1. Introduction
With the development of increasingly intelligent vehicles, it has now become possible to assess the criticality of a situation much before the event actually happens. This makes it imperative to understand the criticality of a situation from the driver’s perspective. While computer vision continues to be the preferred sensing modality for achieving the goal of assessing driver awareness, the use of bio-sensing systems in this context has received wide attention in recent times [
1,
2,
3]. Most of these studies used electroencephalogram (EEG) as the preferred bio-sensing modality.
The emergence of wearable multi-modal bio-sensing systems [
4,
5] opened a new possibility to overcome the limitations of individual sensing modalities through the fusion of features from multiple modalities. For example, the information related to driver’s drowsiness extracted from EEG (which suffers from low spatial resolution especially when not using a very large number of sensors) may be augmented by the use of galvanic skin response (GSR) which does not suffer from electromagnetic noise (but has a low temporal resolution).
Driver awareness depends highly on the driver’s physiology since different people react differently to fatigue and to their surroundings. This means that one-fit-for-all type of approach using computer vision based on eye blinks/closure etc. might not scale very well across drivers. It is here that the use of bio-sensing modalities (EEG, GSR, etc.) may play a useful role in assessing driver awareness by continuously monitoring the human physiology. The fusion of data from vision-based systems and bio-sensors might be able to generate more robust models for the same. Furthermore, EEG with its higher temporal resolution than other common bio-sensors may prove to be very useful for detecting hazardous vs. non-hazardous situations on short time scales (such as 1–2 s) if such situations do not register in the driver’s facial expressions. Additionally, the driver’s physiology may provide insights into how they react to various situations during the drive which may have a correlation with the driver’s safety. For example, heart-rate variability, which was shown to model human stress [
6] may be used as an indicator of when it is unsafe for a person to drive a vehicle.
Deep Learning has many applications in computer vision-based driver-monitoring systems [
7,
8]. However, these advances have not translated towards the data from bio-sensing modalities. This is primarily due to the difficulty in collecting very large scale bio-sensing data which is a prerequisite for training deep neural networks. Collecting bio-sensing data on a large scale is costly, laborious, and time-consuming. It requires sensor preparation and instrumentation on the subject before the data collection can be started, whereas for collecting images/videos even a smartphone’s camera may suffice without the need to undergo any sensor preparation in most cases.
This study focuses on driver awareness and his/her perception of hazardous/non-hazardous situations from bio-sensing as well as vision-based perspectives. We individually use features from three bio-sensing modalities namely EEG, PPG, and GSR, and vision data to compare the performance of these modalities. We also use the fusion of features to understand if and in what circumstances can it be advantageous. To this end, we present a novel feature extraction and classification pipeline that has the ability to work with real-time capability. The pipeline uses pre-trained deep neural networks even in the absence of very large scale bio-sensing data. To the best of our knowledge, this study is the most comprehensive view of using such widely varying sensing modalities towards assessing driver awareness. Finally, we would like to emphasize that the bio-sensors used in this study are very practical to use in the “real world” i.e., they are compact in design, wireless and comfortable to use for prolonged time intervals. This choice of bio-sensors was consciously made so as to bridge the gap between laboratory-controlled experiments and “real-world” driving scenarios.
The framework presented in this paper is not just a user study but a complete scalable framework for signal acquisition, feature extraction, and classification that was designed with the intent to work in real world driving scenarios. The framework is modular since we extract the information from each sensor modality separately. Finally, we test two hypotheses in this paper. First, we test if the modalities with low-temporal resolution (but easily wearable) namely PPG and GSR can work as well as EEG and vision modality for assessing driver’s attention. Second, we test if (and when) the fusion of features from different sensor modalities boost the classification performance over using each modality independently for attention and hazardous/non-hazardous event classification. In the process of studying these two hypotheses, we extract traditional signal processing-based and deep learning-based features from each sensor modality.
2. Related Studies
Driver monitoring for assessing attention, awareness, behavior prediction, etc. was usually done using vision as the preferred modality [
9,
10,
11]. This is carried out by monitoring the subject’s facial expressions and eye-gaze [
12] which are used to train machine learning models. However, almost all such studies using “real-world” driving scenarios were conducted during daylight when ample ambient light is present. Even if infra-red cameras are used to conduct such experiments at night, vision modality suffers from occlusion and widely varying changes in illumination [
9], both of which are not uncommon in such scenarios. Furthermore, it was shown that EEG can classify hazardous vs. non-hazardous situations over short time periods which is not possible with images/videos [
13].
On the other hand, if we focus on the bio-sensing hardware, more than a decade ago, those studies in driving scenarios that used the use of bio-sensing modalities suffered from impracticality in the “real-world” situations. This is because the bio-sensors were usually bulky, required wet electrodes, and were very prone to noise in the environment. Hence, the studies carried out with such sensors required wet electrode application and monitors in front of participants with minimal motion [
14,
15]. In the early years of this decade, such bio-sensing systems gave way to more compact ones capable of transmitting data wirelessly while being more resistant to the noise by better EM (electro-magnetic) shielding and advances in mechanical design. Finally, recent advances have led to the development of multi-modal bio-sensing systems and the ability to design algorithms using the fusion of features from various modalities. This was used for various applications such as in affective computing and virtual reality [
16,
17].
The use of deep learning for various applications relating to driver safety and autonomous driving systems skyrocketed in the past few years. These studies ranged from understanding driving behavior [
18] to autonomous driving systems on highways [
19] to detecting obstacles for cars [
20] among other applications. All such studies only use vision modality, due to, as mentioned previously, the prevalence of large-scale image datasets. However, the use of “pre-trained” neural networks for various applications [
21,
22] may provide a new opportunity. Hence, if bio-sensing data can be represented in the form of an image, it should be possible to use such networks to extract deep learning-based optimal feature representation of the image (henceforth called most significant features) even in the absence of large-scale bio-sensing datasets.
Finally, our system pipeline uses multiple bio-sensing modalities in addition to the vision which is not the case with previous state-of-the-art evaluations done on the KITTI dataset [
23]. Our previous work on EEG and visual modality data with the KITTI dataset [
24] showed the utility of using these two modalities for driver attention monitoring but does not present a holistic view of multiple bio-sensing modalities with short-time-interval analysis on other datasets. The use of another dataset collected by us while driving a car in autonomous mode with the driver strapped with bio-sensing modalities and holistic comparison of multiple sensing modalities is a chief feature of this research study. Also, the previous research studies generally [
13,
25] used a single modality and traditional features (i.e., not based on deep neural networks) for classification. Through our evaluation, we show that we easily beat their results with higher-order features and also evaluate our pipeline on a new driving dataset collected in this study.
3. Research Methods
In this section, we discuss the various research methods that we employed to pre-process the data and extract features from each of the sensor modalities used in this study. We also show the visualization of sensor data for each sensor modality. This is done by showing the time and/or frequency domain sensor data for the sensor modality as no threshold exists which can distinguish between different mental or psychological states directly for each sensing modality even for a single subject.
3.1. EEG-based Feature Extraction
The cognitive processes pertaining to attention and mental load such as while driving are not associated with only one part of the brain. Hence, our goal was to map the interaction between various regions of the brain to extract relevant features related to attention. The EEG was initially recorded from a 14-channel Emotiv EEG headset at 128 Hz sampling rate [
26]. The EEG channel locations as per the International 10–20 system were AF3, AF4, F3, F4, F7, F8, FC5, FC6, T7, T8, P7, P8, O1, and O2. We used the artifact subspace reconstruction (ASR) pipeline in the EEGLAB [
27] toolbox to remove artifacts related to eye blinks, muscle movements, line noise, etc. [
28]. This pipeline is capable of working in real time and unlike Independent Component Analysis (ICA) [
29] has the added advantage of being able to remove noise without much loss of EEG data when a very large number of EEG sensors are not present. For each subject, we verified the output from ASR manually as well as observed the algorithm’s output parameters to make sure that the noise removal is being performed correctly. Then, we band-pass filtered the EEG data between 4–45 Hz. The band-pass filter was designed so as to capture the theta, alpha, beta, and low-gamma EEG bands i.e., frequency information between 4–45 Hz. On this processed EEG data, we employed two distinct and novel methods to extract EEG features that capture the interplay between various brain regions to map human cognition.
3.1.1. Mutual Information-Based Features
To construct the feature space that can map the interaction of EEG information between various regions of the brain, we calculated the mutual information between signals from different parts of the brain. EEG-based mutual information features were used since they measure the changes in EEG across the various regions of the brain as opposed to power spectrum-based features that are local. This is because unlike a steady-state visual-evoked potential (SSVEP) or a P300 type of EEG response which mostly affects a single brain region, driving is a high-level cognition task and hence multiple systems of the brain are involved: vision, auditory, motor, etc. The mutual information
of discrete random variables
X and
Y and their instantaneous observation
x and
y is defined as
where
,
, and
are the probability density function of
X,
Y, and joint probability density function of
X and
Y respectively [
30]. The desired feature of conditional entropy
is related to the mutual information
by
We calculated the conditional entropy using mutual information between all possible pairs of EEG electrodes for a given trial. Hence, for 14 EEG electrodes, we calculated 91 EEG features based on this measure.
