Pavement Distress Detection with Deep Learning Using the Orthoframes Acquired by a Mobile Mapping System †



Abstract
1. Introduction
1.1. Problem Setting and Initial Data
1.2. Literature Review
1.3. Contribution
2. Methodology
2.1. Analysis and Preprocessing of Source Data
- Inconsistent sharpness across the image. This stemmed from the horizontal placement of some of the Ladybug cameras. Due to the simple laws of optics, road surface gradually loses detail as the distance from the original camera shooting location increases. See Figure 2.
- Inconsistent brightness from image to image. This was related to the availability of light at the moment when an image was taken. Note that the situation has improved considerably not only because of the CMOS sensors of Ladybug 5+, but also because Reach-U Ltd. has instructed the MMSdriver to adjust the shutter speed manually during the data collection if the lighting conditions change on the road to avoid under- or over-exposure.
- Comparatively high number of shadows cast by various objects on the road, near the road, by the camera rig, or by the car itself doing the mapping. The intensity of shadows is directly correlated with the availability of light, and their extent is (among other things) dependent on the angle of Sun rays, which is illustrated in Figure 3.
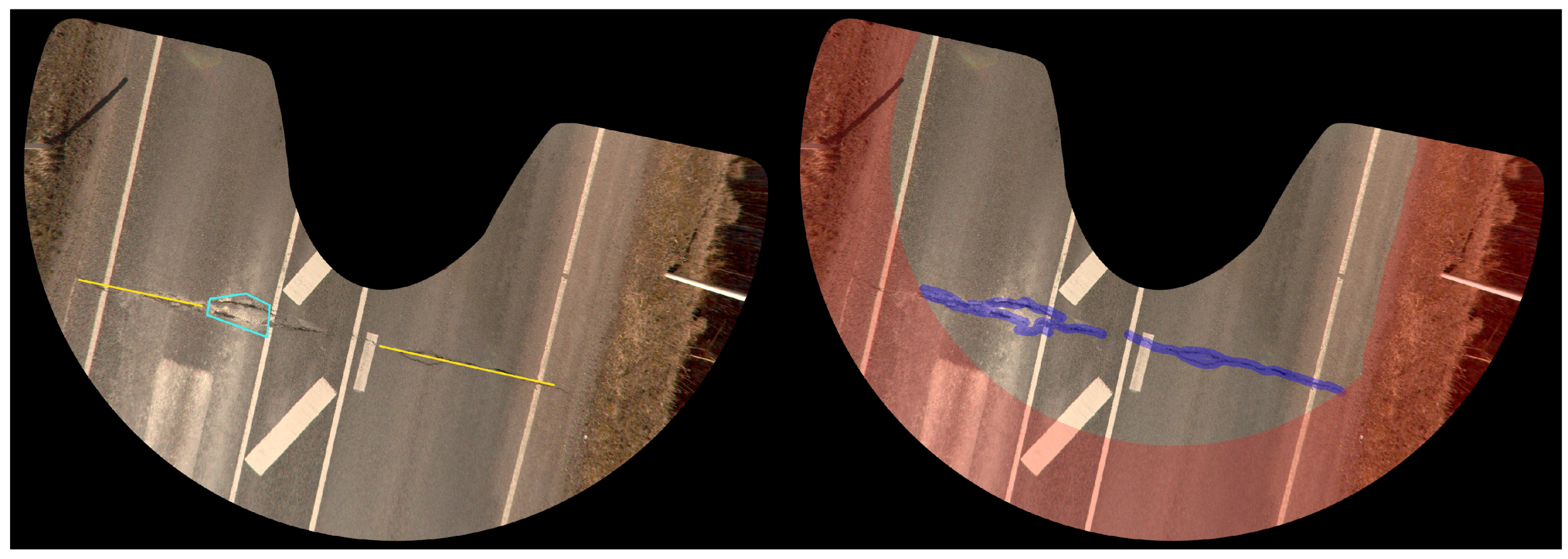
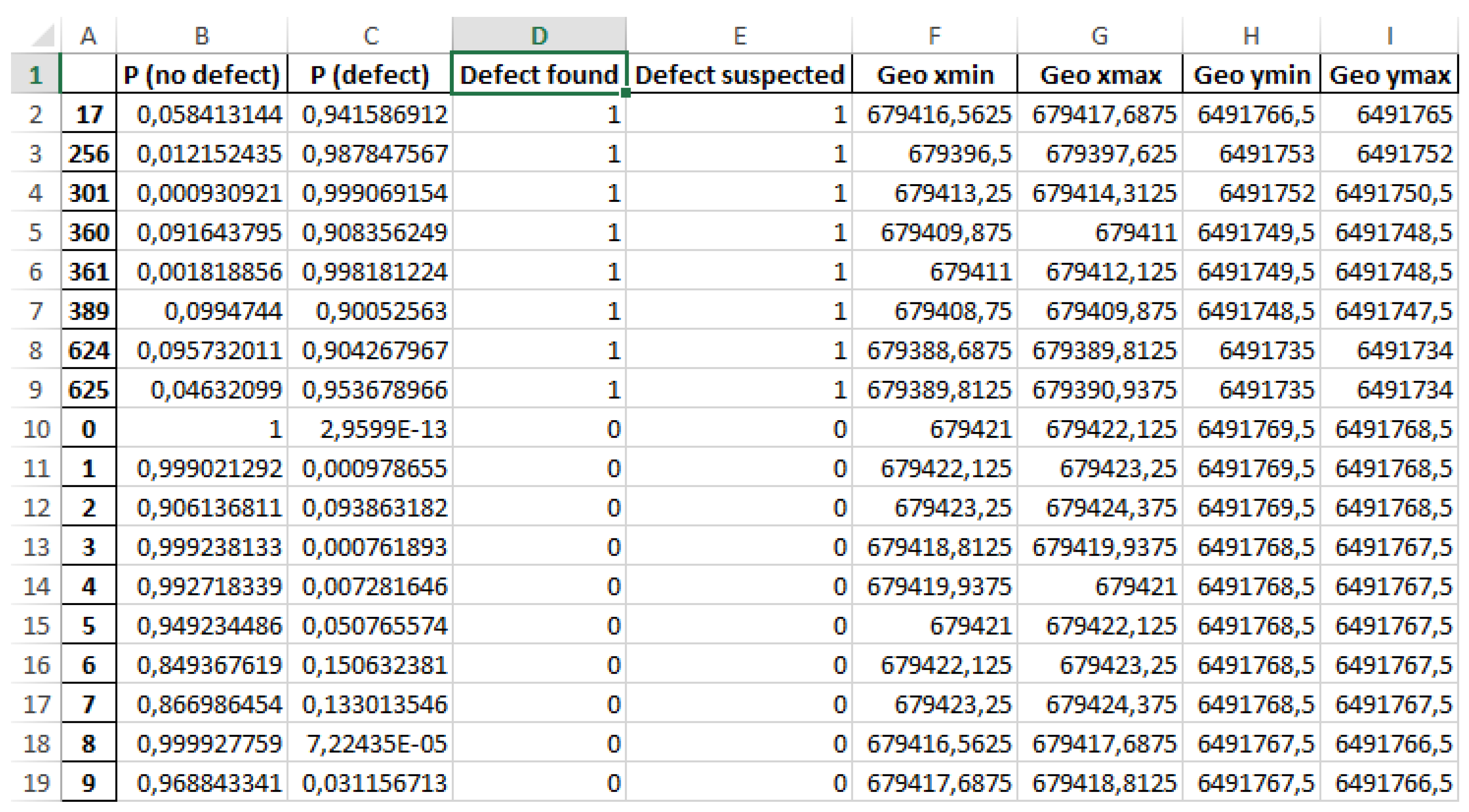
2.2. Pavement Distress Digitization
2.3. Image Partitioning
2.4. Further Data Processing and Augmentation
2.5. Classification Performance Evaluation
- true negative (): there is no defect, and the system does not detect a defect;
- true positive (): there is a defect, and the system correctly detects it;
- false negative (): there is a defect, but the system does not detect it;
- false positive (): there is no defect, but the system detects a defect.
