
Application of nnU-Net for Automatic Segmentation of Lung Lesions on CT Images and Its Implication for Radiomic Models

 , , ,
, , ,  , , ,
, , ,
Abstract
1. Introduction
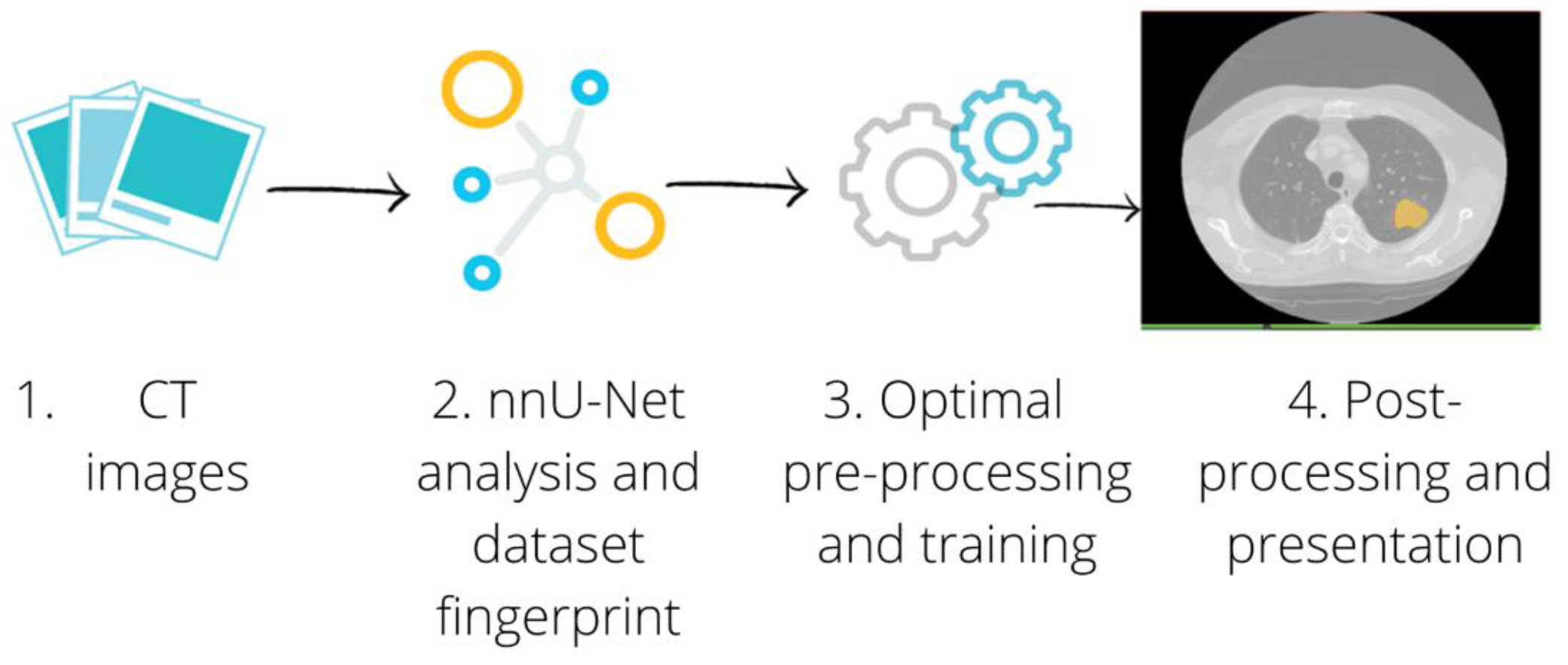
2. Materials and Methods
2.1. Patient Population and CT Acquisition
2.2. Segmentation
2.2.1. Manual Segmentation
2.2.2. Automatic Segmentation: Training and Testing
2.2.3. Automatic Segmentation Performance
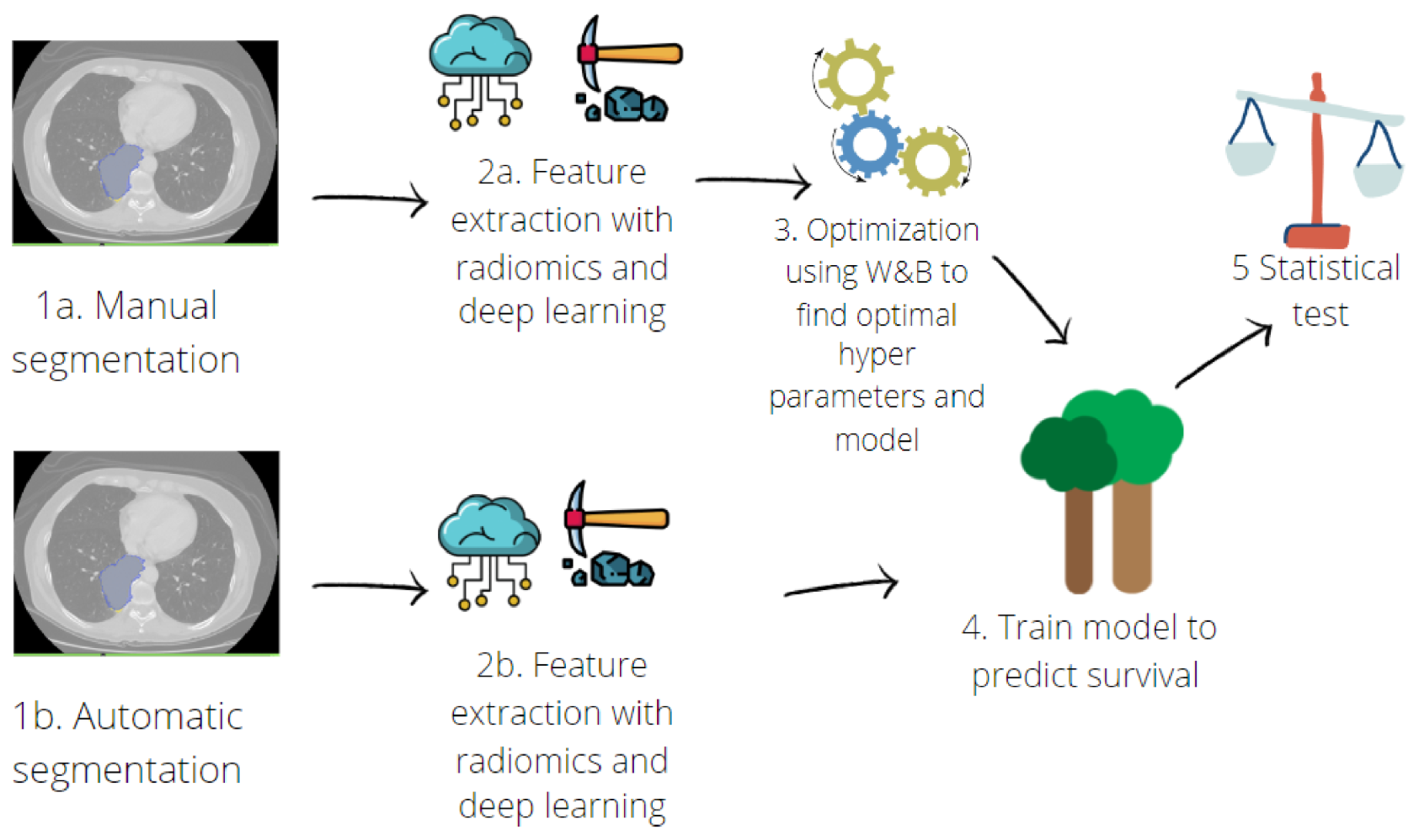
2.3. Survival Prediction
2.3.1. Hand-Crafted Radiomic Features Extraction
2.3.2. Deep-Learning Feature Extraction
2.3.3. Survival Model Implementation
3. Results
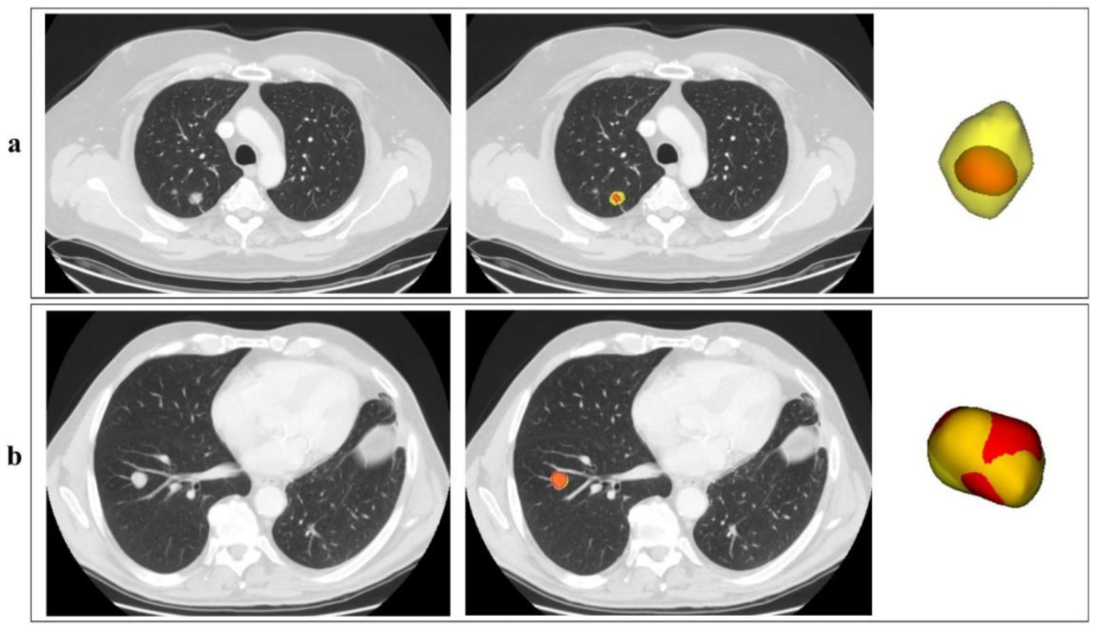
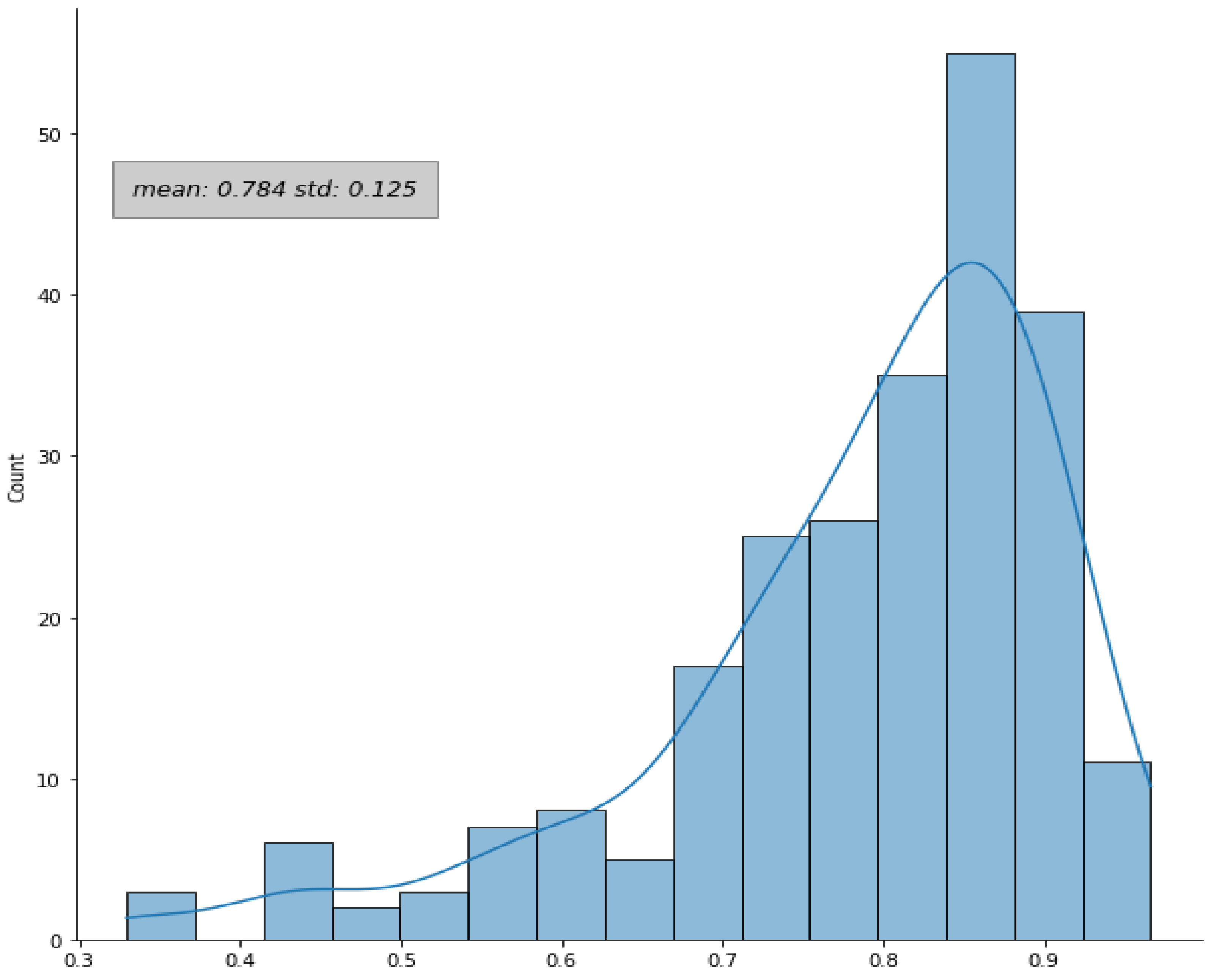
3.1. Manual and Automatic Segmentation
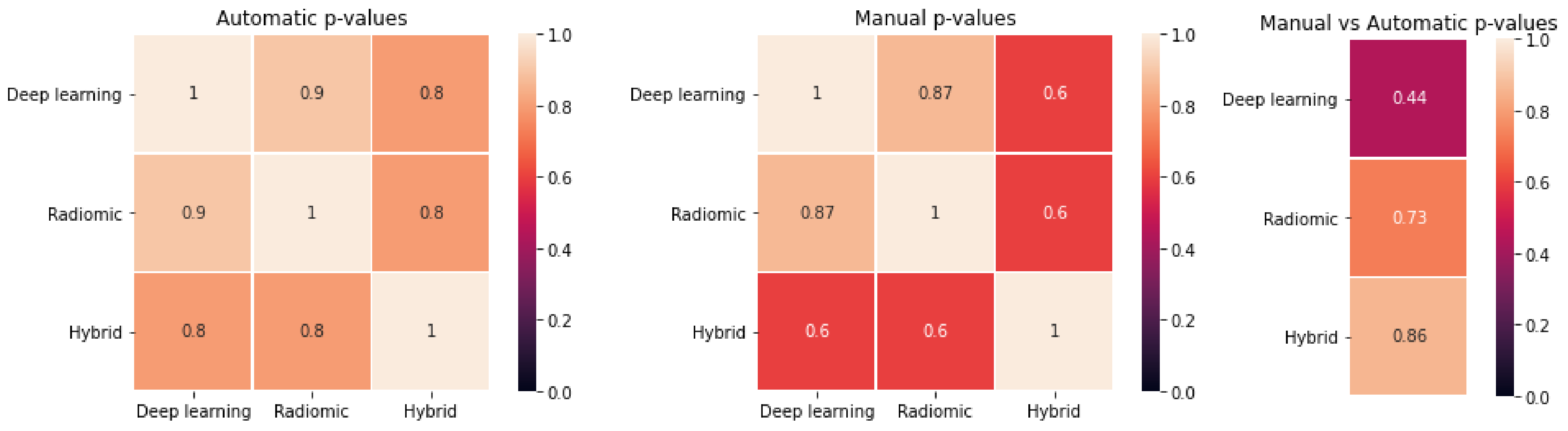
3.2. Survival Model
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
References
- Planchard, D.; Popat, S.; Kerr, K.; Novello, S.; Smit, E.F.; Faivre-Finn, C.; Mok, T.S.; Reck, M.; Van Schil, P.E.; Hellmann, M.D.; et al. Metastatic Non-Small Cell Lung Cancer: ESMO Clinical Practice Guidelines for Diagnosis, Treatment and Follow-Up. Ann. Oncol. 2018, 29, iv192–iv237. [Google Scholar] [CrossRef] [PubMed]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA A Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Fanti, S.; Farsad, M.; Battista, G.; Monetti, F.; Montini, G.C.; Chiti, A.; Savelli, G.; Petrella, F.; Bini, A.; Nanni, C.; et al. Somatostatin Receptor Scintigraphy for Bronchial Carcinoid Follow-Up. Clin. Nucl. Med. 2003, 28, 548–552. [Google Scholar] [CrossRef]
- Guarize, J.; Casiraghi, M.; Donghi, S.; Diotti, C.; Vanoni, N.; Romano, R.; Casadio, C.; Brambilla, D.; Maisonneuve, P.; Petrella, F.; et al. Endobronchial Ultrasound Transbronchial Needle Aspiration in Thoracic Diseases: Much More than Mediastinal Staging. Can. Respir. J. 2018, 2018, 4269798. [Google Scholar] [CrossRef] [PubMed]
- Forghani, R.; Savadjiev, P.; Chatterjee, A.; Muthukrishnan, N.; Reinhold, C.; Forghani, B. Radiomics and Artificial Intelligence for Biomarker and Prediction Model Development in Oncology. Comput. Struct. Biotechnol. J. 2019, 17, 995–1008. [Google Scholar] [CrossRef]
