
Artificial Intelligence (AI)-Empowered Echocardiography Interpretation: A State-of-the-Art Review

 ,
, 
Abstract
1. Introduction
1.1. Transthoracic Echocardiogram
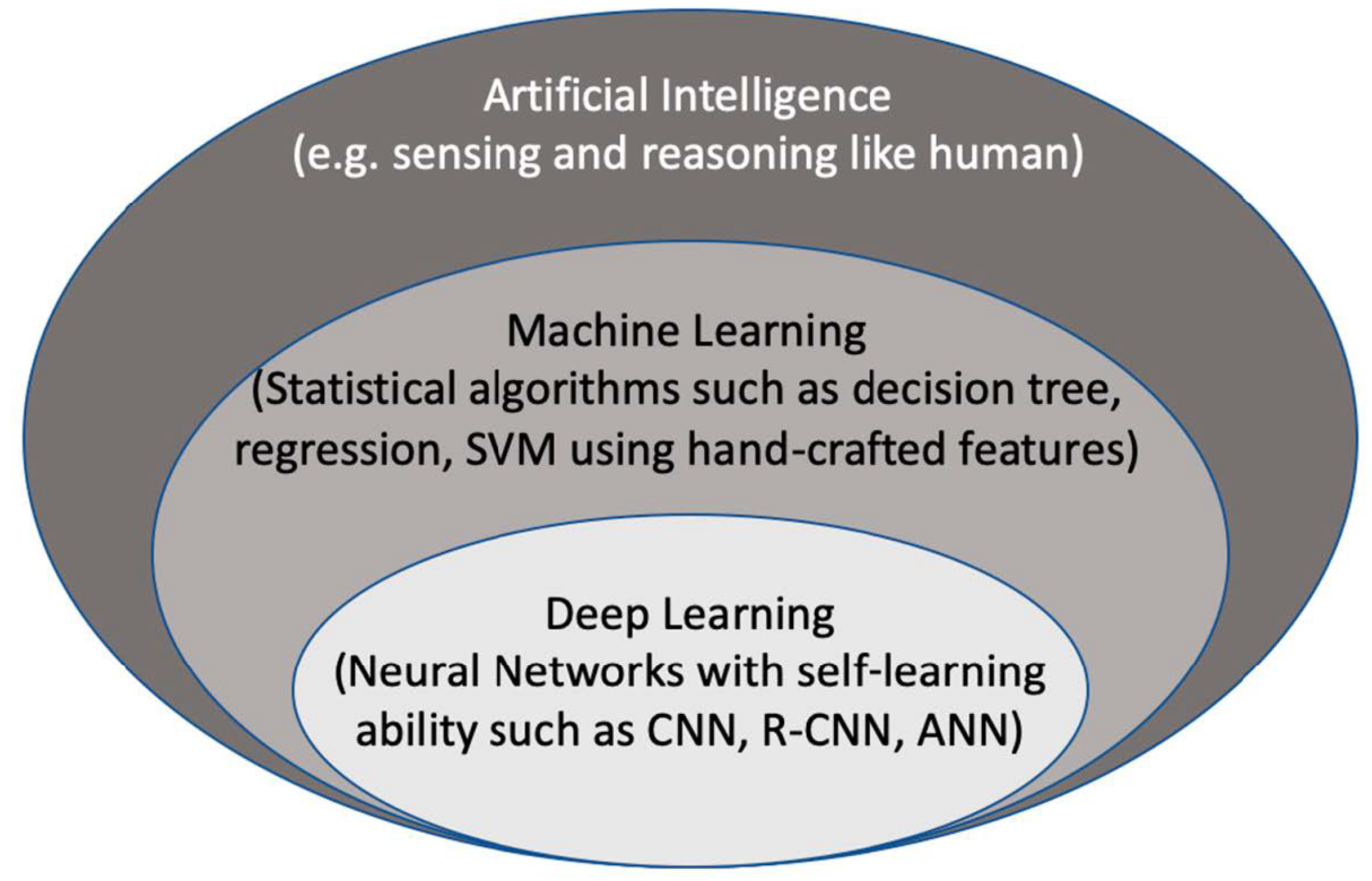
1.2. Artificial Intelligence
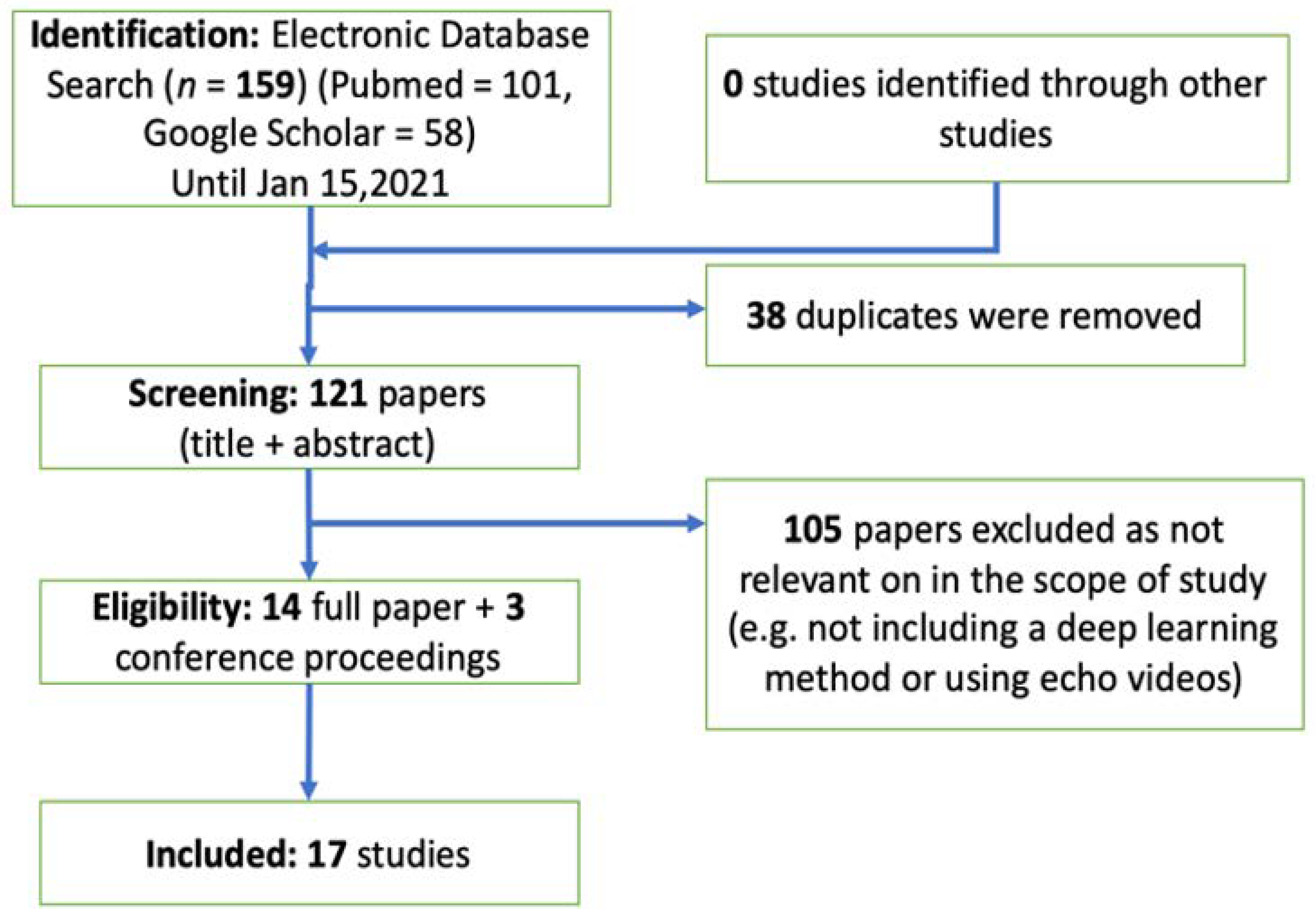
2. Methods and Results: Automated Echo Interpretation
2.1. View Identification and Quality Control
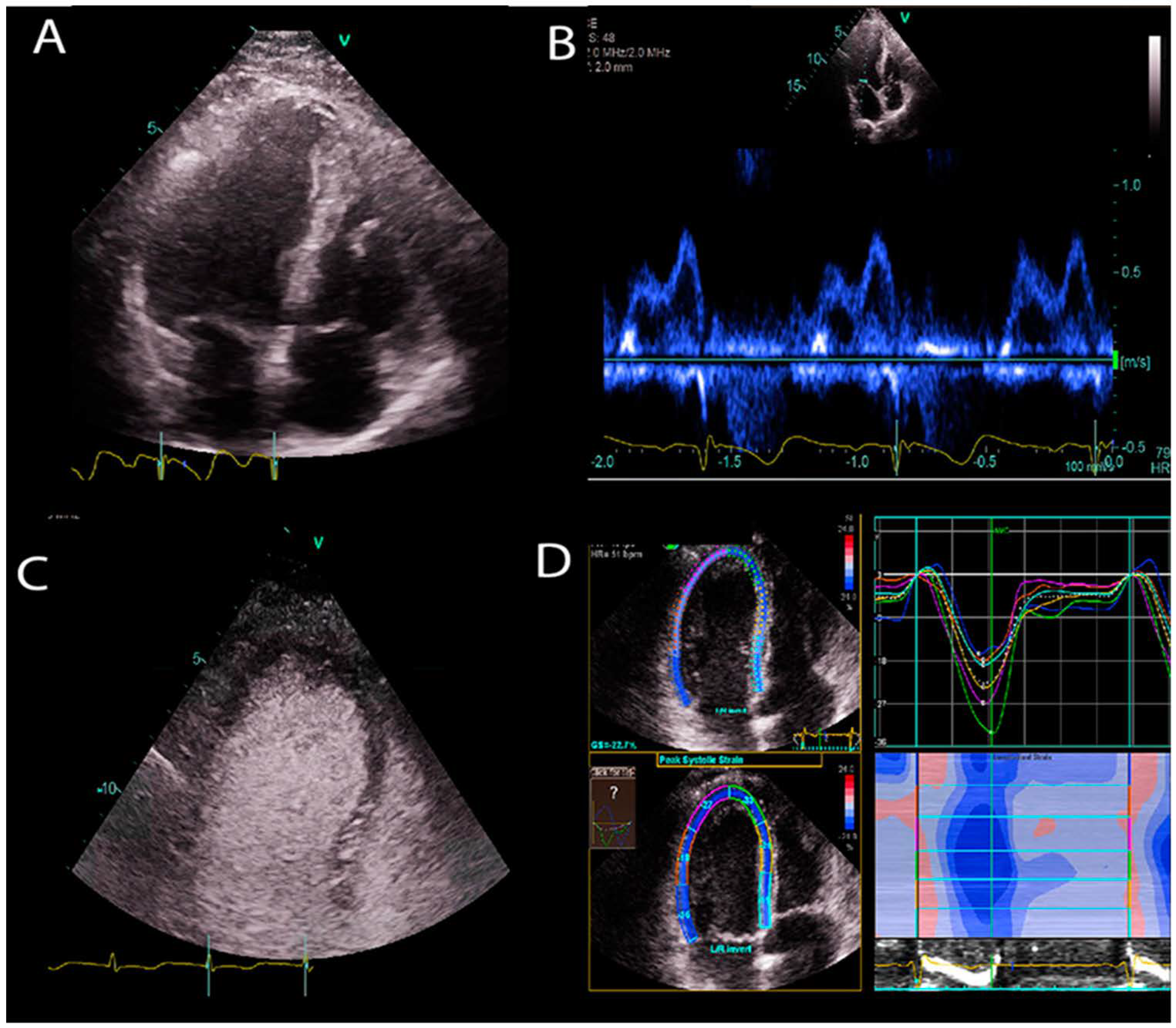
2.2. Image Segmentation and Quantification
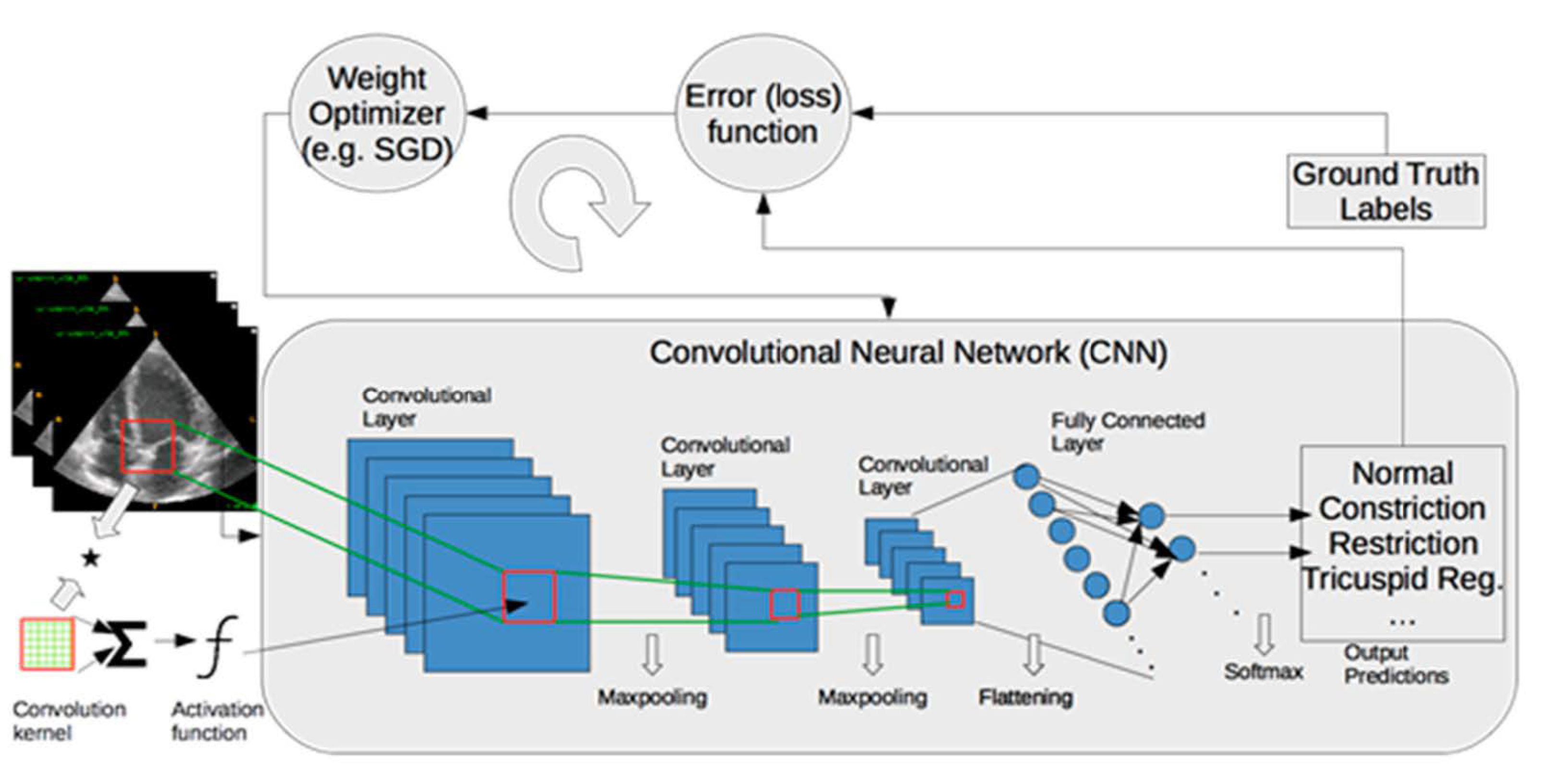
2.3. Disease Diagnosis
3. Discussion and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- Zamzmi, G.; Hsu, L.-Y.; Li, W.; Sachdev, V.; Antani, S. Harnessing Machine Intelligence in Automatic Echocardiogram Analysis: Current Status, Limitations, and Future Directions. IEEE Rev. Biomed. Eng. 2020. [Google Scholar] [CrossRef] [PubMed]
- Alsharqi, M.; Woodward, W.J.; Mumith, J.A.; Markham, D.C.; Upton, R.; Leeson, P. Artificial intelligence and echocardiography. Echo Res. Pract. 2018, 5, R115–R125. [Google Scholar] [CrossRef]