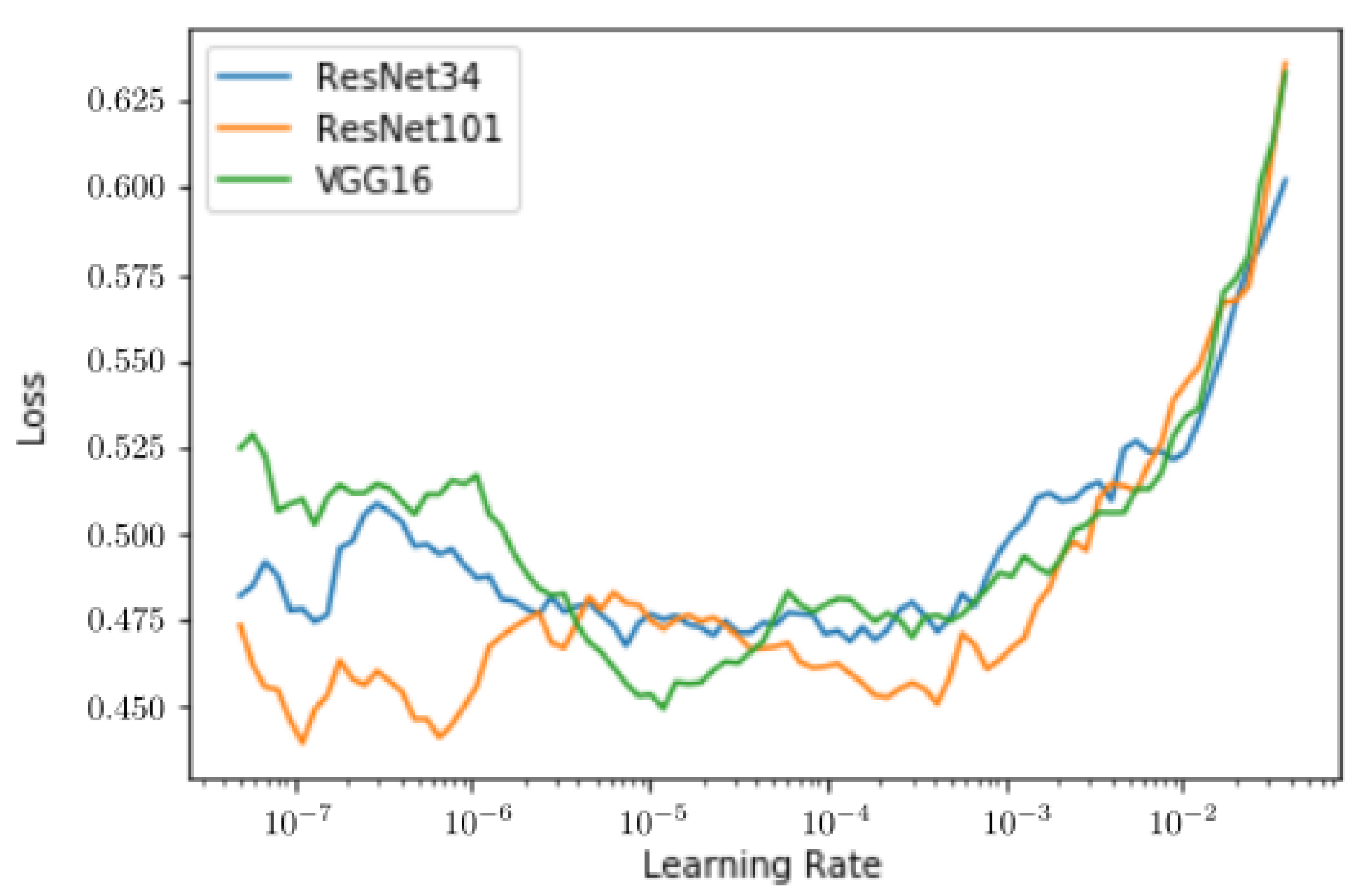
2.6. Deep Neural Networks’ Setup
- VGG16 [83], which was the best performing classifier of ILSVRC in 2014 along with GoogLeNet. This architecture has 16 weight layers, 13 of which consist of 3 × 3 convolutional filters with a total of 4224 filters, followed by three fully connected layers of length 4096, 4096, and 1000, respectively. In total, it has 15,252,034 trainable parameters.
