Early Detection of Septic Shock Onset Using Interpretable Machine Learners

 , ,
, ,  ,
, 

Abstract
1. Introduction
2. Related Works
3. Methods
3.1. Data Sources
3.2. Feature Assessment
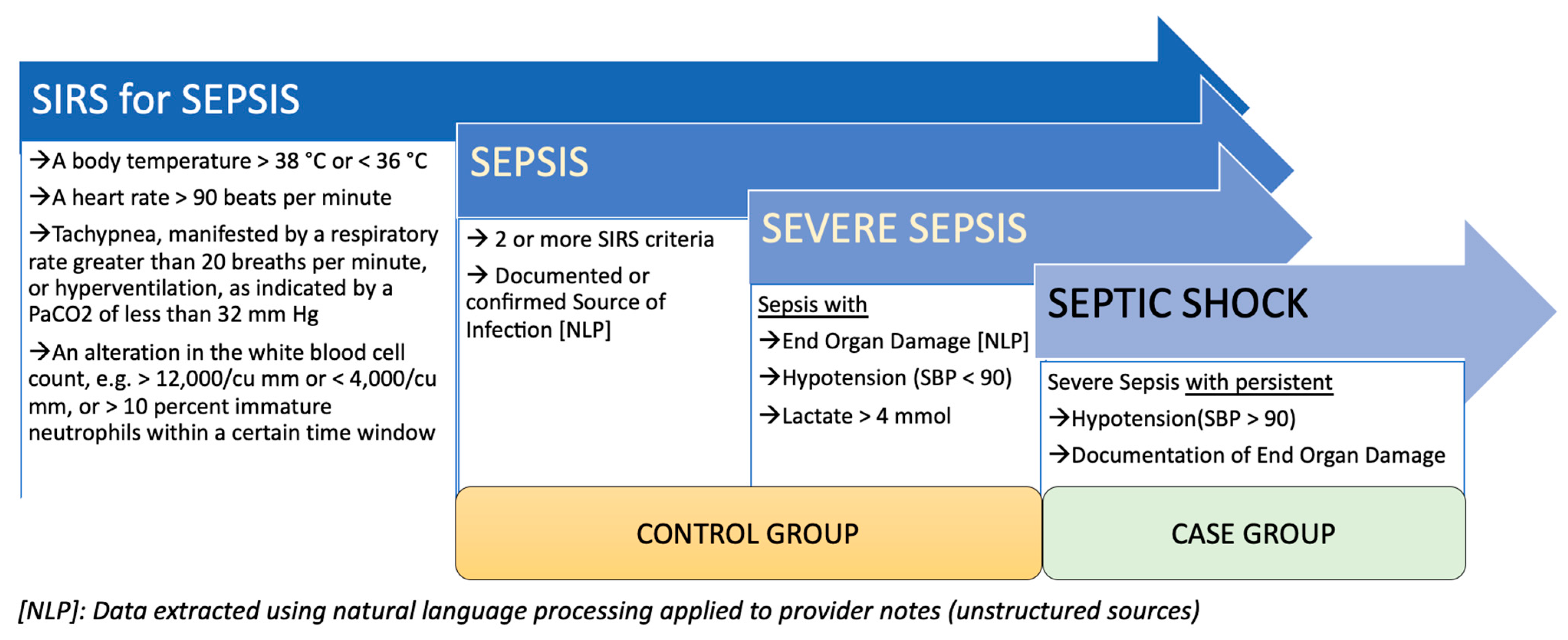
3.3. Cohort Selection
3.4. Data Extraction
3.5. Data Processing
3.5.1. Outlier Removal
3.5.2. Imputation
3.5.3. Class Imbalance
3.6. Modeling Strategy
4. Results
4.1. Patient Characteristics
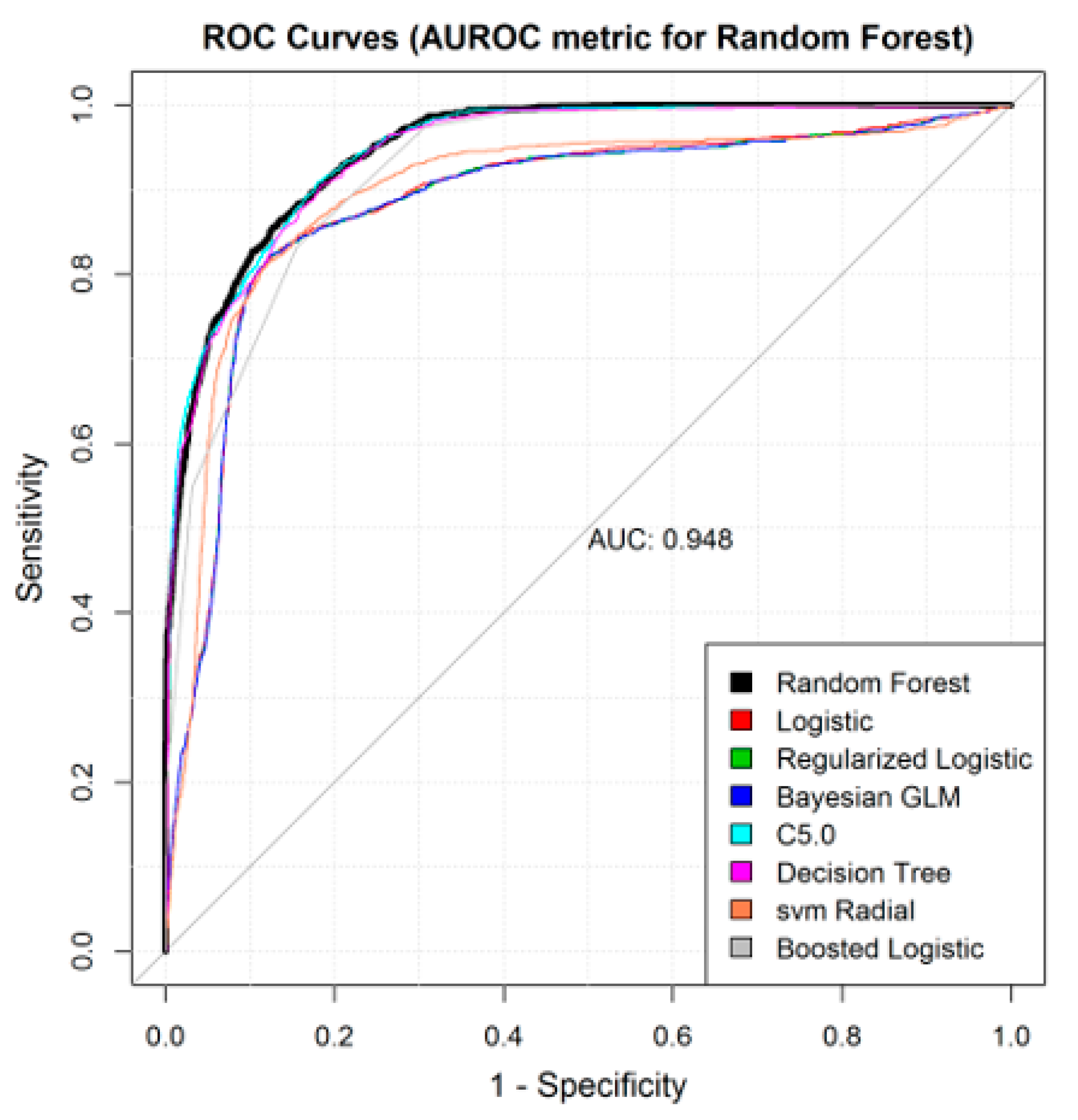
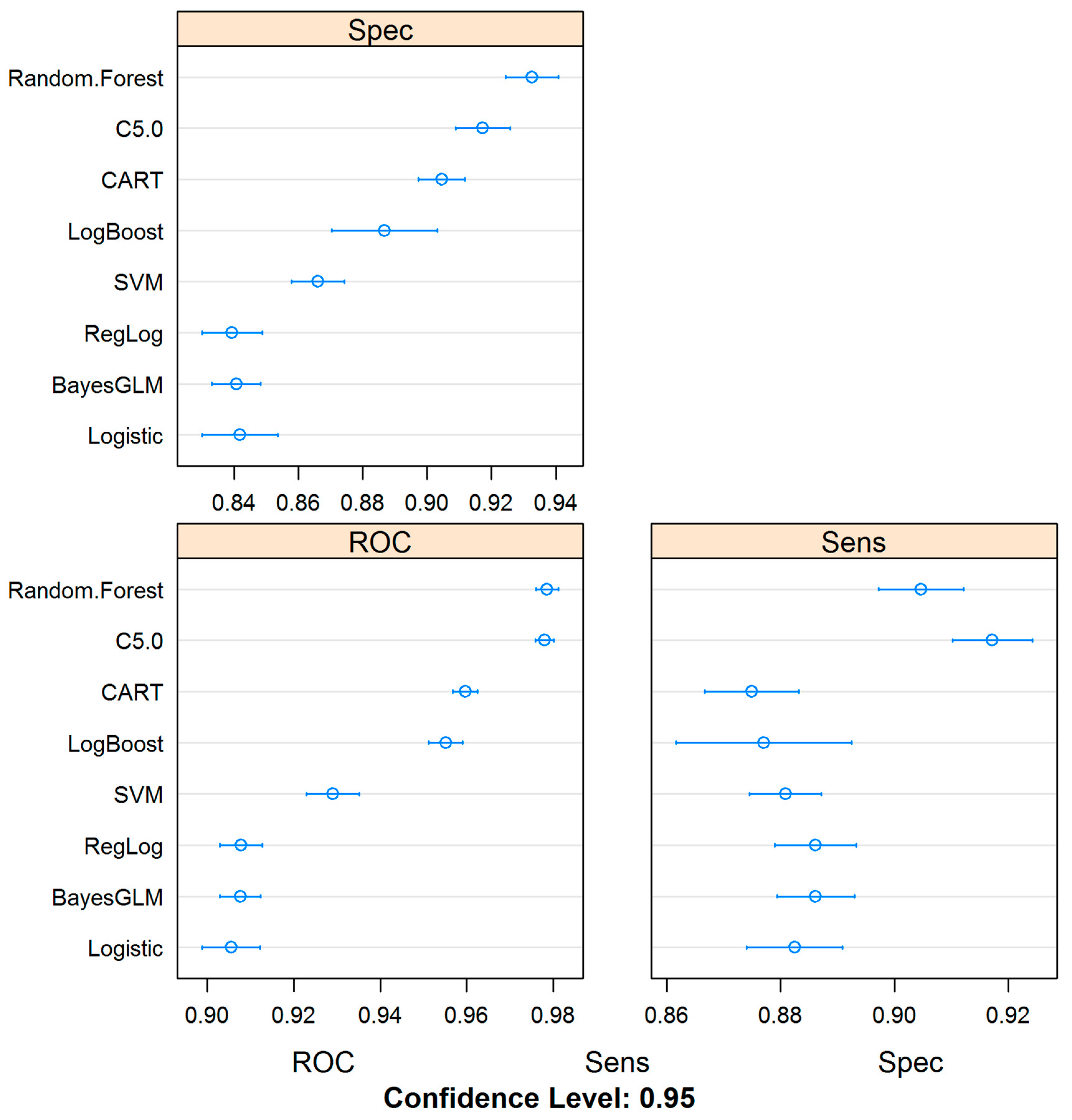
4.2. Machine Learning Models Can Be Trained for the Detection of Septic Shock Using Administrative Datasets
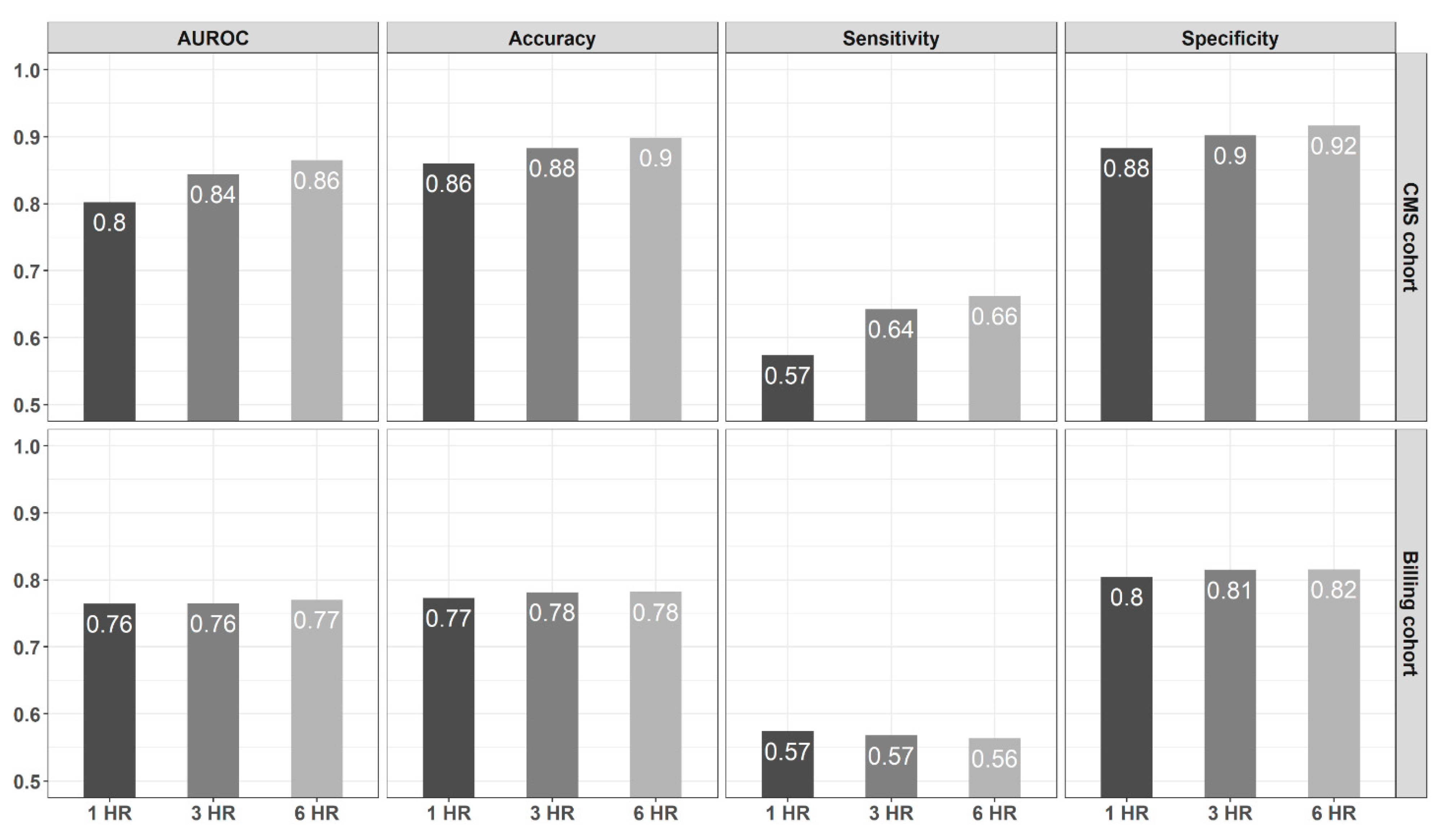
4.3. Model Prediction Performance Improves as the Time from Admission Widens
4.4. Models Based on CMS-Derived Information Have Better Detection Power
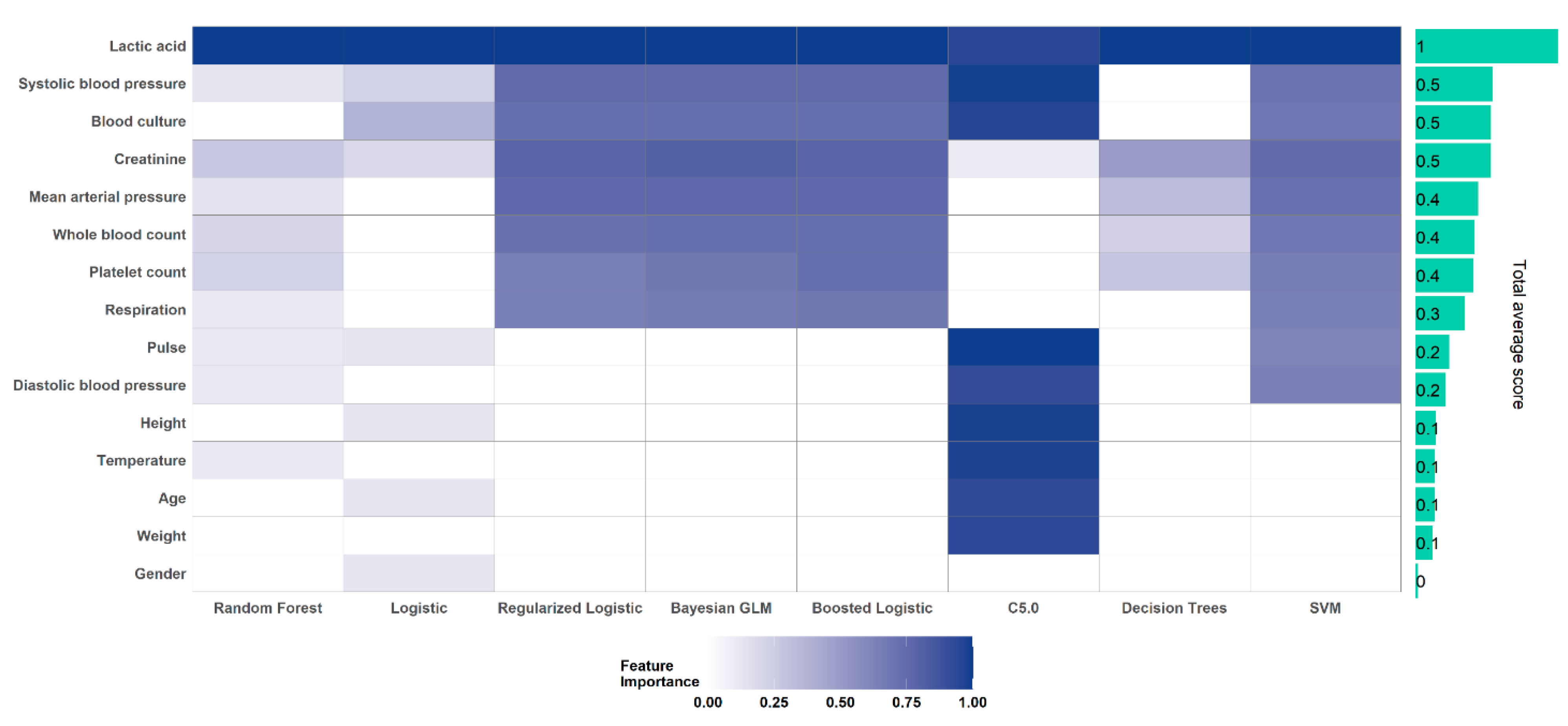
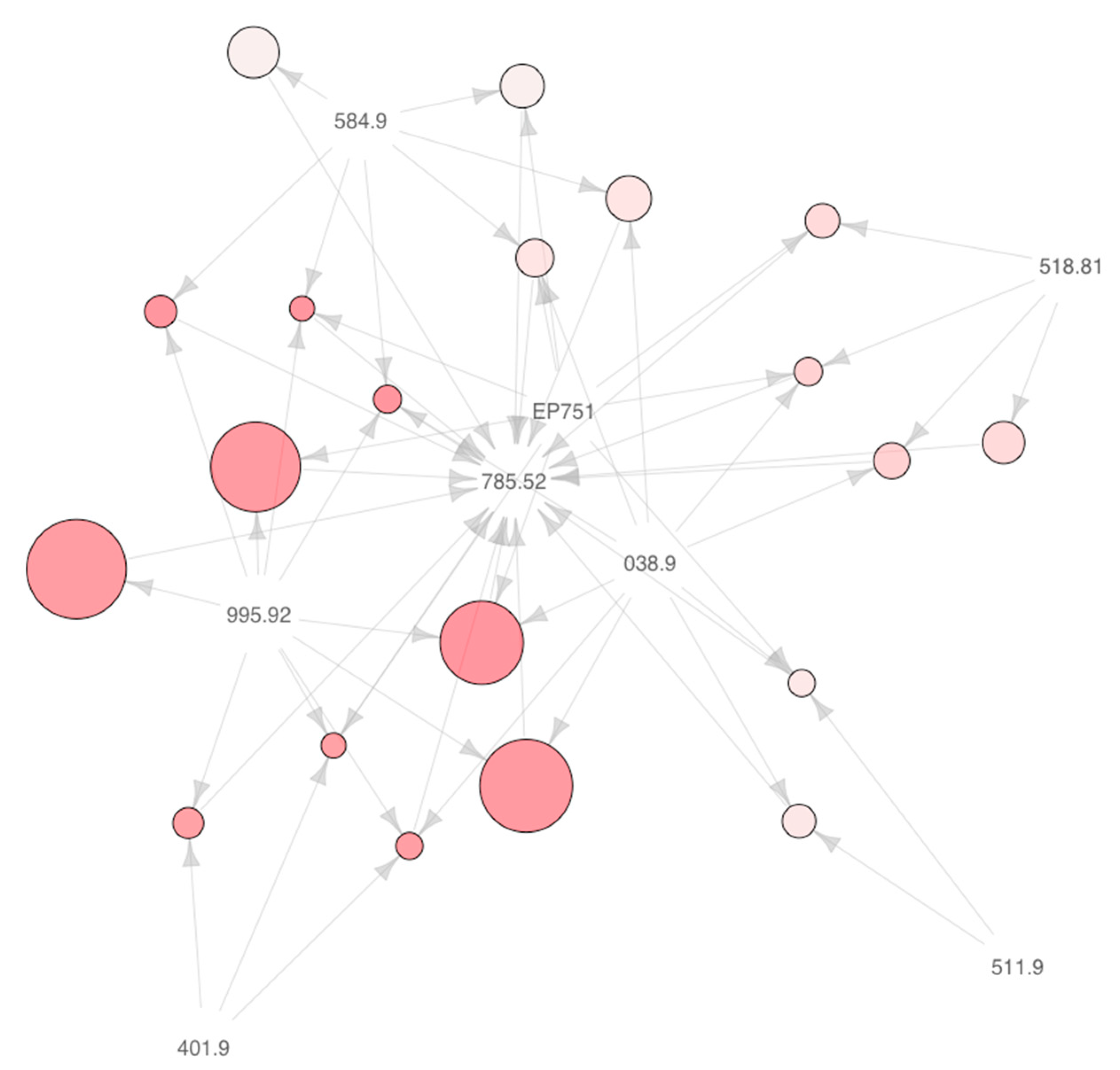
4.5. Important Clinical Markers of Septic Shock
5. Discussion
5.1. Design Consideration for Building a Clinical Decision Support System for Detection of Septic Shock Using Healthcare Data
5.2. Lactic Acid and Other Laboratory Measurements are Highly Important Indicators of Progression to Septic Shock
5.3. Strengths, Limitations, and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MEASURE | LOWER_LIMIT | UPPER_LIMIT |
|---|---|---|
| Temperature | 96.8 | 101 |
| Heart rate (pulse) | 90 | |
| Respiration | 20 | |
| White blood cell count | 4000 | 12,000 |
| Systolic blood pressure (SBP) | 90 | |
| Mean arterial pressure | 65 | |
| SBP decrease | Baseline-40 | |
| Creatinine | 2 | |
| Urine output | 0.5 | |
| Bilirubin | 2 | |
| Platelets | 100,000 | |
