1. Introduction
With the development of semiconductor technology, the application of embedded system is becoming more widely used and it’s architecture is becoming increasingly complex. Because the software processing units (such as CPU, GPU) have the characteristics of short development period, flexibility and easy maintenance, while the hardware processing units (such as ASIC, FPGA) have the characteristics of high efficiency and low power consumption, the development of embedded system needs the hardware and software co-design to satisfy the demands of cost, power, performance and so on.
A task consists of several subtasks, and each subtask may need to be assigned to one type of processing unit. The execution effect of a subtask assigned to the hardware processing unit is different from that assigned to the software processing unit. So the goal of hardware/software partitioning is to get an optimal partitioning scheme to make the system achieve the best performance. Therefore, hardware/software partitioning is the key of the hardware and software co-design.
Hardware/software partitioning is a NP-hard problem [
1]. In recent years, many researchers have focused on the study of hardware/software partitioning algorithms. In general, the algorithms applied to hardware/software partitioning can be divided into two categories. One is the accurate algorithms, the other is the heuristic algorithms. Accurate algorithms mainly include dynamic programming (DP) [
2,
3], integer linear programming (ILP) [
4], branch and bound (B&B) [
5] and so on. The advantage of accurate algorithms is that it can precisely find the absolute optimal solution of the hardware/software partitioning problem. When it comes to large-scale instances of the problem, the execution of accurate algorithms becomes complicated and time-consuming. Therefore, heuristic algorithms are utilized to solve hardware/software partitioning problem increasingly.
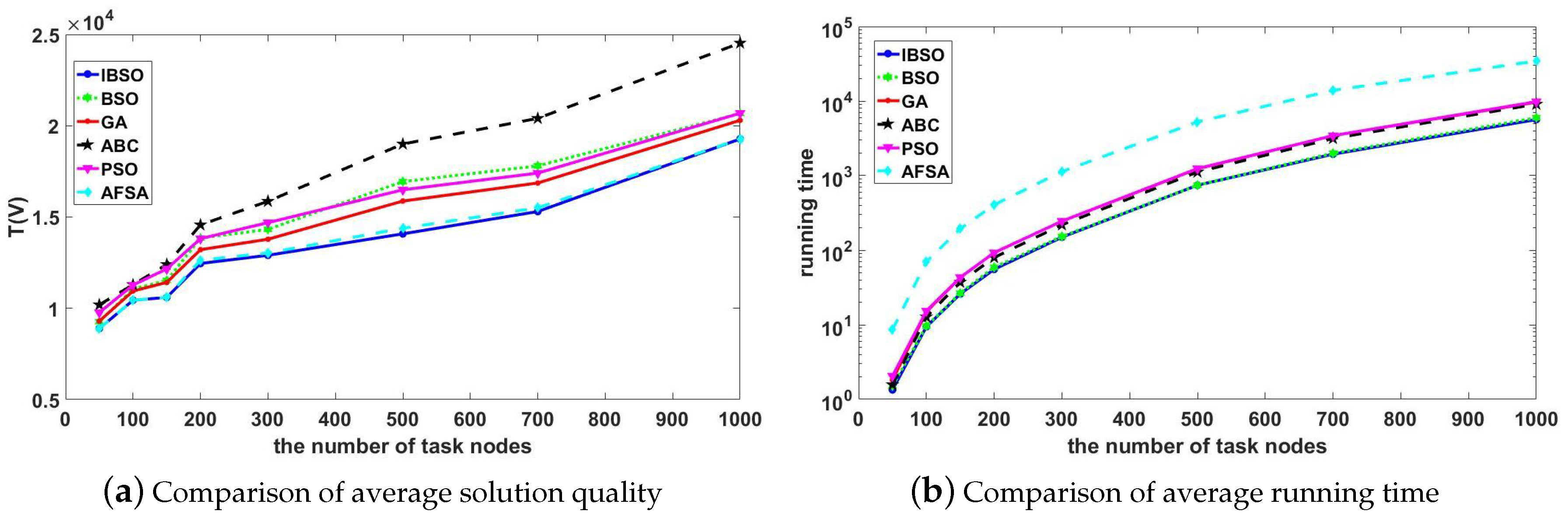
Swarm intelligence (SI) is a discipline inspired by collective behaviors of biological species/systems and consists of many different algorithms. The SI algorithms have the advantages of excellent global search ability and strong robustness. They are suitable for solving complex problems because their optimization process can be seen as a black box [
6]. The common SI algorithms include particle swarm optimization (PSO) [
7], artificial bee colony (ABC) [
8], artificial fish school algorithm (ASFA) [
9], ant colony algorithm (ACO) [
10], shuffled frog leaping algorithm (SFLA) [
11] and so on. In recent years, these algorithms are successfully applied in different areas to solve the complex optimization problems. For example, Fong et al. used the PSO in feature selection [
12], Hashim et al. applied the the ABC to optimize the wireless sensor network [
13], Dai et al. solved the path-planning problem based on the ACO [
14], Qin et al. solved the vehicle routing problem with the ASFA [
15], and in our previous work, we designed a local dimming algorithm based on the SFLA [
16]. In the hardware/software partitioning area, some SI algorithms were also applied and achieved good performance [
17,
18,
19]. When applying SI to hardware/software partitioning, there are two metrics of interest: the quality of the obtained solutions and the execution time of the algorithms. Therefore, the two metrics are usually used to evaluate the performance of the algorithms.
