Bimodal Benefits for Lexical Tone Recognition: An Investigation on Mandarin-speaking Preschoolers with a Cochlear Implant and a Contralateral Hearing Aid




Abstract
1. Introduction
2. Materials and Methods
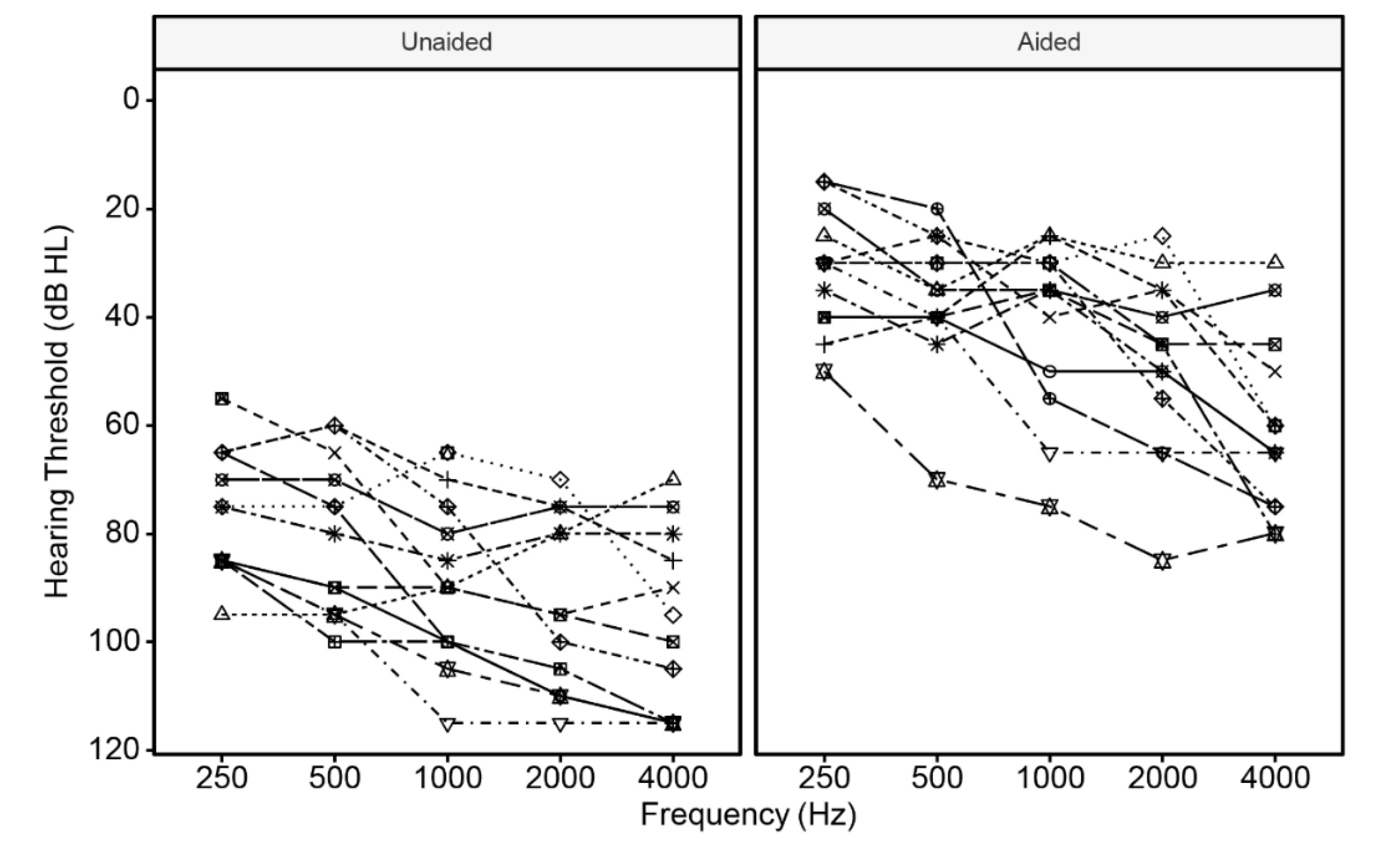
2.1. Participants
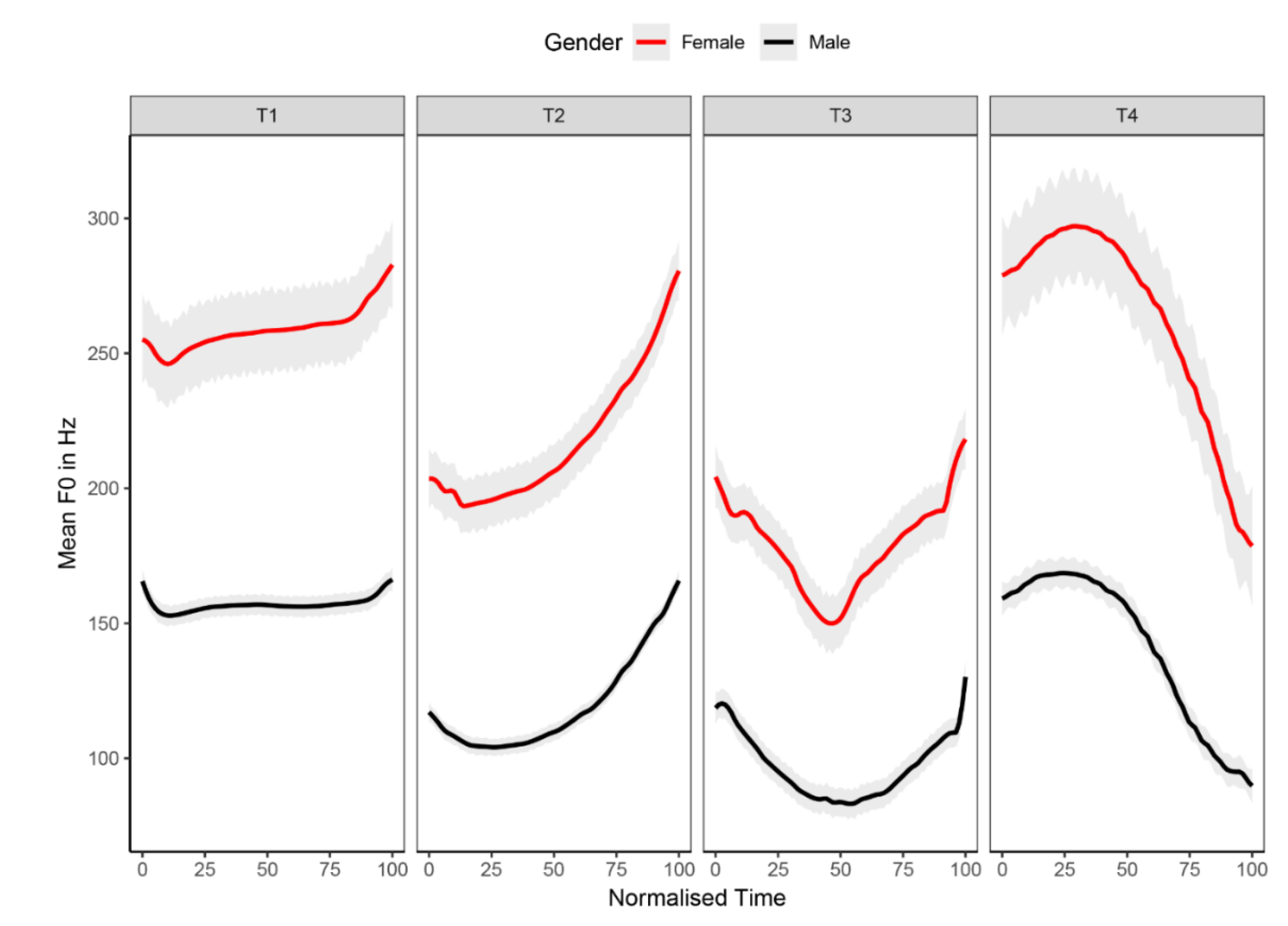
2.2. Stimuli
2.3. Procedures
2.4. Data Analysis
2.4.1. Accuracy Score and Confusion Matrix
2.4.2. Normalized Bimodal Benefit Score
2.4.3. Regression Models for Delineating Relationships
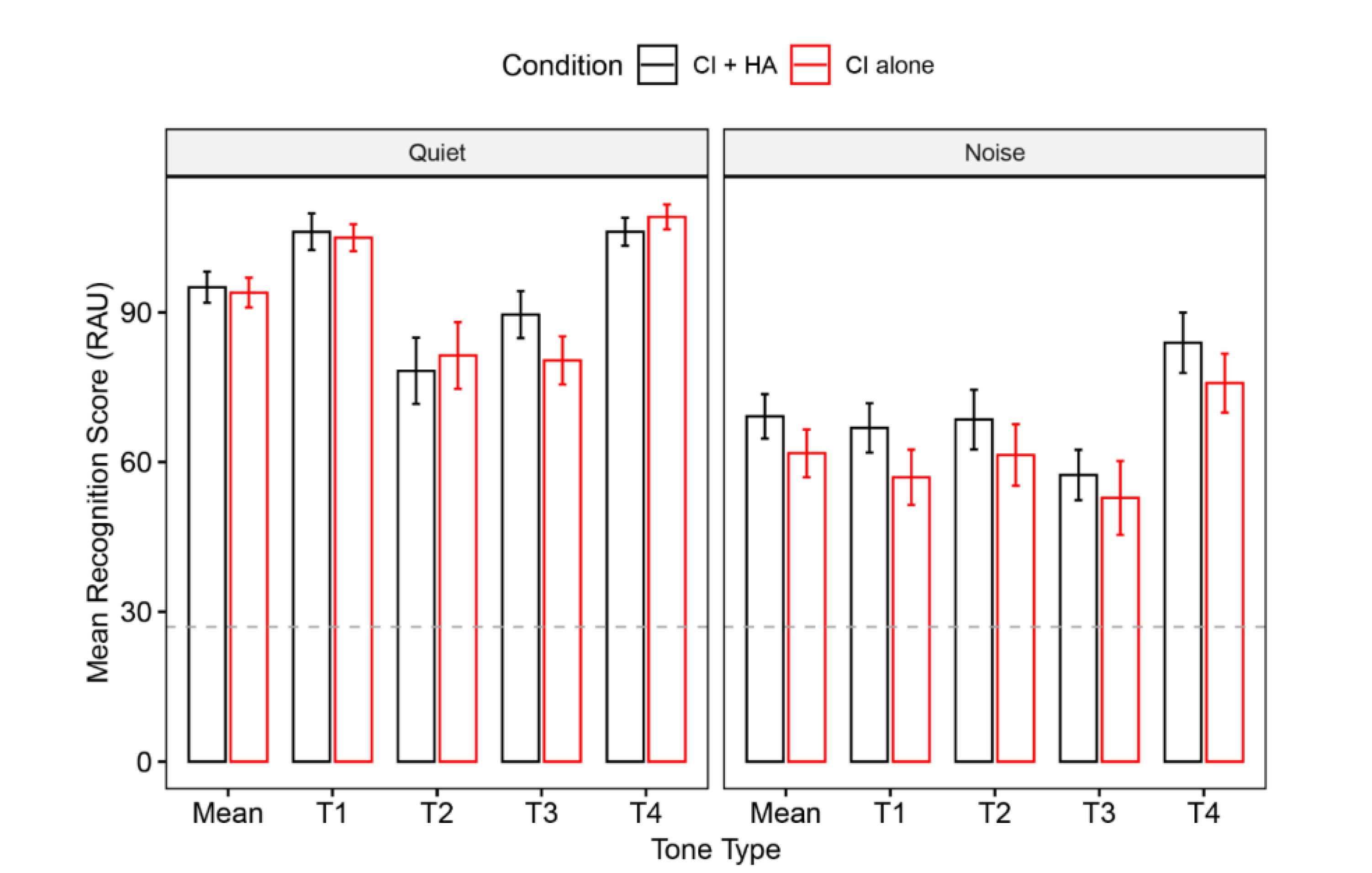
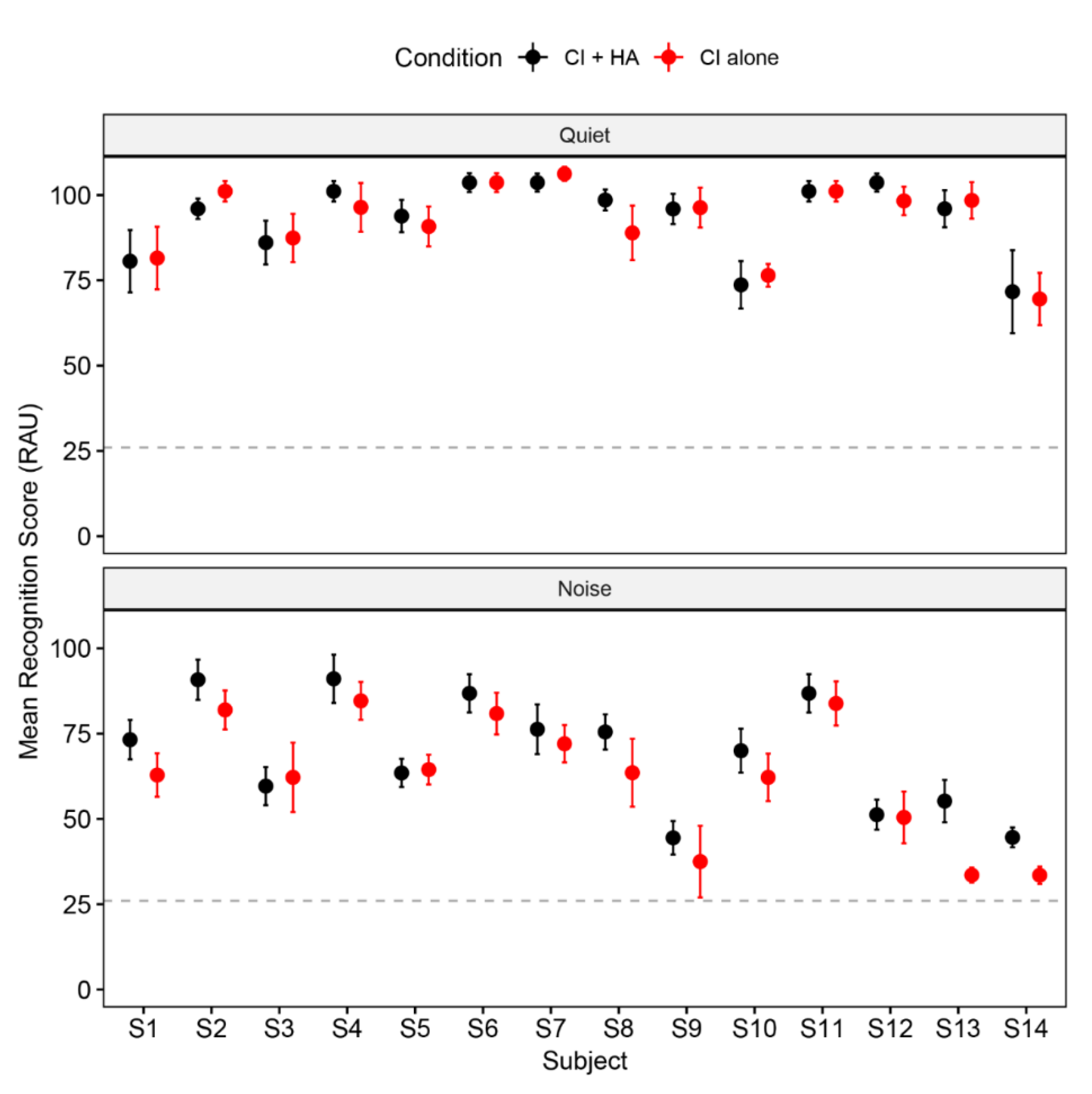
3. Results
3.1. Lexical Tone Recognition
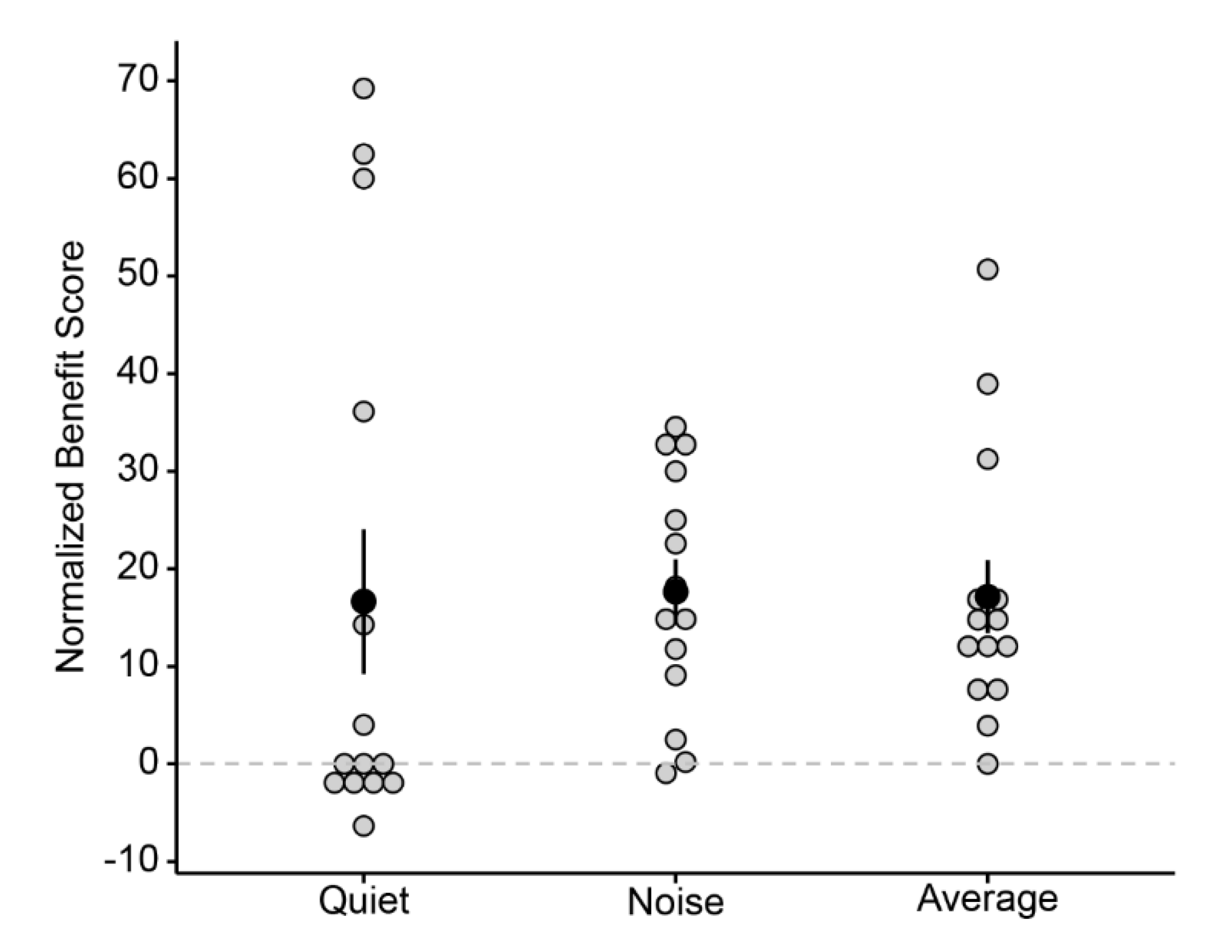
3.2. Normalized Bimodal Benefit
3.3. Regression Analysis Results
4. Discussion
4.1. Bimodal Benefits for Lexical Tone Recognition
4.2. Contributing Variables to Bimodal Benefits
4.3. Limitations and Implications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kral, A.; Dorman, M.F.; Wilson, B.S. Neuronal development of hearing and language: Cochlear implants and critical periods. Annu. Rev. Neurosci. 2019, 42, 47–65. [Google Scholar] [CrossRef] [PubMed]
- Moore, D.R.; Shannon, R. V Beyond cochlear implants: Awakening the deafened brain. Nat. Neurosci. 2009, 12, 686–691. [Google Scholar] [CrossRef] [PubMed]
- Kral, A.; Sharma, A. Developmental neuroplasticity after cochlear implantation. Trends Neurosci. 2012, 35, 111–122. [Google Scholar] [CrossRef] [PubMed]
- van Wieringen, A.; Wouters, J. What can we expect of normally-Developing children implanted at a young age with respect to their auditory, linguistic and cognitive skills? Hear. Res. 2015, 322, 171–179. [Google Scholar] [CrossRef] [PubMed]
