
Identifying Patients with Familial Chylomicronemia Syndrome Using FCS Score-Based Data Mining Methods

 ,
,  , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
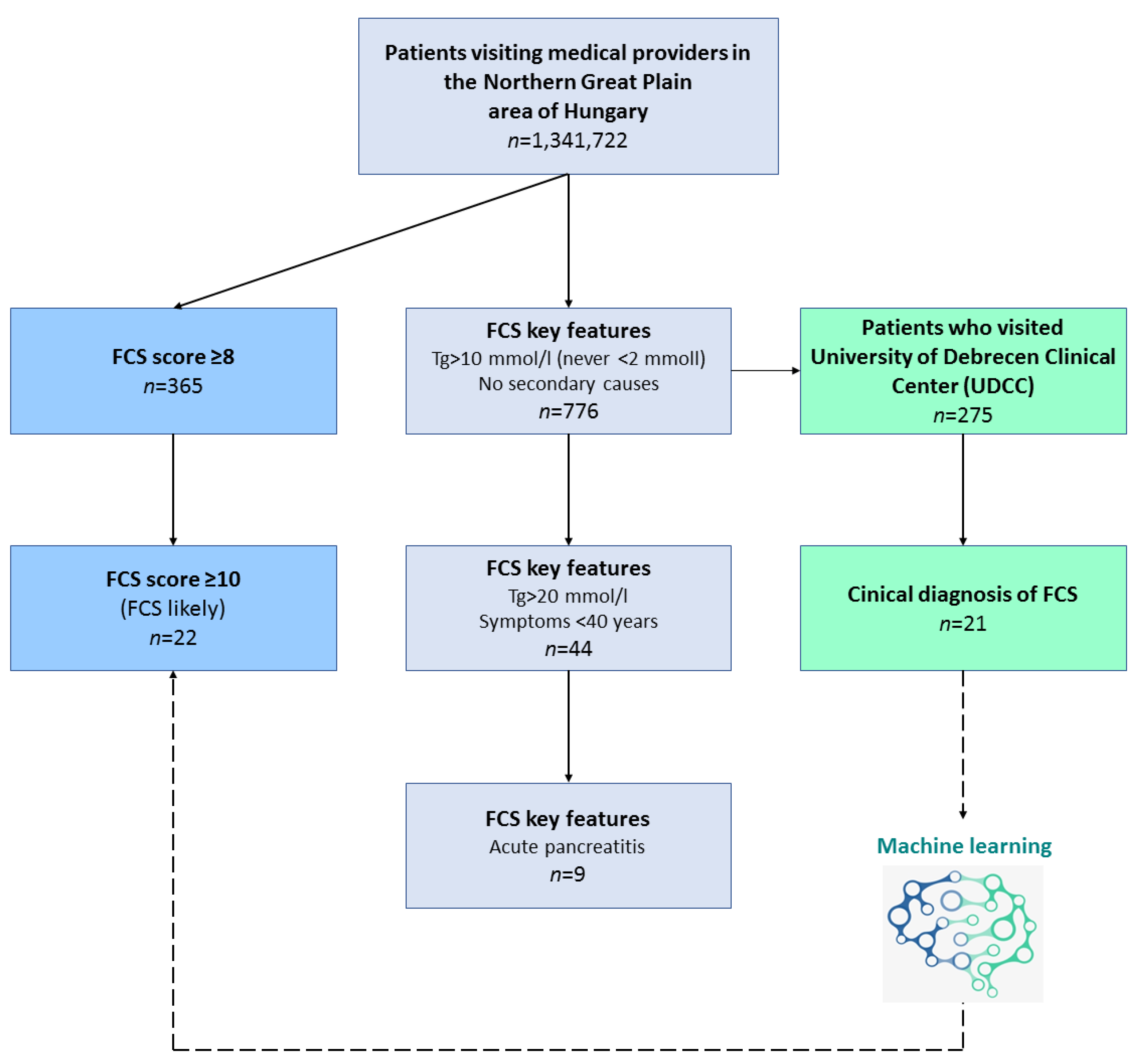
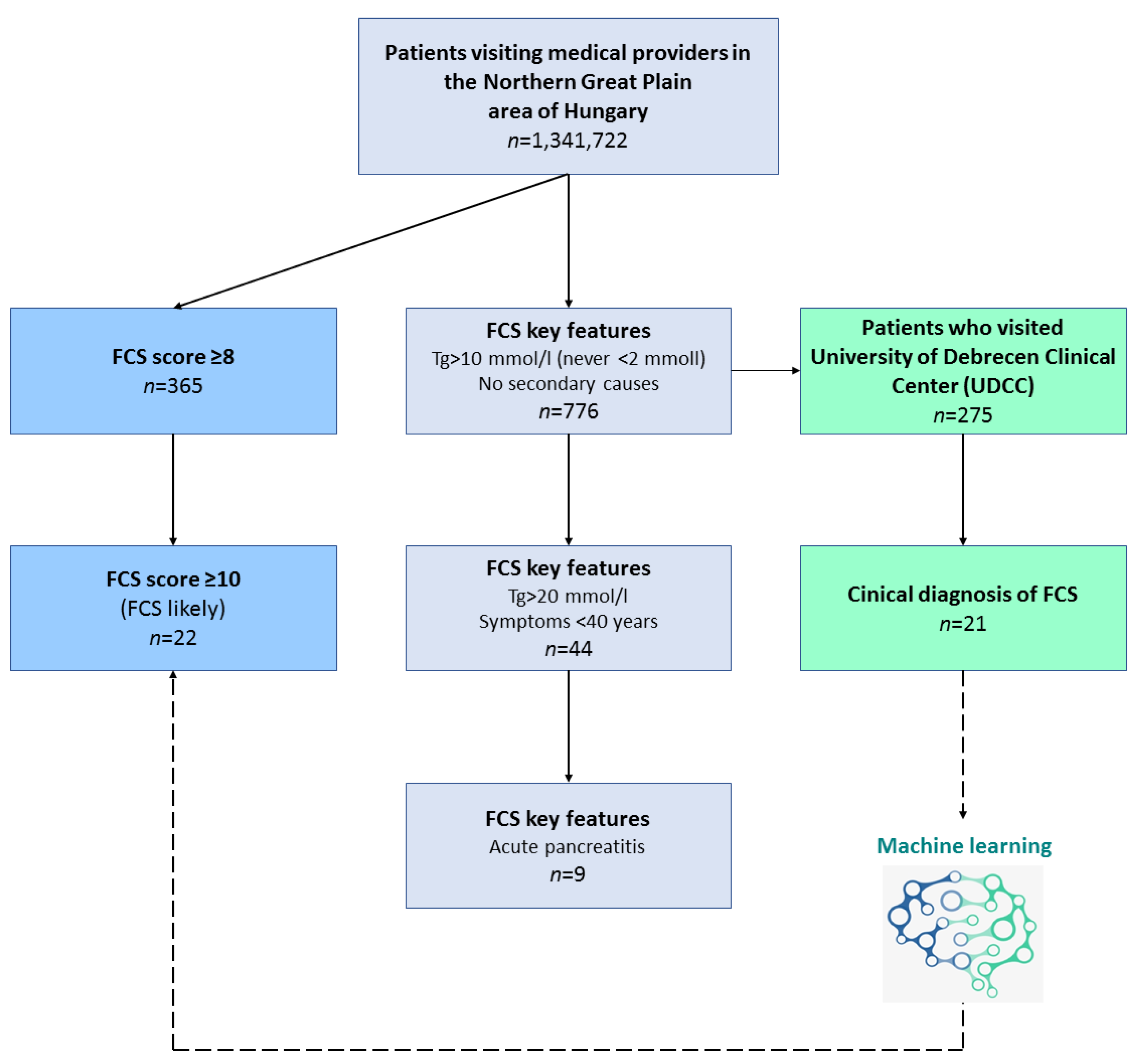
2.1. Patients and Methods
2.2. About Machine Learning
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B
References
- Goldberg, R.B.; Chait, A. A Comprehensive Update on the Chylomicronemia Syndrome. Front. Endocrinol. (Lausanne) 2020, 11, 593931. [Google Scholar] [CrossRef]
- Hegele, R.A.; Berberich, A.J.; Ban, M.R.; Wang, J.; Digenio, A.; Alexander, V.J.; D’Erasmo, L.; Arca, M.; Jones, A.; Bruckert, E.; et al. Clinical and biochemical features of different molecular etiologies of familial chylomicronemia. J. Clin. Lipidol. 2018, 12, 920–927.e4. [Google Scholar] [CrossRef] [Green Version]
- Beigneux, A.P.; Miyashita, K.; Ploug, M.; Blom, D.J.; Ai, M.; Linton, M.F.; Khovidhunkit, W.; Dufour, R.; Garg, A.; McMahon, M.A.; et al. Autoantibodies against GPIHBP1 as a Cause of Hypertriglyceridemia. N. Engl. J. Med. 2017, 376, 1647–1658. [Google Scholar] [CrossRef]
- Dionisi-Vici, C.; Shteyer, E.; Niceta, M.; Rizzo, C.; Pode-Shakked, B.; Chillemi, G.; Bruselles, A.; Semeraro, M.; Barel, O.; Eyal, E.; et al. Expanding the molecular diversity and phenotypic spectrum of glycerol 3-phosphate dehydrogenase 1 deficiency. J. Inherit. Metab. Dis. 2016, 39, 689–695. [Google Scholar] [CrossRef]
- Hegele, R.A.; Ginsberg, H.N.; Chapman, M.J.; Nordestgaard, B.G.; Kuivenhoven, J.A.; Averna, M.; Borén, J.; Bruckert, E.; Catapano, A.L.; Descamps, O.S.; et al. The polygenic nature of hypertriglyceridaemia: Implications for definition, diagnosis, and management. Lancet Diabetes Endocrinol. 2014, 2, 655–666. [Google Scholar] [CrossRef] [Green Version]
- Moulin, P.; Dufour, R.; Averna, M.; Arca, M.; Cefalù, A.B.; Noto, D.; D’Erasmo, L.; Di Costanzo, A.; Marçais, C.; Alvarez-Sala Walther, L.A.; et al. Identification and diagnosis of patients with familial chylomicronaemia syndrome (FCS): Expert panel recommendations and proposal of an “FCS score”. Atherosclerosis 2018, 275, 265–272. [Google Scholar] [CrossRef]
