
Resting-State Functional MRI Adaptation with Attention Graph Convolution Network for Brain Disorder Identification

Abstract
1. Introduction
2. Related Work
2.1. Graph Convolution Network for fMRI Analysis
2.2. Domain Adaptation for Brain Disorder Diagnosis
3. Methodology
3.1. Notation and Problem Formulation
3.2. Proposed Method
3.2.1. Node Representation Learning
3.2.2. Node Attention Mechanism
3.2.3. Domain Adaptation Module
3.3. Implementation
4. Experiments
4.1. Data
4.2. Experimental Settings
4.3. Competing Methods
- (1)
- DC: This method measures the degree of nodes in the FCNs as the features of subjects. Specifically, according to Equation (2), for each subject, we can generate FCN of the size of 116 × 116, where each element in FCN is the correlation coefficient between node pairs calculated by PC. First, the degree centrality (DC) indexes of each node in the FCN are calculated. Then, the model DC takes the 116 × 1-dimensional feature vector representation obtained by computing DC for each subject as the input of the SVM classifier.
- (2)
- BD: This method combines the betweenness centrality (BC) and DC of nodes as the features of subjects. Based on Equation (2), the FCN of each subject is obtained, and then the BC and DC of nodes are respectively calculated. The BC and DC are concatenated into 232 × 1-dimensional vectors according to rows, used as the input of SVM.
- (3)
- BDC: To mitigate the lack of information or noise pollution caused by manually defined features, we further calculate the BC, DC, and closeness centrality (CC) of the node of each subject FCN. The model BDC is further sequentially splicing the DC, BC, and CC values of each subject to form a feature representation of 348 × 1-dimensional as the input of the SVM classifier.
- (4)
- DNN: According to the classical practice, we take the FCN of the subject in the upper triangle and pull it into a vector. In order to prevent dimensional disaster, the principal component analysis (PCA) algorithm limits the dimension of variables to 64 dimensions. Then, the features after dimensionality reduction are used as the input of model DNN. The model DNN is composed of two fully connected layers, and the output dimension is: .
- (5)
- GCN: GCN can combine the topological structure of the graph to deeply mine the potential information of nodes. Our A2GCN is inspired by GCN. Obviously, if we set , A2GCN will crash to GCN. Similar to our proposed A2GCN method, first, we construct the source and target graphs, respectively, based on the FCNs of the subjects. Then, based on the source graphs, the cross entropy loss is optimized to train the classification model with good performance. Finally, the GCN model is applied directly to the target graphs to make prediction. The model GCN consists of two convolutional layers and two fully connected layers, and the output dimension is: .
- (6)
- DNNC: We transform our A2GCN model feature extractor GCN into multi-layer perceptron (MLP) to construct a simple cross-domain classification model. The model inputs are the same as the settings for the DNN model above. The output dimension of the network is set to . At the same time, add CORAL loss minimization domain offset. The covariance between the sample features of the source domain and the target domain is defined as CORAL loss. Meanwhile, CORAL loss can minimize the domain offset without additional parameters. This method is basic and efficient, and it is also one of the losses used in our A2GCN.
- (7)
- MMD: The Maximum Mean Discrepancy (MMD) method aims to reduce differences of the domain distribution by MMD. This deep transfer model uses the GCN as a feature extractor. MAE loss and CORAL loss in our model are replaced by the MMD loss [9]. Then, the two-layer MLP is used as a category classifier for MMD. The number of neurons in the output layer of convolution layer and fully connected layer is consistent with our A2GCN method. The reference code (https://github.com/jindongwang/transferlearning (accessed on 20 September 2022)) is publicly available.
- (8)
- DANN: The Domain Adversarial Neural Network (DANN) [43] is a domain adaptive method based on confrontational learning. The DANN method uses a gradient inversion layer (GRL) as with a reversal gradient to train a domain classifier. The adaptation parameter of GRL refers to [43,44]. Here, x represents the representation of the extracted graph. The two-layer fully connected layer is used as the domain classifier of DANN to establish the adversarial loss. The hidden layer dimension is set to ; the dropout is 0.4, and ReLU is responsible for nonlinear activation. Then, the two-layer MLP is used as a category classifier for DANN. Dimensions of the output layer of the convolution layer or fully connected layer are consistent with A2GCN.
