Object Detection Algorithm Based on Multiheaded Attention

Abstract
:1. Introduction
- (1)
- We propose a framework referred to as MANet that combines feature information at different scales for better performance
- (2)
- To fuse feature information at different scales, we propose a new attention mechanism referred to as the fusion attention
- (3)
- To fuse multiple scale feature information in a more efficient manner, we designed different multihead fusion modules to generate more efficient feature representations
2. Related Studies
3. Methods
3.1. Multihead Fusion Feature
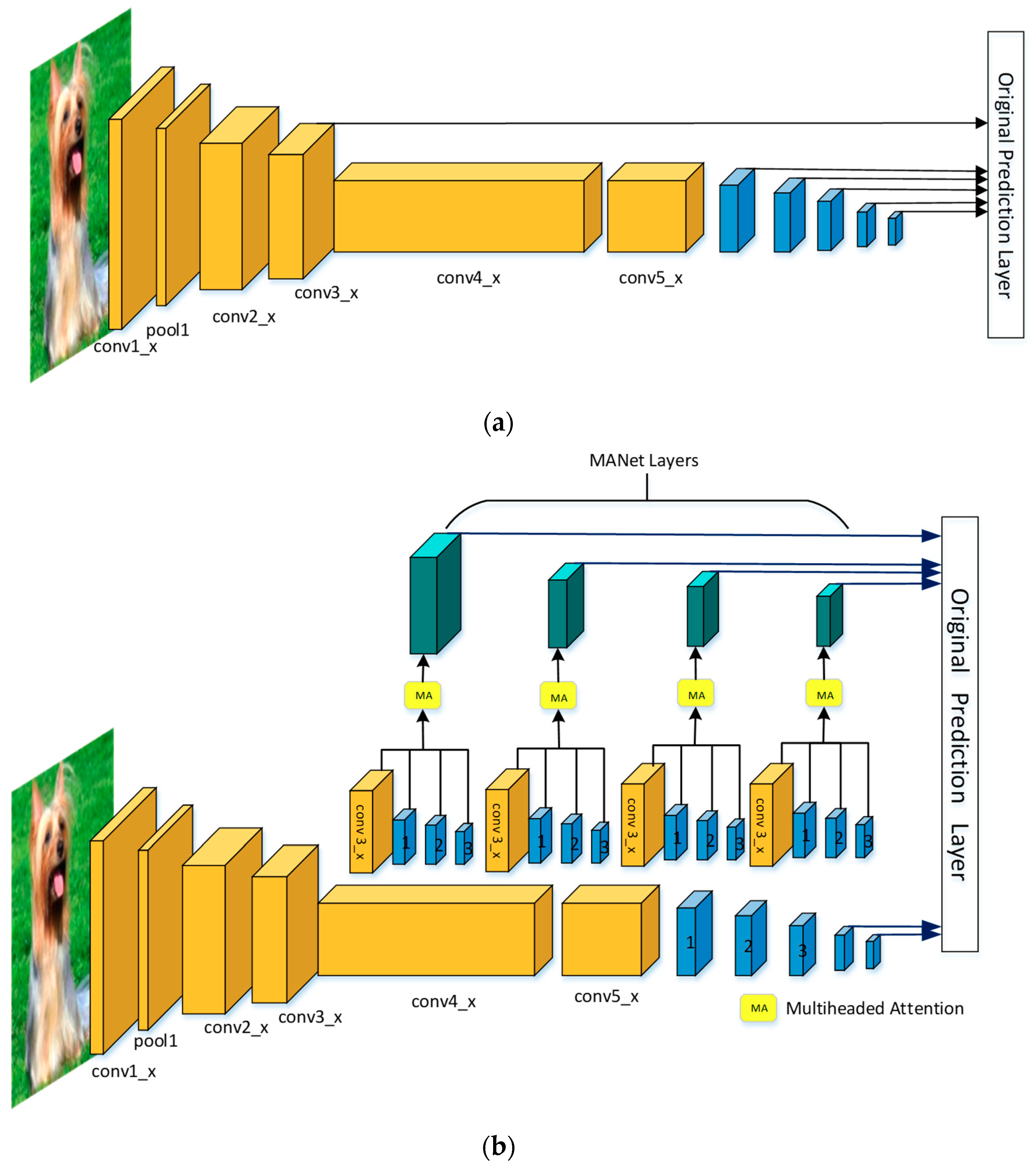
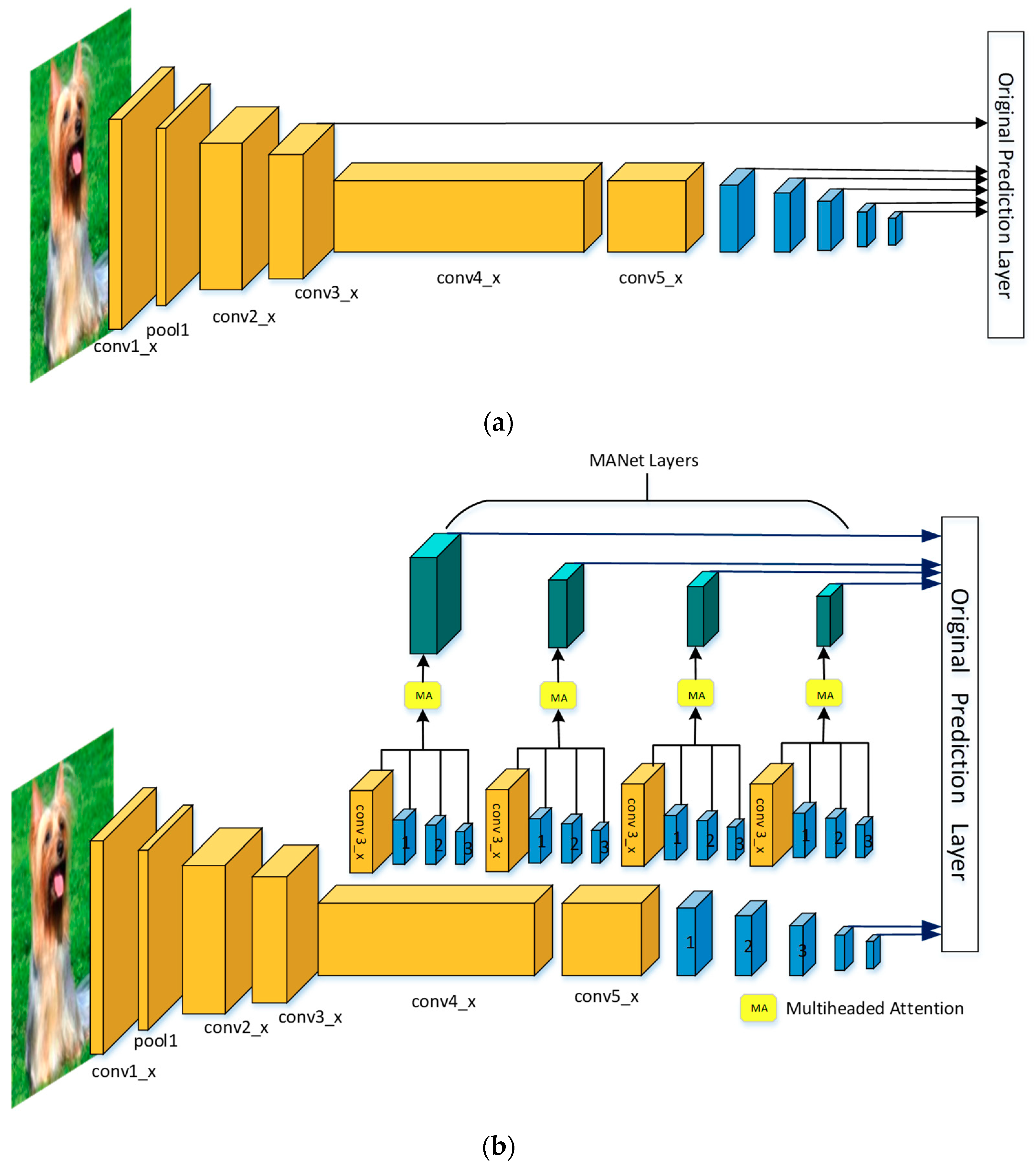
