A Latent State-Based Multimodal Execution Monitor with Anomaly Detection and Classification for Robot Introspection



Abstract
1. Introduction
2. Related Work
2.1. Robot Learning from Demonstration
2.2. Multivariate Time-Series Modeling
2.3. Anomaly Detection and Classification
3. Basic Methodology
3.1. Dynamical Movement Primitive
3.2. Hierarchical Dirichlet Process Vector Auto-Regressive Hidden Markov Models
4. Anomaly Detection
4.1. Hidden-State Representation
4.2. Joint Probability of the Observed Sequence
4.3. Hidden-State Estimation of Auto-Regressive Model
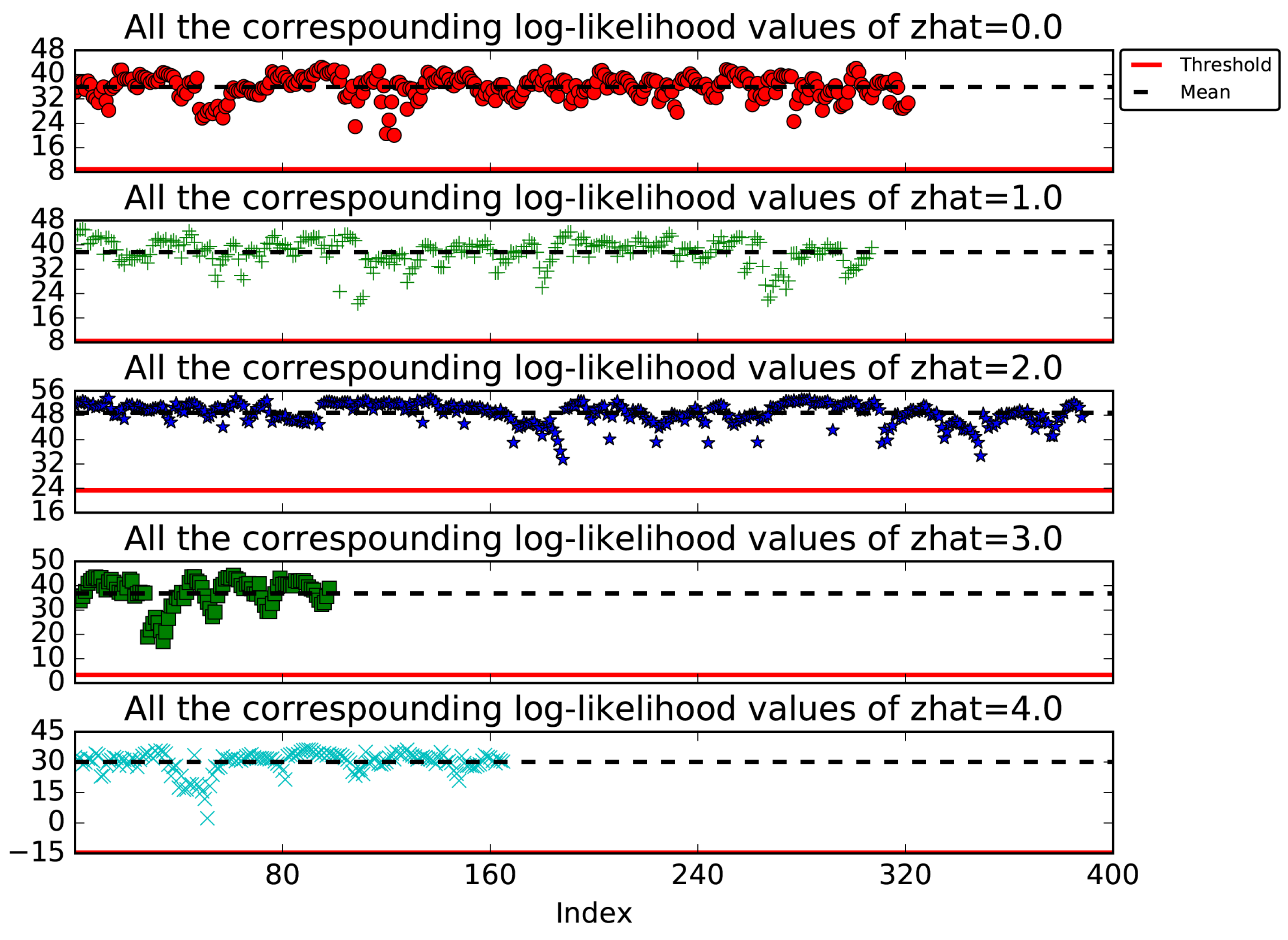
4.4. Threshold Calculation
5. Anomaly Classification
5.1. Problem Formulation
| Algorithm 1: Training model for anomaly classification. |
 |
5.2. Multiple Classes Anomaly Classifier
6. Verification
6.1. Experimental Setup
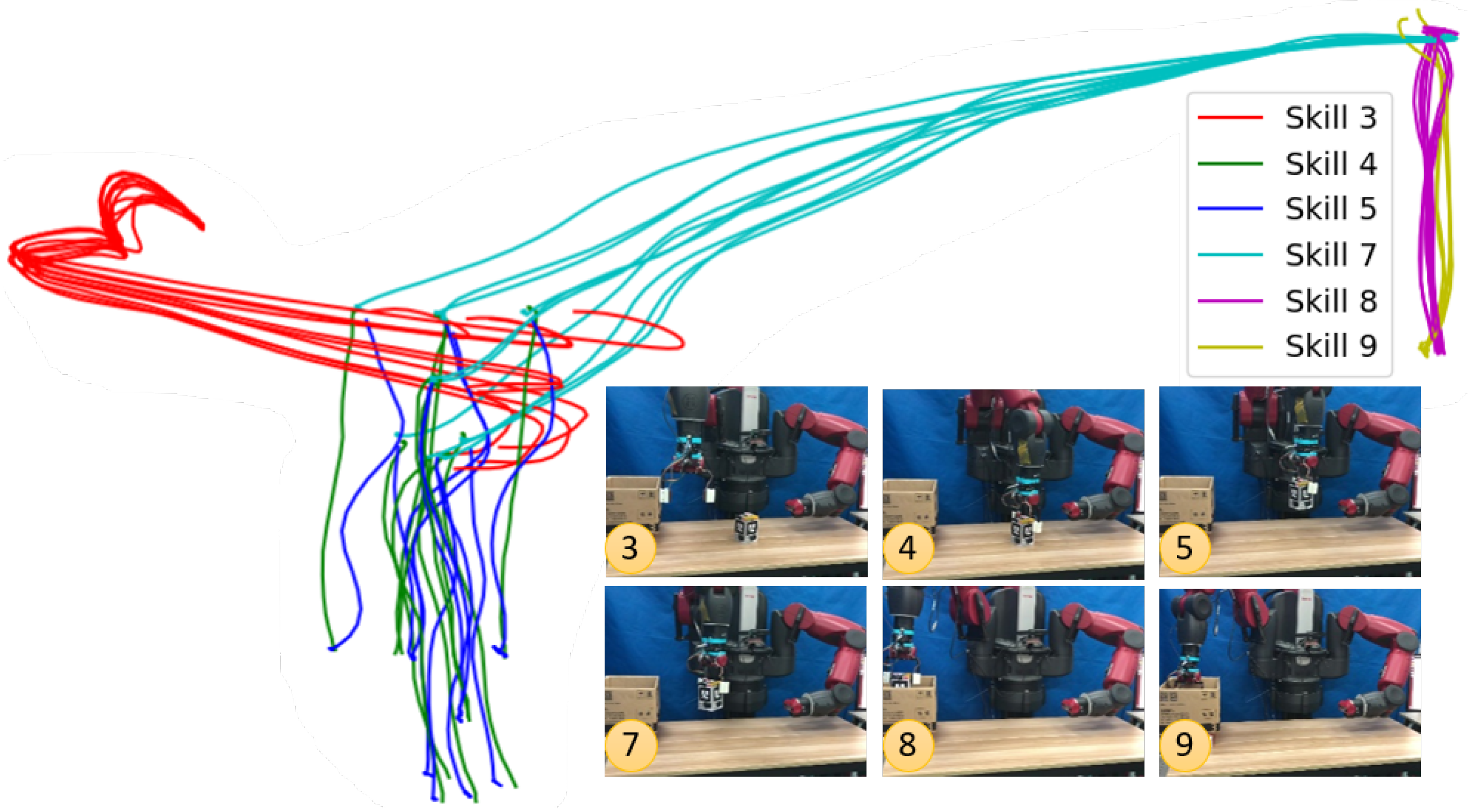
6.1.1. Finite-State Machine Based Kitting Experiment
6.1.2. The Robot
6.1.3. Objects
6.1.4. Visual System
6.1.5. External Disturbances
- For collaborative jobs (such as kitting in warehouses; see the description in Section 6.1.1), humans may experience monotony leading to boredom and loss of attention. In such cases, it is possible for a human co-worker to accidentally collide with the robot manipulator or alter the environment in unexpected ways.
- The user may also accidentally collide or unintentionally move packaging objects in ways a robot may not anticipate. Such variations in the world may lead to tool collisions.
- Picked objects may slip from a robot’s gripper if the grasp is not optimal; or if upon motion, inertial forces acting on the object cause slippage that breaks the grasp.
- Object slips may also be caused due to human collisions. Such phenomena depict a chain of anomaly reactions where one anomaly leads to another.
