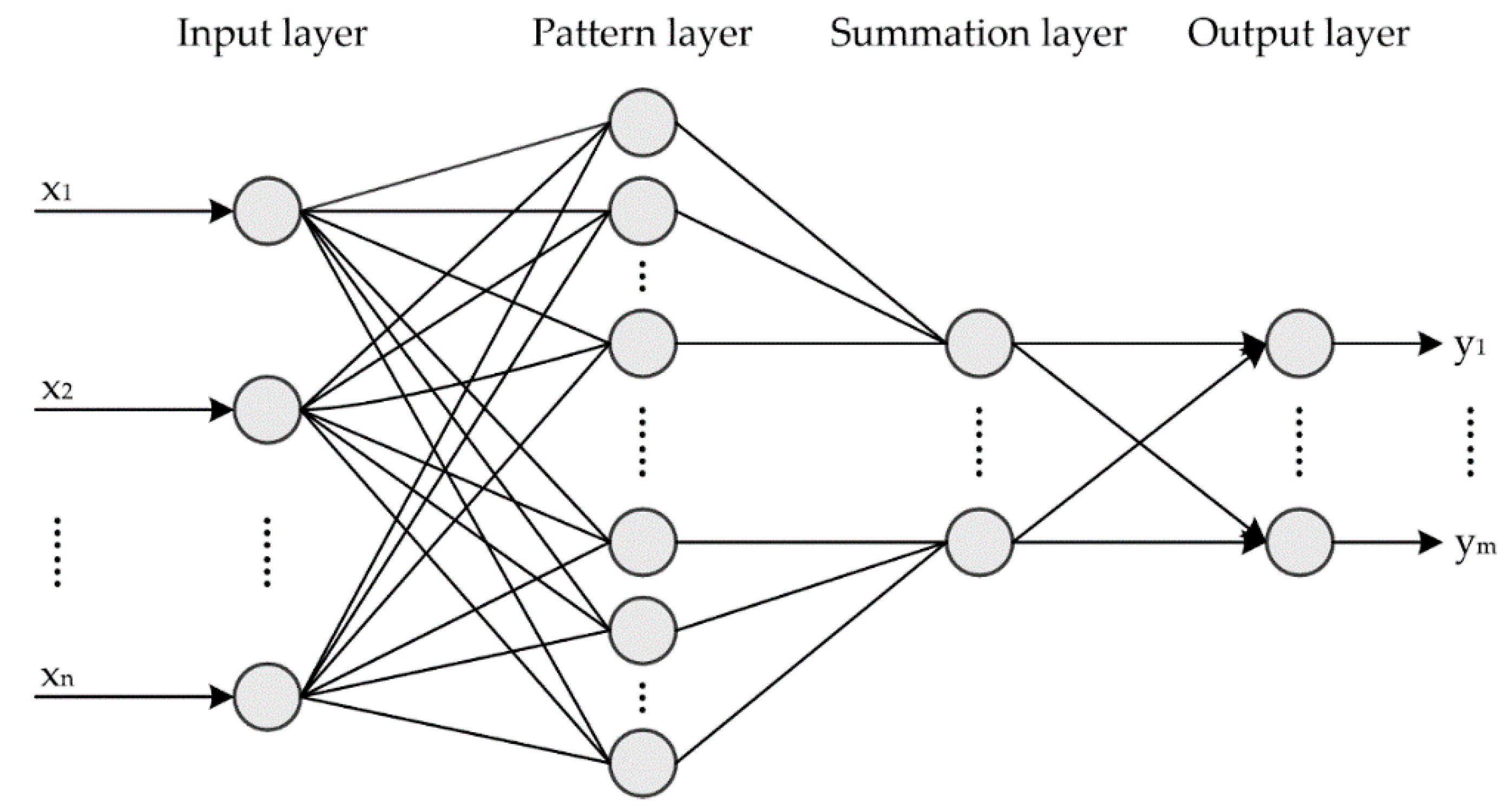
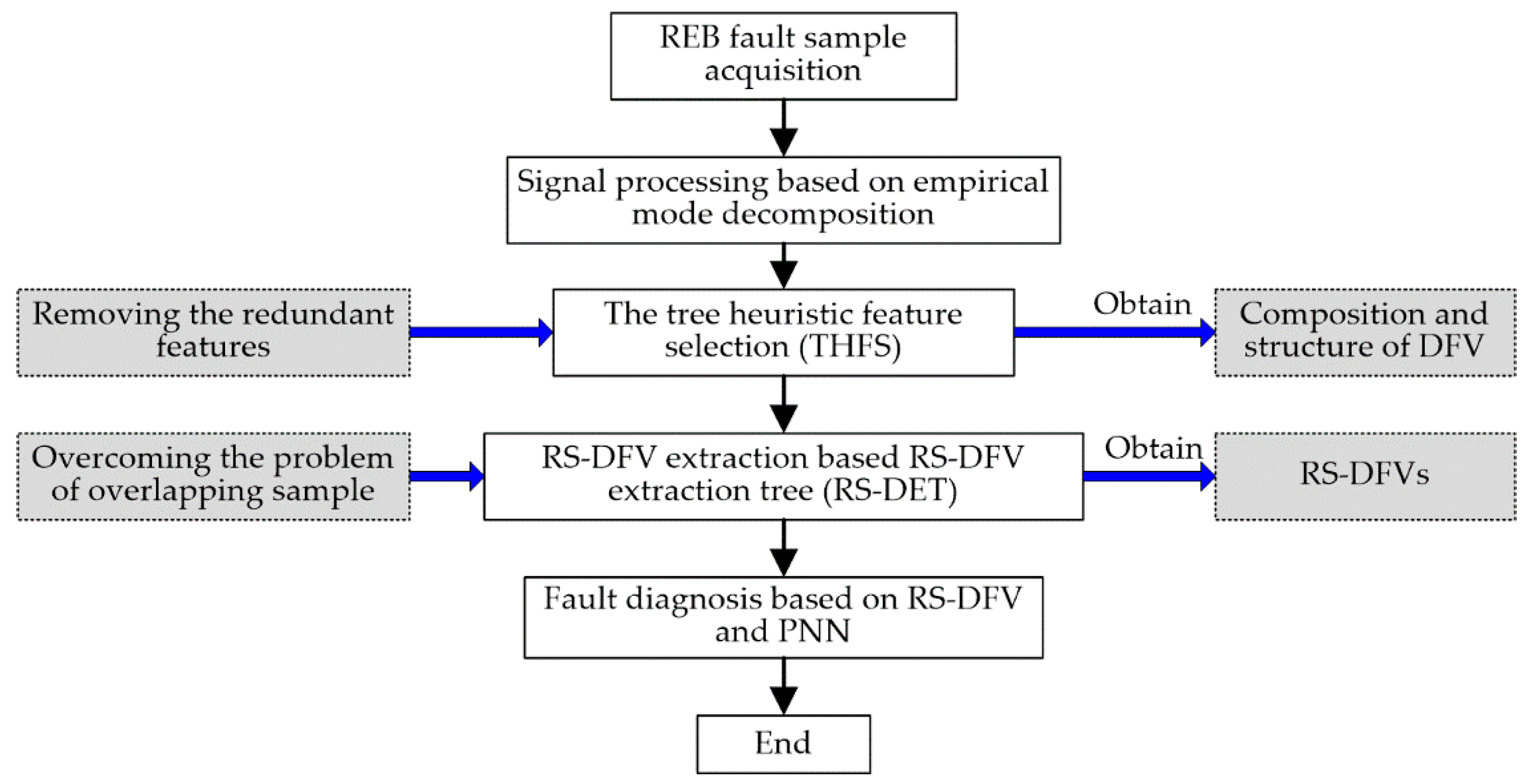
2.2.1. The Basic Concept of DFV
To simulate the object description method of the human brain, one study [
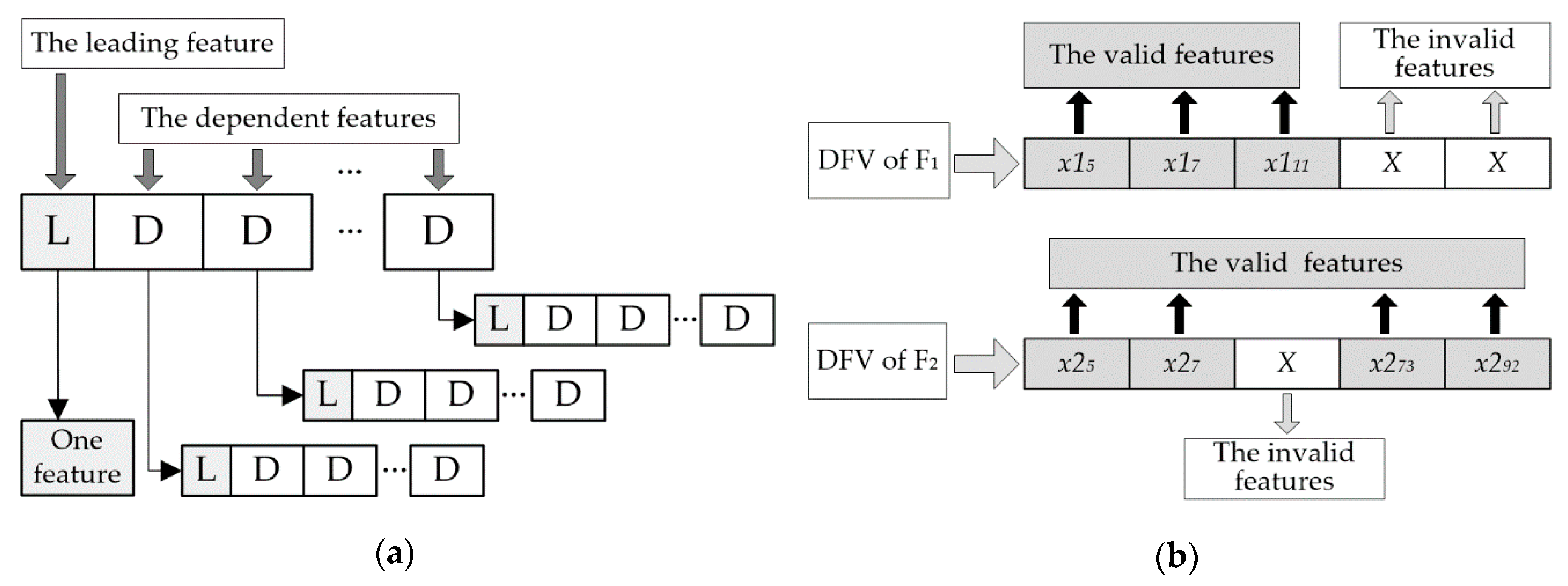
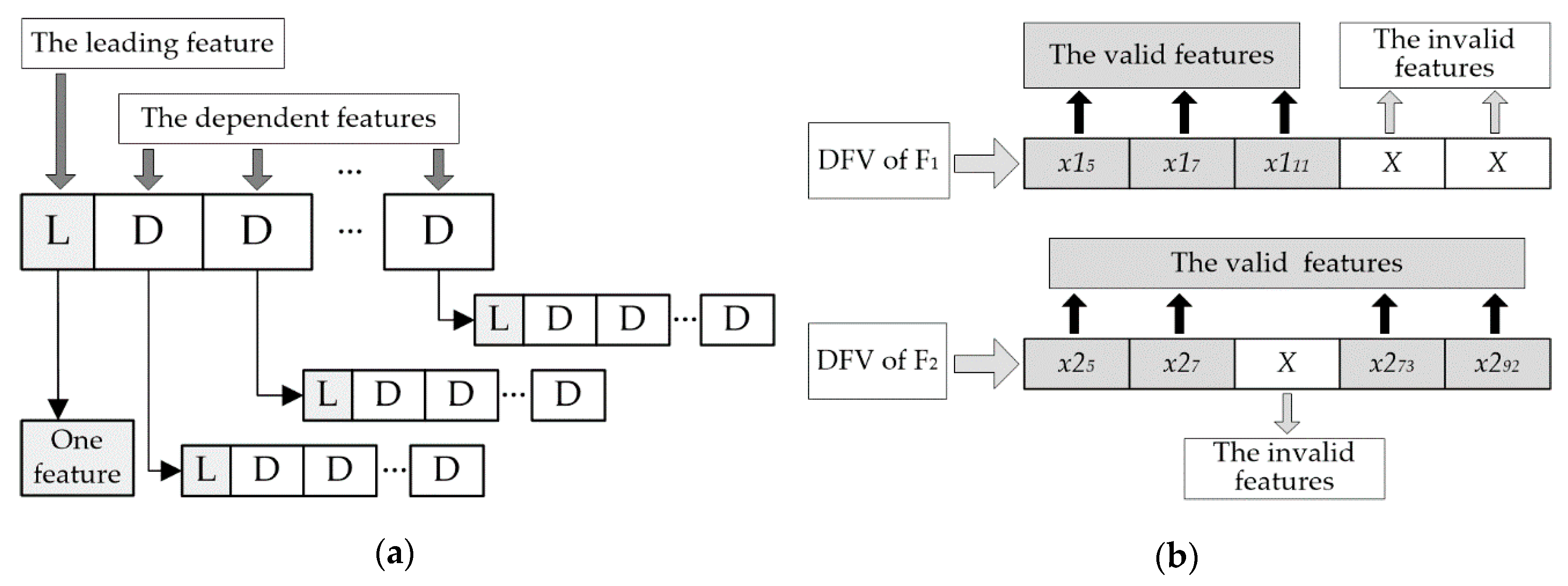
22] designed a special feature vector that was called dependent feature vector (DFV) for REB fault description. The topology and logical structure of DFV is displayed in
Figure 2a. In DFV, there must be at most one leading feature (LF). However, A DFV could include many dependent features (DFs) or no DF. DFV could mining the essential difference among all kinds of faults through its unique nested structure. Moreover, the difference between different faults is magnified by the means of adaptive invalid features of the DFV, and the difference among faults of the same type is reduced at the same time, as illustrated in
Figure 2b and Equations (1)–(7). Therefore, DFV greatly improved the accuracy of fault description and fault diagnosis.
In a DFV, the valid features must be acquired through the analysis of sample data. However, invalid features do not have to be calculated, and it is only necessary to subjectively give an effective value for them. The unified evaluation mechanism of invalid items in a DFV could greatly improve its fault discrimination.
For the examples in
Figure 2b, F1 and F2 are two different fault types,
xij is the
jth feature item of the fault Fi,
is the Euler distance between F1 and F2 based on the traditional feature vector, and
is the Euler distance between F1 and F2 based on the DFV. As long as the value (
