
Inter-Rater Agreement in Assessing Risk of Bias in Melanoma Prediction Studies Using the Prediction Model Risk of Bias Assessment Tool (PROBAST): Results from a Controlled Experiment on the Effect of Specific Rater Training

 , , ,
, , ,  , , , and
, , , and
Abstract
1. Introduction
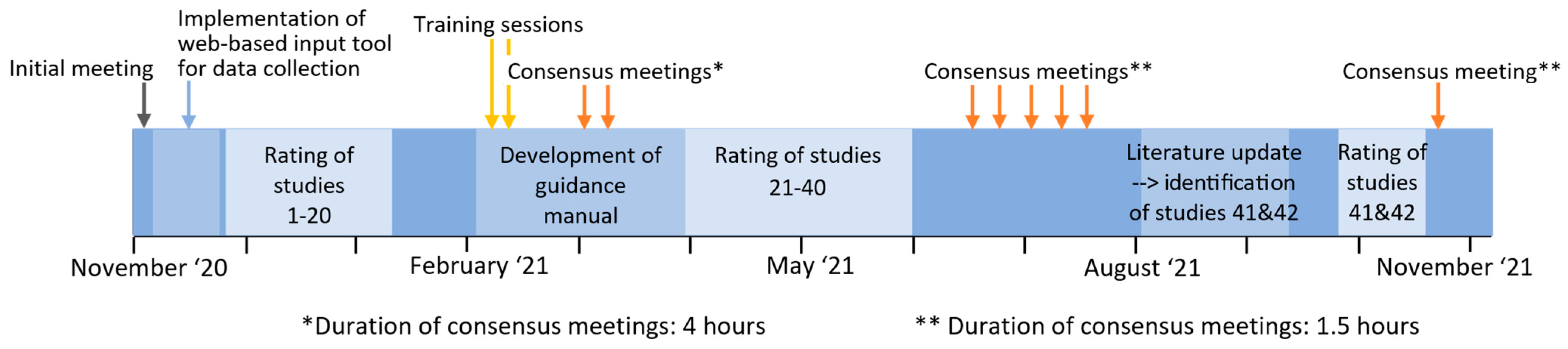
2. Materials and Methods
2.1. Study Selection
2.2. ROB Assessment Using PROBAST
2.3. Rating Process and Training
2.4. Statistical Analysis
3. Results
3.1. Study Characteristics
3.2. Multi-Rater Agreement
3.3. Pairwise Agreement
3.4. Comparison of Raw Agreement, Gwet’s AC1 and Cohen’s κ for Mean Pairwise Agreement
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Use of Gwet’s AC1 as Measure for Inter-Rater Reliability
References
- Sackett, D.L. Bias in analytic research. J. Chronic Dis. 1979, 32, 51–63. [Google Scholar] [CrossRef] [PubMed]
- Moons, K.G.M.; Wolff, R.F.; Riley, R.D.; Whiting, P.F.; Westwood, M.; Collins, G.S.; Reitsma, J.B.; Kleijnen, J.; Mallett, S. PROBAST: A Tool to Assess Risk of Bias and Applicability of Prediction Model Studies: Explanation and Elaboration. Ann. Intern. Med. 2019, 170, W1–W33. [Google Scholar] [CrossRef] [PubMed]
- The Cochrane Collaboration. Cochrane Handbook for Systematic Reviews of Interventions; Version 6.2; Cochrane: London, UK, 2021. [Google Scholar]
- Jeyaraman, M.M.; Al-Yousif, N.; Robson, R.C.; Copstein, L.; Balijepalli, C.; Hofer, K.; Fazeli, M.S.; Ansari, M.T.; Tricco, A.C.; Rabbani, R.; et al. Inter-rater reliability and validity of risk of bias instrument for non-randomized studies of exposures: A study protocol. Syst. Rev. 2020, 9, 32. [Google Scholar] [CrossRef] [PubMed]
- Bohlin, I. Formalizing Syntheses of Medical Knowledge: The Rise of Meta-Analysis and Systematic Reviews. Perspect. Sci. 2012, 20, 273–309. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. J. Clin. Epidemiol. 2021, 134, 178–189. [Google Scholar] [CrossRef]
- Ma, L.L.; Wang, Y.Y.; Yang, Z.H.; Huang, D.; Weng, H.; Zeng, X.T. Methodological quality (risk of bias) assessment tools for primary and secondary medical studies: What are they and which is better? Mil. Med. Res. 2020, 7, 7. [Google Scholar] [CrossRef]
- Wang, Z.T.K.; Allman-Farinelli, M.; Armstrong, B.; Askie, L.; Ghersi, D.; McKenzie, J.; Norris, S.; Page, M.; Rooney, A.; Woodruff, T.; et al. A Systematic Review: Tools for Assessing Methodological Quality of Human Observational Studies; National Health and Medical Research Council: Canberra, Australia, 2019.
