

Human Digital Twin for Personalized Elderly Type 2 Diabetes Management

 , and
, and
Abstract
1. Introduction
1.1. Existing Methods
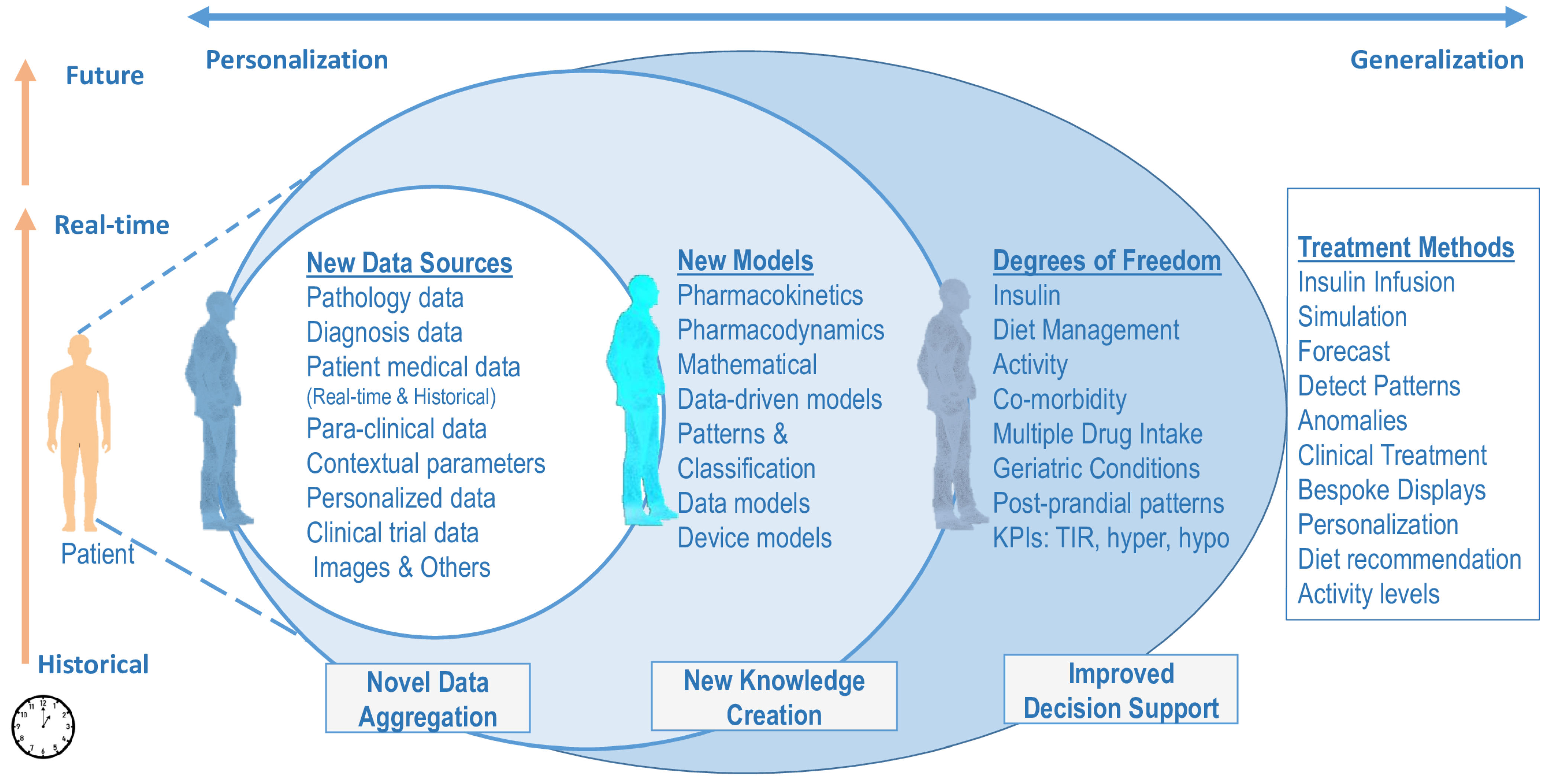
Digital Twin in Healthcare and Medicine
- (i)
- A new HDT framework and architecture towards personalizing E-T2D management with capabilities to aggregate data, a suite of models that build intelligence on the data, and an interface between the VT and PT.
- (ii)
- An IoMT architecture to aggregate data vis-á-vis HDT for E-T2D management.
- (iii)
- Modules for forecasting, food nutrient predictions, time-series trending, and other intelligence required for managing E-T2D.
- (iv)
- An adaptive patient model that personalizes insulin infusion based on geriatric factors and learning-based MPC (LB-MPC) that could embed the deep-learning models to compute precise insulin infusion.
- (v)
- Illustrate the HDT’s capability to manage E-T2D by modeling a personalized patient model and embedding other aspects. To this extent, clinical data from patients are collected for 14 days to obtain patient model and patient-specific contextual data from 15 elderly patients. Using these models and data, simulations are performed to illustrate the HDT’s ability to deliver precision insulin considering various aspects.
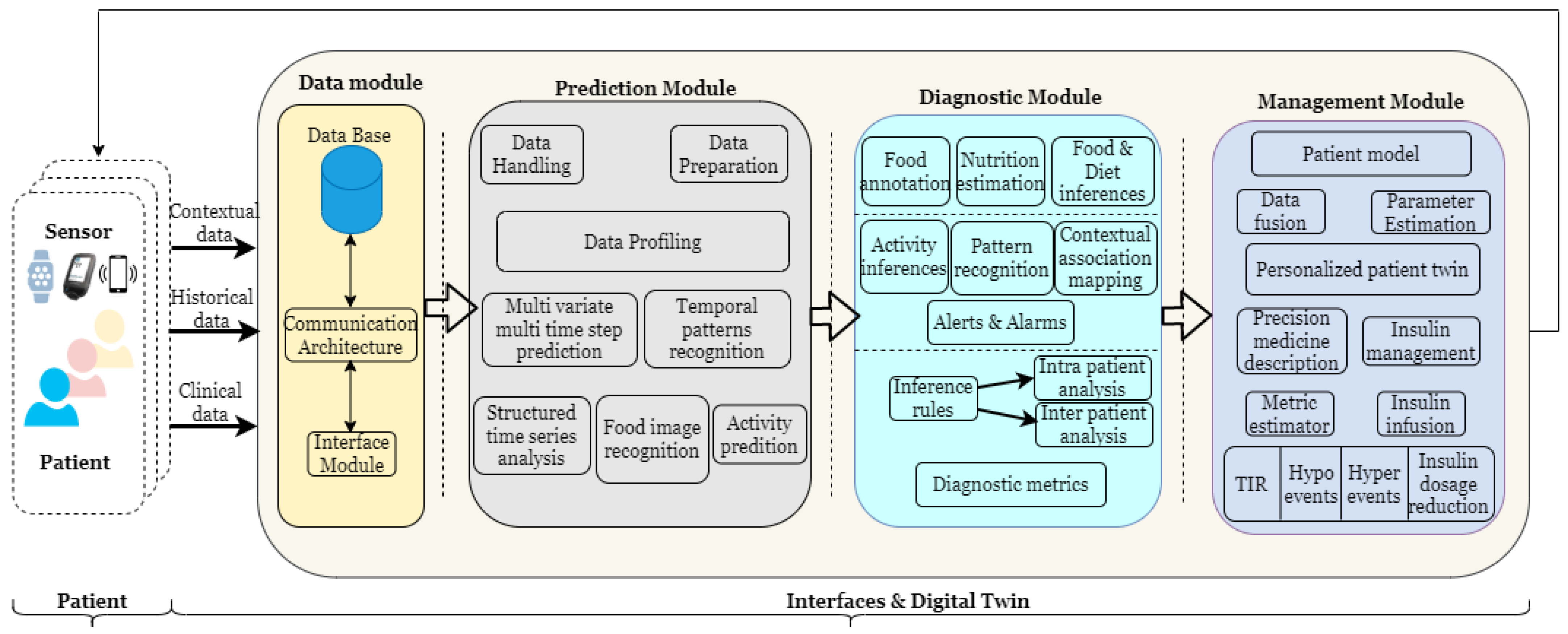
2. HDT Framework Architecture
2.1. HDT Framework Components
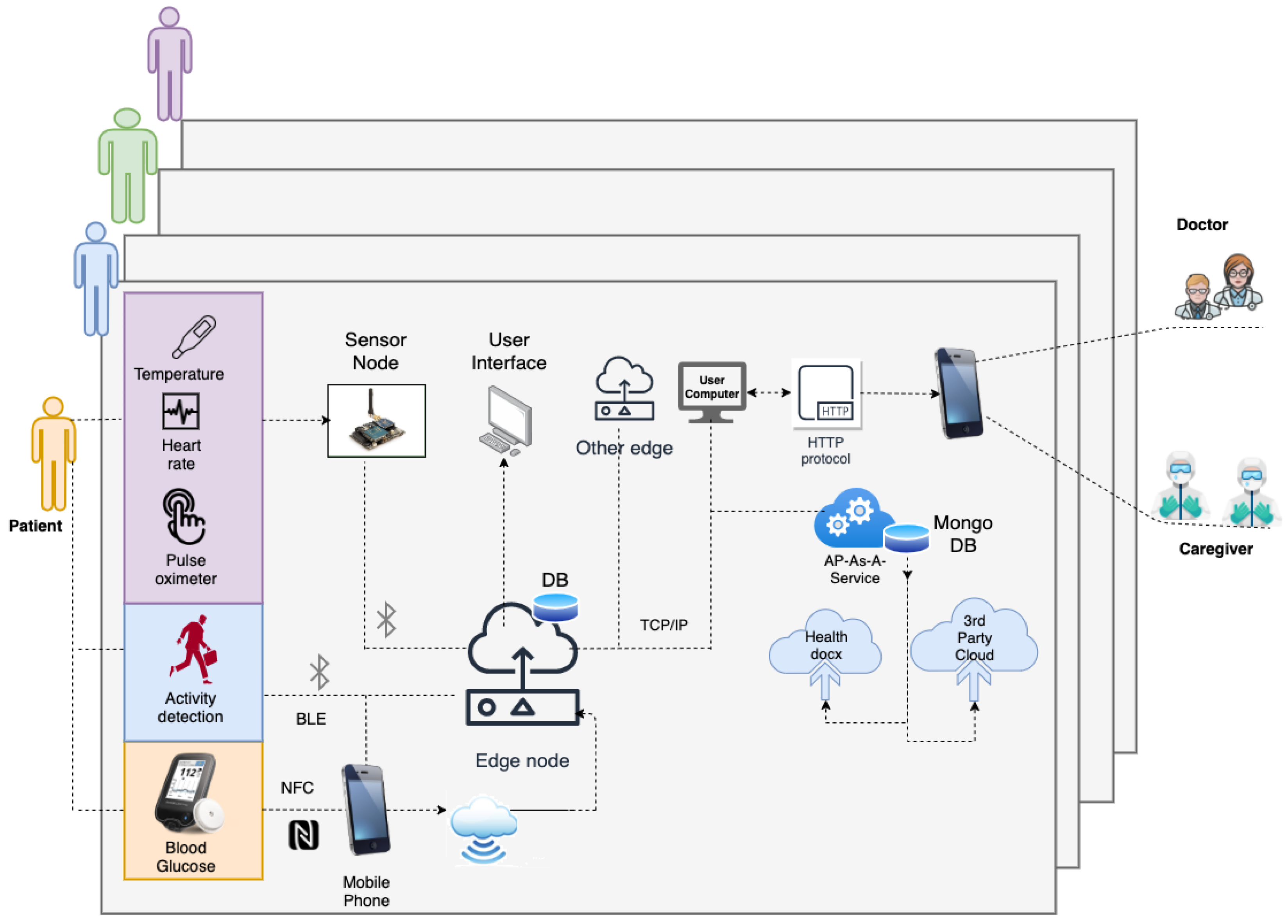
2.2. Data Module
2.3. Prediction Module
2.4. Diagnostic Module
2.5. Management Module
3. HDT Implementation
3.1. IoMT for Data Module
3.2. Prediction Module
