Power Quality Disturbance Recognition Using VMD-Based Feature Extraction and Heuristic Feature Selection


Abstract
:1. Introduction
- (1)
- VMD is more capable of PQD signal decomposition when compared with wavelet packet decomposition due to its adaptive and robust characteristics, especially in dealing with recursive calculation and mode mixing problems. Additionally, the start and end points of a PQD event can be detected by using VMD and permutation entropy.
- (2)
- The two-stage heuristic feature selection technique consists of permutation entropy, and the Fisher score is utilized to eliminate any irrelevant features, which not only enhances the generalization capability and detection accuracy of the classifier, but also releases the computational complexity in terms of efficiency.
- (3)
- The proposed algorithm has sufficient flexibility under different levels of noisy environments, either for the detected sensitivity or specificity of the PQD.
2. Theoretical Background
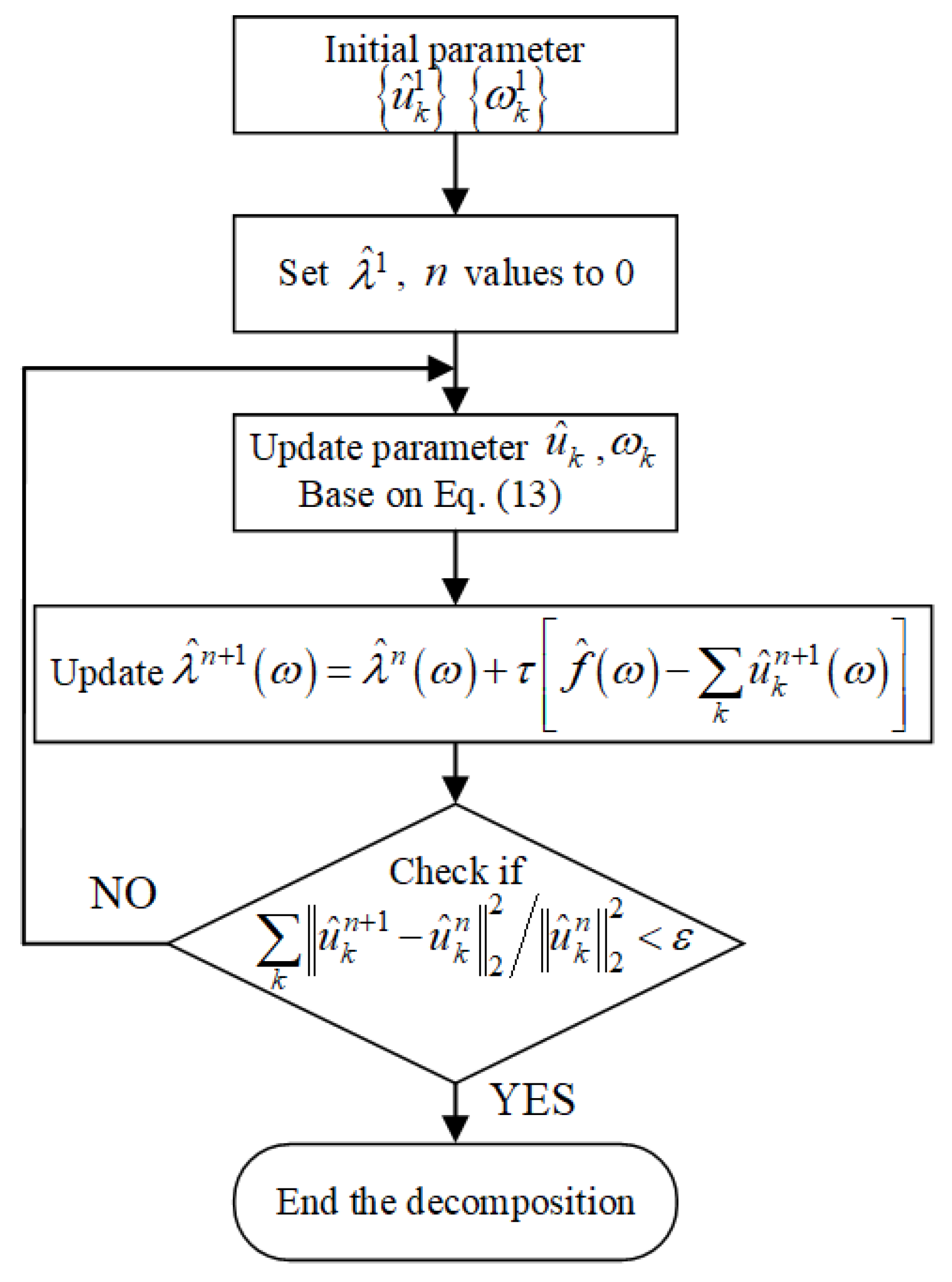
2.1. Variational Mode Decomposition
2.2. Permutation Entropy
2.3. Fisher Score- Based Feature Selection Method
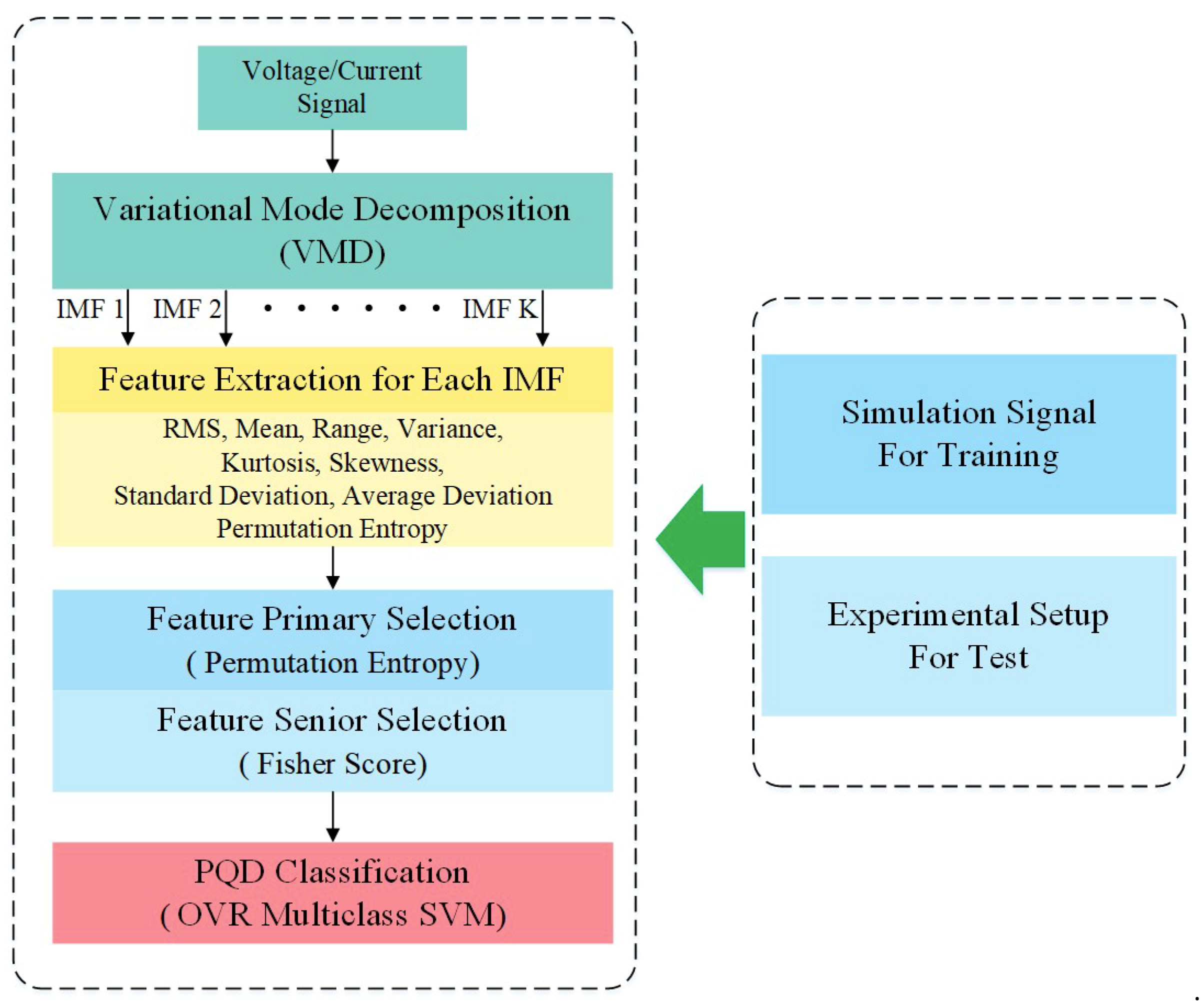
3. Proposed Method
3.1. Computer Simulation of PQDs
3.2. PQD Feature Extraction
3.3. PQD Feature Heuristic Selection
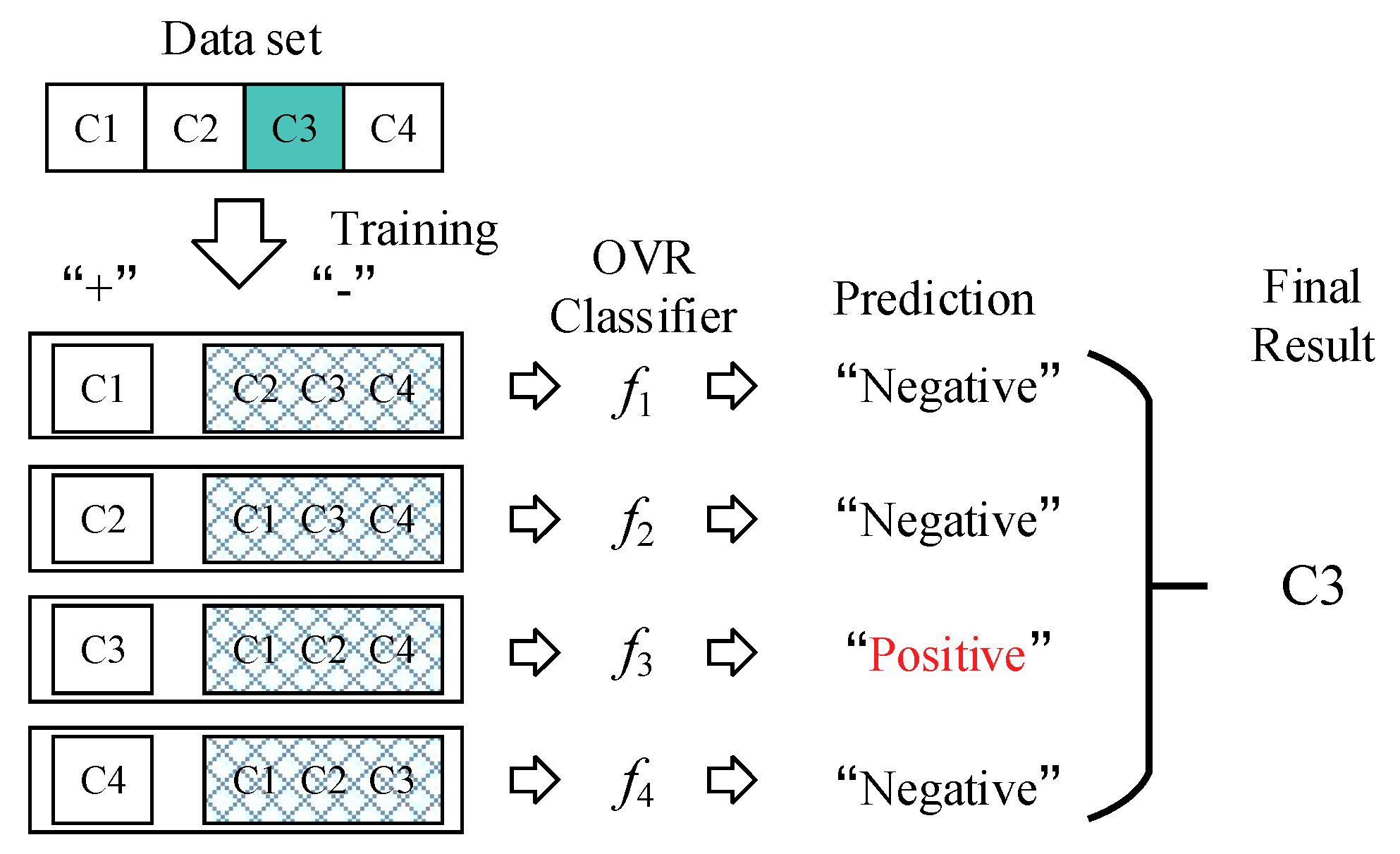
3.4. Multiclass Classification for PQDs
4. Experimental Results and Discussion
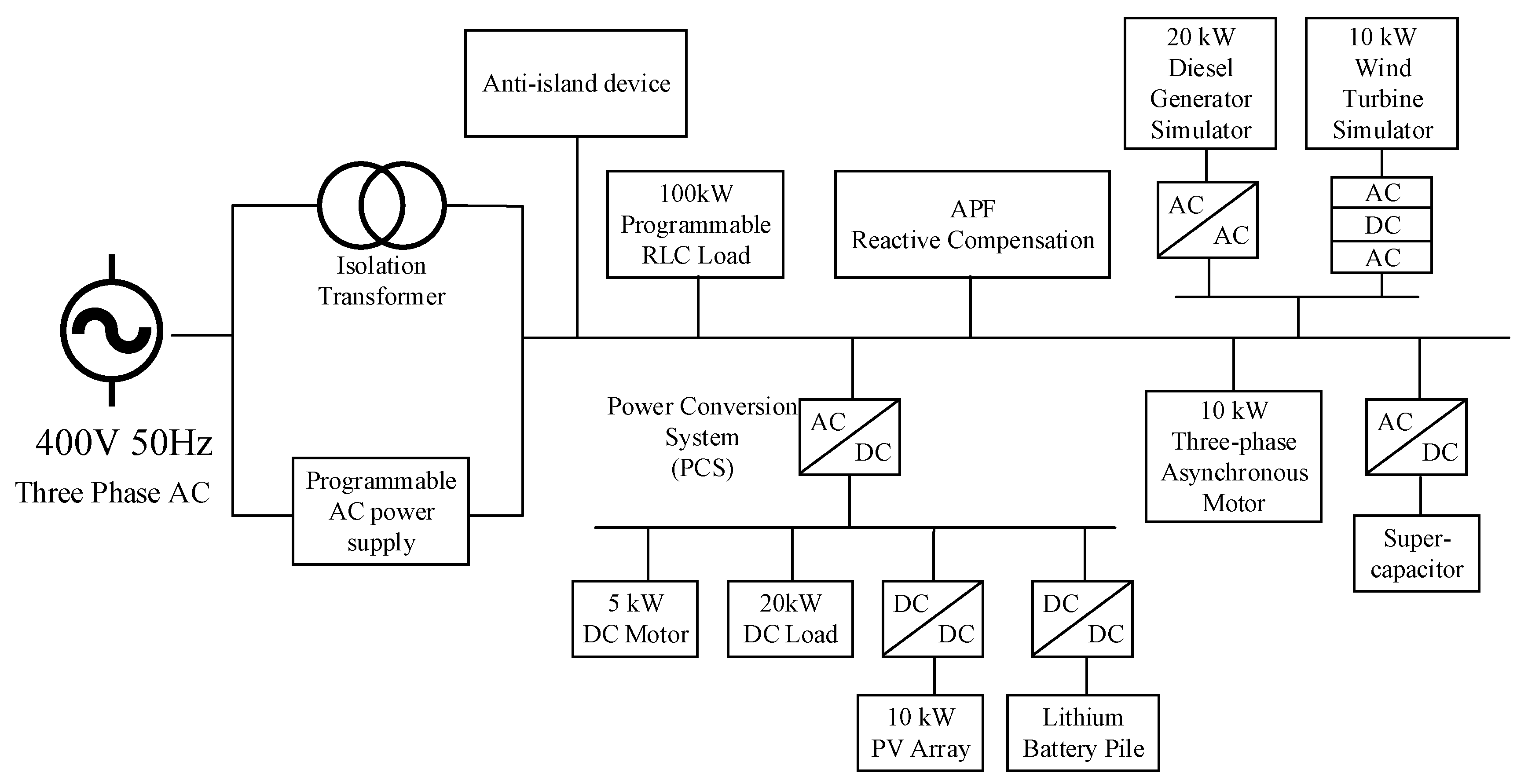
4.1. Experimental Setup