- The robot may also collide with packaging box during kitting.
- Missed grasps (where the robot pinches air) are possible when the target object is moved without the robot noticing.
- Additionally, it is possible to suffer from false positives from the anomaly detector. False positives may occur for numerous reasons: system error, unreachable objects, unfeasible inverse kinematic solutions, unidentifiable objects from the visual system, to name a few.
6.2. Dataset Collection
6.2.1. Deducing Anomalies
6.2.2. Human Collaborators
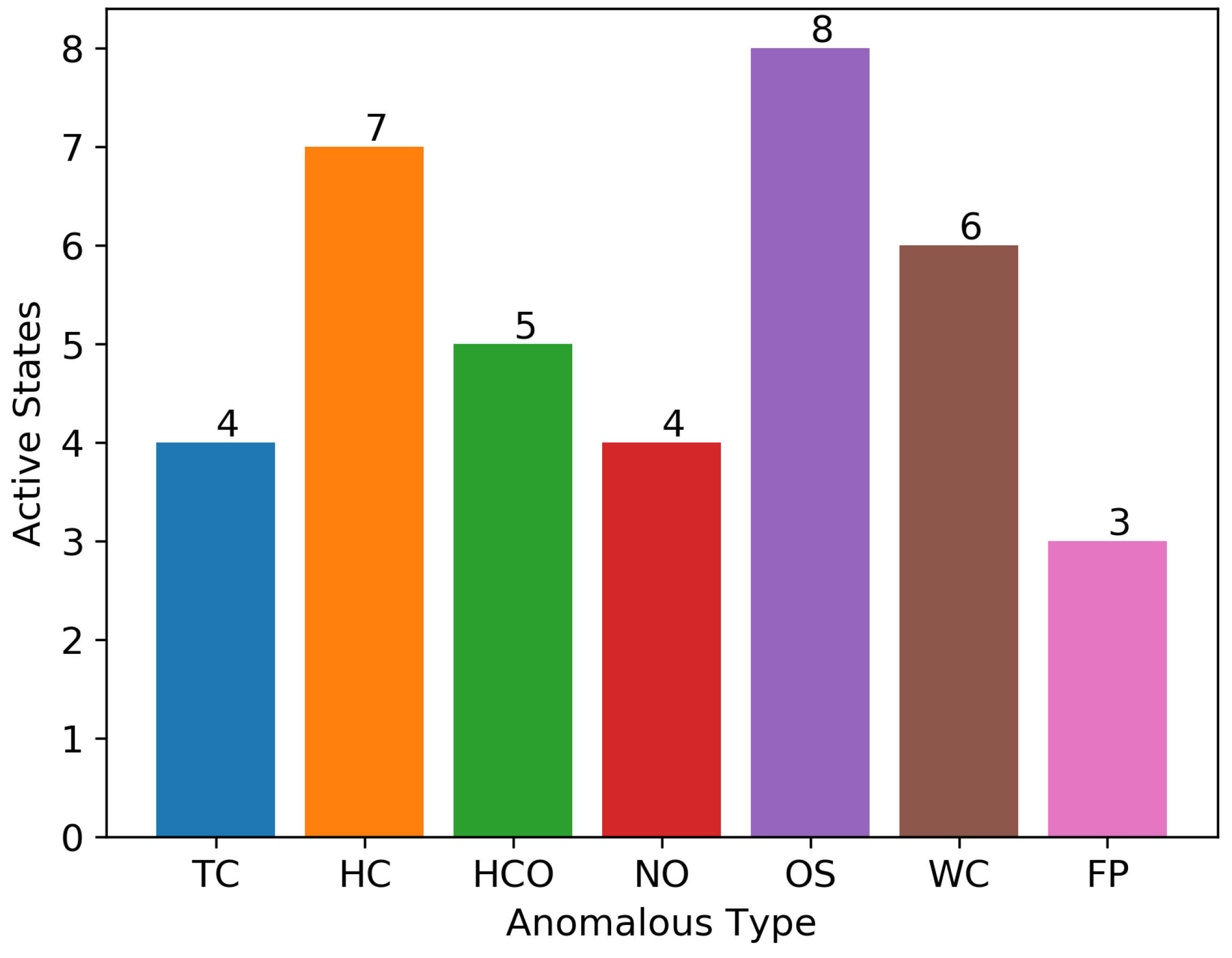
6.2.3. Anomaly Classification Window Considerations
6.3. Sensory Pre-Processing
6.4. Basic Parameter Settings of Each Model
7. Results and Analysis
7.1. Anomaly Detection in Kitting Experiment
7.2. Anomaly Classification in a Kitting Experiment
7.2.1. Dataset
7.2.2. Anomaly Data Online Recording
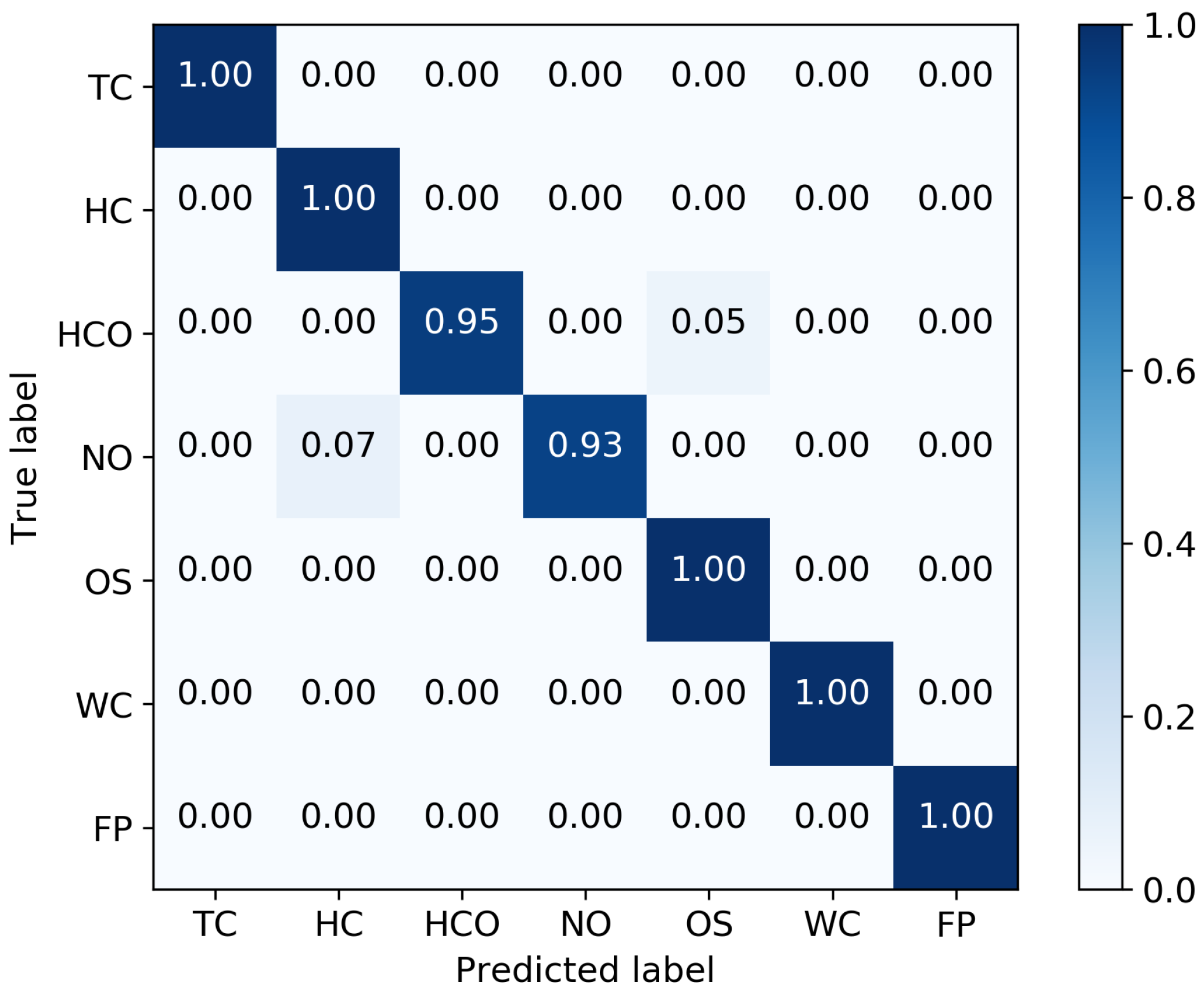
7.2.3. Results
8. Discussion
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| SPAIR | Sence-Plan-Act-Introspection-Recovery |
| HMM | Hidden Markov Model |
| AR-HMM | Auto-regressive Hidden Markov Model |
| HDP-HMM | Hierarchical Dirichlet Process Hidden Markov Model |
| sHDP-HMM | Sticky Hierarchical Dirichlet Process Hidden Markov Model |
| sHDP-VAR-HMM | Sticky Hierarchical Dirichlet Process Hidden Markov Model with |
| Auto-regressive Observation | |
| BP-AR-HMM | Beta-process Prior on Auto-regressive Hidden Markov Model |
| STAR-HMM | State-based Transition Auto-regressive Hidden Markov Model |
| HCRF | Hidden-State Conditional Random Field |
| HULM | Hidden Unit Logistic Model |
| FSM | Finite-State Machine |
| DMP | Dynamical Movement Primitive |
| KNN | K-nearest Neighbors |
| DTW | Dynamic Time Wrapping |
| HC | Human Collisions |
| TC | Tool Collisions |
| OS | Object Slips |
| HCO | Human Collision with Object |
| WC | Wall Collision |
| NO | No Object |
| HSD | Hidden-state Detector |
| GD | Gradient-based Detector |
References
- Wu, H.; Lin, H.; Luo, S.; Duan, S.; Guan, Y.; Rojas, J. Recovering from External Disturbances in Online Manipulation through State-Dependent Revertive Recovery Policies. arXiv, 2017; arXiv:1708.00200. [Google Scholar]