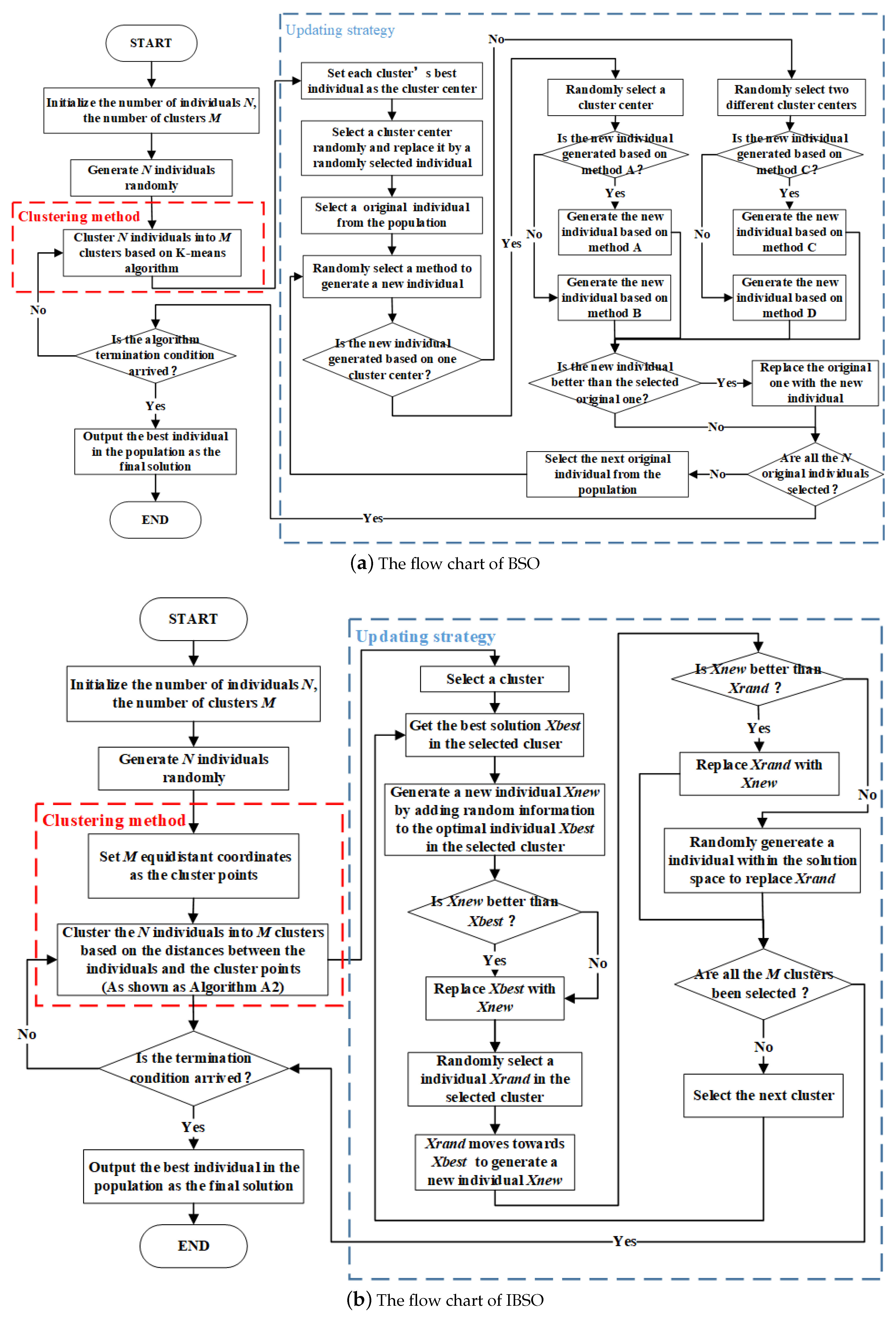
Brainstorm optimization (BSO)is a young and promising SI algorithm proposed by Shi in 2011 [
20]. It was proposed based on the collective behavior of human being, that is, the brainstorming process [
21]. After the algorithm was proposed, it was applied in many areas, such as finding the optimal location and setting of devices in electric power systems [
22], receding horizon control for multiple UAV formation flight [
23], designing the wireless sensor networks [
24], and solving equation systems [
25]. To improve the performance of BSO, a series of variants were proposed. Zhan et al. proposed a simple grouping method to accelerate the algorithm [
26], Zhou et al. proposed the modified step-size to improve the search ability of BSO [
27], Yang and Shi used the chaotic operation to improve the individual generation strategy [
28], Yang et al. utilied the incorporation of inter-and intra-cluster discussions to balance the global and local searching [
29]. There are also some hybrid algorithms. For example, Jia et al. hybridized BSO with simulated annealing algorithm [
30], Krishnanand et al. hybridized BSO with the teaching-learning-based algorithm [
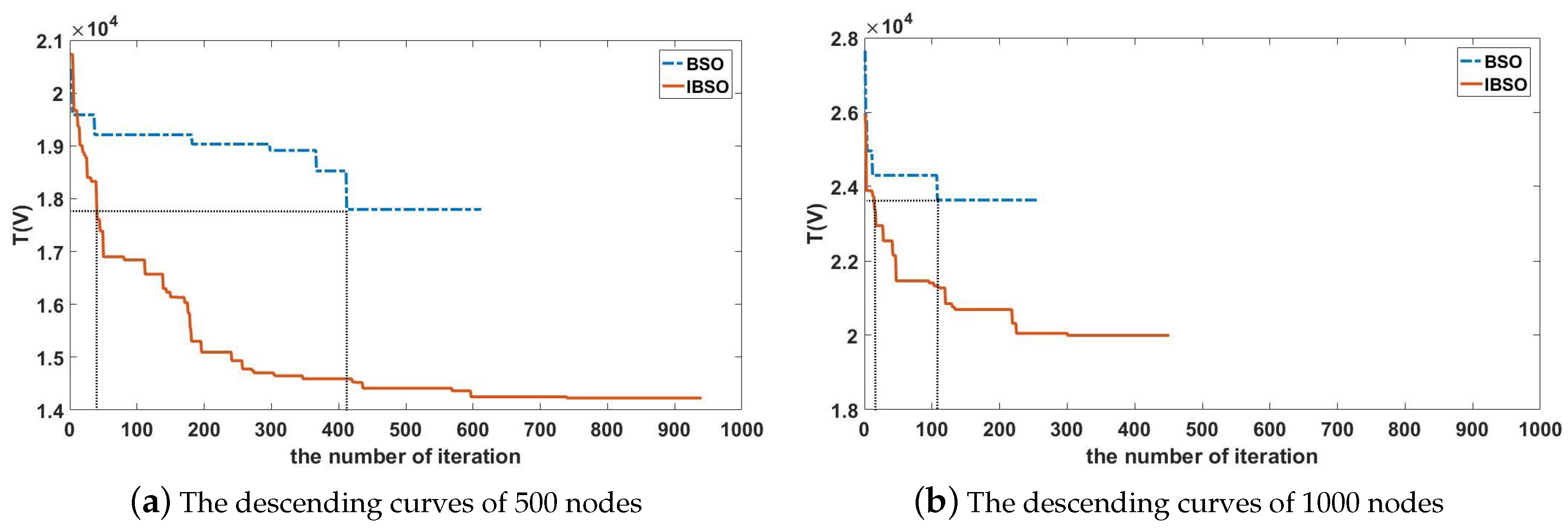
31]. Because BSO performed well in many applications, it is applied to solve the hardware/software problem in this paper. In most of previous researches, BSO was usually applied to solve continuous optimization problems, but the hardware/software partitioning problem is a discrete optimization problem. Therefore, when the BSO is utilized to solve hardware/software partitioning problem, it has the shortage of premature convergence which will directly affect the quality of solutions. At the same time, the algorithm efficiency should be further improved.
From what has been discussed above, this paper applies the BSO algorithm to hardware/software partitioning and improves its clustering method and updating strategy to generate the improved brainstorm optimization (IBSO) algorithm. Experimental results show that the IBSO algorithm performs well on hardware/ software partitioning.
The rest of the paper is organized as follows. In
Section 2, the related knowledge of hardware/ software partitioning problem is described.
Section 3 describes the process of BSO algorithm applied to hardware/software partitioning. In
Section 4, IBSO algorithm is proposed. Finally, the empirical results and conclusion are elaborated in
Section 5 and
Section 6 respectively.
2. The Mathematical Model of Hardware/Software Partitioning
The problem of hardware/software partitioning can be expressed as
.
is a task which has many subtask nodes, where
L is the number of subtask nodes and
is the
i-th subtask node.
represents data dependencies or control process between subtask nodes. A subtask node can be expressed as
where
represents the subtask assignment method,
means the subtask is assigned to software processing unit while
means the subtask is assigned to hardware processing unit.
represents the execution time when the subtask is assigned to software processing unit and
represents the execution time when the subtask is assigned to the hardware processing unit.
represents the communication time between
and
when there is dependency between them.