4.4. Results
- (1)
- The four cross-domain classification models (i.e., DNNC, MMD, DANN, and A2GCN) achieved better results in most cases compared with several single-domain classification models (i.e., DC, BDC, DNN, and GCN). This means that the introduction of domain adaptation learning module helps to enhance the classification performance of the model, which may benefit from the transferable feature representation across sites learned by the model.
- (2)
- Graph-based (i.e., GCN, MMD, DANN, and A2GCN)) methods usually produce better classification results than traditional classical methods based on manually defined node features (i.e., DC, BD, and BDC) and network embeddings (i.e., DNN and DNNC). Because these traditional methods only consider the characteristics of nodes, however, those methods that use GCN as feature extractors can update and aggregate the features of nodes on the graph end-to-end with the help of the underlying topology information of FCNs, in order to learn more discriminative node representation, which may be more beneficial for ASD auxiliary diagnosis.
- (3)
- The experimental results of the proposed A2GCN consistently outperform all competing methods. This indicates that A2GCN can achieve effective domain adaptation and reduce data distribution differences, thus improving the robustness of the model.
- (4)
- Compared with three advanced cross-domain methods (i.e., DNNC, MMD, and DANN), our proposed A2GCN method has a competitive advantage in various domain adaptation tasks. This may be because our method adds node attention mechanism modules, which can make intelligent use of different contributions of brain regions. Meanwhile, our method adopts MAE loss and CORAL loss to align different domains step by step. These operations can partially alleviate the negative effects of noisy areas.
4.5. Ablation Study
- (1)
- A2GCN_A: Similar to the A2GCN method, firstly, the source graph and the target graph are respectively constructed based on the subject’s FCNs. Then, the node representation on the source graph is learned based on GCN. At the same time, the node attention mechanism model mentioned in Section 3.2.2 is added to set different weight values for different nodes/brain regions of the source graph. Then, cross entropy is used to calculate the classification loss. Finally, the model trained in the source domain is applied to the prediction of the target domain graph.
- (2)
- A2GCN_M: First, based on the subject’s FCNs, the model constructs the source graph and the target graph respectively. Then, according to the node representation learning module in Section 3.2.1, the node features on the source graph and the target graph are simultaneously learned based on GCN. Then, the node attention mechanism module in Section 3.2.2 is added, and the weighted node features are used to calculate the MAE loss between domains (domain adaptation module). Finally, the cross entropy is used to calculate the classification loss.
- (3)
- A2GCN_C: First, the model uses FCNs to construct source and target graphs. Like A2GCN, this model learns the node features of different domains based on GCN according to the node representation learning module in Section 3.2.1. Then, after the readout operation, the CORAL loss (domain adaptation module) between domains is calculated based on the extracted graph representation vector. The cross entropy is used to calculate the classification loss of the source domain.
