A Multi-Agent Based Intelligent Training System for Unmanned Surface Vehicles

Abstract
1. Introduction
2. Multi-Agent-Based USVs’ Training Problem
- n is the number of agents
- X is the finite set of states
- is the finite set of actions available to the agents, which form the joint action set
- is the finite set of observations of the agents. The joint observation is denoted as
- is the Markovian state transition function where denotes the probability of reaching state after the joint action in state x. The joint action of all agents at a stage t is denoted as
- , are the reward functions of the agents.
3. Multi-Agent-Based Training System Design
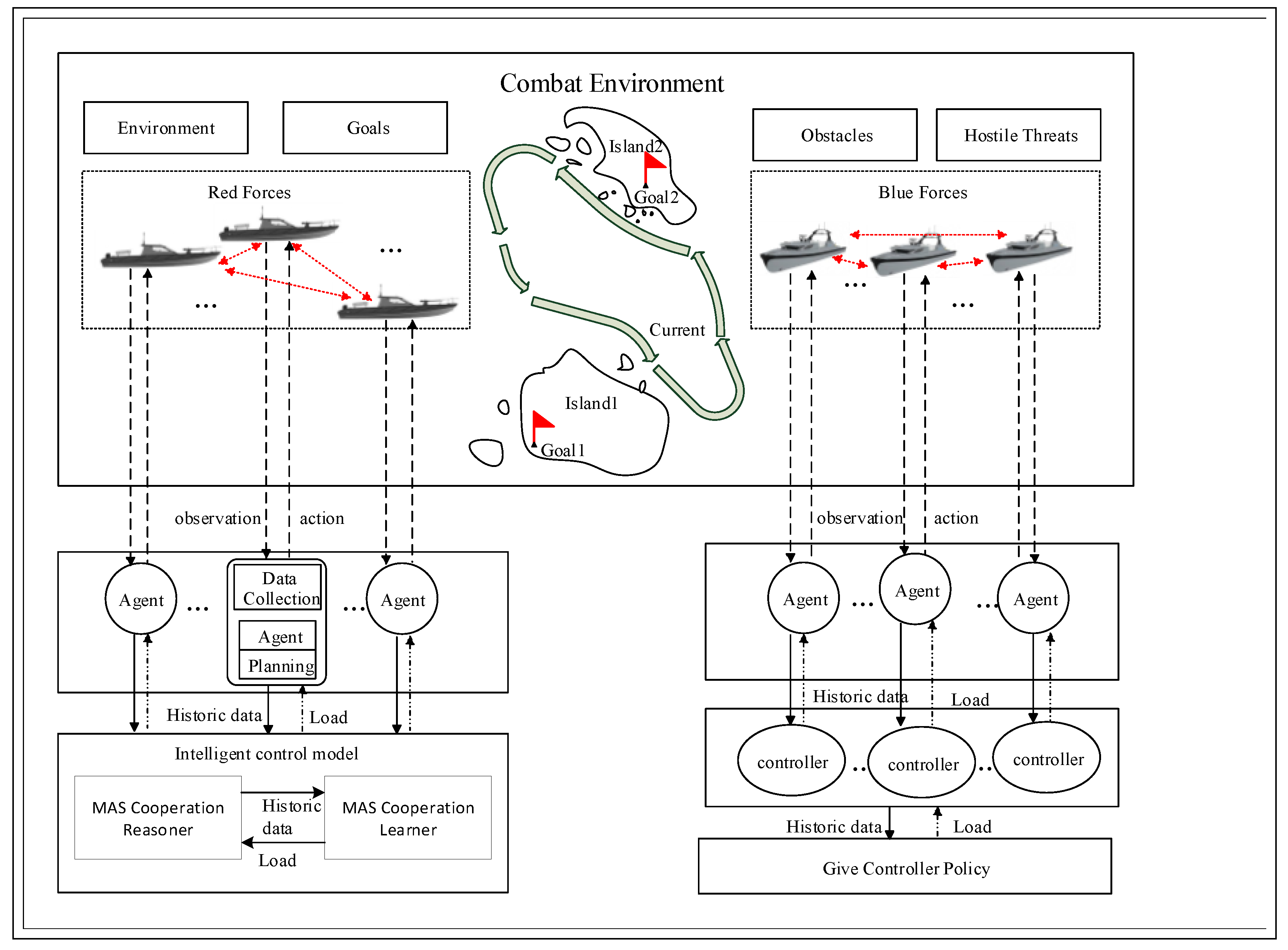
3.1. System Architecture
3.2. Agent Design
3.3. Data Collection Model
- Historical training data level (HTDL): The HTDL layer consists of the entities involved in learning the KB or agents’ policies for a POSG. In situations where the reasoner or policy output corresponds to composite tasks, planning and agent scheduling services may be implemented as modular components in this layer. This layer contains the historical resource data that are leveraged by the underlying learning algorithm to learn the KB.
