Identification of Coal Geographical Origin Using Near Infrared Sensor Based on Broad Learning



Abstract
:1. Introduction
- Inspired by the usage of NIR in agriculture, petrochemical and pharmaceutical industries, we employ NIR to identify coal geographical origin, which is unprecedented. This method is fast and non-destructive.
- Considering the noisy NIR spectral and limited samples, we employ the BL as the modelling algorithm for its advantages of a simple structure, robustness to noise and excellent performance in previous studies. Compared with the traditional methods in the literature, this study improves the classification precision.
- The performance of BL is largely dependent on the network structure. In order to obtain the optimal parameters for the BL model, the PSO algorithm is utilized. The proposed method is able to classify the coal geographical origin accurately.
2. Experimental Preparations
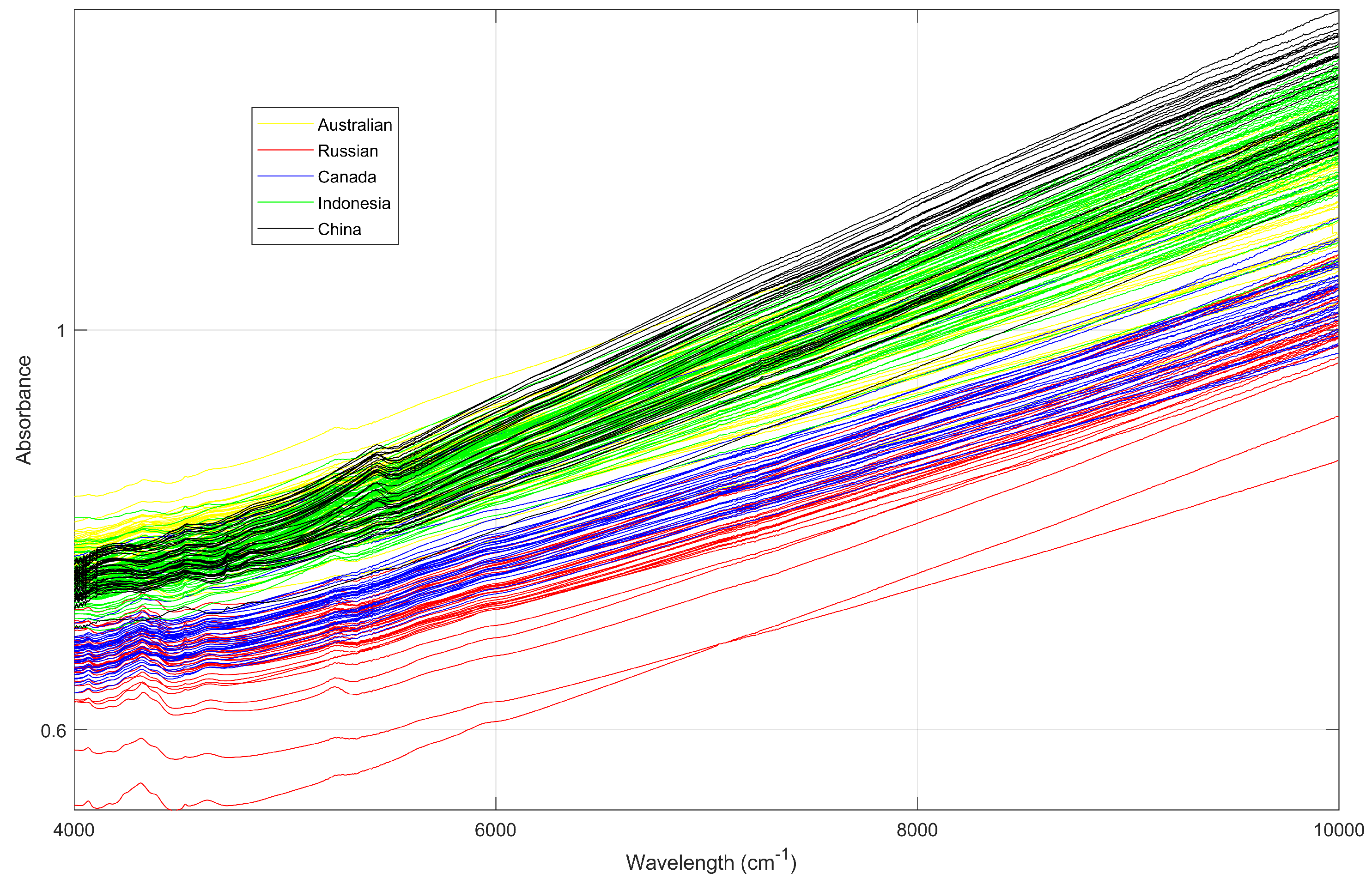
2.1. Experimental Data
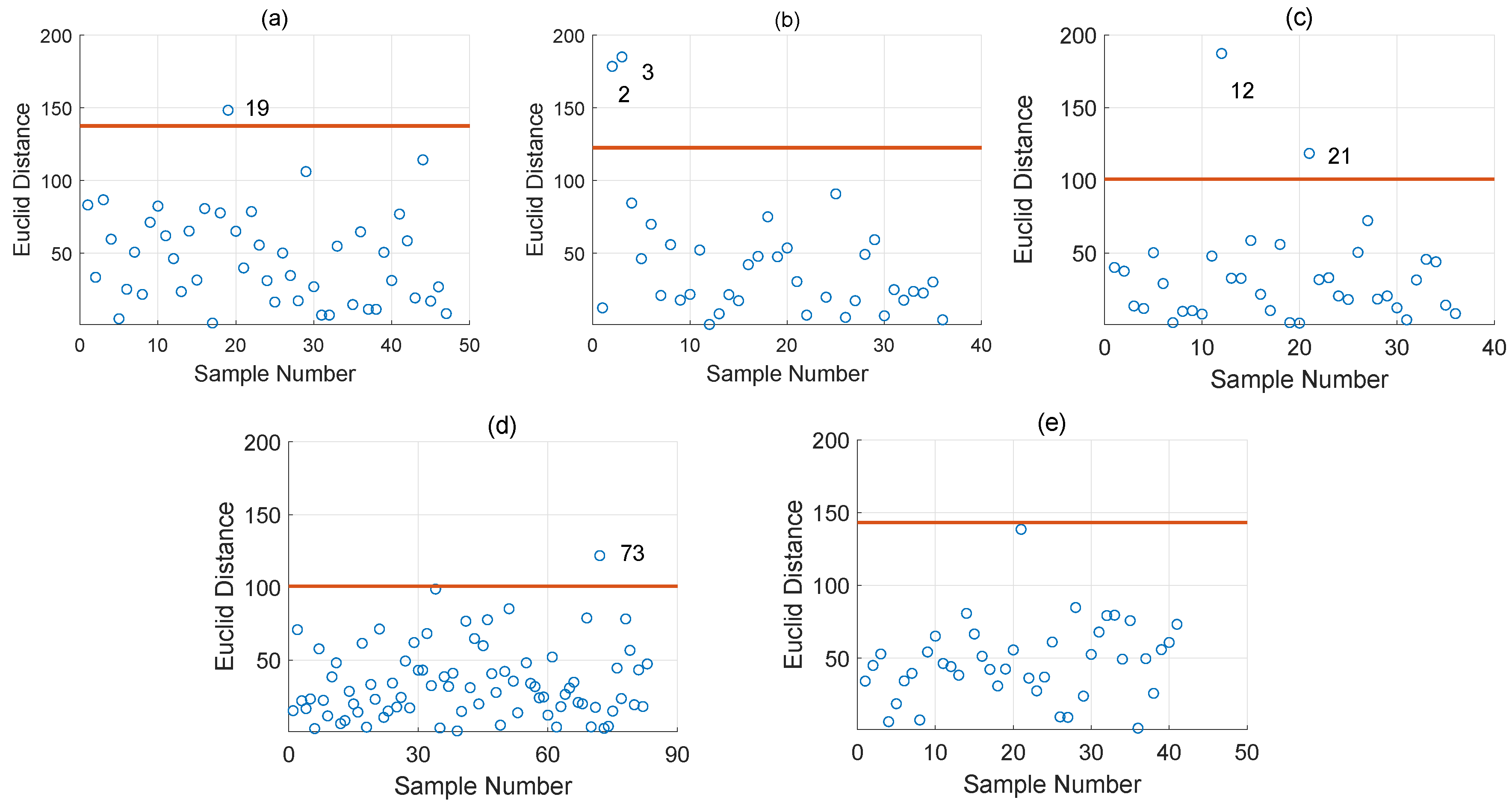
2.2. Outlier Rejection
3. Experimental Methods
3.1. BL Algorithm
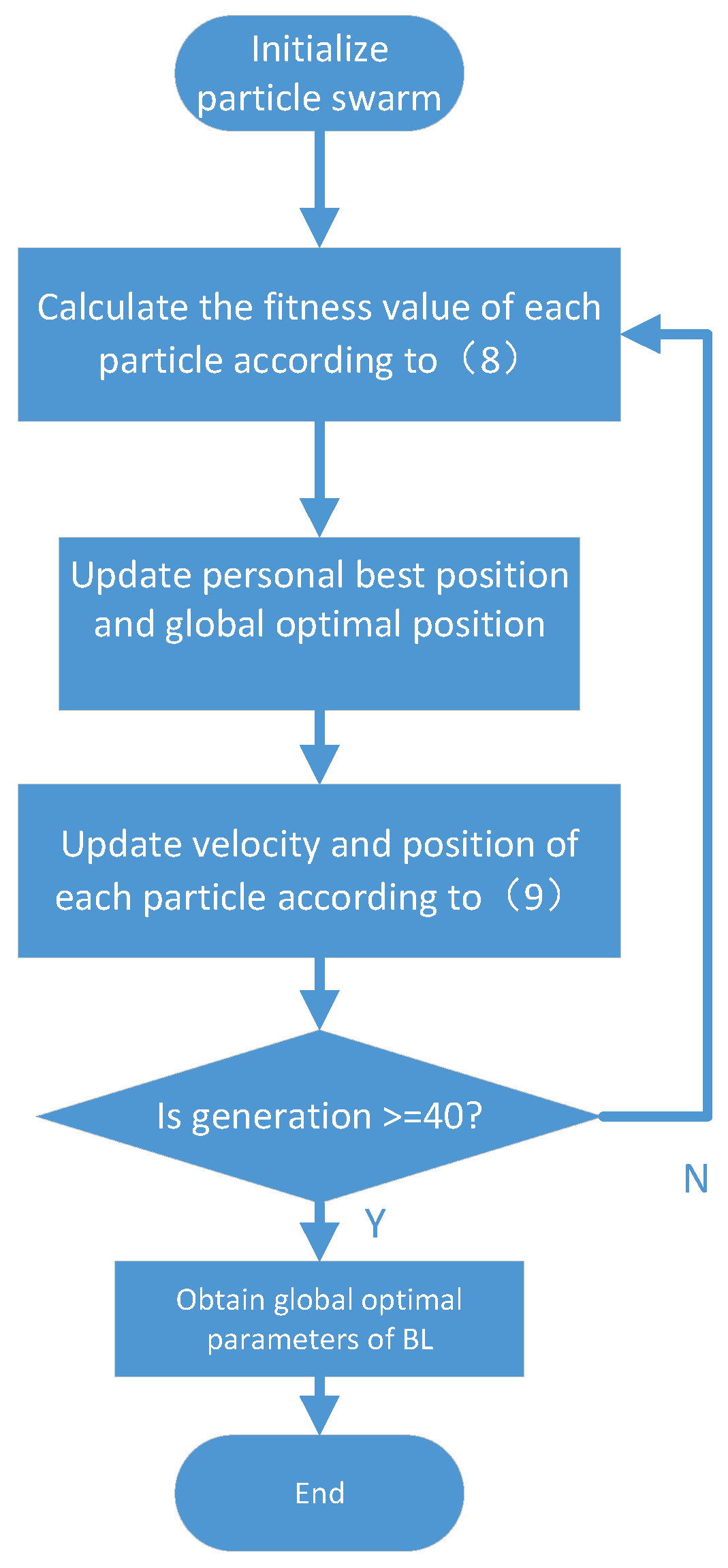
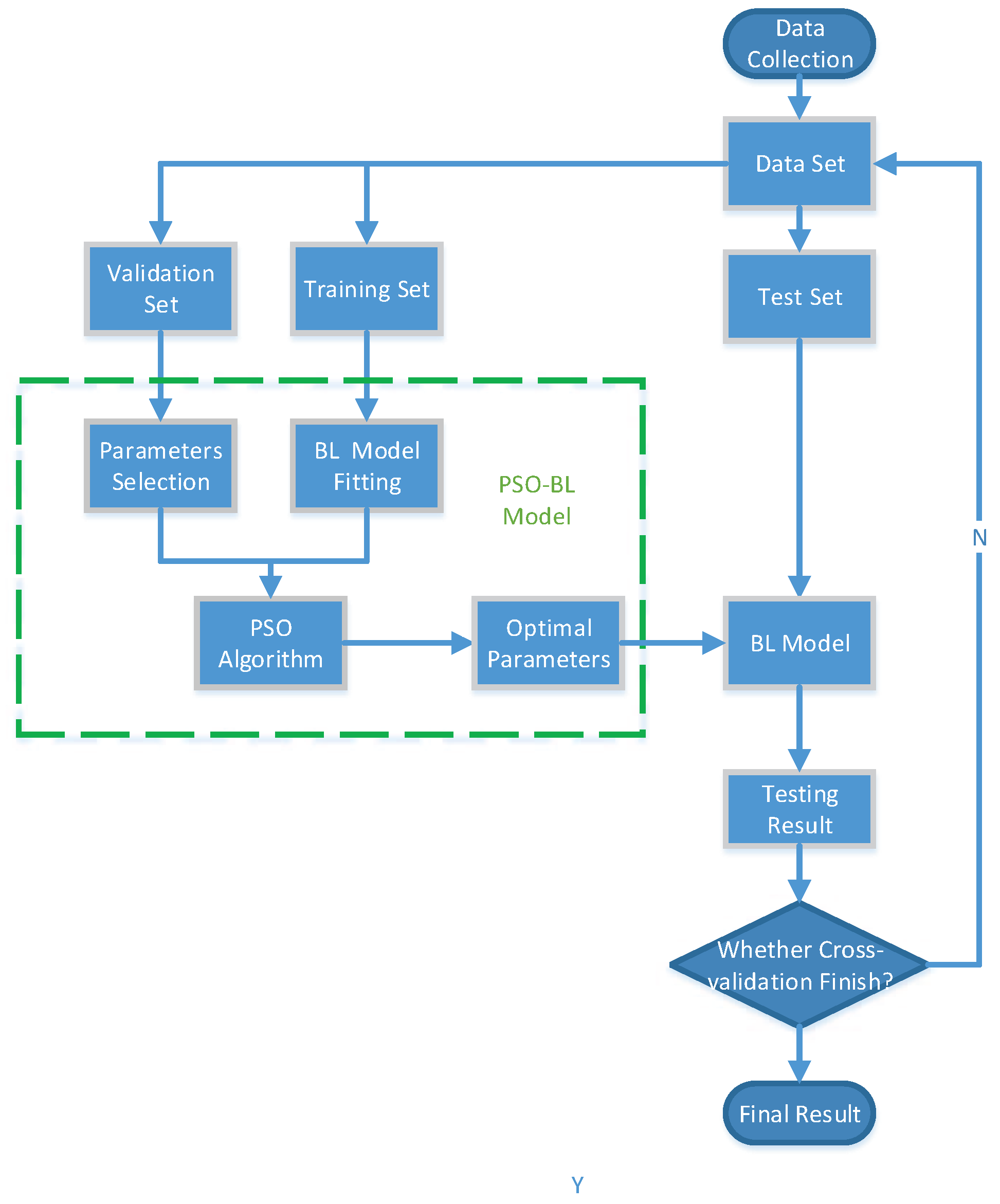
3.2. Proposed PSO-BL Model
| Algorithm 1: The proposed PSO-BL algorithm. |
 |
4. Results and Discussion
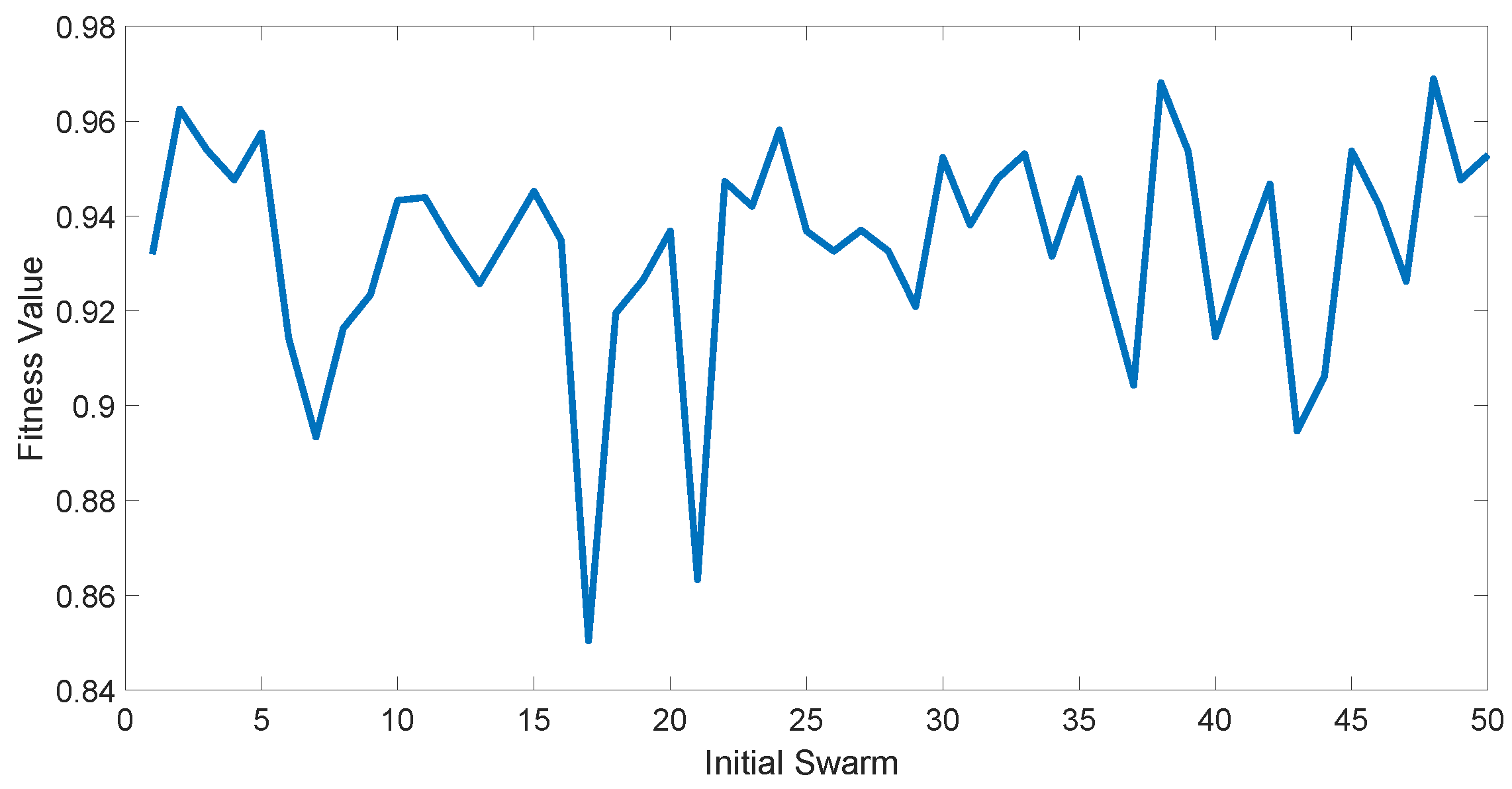
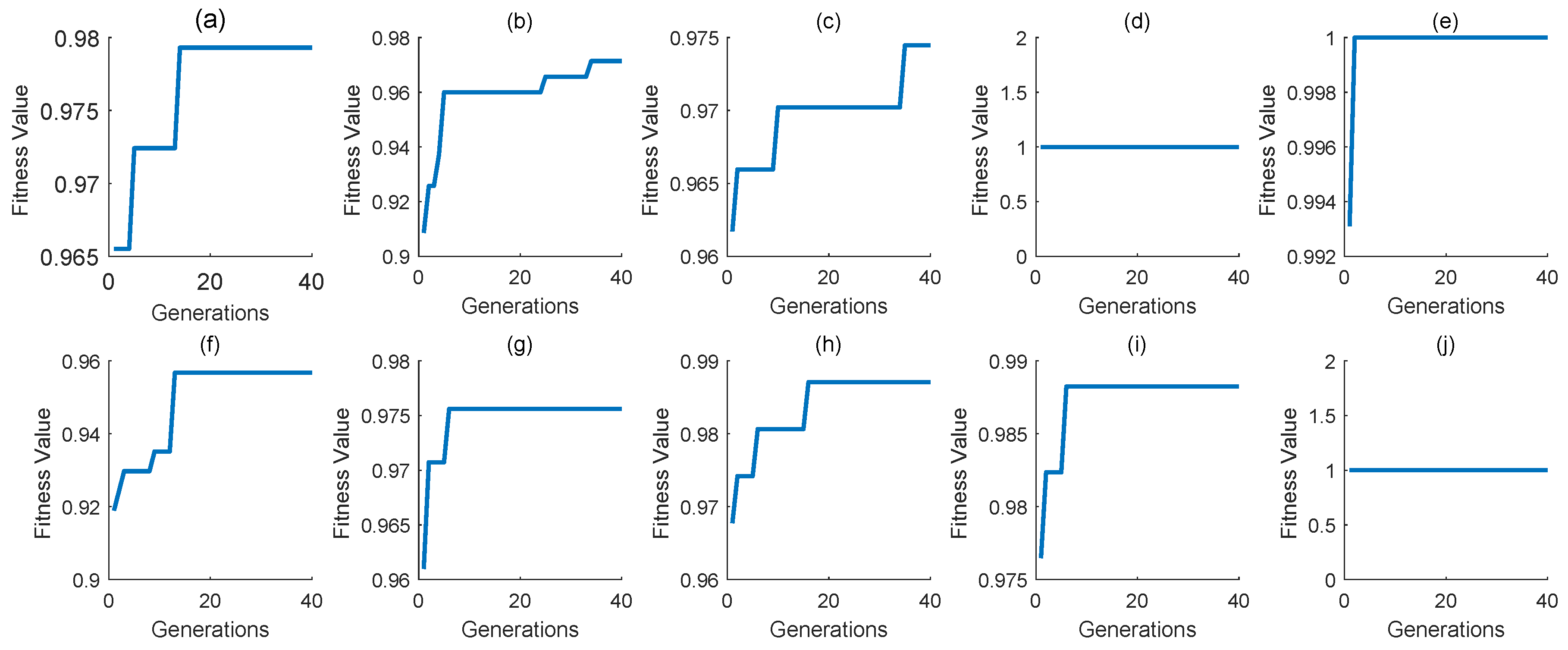
4.1. Model Construction