3.1.2. Deep Learning-Based Features
The most commonly used EEG features are the calculation of power-spectrum density (PSD) of different EEG bands. However, these features in themselves do not take into account the EEG-topography i.e., the location of EEG electrodes for a particular EEG band. Hence, we developed a way to exploit EEG-topography for extracting information regarding the interplay between different brain regions.
Since the 2D spectrum image of the brain PSD has the information about amplitude distribution of each frequency band across the brain, we calculated the PSD of three EEG bands namely theta (4–7 Hz), alpha (7–13 Hz) and Beta (13–30 Hz) for all the EEG channels. The choice of these three specific EEG bands was made since they are the most commonly used bands and are thought to carry a lot of information about human cognition. We averaged the PSD for each band thus calculated over the complete trial. These features from different EEG channels were then used to construct a two-dimensional EEG-PSD heatmap for each of the three EEG bands using bicubic interpolation. These heat-maps now contained the information related to EEG topography in addition to spectrum density at each of these locations.
Figure 1 shows these 2-D heatmaps for each of the three EEG bands. As can be seen from the figure, we plotted each of the three EEG bands using a single color channel i.e., red, green and blue [
31]. We then added these three color band images to get a color RGB image containing information from the three EEG bands. The three color band images were added in proportion to the amount of EEG power in the three bands using alpha blending [
32] by giving weights to the three individual bands’ images by normalizing them using the highest value in the image. Hence, following this procedure we were able to represent the information in the three EEG bands along with their topography using a single color image. The interaction through the mixture of these three colors (thus forming new colors by adding these primary colors) in various quantities was contained the information regarding the distribution of power spectrum density across the various brain regions.
It is notable that we computed PSD in three EEG power bands (theta, alpha, and beta) separately because these three EEG power bands contribute the most towards human cognition. Subsequently, the power in these EEG bands were averaged separately for each band and not together. This process was done so that the RGB colored image with three EEG bands could be constructed using the averaged power of theta, alpha, and beta band separately. It was to execute this complete procedure of generating the RGB colored image with each color band representing the averaged PSD of a particular EEG band that it was not possible to directly average the PSD values between 4–30 Hz.
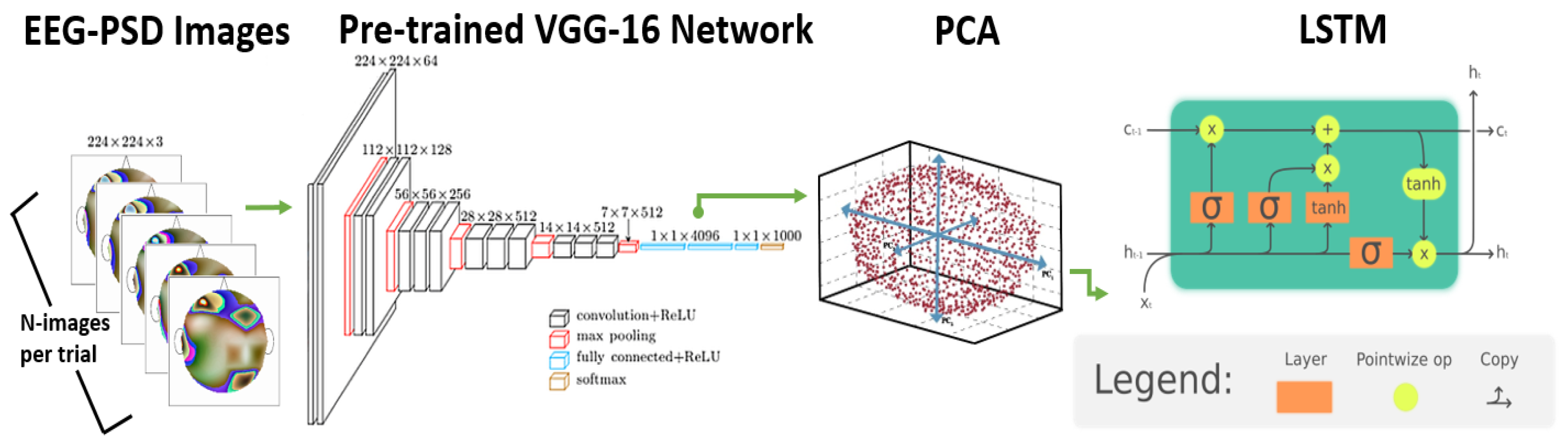
Since it is not possible to train a deep neural network from scratch without thousands of trials from the EEG data (and no such dataset currently exists in driving scenario), the combined colored image representing EEG-PSD with topography information was then fed to a pre-trained deep learning-based VGG-16 convolution neural network [
33] to extract features from this image. This network was trained with more than a million images for 1000 object categories using the Imagenet Database [
34]. Specifically, the VGG-16 deep learning network used by us has a total of 16 layers (as shown in Figure 4), the input to the network being 224 × 224 × 3 sized colored image and Rectified Linear Unit (ReLU) optimizer as the activation function for all hidden layers. The convolution layers are 3 × 3 kernel size while the maxpooling layers are 2 × 2 kernel size and finally there are three layers of the VGG-16 network which are fully connected ones.
Previous research studies [
21,
22] showed that using features from such an “off-the-shelf" neural network can be used for various classification problems with good accuracy. Even for the research problems where the neural networks were trained on a different vision-based problem and applied to a totally different application they still worked very well [
22,
35,
36]. This is mostly because the low-level features such as texture, contrast, etc. reflected in the initial layers of the Convolution Neural Network (CNN) are ubiquitous in any type of image. The EEG-PSD colored image was resized to 224 × 224 × 3 for input to the network. The last layer of the network classifies the image into one of the 1000 classes but since we were only interested in “off-the-shelf” features, we extracted 4096 features from the last but one layer of the network. The EEG features from this method were then combined with those from the previous one for further analysis.
3.2. PPG-Based Feature Extraction
PPG measures the changes in blood volume in the microvascular tissue bed. This is done in order to assess the blood flow as being modulated by the heart beat. Using a simple peak detection algorithm on the PPG signal, it is possible to calculate the peaks of the blood flow and measure the subject’s heart rate in a much more wearable manner than a traditional electrocardiogram (ECG) system. The PPG signal was recorded using an armband (Biovotion) that measures PPG at a sampling rate of 51.2 Hz.
3.2.1. HRV and Statistical Time-Domain Features
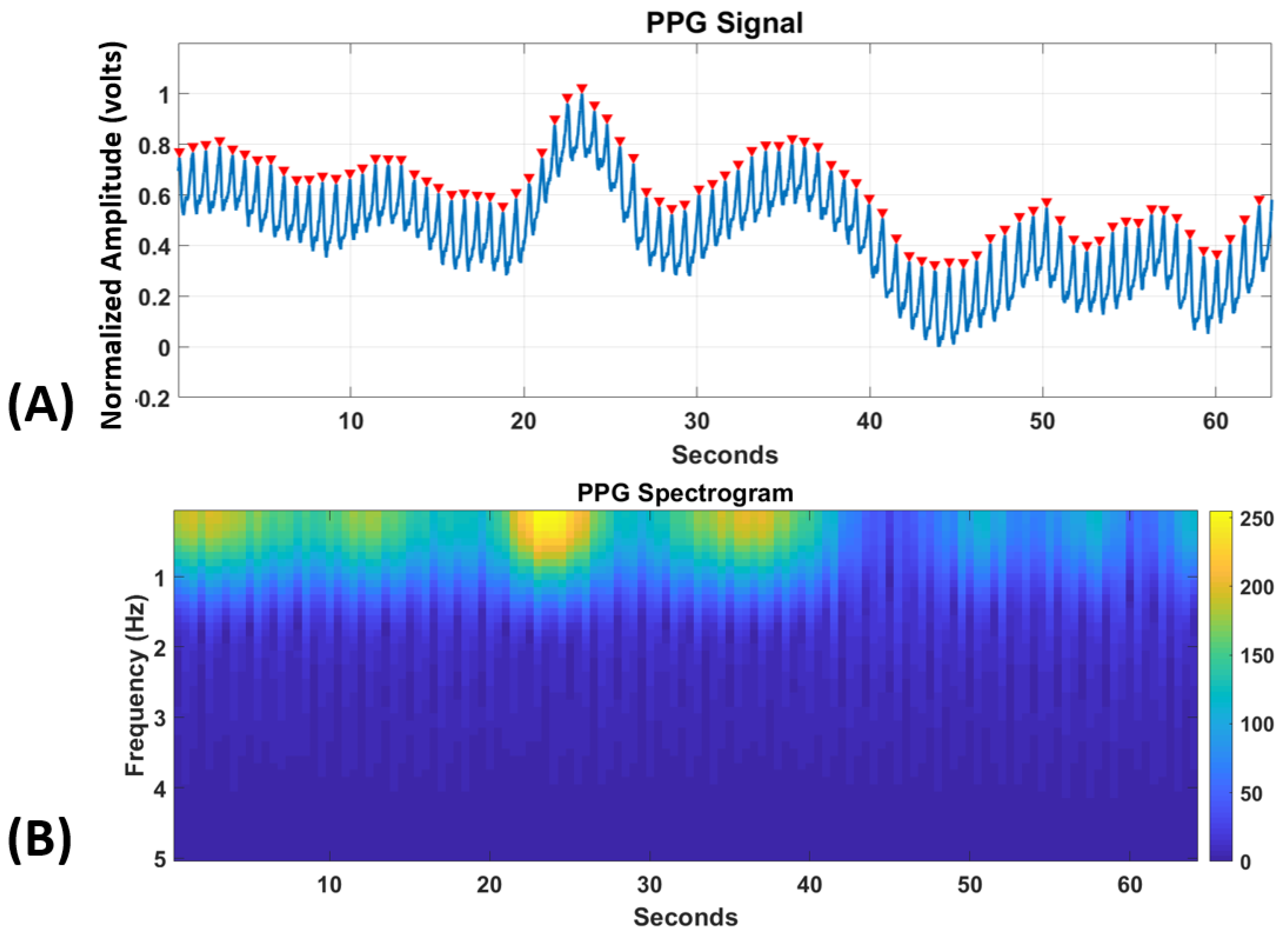
Heart-rate variability (HRV) has shown to be a good measure for classifying cognitive states such as emotional valence and stress [
37]. HRV is much more robust than heart rate (HR) which changes slowly and generally only correspond to physical exertion. A moving-average filter with a window length of 0.25 s for filtering the noise in the PPG data was first used for each trial. The filtered PPG data so obtained was then scaled between 0 and 1 and subsequently a peak-detection algorithm [
38] was applied to find the inter-beat intervals (RR) for the calculation of HRV. The minimum distance between successive peaks was taken to be 0.5 s to remove any false positives as shown in
Figure 2.