- Akkus, Z.; Galimzianova, A.; Hoogi, A.; Rubin, D.L.; Erickson, B.J. Deep Learning for Brain MRI Segmentation: State of The Art and Future Directions. J. Digit. Imaging 2017, 30, 449–459. [Google Scholar] [CrossRef] [PubMed]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2009. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Hong Kong, China, 2012; pp. 1097–1105. [Google Scholar]
- Akkus, Z.; Kostandy, P.; Philbrick, K.A.; Erickson, B.J. Robust brain extraction tool for CT head images. Neurocomputing 2020, 392, 189–195. [Google Scholar] [CrossRef]
- Akkus, Z.; Ali, I.; Sedlář, J.; Agrawal, J.P.; Parney, I.F.; Giannini, C.; Erickson, B.J. Predicting Deletion of Chromosomal Arms 1p/19q in Low-Grade Gliomas from MR Images Using Machine Intelligence. J. Digit. Imaging 2017, 30, 469–476. [Google Scholar] [CrossRef]
- Cai, J.C.; Akkus, Z.; Philbrick, K.A.; Boonrod, A.; Hoodeshenas, S.; Weston, A.D.; Rouzrokh, P.; Conte, G.M.; Zeinoddini, A.; Vogelsang, D.C.; et al. Fully Automated Segmentation of Head CT Neuroanatomy Using Deep Learning. Radiol. Artif. Intell. 2020, 2, e190183. [Google Scholar] [CrossRef]