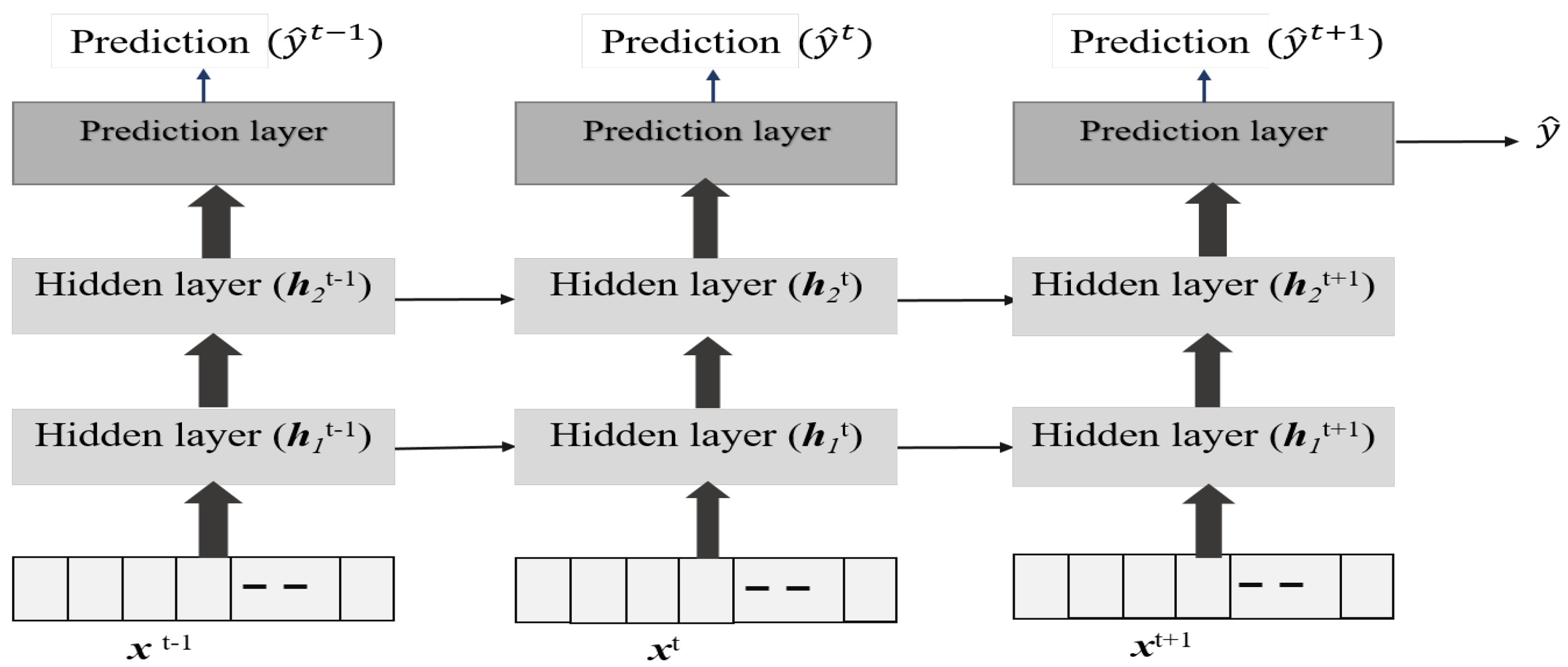
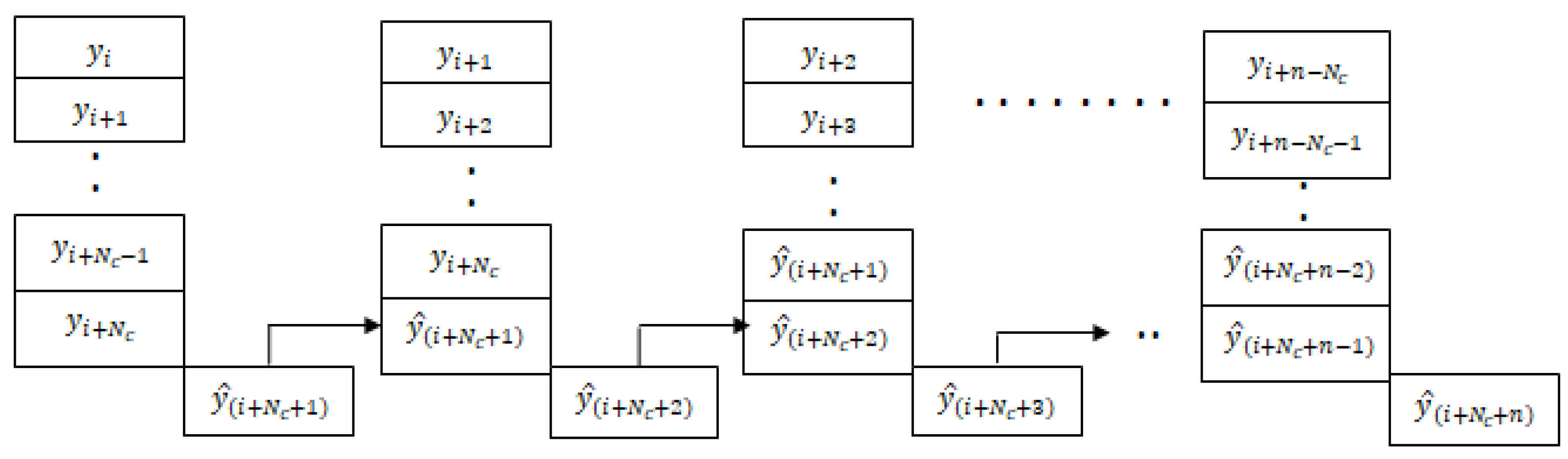
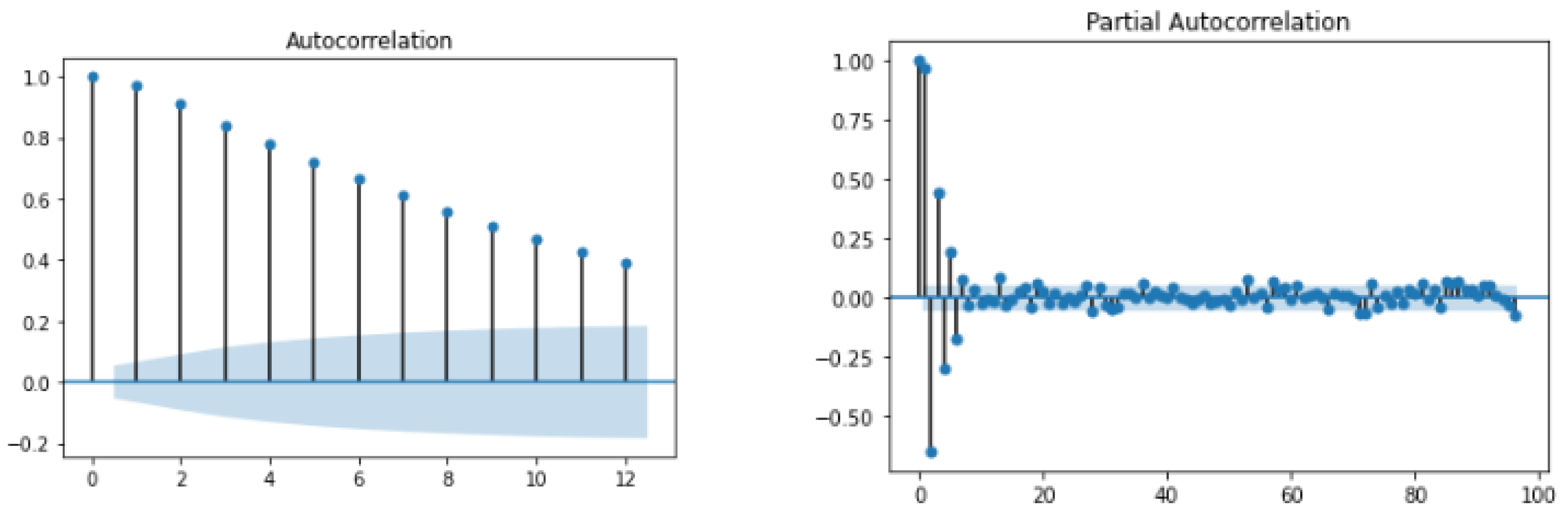
3.2.1. Multi-Time Step and Multi-Variate Time-Series Prediction
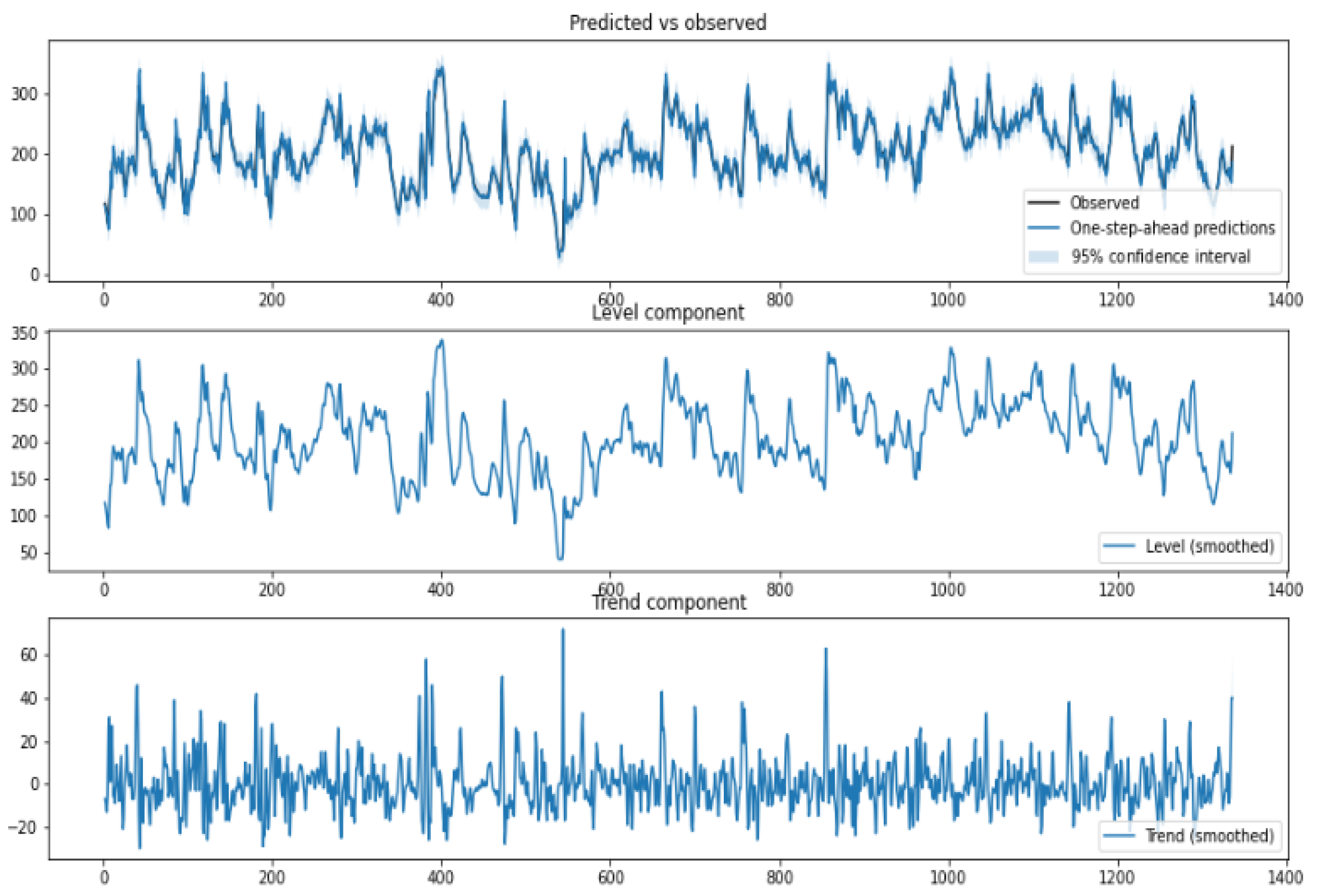
3.2.2. Structured Time-Series Analysis
3.3. Diagnostic Module
- Motif Discovery
- Explainable Diagnostics for Events
3.4. Personalization and Management Module
3.4.1. Adaptive Personalized Patient Model
| Algorithm 1: Dynamic Patient Model Parameter Estimation for BGL Prediction. |
 |
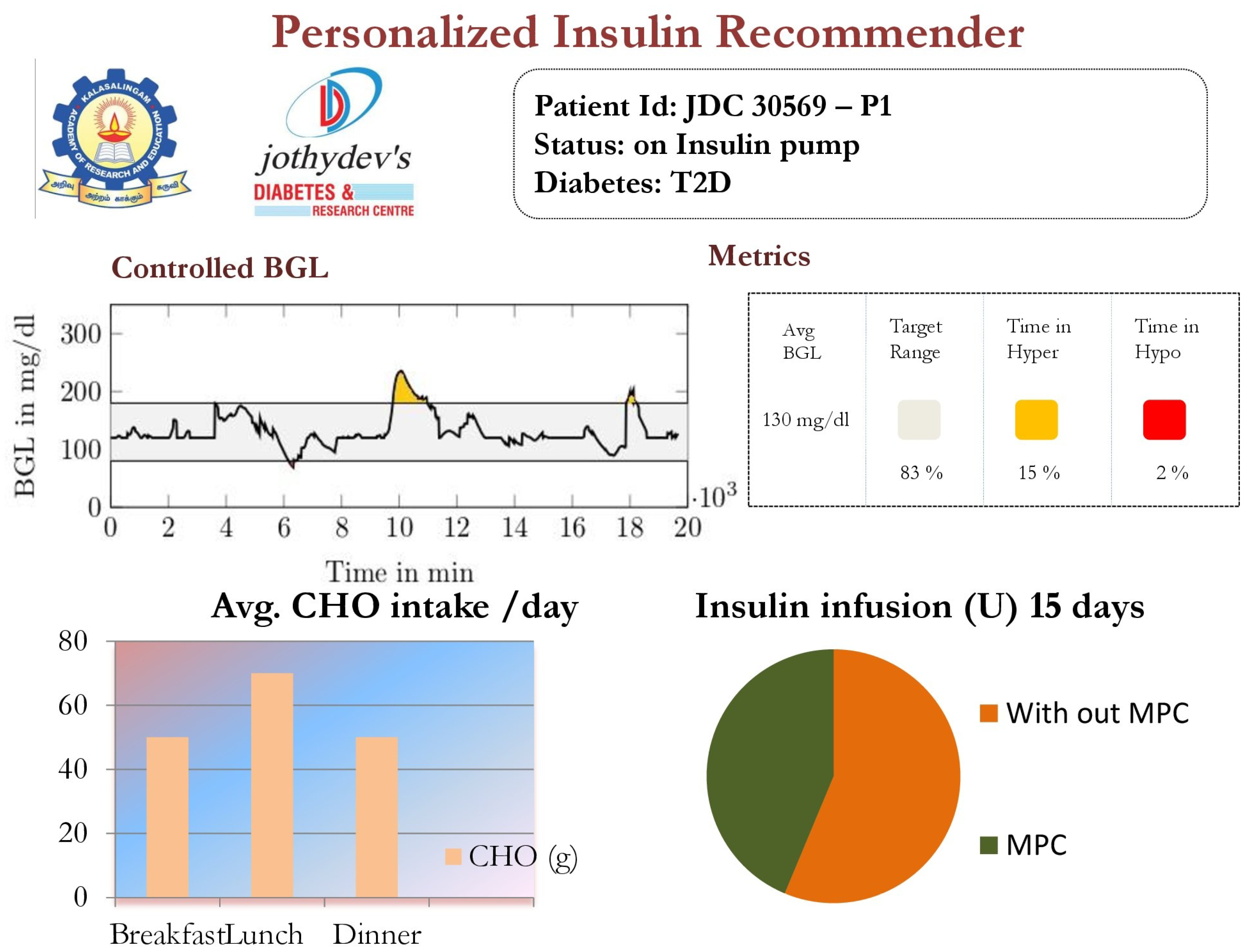
3.4.2. Personalized Insulin Management Module
Perturbation Terms for Geriatric Factors and Nutrient Intake
4. Results
- (i)
- Clinical trials for 14 days on 15 elderly patients to collect patient-relevant data and blood glucose measurements. This is used for our modeling wherein an adaptive patient model, LSTM, STA, XAI, and other models are obtained. In this phase, infusions were done with insulin pumps pre-programmed based on diabetologist recommendations.
- (ii)
- Simulations with the model to compute precision insulin infusion to avoid BGL excursions in E-T2D patients exploiting the different HDT models. The MPC presented is a simulation result that uses the patient model obtained from clinical trials. The diabetologist verified these results and confirmed the findings. Moreover, its implementation with an insulin pump is feasible through pre-programmed inputs from insulin pumps, as with clinical trials. However, due to constraints in volunteer recruitment and re-admissions, only simulation results are provided in the paper.