HR is defined as the total number of peaks per minute in the PPG. pNN50 algorithm [
39] was then used to calculate HRV from RR intervals. To explore the statistics related to the PPG wave itself in time-domain, we calculated six statistical features on the PPG wave as defined in [
40]. These features mapped various trends in the signal by the calculation of mean, standard deviation, etc. at first and subsequent difference signals formed using the original signal.
3.2.2. Spectrogram Deep Learning-Based Features
Recent research studies showed promising results by analyzing PPG in the frequency domain for applications such as blood pressure estimation and gender identification [
41,
42]. Despite the low amount of information that is present in the PPG spectrogram as can be seen from
Figure 2, we had to use this method since only then we could convert the one-dimensional PPG signal into a two-dimensional image for the computation of higher-order deep learning-based features.
The frequency range of PPG signals is low and hence we focus only on 0–5 Hz range.
Figure 2 shows the generated frequency spectrogram [
43] for this frequency range for the PPG signal in a trial. The different color values generated using the “Parula” color-map shows the intensity of the spectrogram at a specific frequency bin. Then, we resized the spectrogram images to feed them to the VGG-16 network (as we did above for the color EEG-PSD images), and after which the 4096 extracted features were extracted from the VGG-CNN network. Time-domain statistical and HRV features from the method above were concatenated with these features for further analysis.
3.3. GSR-Based Feature Extraction
The feature extraction pipeline on the GSR signal was similar to that on the PPG. The same two methods that were applied on the PPG were used for GSR too. Same as PPG, the signals are sampled at 51.2 Hz by the device.
3.3.1. Statistical Features
The GSR data were first low-pass filtered with a moving average window of 0.25 s to remove any bursts in the data. Eight features based on the profile of the signal were then calculated. The first two of these features were the number of peaks and the mean of absolute heights of the peaks in the signal. Such peaks and their time differences may prove to be a good measure of arousal. The remaining six features were calculated as in [
40] like the PPG signal above. For this time-series analysis of GSR signal, the features comptuted based on the peaks of GSR takes into account the Skin Conductance Response (SCR) i.e., the “peaks” of the activity while other features based on the GSR signal profile (by calculating mean and standard deviation of successive differences of the signal) accounts for the Skin Conductance Level (SCL).
3.3.2. Spectrogram Deep Learning-Based Features
Since GSR signals change very slowly we focused only on the 0–2 Hz frequency range. We generated the spectrogram image for GSR in the above frequency range for each trial. This choice of using low-frequency features was done because similar to PPG, GSR signals change very slowly. We then sent the spectrogram image to the VGG-16 deep neural network and extract the most significant 4096 features from the same. These features were then concatenated with the features from the time-domain analysis.
3.4. Facial Expression-Based Feature Extraction
As discussed above, the analysis of facial expressions has been the preferred modality for driver attention analysis. Hence, our goal is to use this method to compare it against the bio-sensing modalities. Furthermore, most of the research work in this area was done by tracking fixed localized points on the face based on face action units (AUs). Hence, below we show a novel deep learning-based method to extract relevant features from the faces for driver attention and hazardous conditions detection.
First, we extracted the face region from the frontal body image of the person captured by the camera for each frame. This was done by fixing a threshold on the image size to reduce its extreme ends and placing a threshold of minimum face size to be 50 × 50 pixels. This resizing was done to remove any false positives and decrease the computational space for face detection. We then used the Viola-Jones object detector with Haar-like features [
44] to detect the most likely face candidate.
3.4.1. Facial-Points Localization-Based Features
Face action units were used for a variety of applications ranging from affective computing to face recognition [
45]. Facial Action Coding System (FACS) is the most commonly used method to code facial expressions and map them to different emotional states [
46]. Our goal was to use face localized points similar to the ones used in FACS without identifying facial expressions such as anger, happiness, etc. since they are not highly relevant in the driving domain and short time intervals. The use of FACS initially involves the identification of multiple facial landmarks that are then tracked to map the changes in facial expressions. We applied the state-of-the-art Chehra algorithm [
47] to the extracted face candidate region from above. This algorithm outputs the coordinates of 49 localized points (landmarks) representing various features of the face as shown in
Figure 3. The choice of this algorithm was done because of its ability to detect these landmarks through its pre-trained models and hence not needing training for any new set of images. These face localized points were then used to calculate 30 different features based on the distances such as between the center of the eyebrow to the midpoint of the eye, between the midpoint of nose and corners of the lower lip, between the midpoints of two eyebrows, etc. and the angles between such line segments. To remove variations by factors such as distance from the camera and face tilt, we normalized these features using the dimensions of the face region. All these features were calculated for individual frames, many of which make a trial. Hence, to map the variation in these features across a trial (which may directly correspond to driver’s attention and driving condition) we calculated the mean, 95th percentile (more robust than maximum), and the standard deviation of these 30 features across the frames in the trial. In this manner, we computed 90 features based on face-localized points from a particular trial.
3.4.2. Deep Learning-Based Features
For the extraction of deep learning-based features, we used the VGG-Faces deep learning network instead of VGG-16 [
48]. This was done to extract features more relevant to faces since the VGG-Faces network was trained on more than 2.6 million face images from more than 2600 people rather than on various object categories in the VGG-16 network. We sent each face region part to the network and extracted the most significant 4096 features. To represent the changes in these features across the trial i.e., across the frames, we calculated the mean, 95th percentile, and standard deviation of the features across the frames in a trial. We then separately analyzed the features from this method to those from the traditionally used face-localized points-based method from above to compare the two.
3.5. Assessing Trends of EEG/Face Features Using Deep Learning
The EEG features discussed in
Section 3.1.2 above were computed over the whole trial such as by generating a single EEG-PSD image for a particular trial. This is a special case when the data from the whole trial is being averaged. Here, we propose a novel method to compute the trend of EEG features i.e., their variation in a trial based on deep learning. To compute features with more resolution we generated multiple EEG-PSD images for successive time durations in a trial. We generated one image per second of the data for driver attention analysis and used 30 images for every second for a 2-s incident classification analysis as detailed below in the Quantitative Analysis section.
Figure 4 shows the network architecture for this method. The EEG-PSD images were generated for multiple successive time durations in a trial each of which was then sent to the VGG-16 network to obtain 4096 most significant features. Similarly, this process was done for conditional entropy features by calculating this over multiple periods in a trial rather than once on the whole trial. We then used principal component analysis (PCA) [
49] to reduce the feature size to 60 to save computational time in the next step. These 60 ×
N (
N = number of successive time intervals) features were then sent as input to a Long Short Term Memory (LSTM) network [
50].
In particular, the use of LSTM was motivated by extracting information from sensor modalities with higher temporal resolution. Example: For the EEG and modality, the extraction of deep-learning features without LSTM was being done by representing the whole trial with a single 2D EEG image. This was a sort of average power-spectrum density image for the whole trial and thus had a bad temporal resolution. Instead, we later calculated one such power-spectrum density image for every second to observe for the 2D image patterns change from second to second. This high temporal resolution was modeled using LSTM which further increases the accuracy by using these shifting patterns.
The LSTM treats each of these features as a time-series and was trained so as to capture the trend in each of them for further analysis. This method could only be applied when the time duration of the trials is fixed since the length of each time series should be the same. Hence, we applied this method only in the trials used for detecting hazardous/non-hazardous situations and on EEG and face i.e., vision sensor modalities. However, since the analysis of such situations was done on a short time intervals basis, we could not use this method for PPG and GSR modalities since they take a few seconds to react physiologically to the situation.