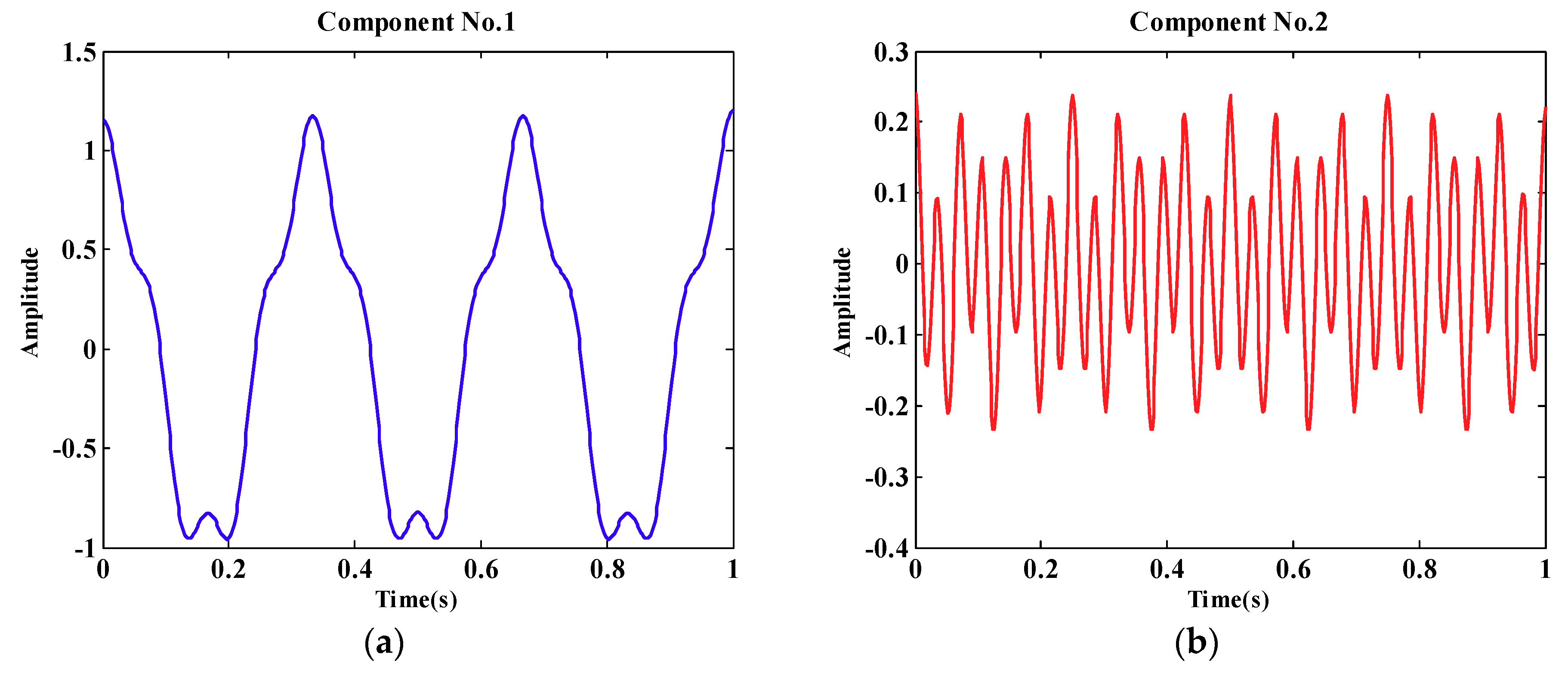
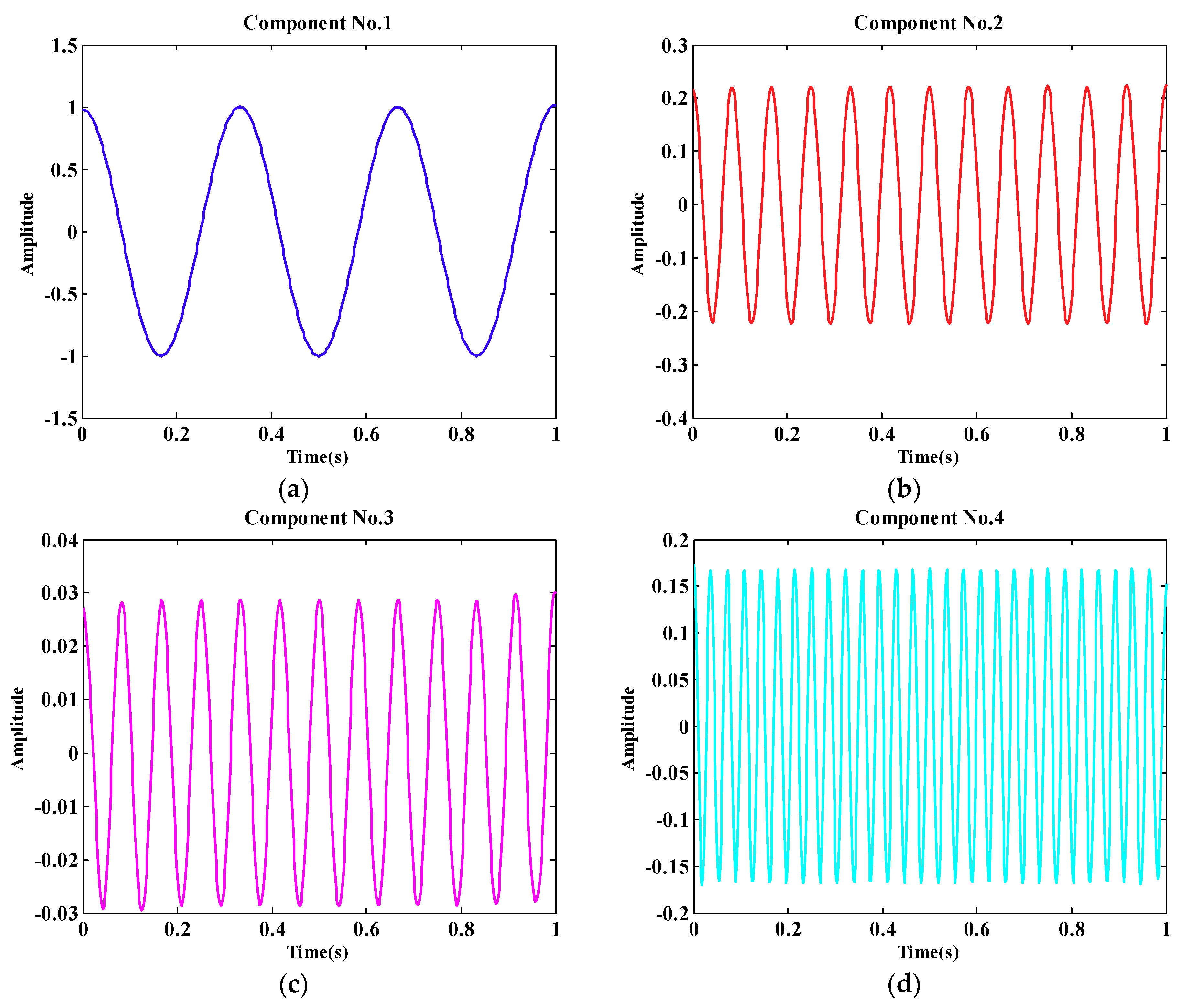
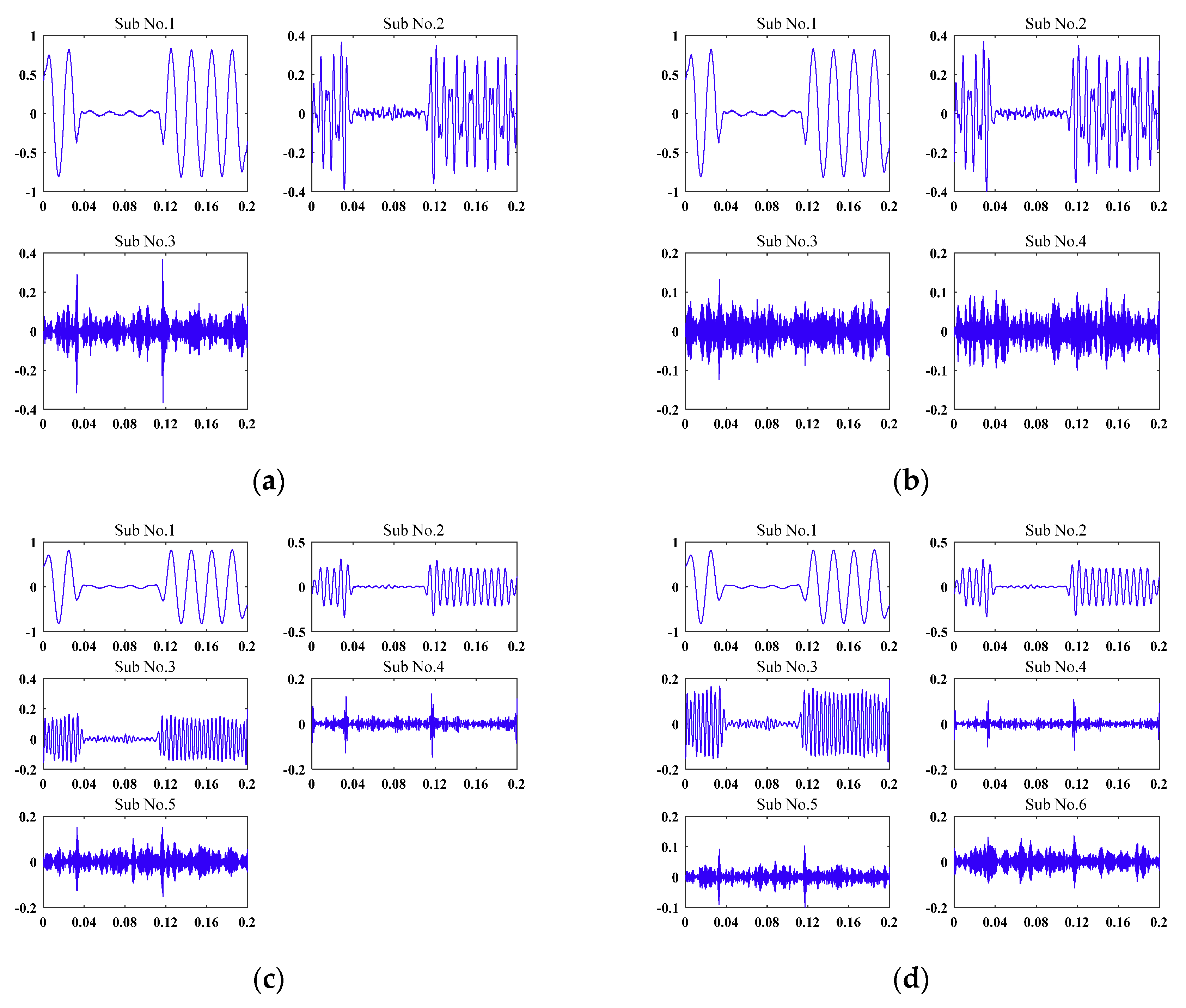
4.2. PQD Signal Decomposition and Detection
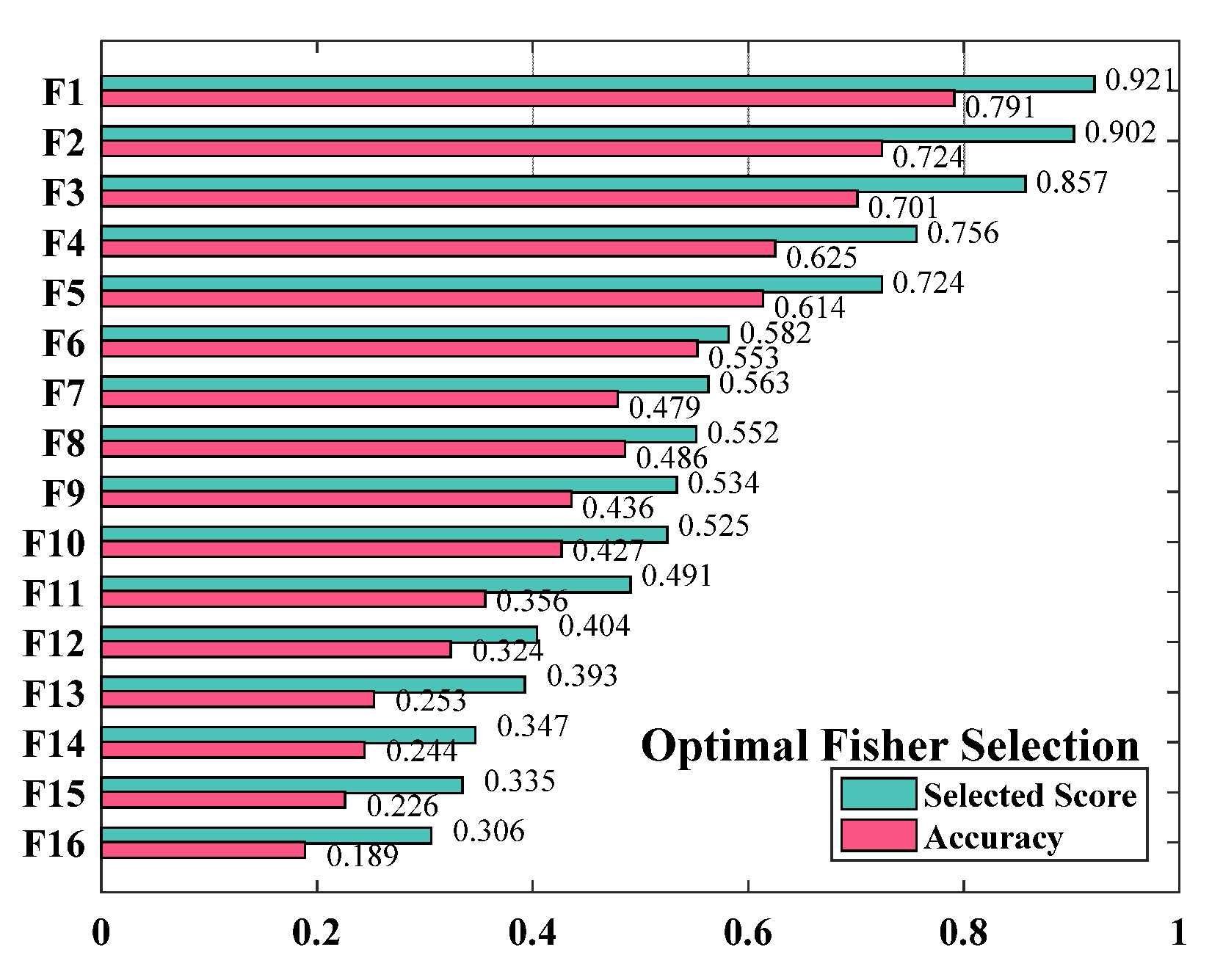
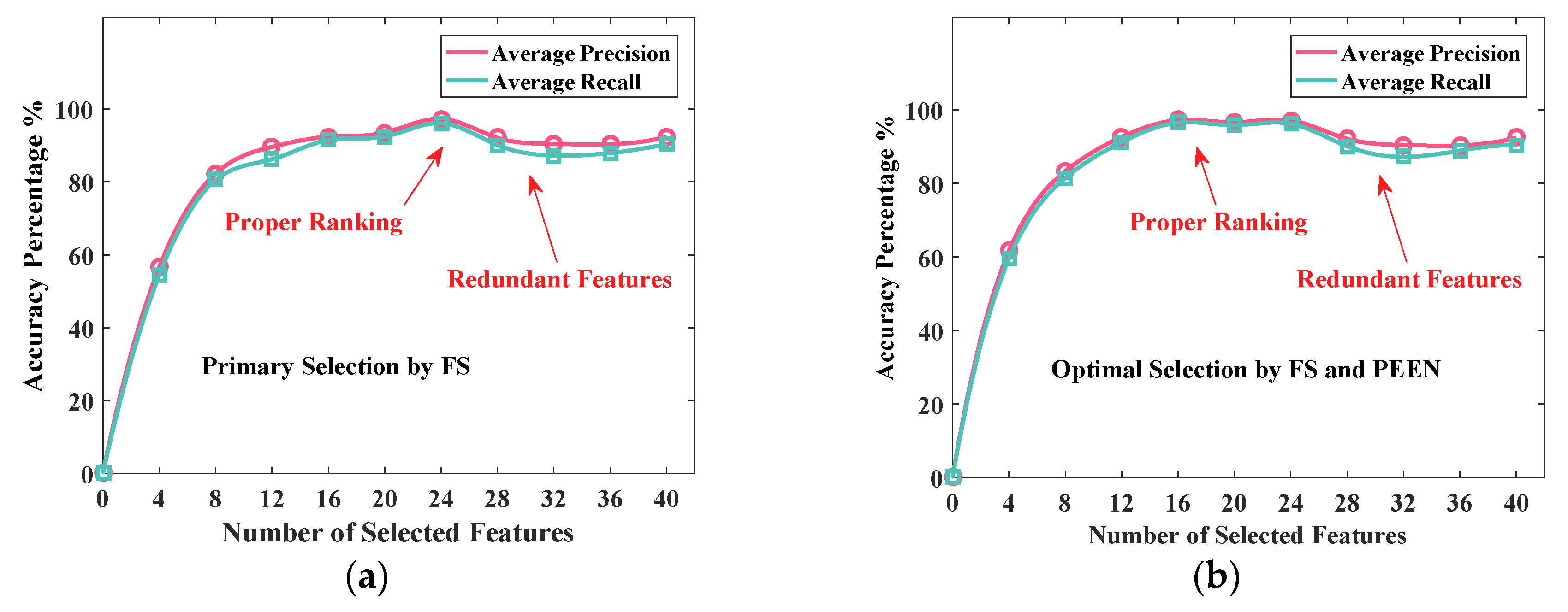
4.3. Feature Selection Analysis
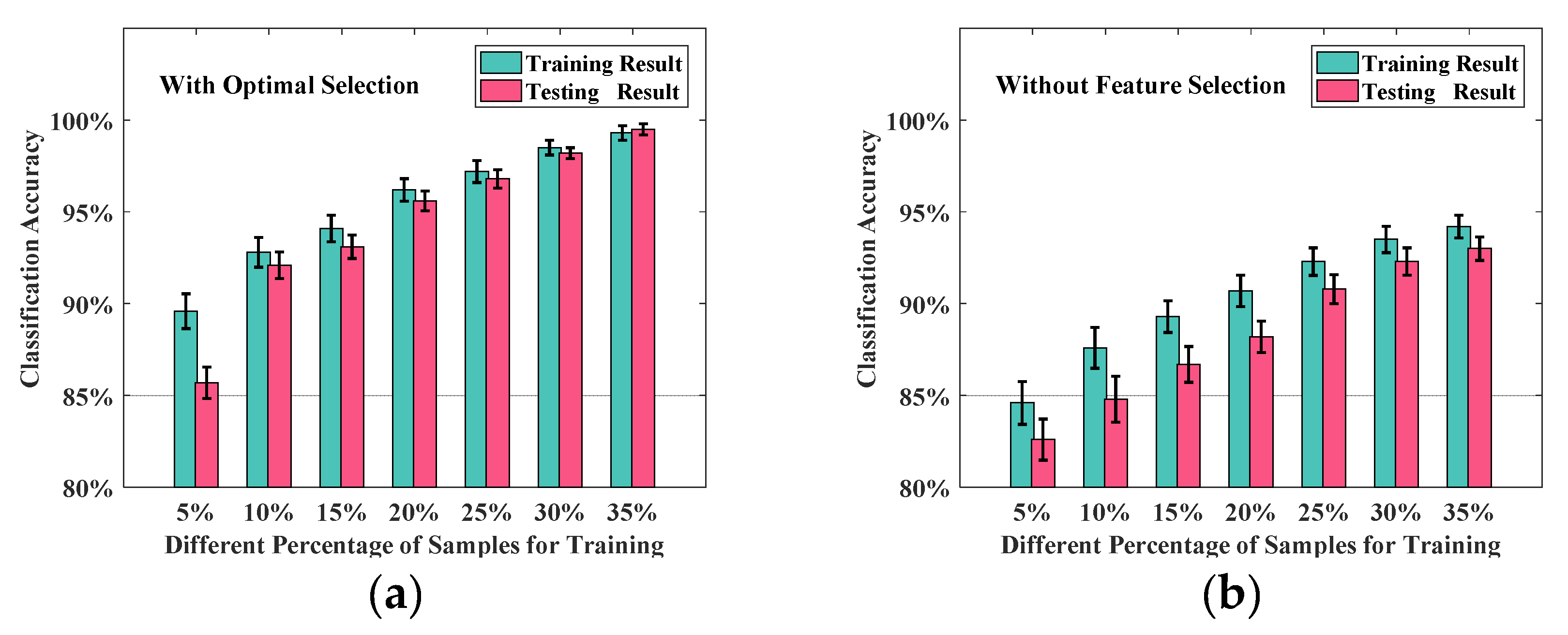
4.4. Performance Analysis
4.5. Accuracy Under a Real Noisy Environment
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

References
- Mesbah, M.; Moses, P.S.; Islam, S.M.; Masoum, M.A.S. Digital implementation of a fault emulator for transient study of power transformers used in grid connection of wind farms. IEEE Trans. Sustain. Energy 2014, 5, 646–654. [Google Scholar] [CrossRef]
- Fu, L.; Wei, Y.D.; Fang, S.; Tian, G.; Zhou, X.J. A wind energy generation replication method with wind shear and tower shadow effects. Adv. Mech. Eng. 2018, 10, 3. [Google Scholar] [CrossRef]
- Teke, A.; Saribulut, L.; Tumay, M. A Novel Reference Signal Generation Method for Power-Quality Improvement of Unified Power-Quality Conditioner. IEEE Trans. Power Deliv. 2011, 26, 2205–2214. [Google Scholar] [CrossRef]
- Ahila, R.; Sadasivam, V.; Manimala, K. An integrated PSO for parameter determination and feature selection of ELM and its application in classification of power system disturbances. Appl. Soft. Comput. 2015, 32, 23–37. [Google Scholar] [CrossRef]
- Brenna, M.; Faranda, R.; Tironi, E. A New Proposal for Power Quality and Custom Power Improvement: OPEN UPQC. IEEE Trans. Power Deliv. 2009, 24, 2107–2116. [Google Scholar] [CrossRef]