5. Discussion
5.1. Visualization of Data Distribution
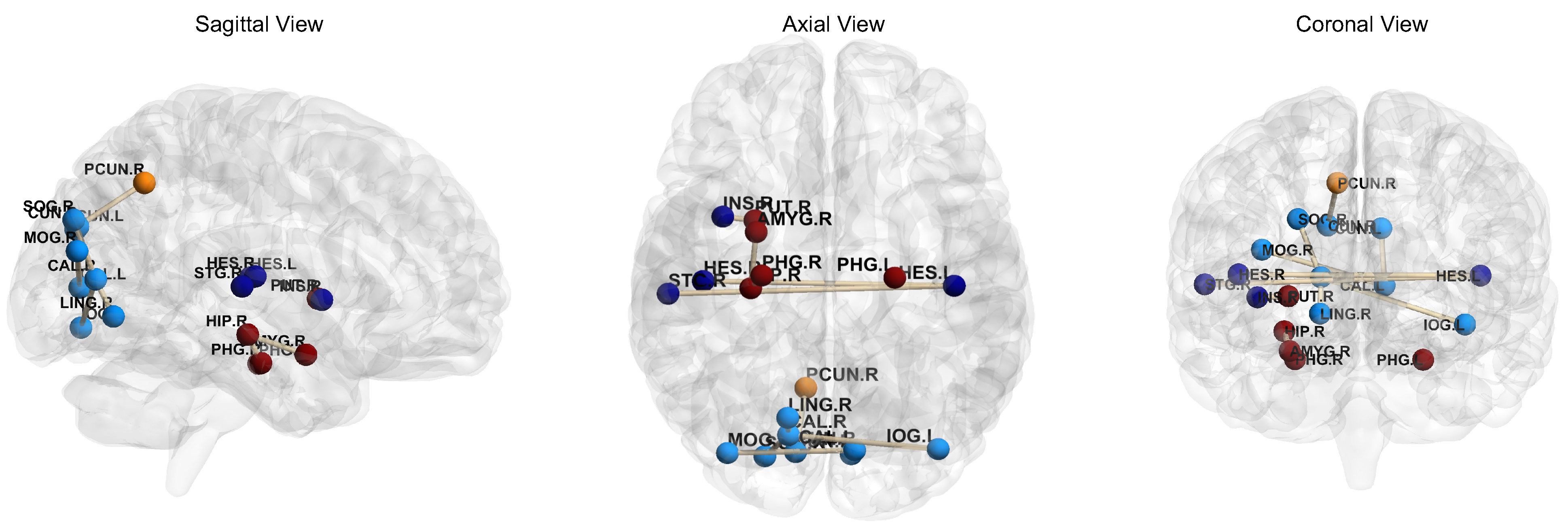
5.2. Most Informative Brain Regions
5.3. Limitations and Future Work
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Buckner, R.L.; Krienen, F.M.; Yeo, B.T. Opportunities and limitations of intrinsic functional connectivity MRI. Nat. Neurosci. 2013, 16, 832–837. [Google Scholar] [CrossRef] [PubMed]
- McCarty, P.J.; Pines, A.R.; Sussman, B.L.; Wyckoff, S.N.; Jensen, A.; Bunch, R.; Boerwinkle, V.L.; Frye, R.E. Resting State Functional Magnetic Resonance Imaging Elucidates Neurotransmitter Deficiency in Autism Spectrum Disorder. J. Pers. Med. 2021, 11, 969. [Google Scholar] [CrossRef] [PubMed]
- Subah, F.Z.; Deb, K.; Dhar, P.K.; Koshiba, T. A deep learning approach to predict Autism Spectrum Disorder using multisite resting-state fMRI. Appl. Sci. 2021, 11, 3636. [Google Scholar] [CrossRef]
- Walsh, M.J.; Wallace, G.L.; Gallegos, S.M.; Braden, B.B. Brain-based sex differences in autism spectrum disorder across the lifespan: A systematic review of structural MRI, fMRI, and DTI findings. NeuroImage Clin. 2021, 31, 102719. [Google Scholar] [CrossRef] [PubMed]
- Shrivastava, S.; Mishra, U.; Singh, N.; Chandra, A.; Verma, S. Control or autism-classification using convolutional neural networks on functional MRI. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–6. [Google Scholar]
- Niu, K.; Guo, J.; Pan, Y.; Gao, X.; Peng, X.; Li, N.; Li, H. Multichannel deep attention neural networks for the classification of Autism Spectrum Disorder using neuroimaging and personal characteristic data. Complexity 2020, 2020. [Google Scholar] [CrossRef]
- Yamashita, A.; Yahata, N.; Itahashi, T.; Lisi, G.; Yamada, T.; Ichikawa, N.; Takamura, M.; Yoshihara, Y.; Kunimatsu, A.; Okada, N.; et al. Harmonization of resting-state functional MRI data across multiple imaging sites via the separation of site differences into sampling bias and measurement bias. PLoS Biol. 2019, 17, e3000042. [Google Scholar] [CrossRef]
- Lee, J.; Kang, E.; Jeon, E.; Suk, H.I. Meta-modulation Network for Domain Generalization in Multi-site fMRI Classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Virtual Event, 27 September–1 October 2021; Springer: Berlin, Germany, 2021; pp. 500–509. [Google Scholar]
- Zhang, Y.; Liu, T.; Long, M.; Jordan, M. Bridging theory and algorithm for domain adaptation. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 7404–7413. [Google Scholar]
- Farahani, A.; Voghoei, S.; Rasheed, K.; Arabnia, H.R. A brief review of domain adaptation. Adv. Data Sci. Inf. Eng. 2021, 877–894. [Google Scholar] [CrossRef]
- You, K.; Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Universal domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2720–2729. [Google Scholar]