3.2. MANet Model
3.2.1. VGG
3.2.2. ResNet
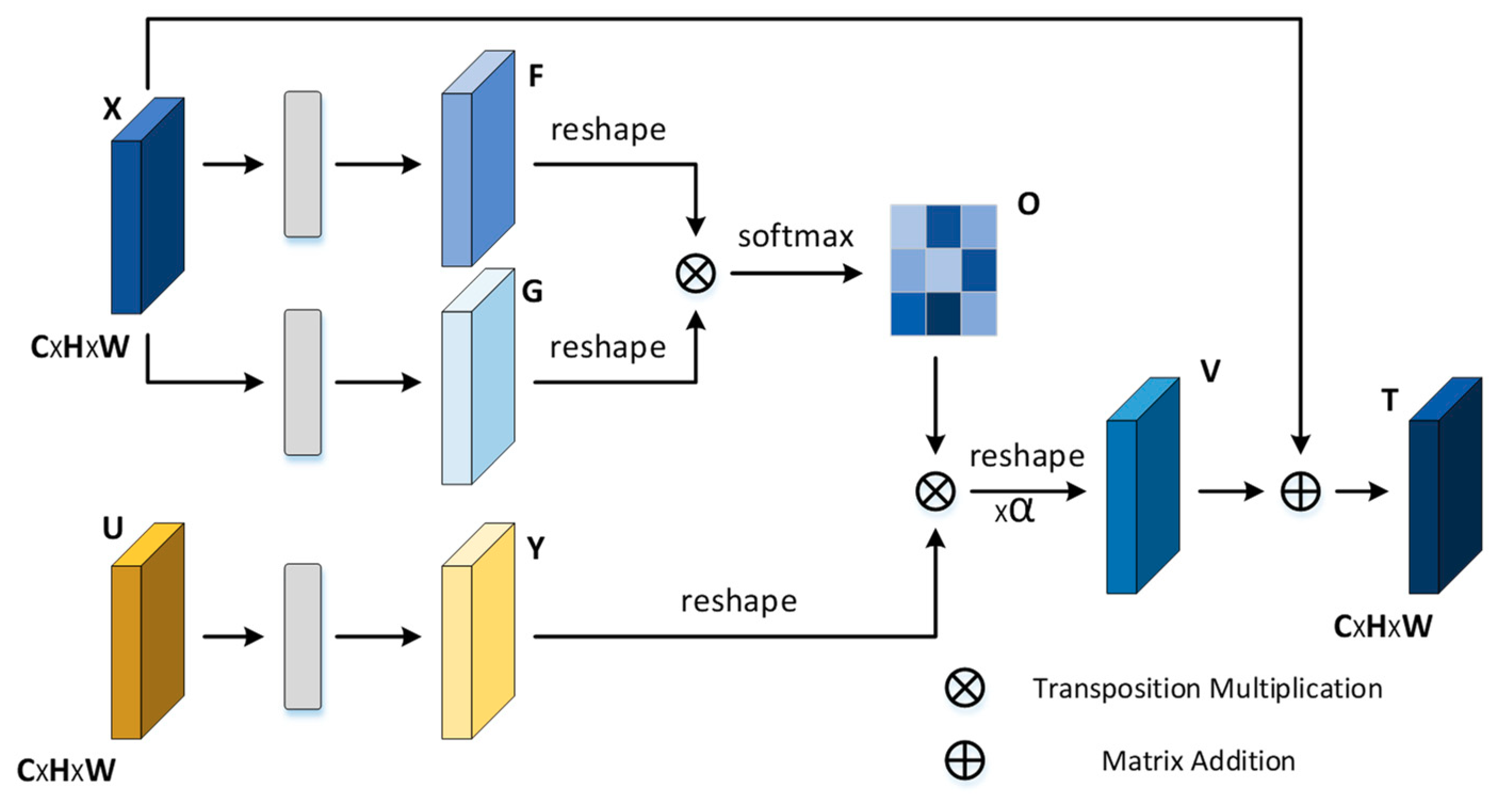
3.2.3. Fusion Attention
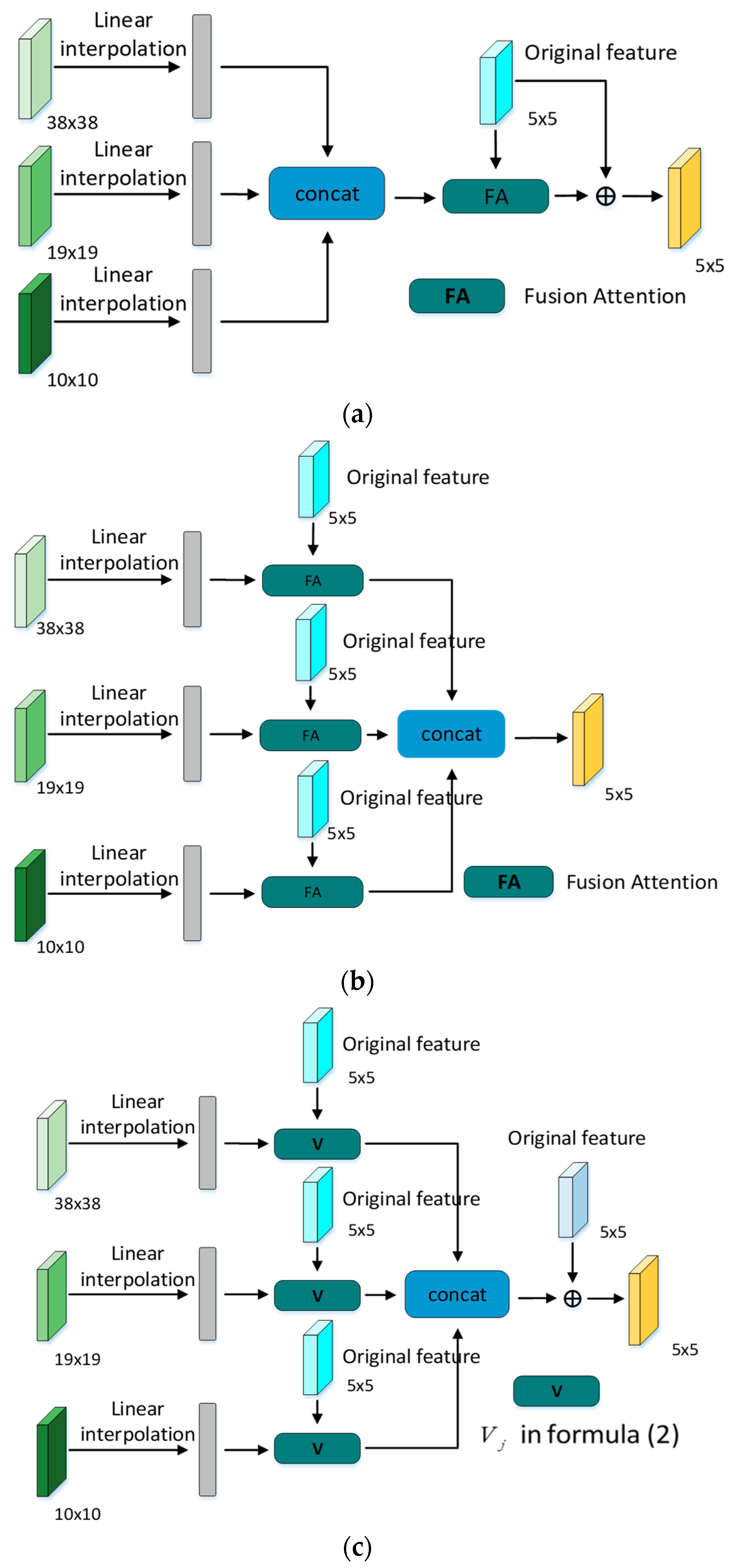
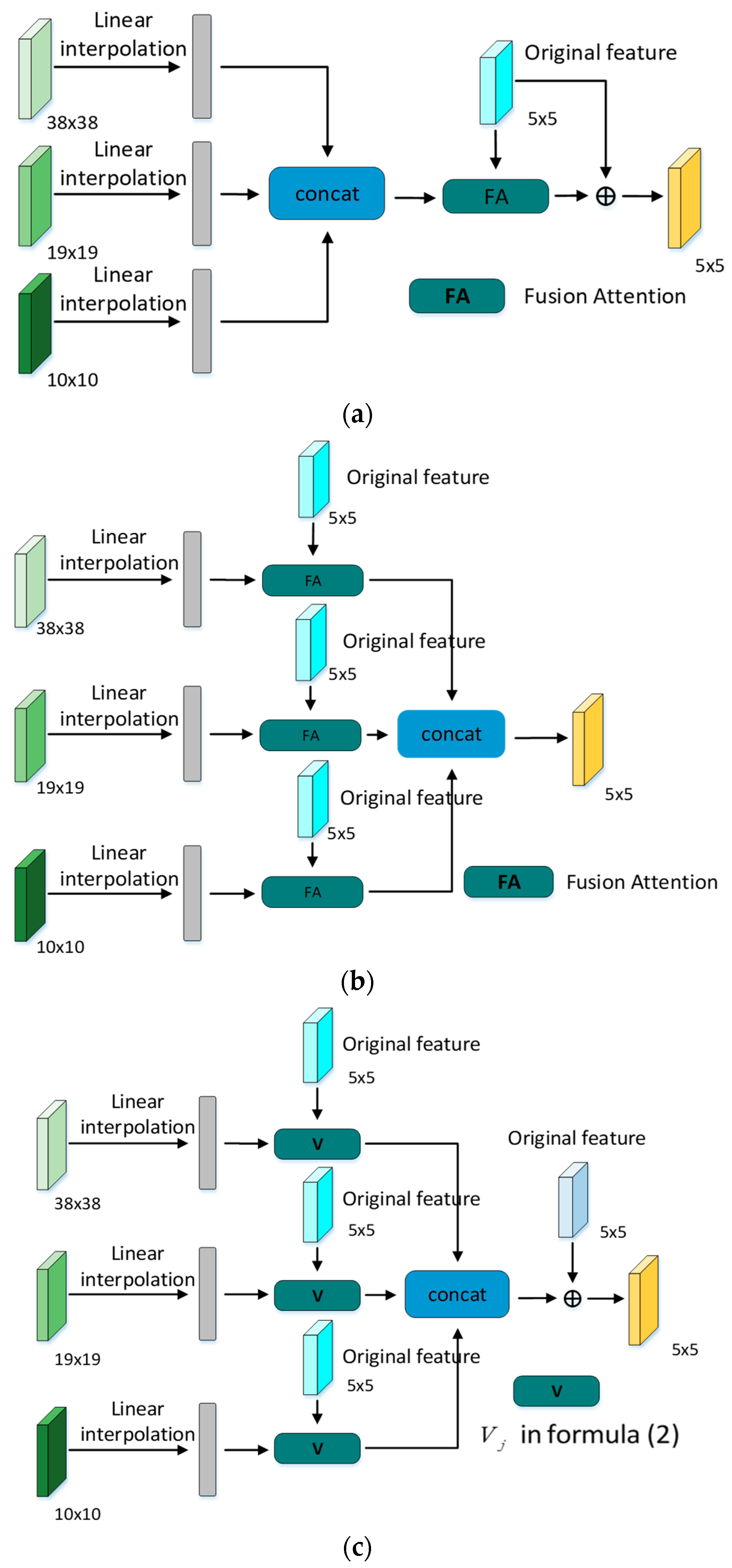
3.2.4. Multiple Modules
- (1)
- Model a performs the concatenation operation on the integrated feature tensor, and then directly inputs it into the fusion attention module to obtain the final fusion result. Equation (3) was used, where denotes the new feature outcome after the application of the concat operation on the three features, and FA is the fusion attention module.
- (2)
- Model b inputs the integrated feature tensors into the fusion attention module, and then concatenates the output results to obtain the final outcome according to Equation (4), where , indicate that the features of different scales are merged with the current feature scales by the fusion attention module to obtain new features, and , are concatenated to obtain the final result.