- Akkus, Z.; Cai, J.; Boonrod, A.; Zeinoddini, A.; Weston, A.D.; Philbrick, K.A.; Erickson, B.J. A Survey of Deep-Learning Applications in Ultrasound: Artificial Intelligence-Powered Ultrasound for Improving Clinical Workflow. J. Am. Coll. Radiol. 2019, 16, 1318–1328. [Google Scholar] [CrossRef]
- Leclerc, S.; Smistad, E.; Pedrosa, J.; Ostvik, A.; Cervenansky, F.; Espinosa, F.; Espeland, T.; Berg, E.A.R.; Jodoin, P.-M.; Grenier, T.; et al. Deep Learning for Segmentation using an Open Large-Scale Dataset in 2D Echocardiography. IEEE Trans. Med. Imaging 2019. [Google Scholar] [CrossRef] [PubMed]
- Jafari, M.H.; Girgis, H.; Van Woudenberg, N.; Liao, Z.; Rohling, R.; Gin, K.; Abolmaesumi, P.; Tsang, T. Automatic biplane left ventricular ejection fraction estimation with mobile point-of-care ultrasound using multi-task learning and adversarial training. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 1027–1037. [Google Scholar] [CrossRef]
- Ouyang, D.; He, B.; Ghorbani, A.; Yuan, N.; Ebinger, J.; Langlotz, C.P.; Heidenreich, P.A.; Harrington, R.A.; Liang, D.H.; Ashley, E.A.; et al. Video-based AI for beat-to-beat assessment of cardiac function. Nature 2020, 580, 252–256. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Gajjala, S.; Agrawal, P.; Tison, G.H.; Hallock, L.A.; Beussink-Nelson, L.; Lassen, M.H.; Fan, E.; Aras, M.A.; Jordan, C.; et al. Fully automated echocardiogram interpretation in clinical practice: Feasibility and diagnostic accuracy. Circulation 2018, 138, 1623–1635. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Gajjala, S.; Agrawal, P.; Tison, G.H.; Hallock, L.A.; Beussink-Nelson, L.; Fan, E.; Aras, M.A.; Jordan, C.; Fleischmann, K.E.; et al. A web-deployed computer vision pipeline for automated determination of cardiac structure and function and detection of disease by two-dimensional echocardiography. arXiv 2017, arXiv:1706.07342. [Google Scholar]
- Deo, R. Echocv. Available online: https://bitbucket.org/rahuldeo/echocv (accessed on 26 March 2021).
