Infants Segment Words from Songs—An EEG Study



Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Materials
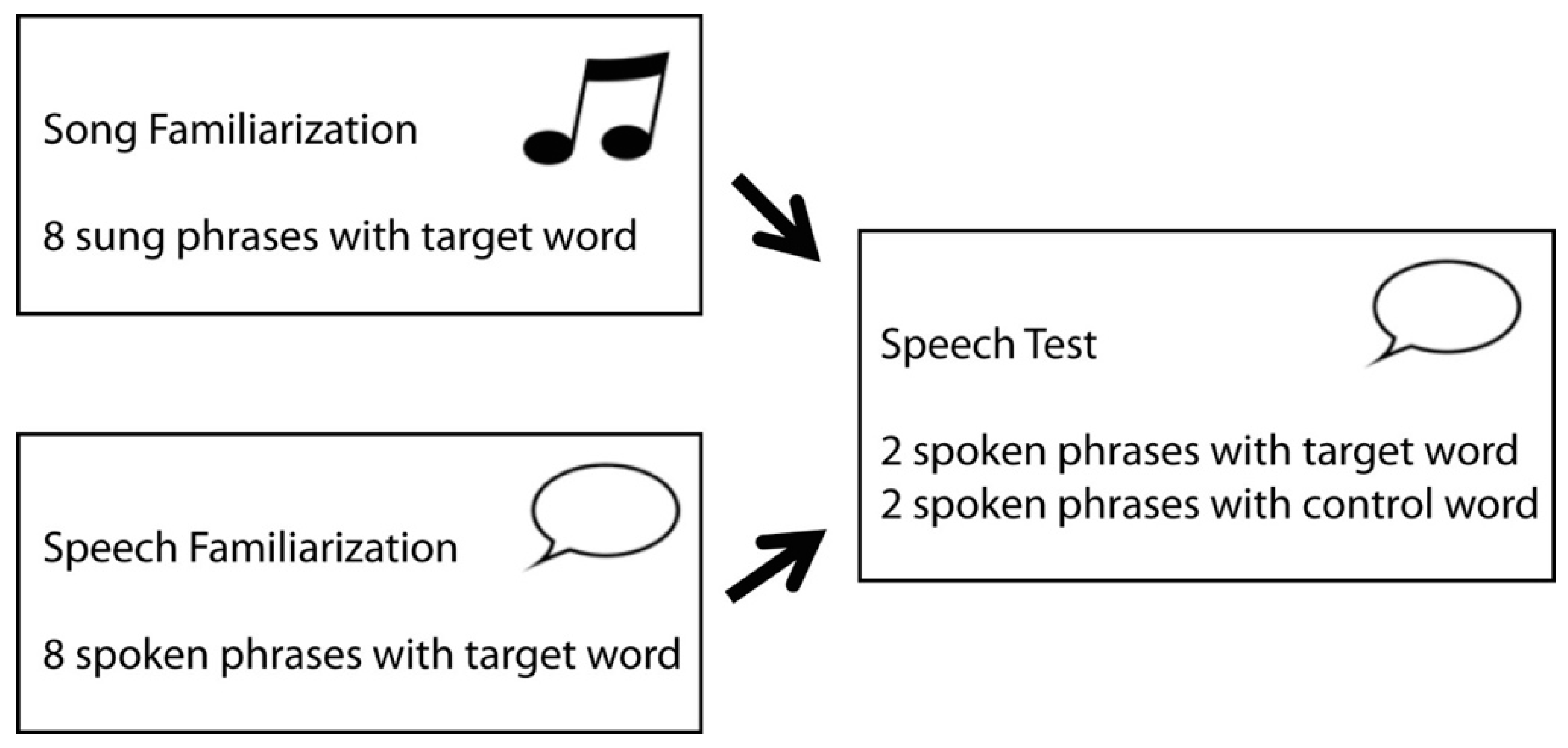
2.3. Procedure
2.4. EEG Recordings
2.5. Data Processing
2.6. Planned ERP Analyses
3. Results
3.1. Planned Analyses—Segmentation from Song and Speech
3.1.1. ERP Familiarity Effect in the Familiarization Phase, Song and Speech Combined
3.1.2. ERP Familiarity Effect in the Familiarization Phase, Comparing Song to Speech
3.2. Planned Analyses Effects in Test Phase (Transfer to Speech)
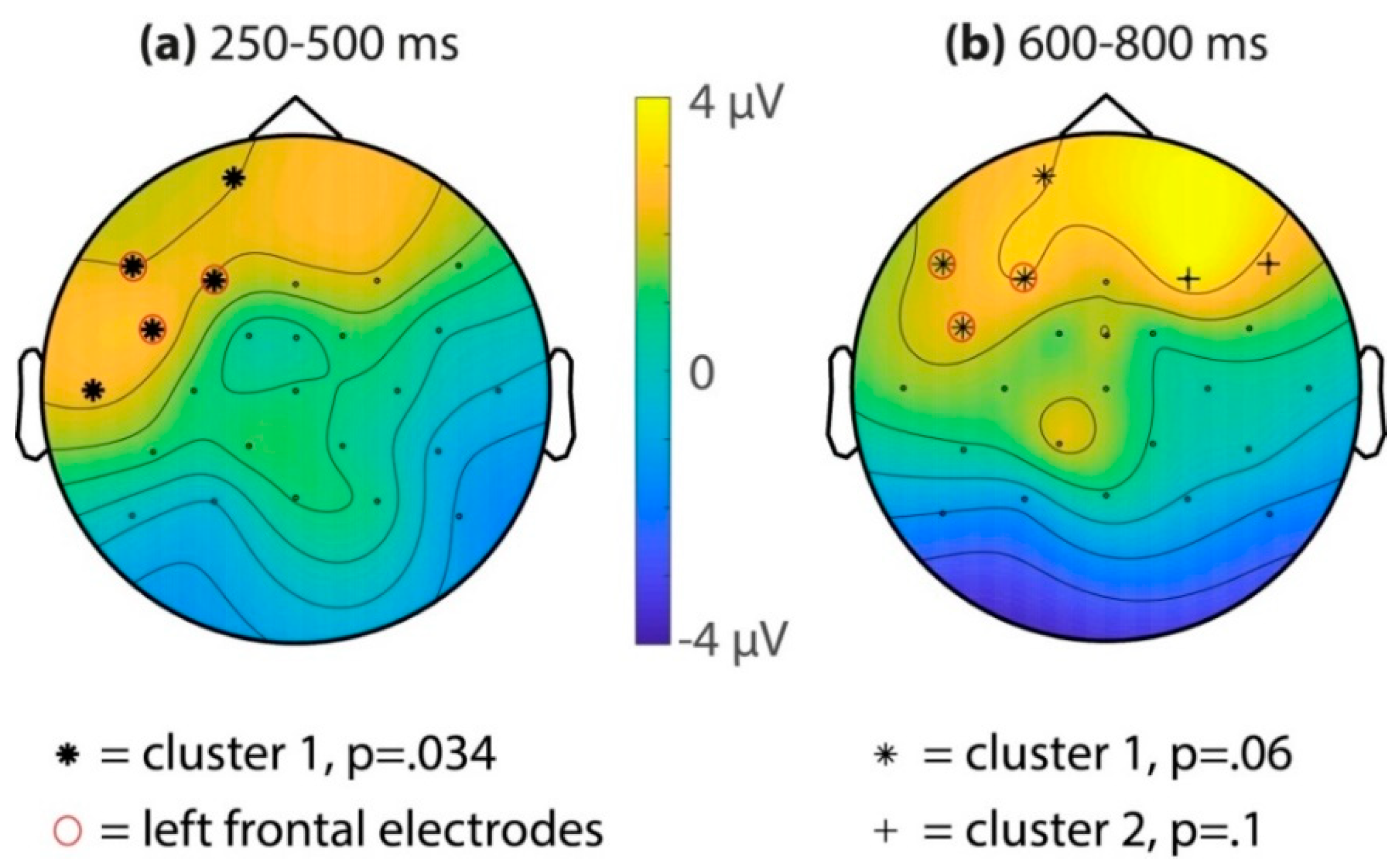
3.2.1. ERP Familiarity Effect in the Test Phase, Song and Speech Combined
3.2.2. ERP Familiarity Effect in the Test Phase, Comparing Song to Speech
3.3. Follow-Up Analyses—Motivation and Methods
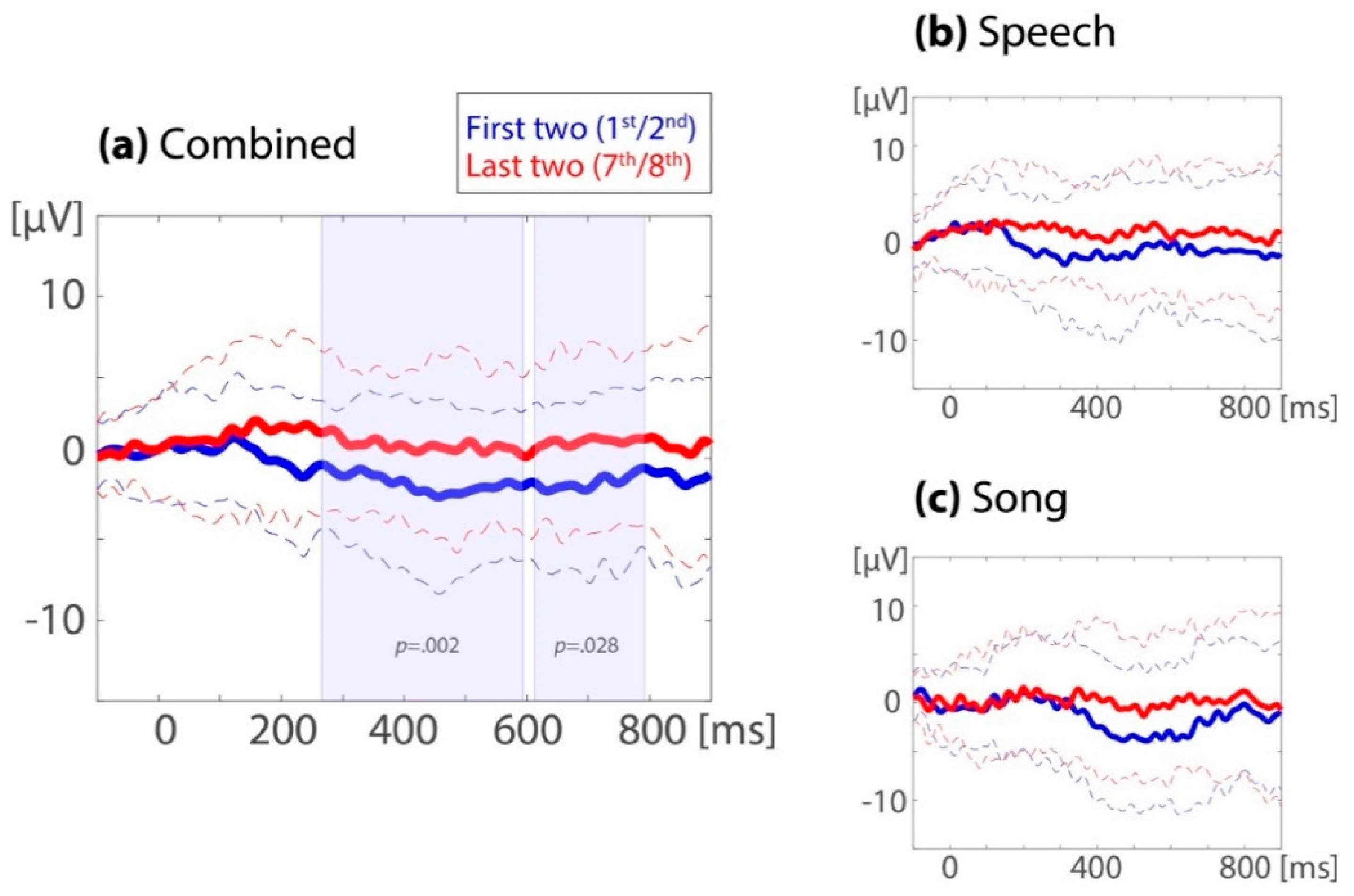
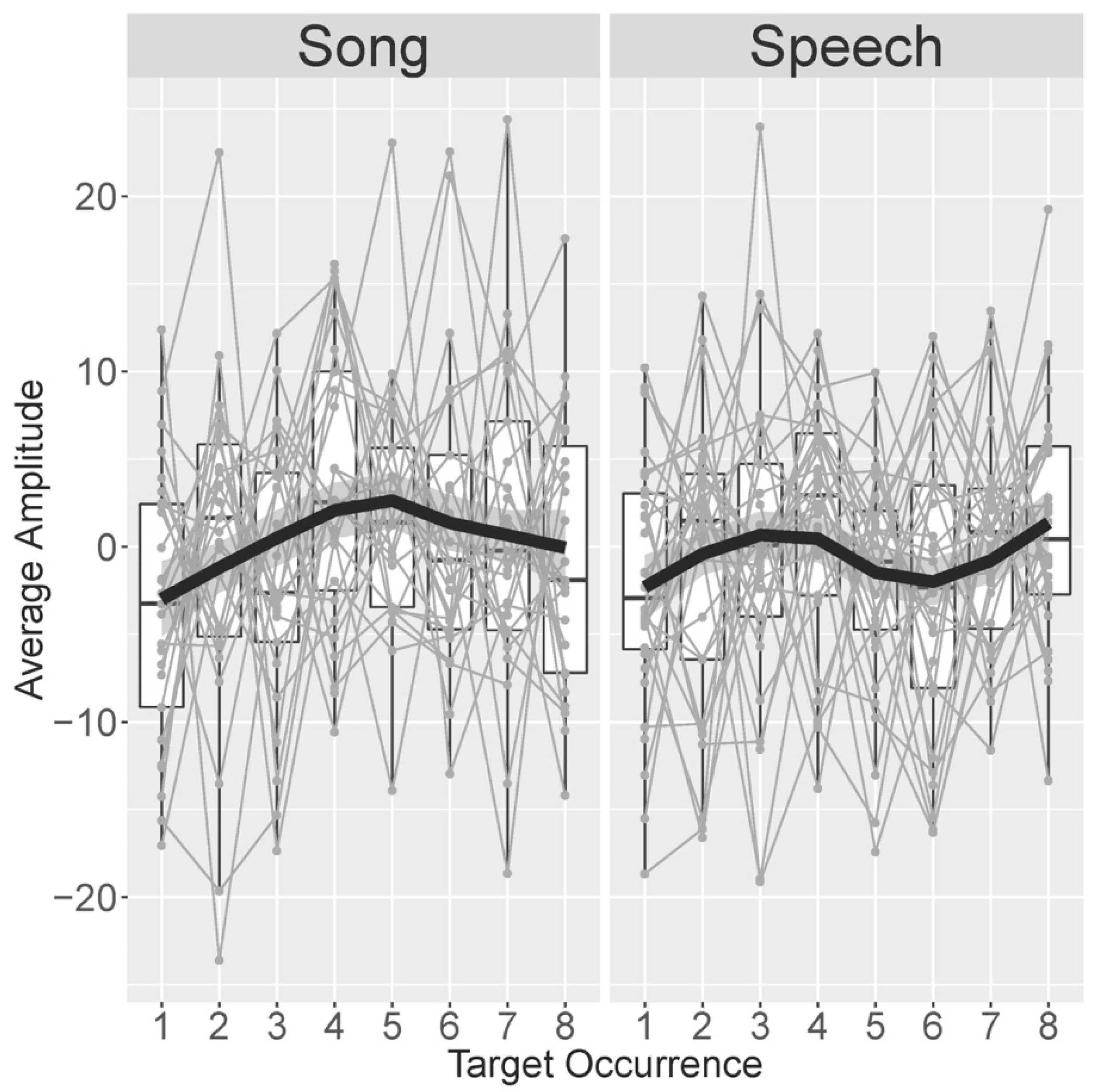
3.3.1. Follow-Up Analysis #1—Development Over Eight Familiarization Occurrences
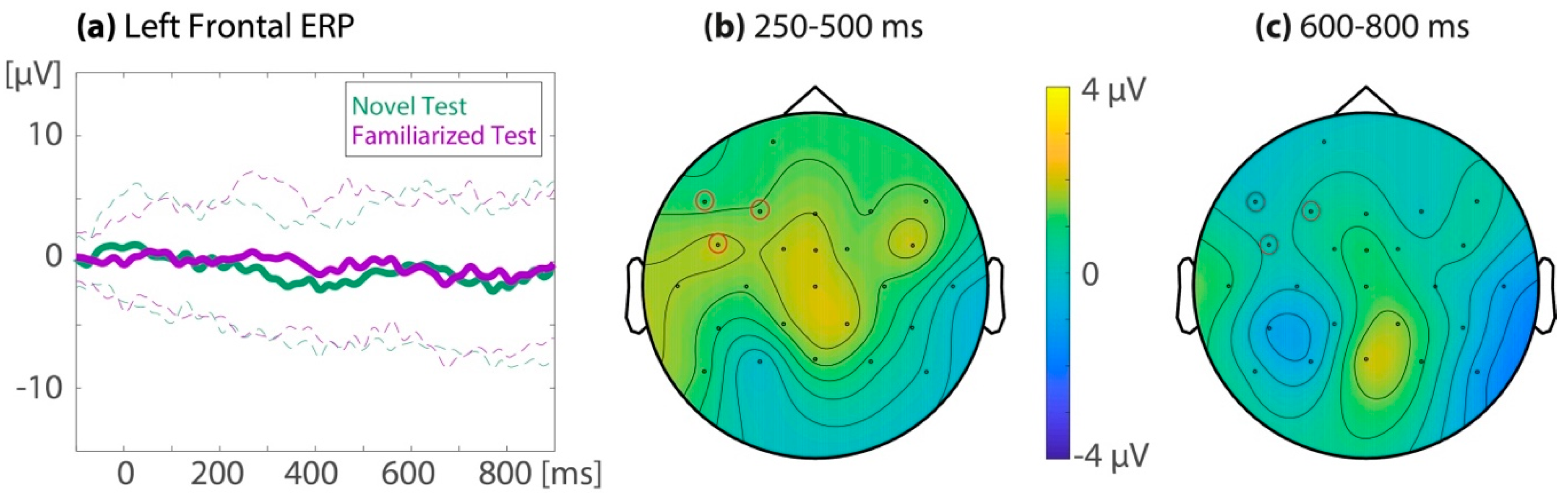
3.3.2. Additional Follow-up Analyses: Responder Types in the Test Trials
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Trehub, S.E.; Trainor, L. Singing to infants: Lullabies and play songs. In Advances in Infancy Research; Rovee-Collier, D., Lipsitt, L., Hayne, H., Eds.; Ablex: Stamford, CT, USA, 1998; Volume 12, pp. 43–77. [Google Scholar]
- Custodero, L.A.; Johnson-Green, E.A. Caregiving in counterpoint: Reciprocal influences in the musical parenting of younger and older infants. Early Child Dev. Care 2008, 178, 15–39. [Google Scholar] [CrossRef]
- Adachi, M.; Trehub, S.E. Musical lives of infants. In Music Learning and Teaching in Infancy, Childhood, and Adolescence. An Oxford Handbook of Music Education; McPherson, G., Welch, G., Eds.; Oxford University Press: New York, NY, USA, 2012; Volume 2, pp. 229–247. [Google Scholar]
- Thiessen, E.D.; Saffran, J.R. How the melody facilitates the message and vice versa in infant learning and memory. Ann. N. Y. Acad. Sci. 2009, 1169, 225–233. [Google Scholar] [CrossRef] [PubMed]
- Lebedeva, G.C.; Kuhl, P.K. Sing that tune: Infants’ perception of melody and lyrics and the facilitation of phonetic recognition in songs. Infant Behav. Dev. 2010, 33, 419–430. [Google Scholar] [CrossRef] [PubMed]
- François, C.; Teixidó, M.; Takerkart, S.; Agut, T.; Bosch, L.; Rodriguez-Fornells, A. Enhanced neonatal brain responses to sung streams predict vocabulary outcomes by age 18 months. Sci. Rep. 2017, 7, 12451. [Google Scholar] [CrossRef] [PubMed]
- Cristia, A. Input to language: The phonetics and perception of infant-directed speech. Lang. Linguist. Compass 2013, 7, 157–170. [Google Scholar] [CrossRef]
- Golinkoff, R.M.; Can, D.D.; Soderstrom, M.; Hirsh-Pasek, K. (Baby) talk to me: The social context of infant-directed speech and its effects on early language acquisition. Curr. Dir. Psychol. Sci. 2015, 24, 339–344. [Google Scholar] [CrossRef]
- Klahr, D.; Chase, W.G.; Lovelace, E.A. Structure and process in alphabetic retrieval. J. Exp. Psychol. Learn. Mem. Cogn. 1983, 9, 462–477. [Google Scholar] [CrossRef]
