Fully Convolutional Neural Network with Augmented Atrous Spatial Pyramid Pool and Fully Connected Fusion Path for High Resolution Remote Sensing Image Segmentation

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Dilated Convolution
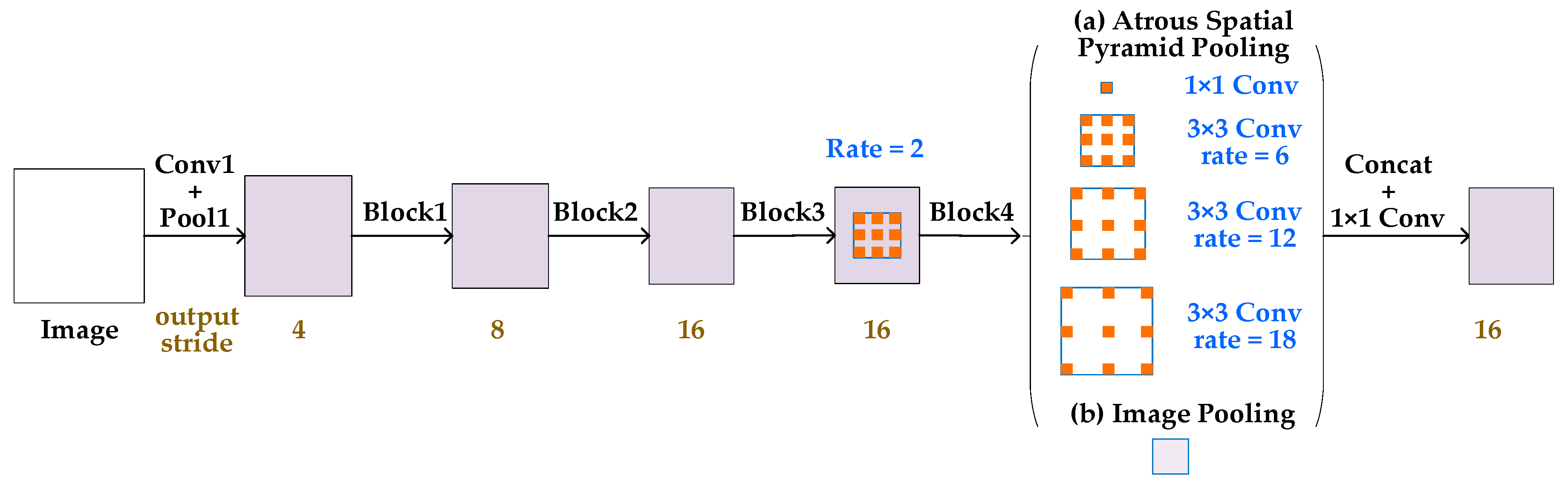
2.2. Architecture of DeeplLab v3
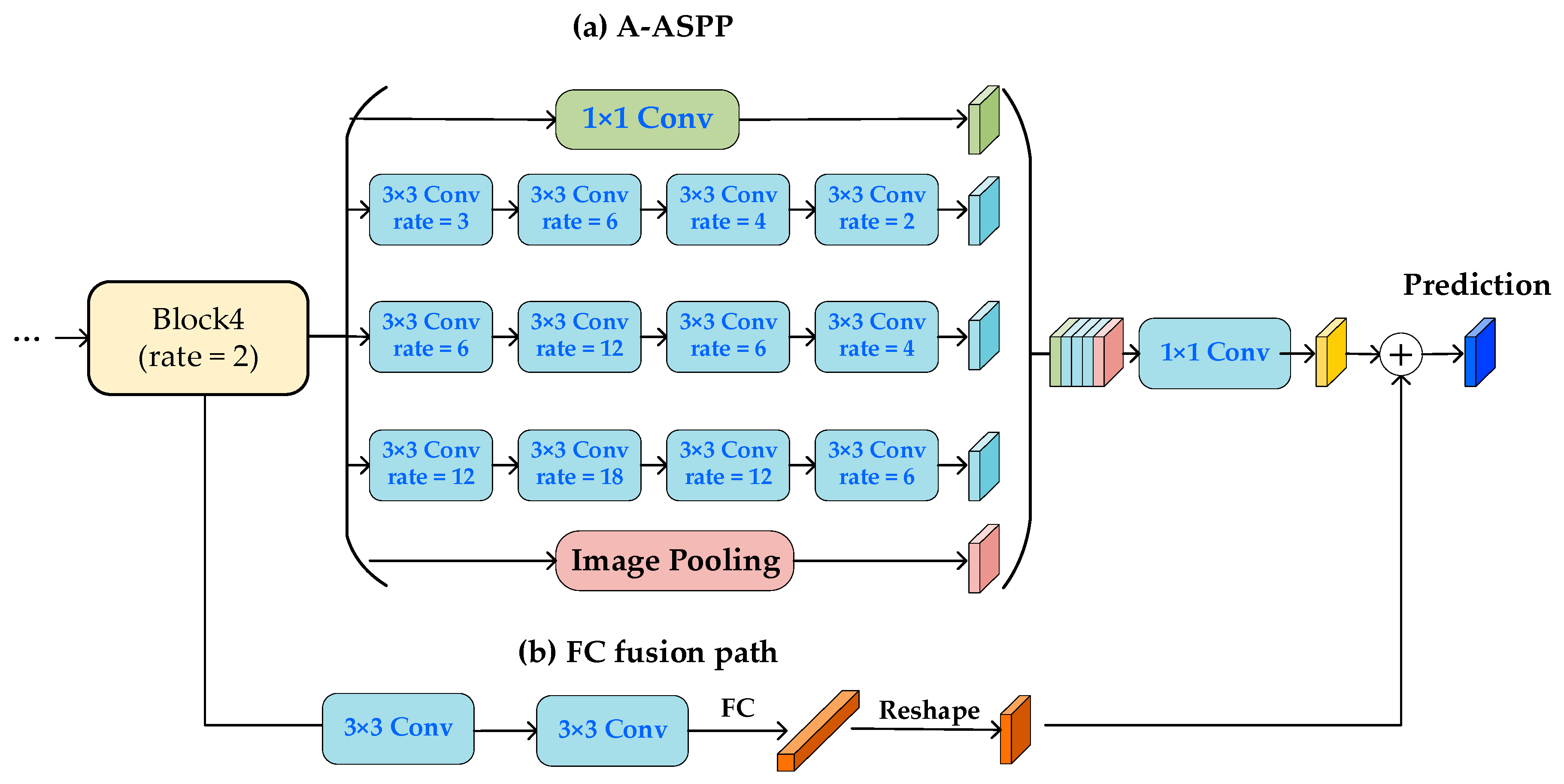
2.3. Proposed Model
2.4. A-ASPP Module
2.5. FC Fusion Path
3. Experimental Results, Analysis and Discussion
3.1. Hardware and Software
3.2. Experiment Dataset
3.3. Evaluation Index
3.4. Experiment and Analysis
3.4.1. Ablation Studies on A-ASPP
3.4.2. Ablation Studies on FC Fusion Path
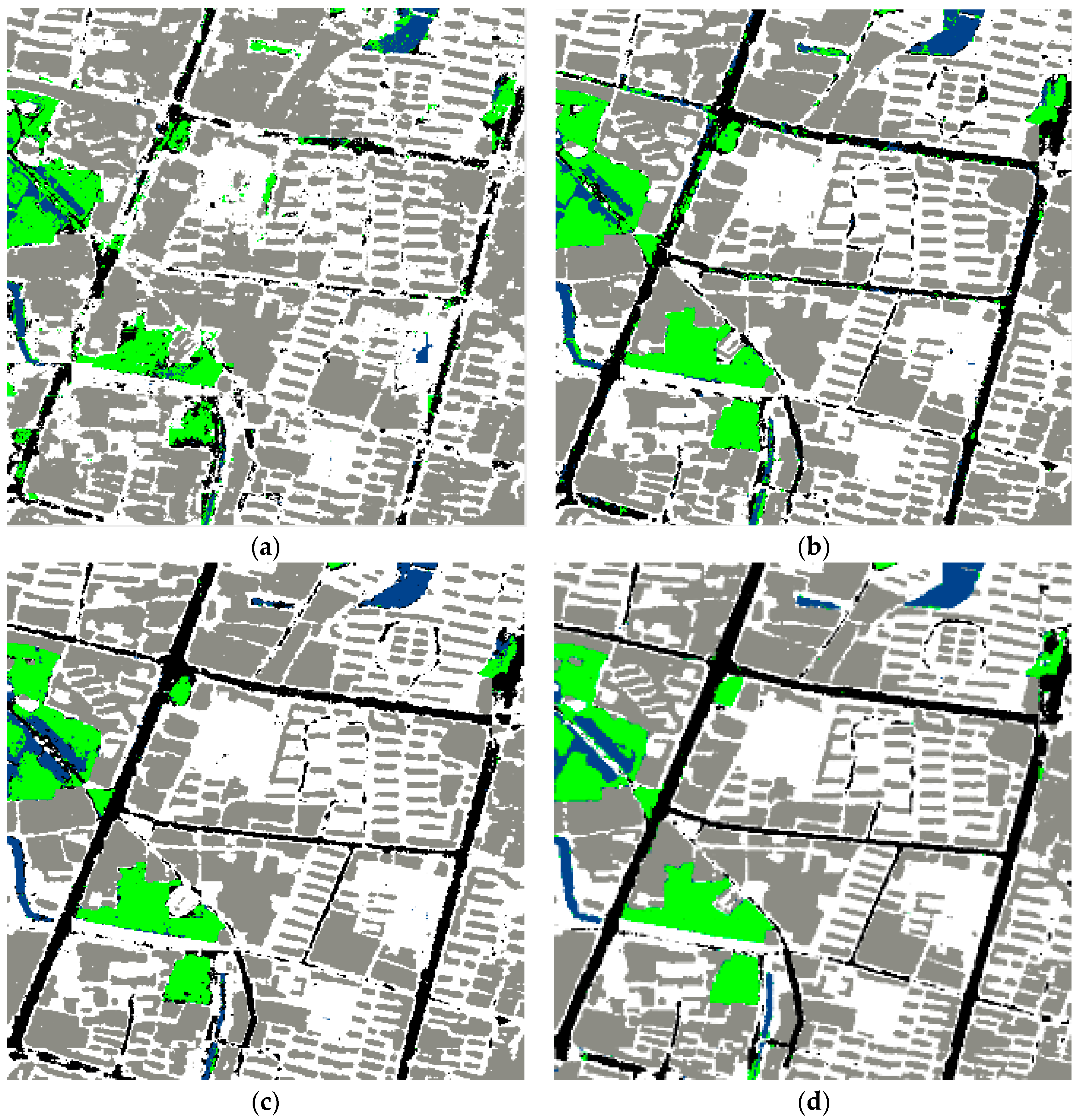
3.4.3. Experiments on HRRS Dataset
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wurm, M.; Stark, T.; Zhu, X.X.; Weigand, M.; Taubenböck, H. Semantic segmentation of slums in satellite images using transfer learning on fully convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2019, 150, 59–69. [Google Scholar] [CrossRef]
- Henry, C.; Azimi, S.M.; Merkle, N. Road segmentation in SAR satellite images with deep fully convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef]
- Li, Y.; Guo, L.; Rao, J.; Xu, L.; Jin, S. Road segmentation based on hybrid convolutional network for high-resolution visible remote sensing image. IEEE Geosci. Remote Sens. Lett. 2019, 16, 613–617. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Zhang, C.; Gao, S.; Yang, X.; Li, F.; Yue, M.; Han, Y.; Fan, K. Convolutional neural network-based remote sensing images segmentation method for extracting winter wheat spatial distribution. Appl. Sci. 2018, 8, 1981. [Google Scholar] [CrossRef]
- Buscombe, D.; Ritchie, A.C. Landscape classification with deep neural networks. Geosciences 2018, 8, 244. [Google Scholar] [CrossRef]
- Cheng, D.; Meng, G.; Cheng, G.; Pan, C. SeNet: Structured edge network for sea-land segmentation. IEEE Geosci. Remote Sens. Lett. 2017, 14, 247–251. [Google Scholar] [CrossRef]