- Sterne, J.A.C.; Savovic, J.; Page, M.J.; Elbers, R.G.; Blencowe, N.S.; Boutron, I.; Cates, C.J.; Cheng, H.Y.; Corbett, M.S.; Eldridge, S.M.; et al. RoB 2: A revised tool for assessing risk of bias in randomised trials. BMJ 2019, 366, l4898. [Google Scholar] [CrossRef]
- Whiting, P.; Savovic, J.; Higgins, J.P.; Caldwell, D.M.; Reeves, B.C.; Shea, B.; Davies, P.; Kleijnen, J.; Churchill, R.; The Robis Group. ROBIS: A new tool to assess risk of bias in systematic reviews was developed. J. Clin. Epidemiol. 2016, 69, 225–234. [Google Scholar] [CrossRef]
- Wolff, R.F.; Moons, K.G.M.; Riley, R.D.; Whiting, P.F.; Westwood, M.; Collins, G.S.; Reitsma, J.B.; Kleijnen, J.; Mallett, S.; Groupdagger, P. PROBAST: A Tool to Assess the Risk of Bias and Applicability of Prediction Model Studies. Ann. Intern. Med. 2019, 170, 51–58. [Google Scholar] [CrossRef]
- PROBAST. Available online: https://www.probast.org/ (accessed on 22 October 2022).
- de Jong, Y.; Ramspek, C.L.; Zoccali, C.; Jager, K.J.; Dekker, F.W.; van Diepen, M. Appraising prediction research: A guide and meta-review on bias and applicability assessment using the Prediction model Risk Of Bias ASsessment Tool (PROBAST). Nephrology 2021, 26, 939–947. [Google Scholar] [CrossRef]
- da Costa, B.R.; Beckett, B.; Diaz, A.; Resta, N.M.; Johnston, B.C.; Egger, M.; Juni, P.; Armijo-Olivo, S. Effect of standardized training on the reliability of the Cochrane risk of bias assessment tool: A prospective study. Syst. Rev. 2017, 6, 44. [Google Scholar] [CrossRef] [PubMed]
- Gates, M.; Gates, A.; Duarte, G.; Cary, M.; Becker, M.; Prediger, B.; Vandermeer, B.; Fernandes, R.M.; Pieper, D.; Hartling, L. Quality and risk of bias appraisals of systematic reviews are inconsistent across reviewers and centers. J. Clin. Epidemiol. 2020, 125, 9–15. [Google Scholar] [CrossRef] [PubMed]
- Minozzi, S.; Cinquini, M.; Gianola, S.; Castellini, G.; Gerardi, C.; Banzi, R. Risk of bias in nonrandomized studies of interventions showed low inter-rater reliability and challenges in its application. J. Clin. Epidemiol. 2019, 112, 28–35. [Google Scholar] [CrossRef] [PubMed]
- Minozzi, S.; Cinquini, M.; Gianola, S.; Gonzalez-Lorenzo, M.; Banzi, R. The revised Cochrane risk of bias tool for randomized trials (RoB 2) showed low interrater reliability and challenges in its application. J. Clin. Epidemiol. 2020, 126, 37–44. [Google Scholar] [CrossRef]
- Kim, S.Y.; Park, J.E.; Lee, Y.J.; Seo, H.J.; Sheen, S.S.; Hahn, S.; Jang, B.H.; Son, H.J. Testing a tool for assessing the risk of bias for nonrandomized studies showed moderate reliability and promising validity. J. Clin. Epidemiol. 2013, 66, 408–414. [Google Scholar] [CrossRef]
- Hartling, L.; Hamm, M.; Milne, A.; Vandermeer, B.; Santaguida, P.L.; Ansari, M.; Tsertsvadze, A.; Hempel, S.; Shekelle, P.; Dryden, D.M. Validity and Inter-Rater Reliability Testing of Quality Assessment Instruments; Agency for Healthcare Research and Quality: Rockville, MD, USA, 2012.