4.2. Experiment Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Vassilev, S.V.; Vassileva, C.G.; Vassilev, V.S. Advantages and disadvantages of composition and properties of biomass in comparison with coal: An overview. Fuel 2015, 158, 330–350. [Google Scholar] [CrossRef]
- Meng, Z.P.; Liu, C.L.; Yi-Ming, J.I. Geological conditions of coalbed methane and shale gas exploitation and their comparison analysis. J. Coal Sci. Eng. 2013, 38, 728–736. [Google Scholar]
- Li, D.; Li, Z.; Li, W.; Liu, Q.; Feng, Z.; Fan, Z. Hydrotreating of low temperature coal tar to produce clean liquid fuels. J. Anal. Appl. Pyrolysis 2013, 100, 245–252. [Google Scholar] [CrossRef]
- Sajdak, M.; Stelmach, S.; Kotyczka-Morańska, M.; Plis, A. Application of chemometric methods to evaluate the origin of solid fuels subjected to thermal conversion. J. Anal. Appl. Pyrolysis 2015, 113, 65–72. [Google Scholar] [CrossRef]
- Galper, A.M.; Adriani, O.; Aptekar, R.L.; Arkhangelskaja, I.V.; Arkhangelskiy, A.I.; Avanesov, G.A.; Bergstrom, L.; Bogomolov, E.A.; Boezio, M.; Bonvicini, V. The space-based gamma-ray telescope GAMMA-400 and its scientific goals. arXiv, 2013; arXiv:1306.6175. [Google Scholar]
- Xia, W.; Yang, J.; Liang, C. A short review of improvement in flotation of low rank/oxidized coals by pretreatments. Powder Technol. 2013, 237, 1–8. [Google Scholar] [CrossRef]
- Mastalerz, M.; He, L.; Melnichenko, Y.B.; Rupp, J.A. Porosity of coal and shale: Insights from gas adsorption and SANS/USANS techniques. Energy Fuels 2012, 26, 5109–5120. [Google Scholar] [CrossRef]