- Luo, S.; Wu, H.; Lin, H.; Duan, S.; Guan, Y.; Juan, R. Robust and Versatile Event Detection through Gradient-Based Scoring of HMM Models. arXiv, 2018; arXiv:1709.07876. [Google Scholar]
- Ijspeert, A.J.; Nakanishi, J.; Hoffmann, H.; Pastor, P.; Schaal, S. Dynamical movement primitives: Learning attractor models for motor behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef] [PubMed]
- Pastor, P.; Hoffmann, H.; Asfour, T.; Schaal, S. Learning and generalization of motor skills by learning from demonstration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation (ICRA’09), Kobe, Japan, 12–17 May 2009; pp. 763–768. [Google Scholar]
- Calinon, S.; Bruno, D.; Caldwell, D.G. A task-parameterized probabilistic model with minimal intervention control. In Proceedings of the 2014 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 3339–3344. [Google Scholar]
- Khansari-Zadeh, S.M.; Billard, A. Learning control Lyapunov function to ensure stability of dynamical system-based robot reaching motions. Robot. Auton. Syst. 2014, 62, 752–765. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.B. Human activity recognition using smartphone sensors with two-stage continuous hidden Markov models. In Proceedings of the 2014 IEEE 10th International Conference on Natural computation (ICNC), Xiamen, China, 19–21 August 2014; pp. 681–686. [Google Scholar]
- Goutsu, Y.; Takano, W.; Nakamura, Y. Classification of Multi-class Daily Human Motion using Discriminative Body Parts and Sentence Descriptions. Int. J. Comput. Vis. 2018, 126, 495–514. [Google Scholar] [CrossRef]
- Wu, H.; Lin, H.; Guan, Y.; Harada, K.; Juan, R. Robot introspection with Bayesian nonparametric vector autoregressive hidden Markov models. In Proceedings of the 2017 IEEE-RAS 17th International Conference on Humanoid Robotics (Humanoids), Birmingham, UK, 15–17 November 2017; pp. 882–888. [Google Scholar]
- Lemme, A.; Meirovitch, Y.; Khansari-Zadeh, S.M.; Flash, T.; Billard, A.; Steil, J.J. Open-Source Benchmarking for Learned Reaching Motion Generation in Robotics. J. Behav. Robot. 2015, 6, 30–41. [Google Scholar] [CrossRef]