- Khokhar, S.; Zin, A.A.M.; Mokhtar, A.S.; Ismail, N.A.M. MATLAB/Simulink Based Modeling and Simulation of Power Quality Disturbances. In Proceedings of the IEEE Conference on Energy Conversion (CENCON), Johor Bahru, Malaysia, 13–14 October 2014; pp. 445–450. [Google Scholar]
- Mahela, O.P.; Shaik, A.G.; Gupta, N. A critical review of detection and classification of power quality events. Renew. Sustain. Energy Rev. 2015, 41, 495–505. [Google Scholar] [CrossRef]
- IEEE Recommended Practice for Monitoring Electric Power Quality; IEEE Standards Board, IEEE Std. 1159–1995; IEEE Inc.: New York, NY, USA, 1995; p. 6.
- Standard Definitions for the Measurement of Electric Power Quantities Under Sinusoidal, Non-Sinusoidal, Balanced, or Unbalanced Conditions; Revision of IEEE Std. 1459–2000, IEEE Standard 1459–2010; IEEE Inc.: New York, NY, USA, 2010; p. 3.
- José, C.A.; Salvador, O.; Nicolás, M.; Francisco, J.G.; Salvador, S. Measurement system for a power quality improvement structure based on IEEE Std. 1459. IEEE Trans. Instrum. Meas. 2013, 62, 3177–3188. [Google Scholar] [CrossRef]
- Kanirajan, P.; Kumar, V.S. Power quality disturbance detection and classification using wavelet and RBFNN. Appl. Soft. Comput. 2015, 35, 470–481. [Google Scholar] [CrossRef]
- He, S.F.; Li, K.C.; Zhang, M. A Real-Time Power Quality Disturbances Classification Using Hybrid Method Based on S-Transform and Dynamics. IEEE Trans. Instrum. Meas. 2013, 62, 2465–2475. [Google Scholar] [CrossRef]
