TrafficWave: Generative Deep Learning Architecture for Vehicular Traffic Flow Prediction



Abstract
1. Introduction
2. Methods
2.1. Mathematical Properties of Traffic Flow
2.2. State of the Art on Deep Learning for Vehicular Traffic Flow Prediction
- (1)
- to briefly review the most used and performing ones (i.e., stacked auto encoders (SAEs), LSTM, GRU),
- (2)
- to introduce a new one named TrafficWave able to outperform the previous,
- (3)
- to perform comparisons under a common testing framework.
2.3. Deep Learning Techniques
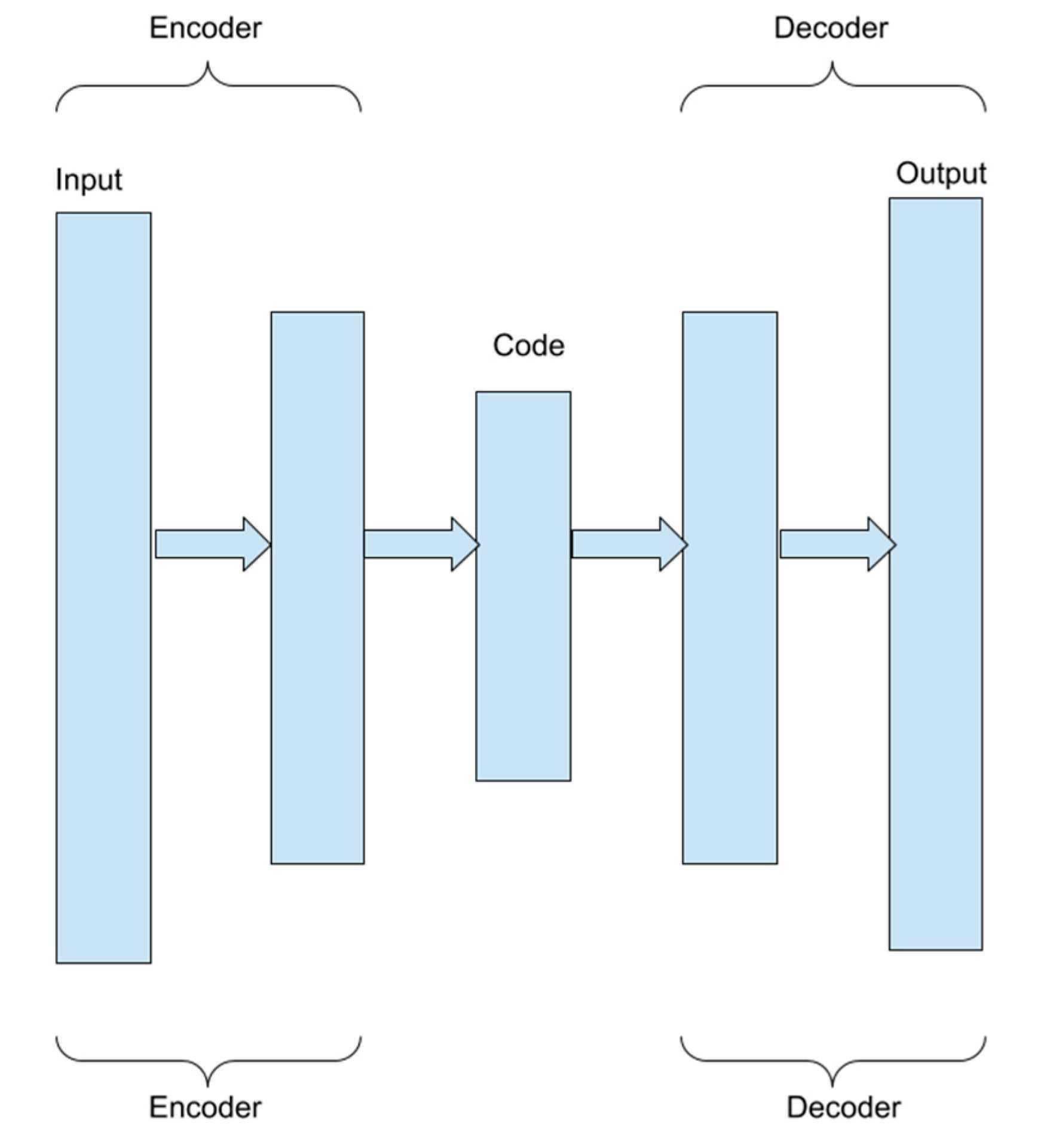
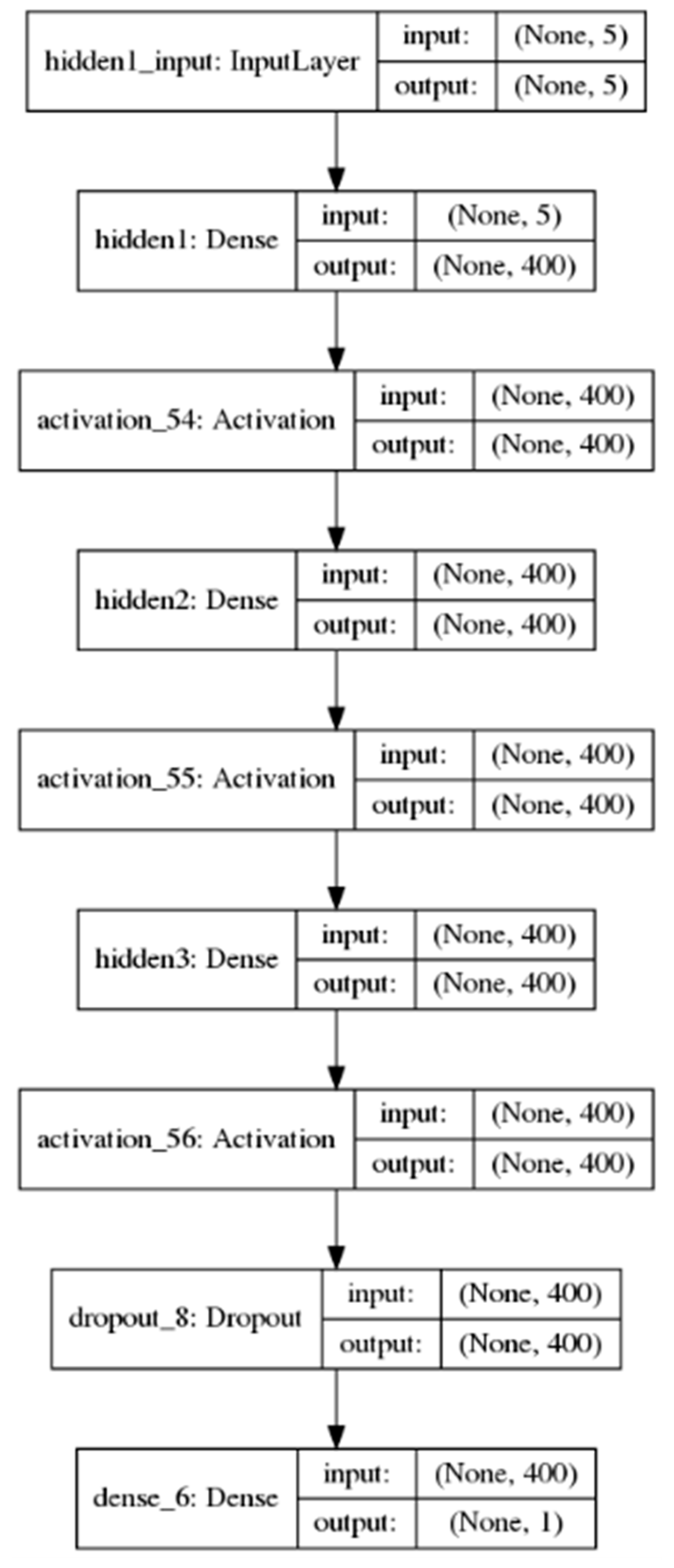
2.3.1. SAEs (Stacked Auto Encoders)
- a weight matrix,
- b a coding polarization vector,
- a decoding matrix,
- c a decoding polarization vector,
- f (x) and g (x) sigmoid functions.