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A survey of robot learning from demonstration. Robot. Auton. Syst. 2009, 57, 469–483. [Google Scholar] [CrossRef]
- Billard, A.; Calinon, S.; Dillmann, R.; Schaal, S. Handbook of Robotics, Chapter 59: Robot Programming by Demonstration. 2007, pp. 131–157. Available online: http://calinon.ch/papers/Billard-handbookOfRobotics.pdf (accessed on 14 March 2019).
- Niekum, S.; Chitta, S.; Marthi, B.; Osentoski, S.; Barto, A.G. Incremental Semantically Grounded Learning from Demonstration. Robot. Sci. Syst. 2013, 9. [Google Scholar] [CrossRef]
- Niekum, S.; Osentoski, S.; Konidaris, G.; Chitta, S.; Marthi, B.; Barto, A.G. Learning grounded finite-state representations from unstructured demonstrations. Int. J. Robot. Res. 2015, 34, 131–157. [Google Scholar] [CrossRef]
- Yu, D.; Deng, L. Automatic Speech Recognition; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Veenendaal, A.; Daly, E.; Jones, E.; Gang, Z.; Vartak, S.; Patwardhan, R.S. Sensor Tracked Points and HMM Based Classifier for Human Action Recognition. Comput. Sci. Emerg. Res. J. 2016, 5, 4–8. [Google Scholar]
- Hovland, G.E.; McCarragher, B.J. Hidden Markov models as a process monitor in robotic assembly. Int. J. Robot. Res. 1998, 17, 153–168. [Google Scholar] [CrossRef]
- Alshraideh, H.; Runger, G. Process monitoring using hidden Markov models. Qual. Reliab. Eng. Int. 2014, 30, 1379–1387. [Google Scholar] [CrossRef]
- Fox, M.; Ghallab, M.; Infantes, G.; Long, D. Robot introspection through learned hidden markov models. Artif. Intell. 2006, 170, 59–113. [Google Scholar] [CrossRef]
- Chuk, T.; Chan, A.B.; Shimojo, S.; Hsiao, J. Mind reading: Discovering individual preferences from eye movements using switching hidden Markov models. In Proceedings of the 38th Annual Conference of the Cognitive Science Society (CogSci 2016), Philadelphia, PA, USA, 10–13 August 2016; Cognitive Science Society. 2016. Available online: http://mindmodeling.org/cogsci2016/index.html (accessed on 20 October 2018).