X) of the invalid features is suitable, Equations (3) and (4) are true. It is obvious that the DFV could magnify the difference between different faults through the value assignment of the invalid features.
is the Euler distance between two faults of type F1 based on the traditional feature vector, and
is the Euler distance between two faults of type F1 based on DFV. No matter what is the value (
X) of the invalid features, Equation (7) is true. Obviously, the DFV was able to significantly lessen the discrepancies among the same faults.
2.2.2. The Tree Heuristic Feature Selection
• Feature evaluation based on information granulation and neighboring clustering
Different feature selection methods required different feature evaluation criteria, but the excellent traditional feature evaluation methods could not provide the best heuristic knowledge for the feature selection method proposed in this paper. So, a feature evaluation method based on information granulation and neighboring clustering is put forward for tree heuristic feature selection (THFS). In this feature evaluation method, information granulation and neighboring clustering were used to delete the features that were obviously ineffective in fault distinguishing at first; then, the remaining features were evaluated through Equations (8)–(11). The specific steps of this feature evaluation method are introduced below.
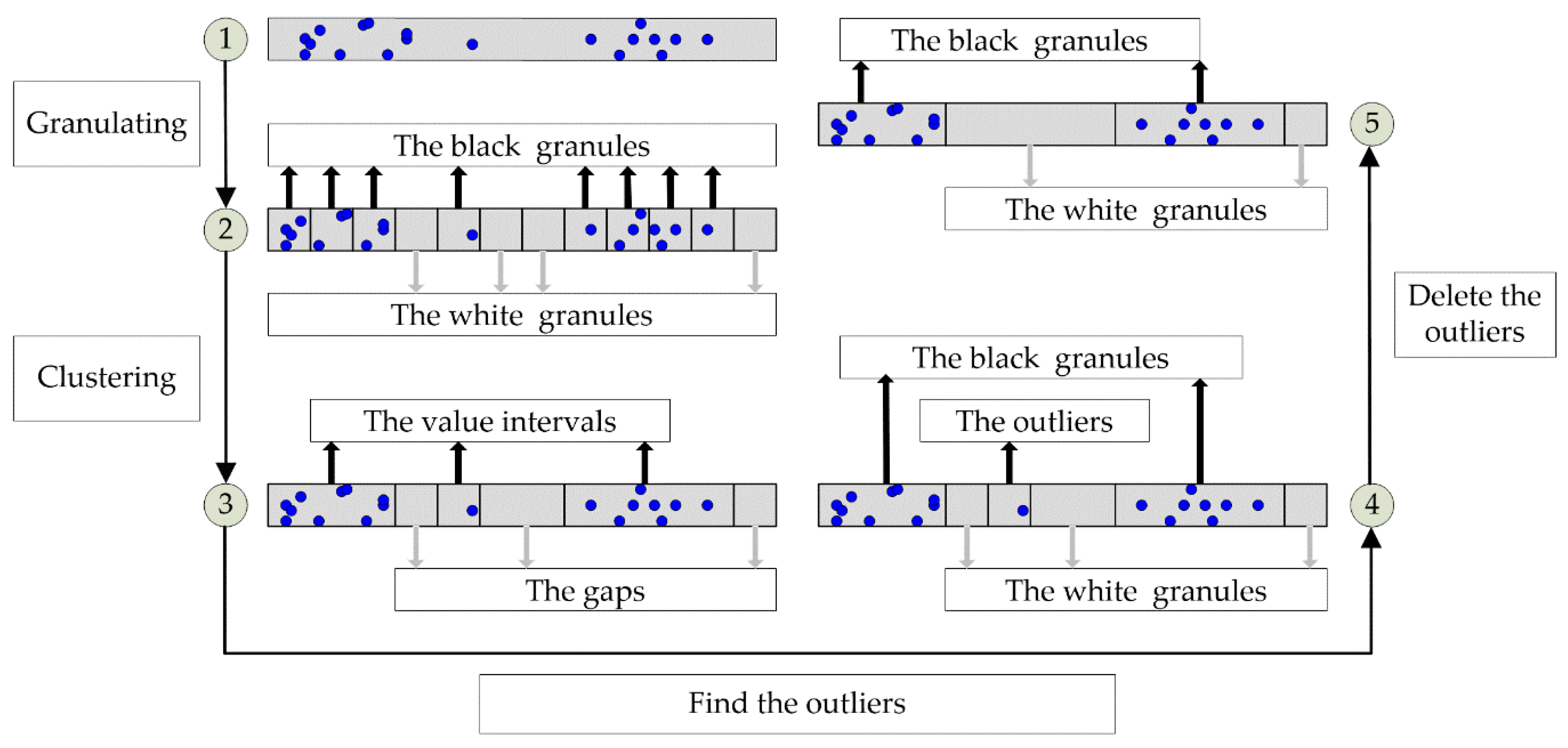
Step 1: The value range of one feature is divided into many small granules evenly in accordance with the same criterion, as illustrated in
Figure 3①–②. The granules that included some feature values of samples are black granules, and the others are white granules.