- Cooperative decision data level: This level consists of entities that handle individual agent-level data for agent decision making. Data at this level are real-time data and observations from the agent.
- Individual agent decision model (IADM): A resource management service for hosting agents’ observations composes this layer. Such a service exposes a uniform set of APIs that can be consumed by the training and control platform or the agents for reasoning or cooperation operations. Modeling the observations as resource data enables the data elements to be uniquely addressed through the APIs.
- Data collection services: Services in this layer receive data from the agents in their raw form and then perform adaptation to a common resource model for use in the training and control platform. Thus, they abstract the heterogeneous forms that agents may report from their local observation.
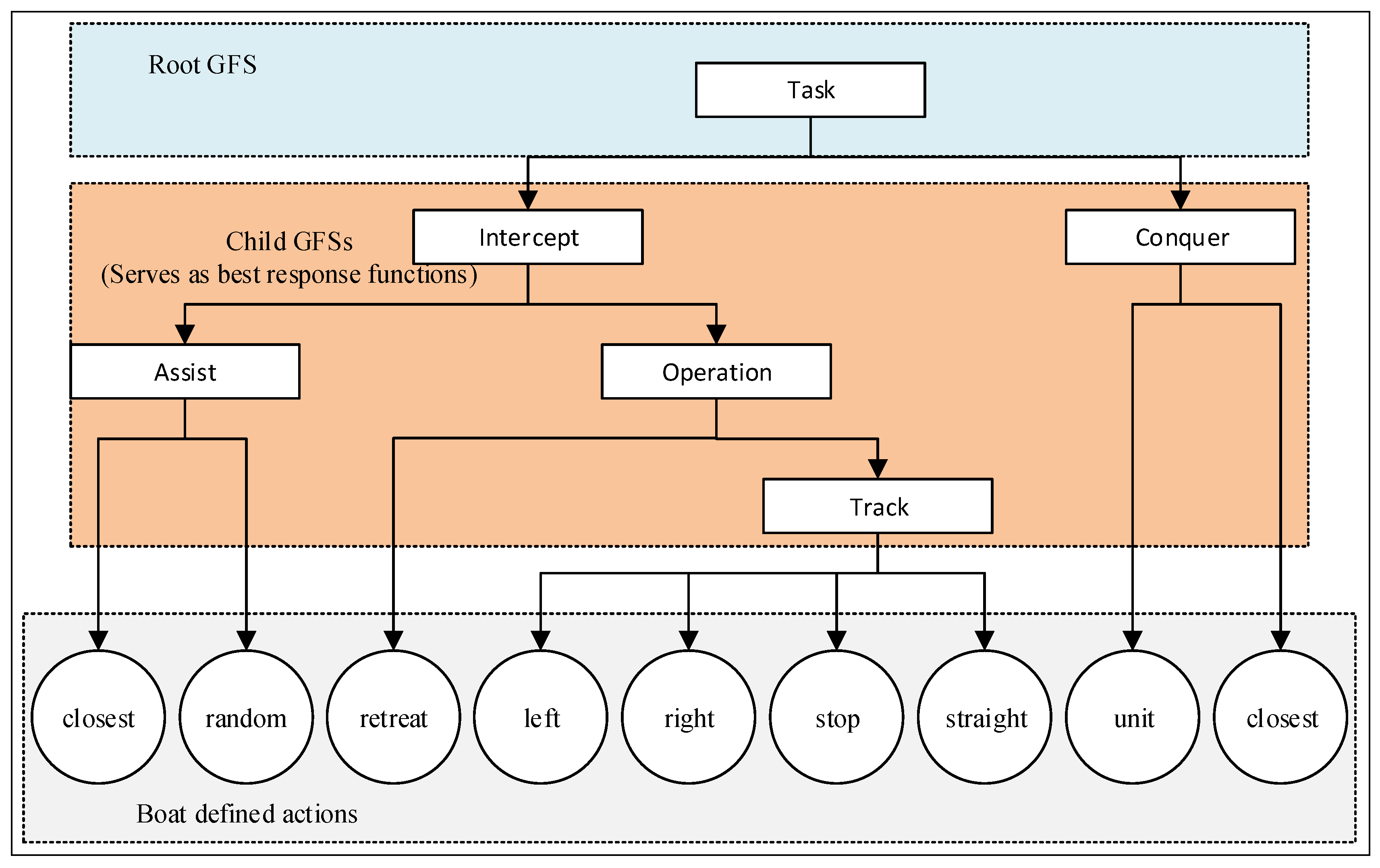
3.4. Multi-Agent-Based USV Training Algorithm Design
- IF X1 IS term1 AND X2 IS term1 THEN Y IS a1
- IF X1 IS term1 AND X2 IS term2 THEN Y IS a2
- IF X1 IS term2 AND X2 IS term1 THEN Y IS a2
- IF X1 IS term2 AND X2 IS term2 THEN Y IS a1
| Algorithm 1 Procedure: GFS procedure. |
|
4. Multi-Agent-Based Simulator Design
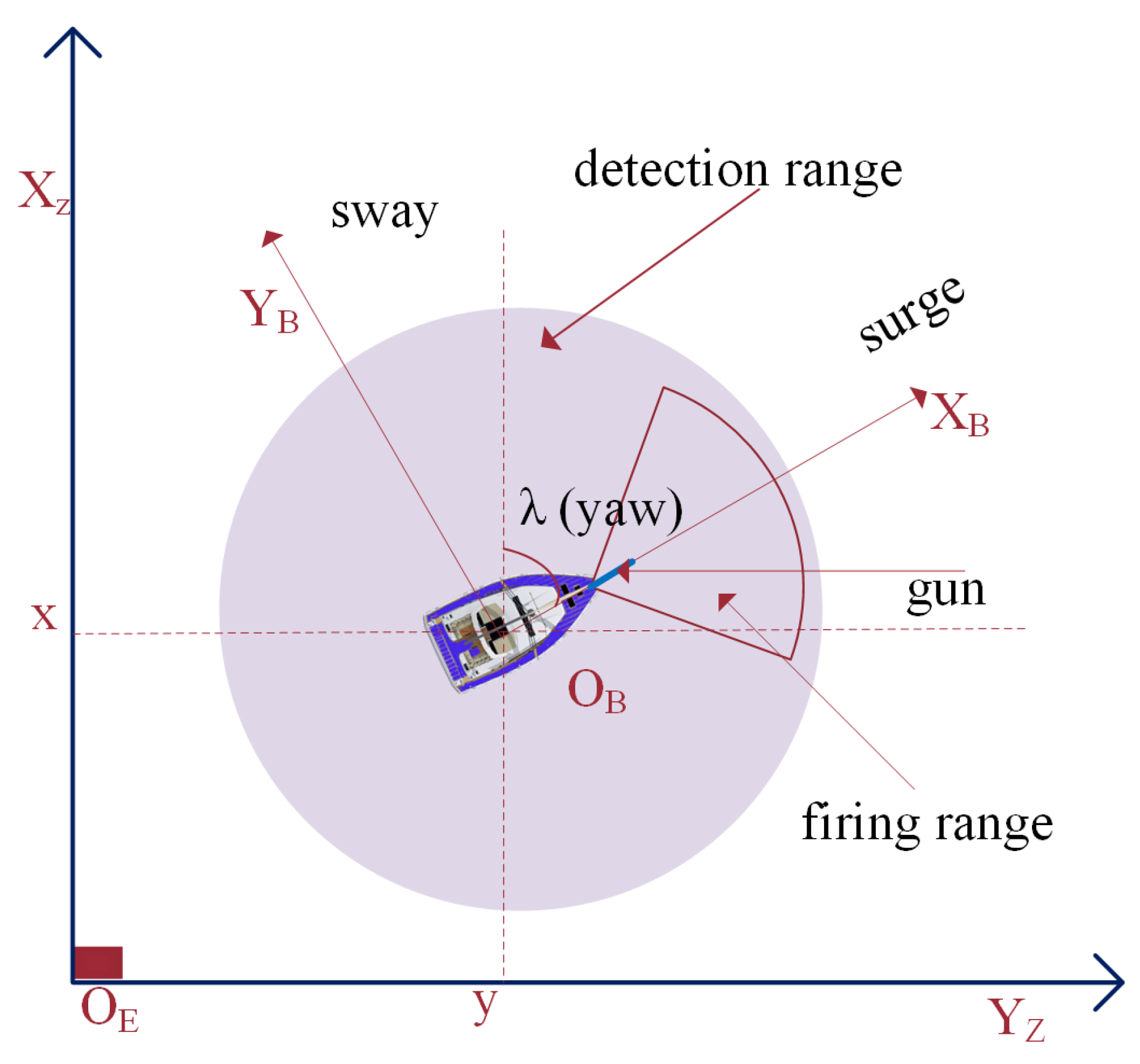
4.1. Environment Setup
- retreat: the agent moves towards its base.