- Madani, A.; Arnaout, R.; Mofrad, M.; Arnaout, R. Fast and accurate view classification of echocardiograms using deep learning. NPJ Digit. Med. 2018, 1. [Google Scholar] [CrossRef]
- Elwazir, M.Y.; Akkus, Z.; Oguz, D.; Ye, Z.; Oh, J.K. Fully Automated Mitral Inflow Doppler Analysis Using Deep Learning. In Proceedings of the 2020 IEEE 20th International Conference on Bioinformatics and Bioengineering (BIBE); IEEE: Piscataway, NJ, USA, 2020; pp. 691–696. [Google Scholar]
- Abdi, A.H.; Luong, C.; Tsang, T.; Allan, G.; Nouranian, S.; Jue, J.; Hawley, D.; Fleming, S.; Gin, K.; Swift, J.; et al. Automatic quality assessment of apical four-chamber echocardiograms using deep convolutional neural networks. In Proceedings of the Medical Imaging 2017: Image Processing; International Society for Optics and Photonics; IEEE: Piscataway, NJ, USA, 2017; Volume 10133, p. 101330S. [Google Scholar]
- Abdi, A.H.; Luong, C.; Tsang, T.; Allan, G.; Nouranian, S.; Jue, J.; Hawley, D.; Fleming, S.; Gin, K.; Swift, J.; et al. Automatic Quality Assessment of Echocardiograms Using Convolutional Neural Networks: Feasibility on the Apical Four-Chamber View. IEEE Trans. Med. Imaging 2017, 36, 1221–1230. [Google Scholar] [CrossRef] [PubMed]
- Abdi, A.H.; Luong, C.; Tsang, T.; Jue, J.; Gin, K.; Yeung, D.; Hawley, D.; Rohling, R.; Abolmaesumi, P. Quality Assessment of Echocardiographic Cine Using Recurrent Neural Networks: Feasibility on Five Standard View Planes. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2017; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 302–310. [Google Scholar]
- Dong, J.; Liu, S.; Liao, Y.; Wen, H.; Lei, B.; Li, S.; Wang, T. A Generic Quality Control Framework for Fetal Ultrasound Cardiac Four-Chamber Planes. IEEE J. Biomed. Health Inform. 2020, 24, 931–942. [Google Scholar] [CrossRef]
- Labs, R.B.; Vrettos, A.; Azarmehr, N.; Howard, J.P.; Shun-shin, M.J.; Cole, G.D.; Francis, D.P.; Zolgharni, M. Automated Assessment of Image Quality in 2D Echocardiography Using Deep Learning. In Proceedings of the International Conference on Radiology, Medical Imaging and Radiation Oncology, Paris, France, 25–26 June 2020. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–6 February 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Lecture Notes in Computer Science; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Munich, Germany, 2015; Volume 9351, pp. 234–241. ISBN 9783319245737. [Google Scholar]
- Leclerc, S.; Smistad, E.; Pedrosa, J.; Ostvik, A. Cardiac Acquisitions for Multi-Structure Ultrasound Segmentation. Available online: https://camus.creatis.insa-lyon.fr/challenge/ (accessed on 26 March 2021).
- Jafari, M.H.; Girgis, H.; Liao, Z.; Behnami, D.; Abdi, A.; Vaseli, H.; Luong, C.; Rohling, R.; Gin, K.; Tsang, T.; et al. A Unified Framework Integrating Recurrent Fully-Convolutional Networks and Optical Flow for Segmentation of the Left Ventricle in Echocardiography Data. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer International Publishing: Granada, Spain, 2018; pp. 29–37. [Google Scholar]
- Chen, H.; Zheng, Y.; Park, J.-H.; Heng, P.-A.; Zhou, S.K. Iterative Multi-domain Regularized Deep Learning for Anatomical Structure Detection and Segmentation from Ultrasound Images. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2016, Athens, Greece, 17–21 October 2016; pp. 487–495. [Google Scholar]
- Oktay, O.; Ferrante, E.; Kamnitsas, K.; Heinrich, M.; Bai, W.; Caballero, J.; Cook, S.A.; de Marvao, A.; Dawes, T.; O’Regan, D.P.; et al. Anatomically Constrained Neural Networks (ACNNs): Application to Cardiac Image Enhancement and Segmentation. IEEE Trans. Med. Imaging 2018, 37, 384–395. [Google Scholar] [CrossRef]
- Ghorbani, A.; Ouyang, D.; Abid, A.; He, B.; Chen, J.H.; Harrington, R.A.; Liang, D.H.; Ashley, E.A.; Zou, J.Y. Deep learning interpretation of echocardiograms. NPJ Digit. Med. 2020, 3, 10. [Google Scholar] [CrossRef]
- Ouyang, D. EchoNet-Dynamic. Available online: https://echonet.github.io/dynamic/ (accessed on 26 March 2021).
