WiFi-Based Gesture Recognition for Vehicular Infotainment System—An Integrated Approach


Abstract
1. Introduction
- We present a WiFi-based device-free innovative framework to address the problem of driver gesture recognition for the application of vehicle infotainment systems leveraging CSI measurements.
- We demonstrate a novel classification model by integrating SRC and a variant of the KNN algorithm to overcome the problem of expensive computational cost.
- To evaluate the performance of our proposed framework, we perform comprehensive experiments in promising application scenarios.
- To validate the results, we compare our system performance with state-of-the-art methods.
2. Related Work
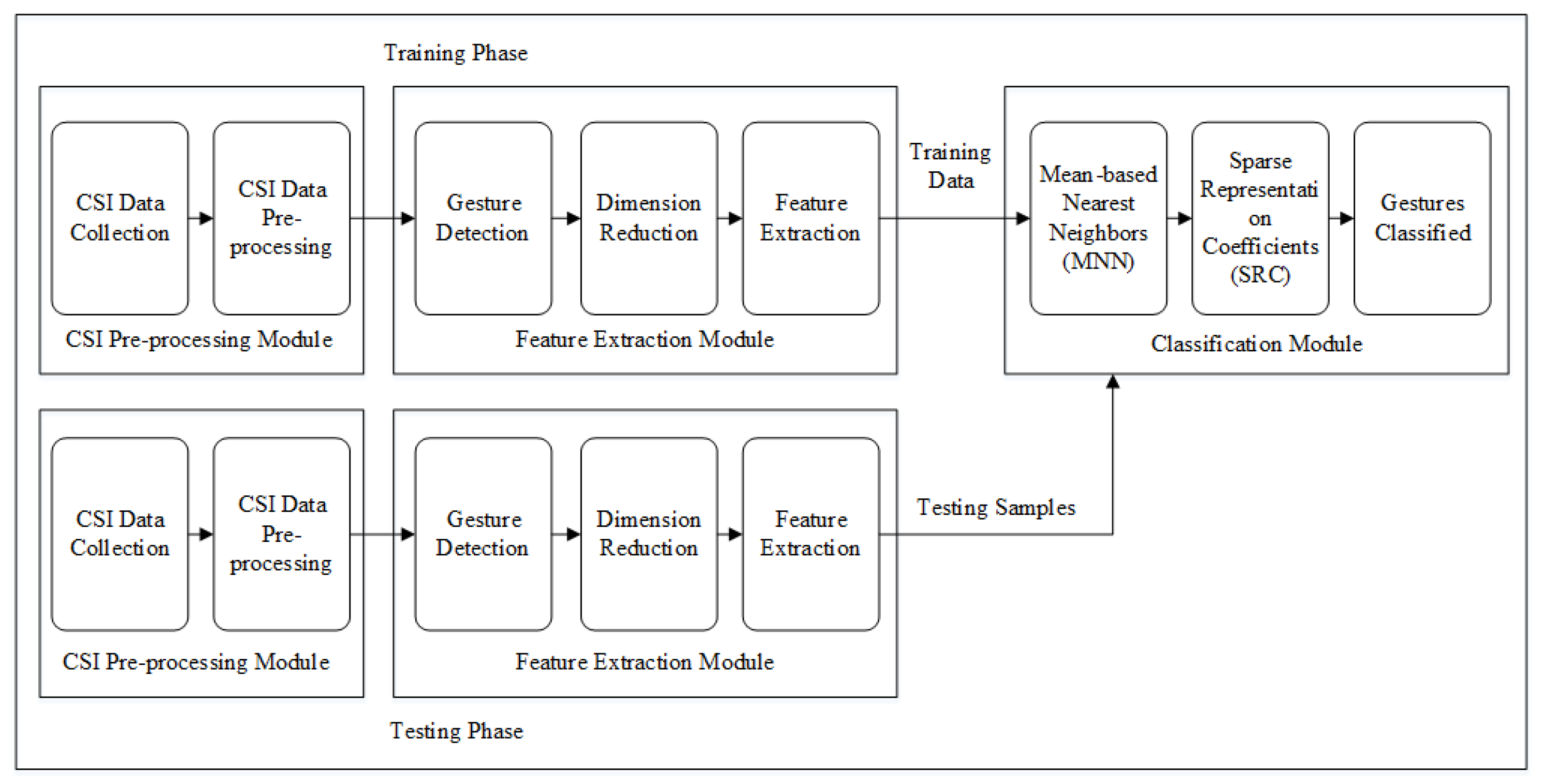
3. System Overview
