The study assessed the accuracy of leading AI chatbots, namely ChatGPT-4o and OpenAI-o1 (OpenAI, San Francisco, CA, USA). While GPT-4o offers improvements in its textual, vocal, pictorial and linguistic analyses, GPT-o1 distinguishes itself from its former versions by allocating more processing time and using “longer chains of thought” to enhance its precision and accuracy [
18,
19,
20,
21].
2.2. Question Selection
The BCSC Self-Assessment Program, offered by the American Academy of Ophthalmology (San Francisco, CA, USA), is an online learning platform consisting of 4522 questions across 13 ophthalmology subspecialities. Amongst these, the refractive surgery section contains 256 questions. For this study, and with permission from the American Academy of Ophthalmology, questions requiring image interpretation were excluded, generating 228 text-only questions. The multiple-choice questions all provided four options labeled either A, B, C, or D from which test-takers select the single correct answer. The approval from the Research Ethics Board was not required, as the study did not involve human or animal participants and the data collection did not contain any form of personal information.
2.3. Prompt Methodology and Data Entry
Our previous study entitled “Evaluating Large Language Models vs. Residents in Cataract & Refractive Surgery: A Comparative Analysis Using the AAO BCSC Self-Assessment Program” concluded that contextualized prompts asking for best-answer selection did not significantly improve language model performance [
16]. Thus, the current study utilized the following prompt: “
Please provide an answer to the following questions.” As such, one session was conducted for each of the models in which such instruction headed the questionnaire. In addition, a privacy request was previously submitted for the account used in this study to prevent data retention or cross-contamination between trials. Hence, no input was used for further training, and therefore the first session conducted using ChatGPT-4o did not impact the following session conducted on OpenAI-o1. All prompts were submitted to the models in a fresh session to reduce memory-based confounding. This design allowed us to simulate a realistic interaction with each model under controlled conditions, comparable to a single-use clinical query. We acknowledge that LLM outputs can vary slightly between runs due to the stochasticity inherent in model generation. Although formal repeatability testing was not conducted in this study, our prompt standardization and privacy isolation protocols were intended to minimize variability and simulate real-world single-query use.
2.4. Response Assessment and Recording
Similarly to our previous study, the models’ selected answers were recorded, and if the response did not include one of the provided options (A, B, C, or D), the chatbot’s response was automatically recorded as being incorrect. This approach simulated the examination setting, where multiple-choice questions left unanswered were considered incorrect.
2.5. BCSC Self-Assessment User Statistics Regarding the Refractive Surgery Section
Obtained with the help of American Academy of Ophthalmology, a report averaged the scores for the questions pertaining to the Refractive Surgery section of all users of the BCSC Self-Assessment Program in the past 12 months, which eventuated to the usage of the data for 1983 users.
2.6. Data and Statistical Analysis
Performance was measured by calculating the proportion of correct answers provided by each model. To ensure a robust comparison between models, performance evaluation was not limited to raw accuracy. We applied statistics to determine whether observed differences were statistically meaningful. To determine if one of the models performed in a manner significantly different to the others, a chi-squared test to assess for independence was conducted. A 95% confidence interval was reported for each estimate and statistical significance was set to a p-value of less than 0.05.