4. Dataset Description
Figure 5 shows the experimental setup for data collection with driving videos used as the stimulus in our dataset. Twelve participants (most of them in their 20 s with two older than 30 years) based in San Diego participated in our study. The participants were comfortably seated equipped with EEG headset (Emotiv EPOC) containing 14 EEG channels (sampling rate of 128 Hz.) and an armband (Biovotion) for collecting PPG and GSR (sampling rate of 51.2 Hz). This EEG headset was chosen since it is easily wearable and does not require the application of electrode gel. This made the headset conform more closely to real-world applications such as in the driving context. However, these advantages came at the cost of two limitations, namely, lower sampling rate and fewer EEG channels as compared to bulky EEG headsets used in the laboratory. The positioning of the GSR sensor was however sub-optimal since we do not place the sensor at the palm or the feet. This choice was driven by the practicality of data collection in the driving scenario since users interact with multiple vehicle modules from their palms and feet during driving. The facial expressions of the subject were recorded using a camera in front of him/her. The participants were asked to use a driving simulator which they were instructed to control as per the situation in the driving stimulus. For example, if there was a “red light” or “stop sign” at any point in a driving stimulus video, the participants should press and hold the brake.
For consistency between our work and other previous studies [
13,
25], we used 15 video sequences from the KITTI dataset [
23]. These previous research studies used the same dataset but without detailing the exact image sequences used to generate the video sequences. Thus, the video sequences in this study chosen based on external annotation by two subjects to judge them based on potential hazardous events in them. These video sequences ranged from 14 to 105 s. These video sequences in the dataset were recorded at 1242 × 375 resolution at 10 frames-per-second (fps). We resized the videos to 1920 × 580 to fit the display screen in a more naturalistic manner. However, video sequences from the KITTI dataset suffer from three limitations namely low resolution, low fps, and a few sequences of driving on highways. Additionally, since the images in the KITTI dataset were captured at 10 fps it may produce steady-state visual-evoked potential (SSVEP) effect in EEG [
51]. This is undesirable since we only focus on driver attention and hazardous/non-hazardous events analysis and SSVEP might act as a noise in the process.
Hence, we also collected our own dataset of 20 video sequences containing real-world driving data on freeways and downtown San Diego, California. This dataset was collected using our LISA-T vehicle testbed in which a Tesla Model 3 is equipped with 6 external facing GoPro cameras. It is also to be noted that while capturing these videos the vehicle was in the autonomous driving mode making LISA dataset the first of its kind. The cameras were operating at 122 degrees field-of-view which is very representative of the human vision. Furthermore, we presented these video sequences on a large screen (45.9 inches diagonally) at a distance of a meter from the participants to model a real-world driving scenario. These video sequences ranged from 30 to 50 s in length and were shown to the participants with 1920 × 1200 resolution at 30 fps. External annotation was done to classify parts of the video sequences from both datasets into hazardous/non-hazardous events. For example, an event where a pedestrian suddenly appears to cross the road illegally was termed hazardous whereas an event where a stop sign can be seen from a distance and the vehicle’s speed is decreasing was termed non-hazardous. External annotation was performed to classify every video sequence into how attentive the driver ought to be in that particular sequence. In
Table 1, we catalog the different datasets and features that we used in the evaluation of our proposed pipeline. In
Figure 6, we show some examples of driving conditions from KITTI and LISA dataset.
5. Quantitative Analysis of Multi-Modal Bio-Sensing and Vision Sensor Modalities
In this section, we present the various singular modality and multi-modal evaluation results for driver attention analysis and hazardous/non-hazardous instances classification. First, the videos in both datasets were externally annotated by two annotators for low/high driver attention required. For example, the video instances where the car is not moving at all were characterized as low attention instances whereas driving through narrow streets with pedestrians on the road were labeled as instances with high driver attention required. Hence, among the 35 videos (15 from KITTI dataset and 20 from LISA dataset), 20 were characterized as requiring low-attention and 15 as high-attention ones.
Second, 70 instances, each two-second long were found in the videos and were characterized as hazardous/non-hazardous.
Figure 7 presents some examples of instances from both categories. As an example, a pedestrian suddenly crossing the road “unlawfully” or a vehicle overtaking suddenly represents hazardous events whereas “red” traffic sign at a distance and a pedestrian at a crossing with ego vehicle not in motion are examples of non-hazardous events. Among the 70 instances, 30 instances were labeled as hazardous whereas rest were labeled as non-hazardous. Hence, the goal was to classify such instances in a short time period of two seconds using the above modalities. Since PPG and GSR have low temporal resolution and do not reflect changes in such short time intervals, we used only facial features and EEG for hazardous/non-hazardous event classification.
For each modality, we first used PCA [
49] to reduce the number of features from the above algorithms to 30. We then used extreme learning machines (ELM) [
52] for classification. The choice of using ELM over other feature classification methods was driven by previous studies that showed how ELM performs better for features derived from bio-signals [
53,
54]. These features were normalized between −1 and 1 across the subjects before training. A single hidden layer ELM was used with a triangular basis function for activation. For the method with trend-based temporal EEG and face feature data, we used two-layer LSTM with 200 and 100 neurons in respective layers instead of ELM for classification. The LSTM network’s training was done using stochastic gradient descent with a momentum (SGDM) optimizer. We performed leave-one-subject-out cross-validation for each case. This meant that the data from 11 subjects (385 trials) were used for training at a time and the classification was done on the 35 trials from the remaining 12th subject. This choice of cross-validation was driven by two factors. First, this method of cross-validation is much more robust and less prone to bias than models such as leave-one-sample-out cross-validation that constitutes training data from all the subjects at any given time. Second, since the data contained 420 trials only as opposed to thousands of trials for any decent image-based deep-learning dataset, it does not make sense to randomly divide such a small number of trials to training, validation and test sets since it might introduce bias by uneven division across trials from individual subjects.
Both of the feature classification methods i.e., LSTM-based and ELM-based were used independently for feature classification with labels. When a higher temporal resolution was taken into consideration i.e., trends in a series of EEG-PSD images, then the LSTM-based method was used for feature classification. This is because now the features vary as a time series for each trial and ELM cannot be used for such a time-series-based classification. The ELM-based method was performed for the other case i.e., the case when high temporal resolution data (multiple data point features for each trial) were not present. The data from the complete trial was represented by a single (non-varying in time) value for each feature.
As pointed out by a reviewer of our manuscript, accuracy in itself may not be the best metric for evaluation in 2-class classification problems [
55]. This is because 50% is not an optimal threshold in itself since the number of training and testing samples in the two-class classification problem in most datasets (including ours) are not exactly equal and this threshold only works for an infinite number of data samples. We used accuracy as a metric in consonance with previous research studies using the same in the field of multi-modal bio-sensing research [
56,
57] while we also note the area under the curve (AUC) as another metric in our analysis. AUC is a more robust classification metric for 2-class classification problems and was used by previous research studies in driver attention analysis [
13,
25].
5.1. Evaluating Attention Analysis Performance
In this section, we evaluate single and multi-modality performance for assessing the driver’s attention across the video trials. For all the four modalities, the features as defined above were calculated for data from each video trial. The ELM-based classifier was then trained based on each video trial divided into one of the two classes representing low-attention and high-attention required by the driver.
5.1.1. Singular Modality Analysis
To compare the performance among the different modalities, the number of neurons in the hidden layer was set to 170 for each of the modality. In
Figure 8 we show these results. Clearly, EEG performs the best among the four modalities for driver attention classification. The average classification accuracy for EEG, PPG, GSR, and face-videos were
, and
, respectively. The AUC (area under the curve) for the above four cases were
, and
respectively. We also performed statistical t-test on our observations. The p-values for the above four classification cases were
,
,
, and
respectively. Hence, GSR performs only at about chance level whereas on average PPG and face videos perform equally well. Thus, we see that the sensor modalities with good temporal resolution i.e., EEG and vision perform better or at least as good as the ones with low temporal resolution (PPG and GSR) thus evaluating our first hypotheses. We performed pairwise t-test for all six pair combinations of the above four signal modalities and the p-values were less than 0.05 for all cases. Thus, the statistical tests showed the results to be statistically significant. We also see that for all the subjects except one, EEG’s classification accuracy is above 90% while for three modalities (EEG, GSR, and vision) the standard deviation in performance across the subjects is not too high.