| INR 1 | 1.5 | |
| APTT 2 | 60 | |
| Lactate | 2 |


References
- Bone, R.C.; Balk, R.A.; Cerra, F.B.; Dellinger, R.P.; Fein, A.M.; Knaus, W.A.; Schein, R.M.; Sibbald, W.J. Definitions for sepsis and organ failure and guidelines for the use of innovative therapies in sepsis. Chest 1992, 101, 1644–1655. [Google Scholar] [CrossRef] [PubMed]
- Gul, F.; Arslantas, M.K.; Cinel, I.; Kumar, A. Changing Definitions of Sepsis. Turk. J. Anesth. Reanim. 2017, 45, 129–138. [Google Scholar] [CrossRef] [PubMed]
- Marik, P.E.; Taeb, A.M. SIRS, qSOFA and new sepsis definition. J. Thorac. Dis. 2017, 9, 943–945. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Roberts, D.; Wood, K.E.; Light, B.; Parrillo, J.E.; Sharma, S.; Suppes, R.; Feinstein, D.; Zanotti, S.; Taiberg, L.; et al. Duration of hypotension before initiation of effective antimicrobial therapy is the critical determinant of survival in human septic shock*. Crit. Care Med. 2006, 34, 1589–1596. [Google Scholar] [CrossRef] [PubMed]
- Rivers, E.P.; Nguyen, B.; Havstad, S.; Ressler, J.; Muzzin, A.; Knoblich, B.; Peterson, E.; Tomlanovich, M. Early Goal-Directed Therapy in the Treatment of Severe Sepsis and Septic Shock. N. Engl. J. Med. 2001, 345, 1368–1377. [Google Scholar] [CrossRef] [PubMed]
- Mayr, F.B.; Yende, S.; Angus, D.C. Epidemiology of severe sepsis. Virulence 2014, 5, 4–11. [Google Scholar] [CrossRef]
- Ruokonen, E.; Takala, J.; Kari, A.; Alhava, E. Septic shock and multiple organ failure. Crit. Care Med. 1991, 19, 1146–1151. [Google Scholar] [CrossRef]