- Kinnon, E.C.P.; Golding, S.D.; Boreham, C.J.; Baublys, K.A.; Esterle, J.S. Stable isotope and water quality analysis of coal bed methane production waters and gases from the Bowen Basin, Australia. Int. J. Coal Geol. 2010, 82, 219–231. [Google Scholar] [CrossRef]
- Balabin, R.M. Near-infrared (NIR) spectroscopy for biodiesel analysis: Fractional composition, iodine value, and cold filter plugging point from one vibrational spectrum. Energy Fuels 2011, 25, 2373–2382. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, M.; Wei, G.; Hu, R.; Luo, Z.; Li, G. Improved PLS regression based on SVM classification for rapid analysis of coal properties by near-infrared reflectance spectroscopy. Sens. Actuators B Chem. 2014, 193, 723–729. [Google Scholar] [CrossRef]
- Yang, E.; Ge, S.; Wang, S. Characterization and identification of coal and carbonaceous shale using visible and near-infrared reflectance spectroscopy. J. Spectrosc. 2018, 2018. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, X.; Liu, X.; He, Y. Identification of hybrid okra seeds based on near-infrared hyperspectral imaging technology. Appl. Sci. 2018, 8, 1793. [Google Scholar] [CrossRef]
- Hu, Y.; Zou, L.; Huang, X.; Lu, X. Detection and quantification of offal content in ground beef meat using vibrational spectroscopic-based chemometric analysis. Sci. Rep. 2017, 7, 15162. [Google Scholar] [CrossRef] [PubMed]