3. Results
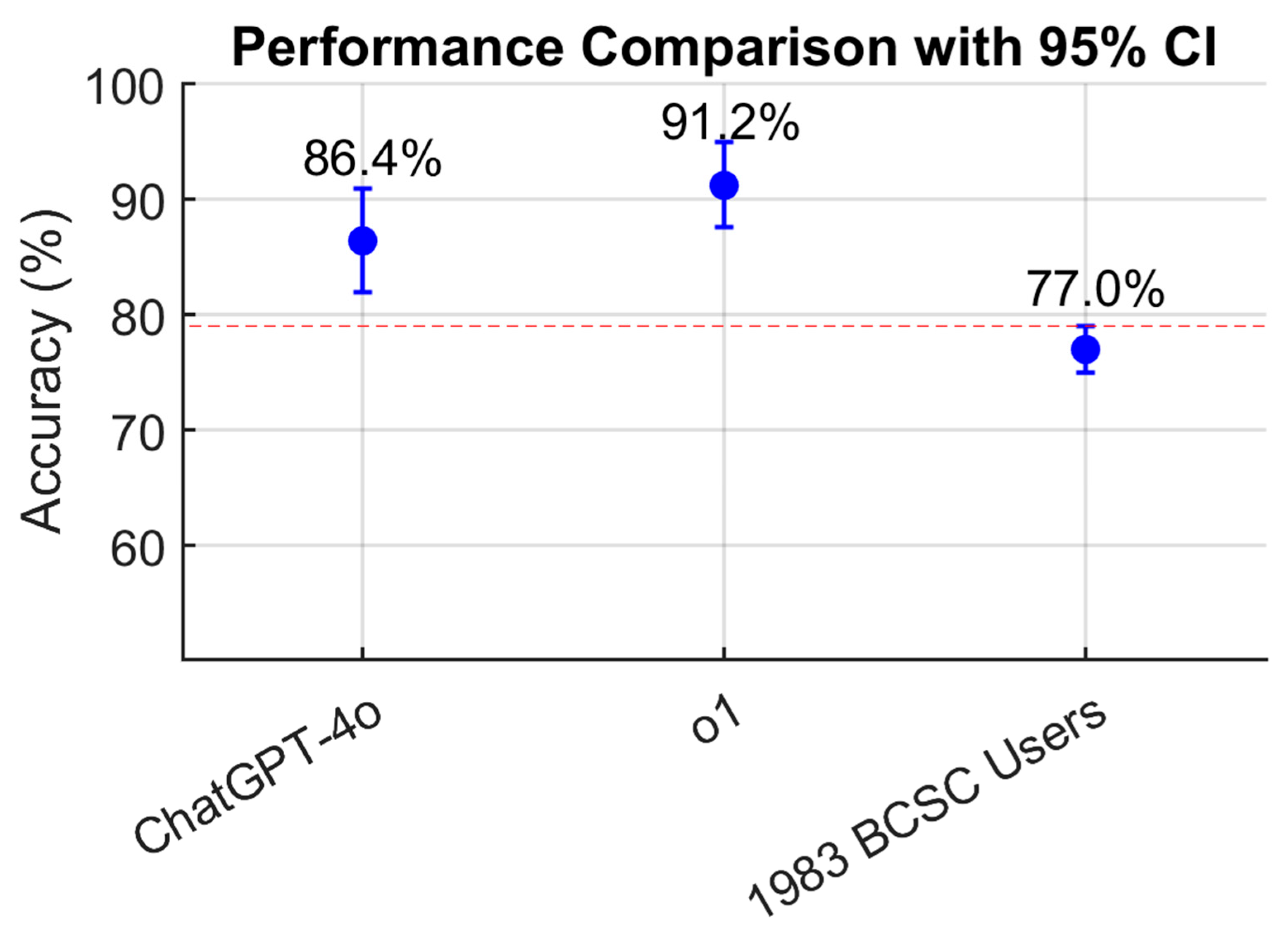
A total of 228 questions, selected to exclude those requiring image interpretation, were included in the analysis. ChatGPT-4o answered 197 questions correctly, corresponding to 86.4% accuracy (95% CI, 81.9–90.9%). OpenAI-o1 answered 208 questions correctly, achieving 91.2% accuracy (95% CI, 87.6–95.0%) (
Table 1). When compared to the average score of 1983 BCSC users (77%, 95% CI, 75.2–78.8%), both ChatGPT-4o and OpenAI-o1 demonstrated statistically superior performance.
As illustrated in
Figure 1, a dot plot with vertical error bars demonstrates that the CIs for ChatGPT models do not include the 95% CI margins of the BCSC users’ performance (red dashed line), indicating a greater and statistically superior performance relative to the resident benchmark (
p < 0.05). Markedly, OpenAI-o1 obtained a 14.2% higher score than the average BCSC user grade (
p < 0.05). However, while OpenAI-o1 outperformed, obtaining a mark 4.8% higher than ChatGPT-4o, this difference was not statistically significant (
p = 0.1045).
4. Discussion
This study evaluated the accuracy of two current LLMs, ChatGPT-4o and OpenAI-o1, when tested on refractive-surgery questions from the AAO BCSC Self-Assessment Program, an online platform often used by ophthalmology residents to prepare for their Ophthalmic Knowledge Assessment Program (OKAP) examination. The questions were obtained with the assistance of the AAO. By benchmarking the models against a real-world cohort of 1983 residents and practicing clinicians, our evaluation is rooted in evidence that directly impacts clinical medicine rather than relying on abstract AI-only comparisons.