- Jiang, X.; Zhang, L.; Qiao, L.; Shen, D. Estimating functional connectivity networks via low-rank tensor approximation with applications to MCI identification. IEEE Trans. Biomed. Eng. 2019, 67, 1912–1920. [Google Scholar] [CrossRef]
- Xing, X.; Li, Q.; Wei, H.; Zhang, M.; Zhan, Y.; Zhou, X.S.; Xue, Z.; Shi, F. Dynamic spectral graph convolution networks with assistant task training for early MCI diagnosis. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin, Germany, 2019; pp. 639–646. [Google Scholar]
- Jie, B.; Wee, C.Y.; Shen, D.; Zhang, D. Hyper-connectivity of functional networks for brain disease diagnosis. Med. Image Anal. 2016, 32, 84–100. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, X.; Qiao, L.; Liu, M. Modularity-Guided Functional Brain Network Analysis for Early-Stage Dementia Identification. Front. Neurosci. 2021, 15, 956. [Google Scholar] [CrossRef]
- Zhang, D.; Huang, J.; Jie, B.; Du, J.; Tu, L.; Liu, M. Ordinal pattern: A new descriptor for brain connectivity networks. IEEE Trans. Med. Imaging 2018, 37, 1711–1722. [Google Scholar] [CrossRef] [PubMed]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning convolutional neural networks for graphs. In Proceedings of the International Conference on Machine Learning (PMLR), New York, NY, USA, 20–22 June 2016; pp. 2014–2023. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Anirudh, R.; Thiagarajan, J.J. Bootstrapping graph convolutional neural networks for Autism spectrum disorder classification. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3197–3201. [Google Scholar]
- Cao, M.; Yang, M.; Qin, C.; Zhu, X.; Chen, Y.; Wang, J.; Liu, T. Using DeepGCN to identify the Autism spectrum disorder from multi-site resting-state data. Biomed. Signal Process. Control 2021, 70, 103015. [Google Scholar] [CrossRef]
- Yu, S.; Wang, S.; Xiao, X.; Cao, J.; Yue, G.; Liu, D.; Wang, T.; Xu, Y.; Lei, B. Multi-scale enhanced graph convolutional network for early mild cognitive impairment detection. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer: Berlin, Germany, 2020; pp. 228–237. [Google Scholar]
- Parisot, S.; Ktena, S.I.; Ferrante, E.; Lee, M.; Guerrero, R.; Glocker, B.; Rueckert, D. Disease Prediction Using Graph Convolutional Networks: Application to Autism Spectrum Disorder and Alzheimer’s Disease. Med. Image Anal. 2018, 48, 117–130. [Google Scholar] [CrossRef]
- Di Martino, A.; Yan, C.G.; Li, Q.; Denio, E.; Castellanos, F.X.; Alaerts, K.; Anderson, J.S.; Assaf, M.; Bookheimer, S.Y.; Dapretto, M.; et al. The Autism brain imaging data exchange: Towards a large-scale evaluation of the intrinsic brain architecture in Autism. Mol. Psychiatry 2014, 19, 659–667. [Google Scholar] [CrossRef]