- Paoli, C.J.; Reynolds, M.A.; Sinha, M.; Gitlin, M.; Crouser, E. Epidemiology and Costs of Sepsis in the United States—An Analysis Based on Timing of Diagnosis and Severity Level. Crit. Care Med. 2018, 46, 1889–1897. [Google Scholar] [CrossRef]
- Nam, J.G.; Park, S.; Hwang, E.J.; Lee, J.H.; Jin, K.-N.; Lim, K.Y.; Vu, T.H.; Sohn, J.H.; Hwang, S.; Goo, J.M.; et al. Development and Validation of Deep Learning–based Automatic Detection Algorithm for Malignant Pulmonary Nodules on Chest Radiographs. Radiology 2019, 290, 218–228. [Google Scholar] [CrossRef]
- Wu, N.; Phang, J.; Park, J.; Shen, Y.; Huang, Z.; Zorin, M.; Jastrzebski, S.; Fevry, T.; Katsnelson, J.; Kim, E.; et al. Deep Neural Networks Improve Radiologists’ Performance in Breast Cancer Screening. IEEE Trans. Med. Imaging 2020, 39, 1184–1194. [Google Scholar] [CrossRef]
- Noorbakhsh-Sabet, N.; Zand, R.; Zhang, Y.; Abedi, V. Artificial Intelligence Transforms the Future of Health Care. Am. J. Med. 2019, 132, 795–801. [Google Scholar] [CrossRef] [PubMed]
- Singh, R.; Kalra, M.K.; Nitiwarangkul, C.; Patti, J.A.; Homayounieh, F.; Padole, A.; Rao, P.; Putha, P.; Muse, V.V.; Sharma, A.; et al. Deep learning in chest radiography: Detection of findings and presence of change. PLoS ONE 2018, 13, e0204155. [Google Scholar] [CrossRef] [PubMed]
- Karunakaran, B.; Misra, D.; Marshall, K.; Mathrawala, D.; Kethireddy, S. Closing the loop—Finding lung cancer patients using NLP. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 2452–2461. [Google Scholar]
- Zheng, L.; Wang, Y.; Hao, S.; Sylvester, K.G.; Ling, X.B.; Shin, A.Y.; Jin, B.; Zhu, C.; Jin, H.; Dai, D.; et al. Risk prediction of stroke: A prospective statewide study on patients in Maine. In Proceedings of the 2015 IEEE International Conference on Bioinformatics and Biomedicine, BIBM, Washington, DC, USA, 9–12 November 2015; pp. 853–855. [Google Scholar] [CrossRef]