OpenAI-o1 (91.2%, 95% CI 87.6–95.0%) obtained a higher score than ChatGPT-4o (86.4%, 95% CI 81.9–90.9%), although the difference did not reach statistical significance (p = 0.1045). However, both LLMs significantly outperformed the users of the BCSC Self-Assessment Program. This 4.8% difference, although not statistically significant, is still noteworthy. A five-percentage-point margin corresponds to one extra correct surgical decision in twenty, which could mean identifying a subtle topographic contraindicator to LASIK, selecting a more appropriate phakic IOL size or recognizing an early ectasia pattern that warrants cross-linking rather than surgery. Similarly to findings in other domains, architectural refinements in newer LLMs may yield only marginal gains in narrowly scoped, high-performing domains such as refractive surgery. As models approach ceiling-level performance, additional improvements tend to produce diminishing returns. This highlights the importance of critically evaluating marketing claims about “advanced reasoning” by validating model performance against rigorous task-specific benchmarks.
Notably, ChatGPT-4o behaved in a manner similar to its performance in our previous publication comparing five different LLMs. In our previous study, ChatGPT-4o was given 100 questions from the Refractive Surgery section of the BCSC Self-Assessment Program [
16], achieving accuracies of 84% (95% CI 77–91%) with a simple prompt and 86% (95% CI 79–93%) with a contextualized prompt [
16]. Despite the larger sample size of 228 questions in the current study, ChatGPT-4o’s accuracy remained comparable, showing how reproducible its ability is. Such consistency is clinically relevant, because decision support tools must deliver stable recommendations across encounters and institutions.
It is also important to underscore that, unlike the human BCSC users, who typically train using the official BCSC manuals and other curated course materials, the LLMs evaluated in this study had no such targeted preparation for the material. Most high-quality ophthalmology content, including the BCSC series, is proprietary and was not part of the training corpus made available to OpenAI’s models. While LLMs are trained on a wide array of open access content, they cannot retrieve pay-walled academic content. Thus, the fact that ChatGPT-4o and OpenAI-o1 achieved higher accuracy than human users without direct exposure to the source material highlights the remarkable generalization ability of these models. For clinicians, this implies that LLMs could already function as real-time “second readers” during pre-operative workups, even without bespoke fine-tuning, thereby reducing cognitive load and standardizing care. It is likely that if these models had been fine-tuned on BCSC specific content, their performance would likely have been even higher. While raw accuracy metrics, such as the percentage of accurately answered questions, provide a quantitative basis for comparison, they do not fully capture the reliability or clinical applicability of LLMs in educational or decision support contexts. For instance, an LLM might answer correctly by chance or without reliable internal reasoning, and accuracy scoring alone may mask issues like overconfidence in incorrect responses or inconsistency across content domains. Future work should pair accuracy with calibration analyses, session-to-session reproducibility, and prospective simulations that track downstream outcomes such as complications rates or patient-reported quality of vision and satisfaction.
Limitations
This study demonstrates that both ChatGPT-4o and OpenAI-o1 significantly outperformed the users of the BSCS Self-Assessment program. However, while OpenAI-o1 obtained a higher score than ChatGPT-4o, this difference was not statistically significant. This may partially be explained by the relatively small sample size of 228 questions. If the database had a larger number of questions, the observed difference could have achieved statistical significance with an estimated p-value smaller than 0.05.
Another limitation lies in the diversity of the user base of the BCSC comparison group, which included individuals ranging from first-year ophthalmology residents to experienced ophthalmologists in practice. The exact proportion of refractive-surgery subspecialists among the 1983 BCSC users is unknown, and it is likely that a cohort composed exclusively of refractive experts would have achieved a higher average score than the observed 77%. Nonetheless, the fact that LLMs reached a 92% score in this context remains noteworthy and highlights their potential as clinical decision support tools, even when benchmarked against a broad real-world user base. Additionally, the self-assessment platform enables users to answer questions multiple times, with their scores reflecting their most recent attempt rather than a first-time result. This could lead to inflated scores that do not accurately represent first-time knowledge or decision making capabilities.