- Paquette, M.; Bernard, S.; Hegele, R.A.; Baass, A. Chylomicronemia: Differences between familial chylomicronemia syndrome and multifactorial chylomicronemia. Atherosclerosis 2019, 283, 137–142. [Google Scholar] [CrossRef] [PubMed]
- Chait, A.; Eckel, R.H. The Chylomicronemia Syndrome Is Most Often Multifactorial: A Narrative Review of Causes and Treatment. Ann. Intern. Med. 2019, 170, 626–634. [Google Scholar] [CrossRef]
- Paragh, G.; Harangi, M.; Karányi, Z.; Daróczy, B.; Németh, Á.; Fülöp, P. Identifying patients with familial hypercholesterolemia using data mining methods in the Northern Great Plain region of Hungary. Atherosclerosis 2018, 277, 262–266. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.; Chervonenkis, A. On the uniform convergence of realtive frequencies of events to their probabilities. Theory Probab. Its Appl. 1971, 16, 264–280. [Google Scholar] [CrossRef]
- Nagarajan, V.; Kotler, J. Uniform convergence may be unable to explain generalization in deep learning. In Proceedings of the 32nd Advances in Neural Information Processing Systems (NeurIPS ’19), Vancouver, BC, Canada, 8–14 December 2019; pp. 11615–11626. [Google Scholar]
- Devroye, L.; Győrfi, L.; Lugosi, G. A Probabilistic Theory of Pattern Recognition; Springer: New York, NY, USA, 1996; Volume 31. [Google Scholar]
- Freund, Y.; Schapire, R. A decision-theoretic generalisation of on-line learing and application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J. Greedy function approximation: A gradient boosting machine. Adv. Neural Inf. Process. Syst. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Montufar, G.F.; Pascanu, R.; Cho, K.; Bengio, Y. On the number of linear regions of deep neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 1–17. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimalization. In Proceedings of the 3nd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Brahm, A.J.; Hegele, R.A. Chylomicronaemia—Current diagnosis and future therapies. Nat. Rev. Endocrinol. 2015, 11, 352–362. [Google Scholar] [CrossRef]
- Pallazola, V.A.; Sajja, A.; Derenbecker, R.; Ogunmoroti, O.; Park, J.; Sathiyakumar, V.; Martin, S.S. Prevalence of familial chylomicronemia syndrome in a quaternary care center. Eur. J. Prev. Cardiol. 2020, 27, 2276–2278. [Google Scholar] [CrossRef]