- Fu, Q.-J.; Galvin, J.J., III. Perceptual learning and auditory training in cochlear implant recipients. Trends Amplif. 2007, 11, 193–205. [Google Scholar] [CrossRef]
- Ingvalson, E.M.; Lee, B.; Fiebig, P.; Wong, P.C.M. The effects of short-Term computerized speech-In-Noise training on postlingually deafened adult cochlear implant recipients. J. Speech Lang. Hear. Res. 2013, 56, 81–88. [Google Scholar] [CrossRef]
- Glennon, E.; Svirsky, M.A.; Froemke, R.C. Auditory cortical plasticity in cochlear implant users. Curr. Opin. Neurobiol. 2020, 60, 108–114. [Google Scholar] [CrossRef]
- Chandramouli, S.H.; Kronenberger, W.G.; Pisoni, D.B. Verbal learning and memory in early-Implanted, prelingually deaf adolescent and adult cochlear implant users. J. Speech Lang. Hear. Res. 2019, 62, 1033–1050. [Google Scholar] [CrossRef]
- Miller, S.; Zhang, Y.; Nelson, P. Neural correlates of phonetic learning in postlingually deafened cochlear implant listeners. Ear Hear. 2016, 37, 514–528. [Google Scholar] [CrossRef]
- Chatterjee, M.; Zion, D.J.; Deroche, M.L.; Burianek, B.A.; Limb, C.J.; Goren, A.P.; Kulkarni, A.M.; Christensen, J.A. Voice emotion recognition by cochlear-implanted children and their normally-Hearing peers. Hear. Res. 2015, 322, 151–162. [Google Scholar] [CrossRef]
- Jiam, N.T.; Caldwell, M.; Deroche, M.L.; Chatterjee, M.; Limb, C.J. Voice emotion perception and production in cochlear implant users. Hear. Res. 2017, 352, 30–39. [Google Scholar] [CrossRef] [PubMed]
- Paquette, S.; Ahmed, G.D.; Goffi-Gomez, M.V.; Hoshino, A.C.H.; Peretz, I.; Lehmann, A. Musical and vocal emotion perception for cochlear implants users. Hear. Res. 2018, 370, 272–282. [Google Scholar] [CrossRef]