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Kaiser, I.; Pfahlberg, A.B.; Uter, W.; Heppt, M.V.; Veierod, M.B.; Gefeller, O. Risk Prediction Models for Melanoma: A Systematic Review on the Heterogeneity in Model Development and Validation. Int. J. Environ. Res. Public Health 2020, 17, 7919. [Google Scholar] [CrossRef]
- Usher-Smith, J.A.; Emery, J.; Kassianos, A.P.; Walter, F.M. Risk prediction models for melanoma: A systematic review. Cancer Epidemiol. Biomark. Prev. 2014, 23, 1450–1463. [Google Scholar] [CrossRef]
- Vuong, K.; McGeechan, K.; Armstrong, B.K.; Cust, A.E. Risk prediction models for incident primary cutaneous melanoma: A systematic review. JAMA Derm. 2014, 150, 434–444. [Google Scholar] [CrossRef]
- Kaiser, I.; Mathes, S.; Pfahlberg, A.B.; Uter, W.; Berking, C.; Heppt, M.V.; Steeb, T.; Diehl, K.; Gefeller, O. Using the Prediction Model Risk of Bias Assessment Tool (PROBAST) to Evaluate Melanoma Prediction Studies. Cancers 2022, 14, 33. [Google Scholar] [CrossRef]
- Gwet, K.L. Computing inter-rater reliability and its variance in the presence of high agreement. Br. J. Math. Stat. Psychol. 2008, 61, 29–48. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J.F. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Conger, A.J. Integration and Generalization of Kappas for Multiple Raters. Psychol. Bull. 1980, 88, 322–328. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Efron, B. Better Bootstrap Confidence-Intervals. J. Am. Stat. Assoc. 1987, 82, 171–185. [Google Scholar] [CrossRef]
- R Development Core Team R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022.
- Augustsson, A. Melanocytic naevi, melanoma and sun exposure. Acta Derm. Venereol. Suppl. 1991, 166, 1–34. [Google Scholar]
- Bakos, L.; Mastroeni, S.; Bonamigo, R.R.; Melchi, F.; Pasquini, P.; Fortes, C. A melanoma risk score in a Brazilian population. Bras. Derm. 2013, 88, 226–232. [Google Scholar] [CrossRef]
- Bakshi, A.; Yan, M.; Riaz, M.; Polekhina, G.; Orchard, S.G.; Tiller, J.; Wolfe, R.; Joshi, A.; Cao, Y.; McInerney-Leo, A.M.; et al. Genomic Risk Score for Melanoma in a Prospective Study of Older Individuals. J. Natl. Cancer Inst. 2021, 113, 1379–1385. [Google Scholar] [CrossRef]
- Barbini, P.; Cevenini, G.; Rubegni, P.; Massai, M.R.; Flori, M.L.; Carli, P.; Andreassi, L. Instrumental measurement of skin colour and skin type as risk factors for melanoma: A statistical classification procedure. Melanoma Res. 1998, 8, 439–447. [Google Scholar] [CrossRef]
- Cho, E.; Rosner, B.A.; Feskanich, D.; Colditz, G.A. Risk factors and individual probabilities of melanoma for whites. J. Clin. Oncol. 2005, 23, 2669–2675. [Google Scholar] [CrossRef]
- Cho, H.G.; Ransohoff, K.J.; Yang, L.; Hedlin, H.; Assimes, T.; Han, J.; Stefanick, M.; Tang, J.Y.; Sarin, K.Y. Melanoma risk prediction using a multilocus genetic risk score in the Women’s Health Initiative cohort. J. Am. Acad. Derm. 2018, 79, 36–41.e10. [Google Scholar] [CrossRef] [PubMed]
