1. Background
Sepsis is a medical emergency characterized by the body’s systemic immune response to an infectious process, which may lead to organ dysfunction and death [
1]. Data acquired for this research were in line where sepsis is defined as the presence of an infection and detection of two or more Systemic Inflammatory Response Syndrome (SIRS) criteria, which places more priority on signs and symptoms of the disease [
2]. The prevalence of sepsis is anticipated to continue growing, particularly among patients with pre-comorbidities, making the issue a continuing concern [
3,
4]. Early prediction of sepsis is crucial to avoid sepsis mortality, as the probability of deaths significantly increases with each hour delay in administering antibiotics [
5].
Intensive Care Unit (ICU) mortality among septic patients is on the rise, so it is essential to prevent patients’ conditions from deteriorating and to administer treatments expeditiously, since each hour of delayed treatment is related with a 3.6–9.9% increase in fatality [
3]. Worldwide, the World Health Organization (WHO) projected 48.9 million sepsis cases and 11 million sepsis-related mortalities, which account for 20% of all death tolls [
5]. The number of patients with severe sepsis increased from 27% to 41%, but the death rate decreased by just 2.7%, remaining at 24.1% [
6]. Additionally, sepsis became the leading cause of ICU admission and mortality [
7]. Multiple studies have indicated that men had a 70% greater risk of sepsis-related mortality than females [
8,
9,
10]. A variety of factors are sources of sepsis, involving community-acquired infections (over 60%), healthcare-associated infections (26%), and hospital-acquired infections (11%). In total, 64% (pneumonia), 20% (abdominal), 14% (gastro and urinary), and 14% (intestinal and urinary) are the most prevalent regions of infection among septic patients who were admitted to the ICU [
11].
Due to the direct and indirect expenses of the disease, sepsis may place a substantial monetary burden on society. The direct cost of sepsis hospital charges in the United States was estimated to be USD 24 billion in 2013 [
12,
13]. Moreover, sepsis imposes a substantial indirect cost on patients; for instance, a decrease in productivity due to absence from work, in addition to impairment days and retirement at an early age. However, data on this aspect is rare and the financial strain on society was approximated to be between USD 484 and USD 686 million per year for 6700 to 9500 patients [
14].
The natural physiological and immunological reaction of the human body is the eradication of any invading infection. Due to pathogen stimulation, normal homeostasis becomes unbalanced in sepsis [
15]. If somehow the bacteria penetrates into the blood circulation, it will produce toxins that trigger inflammatory responses, such as cytokines and platelet activation factors [
16]. In addition, septic patients will encounter a rapid apoptosis of lymphocytes, an upsurge in coagulation, and a decline in fibrinolytic activity, which will direct an aggregate or plaque buildup and poor circulation. As a consequence, the fluid will dissipate and the patient will become hypotensive, which signifies that some organs are not being perfused, thereby resulting in tissue hypoxia [
14,
16].
SIRS was the primary diagnostic criterion, and patients were categorized as septic if they fulfilled two of four criteria: hyper or hypothermia, tachycardia, tachypnea, leukocytosis, or leukopenia. SIRS might detect sepsis in its earliest stages, prior to the development of further problems or the onset of septic shock and organ failure. However, these deficits in homeostasis might be attributed to medical conditions other than sepsis; hence, the Acute Physiology and Chronic Health Evaluation (APACHE) score and Sequential Organ Failure Assessment (SOFA) Score were subsequently adopted for ICU patients [
17]. SOFA provides a more comprehensive scoring method used to evaluate the functionality of 12 human organs: the neurologic, liver, blood, hemodynamic, and kidneys [
18]. In addition, SOFA is acclaimed for predicting ICU mortality for septic patients admitted to the ICU, which allows for a more accurate prognosis than other grading systems [
19].
For the diagnosis and management of sepsis, a criterion is employed to define the sickness stage among patients, which will dictate the treatment strategy. Managing patients with multi-organ disease like sepsis needs interpretation of multiple interlayers of information. Physicians integrate these data into clinical scores, and individual judgement is based on data, physical and established clinical guidelines [
20]. However, sepsis patients are managed by clinicians in ICU wards where their work is organized in shifts, and experiences and clinical judgements might vary significantly between physicians. Therefore, more objective measures of patients and disease trajectories could lead to better health outcomes and decision processes.