Step 2: The adjoining granules of the same type are merged to a larger one through the neighboring clustering method, as illustrated in
Figure 3②–③. The black granules that included very few samples and the white granules with a tiny length are outliers (
Figure 3④).
Step 3: The black outlier is first changed to be white and amalgamated with white granules adjacent to it. Then, the white outlier is changed to be black and amalgamated with black granules adjacent to it, as illustrated in
Figure 3④–⑤.
Step 4: If there is only one black granule or two different black granules both with some samples of the same type, this feature is considered to be ineffective in fault distinguishing and deleted.
Step 5: The remaining features are evaluated through Equations (8)–(11):
where
Li is the length of the No.
i black granule,
xi+ is its upper bound, and
xi− is its lower bound.
Li (
i+1) is the length of the white granule between the No.
i and No. (
i+1) black granules.
Vi (
i+1) is the separability between the No.
i and No. (
i+1) black granules, and
N is the number of the black granules.
P(
x) is the score of this feature, and a large
P(
x) displayed its high separability among the black granules.
• Feature selection based on the tree heuristic search strategy
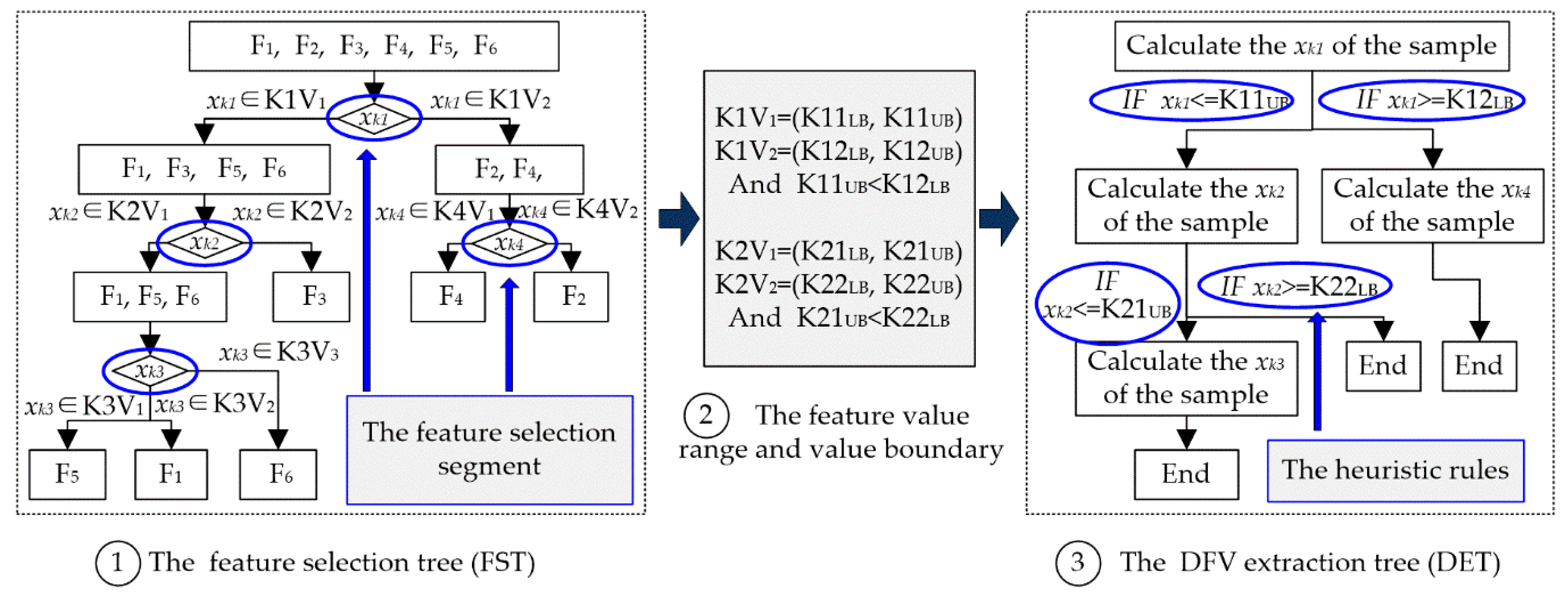
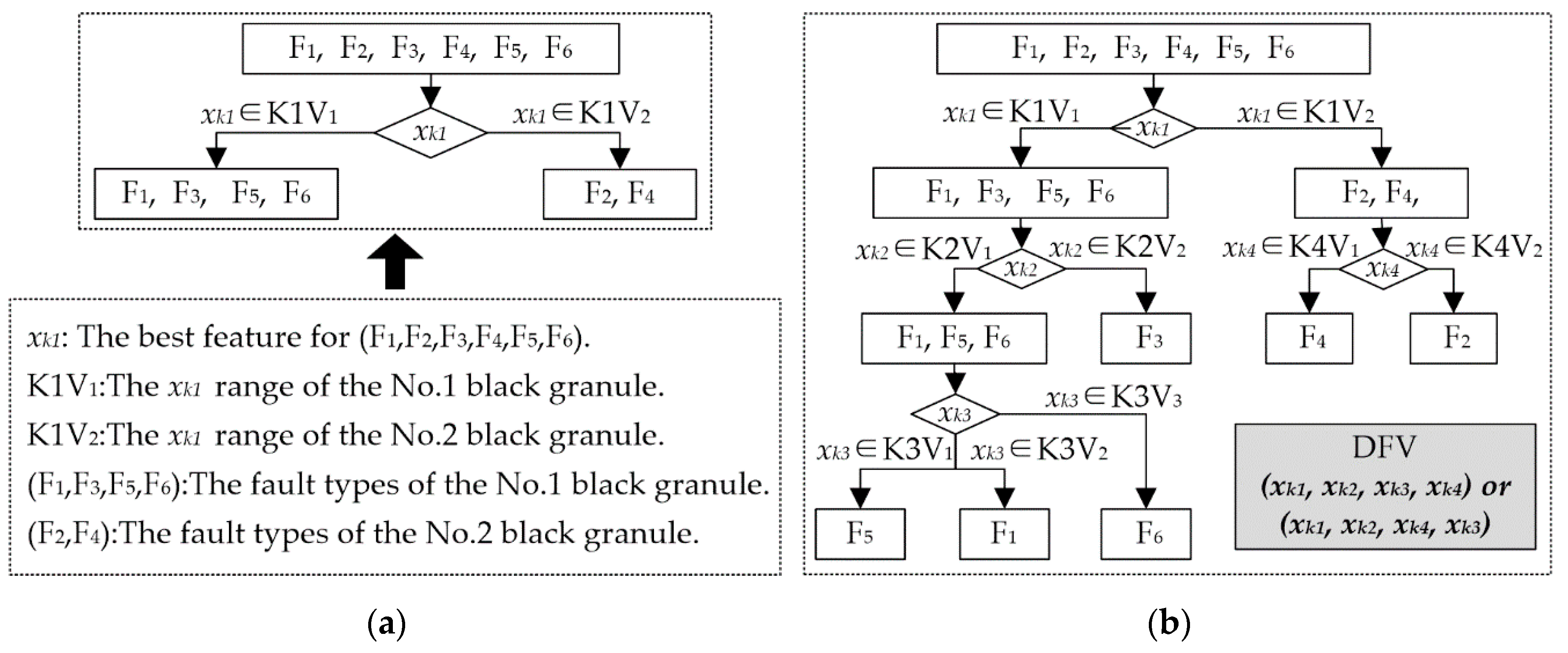
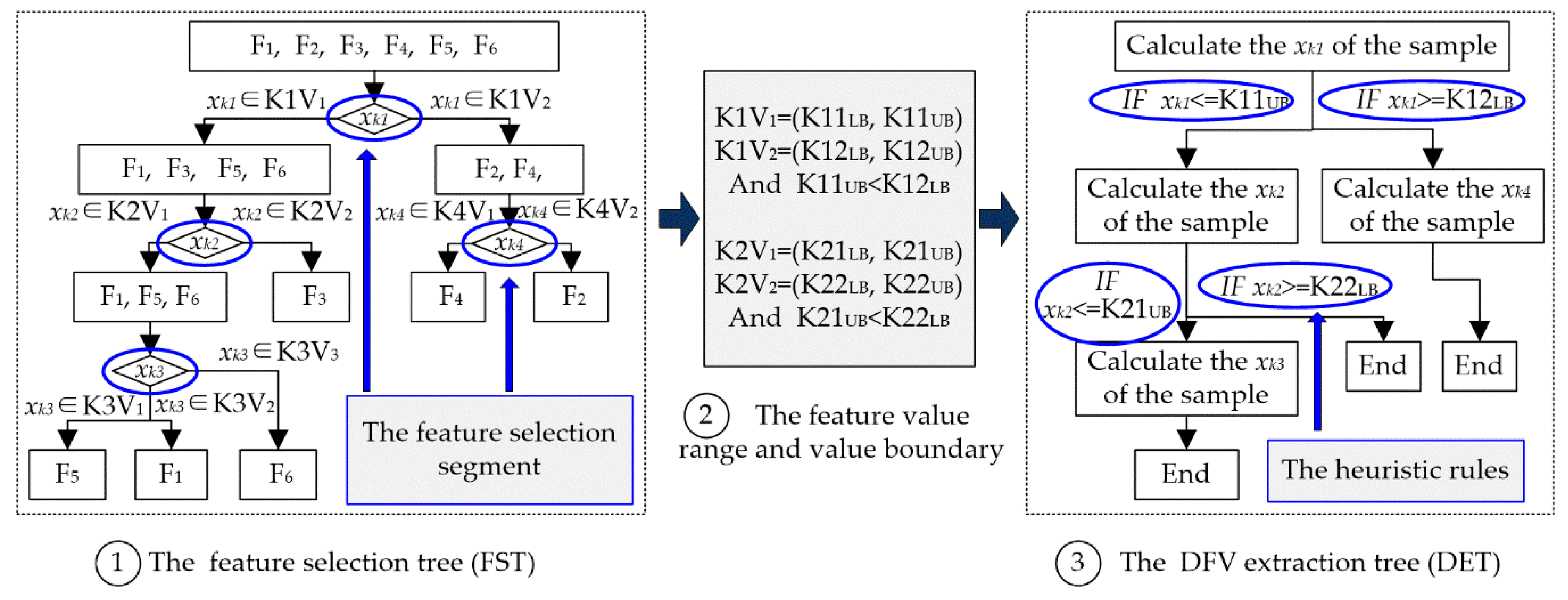
The structure establishment of the feature vector is a very important basis for DFV. To adapt to the uniqueness of DFV, this study proposes a feature selection method based on THFS to establish the structure of DFV. The workflow of THFS is illustrated in
Figure 4.
The most efficient feature (