- Patni, N.; Li, X.; Adams-Huet, B.; Garg, A. The prevalence and etiology of extreme hypertriglyceridemia in children: Data from a tertiary children’s hospital. J. Clin. Lipidol. 2018, 12, 305–310. [Google Scholar] [CrossRef]
- Ohm, F.; Vogel, D.; Sehner, S.; Wijnen-Meijer, M.; Harendza, S. Details acquired from medical history and patients’ experience of empathy--two sides of the same coin. BMC Med. Educ. 2013, 13, 67. [Google Scholar] [CrossRef] [Green Version]
- Németh, Á.; Daróczy, B.; Juhász, L.; Fülöp, P.; Harangi, M.; Paragh, G. Assessment of Associations Between Serum Lipoprotein (a) Levels and Atherosclerotic Vascular Diseases in Hungarian Patients With Familial Hypercholesterolemia Using Data Mining and Machine Learning. Front. Genet. 2022, 13, 849197. [Google Scholar] [CrossRef]
- Dallinga-Thie, G.M.; Kroon, J.; Borén, J.; Chapman, M.J. Triglyceride-Rich Lipoproteins and Remnants: Targets for Therapy? Curr. Cardiol. Rep. 2016, 18, 67. [Google Scholar] [CrossRef] [Green Version]
- Maltais, M.; Brisson, D.; Gaudet, D. Non-Alcoholic Fatty Liver in Patients with Chylomicronemia. J. Clin. Med. 2021, 10, 669. [Google Scholar] [CrossRef] [PubMed]
- Belhassen, M.; Van Ganse, E.; Nolin, M.; Bérard, M.; Bada, H.; Bruckert, E.; Krempf, M.; Rebours, V.; Valero, R.; Moulin, P. 10-Year Comparative Follow-up of Familial versus Multifactorial Chylomicronemia Syndromes. J. Clin. Endocrinol. Metab. 2021, 106, e1332–e1342. [Google Scholar] [CrossRef]

{kind=link}
| Score | |
| 1. Fasting TGs > 10 mmol/L for three consecutive blood analyses | +5 |
| Fasting TGs > 20 mmol/L at least once | +1 |
| 2. Previous TGs < 2 mmol/L | −5 |
| 3. No secondary factor (except pregnancy and ethinylestradiol) | +2 |
| 4. History of pancreatitis | +1 |
| 5. Unexplained recurrent abdominal pain | +1 |
| 6. No history of familial combined hyperlipidemia | +1 |
| 7. No response (TG decrease <20%) to hypolipidemic treatment | +1 |
8. Onset of symptoms at age:
| +1 +2 +3 |
| Training Set | Test Set | Method | Exp. | Mean AUC | Std AUC | Mean ACC | Std ACC | Mean Sens. | Std Sens. | Mean Spec. | Std Spec. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 50% Exam. | Ind. 50% Exam. | ReLU | 30 | 0.735 | 0.064 | 0.895 | 0.024 | 0.212 | 0.160 | 0.950 | 0.029 |
| SVM | 30 | 0.792 | 0.054 | 0.927 | 0.013 | 0.0 | 0.0 | 0.999 | 0.001 | ||