While dealing with sepsis patients, a particular challenge for physicians is to make decisions when to stop treatment [
20,
21,
22,
23,
24]. Following the clinical guidelines, patients who do not benefit from the ICU should not be admitted. However, making this critical judgement by a physician could be impossible at admission when only limited data are available for a patient. Additionally, during that time, physicians need to assess further information on concomitant diseases, pre-admission comorbidities and frailty, and responsiveness to treatment. In reality, often physician’s decisions on ICU services or any treatment restrictions are made after consulting with other healthcare providers, the patient, and their family [
24]. Nevertheless, given a large volume of information generated from a septic patient’s ICU stay, making this judgment is often tricky, and outcome prediction remains challenging. Consequently, machine learning methods that intrinsically integrate and process a large amount of data could play an important role in facilitating clinical decision making.
A high prevalence of sepsis-related ICU death was attributed to poor blood circulation, tissue perfusion damage, and the onset of organ failure; however, the ICU mortality rate was greater among patients with failure in four or more organs than among those with failure in one organ: 60.8% against 9.2%. Research found a correlation between high ICU death rates and lung infection (34.7%). In patients with positive cultures, Gram-positive organism’s “staphylococcus” and Gram-negative species “Pseudomonas and Acinetobacter” were shown to be related with increased ICU mortality (56%, 49.5%, and 44.9%, respectively). Other independent risk factors reported to be related with sepsis include a high APACHE II score, concomitant cardiovascular illnesses, malignancies, and the use of Renal Replacement therapy [
25].
A study demonstrated that ICU mortality is higher among septic patients with elevated SOFA scores (90% sensitivity and 80% specificity); additionally, it was observed that patients receiving invasive mechanical ventilation (IMV) had a seven-fold higher rate of ICU mortality than those receiving non-invasive mechanical ventilation (NIMV) due to the growth of multidrug-resistant microorganisms [
26]. The appearance of thrombocytopenia and an elevation in the circulation of immature platelets as a consequence of an infection was discovered to increase ICU mortality among septic patients [
27]. Each hour of delayed treatment and each extra hour until treatment completion were associated with an extra 4% ICU mortality risk for septic patients [
28].
Artificial intelligence has been increasingly used in medical research to achieve better/or early clinical diagnoses and suggest appropriate treatments. Machine learning (ML) is particularly useful for predicting outcomes in intensive care settings because it can integrate complex information from different sources relatively easily [