- Azimi, S.M.; Fischer, P.; Korner, M.; Reinartz, P. Aerial LaneNet: Lane-marking semantic segmentation in aerial imagery using wavelet-enhanced cost-sensitive symmetric fully convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2018, 1–19. [Google Scholar] [CrossRef]
- Song, N.; Wang, N.; Lin, W.; Wu, N. Using satellite remote sensing and numerical modelling for the monitoring of suspended particulate matter concentration during reclamation construction at Dalian offshore airport in China. Eur. J. Remote Sens. 2018, 51, 878–888. [Google Scholar] [CrossRef]
- Salzano, R.; Salvatori, R.; Valt, M.; Giuliani, G.; Chatenoux, B.; Ioppi, L. Automated Classification of Terrestrial Images: The Contribution to the Remote Sensing of Snow Cover. Geosciences 2019, 9, 97. [Google Scholar] [CrossRef]
- Wei, W.; Polap, D.; Li, X.; Woźniak, M.; Liu, J. Study on remote sensing image vegetation classification method based on decision tree classifier. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 2292–2297. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Luo, B.; Zhang, L. Robust Autodual Morphological Profiles for the Classification of High-Resolution Satellite Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1451–1462. [Google Scholar] [CrossRef]
- Zheng, P.; Qi, Y.; Zhou, Y.; Chen, P.; Zhan, J.; Lyu, M.R.-T. An Automatic Framework for Detecting and Characterizing the Performance Degradation of Software Systems. IEEE Trans. Reliab. 2014, 63, 927–943. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Guo, Z.; Shao, X.; Xu, Y.; Miyazaki, H.; Ohira, W.; Shibasaki, R. Identification of Village Building via Google Earth Images and Supervised Machine Learning Methods. Remote Sens. 2016, 8, 271. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Audebert, N.; Saux, B.L.; Lefèvre, S. Semantic Segmentation of Earth Observation Data Using Multimodal and Multi-scale Deep Networks. In Computer Vision—ACCV 2016; Lai, S.H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer: Cham, Switzerland, 2016; Volume 10111, pp. 180–196. [Google Scholar]