- Manogaran, G.; Vijayakumar, V.; Varatharajan, R.; Kumar, P.M.; Sundarasekar, R.; Hsu, C.H. Machine learning based big data processing framework for cancer diagnosis using hidden Markov model and GM clustering. Wirel. Pers. Commun. 2017, 102, 2099–2116. [Google Scholar] [CrossRef]
- Kroemer, O.; Van Hoof, H.; Neumann, G.; Peters, J. Learning to predict phases of manipulation tasks as hidden states. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 4009–4014. [Google Scholar]
- Kroemer, O.; Daniel, C.; Neumann, G.; van Hoof, H.; Peters, J. Towards Learning Hierarchical Skills for Multi-Phase Manipulation Tasks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Teh, Y.W.; Jordan, M.I. Hierarchical Bayesian nonparametric models with applications. In Bayesian Nonparametrics; Cambridge University Press: Cambridge, UK, 2010; Volume 1, pp. 158–207. [Google Scholar]
- Fox, E.B.; Sudderth, E.B.; Jordan, M.I.; Willsky, A.S. An HDP-HMM for systems with state persistence. In Proceedings of the ACM 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 312–319. [Google Scholar]
- Bryan, J.D.; Levinson, S.E. Autoregressive Hidden Markov Model and the Speech Signal. Procedia Comput. Sci. 2015, 61, 328–333. [Google Scholar] [CrossRef]
- Stanculescu, I.; Williams, C.K.; Freer, Y. Autoregressive hidden Markov models for the early detection of neonatal sepsis. IEEE J. Biomed. Health Inform. 2014, 18, 1560–1570. [Google Scholar] [CrossRef]
- Park, D.; Erickson, Z.; Bhattacharjee, T.; Kemp, C.C. Multimodal execution monitoring for anomaly detection during robot manipulation. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 407–414. [Google Scholar] [CrossRef]
- Zhang, A.; Gultekin, S.; Paisley, J. Stochastic variational inference for the HDP-HMM. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 800–808. [Google Scholar]
- Johnson, M.; Willsky, A. Stochastic variational inference for Bayesian time series models. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2014; pp. 1854–1862. [Google Scholar]
- Hughes, M.C.; Fox, E.; Sudderth, E.B. Effective Split-Merge Monte Carlo Methods for Nonparametric Models of Sequential Data. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1295–1303. [Google Scholar]
- Hughes, M.C.; Sudderth, E.B. Bnpy: Reliable and scalable variational inference for bayesian nonparametric models. In Proceedings of the NIPS Probabilistic Programimming Workshop, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Sölch, M.; Bayer, J.; Ludersdorfer, M.; van der Smagt, P. Variational inference for on-line anomaly detection in high-dimensional time series. arXiv, 2016; arXiv:1602.07109. [Google Scholar]
- Pimentel, M.A.; Clifton, D.A.; Clifton, L.; Tarassenko, L. A review of novelty detection. Signal Process. 2014, 99, 215–249. [Google Scholar] [CrossRef]
- Milacski, Z.Á.; Ludersdorfer, M.; Lőrincz, A.; Van Der Smagt, P. Robust detection of anomalies via sparse methods. In International Conference on Neural Information Processing; Springer: Cham, Switzerland, 2015; pp. 419–426. [Google Scholar]
- Rojas, J.; Luo, S.; Zhu, D.; Du, Y.; Lin, H.; Huang, Z.; Kuang, W.; Harada, K. Online Robot Introspection via Wrench-based Action Grammars. arXiv, 2017; arXiv:1702.08695. [Google Scholar]
- Enrico, D.L.; Tinne, D.L.; Berman, B. HDP-HMM for abnormality detection in robotic assembly. In Proceedings of the NIPS Workshop on Bayesian Nonparametric Models for Reliable Planning and Decision-Making under Uncertainty, Stateline, NV, USA, 3–6 December 2012; pp. 131–157. [Google Scholar]
- Di Lello, E.; Klotzbucher, M.; De Laet, T.; Bruyninckx, H. Bayesian time-series models for continuous fault detection and recognition in industrial robotic tasks. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 5827–5833. [Google Scholar]
- Hu, D.H.; Zhang, X.X.; Yin, J.; Zheng, V.W.; Yang, Q. Abnormal Activity Recognition Based on HDP-HMM Models. In Proceedings of the Twenty-First International Joint Conference on Artificial Intelligence (IJCAI), Pasadena, CA, USA, 11–17 July 2009; pp. 1715–1720. [Google Scholar]
- Fu, Y. Human Activity Recognition and Prediction; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Geurts, P. Pattern extraction for time series classification. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Freiburg, Germany, 3–5 September 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 115–127. [Google Scholar]
- Pavlovic, V.; Frey, B.J.; Huang, T.S. Time-series classification using mixed-state dynamic Bayesian networks. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; Volume 2, pp. 609–615. [Google Scholar]
- Park, D.; Kim, H.; Hoshi, Y.; Erickson, Z.; Kapusta, A.; Kemp, C.C. A multimodal execution monitor with anomaly classification for robot-assisted feeding. In Proceedings of the 2016 IEEE International Conference on Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Pettersson, O. Execution monitoring in robotics: A survey. Robot. Auton. Syst. 2005, 53, 73–88. [Google Scholar] [CrossRef]
- Bjäreland, M. Model-Based Execution Monitoring. Linköping Studies in Science and Technology, Dissertation No. 688. 2001. Available online: http://www.ida.liu.se/labs/kplab/people/marbj (accessed on 16 December 2018).