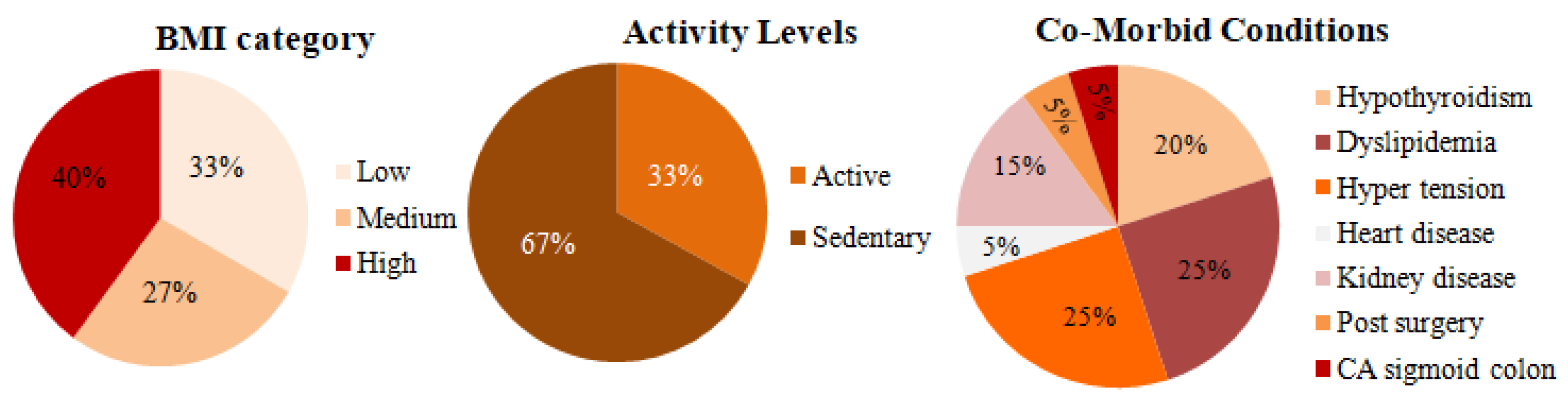
4.1. Clinical Data Description
4.2. Clinical Data Collection
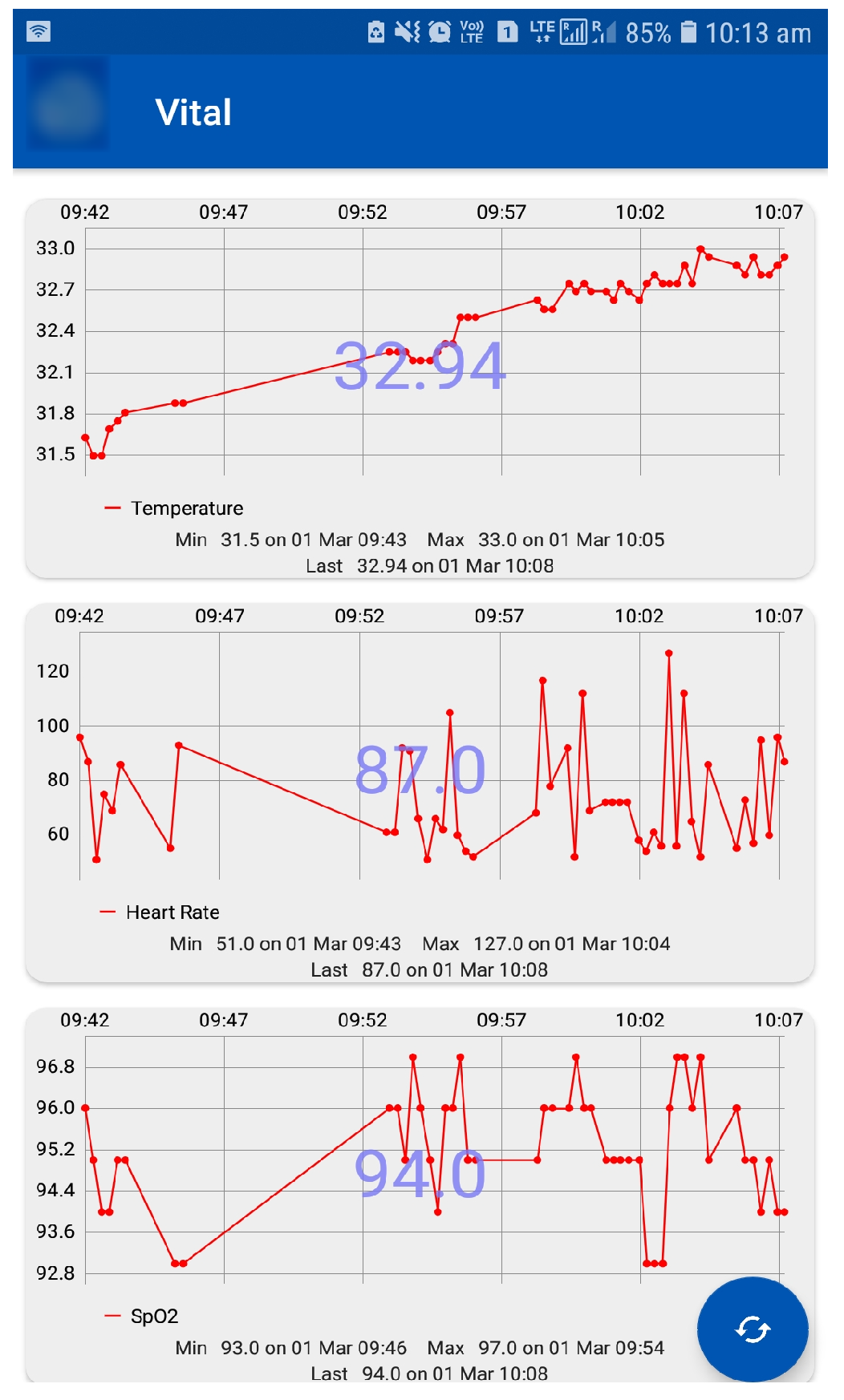
4.3. Vital Signs and Activity Data
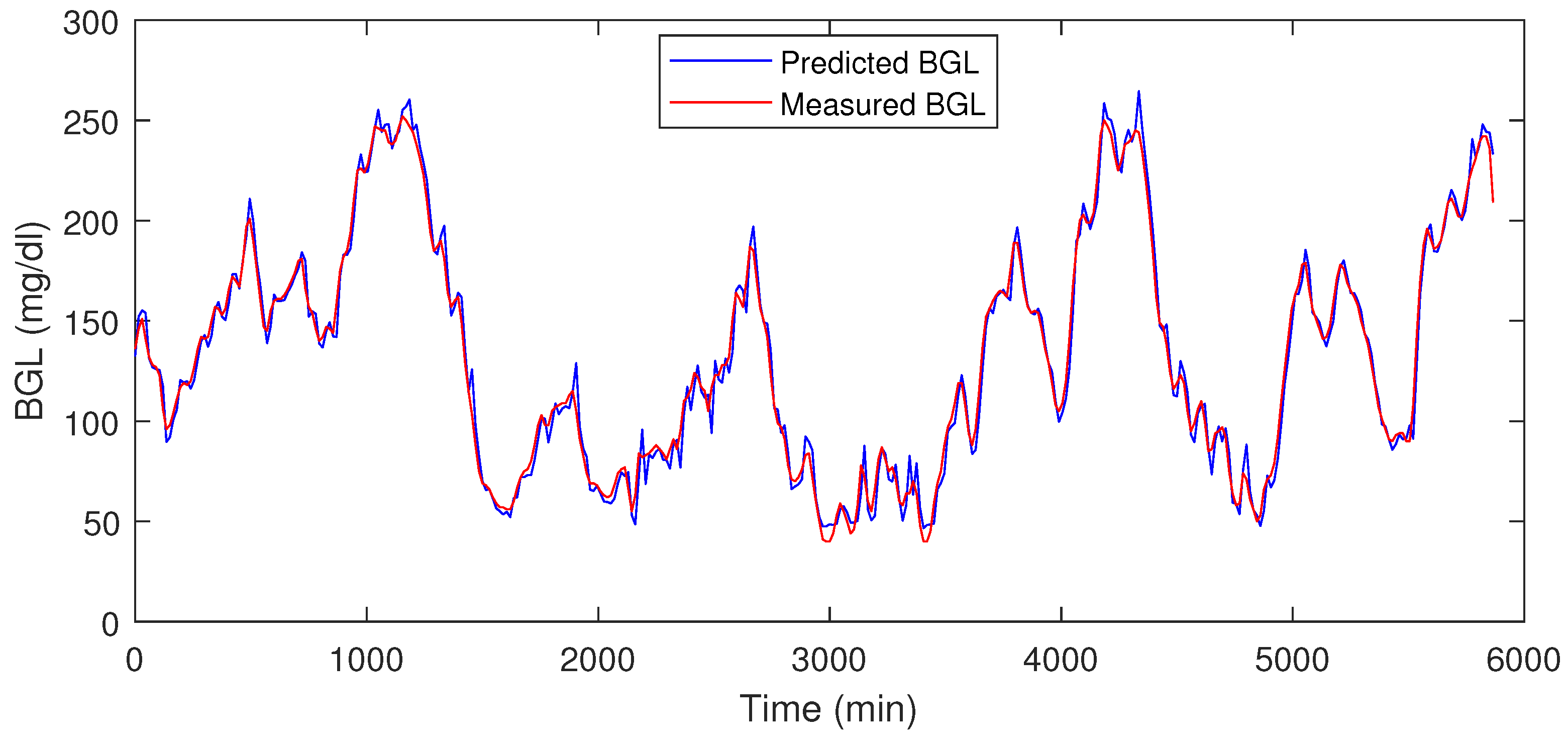
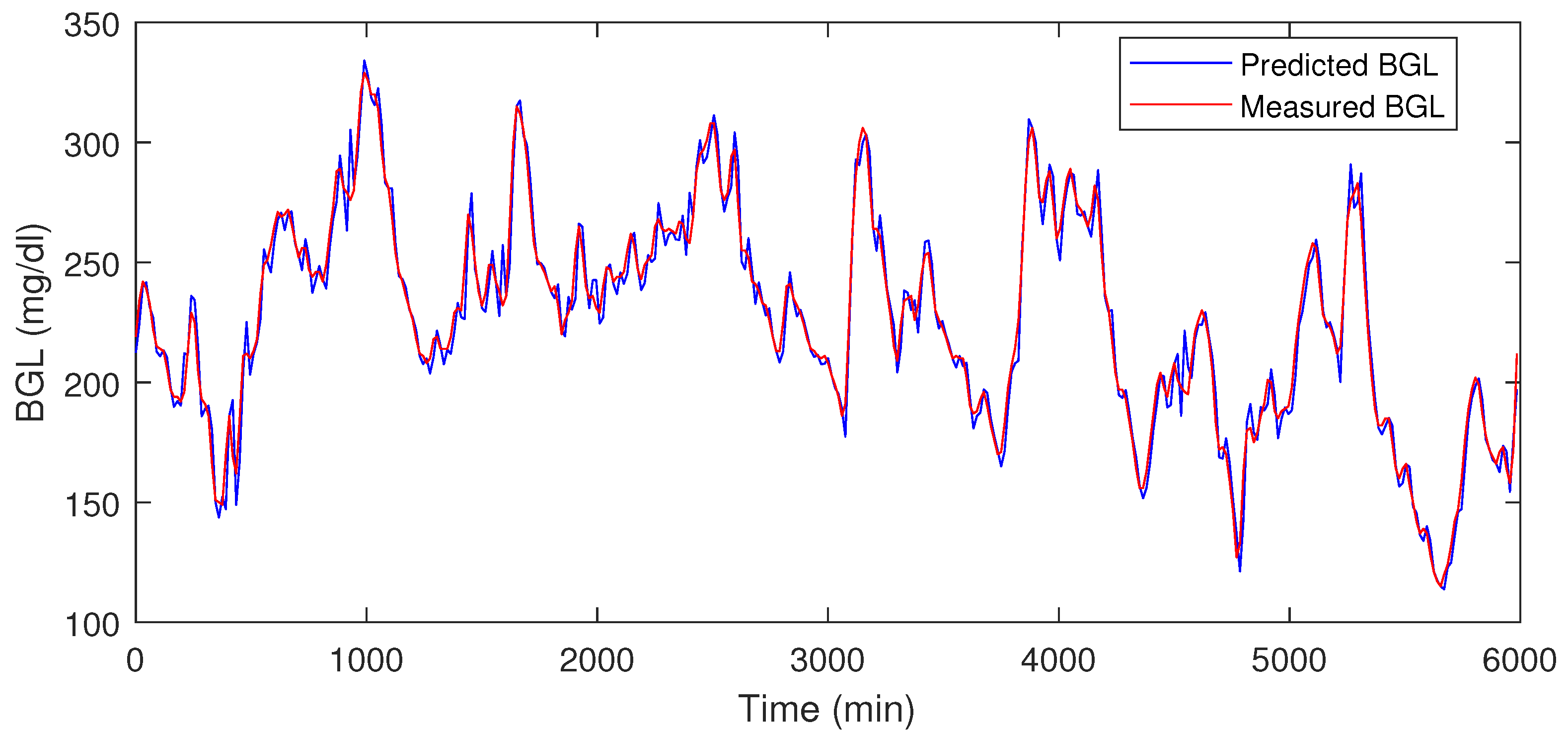
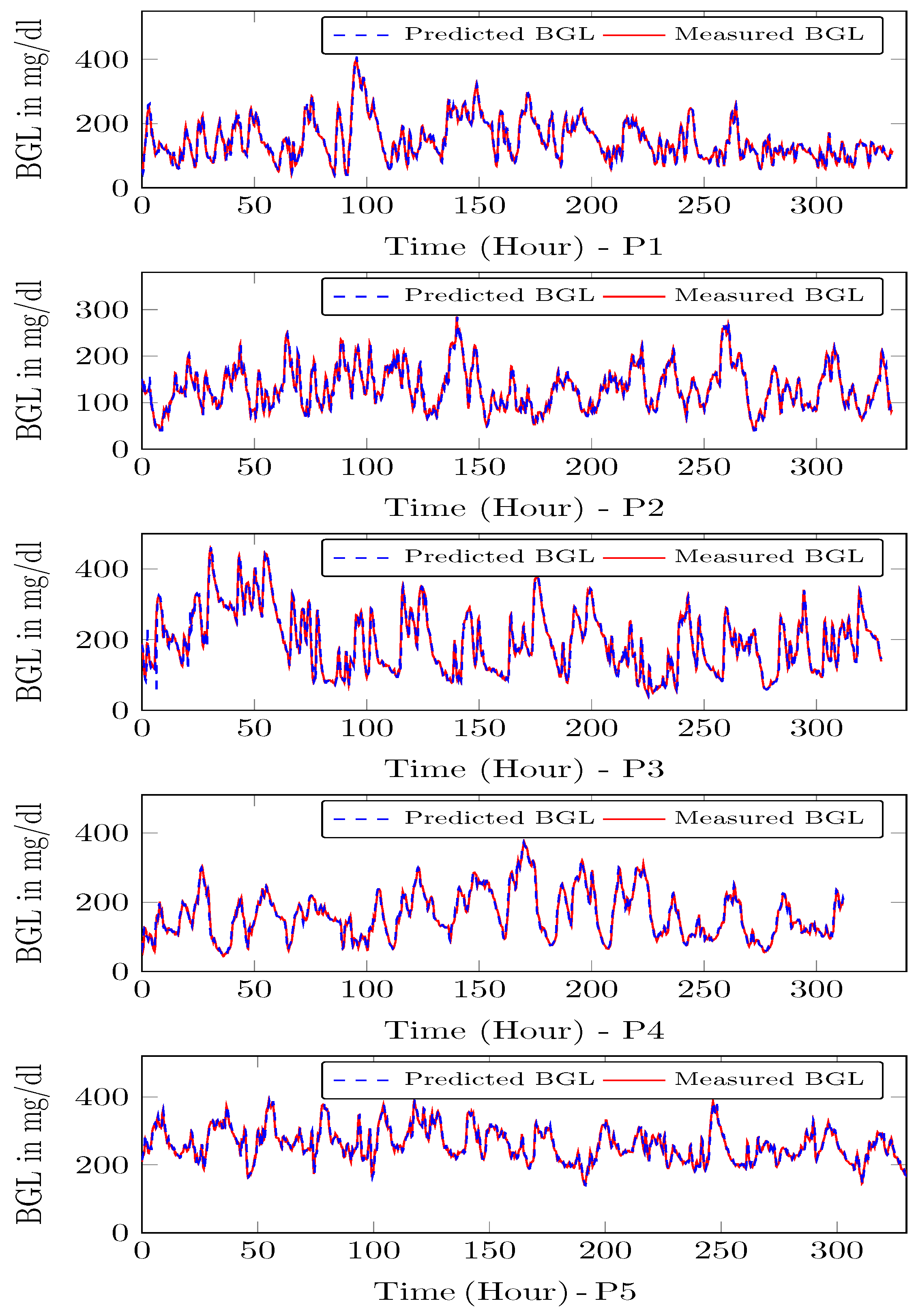
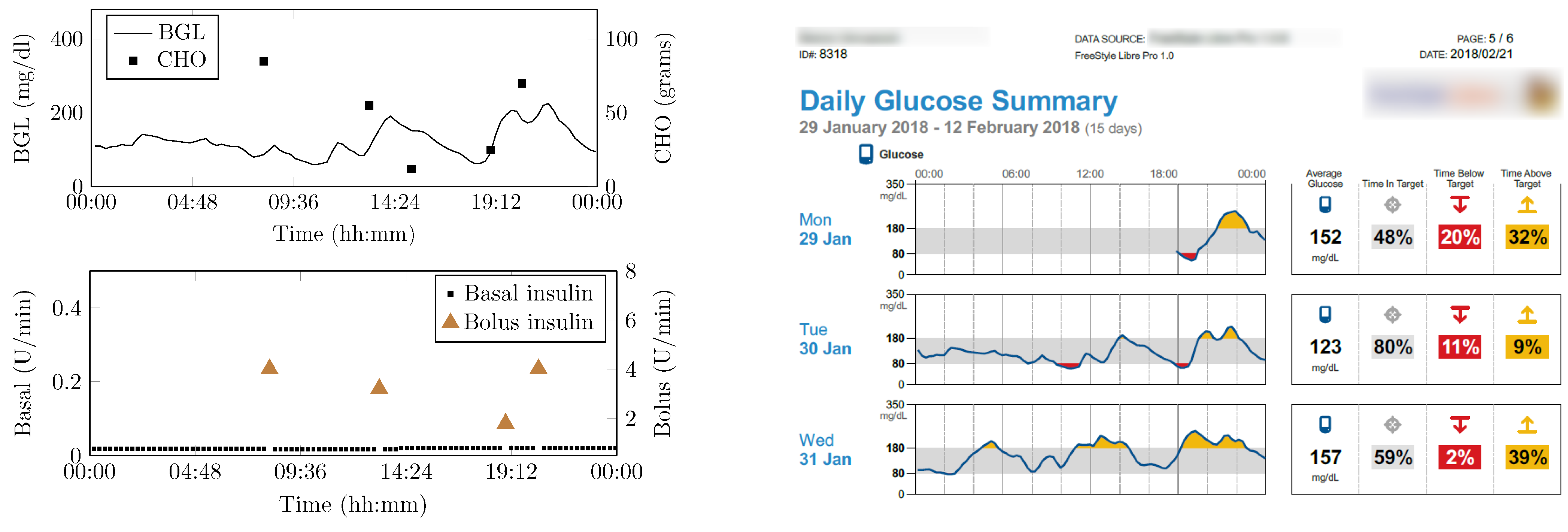
4.4. Prediction Module Data Analysis
4.5. HDT Diagnostic Module Results
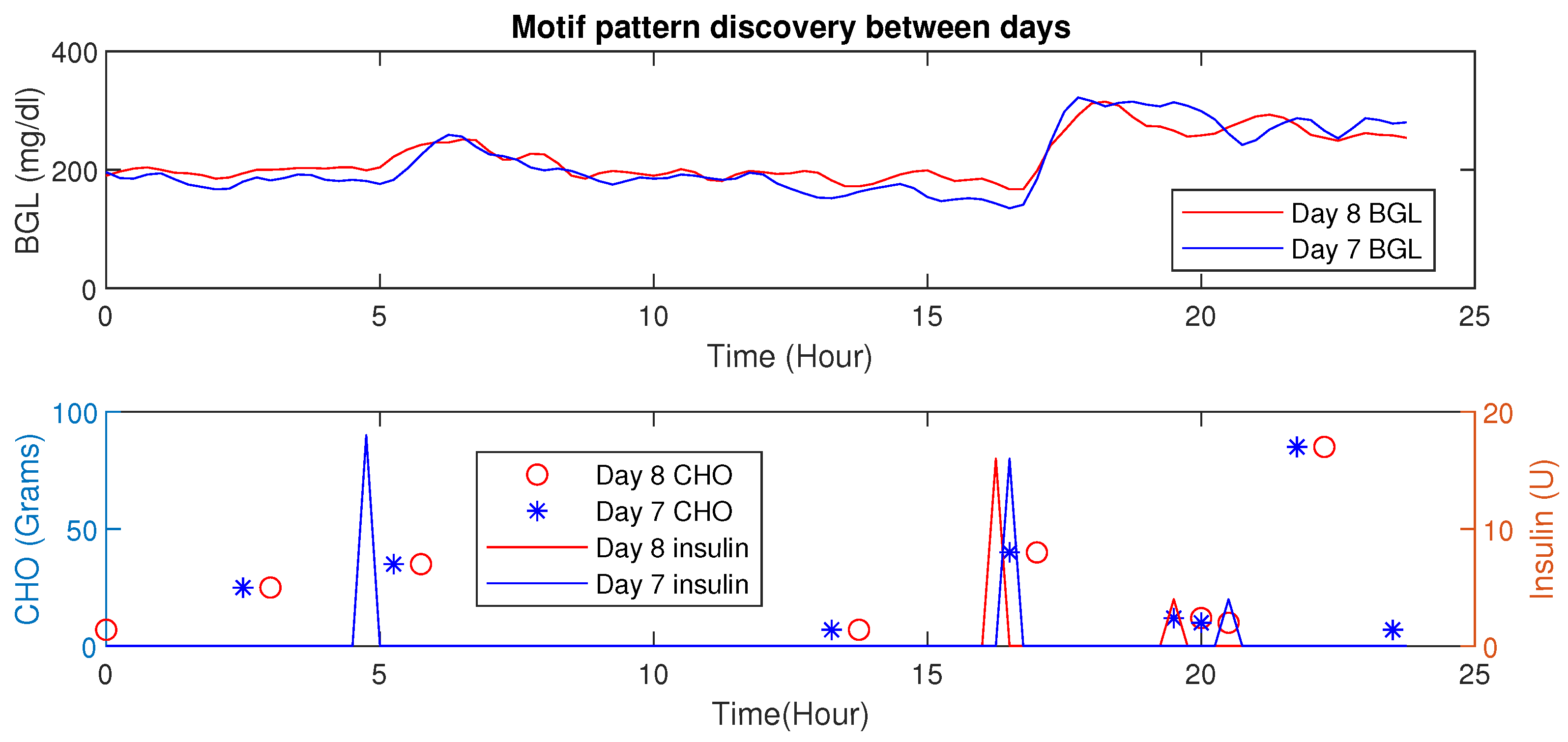
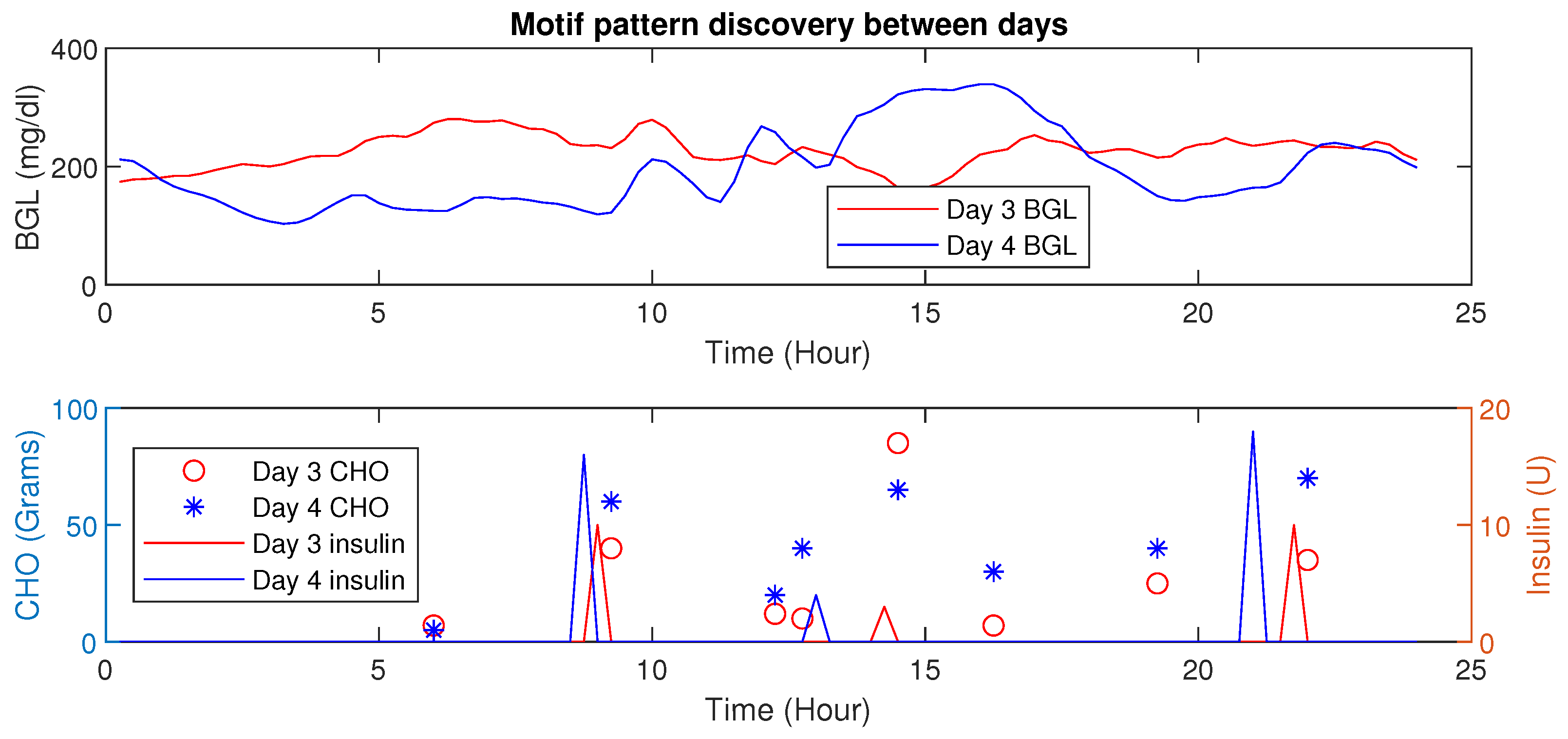
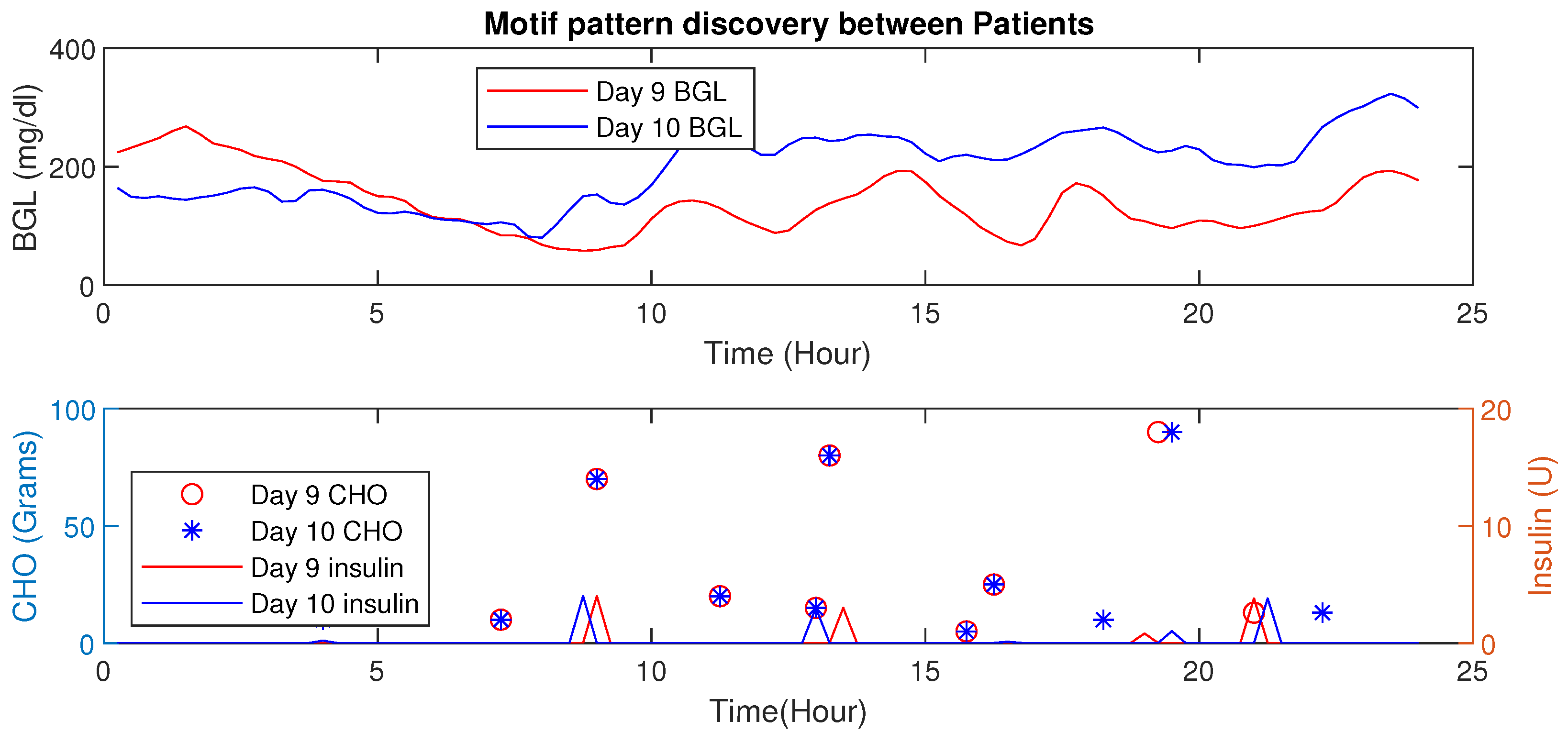
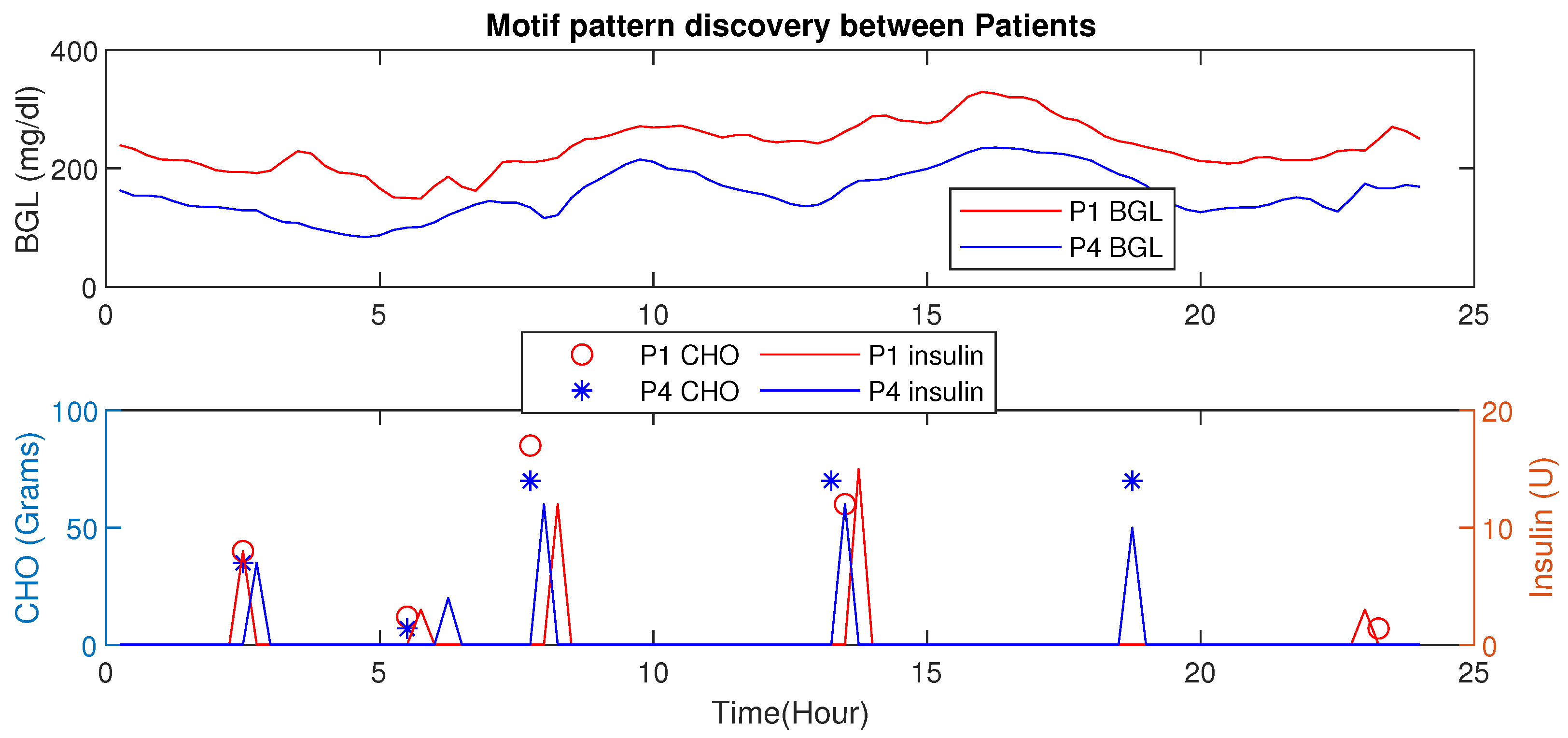
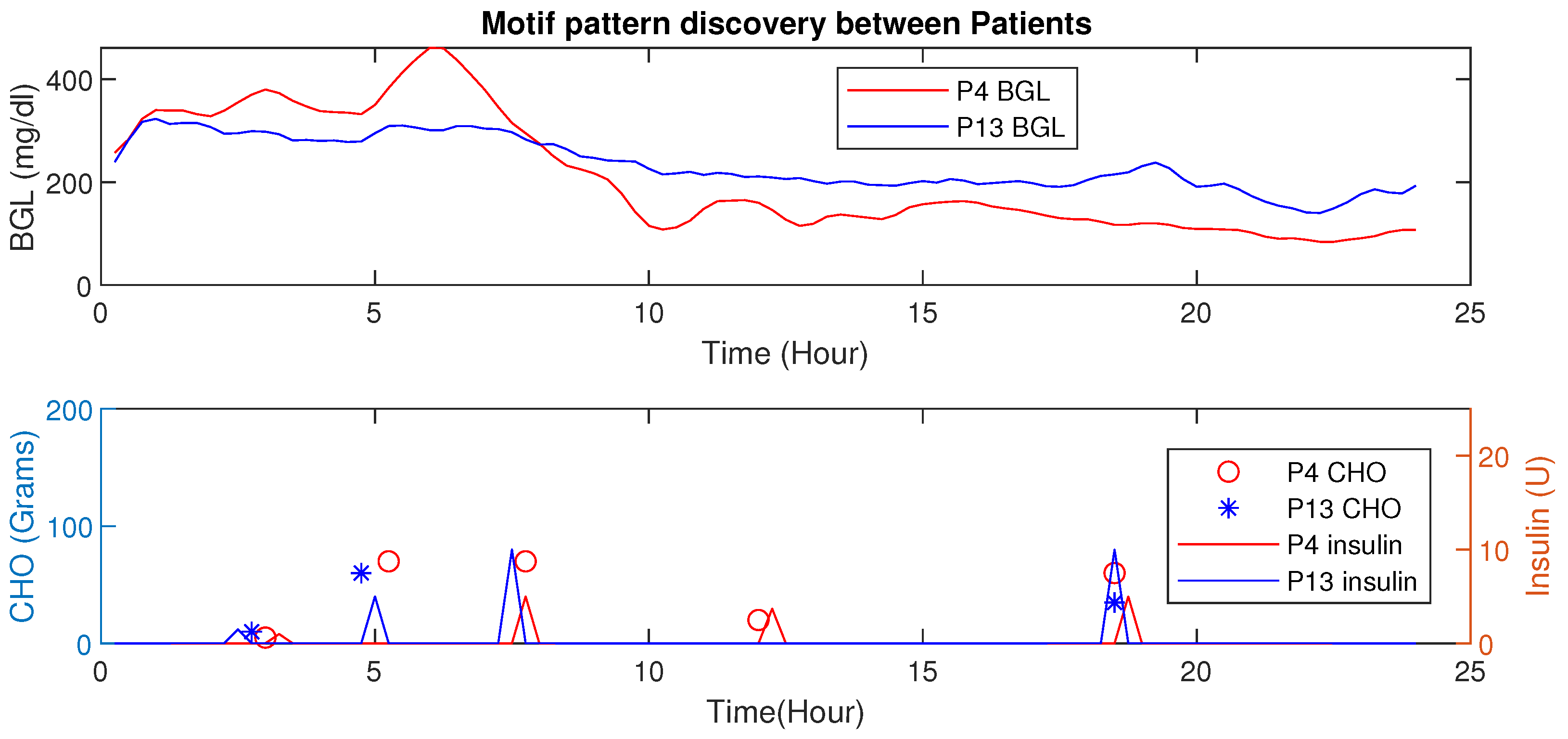
Motif Detection for Interpersonal Variations Detection
4.6. Motif Based Intra-Personal Variations Detection
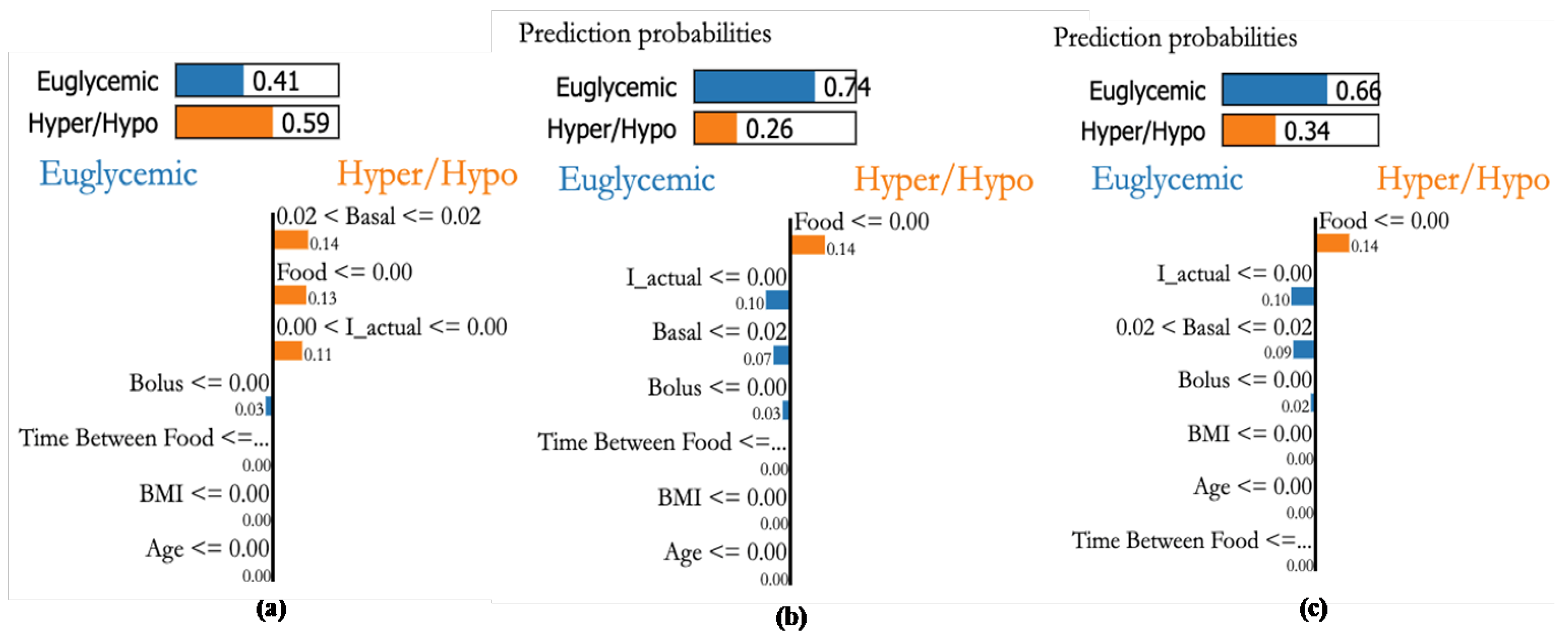
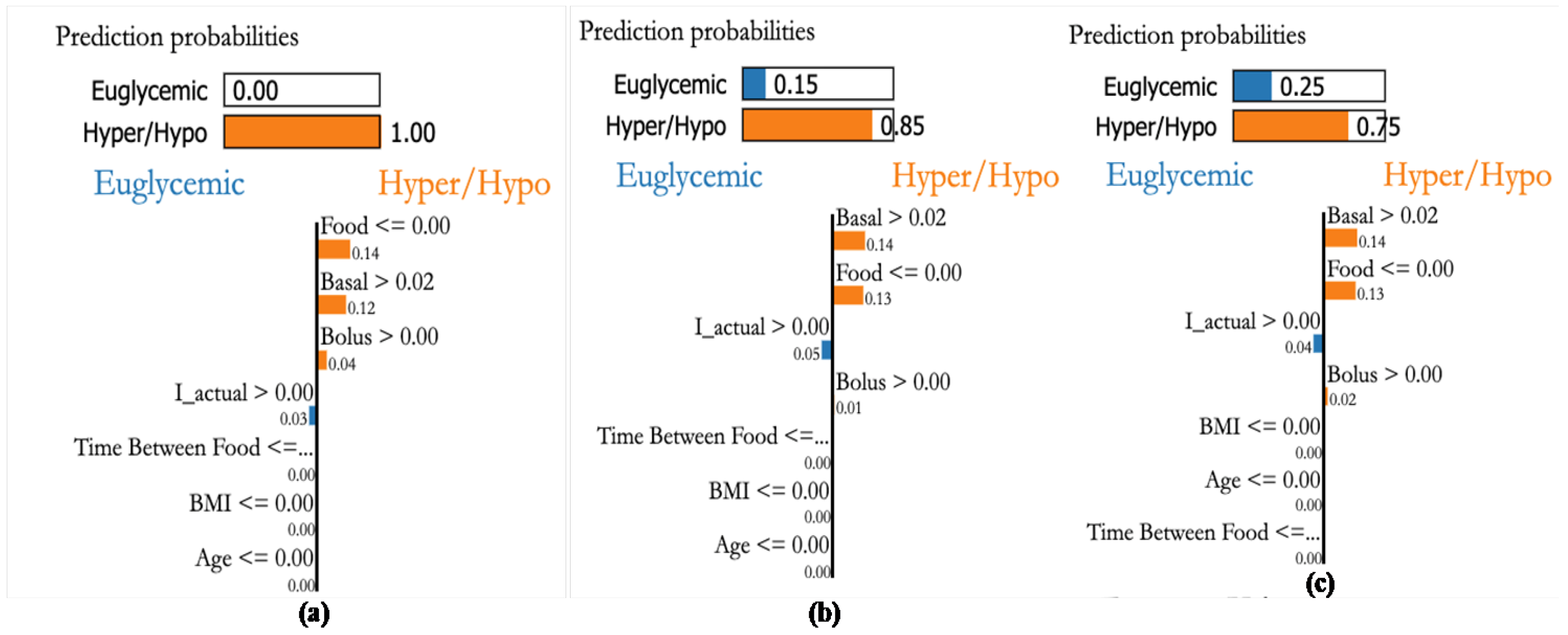
4.7. Personalization Module with XAI
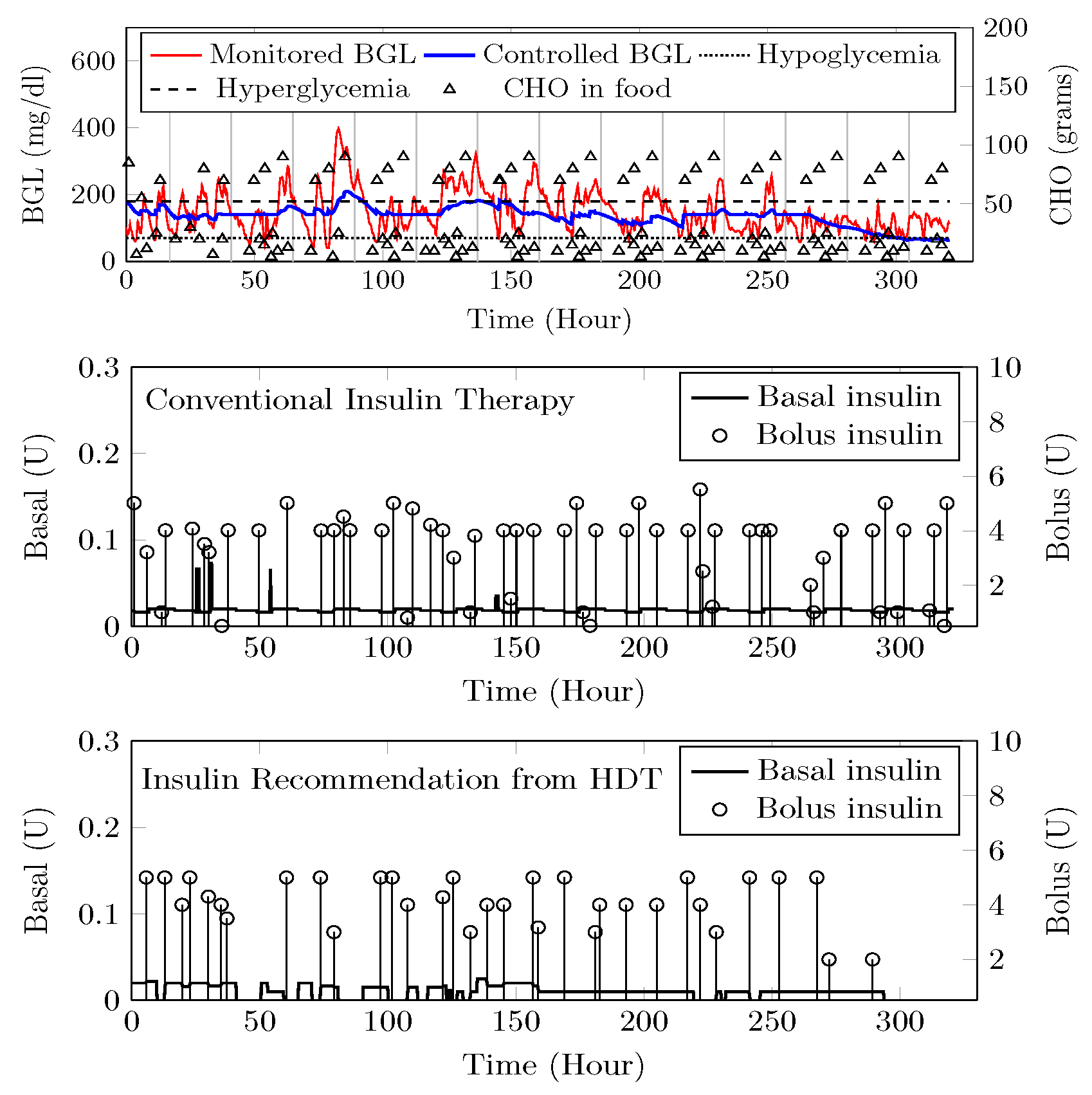
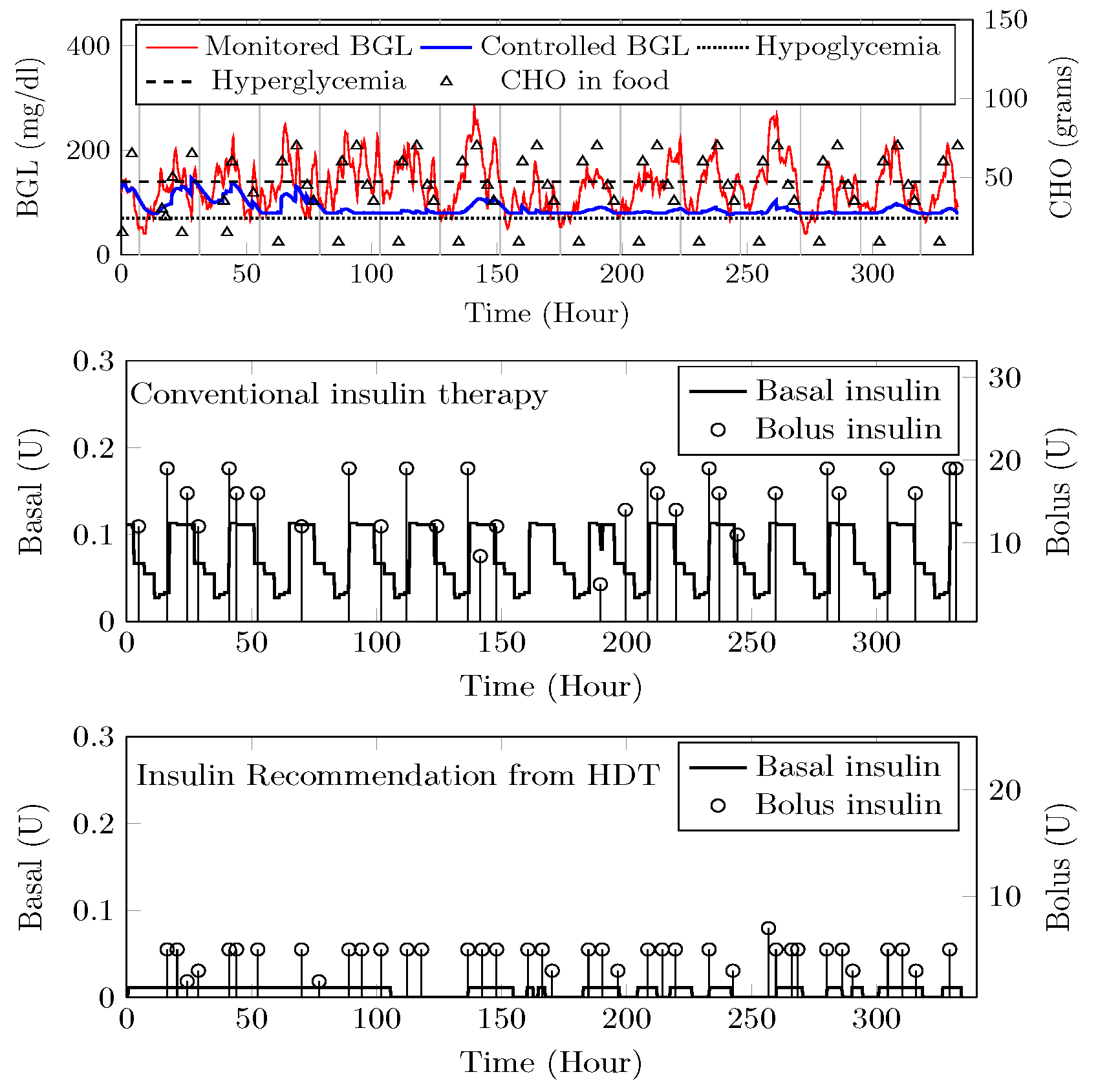
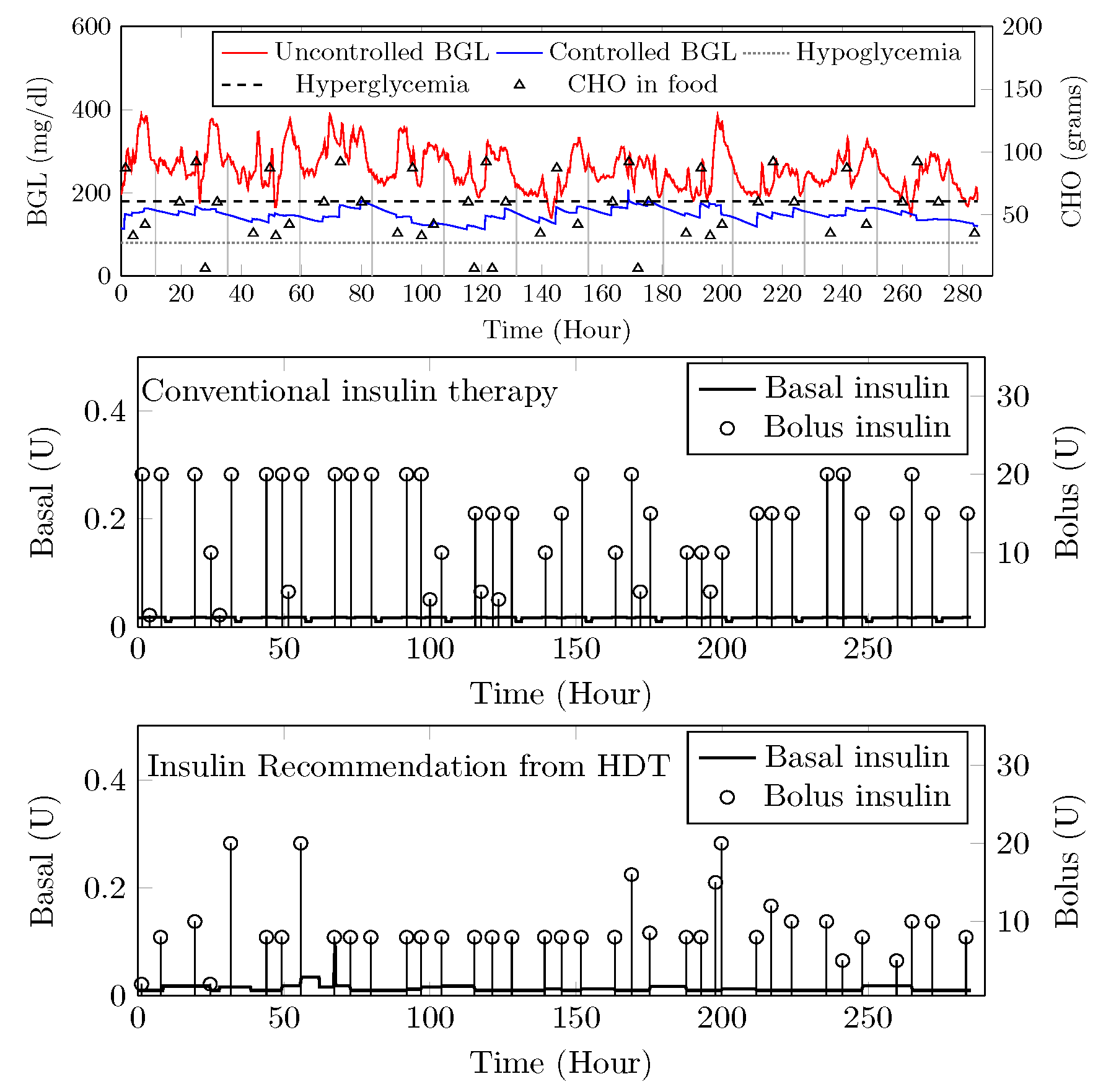
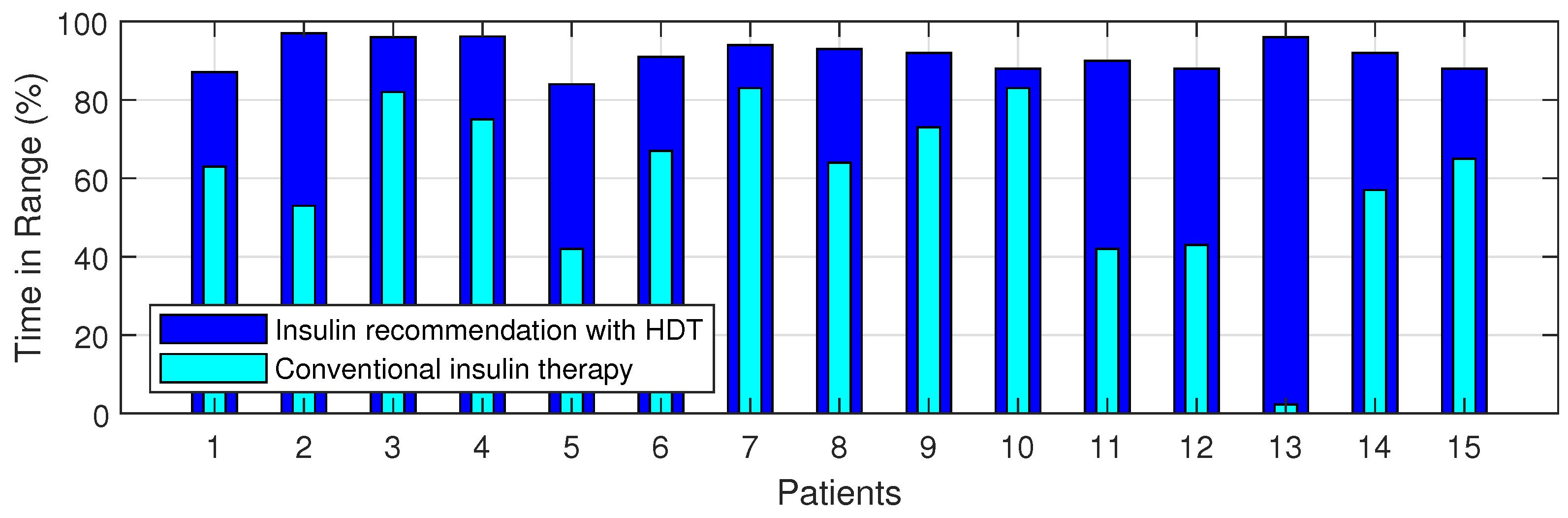
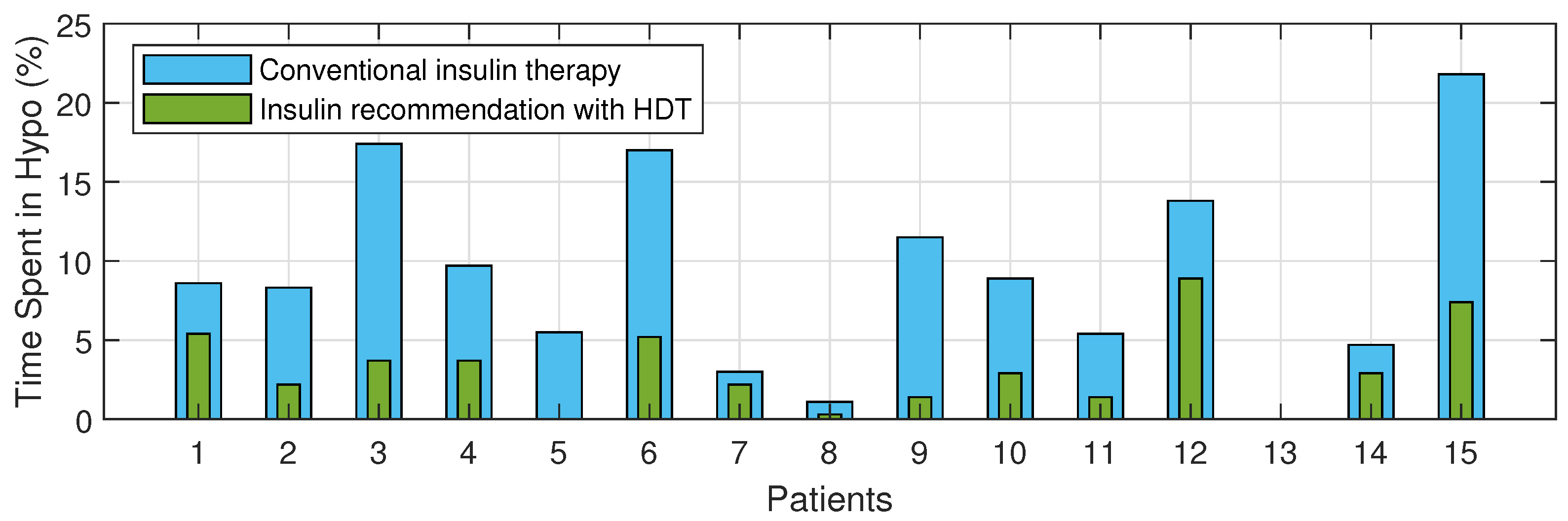
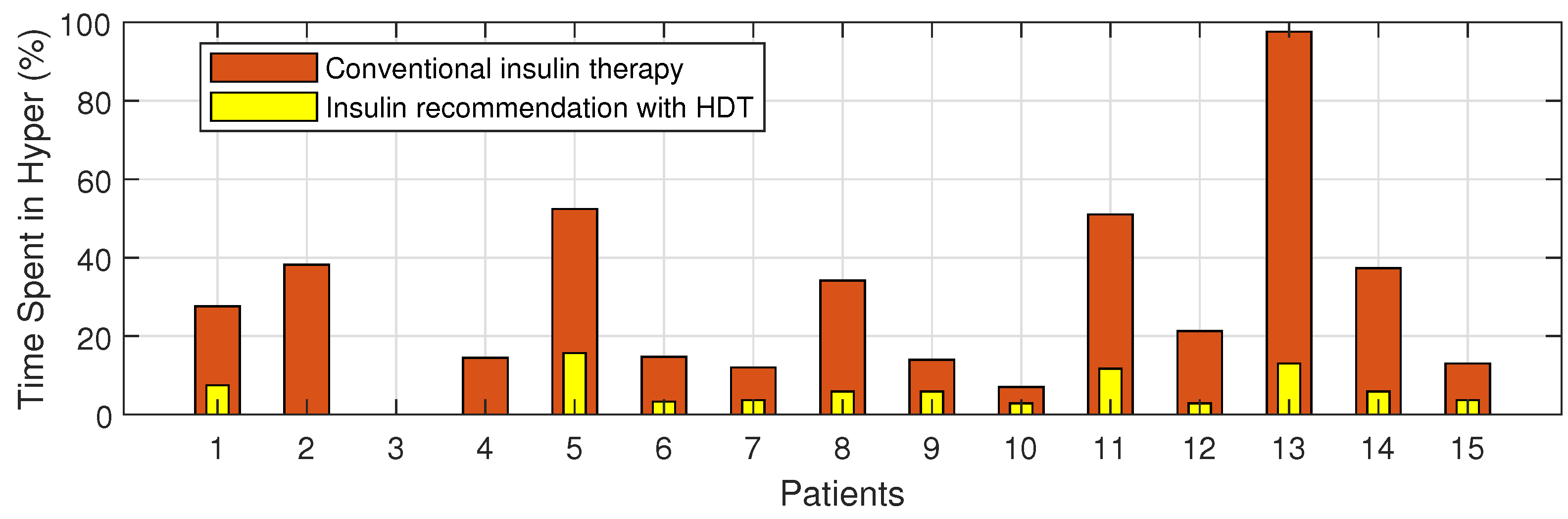
4.8. BGL Management through Precision Insulin Infusion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Software Implementation
References
- Cole, J.B.; Florez, J.C. Genetics of diabetes mellitus and diabetes complications. Nat. Rev. Nephrol. 2020, 16, 377–390. [Google Scholar] [CrossRef]
- Ferlita, S.; Yegiazaryan, A.; Noori, N.; Lal, G.; Nguyen, T.; To, K.; Venketaraman, V. Type 2 diabetes mellitus and altered immune system leading to susceptibility to pathogens, especially Mycobacterium tuberculosis. J. Clin. Med. 2019, 8, 2219. [Google Scholar] [CrossRef]
- Triposkiadis, F.; Xanthopoulos, A.; Bargiota, A.; Kitai, T.; Katsiki, N.; Farmakis, D.; Skoularigis, J.; Starling, R.C.; Iliodromitis, E. Diabetes mellitus and heart failure. J. Clin. Med. 2021, 10, 3682. [Google Scholar] [CrossRef]
- Bellary, S.; Kyrou, I.; Brown, J.E.; Bailey, C.J. Type 2 diabetes mellitus in older adults: Clinical considerations and management. Nat. Rev. Endocrinol. 2021, 17, 534–548. [Google Scholar] [CrossRef]
- McAdams, B.H.; Rizvi, A.A. An overview of insulin pumps and glucose sensors for the generalist. J. Clin. Med. 2016, 5, 5. [Google Scholar] [CrossRef]
- León-Vargas, F.; Arango Oviedo, J.A.; Luna Wandurraga, H.J. Two Decades of Research in Artificial Pancreas: Insights from a Bibliometric Analysis. J. Diabetes Sci. Technol. 2022, 16, 434–445. [Google Scholar] [CrossRef]
- Alshalalfah, A.L.; Hamad, G.B.; Mohamed, O.A. Towards safe and robust closed-loop artificial pancreas using improved PID-based control strategies. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 3147–3157. [Google Scholar] [CrossRef]
- Pintaudi, B.; Gironi, I.; Nicosia, R.; Meneghini, E.; Disoteo, O.; Mion, E.; Bertuzzi, F. Minimed Medtronic 780G optimizes glucose control in patients with type 1 diabetes mellitus. Nutr. Metab. Cardiovasc. Dis. 2022, 32, 1719–1724. [Google Scholar] [CrossRef]
- Yan, S.R.; Alattas, K.A.; Bakouri, M.; Alanazi, A.K.; Mohammadzadeh, A.; Mobayen, S.; Zhilenkov, A.; Guo, W. Generalized Type-2 Fuzzy Control for Type-I Diabetes: Analytical Robust System. Mathematics 2022, 10, 690. [Google Scholar] [CrossRef]
