IoT Implementation of Kalman Filter to Improve Accuracy of Air Quality Monitoring and Prediction

Abstract
1. Introduction
2. Related Work
2.1. Edge Computing on IoT
2.2. Air Quality Monitoring System
2.3. Prediction Model
3. Materials and Methods
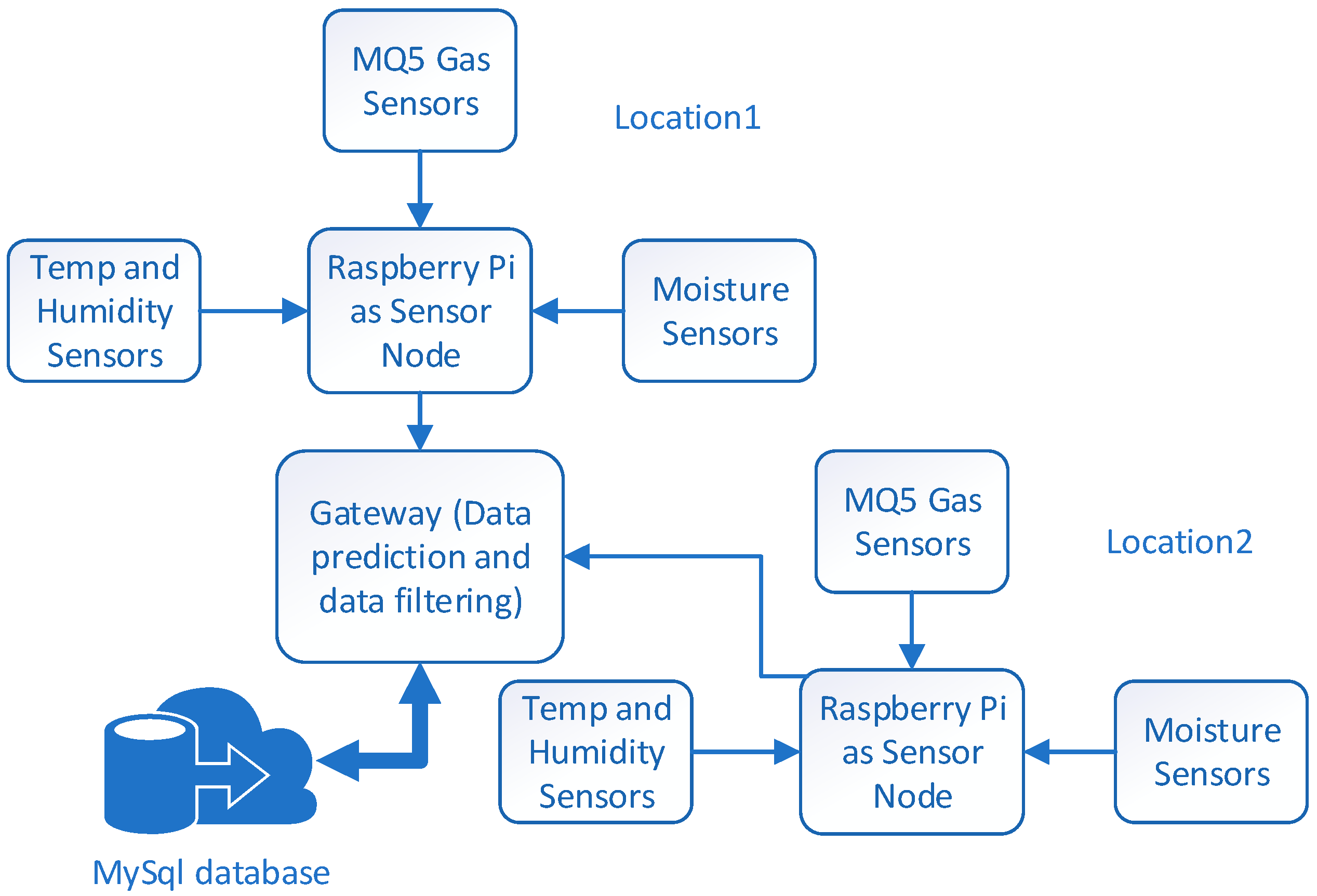
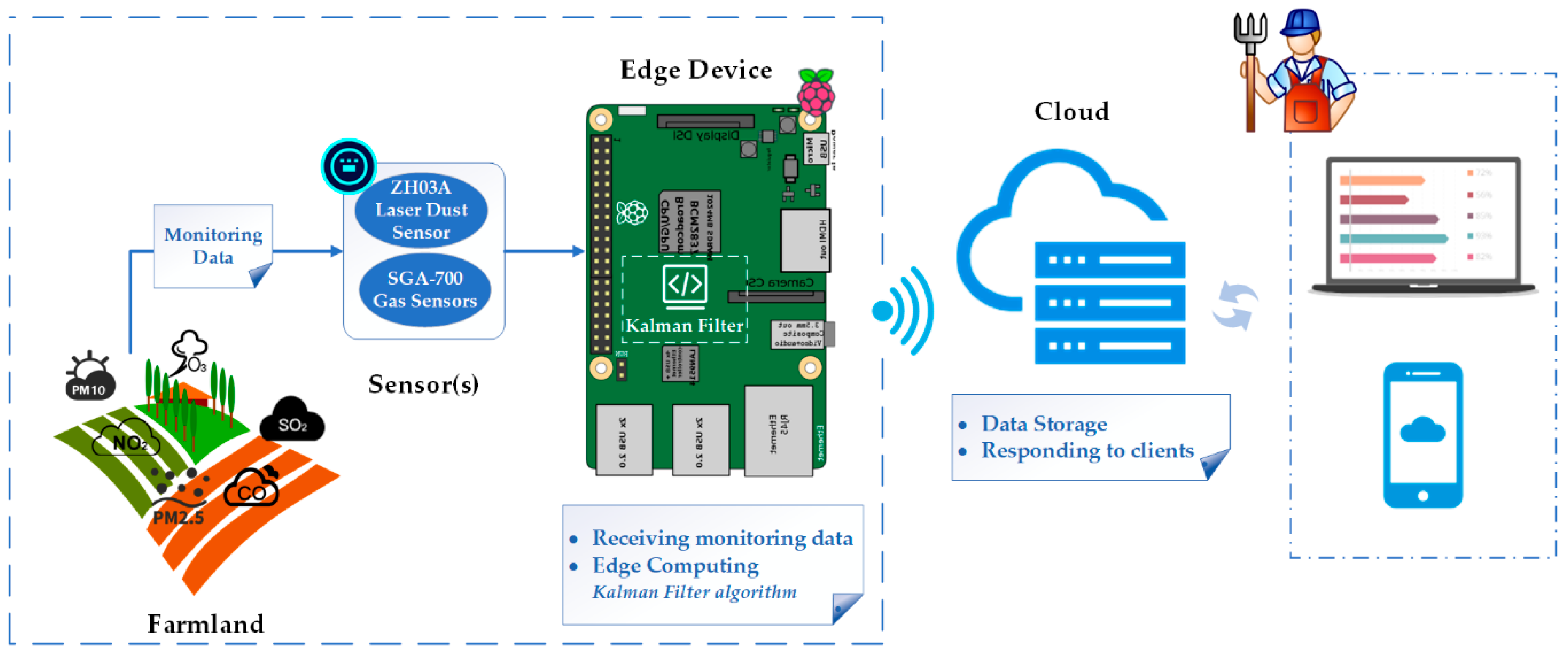
3.1. The Proposed System Architecture
3.2. Hardware
3.2.1. Raspberry Pi
3.2.2. Sensors
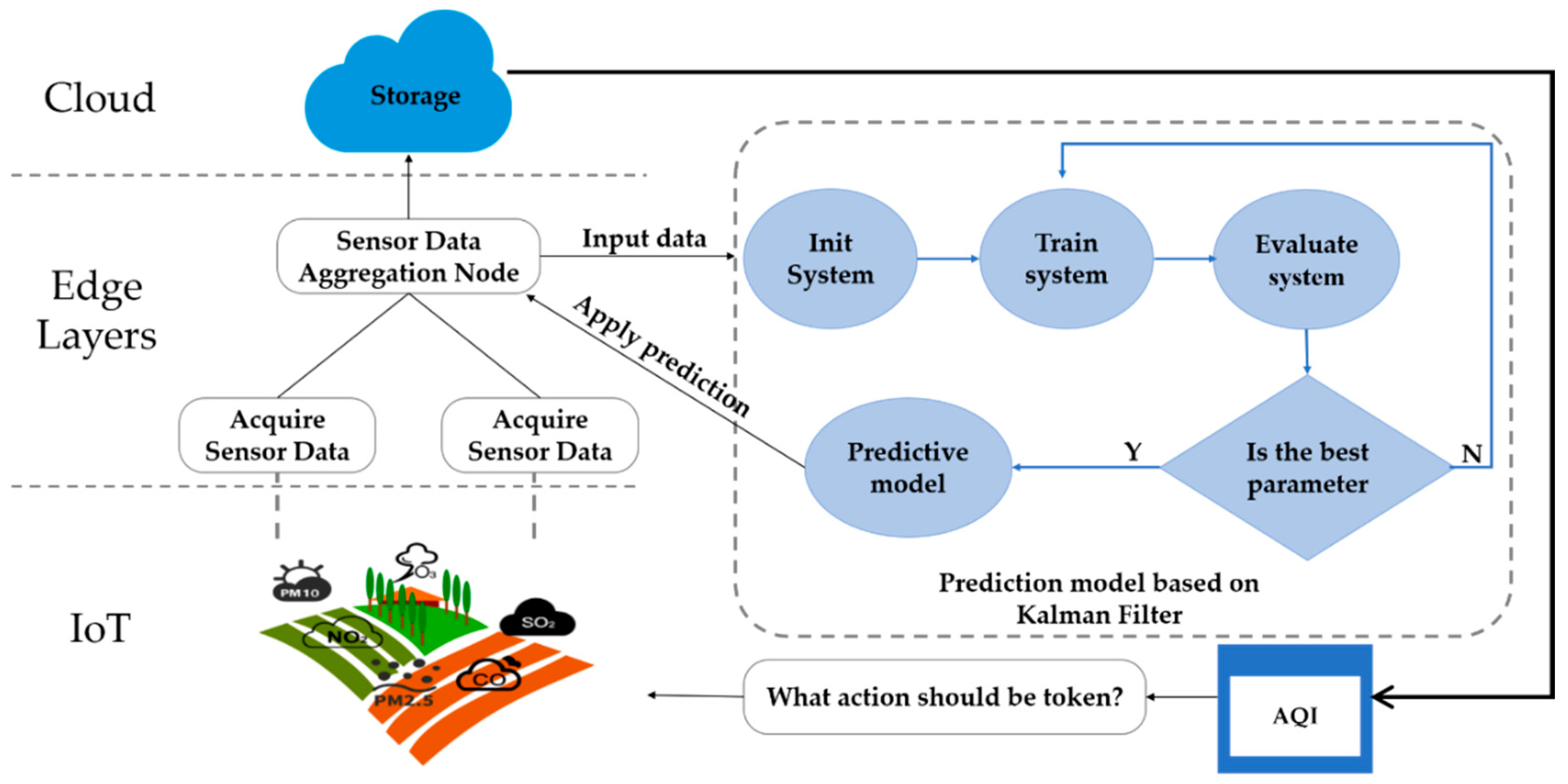
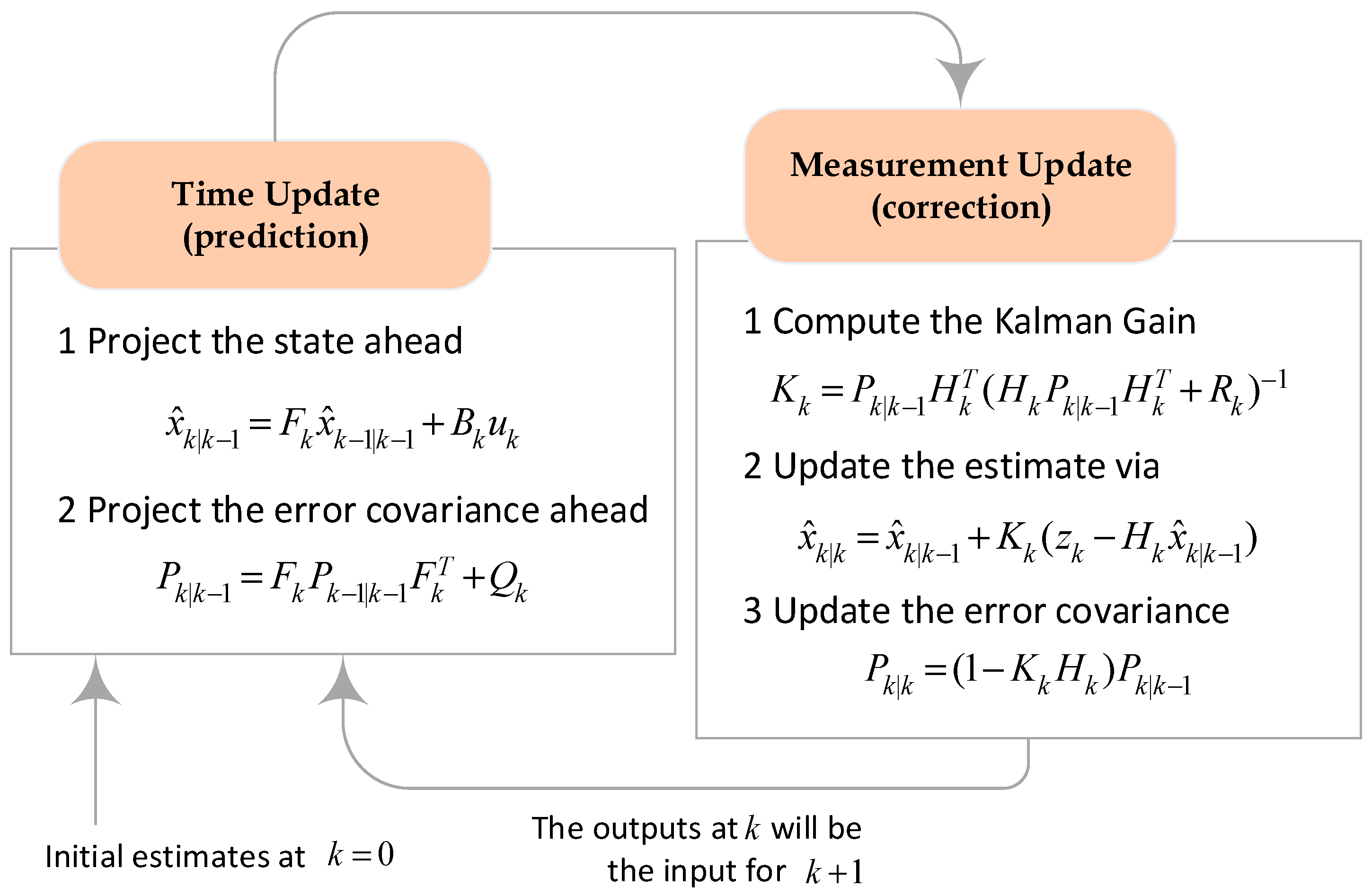
3.3. Kalman Filter Algorithm
- The object of the KF algorithm research is a stochastic process, with sequential data.
- The goal of filtering is to predict all random processes even with useless noise.
- Differing from the least squares method, the white noise existing in the dynamic system or the observation error existing in the observation data does not need to be filtered. The statistical characteristics of this noise information will be used by the model in the prediction process.
- The KF algorithm uses a recursive algorithm, and spatial state representation equations are used to construct time-domain filters for prediction of multidimensional random variables (the predicted system state consists of multiple features).
- Compared to the ARIMA model, the time series data used for prediction can be smooth or not.
- The prediction process only considers the process noise, the noise generated by the observation method and the statistical characteristics of the system at the current time point. Besides, the model calculation is small, which is very suitable for real-time prediction.