- Ludke, K.M.; Ferreira, F.; Overy, K. Singing can facilitate foreign language learning. Mem. Cogn. 2014, 42, 41–52. [Google Scholar] [CrossRef]
- Calvert, S.L.; Billingsley, R.L. Young children’s recitation and comprehension of information presented by songs. J. Appl. Dev. Psychol. 1998, 19, 97–108. [Google Scholar] [CrossRef]
- Engh, D. Why use music in English language learning? A survey of the literature. Engl. Lang. Teach. 2013, 6, 113–127. [Google Scholar] [CrossRef]
- Davis, G.M. Songs in the young learner classroom: A critical review of evidence. Engl. Lang. Teach. 2017, 71, 445–455. [Google Scholar] [CrossRef]
- Benz, S.; Sellaro, R.; Hommel, B.; Colzato, L.S. Music makes the world go round: The impact of musical training on non-musical cognitive functions—A review. Front. Psychol. 2016, 6, 2023. [Google Scholar] [CrossRef]
- Francois, C.; Chobert, J.; Besson, M.; Schon, D. Music training for the development of speech segmentation. Cereb. Cortex 2013, 23, 2038–2043. [Google Scholar] [CrossRef] [PubMed]
- Bhide, A.; Power, A.; Goswami, U. A rhythmic musical intervention for poor readers: A comparison of efficacy with a letter-based intervention. Mind Brain Educ. 2013, 7, 113–123. [Google Scholar] [CrossRef]
- Thompson, W.F.; Schellenberg, E.G.; Husain, G. Decoding speech prosody: Do music lessons help? Emotion 2004, 4, 46–64. [Google Scholar] [CrossRef] [PubMed]
- Chobert, J.; Francois, C.; Velay, J.-L.; Besson, M. Twelve months of active musical training in 8- to 10-year-old children enhances the preattentive processing of syllabic duration and voice onset time. Cereb. Cortex 2014, 24, 956–967. [Google Scholar] [CrossRef] [PubMed]
- Besson, M.; Chobert, J.; Marie, C. Transfer of training between music and speech: Common processing, attention, and memory. Front. Psychol. 2011, 2, 94. [Google Scholar] [CrossRef]
- Strait, D.; Kraus, N. Playing music for a smarter ear: Cognitive, perceptual and neurobiological evidence. Music Percept. Interdiscip. J. 2011, 29, 133–146. [Google Scholar] [CrossRef]
- Patel, A.D. Why would musical training benefit the neural encoding of speech? The OPERA hypothesis. Front. Psychol. 2011, 2, 142. [Google Scholar] [CrossRef]
- Patel, A.D. The OPERA hypothesis: Assumptions and clarifications. Ann. N. Y. Acad. Sci. 2012, 1252, 124–128. [Google Scholar] [CrossRef]
- Patel, A.D. Can nonlinguistic musical training change the way the brain processes speech? The expanded OPERA hypothesis. Hear. Res. 2014, 308, 98–108. [Google Scholar] [CrossRef] [PubMed]
- Wallace, W.T. Memory for music: Effect of melody on recall of text. J. Exp. Psychol. Learn. Mem. Cogn. 1994, 20, 1471. [Google Scholar] [CrossRef]
- Large, E.W.; Jones, M.R. The dynamics of attending: How people track time-varying events. Psychol. Rev. 1999, 106, 119–159. [Google Scholar] [CrossRef]
- Schroeder, C.E.; Lakatos, P. Low-frequency neuronal oscillations as instruments of sensory selection. Trends Neurosci. 2009, 32, 9–18. [Google Scholar] [CrossRef] [PubMed]