- Abu-El-Haija, S.; Kapoor, A.; Perozzi, B.; Lee, J. N-GCN: Multi-scale graph convolution for semi-supervised node classification. In Proceedings of the Uncertainty In Artificial Intelligence (PMLR), Virtual, 3–6 August 2020; pp. 841–851. [Google Scholar]
- Zhang, M.; Cui, Z.; Neumann, M.; Chen, Y. An end-to-end deep learning architecture for graph classification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Chen, Y.; Ma, G.; Yuan, C.; Li, B.; Zhang, H.; Wang, F.; Hu, W. Graph convolutional network with structure pooling and joint-wise channel attention for action recognition. Pattern Recognit. 2020, 103, 107321. [Google Scholar] [CrossRef]
- Ktena, S.I.; Parisot, S.; Ferrante, E.; Rajchl, M.; Lee, M.; Glocker, B.; Rueckert, D. Metric learning with spectral graph convolutions on brain connectivity networks. NeuroImage 2018, 169, 431–442. [Google Scholar] [CrossRef]
- Wang, L.; Li, K.; Hu, X.P. Graph convolutional network for fMRI analysis based on connectivity neighborhood. Netw. Neurosci. 2021, 5, 83–95. [Google Scholar] [CrossRef]
- Yao, D.; Sui, J.; Yang, E.; Yap, P.T.; Shen, D.; Liu, M. Temporal-adaptive graph convolutional network for automated identification of major depressive disorder using resting-state fMRI. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Lima, Peru, 4 October 2020; Springer: Berlin, Germany, 2020; pp. 1–10. [Google Scholar]
- Gadgil, S.; Zhao, Q.; Pfefferbaum, A.; Sullivan, E.V.; Adeli, E.; Pohl, K.M. Spatio-temporal graph convolution for resting-state fMRI analysis. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer: Berlin, Germany, 2020; pp. 528–538. [Google Scholar]
- Csurka, G. A comprehensive survey on domain adaptation for visual applications. Domain Adapt. Comput. Vis. Appl. 2017, 1–35. [Google Scholar] [CrossRef]
- Guan, H.; Liu, Y.; Yang, E.; Yap, P.T.; Shen, D.; Liu, M. Multi-site MRI harmonization via attention-guided deep domain adaptation for brain disorder identification. Med. Image Anal. 2021, 71, 102076. [Google Scholar] [CrossRef]
- Guan, H.; Liu, M. Domain adaptation for medical image analysis: A survey. IEEE Trans. Biomed. Eng. 2021, 69, 1173–1185. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef]
- Ingalhalikar, M.; Shinde, S.; Karmarkar, A.; Rajan, A.; Rangaprakash, D.; Deshpande, G. Functional connectivity-based prediction of Autism on site harmonized ABIDE dataset. IEEE Trans. Biomed. Eng. 2021, 68, 3628–3637. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Liu, M.; Pan, Y.; Shen, D. Unsupervised conditional consensus adversarial network for brain disease identification with structural MRI. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Shenzhen, China, 13–17 October 2019; Springer: Berlin, Germany, 2019; pp. 391–399. [Google Scholar]