3.1. Background of SRC and MNN Algorithms
3.2. Integration of SRC and MNN Algorithms
3.3. CSI Overview
3.4. System Architecture
4. Methodology
4.1. CSI Pre-Processing
4.1.1. Phase Calibration
4.1.2. Amplitude Information Processing
4.2. Gesture Detection
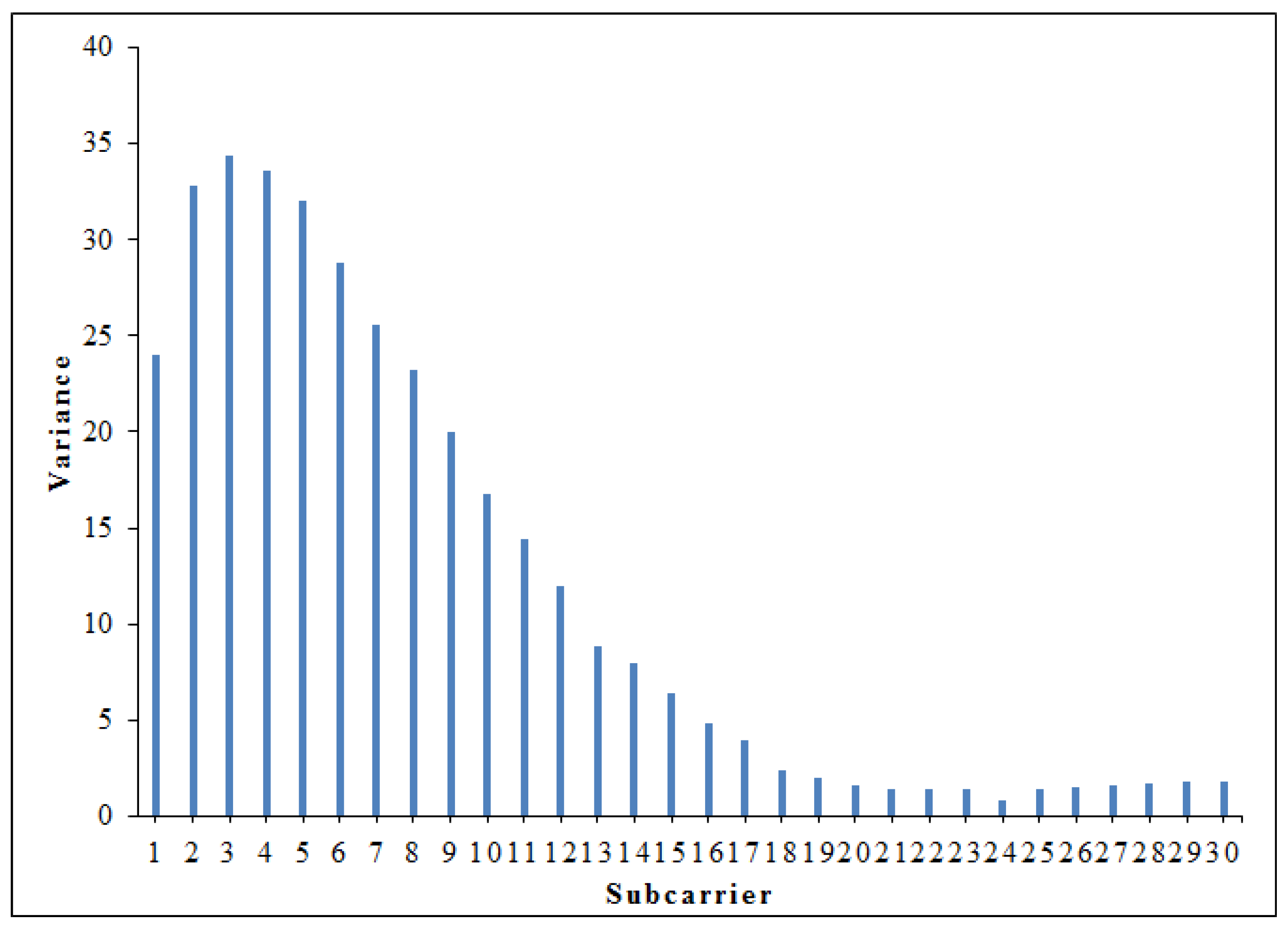
4.2.1. Dimensionality Reduction
4.2.2. Feature Extraction
4.3. Classification Module
4.3.1. K Nearest Neighbor
4.3.2. Mean of Nearest Neighbor (MNN)
4.3.3. Sparse Representation Based Classification (SRC)
4.3.4. MNN Induced SRC (MNN-SRC)
5. Experimentation and Evaluation
5.1. Experimentation Settings
- Scenario-I (Indoor environment)—In this scenario, all prescribed gestures are performed in an empty room of size feet, while sitting on a chair between Tx and Rx, separated by a distance of 2 m.