- Cust, A.E.; Drummond, M.; Kanetsky, P.A.; Australian Melanoma Family Study, I.; Leeds Case-Control Study, I.; Goldstein, A.M.; Barrett, J.H.; MacGregor, S.; Law, M.H.; Iles, M.M.; et al. Assessing the Incremental Contribution of Common Genomic Variants to Melanoma Risk Prediction in Two Population-Based Studies. J. Investig. Derm. 2018, 138, 2617–2624. [Google Scholar] [CrossRef] [PubMed]
- Cust, A.E.; Goumas, C.; Vuong, K.; Davies, J.R.; Barrett, J.H.; Holland, E.A.; Schmid, H.; Agha-Hamilton, C.; Armstrong, B.K.; Kefford, R.F.; et al. MC1R genotype as a predictor of early-onset melanoma, compared with self-reported and physician-measured traditional risk factors: An Australian case-control-family study. BMC Cancer 2013, 13, 406. [Google Scholar] [CrossRef] [PubMed]
- Davies, J.R.; Chang, Y.M.; Bishop, D.T.; Armstrong, B.K.; Bataille, V.; Bergman, W.; Berwick, M.; Bracci, P.M.; Elwood, J.M.; Ernstoff, M.S.; et al. Development and validation of a melanoma risk score based on pooled data from 16 case-control studies. Cancer Epidemiol. Biomark. Prev. 2015, 24, 817–824. [Google Scholar] [CrossRef] [PubMed]
- Dwyer, T.; Stankovich, J.M.; Blizzard, L.; FitzGerald, L.M.; Dickinson, J.L.; Reilly, A.; Williamson, J.; Ashbolt, R.; Berwick, M.; Sale, M.M. Does the addition of information on genotype improve prediction of the risk of melanoma and nonmelanoma skin cancer beyond that obtained from skin phenotype? Am. J. Epidemiol. 2004, 159, 826–833. [Google Scholar] [CrossRef] [PubMed]
- English, D.R.; Armstrong, B.K. Identifying people at high risk of cutaneous malignant melanoma: Results from a case-control study in Western Australia. Br. Med. J. Clin. Res. Ed. 1988, 296, 1285–1288. [Google Scholar] [CrossRef]
- Fang, S.; Han, J.; Zhang, M.; Wang, L.E.; Wei, Q.; Amos, C.I.; Lee, J.E. Joint effect of multiple common SNPs predicts melanoma susceptibility. PLoS ONE 2013, 8, e85642. [Google Scholar] [CrossRef]
- Fargnoli, M.C.; Piccolo, D.; Altobelli, E.; Formicone, F.; Chimenti, S.; Peris, K. Constitutional and environmental risk factors for cutaneous melanoma in an Italian population. A case-control study. Melanoma Res. 2004, 14, 151–157. [Google Scholar] [CrossRef]
- Fears, T.R.; Guerry, D.T.; Pfeiffer, R.M.; Sagebiel, R.W.; Elder, D.E.; Halpern, A.; Holly, E.A.; Hartge, P.; Tucker, M.A. Identifying individuals at high risk of melanoma: A practical predictor of absolute risk. J. Clin. Oncol. 2006, 24, 3590–3596. [Google Scholar] [CrossRef]
- Fontanillas, P.; Alipanahi, B.; Furlotte, N.A.; Johnson, M.; Wilson, C.H.; andMe Research, T.; Pitts, S.J.; Gentleman, R.; Auton, A. Disease risk scores for skin cancers. Nat. Commun. 2021, 12, 160. [Google Scholar] [CrossRef]
- Fortes, C.; Mastroeni, S.; Bakos, L.; Antonelli, G.; Alessandroni, L.; Pilla, M.A.; Alotto, M.; Zappala, A.; Manoorannparampill, T.; Bonamigo, R.; et al. Identifying individuals at high risk of melanoma: A simple tool. Eur. J. Cancer. Prev. 2010, 19, 393–400. [Google Scholar] [CrossRef] [PubMed]
- Garbe, C.; Buttner, P.; Weiss, J.; Soyer, H.P.; Stocker, U.; Kruger, S.; Roser, M.; Weckbecker, J.; Panizzon, R.; Bahmer, F.; et al. Risk factors for developing cutaneous melanoma and criteria for identifying persons at risk: Multicenter case-control study of the Central Malignant Melanoma Registry of the German Dermatological Society. J. Investig. Derm. 1994, 102, 695–699. [Google Scholar] [CrossRef] [PubMed]