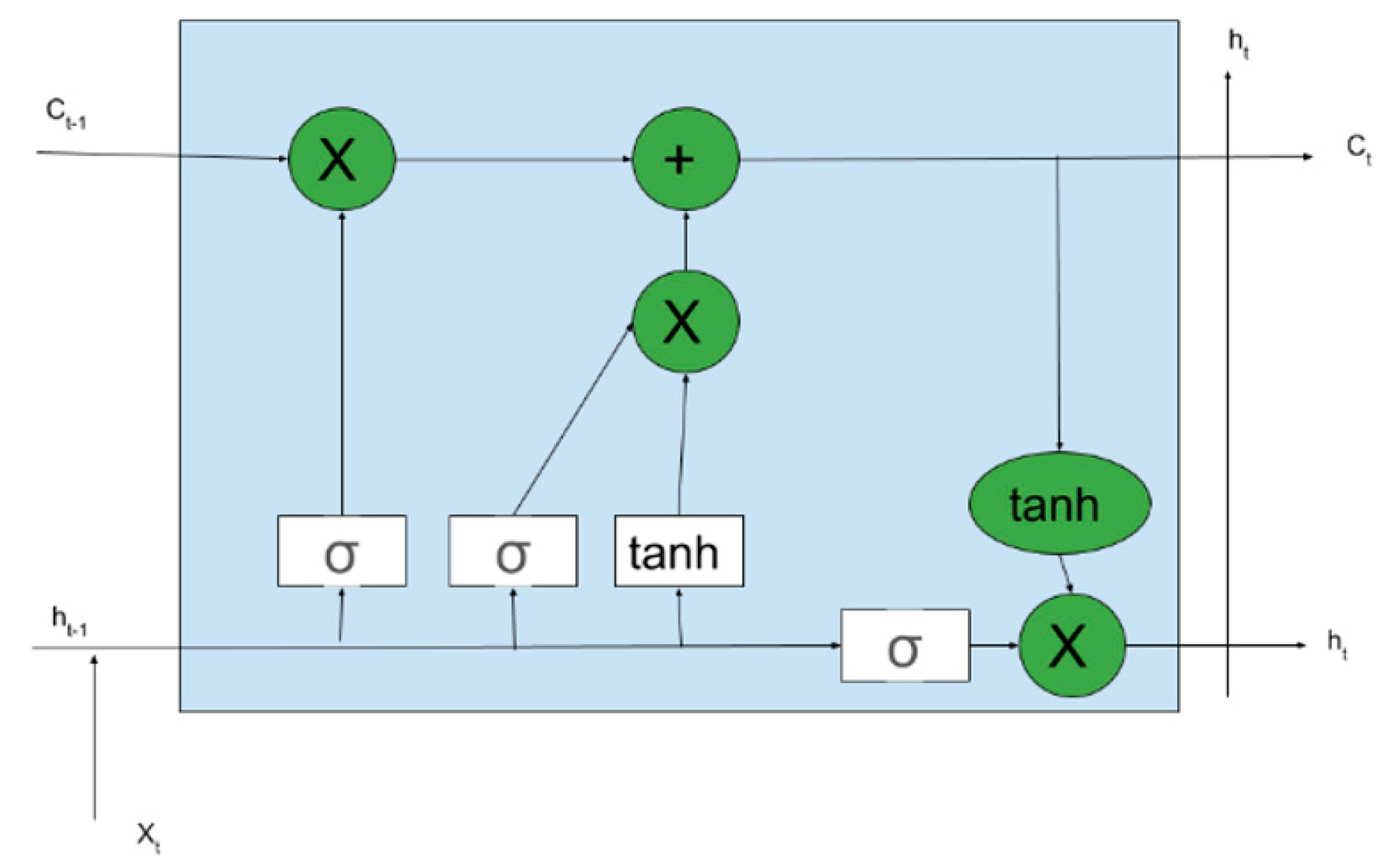
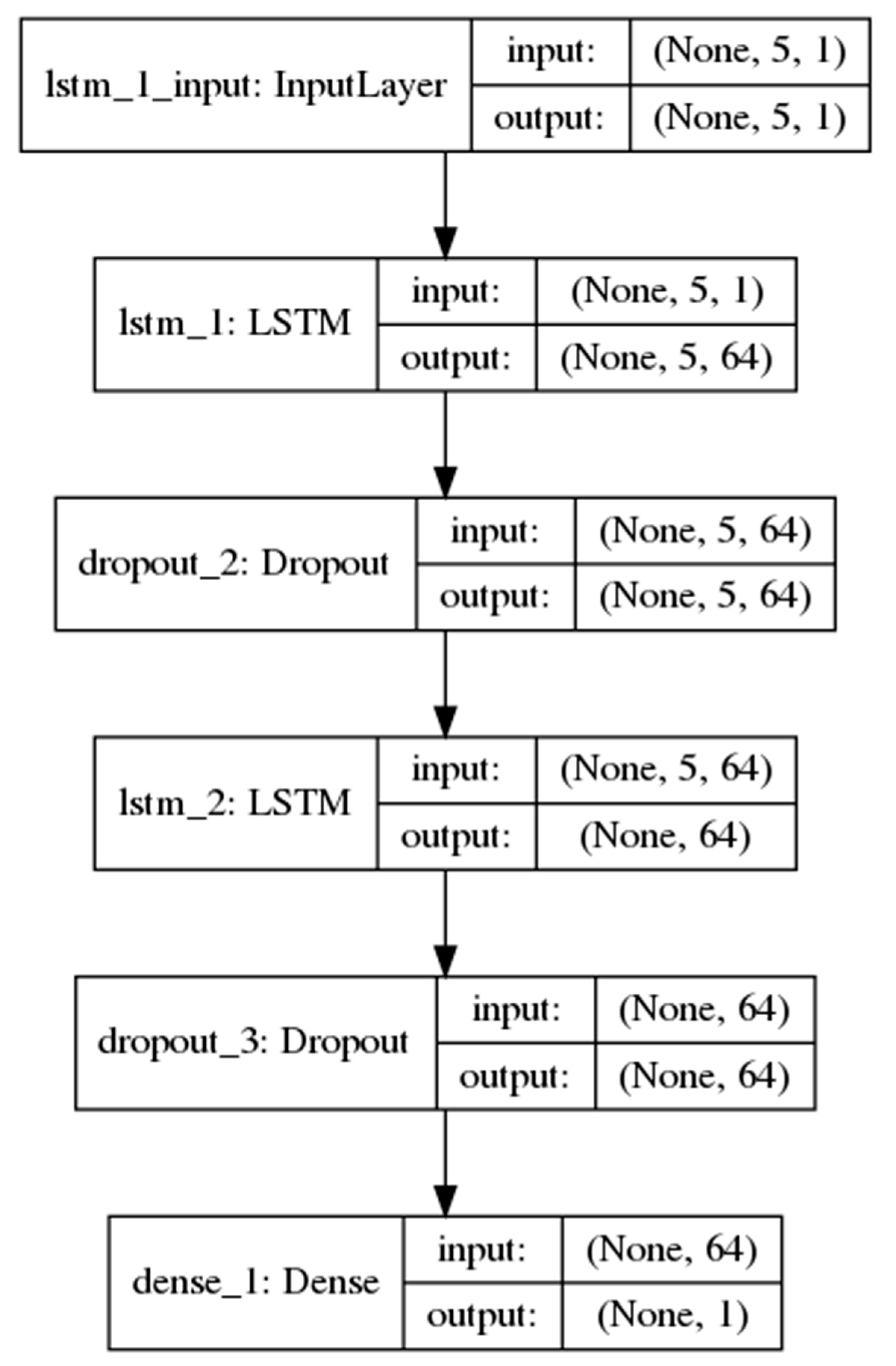
2.3.2. LSTM (Long–Short Term Memory)
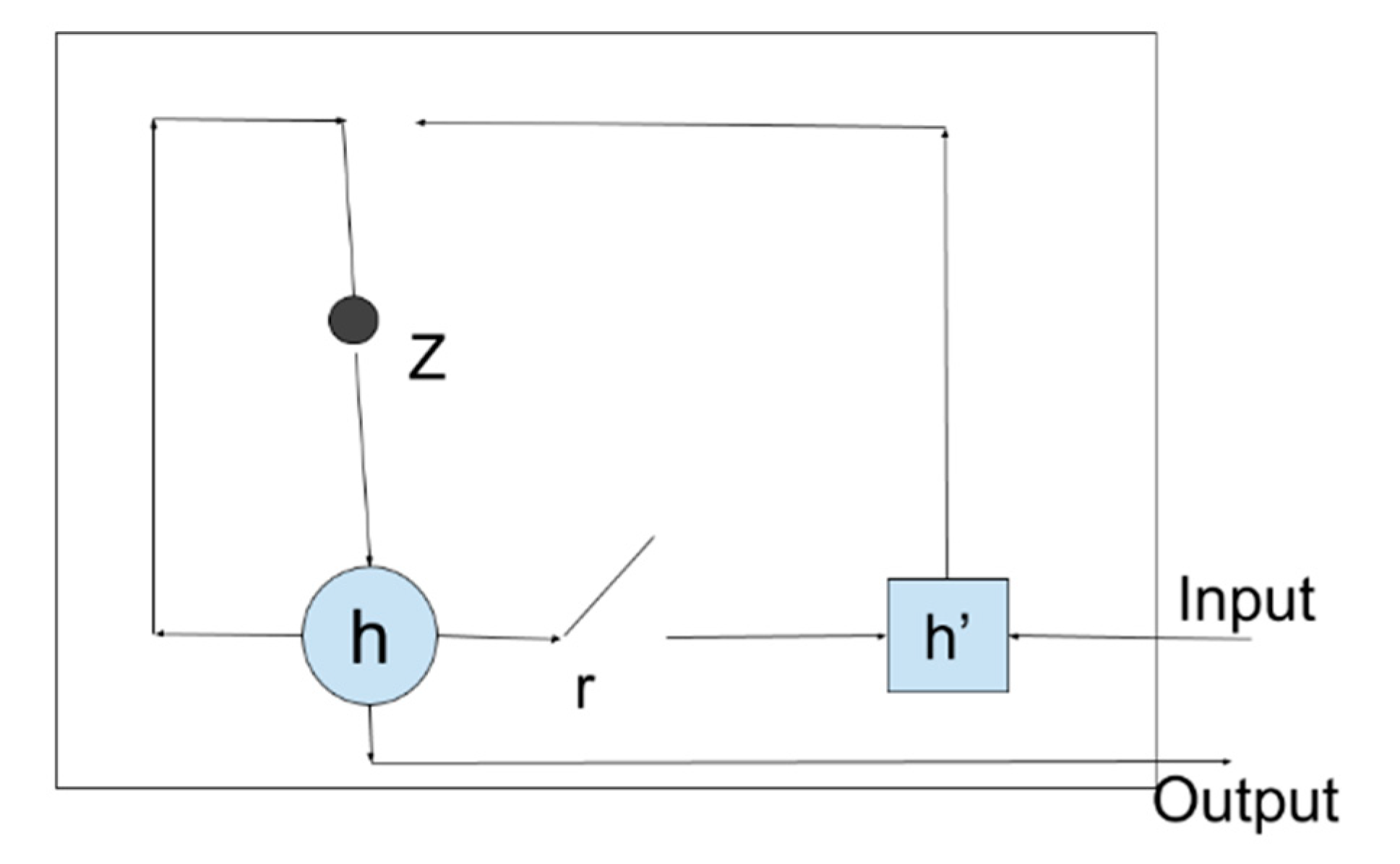
2.3.3. GRU (Gated Recurrent Unit)
