1. Introduction
Epilepsy is a functional disorder caused by paroxysmal abnormal discharge of brain cells. According to the World Health Organization, about 50 million patients worldwide of all ages are suffering from epilepsy [
1]. Conventional manual seizure inspection of long-term EEG monitors is time-consuming. With the rapid development of pervasive sensing in daily healthcare system and machine learning technologies, computer-aided diagnosis mechanisms, such as automated seizure detection based on electroencephalogram (EEG), provides tremendous support for a patient’s health and quality of life [
2]. Such automated seizure detectors can trigger alarm when users are or will possibly be in a state of seizure. So far, algorithms for automated epileptic seizure detection proposed in most studies consist of three parts: (1) signal domain transformation, such as frequency domain via Fourier transform [
3], wavelet time-frequency domain via discrete wavelet transform (DWT) [
4,
5], weighted and specific shapes via Hermite transformation [
6] or original domain without transformation [
7]; (2) feature extraction in the target domain, such as energy features [
8] and complexity features [
9]; and (3) machine learning based classification using a support vector machine (SVM) [
10], k-nearest neighbor (KNN) [
11] or artificial neural network (ANN) [
12]. However, all the aforementioned three parts have shown limitations in some application scenarios, which are discussed in the following paragraphs separately.
For signal domain transformation, in spite of the many transformed domains explored for automated epileptic seizure detection, the most discriminative information resides in the time-frequency domain due to the evident transient characteristics and rich frequency components of epilepsy EEG. Accordingly, discrete wavelet transform (DWT) [
4,
5] has been widely applied in EEG based epileptic seizure detection applications because it can represent both the time and frequency characteristics of EEG signals. However, some drawbacks of DWT, such as shift variance, lack of directionality and the oscillation attribute of DWT coefficients [
13], limit its effectiveness in some applications. Moreover, the iterated downsampling operations during wavelet decomposition may introduce severe aliasing [
13]. Such aliasing can lead to information loss of original signals. Dual tree DWT (DTDWT) [
13] can overcome the aforementioned drawbacks of DWT at the cost of increasing information redundancy (a
redundancy factor for
d-dimensional signals). But large redundancy may greatly reduce learning efficiency, which in turn weakens the performance of the trained models.
For feature extraction in the target domain, complexity features [
9] have received a great deal of attention in the biomedical signal processing field in recent years. To measure the complexity property of EEG signals during epileptic seizures, entropy-based features have been widely used, such as sample entropy [
9], fuzzy entropy [
10], approximate entropy [
14], permutation entropy [
15] and distribution entropy [
9]. All these entropy indicators listed above measure EEG complexity on a single scale. The single scale complexity measure may fail to quantify the underlying dynamics of the extremely complex physiological signals. Therefore, multi-scale entropy (MSE) was proposed [
16]. However, the coarse-graining procedure during MSE computation can shorten the length of time sequence but a precise entropy relies heavily on a longer sequence length.
For machine learning based classification between normal (or interictal) and ictal seizure EEG, as mentioned earlier, large redundancy may greatly reduce the learning efficiency and increase model complexity. Epileptic seizure detection is a pattern recognition task with a small dataset size due to the scarcity of ictal seizure EEG. With only a small database available for model training, the large amount of redundancy in the seizure detection scenario will especially weaken the model performance. Due to the huge cost of data collection and data labeling, another alternative solution is to construct a compact data representation, reducing the dependence on data volume. Therefore, redundancy removal is crucial. Some classical redundancy reduction methods, such as principal component analysis (PCA) [
17] do not take feature separability into consideration. For a pattern recognition problem, the high feature separability and low redundancy are both important.