- Escobar, G.J.; Turk, B.J.; Ragins, A.; Ha, J.; Hoberman, B.; LeVine, S.M.; Ballesca, M.A.; Liu, V.; Kipnis, P. Piloting electronic medical record—based early detection of inpatient deterioration in community hospitals. J. Hosp. Med. 2016, 11, S18–S24. [Google Scholar] [CrossRef] [PubMed]
- Brun-Buisson, C.; Doyon, F.; Carlet, J.; Dellamonica, P.; Gouin, F.; Lepoutre, A.; Mercier, J.-C.; Offenstadt, G.; Régnier, B. Incidence, Risk Factors, and Outcome of Severe Sepsis and Septic Shock in Adults. JAMA 1995, 274, 968–974. [Google Scholar] [CrossRef] [PubMed]
- Raghu, A.; Komorowski, M.; Ahmed, I.; Celi, L.; Szolovits, P.; Ghassemi, M. Deep reinforcement learning for sepsis treatment. arXiv 2017, arXiv:1711.09602. [Google Scholar]
- Lagu, T.; Rothberg, M.B.; Shieh, M.-S.; Pekow, P.S.; Steingrub, J.S.; Lindenauer, P.K. Hospitalizations, costs, and outcomes of severe sepsis in the United States 2003 to 2007. Crit. Care Med. 2012, 40, 754–761. [Google Scholar] [CrossRef]
- Vogel, T.R.; Dombrovskiy, V.Y.; Lowry, S.F. Trends in Postoperative Sepsis: Are We Improving Outcomes? Surg. Infect. 2009, 10, 71–78. [Google Scholar] [CrossRef]
- Nemati, S.; Holder, A.; Razmi, F.; Stanley, M.D.; Clifford, G.D.; Buchman, T.G. An Interpretable Machine Learning Model for Accurate Prediction of Sepsis in the ICU. Crit. Care Med. 2018, 46, 547–553. [Google Scholar] [CrossRef]
