Semantic Network Analysis Pipeline—Interactive Text Mining Framework for Exploration of Semantic Flows in Large Corpus of Text

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Background
3. Work-Flow
3.1. From Unstructured Text to Semantic Flows
3.2. Semantic Concept
3.3. Semantic Flows
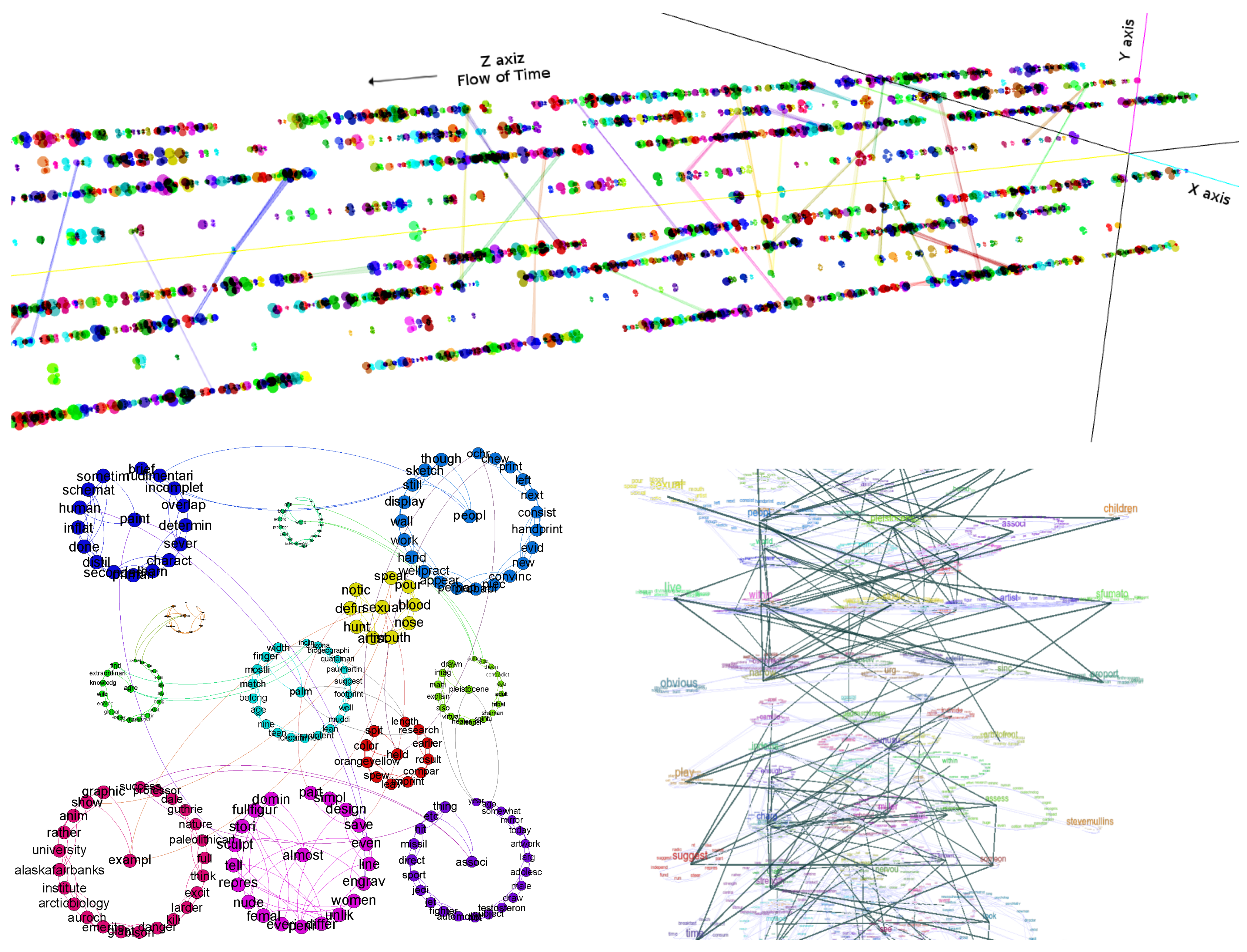
3.4. 3D Network Visualization
3.5. Implementation Notes
4. Sample Corpus Analysis
4.1. Moby Dick
4.2. U.S. Senate Hearings
4.3. Australian Broadcast Commission
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Smith, A.E. Automatic extraction of semantic networks from text using Leximancer. In Companion Volume of the Proceedings of HLT-NAACL 2003-Demonstrations; ACL: Edmonton, AB, Canada, 2003. [Google Scholar]
- Sowa, J.F. Principles of Semantic Networks: Explorations in the Representation of knowledge; Morgan Kaufmann: Burlington, MA, USA, 2014. [Google Scholar]
- Donovan, R.E.; Woodland, P.C. A hidden Markov-model-based trainable speech synthesizer. Comput. Speech Lang. 1999, 13, 223–241. [Google Scholar] [CrossRef]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural language processing: An introduction. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed]
- Cenek, M. Semantic Network Analysis Project (SNAP). 2006. Available online: https://github.com/mcenek/SNAP (accessed on 10 May 2019).