| ADA | 30 | 0.770 | 0.053 | 0.902 | 0.014 | 0.110 | 0.121 | 0.970 | 0.023 | ||
| XGB | 30 | 0.810 | 0.042 | 0.909 | 0.018 | 0.070 | 0.104 | 0.976 | 0.025 | ||
| 50% Exam. | Ind. 50% Exam. UDCC 5000 patients w/o FCS | ReLU | 30 | 0.599 | 0.088 | 0.857 | 0.112 | 0.237 | 0.184 | 0.859 | 0.113 |
| SVM | 30 | 0.872 | 0.057 | 0.998 | 0.001 | 0.0 | 0.0 | 0.999 | 0.001 | ||
| ADA | 30 | 0.824 | 0.092 | 0.996 | 0.002 | 0.110 | 0.121 | 0.999 | 0.002 | ||
| XGB | 30 | 0.871 | 0.074 | 0.997 | 0.001 | 0.070 | 0.104 | 0.999 | 0.001 | ||
| 50% Exam. & UDCC 1000 patients w/o FCS | Ind. 50% Exam. UDCC 5000 patients w/o FCS | ReLU | 30 | 0.906 | 0.041 | 0.997 | 0.001 | 0.245 | 0.142 | 0.999 | 0.011 |
| SVM | 30 | 0.955 | 0.024 | 0.999 | 0.001 | 0.0 | 0.0 | 0.999 | 0.001 | ||
| ADA | 30 | 0.923 | 0.051 | 0.996 | 0.002 | 0.110 | 0.121 | 0.999 | 0.001 | ||
| XGB | 30 | 0.982 | 0.015 | 0.997 | 0.001 | 0.091 | 0.096 | 0.999 | 0.001 |
| Cluster | FCS Score | Male Patients | Female Patients | Total Patients | Percentage of Patients |
|---|---|---|---|---|---|
| Highly unlikely FCS | 0+ | 602.258 (45%) | 739.464 (55%) | 1.341.722 | 100% |
| 1+ | 5.612 (56%) | 4.334 (44%) | 9.946 | 7.41‰ | |
| 2+ | 1.659 (75%) | 558 (25%) | 2.217 | 1.65‰ | |
| 3+ | 1.441 (75%) | 493 (25%) | 1.934 | 1.44‰ | |
| 4+ | 1.307 (74%) | 461 (26%) | 1.768 | 1.32‰ | |
| 5+ | 1.272 (74%) | 453 (26%) | 1.725 | 1.29‰ | |
| 6+ | 909 (78%) | 254 (22%) | 1.163 | 8.67‱ | |
| 7+ | 705 (79%) | 182 (21%) | 887 | 6.61‱ | |
| Unlikely FCS | 8+ | 298 (82%) | 67 (18%) | 365 | 2.72‱ |
| 9+ | 56 (81%) | 13 (19%) | 69 | 5.14 pcm | |
| Likely FCS | 10+ | 17 (77%) | 5 (23%) | 22 | 1.64 pcm |
| 11+ | 3 (75%) | 1 (25%) | 4 | 2.98 ppm |
| A. FCS score estimation on key features (UDCC, all patients *) | ||||
| Cluster | Feature | FCS Score | Number of Patients | Percentage of Patients |
| Highly unlikely FCS | Clinical site patients | 0+ | 590.500 | 100% |
| TG 10+ mmol/L and TG never 2- mmol/L | 5+ | 665 | 1.13‰ | |
| No secondary medical factors ** | 7+ | 275 | 4.67‱ | |
| Unlikely FCS | TG 20+ mmol/L at least once | 8+ | 85 | 1.44‱ |
| Symptoms below age 40 | 9+ | 24 | 4.06 pcm | |
| Likely FCS | Treated with acute pancreatitis | 10+ | 5 | 8.47 ppm |
| B. FCS score estimation on key features (CHSSB, all patients *) | ||||