- Yuan, J. Automatic Building Extraction in Aerial Scenes Using Convolutional Networks. arXiv 2016, arXiv:1602.06564. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef]
- Mboga, N.; Georganos, S.; Grippa, T.; Lennert, M.; Vanhuysse, S.; Wolff, E. Fully Convolutional Networks and Geographic Object-Based Image Analysis for the Classification of VHR Imagery. Remote Sens. 2019, 11, 597. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for High Resolution Remote Sensing Imagery Using a Fully Convolutional Network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Kulikajevas, A.; Maskeliūnas, R.; Damaševičius, R.; Misra, S. Reconstruction of 3D Object Shape Using Hybrid Modular Neural Network Architecture Trained on 3D Models from ShapeNetCore Dataset. Sensors 2019, 19, 1553. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Scene Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A deep fully convolutional network for pixel-level sea-land segmentation. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef]
- Li, Y.; Xu, L.; Rao, J.; Guo, L.; Yan, Z.; Jin, S. A Y-net deep learning method for road segmentation using high-resolution visible remote sensing images. Remote Sens. Lett. 2019, 10, 381–390. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Hartwig, A. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Hu, P.; Ramanan, D. Finding Tiny Faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Wei, W.; Yang, X.L.; Zhou, B.; Feng, J.; Shen, P.Y. Combined energy minimization for image reconstruction from few views. Math. Probl. Eng. 2012, 2012, 154630. [Google Scholar] [CrossRef]
- Ke, Q.; Zhang, J.; Song, H.; Wan, Y. Big Data Analytics Enabled by Feature Extraction Based on Partial Independence. Neurocomputing 2018, 288, 3–10. [Google Scholar] [CrossRef]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a Discriminative Feature Network for Semantic Segmentation. arXiv 2018, arXiv:1804.09337. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters—Improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1743–1751. [Google Scholar]