- ResNet34 and ResNet101 [84], which introduced residual blocks to the typical ConvNet architecture and won ILSVRC in 2015. The residual block allows connections from earlier preceding convolutional layers, not only the immediately preceding one. This allows deeper models to be trained while also maintaining information only a shallower network would be able to capture [85]. As for the convolutional layers, ResNet follows the design of VGG16 with 3 × 3 convolutional filters, except for the first layer, which has 7 × 7 filters. In our work, ResNet34 had 33 convolutional layers and two fully connected layers of length 1024 and 512 and a total of 21,813,570 trainable parameters. Its deeper counterpart ResNet101 had 100 convolutional layers and two fully connected layers of length 4096 and 512, with a total of 44,608,066 trainable parameters.
3. Experimental Results
3.1. Data Selection
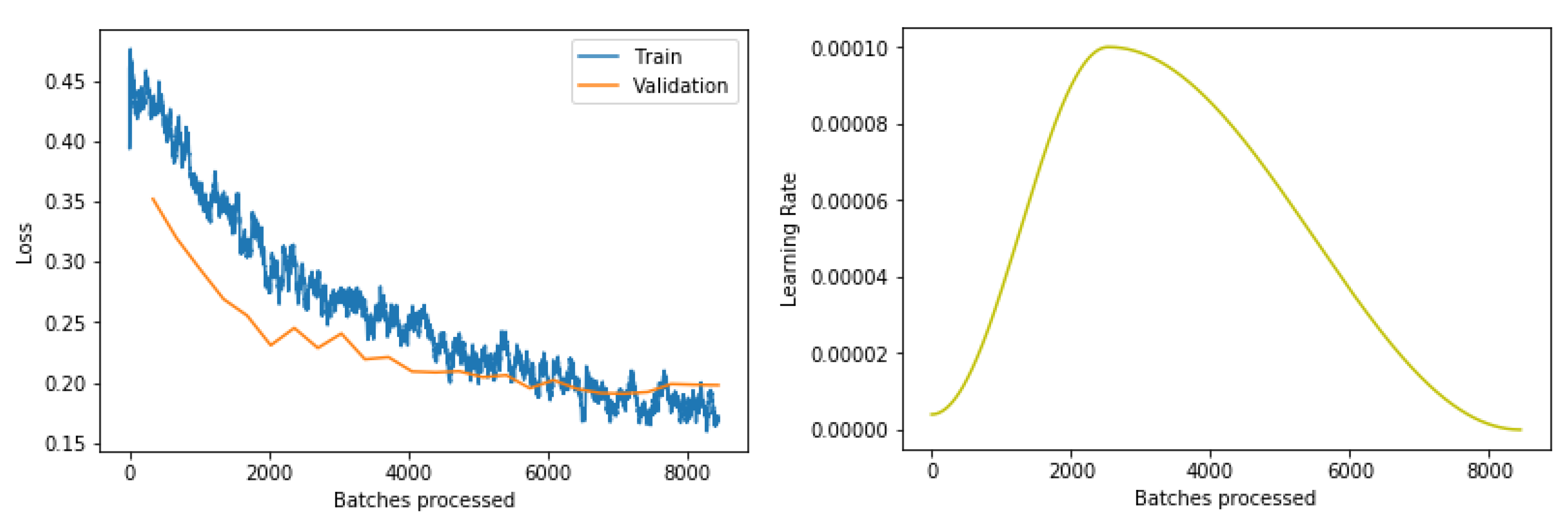
3.2. Deep Learning
3.3. Results
3.4. Software Solution
4. Discussion
- In [2], it was claimed that detection of shadow regions in the orthoframe is a critical component of the complete pavement distress detection system. However, our current tests did not completely confirm this as the system seemed to be robust to such visual artifacts. Hard shadows from tree branches still presented a problem, however, as they resembled pavement cracks.