Finally, the rapid release cycle of LLMs represents an ongoing challenge for longitudinal validation. Since completing data collection, OpenAI has already introduced newer iterations beyond o1, including o3 and o4-mini. These evolving versions can exhibit fluctuating performance characteristics, making it critical to treat each evaluation as a time-stamped benchmark rather than a definitive ranking. Adopting version-controlled benchmarking, coupled with prospective clinical trials that integrate LLM suggestions into refractive-surgery planning and measuring hard endpoints such as enhancement frequency or uncorrected visual acuity, will be essential to determine whether these tools translate into measurable patient benefit.
5. Conclusions
In this focused evaluation of two current large language models, ChatGPT-4o and OpenAI-o1 both outperformed 1983 ophthalmology residents and clinicians on 228 refractive-surgery questions from the AAO BCSC Self-Assessment Program, a validated benchmark that mirrors routine clinical decision making in ophthalmology and medicine. Both models demonstrated excellent generalization abilities within a highly specialized domain, without task-specific fine-tuning. OpenAI-o1 achieved the highest accuracy, of 91.2 percent versus 86.4 percent for ChatGPT-4o, yet this margin did not reach statistical significance in this current sample, although even a five-point edge could translate into fewer missed ectasia risks or suboptimal IOL choices in real patients. These findings suggest that while Open AI’s newer “advanced reasoning” architecture shows promise, its incremental gains must be weighed against real-world workflow integration and safety considerations. Future validation should couple version-controlled benchmarking with prospective clinical studies that measure tangible endpoints such as complications rates, uncorrected and corrected visual acuity, and patient satisfaction. Continuous evaluation will be critical to assess model improvements over time before LLMs can be adopted safely as an educational or medical decision-support tool that directly affects clinical outcomes in refractive-surgery practice.
Author Contributions
Conceptualization, A.W., T.R. and M.G.; Methodology, T.R. and M.G.; Validation, M.G.; Formal analysis, T.R. and M.G.; Investigation, T.R. and M.G.; Resources, A.W.; Writing—original draft, T.R. and M.G.; Writing—review & editing, A.W., T.R. and M.G.; Visualization, T.R. and M.G.; Supervision, A.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
As no identifiable private information or data requiring REB oversight are being used, this study was exempt from further ERB review and approval requirements by the Canadian Ophthalmic Research Review and Ethics Compliance Team (CORRECT).
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
The authors would like to acknowledge the American Academy of Ophthalmology Basic and Clinical Science Course Self-Assessment Program.
Conflicts of Interest
The authors have no conflicts of interest to disclose and no financial interests in the subject matter or materials presented herein.
References
- Antaki, F.; Milad, D.; Chia, M.A.; Giguere, C.E.; Touma, S.; El-Khoury, J.; Keane, P.A.; Duval, R. Capabilities of GPT-4 in ophthalmology: An analysis of model entropy and progress towards human-level medical question answering. Br. J. Ophthalmol. 2024, 108, 1371–1378. [Google Scholar] [CrossRef] [PubMed]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology: An Analysis of Its Successes and Shortcomings. Ophthalmol. Sci. 2023, 3, 100324. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.Z.; Shaheen, A.; Jin, A.; Fukui, R.; Yi, J.S.; Yannuzzi, N.; Alabiad, C. Performance of Generative Large Language Models on Ophthalmology Board-Style Questions. Am. J. Ophthalmol. 2023, 254, 141–149. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.C.; Younessi, D.N.; Kurapati, S.S.; Tang, O.Y.; Scott, I.U. Comparison of GPT-3.5, GPT-4, and human user performance on a practice ophthalmology written examination. Eye 2023, 37, 3694–3695. [Google Scholar] [CrossRef] [PubMed]