- Ray, P.K.; Mohanty, S.R.; Kishor, N.; Catalao, J.P.S. Optimal Feature and Decision Tree-Based Classification of Power Quality Disturbances in Distributed Generation Systems. IEEE Trans. Sustain. Energy 2014, 5, 200–208. [Google Scholar] [CrossRef]
- Jurado, F.; Saenz, J.R. Comparison between discrete STFT and wavelets for the analysis of power quality events. Electr. Power Syst. Res. 2002, 62, 183–190. [Google Scholar] [CrossRef]
- Eristi, H.; Ucar, A.; Demir, Y. Wavelet-based feature extraction and selection for classification of power system disturbances using support vector machines. Electr. Power Syst. Res. 2010, 80, 743–752. [Google Scholar] [CrossRef]
- Biswal, B.; Dash, P.K.; Panigrahi, B.K. Non-stationary power signal processing for pattern recognition using HS-transform. Electr. Appl. Soft. Comput. 2009, 9, 107–117. [Google Scholar] [CrossRef]
- Zhang, Y.; Ji, T.Y.; Li, M.S.; Wu, Q.H. Identification of Power Disturbances Using Generalized Morphological Open-Closing and Close-Opening Undecimated Wavelet. IEEE Trans. Ind. Electron. 2016, 63, 2330–2339. [Google Scholar] [CrossRef]
- Camarena-Martinez, D.; Valtierra-Rodriguez, M.; Perez-Ramirez, C.A.; Amezquita-Sanchez, J.P.; Romero-Troncoso, R.D.; Garcia-Perez, A. Novel Downsampling Empirical Mode Decomposition Approach for Power Quality Analysis. IEEE Trans. Ind. Electron. 2016, 63, 2369–2378. [Google Scholar] [CrossRef]