- Chatterjee, M.; Peng, S.-C. Processing F0 with cochlear implants: Modulation frequency discrimination and speech intonation recognition. Hear. Res. 2008, 235, 143–156. [Google Scholar] [CrossRef]
- Peng, S.-C.; Tomblin, J.B.; Turner, C.W. Production and perception of speech intonation in pediatric cochlear implant recipients and individuals with normal hearing. Ear Hear. 2008, 29, 336–351. [Google Scholar] [CrossRef] [PubMed]
- Holt, C.M.; Demuth, K.; Yuen, I. The use of prosodic cues in sentence processing by prelingually deaf users of cochlear implants. Ear Hear. 2016, 37, e256–e262. [Google Scholar] [CrossRef]
- Gu, X.; Liu, B.; Liu, Z.; Qi, B.; Wang, S.; Dong, R.; Chen, X.; Zhou, Q. A follow-Up study on music and lexical tone perception in adult Mandarin-Speaking cochlear implant users. Otol. Neurotol. 2017, 38, e421–e428. [Google Scholar] [CrossRef]
- McDermott, H.J. Music perception with cochlear implants: A review. Trends Amplif. 2004, 8, 49–82. [Google Scholar] [CrossRef]
- Tao, D.; Deng, R.; Jiang, Y.; Galvin III, J.J.; Fu, Q.-J.; Chen, B. Melodic pitch perception and lexical tone perception in Mandarin-Speaking cochlear implant users. Ear Hear. 2015, 36, 102–110. [Google Scholar] [CrossRef]
- Holt, C.M.; Lee, K.Y.S.; Dowell, R.C.; Vogel, A.P. Perception of Cantonese lexical tones by pediatric cochlear implant users. J. Speech Lang. Hear. Res. 2018, 61, 174–185. [Google Scholar] [CrossRef]
- Peng, S.-C.; Tomblin, J.B.; Cheung, H.; Lin, Y.-S.; Wang, L.-S. Perception and production of Mandarin tones in prelingually deaf children with cochlear implants. Ear Hear. 2004, 25, 251–264. [Google Scholar] [CrossRef]
- Peng, S.-C.; Lu, H.-P.; Lu, N.; Lin, Y.-S.; Deroche, M.L.D.; Chatterjee, M. Processing of acoustic cues in lexical-Tone identification by pediatric cochlear-implant recipients. J. Speech Lang. Hear. Res. 2017, 60, 1223–1235. [Google Scholar] [CrossRef] [PubMed]