- Cangea, C.; Veličković, P.; Jovanović, N.; Kipf, T.; Liò, P. Towards sparse hierarchical graph classifiers. arXiv 2018, arXiv:1811.01287. [Google Scholar]
- Lee, J.; Lee, I.; Kang, J. Self-attention graph pooling. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 3734–3743. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin, Germany, 2016; pp. 443–450. [Google Scholar]
- Wang, M.; Zhang, D.; Huang, J.; Yap, P.T.; Shen, D.; Liu, M. Identifying Autism Spectrum Disorder with multi-site fMRI via low-rank domain adaptation. IEEE Trans. Med. Imaging 2019, 39, 644–655. [Google Scholar] [CrossRef]
- Craddock, C.; Sikka, S.; Cheung, B.; Khanuja, R.; Ghosh, S.S.; Yan, C.; Li, Q.; Lurie, D.; Vogelstein, J.; Burns, R.; et al. Towards automated analysis of connectomes: The configurable pipeline for the analysis of connectomes (C-PAC). Front. Neuroinform. 2013, 42, 10–3389. [Google Scholar]
- Tzourio-Mazoyer, N.; Landeau, B.; Papathanassiou, D.; Crivello, F.; Etard, O.; Delcroix, N.; Mazoyer, B.; Joliot, M. Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. Neuroimage 2002, 15, 273–289. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096-2030. [Google Scholar]
- Wu, M.; Pan, S.; Zhou, C.; Chang, X.; Zhu, X. Unsupervised domain adaptive graph convolutional networks. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1457–1467. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Xia, M.; Wang, J.; He, Y. BrainNet Viewer: A network visualization tool for human brain connectomics. PLoS ONE 2013, 8, e68910. [Google Scholar] [CrossRef]
- Sussman, D.; Leung, R.; Vogan, V.; Lee, W.; Trelle, S.; Lin, S.; Cassel, D.; Chakravarty, M.; Lerch, J.; Anagnostou, E.; et al. The Autism puzzle: Diffuse but not pervasive neuroanatomical abnormalities in children with ASD. NeuroImage Clin. 2015, 8, 170–179. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Xue, Y.; Zhang, Y.; Qiao, L.; Zhang, L.; Liu, M. Estimating sparse functional connectivity networks via hyperparameter-free learning model. Artif. Intell. Med. 2021, 111, 102004. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Source graph | |
| Target graph | |
| Set of nodes | |
| Source data label | |
| Adjacency matrix | |
| Source feature matrix | |
| Target feature matrix | |
| Learned features | |
| Learned features | |
| Number of samples | |
| Number of nodes on the graph | |
| Feature dimension | |
| Source domain classifier | |
| Loss function | |
| The balance parameters |
| Name of the site | Category | Gender (M/F) | Age |
|---|---|---|---|
| NYU | ASD (N = 71) | 66/5 | 17.59 ± 7.84 |
| HC (N = 93) | 79/14 | 16.49 ± 7.68 | |
| UM | ASD (N = 48) | 43/5 | 17.05 ± 8.36 |