29]. Although ML approaches can process a large number of complex and multidimensional information, the likelihood of implementing an algorithm is reduced with the number of parameters taken into consideration. Essentially, in relation to the external validity of the machine learning tool, it would be useful to limit the number of parameters to only common parameters [
24]. Typically, machine learning models can process many data sources, such as biomarkers, ventilation settings, blood pressure, and medications. However, the availability of all these data may differ significantly between ICU units across healthcare systems; for example, a highly equipped ICU can generate a larger volume of data compared to others. Nonetheless, the use of machine learning tools should not be limited to large amounts of data for sepsis patients generated by high-end ICUs only.
ML methods can predict hospital ICU mortality in sepsis patients [
21]. It is essential to investigate and analyze the predictability of machine learning algorithms to determine which model is more accurate at forecasting the chance of ICU mortality, hence, can offer an effective treatment for patients. In predicting hospital ICU mortality of patients with sepsis, a machine learning approach appeared to be outperforming conventional clinical decision rules [
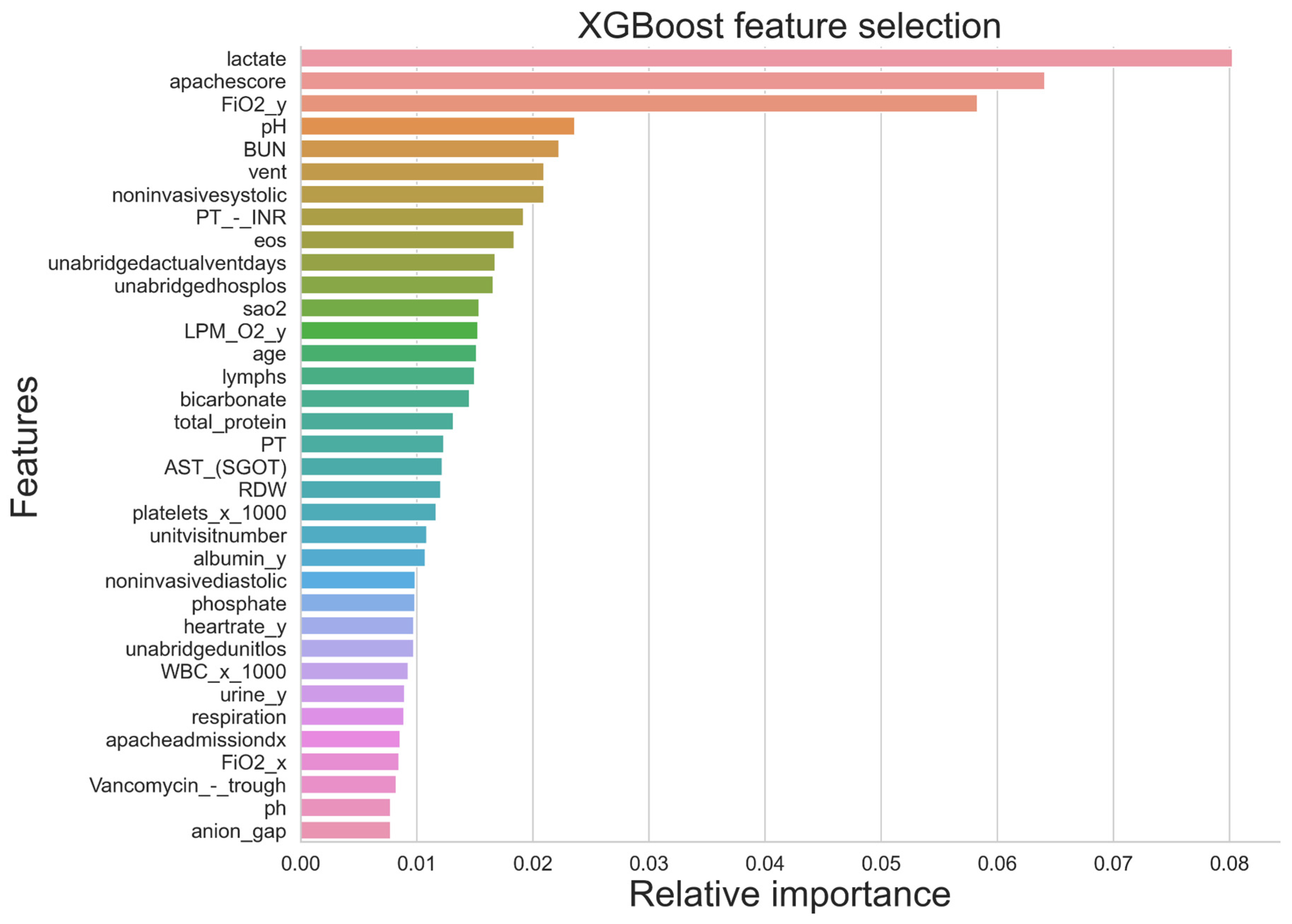
22]. However, most previous prediction models for mortality require a large number of variables, including the underlying disease, laboratory data, and clinical parameters. This is particularly true for sepsis ICU patients, with a complex disease trajectory which generates a vast array of data that need to be used in clinical decision making. To predict ICU mortality, ICU length of stay, and severity among septic patients, a study employed three machine learning algorithms (Logistic Regression (LR), Random Forest (RF), and eXtreme Gradient Boosting (XGBoost)), where the RF classifier demonstrated the best classification results for prediction of the severity of sepsis (True Positive = 0.65, True Negative = 0.73, F1 measures = 0.72, AUC = 0.79) [
27]. Similarly, for mortality predication, RF illustrated better performance (true positive = 0.50, true negative = 0.84, F1 measures = 0.66, AUC = 0.74) along with prediction of ICU Length of stay (sensitivity = 0.50, specificity = 0.84, F1 score = 0.66, AUC = 0.74). Moreover, Synthetic Minority Over-sampling Technique (SMOTE) was conducted for the minority group to make the dataset balance which increased the sensitivity to 0.49 from 0.13 [
30].
The purpose of this study is to develop and compare machine learning models using Extra Trees (ET), Random Forest (RF), and Support Vector Classifier (SVC) for predicting mortality among sepsis ICU patients using their ICU patient records. A machine learning prediction model could benefit physicians in their decision-making on better treatment strategies for sepsis patients during their stay in ICUs and to avoid sepsis ICU mortality.