- Sun, W.; Wang, R. Fully Convolutional Networks for Semantic Segmentation of Very High Resolution Remotely Sensed Images Combined With DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Połap, D.; Woźniak, M.; Wei, W.; Damaševičius, R. Multi-threaded learning control mechanism for neural networks. Future Gener. Comput. Syst. 2018, 87, 16–34. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Y.; Zhang, Q.; Xiang, S.; Pan, C. Gated Convolutional Neural Network for Semantic Segmentation in High-Resolution Images. Remote Sens. 2017, 9, 446. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Xu, X.; Shi, T.; Zhang, N.; Zhu, X. CoinNet: Copy initialization network for multispectral imagery semantic segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 816–820. [Google Scholar] [CrossRef]
- Yan, J.; Wang, H.; Yan, M.; Diao, W.; Sun, X.; Li, H. IoU-adaptive deformable R-CNN: Make full use of IoU for multi-class object detection in remote sensing imagery. Remote Sens. 2019, 11, 286. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Deformable Faster R-CNN with Aggregating Multi-Layer Features for Partially Occluded Object Detection in Optical Remote Sensing Images. Remote Sens. 2018, 10, 1470. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Chen, Y.; Wang, M. Very high resolution remote sensing image classification with SEEDS-CNN and scale effect analysis for superpixel CNN classification. Int. J. Remote Sens. 2019, 40, 506–531. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery. Int. J. Remote Sens. 2018, 3308–3322. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Semantic Segmentation on Remotely Sensed Images Using an Enhanced Global Convolutional Network with Channel Attention and Domain Specific Transfer Learning. Remote Sens. 2019, 11, 83. [Google Scholar] [CrossRef]
- Shrestha, S.; Vanneschi, L. Improved Fully Convolutional Network with Conditional Random Fields for Building Extraction. Remote Sens. 2018, 10, 1135. [Google Scholar] [CrossRef]