- Ibrahim, A.; Primakov, S.; Beuque, M.; Woodruff, H.C.; Halilaj, I.; Wu, G.; Refaee, T.; Granzier, R.; Widaatalla, Y.; Hustinx, R.; et al. Radiomics for Precision Medicine: Current Challenges, Future Prospects, and the Proposal of a New Framework. Methods 2021, 188, 20–29. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, Z.; He, L.; Chen, X.; Pan, D.; Ma, Z.; Liang, C.; Tian, J.; Liang, C. Radiomics Signature: A Potential Biomarker for the Prediction of Disease-Free Survival in Early-Stage (I or II) Non—Small Cell Lung Cancer. Radiology 2016, 281, 947–957. [Google Scholar] [CrossRef]
- Zhang, Y.; Oikonomou, A.; Wong, A.; Haider, M.A.; Khalvati, F. Radiomics-Based Prognosis Analysis for Non-Small Cell Lung Cancer. Sci. Rep. 2017, 7, 46349. [Google Scholar] [CrossRef]
- De Jong, E.E.; Van Elmpt, W.; Rizzo, S.; Colarieti, A.; Spitaleri, G.; Leijenaar, R.T.H.; Jochems, A.; Hendriks, L.E.L.; Troost, E.G.C.; Reymen, B.; et al. Applicability of a Prognostic CT-based Radiomic Signature Model Trained on Stage I-III Non-Small Cell Lung Cancer in Stage IV Non-Small Cell Lung Cancer. Lung Cancer 2018, 124, 6–11. [Google Scholar] [CrossRef]
- Botta, F.; Raimondi, S.; Rinaldi, L.; Bellerba, F.; Corso, F.; Bagnardi, V.; Origgi, D.; Minelli, R.; Pitoni, G.; Petrella, F.; et al. Association of a CT-Based Clinical and Radiomics Score of Non-Small Cell Lung Cancer (NSCLC) with Lymph Node Status and Overall Survival. Cancers 2020, 12, 1432. [Google Scholar] [CrossRef]
- Ninatti, G.; Kirienko, M.; Neri, E.; Sollini, M.; Chiti, A. Imaging-Based Prediction of Molecular Therapy Targets in NSCLC by Radiogenomics and AI Approaches: A Systematic Review. Diagnostics 2020, 10, 359. [Google Scholar] [CrossRef]
- Cucchiara, F.; Petrini, I.; Romei, C.; Crucitta, S.; Lucchesi, M.; Valleggi, S.; Scavone, C.; Capuano, A.; De Liperi, A.; Chella, A.; et al. Combining Liquid Biopsy and Radiomics for Personalized Treatment of Lung Cancer Patients. State of the Art and New Perspectives. Pharmacol. Res. 2021, 169, 105643. [Google Scholar] [CrossRef]
- Hosny, A.; Parmar, C.; Coroller, T.P.; Grossmann, P.; Zeleznik, R.; Kumar, A.; Bussink, J.; Gillies, R.J.; Mak, R.H.; Aerts, H.J.W.L. Deep Learning for Lung Cancer Prognostication: A Retrospective Multi-Cohort Radiomics Study. PLoS Med. 2018, 15, e1002711. [Google Scholar] [CrossRef]
- Coudray, N.; Ocampo, P.S.; Sakellaropoulos, T.; Narula, N.; Snuderl, M.; Fenyö, D.; Moreira, A.L.; Razavian, N.; Tsirigos, A. Classification and Mutation Prediction from Non–Small Cell Lung Cancer Histopathology Images Using Deep Learning. Nat. Med. 2018, 24, 1559–1567. [Google Scholar] [CrossRef]