- left: turn left and move.
- right: turn right and move.
- straight: move forward at the current heading.
- stop: stop moving.
- assist: move to help a teammate that is under enemy fire; a boat can assist a random or the closest teammate.
- units: causes a boat to team up with other ally boats to conquer an island.
- closest: the boat conquers an unconquered island that is closest to it.
4.2. Competition Objective
4.3. Data Collector for Training and Learning
- Simulation information: This node provides general information about the simulation for a given time step.
- Observation: This provides the observation made by all agents in the team. Each agent also reports opponents that have been detected, as well as the observable properties of each detected opponent.
- System data: All miscellaneous data concerning the simulation platform (e.g., time, CPU consumption, memory usage, etc.) may be provided under this resource element.
4.4. Training and Learning Algorithm
- PGF_attacked: reports the confidence level that the detected enemy boats are attacking
- PGF_moved: reports the confidence level that the detected enemy boats are moving towards an island or the agent whose local observations are being used for reasoning
- PGF_conquered: computes the confidence level that the detected enemies are conquering an island
- PGF_retreated: evaluates the confidence level that the detected enemies are withdrawing to their initial positions or base.
- UnconqueredIslands: The number of islands not conquered by the team to which a boat belongs.
- DetectedEnemies: The number of detected enemies by a boat.
- FactionDetectedEnemies: The number of detected enemies by a team.
- InEnemyFiringRange: Returns 1 if this boat is in the enemies’ firing range, and 0 otherwise.
- HeadingDifference: The difference in heading between this boat and the target boat.
- DistanceToEnemy: The distance between this boat and the target boat.
- StayingPower: The current strength of a boat to sustain enemy attacks.
- TeammatesUnderFire: Reports the number of teammates a boat has observed to be under attack by opponent boats.
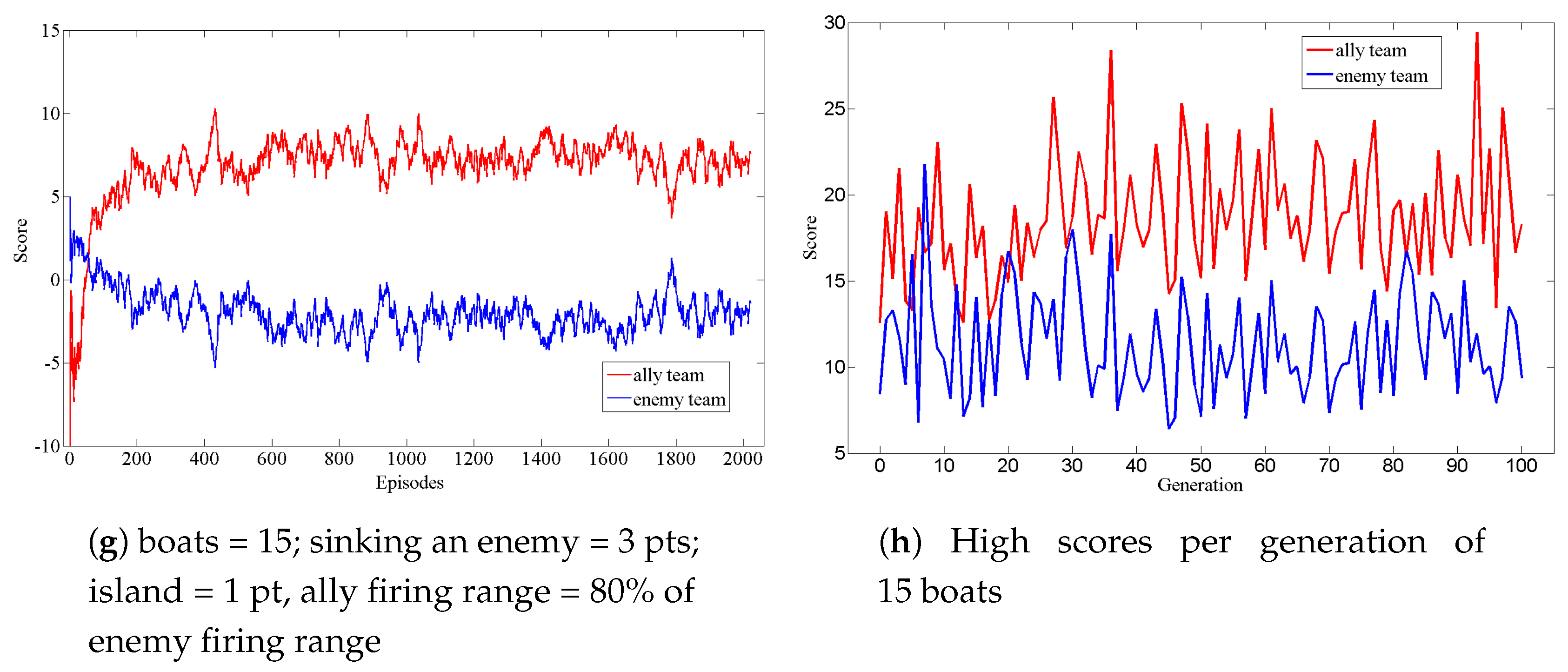
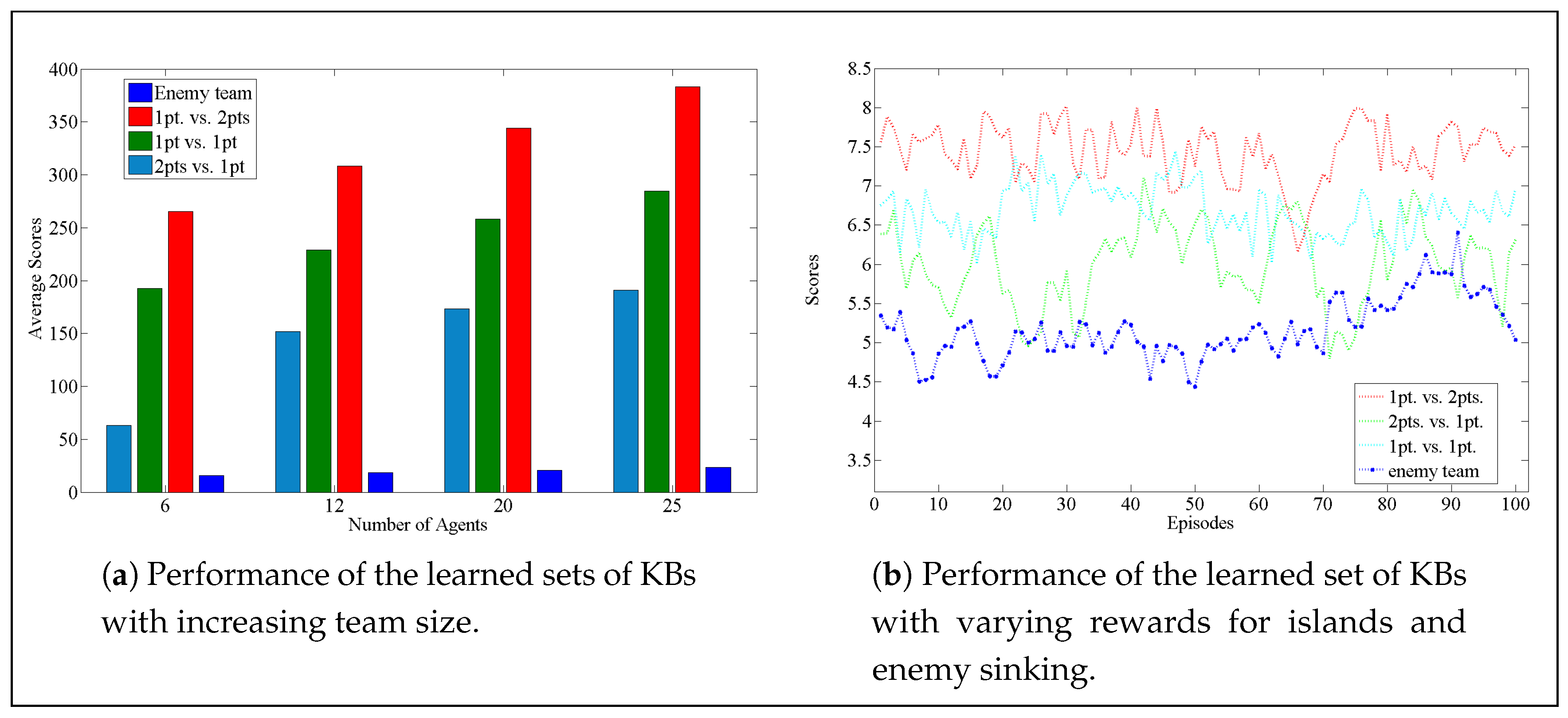
4.5. Experiment Results and Validation Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Weyns, D.; Van Dyke Parunak, H.; Michel, F.; Holvoet, T.; Ferber, J. Environments for Multiagent Systems State-of-the-Art and Research Challenges. In Environments for Multi-Agent Systems; Weyns, D., Van Dyke Parunak, H., Michel, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–47. [Google Scholar]