- Shpak, T.; Most, T.; Luntz, M. Fundamental frequency information for speech recognition via bimodal stimulation: Cochlear implant in one ear and hearing aid in the other. Ear Hear. 2014, 35, 97–109. [Google Scholar] [CrossRef]
- Morera, C.; Manrique, M.; Ramos, A.; Garcia-Ibanez, L.; Cavalle, L.; Huarte, A.; Castillo, C.; Estrada, E. Advantages of binaural hearing provided through bimodal stimulation via a cochlear implant and a conventional hearing aid: A 6-Month comparative study. Acta Otolaryngol. 2005, 125, 596–606. [Google Scholar] [CrossRef] [PubMed]
- Dorman, M.F.; Spahr, T.; Gifford, R.; Loiselle, L.; McKarns, S.; Holden, T.; Skinner, M.; Finley, C. An electric frequency-To-Place map for a cochlear implant patient with hearing in the nonimplanted ear. J. Assoc. Res. Otolaryngol. 2007, 8, 234–240. [Google Scholar] [CrossRef] [PubMed]
- Mok, M.; Grayden, D.; Dowell, R.C.; Lawrence, D. Speech perception for adults who use hearing aids in conjunction with cochlear implants in opposite ears. J. Speech Lang. Hear. Res. 2006, 49, 338–351. [Google Scholar] [CrossRef]
- Mok, M.; Galvin, K.L.; Dowell, R.C.; McKay, C.M. Speech perception benefit for children with a cochlear implant and a hearing aid in opposite ears and children with bilateral cochlear implants. Audiol. Neurotol. 2010, 15, 44–56. [Google Scholar] [CrossRef]
- Cullington, H.E.; Zeng, F.-G. Comparison of bimodal and bilateral cochlear implant users on speech recognition with competing talker, music perception, affective prosody discrimination and talker identification. Ear Hear. 2011, 32, 16–30. [Google Scholar] [CrossRef]