- Xu, Y.; Hosny, A.; Zeleznik, R.; Parmar, C.; Coroller, T.; Franco, I.; Mak, R.H.; Aerts, H.J.W.L. Deep Learning Predicts Lung Cancer Treatment Response from Serial Medical Imaging. Clin. Cancer Res. 2019, 25, 3266–3275. [Google Scholar] [CrossRef]
- Lakshmanaprabu, S.K.; Mohanty, S.N.; Shankar, K.; Arunkumar, N.; Ramirez, G. Optimal Deep Learning Model for Classification of Lung Cancer on CT Images. Future Gener. Comput. Syst. 2019, 92, 374–382. [Google Scholar] [CrossRef]
- Avanzo, M.; Stancanello, J.; Pirrone, G.; Sartor, G. Radiomics and Deep Learning in Lung Cancer. Strahlenther. Onkol. 2020, 196, 879–887. [Google Scholar] [CrossRef]
- Binczyk, F.; Prazuch, W.; Bozek, P.; Polanska, J. Radiomics and Artificial Intelligence in Lung Cancer Screening. Transl. Lung Cancer Res. 2021, 10, 1186–1199. [Google Scholar] [CrossRef]
- Jiao, Z.; Li, H.; Xiao, Y.; Dorsey, J.; Simone, C.B.; Feigenberg, S.; Kao, G.; Fan, Y. Integration of Deep Learning Radiomics and Counts of Circulating Tumor Cells Improves Prediction of Outcomes of Early Stage NSCLC Patients Treated With Stereotactic Body Radiation Therapy. Int. J. Radiat. Oncol. Biol. Phys. 2022, 112, 1045–1054. [Google Scholar] [CrossRef]
- Yip, S.S.F.; Liu, Y.; Parmar, C.; Li, Q.; Liu, S.; Qu, F.; Ye, Z.; Gillies, R.J.; Aerts, H.J.W.L. Associations between Radiologist-Defined Semantic and Automatically Computed Radiomic Features in Non-Small Cell Lung Cancer. Sci. Rep. 2017, 7, 3519. [Google Scholar] [CrossRef]
- El-Baz, A.; Beache, G.M.; Gimel’farb, G.; Suzuki, K.; Okada, K.; Elnakib, A.; Soliman, A.; Abdollahi, B. Computer-Aided Diagnosis Systems for Lung Cancer: Challenges and Methodologies. Int. J. Biomed. Imaging 2013, 2013, e942353. [Google Scholar] [CrossRef] [PubMed]
- Zwanenburg, A. Radiomics in Nuclear Medicine: Robustness, Reproducibility, Standardization, and How to Avoid Data Analysis Traps and Replication Crisis. Eur. J. Nucl. Med. Mol. Imaging 2019, 46, 2638–2655. [Google Scholar] [CrossRef] [PubMed]
- Gillies, R.J.; Kinahan, P.E.; Hricak, H. Radiomics: Images Are More than Pictures, They Are Data. Radiology 2016, 278, 563–577. [Google Scholar] [CrossRef] [PubMed]
- Hosny, A.; Parmar, C.; Quackenbush, J.; Schwartz, L.H.; Aerts, H.J.W.L. Artificial Intelligence in Radiology. Nat. Rev. Cancer 2018, 18, 500–510. [Google Scholar] [CrossRef] [PubMed]
- Afshar, P.; Mohammadi, A.; Plataniotis, K.N.; Oikonomou, A.; Benali, H. From Handcrafted to Deep-Learning-Based Cancer Radiomics: Challenges and Opportunities. IEEE Signal Process. Mag. 2019, 36, 132–160. [Google Scholar] [CrossRef]