- Sun, X.; Rashid, M.; Hobbs, N.; Brandt, R.; Askari, M.R.; Cinar, A. Incorporating prior information in adaptive model predictive control for multivariable artificial pancreas systems. J. Diabetes Sci. Technol. 2022, 16, 19–28. [Google Scholar] [CrossRef]
- Esfahani, H.N.; Kordabad, A.B.; Gros, S. Reinforcement learning based on MPC/MHE for unmodeled and partially observable dynamics. In Proceedings of the 2021 American Control Conference (ACC), New Orleans, LA, USA, 25–28 May 2021; pp. 2121–2126. [Google Scholar]
- Keshary, S.; Bekiroglu, K.; Seshadhri, S.; Srinivasan, S.; Thamodharan, P. Multimedia Data-Based Artificial Pancreas for Type 2 Diabetes. IEEE MultiMedia 2022, 29, 18–27. [Google Scholar] [CrossRef]
- Padmapritha, T.; Subathra, B.; Ozyetkin, M.M.; Srinivasan, S.; Bekirogulu, K.; Kesavadev, J.; Krishnan, G.; Sanal, G. Smart artificial pancreas with diet recommender system for elderly diabetes. IFAC-PapersOnLine 2020, 53, 16366–16371. [Google Scholar] [CrossRef]
- Anjana, R.M.; Srinivasan, S.; Sudha, V.; Joshi, S.R.; Saboo, B.; Tandon, N.; Das, A.K.; Jabbar, P.K.; Madhu, S.V.; Gupta, A.; et al. Macronutrient Recommendations for Remission and Prevention of Diabetes in Asian Indians Based on a Data-Driven Optimization Model: The ICMR-INDIAB National Study. Diabetes Care 2022, 45, 2883–2891. [Google Scholar] [CrossRef]
- Cobry, E.C.; Berget, C.; Messer, L.H.; Forlenza, G.P. Review of the Omnipod® 5 automated glucose control system powered by Horizon™ for the treatment of type 1 diabetes. Ther. Deliv. 2020, 11, 507–519. [Google Scholar] [CrossRef]
- Ekhlaspour, L.; Schoelwer, M.J.; Forlenza, G.P.; DeBoer, M.D.; Norlander, L.; Hsu, L.; Kingman, R.; Boranian, E.; Berget, C.; Emory, E.; et al. Safety and performance of the Tandem t: Slim X2 with Control-IQ automated insulin delivery system in toddlers and preschoolers. Diabetes Technol. Ther. 2021, 23, 384–391. [Google Scholar] [CrossRef]
- Williams, D.M.; Jones, H.; Stephens, J.W. Personalized type 2 diabetes management: An update on recent advances and recommendations. Diabetes, Metab. Syndr. Obes. Targets Ther. 2022, 15, 281. [Google Scholar] [CrossRef]
- Pinsker, J.E.; Lee, J.B.; Dassau, E.; Seborg, D.E.; Bradley, P.K.; Gondhalekar, R.; Bevier, W.C.; Huyett, L.; Zisser, H.C.; Doyle, F.J. Randomized crossover comparison of personalized MPC and PID control algorithms for the artificial pancreas. Diabetes Care 2016, 39, 1135–1142. [Google Scholar] [CrossRef]
- Eckstein, M.L.; Weilguni, B.; Tauschmann, M.; Zimmer, R.T.; Aziz, F.; Sourij, H.; Moser, O. Time in range for closed-loop systems versus standard of care during physical exercise in people with type 1 diabetes: A systematic review and meta-analysis. J. Clin. Med. 2021, 10, 2445. [Google Scholar] [CrossRef]
- Renard, E.; Farret, A.; Kropff, J.; Bruttomesso, D.; Messori, M.; Place, J.; Visentin, R.; Calore, R.; Toffanin, C.; Di Palma, F.; et al. Day-and-night closed-loop glucose control in patients with type 1 diabetes under free-living conditions: Results of a single-arm 1-month experience compared with a previously reported feasibility study of evening and night at home. Diabetes Care 2016, 39, 1151–1160. [Google Scholar] [CrossRef]