- Most, T.; Harel, T.; Shpak, T.; Luntz, M. Perception of suprasegmental speech features via bimodal stimulation: Cochlear implant on one ear and hearing aid on the other. J. Speech Lang. Hear. Res. 2011, 54, 668–678. [Google Scholar] [CrossRef]
- Kong, Y.-Y.; Stickney, G.S.; Zeng, F.-G. Speech and melody recognition in binaurally combined acoustic and electric hearing. J. Acoust. Soc. Am. 2005, 117, 1351–1361. [Google Scholar] [CrossRef]
- Zhang, T.; Spahr, A.J.; Dorman, M.F.; Saoji, A. The relationship between auditory function of non-implanted ears and bimodal benefit. Ear Hear. 2013, 34, 133–141. [Google Scholar] [CrossRef]
- Chang, Y.; Chang, R.Y.; Lin, C.-Y.; Luo, X. Mandarin tone and vowel recognition in cochlear implant users: Effects of talker variability and bimodal hearing. Ear Hear. 2016, 37, 271–281. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhang, G.; Galvin III, J.J.; Fu, Q.-J. Mandarin speech perception in combined electric and acoustic stimulation. PLoS ONE 2014, 9, e112471. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Chang, Y.; Lin, C.-Y.; Chang, R.Y. Contribution of bimodal hearing to lexical tone normalization in Mandarin-Speaking cochlear implant users. Hear. Res. 2014, 312, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Mok, M.; Holt, C.M.; Lee, K.; Dowell, R.C.; Vogel, A.P. Cantonese tone perception for children who use a hearing aid and a cochlear implant in opposite ears. Ear Hear. 2017, 38, e359–e368. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.-I.; Zeng, F.-G. Bimodal benefits in Mandarin-Speaking cochlear implant users with contralateral residual acoustic hearing. Int. J. Audiol. 2017, 56, S17–S22. [Google Scholar] [CrossRef]