- Roberts, J.; Power, A.; Chapman, J.; Chandra, S.; Cozzolino, D. A short update on the advantages, applications and limitations of hyperspectral and chemical imaging in food authentication. Appl. Sci. 2018, 8, 505. [Google Scholar] [CrossRef]
- Zhu, Z.; Yuan, H.; Song, C.; Li, X.; Fang, D.; Guo, Z.; Zhu, X.; Liu, W.; Yan, G. High-speed sex identification and sorting of living silkworm pupae using near-infrared spectroscopy combined with chemometrics. Sens. Actuators B Chem. 2018, 268, 299–309. [Google Scholar] [CrossRef]
- Lin, H.; Zhao, J.; Chen, Q.; Zhou, F.; Sun, L. Discrimination of Radix Pseudostellariae according to geographical origins using NIR spectroscopy and support vector data description. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2011, 79, 1381–1385. [Google Scholar] [CrossRef] [PubMed]
- Tony, W.; Gerard, D.; Daniel, J.K.; Colm, O. Geographical classification of honey samples by near-infrared spectroscopy: A feasibility study. J. Agric. Food Chem. 2007, 55, 9128–9134. [Google Scholar]
- Li, G.F.; Yin, Q.B.; Zhang, L.; Kang, M.; Fu, H.Y.; Cai, C.B.; Xu, L. Fine classification and untargeted detection of multiple adulterants of Gastrodia elata BI.(GE) by near-infrared spectroscopy coupled with chemometrics. Anal. Methods 2017, 9, 1897–1904. [Google Scholar] [CrossRef]
- Joachims, T. Making large-scale svm learining practical. Adv. Kernel Methods Support Vector Learn. 2006, 8, 499–526. [Google Scholar]