- Scenario-II (Vehicle standing in a garage)—In this scenario, all gestures are performed in a vehicle standing in a garage of size feet.
- Scenario-III (Actual driving)—In this scenario, all prescribed gestures are performed while driving a vehicle on a straight road of 30 km inside university campus, with average speed of 20 km/h. During gesture performance, no other activity is performed to avoid interference.
5.2. Performance Evaluation
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Haseeb, M.A.A.; Parasuraman, R. Wisture: Touch-Less Hand Gesture Classification in Unmodified Smartphones Using Wi-Fi Signals. IEEE Sens. J. 2019, 19, 257–267. [Google Scholar] [CrossRef]
- Li, Y.; Huang, J.; Tian, F.; Wang, H.A.; Dai, G.Z. Gesture interaction in virtual reality. Virtual Real. Intell. Hardw. 2019, 1, 84–112. [Google Scholar] [CrossRef]
- Vuletic, T.; Duffy, A.; Hay, L.; McTeague, C.; Campbell, G.; Grealy, M. Systematic literature review of hand gestures used in human computer interaction interfaces. Int. J. Hum.-Comput. Stud. 2019, 129, 74–94. [Google Scholar] [CrossRef]
- Grifa, H.S.; Turc, T. Human hand gesture based system for mouse cursor control. Procedia Manuf. 2018, 22, 1038–1042. [Google Scholar] [CrossRef]
- Suchitra, T.; Brinda, R. Hand Gesture Recognition Based Auto Navigation System for Leg Impaired Persons. Int. J. Adv. Res. Electr. Electron. Instrum. Eng. 2017, 6, 251–257. [Google Scholar]
- Ahmed, S.; Khan, F.; Ghaffar, A.; Hussain, F.; Cho, S.H. Finger-Counting-Based Gesture Recognition within Cars Using Impulse Radar with Convolutional Neural Network. Sensors 2019, 19, 1429. [Google Scholar] [CrossRef]
- Zengeler, N.; Kopinski, T.; Handmann, U. Hand Gesture Recognition in Automotive Human-Machine Interaction Using Depth Cameras. Sensors 2019, 19, 59. [Google Scholar] [CrossRef]
- Khan, F.; Leem, S.K.; Cho, S.H. Hand-Based Gesture Recognition for Vehicular Applications Using IR-UWB Radar. Sensors 2017, 17, 833. [Google Scholar] [CrossRef]
- Cao, Z.; Xu, X.; Hu, B.; Zhou, M.; Li, Q. Real-time gesture recognition based on feature recalibration network with multi-scale information. Neurocomputing 2019, 347, 119–130. [Google Scholar] [CrossRef]
- Large, D.R.; Harrington, K.; Burnett, G.; Georgiou, O. Feel the noise: Mid-air ultrasound haptics as a novel human-vehicle interaction paradigm. Appl. Ergon. 2019, 81, 102909. [Google Scholar] [CrossRef]
- He, W.; Wu, K.; Zou, Y.; Ming, Z. WiG: WiFi-Based Gesture Recognition System. In Proceedings of the 24th International Conference on Computer Communication and Networks (ICCCN), Las Vegas, NV, USA, 3–6 August 2015. [Google Scholar]