- Mihalache, A.; Popovic, M.M.; Muni, R.H. Performance of an Artificial Intelligence Chatbot in Ophthalmic Knowledge Assessment. JAMA Ophthalmol. 2023, 141, 589–597. [Google Scholar] [CrossRef] [PubMed]
- Moshirfar, M.; Altaf, A.W.; Stoakes, I.M.; Tuttle, J.J.; Hoopes, P.C. Artificial Intelligence in Ophthalmology: A Comparative Analysis of GPT-3.5, GPT-4, and Human Expertise in Answering StatPearls Questions. Cureus 2023, 15, e40822. [Google Scholar] [CrossRef] [PubMed]
- Olis, M.; Dyjak, P.; Weppelmann, T.A. Performance of three artificial intelligence chatbots on Ophthalmic Knowledge Assessment Program materials. Can. J. Ophthalmol. 2024, 59, e380–e381. [Google Scholar] [CrossRef] [PubMed]
- Raimondi, R.; Tzoumas, N.; Salisbury, T.; Di Simplicio, S.; Romano, M.R.; North East Trainee Research in Ophthalmology Network (NETRiON). Comparative analysis of large language models in the Royal College of Ophthalmologists fellowship exams. Eye 2023, 37, 3530–3533. [Google Scholar] [CrossRef] [PubMed]
- Singer, M.B.; Fu, J.J.; Chow, J.; Teng, C.C. Development and Evaluation of Aeyeconsult: A Novel Ophthalmology Chatbot Leveraging Verified Textbook Knowledge and GPT-4. J. Surg. Educ. 2024, 81, 438–443. [Google Scholar] [CrossRef] [PubMed]
- Teebagy, S.; Colwell, L.; Wood, E.; Yaghy, A.; Faustina, M. Improved Performance of ChatGPT-4 on the OKAP Examination: A Comparative Study with ChatGPT-3.5. J. Acad. Ophthalmol. 2023, 15, e184–e187. [Google Scholar] [CrossRef] [PubMed]
- Thirunavukarasu, A.J.; Mahmood, S.; Malem, A.; Foster, W.P.; Sanghera, R.; Hassan, R.; Zhou, S.; Wong, S.W.; Wong, Y.L.; Chong, Y.J.; et al. Large language models approach expert-level clinical knowledge and reasoning in ophthalmology: A head-to-head cross-sectional study. PLoS Digit. Health 2024, 3, e0000341. [Google Scholar] [CrossRef] [PubMed]
- Ferro Desideri, L.; Roth, J.; Zinkernagel, M.; Anguita, R. Application and accuracy of artificial intelligence-derived large language models in patients with age related macular degeneration. Int. J. Retin. Vitr. 2023, 9, 71. [Google Scholar] [CrossRef] [PubMed]
- Lim, Z.W.; Pushpanathan, K.; Yew, S.M.E.; Lai, Y.; Sun, C.H.; Lam, J.S.H.; Chen, D.Z.; Goh, J.H.L.; Tan, M.C.J.; Sheng, B.; et al. Benchmarking large language models’ performances for myopia care: A comparative analysis of ChatGPT-3.5, ChatGPT-4.0, and Google Bard. EBioMedicine 2023, 95, 104770. [Google Scholar] [CrossRef] [PubMed]
- Anguita, R.; Downie, C.; Ferro Desideri, L.; Sagoo, M.S. Assessing large language models’ accuracy in providing patient support for choroidal melanoma. Eye 2024, 38, 3113–3117. [Google Scholar] [CrossRef] [PubMed]
- Durmaz Engin, C.; Karatas, E.; Ozturk, T. Exploring the Role of ChatGPT-4, BingAI, and Gemini as Virtual Consultants to Educate Families about Retinopathy of Prematurity. Children 2024, 11, 750. [Google Scholar] [CrossRef] [PubMed]
- Wallerstein, A.; Ramnawaz, T.; Gauvin, M. Evaluating Large Language Models vs. Residents in Cataract & Refractive Surgery: A Comparative Analysis Using the AAO BCSC Self-Assessment Program. J. Cataract. Refract. Surg. 2025, 2025. [Google Scholar] [CrossRef]
- Temsah, M.H.; Jamal, A.; Alhasan, K.; Temsah, A.A.; Malki, K.H. OpenAI o1-Preview vs. ChatGPT in Healthcare: A New Frontier in Medical AI Reasoning. Cureus 2024, 16, e70640. [Google Scholar] [CrossRef] [PubMed]
- What is Artificial Intelligence in Medicine? Available online: https://www.ibm.com/topics/artificial-intelligence-medicine (accessed on 1 December 2024).
- Introducing GPT-4o and More Tools to ChatGPT Free Users. Available online: https://openai.com/index/gpt-4o-and-more-tools-to-chatgpt-free/ (accessed on 28 July 2024).
- Introducing OpenAI o1-Preview. Available online: https://openai.com/index/introducing-openai-o1-preview/ (accessed on 1 December 2024).
- Shabanov, I. The New Chat GPT Update: o1 vs GPT-4o. Available online: https://effortlessacademic.com/the-new-chat-gpt-update-o1-vs-gpt-4o/ (accessed on 1 December 2024).
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}