4. Results
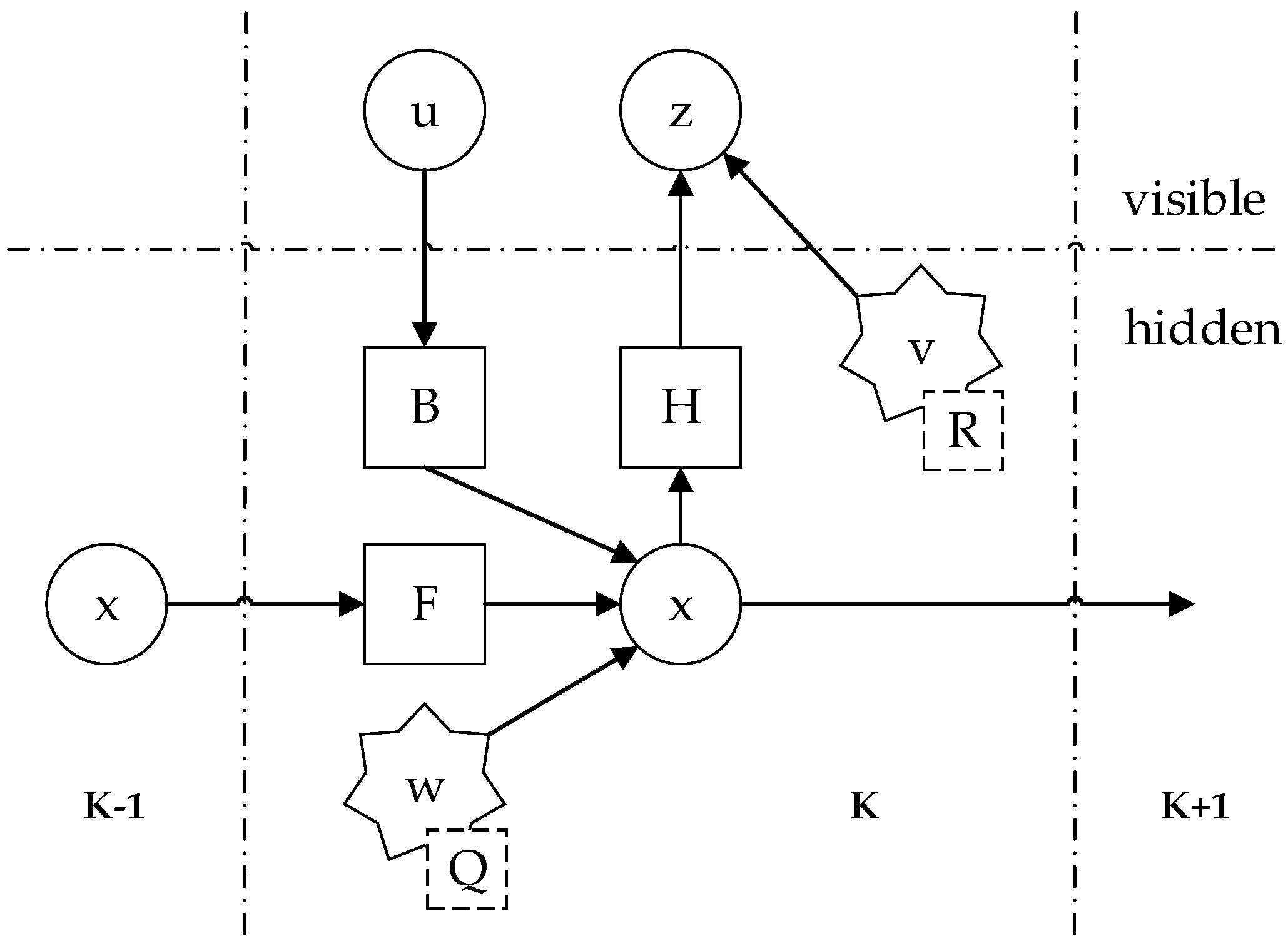
4.1. Basic Dynamic System Model
4.2. Kalman Filter Algorithm Implementation
- represents an estimate of the system state at time ;
- represents the covariance matrix of the state estimation error at time , which measures the accuracy of the estimation.
4.2.1. Prediction
4.2.2. Correction
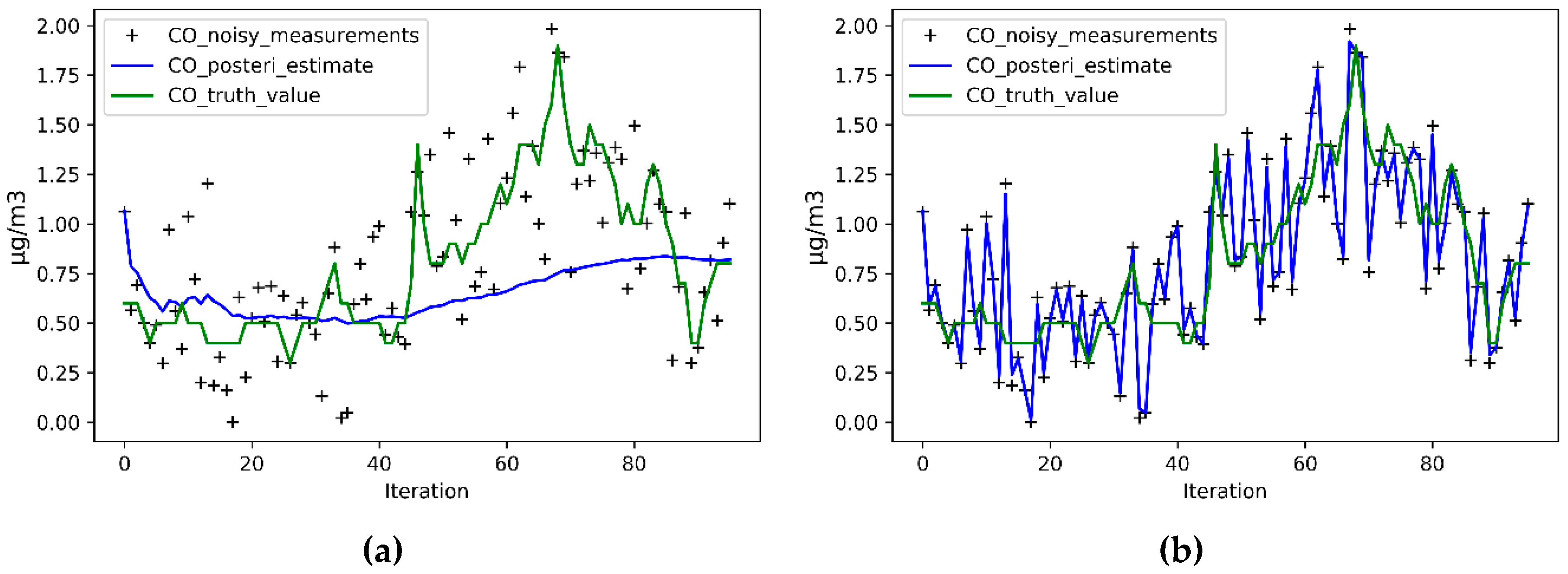
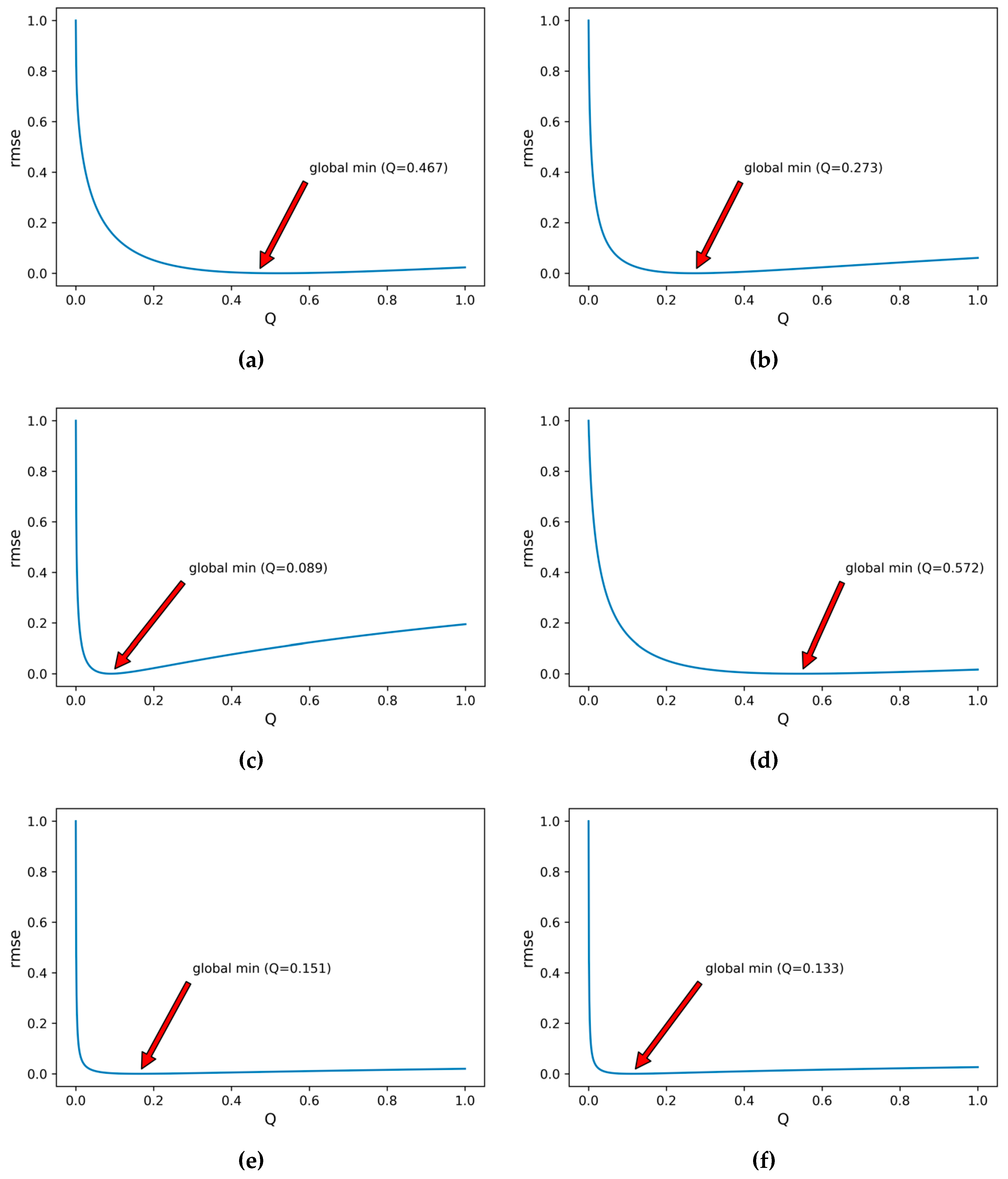
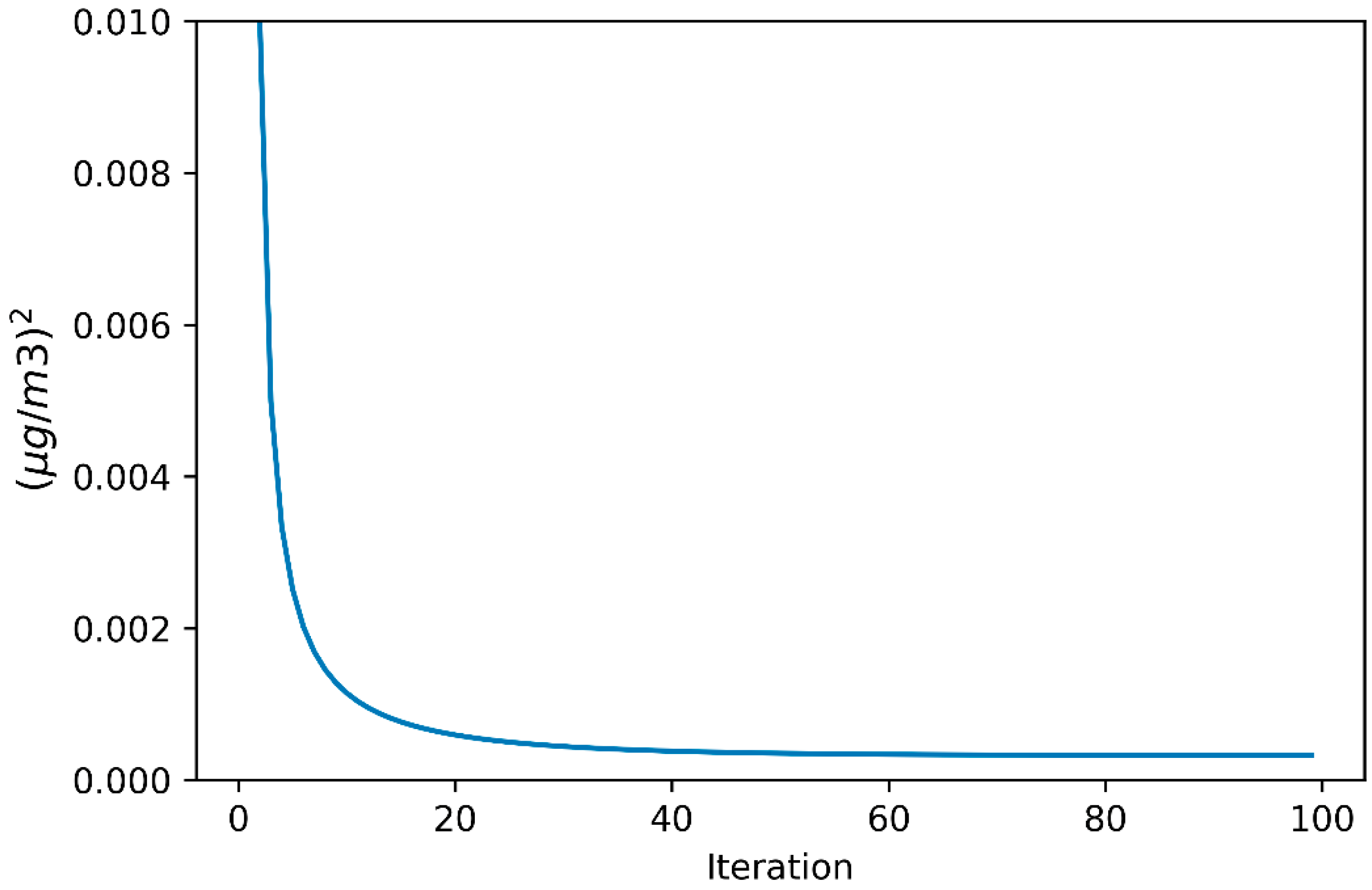
4.2.3. Setting Parameters
5. Discussion
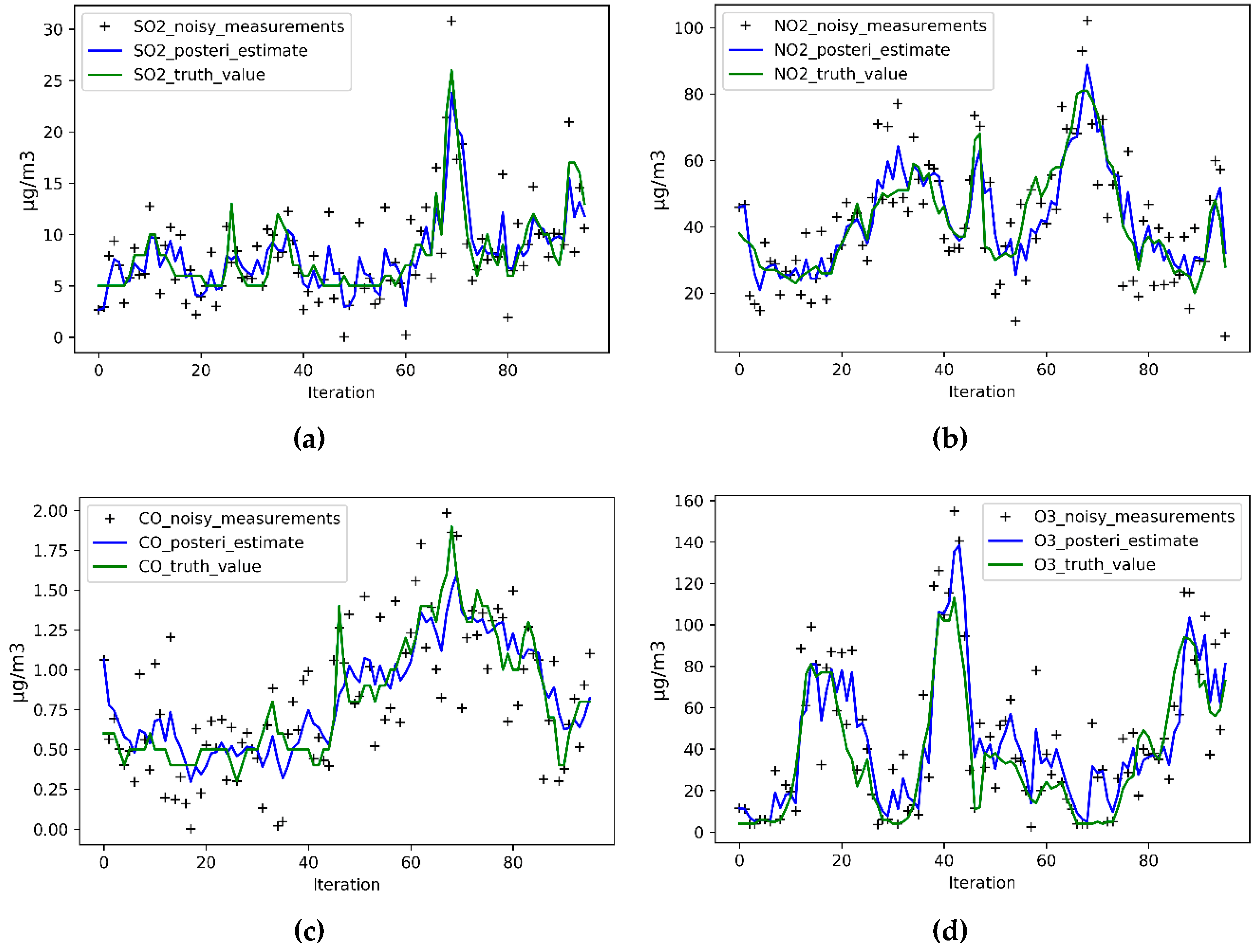
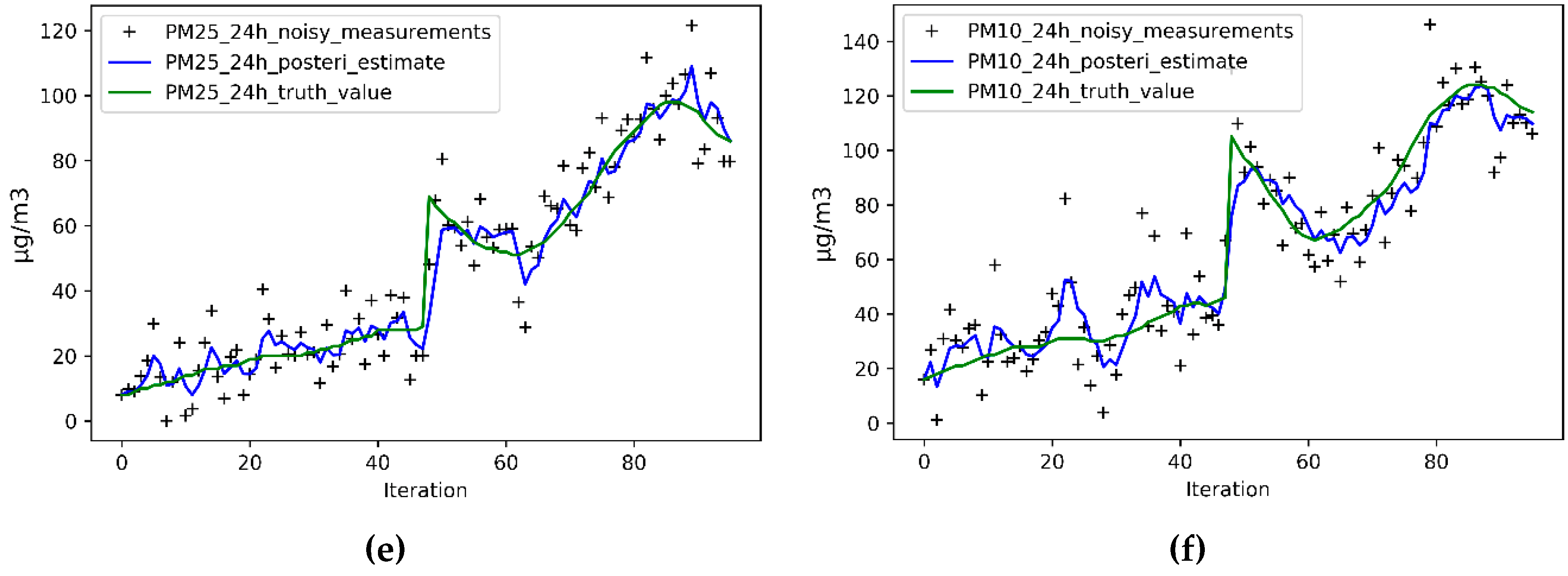
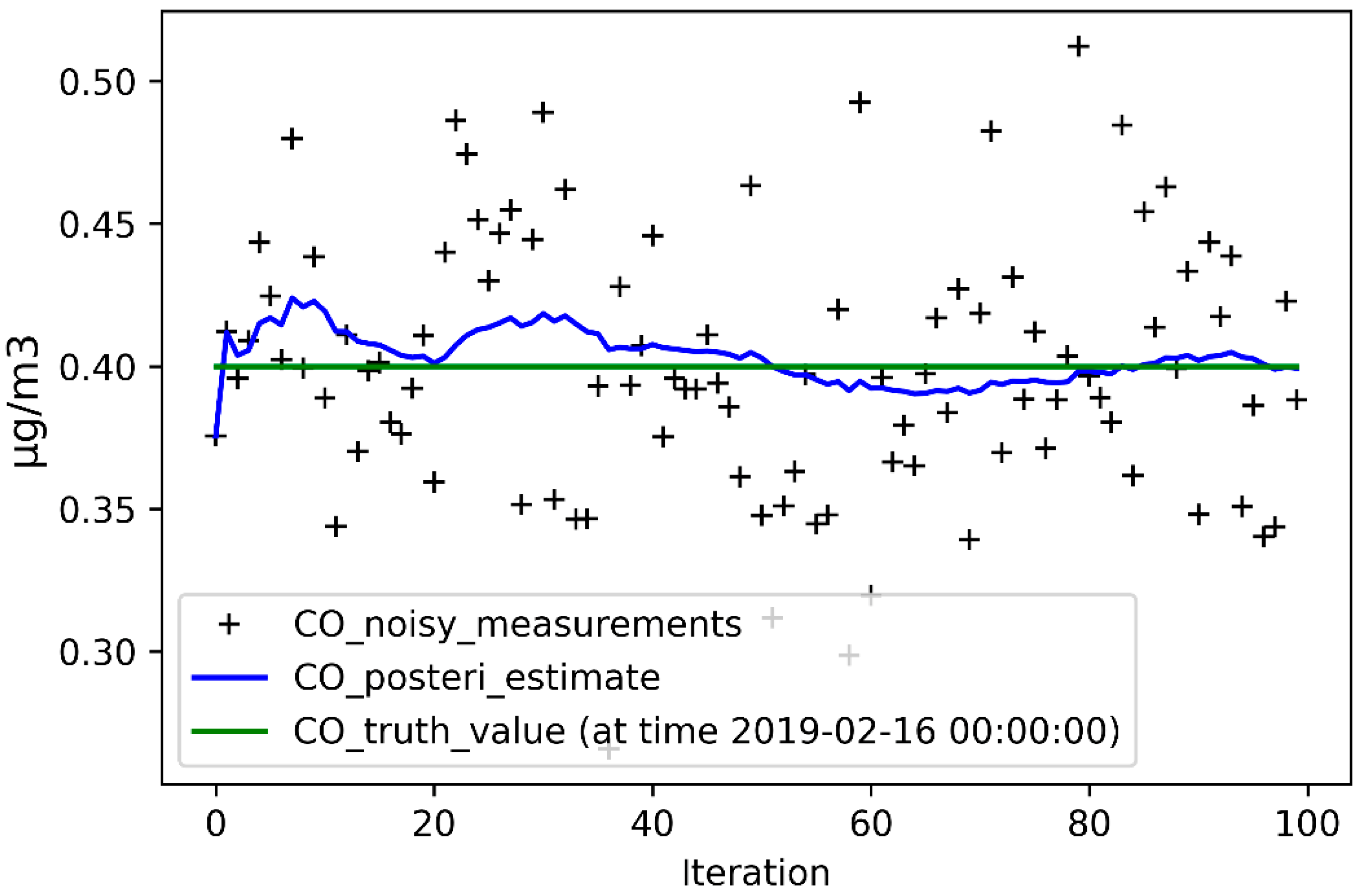
5.1. Accuracy Improvement Analysis
5.2. Predictive Ability Analysis
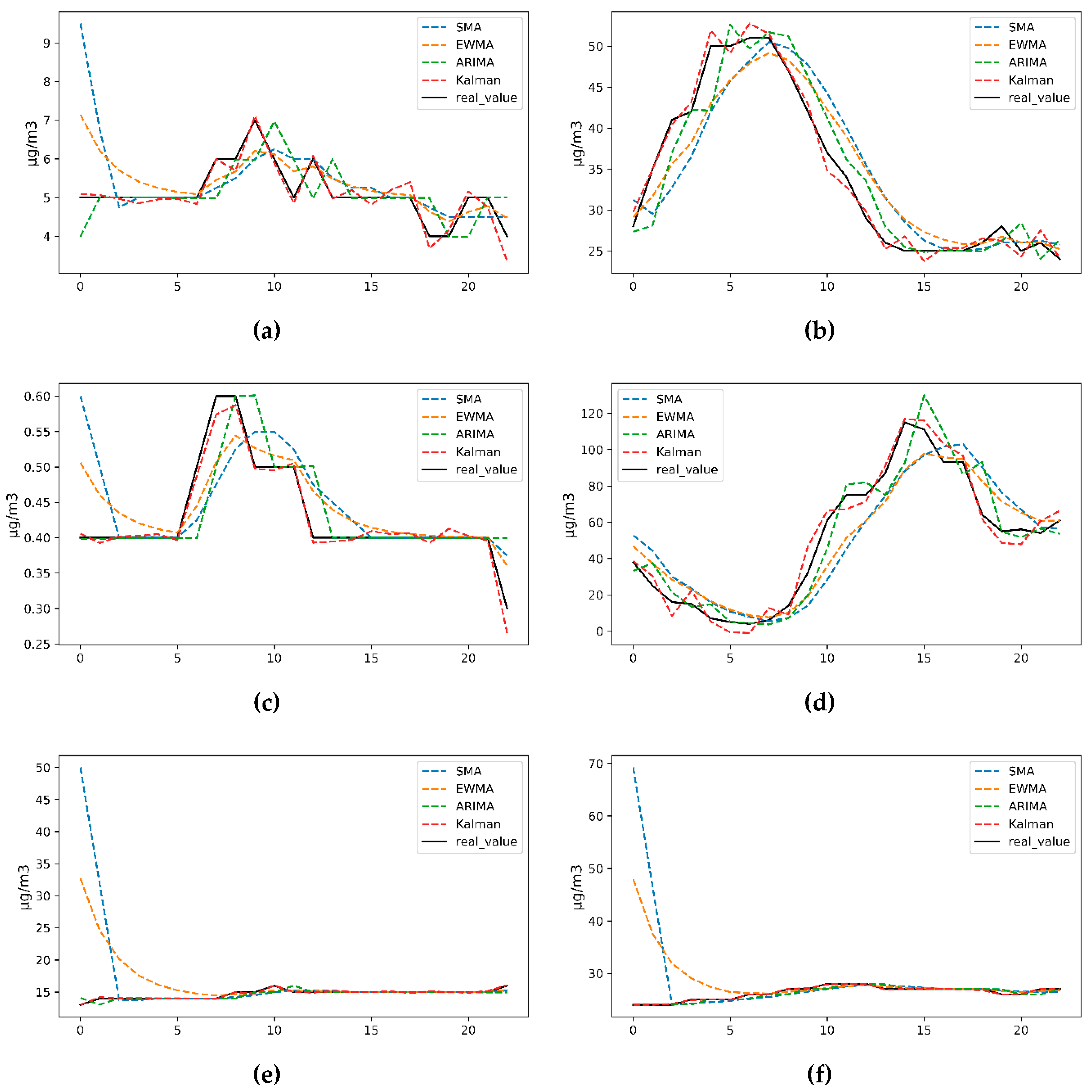
5.3. Predictive Trend Comparison
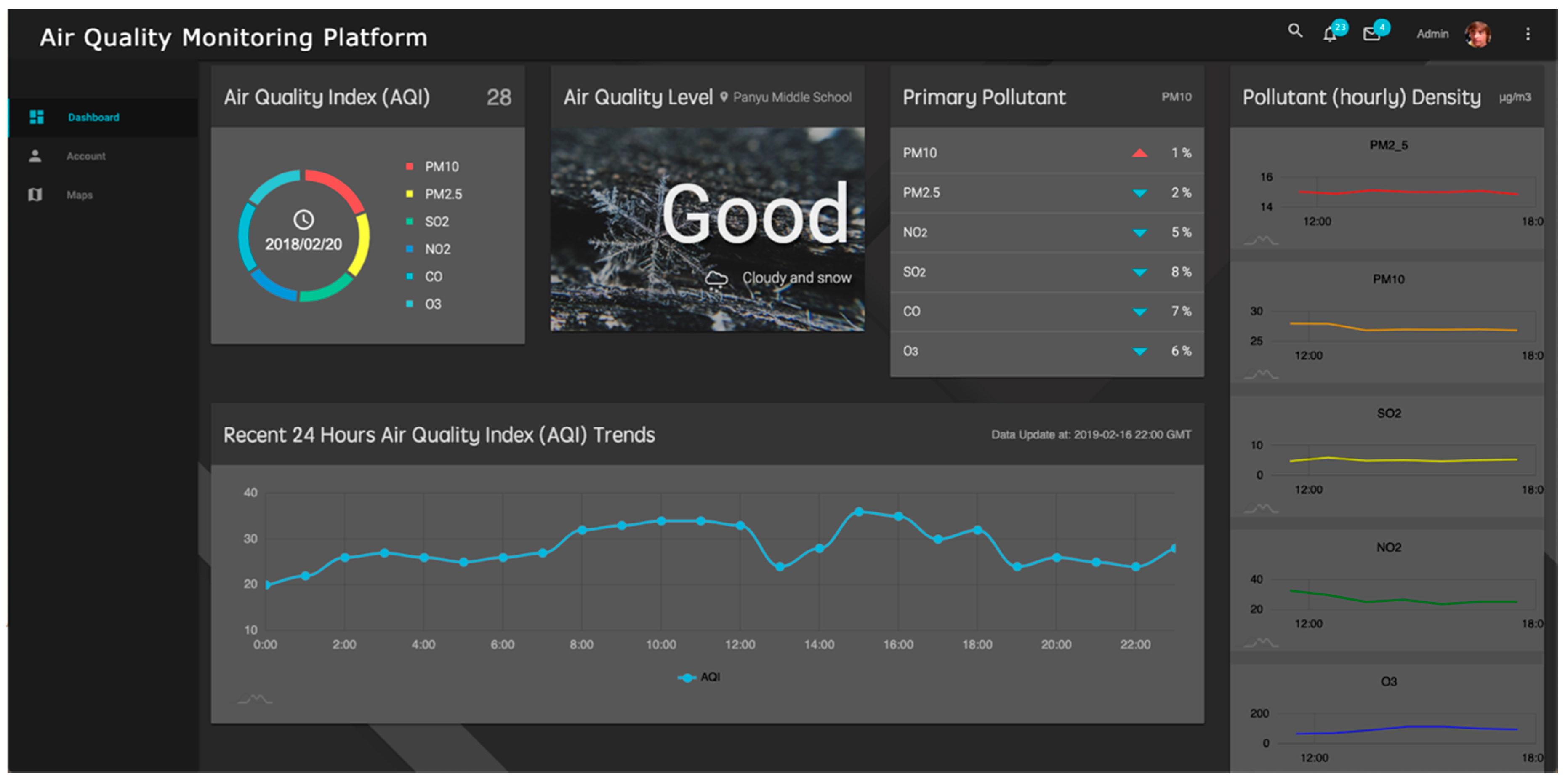
5.4. Client Interface Design
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Stočes, M.; Vaněk, J.; Masner, J. Internet of things (iot) in agriculture-selected aspects. Informatics 2016, 8, 83–88. [Google Scholar] [CrossRef]
- Chen, S.; Xu, H.; Lin, D. A vision of IoT: Applications, challenges, and opportunities with china perspective. IEEE Internet Things J. 2014, 1, 349–359. [Google Scholar] [CrossRef]
- El-Sayed, H.; Sankar, S.; Prasad, M. Edge of things: The big picture on the integration of edge, IoT and the cloud in a distributed computing environment. IEEE Access 2018, 6, 1706–1717. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- TongKe, F. Smart agriculture based on cloud computing and IOT. J. Converg. Inf. Technol. 2013, 8, 210–216. [Google Scholar]
- Shenoy, J.; Pingle, Y. IOT in agriculture. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; IEEE: Piscataway, NJ, USA; pp. 1456–1458. [Google Scholar]
- European Environment Agency. Air Pollution; Report; EEA: Copenhagen, Denmark, 2001. [Google Scholar]
- Jamil, M.S.; Jamil, M.A.; Mazhar, A.; Ikram, A.; Ahmed, A.; Munawar, U. Smart environment monitoring system by employing wireless sensor networks on vehicles for pollution free smart cities. Procedia Eng. 2015, 107, 480–484. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, J. A study on the fire IOT development strategy. Procedia Eng. 2013, 52, 314–319. [Google Scholar] [CrossRef]