- Xiong, H.; Gong, F.; Qu, L.; Du, C.; Harfoush, K. CSI-based Device-free Gesture Detection. In Proceedings of the 12th International Conference on High-Capacity Optical Networks and Enabling/Emerging Technologies (HONET), Islamabad, Pakistan, 21–23 December 2015. [Google Scholar]
- Li, H.; Yang, W.; Wang, J.; Xu, Y.; Huang, L. WiFinger: Talk to Your Smart Devices with Finger-grained Gesture. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 250–261. [Google Scholar]
- Abdelnasser, H.; Harras, K.; Youssef, M. A Ubiquitous WiFi-based Fine-Grained Gesture Recognition System. IEEE Trans. Mob. Comput. 2018, 18, 2474–2487. [Google Scholar] [CrossRef]
- Zhou, Q.; Xing, J.; Chen, W.; Zhang, X.; Yang, Q. From Signal to Image: Enabling Fine-Grained Gesture Recognition with Commercial Wi-Fi Devices. Sensors 2018, 18, 3142. [Google Scholar] [CrossRef] [PubMed]
- Ali, K.; Liu, A.X.; Wang, W.; Shahzad, M. Recognizing Keystrokes Using WiFi Devices. IEEE J. Sel. Areas Commun. 2017, 35, 1175–1190. [Google Scholar] [CrossRef]
- Tan, B.; Chen, Q.; Chetty, K.; Woodbridge, K.; Li, W.; Piechocki, R. Exploiting WiFi Channel State Information for Residential Healthcare Informatics. IEEE Commun. Mag. 2018, 56, 130–137. [Google Scholar] [CrossRef]
- Al-qaness, M.A.A.; Li, F.; Ma, X.; Zhang, Y.; Liu, G. Device-Free Indoor Activity Recognition System. Appl. Sci. 2016, 6, 329. [Google Scholar] [CrossRef]
- Mitani, Y.; Hamamoto, Y. A local mean-based nonparametric classifier. Pattern Recognit. Lett. 2006, 27, 1151–1159. [Google Scholar] [CrossRef]
- Gou, J.; Ma, H.; Ou, W.; Zeng, S.; Rao, Y.; Yang, H. A generalized mean distance-based k-nearest neighbor classifier. Expert Syst. Appl. 2019, 115, 356–372. [Google Scholar] [CrossRef]
- Gou, J.; Qiu, W.; Yi, Z.; Xu, Y.; Mao, Q.; Zhan, Y. A Local Mean Representation-based K-Nearest Neighbor Classifier. ACM Trans. Intell. Syst. Technol. 2019, 10, 29. [Google Scholar] [CrossRef]
- Zou, J.; Li, W.; Du, Q. Sparse Representation-Based Nearest Neighbor Classifiers for Hyperspectral Imagery. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2418–2422. [Google Scholar]
- Yang, J.; Zhang, L.; Yang, J.Y.; Zhang, D. From classifiers to discriminators: A nearest neighbor rule induced discriminant analysis. Pattern Recognit. 2011, 44, 1387–1402. [Google Scholar] [CrossRef]
- Bulut, F.; Amasyali, M.F. Locally adaptive k parameter selection for nearest neighbor classifier: One nearest cluster. Pattern Anal. Appl. 2017, 20, 415–425. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Wang, R. Efficient kNN Classification With Different Numbers of Nearest Neighbors. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1774–1785. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Yang, J. K Nearest Neighbor Based Local Sparse Representation Classifier. In Proceedings of the 2010 Chinese Conference on Pattern Recognition (CCPR), Chongqing, China, 21–23 October 2010. [Google Scholar]