- Giannini, H.M.; Ginestra, J.C.; Chivers, C.; Draugelis, M.; Hanish, A.; Schweickert, W.D.; Fuchs, B.D.; Meadows, L.R.; Lynch, M.; Donnelly, P.J.; et al. A machine learning algorithm to predict severe sepsis and septic shock: Development, implementation, and impact on clinical practice. Read Online Crit. Care Med. Soc. Crit. Care Med. 2019, 47, 1485–1492. [Google Scholar] [CrossRef]
- Kim, J.; Chang, H.; Kim, D.; Jang, D.-H.; Park, I.; Kim, K. Machine learning for prediction of septic shock at initial triage in emergency department. J. Crit. Care 2020, 55, 163–170. [Google Scholar] [CrossRef]
- Schoenberg, M.H.; Weiss, M.; Radermacher, P. Outcome of patients with sepsis and septic shock after ICU treatment. Langenbeck’s Arch. Surg. 1998, 383, 44–48. [Google Scholar] [CrossRef] [PubMed]
- Shimabukuro, D.W.; Barton, C.W.; Feldman, M.D.; Mataraso, S.J.; Das, R. Effect of a machine learning-based severe sepsis prediction algorithm on patient survival and hospital length of stay: A randomised clinical trial. BMJ Open Respir. Res. 2017, 4, e000234. [Google Scholar] [CrossRef] [PubMed]
- Iwashyna, T.J.; Odden, A.; Rohde, J.; Bonham, C.; Kuhn, L.; Malani, P.; Chen, L.; Flanders, S. Identifying Patients With Severe Sepsis Using Administrative Claims. Med. Care 2014, 52, e39–e43. [Google Scholar] [CrossRef] [PubMed]
- Khoshnevisan, F.; Ivy, J.; Capan, M.; Arnold, R.; Huddleston, J.; Chi, M. Recent Temporal Pattern Mining for Septic Shock Early Prediction. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York, NY, USA, 4–7 June 2018; pp. 229–240. [Google Scholar]