- Omar, H.A.; Domingos, J.S.; Patra, A.; Upton, R.; Leeson, P.; Noble, J.A. Quantification of cardiac bull’s-eye map based on principal strain analysis for myocardial wall motion assessment in stress echocardiography. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 1195–1198. [Google Scholar]
- Kusunose, K.; Abe, T.; Haga, A.; Fukuda, D.; Yamada, H.; Harada, M.; Sata, M. A Deep Learning Approach for Assessment of Regional Wall Motion Abnormality from Echocardiographic Images. JACC Cardiovasc. Imaging 2020, 13, 374–381. [Google Scholar] [CrossRef] [PubMed]
- Narula, S.; Shameer, K.; Salem Omar, A.M.; Dudley, J.T.; Sengupta, P.P. Machine-Learning Algorithms to Automate Morphological and Functional Assessments in 2D Echocardiography. J. Am. Coll. Cardiol. 2016, 68, 2287–2295. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Lecture Notes in Computer Science, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the 2011 International Conference on Computer Vision, Washington, DC, USA, 6–13 November 2011. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional Networks; IEEE Computer Society: San Francisco, CA, USA, 2010; pp. 2528–2535. ISBN 9781424469840. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Li, G.; Yu, Y. Visual Saliency Detection Based on Multiscale Deep CNN Features. IEEE Trans. Image Process. 2016, 25, 5012–5024. [Google Scholar] [CrossRef] [PubMed]
- Philbrick, K.A.; Yoshida, K.; Inoue, D.; Akkus, Z.; Kline, T.L.; Weston, A.D.; Korfiatis, P.; Takahashi, N.; Erickson, B.J. What Does Deep Learning See? Insights from a Classifier Trained to Predict Contrast Enhancement Phase from CT Images. AJR Am. J. Roentgenol. 2018, 211, 1184–1193. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
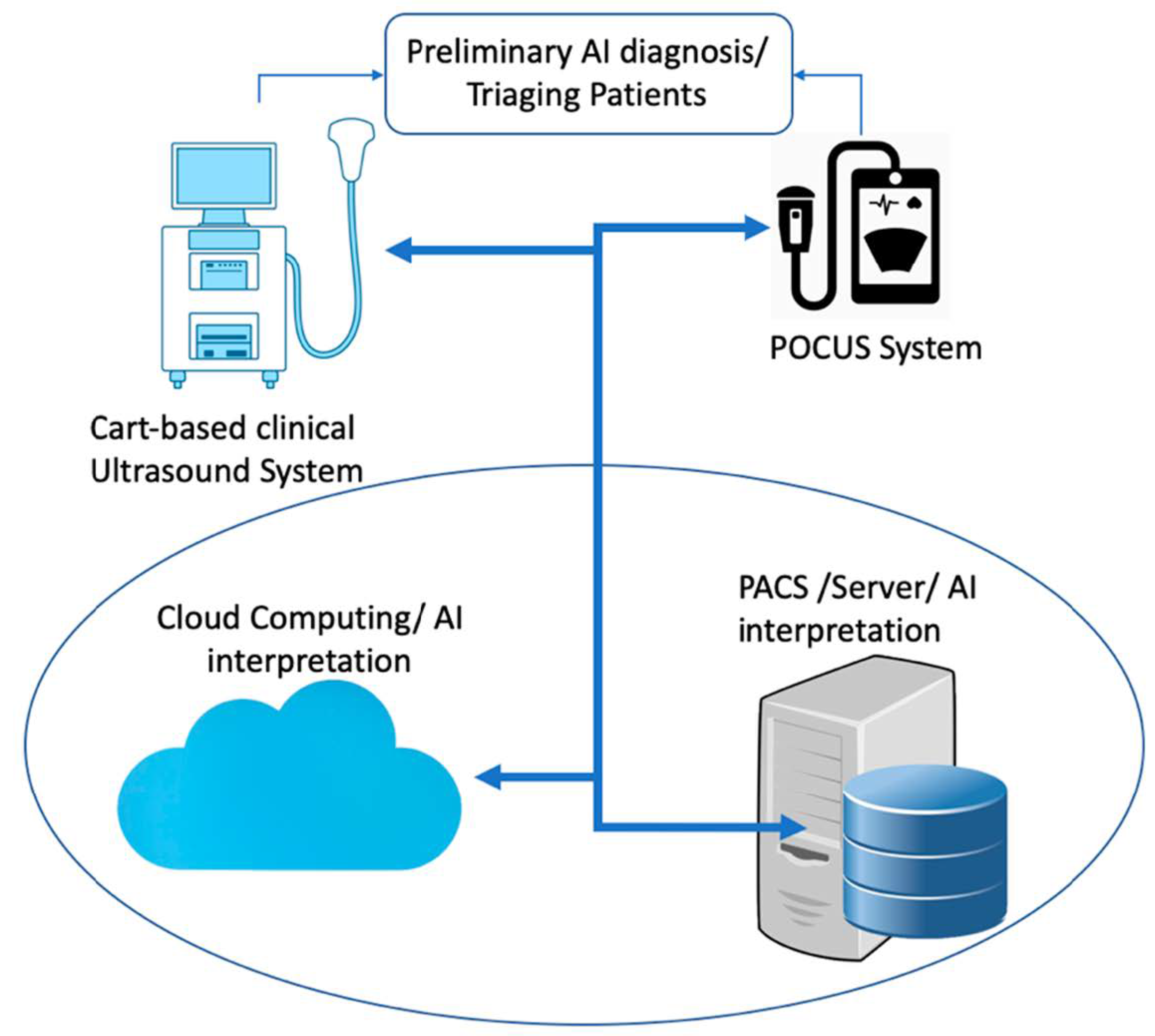{kind=link}
| Company | Software Package | AI-Empowered Tools |
|---|---|---|
| Siemens Medical Solutions Inc., USA | syngo Auto Left Heart, Acuson S2000 US system. | Auto EF, Auto LV and LA volumes, Auto Strain for manually selected views. |
| GE Healthcare, Inc., USA | Ultra Edition Package, Vivid Ultrasound Systems | Auto EF, Auto LV and LA volumes, Auto Strain for manually selected views |
| TOMTEC Imaging Systems GmbH, Germany | Tomtec-Arena/Tomtec-Zero | Auto EF, Auto LV and LA volumes, Auto Strain for manually selected views |
| Ultromics Ltd., United Kingdom | Echo Go/Echo Go Pro | Auto EF, Auto LV and LA volumes, Auto Strain, Auto identification of CHD (Fully automated) |
| Dia Imaging Analysis Ltd., Israel | DiaCardio’s LVivoEF Software/LVivo Seamless | Auto EF and Auto standard echo view identification (Fully automated) |
| Caption Health, Inc., USA | The Caption Guidance software | AI tool for assisting to capture images of a patient’s heart |
| Task | DL Model | Data/Validation | Performance | |
|---|---|---|---|---|
| Zhang et al. [16,17] | 23 standard echo view classification | Customized 13-layer CNN model | 5-fold cross validation/7168 cine clips of 277 studies | Overall accuracy: 84% at individual image level |