- Muradore, R.; Fiorini, P. A PLS-based statistical approach for fault detection and isolation of robotic manipulators. IEEE Trans. Ind. Electron. 2012, 59, 3167–3175. [Google Scholar] [CrossRef]
- Orsenigo, C.; Vercellis, C. Combining discrete SVM and fixed cardinality warping distances for multivariate time series classification. Pattern Recognit. 2010, 43, 3787–3794. [Google Scholar] [CrossRef]
- Seto, S.; Zhang, W.; Zhou, Y. Multivariate time series classification using dynamic time warping template selection for human activity recognition. In Proceedings of the 2015 IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 7–10 December 2015; pp. 1399–1406. [Google Scholar]
- Karim, F.; Majumdar, S.; Darabi, H.; Harford, S. Multivariate LSTM-FCNs for Time Series Classification. arXiv, 2018; arXiv:1801.04503. [Google Scholar]
- Pei, W.; Dibeklioğlu, H.; Tax, D.M.; van der Maaten, L. Multivariate time-series classification using the hidden-unit logistic model. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 920–931. [Google Scholar] [CrossRef]
- Baydogan, M.G.; Runger, G. Learning a symbolic representation for multivariate time series classification. Data Min. Knowl. Discov. 2015, 29, 400–422. [Google Scholar] [CrossRef]
- Schaal, S.; Peters, J.; Nakanishi, J.; Ijspeert, A. Learning movement primitives. In Eleventh International Symposium on Robotics Research; Springer: Berlin/Heidelberg, Germany, 2005; pp. 561–572. [Google Scholar]
- Hughes, M.C.; Stephenson, W.T.; Sudderth, E. Scalable adaptation of state complexity for nonparametric hidden Markov models. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS’15), Montreal, QC, Canada, 7–12 December 2015; pp. 1198–1206. [Google Scholar]
- Le, T.H.L.; Maslyczyk, A.; Roberge, J.-P.; Duchaine, V. A highly sensitive multimodal capacitive tactile sensor. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 407–412. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++: The advantages of careful seeding. In Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007. [Google Scholar]
- Welch, L.R. Hidden Markov models and the Baum-Welch algorithm. IEEE Inf. Theory Soc. Newsl. 2003, 53, 10–13. [Google Scholar]
- McGrory, C.A.; Titterington, D. Variational Bayesian analysis for hidden Markov models. Aust. N. Z. J. Stat. 2009, 51, 227–244. [Google Scholar] [CrossRef]
- Hughes, M.C.; Sudderth, E. Memoized online variational inference for Dirichlet process mixture models. In Proceedings of the 26th International Conference on Neural Information Processing Systems (NIPS’13), Lake Tahoe, Nevada, 5–10 December 2013; pp. 1133–1141. [Google Scholar]
- Bicchi, A.; Peshkin, M.A.; Colgate, J.E. Safety for physical human–robot interaction. In Springer Handbook of Robotics; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1335–1348. [Google Scholar]
- Raman, N.; Maybank, S.J. Action classification using a discriminative multilevel HDP-HMM. Neurocomputing 2015, 154, 149–161. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kitting Experiment | Testing Information | Precision | Recall | F1-Score | Accuracy | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Movements | Success | Anomalies | GD | HSD | GD | HSD | GD | HSD | GD | HSD |