5.1.2. Multi-Modality Analysis
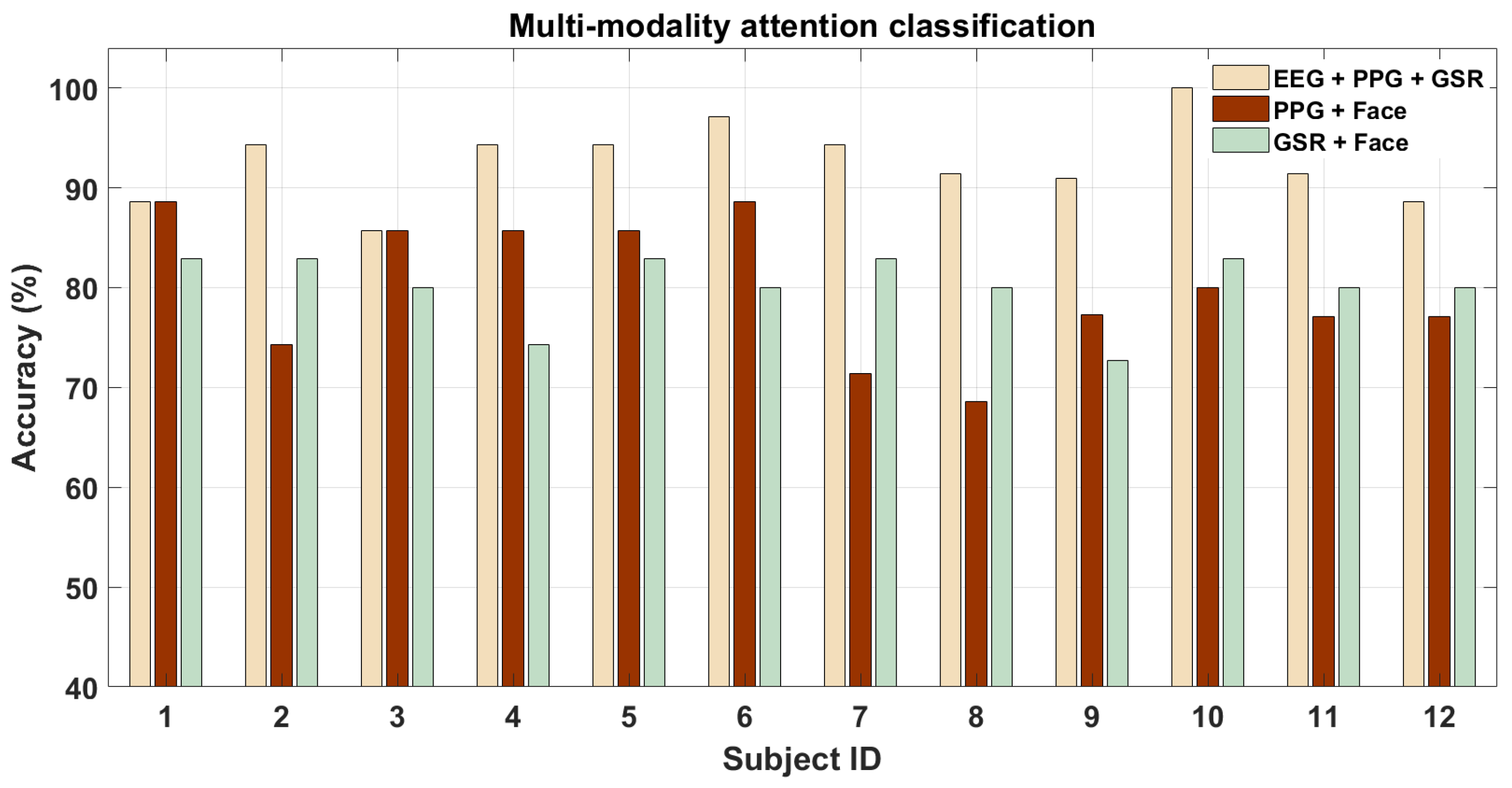
Since EEG performs best among the four modalities by far, we do not expect much further increase in classification accuracy while combining it with other modalities that perform much worse.
Figure 9 shows that on combining EEG with PPG and GSR there is no increase in the performance across the subjects (it might be that for a few subjects this is not the case). On the contrary, when the features from the low-performing (and poor temporal resolution) modalities i.e., PPG and GSR are combined with EEG, the performance is not as good as EEG alone for most of them. The mean accuracy across all the subjects were
, and
for the three cases respectively, all of which were significantly above the chance accuracy. The AUC for the above three cases were
, and
respectively. The p-values for the above four classification cases were
,
, and
respectively. To compare the different signal combinations, we also performed pairwise t-test for the above cases. The p-values of pairwise t-test for multi-modal attention classification were
between (EEG + PPG + GSR) and (GSR +Face) cases and 0.9 between (GSR + Face) and (PPG + Face). Finally, we also performed pairwise t-test analysis between multi-modality and single-modality cases and found that the p-values between all four singular modalities (EEG, PPG, GSR, and Face) and the three multi-modality cases mentioned above were less than 0.05. These p-values thus denote that not all signal combination cases between multi-modality cases are statistically significant in a pairwise manner while those between singular and multi-modality cases were statistically significant. Hence, we see that it is not always beneficial to use features from multiple sensor modalities. For most of the subjects and modalities, the fusion of features does not perform better at all and hence may not be advantageous in this case. We think that this is because of the vast difference in the performance of each modality when used independently, based on the subject’s physiology. This leads to an increase in performance for some of the subjects but not for all. However, for all combinations of sensor modalities we see that the accuracy values were as good or better than using individual sensor modalities which proves our hypotheses about the performance improvement that could be gained by the use of multiple sensor modalities.
5.2. Evaluating Hazardous/Non-hazardous Incidents Classification
In this section, we present the results of the evaluation of the modalities over very short time intervals (2 s) pertaining to hazardous/non-hazardous driving incidents as shown in
Figure 7. Since GSR and PPG do not provide such a fine temporal resolution, we do not use these modalities for this evaluation. This is because GSR changes very slowly i.e., take more than a few seconds to vary and PPG for a very short time period such as 2 s would mean only 2–4 heartbeats which are not enough for computing heart-rate or heart-rate variability. Previous studies to assess human emotions using GSR and PPG on the order of multiple seconds (significantly greater than two seconds hazardous incident evaluation for driving context) [
58]. Also, it is not possible for the subjects to tag the incidents while they are participating in the driving simulator experiment and hence these incidents were marked by the external annotators as mentioned above in
Section 5.
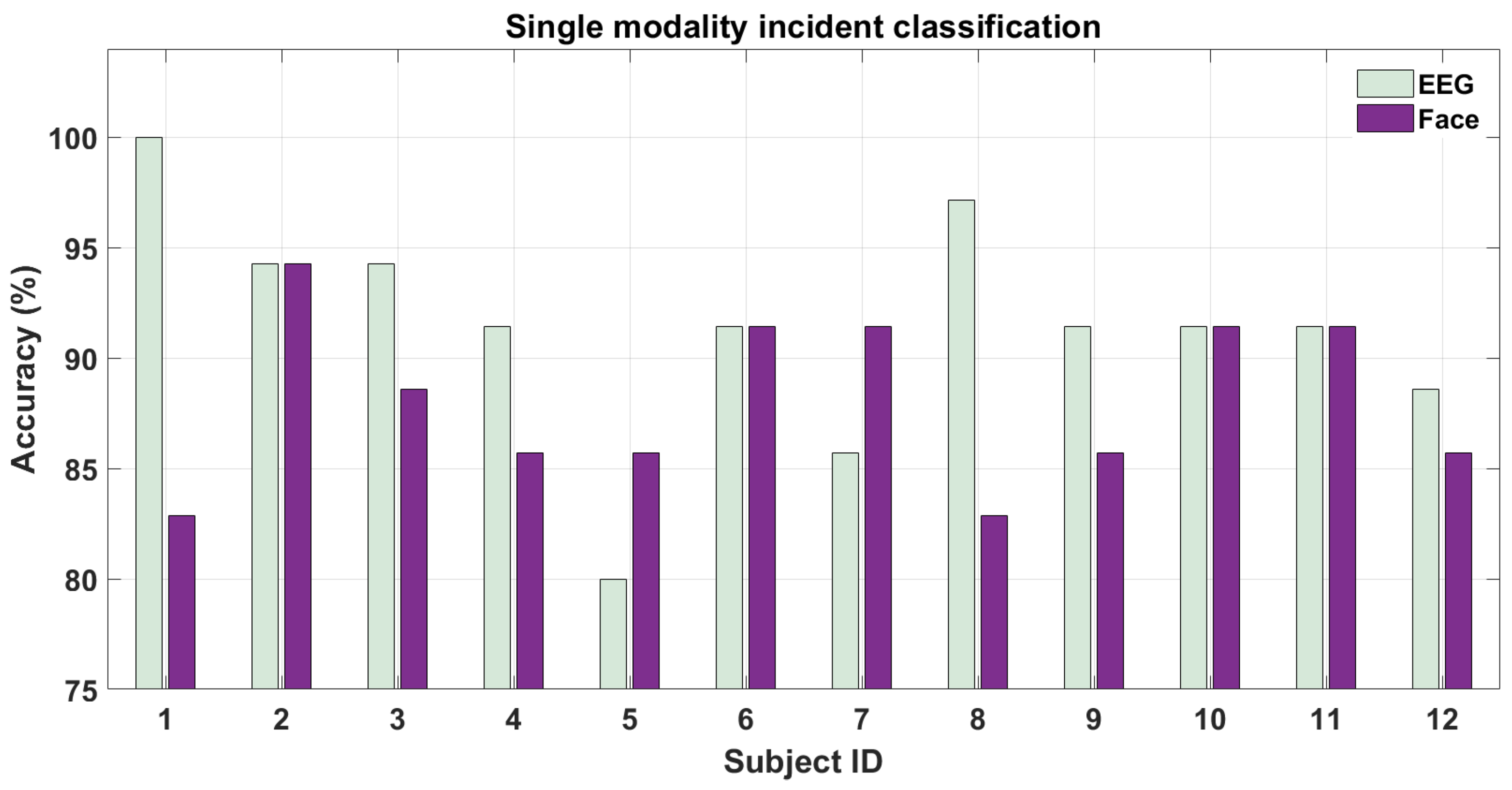
5.2.1. Single-Modality Analysis
Figure 10 shows the results for classifying hazardous/non-hazardous incidents using EEG and face-expression features. As we can see from the figure, the accuracy for both modalities for all the subjects is well above chance level (50%). The inter-subject variability for different sensor modalities can also been visualized from the above figure. For example, EEG outperforms face-based features for half of the participants but not for the other half. This bolsters our earlier argument: it may be so that bio-sensing modality (here EEG) may outperform vision modality depending on the user’s physiology. This variation in results is natural since some people tend to be more expressive with their facial expressions while on the other hand, the “perceived hazardousness” of a situation varies across subjects. The mean accuracy among subjects were
and
for EEG- and face-based features respectively. The AUC for these two cases were
and
respectively. The p-values for the above two classification cases were
and
respectively. Finally, we also performed statistical pairwise t-test on the above two sensor modalities and the p-values was found to be
. Thus, statistical significance was found within pairwise EEG and Face sensor modalities. Since the evaluation was done on 2-s time intervals i.e., without a lot of data we note that such a high mean accuracy for both modalities was only possible due to using deep learning-based features in addition to the traditional features for both modalities. This is further substantiated by the fact that we used an EEG system with a much lesser number of channels than such previous studies using EEG [
13]. We show that using such deep learning features our method outperforms the previous results for EEG on the KITTI dataset [
13,
25] in a similar experimental setup with hazardous/non-hazardous event classification. Specifically, our single-modality approach for both EEG (AUC 0.85) and Face-videos (AUC 0.84) outperform on both datasets the previous best result (AUC 0.79) shown only on the KITTI dataset using EEG alone in [
13].