- Garbe, C.; Kruger, S.; Stadler, R.; Guggenmoos-Holzmann, I.; Orfanos, C.E. Markers and relative risk in a German population for developing malignant melanoma. Int. J. Derm. 1989, 28, 517–523. [Google Scholar] [CrossRef] [PubMed]
- Goldberg, M.S.; Doucette, J.T.; Lim, H.W.; Spencer, J.; Carucci, J.A.; Rigel, D.S. Risk factors for presumptive melanoma in skin cancer screening: American Academy of Dermatology National Melanoma/Skin Cancer Screening Program experience 2001-2005. J. Am. Acad. Derm. 2007, 57, 60–66. [Google Scholar] [CrossRef] [PubMed]
- Gu, F.; Chen, T.H.; Pfeiffer, R.M.; Fargnoli, M.C.; Calista, D.; Ghiorzo, P.; Peris, K.; Puig, S.; Menin, C.; De Nicolo, A.; et al. Combining common genetic variants and non-genetic risk factors to predict risk of cutaneous melanoma. Hum. Mol. Genet. 2018, 27, 4145–4156. [Google Scholar] [CrossRef] [PubMed]
- Guther, S.; Ramrath, K.; Dyall-Smith, D.; Landthaler, M.; Stolz, W. Development of a targeted risk-group model for skin cancer screening based on more than 100,000 total skin examinations. J. Eur. Acad. Derm. Venereol. 2012, 26, 86–94. [Google Scholar] [CrossRef]
- Harbauer, A.; Binder, M.; Pehamberger, H.; Wolff, K.; Kittler, H. Validity of an unsupervised self-administered questionnaire for self-assessment of melanoma risk. Melanoma Res. 2003, 13, 537–542. [Google Scholar] [CrossRef]
- Hubner, J.; Waldmann, A.; Eisemann, N.; Noftz, M.; Geller, A.C.; Weinstock, M.A.; Volkmer, B.; Greinert, R.; Breitbart, E.W.; Katalinic, A. Association between risk factors and detection of cutaneous melanoma in the setting of a population-based skin cancer screening. Eur. J. Cancer Prev. 2018, 27, 563–569. [Google Scholar] [CrossRef]
- Kypreou, K.P.; Stefanaki, I.; Antonopoulou, K.; Karagianni, F.; Ntritsos, G.; Zaras, A.; Nikolaou, V.; Kalfa, I.; Chasapi, V.; Polydorou, D.; et al. Prediction of Melanoma Risk in a Southern European Population Based on a Weighted Genetic Risk Score. J. Invest. Derm. 2016, 136, 690–695. [Google Scholar] [CrossRef]
- Landi, M.T.; Baccarelli, A.; Calista, D.; Pesatori, A.; Fears, T.; Tucker, M.A.; Landi, G. Combined risk factors for melanoma in a Mediterranean population. Br. J. Cancer 2001, 85, 1304–1310. [Google Scholar] [CrossRef]
- MacKie, R.M.; Freudenberger, T.; Aitchison, T.C. Personal risk-factor chart for cutaneous melanoma. Lancet 1989, 2, 487–490. [Google Scholar] [CrossRef] [PubMed]
- Mar, V.; Wolfe, R.; Kelly, J.W. Predicting melanoma risk for the Australian population. Australas J. Derm. 2011, 52, 109–116. [Google Scholar] [CrossRef] [PubMed]
- Marrett, L.D.; King, W.D.; Walter, S.D.; From, L. Use of Host Factors to Identify People at High-Risk for Cutaneous Malignant-Melanoma. Can. Med. Assoc. J. 1992, 147, 445–452. [Google Scholar]
- Nielsen, K.; Masback, A.; Olsson, H.; Ingvar, C. A prospective, population-based study of 40,000 women regarding host factors, UV exposure and sunbed use in relation to risk and anatomic site of cutaneous melanoma. Int. J. Cancer 2012, 131, 706–715. [Google Scholar] [CrossRef] [PubMed]