4. Discussion
Sepsis costs the healthcare system more money when its occurrence rates rise. Through a multidisciplinary relationship between public health specialists, healthcare providers, patients, and the community, sepsis prevention problems are addressed. Thus, it is clear how crucial it is to use machine learning techniques for accurate and early mortality prediction.
According to the research, male septic patients had a greater mortality rate than female septic patients (p value = 0.0480). Additionally, the study findings supported the existing evidence base in that sepsis mortality was more common in men than in women (p value < 0.001); however, this may have been a result of the genders’ unadjusted baseline rates of death, which were 54.2% for male and 45.8% for female.
Glomerular filtration rate (GFR), despite information about dialysis and urine output being provided, was one factor that might have been linked to the prediction of ICU mortality for sepsis patients but was not included in the dataset. In addition, such information was required to estimate the stage of kidney disease as it is important in determining organ failure and severity of sepsis.
Sepsis mortality is influenced by a variety of factors, including differences in genetic make-up and biological characteristics, which are strongly influenced by race. Numerous studies have shown a strong correlation between Black people’s death and their race; one of these studies showed that Black people had a case fatality rate of 32%, which was much higher than that of Hispanic and White people (30.4% and 29.3%, respectively) [
45]. These results, however, did not support the conclusions of the current investigation because Hispanic ethnicity was associated with a higher mortality risk than Black ethnicity (OR: 1.118, 95% CI: 0.765–2.074
p value 0.660); however, this association was found to be statistically insignificant. Another study with contradicting findings found that mortality among White people was higher than that of Black people (OR: 0.85; 95% CI: 0.84–0.86) [