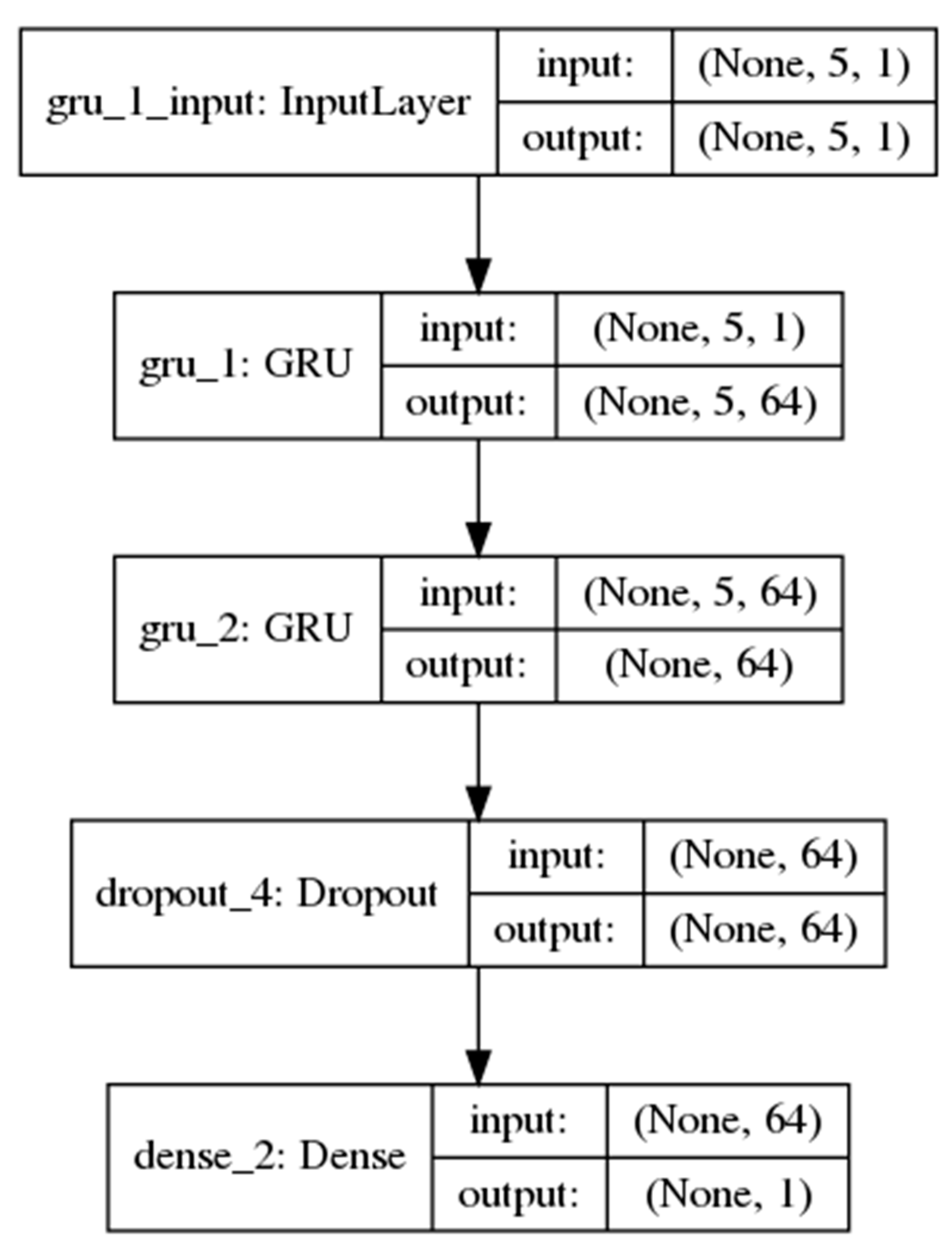
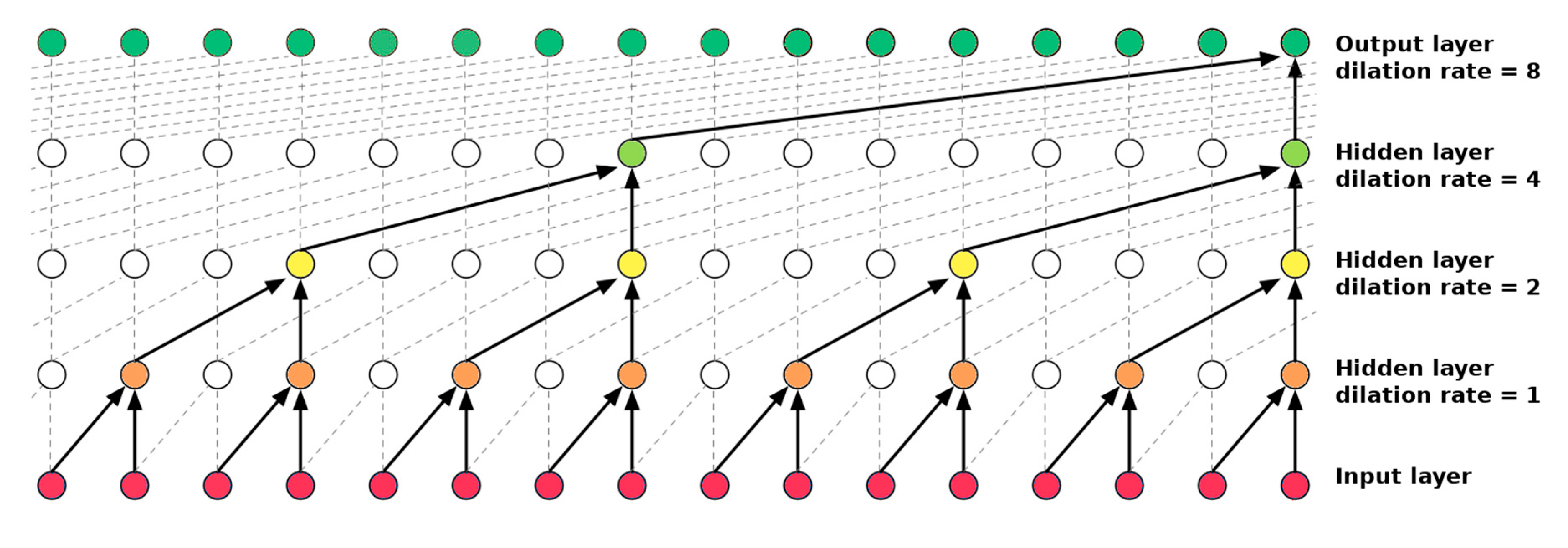
3. TrafficWave Architecture
4. Dataset and Experimental Set-Up
4.1. PeMS (Caltrans Performance Measurement System)
4.2. TRAP-2017 (Traffic Mining Applied to Police Activities)
- To be consistent with other authors implementations (comparison aims);
- Δ = 5 min produce the best accuracy for all models with respect to other solutions (i.e., 15, 30 and 45 min);
- Δ = 5 min implies a near real-time prediction, therefore it allows to promptly implement strategies of traffic control.