- Shukla, S.; Mishra, S.; Singh, B. Empirical-Mode Decomposition with Hilbert Transform for Power-Quality Assessment. IEEE Trans. Power Deliv. 2009, 24, 2159–2165. [Google Scholar] [CrossRef]
- Lima, M.A.A.; Cerqueira, A.S.; Coury, D.V.; Duque, C.A. A novel method for power quality multiple disturbance decomposition based on Independent Component Analysis. Int. J. Electr. Power Energy Syst. 2012, 42, 593–604. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Fu, L.; Wei, Y.D.; Fang, S.; Zhou, X.J.; Lou, J.Q. Condition Monitoring for Roller Bearings of Wind Turbines Based on Health Evaluation under Variable Operating States. Energies 2017, 10, 1564. [Google Scholar] [CrossRef]
- Achlerkar, P.D.; Samantaray, S.R.; Manikandan, M.S. Variational Mode Decomposition and Decision Tree Based Detection and Classification of Power Quality Disturbances in Grid-Connected Distributed Generation System. IEEE Trans. Smart Grids 2018, 9, 3122–3132. [Google Scholar] [CrossRef]
- Abdoos, A.A.; Mianaei, P.K.; Ghadikolaei, M.R. Combined VMD-SVM based feature selection method for classification of power quality events. Appl. Soft. Comput. 2016, 38, 637–646. [Google Scholar] [CrossRef]
- Fu, L.; Zhu, T.T.; Zhu, K.; Yang, Y.L. Condition Monitoring for the Roller Bearings of Wind Turbines under Variable Working Conditions Based on the Fisher Score and Permutation Entropy. Energies 2019, 12, 3085. [Google Scholar] [CrossRef]
- Wang, Y.X.; Liu, F.Y.; Jiang, Z.S.; He, S.L.; Mo, Q.Y. Complex variational mode decomposition for signal processing applications. Mech. Syst. Signal Proc. 2018, 86, 75–85. [Google Scholar] [CrossRef]