- (3)
- Model c is different from the previous two models. Instead of directly using the fusion attention module, V is correspondingly calculated at different scales, and the results are concatenated and then compared with the feature scale of the layer, which is added to yield the final Equation (5) is used as follows,where V is the in the fusion attention module.
4. Experiments
4.1. Base Network
4.2. Results on Pascal VOC 2007
4.2.1. Multiheaded Attention
4.2.2. Small Objects Detection
4.3. VOC 2007 Ablation Study
4.3.1. Variants of Multiple Models
4.3.2. Impacts of Different Scales
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Jian, S. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 2 July 2004; pp. 580–587. [Google Scholar]
- Dai, J.; Yi, L.; He, K.; Jian, S. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv 2016, arXiv:1605.0640. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 2999–3007. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition (CVPR’05), San Diego, CA, USA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; McAllester, D.A.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; p. 7. [Google Scholar]
- Purkait, P.; Zhao, C.; Zach, C. Spp-net: Deep absolute pose regression with synthetic views. arXiv 2017, arXiv:1712.0345. [Google Scholar]
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 391–405. [Google Scholar]
- Carreira, J.; Sminchisescu, C. CPMC: Automatic object segmentation using constrained parametric min-cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1312–1328. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 354–370. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. arXiv 2017, arXiv:1705.09587. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Leng, J.; Liu, Y. An enhanced SSD with feature fusion and visual reasoning for object detection. Neural Comput. Appl. 2018, 1–10. [Google Scholar] [CrossRef]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Woo, S.; Hwang, S.; Kweon, I.S. Stairnet: Top-down semantic aggregation for accurate one shot detection. In Proceedings of the the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1093–1102. [Google Scholar]
- Cao, G.; Xie, X.; Yang, W.; Liao, Q.; Shi, G.; Wu, J. Feature-fused SSD: Fast detection for small objects. In Proceedings of the 9th International Conference on Graphic and Image Processing (ICGIP 2017), Qingdao, China, 14–16 October 2017; p. 106151E. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4898–4906. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Cherry, J.M.; Adler, C.; Ball, C.; Chervitz, S.A.; Dwight, S.S.; Hester, E.T.; Jia, Y.; Juvik, G.; Roe, T.; Schroeder, M. SGD: Saccharomyces genome database. Nucleic Acids Res. 1998, 26, 73–79. [Google Scholar] [CrossRef] [PubMed]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 Jun–1 July 2016; pp. 761–769. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Bell, S.; Lawrence Zitnick, C.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Tay, Y.; Tuan, L.A.; Hui, S.C. CoupleNet: Paying Attention to Couples with Coupled Attention for Relationship Recommendation. In Proceedings of the 12th International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.-G.; Chen, Y.; Xue, X. Dsod: Learning deeply supervised object detectors from scratch. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 Octtober 2017; pp. 1919–1927. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VGG | Conv4_3 | Conv7 | Conv8_2 | Conv9_2 | Conv10_2 | Conv11_2 |