- Data have been aggregated over 5-min time window: the number of vehicles which have transited under the gate 1 every 5 min are reported along with the time stamp captured of the last vehicle belonging to the 5 min time window.
- Time windows with 0 transited cars, have been reported as 0.
- Data have been separated in months and days.
- Data has been normalized with min-max rule within [0.1–1.0].
- The sliding window approach has been then used on the normalized data (lag = 5).
- Monday has been selected as the day of forecasting.
- The preprocessed data is then fed to the various neural network architectures.
5. Results
6. Conclusions and Future Research
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety 2015; World Healt Organization: Geneva, Switzerland, 2015. [Google Scholar]
- Cavallaro, F. Policy implications from the economic valuation of freight transport externalities along the Brenner corridor. Case Stud. Transp. Policy 2018, 6, 133–146. [Google Scholar] [CrossRef]
- Askari, H.; Hashemi, E.; Khajepour, A.; Khamesee, M.B.; Wang, Z.L. Towards self-powered sensing using nanogenerators for automotive systems. Nano Energy 2018, 53, 1003–1019. [Google Scholar] [CrossRef]
- Impedovo, D.; Balducci, F.; Dentamaro, V.; Pirlo, G. Vehicular Traffic Congestion Classification by Visual Features and Deep Learning Approaches: A Comparison. Sensors 2019, 19, 5213. [Google Scholar] [CrossRef] [PubMed]
- Oord, A.V.D.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Nicholls, H.; Rose, G.; Johnson, M.; Carlisle, R. Cyclists and Left Turning Drivers: A Study of Infrastructure and Behaviour at Intersections. In Proceedings of the 39th Australasian Transport Research Forum (ATRF 2017), Auckland, New Zealand, 27–29 November 2017. [Google Scholar]
- Perez-Murueta, P.; Gómez-Espinosa, A.; Cardenas, C.; Gonzalez-Mendoza, M., Jr. Deep Learning System for Vehicular Re-Routing and Congestion Avoidance. Appl. Sci. 2019, 9, 2717. [Google Scholar] [CrossRef]
- Ni, D. Traffic Flow Theory: Characteristics, Experimental Methods, and Numerical Techniques; Butterworth-Heinemann: Oxford, UK, 2015. [Google Scholar]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.Y. Traffic flow prediction with big data: A deep learning approach. IEEE Trans. Intell. Transp. Syst. 2014, 16, 865–873. [Google Scholar] [CrossRef]
- Chen, Y.; Shu, L.; Wang, L. Traffic flow prediction with big data: A deep learning based time series model. In Proceedings of the 2017 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Atlanta, GA, USA, 1–4 May 2017; pp. 1010–1011. [Google Scholar]
- Koesdwiady, A.; Soua, R.; Karray, F. Improving Traffic Flow Prediction with Weather Information in Connected Cars: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2016, 65, 9508–9517. [Google Scholar] [CrossRef]
- Aqib, M.; Mehmood, R.; Alzahrani, A.; Katib, I.; Albeshri, A.; Altowaijri, S.M. Smarter traffic prediction using big data, in-memory computing, deep learning and GPUs. Sensors 2019, 19, 2206. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Song, G.; Hong, H.; Xie, K. Deep architecture for traffic flow prediction: Deep belief networks with multitask learning. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2191–2201. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Qin, L.; Ran, B.; Jiang, Z. A hybrid deep learning based traffic flow prediction method and its understanding. Transp. Res. Part C Emerg. Technol. 2018, 90, 166–180. [Google Scholar] [CrossRef]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Polson, N.G.; Sokolov, V.O. Deep learning for short-term traffic flow prediction. Transp. Res. Part C Emerg. Technol. 2017, 79, 1–17. [Google Scholar] [CrossRef]
- Huang, W.; Hong, H.; Li, M.; Hu, W.; Song, G.; Xie, K. Deep architecture for traffic flow prediction. In International Conference on Advanced Data Mining and Applications; Springer: Berlin/Heidelberg, Germany, December 2013; pp. 165–176. [Google Scholar]