- Thaut, M.H. Temporal entrainment of cognitive functions: Musical mnemonics induce brain plasticity and oscillatory synchrony in neural networks underlying memory. Ann. N. Y. Acad. Sci. 2005, 1060, 243–254. [Google Scholar] [CrossRef] [PubMed]
- Doelling, K.B.; Poeppel, D. Cortical entrainment to music and its modulation by expertise. Proc. Natl. Acad. Sci. USA 2015, 112, E6233–E6242. [Google Scholar] [CrossRef]
- Myers, B.R.; Lense, M.D.; Gordon, R.L. Pushing the envelope: Developments in neural entrainment to speech and the biological underpinnings of prosody perception. Brain Sci. 2019, 9, 70. [Google Scholar] [CrossRef]
- Corbeil, M.; Trehub, S.; Peretz, I. Speech vs. singing: Infants choose happier sounds. Front. Psychol. 2013, 4, 372. [Google Scholar] [CrossRef]
- Costa-Giomi, E.; Ilari, B. Infants’ preferential attention to sung and spoken stimuli. J. Res. Music Educ. 2014, 62, 188–194. [Google Scholar] [CrossRef]
- Trehub, S.E.; Plantinga, J.; Russo, F.A. Maternal vocal interactions with infants: Reciprocal visual influences. Soc. Dev. 2016, 25, 665–683. [Google Scholar] [CrossRef]
- Nakata, T.; Trehub, S.E. Infants’ responsiveness to maternal speech and singing. Infant Behav. Dev. 2004, 27, 455–464. [Google Scholar] [CrossRef]
- Tsang, C.D.; Falk, S.; Hessel, A. Infants prefer infant-directed song over speech. Child. Dev. 2017, 88, 1207–1215. [Google Scholar] [CrossRef] [PubMed]
- Corbeil, M.; Trehub, S.E.; Peretz, I. Singing delays the onset of infant distress. Infancy 2016, 21, 373–391. [Google Scholar] [CrossRef]
- Trehub, S.E.; Ghazban, N.; Corbeil, M. Musical affect regulation in infancy: Musical affect regulation in infancy. Ann. N. Y. Acad. Sci. 2015, 1337, 186–192. [Google Scholar] [CrossRef]
- Nazzi, T.; Nelson, D.G.K.; Jusczyk, P.W.; Jusczyk, A.M. Six-month-olds’ detection of clauses embedded in continuous speech: Effects of prosodic well-formedness. Infancy 2000, 1, 123–147. [Google Scholar] [CrossRef]
- Johnson, E.K.; Seidl, A. Clause segmentation by 6-month-old infants: A crosslinguistic perspective. Infancy 2008, 13, 440–455. [Google Scholar] [CrossRef]
- Nazzi, T.; Bertoncini, J.; Mehler, J. Language discrimination by newborns: Toward an understanding of the role of rhythm. J. Exp. Psychol. Hum. Percept. Perform. 1998, 24, 756. [Google Scholar] [CrossRef]
- Ramus, F. Language discrimination by newborns: Teasing apart phonotactic, rhythmic, and intonational cues. Annu. Rev. Lang. Acquis. 2002, 2, 85–115. [Google Scholar] [CrossRef]
- Falk, S.; Maslow, E.; Thum, G.; Hoole, P. Temporal variability in sung productions of adolescents who stutter. J. Commun. Disord. 2016, 62, 101–114. [Google Scholar] [CrossRef]
- Evan, D. Bradley A comparison of the acoustic vowel spaces of speech and song. Linguist. Res. 2018, 35, 381–394. [Google Scholar] [CrossRef]
- Audibert, N.; Falk, S. Vowel space and f0 characteristics of infant-directed singing and speech. In Proceedings of the 9th International Conference on Speech Prosody, Poznań, Poland, 13–16 June 2018; pp. 153–157. [Google Scholar]