- Yuen, K.C.P.; Cao, K.; Wei, C.; Luan, L.; Li, H.; Zhang, Z. Lexical tone and word recognition in noise of Mandarin-Speaking children who use cochlear implants and hearing aids in opposite ears. Cochlear Implant. Int. 2009, 10, 120–129. [Google Scholar] [CrossRef]
- Chen, Y.; Wong, L.L.N.; Chen, F.; Xi, X. Tone and sentence perception in young Mandarin-speaking children with cochlear implants. Int. J. Pediatr. Otorhinolaryngol. 2014, 78, 1923–1930. [Google Scholar] [CrossRef]
- Zhou, N.; Huang, J.; Chen, X.; Xu, L. Relationship between tone perception and production in prelingually-Deafened children with cochlear implants. Otol. Neurotol. 2013, 34, 499–509. [Google Scholar] [CrossRef]
- Hong, T.; Wang, J.; Zhang, L.; Zhang, Y.; Shu, H.; Li, P. Age-Sensitive associations of segmental and suprasegmental perception with sentence-Level language skills in Mandarin-speaking children with cochlear implants. Res. Dev. Disabil. 2019, 93, 103453. [Google Scholar] [CrossRef]
- Kral, A. Auditory critical periods: A review from system’s perspective. Neuroscience 2013, 247, 117–133. [Google Scholar] [CrossRef]
- Irvine, D.R.F. Plasticity in the auditory system. Hear. Res. 2018, 362, 61–73. [Google Scholar] [CrossRef] [PubMed]
- Crew, J.D.; Galvin III, J.J.; Landsberger, D.M.; Fu, Q.-J. Contributions of electric and acoustic hearing to bimodal speech and music perception. PLoS ONE 2015, 10, e0120279. [Google Scholar] [CrossRef] [PubMed]
- Hiskey, M.S. Hiskey-Nebraska Test of Learning Aptitude; Union College Press: Cambridge, UK, 1966. [Google Scholar]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer (Computer Program, Version 6.0.33). Available online: http://www.fon.hum.uva.nl/praat/ (accessed on 26 September 2017).