- Li, E.; Coates, K.; Li, X.; Ye, X.; Leipnik, M. Analyzing agricultural agglomeration in China. Sustainability 2017, 9, 313. [Google Scholar] [CrossRef]
- Hajji, W.; Tso, F. Understanding the performance of low power Raspberry Pi Cloud for big data. Electronics 2016, 5, 29. [Google Scholar] [CrossRef]
- Semwal, T.; Nair, S. Agpi: Agents on raspberry pi. Electronics 2016, 5, 72. [Google Scholar] [CrossRef]
- Pahl, C.; Helmer, S.; Miori, L.; Sanin, J.; Lee, B. A container-based edge cloud paas architecture based on raspberry pi clusters. In Proceedings of the 2016 IEEE 4th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Vienna, Austria, 22–24 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 117–124. [Google Scholar]
- Satyanarayanan, M. The emergence of edge computing. Computer 2017, 50, 30–39. [Google Scholar] [CrossRef]
- Bilal, K.; Khalid, O.; Erbad, A.; Khan, S.U. Potentials, trends, and prospects in edge technologies: Fog, cloudlet, mobile edge, and micro data centers. Comput. Netw. 2018, 130, 94–120. [Google Scholar] [CrossRef]
- Brzoza-Woch, R.; Konieczny, M.; Nawrocki, P.; Szydlo, T.; Zielinski, K. Embedded systems in the application of fog computing—Levee monitoring use case. In Proceedings of the 2016 11th IEEE Symposium on Industrial Embedded Systems (SIES), Krakow, Poland, 23–25 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Intel IoT Solutions Transform Smart Buildings from the Ground Up. Available online: https://blogs.intel.com/iot/2016/06/07/intel-iot-solutions-transforming-smart-buildings-ground/ (accessed on 1 February 2019).
- Datta, S.K.; Bonnet, C.; Haerri, J. Fog computing architecture to enable consumer centric internet of things services. In Proceedings of the 2015 International Symposium on Consumer Electronics (ISCE), Madrid, Spain, 24–26 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–2. [Google Scholar]
- Lo’ai, A.T.; Bakheder, W.; Song, H. A mobile cloud computing model using the cloudlet scheme for big data applications. In Proceedings of the 2016 IEEE First International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Washington, DC, USA, 27–29 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 73–77. [Google Scholar]