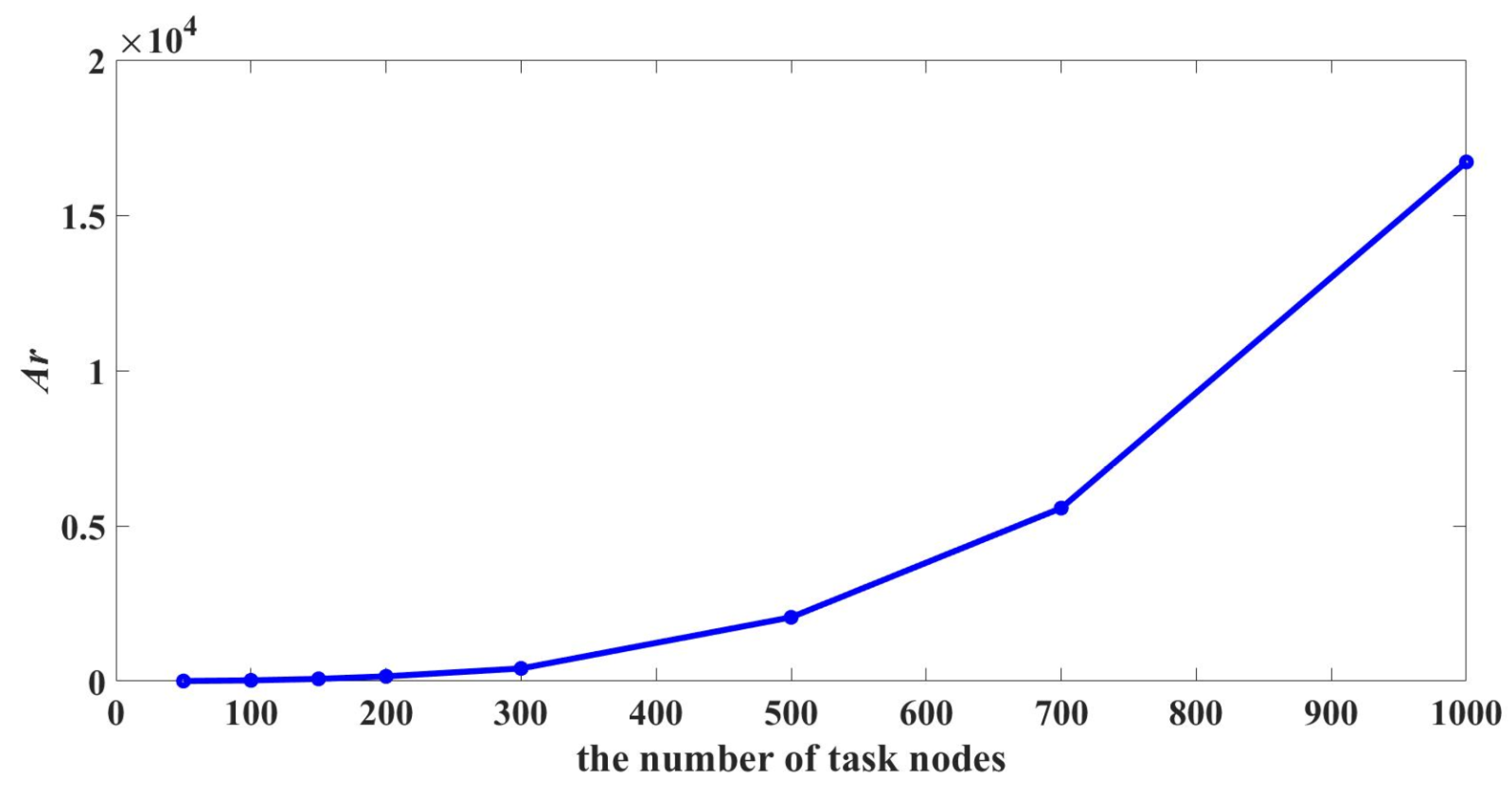
is the required hardware area when the subtask is assigned to hardware processing unit. Compared with hardware processing unit, the required area of software processing unit is much less. So the required area of software processing unit is ignored. In this paper, the total required area of processing units is taken as the constraint, and the time required for the system to complete the task (the completion time of the whole task) is taken as the optimization objective. The mathematical description is given in (
2).
where
denotes the completion time of the whole task.
denotes the completion time of the
ith path of the task.
A denotes the total required area of processing units and
is the constraint value.