- Zhu, T.; Qu, Z.; Xu, H.; Zhang, J.; Shao, Z.; Chen, Y.; Prabhakar, S.; Yang, J. RiskCog: Unobtrusive real-time user authentication on mobile devices in the wild. IEEE Trans. Mob. Comput. 2019. [Google Scholar] [CrossRef]
- Tan, D.P.; Li, P.Y.; Ji, Y.X.; Wen, D.H.; Li, C. SA-ANN-based slag carry-over detection method and the embedded WME platform. IEEE Trans. Ind. Electron. 2013, 60, 4702–4713. [Google Scholar] [CrossRef]
- Bhuiyan, S.M.A.; Khan, J.; Murphy, G. WPD for Detecting Disturbances in Presence of Noise in Smart Grid for PQ Monitoring. IEEE Trans. Ind. Appl. 2018, 54, 702–711. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Liang, Y.T.; Zhou, J.Z.; Zang, Y. A novel bearing fault diagnosis model integrated permutation entropy, ensemble empirical mode decomposition and optimized SVM. Measurement 2015, 69, 164–179. [Google Scholar] [CrossRef]
- Tan, D.P.; Li, L.; Zhu, Y.L.; Zheng, S.; Ruan, H.J.; Jiang, X.Y. An embedded cloud database service method for distributed industry monitoring. IEEE Trans. Ind. Inf. 2018, 14, 2881–2893. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | PQD Type | Mathematical Mode | Parameters |
|---|---|---|---|
| C1 | Pure Sine | ||
| C2 | Sag | ||
| C3 | Swell | ||
| C4 | Interrupt | ||
| C5 | Harmonics | ||
| C6 | Flicker | ||
| C7 | Oscillatory transient | ||
| C8 | Impulsive transient | ||
| C9 | Periodic notch | ||
| C10 | Spike | ||
| C11 | Sag with harmonics | ||