| Cluster | Key Condition | FCS Score | Number of Patients | Percentage of Patients |
| Highly unlikely FCS | Clinical site patients | 0+ | 751.624 | 100% |
| TG 10+ mmol/L and TG never 2− mmol/L | 5+ | 1.046 | 1.39 ‰ | |
| No secondary medical factors ** | 7+ | 501 | 6.67‱ | |
| Unlikely FCS | TG 20+ mmol/L at least once | 8+ | 93 | 1.23‱ |
| Symptoms below age 40 | 9+ | 20 | 2.66 pcm | |
| Likely FCS | Treated with acute pancreatitis | 10+ | 4 | 5.32 ppm |
| Cluster | FCS Score | Males (n) | Females (n) | Total (n) | Percentage |
|---|---|---|---|---|---|
| A. FCS score calculation of individual patients (UDCC, all patients *) | |||||
| Highly unlikely FCS | 0+ | 251.949 (43%) | 338.149 (57%) | 590.098 | 100% |
| 1+ | 2368 (53%) | 2.108 (47%) | 4.476 | 7.59‰ | |
| 2+ | 589 (74%) | 208 (26%) | 797 | 1.35‰ | |
| 3+ | 538 (73%) | 198 (27%) | 736 | 1.25‰ | |
| 4+ | 506 (73%) | 188 (27%) | 694 | 1.18‰ | |
| 5+ | 490 (73%) | 183 (27%) | 673 | 1.14‰ | |
| 6+ | 340 (76%) | 107 (24%) | 447 | 7.58‱ | |
| 7+ | 250 (78%) | 71 (22%) | 321 | 5.44‱ | |
| Unlikely FCS | 8+ | 110 (77%) | 32 (23%) | 142 | 2.41‱ |
| 9+ | 31 (82%) | 7 (18%) | 38 | 6.44 pcm | |
| Likely FCS | 10+ | 10 (77%) | 3 (23%) | 13 | 2.20 pcm |
| 11+ | 2 (67%) | 1 (33%) | 3 | 5.08 ppm | |
| B. FCS score calculation of individual patients (CHSSB, all patients *) | |||||
| Highly unlikely FCS | 0+ | 350.309 (47%) | 401.315 (53%) | 751.624 | 100% |
| 1+ | 3.244 (59%) | 2.226 (41%) | 5.470 | 7.28‰ | |
| 2+ | 1070 (75%) | 350 (25%) | 1.420 | 1.89‰ | |
| 3+ | 903 (75%) | 295 (25%) | 1.198 | 1.59‰ | |
| 4+ | 801 (75%) | 273 (25%) | 1.074 | 1.42‰ | |
| 5+ | 782 (74%) | 270 (26%) | 1.052 | 1.40‰ | |
| 6+ | 569 (79%) | 147 (21%) | 716 | 9.53‱ | |
| 7+ | 455 (80%) | 111 (20%) | 566 | 7.53‱ | |
| Unlikely FCS | 8+ | 188 (84%) | 35 (16%) | 223 | 2.97‱ |
| 9+ | 25 (81%) | 6 (19%) | 31 | 4.12 pcm | |
| Likely FCS | 10+ | 7 (78%) | 2 (22%) | 9 | 1.19 pcm |
| 11+ | 1(100%) | 0 (0%) | 1 | 1.33 ppm | |
| Confirmed and Potential FCS Patients vs. Patients with FCS Score of 7+ | Confirmed and Potential FCS Patients vs. Random Individuals | ||
|---|---|---|---|
| Condition | Importance | Condition | Importance |
| Highest triglyceride | 100 | Average triglyceride | 100 |
| Average triglyceride | 50 | Highest triglyceride | 70 |