- Gómez, J.E.; Marcillo, F.R.; Triana, F.L.; Gallo, V.T.; Oviedo, B.W.; Hernández, V.L. IoT for environmental variables in urban areas. Procedia Comput. Sci. 2017, 109, 67–74. [Google Scholar] [CrossRef]
- Raipure, S.; Mehetre, D. Wireless sensor network based pollution monitoring system in metropolitan cities. In Proceedings of the 2015 International Conference on Communications and Signal Processing (ICCSP), Melmaruvathur, India, 2–4 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1835–1838. [Google Scholar]
- Shinde, D.; Siddiqui, N. IOT Based environment change monitoring & controlling in greenhouse using WSN. In Proceedings of the 2018 International Conference on Information, Communication, Engineering and Technology (ICICET), Pune, India, 29–31 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Xiaojun, C.; Xianpeng, L.; Peng, X. IOT-based air pollution monitoring and forecasting system. In Proceedings of the 2015 International Conference on Computer and Computational Sciences (ICCCS), Noida, India, 27–29 January 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 257–260. [Google Scholar]
- Kiruthika, R.; Umamakeswari, A. Low cost pollution control and air quality monitoring system using Raspberry Pi for Internet of Things. In Proceedings of the 2017 International Conference on Energy, Communication, Data Analytics and Soft Computing (ICECDS), Chennai, India, 1–2 August 2017; IEEE: Piscataway, NJ, USA, 2015; pp. 2319–2326. [Google Scholar]
- Maksimović, M.; Vujović, V.; Davidović, N.; Milošević, V.; Perišić, B. Raspberry Pi as Internet of things hardware: Performances and constraints. In Proceedings of the International Conference on Electrical, Electronic, and Computing Engineering, Vrnjačka Banja, Serbia, 2–5 June 2014; Volume 3, p. 8. [Google Scholar]
- Vujović, V.; Maksimović, M. Raspberry Pi as a Sensor Web node for home automation. Comput. Electr. Eng. 2015, 44, 153–171. [Google Scholar] [CrossRef]
- Li, S.; Da, X.L.; Zhao, S. The internet of things: A survey. Inf. Syst. Front. 2015, 17, 243–259. [Google Scholar] [CrossRef]