- Abraham, M.B.; de Bock, M.; Smith, G.J.; Dart, J.; Fairchild, J.M.; King, B.R.; Ambler, G.R.; Cameron, F.J.; McAuley, S.A.; Keech, A.C.; et al. Effect of a hybrid closed-loop system on glycemic and psychosocial outcomes in children and adolescents with type 1 diabetes: A randomized clinical trial. JAMA Pediatr. 2021, 175, 1227–1235. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, K.; Zhang, Y. Digital twin networks: A survey. IEEE Internet Things J. 2021, 8, 13789–13804. [Google Scholar] [CrossRef]
- Grieves, M. Digital twin: Manufacturing excellence through virtual factory replication. 2014. White Pap. 2017, 1, 1–7. [Google Scholar]
- Tao, F.; Zhang, M.; Nee, A.Y.C. Digital Twin Driven Smart Manufacturing; Academic Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Liu, M.; Fang, S.; Dong, H.; Xu, C. Review of digital twin about concepts, technologies, and industrial applications. J. Manuf. Syst. 2021, 58, 346–361. [Google Scholar] [CrossRef]
- Wang, Z.; Gupta, R.; Han, K.; Wang, H.; Ganlath, A.; Ammar, N.; Tiwari, P. Mobility Digital Twin: Concept, Architecture, Case Study, and Future Challenges. IEEE Internet Things J. 2022, 9, 17452–17467. [Google Scholar] [CrossRef]
- Mihai, S.; Yaqoob, M.; Hung, D.V.; Davis, W.; Towakel, P.; Raza, M.; Karamanoglu, M.; Barn, B.; Shetve, D.; Prasad, R.V.; et al. Digital twins: A survey on enabling technologies, challenges, trends and future prospects. IEEE Commun. Surv. Tutor. 2022, 24, 2255–2291. [Google Scholar] [CrossRef]
- Wang, W.; Hu, H.; Zhang, J.; Hu, Z. Digital twin-based framework for green building maintenance system. In Proceedings of the 2020 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 14–17 December 2020; pp. 1301–1305. [Google Scholar]
- Khajavi, S.H.; Motlagh, N.H.; Jaribion, A.; Werner, L.C.; Holmström, J. Digital twin: Vision, benefits, boundaries, and creation for buildings. IEEE Access 2019, 7, 147406–147419. [Google Scholar] [CrossRef]
- Fahim, M.; Sharma, V.; Cao, T.V.; Canberk, B.; Duong, T.Q. Machine learning-based digital twin for predictive modeling in wind turbines. IEEE Access 2022, 10, 14184–14194. [Google Scholar] [CrossRef]
- Li, Y.; Shen, X. A Novel Wind Speed-Sensing Methodology for Wind Turbines Based on Digital Twin Technology. IEEE Trans. Instrum. Meas. 2021, 71, 1–13. [Google Scholar] [CrossRef]
- Han, J.; Hong, Q.; Syed, M.H.; Khan, M.A.U.; Yang, G.; Burt, G.; Booth, C. Cloud-edge hosted digital twins for coordinated control of distributed energy resources. IEEE Trans. Cloud Comput. 2022, 1–15. [Google Scholar] [CrossRef]
- Appl, C.; Moser, A.; Baganz, F.; Hass, V.C. Digital Twins for bioprocess control strategy development and realisation. In Digital Twins; Springer: Berlin/Heidelberg, Germany, 2020; pp. 63–94. [Google Scholar]
- Scheper, T.; Beutel, S.; McGuinness, N.; Heiden, S.; Oldiges, M.; Lammers, F.; Reardon, K.F. Digitalization and bioprocessing: Promises and challenges. In Digital Twins; Springer: Berlin/Heidelberg, Germany, 2020; pp. 57–69. [Google Scholar]
- Zhou, H.; Yang, C.; Sun, Y. A Collaborative Optimization Strategy for Energy Reduction in Ironmaking Digital Twin. IEEE Access 2020, 8, 177570–177579. [Google Scholar] [CrossRef]