- Al-kaf, H.A.G.; Chia, K.S.; Alduais, N.A.M. A comparison between single layer and multilayer artificial neural networks in predicting diesel fuel properties using near infrared spectrum. Pet. Sci. Technol. 2018, 36, 411–418. [Google Scholar] [CrossRef]
- Zou, L.; Huang, Q.; Li, A.; Wang, M. A genome-wide association study of Alzheimer’s disease using random forests and enrichment analysis. Sci. China Life Sci. 2012, 55, 618–625. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, L.D.S.; Gentilin, F.A.; Franca, J.A.D.; Franca, M.B.D.M. Development of a hardware platform for detection of milk adulteration based on near-infrared diffuse reflection. IEEE Trans. Instrum. Meas. 2016, 65, 1698–1706. [Google Scholar] [CrossRef]
- Zhao, L.; Chen, Z.; Yang, L.T.; Deen, M.J.; Wang, Z.J. Deep semantic mapping for heterogeneous multimedia transfer learning co-occurrence data. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2019, 15, 9. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Liu, Z. Broad learning system: An effective and efficient incremental learning Ssystem without the need for deep architecture. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 10–24. [Google Scholar] [CrossRef] [PubMed]
- Moreira, M.; França, J.A.D.; Filho, D.D.O.T.; Beloti, V.; Yamada, A.K.; França, M.B.D.M.; Ribeiro, L.D.S. A low-cost NIR digital photometer based on InGaAs Ssensors for the detection of milk adulterations with water. IEEE Sens. J. 2016, 16, 3653–3663. [Google Scholar] [CrossRef]