- Xu, Z.; Xu, X.; Wang, L.; Yang, R.; Pu, F. Deformable ConvNet with Aspect Ratio Constrained NMS for Object Detection in Remote Sensing Imagery. Remote Sens. 2017, 9, 1312. [Google Scholar] [CrossRef]
- Zhao, W.; Zhang, H.; Yan, Y.; Fu, Y.; Wang, H. A Semantic Segmentation Algorithm Using FCN with Combination of BSLIC. Appl. Sci. 2018, 8, 500. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structure | Parallel Conv1 | Parallel Conv2 | Parallel Conv3 | Road | Water | Arch | Plant | Back | mIoU | Acc |
|---|---|---|---|---|---|---|---|---|---|---|
| ASPP | (6) | (12) | (18) | 40.4 | 47.5 | 83.6 | 74.2 | 75.4 | 64.2 | 77.2 |
| Two layers | (3,6) | (6,12) | (12,18) | 42.1 | 48.2 | 84.7 | 73.7 | 73.9 | 64.5 | 79.9 |
| Three layers | (2,3,6) | (4,6,12) | (6,12,18) | 44.5 | 50.9 | 83.9 | 74.3 | 75.1 | 65.7 | 83.2 |
| Four layers | (2,3,4,6) | (4,6,6,12) | (6,12,12,18) | 49.2 | 53.3 | 83.6 | 74.2 | 76.4 | 67.3 | 85.7 |
| Five layers | (2,3,4,5,6) | (4,6,6,6,12) | (6,12,12,12,18) | 48.7 | 51.9 | 81.5 | 73.8 | 76.3 | 66.4 | 83.4 |
| Increase | (2,3,4,6) | (4,6,6,12) | (6,12,12,18) | 49.2 | 53.3 | 83.6 | 74.2 | 76.4 | 67.3 | 85.7 |
| Decrease | (6,4,3,2) | (12,6,6,4) | (18,12,12,6) | 49.1 | 51.9 | 84.9 | 74.1 | 77.3 | 67.5 | 86.2 |
| Increase-Decrease | (3,6,4,2) | (6,12,6,4) | (12,18,12,6) | 50.7 | 53.7 | 84.4 | 75.3 | 76.1 | 68.0 | 88.9 |
| FC-Block | Road | Water | Architecture | Plant | Background | mIoU | Acc |
|---|---|---|---|---|---|---|---|
| baseline | 40.4 | 47.5 | 83.6 | 74.2 | 75.4 | 64.2 | 77.2 |
| block1 | 41.1 | 46.9 | 83.0 | 74.4 | 76.9 | 64.5 | 79.0 |
| block2 | 43.2 | 48.4 | 84.3 | 74.2 | 75.4 | 65.1 | 83.2 |
| block3 | 43.7 | 49.5 | 83.1 | 75.3 | 76.8 | 65.7 | 85.6 |
| block4 | 44.2 | 49.9 | 83.9 | 75.1 | 77.2 | 66.1 | 87.1 |
| PROD | 43.4 | 49.1 | 83.6 | 74.9 | 75.8 | 65.4 | 85.7 |
| SUM | 44.2 | 49.9 | 83.9 | 75.1 | 77.2 | 66.1 | 87.1 |
| MAX | 42.9 | 48.8 | 83.4 | 74.8 | 76.9 | 65.4 | 84.8 |