| C12 | Swell with harmonics | ||
| C13 | Interrupt with harmonics |
| No. | Statistical Feature | Expression |
|---|---|---|
| 1 | RMS | |
| 2 | Mean | |
| 3 | Standard Deviation | |
| 4 | Variance | |
| 5 | Range | |
| 6 | Kurtosis | |
| 7 | Skewness | |
| 8 | Average Deviation | |
| 9 | Permutation Entropy |
| Assigned Class | True Class | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | |
| C1 | 418 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C2 | 0 | 394 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C3 | 0 | 0 | 390 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C4 | 0 | 5 | 0 | 411 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C5 | 0 | 0 | 0 | 0 | 397 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C6 | 0 | 0 | 0 | 0 | 0 | 427 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C7 | 0 | 0 | 0 | 0 | 0 | 0 | 407 | 0 | 0 | 0 | 0 | 0 | 0 |
| C8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 396 | 0 | 0 | 0 | 0 | 0 |
| C9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 407 | 0 | 0 | 0 | 0 |
| C10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 406 | 0 | 0 | 0 |
| C11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 401 | 3 | 4 |
| C12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 413 | 0 |
| C13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 398 |
| Assigned Class | Signal to Noise Ratio | |||
|---|---|---|---|---|
| 20 dB | 30 dB | 40 dB | 50 dB | |
| C1 | 100% | 100% | 100% | 100% |