- Zou, L.; Zheng, J.; Miao, C.; Mckeown, M.J.; Wang, Z.J. 3D CNN based automatic diagnosis of attention deficit hyperactivity disorder using functional and structural MRI. IEEE Access 2017, 5, 23626–23636. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Pluhacek, M.; Senkerik, R.; Davendra, D.; Oplatkova, Z.K.; Zelinka, I. On the behaviour and performance of chaos driven PSO algorithm with inertia weight. Comput. Math. Appl. 2013, 66, 122–134. [Google Scholar] [CrossRef]
- Li, T.; Dai, S.F.; Zou, J.H.; Zhang, S.; Tian, H.H.; Zhao, L.X. Composition and mode of occurrence of minerals in Late Permian coals from Zhenxiong County, northeastern Yunnan, China. Int. J. Coal Sci. Technol. 2014, 1, 13–22. [Google Scholar] [CrossRef]
- Rousseeuw, P.J.; Debruyne, M.; Engelen, S.; Hubert, M. Robustness and outlier detection in chemometrics. Crit. Rev. Anal. Chem. 2006, 36, 221–242. [Google Scholar] [CrossRef]
- Shan, J.; Suzuki, T.; Suhandy, D.; Ogawa, Y.; Kondo, N. Chlorogenic acid (CGA) determination in roasted coffee beans by Near Infrared (NIR) spectroscopy. Eng. Agric. Environ. Food 2014, 7, 139–142. [Google Scholar] [CrossRef]
- Pao, Y.H.; Takefuji, Y. Functional-link net computing: Theory, system architecture, and functionalities. Computer 1992, 25, 76–79. [Google Scholar] [CrossRef]