- Ernest, N.D. Genetic Fuzzy Trees for Intelligent Control of Unmanned Combat Aerial Vehicles. Ph.D. Thesis, University of Cincinnati, Cincinnati, OH, USA, 2015. [Google Scholar]
- Magessi, N.T.; Antunes, L. Modelling Agents’ Perception: Issues and Challenges in Multi-agents Based Systems. In Progress in Artificial Intelligence; Pereira, F., Machado, P., Costa, E., Cardoso, A., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 687–695. [Google Scholar]
- Weyns, D.; Michel, F.; Parunak, V.; Boissier, O.; Schumacher, M.; Ricci, A.; Brandao, A.; Carrascosa, C.; Dikenelli, O.; Galland, S.; et al. Agent Environments for Multi-agent Systems—A Research Roadmap. In Introduction and Challenges of Environment Architectures for Collective Intelligence Systems; Springer-Verlag: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Pipattanasomporn, M.; Feroze, H.; Rahman, S. Multi-agent systems in a distributed smart grid: Design and implementation. In Proceedings of the 2009 IEEE/PES Power Systems Conference and Exposition, Seattle, WA, USA, 15–18 March 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Valogianni, K.; Ketter, W.; Collins, J. A Multiagent Approach to Variable-Rate Electric Vehicle Charging Coordination. In Proceedings of the 2015 International Conference on Autonomous Agents and Multiagent Systems (AAMAS ’15), Istanbul, Turkey, 4–8 May 2015; pp. 1131–1139. [Google Scholar]
- Riedmiller, M.; Moore, A.; Schneider, J. Reinforcement Learning for Cooperating and Communicating Reactive Agents in Electrical Power Grids. In Balancing Reactivity and Social Deliberation in Multi-Agent Systems; Springer: Berlin/Heidelberg, Germany, 2001; pp. 137–149. [Google Scholar]
- Pita, J.; Jain, M.; Ordóñez, F.; Portway, C.; Tambe, M.; Western, C.; Paruchuri, P.; Kraus, S. Using Game Theory for Los Angeles Airport Security. AI Mag. 2009, 30, 43–57. [Google Scholar] [CrossRef]
- Stone, P.; Veloso, M. Multiagent Systems: A Survey from a Machine Learning Perspective. Auton. Robots 2000, 8, 345–383. [Google Scholar] [CrossRef]
- Crites, R.H.; Barto, A.G. Elevator Group Control Using Multiple Reinforcement Learning Agents. Mach. Learn. 1998, 33, 235–262. [Google Scholar] [CrossRef]
- Busoniu, L.; Babuska, R.; Schutter, B.D. A Comprehensive Survey of Multiagent Reinforcement Learning. IEEE Trans. Syst. Man Cybern. Part C 2008, 38, 156–172. [Google Scholar] [CrossRef]