- Castiglioni, I.; Rundo, L.; Codari, M.; Di Leo, G.; Salvatore, C.; Interlenghi, M.; Gallivanone, F.; Cozzi, A.; D’Amico, N.C.; Sardanelli, F. AI Applications to Medical Images: From Machine Learning to Deep Learning. Phys. Med. 2021, 83, 9–24. [Google Scholar] [CrossRef]
- Papadimitroulas, P.; Brocki, L.; Christopher Chung, N.; Marchadour, W.; Vermet, F.; Gaubert, L.; Eleftheriadis, V.; Plachouris, D.; Visvikis, D.; Kagadis, G.C.; et al. Artificial Intelligence: Deep Learning in Oncological Radiomics and Challenges of Interpretability and Data Harmonization. Phys. Med. 2021, 83, 108–121. [Google Scholar] [CrossRef]
- Pham, D.L.; Xu, C.; Prince, J.L. Current Methods in Medical Image Segmentation. Annu. Rev. Biomed. Eng. 2000, 2, 315–337. [Google Scholar] [CrossRef]
- Dehmeshki, J.; Amin, H.; Valdivieso, M.; Ye, X. Segmentation of Pulmonary Nodules in Thoracic CT Scans: A Region Growing Approach. IEEE Trans. Med. Imaging 2008, 27, 467–480. [Google Scholar] [CrossRef]
- Owens, C.A.; Peterson, C.B.; Tang, C.; Koay, E.J.; Yu, W.; Mackin, D.S.; Li, J.; Salehpour, M.R.; Fuentes, D.T.; Court, L.E.; et al. Lung Tumor Segmentation Methods: Impact on the Uncertainty of Radiomics Features for Non-Small Cell Lung Cancer. PLoS ONE 2018, 13, e0205003. [Google Scholar] [CrossRef]
- Parmar, C.; Rios Velazquez, E.; Leijenaar, R.; Jermoumi, M.; Carvalho, S.; Mak, R.H.; Mitra, S.; Shankar, B.U.; Kikinis, R.; Haibe-Kains, B.; et al. Robust Radiomics Feature Quantification Using Semiautomatic Volumetric Segmentation. PLoS ONE 2014, 9, e102107. [Google Scholar] [CrossRef]
- Pavic, M.; Bogowicz, M.; Würms, X.; Glatz, S.; Finazzi, T.; Riesterer, O.; Roesch, J.; Rudofsky, L.; Friess, M.; Veit-Haibach, P.; et al. Influence of Inter-Observer Delineation Variability on Radiomics Stability in Different Tumor Sites. Acta Oncol. 2018, 57, 1070–1074. [Google Scholar] [CrossRef]
- Joskowicz, L.; Cohen, D.; Caplan, N.; Sosna, J. Inter-Observer Variability of Manual Contour Delineation of Structures in CT. Eur. Radiol. 2019, 29, 1391–1399. [Google Scholar] [CrossRef]