- Zhu, S.; Wong, L.L.N.; Chen, F. Development and validation of a new Mandarin tone identification test. Int. J. Pediatr. Otorhinolaryngol. 2014, 78, 2174–2182. [Google Scholar] [CrossRef] [PubMed]
- Gifford, R.H.; Dorman, M.F. Bimodal hearing or bilateral cochlear implants? Ask the patient. Ear Hear. 2019, 40, 501–516. [Google Scholar] [CrossRef]
- Studebaker, G.A. A “rationalized” arcsine transform. J. Speech Lang. Hear. Res. 1985, 28, 455–462. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, J.; Hong, T.; Li, Y.; Zhang, Y.; Shu, H. Mandarin-Speaking, kindergarten-Aged children with cochlear implants benefit from natural F0 patterns in the use of semantic context during speech recognition. J. Speech Lang. Hear. Res. 2018, 61, 2146–2152. [Google Scholar] [CrossRef]
- Bates, D.; Mächler, M.; Bolker, B.M.; Walker, S.C. Fitting linear mixed-Effects models using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Brockhoff, P.B.; Christensen, R.H.B. lmerTest package: Tests in linear mixed effects models. J. Stat. Softw. 2017, 82, 1–26. [Google Scholar] [CrossRef]
- Lenth, R.V. Least-Squares means: The R package lsmeans. J. Stat. Softw. 2016, 69, 1–33. [Google Scholar] [CrossRef]
- Devocht, E.M.J.; Janssen, A.M.L.; Chalupper, J.; Stokroos, R.J.; George, E.L.J. The benefits of bimodal aiding on extended dimensions of speech perception: Intelligibility, listening effort, and sound quality. Trends Hear. 2017, 21. [Google Scholar] [CrossRef]
- Gifford, R.H.; Stecker, G.C. Binaural cue sensitivity in cochlear implant recipients with acoustic hearing preservation. Hear. Res. 2020, 390, 107929. [Google Scholar] [CrossRef] [PubMed]
- Hoppe, U.; Hocke, T.; Digeser, F. Bimodal benefit for cochlear implant listeners with different grades of hearing loss in the opposite ear. Acta Otolaryngol. 2018, 138, 713–721. [Google Scholar] [CrossRef] [PubMed]
- Kessler, D.M.; Ananthakrishnan, S.; Smith, S.B.; D′Onofrio, K.; Gifford, R.H. Frequency following response and speech recognition benefit for combining a cochlear implant and contralateral hearing aid. Trends Hear. 2020, 24, 2331216520902001. [Google Scholar] [CrossRef]
- Oh, S.H.; Donaldson, G.S.; Kong, Y.-Y. Top-Down processes in simulated electric-acoustic hearing: The effect of linguistic context on bimodal benefit for temporally interrupted speech. Ear Hear. 2016, 37, 582. [Google Scholar] [CrossRef]
- Perreau, A.E.; Ou, H.; Tyler, R.; Dunn, C. Self-Reported spatial hearing abilities across different cochlear implant profiles. Am. J. Audiol. 2014, 23, 374–384. [Google Scholar] [CrossRef]
- Shen, X.S.; Lin, M. A perceptual study of Mandarin tones 2 and 3. Lang. Speech 1991, 34, 145–156. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y. Neural plasticity in speech acquisition and learning. Biling. Lang. Cogn. 2007, 10, 147–160. [Google Scholar] [CrossRef]
- Chang, J.E.; Bai, J.Y.; Zeng, F.-G. Unintelligible low-Frequency sound enhances simulated cochlear-Implant speech recognition in noise. IEEE Trans. Biomed. Eng. 2006, 53, 2598–2601. [Google Scholar] [CrossRef]
- Brown, C.A.; Bacon, S.P. Fundamental frequency and speech intelligibility in background noise. Hear. Res. 2010, 266, 52–59. [Google Scholar] [CrossRef]
- Zhang, T.; Dorman, M.F.; Spahr, A.J. Information from the voice fundamental frequency (F0) region accounts for the majority of the benefit when acoustic stimulation is added to electric stimulation. Ear Hear. 2010, 31, 63–69. [Google Scholar] [CrossRef]
- Li, N.; Loizou, P.C. A glimpsing account for the benefit of simulated combined acoustic and electric hearing. J. Acoust. Soc. Am. 2008, 123, 2287–2294. [Google Scholar] [CrossRef] [PubMed]
- Kong, Y.-Y.; Carlyon, R.P. Improved speech recognition in noise in simulated binaurally combined acoustic and electric stimulation. J. Acoust. Soc. Am. 2007, 121, 3717–3727. [Google Scholar] [CrossRef] [PubMed]
- Cooke, M. A glimpsing model of speech perception in noise. J. Acoust. Soc. Am. 2006, 119, 1562–1573. [Google Scholar] [CrossRef] [PubMed]