- Xiao, J.; Zhou, Z.; Yi, Y.; Ni, L.M. A Survey on Wireless Indoor Localization from the Device Perspective. ACM Comput. Surv. (CSUR) 2016, 49, 25. [Google Scholar] [CrossRef]
- Zhang, L.; Gao, Q.; Ma, X.; Wang, J.; Yang, T.; Wang, H. DeFi: Robust Training-Free Device-Free Wireless Localization With WiFi. IEEE Trans. Veh. Technol. 2018, 67, 8822–8831. [Google Scholar] [CrossRef]
- Pu, Q.; Gupta, S.; Gollakota, S.; Patel, S. Whole-home gesture recognition using wireless signals. In Proceedings of the 19th Annual International Conference on Mobile Computing & Networking, Miami, FL, USA, 30 September–4 October 2013. [Google Scholar]
- Adib, F.; Katabi, D. See through walls with WiFi. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 75–86. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, L.; Yang, P.; Lu, L.; Gong, L. Wi-Run: Device-free step estimation system with commodity Wi-Fi. J. Netw. Comput. Appl. 2019, 143, 77–88. [Google Scholar] [CrossRef]
- Li, F.; Al-qaness, M.A.A.; Zhang, Y.; Zhao, B.; Luan, X. A Robust and Device-Free System for the Recognition and Classification of Elderly Activities. Sensors 2016, 16, 2043. [Google Scholar] [CrossRef]
- Dong, Z.; Li, F.; Ying, J.; Pahlavan, K. Indoor Motion Detection Using Wi-Fi Channel State Information in Flat Floor Environments Versus in Staircase Environments. Sensors 2018, 18, 2177. [Google Scholar] [CrossRef]
- Yang, X.; Xiong, F.; Shao, Y.; Niu, Q. WmFall: WiFi-based multistage fall detection with channel state information. Int. J. Distrib. Sens. Netw. 2018, 14, 1550147718805718. [Google Scholar] [CrossRef]
- Al-qaness, M.A.A. Device-free human micro-activity recognition method using WiFi signals. Geo-Spat. Inf. Sci. 2019, 22, 128–137. [Google Scholar] [CrossRef]
- Lv, J.; Man, D.; Yang, W.; Gong, L.; Du, X.; Yu, M. Robust Device-Free Intrusion Detection Using Physical Layer Information of WiFi Signals. Appl. Sci. 2019, 9, 175. [Google Scholar] [CrossRef]
- Wang, T.; Yang, D.; Zhang, S.; Wu, Y.; Xu, S. Wi-Alarm: Low-Cost Passive Intrusion Detection Using WiFi. Sensors 2019, 19, 2335. [Google Scholar] [CrossRef] [PubMed]
- Ding, E.; Li, X.; Zhao, T.; Zhang, L.; Hu, Y. A Robust Passive Intrusion Detection System with Commodity WiFi Devices. J. Sens. 2018, 2018, 8243905. [Google Scholar] [CrossRef]
- Al-qaness, M.A.A.; Li, F. WiGeR: WiFi-Based Gesture Recognition System. ISPRS Int. J. Geo-Inf. 2016, 5, 92. [Google Scholar] [CrossRef]
- Fu, Z.; Xu, J.; Zhu, Z.; Liu, A.X.; Sun, X. Writing in the Air with WiFi Signals for Virtual Reality Devices. IEEE Trans. Mob. Comput. 2019, 18, 473–484. [Google Scholar] [CrossRef]
- Tian, Z.; Wang, J.; Yang, X.; Zhou, M. WiCatch: A Wi-Fi Based Hand Gesture Recognition System. IEEE Access 2018, 6, 16911–16923. [Google Scholar] [CrossRef]