| Mandani et al. [19] | 15 standard echo view classification | VGG [26] | Training: 180,294 images of 213 studies Testing: 21,747 images of 27 studies | Overall accuracy: 97.8% at individual image level and 91.7% at cine-lip level |
| Akkus et al. [20] | 24 Doppler image classes | Inception_resnet [27] | Training: 5544 images of 140 studies Testing: 1737 images of 40 studies | Overall accuracy of 97% |
| Abdi et al. [21,22] | Rating quality of apical 4 chamber views (0–5 scores) | A customized fully connected CNN | 3-fold cross validation/6196 images | MAE: 0.71 ± 0.58 |
| Abdi et al. [23] | Quality assessment for five standard view planes | CNN regression architecture | Total dataset: 2435 cine clips Training: 80% Testing: 20% | Average of 85% accuracy |
| Dong et al. [24] | QC for fetal ultrasound cardiac four chamber planes | Ensembled three CNN model | 5-fold cross validation (7032 images) | Mean average precision of 93.52%. |
| Labs et al. [25] | Assessing quality of apical 4 chamber view | Hybrid model including CNN and LSTM layers | Training/validation/testing (60/20/20%) of in total of 1039 images | Average accuracy of 86% on the test set |
| Task | DL Model | Data/Validation | Performance | |
|---|---|---|---|---|
| Zhang et al. [16,17] | LV/LA segmentation; LVEF, LV and LA volumes, LV mass, global longitudinal strain | U-Net [28] | LV segmentation: 5-fold cross validation on 791 images; LV volumes: 4748 measurements; LV mass: 4012 measurements; strain: 526 studies | IOU: 0.72–0.90 for LV segmentation; MAD of 9.7% for LVEF; MAD of 15–17% for LV/LA volumes and LV mass; MAD of 9% for strain. |
| Leclerc et al. [13] | LVEF, LV volumes | U-Net [28] | 500 patients | LVEF: AME of 5.6% LV volumes: AME of 9.7 mL |
| Jafari et al. [14] | LV segmentation and bi-plane LVEF | A shallow U-Net with multi-task learning and adversarial training | 854 studies split into 80% training and 20% testing sets | DICE of 0.92 for LV segmentation; MAE of 6.2% for LVEF |
| Chen et al. [31] | LV segmentation in apical 2, 3, 4, or 5 chamber views | An encoder–decoder type CNN with multi-view regularization | Training set: 33,058 images; test set: 8204 images | Average DICE of 0.88 |
| Oktay et al. [32] | LV segmentation; LVEF | Anatomically constrained CNN model | CETUS’14 3D US challenge dataset. (training set: 15 studies; test set: 30 studies) | DICE of 0.91 ± 0.23 for LV segmentation; correlation of 0.91 for LVEF |
| Ghorbani et al. [33] | LV systolic and diastolic volumes; LVEF | A customized CNN model (EchoNet) for semantic segmentation | Training set: 1.6 million images from 2850 patients; test set: 169,000 images from 373 studies | Systolic and diastolic volumes (R2 = 0.74 and R2 = 0.70); R2 = 0.50 for LVEF |
| Ouyang et al. [15] | LVEF | 3D CNN model with residual connections | Training set: 7465 echo videos; internal test dataset (n = 1277); external test dataset (n = 2895) | MAE of 4.1% and 6% for internal and external datasets |