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL on Interactive Presentation Sessions, Sydney, Australia, 17–21 July 2006; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006; pp. 69–72. [Google Scholar]
- spaCy-Industrial-Strength Natural Language Processing in Python. Available online: https://spacy.io/ (accessed on 30 June 2018).
- Stanford Natural Language Processing Group. Available online: https://nlp.stanford.edu/software/ (accessed on 10 May 2019).
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The stanford corenlp natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Richens, R.H. Interlingual machine translation. Comput. J. 1958, 1, 144–147. [Google Scholar] [CrossRef]
- Fatima, Q.; Cenek, M.; Cenek, M. New graph-based text summarization method. In Proceedings of the 2015 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 24–26 August 2015; pp. 396–401. [Google Scholar]
- Jarmasz, M.; Szpakowicz, S. Not as easy as it seems: Automating the construction of lexical chains using roget’s thesaurus. In Proceedings of the Conference of the Canadian Society for Computational Studies of Intelligence, Halifax, NS, Canada, 11–13 June 2003; pp. 544–549. [Google Scholar]
- Patel, S.M.; Dabhi, V.K.; Prajapati, H.B. Extractive Based Automatic Text Summarization. JCP 2017, 12, 550–563. [Google Scholar] [CrossRef]
- Singhal, A. Introducing the Knowledge Graph: Things, Not Strings; Official Google Blog. Available online: www.blog.google (accessed on 4 December 2019).
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Fellbaum, C. WordNet. In Theory and Applications of Ontology: Computer Applications; Springer: Berlin/Heidelberg, Germany, 2010; pp. 231–243. [Google Scholar]
- Vossen, P. A multilingual Database with Lexical Semantic Networks; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Tur, G.; Celikyilmaz, A.; He, X.; Hakkani-Tur, D.; Deng, L. Deep Learning in Conversational Language Understanding. In Deep Learning in Natural Language Processing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 23–48. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Zheng, R.; Chen, J.; Qiu, X. Same representation, different attentions: Shareable sentence representation learning from multiple tasks. arXiv 2018, arXiv:1804.08139. [Google Scholar]
- Barzilay, R.; Elhadad, M. Using lexical chains for text summarization. In Advances in Automatic Text Summarization; MIT Press: Cambridge, MA, USA, 1999; pp. 111–121. [Google Scholar]
- Barzilay, R. Lexical Chains for Summarization. Ph.D. Thesis, Ben-Gurion University of the Negev, Beersheba, Israel, 1997. [Google Scholar]
- Galley, M.; McKeown, K. Improving word sense disambiguation in lexical chaining. In Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence, Acapulco, Mexico, 9–15 August 2003; Volume 3, pp. 1486–1488. [Google Scholar]
- Dang, J.; Kalender, M.; Toklu, C.; Hampel, K. Semantic Search Tool for Document Tagging, Indexing and Search. U.S. Patent 9,684,683, 20 June 2017. [Google Scholar]
- Steyvers, M.; Tenenbaum, J.B. The Large-Scale Structure of Semantic Networks: Statistical Analyses and a Model of Semantic Growth. Cogn. Sci. 2005, 29, 41–78. [Google Scholar] [CrossRef] [PubMed]
- Ensan, F.; Bagheri, E. Document Retrieval Model Through Semantic Linking. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 181–190. [Google Scholar]
- Navigli, R. Consistent validation of manual and automatic sense annotations with the aid of semantic graphs. Comput. Linguist. 2006, 32, 273–281. [Google Scholar] [CrossRef][Green Version]
- Overview Project: Completed News Stories. 2017. Available online: https://github.com/overview/overviewserver/wiki/News-stories (accessed on 10 May 2019).
- Document Cloud: Analyze, Annotate, Publish. Turn Documents into Data. 2017. Available online: https://www.documentcloud.org/ (accessed on 10 May 2019).
- Apache UIMA—Apache UIMA. Available online: http://incubator.apache.org/uima/ (accessed on 10 May 2019).
- IBM Watson: AlchemyAPI. Available online: https://www.ibm.com/watson/alchemy-api.html (accessed on 10 May 2019).