- Bianconi, F.; Fravolini, M.L.; Palumbo, I.; Pascoletti, G.; Nuvoli, S.; Rondini, M.; Spanu, A.; Palumbo, B. Impact of Lesion Delineation and Intensity Quantisation on the Stability of Texture Features from Lung Nodules on CT: A Reproducible Study. Diagnostics 2021, 11, 1224. [Google Scholar] [CrossRef]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-Net and Its Variants for Medical Image Segmentation: A Review of Theory and Applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Yu, X.; Jin, F.; Luo, H.; Lei, Q.; Wu, Y. Gross Tumor Volume Segmentation for Stage III NSCLC Radiotherapy Using 3D ResSE-Unet. Technol. Cancer Res. Treat. 2022, 21, 153303382210908. [Google Scholar] [CrossRef]
- Kido, S.; Hirano, Y.; Mabu, S. Deep Learning for Pulmonary Image Analysis: Classification, Detection, and Segmentation. In Deep Learning in Medical Image Analysis: Challenges and Applications; Advances in Experimental Medicine and Biology; Lee, G., Fujita, H., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 47–58. ISBN 978-3-030-33130-6. [Google Scholar]
- Liu, X.; Li, K.-W.; Yang, R.; Geng, L.-S. Review of Deep Learning Based Automatic Segmentation for Lung Cancer Radiotherapy. Front. Oncol. 2021, 11, 717039. [Google Scholar] [CrossRef]
- Bianconi, F.; Fravolini, M.L.; Pizzoli, S.; Palumbo, I.; Minestrini, M.; Rondini, M.; Nuvoli, S.; Spanu, A.; Palumbo, B. Comparative Evaluation of Conventional and Deep Learning Methods for Semi-Automated Segmentation of Pulmonary Nodules on CT. Quant. Imaging Med. Surg. 2021, 11, 3286–3305. [Google Scholar] [CrossRef]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.A.; Petersen, J.; Maier-Hein, K.H. NnU-Net: A Self-Configuring Method for Deep Learning-Based Biomedical Image Segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef]
- Aerts, H.J.W.L.; Wee, L.; Rios Velazquez, E.; Leijenaar, R.T.H.; Parmar, C.; Grossmann, P.; Carvalho, S.; Bussink, J.; Monshouwer, R.; Haibe-Kains, B.; et al. Data From NSCLC-Radiomics [Data Set]. Cancer Imaging Arch. 2019. [Google Scholar] [CrossRef]
- Clark, K.; Vendt, B.; Smith, K.; Freymann, J.; Kirby, J.; Koppel, P.; Moore, S.; Phillips, S.; Maffitt, D.; Pringle, M.; et al. The Cancer Imaging Archive (TCIA): Maintaining and Operating a Public Information Repository. J. Digit. Imaging 2013, 26, 1045–1057. [Google Scholar] [CrossRef] [PubMed]
- Aerts, H.J.W.L.; Velazquez, E.R.; Leijenaar, R.T.H.; Parmar, C.; Grossmann, P.; Carvalho, S.; Bussink, J.; Monshouwer, R.; Haibe-Kains, B.; Rietveld, D.; et al. Decoding Tumour Phenotype by Noninvasive Imaging Using a Quantitative Radiomics Approach. Nat. Commun. 2014, 5, 4006. [Google Scholar] [CrossRef] [PubMed]