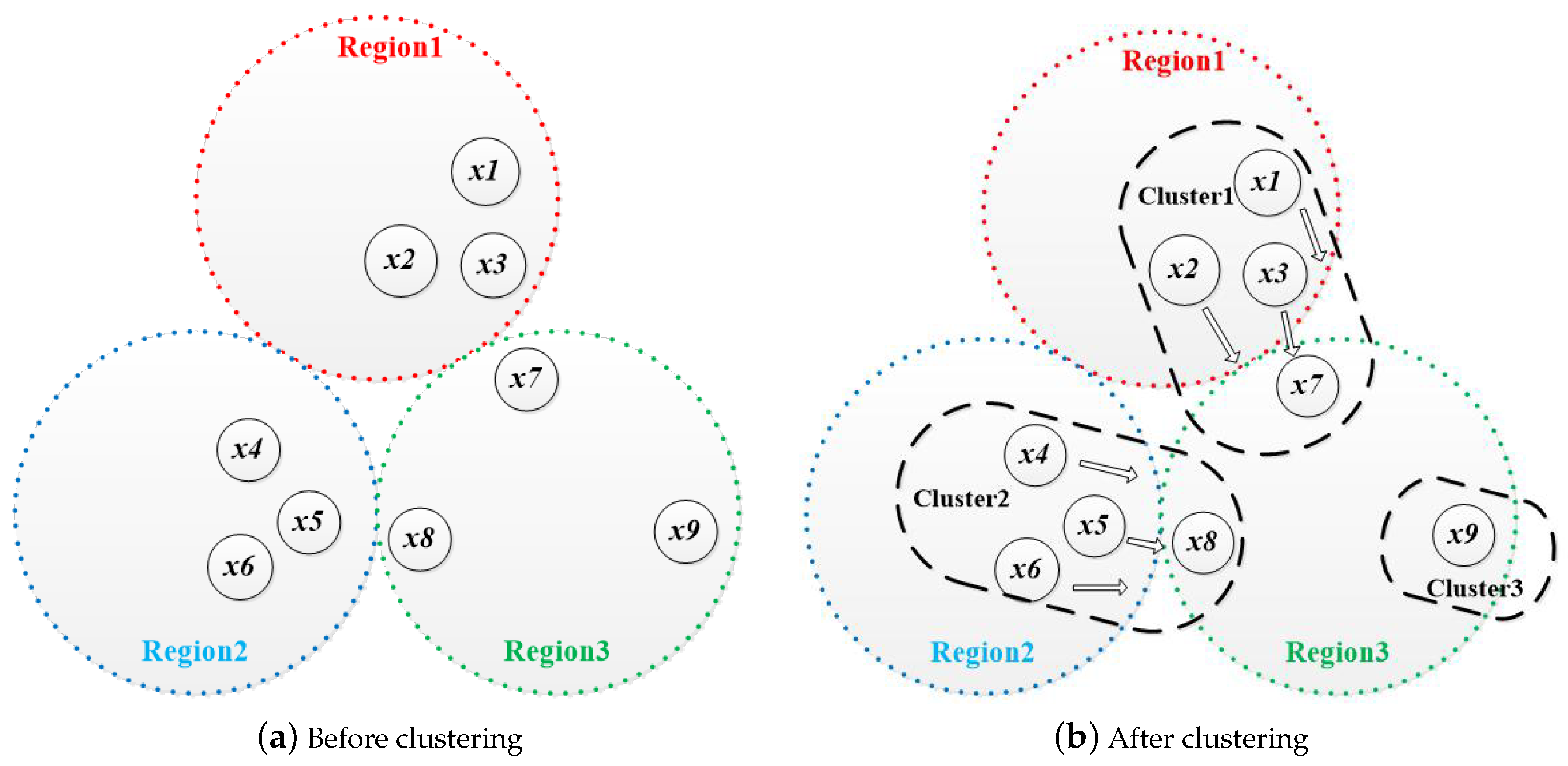
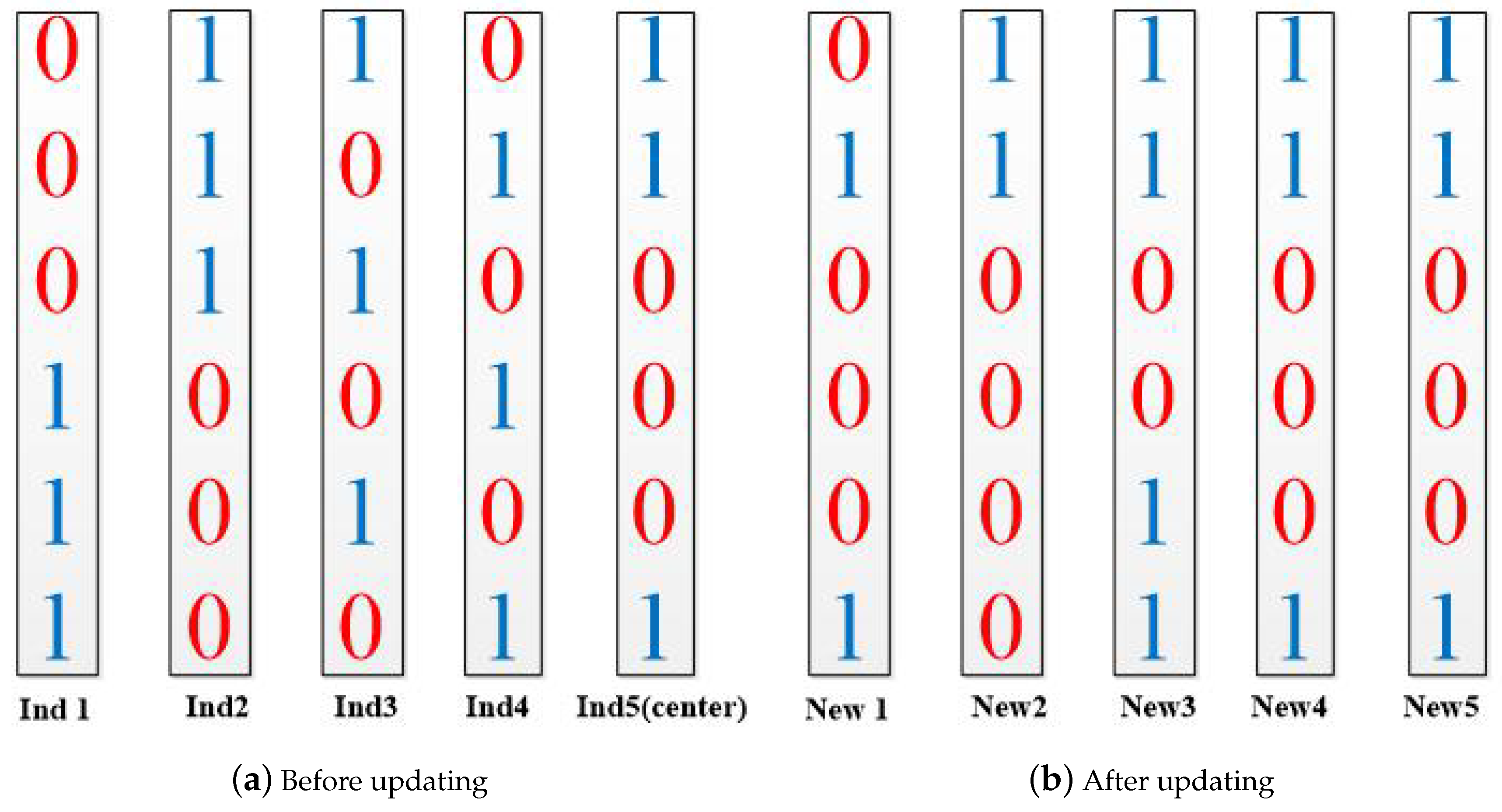
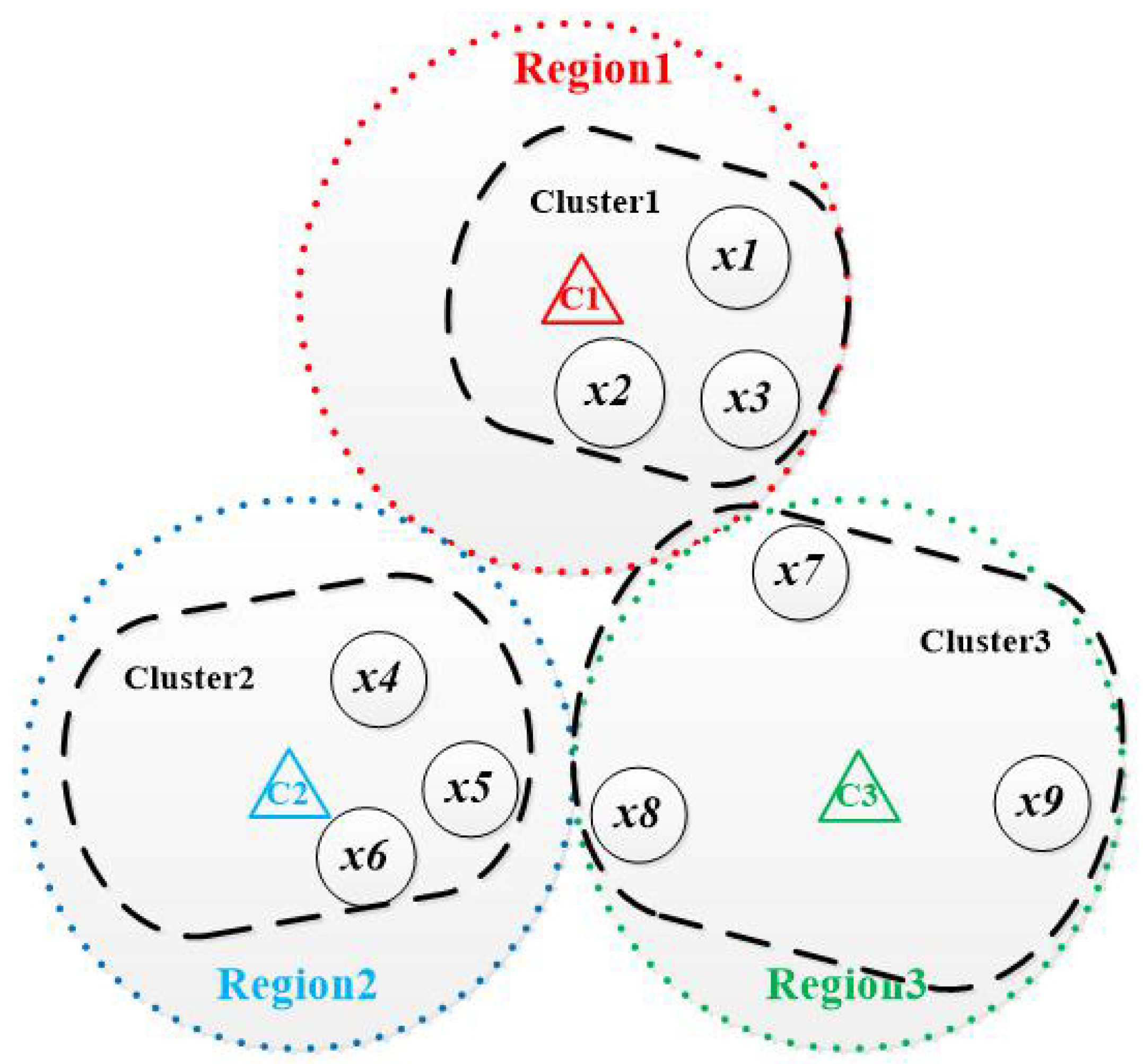
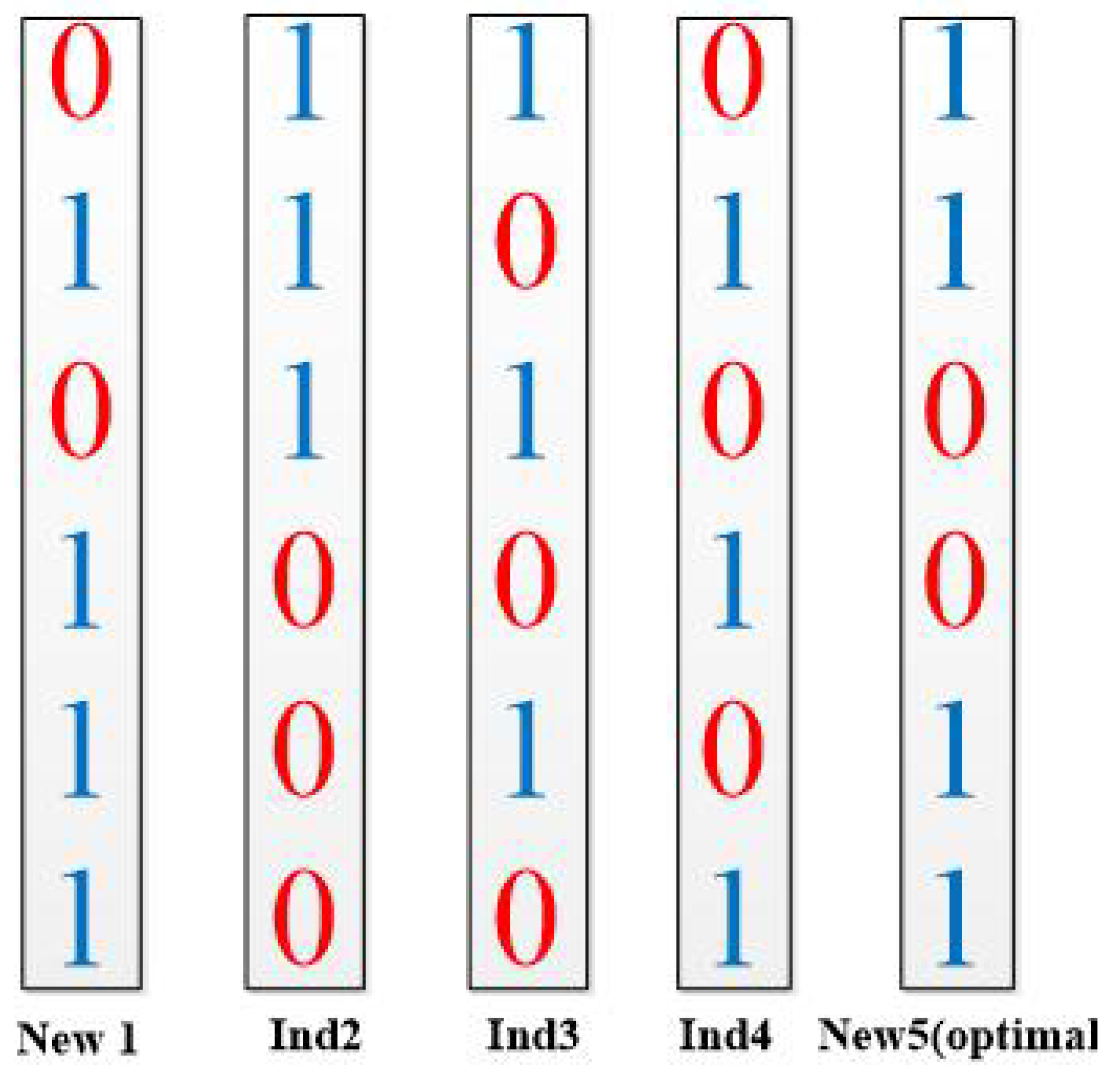
The solution space of hardware/software partitioning