| Task | DL Model | Data/Validation | Performance | |
|---|---|---|---|---|
| Zhang et al. [16,17] | Diagnosis of hypertrophic cardiomyopathy (HCM), cardiac amyloidosis (amyloid), and pulmonary hypertension (PAH) | VGG [26] | HCM: 495/2244 Amyloid:179/804 PAH:584/2487 (Diseased/Control) 5-fold cross validation | Hypertrophic cardiomyopathy: AUC of 0.93; cardiac amyloidosis: AUC of 0.87; pulmonary hypertension: AUC of 0.85 |
| Ghorbani et al. [33] | Diagnose presence of pacemaker leads; enlarged left atrium; LV hypertrophy | A customized CNN model | Training set: 1.6 million images from 2850 patients; test set: 169,000 images from 373 studies | Presence of pacemaker leads with AUC = 0.89; enlarged left atrium with AUC = 0.86, left ventricular hypertrophy with AUC = 0.75. |
| Ouyang et al. [15] | Predict presence of HF with reduced EF | 3D convolutions with residual connection | Training set: 7465 echo videos; internal test dataset (n = 1277); external test dataset (n = 2895) | AUC of 0.97 |
| Omar et al. [35] | Detecting wall motion abnormalities | Modified VGG-16 [26] | 120 echo studies. One-leave-out cross validation | Accuracy: RF = 72.1%, SVM = 70.5% CNN = 75.0% |
| Kusunose et al. [36] | Detecting wall motion abnormalities (WMA) | Resnet [38] | 300 patients with WMA +100 normal control. Training = 64% Validation:16% Test: 20% | AUC of 0.99 |
| Narula et al. [37] | Differentiate HCM from ATH | A customized ANN | 77 ATH and 62 HCM patients. Ten-fold cross validation | Sensitivity: 87% Specificity: 82% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akkus, Z.; Aly, Y.H.; Attia, I.Z.; Lopez-Jimenez, F.; Arruda-Olson, A.M.; Pellikka, P.A.; Pislaru, S.V.; Kane, G.C.; Friedman, P.A.; Oh, J.K. Artificial Intelligence (AI)-Empowered Echocardiography Interpretation: A State-of-the-Art Review. J. Clin. Med. 2021, 10, 1391. https://doi.org/10.3390/jcm10071391
Akkus Z, Aly YH, Attia IZ, Lopez-Jimenez F, Arruda-Olson AM, Pellikka PA, Pislaru SV, Kane GC, Friedman PA, Oh JK. Artificial Intelligence (AI)-Empowered Echocardiography Interpretation: A State-of-the-Art Review. Journal of Clinical Medicine. 2021; 10(7):1391. https://doi.org/10.3390/jcm10071391
Chicago/Turabian StyleAkkus, Zeynettin, Yousof H. Aly, Itzhak Z. Attia, Francisco Lopez-Jimenez, Adelaide M. Arruda-Olson, Patricia A. Pellikka, Sorin V. Pislaru, Garvan C. Kane, Paul A. Friedman, and Jae K. Oh. 2021. "Artificial Intelligence (AI)-Empowered Echocardiography Interpretation: A State-of-the-Art Review" Journal of Clinical Medicine 10, no. 7: 1391. https://doi.org/10.3390/jcm10071391
APA StyleAkkus, Z., Aly, Y. H., Attia, I. Z., Lopez-Jimenez, F., Arruda-Olson, A. M., Pellikka, P. A., Pislaru, S. V., Kane, G. C., Friedman, P. A., & Oh, J. K. (2021). Artificial Intelligence (AI)-Empowered Echocardiography Interpretation: A State-of-the-Art Review. Journal of Clinical Medicine, 10(7), 1391. https://doi.org/10.3390/jcm10071391