- Bibuli, M.; Singh, Y.; Sharma, S.; Sutton, R.; Hatton, D.; Khan, A. A Two Layered Optimal Approach towards Cooperative Motion Planning of Unmanned Surface Vehicles in a Constrained Maritime Environment. IFAC-PapersOnLine 2018, 51, 378–383. [Google Scholar] [CrossRef]
- Polvara, R.; Patacchiola, M.; Sharma, S.; Wan, J.; Manning, A.; Sutton, R.; Cangelosi, A. Toward End-to-End Control for UAV Autonomous Landing via Deep Reinforcement Learning. In Proceedings of the 2018 International Conference on Unmanned Aircraft Systems (ICUAS), Dallas, TX, USA, 12–15 June 2018; pp. 115–123. [Google Scholar] [CrossRef]
- Obst, O. Using a Planner for Coordination of Multiagent Team Behavior. In Programming Multi-Agent Systems; Bordini, R.H., Dastani, M.M., Dix, J., El Fallah Seghrouchni, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 90–100. [Google Scholar]
- Nalepka, P.; Kallen, R.W.; Chemero, A.; Saltzman, E.; Richardson, M.J. Herd Those Sheep: Emergent Multiagent Coordination and Behavioral-Mode Switching. Psychol. Sci. 2017, 28, 630–650. [Google Scholar] [CrossRef] [PubMed]
- Foerster, J.; Assael, I.A.; de Freitas, N.; Whiteson, S. Learning to Communicate with Deep Multi-Agent Reinforcement Learning. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 2137–2145. [Google Scholar]
- Heins, P.H.; Jones, B.L.; Taunton, D.J. Design and validation of an unmanned surface vehicle simulation model. Appl. Math. Model. 2017, 48, 749–774. [Google Scholar] [CrossRef]
- Sonnenburg, C.R.; Woolsey, C. Modeling, Identification, and Control of an Unmanned Surface Vehicle. J. Field Robot. 2013, 30, 371–398. [Google Scholar] [CrossRef]
- Yue, J.; Ren, G.; Liang, X.; Qi, X.W.; Li, G.T. Motion Modeling and Simulation of High-Speed Unmanned Surface Vehicle. Frontiers of Manufacturing and Design Science. Appl. Mech. Mater. 2011, 44–47, 1588–1592. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Y.; Yu, X.; Yuan, C. Unmanned surface vehicles: An overview of developments and challenges. Ann. Rev. Control 2016, 41, 71–93. [Google Scholar] [CrossRef]
- Yan, R.j.; Pang, S.; Sun, H.b.; Pang, Y.j. Development and missions of unmanned surface vehicle. J. Mar. Sci. Appl. 2010, 9, 451–457. [Google Scholar] [CrossRef]
- IsraelDefense. Rafael’s Protector USV Conducts Successful Missile Firing Demo for NATO. 2018. Available online: https://www.israeldefense.co.il/en/node/34530 (accessed on 14 March 2019).
- Opall-Rome, B. Israel’s Elbit Unveils USV for Anti-Sub, Anti-Mine Missions. 2016. Available online: https://www.defensenews.com/naval/2016/02/08/israels-elbit-unveils-usv-for-anti-sub-anti-mine-missions/ (accessed on 14 March 2019).
