On the Performance of Deep Reinforcement Learning-Based Anti-Jamming Method Confronting Intelligent Jammer

 , ,
, ,
Abstract
1. Introduction
- We investigate the performance of DRL-based anti-jamming method in face of different jamming modes. Without the prior information of users, we designed an RL-based jamming algorithm to against the DRL algorithm, and the simulation results verify the effectiveness of the jamming method.
- We theoretically analyze the condition when the DRL-based algorithm cannot converge, and verified it by simulation.
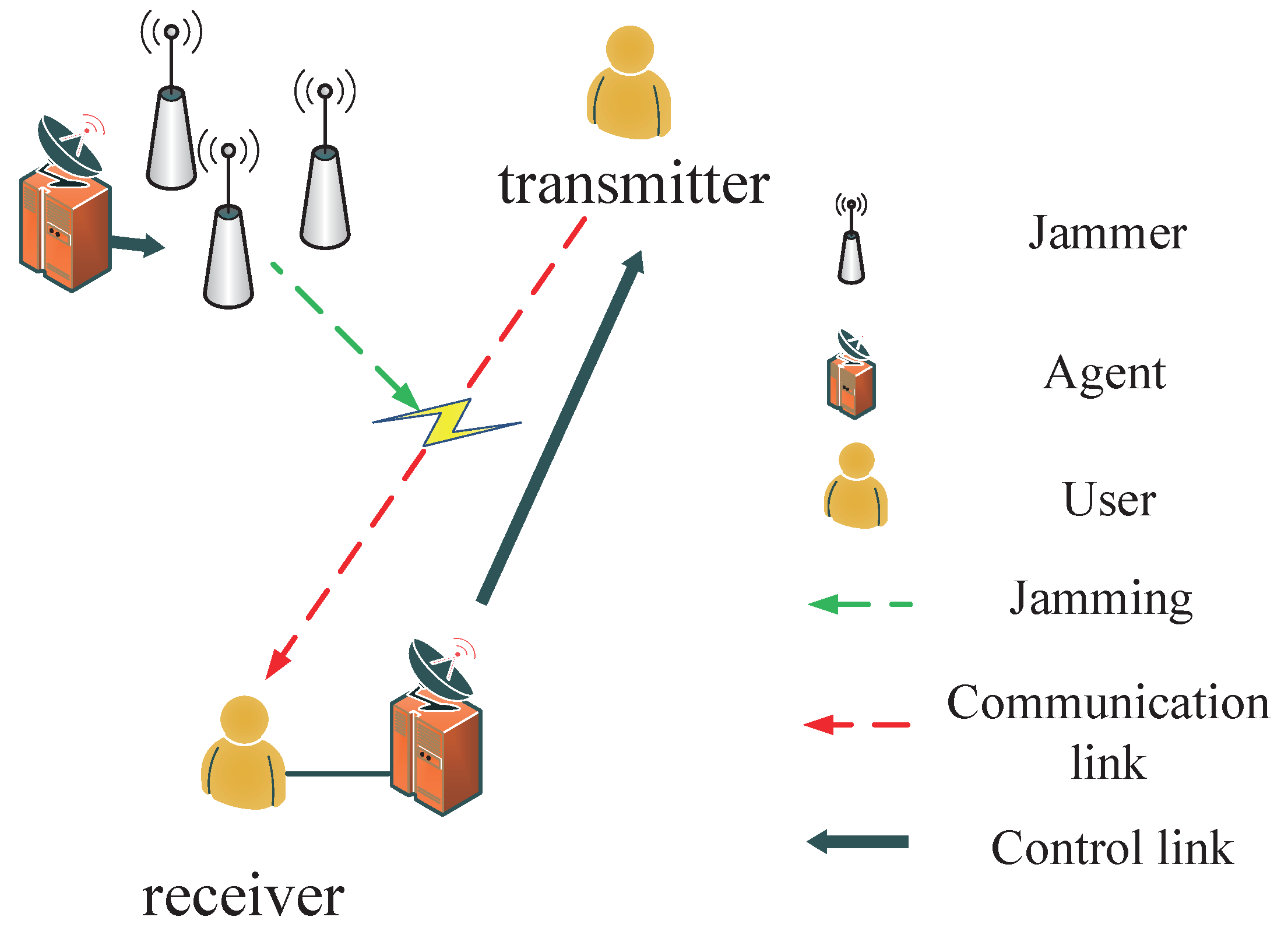
2. System Model and Problem Formulation
Agent and Optimized Objective of Jammers
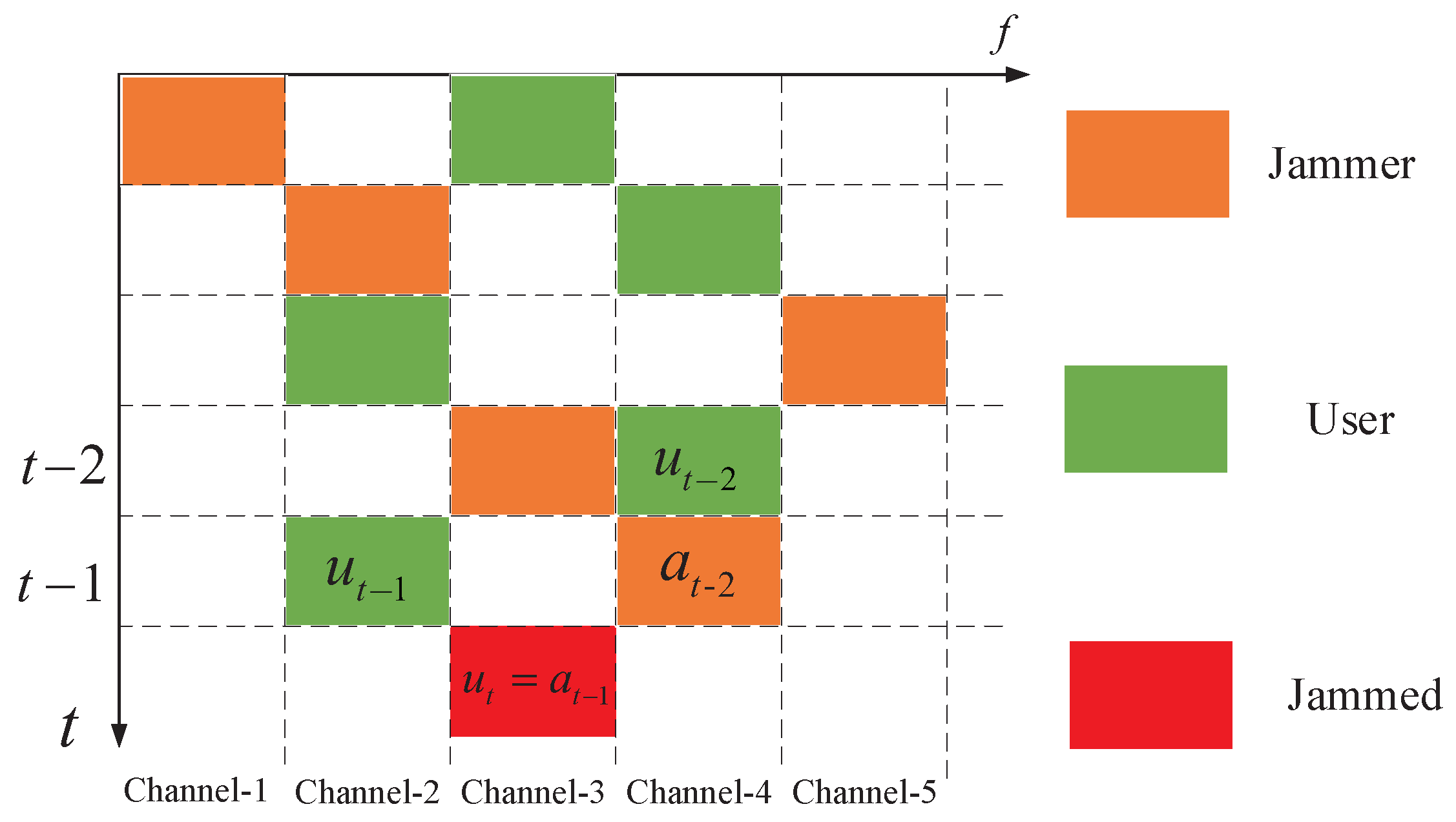
3. RL-Based Jamming Algorithm
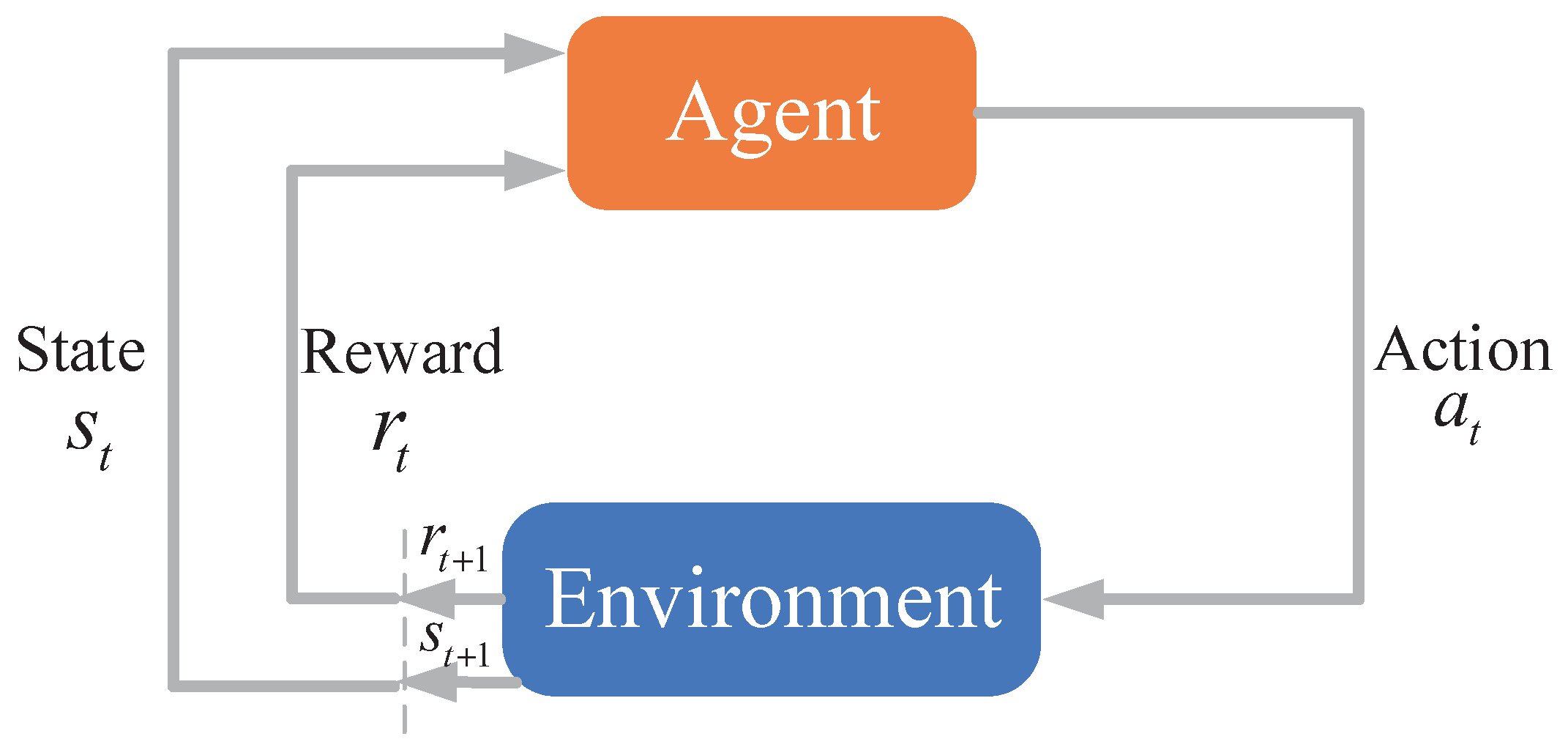
- Agent: The agent is responsible for making decisions. It usually has the capability of sensing the environment and taking actions. In our case, the agent could sense the frequency spectrum and guides jammer to choose jamming band.