- Nikolic, J.; Loncar-Turukalo, T.; Sladojevic, S.; Marinkovic, M.; Janjic, Z. Melanoma risk prediction models. Vojn. Pregl. 2014, 71, 757–766. [Google Scholar] [CrossRef] [PubMed]
- Olsen, C.M.; Pandeya, N.; Thompson, B.S.; Dusingize, J.C.; Webb, P.M.; Green, A.C.; Neale, R.E.; Whiteman, D.C.; Study, Q.S. Risk Stratification for Melanoma: Models Derived and Validated in a Purpose-Designed Prospective Cohort. J. Natl. Cancer Inst. 2018, 110, 1075–1083. [Google Scholar] [CrossRef] [PubMed]
- Penn, L.A.; Qian, M.; Zhang, E.; Ng, E.; Shao, Y.; Berwick, M.; Lazovich, D.; Polsky, D. Development of a melanoma risk prediction model incorporating MC1R genotype and indoor tanning exposure: Impact of mole phenotype on model performance. PLoS ONE 2014, 9, e101507. [Google Scholar] [CrossRef]
- Quereux, G.; Moyse, D.; Lequeux, Y.; Jumbou, O.; Brocard, A.; Antonioli, D.; Dreno, B.; Nguyen, J.M. Development of an individual score for melanoma risk. Eur. J. Cancer. Prev. 2011, 20, 217–224. [Google Scholar] [CrossRef]
- Richter, A.; Khoshgoftaar, T. Melanoma Risk Prediction with Structured Electronic Health Records. In Proceedings of the ACM-BCB’18: 9th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Washington, DC, USA, 29 August–1 September 2018. [Google Scholar]
- Smith, L.A.; Qian, M.; Ng, E.; Shao, Y.Z.; Berwick, M.; Lazovich, D.; Polsky, D. Development of a melanoma risk prediction model incorporating MC1R genotype and indoor tanning exposure. J. Clin. Oncol. 2012, 30, 8574. [Google Scholar] [CrossRef]
- Sneyd, M.J.; Cameron, C.; Cox, B. Individual risk of cutaneous melanoma in New Zealand: Developing a clinical prediction aid. BMC Cancer 2014, 14, 359. [Google Scholar] [CrossRef]
- Stefanaki, I.; Panagiotou, O.A.; Kodela, E.; Gogas, H.; Kypreou, K.P.; Chatzinasiou, F.; Nikolaou, V.; Plaka, M.; Kalfa, I.; Antoniou, C.; et al. Replication and predictive value of SNPs associated with melanoma and pigmentation traits in a Southern European case-control study. PLoS ONE 2013, 8, e55712. [Google Scholar] [CrossRef] [PubMed]
- Tagliabue, E.; Gandini, S.; Bellocco, R.; Maisonneuve, P.; Newton-Bishop, J.; Polsky, D.; Lazovich, D.; Kanetsky, P.A.; Ghiorzo, P.; Gruis, N.A.; et al. MC1R variants as melanoma risk factors independent of at-risk phenotypic characteristics: A pooled analysis from the M-SKIP project. Cancer Manag. Res. 2018, 10, 1143–1154. [Google Scholar] [CrossRef]
- Vuong, K.; Armstrong, B.K.; Drummond, M.; Hopper, J.L.; Barrett, J.H.; Davies, J.R.; Bishop, D.T.; Newton-Bishop, J.; Aitken, J.F.; Giles, G.G.; et al. Development and external validation study of a melanoma risk prediction model incorporating clinically assessed naevi and solar lentigines. Br. J. Derm. 2020, 182, 1262–1268. [Google Scholar] [CrossRef] [PubMed]
- Vuong, K.; Armstrong, B.K.; Weiderpass, E.; Lund, E.; Adami, H.O.; Veierod, M.B.; Barrett, J.H.; Davies, J.R.; Bishop, D.T.; Whiteman, D.C.; et al. Development and External Validation of a Melanoma Risk Prediction Model Based on Self-assessed Risk Factors. JAMA Derm. 2016, 152, 889–896. [Google Scholar] [CrossRef]
- Whiteman, D.C.; Green, A.C. A risk prediction tool for melanoma? Cancer Epidemiol. Biomark. Prev. 2005, 14, 761–763. [Google Scholar] [CrossRef]