5.2.2. Multi-Modality Analysis
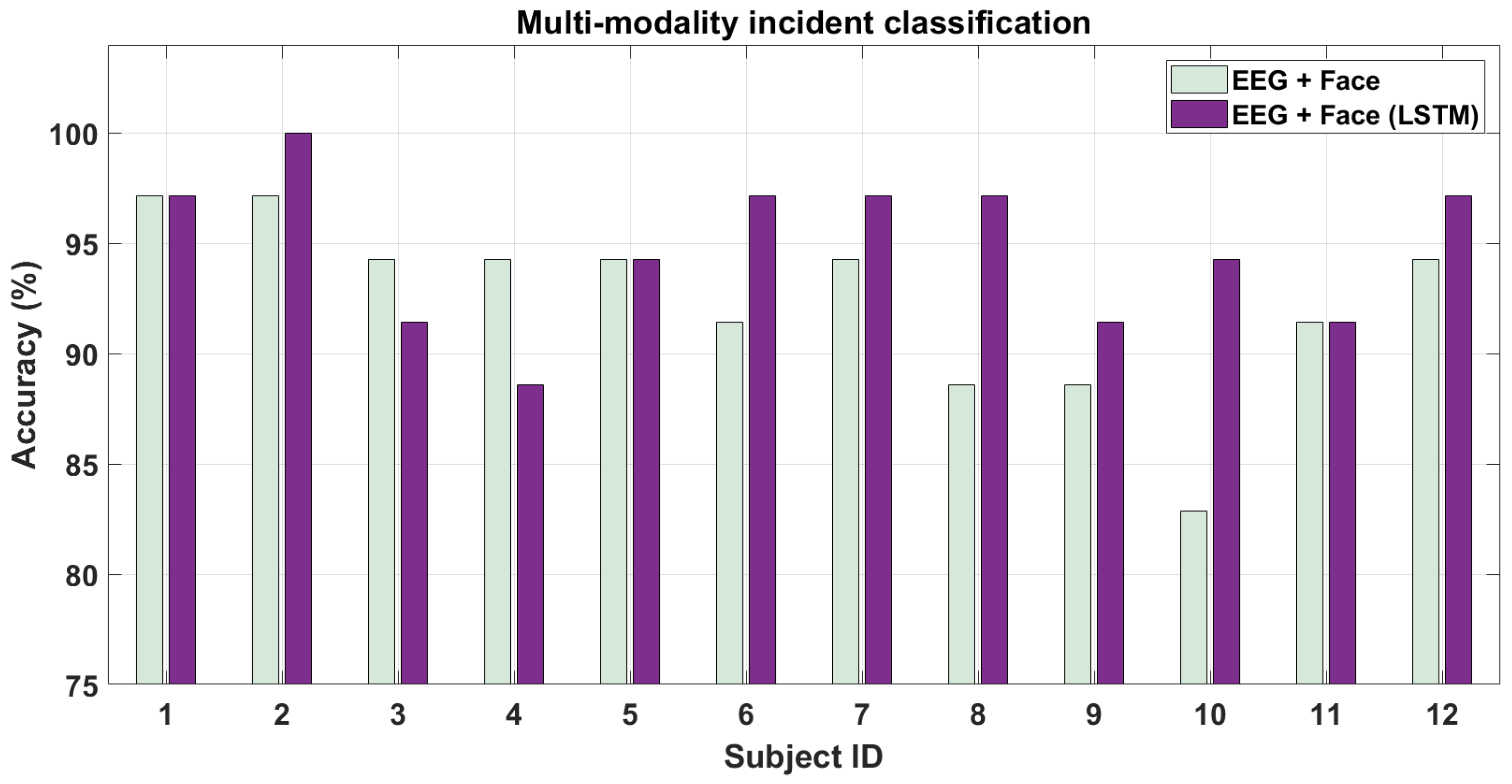
In this section, we present the results for classifying hazardous/non-hazardous incidents combining features from EEG and face modalities. We do this in two ways. First, directly combining the features from single modality analysis by concatenating them. Second, as mentioned in
Section 3.5, we use an LSTM classifier over the features from both modalities calculated for every frame in the 2-s long sequence. The trend of these features is then fed to LSTM for training.
Figure 11 shows the results of the two approaches. As is clear from the figure, combining the features from the two modalities may or may not increase the performance further compared to using individual modalities shown earlier in
Figure 10. However, we note that on taking the trend of features i.e., increased temporal resolution into account, the performance of combining the modalities increases further for most of the subjects. This can be seen from
Figure 10 where using LSTM-based method, the accuracy increases across the subjects. The average accuracy across subjects being
and
respectively are also more than for singular modality analysis. The AUC for these two cases were
and
respectively. The p-values for the above two classification cases were
and
respectively. We also performed the pairwise t-test for the above multi-modal cases. The pairwise p-vaue was 0.10 for driving hazardous/non-hazardous incident classification between (EEG + Face) and (EEG + Face (LSTM)) cases and thus show that unlike individual modality cases, the pairwise statistical analysis was not significant for the above pair of signal modality combinations. Finally, we also performed statistical pairwise t-test evaluation between singular sensor modalities from
Figure 10 and multiple modalities from
Figure 11. The p-values between the two singular sensor modality cases (EEG and Face) and two multi-modality cases were less than 0.05. Thus, statistical significance was observed between singular and multi-modality sensor combinations as well. In conclusion, to use multiple modalities with high temporal resolution (EEG and vision) may prove to be best when computing features over a short time duration with their trend (though it will involve more computational power).
Since EEG and Face modalities can be used in short-time intervals, in
Table 2 we show the mean accuracy across subjects for using EEG and faces separately and combining them for the two types of analysis done above. We can see that the performance of EEG combined with faces can be better than when either modality is used independently for hazardous incident analysis when using features from the LSTM i.e., trend over the changes in features. However, adding multiple modalities together without using trend-based LSTM analysis may not prove much beneficial. This answers our second hypotheses by showing that it is beneficial to use a fusion of the modalities if both modalities have a good temporal resolution so as to extract short-duration features over them to map the trend. Thus, connecting dots with the single-modality analysis above in
Section 5.2.1, we can say that multi-modality boosts performance over using individual modalities for hazardous/non-hazarodus incident classification (as it did for driver attention analysis) while further improvement in performance is observed by using higher temporal resolution using LSTMs.
6. Concluding Remarks
The use of multiple bio-sensing modalities combined with audio-visual ones is rapidly expanding. With the advent of compact bio-sensing systems capable of collecting data during real-world tasks such as driving, it is natural that this research area will gather more interest in the coming years. This work evaluated multiple bio-sensing modalities with the vision modality for driver attention and hazardous event analysis. We also presented a pipeline to process data from individual modalities by being able to use pre-trained convolution neural networks to extract deep learning-based features from these modalities in addition to traditionally used ones. In this process, we were able to compare the performance of the modalities against each other while also combining them.
Specifically, as suggested by the academic editor of our manuscript, we also performed Analysis of Variance (ANOVA) test between all singular modality cases from
Figure 8 and multi-modality from
Figure 9, and found the F-statistic to be 0.15. This showed that the between group variance was much lesser than the within group variances. We think that this is due to the fact that within each group there are multiple subjects whose varying physiology accounts for the wide difference in the variances in each sensor modality’s evaluation. This is also visible from the two figures in which for most modalities, the accuracy values across the modalities vary a lot between subjects. Similarly, we performed ANOVA test for the singular modality cases from
Figure 10 and multiple modality cases from
Figure 11, and found the F-statistic to be 0.82. This shows that again the between group variance was lesser than the within group variances though not as much as in the driver attention classification evaluation. We think that again this is because human physiology varies widely across subjects and much more data collection needs to be done in the second phase of our study to understand this variation as described below.