- State: Environment state for the corresponding action. In our case, the state is the frequency spectrum that agent senses.
- Action: All actions can be taken by the agent, or under the guidance of agent. In our case, action is to jam which frequency band.
- Reward: Feedback of the corresponding action in the environment. In our case, reward is the jamming effect.
3.1. Reward
- Detect negative acknowledgement (NACK). In ref. [33], NACK is used as reward standard. If NACK is detected, we affirm , . Since the communication protocol of civil communication system is public, jammers can easily recognize NACK. However, in the actual situation, the users’ communication protocol is unknown. Auxiliary methods are needed for the jammers.
- Detect change of communication power. In ref. [34], the detection of increasing power is the sign of successful jamming. Many wireless communication devices are designed to increase power when it gets the interference or noise in the environment. Take a cell phone for example, when it can not communicate well to base station, a cell phone increases the communication power. By sensing the changing transmit power of users, we could affirm , .
- Detect users switching channels. In actual communication, switching channels usually requires negotiation between the transmitter and receiver and often consumes more energy. Due to the limited energy, users are more inclined to stay on the current channel to communication. Therefore, detecting the channel switching can also evaluate jammer effect.
3.2. Q-Learning
| Algorithm 1 Reinforcement learning jamming algorithm (RLJA). |
| Initialize: Set learning rate , discount rate , , training time T, and probability of random action . The number of jamming frequency bands is n. for do