- Jia, W.; Peng, H.; Ruan, N.; Tang, Z.; Zhao, W. WiFind: Driver Fatigue Detection with Fine-Grained Wi-Fi Signal Features. IEEE Trans. Big Data (Early Access) 2018. [Google Scholar] [CrossRef]
- Duan, S.; Yu, T.; He, J. WiDriver: Driver Activity Recognition System Based on WiFi CSI. Int. J. Wirel. Inf. Netw. 2018, 25, 146–156. [Google Scholar] [CrossRef]
- Arshad, S.; Feng, C.; Elujide, I.; Zhou, S.; Liu, Y. SafeDrive-Fi: A Multimodal and Device Free Dangerous Driving Recognition System Using WiFi. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018. [Google Scholar]
- Halperin, D.; Hu, W.; Sheth, A.; Wetherall, D. Tool release: Gathering 802.11n traces with channel state information. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 53. [Google Scholar] [CrossRef]
- Sen, S.; Radunovic, B.; Choudhury, R.R.; Minka, T. You are facing the Mona Lisa: Spot localization using PHY layer information. In Proceedings of the ACM 10th International Conference on Mobile Systems, Applications, and Services, Lake District, UK, 25–29 June 2012. [Google Scholar]
- Wang, Y.; Wu, K.; Ni, L.M. WiFall: Device-Free Fall Detection by Wireless Networks. IEEE Trans. Mob. Comput. 2016, 16, 581–594. [Google Scholar] [CrossRef]
- Feng, C.; Arshad, S.; Yu, R.; Liu, Y. Evaluation and Improvement of Activity Detection Systems with Recurrent Neural Network. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018. [Google Scholar]
- Wang, W.; Liu, A.X.; Shahzad, M.; Ling, K.; Lu, S. Device-Free Human Activity Recognition Using Commercial WiFi Devices. IEEE J. Sel. Areas Commun. 2017, 35, 1118–1131. [Google Scholar] [CrossRef]
- Arshad, S.; Feng, C.; Liu, Y.; Hu, Y.; Yu, R.; Zhou, S. Wi-chase: A WiFi based human activity recognition system for sensorless environments. In Proceedings of the 2017 IEEE 18th International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM), Macau, China, 12–15 June 2017. [Google Scholar]
- Wu, C.T.; Dillon, D.G.; Hsu, H.C.; Huang, S.; Barrick, E.; Liu, Y.H. Depression Detection Using Relative EEG Power Induced by Emotionally Positive Images and a Conformal Kernel Support Vector Machine. Appl. Sci. 2018, 8, 1244. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gesture Type | Gesture Performed | Associated Task | Gesture Label |
|---|---|---|---|
| Hand Gesture | Swipe left | (+) Change channel | SL |
| Swipe right | (−) Change channel | SR | |
| Hand going up | (+) Volume | HU | |
| Hand going down | (−) Volume | HD | |
| Flick | Zoom in | FK | |
| Grab | Zoom out | GB | |
| Push hand forward | (+) Temperature setting | PF | |
| Pull hand backward | (−) Temperature setting | PB | |
| Rotate hand clock-wise | (+) Fan speed | RC | |
| Rotate hand anti-clock-wise | (−) Fan speed | RA | |