46].
Patients from different ethnic groups were included in the US dataset that was used in the study. Although some patients from the Middle East may have been included in the other ethnicity groups designated as “other/unknown”, the model can still be trusted even if Middle Easterners were not among the ethnic groups studied because it was built using training data from 80% of the data cases using the available predictors for the outcome. The other 20% of data cases, which were not part of the training set, were test data, suggesting that external validity was taken into account.
In order to anticipate future events with a high degree of accuracy and to demonstrate the incremental validity, machine learning (ML) models of prediction produce parameters based on the relationship of various factors in the training set. Additionally, it enables the evaluation of clinical factors to determine whether or not they influence mortality prediction. It is tailored as a technique to reduce mortality among ICU septic patients because prediction models are typically constructed to tailor the intensity of characteristics into the preventive. Additionally, it aids in resource allocation so that ICU mortality in the future can be managed.
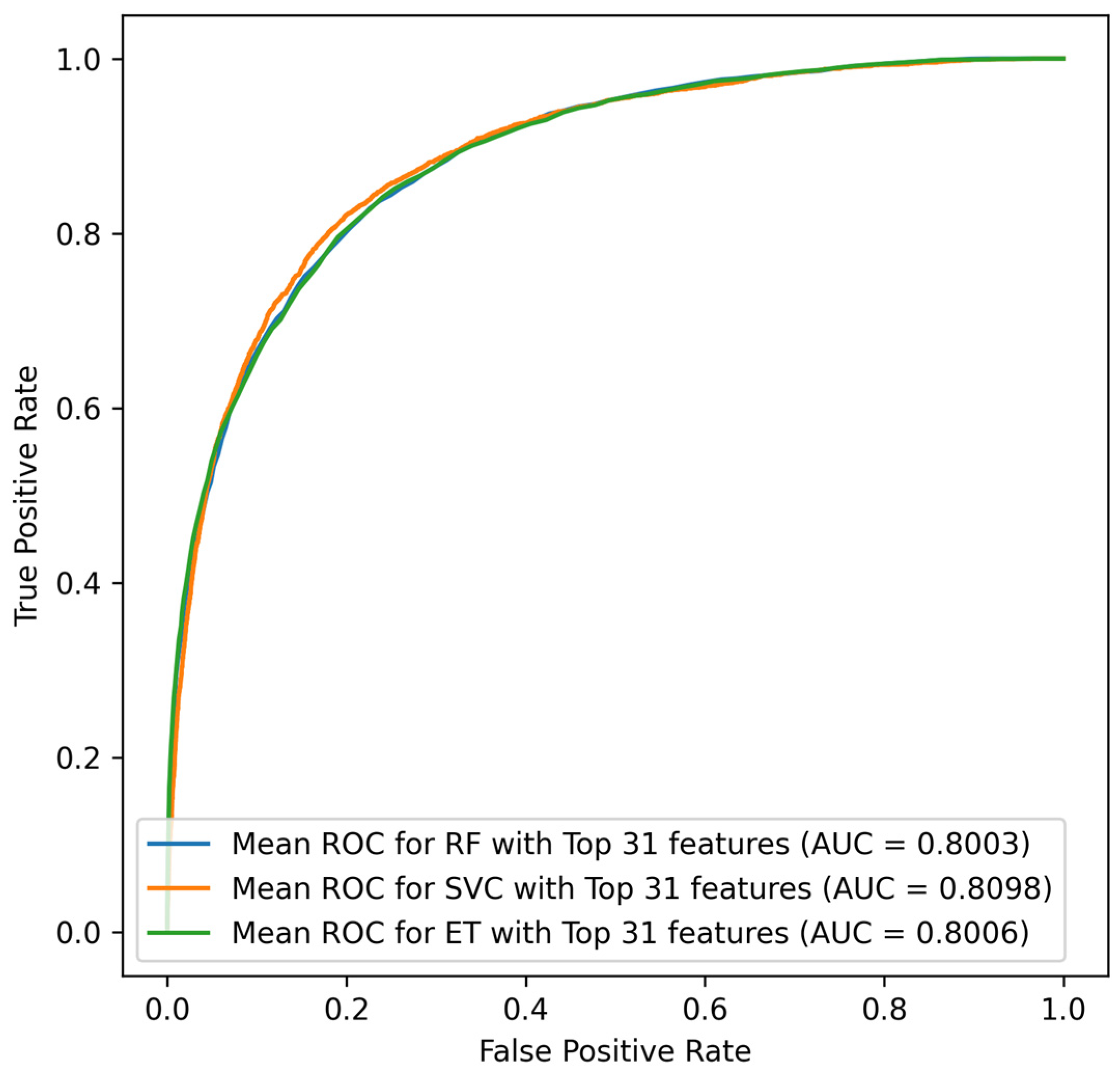
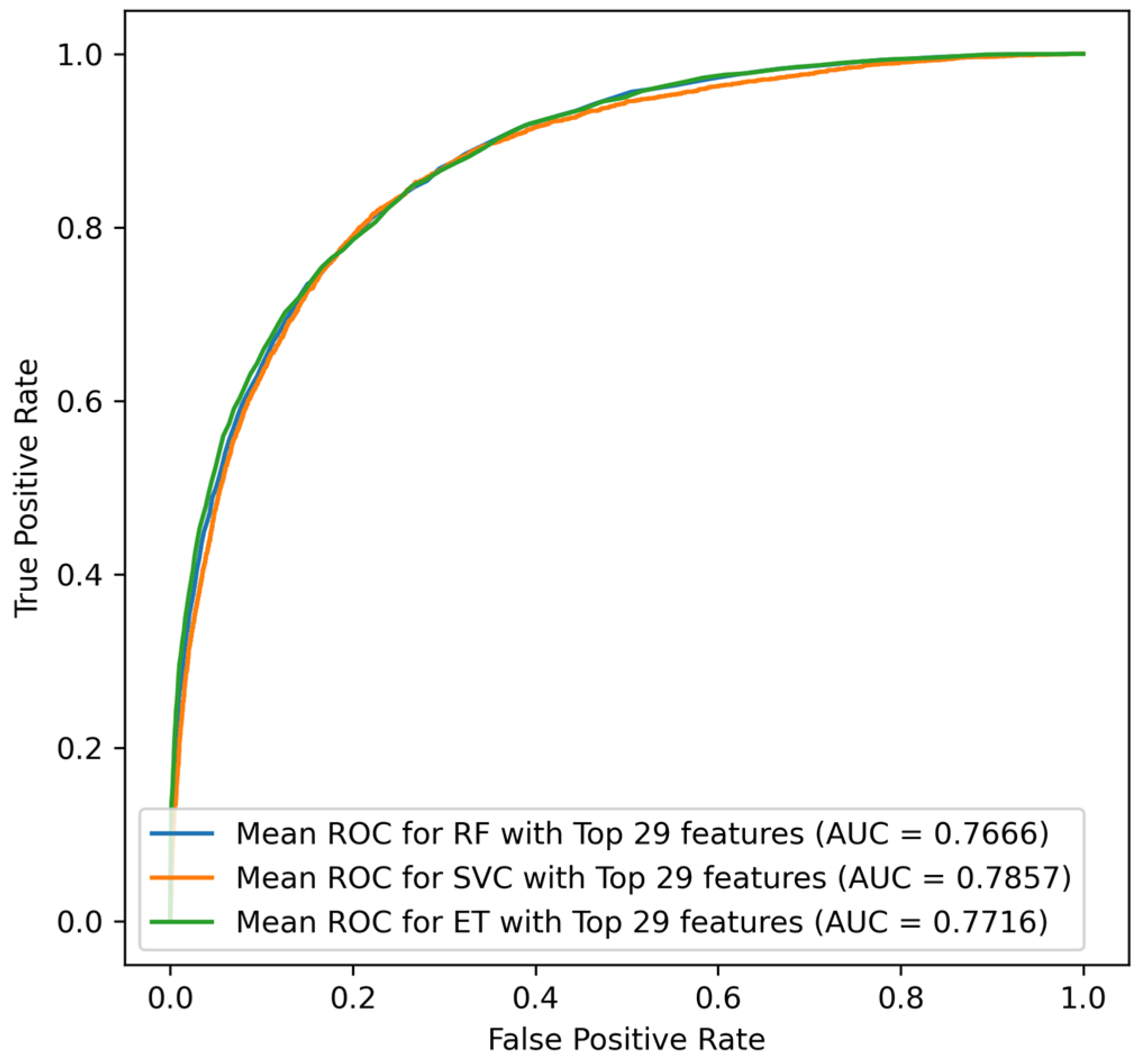
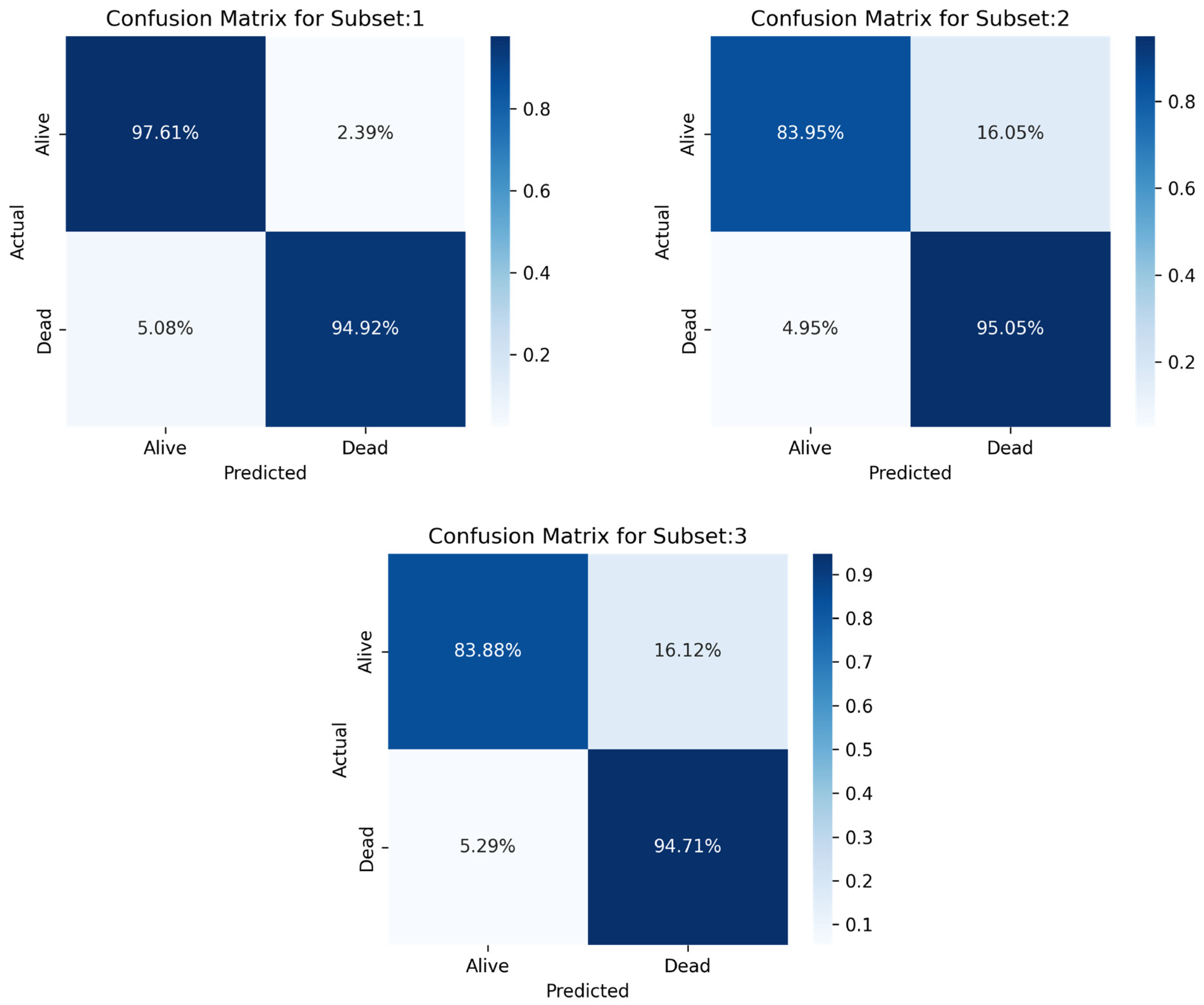
In this study, ML models were created to forecast ICU mortality for patients with sepsis using a variety of indicators. The primary objective of the study was to assess the efficacy of various machine learning algorithms, of which the three best models are deployed (MLP, RF, and LR) to predict outcomes using patient electronic health information. In the last study, a stacking classifier with three boosting classifiers acting as primary models and LR serving as the final estimator was used.