- Schnoor, R.T. Modularized unmanned vehicle packages for the littoral combat ship mine countermeasures missions. In Proceedings of the Oceans 2003: Celebrating the Past ... Teaming Toward the Future (IEEE Cat. No. 03CH37492), San Diego, CA, USA, 22–26 September 2003; Volume 3, pp. 1437–1439. [Google Scholar] [CrossRef]
- Manley, J. Unmanned surface vehicles, 15 years of development. In Proceedings of the OCEANS 2008, Quebec City, QC, Canada, 15–18 September 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Wen, G.X. Neural-network-based adaptive leader-following consensus control for second-order non-linear multi-agent systems. IET Control Theory Appl. 2015, 9, 1927–1934. [Google Scholar] [CrossRef]
- Cordón, Ó.; Herrera, F.; Hoffmann, F.; Magdalena, L. Genetic Fuzzy Systems: Evolutionary Tuning and Learning Of Fuzzy Knowledge Bases; World Scientific: London, UK, 2004; Volume 141, pp. 161–162. [Google Scholar]
- Holland, J.H.; Reitman, J.S. Cognitive Systems Based on Adaptive Algorithms. SIGART Bull. 1977, 49. [Google Scholar] [CrossRef]
- Smith, S.F. A Learning System Based on Genetic Adaptive Algorithms. Ph.D. Thesis, University of Pittsburgh, Pittsburgh, PA, USA, 1980. [Google Scholar]
- Herrera, F.; Lozano, M.; Verdegay, J. A learning process for fuzzy control rules using genetic algorithms. Fuzzy Sets Syst. 1998, 100, 143–158. [Google Scholar] [CrossRef]
- Herrera, F.; Lozano, M.; Verdegay, J.L. Tackling Real-Coded Genetic Algorithms: Operators and Tools for Behavioural Analysis. Artif. Intell. Rev. 1998, 12, 265–319. [Google Scholar] [CrossRef]
- Hernandez-Leal, P.; Kaisers, M.; Baarslag, T.; de Cote, E.M. A Survey of Learning in Multiagent Environments: Dealing with Non-Stationarity. arXiv, 2017; arXiv:1707.09183. [Google Scholar]
- Claus, C.; Boutilier, C. The Dynamics of Reinforcement Learning in Cooperative Multiagent Systems. In Proceedings of the Fifteenth National/Tenth Conference on Artificial Intelligence/Innovative Applications of Artificial Intelligence (AAAI ’98/IAAI ’98), Madison, WI, USA, 26–30 July 1998; American Association for Artificial Intelligence: Menlo Park, CA, USA, 1998; pp. 746–752. [Google Scholar]
- Rada-Vilela, J. Fuzzylite: A Fuzzy Logic Control Library in C++. 2017. Available online: https://pdfs.semanticscholar.org/ec93/4e26ea2950d0f3ab30d31eb8ac239373b4e8.pdf (accessed on 14 March 2019).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unconquered | DetectedEnemies | TaskOutput |
|---|---|---|
| None | None | Retreat |
| None | Moderate | Intercept |
| None | Many | Intercept |
| Moderate | None | Conquer |