- Ensemble classifiers were not introduced in this work as acceptable performance was obtained without complicating the system architecture. An attempt to make the detector context sensitive, i.e., use progressive zoom where a defect was suspected in the orthoframe, was considered as a possible next step in improving detection performance especially as a countermeasure for hard, fine-detail shadows.
- Data augmentation was updated to include orthoframe segment exposure variation and apparently led to improved generalization ability of the resulting ConvNet.
- Finally, the current classifier could only be regarded as a detector since the predictions about orthoframe segments were essentially binary, whether a defect was detected or not, with the additional possibility to consider suspected defects. In the future, a more advanced segmentation feature can be implemented whereby different types of defects will have related ground truth information provided by means of manual annotation for which the corresponding software package was also developed as part of this effort. In this case, however, as was shown previously, the issue of imbalanced data will have to be solved.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mohan, A.; Poobal, S. Crack detection using image processing: A critical review and analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Tepljakov, A.; Riid, A.; Pihlak, R.; Vassiljeva, K.; Petlenkov, E. Deep Learning for Detection of Pavement Distress using Nonideal Photographic Images. In Proceedings of the 42nd International Conference on Telecommunications and Signal Processing, Budapest, Hungary, 1 July 2019. [Google Scholar] [CrossRef]
- Yandell, W.; Pham, T. A fuzzy-control procedure for predicting fatigue crack initiation in asphaltic concrete pavements. In Proceedings of the 1994 IEEE 3rd International Fuzzy Systems Conference, Orlando, FL, USA, 26–29 June 1994; pp. 1057–1062. [Google Scholar] [CrossRef]
- Tsubota, T.; Yoshii, T.; Shirayanagi, H.; Kurauchi, S. Effect of Pavement Conditions on Accident Risk in Rural Expressways. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, Maui, HI, USA, 4–7 November 2018; pp. 3613–3618. [Google Scholar] [CrossRef]
- Tsukamoto, A.; Hato, T.; Adachi, S.; Oshikubo, Y.; Cheng, W.; Enpuku, K.; Tsukada, K.; Tanabe, K. Eddy Current Testing System Using HTS-SQUID with External Pickup Coil Made of HTS Wire. IEEE Trans. Appl. Supercond. 2017, 27. [Google Scholar] [CrossRef]
- Wang, M.; Sun, M.; Zhang, X.; Wang, Y.; Li, J. Mechanical behaviors of the thin-walled SHCC pipes under compression. In Proceedings of the ICTIS 2015—3rd International Conference on Transportation Information and Safety, Wuhan, China, 25–28 June 2015; pp. 797–801. [Google Scholar] [CrossRef]
- Jenkins, M.D.; Carr, T.A.; Iglesias, M.I.; Buggy, T.; Morison, G. A deep convolutional neural network for semantic pixel-wise segmentation of road and pavement surface cracks. In Proceedings of the European Signal Processing Conference, Rome, Italy, 3–7 September 2018; pp. 2120–2124. [Google Scholar] [CrossRef]
- Konig, J.; David Jenkins, M.; Barrie, P.; Mannion, M.; Morison, G. A Convolutional Neural Network for Pavement Surface Crack Segmentation Using Residual Connections and Attention Gating. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1460–1464. [Google Scholar] [CrossRef]
- Mandal, V.; Uong, L.; Adu-Gyamfi, Y. Automated Road Crack Detection Using Deep Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 5212–5215. [Google Scholar] [CrossRef]