- Williams, L.H.; Shors, A.R.; Barlow, W.E.; Solomon, C.; White, E. Identifying Persons at Highest Risk of Melanoma Using Self-Assessed Risk Factors. J. Clin. Exp. Derm. Res. 2011, 2, 1000129. [Google Scholar] [CrossRef]
- Venema, E.; Wessler, B.S.; Paulus, J.K.; Salah, R.; Raman, G.; Leung, L.Y.; Koethe, B.C.; Nelson, J.; Park, J.G.; van Klaveren, D.; et al. Large-scale validation of the prediction model risk of bias assessment Tool (PROBAST) using a short form: High risk of bias models show poorer discrimination. J. Clin. Epidemiol. 2021, 138, 32–39. [Google Scholar] [CrossRef]
- Konsgen, N.; Barcot, O.; Hess, S.; Puljak, L.; Goossen, K.; Rombey, T.; Pieper, D. Inter-review agreement of risk-of-bias judgments varied in Cochrane reviews. J. Clin. Epidemiol. 2020, 120, 25–32. [Google Scholar] [CrossRef]
- Hartling, L.; Hamm, M.P.; Milne, A.; Vandermeer, B.; Santaguida, P.L.; Ansari, M.; Tsertsvadze, A.; Hempel, S.; Shekelle, P.; Dryden, D.M. Testing the risk of bias tool showed low reliability between individual reviewers and across consensus assessments of reviewer pairs. J. Clin. Epidemiol. 2013, 66, 973–981. [Google Scholar] [CrossRef]
- Momen, N.C.; Streicher, K.N.; da Silva, D.T.C.; Descatha, A.; Frings-Dresen, M.H.W.; Gagliardi, D.; Godderis, L.; Loney, T.; Mandrioli, D.; Modenese, A.; et al. Assessor burden, inter-rater agreement and user experience of the RoB-SPEO tool for assessing risk of bias in studies estimating prevalence of exposure to occupational risk factors: An analysis from the WHO/ILO Joint Estimates of the Work-related Burden of Disease and Injury. Environ. Int. 2022, 158, 107005. [Google Scholar] [CrossRef]
- Hoy, D.; Brooks, P.; Woolf, A.; Blyth, F.; March, L.; Bain, C.; Baker, P.; Smith, E.; Buchbinder, R. Assessing risk of bias in prevalence studies: Modification of an existing tool and evidence of interrater agreement. J. Clin. Epidemiol. 2012, 65, 934–939. [Google Scholar] [CrossRef] [PubMed]
- Pieper, D.; Jacobs, A.; Weikert, B.; Fishta, A.; Wegewitz, U. Inter-rater reliability of AMSTAR is dependent on the pair of reviewers. Bmc Med. Res. Methodol. 2017, 17, 98. [Google Scholar] [CrossRef]
- Byrt, T.; Bishop, J.; Carlin, J.B. Bias, Prevalence and Kappa. J. Clin. Epidemiol. 1993, 46, 423–429. [Google Scholar] [CrossRef]
- Feinstein, A.R.; Cicchetti, D.V. High Agreement but Low Kappa. 1. The Problems of 2 Paradoxes. J. Clin. Epidemiol. 1990, 43, 543–549. [Google Scholar] [CrossRef]
- Jeyaraman, M.M.; Rabbani, R.; Al-Yousif, N.; Robson, R.C.; Copstein, L.; Xia, J.; Pollock, M.; Mansour, S.; Ansari, M.T.; Tricco, A.C.; et al. Inter-rater reliability and concurrent validity of ROBINS-I: Protocol for a cross-sectional study. Syst. Rev. 2020, 9, 12. [Google Scholar] [CrossRef]
- Martin Andres, A.; Alvarez Hernandez, M. Hubert’s multi-rater kappa revisited. Br. J. Math. Stat. Psychol. 2020, 73, 1–22. [Google Scholar] [CrossRef]
- Konstantinidis, M.; Le, L.W.; Gao, X. An Empirical Comparative Assessment of Inter-Rater Agreement of Binary Outcomes and Multiple Raters. Symmetry 2022, 14, 262. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rater 1 | Rater 2 | Rater 3 | Rater 4 | Rater 5 | Rater 6 | |