- Wright, S. The Death of Lady Mondegreen. Harper’s Mag. 1954, 209, 48–51. [Google Scholar]
- Otake, T. Interlingual near homophonic words and phrases in L2 listening: Evidence from misheard song lyrics. In Proceedings of the 16th International Congress of Phonetic Sciences (ICPhS 2007), Saarbrücken, Germany, 6–10 August 2007; pp. 777–780. [Google Scholar]
- Kentner, G. Rhythmic segmentation in auditory illusions—Evidence from cross-linguistic mondegreens. In Proceedings of the 18th International Congress of Phonetic Sciences, Glasgow, UK, 10–14 August 2015. [Google Scholar]
- Houston, D.M.; Jusczyk, P.W. The role of talker-specific information in word segmentation by infants. J. Exp. Psychol. Hum. Percept. Perform. 2000, 26, 1570–1582. [Google Scholar] [CrossRef] [PubMed]
- Singh, L.; Morgan, J.L.; White, K.S. Preference and processing: The role of speech affect in early spoken word recognition. J. Mem. Lang. 2004, 51, 173–189. [Google Scholar] [CrossRef]
- Schmale, R.; Seidl, A. Accommodating variability in voice and foreign accent: Flexibility of early word representations. Dev. Sci. 2009, 12, 583–601. [Google Scholar] [CrossRef]
- Schmale, R.; Cristià, A.; Seidl, A.; Johnson, E.K. Developmental changes in infants’ ability to cope with dialect variation in word recognition. Infancy 2010, 15, 650–662. [Google Scholar] [CrossRef]
- Bergelson, E.; Swingley, D. Young infants’ word comprehension given an unfamiliar talker or altered pronunciations. Child Dev. 2018, 89, 1567–1576. [Google Scholar] [CrossRef]
- Schön, D.; Boyer, M.; Moreno, S.; Besson, M.; Peretz, I.; Kolinsky, R. Songs as an aid for language acquisition. Cognition 2008, 106, 975–983. [Google Scholar] [CrossRef]
- Francois, C.; Schön, D. Musical expertise boosts implicit learning of both musical and linguistic structures. Cereb. Cortex 2011, 21, 2357–2365. [Google Scholar] [CrossRef]
- François, C.; Tillmann, B.; Schön, D. Cognitive and methodological considerations on the effects of musical expertise on speech segmentation. Ann. N. Y. Acad. Sci. 2012, 1252, 108–115. [Google Scholar] [CrossRef]
- François, C.; Jaillet, F.; Takerkar, S.; Schön, D. Faster sound stream segmentation in musicians than in nonmusicians. PLoS ONE 2014, 9, e101340. [Google Scholar] [CrossRef]
- Shook, A.; Marian, V.; Bartolotti, J.; Schroeder, S.R. Musical experience influences statistical learning of a novel language. Am. J. Psychol. 2013, 126, 95. [Google Scholar] [CrossRef] [PubMed]
- Larrouy-Maestri, P.; Leybaert, J.; Kolinsky, R. The benefit of musical and linguistic expertise on language acquisition in sung material. Musicae Sci. 2013, 17, 217–228. [Google Scholar] [CrossRef]
- Morgan, J.L. Prosody and the roots of parsing. Lang. Cogn. Process. 1996, 11, 69–106. [Google Scholar] [CrossRef]
- Brent, M.R.; Siskind, J.M. The role of exposure to isolated words in early vocabulary development. Cognition 2001, 81, 33–44. [Google Scholar] [CrossRef]
- Aslin, R.N.; Woodward, J.Z.; LaMendola, N.P. Models of word segmentation in fluent maternal speech to infants. In Signal to Syntax; Psychology Press: New York, NY, USA; London, UK, 1996; pp. 117–134. [Google Scholar]