As one of the reviewers of our manuscript pointed out, we could not capture the driver-specific baseline for each bio-sensing modality in our evaluation. In fact, we did try to model the driver-specific baseline on our end but could not do so with the present data ( 30 min per subject) that we collected in this study. The temporal dynamics of bio-sensors especially EEG are hard to model for such short time-intervals. We also think that having only twelve subjects limited our capability of studying the driver baselines and cluster them into particular categories for analysis. Thus, we are planning to conduct a larger study and perhaps with the real-world driving scenario i.e., driving an actual automobile for the study. The current manuscript acts as a base toward that direction since we were able to develop signal processing and feature extraction pipelines for all sensor modalities. We are sure that with more number of subjects we should be able to better model the driver baselines by categorizing them into clusters. Our ultimate aim in the long-term would be to construct individual models of each driver. This may need a lot of driving data (tens of hours) for every driver with tens of drivers in the study.
As the next step to this preliminary study, we would also collect data in the future in more complex and safety-critical situations from “real-world" driving. The current system for data collection, noise removal, feature extraction, and classification works in real time but the data tagging for hazardous/non-hazardous events is still manual. This makes the relevance of our current system restricted to gaming, attention monitoring, etc. in driving simulators. Hence, we would like to make a model based on computer vision that can automatically predict hazardous/non-hazardous events during a real-world drive instead of manual tagging so that our system can be deployed in the “real-world” drives. We would also like to devise a real-time feedback system based on the driver’s attention to verify our pipeline’s performance during the real-world driving scenario.
Author Contributions
Conceptualization, S.S. and M.M.T.; methodology, S.S. and M.M.T.; software, S.S.; validation, S.S. and M.M.T.; formal analysis, S.S.; investigation, S.S. and M.M.T.; writing—original draft preparation, S.S.; writing—review and editing, S.S. and M.M.T.; supervision, M.M.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
We would like to thank Tzyy-Ping Jung for helping us in revising the manuscript and providing helpful suggestions regarding the same. We would also like to thank our colleagues at the LISA Lab for helping us in the data collection for this study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Guo, Z.; Pan, Y.; Zhao, G.; Cao, S.; Zhang, J. Detection of Driver Vigilance Level Using EEG Signals and Driving Contexts. IEEE Trans. Reliab. 2018, 67, 370–380. [Google Scholar] [CrossRef]
- Chai, R.; Naik, G.R.; Nguyen, T.N.; Ling, S.H.; Tran, Y.; Craig, A.; Nguyen, H.T. Driver fatigue classification with independent component by entropy rate bound minimization analysis in an EEG-based system. IEEE J. Biomed. Health Inf. 2017, 21, 715–724. [Google Scholar] [CrossRef] [PubMed]
- Chai, R.; Ling, S.H.; San, P.P.; Naik, G.R.; Nguyen, T.N.; Tran, Y.; Craig, A.; Nguyen, H.T. Improving eeg-based driver fatigue classification using sparse-deep belief networks. Front. Neurosci. 2017, 11, 103. [Google Scholar] [CrossRef]
- Siddharth, S.; Patel, A.; Jung, T.P.; Sejnowski, T. A Wearable Multi-modal Bio-sensing System Towards Real-world Applications. IEEE Trans. Biomed. Eng. 2018, 66, 1137–1147. [Google Scholar] [CrossRef] [PubMed]
- Wyss, T.; Roos, L.; Beeler, N.; Veenstra, B.; Delves, S.; Buller, M.; Friedl, K. The comfort, acceptability and accuracy of energy expenditure estimation from wearable ambulatory physical activity monitoring systems in soldiers. J. Sci. Med. Sport 2017, 20, S133–S134. [Google Scholar] [CrossRef]
- Dishman, R.K.; Nakamura, Y.; Garcia, M.E.; Thompson, R.W.; Dunn, A.L.; Blair, S.N. Heart rate variability, trait anxiety, and perceived stress among physically fit men and women. Int. J. Psychophysiol. 2000, 37, 121–133. [Google Scholar] [CrossRef]
- Kuefler, A.; Morton, J.; Wheeler, T.; Kochenderfer, M. Imitating driver behavior with generative adversarial networks. In Proceedings of the Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 204–211. [Google Scholar]
- Dwivedi, K.; Biswaranjan, K.; Sethi, A. Drowsy driver detection using representation learning. In Proceedings of the IEEE International Advance Computing Conference (IACC), Gurgaon, India, 21–22 February 2014; pp. 995–999. [Google Scholar]
- Dong, Y.; Hu, Z.; Uchimura, K.; Murayama, N. Driver inattention monitoring system for intelligent vehicles: A review. IEEE Trans. Intell. Transp. Syst. 2011, 12, 596–614. [Google Scholar] [CrossRef]
- Doshi, A.; Trivedi, M.M. Tactical driver behavior prediction and intent inference: A review. In Proceedings of the 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 1892–1897. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M.M. Looking at humans in the age of self-driving and highly automated vehicles. IEEE Trans. Intell. Veh. 2016, 1, 90–104. [Google Scholar] [CrossRef]
- Martin, S.; Vora, S.; Yuen, K.; Trivedi, M.M. Dynamics of Driver’s Gaze: Explorations in Behavior Modeling and Maneuver Prediction. IEEE Trans. Intell. Veh. 2018, 3, 141–150. [Google Scholar] [CrossRef]
- Kolkhorst, H.; Burgard, W.; Tangermann, M. Decoding Hazardous Events in Driving Videos. In Proceedings of the 7th Graz Brain-Computer Interface Conference, Graz, Austria, 18–22 September 2017. [Google Scholar]
- Papadelis, C.; Kourtidou-Papadeli, C.; Bamidis, P.D.; Chouvarda, I.; Koufogiannis, D.; Bekiaris, E.; Maglaveras, N. Indicators of sleepiness in an ambulatory EEG study of night driving. In Proceedings of the IEEE 28th Annual International Conference on the Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006; pp. 6201–6204. [Google Scholar]
- Lal, S.K.; Craig, A.; Boord, P.; Kirkup, L.; Nguyen, H. Development of an algorithm for an EEG-based driver fatigue countermeasure. J. Saf. Res. 2003, 34, 321–328. [Google Scholar] [CrossRef]
- Siddharth, S.; Jung, T.P.; Sejnowski, T.J. Utilizing Deep Learning Towards Multi-modal Bio-sensing and Vision-based Affective Computing. IEEE Trans. Affect. Comput. 2019. [Google Scholar] [CrossRef]
- Ma, X.; Yao, Z.; Wang, Y.; Pei, W.; Chen, H. Combining Brain-Computer Interface and Eye Tracking for High-Speed Text Entry in Virtual Reality. In Proceedings of the 23rd International Conference on Intelligent User Interfaces, Tokyo, Japan, 7–11 March 2018; pp. 263–267. [Google Scholar]
- Liu, H.; Taniguchi, T.; Tanaka, Y.; Takenaka, K.; Bando, T. Visualization of driving behavior based on hidden feature extraction by using deep learning. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2477–2489. [Google Scholar] [CrossRef]
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Cheng-Yue, R.; et al. An empirical evaluation of deep learning on highway driving. arXiv 2015, arXiv:1504.01716. [Google Scholar]
- Ramos, S.; Gehrig, S.; Pinggera, P.; Franke, U.; Rother, C. Detecting unexpected obstacles for self-driving cars: Fusing deep learning and geometric modeling. In Proceedings of the Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1025–1032. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features off-the-shelf: An Astounding Baseline for Recognition. arXiv 2014, arXiv:1403.6382v3. [Google Scholar]
- Siddharth; Rangesh, A.; Ohn-Bar, E.; Trivedi, M.M. Driver hand localization and grasp analysis: A vision-based real-time approach. In Proceedings of the IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2545–2550. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Siddharth, S.; Trivedi, M.M. Attention Monitoring and Hazard Assessment with Bio-Sensing and Vision: Empirical Analysis Utilizing CNNs on the KITTI Dataset. arXiv 2019, arXiv:1905.00503. [Google Scholar]
- Kolkhorst, H.; Tangermann, M.; Burgard, W. Decoding Perceived Hazardousness from User’s Brain States to Shape Human-Robot Interaction. In Proceedings of the Companion of the ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017; pp. 349–350. [Google Scholar]
- Stytsenko, K.; Jablonskis, E.; Prahm, C. Evaluation of consumer EEG device Emotiv EPOC. In Proceedings of the MEi: CogSci Conference, Ljubljana, Slovenia, 17–18 June 2011. [Google Scholar]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef]
- Mullen, T.; Kothe, C.; Chi, Y.M.; Ojeda, A.; Kerth, T.; Makeig, S.; Cauwenberghs, G.; Jung, T.P. Real-time modeling and 3D visualization of source dynamics and connectivity using wearable EEG. In Proceedings of the 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 2184–2187. [Google Scholar]
- Makeig, S.; Bell, A.J.; Jung, T.P.; Sejnowski, T.J. Independent component analysis of electroencephalographic data. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1996; pp. 145–151. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv 2015, arXiv:1511.06448. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Carneiro, G.; Nascimento, J.; Bradley, A.P. Unregistered multiview mammogram analysis with pre-trained deep learning models. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 652–660. [Google Scholar]