In comparison to MLP and RF, LR recorded a good prediction with low biases and less deference between accuracy and precision performance. The key findings of this study demonstrated that among the three machine learning algorithms, LR showed the highest performance measures across the three sampling techniques (Sensitivity = 0.808070, Specificity = 0.970375, Precision = 0.918418, Accuracy = 0.917757, F1-score = 0.916139, AUC = 0.88).
This study has several advantages. The fact that the data were collected at random gave the study one of its many advantages, reducing the likelihood of biases and allowing generalization of the results. Additionally, three machine learning algorithms were used, by employing three different sampling strategies to allow the data to be over- and under-sampled. This approach was simple to deploy, economical, quick, and non-invasive because it did not require direct interaction with the patients. The relationship between clinical variables was examined with the help of a general physician to make sure that the variables and test results made clinical sense in order to prevent any misleading or wrong results.
Although our model demonstrates reliable mortality predictions using single-entry ICU data, incorporating longitudinal data could significantly enhance model performance. Predictions at different time points (initial admission, post-resuscitation, and chronic stages of critical illness) can offer tailored insights, thus guiding timely clinical interventions. Future studies are encouraged to examine the temporal dimensions of ICU mortality prediction systematically.
Limitation
This study demonstrated that just one machine learning method had an accuracy level of 91.77% for predicting ICU mortality. Therefore, the goal of predicting ICU mortality cannot be discounted because it helps healthcare professionals identify patients at high risk. Predicting ICU mortality will be advantageous not only on an individual basis but also on a