- Lin, C.; Zhang, Y.; Ivy, J.; Capan, M.; Arnold, R.; Huddleston, J.M.; Chi, M. Early Diagnosis and Prediction of Sepsis Shock by Combining Static and Dynamic Information Using Convolutional-LSTM. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York, NY, USA, 4–7 June 2018; pp. 219–228. [Google Scholar]
- Klompas, M.; Rhee, C. The CMS Sepsis Mandate: Right Disease, Wrong Measure. Ann. Intern. Med. 2016, 165, 517. [Google Scholar] [CrossRef] [PubMed]
- Allison, M.G.; Schenkel, S.M. SEP-1: A Sepsis Measure in Need of Resuscitation? Ann. Emerg. Med. 2017, 71, 18–20. [Google Scholar] [CrossRef] [PubMed]
- Davies, M.G.; Hagen, P.-O. Systemic inflammatory response syndrome. BJS 1997, 84, 920–935. [Google Scholar] [CrossRef] [PubMed]
- Bodenreider, O. The Unified Medical Language System (UMLS): Integrating biomedical terminology. Nucleic Acids Res. 2004, 32, D267–D270. [Google Scholar] [CrossRef]
- Spackman, K.A.; Campbell, K.E.; Côté, R.A. SNOMED RT: A reference terminology for health care. In Proceedings of the AMIA Annual fall Symposium, Nashville, TN, USA, 25–29 October 1997; p. 640. [Google Scholar]
- McDonald, C.J.; Huff, S.M.; Suico, J.G.; Hill, G.; Leavelle, D.; Aller, R.; Forrey, A.; Mercer, K.; Demoor, G.; Hook, J.; et al. LOINC, a Universal Standard for Identifying Laboratory Observations: A 5-Year Update. Clin. Chem. 2003, 49, 624–633. [Google Scholar] [CrossRef]
- World Health Organization. Enth Revision of the International Classification of Diseases Chapter V (F: Mental, Behavioural and Developmental Disorders, Clinical Descriptions and Diagnostic Guidelines, Rev. 2 1988 Draft; Verlag Hans Huber, Ed.; World Health Organization: Bern, Switzerland, 1991; Available online: https://apps.who.int/iris/handle/10665/61362 (accessed on 1 October 2020).