- Johnson, E.K.; Lahey, M.; Ernestus, M.; Cutler, A. A multimodal corpus of speech to infant and adult listeners. J. Acoust. Soc. Am. 2013, 134, EL534–EL540. [Google Scholar] [CrossRef] [PubMed]
- Graf Estes, K.; Evans, J.L.; Alibali, M.W.; Saffran, J.R. Can infants map meaning to newly segmented words? Statistical segmentation and word learning. Psychol. Sci. 2007, 18, 254–260. [Google Scholar] [CrossRef]
- Swingley, D. Lexical exposure and word-form encoding in 1.5-year-olds. Dev. Psychol. 2007, 43, 454–464. [Google Scholar] [CrossRef]
- Lany, J.; Saffran, J.R. From statistics to meaning: Infants’ acquisition of lexical categories. Psychol. Sci. 2010, 21, 284–291. [Google Scholar] [CrossRef]
- Hay, J.F.; Pelucchi, B.; Estes, K.G.; Saffran, J.R. Linking sounds to meanings: Infant statistical learning in a natural language. Cogn. Psychol. 2011, 63, 93–106. [Google Scholar] [CrossRef]
- Newman, R.; Bersntein Ratner, N.; Jusczyk, A.M.; Jusczyk, P.W.; Dow, K.A. Infants’ early ability to segment the conversational speech signal predicts later language development: A retrospective analysis. Dev. Psychol. 2006, 42, 643–655. [Google Scholar] [CrossRef]
- Junge, C.; Kooijman, V.; Hagoort, P.; Cutler, A. Rapid recognition at 10 months as a predictor of language development. Dev. Sci. 2012, 15, 463–473. [Google Scholar] [CrossRef] [PubMed]
- Singh, L.; Steven Reznick, J.; Xuehua, L. Infant word segmentation and childhood vocabulary development: A longitudinal analysis. Dev. Sci. 2012, 15, 482–495. [Google Scholar] [CrossRef] [PubMed]
- Kooijman, V.; Junge, C.; Johnson, E.K.; Hagoort, P.; Cutler, A. Predictive brain signals of linguistic development. Front. Psychol. 2013, 4, 25. [Google Scholar] [CrossRef] [PubMed]
- Junge, C.; Cutler, A. Early word recognition and later language skills. Brain Sci. 2014, 4, 532–559. [Google Scholar] [CrossRef] [PubMed]
- Kidd, E.; Junge, C.; Spokes, T.; Morrison, L.; Cutler, A. Individual differences in infant speech segmentation: Achieving the lexical shift. Infancy 2018, 23, 770–794. [Google Scholar] [CrossRef]
- Floccia, C.; Keren-Portnoy, T.; DePaolis, R.; Duffy, H.; Delle Luche, C.; Durrant, S.; White, L.; Goslin, J.; Vihman, M. British English infants segment words only with exaggerated infant-directed speech stimuli. Cognition 2016, 148, 1–9. [Google Scholar] [CrossRef]
- Bergmann, C.; Cristia, A. Development of infants’ segmentation of words from native speech: A meta-analytic approach. Dev. Sci. 2016, 19, 901–917. [Google Scholar] [CrossRef]
- Cutler, A. Segmentation problems, rhythmic solutions. Lingua 1994, 92, 81–104. [Google Scholar] [CrossRef]
- Jusczyk, P.W.; Houston, D.M.; Newsome, M. The beginnings of word segmentation in English-learning infants. Cogn. Psychol. 1999, 39, 159–207. [Google Scholar] [CrossRef]
- Houston, D.M.; Jusczyk, P.W.; Kuijpers, C.; Coolen, R.; Cutler, A. Cross-language word segmentation by 9-month-olds. Psychon. Bull. Rev. 2000, 7, 504–509. [Google Scholar] [CrossRef]