- Nie, M.; Wang, K. Pavement Distress Detection Based on Transfer Learning. In Proceedings of the 2018 5th International Conference on Systems and Informatics, Nanjing, China, 10–12 November 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 435–439. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Daniel Zhang, Y.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Cafiso, S.; D’Agostino, C.; Delfino, E.; Montella, A. From manual to automatic pavement distress detection and classification. In Proceedings of the 2017 5th IEEE International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Naples, Italy, 26–28 June 2017; pp. 433–438. [Google Scholar] [CrossRef]
- Wang, X.; Hu, Z. Grid-based pavement crack analysis using deep learning. In Proceedings of the 2017 4th International Conference on Transportation Information and Safety (ICTIS), Banff, AB, Canada, 8–10 August 2017; pp. 917–924. [Google Scholar] [CrossRef]
- Yusof, N.A.; Osman, M.K.; Noor, M.H.; Ibrahim, A.; Tahir, N.M.; Yusof, N.M. Crack detection and classification in asphalt pavement images using deep convolution neural network. In Proceedings of the 8th IEEE International Conference on Control System, Computing and Engineering, Penang, Malaysia, 23–25 November 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 227–232. [Google Scholar] [CrossRef]
- Le Bastard, C.; Pan, J.; Wang, Y.; Sun, M.; Todkar, S.S.; Baltazart, V.; Pinel, N.; Ihamouten, A.; Derobert, X.; Bourlier, C. A Linear Prediction and Support Vector Regression-Based Debonding Detection Method Using Step-Frequency Ground Penetrating Radar. IEEE Geosci. Remote. Sens. Lett. 2019, 16, 367–371. [Google Scholar] [CrossRef]
- Salari, E.; Ouyang, D. An image-based pavement distress detection and classification. In Proceedings of the IEEE International Conference on Electro Information Technology, Indianapolis, IN, USA, 6–8 May 2012. [Google Scholar] [CrossRef]
- Savant Todkar, S.; Le Bastard, C.; Baltazart, V.; Ihamouten, A.; Dérobert, X. Comparative study of classification algorithms to detect interlayer debondings within pavement structures from Step-frequency radar data. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 6820–6823. [Google Scholar] [CrossRef]
- Todkar, S.S.; Le Bastard, C.; Ihamouten, A.; Baltazart, V.; Dérobert, X.; Fauchard, C.; Guilbert, D.; Bosc, F. Detection of debondings with ground penetrating radar using a machine learning method. In Proceedings of the 2017 9th International Workshop on Advanced Ground Penetrating Radar, Edinburgh, UK, 28–30 June 2017. [Google Scholar] [CrossRef]
- Aggarwal, P. Predicting dynamic modulus for bituminous concrete using support vector machine. In Proceedings of the 2017 International Conference on Infocom Technologies and Unmanned Systems: Trends and Future Directions, Dubai, UAE, 18–20 December 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 751–755. [Google Scholar] [CrossRef]
- Ai, D.; Jiang, G.; Siew Kei, L.; Li, C. Automatic Pixel-Level Pavement Crack Detection Using Information of Multi-Scale Neighborhoods. IEEE Access 2018, 6, 24452–24463. [Google Scholar] [CrossRef]
- Brayan, B.A.; Bladimir, B.C.; Sandra, N.R. Pavement and base layers local thickness estimation using computer vision. In Proceedings of the 2015 10th Colombian Computing Conference, Bogota, Colombia, 21–25 September 2015; pp. 324–330. [Google Scholar] [CrossRef]
- Hassan, N.; Mathavan, S.; Kamal, K. Road crack detection using the particle filter. In Proceedings of the 2017 23rd IEEE International Conference on Automation and Computing: Addressing Global Challenges through Automation and Computing, Huddersfield, UK, 7–8 September 2017. [Google Scholar] [CrossRef]
- Salman, M.; Mathavan, S.; Kamal, K.; Rahman, M. Pavement crack detection using the Gabor filter. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013; pp. 2039–2044. [Google Scholar] [CrossRef]