- Jadhav, G.; Jadhav, K.; Nadlamani, K. Environment monitoring system using raspberry-Pi. Int. Res. J. Eng. Technol. (IRJET) 2016, 3, 4. [Google Scholar]
- Lanzafame, R.; Monforte, P.; Patanè, G.; Strano, S. Trend analysis of air quality index in Catania from 2010 to 2014. Energy Procedia 2015, 82, 708–715. [Google Scholar] [CrossRef]
- Donnelly, A.; Misstear, B.; Broderick, B. Real time air quality forecasting using integrated parametric and non-parametric regression techniques. Atmos. Environ. 2015, 103, 53–65. [Google Scholar] [CrossRef]
- Zhu, J.; Zhang, R.; Fu, B.; Jin, R. Comparison of ARIMA model and exponential smoothing model on 2014 air quality index in Yanqing county, Beijing, China. Appl. Comput. Math. 2015, 4, 456–461. [Google Scholar] [CrossRef][Green Version]
- Kadilar, G.Ö.; Kadilar, C. Assessing air quality in Aksaray with time series analysis. In Proceedings of the AIP Conference Proceedings, Antalya, Turkey, 18–21 April 2017; AIP Publishing: Melville, NY, USA, 2017; Volume 1833, p. 020112. [Google Scholar]
- Xia, X.; Zhao, W.; Rui, X.; Wang, Y.; Bai, X.; Yin, W.; Don, J. A comprehensive evaluation of air pollution prediction improvement by a machine learning method. In Proceedings of the 2015 IEEE International Conference on Service Operations and Logistics, And Informatics (SOLI), Hammamet, Tunisia, 15–17 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 176–181. [Google Scholar]
- Taneja, S.; Sharma, N.; Oberoi, K.; Navoria, Y. Predicting trends in air pollution in Delhi using data mining. In Proceedings of the 2016 1st India International Conference on Information Processing (IICIP), Delhi, India, 12–14 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Rybarczyk, Y.; Zalakeviciute, R. Machine learning approach to forecasting urban pollution. In Proceedings of the 2016 IEEE Ecuador Technical Chapters Meeting (ETCM), Guayaquil, Ecuador, 12–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Sousa, S.I.V.; Martins, F.G.; Alvim-Ferraz, M.C.M.; Pereira, M.C. Multiple linear regression and artificial neural networks based on principal components to predict ozone concentrations. Environ. Modell. Softw. 