| Finger Gesture | Swipe V | Open function | SV |
| Swipe X | Close function | SX | |
| Swipe + | Play next track | SP | |
| Swipe − | Play previous track | SN | |
| Head Gesture | Head tilting down | Pick phone call | HM |
| Head tilting right | Do not pick call | HR |
| Feature Type | Gesture Class | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SL | SR | HU | HD | FK | GB | PF | PB | RC | RA | SV | SX | SP | SN | HM | HR | |
| 1.54 | 1.33 | 0.81 | 0.74 | 1.42 | 2.16 | 2.25 | 3.52 | 0.96 | 0.91 | 1.63 | 1.49 | 2.28 | 1.71 | 2.13 | 2.66 | |
| 0.73 | 0.96 | 0.68 | 0.66 | 1.89 | 1.97 | 1.20 | 1.14 | 0.62 | 0.76 | 1.27 | 1.35 | 1.73 | 1.16 | 1.81 | 1.46 | |
| 0.48 | 0.64 | 0.45 | 0.43 | 1.37 | 1.31 | 0.83 | 0.76 | 0.41 | 0.50 | 0.84 | 0.90 | 1.15 | 0.73 | 1.21 | 0.97 | |
| 3.58 | 3.97 | 5.88 | 6.31 | 8.24 | 6.04 | 7.73 | 9.02 | 8.85 | 6.57 | 4.96 | 7.22 | 5.94 | 6.39 | 7.63 | 5.99 | |
| 0.69 | 0.60 | 0.27 | 0.37 | 0.58 | 0.82 | 0.98 | 1.22 | 0.35 | 0.44 | 0.64 | 0.51 | 0.77 | 0.65 | 0.95 | 0.91 | |
| 2.11 | 1.83 | 0.86 | 0.92 | 1.76 | 2.57 | 2.93 | 3.71 | 1.01 | 1.34 | 1.95 | 1.55 | 2.35 | 1.98 | 2.88 | 2.73 | |
| Experiment | Gesture | SL | SR | HU | HD | FK | GB | PF | PB | RC | RA | SV | SX | SP | SN | HM | HR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Scenario-I | TPR (%) | 92.7 | 91.0 | 95.9 | 96.9 | 89.0 | 89.1 | 87.4 | 85.6 | 89.3 | 90.1 | 93.8 | 88.2 | 87.6 | 96.8 | 95.0 | 96.0 |
| FNR (%) | 7.3 | 9.0 | 4.1 | 3.1 | 11.0 | 10.9 | 12.6 | 14.4 | 10.7 | 9.9 | 6.2 | 11.8 | 12.4 | 3.2 | 5.0 | 4.0 | |
| Scenario-II | TPR (%) | 94.6 | 95.8 | 96.7 | 93.0 | 89.7 | 89.1 | 85.0 | 86.4 | 86.9 | 87.6 | 88.2 | 90.0 | 87.5 | 93.7 | 93.1 | 93.9 |
| FNR (%) | 5.4 | 4.2 | 3.3 | 7.0 | 10.3 | 10.9 | 15.0 | 13.6 | 13.1 | 12.4 | 11.8 | 10.0 | 12.5 | 6.3 | 6.9 | 6.1 | |
| Scenario-III | TPR (%) | 92.5 | 92.7 | 93.6 | 92.8 | 86.7 | 86.5 | 86.7 | 82.9 | 85.1 | 84.6 | 89.9 | 88.0 | 80.4 | 91.6 | 94.8 | 93.0 |
| FNR (%) | 7.5 | 7.3 | 6.4 | 7.2 | 13.3 | 13.5 | 13.3 | 17.1 | 14.9 | 15.4 | 10.1 | 12.0 | 19.6 | 8.4 | 5.2 | 7.0 |
| Experiment | Average Recognition Accuracy (%) | ||||||
|---|---|---|---|---|---|---|---|
| NB | SVM | KNN | MNN | SRC | KNN-SRC | MNN-SRC | |
| Scenario-I | 85.9 | 88.5 | 87.1 | 87.5 | 89.5 | 90.7 | 91.4 |
| Scenario-II | 84.1 | 86.6 | 85.4 | 86.2 | 88 | 90.1 | 90.6 |
| Scenario-III | 82.5 | 85.1 | 84.3 | 84.5 | 86.6 | 88.1 | 88.7 |
| K Value | Gesture Class | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SL | SR | HU | HD | FK | GB | PF | PB | RC | RA | SV | SX | SP | SN | HM | HR | |
| K = 1 | 88.3 | 90.5 | 90.4 | 89.3 | 87.1 | 87.7 | 88.3 | 87.9 | 91.4 | 89.3 | 90.6 | 90.1 | 92.3 | 90.3 | 96.0 | 94.5 |
| <88.8 | <90.8 | <91.8 | <90.5 | <87.7 | <88.6 | <89.2 | <88.2 | <91.8 | <90.4 | <89.5 | <90.3 | <91.9 | <90.1 | <95.8 | <94.7 | |