- Johnson, E.K.; Jusczyk, P.W. Word segmentation by 8-month-olds: When speech cues count more than statistics. J. Mem. Lang. 2001, 44, 548–567. [Google Scholar] [CrossRef]
- Curtin, S.; Mintz, T.H.; Christiansen, M.H. Stress changes the representational landscape: Evidence from word segmentation. Cognition 2005, 96, 233–262. [Google Scholar] [CrossRef] [PubMed]
- Kooijman, V.K.; Hagoort, P.; Cutler, A. Prosodic structure in early word segmentation: ERP evidence from Dutch 10-month-olds. Infancy 2009, 14, 591–612. [Google Scholar] [CrossRef]
- Nazzi, T.; Iakimova, G.; Bertoncini, J.; Frédonie, S.; Alcantara, C. Early segmentation of fluent speech by infants acquiring French: Emerging evidence for crosslinguistic differences. J. Mem. Lang. 2006, 54, 283–299. [Google Scholar] [CrossRef]
- Nazzi, T.; Mersad, K.; Sundara, M.; Iakimova, G.; Polka, L. Early word segmentation in infants acquiring Parisian French: Task-dependent and dialect-specific aspects. J. Child Lang. 2014, 41, 600–633. [Google Scholar] [CrossRef]
- Polka, L.; Sundara, M. Word segmentation in monolingual infants acquiring Canadian English and Canadian French: Native language, cross-dialect, and cross-language comparisons. Infancy 2012, 17, 198–232. [Google Scholar] [CrossRef]
- Männel, C.; Friederici, A.D. Accentuate or repeat? Brain signatures of developmental periods in infant word recognition. Cortex 2013, 49, 2788–2798. [Google Scholar] [CrossRef]
- Zahner, K.; Schönhuber, M.; Braun, B. The limits of metrical segmentation: Intonation modulates infants’ extraction of embedded trochees. J. Child Lang. 2016, 43, 1338–1364. [Google Scholar] [CrossRef]
- Thiessen, E.D.; Hill, E.A.; Saffran, J.R. Infant-directed speech facilitates word segmentation. Infancy 2005, 7, 53–71. [Google Scholar] [CrossRef]
- Bosseler, A.N.; Teinonen, T.; Tervaniemi, M.; Huotilainen, M. Infant directed speech enhances statistical learning in newborn infants: An ERP study. PLoS ONE 2016, 11, e0162177. [Google Scholar] [CrossRef]
- Schreiner, M.S.; Altvater-Mackensen, N.; Mani, N. Early word segmentation in naturalistic environments: Limited effects of speech register. Infancy 2016, 21, 625–647. [Google Scholar] [CrossRef]
- Kooijman, V.; Hagoort, P.; Cutler, A. Electrophysiological evidence for prelinguistic infants’ word recognition in continuous speech. Cogn. Brain Res. 2005, 24, 109–116. [Google Scholar] [CrossRef] [PubMed]
- Junge, C.; Cutler, A.; Hagoort, P. Successful word recognition by 10-month-olds given continuous speech both at initial exposure and test. Infancy 2014, 19, 179–193. [Google Scholar] [CrossRef]
- Jusczyk, P.W.; Hohne, E.A. Infants’ memory for spoken words. Science 1997, 277, 1984–1986. [Google Scholar] [CrossRef]
- Kuijpers, C.T.L.; Coolen, R.; Houston, D.; Cutler, A. Using the head-turning technique to explore cross-linguistic performance differences. In Advances in Infancy Research; Rovee-Collier, D., Lipsitt, L., Hayne, H., Eds.; Ablex: Stamford, CT, USA, 1998; Volume 12, pp. 205–220. [Google Scholar]