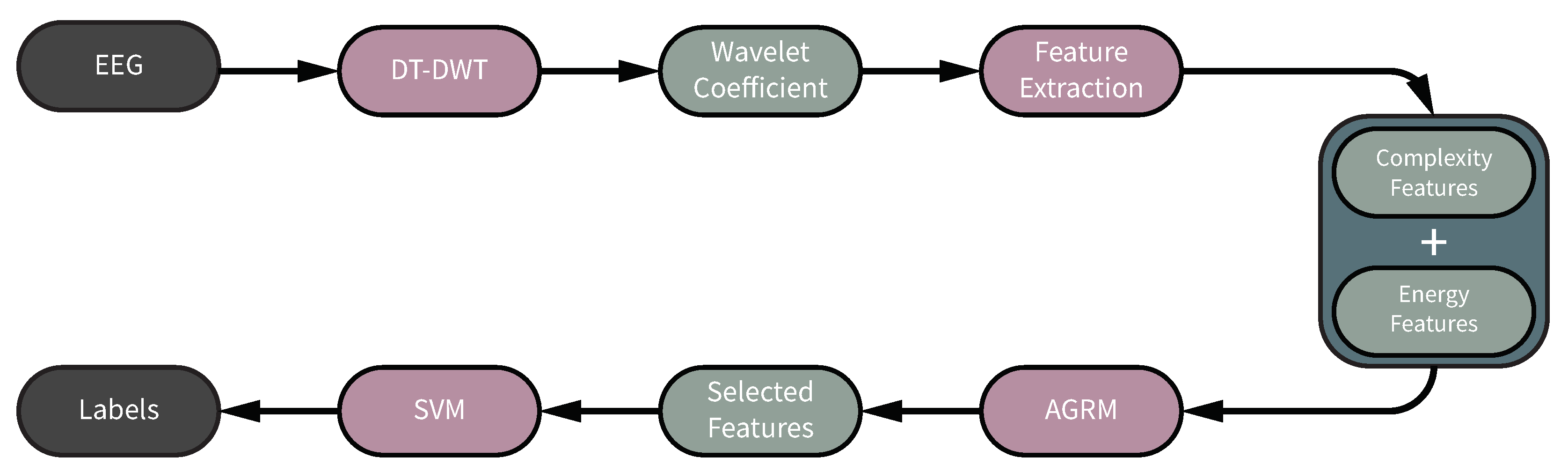
To address the aforementioned issues, we propose a novel framework of redundancy removed DTDWT (RR-DTDWT) to reduce global redundancy introduced by DTDWT and achieve a compact signal representation through low-redundancy features in the wavelet domain. First, DTDWT was employed to represent EEG signals in dural tree wavelet domain and at the same time, to overcome the drawbacks of DWT at the cost of increasing information redundancy. Then, energy and complexity features were both extracted for classification in our method. The energy features refer to the mean absolute values and variance-like statistic metrics. To measure the complexity property of EEG signals and reduce the influence of the short length of time sequence on entropy calculation, we used modified multi-scale entropy (MMSE) [
18] to represent the complexity of EEG signals. MMSE can overcome the shortcoming of MSE by replacing the coarse-graining procedure with a moving-average procedure. To the best of our knowledge, this is the first study to evaluate the effectiveness of MMSE for seizure detection. We constructed a complete picture to represent mental electrophysiological activity in wavelet domain with both a wealth of useful information and redundancy. The redundancy in this work was introduced from three levels: (1) redundancy between adjacent EEG channels, (2) redundancy between dual wavelet trees and (3) redundancy between entropy in different scales. Therefore, in the next step, we aimed to minimize the global redundancy, and meanwhile retain the feature separability. In our work, auto-weighted feature selection via global redundancy minimization (AGRM) [
19] was used to reduce the information redundancy. AGRM can take both feature redundancy and separability into account. Moreover, the optimization problem involved in AGRM is convex, so that a global optimum instead of local optimum can be obtained. In our work, a compact representation of the EEG signal can be obtained after removing information redundancy by AGRM. We validated the proposed RR-DTDWT framework on two benchmark databases (Bonn database and CHB-MIT database). The results on both databases demonstrate that RR-DTDWT can yield competitive results compared with previous studies.