xk1) for the sample space is first chosen through the feature evaluation method based on information granulation and neighboring clustering, which is introduced above, and the black granules are obtained. Each black granule includes some fault types, and the samples of these types make a fault subspace. Then, the sample space is made the root node, the subspaces are made the leaf nodes, and the
xk1 value range of each leaf node is marked. Thus, the local structure connected to the root of the heuristic tree is established, as illustrated in
Figure 4a. If a leaf node includes faults of more than one type, its subtree is built using the same method. When all leaf nodes contain faults of only one type, the heuristic tree has completed its growth and gained complete tree, as illustrated in
Figure 4b.
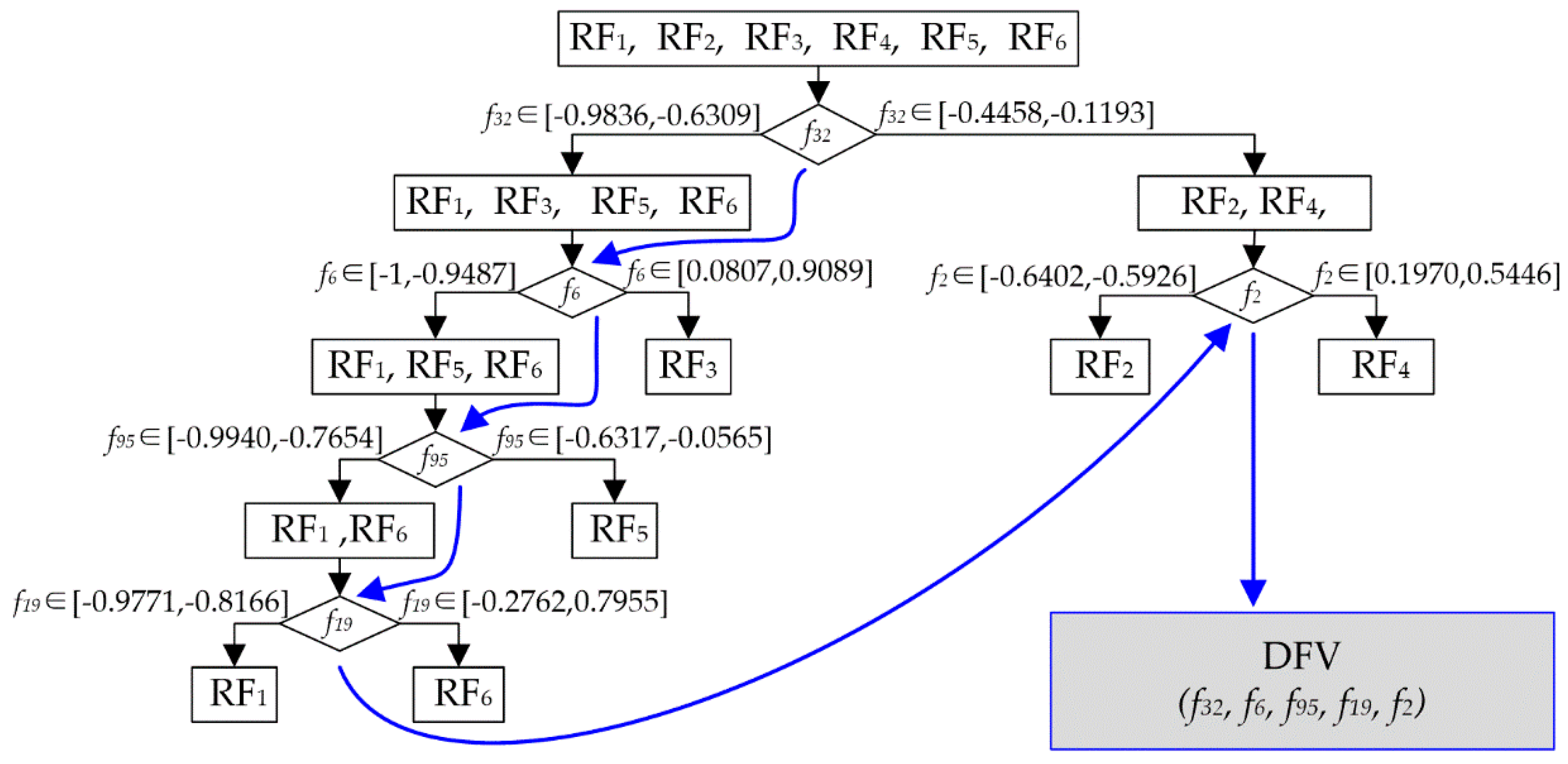
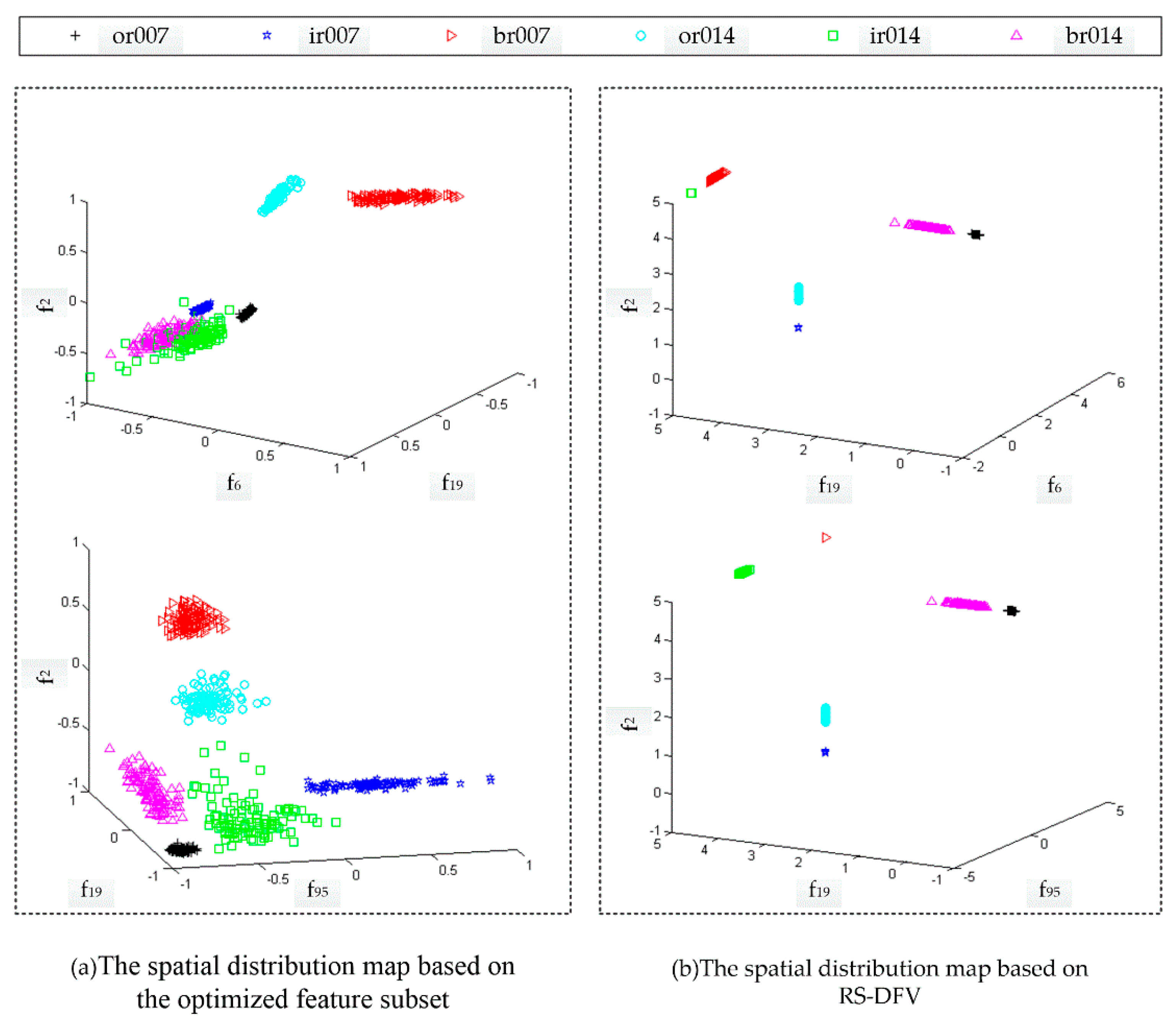
The optimization feature subset is obtained through traversing the heuristic tree. Because the position of each feature in a DFV is fixed, traversing the heuristic tree with a different method could get a different DFV. For example, in
Figure 4b, depth-first traversal of the heuristic tree could get a DFV (
xk1,
xk2,
xk3,
xk4), but breadth-first traversal could get another DFV (
xk1,
xk2,
xk4,
xk3). Therefore, THFS not only has completed the feature selection and the optimization of feature subset but also could establish the structure of the DFV.
2.2.3. RS-DFV Extraction
• DFV Extraction Tree