- Fedorov, A.; Beichel, R.; Kalpathy-Cramer, J.; Fillion-Robin, J.-C.; Pujol, S.; Bauer, C.; Jennings, D.; Fennessy, F.; Sonka, M.; Buatti, J.; et al. 3D Slicer as an Image Computing Platform for the Quantitative Imaging Network. Magn. Reson. Imaging 2013, 28, 1323–1341. [Google Scholar] [CrossRef] [PubMed]
- Yaniv, Z.; Lowekamp, B.C.; Johnson, H.J.; Beare, R. SimpleITK Image-Analysis Notebooks: A Collaborative Environment for Education and Reproducible Research. J. Digit. Imaging 2018, 31, 290–303. [Google Scholar] [CrossRef] [PubMed]
- Rizwan, I.; Haque, I.; Neubert, J. Deep Learning Approaches to Biomedical Image Segmentation. Inform. Med. Unlocked 2020, 18, 100297. [Google Scholar] [CrossRef]
- Haarburger, C.; Müller-Franzes, G.; Weninger, L.; Kuhl, C.; Truhn, D.; Merhof, D. Radiomics Feature Reproducibility under Inter-Rater Variability in Segmentations of CT Images. Sci. Rep. 2020, 10, 12688. [Google Scholar] [CrossRef]
- Van Griethuysen, J.J.M.; Fedorov, A.; Parmar, C.; Hosny, A.; Aucoin, N.; Narayan, V.; Beets-Tan, R.G.H.; Fillion-Robin, J.-C.; Pieper, S.; Aerts, H.J.W.L. Computational Radiomics System to Decode the Radiographic Phenotype. Cancer Res. 2017, 77, e104–e107. [Google Scholar] [CrossRef]
- Rinaldi, L.; Pezzotta, F.; Santaniello, T.; De Marco, P.; Bianchini, L.; Origgi, D.; Cremonesi, M.; Milani, P.; Mariani, M.; Botta, F. HeLLePhant: A Phantom Mimicking Non-Small Cell Lung Cancer for Texture Analysis in CT Images. Phys. Med. 2022, 97, 13–24. [Google Scholar] [CrossRef]
- Koo, T.K.; Li, M.Y. A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research. J. Chiropr. Med. 2016, 15, 155–163. [Google Scholar] [CrossRef]
- MONAI Consortium MONAI: Medical Open Network for AI. 2020. Available online: https://monai.io/ (accessed on 24 September 2021).
- Yang, J.; Huang, X.; He, Y.; Xu, J.; Yang, C.; Xu, G.; Ni, B. Reinventing 2D Convolutions for 3D Images. IEEE J. Biomed. Health Inform. 2021, 25, 3009–3018. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 8024–8035. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27 June 2016; IEEE: Manhattan, NY, USA, 2016; pp. 770–778. [Google Scholar]
- Goldstraw, P.; Chansky, K.; Crowley, J.; Rami-Porta, R.; Asamura, H.; Eberhardt, W.E.E.; Nicholson, A.G.; Groome, P.; Mitchell, A.; Bolejack, V.; et al. The IASLC Lung Cancer Staging Project: Proposals for Revision of the TNM Stage Groupings in the Forthcoming (Eighth) Edition of the TNM Classification for Lung Cancer. J. Thorac. Oncol. 2016, 11, 39–51. [Google Scholar] [CrossRef]