- Albertengo, G.; Hassan, W. Short term urban traffic forecasting using deep learning. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 3–10. [Google Scholar] [CrossRef]
- Wei, W.; Wu, H.; Ma, H. An AutoEncoder and LSTM-Based Traffic Flow Prediction Method. Sensors 2019, 19, 2946. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.; Zhang, Y.; Kong, D.; Yin, B. Improved Spatio-Temporal Residual Networks for Bus Traffic Flow Prediction. Appl. Sci. 2019, 9, 615. [Google Scholar] [CrossRef]
- Choi, Y.Y.; Shon, H.; Byon, Y.J.; Kim, D.K.; Kang, S. Enhanced Application of Principal Component Analysis in Machine Learning for Imputation of Missing Traffic Data. Appl. Sci. 2019, 9, 2149. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, Y.; Hu, J.; Zhao, Y.; Li, S.; Hu, J. Deep autoencoder neural networks for short-term traffic congestion prediction of transportation networks. Sensors 2019, 19, 2229. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wang, J. Short term traffic flow prediction based on deep learning. In Proceedings of the International Conference on Robots & Intelligent System (ICRIS), Haikou, China, 15–16 June 2019; pp. 466–469. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Chen, L.; Ampountolas, K.; Thakuriah, P. Predicting Uber Demand in NYC with Wavenet. In Proceedings of the Fourth International Conference on Universal Accessibility in the Internet of Things and Smart Environments, Athens, Greece, 24–28 February 2019; p. 1. [Google Scholar]
- Kechyn, G.; Yu, L.; Zang, Y.; Kechyn, S. Sales forecasting using WaveNet within the framework of the Kaggle competition. arXiv 2018, arXiv:1803.04037. [Google Scholar]
- Caltrans, Performance Measurement System (PeMS). 2014. Available online: http://pems.dot.ca.gov (accessed on 13 December 2019).
- TRAP 2017. TRAP 2017: First European Conference on Traffic Mining Applied to Police Activities. Available online: http://www.wikicfp.com/cfp/servlet/event.showcfp?eventid=64497©ownerid (accessed on 14 October 2019).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MAPE | MAE | RMSE | TIME | |
|---|---|---|---|---|
| TrafficWave | 15.522% | 6.229 | 8.668 | 5293s |
| LSTM | 15.703% | 6.274 | 8.734 | 820s |
| GRU | 17.757% | 6.323 | 8.637 | 641s |
| SAEs | 16.742% | 6.095 | 8.335 | 1163s |
| Wei et al. [19] | NA | 25.26 | 35.45 | NA |
| Fu et al. [15] | NA | 17.211 | 25.86 | NA |
| Lv et al. [9] | NA | 34.1.8 | 50.0 | NA |
| MAPE | MAE | RMSE | TIME | |
|---|---|---|---|---|
| TrafficWave | 14.929% | 35.406 | 50.902 | 893s |
| LSTM | 15.991% | 37.959 | 53.552 | 292s |
| GRU | 15.964% | 37.879 | 53.669 | 245s |
| SAEs | 16.674% | 36.374 | 51.267 | 198s |
| Monday | Tuesday | Wednesday | Thursday | Friday | Saturday | Sunday | |
|---|---|---|---|---|---|---|---|
| TrafficWave | 14.929% | 17.354% | 14.998% | 12.190% | 14.779% | 14.891% | 17.439% |
| LSTM | 15.991% | 18.041% | 16.835% | 12.394% | 14.884% | 23.253% | 17.483% |
| GRU | 15.964% | 22.478% | 17.119% | 12.212% | 15.463% | 16.591% | 17.950% |
| SAEs | 16.674% | 18.620% | 15.593% | 21.260% | 14.986% | 15.895% | 17.580% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Impedovo, D.; Dentamaro, V.; Pirlo, G.; Sarcinella, L. TrafficWave: Generative Deep Learning Architecture for Vehicular Traffic Flow Prediction. Appl. Sci. 2019, 9, 5504. https://doi.org/10.3390/app9245504
Impedovo D, Dentamaro V, Pirlo G, Sarcinella L. TrafficWave: Generative Deep Learning Architecture for Vehicular Traffic Flow Prediction. Applied Sciences. 2019; 9(24):5504. https://doi.org/10.3390/app9245504
Chicago/Turabian StyleImpedovo, Donato, Vincenzo Dentamaro, Giuseppe Pirlo, and Lucia Sarcinella. 2019. "TrafficWave: Generative Deep Learning Architecture for Vehicular Traffic Flow Prediction" Applied Sciences 9, no. 24: 5504. https://doi.org/10.3390/app9245504
APA StyleImpedovo, D., Dentamaro, V., Pirlo, G., & Sarcinella, L. (2019). TrafficWave: Generative Deep Learning Architecture for Vehicular Traffic Flow Prediction. Applied Sciences, 9(24), 5504. https://doi.org/10.3390/app9245504