Extracting the DFV of fault samples is another key step of the fault diagnosis method presented in this paper. The DFV is different from the traditional feature vector because of its unique structure. In a DFV, the importance of each feature item is not equal: some of them are valid feature items, and the others are invalid. More importantly, faults of different types had different valid feature items and invalid feature items, i.e., the same feature is of different importance for different faults. In addition, only the valid feature items of DFV need to be calculated from the sample data and the value of the invalid items are set subjectively, based on the requirement of the fault classification. All these differences considerably increased the difficulties of DFV extraction. Moreover, for a fault sample that has to be diagnosed, features that are valid items in the sample’s DFV are unknown. This made the DFV extraction more difficult.
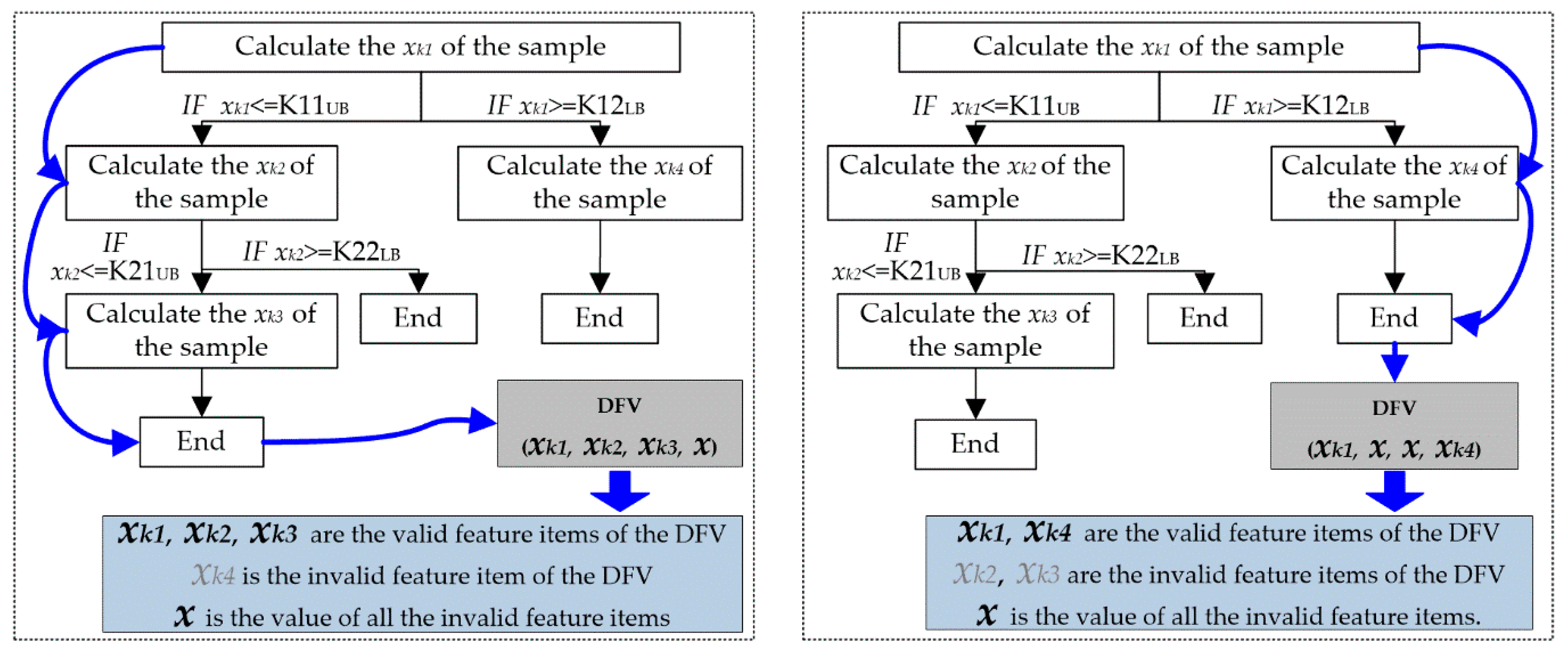
To overcome those problems in the DFV extraction mentioned above, a tree heuristic feature extraction method is put forward to extract the DFV in this paper, as illustrated in
Figure 5.
First, a DFV extraction tree (DET) that inherited the heuristic rules of the feature selection tree (FST) is put forward in this paper, as illustrated in
Figure 5③. The DET is constructed based on the FST: (1) The FST is traversed. When a non-leaf node is passed, continue; when a feature selection segment is passed, a feature calculation node for the DET is built; when a leaf node is passed, an end-node for the DET is built. (2) A connection relationship is established among the nodes for the DET, and consistency with the FST is ensured. (3) According to the value ranges of the child nodes that had the same parent node in the FST, heuristic rules that could guide the subsequent feature calculation for the DET are built.