| C2 | 95.4% | 98.2% | 98.8% | 99.2% |
| C3 | 99.2% | 100% | 100% | 100% |
| C4 | 100% | 100% | 100% | 100% |
| C5 | 94.2% | 97.8% | 97.8% | 99.6% |
| C6 | 94.4% | 98.0% | 99.6% | 100% |
| C7 | 97.6% | 99.6% | 99.6% | 99.6% |
| C8 | 100% | 100% | 100% | 100% |
| C9 | 100% | 100% | 100% | 100% |
| C10 | 98.0% | 98.4% | 99.8% | 100% |
| C11 | 95.4% | 95.8% | 97.2% | 98.8% |
| C12 | 96.2% | 96.6% | 97.6% | 98.4% |
| C13 | 95.6% | 97.8% | 98.6% | 99.2% |
| Overall | 97.38% | 98.63% | 99.15% | 99.60% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, L.; Zhu, T.; Pan, G.; Chen, S.; Zhong, Q.; Wei, Y. Power Quality Disturbance Recognition Using VMD-Based Feature Extraction and Heuristic Feature Selection. Appl. Sci. 2019, 9, 4901. https://doi.org/10.3390/app9224901
Fu L, Zhu T, Pan G, Chen S, Zhong Q, Wei Y. Power Quality Disturbance Recognition Using VMD-Based Feature Extraction and Heuristic Feature Selection. Applied Sciences. 2019; 9(22):4901. https://doi.org/10.3390/app9224901
Chicago/Turabian StyleFu, Lei, Tiantian Zhu, Guobing Pan, Sihan Chen, Qi Zhong, and Yanding Wei. 2019. "Power Quality Disturbance Recognition Using VMD-Based Feature Extraction and Heuristic Feature Selection" Applied Sciences 9, no. 22: 4901. https://doi.org/10.3390/app9224901
APA StyleFu, L., Zhu, T., Pan, G., Chen, S., Zhong, Q., & Wei, Y. (2019). Power Quality Disturbance Recognition Using VMD-Based Feature Extraction and Heuristic Feature Selection. Applied Sciences, 9(22), 4901. https://doi.org/10.3390/app9224901