- Wanasinghe, T.R.; Wroblewski, L.; Petersen, B.K.; Gosine, R.G.; James, L.A.; De Silva, O.; Mann, G.K.; Warrian, P.J. Digital twin for the oil and gas industry: Overview, research trends, opportunities, and challenges. IEEE Access 2020, 8, 104175–104197. [Google Scholar] [CrossRef]
- Bhatti, G.; Mohan, H.; Singh, R.R. Towards the future of smart electric vehicles: Digital twin technology. Renew. Sustain. Energy Rev. 2021, 141, 110801. [Google Scholar] [CrossRef]
- Ibrahim, M.; Rassõlkin, A.; Vaimann, T.; Kallaste, A. Overview on Digital Twin for Autonomous Electrical Vehicles Propulsion Drive System. Sustainability 2022, 14, 601. [Google Scholar] [CrossRef]
- Hu, Z.; Lou, S.; Xing, Y.; Wang, X.; Cao, D.; Lv, C. Review and perspectives on driver digital twin and its enabling technologies for intelligent vehicles. IEEE Trans. Intell. Veh. 2022, 7, 417–440. [Google Scholar] [CrossRef]
- Sousa, B.; Arieiro, M.; Pereira, V.; Correia, J.; Lourenço, N.; Cruz, T. Elegant: Security of critical infrastructures with digital twins. IEEE Access 2021, 9, 107574–107588. [Google Scholar] [CrossRef]
- Broo, D.G.; Bravo-Haro, M.; Schooling, J. Design and implementation of a smart infrastructure digital twin. Autom. Constr. 2022, 136, 104171. [Google Scholar] [CrossRef]
- Alcaraz, C.; Lopez, J. Digital Twin: A Comprehensive Survey of Security Threats. IEEE Commun. Surv. Tutorials 2022, 24, 1475–1503. [Google Scholar] [CrossRef]
- Alazab, M.; Khan, L.U.; Koppu, S.; Ramu, S.P.; Iyapparaja, M.; Boobalan, P.; Baker, T.; Maddikunta, P.K.R.; Gadekallu, T.R.; Aljuhani, A. Digital Twins for Healthcare 4.0-Recent Advances, Architecture, and Open Challenges. IEEE Consum. Electron. Mag. 2022, 1–8. [Google Scholar] [CrossRef]
- Rivera, L.F.; Jiménez, M.; Angara, P.; Villegas, N.M.; Tamura, G.; Müller, H.A. Towards continuous monitoring in personalized healthcare through digital twins. In Proceedings of the 29th Annual International Conference on Computer Science and Software Engineering, Toronto, ON, Canada, 4–6 November 2019; pp. 329–335. [Google Scholar]
- Hassani, H.; Huang, X.; MacFeely, S. Impactful Digital Twin in the Healthcare Revolution. Big Data Cogn. Comput. 2022, 6, 83. [Google Scholar] [CrossRef]
- Pesapane, F.; Rotili, A.; Penco, S.; Nicosia, L.; Cassano, E. Digital Twins in Radiology. J. Clin. Med. 2022, 11, 6553. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Zhang, L.; Yang, Y.; Zhou, L.; Ren, L.; Wang, F.; Liu, R.; Pang, Z.; Deen, M.J. A novel cloud-based framework for the elderly healthcare services using digital twin. IEEE Access 2019, 7, 49088–49101. [Google Scholar] [CrossRef]
- Karakra, A.; Fontanili, F.; Lamine, E.; Lamothe, J.; Taweel, A. Pervasive computing integrated discrete event simulation for a hospital digital twin. In Proceedings of the 2018 IEEE/ACS 15th international conference on computer systems and Applications (AICCSA), Aqaba, Jordan, 28 October–1 November 2018; pp. 1–6. [Google Scholar]
- Zarrin, P.S.; Zimmer, R.; Wenger, C.; Masquelier, T. Epileptic seizure detection using a neuromorphic-compatible deep spiking neural network. In Proceedings of the International Work-Conference on Bioinformatics and Biomedical Engineering, Granada, Spain, 6–8 May 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 389–394. [Google Scholar]