- Biewald, L. Experiment Tracking with Weights and Biases. Available online: https://wandb.ai/site/ (accessed on 24 August 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Gan, W.; Wang, H.; Gu, H.; Duan, Y.; Shao, Y.; Chen, H.; Feng, A.; Huang, Y.; Fu, X.; Ying, Y.; et al. Automatic Segmentation of Lung Tumors on CT Images Based on a 2D & 3D Hybrid Convolutional Neural Network. BJR 2021, 94, 20210038. [Google Scholar] [CrossRef]
- Armato, S.G.; McLennan, G.; Bidaut, L.; McNitt-Gray, M.F.; Meyer, C.R.; Reeves, A.P.; Zhao, B.; Aberle, D.R.; Henschke, C.I.; Hoffman, E.A.; et al. The Lung Image Database Consortium (LIDC) and Image Database Resource Initiative (IDRI): A Completed Reference Database of Lung Nodules on CT Scans: The LIDC/IDRI Thoracic CT Database of Lung Nodules. Med. Phys. 2011, 38, 915–931. [Google Scholar] [CrossRef]
- Baumgartner, C.F.; Tezcan, K.C.; Chaitanya, K.; Hötker, A.M.; Muehlematter, U.J.; Schawkat, K.; Becker, A.S.; Donati, O.; Konukoglu, E. PHiSeg: Capturing Uncertainty in Medical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019, Shenzhen, China, 13–17 October 2019; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.-T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 119–127. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration ^ | Training Modality | Initial Image Resolution | # pts Training | # pts Testing | ||
|---|---|---|---|---|---|---|
| # | Training Dataset | Testing Dataset | ||||
| 1 | A | A * | ensemble(2D, 3D fullres) | 256 × 256 | 220 | 50 |
| 2 | A + B | A + B * | ensemble(2D, 3D fullres) | 256 × 256 | 296 | 128 |
| 3 | A + B | A + B * | ensemble(cascade, 3D fullres) | 512 × 512 | 340 | 147 |
| 4 | C | C * | ensemble(2D, 3D fullres) | 512 × 512 | 328 | 84 |
| 5 | C | A | ensemble(2D, 3D fullres) | 512 × 512 | 328 | 79 |
| 6 | C | B | ensemble(2D, 3D fullres) | 512 × 512 | 328 | 66 |
| 7 | C | A + B | ensemble(2D, 3D fullres) | 512 × 512 | 328 | 147 |
| 8 | A + B + C | A | ensemble(2D, 3D fullres) | 512 × 512 | 668 | 80 |
| 9 | A + B + C | B | ensemble(2D, 3D fullres) | 512 × 512 | 668 | 67 |
| 10 | A + B + C | C | ensemble(2D, 3D fullres) | 512 × 512 | 668 | 84 |
| 11 | A + B + C | A + B + C * | ensemble(2D, 3D fullres) | 512 × 512 | 668 | 231 |
| 12 | B + C | A | ensemble(2D, 3D fullres) | 512 × 512 | 629 | 270 |
| Configuration ^ | DICE | % correctly Identified (DICE > 0) Lesions | % Lesions with DICE > 0.50 | % Lesions with DICE > 0.80 | ||