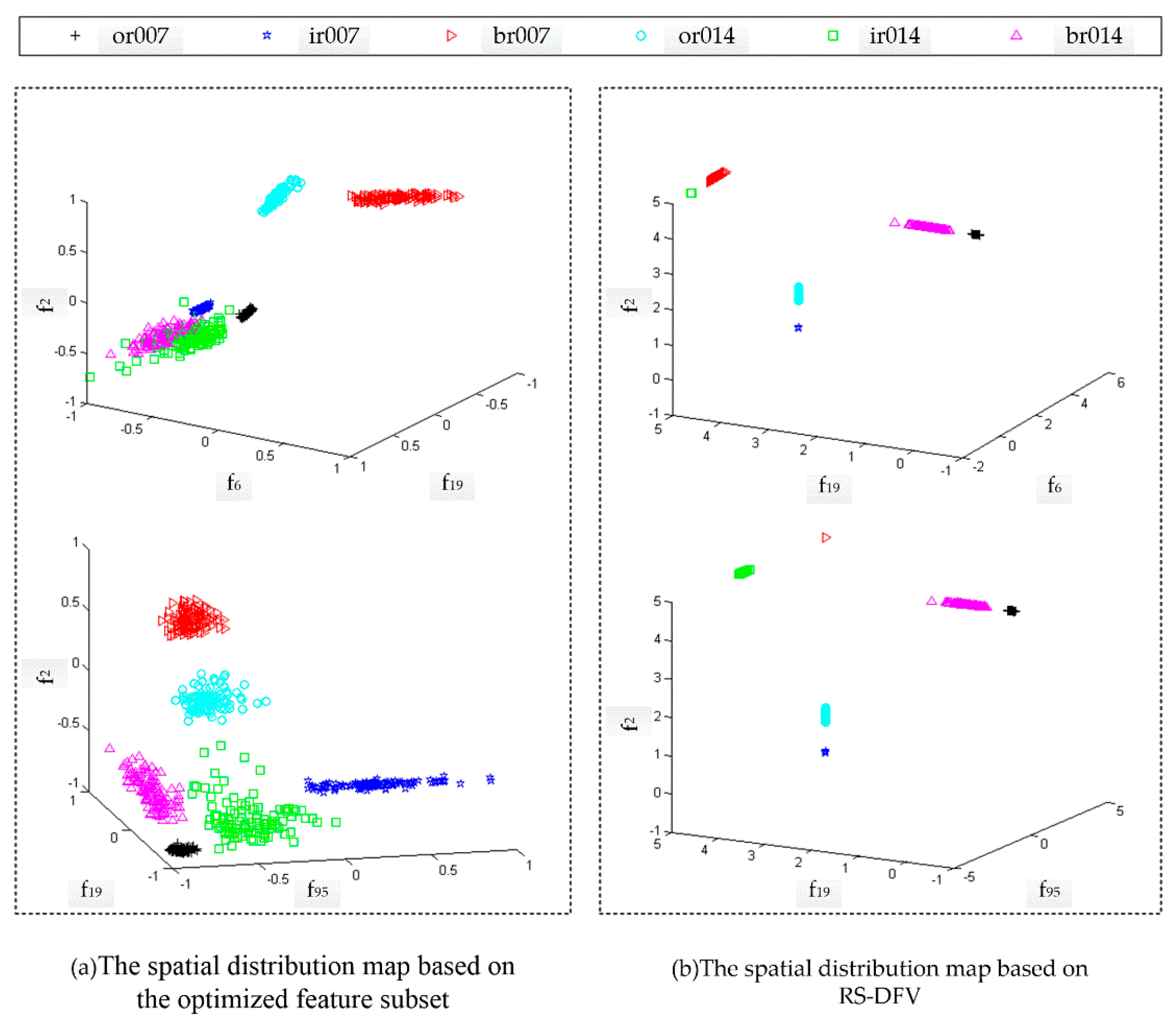
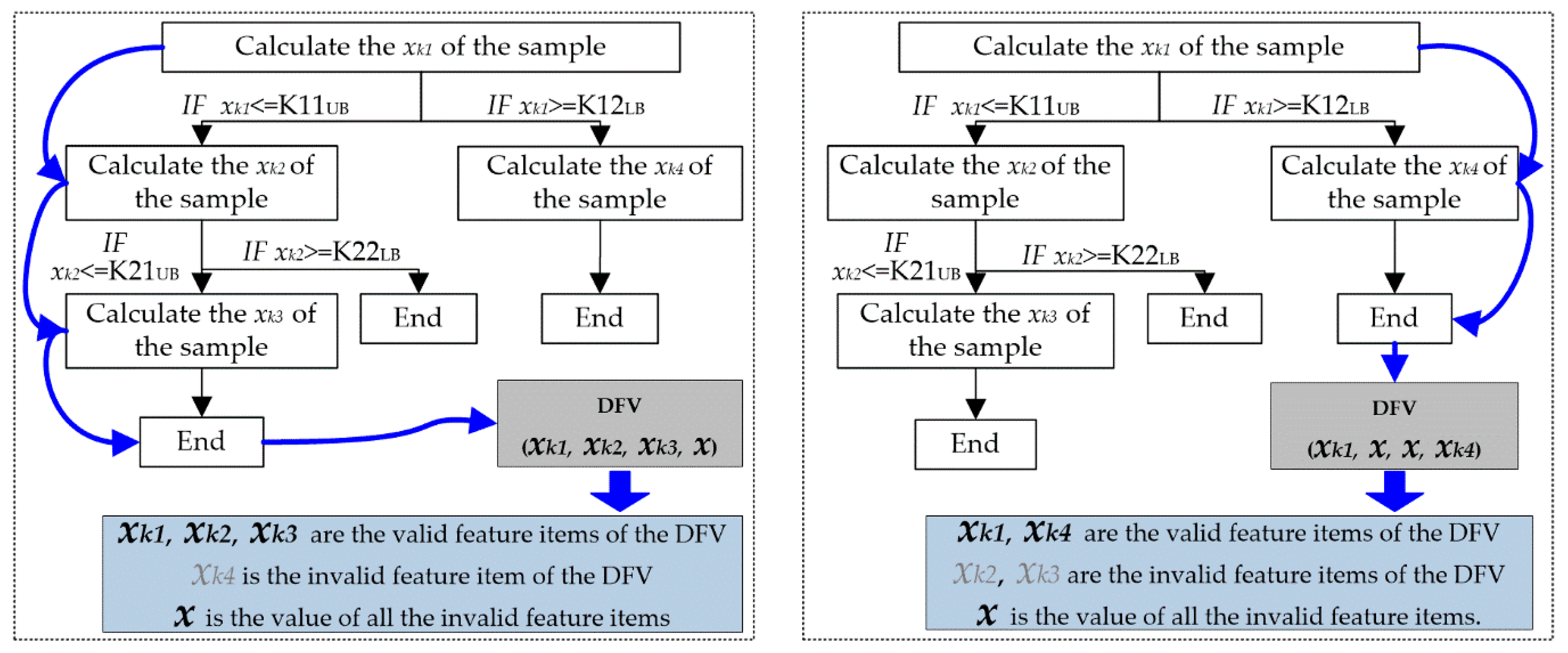
Then, for a new fault sample, the values of all valid feature items are calculated in turn according to the guidance of the (DET); hence, the valid feature items of the DFV are obtained. As illustrated in
Figure 6, different faults have different valid features, but their valid features all could be accurately calculated through DET.
Finally, the other feature items in the DFV are the invalid feature items of this fault sample, and all invalid features are subjectively assigned the same specific value. Therefore, the DFV of all fault samples could be acquired in this manner.