- Okegbile, S.D.; Cai, J.; Yi, C.; Niyato, D. Human digital twin for personalized healthcare: Vision, architecture and future directions. IEEE Netw. 2022, 1–7. [Google Scholar] [CrossRef]
- Khanna, N.N.; Maindarkar, M.A.; Viswanathan, V.; Puvvula, A.; Paul, S.; Bhagawati, M.; Ahluwalia, P.; Ruzsa, Z.; Sharma, A.; Kolluri, R.; et al. Cardiovascular/Stroke Risk Stratification in Diabetic Foot Infection Patients Using Deep Learning-Based Artificial Intelligence: An Investigative Study. J. Clin. Med. 2022, 11, 6844. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Rong, W.; Liu, J.; Zhou, D.; Ouyang, Y.; Xiong, Z. LSTM-Based End-to-End Framework for Biomedical Event Extraction. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 17, 2029–2039. [Google Scholar] [CrossRef]
- Thuy, H.T.T.; Anh, D.T.; Chau, V.T.N. Efficient segmentation-based methods for anomaly detection in static and streaming time series under dynamic time warping. J. Intell. Inf. Syst. 2021, 56, 121–146. [Google Scholar] [CrossRef]
- Palatnik de Sousa, I.; Maria Bernardes Rebuzzi Vellasco, M.; Costa da Silva, E. Local interpretable model-agnostic explanations for classification of lymph node metastases. Sensors 2019, 19, 2969. [Google Scholar] [CrossRef] [PubMed]
- Radhakrishnan, N.; Srinivasan, S.; Su, R.; Poolla, K. Learning-based hierarchical distributed HVAC scheduling with operational constraints. IEEE Trans. Control Syst. Technol. 2017, 26, 1892–1900. [Google Scholar] [CrossRef]






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | Prediction Error (%) | Normalized RMSE | Normalized MAE |
|---|---|---|---|
| P1 | 3.06 | 0.69 | 0.49 |
| P2 | 5.12 | 0.96 | 0.89 |
| P3 | 4.51 | 0.79 | 0.64 |
| P4 | 5.02 | 0.92 | 0.85 |
| P5 | 4.92 | 0.89 | 0.79 |
| S. No | Prediction Error Range (mg/dL) | Percentage of Error (%) | RMSE | ||
|---|---|---|---|---|---|
| Min | Max | Min | Max | ||
| P1 | −14.55 | 8.21 | 3.85 | 6.53 | 5.01 |
| P2 | −7.22 | 5.35 | 4.5 | 5.2 | 3.27 |
| P3 | −12.25 | 8.25 | 4.3 | 6.34 | 4.87 |
| P4 | −3.25 | 5.25 | 2.5 | 3.9 | 1.89 |
| P5 | −4.58 | 10.56 | 1.8 | 3.5 | 3.32 |
| S. No | Age | Sex | BMI | Co-Morbidity Conditions | Target BGL Range (mg/dL) | Avg. CHO/day (g) | Life Style | Oral Drugs |
|---|---|---|---|---|---|---|---|---|
| P1 | 63 | M | 24.2 | Hypothyroidism, Dyslipidemia | 80–180 | 240 | Sedentary | Glycomet 250 mg |
| P2 | 60 | F | 23.6 | Hypothyroidism, Dyslipidemia, hypertension (HTN) | 80–150 | 300 | Sedentary | Metadoze-1, Hepsodil-1, Victoza-1, Blisto-1/2 |
| P3 | 36 | F | 32.4 | Dyslipidemia, HTN, kidney transplant | 80–140 | 300 | Sedentary | Trajenta Duo 2.5/500, Metadose IPR |
| P4 | 59 | M | 25.7 | Liver problem | 80–180 | 320 | Active | Glycomet, Metadoze |
| P5 | 63 | M | 27.5 | Dyslipidemia, Heart disease, CKD | 80–180 | 240 | Sedentary | Glycomet, Glimepiride, Aplazar, D-Rise, Metadoze, Carfer, Ril 2.5, Preganerve, Roliptin, Trajenta, Cilnipres |
| P6 | 72 | M | 25.1 | HTN, mild NPDR | 80–180 | 280 | Active | Kombiglyza 5/500, Jardiance-25 mg, Cetapin-500 |