- Schwarz, M.; Schulz, H.; Behnke, S. RGB-D object recognition and pose estimation based on pre-trained convolutional neural network features. In Proceedings of the EEE International Conference on Robotics and Automation (ICRA), I, Seattle, WA, USA, 26–30 May 2015; pp. 1329–1335. [Google Scholar]
- Orini, M.; Bailón, R.; Enk, R.; Koelsch, S.; Mainardi, L.; Laguna, P. A method for continuously assessing the autonomic response to music-induced emotions through HRV analysis. Med. Biol. Eng. Comput. 2010, 48, 423–433. [Google Scholar] [CrossRef] [PubMed]
- Billauer, E. Peakdet: Peak Detection Using MATLAB; Detect Peaks in a Vector; Billauer, E., Ed.; Haifa, Israel, 2012. [Google Scholar]
- Ewing, D.J.; Neilson, J.M.; Travis, P.A.U.L. New method for assessing cardiac parasympathetic activity using 24 h electrocardiograms. Heart 1984, 52, 396–402. [Google Scholar] [CrossRef]
- Mera, K.; Ichimura, T. Emotion analyzing method using physiological state. In Proceedings of the Knowledge-Based Intelligent Information and Engineering Systems, Wellington, New Zealand, 20–25 September 2004; pp. 195–201. [Google Scholar]
- Ding, X.R.; Zhang, Y.T.; Liu, J.; Dai, W.X.; Tsang, H.K. Continuous cuffless blood pressure estimation using pulse transit time and photoplethysmogram intensity ratio. IEEE Trans. Biomed. Eng. 2016, 63, 964–972. [Google Scholar] [CrossRef] [PubMed]
- Djawad, Y.A.; Mu’nisa, A.; Rusung, P.; Kurniawan, A.; Idris, I.S.; Taiyeb, M. Essential Feature Extraction of Photoplethysmography Signal of Men and Women in Their 20s. Eng. J. 2017, 21, 259–272. [Google Scholar] [CrossRef]
- Fulop, S.A.; Fitz, K. Algorithms for computing the time-corrected instantaneous frequency (reassigned) spectrogram, with applications. J. Acoust. Soc. Am. 2006, 119, 360–371. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Tian, Y.I.; Kanade, T.; Cohn, J.F. Recognizing action units for facial expression analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 97–115. [Google Scholar] [CrossRef]
- Ekman, P.; Rosenberg, E.L. (Eds.) What the face reveals: Basic and Applied Studies of Spontaneous Expression Using the Facial Action Coding System (FACS); Oxford University Press: Oxford, UK, 1997. [Google Scholar]
- Asthana, A.; Zafeiriou, S.; Cheng, S.; Pantic, M. Incremental face alignment in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1859–1866. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the 26th British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; Volume 1, p. 6. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zhu, D.; Bieger, J.; Molina, G.G.; Aarts, R.M. A survey of stimulation methods used in SSVEP-based BCIs. Comput. Intell. Neurosci. 2010, 2010, 1. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Zheng, W.L.; Zhu, J.Y.; Lu, B.L. Identifying stable patterns over time for emotion recognition from EEG. IEEE Trans. Affect. Comput. 2017, 10, 417–429. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhou, W.; Li, S.; Cai, D. Epileptic EEG classification based on extreme learning machine and nonlinear features. Epilepsy Res. 2011, 96, 29–38. [Google Scholar] [CrossRef]
- Combrisson, E.; Jerbi, K. Exceeding chance level by chance: The caveat of theoretical chance levels in brain signal classification and statistical assessment of decoding accuracy. J. Neurosci. Methods 2015, 250, 126–136. [Google Scholar] [CrossRef] [PubMed]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. Deap: A database for emotion analysis; using physiological signals. IEEE Trans. Affect. Comput. 2011, 3, 18–31. [Google Scholar] [CrossRef]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A multimodal database for affect recognition and implicit tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef]
- Cheng, K.S.; Chen, Y.S.; Wang, T. Physiological Parameters Assessment for Emotion Recognition. In Proceedings of the IEEE EMBS Conference on Biomedical Engineering and Sciences (IECBES), Langkawi, Malaysia, 17–19 December 2012; pp. 995–998. [Google Scholar]
Figure 1.
PSD heat-maps of the three EEG bands i.e., theta (red), alpha (green), and beta (blue) EEG bands are added according to respective color-bar range to get combined RGB heat-map image.(Circular outline, nose, ears, and color-bars were added for visualization only. All units are in Watt per Hz.)
Figure 1.
PSD heat-maps of the three EEG bands i.e., theta (red), alpha (green), and beta (blue) EEG bands are added according to respective color-bar range to get combined RGB heat-map image.(Circular outline, nose, ears, and color-bars were added for visualization only. All units are in Watt per Hz.)
Figure 2.
For a trial, PPG signal with peaks (in red) being detected for the calculation of RRs and HRV (above), and PPG spectrogram (below).
Figure 2.
For a trial, PPG signal with peaks (in red) being detected for the calculation of RRs and HRV (above), and PPG spectrogram (below).
Figure 3.
Detected face (marked in red) and face localized points (marked in green) for two participants (left and center) in the study, and some of the features (marked in yellow) computed using the coordinates of the face localized points. These features were then normalized using the size of the face in the camera i.e., number of pixels in height (H) and width (W).
Figure 3.
Detected face (marked in red) and face localized points (marked in green) for two participants (left and center) in the study, and some of the features (marked in yellow) computed using the coordinates of the face localized points. These features were then normalized using the size of the face in the camera i.e., number of pixels in height (H) and width (W).
Figure 4.
Network architecture for EEG-PSD trend-based Deep Learning method.
Figure 4.
Network architecture for EEG-PSD trend-based Deep Learning method.
Figure 5.
Experiment setup for multi-modal data collection. (A) EEG Headset, (B) PPG and GSR armband, (C) External camera, and (D) Driving videos displayed on the screen. The subject sits with her/his arms and feet on a driving simulator with which s/he interacts while watching the driving videos.
Figure 5.
Experiment setup for multi-modal data collection. (A) EEG Headset, (B) PPG and GSR armband, (C) External camera, and (D) Driving videos displayed on the screen. The subject sits with her/his arms and feet on a driving simulator with which s/he interacts while watching the driving videos.
Figure 6.
Various image instances with varying illumination conditions and type of road (street, single-lane, highway, etc.) from (A) LISA Dataset and (B) KITTI Dataset.
Figure 6.
Various image instances with varying illumination conditions and type of road (street, single-lane, highway, etc.) from (A) LISA Dataset and (B) KITTI Dataset.
Figure 7.
(A) Examples of 2-seconds incidents classified as hazardous. Examples include pedestrians crossing the street without a crosswalk while the ego vehicle is being driven and another vehicle overtaking suddenly. (B) Examples of 2-seconds incidents classified as non-hazardous. Examples include stop signs and railway crossing signs. For each category, the top images are from KITTI dataset whereas the bottom images are from LISA dataset.
Figure 7.
(A) Examples of 2-seconds incidents classified as hazardous. Examples include pedestrians crossing the street without a crosswalk while the ego vehicle is being driven and another vehicle overtaking suddenly. (B) Examples of 2-seconds incidents classified as non-hazardous. Examples include stop signs and railway crossing signs. For each category, the top images are from KITTI dataset whereas the bottom images are from LISA dataset.
Figure 8.
Single modality classification performance for driver attention analysis.
Figure 8.
Single modality classification performance for driver attention analysis.
Figure 9.
Multi-modality classification performance for driver attention analysis.
Figure 9.
Multi-modality classification performance for driver attention analysis.
Figure 10.
Single-modality classification performance for driver attention during hazardous/non-hazardous incidents.
Figure 10.
Single-modality classification performance for driver attention during hazardous/non-hazardous incidents.
Figure 11.
Multi-modality classification performance for driver attention during hazardous/non-hazardous incidents.
Figure 11.
Multi-modality classification performance for driver attention during hazardous/non-hazardous incidents.
Table 1.
Dataset-related parameters
Table 1.
Dataset-related parameters
| Dataset | KITTI | LISA |
|---|
| Number of video sequences | 15 | 20 |
| Time Duration per video (s) | 14–105 | 30–50 |
| Frames per second | 10 | 30 |
| Video resolution | 1920 × 580 | 1920 × 1200 |
| Sensor Modality | Traditional Features | Deep-learning Features |
| EEG | 96 (Conditional Entropy) | 4096 (EEG-PSD 2-D spectrum image) |
| PPG | 7 (HRV and Statistical) | 4096 (PPG spectrogram image) |
| GSR | 8 (Statistical) | 4096 (GSR spectrogram image) |
| Face video | 30 (Face AUs-based) | 4096 (Face image-based) |
Table 2.
Single vs. Multi-Modality Performance Evaluation.
Table 2.
Single vs. Multi-Modality Performance Evaluation.
| Modality | Attention Analysis | Incident Analysis |
|---|
| EEG | | |
| Faces | | |
| EEG + Faces | | |
| EEG + Faces (LSTM) | — | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}