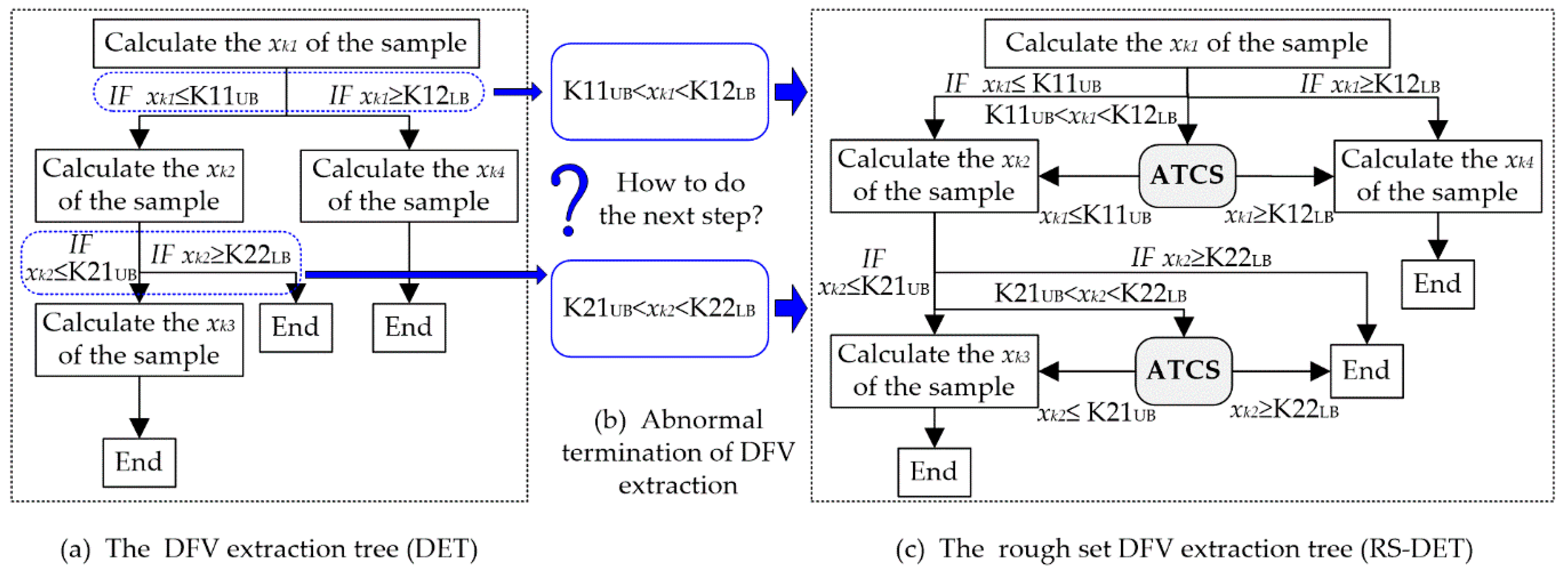
• RS-DFV Extraction Tree
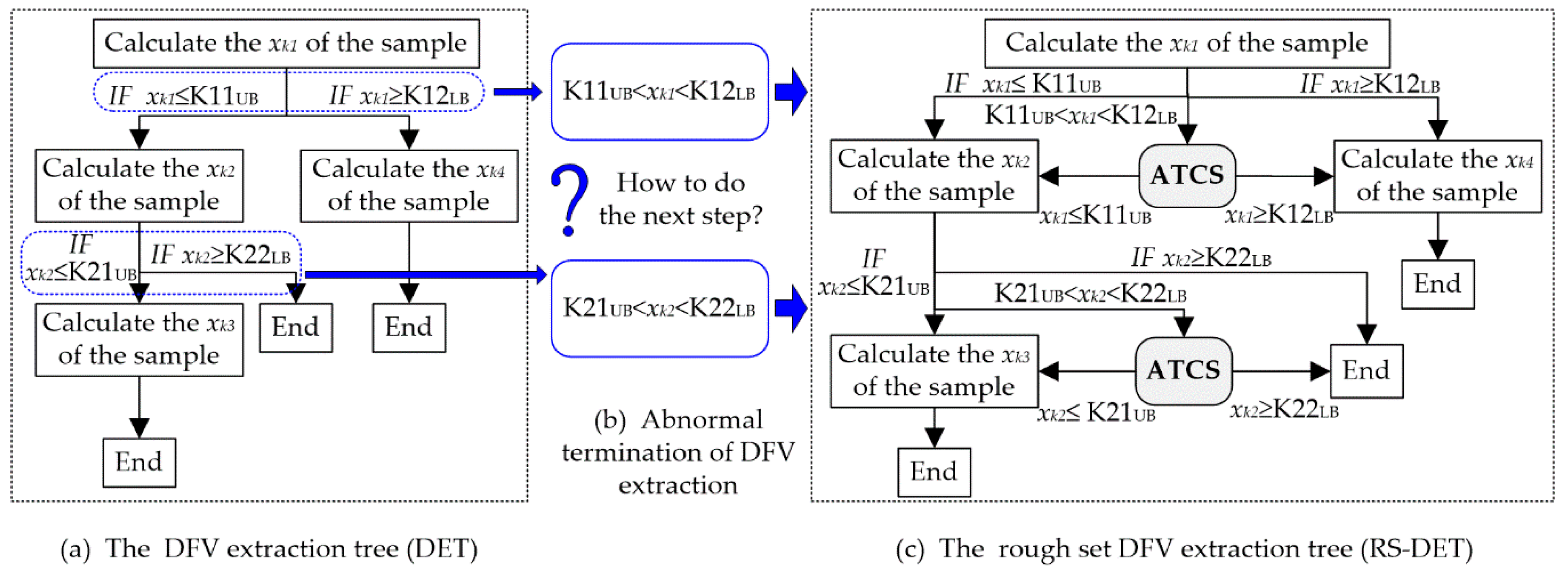
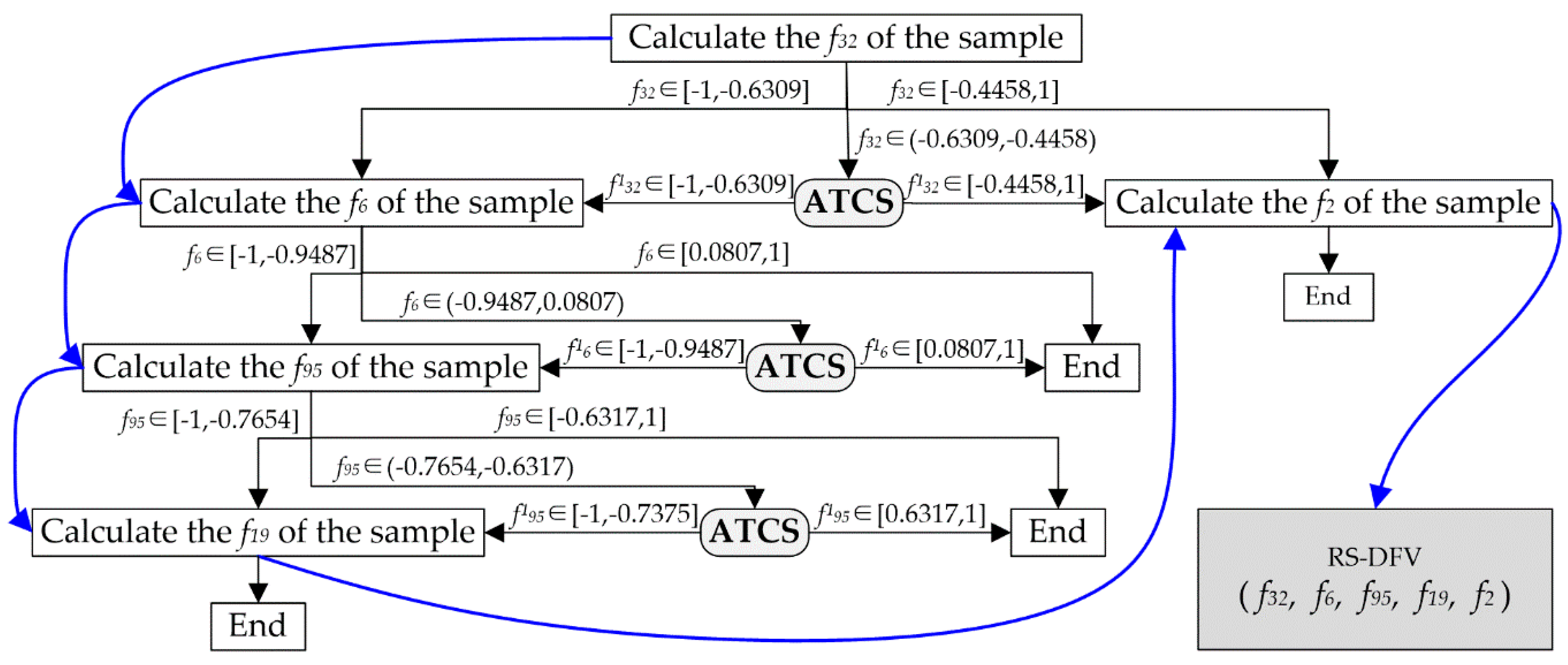
Although the tree heuristic feature extraction method overcomes the difficulties in DFV extraction, it could efficiently and accurately start the calculation of an unknown fault sample and successfully calculated the DFV of most of the fault samples. However, there is still another weakness in the DFV: The feature value obtained in the parent feature calculation node of the DFV extraction tree could not meet the demand of any one heuristic rule connected to this feature, and there is be no inspire information for the next step, as illustrated in
Figure 7a,b. This could lead to an abnormal termination in the DFV extraction and inaccurate calculation of the sample DFV.