| Average cholesterol | 25 | Lowest triglyceride | 40 |
| Triglyceride fluctuation | 20 | Triglyceride fluctuation | 35 |
| Lowest triglyceride | 17 | Average cholesterol | 30 |
| Lowest carbamide | 16 | Highest cholesterol | 25 |
| Highest cholesterol | 15 | Lowest cholesterol | 15 |
| Average hemoglobin | 14 | Cholesterol fluctuation | 15 |
| Lowest glucose | 12 | Average hemoglobin | 10 |
| Average alkaline phosphatase | 10 | Glucose fluctuation | 10 |
| Laboratory Parameter | Cut (>) | Impact |
|---|---|---|
| Triglyceride | 30 mmol/L | + |
| Triglyceride | 18 mmol/L | + |
| Triglyceride | 6.5 mmol/L | + |
| Cholesterol | 11 mmol/L | − |
| Cholesterol | 6.5 mmol/L | + |
| Cholesterol | 4.0 mmol/L | + |
| Hemoglobin | 95 g/L | + |
| MCHC | 330 (g/L) | + |
| Amylase | 20 U/L | + |
| Basophile granulocyte | 0.6% | + |
| Lymphocyte | 20% | + |
| Sodium | 145 mmol/L | − |
| White Blood Cell | 6.5 G/L | − |
| Neutrophile granulocyte | 65% | − |
| GPT | 15 U/L | − |
| GPT | 200 U/L | − |
| GGT | 35 U/L | − |
| GGT | 350 U/L | − |
| Creatinine | 68 µmol/L | − |
| CRP | 5.0 mg/L | − |
| Glucose (fasting) | 6.0 mmol/L | − |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Németh, Á.; Harangi, M.; Daróczy, B.; Juhász, L.; Paragh, G.; Fülöp, P. Identifying Patients with Familial Chylomicronemia Syndrome Using FCS Score-Based Data Mining Methods. J. Clin. Med. 2022, 11, 4311. https://doi.org/10.3390/jcm11154311
Németh Á, Harangi M, Daróczy B, Juhász L, Paragh G, Fülöp P. Identifying Patients with Familial Chylomicronemia Syndrome Using FCS Score-Based Data Mining Methods. Journal of Clinical Medicine. 2022; 11(15):4311. https://doi.org/10.3390/jcm11154311
Chicago/Turabian StyleNémeth, Ákos, Mariann Harangi, Bálint Daróczy, Lilla Juhász, György Paragh, and Péter Fülöp. 2022. "Identifying Patients with Familial Chylomicronemia Syndrome Using FCS Score-Based Data Mining Methods" Journal of Clinical Medicine 11, no. 15: 4311. https://doi.org/10.3390/jcm11154311
APA StyleNémeth, Á., Harangi, M., Daróczy, B., Juhász, L., Paragh, G., & Fülöp, P. (2022). Identifying Patients with Familial Chylomicronemia Syndrome Using FCS Score-Based Data Mining Methods. Journal of Clinical Medicine, 11(15), 4311. https://doi.org/10.3390/jcm11154311