| Moderate | Moderate | Conquer |
| Moderate | None | Conquer |
| Moderate | Many | Intercept |
| Many | Many | Intercept |
| Many | Moderate | Conquer |
| GFS | Input Variables | Output Variable | Output Variable Terms | RBSize | No. of MF Tuning Parameters |
|---|---|---|---|---|---|
| Task | UnconquredIslands | BeliefFunction | conquering Intercepting | 243 | 30 |
| PGF_attacked | |||||
| PGF_moved | |||||
| PGF_conquered | |||||
| PGF_retreated | |||||
| Intercept | DetectedEnemies | InterceptOutput | Assist Operation | 6 | 6 |
| InEnemyFiringRange | |||||
| Assist | DetectedEnemies | InterceptOutput | assistClosest assistRandom | 9 | 12 |
| FactionDetectedEnemies | |||||
| Operation | StayingPower | OperationOutput | track retreat | 9 | 12 |
| DetectedEnemies | |||||
| Track | DistanceToEnemy | TrackOutput | left, right stop, straight | 21 | 20 |
| HeadingDifference | |||||
| Conquer | UnconqueredIslands | UnconqueredIslands | conquer in units conquer closest | 3 | 6 |
| Parameter | Value |
|---|---|
| Population size | 20 |
| Number of generations | 101 (initial population included) |
| Crossover probability | 0.7 |
| Mutation probability | 0.1 |
| Mutation decay Schedule | Exponential decay (decay rate = 0.15) |
| Crossover operator | BLXcrossover (alpha = 0.15) |
| Mutation operator | Adaptive non-uniform mutation (b = 5) |
| Selection operator | Tournament selection |
| Parameter | Value |
|---|---|
| Number of boats per team | 6 |
| Number of islands | 5 |
| Simulation steps per episode | 30 |
| Time per step | 3 s |
| Radar radius | 140 |
| Forward firing angle | 20 |
| Boat’s velocity | 4/system iteration |
| Firing range | 100 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, W.; Zhang, B.; Wang, Q.; Luo, J.; Ran, W.; Xu, Y. A Multi-Agent Based Intelligent Training System for Unmanned Surface Vehicles. Appl. Sci. 2019, 9, 1089. https://doi.org/10.3390/app9061089
Han W, Zhang B, Wang Q, Luo J, Ran W, Xu Y. A Multi-Agent Based Intelligent Training System for Unmanned Surface Vehicles. Applied Sciences. 2019; 9(6):1089. https://doi.org/10.3390/app9061089
Chicago/Turabian StyleHan, Wei, Bing Zhang, Qianyi Wang, Jun Luo, Weizhi Ran, and Yang Xu. 2019. "A Multi-Agent Based Intelligent Training System for Unmanned Surface Vehicles" Applied Sciences 9, no. 6: 1089. https://doi.org/10.3390/app9061089
APA StyleHan, W., Zhang, B., Wang, Q., Luo, J., Ran, W., & Xu, Y. (2019). A Multi-Agent Based Intelligent Training System for Unmanned Surface Vehicles. Applied Sciences, 9(6), 1089. https://doi.org/10.3390/app9061089