2007, 22, 97–103. [Google Scholar] [CrossRef]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2. 5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Richardson, M.; Wallace, S. Getting Started with Raspberry PI; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Chang, H.; Hari, A.; Mukherjee, S.; Lakshman, T.V. Bringing the cloud to the edge. In Proceedings of the 2014 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 27 April–2 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 346–351. [Google Scholar]
- Ujjainiya, L.; Chakravarthi, M.K. Raspberry—Pi based cost effective vehicle collision avoidance system using image processing. ARPN J. Eng. Appl. Sci 2015, 10, 1819–6608. [Google Scholar]
- Pannu, G.S.; Ansari, M.D.; Gupta, P. Design and implementation of autonomous car using Raspberry Pi. In. J. Comput. Appl. 2015, 113, 22–29. [Google Scholar]
- Senthilkumar, G.; Gopalakrishnan, K.; Kumar, V. Embedded image capturing system using raspberry pi system. Int. J. Emerg. Trends Technol. Comput. Sci. 2014, 3, 213–215. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Lipfert, F.W.; Wyzga, R.E.; Baty, J.D.; Miller, J.P. Traffic density as a surrogate measure of environmental exposures in studies of air pollution health effects: Long-term mortality in a cohort of US veterans. Atmos. Environ. 2006, 40, 154–169. [Google Scholar] [CrossRef]
- Qiao, Y. A review of machine learning related algorithms based on numerical prediction. J. Anyang Inst. Technol. 2017, 16, 71–74. [Google Scholar]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Fildes, R. Forecasting, structural time series models and the Kalman Filter: Bayesian forecasting and dynamic models. J. Opt. Res. Soc. 1991, 42, 1031–1033. [Google Scholar] [CrossRef]
- Bishop, G.; Welch, G. An introduction to the kalman filter. Proc. Siggr. Course 2001, 8, 41. [Google Scholar]
- Welch, G.F.; Bishop, G. SCAAT: Incremental Tracking with Incomplete Information. Ph.D. Thesis, University of North Carolina at Chapel Hill, Chapel Hill, NY, USA, October 1996. [Google Scholar]
- Guangzhou PM2.5 and Air Quality Index (AQI). Available online: http://pm25.in/guangzhou (accessed on 12 February 2019).