- Goyet, L.; de Schonen, S.; Nazzi, T. Words and syllables in fluent speech segmentation by French-learning infants: An ERP study. Brain Res. 2010, 1332, 75–89. [Google Scholar] [CrossRef]
- Von Holzen, K.; Nishibayashi, L.-L.; Nazzi, T. Consonant and vowel processing in word form segmentation: An infant ERP study. Brain Sci. 2018, 8, 24. [Google Scholar] [CrossRef]
- Trainor, L.; McFadden, M.; Hodgson, L.; Darragh, L.; Barlow, J.; Matsos, L.; Sonnadara, R. Changes in auditory cortex and the development of mismatch negativity between 2 and 6 months of age. Int. J. Psychophysiol. 2003, 51, 5–15. [Google Scholar] [CrossRef]
- Moore, J.K.; Guan, Y.-L. Cytoarchitectural and axonal maturation in human auditory cortex. J. Assoc. Res. Otolaryngol. 2001, 2, 297–311. [Google Scholar] [CrossRef]
- Moore, J.K.; Linthicum, F.H. The human auditory system: A timeline of development. Int. J. Audiol. 2007, 46, 460–478. [Google Scholar] [CrossRef]
- Eggermont, J.J.; Moore, J.K. Morphological and functional development of the auditory nervous system. In Human Auditory Development; Werner, L., Fay, R.R., Popper, A.N., Eds.; Springer Handbook of Auditory Research; Springer: New York, NY, USA, 2012; pp. 61–105. [Google Scholar]
- Luck, S.J. Ten simple rules for designing and interpreting ERP experiments. In Event-related Potentials: A Methods Handbook; Handy, T.C., Ed.; MIT Press: Cambridge, MA, USA, 2005; pp. 17–32. [Google Scholar]
- Snijders, T.M.; Kooijman, V.; Cutler, A.; Hagoort, P. Neurophysiological evidence of delayed segmentation in a foreign language. Brain Res. 2007, 1178, 106–113. [Google Scholar] [CrossRef]
- Grill-Spector, K.; Henson, R.; Martin, A. Repetition and the brain: Neural models of stimulus-specific effects. Trends Cogn. Sci. 2006, 10, 14–23. [Google Scholar] [CrossRef] [PubMed]
- Henson, R.N.A.; Rugg, M.D. Neural response suppression, haemodynamic repetition effects, and behavioural priming. Neuropsychologia 2003, 41, 263–270. [Google Scholar] [CrossRef]
- Henson, R.; Shallice, T.; Dolan, R. Neuroimaging evidence for dissociable forms of repetition priming. Science 2000, 287, 1269–1272. [Google Scholar] [CrossRef] [PubMed]
- Weber, K.; Christiansen, M.H.; Petersson, K.M.; Indefrey, P.; Hagoort, P. fMRI syntactic and lexical repetition effects reveal the initial stages of learning a new language. J. Neurosci. 2016, 36, 6872–6880. [Google Scholar] [CrossRef]
- Segaert, K.; Weber, K.; de Lange, F.P.; Petersson, K.M.; Hagoort, P. The suppression of repetition enhancement: A review of fMRI studies. Neuropsychologia 2013, 51, 59–66. [Google Scholar] [CrossRef]
- Baayen, R.H.; Piepenbrock, R.; Gulikers, L. The CELEX Lexical Database (CD-ROM); Linguistic Data Consortium, University of Pennsylvania: Philadelphia, PA, USA, 1993. [Google Scholar]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer, Version 5.3.45; Available online: http://www.fon.hum.uva.nl/praat/ (accessed on 22 April 2013).
- Neurobehavioral Systems. Available online: https://www.neurobs.com (accessed on 2 February 2015).