- Newman, D.; Noh, Y.; Talley, E.; Karimi, S.; Baldwin, T. Evaluating topic models for digital libraries. In Proceedings of the 10th Annual Joint Conference on Digital Libraries, Queensland, Australia, 21–25 June 2010; pp. 215–224. [Google Scholar]
- Suen, C.; Huang, S.; Eksombatchai, C.; Sosic, R.; Leskovec, J. Nifty: A system for large scale information flow tracking and clustering. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1237–1248. [Google Scholar]
- Dou, W.; Yu, L.; Wang, X.; Ma, Z.; Ribarsky, W. Hierarchicaltopics: Visually exploring large text collections using topic hierarchies. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2002–2011. [Google Scholar] [PubMed]
- Chaney, A.J.B.; Blei, D.M. Visualizing Topic Models. In Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–7 June 2012. [Google Scholar]
- DiMaggio, P.; Nag, M.; Blei, D. Exploiting affinities between topic modeling and the sociological perspective on culture: Application to newspaper coverage of US government arts funding. Poetics 2013, 41, 570–606. [Google Scholar] [CrossRef]
- Cui, W.; Liu, S.; Tan, L.; Shi, C.; Song, Y.; Gao, Z.; Qu, H.; Tong, X. Textflow: Towards better understanding of evolving topics in text. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2412–2421. [Google Scholar] [CrossRef] [PubMed]
- Chuang, J.; Ramage, D.; Manning, C.; Heer, J. Interpretation and trust: Designing model-driven visualizations for text analysis. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 443–452. [Google Scholar]
- Altaweel, M.R.; Alessa, L.N.; Kliskey, A.D.; Bone, C.E. Monitoring land use: Capturing change through an information fusion approach. Sustainability 2010, 2, 1182–1203. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An Open Source Software for Exploring and Manipulating Networks. In Proceedings of the Third International AAAI Conference on Weblogs and Social Media, San Jose, CA, USA, 17–20 May 2009. [Google Scholar]
- Gephi—The Open Graph. Available online: http://gephi.org (accessed on 30 June 2017).
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Lambiotte, R.; Delvenne, J.C.; Barahona, M. Laplacian dynamics and multiscale modular structure in networks. arXiv 2008, arXiv:0812.1770. [Google Scholar]
- Ruhnau, B. Eigenvector-centrality—A node-centrality? Soc. Netw. 2000, 22, 357–365. [Google Scholar] [CrossRef]
- Brandes, U. A faster algorithm for betweenness centrality. J. Math. Sociol. 2001, 25, 163–177. [Google Scholar] [CrossRef]
- Abbott, B. The Digital Universe Guide for Partiview. 2006. Available online: http://haydenplanetarium. org/universe/duguide (accessed on 10 May 2019).
- WAMP, LAMP and MAMP Stacks: Softwaculous AAMPS. 2019. Available online: http://www.ampps.com/ (accessed on 1 June 2019).
- CodeIgniter Web Framework. 2019. Available online: https://www.codeigniter.com/ (accessed on 1 June 2019).
- 3D JavaScript Libraries. 2019. Available online: https://threejs.org (accessed on 1 June 2019).
- Partiview. 2019. Available online: http://virdir.ncsa.illinois.edu/partiview/ (accessed on 1 June 2019).
- Melville, H. Moby-Dick; Courier Corporation: Garden City, NY, USA, 2003. [Google Scholar]
- U.S. Government Publishing Office, W.D. U.S. Senate, Committee on Environment and Public Works, 2016. Available online: http://www.gpo.gov/fdsys (accessed on 10 May 2019).
- Australian Broadcasting Commission 2006. 2006. Available online: https://github.com/nltk (accessed on 10 May 2019).




© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cenek, M.; Bulkow, R.; Pak, E.; Oyster, L.; Ching, B.; Mulagada, A. Semantic Network Analysis Pipeline—Interactive Text Mining Framework for Exploration of Semantic Flows in Large Corpus of Text. Appl. Sci. 2019, 9, 5302. https://doi.org/10.3390/app9245302
Cenek M, Bulkow R, Pak E, Oyster L, Ching B, Mulagada A. Semantic Network Analysis Pipeline—Interactive Text Mining Framework for Exploration of Semantic Flows in Large Corpus of Text. Applied Sciences. 2019; 9(24):5302. https://doi.org/10.3390/app9245302
Chicago/Turabian StyleCenek, Martin, Rowan Bulkow, Eric Pak, Levi Oyster, Boyd Ching, and Ashika Mulagada. 2019. "Semantic Network Analysis Pipeline—Interactive Text Mining Framework for Exploration of Semantic Flows in Large Corpus of Text" Applied Sciences 9, no. 24: 5302. https://doi.org/10.3390/app9245302
APA StyleCenek, M., Bulkow, R., Pak, E., Oyster, L., Ching, B., & Mulagada, A. (2019). Semantic Network Analysis Pipeline—Interactive Text Mining Framework for Exploration of Semantic Flows in Large Corpus of Text. Applied Sciences, 9(24), 5302. https://doi.org/10.3390/app9245302