4. Discussion
In this work, we proposed a RR-DTDWT framework for automated epileptic seizure detection. The propsed RR-DTDWT consists of four parts: (1) DTDWT-based signal domain transformation; (2) feature extraction; (3) feature selection and (4) classification. In the signal domain transformation part, the signal representation was obtained through DTDWT. DTDWT can reduce information loss during the iterated downsampling operation of DWT, at the cost of introducing information redundancy. In feature extraction part, energy and complexity features were extracted. MMSE was employed as an indicator of epileptic seizures for the first time. Then, AGRM-based feature selection could reduce the information redundancy and take feature separability into consideration at the same time. Finally, the label of each EEG segment was given by a patient-specific SVM classifier. In the following subsections, the comparison between our method and the ones from previous studies, the computational cost analysis and the limitations of our method are presented separately.
4.1. Comparison with Previous Studies
In this subsection, method comparison between the proposed RR-DTDWT algorithm and latest studies (after 2014) utilizing the same databases is presented.
4.1.1. Comparison with Previous Studies Based on Bonn Database
For Bonn database, method comparisons on two classification tasks, namely, “normal versus ictal” and “interictal versus ictal,” are presented in
Table 4 and
Table 5 respectively. Because the data in Bonn database are balanced between each category, classification accuracy was expected to be a good metric to characterize method performance. Obviously, the proposed RR-DTDWT method outperformed most other latest methods, achieving an accuracy of 100% for both cases. As previously mentioned, Bonn database contains artifact-free EEG signals. The artifacts due to muscle activity and eye movements were pre-removed through visual examination. Accordingly, Bonn database cannot simulate the challenging practical application scenarios, although it can be utilized for method comparison. Some previous studies have also reported a 100% accuracy. For example, Battacharyya et al. [
41] employed tunable-Q wavelet transform to develop a seizure detector which also achieved an accuracy of 100% for “normal versus ictal” problem. The model of Kumar et al. [
4] can discriminate normal data from ictal data with a 100% accuracy and also discriminate interictal data from ictal data with a very low error rate. Methods proposed by Raghu et al. [
42] yielded excellent performance for both classification tasks on Bonn database. Moreover, previous studies also proposed wavelet-based methods [
43,
44] and achieved a 100% or almost 100% classification accuracy. Akut et al. [
45] proposed a wavelet-based deep learning approach in which no manual feature extraction was required. This method can achieve a high accuracy on small EEG database. All these studies made great contributions to the epilepsy monitoring field. Although our method achieved a 100% classification accuracy and outperformed most previous studies on Bonn database, its superior performance compared with other studies on the practical and challenging CHB-MIT database is described next.
4.1.2. Comparison with Previous Studies Based on CHB-MIT Database
For the CHB-MIT database, a method comparison is shown in
Table 6. Different studies based on CHB-MIT database employed a wide variety of metric combinations to evaluate algorithm performance. For example, study [
10,
56] applied specificity and false positive rate (FPR) to characterize model performance respectively. To compare all methods consistently, we converted the two metrics into each other. For the proposed method, a specificity of 99.63% is equivalent to a false positive rate of 0.44/hour, under the assumption of 30 s EEG segments. The proposed RR-DTDWT can achieve a higher F1 score than most latest studies validated on CHB-MIT database. Only the F1 score of the detector developed by Xiang et al. [
10] is slightly higher than ours. However, due to the long time EEG monitoring for epileptic seizure detection and the scarcity of ictal data, the acquired EEG data in real application scenarios characterize an extremely imbalanced ratio between ictal and interictal segments. Therefore, a high specificity in this application scenario may be equivalent to an unacceptable false alarm rate. For example, a detector with a seemingly high specificity of 95% is expected to trigger six false alarms per hour, which cannot be permitted in a practical application. Compared with the performance of [
10], our detector approximately achieves a four fold reduction of FPR (from 2.03/h to 0.44/h) only at the cost of a slight reduction in sensitivity (from 98.27% to 96.69%). Based on the above discussions, our RR-DTDWT based detector is more suitable for realistic application scenarios compared with those listed in
Table 6. Raghu et al. [
57] also proposed an automated epileptic seizure detection method based on DWT and complexity measure via sigmoid entropy, achieving a sensitivity of 94.21% and an accuracy of 94.38%, which is less effective than our method. Previous studies such as [
35] evaluated the performance of their method using both Bonn and CHB-MIT databases. Although their model has also shown a perfect performance on both of the two classification tasks (“normal versus ictal” and “interictal versus ictal”) on the Bonn dataset (see
Table 4 and
Table 5), its accuracy (97.5%) on more challenging CHB-MIT database shown in
Table 6 is lower than ours (98.89%). Promisingly, our RR-DTDWT algorithm can further promote the development of automated seizure detection technology.