- Oostenveld, R.; Fries, P.; Maris, E.; Schoffelen, J.-M. FieldTrip: Open Source Software for Advanced Analysis of MEG, EEG, and Invasive Electrophysiological Data. Comput. Intell. Neurosci. 2011, 156869. [Google Scholar] [CrossRef]
- Makeig, S.; Bell, A.J.; Jung, T.-P.; Sejnowski, T.J. Independent component analysis of electroencephalographic data. In Advances in Neural Information Processing Systems 8; Touretzky, D., Mozer, M., Hasselmo, M., Eds.; MIT Press: Cambridge, MA, USA, 1996; pp. 145–151. [Google Scholar]
- Bell, A.J.; Sejnowski, T.J. An information-maximization approach to blind separation and blind deconvolution. Neural Comput. 1995, 7, 1129–1159. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef]
- Perrin, F.; Pernier, J.; Bertrand, O.; Echallier, J.F. Spherical splines for scalp potential and current density mapping. Electroencephalogr. Clin. Neurophysiol. 1989, 72, 184–187. [Google Scholar] [CrossRef]
- Maris, E.; Oostenveld, R. Nonparametric statistical testing of EEG- and MEG-data. J. Neurosci. Methods 2007, 164, 177–190. [Google Scholar] [CrossRef]
- Sassenhagen, J.; Draschkow, D. Cluster-based permutation tests of MEG/EEG data do not establish significance of effect latency or location. Psychophysiology 2019, 56, e13335. [Google Scholar] [CrossRef] [PubMed]
- Bates, D.; Maechler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Bates, D.; Kliegl, R.; Vasishth, S.; Baayen, H. Parsimonious mixed models. arXiv 2015, arXiv:1506.04967. [Google Scholar]
- Soderstrom, M. Beyond Babytalk: Re-evaluating the nature and content of speech input to preverbal infants. Dev. Rev. 2007, 27, 501–532. [Google Scholar] [CrossRef]
- Song, J.Y.; Demuth, K.; Morgan, J. Effects of the acoustic properties of infant-directed speech on infant word recognition. J. Acoust. Soc. Am. 2010, 128, 389–400. [Google Scholar] [CrossRef]
- Martin, A.; Igarashi, Y.; Jincho, N.; Mazuka, R. Utterances in infant-directed speech are shorter, not slower. Cognition 2016, 156, 52–59. [Google Scholar] [CrossRef]
- Wang, Y.; Llanos, F.; Seidl, A. Infants adapt to speaking rate differences in word segmentation. J. Acoust. Soc. Am. 2017, 141, 2569–2578. [Google Scholar] [CrossRef]
- Fernald, A.; Mazzie, C. Prosody and focus in speech to infants and adults. Dev. Psychol. 1991, 27, 209–221. [Google Scholar] [CrossRef]
- Beck, C.; Kardatzki, B.; Ethofer, T. Mondegreens and soramimi as a method to induce misperceptions of speech content - Influence of familiarity, wittiness, and language competence. PLoS ONE 2014, 9, e84667. [Google Scholar] [CrossRef]
- Gomes, H. The development of auditory attention in children. Front. Biosci. 2000, 5, d108. [Google Scholar] [CrossRef]
- Benders, T. Mommy is only happy! Dutch mothers’ realisation of speech sounds in infant-directed speech expresses emotion, not didactic intent. Infant Behav. Dev. 2013, 36, 847–862. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Familiarization Phase (Sung or Spoken) | Word-for-Word Translation | Semantic Translation | |
|---|---|---|---|
| Luister eens! | Listen once! | Listen to this! | |
| 1. | Met bellers kun je lachen | With callers can you laugh | One can have a laugh with callers |
| 2. | De vrouw vindt bellers stom | The woman regards callers stupid | The woman thinks callers are stupid |
| 3. | We spraken met de woeste bellers | We spoke to the wild callers | We spoke to the wild callers |
| 4. | Dan praten bellers graag | Then speak callers preferably | Callers prefer to speak then |
| 5. | Daar achterin zijn bellers | There behind are callers | Callers are there in the back |
| 6. | Wat lopen bellers snel | What walk callers fast | Callers walk that fast |
| 7. | Jouw bellers kletsen makkelijk | Your callers chat easily | Your callers are at ease chatting |
| 8. | Ik zag de bellers niet | I saw the callers not | I did not see the callers |
| Test phase (spoken) | |||
| Luister eens! | Listen once! | Listen to this! | |
| 9. | Aan die piefen gaf hij koffie | To those hotshots gave he coffee | He served those hotshots coffee |
| 10. | Vaak gaan bellers op reis | Often go callers to travel | Callers travel often |
| 11. | Alle bellers stappen laat uit | All callers get late off | All callers get off late |
| 12. | Zij zijn goede piefen geworden | They have good hotshots become | They have become good hotshots |
| Word 1 | Word 2 | Song that Melody Was Based on | |||
|---|---|---|---|---|---|
| 1 | bellers | (callers) | piefen | (hotshots) | If all the world were paper (English) |
| 2 | hinde | (doe) | emoe | (emu) | Sing a song of sixpence (English) |
| 3 | gondels | (gondolas) | schuiten | (barques) | See-saw Margery Daw (English) |
| 4 | drummer | (drummer) | cantor | (cantor) | Georgie Porgie (English) |
| 5 | gieter | (watering cans) | silo’s | (silos) | There was a crooked man (English) |
| 6 | hommels | (bumblebees) | kevers | (beetle) | Pat-a-cake (English) |
| 7 | fakirs | (fakirs) | dansers | (dancers) | Little Tommy Tucker (English) |
| 8 | krekels | (crickets) | hoenders | (fowl) | En elefant kom marsjerende (Norwegian) |
| 9 | krokus | (crocus) | anjer | (carnation) | Smil og vær glad (Norwegian) |
| 10 | lener | (borrower) | preses | (president) | Ute På Den Grønne Eng (Norwegian) |
| 11 | mammoet | (mammoth) | orka | (orca) | Jeg snører min sekk (Norwegian) |
| 12 | monnik | (monk) | frater | (friar) | Auf de Swäb’sche Eisenbahne (German) |
| 13 | otters | (otter) | lama’s | (llamas) | Suse, liebe Suse (German) |
| 14 | mosterd | (mustard) | soja | (soya) | Schneeflöckchen Weißröckchen (German) |
| 15 | pelgrims | (pilgrim) | lopers | (runners) | Wem Gott will rechte Gunst erweisen (Ger.) |
| 16 | pudding | (pudding) | sorbet | (sorbet) | Wiesje (Dutch) |
| 17 | ronde | (round) | kuier | (saunter) | A l’intérieur d’une citrouille (French) |
| 18 | sitar | (sitar) | banjo | (banjo) | La bonne avonture o gué (French) |
| 19 | sultan | (sultan) | viking | (Viking) | Neige neige blanche (French) |
| 20 | zwaluw | (swallow) | kievit | (lapwing) | Entre le boeuf e l’âne gris (French) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Snijders, T.M.; Benders, T.; Fikkert, P. Infants Segment Words from Songs—An EEG Study. Brain Sci. 2020, 10, 39. https://doi.org/10.3390/brainsci10010039
Snijders TM, Benders T, Fikkert P. Infants Segment Words from Songs—An EEG Study. Brain Sciences. 2020; 10(1):39. https://doi.org/10.3390/brainsci10010039
Chicago/Turabian StyleSnijders, Tineke M., Titia Benders, and Paula Fikkert. 2020. "Infants Segment Words from Songs—An EEG Study" Brain Sciences 10, no. 1: 39. https://doi.org/10.3390/brainsci10010039
APA StyleSnijders, T. M., Benders, T., & Fikkert, P. (2020). Infants Segment Words from Songs—An EEG Study. Brain Sciences, 10(1), 39. https://doi.org/10.3390/brainsci10010039