Generate random value if then Agent chooses n action from randomly (, ) gets reward, update Q matrix: if then Agent choose action top n action, , , gets reward, updates Q matrix: else Agent chooses n action from randomly, gets reward, updates Q matrix: end if else Finish training end if Agent guides actions based on Q matrix end for |
4. Theoretical Analysis of the Condition When DRL-Based Algorithm Does Not Converge
5. Numerical Results and Discussion
5.1. Simulation Parameters
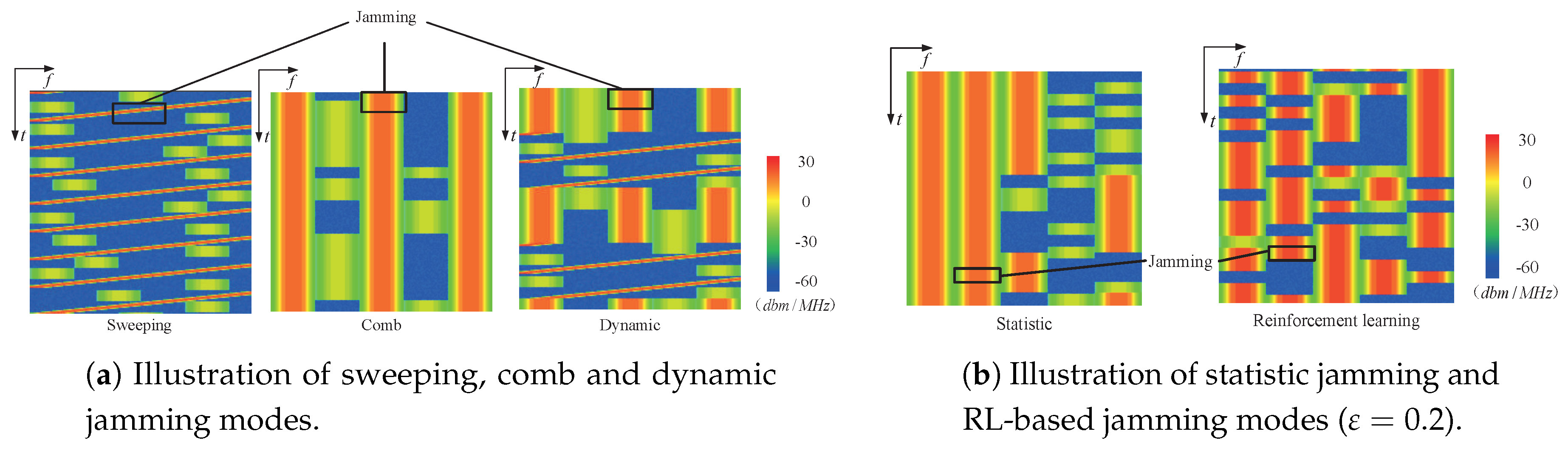
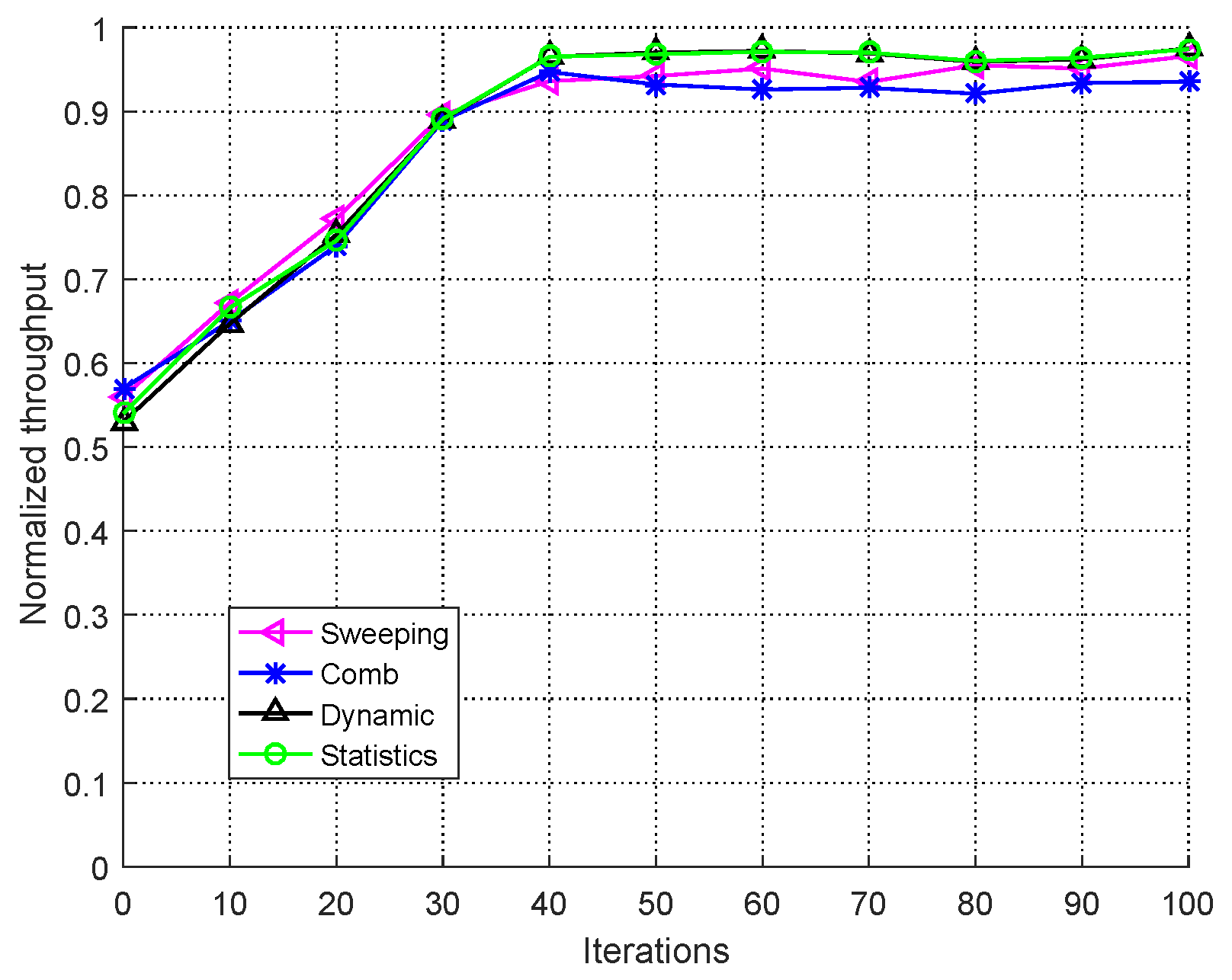
- Sweeping jamming (sweeping speed is 0.8 GHz/s);
- Comb jamming (jamming at 2 MHz, 10 MHz, and 18 MHz simultaneously);
- Dynamic jamming (change the sweeping and comb jamming patterns periodically for every 100 ms);
- Jamming based on statistics (select top three the most frequently used channels by users in 100 ms);
- RL-based jamming method (jamming three bands).