|---|---|---|---|---|---|---|
| Domain 1: Participants | ||||||
| Before training | 0.730 | 0.148 | 0.181 | 0.173 | 0.260 | 0.652 |
| After training | 0.675 | 0.805 | 0.549 | 0.546 | 0.074 | 0.679 |
| Domain 2: Predictors | ||||||
| Before training | 0.428 | 0.125 | 0.394 | 0.214 | 0.202 | 0.643 |
| After training | 0.636 | 0.698 | 0.243 | 0.308 | 0.314 | 0.726 |
| Domain 3: Outcome | ||||||
| Before training | 0.572 | 0.588 | 0.278 | 0.510 | 0.774 | 0.647 |
| After training | 0.851 | 0.776 | 0.899 | 0.899 | 0.683 | 0.947 |
| Domain 4: Analysis | ||||||
| Before training | 0.493 | 0.635 | 0.085 | 0.108 | 0.145 | 0.629 |
| After training | 0.606 | 0.740 | 0.222 | 0.413 | −0.022 | 0.802 |
| Overall | ||||||
| Before training | 0.562 | 0.479 | 0.216 | −0.313 | −0.256 | 0.694 |
| After training | 0.711 | 0.713 | 0.423 | 0.537 | 0.392 | 0.893 |
| Mean Raw Agreement | Mean Pairwise AC1 | Mean Cohen’s κ | ||||
|---|---|---|---|---|---|---|
| Before Training | After Training | Before Training | After Training | Before Training | After Training | |
| Domain 1: Participants | 0.530 | 0.615 | 0.357 | 0.464 | 0.167 | 0.396 |
| Domain 2: Predictors | 0.465 | 0.494 | 0.284 | 0.297 | 0.019 | 0.171 |
| Domain 3: Outcome | 0.637 | 0.809 | 0.534 | 0.776 | 0.183 | 0.310 |
| Domain 4: Analysis | 0.397 | 0.524 | 0.142 | 0.298 | 0.134 | 0.287 |
| Overall | 0.377 | 0.612 | 0.098 | 0.474 | 0.132 | 0.261 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaiser, I.; Pfahlberg, A.B.; Mathes, S.; Uter, W.; Diehl, K.; Steeb, T.; Heppt, M.V.; Gefeller, O. Inter-Rater Agreement in Assessing Risk of Bias in Melanoma Prediction Studies Using the Prediction Model Risk of Bias Assessment Tool (PROBAST): Results from a Controlled Experiment on the Effect of Specific Rater Training. J. Clin. Med. 2023, 12, 1976. https://doi.org/10.3390/jcm12051976
Kaiser I, Pfahlberg AB, Mathes S, Uter W, Diehl K, Steeb T, Heppt MV, Gefeller O. Inter-Rater Agreement in Assessing Risk of Bias in Melanoma Prediction Studies Using the Prediction Model Risk of Bias Assessment Tool (PROBAST): Results from a Controlled Experiment on the Effect of Specific Rater Training. Journal of Clinical Medicine. 2023; 12(5):1976. https://doi.org/10.3390/jcm12051976
Chicago/Turabian StyleKaiser, Isabelle, Annette B. Pfahlberg, Sonja Mathes, Wolfgang Uter, Katharina Diehl, Theresa Steeb, Markus V. Heppt, and Olaf Gefeller. 2023. "Inter-Rater Agreement in Assessing Risk of Bias in Melanoma Prediction Studies Using the Prediction Model Risk of Bias Assessment Tool (PROBAST): Results from a Controlled Experiment on the Effect of Specific Rater Training" Journal of Clinical Medicine 12, no. 5: 1976. https://doi.org/10.3390/jcm12051976
APA StyleKaiser, I., Pfahlberg, A. B., Mathes, S., Uter, W., Diehl, K., Steeb, T., Heppt, M. V., & Gefeller, O. (2023). Inter-Rater Agreement in Assessing Risk of Bias in Melanoma Prediction Studies Using the Prediction Model Risk of Bias Assessment Tool (PROBAST): Results from a Controlled Experiment on the Effect of Specific Rater Training. Journal of Clinical Medicine, 12(5), 1976. https://doi.org/10.3390/jcm12051976