|---|---|---|---|---|---|---|
| # | Training Dataset | Testing Dataset | ||||
| 1 | A | A * | 0.65 ± 0.29 | 94% | 74% | 38% |
| 2 | A + B | A + B * | 0.74 ± 0.28 | 93% | 82% | 51% |
| 3 | A + B | A + B * | 0.66 ± 0.32 | 93% | 71% | 41% |
| 4 | C | C * | 0.68 ± 0.33 | 86% | 71% | 32% |
| 5 | C | A | 0.69 ± 0.33 | 83% | 69% | 35% |
| 6 | C | B | 0.71 ± 0.32 | 85% | 73% | 40% |
| 7 | C | A + B | 0.70 ± 0.33 | 84% | 71% | 37% |
| 8 | A + B + C | A | 0.71 ± 0.32 | 88% | 70% | 48% |
| 9 | A + B + C | B | 0.77 ± 0.31 | 87% | 79% | 48% |
| 10 | A + B + C | C | 0.67 ± 0.32 | 83% | 68% | 31% |
| 11 | A + B + C | A + B + C * | 0.71 ± 0.32 | 86% | 72% | 42% |
| 12 | B + C | A | 0.72 ± 0.29 | 91% | 78% | 45% |
| Manual | Automatic | |
|---|---|---|
| Hand-crafted features | 0.73 | 0.78 |
| Deep features | 0.65 | 0.78 |
| Hybrid features | 0.70 | 0.78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferrante, M.; Rinaldi, L.; Botta, F.; Hu, X.; Dolp, A.; Minotti, M.; De Piano, F.; Funicelli, G.; Volpe, S.; Bellerba, F.; et al. Application of nnU-Net for Automatic Segmentation of Lung Lesions on CT Images and Its Implication for Radiomic Models. J. Clin. Med. 2022, 11, 7334. https://doi.org/10.3390/jcm11247334
Ferrante M, Rinaldi L, Botta F, Hu X, Dolp A, Minotti M, De Piano F, Funicelli G, Volpe S, Bellerba F, et al. Application of nnU-Net for Automatic Segmentation of Lung Lesions on CT Images and Its Implication for Radiomic Models. Journal of Clinical Medicine. 2022; 11(24):7334. https://doi.org/10.3390/jcm11247334
Chicago/Turabian StyleFerrante, Matteo, Lisa Rinaldi, Francesca Botta, Xiaobin Hu, Andreas Dolp, Marta Minotti, Francesca De Piano, Gianluigi Funicelli, Stefania Volpe, Federica Bellerba, and et al. 2022. "Application of nnU-Net for Automatic Segmentation of Lung Lesions on CT Images and Its Implication for Radiomic Models" Journal of Clinical Medicine 11, no. 24: 7334. https://doi.org/10.3390/jcm11247334
APA StyleFerrante, M., Rinaldi, L., Botta, F., Hu, X., Dolp, A., Minotti, M., De Piano, F., Funicelli, G., Volpe, S., Bellerba, F., De Marco, P., Raimondi, S., Rizzo, S., Shi, K., Cremonesi, M., Jereczek-Fossa, B. A., Spaggiari, L., De Marinis, F., Orecchia, R., & Origgi, D. (2022). Application of nnU-Net for Automatic Segmentation of Lung Lesions on CT Images and Its Implication for Radiomic Models. Journal of Clinical Medicine, 11(24), 7334. https://doi.org/10.3390/jcm11247334