|---|---|---|---|---|---|---|
| Resolution Depth | 38 38 13 | 19 19 20 | 10 10 22 | 5 5 24 | 3 3 26 | 1 27 |
| ResNet–101 | Conv3_x | Conv5_x | Conv6_x | Conv7_x | Conv8_x | Conv9_x |
| Resolution Depth | 40 40 23 | 20 20 101 | 10 10 104 | 5 5 107 | 3 3 110 | 1 113 |
| Method | Backbone | Input Resolution | GPU | FPS | mAP (%) |
|---|---|---|---|---|---|
| Two-stage Fast R–CNN [12] | VGG16 | 1000 600 | Titan X | 0.5 | 70.0 |
| Faster R–CNN [3] | VGG16 | 1000 600 | Titan X | 7.0 | 73.2 |
| OHEM [28] | VGG16 | 1000 600 | Titan X | 7.0 | 74.6 |
| HyperNet [29] | VGG16 | 1000 600 | Titan X | 0.9 | 76.3 |
| ION [30] | VGG16 | 1000 600 | Titan X | 1.3 | 76.5 |
| Faster R–CNN [3] | ResNet–101 | 1000 600 | K40 | 2.4 | 76.4 |
| R–FCN [5] | ResNet–101 | 1000 600 | Titan X | 9.0 | 80.5 |
| CoupleNet [31] | ResNet–101 | 1000 600 | Titan X | 8.2 | 82.7 |
| Single-stage YOLO [1] | GoogleNet | 448 448 | Titan X | 45.0 | 63.4 |
| YOLOv2 [32] | DarkNet19 [32] | 544 544 | Titan X | 40.0 | 78.6 |
| DSOD300 [33] | DenseNet [34] | 300 300 | Titan X | 17.4 | 77.7 |
| SSD300 [2] | VGG16 | 300 300 | Titan X | 46.0 | 77.2 |
| SSD300 [2] | VGG16 | 300 300 | 1080Ti | 71.0 | 77.7 |
| SSD512 [2] | VGG16 | 512 512 | Titan X | 19.0 | 79.8 |
| SSD321 [20] | ResNet–101 | 321 321 | Titan X | 11.2 | 77.1 |
| SSD513 [20] | ResNet–101 | 513 513 | Titan X | 6.8 | 80.6 |
| DSSD321 [20] | ResNet–101 | 321 321 | Titan X | 9.5 | 78.6 |
| DSSD513 [20] | ResNet–101 | 513 513 | Titan X | 5.5 | 81.5 |
| Feature-fused SSD [22] | VGG16 | 300 300 | Titan X | 43.0 | 78.9 |
| R–SSD300 [17] | VGG16 | 300 300 | Titan X | 35.0 | 78.5 |
| R–SSD512 [17] | VGG16 | 512 512 | Titan X | 16.6 | 80.8 |
| FSSD300 [18] | VGG16 | 300 300 | 1080Ti | 65.8 | 78.8 |
| FSSD512 [18] | VGG16 | 512 512 | 1080Ti | 35.7 | 80.9 |
| ESSD300 [19] | VGG16 | 300 300 | - | 52.0 | 79.2 |
| ESSD512 [19] | VGG16 | 512 512 | - | 18.6 | 82.4 |
| MANet300 MANet300 | VGG16 ResNet-101 | 300 300 300 300 | 1080Ti 1080Ti | 50.0 37.0 | 79.1 79.4 |
| MANet320 | ResNet–101 | 320 320 | 1080Ti | 34.0 | 80.2 |
| MANet512 | ResNet–101 | 512 512 | 1080Ti | 25.0 | 82.7 |
| Method | Network | Map |
|---|---|---|
| MANet (a) | ResNet–50 | 78.97 |
| MANet (b) | ResNet–50 | 79.21 |
| MANet (c) | ResNet–50 | 79.32 |
| Convolution | Map (%) |
|---|---|
| — | 76.67 |
| 38 × 38 | 77.00 |
| 38 × 38 + 19 × 19 | 78.61 |
| 38 × 38 + 19 × 19 + 10 × 10 | 78.71 |
| 38 × 38 + 19 × 19 + 10 × 10 + 5 × 5 | 79.32 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, J.; Xu, H.; Zhang, S.; Fang, Y. Object Detection Algorithm Based on Multiheaded Attention. Appl. Sci. 2019, 9, 1829. https://doi.org/10.3390/app9091829
Jiang J, Xu H, Zhang S, Fang Y. Object Detection Algorithm Based on Multiheaded Attention. Applied Sciences. 2019; 9(9):1829. https://doi.org/10.3390/app9091829
Chicago/Turabian StyleJiang, Jie, Hui Xu, Shichang Zhang, and Yujie Fang. 2019. "Object Detection Algorithm Based on Multiheaded Attention" Applied Sciences 9, no. 9: 1829. https://doi.org/10.3390/app9091829
APA StyleJiang, J., Xu, H., Zhang, S., & Fang, Y. (2019). Object Detection Algorithm Based on Multiheaded Attention. Applied Sciences, 9(9), 1829. https://doi.org/10.3390/app9091829