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. ACM SIGMOD Rec. 1993, 22, 207–216. [Google Scholar] [CrossRef]
- Savova, G.K.; Masanz, J.J.; Ogren, P.V.; Zheng, J.; Sohn, S.; Kipper-Schuler, K.C.; Chute, C.G. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): Architecture, component evaluation and applications. J. Am. Med. Inform. Assoc. 2010, 17, 507–513. [Google Scholar] [CrossRef]
- Vavilapalli, V.K.; Murthy, A.C.; Douglas, C.; Agarwal, S.; Konar, M.; Evans, R.; Graves, T.; Lowe, J.; Shah, H.; Seth, S.; et al. Apache hadoop yarn: Yet another resource negotiator. In Proceedings of the 4th Annual Symposium on Cloud Computing; Association for Computing Machinery: Santa Clara, CA, USA, 2013; pp. 1–16. [Google Scholar]
- Zhang, Z. Missing data imputation: Focusing on single imputation. Ann. Transl. Med. 2016, 4, 9. [Google Scholar] [PubMed]
- Venkataraman, S.; Yang, Z.; Liu, D.; Liang, E.; Falaki, H.; Meng, X.; Xin, R.; Ghodsi, A.; Franklin, M.; Stoica, I.; et al. Sparkr: Scaling r programs with spark. In Proceedings of the 2016 International Conference on Management of Data; Association for Computing Machinery: San Francisco, CA, USA, 2016; pp. 1099–1104. [Google Scholar]
- Wilson, D.L. Asymptotic Properties of Nearest Neighbor Rules Using Edited Data. IEEE Trans. Syst. Man Cybern. 1972, SMC-2, 408–421. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Tahir, M.A.; Kittler, J.; Mikolajczyk, K.; Yan, F. A multiple expert approach to the class imbalance problem using inverse random under sampling. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2009; pp. 82–91. [Google Scholar]
- Abramson, N.; Braverman, D.; Sebestyen, G. Pattern recognition and machine learning. IEEE Trans. Inf. Theory 2004, 9, 257–261. [Google Scholar] [CrossRef]
- Lee, S.-I.; Lee, H.; Abbeel, P.; Ng, A.Y. Efficient l~1 regularized logistic regression. Aaai 2006, 6, 401–408. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001; Volume 1. [Google Scholar]
- Pandya, R.; Pandya, J. C5. 0 Algorithm to Improved Decision Tree with Feature Selection and Reduced Error Pruning. Int. J. Comput. Appl. 2015, 117, 18–21. [Google Scholar] [CrossRef]
- Quinlan, J. Decision trees and decision-making. IEEE Trans. Syst. Man Cybern. 1990, 20, 339–3460. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Ho, T.K. Random decision forests. Proceedings of 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Nasrabadi, N.M. Pattern recognition and machine learning. J. Electron. Imaging 2007, 16, 49901. [Google Scholar]
- Thiel, S.W.; Rosini, J.M.; Shannon, W.; Doherty, J.A.; Micek, S.T.; Kollef, M.H. Early prediction of septic shock in hospitalized patients. J. Hosp. Med. 2010, 5, 19–25. [Google Scholar] [CrossRef]
- Jones, M. NEWSDIG: The National Early Warning Score Development and Implementation Group. Clin. Med. 2012, 12, 501–503. [Google Scholar] [CrossRef]
- Fleuren, L.M.; Klausch, T.L.T.; Zwager, C.L.; Schoonmade, L.J.; Guo, T.; Roggeveen, L.F.; Swart, E.L.; Girbes, A.R.J.; Thoral, P.; Ercole, A.; et al. Machine learning for the prediction of sepsis: A systematic review and meta-analysis of diagnostic test accuracy. Intensiv. Care Med. 2020, 46, 383–400. [Google Scholar] [CrossRef] [PubMed]
- Abedi, V.; Li, J.; Shivakumar, M.K.; Avula, V.; Chaudhary, D.P.; Shellenberger, M.J.; Khara, H.S.; Zhang, Y.; Lee, M.T.M.; Wolk, D.M.; et al. Increasing the Density of Laboratory Measures for Machine Learning Applications. J. Clin. Med. 2020, 10, 103. [Google Scholar] [CrossRef] [PubMed]
- Opitz, D.W.; Maclin, R. Popular Ensemble Methods: An Empirical Study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Hiensch, R.; Poeran, J.; Saunders-Hao, P.; Adams, V.; Powell, C.A.; Glasser, A.; Mazumdar, M.; Patel, G. Impact of an electronic sepsis initiative on antibiotic use and health care facility–onset Clostridium difficile infection rates. Am. J. Infect. Control. 2017, 45, 1091–1100. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. 2014. Available online: http://arxiv.org/abs/1412.6572 (accessed on 1 October 2020).