| P7 | 79 | M | 32.1 | CA sigmoid colon, CKD, HTN | 80–150 | 220 | Active | Glycomet 300 mg, Metadoze. |
| P8 | 80 | F | 31.9 | CKD, Hypertension | 80–180 | 20 | Sedentary | GP-0.5, Metadoze |
| P9 | 58 | F | 23.1 | Hypothyroidism, Dyslipidemia | 70–180 | 300 | Sedentary | Metadoze-1, Roliptin |
| P10 | 55 | M | 23.2 | Dyslipidemia, CKD | 80–180 | 234 | Sedentary | Metafort 500 mg, victoza injection |
| P11 | 57 | M | 30.1 | Hypothyroidism, Dyslipidemia | 80–180 | 270 | Active | Diafer 250, Jerdiance 100 mg |
| P12 | 66 | F | 30.8 | Hypothyroidism, Dyslipidemia | 80–140 | 300 | Active | Metafort 1000 mg, Gride 1 mg, Victoza injection |
| P13 | 70 | F | 24.7 | HTN, Coronary artery bypass graft surgery (CABG) | 90–180 | 280 | Sedentary | T-Semi-Amaryl 0.5, PPG Met 0.2 |
| P14 | 65 | F | 34.5 | Dyslipidemia, HTN, Anemia, CABG | 80–140 | 320 | Sedentary | Diafer 250 |
| P15 | 62 | F | 29.1 | CKD, HTN | 90–180 | 250 | Sedentary | T-semi-Armyl 0.5 mg |
| S. No | Days Compared | Euclidean Distance |
|---|---|---|
| 1 | Day 1 & 2 | 3.88 |
| 2 | Day 3 & 4 | 6.15 |
| 3 | Day 5 & 6 | 5.55 |
| 4 | Day 7 & 8 | 2.01 |
| 5 | Day 9 & 10 | 5.31 |
| 6 | Day 11 & 12 | 6.27 |
| S. No | HDT Based PM | Conventional Insulin Therapy | ||||
|---|---|---|---|---|---|---|
| TIR (%) | Time Spent in Hypo (%) | Time Spent in Hyper (%) | TIR (%) | Time Spent in Hypo (%) | Time Spent in Hyper (%) | |
| P1 | 87.1 | 5.4 | 7.5 | 63 | 8.6 | 27.6 |
| P2 | 97 | 0 | 2.2 | 53 | 8.32 | 38.2 |
| P3 | 96 | 3.7 | 0 | 82 | 17.4 | 0 |
| P4 | 96.2 | 3.7 | 0 | 75 | 9.7 | 14.5 |
| P5 | 84 | 0 | 15.7 | 42 | 5.5 | 52.4 |
| P6 | 91 | 5.2 | 3.3 | 67 | 17 | 14.7 |
| P7 | 94 | 2.2 | 3.7 | 83 | 3 | 12 |
| P8 | 93 | 0.3 | 5.9 | 64 | 1.1 | 34.2 |
| P9 | 92 | 1.4 | 5.9 | 73 | 11.5 | 14 |
| P10 | 88 | 2.9 | 2.9 | 83 | 8.9 | 7 |
| P11 | 90 | 1.4 | 11.7 | 42 | 5.4 | 51 |
| P12 | 88 | 8.9 | 2.9 | 43 | 13.8 | 21.3 |
| P13 | 87 | 0 | 13 | 2.3 | 0 | 97.6 |
| P14 | 92 | 2.9 | 5.9 | 57 | 4.7 | 37.3 |
| P15 | 88 | 7.4 | 3.7 | 65 | 21.8 | 13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thamotharan, P.; Srinivasan, S.; Kesavadev, J.; Krishnan, G.; Mohan, V.; Seshadhri, S.; Bekiroglu, K.; Toffanin, C. Human Digital Twin for Personalized Elderly Type 2 Diabetes Management. J. Clin. Med. 2023, 12, 2094. https://doi.org/10.3390/jcm12062094
Thamotharan P, Srinivasan S, Kesavadev J, Krishnan G, Mohan V, Seshadhri S, Bekiroglu K, Toffanin C. Human Digital Twin for Personalized Elderly Type 2 Diabetes Management. Journal of Clinical Medicine. 2023; 12(6):2094. https://doi.org/10.3390/jcm12062094
Chicago/Turabian StyleThamotharan, Padmapritha, Seshadhri Srinivasan, Jothydev Kesavadev, Gopika Krishnan, Viswanathan Mohan, Subathra Seshadhri, Korkut Bekiroglu, and Chiara Toffanin. 2023. "Human Digital Twin for Personalized Elderly Type 2 Diabetes Management" Journal of Clinical Medicine 12, no. 6: 2094. https://doi.org/10.3390/jcm12062094
APA StyleThamotharan, P., Srinivasan, S., Kesavadev, J., Krishnan, G., Mohan, V., Seshadhri, S., Bekiroglu, K., & Toffanin, C. (2023). Human Digital Twin for Personalized Elderly Type 2 Diabetes Management. Journal of Clinical Medicine, 12(6), 2094. https://doi.org/10.3390/jcm12062094