| Home → Pre-prick | 141 | 6 | 1.0 | 1.0 | 0.33 | 0.50 | 0.50 | 0.67 | 0.973 | 0.980 |
| Pre-prick → Prick | 112 | 23 | 1.0 | 1.0 | 0.78 | 0.78 | 0.878 | 0.88 | 0.963 | 0.963 |
| Prick → Pre-prick | 83 | 28 | 1.0 | 0.80 | 0.04 | 0.31 | 0.069 | 0.45 | 0.757 | 0.820 |
| Pre-prick → Pre-place | 13 | 70 | 1.0 | 0.84 | 0.54 | 0.97 | 0.704 | 0.90 | 0.614 | 0.843 |
| Pre-place → Place | 11 | 6 | 1.0 | 0.40 | 1.0 | 1.0 | 1.0 | 0.57 | 1.0 | 0.769 |
| Place → Pre-Place | 8 | 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.889 | 0.889 |
| Across all skills: | 368 | 136 | 0.98 | 0.84 | 0.47 | 0.76 | 0.64 | 0.80 | 0.861 | 0.910 |
| States | Methods | TC | HC | HCO | NO | OS | WC | OTHER | Total Accuracy |
|---|---|---|---|---|---|---|---|---|---|
| 3 | HMM-Gauss-EM | 1.0 | 0.89 | 0.89 | 0.78 | 0.83 | 1.0 | 0.67 | 0.876 |
| HMM-Gauss-VB | 1.0 | 0.94 | 0.95 | 0.96 | 0.88 | 1.0 | 0.67 | 0.915 | |
| HMM-AR-VB | 1.0 | 0.89 | 0.90 | 0.93 | 0.94 | 1.0 | 0.67 | 0.929 | |
| 5 | HMM-Gauss-EM | 1.0 | 0.78 | 0.84 | 0.79 | 0.79 | 1.0 | 0.67 | 0.838 |
| HMM-Gauss-VB | 0.94 | 0.94 | 0.89 | 0.86 | 0.85 | 1.0 | 0.67 | 0.889 | |
| HMM-AR-VB | 1.0 | 0.89 | 0.95 | 1.0 | 0.98 | 1.0 | 0.67 | 0.957 | |
| 7 | HMM-Gauss-EM | 1.0 | 0.83 | 0.95 | 0.71 | 0.77 | 0.83 | 0.67 | 0.826 |
| HMM-Gauss-VB | 1.0 | 0.83 | 0.86 | 0.79 | 0.82 | 1.0 | 0.67 | 0.863 | |
| HMM-AR-VB | 1.0 | 0.95 | 1.0 | 0.93 | 0.96 | 1.0 | 0.67 | 0.957 | |
| 10 | HMM-Gauss-EM | 0.94 | 0.72 | 0.85 | 0.86 | 0.79 | 0.94 | 0.67 | 0.826 |
| HMM-Gauss-VB | 0.94 | 0.83 | 0.95 | 0.72 | 0.86 | 1.0 | 0.67 | 0.876 | |
| HMM-AR-VB | 0.95 | 0.83 | 0.82 | 0.93 | 0.92 | 0.95 | 0.67 | 0.889 | |
| 10 | HDP-HMM-Gauss-VB | 0.94 | 0.95 | 0.95 | 0.86 | 0.94 | 0.90 | 0.67 | 0.915 |
| HDP-HMM-Gauss-moVB | 0.88 | 0.95 | 0.95 | 0.93 | 0.94 | 0.95 | 0.83 | 0.929 | |
| HDP-HMM-AR-VB | 0.94 | 0.84 | 0.86 | 0.93 | 0.96 | 0.95 | 0.83 | 0.915 | |
| HDP-HMM-AR-moVB | 1.0 | 0.95 | 0.95 | 0.93 | 0.98 | 1.0 | 1.0 | 0.971 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Guan, Y.; Rojas, J. A Latent State-Based Multimodal Execution Monitor with Anomaly Detection and Classification for Robot Introspection. Appl. Sci. 2019, 9, 1072. https://doi.org/10.3390/app9061072
Wu H, Guan Y, Rojas J. A Latent State-Based Multimodal Execution Monitor with Anomaly Detection and Classification for Robot Introspection. Applied Sciences. 2019; 9(6):1072. https://doi.org/10.3390/app9061072
Chicago/Turabian StyleWu, Hongmin, Yisheng Guan, and Juan Rojas. 2019. "A Latent State-Based Multimodal Execution Monitor with Anomaly Detection and Classification for Robot Introspection" Applied Sciences 9, no. 6: 1072. https://doi.org/10.3390/app9061072
APA StyleWu, H., Guan, Y., & Rojas, J. (2019). A Latent State-Based Multimodal Execution Monitor with Anomaly Detection and Classification for Robot Introspection. Applied Sciences, 9(6), 1072. https://doi.org/10.3390/app9061072