problem can be represented by a L-dimensional discrete space , where L is the number of subtask nodes. A solution can be represented by a L-dimensional vector in this space, , where represents the i-th subtask is assigned to software processing unit, while represents the i-th subtask is assigned to hardware processing unit. For example, a solution of hareware/software partitioning means that the first, the third and the fourth subtasks are assigned to the hardware processing unit, and the second subtask is assigned to the software processing unit.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
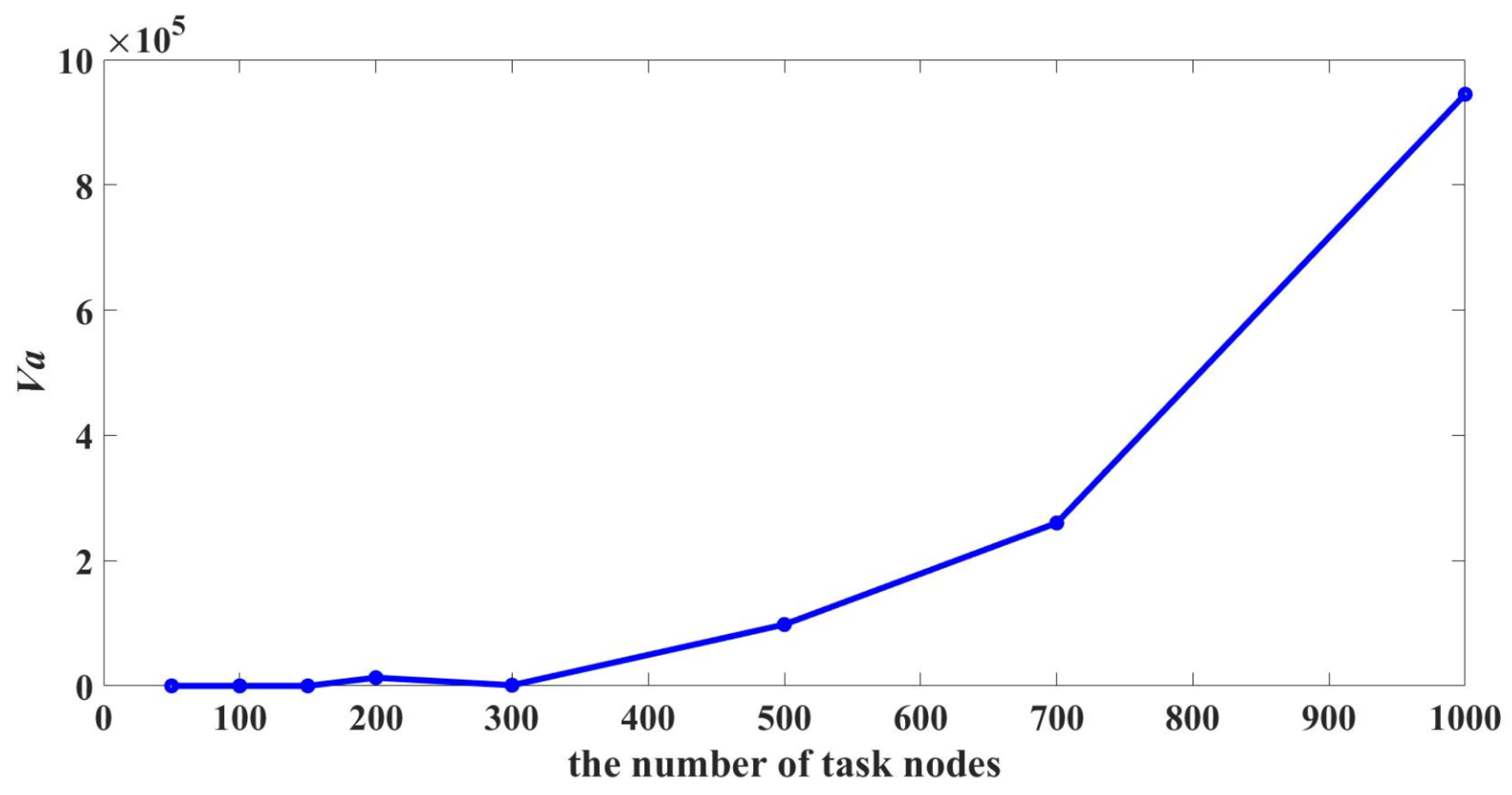{kind=link}