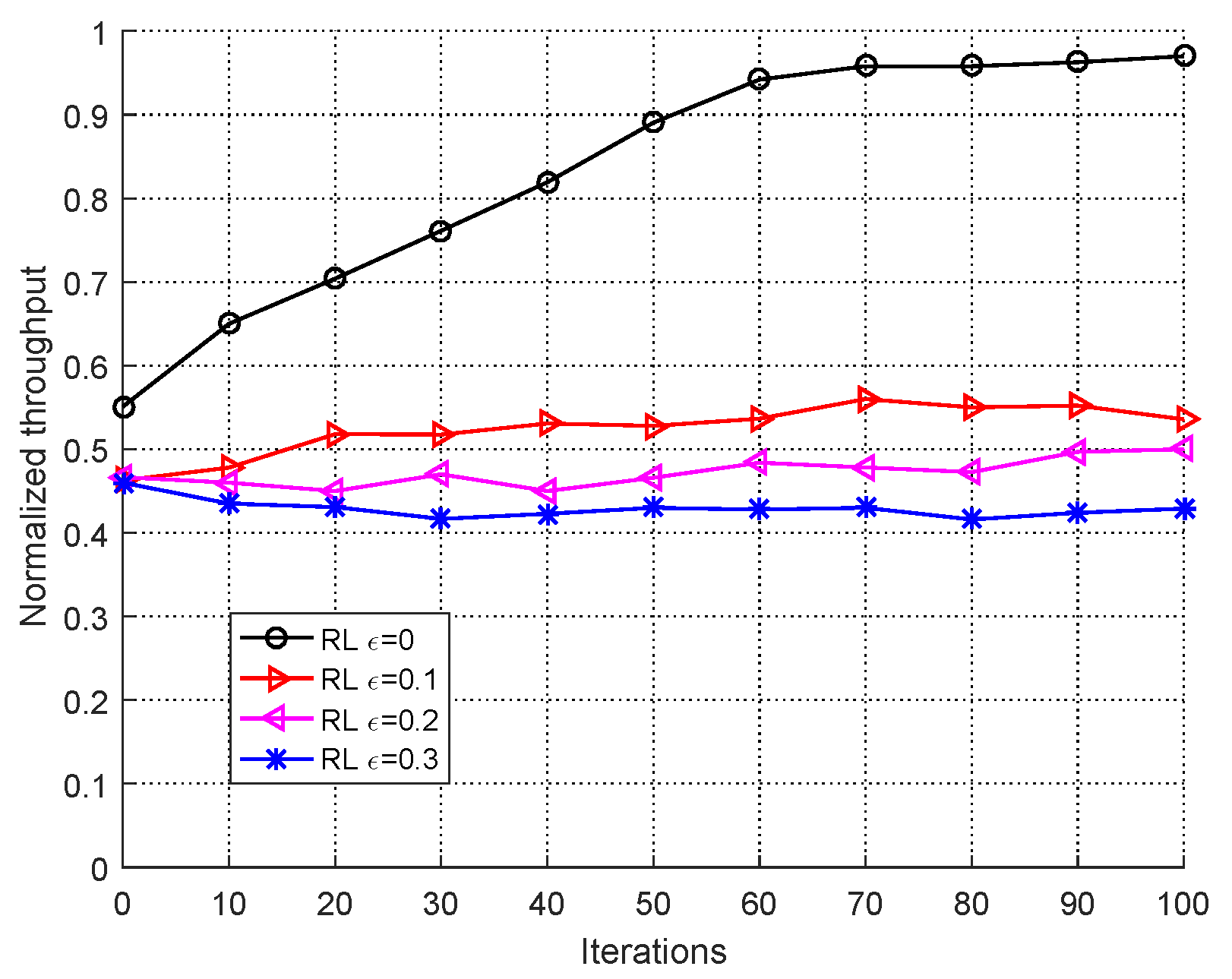
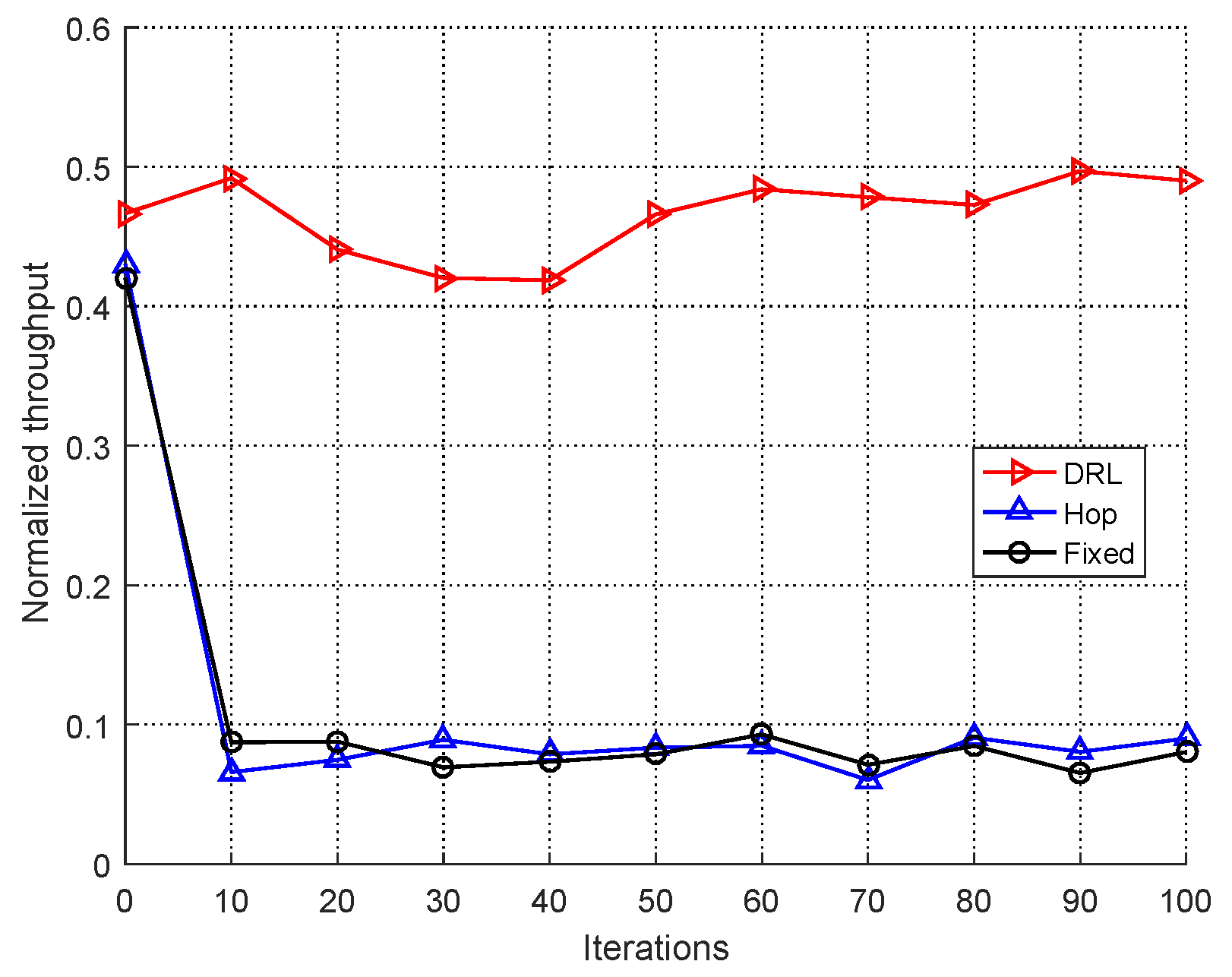
5.2. Performance Analysis of User versus Jammers
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pärlin, K.; Alam, M.M.; Le Moullec, Y. Jamming of UAV remote control systems using software defined radio. In Proceedings of the 2018 International Conference on Military Communications and Information Systems (ICMCIS), Warsaw, Poland, 22–23 May 2018; Volume 1, pp. 1–6. [Google Scholar] [CrossRef]
- Vardhan, S.; Garg, A. Information jamming in Electronic warfare: Operational requirements and techniques. In Proceedings of the 2014 International Conference on Electronics, Communication and Computational Engineering (ICECCE), Hosur, India, 17–18 November 2014; pp. 49–54. [Google Scholar] [CrossRef]
- Kumar, N.; Kharkwal, N.; Kohli, R.; Choudhary, S. Ethical aspects and future of artificial intelligence. In Proceedings of the 2016 International Conference on Innovation and Challenges in Cyber Security (ICICCS-INBUSH), Noida, India, 3–5 February 2016; pp. 111–114. [Google Scholar] [CrossRef]
- Zou, Y.; Zhu, J.; Wang, X.; Hanzo, L. A Survey on Wireless Security: Technical Challenges, Recent Advances, and Future Trends. Proc. IEEE 2016, 104, 1727–1765. [Google Scholar] [CrossRef]
- Liu, X.; Xu, Y.; Cheng, Y.; Li, Y.; Zhao, L.; Zhang, X. A heterogeneous information fusion deep reinforcement learning for intelligent frequency selection of HF communication. China Commun. 2018, 15, 73–84. [Google Scholar] [CrossRef]
- Jia, L.; Yao, F.; Sun, Y.; Xu, Y.; Feng, S.; Anpalagan, A. A Hierarchical Learning Solution for Anti-Jamming Stackelberg Game With Discrete Power Strategies. IEEE Wirel. Commun. Lett. 2017, 6, 818–821. [Google Scholar] [CrossRef]
- Jaitly, S.; Malhotra, H.; Bhushan, B. Security vulnerabilities and countermeasures against jamming attacks in Wireless Sensor Networks: A survey. In Proceedings of the International Conference on Computer, Communications and Electronics, Jaipur, India, 1–2 July 2017; pp. 559–564. [Google Scholar]
- Machuzak, S.; Jayaweera, S.K. Reinforcement learning based anti-jamming with wideband autonomous cognitive radios. In Proceedings of the 2016 IEEE/CIC International Conference on Communications in China (ICCC), Chengdu, China, 27–29 July 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Mpitziopoulos, A.; Gavalas, D.; Konstantopoulos, C.; Pantziou, G. A survey on jamming attacks and countermeasures in WSNs. IEEE Commun. Surv. Tutor. 2009, 11, 42–56. [Google Scholar] [CrossRef]
- Du, Y.; Gao, Y.; Liu, J.; Xi, X. Frequency-Space Domain Anti-Jamming Algorithm Assisted with Probability Statistics. In Proceedings of the 2013 International Conference on Information Technology and Applications, Chengdu, China, 16–17 November 2013; pp. 5–8. [Google Scholar] [CrossRef]