- Hahsler, M.; Chelluboina, S. Visualizing association rules: Introduction to the R-extension package arulesViz. R Project Module 2011, 223–238. [Google Scholar]




| SEPSIS DATASET | 1 H | 3 H | 6 H | |||
|---|---|---|---|---|---|---|
| Cases | Controls | Cases | Controls | Cases | Controls | |
| PATIENTS, N | 5784 | 30,192 | 5845 | 31,668 | 5852 | 32,329 |
| ENCOUNTERS, N | 6409 | 40,242 | 6475 | 42,475 | 6486 | 43,332 |
| MALE, N(%) | 3322(51) | 18,468(51) | 3355(51) | 19,130(51) | 3360(51) | 17,984(49) |
| MEAN AGE(SD) | 51(27) | 48(29) | 65(19) | 62(21) | 65(19) | 62(21) |
| MEDIAN AGE(IQR) | 56(11–101) | 50(5–95) | 67(44–90) | 67(42–92) | 69(46–92) | 66(41–91) |
| MEAN WEIGHT(SD) | 166.55(76.46) | 158.13(81.50) | 179.34(67.18) | 178.75(71.28) | 179.30(67.26) | 178.51(71.51) |
| VITALS, MEAN(SD) | ||||||
| DIASTOLIC BP | 72.3(16.6) | 73.8(16.9) | 63.2(20.8) | 67.4(17.9) | 63.2(20.8) | 67.3(17.9) |
| SYSTOLIC BP | 129.8(26.3) | 129.2(25.6) | 111.0(29.4) | 123.5(28.1) | 110.9(29.5) | 123.3(28.2) |
| PULSE | 95.80(27.06) | 101.54(28.30) | 108.20(26.23) | 100.89(24.65) | 108.22(26.26) | 100.83(24.69) |
| RESPIRATION | 20.90(8.04) | 21.92(9.08) | 23.46(8.53) | 21.64(7.85) | 23.49(8.64) | 21.65(7.93) |
| TEMPERATURE | 98.59(1.91) | 98.84(1.99) | 99.32(2.94) | 99.44(2.33) | 99.29(2.93) | 99.41(2.32) |
| MAP 1 | 92.14(18.02) | 92.55(17.73) | 79.91(22.15) | 86.59(19.20) | 79.66(22.30) | 85.96(19.58) |
| GCS 2 | 4.93(0.40) | 4.95(0.32) | 4.76(0.76) | 4.88(0.51) | 4.75(0.77) | 4.88(0.51) |
| LABORATORY MEASURES, MEAN(SD) | ||||||
| CREATININE | 1.446(1.445) | 1.459(1.470) | 1.912(1.637) | 1.645(1.605) | 1.914(1.650) | 1.645(1.610) |
| LACTIC ACID | 2.59(2.49) | 2.07(1.38) | 4.48(3.53) | 2.15(1.50) | 4.51(3.54) | 2.12(1.46) |
| APTT 3 | 35.17(12.56) | 35.17(11.57) | 37.24(13.86) | 36.49(12.38) | 37.45(14.09) | 36.56(12.43) |
| PLATELET COUNT | 231.20(101.84) | 237.76(106.06) | 221.66(126.62) | 231.20(120.81) | 220.82(126.11) | 231.10(121.14) |
| PT/INR 4 | 1.55(0.94) | 1.53(0.90) | 1.74(1.09) | 1.61(0.95) | 1.77(1.12) | 1.61(0.96) |
| WBC | 15.33(10.82) | 13.98(9.34) | 15.47(11.12) | 13.99(9.93) | 15.47(11.12) | 13.95(9.93) |
| MODELS | AUROC | SENSITIVITY | SPECIFICITY | HYPER PARAMETERS | TUNED HP VALUES |
|---|---|---|---|---|---|
| RF | 0.9483 | 0.8392 | 0.8814 | mtry, maxTree, maxdepth | 2, 1000, 4 |
| C5.0 | 0.9474 | 0.8087 | 0.8944 | Model, Winnowing, Boosting Iterations | Rules, False, 20 |
| DT | 0.9436 | 0.8553 | 0.8577 | Complexity Parameter | 0.000351617 |
| BL | 0.9239 | 0.8328 | 0.8448 | Boosting Iterations | 31 |
| SVM | 0.8962 | 0.8336 | 0.851 | Sigma, Cost | 0.01898621, 16 |
| LR | 0.8839 | 0.8304 | 0.8622 | ||
| RLR | 0.8821 | 0.8288 | 0.8615 | Cost, Loss Function, Epsilon | 2, L1, 0.001 |
| BGLM | 0.882 | 0.828 | 0.8625 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Misra, D.; Avula, V.; Wolk, D.M.; Farag, H.A.; Li, J.; Mehta, Y.B.; Sandhu, R.; Karunakaran, B.; Kethireddy, S.; Zand, R.; et al. Early Detection of Septic Shock Onset Using Interpretable Machine Learners. J. Clin. Med. 2021, 10, 301. https://doi.org/10.3390/jcm10020301
Misra D, Avula V, Wolk DM, Farag HA, Li J, Mehta YB, Sandhu R, Karunakaran B, Kethireddy S, Zand R, et al. Early Detection of Septic Shock Onset Using Interpretable Machine Learners. Journal of Clinical Medicine. 2021; 10(2):301. https://doi.org/10.3390/jcm10020301
Chicago/Turabian StyleMisra, Debdipto, Venkatesh Avula, Donna M. Wolk, Hosam A. Farag, Jiang Li, Yatin B. Mehta, Ranjeet Sandhu, Bipin Karunakaran, Shravan Kethireddy, Ramin Zand, and et al. 2021. "Early Detection of Septic Shock Onset Using Interpretable Machine Learners" Journal of Clinical Medicine 10, no. 2: 301. https://doi.org/10.3390/jcm10020301
APA StyleMisra, D., Avula, V., Wolk, D. M., Farag, H. A., Li, J., Mehta, Y. B., Sandhu, R., Karunakaran, B., Kethireddy, S., Zand, R., & Abedi, V. (2021). Early Detection of Septic Shock Onset Using Interpretable Machine Learners. Journal of Clinical Medicine, 10(2), 301. https://doi.org/10.3390/jcm10020301