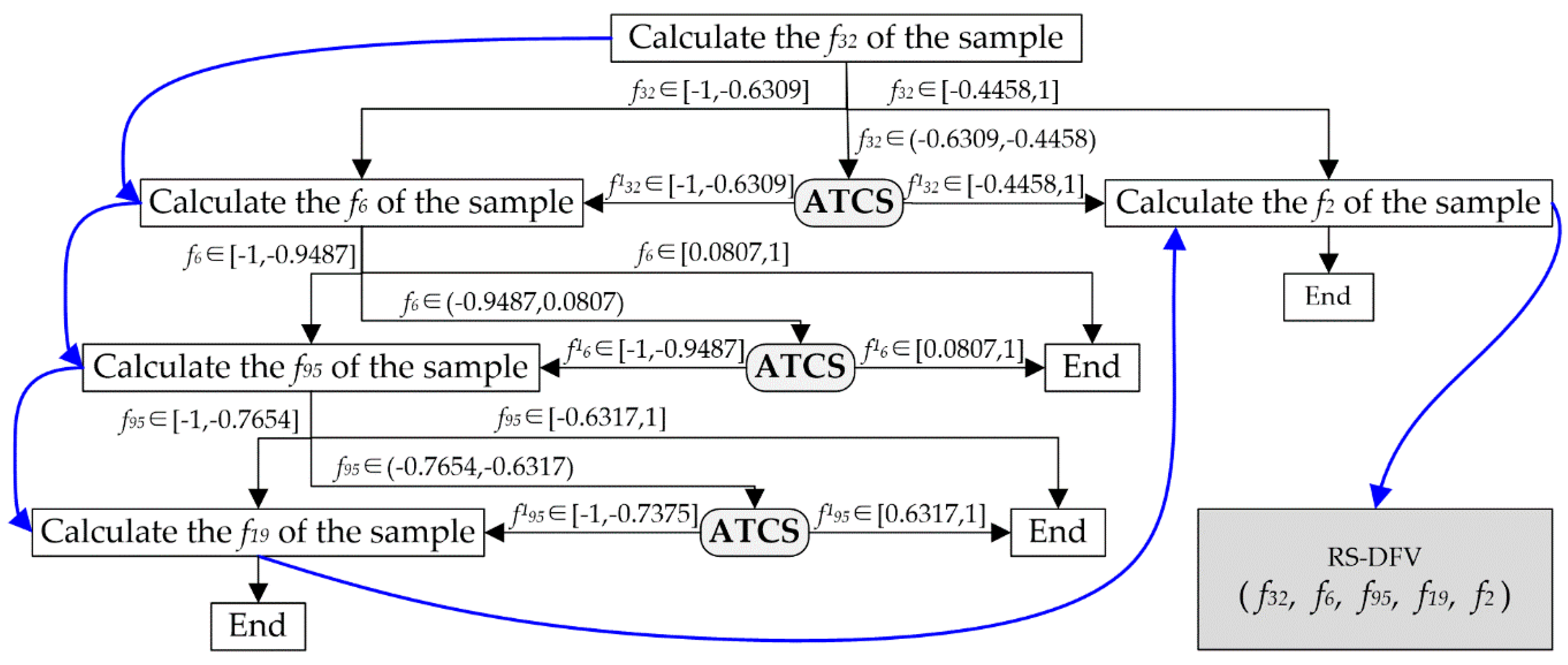
To overcome the problem mentioned above, a rough set is introduced to solve the boundary problem of heuristic rule in the DFV extraction tree, and a DFV extraction method based on the rough set and the DFV extraction tree is presented in this paper. As illustrated in
Figure 7c, a new DFV extraction tree combining the rough set and DET (RS-DET) is designed. The RS-DET increased an abnormal termination correction segment (ATCS) for each node that had more than one child nodes. When an abnormal DFV extraction termination occurred, the corresponding ATCS responded quickly and reasonably amended the value of the current heuristic feature to be instructive. Obviously, RS-DET could effectively overcome the abnormal suspension of DET and was able to complete the DFV extraction of each sample. The procedure of the ATCS is displayed below.
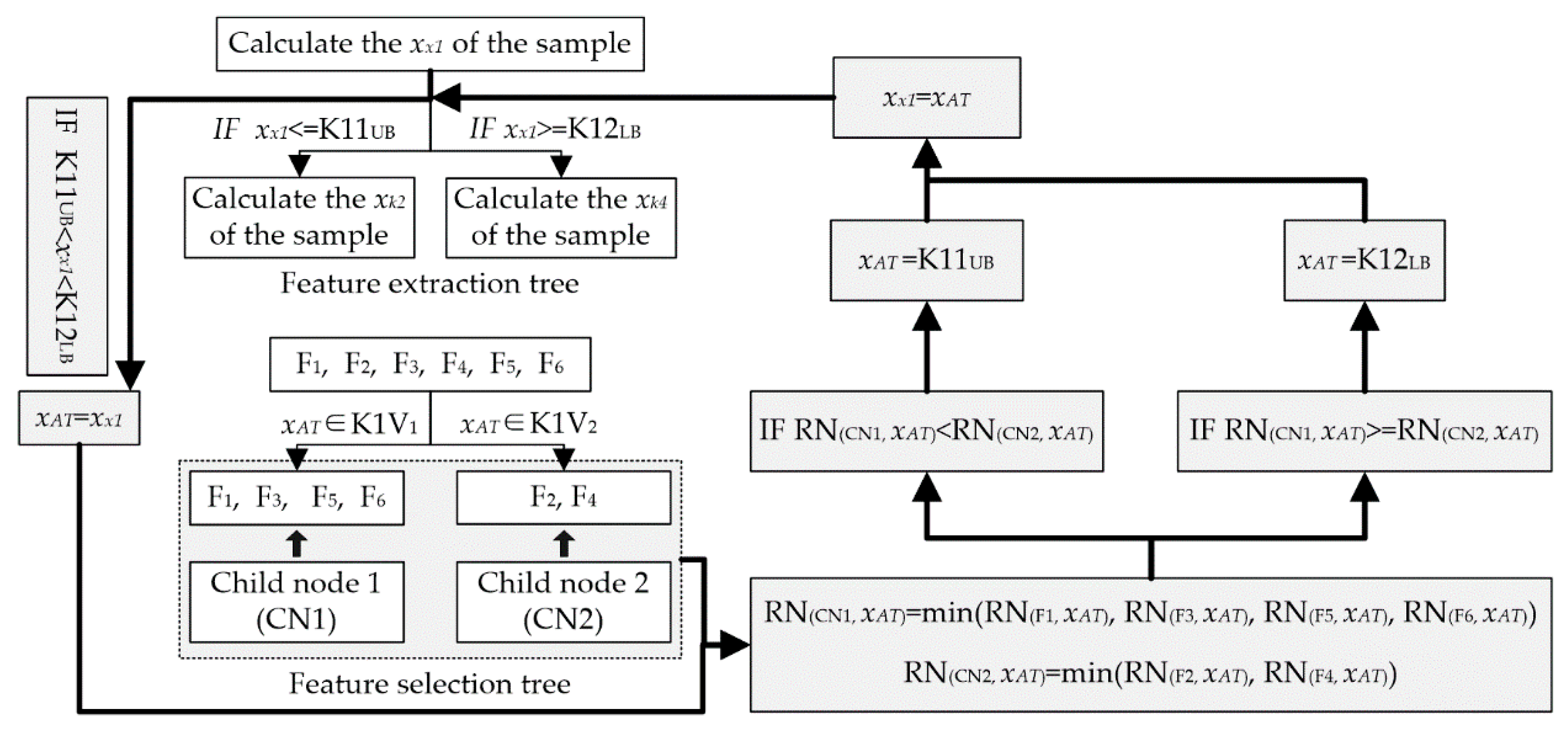
Step 1: Extract the DFV in accordance with the instructions of the RS-DET until an abnormal termination appeared, record the current fault sample as an AT fault sample, record the current node as an ATN, and record the current heuristic feature as an AT feature (xAT).
Step 2: Find the all child nodes of the ATN in the RS-DET and put them into the node set CN-ATN.
Step 3: For each node in CN-ATN, find fault types that were included in it, construct a rough set on
xAT for each fault type, and calculate the roughness of this node based on
Figure 8 and Equations (12)–(14).
Step 4: Amend the value of
xAT according to the roughness of the child nodes illustrated in
Figure 9 and Equations (12) and (13).
Step 5: Go back to step 1.
• Feature Correction based on the Rough Set
The ATCS could overcome the problem of abnormal termination in DFV extraction; hence, it is a most important part in RS-DET. In this paper, a rough set is applied to amend the current heuristic feature.
First, the fault sample that caused an abnormal termination is treated as a fault sample in fault type
F, and the rough set of
F is obtained through the method illustrated in
Figure 8.
F-(x) is the value range of the current heuristic feature for all the training samples in fault type
F, and
RN(F,
xAT) is the roughness of fault type
F based on the current heuristic feature. Through Equation (12), the roughness of every fault type based on the current heuristic feature could be acquired. Then, for the child nodes of the ATD,
RN(CNh,
xAT) is the roughness of the
hth child node, and, as illustrated in Equation (13),
RN(CNh, xAT) is the minimum roughness of all fault types in the
hth child node. Finally, the child node that included the fault type with the minimum roughness is found, the value range (
X) of the current heuristic feature for all the training samples in this child node is obtained, and the value of
xAT toward
X is amended based on Equation (14). Therefore, the ATCS solved the problem of abnormal termination in DFV extraction and made it possible for DFV extraction to be accurately completed.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}