- Jia, L.; Xu, Y.; Sun, Y.; Feng, S.; Yu, L.; Anpalagan, A. A Multi-Domain Anti-Jamming Defense Scheme in Heterogeneous Wireless Networks. IEEE Access 2018, 6, 40177–40188. [Google Scholar] [CrossRef]
- Liu, Y.; Ning, P.; Dai, H.; Liu, A. Randomized Differential DSSS: Jamming-Resistant Wireless Broadcast Communication. In Proceedings of the 2010 Proceedings IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–9. [Google Scholar] [CrossRef]
- Li, H.; Han, Z. Dogfight in Spectrum: Jamming and Anti-Jamming in Multichannel Cognitive Radio Systems. In Proceedings of the GLOBECOM 2009—2009 IEEE Global Telecommunications Conference, Honolulu, HI, USA, 30 November–4 December 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Yao, F.; Jia, L.; Sun, Y.; Xu, Y.; Feng, S.; Zhu, Y. A hierarchical learning approach to anti-jamming channel selection strategies. Wirel. Netw. 2019, 25, 201–213. [Google Scholar] [CrossRef]
- Yu, L.; Li, Y.; Pan, C.; Jia, L. Anti-jamming power control game for data packets transmission. In Proceedings of the 2017 IEEE 17th International Conference on Communication Technology (ICCT), Chengdu, China, 27–30 October 2017; pp. 1255–1259. [Google Scholar] [CrossRef]
- Popper, C.; Strasser, M.; Capkun, S. Anti-jamming broadcast communication using uncoordinated spread spectrum techniques. IEEE J. Sel. Areas Commun. 2010, 28, 703–715. [Google Scholar] [CrossRef]
- Hamza, T.; Kaddoum, G.; Meddeb, A.; Matar, G. A survey on intelligent MAC layer jamming attacks and countermeasures in WSNs. In Proceedings of the 2016 IEEE 84th Vehicular Technology Conference (VTC-Fall), Montreal, QC, Canada, 18–21 September 2016; pp. 1–5. [Google Scholar]
- Jameel, F.; Wyne, S.; Kaddoum, G.; Duong, T.Q. A comprehensive survey on cooperative relaying and jamming strategies for physical layer security. IEEE Commun. Surv. Tutor. 2018. [Google Scholar] [CrossRef]
- Bayram, S.; Vanli, N.D.; Dulek, B.; Sezer, I.; Gezici, S. Optimum Power Allocation for Average Power Constrained Jammers in the Presence of Non-Gaussian Noise. IEEE Commun. Lett. 2012, 16, 1153–1156. [Google Scholar] [CrossRef]
- Sagduyu, Y.E.; Berry, R.A.; Ephremides, A. Jamming games in wireless networks with incomplete information. IEEE Commun. Mag. 2011, 49, 112–118. [Google Scholar] [CrossRef]
- Shamai, S.; Verdu, S. Worst-case power-constrained noise for binary-input channels. IEEE Trans. Inf. Theory 1992, 38, 1494–1511. [Google Scholar] [CrossRef]
- McEliece, R.; Stark, W. An information theoretic study of communication in the presence of jamming. In Proceedings of the ICC’81: International Conference on Communications, Denver, CO, USA, 14–18 June 1981; Volume 3, pp. 45–3. [Google Scholar]