4.2. Computational Cost Analysis of the Proposed Redundancy Removed DTDWT (RR-DTDWT)
In this subsection, we analyze the computational cost of the proposed RR-DTDWT framework. In signal domain transformation part, DTDWT can be calculated with a computational cost of
[
61], for a EEG segment with a length of
N. In the energy-based feature extraction part, both mean absolute values and variance features can be calculated in
computational time. Complexity-based features such as sample entropy require
computation time. Using the fast computation algorithms, the computation time can be reduced to
[
62]. Moreover, considering that biomedical signals are normally saved as digitized integer-type data, the computation time of sample entropy using a fast computation algorithm is only
, or precisely,
[
62], where
B is the digital resolution (12 bits for Bonn database and 16 bits for CHB-MIT database) and
m is the parameter used for sample entropy calculation (as aforementioned,
in this work). Feature selection methods can be divided into two categories: filter-based and embedded-based methods [
63]. Filter-based methods rank all potential features according to a predefined feature score based on the intrinsic property of data, which is independent of the following classification procedure. Embedded-based feature selection methods integrate feature selection into the learning procedure, involving more parameters to be fine-tuned. Therefore, embedded-based methods are computationally expensive. The AGRM algorithm used in our work is a filter-based method which is computationally efficient. Moreover, the feature score was pre-calculated using training set in our work. To develop an online seizure detector, the AGRM-based feature selection adds no additional computational burden. In contrast, by selecting only those features with the minimal redundancy, the computational cost is further reduced. In the classification procedure, the computational cost of SVM model is only
for a given feature vector of a specific EEG segment. In summary, the computational cost of the proposed RR-DTDWT is
, which can support its application to an online system.
4.3. Limitations of the Proposed RR-DTDWT
One limitation of the RR-DTDWT based seizure detection model is the generalization performance when applied to a new patient. The automated seizure detection models in literature can be divided into two categories; namely, the patient-nonspecific model [
64] and the patient-specific model [
7]. The former one refers to the model trained by the data of other patients with no data of the test patient involved in model training. This kind of model can save huge costs on data collection and data labeling because for a new patient, no further data collection is required and the model can be used immediately. Data from the other patients can be reserved beforehand, which can be viewed as cost-free. For example, Deng et al. [
64] proposed an enhanced, transductive, transfer learning Takagi–Sugeno–Kang fuzzy system construction method (ETTL-TSK-FS) to enhance the generalization performance of automated seizure detection models. The ETTL-TSK-FS method achieved a sensitivity of 91.91%, specificity of 93.16% and accuracy of 94.04% on the CHB-MIT dataset. Although its performance is less effective than most patient-specific models, ETTL-TSK-FS can be viewed as the current state-of-the-art patient-nonspecific model. The patient-specific models take advantage of the useful information of the test patient. However, acquisition of data from the test patient is required to train the seizure detection model or fine-tune the pre-trained model. Most automated seizure detection studies in literature focus on patient-specific classification models [
7,
38,
39]. The generalization performance is a common limitation and remains a future work of our study.








{kind=link}
{kind=link}
{kind=link}
{kind=link}