- Nair, M.V.; Dudek, P. Gradient-descent-based learning in memristive crossbar arrays. In Proceedings of the International Joint Conference on Neural Networks, Killarney, Ireland, 11–16 July 2015. [Google Scholar]
- Mcdonald, G.C. Tracing ridge regression coefficients. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 695–703. [Google Scholar] [CrossRef]
- Liu, B.; Wang, L.; Jin, Y.H. An effective PSO-based memetic algorithm for flow shop scheduling. IEEE Trans. Syst. Man Cybern. Part B. 2007, 37, 18–27. [Google Scholar] [CrossRef]
- Bijalwan, V.; Kumar, V.; Kumari, P.; Pascual, J. KNN based machine learning approach for text and document mining. Int. J. Database Theory Appl. 2014, 7, 61–70. [Google Scholar] [CrossRef]
- Aljarah, I.; Faris, H.; Mirjalili, S.; Al-Madi, N. Training radial basis function networks using biogeography-based optimizer. Neural Comput. Appl. 2018, 29, 529–553. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Times | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 1 | 0.917 | 0.958 | 0.958 | 1 | 1 | 1 | 0.913 | 1 | 0.957 |
| Method | Index | Geographical Origin | Overall Accuracy | ||||
|---|---|---|---|---|---|---|---|
| AUS | RUS | CAN | IND | CHN | |||
| SVM | misclassification | 6 | 4 | 5 | 2 | 2 | 92.83% |
| accuracy | 87.0% | 88.2% | 85.3% | 97.6% | 95.1% | ||
| BPNN | misclassification | 5 | 3 | 5 | 5 | 0 | 92.40% |
| accuracy | 89.1% | 91.2% | 85.3% | 93.9% | 100% | ||
| RBFNN | misclassification | 4 | 5 | 6 | 2 | 1 | 92.40% |