| Method | Road | Water | Architecture | Plant | Background | mIoU | Acc |
|---|---|---|---|---|---|---|---|
| FCN-8s | 23.4 | 37.5 | 53.2 | 52.2 | 55.1 | 44.3 | 61.4 |
| Unet | 36.1 | 41.9 | 66.1 | 62.1 | 57.2 | 52.7 | 67.5 |
| SegNet | 39.2 | 47.8 | 70.1 | 64.4 | 65.3 | 57.4 | 71.7 |
| PSPNet | 42.4 | 50.1 | 72.6 | 73.2 | 72.8 | 62.2 | 74.5 |
| RefineNet | 41.3 | 49.7 | 76.7 | 72.4 | 73.5 | 62.7 | 76.2 |
| DeepLabv3 | 40.4 | 47.5 | 83.6 | 74.2 | 75.4 | 64.2 | 77.2 |
| A-ASPP | 50.7 | 53.7 | 84.4 | 75.3 | 76.1 | 68.0 | 88.9 |
| ASPP + FC | 44.2 | 49.9 | 83.9 | 75.1 | 77.2 | 66.1 | 87.1 |
| A-ASPP + FC | 52.5 | 54.2 | 84.9 | 76.1 | 77.8 | 69.1 | 91.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, G.; Li, C.; Wei, W.; Jing, W.; Woźniak, M.; Blažauskas, T.; Damaševičius, R. Fully Convolutional Neural Network with Augmented Atrous Spatial Pyramid Pool and Fully Connected Fusion Path for High Resolution Remote Sensing Image Segmentation. Appl. Sci. 2019, 9, 1816. https://doi.org/10.3390/app9091816
Chen G, Li C, Wei W, Jing W, Woźniak M, Blažauskas T, Damaševičius R. Fully Convolutional Neural Network with Augmented Atrous Spatial Pyramid Pool and Fully Connected Fusion Path for High Resolution Remote Sensing Image Segmentation. Applied Sciences. 2019; 9(9):1816. https://doi.org/10.3390/app9091816
Chicago/Turabian StyleChen, Guangsheng, Chao Li, Wei Wei, Weipeng Jing, Marcin Woźniak, Tomas Blažauskas, and Robertas Damaševičius. 2019. "Fully Convolutional Neural Network with Augmented Atrous Spatial Pyramid Pool and Fully Connected Fusion Path for High Resolution Remote Sensing Image Segmentation" Applied Sciences 9, no. 9: 1816. https://doi.org/10.3390/app9091816
APA StyleChen, G., Li, C., Wei, W., Jing, W., Woźniak, M., Blažauskas, T., & Damaševičius, R. (2019). Fully Convolutional Neural Network with Augmented Atrous Spatial Pyramid Pool and Fully Connected Fusion Path for High Resolution Remote Sensing Image Segmentation. Applied Sciences, 9(9), 1816. https://doi.org/10.3390/app9091816