- Easwar, V.; Yamazaki, H.; Deighton, M.; Papsin, B.; Gordon, K. Cortical representation of interaural time difference is impaired by deafness in development: Evidence from children with early long-term access to sound through bilateral cochlear implants provided simultaneously. J. Neurosci. 2017, 37, 2349–2361. [Google Scholar] [CrossRef]
- Polonenko, M.J.; Papsin, B.C.; Gordon, K.A. Delayed access to bilateral input alters cortical organization in children with asymmetric hearing. NeuroImage Clin. 2018, 17, 415–425. [Google Scholar] [CrossRef]
- Polonenko, M.J.; Papsin, B.C.; Gordon, K.A. Cortical plasticity with bimodal hearing in children with asymmetric hearing loss. Hear. Res. 2019, 372, 88–98. [Google Scholar] [CrossRef]
- Koerner, T.; Zhang, Y. Application of linear mixed-effects models in human neuroscience research: A comparison with Pearson correlation in two auditory electrophysiology studies. Brain Sci. 2017, 7, 26. [Google Scholar] [CrossRef]
- Brungart, D.S. Informational and energetic masking effects in the perception of two simultaneous talkers. J. Acoust. Soc. Am. 2001, 109, 1101–1109. [Google Scholar] [CrossRef]
- Neuman, A.C.; Waltzman, S.B.; Shapiro, W.H.; Neukam, J.D.; Zeman, A.M.; Svirsky, M.A. Self-Reported usage, functional benefit, and audiologic characteristics of cochlear implant patients who use a contralateral hearing aid. Trends Hear. 2017, 21, 1–14. [Google Scholar] [CrossRef]
- Miller, S.E.; Zhang, Y.; Nelson, P.B. Efficacy of multiple-Talker phonetic identification training in postlingually deafened cochlear implant listeners. J. Speech Lang. Hear. Res. 2016, 59, 90–98. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject (Sex) | CA (yrs) | CI (ear) | Speech Strategy | HA | Age at CI (yrs) | CI Duration (yrs) | Age at Bimodal (yrs) | Bimodal Duration (yrs) | PTA (dB HL) |
|---|---|---|---|---|---|---|---|---|---|
| S1 (M) | 4.9 | OPUS2 (R) | FS4-P | Phonak Bolero Q50 | 0.9 | 4.0 | 0.9 | 4.0 | 85 |
| S2 (M) | 5.9 | OPUS2 (R) | FS4-P | Widex C4-FS | 0.9 | 5.0 | 0.9 | 5.0 | 83 |
| S3 (M) | 5.6 | Naida (R) | HiRes-Optima | Phonak Naida S IX | 2.7 | 2.9 | 2.7 | 2.9 | 78 |
| S4 (M) | 5.3 | Nucleus6 (L) | ACE | ReSound AL777 | 2.7 | 2.6 | 3.6 | 1.7 | 67 |
| S5 (M) | 5.7 | OPUS2 (R) | FS4-P | Widex C3-FS | 1.7 | 4.0 | 1.7 | 4.0 | 65 |
| S6 (M) | 5.6 | OPUS2 (R) | FS4-P | Phonak Naida S IX | 1.0 | 4.6 | 1.0 | 4.6 | 88 |
| S7 (M) | 4.8 | Nucleus6 (R) | ACE | Phonak Naida S IX | 1.5 | 3.3 | 1.5 | 3.3 | 83 |
| S8 (M) | 6.6 | OPUS2 (R) | FS4-P | Widex C4-FS | 1.4 | 5.2 | 4.6 | 2.0 | 68 |
| S9 (F) | 5.6 | Nucleus6 (L) | ACE | Phonak Q90 SP | 3.3 | 2.3 | 3.3 | 2.3 | 56 |
| S10 (F) | 5.4 | Nucleus6 (R) | ACE | Phonak Naida S IX | 3.0 | 2.4 | 3.7 | 1.7 | 92 |
| S11 (F) | 6.2 | Nucleus5 (R) | ACE | Phonak Naida S IX | 1.1 | 5.1 | 1.2 | 5.0 | 63 |
| S12 (F) | 5.5 | Nucleus6 (R) | ACE | Phonak SKY Q90-RIC | 2.8 | 2.7 | 2.8 | 2.7 | 60 |
| S13 (F) | 5.8 | Nucleus5 (L) | ACE | Phonak Q90 UP | 3.2 | 2.6 | 3.3 | 2.5 | 77 |
| S14 (F) | 4.7 | Freedom (R) | ACE | Phonak Naida S V SP | 1.2 | 3.5 | 1.2 | 3.5 | 83 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Zhang, J.; Ding, H.; Zhang, Y. Bimodal Benefits for Lexical Tone Recognition: An Investigation on Mandarin-speaking Preschoolers with a Cochlear Implant and a Contralateral Hearing Aid. Brain Sci. 2020, 10, 238. https://doi.org/10.3390/brainsci10040238
Zhang H, Zhang J, Ding H, Zhang Y. Bimodal Benefits for Lexical Tone Recognition: An Investigation on Mandarin-speaking Preschoolers with a Cochlear Implant and a Contralateral Hearing Aid. Brain Sciences. 2020; 10(4):238. https://doi.org/10.3390/brainsci10040238
Chicago/Turabian StyleZhang, Hao, Jing Zhang, Hongwei Ding, and Yang Zhang. 2020. "Bimodal Benefits for Lexical Tone Recognition: An Investigation on Mandarin-speaking Preschoolers with a Cochlear Implant and a Contralateral Hearing Aid" Brain Sciences 10, no. 4: 238. https://doi.org/10.3390/brainsci10040238
APA StyleZhang, H., Zhang, J., Ding, H., & Zhang, Y. (2020). Bimodal Benefits for Lexical Tone Recognition: An Investigation on Mandarin-speaking Preschoolers with a Cochlear Implant and a Contralateral Hearing Aid. Brain Sciences, 10(4), 238. https://doi.org/10.3390/brainsci10040238