| K = 5 | 89.2 | 91.0 | 93.1 | 91.7 | 88.3 | 89.4 | 90.1 | 88.5 | 92.1 | 91.5 | 90.1 | 90.2 | 92.1 | 90.2 | 95.9 | 94.6 |
| <89.2 | <90.8 | <92.8 | <91.7 | <88.7 | <89.1 | <89.8 | <88.2 | <92.0 | <90.9 | <90.4 | <89.7 | <92.0 | <89.5 | <94.7 | <94.1 | |
| K = 10 | 89.1 | 90.6 | 92.4 | 91.6 | 89.1 | 88.8 | 89.5 | 87.9 | 91.8 | 90.2 | 89.3 | 89.5 | 91.2 | 89.1 | 95.3 | 94.0 |
| <88.7 | <90.9 | <92.7 | <92.0 | <89.0 | <89.3 | <89.8 | <87.7 | <92.1 | <90.4 | <90.0 | <90.0 | <91.9 | <89.8 | <95.5 | <94.4 | |
| K = 15 | 88.2 | 91.1 | 93.0 | 92.3 | 88.9 | 89.8 | 90.1 | 87.5 | 92.3 | 90.5 | 90.2 | 90.1 | 92.0 | 89.8 | 95.7 | 95.1 |
| <88.6 | <91.3 | <93.4 | <92.7 | <89.1 | <89.8 | <90.2 | <88.1 | <92.4 | <90.6 | <90.7 | <89.8 | <92.2 | <89.5 | <95.6 | <95.2 | |
| K = 20 | 88.9 | 91.4 | 93.7 | 93.1 | 89.2 | 89.7 | 90.3 | 88.6 | 92.4 | 90.7 | 91.1 | 89.6 | 92.3 | 89.6 | 95.9 | 95.2 |
| <89.4 | <91.3 | <93.4 | <93.0 | <89.4 | <89.4 | <90.5 | <87.9 | <92.2 | <90.5 | <90.2 | <89.9 | <92.6 | <90.1 | <96.0 | <94.6 | |
| K = 25 | 89.8 | 91.1 | 93.1 | 92.8 | 89.6 | 89.1 | 90.6 | 87.2 | 92.0 | 90.4 | 90.2 | 89.7 | 92.0 | 89.8 | 95.6 | 94.6 |
| <89.0 | <91.1 | <93.0 | <92.4 | <89.7 | <88.8 | <89.9 | <87.5 | <92.1 | <90.3 | <90.1 | <89.9 | <92.2 | <89.7 | <95.0 | <94.8 | |
| K = 30 | 88.2 | 91.0 | 92.8 | 91.9 | 89.7 | 88.5 | 89.1 | 87.7 | 92.2 | 90.3 | 90.2 | 89.9 | 92.1 | 89.8 | 95.4 | 94.7 |
| <88.5 | <90.9 | <92.7 | <91.8 | <89.4 | <88.3 | <88.8 | <87.5 | <92.4 | <90.3 | <89.9 | <89.6 | <91.8 | <89.8 | <95.6 | <94.3 | |
| K = 40 | 88.7 | 90.8 | 92.6 | 91.7 | 89.1 | 88.1 | 88.5 | 87.3 | 92.5 | 90.3 | 88.3 | 89.1 | 91.6 | 89.5 | 95.3 | 93.9 |
| <88.5 | <90.5 | <91.5 | <91.0 | <88.3 | <87.6 | <88.1 | <87.2 | <91.5 | <89.7 | <88.1 | <89.0 | <91.3 | <88.7 | <94.9 | <94.6 | |
| K = 50 | 88.3 | 90.1 | 90.3 | 90.2 | 87.4 | 87.1 | 87.7 | 87.0 | 90.4 | 89.1 | 88.2 | 88.7 | 91.1 | 88.3 | 94.5 | 93.7 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akhtar, Z.U.A.; Wang, H. WiFi-Based Gesture Recognition for Vehicular Infotainment System—An Integrated Approach. Appl. Sci. 2019, 9, 5268. https://doi.org/10.3390/app9245268
Akhtar ZUA, Wang H. WiFi-Based Gesture Recognition for Vehicular Infotainment System—An Integrated Approach. Applied Sciences. 2019; 9(24):5268. https://doi.org/10.3390/app9245268
Chicago/Turabian StyleAkhtar, Zain Ul Abiden, and Hongyu Wang. 2019. "WiFi-Based Gesture Recognition for Vehicular Infotainment System—An Integrated Approach" Applied Sciences 9, no. 24: 5268. https://doi.org/10.3390/app9245268
APA StyleAkhtar, Z. U. A., & Wang, H. (2019). WiFi-Based Gesture Recognition for Vehicular Infotainment System—An Integrated Approach. Applied Sciences, 9(24), 5268. https://doi.org/10.3390/app9245268