- Amuru, S.; Tekin, C.; Van der Schaar, M.; Buehrer, R.M. A systematic learning method for optimal jamming. In Proceedings of the IEEE International Conference on Communications, London, UK, 8–12 June 2015; pp. 2822–2827. [Google Scholar]
- Liu, X.; Xu, Y.; Jia, L.; Wu, Q.; Anpalagan, A. Anti-Jamming Communications Using Spectrum Waterfall: A Deep Reinforcement Learning Approach. IEEE Commun. Lett. 2018, 22, 998–1001. [Google Scholar] [CrossRef]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. arXiv, 2017; arXiv:1709.06560. [Google Scholar]
- Wang, Q.; Zhan, Z. Reinforcement learning model, algorithms and its application. In Proceedings of the 2011 International Conference on Mechatronic Science, Electric Engineering and Computer (MEC), Jilin, China, 19–22 August 2011; pp. 1143–1146. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, J.; Wu, Q.; Zheng, J.; Shen, L.; Anpalagan, A. Dynamic Spectrum Access in Time-Varying Environment: Distributed Learning Beyond Expectation Optimization. IEEE Trans. Commun. 2017, 65, 5305–5318. [Google Scholar] [CrossRef]
- Gwon, Y.; Dastangoo, S.; Fossa, C.; Kung, H.T. Competing Mobile Network Game: Embracing antijamming and jamming strategies with reinforcement learning. In Proceedings of the 2013 IEEE Conference on Communications and Network Security (CNS), National Harbor, MD, USA, 14–16 October 2013; pp. 28–36. [Google Scholar] [CrossRef]
- Fan, Y.; Xiao, X.; Feng, W. An Anti-Jamming Game in VANET Platoon with Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Taichung, Taiwan, 19–21 May 2018; pp. 1–2. [Google Scholar] [CrossRef]
- Singh, S.; Trivedi, A. Anti-jamming in cognitive radio networks using reinforcement learning algorithms. In Proceedings of the 2012 Ninth International Conference on Wireless and Optical Communications Networks (WOCN), Indore, India, 20–22 September 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Aref, M.A.; Jayaweera, S.K. A novel cognitive anti-jamming stochastic game. In Proceedings of the 2017 Cognitive Communications for Aerospace Applications Workshop (CCAA), Cleveland, OH, USA, 27–28 June 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Kiumarsi, B.; Vamvoudakis, K.G.; Modares, H.; Lewis, F.L. Optimal and Autonomous Control Using Reinforcement Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2042–2062. [Google Scholar] [CrossRef]
- ZhuanSun, S.; Yang, J.; Liu, H.; Huang, K. A novel jamming strategy-greedy bandit. In Proceedings of the 2017 IEEE 9th International Conference on Communication Software and Networks (ICCSN), Guangzhou, China, 6–8 May 2017; pp. 1142–1146. [Google Scholar] [CrossRef]