| accuracy | 91.2% | 85.3% | 82.4% | 97.6% | 97.6% | ||
| K-NN | misclassification | 6 | 6 | 8 | 18 | 12 | 78.90% |
| accuracy | 87.0% | 82.4% | 76.5% | 78.0% | 70.7% | ||
| RF | misclassification | 7 | 7 | 9 | 13 | 9 | 81.01% |
| accuracy | 84.8% | 79.4% | 73.5% | 84.1% | 78.0% | ||
| BL | misclassification | 2 | 1 | 4 | 3 | 0 | 95.78% |
| accuracy | 95.7% | 97.1% | 88.2% | 96.3% | 100% | ||
| PSO-BL | misclassification | 1 | 1 | 1 | 3 | 1 | 97.05% |
| accuracy | 97.8% | 97.1% | 97.1% | 96.3% | 97.6% | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, M.; Rao, Z.; Li, M.; Yu, X.; Zou, L. Identification of Coal Geographical Origin Using Near Infrared Sensor Based on Broad Learning. Appl. Sci. 2019, 9, 1111. https://doi.org/10.3390/app9061111
Lei M, Rao Z, Li M, Yu X, Zou L. Identification of Coal Geographical Origin Using Near Infrared Sensor Based on Broad Learning. Applied Sciences. 2019; 9(6):1111. https://doi.org/10.3390/app9061111
Chicago/Turabian StyleLei, Meng, Zhongyu Rao, Ming Li, Xinhui Yu, and Liang Zou. 2019. "Identification of Coal Geographical Origin Using Near Infrared Sensor Based on Broad Learning" Applied Sciences 9, no. 6: 1111. https://doi.org/10.3390/app9061111
APA StyleLei, M., Rao, Z., Li, M., Yu, X., & Zou, L. (2019). Identification of Coal Geographical Origin Using Near Infrared Sensor Based on Broad Learning. Applied Sciences, 9(6), 1111. https://doi.org/10.3390/app9061111