social, departmental, and corporate level, which can speed up the process of making a strategic decision. Furthermore, by understanding effective resource allocation strategies, healthcare officials can utilize machine learning as a guide to establish new programs based on the proportion of high-risk persons in a specific region or for each health organization.
The technique of data gathering was one of the major weaknesses of the study. It was a secondary database which was publicly accessible for credential account holders. There might be ambiguities in relation to data collection, data process, and data storage that needed to be reviewed and deleted. All of the clinical and demographic data were obtained by registered nurses working in the ICU. Another drawback was the absence of information on the use of pacemakers. As a result, we were unable to rule out patients whose temperatures were below 22 °C, which can be a sign of cardiac arrest; nevertheless, since they were still alive, it was presumed that a pacemaker had been used [
47]. Similar to this, some patients who had a heart rate below 45 bpm, which is often indicative of Third-Degree Atrioventricular Block and were still alive, were not disqualified from receiving a pacemaker [
48,
49].
Algorithm bias is one of the limitations that could be found in such studies, despite the fact that artificial intelligence (AI) is known to lessen the impact of human biases. Algorithm bias is the unfair outcome that a computer system can create due to some repeatable and systematic errors, such as the privilege of one group over the other (living cases over the deceased). In other words, it could happen if the study’s algorithm yields biased results as a result of false assumptions made during the machine learning process [
50,
51]. However, it was determined that because three sampling criteria were used, the likelihood of this kind of bias is minimal.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}