- Johnston, F.R.; Boyland, J.E.; Meadows, M.; Shale, E. Some properties of a simple moving average when applied to forecasting a time series. J. Oper. Res. Soc. 1999, 50, 1267–1271. [Google Scholar] [CrossRef]
- Osborne, J.W. Prediction in multiple regression. Pract. Assess. Res. Eval. 2000, 7, 1–9. [Google Scholar]
- Ren, H.; Guo, J.; Sun, L.; Han, C. Prediction algorithm based on weather forecast for energy-harvesting wireless sensor networks. In Proceedings of the 2018 17th IEEE International Conference On Trust, Security and Privacy In Computing And Communications/12th IEEE International Conference On Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1785–1790. [Google Scholar]
- Kumar, S.V.; Vanajakshi, L. Short-term traffic flow prediction using seasonal ARIMA model with limited input data. Eur. Transp. Res. Rev. 2015, 7, 21. [Google Scholar] [CrossRef]
- Cole, L.J.; Frantz, C.J.; Lee, J.; Ordanic, Z.; Plank, L.K. Centralized Management in a Computer Network. U.S. Patent US4995035A, 19 February 1991. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Algorithm | MSE | RMSE | MAE |
|---|---|---|---|---|
| SO2 | Kalman Filter | 0.0754 | 0.2747 | 0.2032 |
| Sensor | 0.1265 | 0.3557 | 0.2775 | |
| NO2 | Kalman Filter | 1.6172 | 1.2717 | 1.0659 |
| Sensor | 2.8765 | 1.6960 | 1.3334 | |
| CO | Kalman Filter | 0.0003 | 0.0185 | 0.0138 |
| Sensor | 0.0004 | 0.0195 | 0.0163 | |
| O3 | Kalman Filter | 41.3410 | 6.4297 | 5.7242 |
| Sensor | 69.3231 | 8.3260 | 6.8198 | |
| PM2.5 | Kalman Filter | 0.0110 | 0.1047 | 0.0805 |
| Sensor | 0.0165 | 0.1285 | 0.0991 | |
| PM10 | Kalman Filter | 0.0071 | 0.0842 | 0.0613 |
| Sensor | 0.0133 | 0.1152 | 0.1006 |
| Type | MSE_Diff(%) | RMSE_Diff(%) | MAE_Diff(%) |
|---|---|---|---|
| SO2 | 40.3723 | 22.7810 | 26.7748 |
| NO2 | 43.7776 | 25.0184 | 20.0589 |
| CO | 25.0023 | 5.0527 | 15.2650 |
| O3 | 40.3647 | 22.7761 | 16.0641 |
| PM2.5 | 33.6763 | 18.5606 | 18.7659 |
| PM10 | 46.5858 | 26.9149 | 39.0487 |
| Mean | 38.2965 | 20.1840 | 22.6634 |
| Type | Algorithm | MSE | RMSE | MAE |
|---|---|---|---|---|
| SO2 | Kalman Filter | 0.0834 | 0.2888 | 0.2292 |
| ARIMA | 0.4382 | 0.6620 | 0.4411 | |
| EWMA | 0.4202 | 0.6483 | 0.4696 | |
| SMA | 1.2255 | 1.1071 | 0.5978 | |
| NO2 | Kalman Filter | 2.0523 | 1.4326 | 1.1996 |
| ARIMA | 10.6014 | 3.2560 | 2.4728 | |
| EWMA | 12.8009 | 3.5778 | 2.9709 | |
| SMA | 19.7065 | 4.4392 | 3.5870 | |
| CO | Kalman Filter | 0.0005 | 0.0228 | 0.0186 |
| ARIMA | 0.0022 | 0.0468 | 0.0223 | |
| EWMA | 0.0019 | 0.0432 | 0.0313 | |
| SMA | 0.0042 | 0.0649 | 0.0402 | |
| O3 | Kalman Filter | 49.8062 | 7.0574 | 6.1945 |
| ARIMA | 132.2546 | 11.5002 | 8.8032 | |
| EWMA | 175.5706 | 13.2503 | 11.0526 | |
| SMA | 262.6821 | 16.2075 | 13.6848 | |
| PM2.5 | Kalman Filter | 0.0071 | 0.0844 | 0.0681 |
| ARIMA | 0.2679 | 0.5176 | 0.2840 | |
| EWMA | 24.3083 | 4.9303 | 2.0415 | |
| SMA | 73.3370 | 8.5637 | 2.5652 | |
| PM10 | Kalman Filter | 0.0076 | 0.0871 | 0.0671 |
| ARIMA | 0.2967 | 0.5447 | 0.3236 | |
| EWMA | 36.6994 | 6.0580 | 2.5465 | |
| SMA | 111.3152 | 10.5506 | 3.3696 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, X.; Yang, T.; Wang, Z.; Chen, P. IoT Implementation of Kalman Filter to Improve Accuracy of Air Quality Monitoring and Prediction. Appl. Sci. 2019, 9, 1831. https://doi.org/10.3390/app9091831
Lai X, Yang T, Wang Z, Chen P. IoT Implementation of Kalman Filter to Improve Accuracy of Air Quality Monitoring and Prediction. Applied Sciences. 2019; 9(9):1831. https://doi.org/10.3390/app9091831
Chicago/Turabian StyleLai, Xiaozheng, Ting Yang, Zetao Wang, and Peng Chen. 2019. "IoT Implementation of Kalman Filter to Improve Accuracy of Air Quality Monitoring and Prediction" Applied Sciences 9, no. 9: 1831. https://doi.org/10.3390/app9091831
APA StyleLai, X., Yang, T., Wang, Z., & Chen, P. (2019). IoT Implementation of Kalman Filter to Improve Accuracy of Air Quality Monitoring and Prediction. Applied Sciences, 9(9), 1831. https://doi.org/10.3390/app9091831