| HC (N = 65) | 56/9 | 17.35 ± 7.12 | |
| UCLA | ASD (N = 36) | 28/8 | 16.27 ± 6.48 |
| HC (N = 38) | 31/7 | 14.65 ± 4.97 |
| Source→Target | Method | ACC (%) | Pre (%) | Rec (%) | F1 (%) | BAC (%) | NPV (%) | AUC (%) |
|---|---|---|---|---|---|---|---|---|
| DC | 53.54 ± 1.88 | 46.33 ± 0.25 | 54.60 ± 1.89 | 50.55 ± 9.32 | 54.17 ± 1.45 | 62.86 ± 4.04 | 54.60 ± 1.89 | |
| BD | 56.64 ± 1.25 | 49.29 ± 1.01 | 58.17 ± 0.23 | 57.00 ± 0.90 | 58.09 ± 0.52 | 67.06 ± 0.54 | 58.17 ± 0.23 | |
| BDC | 54.43 ± 1.87 | 47.48 ± 1.55 | 56.51 ± 2.12 | 56.17 ± 2.07 | 56.3 ± 2.02 | 65.54 ± 2.69 | 56.51 ± 2.12 | |
| DNN | 58.85 ± 0.62 | 58.67 ± 1.60 | 58.78 ± 1.70 | 58.39 ± 1.17 | 58.78 ± 1.70 | 65.99 ± 2.73 | 51.72 ± 4.19 | |
| NYU→UM | GCN | 61.07 ± 1.25 | 60.65 ± 0.95 | 60.84 ± 0.89 | 60.61 ± 1.05 | 60.84 ± 0.89 | 67.49 ± 0.35 | 59.28 ± 0.02 |
| DNNC | 61.07 ± 1.25 | 61.36 ± 3.49 | 61.11 ± 3.59 | 60.27 ± 2.35 | 61.11 ± 3.59 | 69.10 ± 6.80 | 59.89 ± 9.31 | |
| MMD | 66.82 ± 0.63 | 66.20 ± 0.69 | 66.04 ± 0.46 | 66.09 ± 0.45 | 66.12 ± 0.35 | 71.32 ± 0.16 | 65.77 ± 1.32 | |
| DANN | 66.82 ± 0.63 | 66.72 ± 0.20 | 67.07 ± 0.16 | 66.56 ± 0.45 | 65.19 ± 2.51 | 70.61 ± 5.57 | 64.35 ± 0.84 | |
| A2GCN (Ours) | 72.27 ± 0.51 | 71.94 ± 0.50 | 72.35 ± 0.52 | 71.97 ± 0.49 | 72.35 ± 0.52 | 78.23 ± 0.97 | 70.90 ± 1.53 | |
| DC | 58.79 ± 2.86 | 57.51 ± 2.76 | 58.77 ± 2.88 | 57.92 ± 3.33 | 58.78 ± 2.89 | 60.03 ± 3.02 | 58.77 ± 2.88 | |
| BD | 56.08 ± 2.87 | 55.04 ± 2.97 | 56.02 ± 2.89 | 53.89 ± 3.47 | 56.00 ± 2.89 | 56.99 ± 2.81 | 56.02 ± 2.89 | |
| BDC | 58.79 ± 0.95 | 57.74 ± 0.84 | 58.75 ± 0.97 | 57.34 ± 1.41 | 58.74 ± 0.98 | 59.75 ± 1.10 | 60.11 ± 0.96 | |
| DNN | 60.14 ± 0.95 | 60.11 ± 0.96 | 60.05 ± 0.88 | 60.03 ± 0.85 | 60.05 ± 0.88 | 60.76 ± 0.32 | 59.83 ± 1.91 | |
| NYU→UCLA | GCN | 61.49 ± 0.95 | 61.50 ± 1.00 | 61.44 ± 1.09 | 61.40 ± 1.08 | 61.44 ± 1.09 | 62.44 ± 2.06 | 58.19 ± 1.76 |
| DNNC | 60.81 ± 3.82 | 60.88 ± 3.92 | 60.60 ± 3.83 | 60.46 ± 3.85 | 60.60 ± 3.83 | 60.47 ± 3.29 | 53.77 ± 3.98 | |
| MMD | 66.89 ± 0.96 | 66.94 ± 0.85 | 66.92 ± 0.88 | 66.88 ± 0.94 | 66.92 ± 0.88 | 68.50 ± 0.11 | 64.51 ± 1.91 | |
| DANN | 66.90 ± 0.95 | 67.14 ± 1.34 | 66.96 ± 1.14 | 66.82 ± 0.93 | 66.96 ± 1.14 | 69.28 ± 3.68 | 65.87 ± 0.52 | |
| A2GCN (Ours) | 69.82 ± 1.56 | 70.09 ± 1.56 | 69.83 ± 1.56 | 69.71 ± 1.56 | 69.83 ± 1.56 | 71.38 ± 1.56 | 67.03 ± 1.56 | |
| DC | 53.66 ± 0.86 | 46.31 ± 1.41 | 52.66 ± 1.41 | 45.62 ± 3.76 | 52.65 ± 1.46 | 59.00 ± 1.41 | 52.66 ± 1.41 | |
| BD | 57.02 ± 0.43 | 50.33 ± 0.46 | 56.45 ± 0.68 | 51.53 ± 1.66 | 56.52 ± 0.73 | 62.59 ± 0.89 | 56.46 ± 0.67 | |
| BDC | 53.66 ± 0.86 | 47.23 ± 0.91 | 54.46 ± 1.27 | 53.06 ± 2.11 | 54.48 ± 1.24 | 61.70 ± 1.65 | 54.46 ± 1.27 | |