- Amuru, S.; Tekin, C.; van der Schaar, M.; Buehrer, R.M. Jamming Bandits: A Novel Learning Method for Optimal Jamming. IEEE Trans. Wirel. Commun. 2016, 15, 2792–2808. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef]
- Lippmann, R. An introduction to computing with neural nets. IEEE ASSP Mag. 1987, 4, 4–22. [Google Scholar] [CrossRef]
- Tsitsiklis, J.N.; Roy, B.V. An analysis of temporal-difference learning with function approximation. IEEE Trans. Autom. Control 1997, 42, 674–690. [Google Scholar] [CrossRef]
- Dayan, P. The convergence of TD (λ) for general λ. Mach. Learn. 1992, 8, 341–362. [Google Scholar] [CrossRef]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]
- Xiao, L.; Wan, X.; Su, W.; Tang, Y. Anti-jamming underwater transmission with mobility and learning. IEEE Commun. Lett. 2018, 22, 542–545. [Google Scholar] [CrossRef]
- Lu, X.; Xiao, L.; Dai, C. Uav-aided 5g communications with deep reinforcement learning against jamming. arXiv, 2018; arXiv:1805.06628. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Current frequency | 2 Mhz | 6 Mhz | 10 Mhz | 14 Mhz | 18 Mhz |
| Next hop | 18 Mhz | 14 Mhz | 2 Mhz | 10 Mhz | 6 Mhz |
| Jammer Mode | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Sweeping | Comb | Dynamic | Statistic | RL ( = 0.2) | ||||||
| User Mode | Iteration | Normalized Throughput | Iteration | Normalized Throughput | Iteration | Normalized Throughput | Iteration | Normalized Throughput | Iteration | Normalized Throughput |
| Hopping frequency | \ | 0.4 | \ | 0.4 | \ | 0.5 | \ | 0.4 | 10 | 0.08 |
| Fixed frequency | \ | 0.4 | \ | 0 or 1 | \ | 0.2 or 0.7 | \ | 0 | 10 | 0.08 |
| DRL | 50 | 0.97 | 50 | 0.95 | 50 | 0.95 | 50 | 0.95 | ∞ | 0.46 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, X.; Liu, D.; Guo, Q.; Liu, X.; Zhang, J.; Xu, Y. On the Performance of Deep Reinforcement Learning-Based Anti-Jamming Method Confronting Intelligent Jammer. Appl. Sci. 2019, 9, 1361. https://doi.org/10.3390/app9071361
Li Y, Wang X, Liu D, Guo Q, Liu X, Zhang J, Xu Y. On the Performance of Deep Reinforcement Learning-Based Anti-Jamming Method Confronting Intelligent Jammer. Applied Sciences. 2019; 9(7):1361. https://doi.org/10.3390/app9071361
Chicago/Turabian StyleLi, Yangyang, Ximing Wang, Dianxiong Liu, Qiuju Guo, Xin Liu, Jie Zhang, and Yitao Xu. 2019. "On the Performance of Deep Reinforcement Learning-Based Anti-Jamming Method Confronting Intelligent Jammer" Applied Sciences 9, no. 7: 1361. https://doi.org/10.3390/app9071361
APA StyleLi, Y., Wang, X., Liu, D., Guo, Q., Liu, X., Zhang, J., & Xu, Y. (2019). On the Performance of Deep Reinforcement Learning-Based Anti-Jamming Method Confronting Intelligent Jammer. Applied Sciences, 9(7), 1361. https://doi.org/10.3390/app9071361