| DNN | 59.15 ± 1.73 | 58.57 ± 1.74 | 58.65 ± 1.75 | 58.59 ± 1.75 | 58.65 ± 1.75 | 64.45 ± 1.58 | 55.49 ± 2.08 | |
| UM→NYU | GCN | 63.11 ± 0.43 | 62.96 ± 0.03 | 63.15 ± 0.09 | 62.83 ± 0.20 | 63.15 ± 0.09 | 69.27 ± 1.03 | 64.35 ± 0.24 |
| DNNC | 60.68 ± 1.29 | 59.99 ± 1.65 | 60.00 ± 1.85 | 59.95 ± 1.73 | 60.00 ± 1.85 | 65.49 ± 2.21 | 62.68 ± 3.57 | |
| MMD | 66.16 ± 1.29 | 65.44 ± 1.34 | 65.08 ± 1.26 | 65.18 ± 1.27 | 65.08 ± 1.26 | 69.04 ± 0.94 | 66.18 ± 2.17 | |
| DANN | 66.16 ± 0.43 | 65.59 ± 0.67 | 65.50 ± 1.09 | 65.47 ± 0.90 | 65.50 ± 1.09 | 70.14 ± 2.05 | 65.34 ± 0.69 | |
| A2GCN (Ours) | 68.70 ± 0.70 | 68.73 ± 0.63 | 69.07 ± 0.65 | 68.56 ± 0.68 | 69.07 ± 0.65 | 75.52 ± 0.71 | 66.77 ± 0.43 | |
| DC | 54.73 ± 0.95 | 53.81 ± 0.68 | 54.65 ± 1.00 | 51.00 ± 3.56 | 54.57 ± 1.09 | 55.48 ± 1.32 | 54.65 ± 1.00 | |
| BD | 54.73 ± 0.96 | 53.28 ± 1.10 | 54.80 ± 0.86 | 55.03 ± 0.33 | 54.79 ± 0.88 | 56.32 ± 0.62 | 54.80 ± 0.86 | |
| BDC | 56.08 ± 4.78 | 54.39 ± 4.40 | 56.21 ± 4.84 | 56.93 ± 5.09 | 56.18 ± 4.81 | 58.03 ± 5.28 | 56.21 ± 4.84 | |
| DNN | 56.76 ± 3.83 | 56.79 ± 4.02 | 56.69 ± 4.09 | 56.47 ± 4.19 | 56.69 ± 4.09 | 58.16 ± 5.10 | 52.31 ± 1.39 | |
| UM→UCLA | GCN | 61.49 ± 0.95 | 61.47 ± 0.93 | 61.44 ± 0.88 | 61.43 ± 0.88 | 61.44 ± 0.88 | 62.33 ± 0.24 | 58.52 ± 1.50 |
| DNNC | 60.14 ± 0.95 | 60.13 ± 0.96 | 60.05 ± 1.09 | 60.00 ± 1.14 | 60.05 ± 1.09 | 60.84 ± 1.87 | 46.50 ± 4.86 | |
| MMD | 65.54 ± 0.96 | 65.54 ± 0.97 | 65.50 ± 1.03 | 65.49 ± 1.03 | 65.50 ± 1.03 | 66.29 ± 1.82 | 65.24 ± 1.60 | |
| DANN | 65.54 ± 0.96 | 65.57 ± 0.93 | 65.57 ± 0.93 | 65.54 ± 0.95 | 65.57 ± 0.93 | 67.12 ± 0.64 | 61.26 ± 4.45 | |
| A2GCN (Ours) | 70.61 ± 2.56 | 71.71 ± 3.42 | 70.65 ± 2.20 | 70.22 ± 2.23 | 70.52 ± 2.29 | 70.92 ± 3.09 | 71.29 ± 1.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, Y.; Ren, H.; Qiao, L.; Liu, M. Resting-State Functional MRI Adaptation with Attention Graph Convolution Network for Brain Disorder Identification. Brain Sci. 2022, 12, 1413. https://doi.org/10.3390/brainsci12101413
Chu Y, Ren H, Qiao L, Liu M. Resting-State Functional MRI Adaptation with Attention Graph Convolution Network for Brain Disorder Identification. Brain Sciences. 2022; 12(10):1413. https://doi.org/10.3390/brainsci12101413
Chicago/Turabian StyleChu, Ying, Haonan Ren, Lishan Qiao, and Mingxia Liu. 2022. "Resting-State Functional MRI Adaptation with Attention Graph Convolution Network for Brain Disorder Identification" Brain Sciences 12, no. 10: 1413. https://doi.org/10.3390/brainsci12101413
APA StyleChu, Y., Ren, H., Qiao, L., & Liu, M. (2022). Resting-State Functional MRI Adaptation with Attention Graph Convolution Network for Brain Disorder Identification. Brain Sciences, 12(10), 1413. https://doi.org/10.3390/brainsci12101413