- Strisciuglio, N.; Azzopardi, G.; Petkov, N. Robust Inhibition-Augmented Operator for Delineation of Curvilinear Structures. IEEE Trans. Image Process. 2019, 28, 5852–5866. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Q. Pavement crack detection algorithm Based on image processing analysis. In Proceedings of the 2016 8th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 27–28 August 2016; Volume 1, pp. 15–18. [Google Scholar] [CrossRef]
- Qian, B.; Tang, Z.; Xu, W. Pavement crack detection based on improved tensor voting. In Proceedings of the 9th International Conference on Computer Science and Education, Vancouver, BC, Canada, 22–24 August 2014; pp. 397–402. [Google Scholar] [CrossRef]
- Quan, Y.; Sun, J.; Zhang, Y.; Zhang, H. The Method of the Road Surface Crack Detection by the Improved Otsu Threshold. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 1615–1620. [Google Scholar] [CrossRef]
- Ahmed, N.B.C.; Lahouar, S.; Souani, C.; Besbes, K. Automatic crack detection from pavement images using fuzzy thresholding. In Proceedings of the 2017 International Conference on Control, Automation and Diagnosis, Hammamet, Tunisia, 19–21 January 2017; pp. 528–533. [Google Scholar] [CrossRef]
- Akagic, A.; Buza, E.; Omanovic, S.; Karabegovic, A. Pavement crack detection using Otsu thresholding for image segmentation. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics, Opatija, Croatia, 21–25 May 2018; pp. 1092–1097. [Google Scholar] [CrossRef]
- Sun, Z.; Li, W.; Sha, A. Automatic pavement cracks detection system based on visual studio C++ 6.0. In Proceedings of the 2010 6th International Conference on Natural Computation, Yantai, China, 10–12 August 2010; Volume 4, pp. 2016–2019. [Google Scholar] [CrossRef]
- Amhaz, R.; Chambon, S.; Idier, J.; Baltazart, V. A new minimal path selection algorithm for automatic crack detection on pavement images. In Proceedings of the 2014 IEEE International Conference on Image Processing, Paris, France, 27–30 October 2014; pp. 788–792. [Google Scholar] [CrossRef]
- Baltazart, V.; Nicolle, P.; Yang, L. Ongoing Tests and Improvements of the MPS algorithm for the automatic crack detection within grey level pavement images. In Proceedings of the 25th European Signal Processing Conference, Kos, Greece, 28 August–2 September 2017; pp. 2016–2020. [Google Scholar] [CrossRef]
- Chatterjee, A.; Tsai, Y.C. A fast and accurate automated pavement crack detection algorithm. In Proceedings of the European Signal Processing Conference. European Signal Processing Conference, Rome, Italy, 3–7 September 2018; pp. 2140–2144. [Google Scholar] [CrossRef]
- Zou, Q.; Li, Q.; Zhang, F.; Xiong Qian Wang, Z.; Wang, Q. Path voting based pavement crack detection from laser range images. In Proceedings of the International Conference on Digital Signal Processing, DSP, Beijing, China, 16–18 October 2016; pp. 432–436. [Google Scholar] [CrossRef]
- Dabbiru, L.; Wei, P.; Harsh, A.; White, J.; Ball, J.E.; Aanstoos, J.; Donohoe, P.; Doyle, J.; Jackson, S.; Newman, J. Runway assessment via remote sensing. In Proceedings of the 2015 IEEE Applied Imagery Pattern Recognition Workshop, Washington, DC, USA, 13–15 October 2015; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2016. [Google Scholar] [CrossRef]
- Pudova, N.; Shirobokov, M.; Kuvaldin, A. Application of the Attribute Analysis for Interpretation of GPR Survey Data. In Proceedings of the 2018 17th International Conference on Ground Penetrating Radar, Rapperswil, Switzerland, 18–21 June 2018. [Google Scholar] [CrossRef]
- Yi, L.; Zou, L.; Sato, M. A simplified velocity estimation method for monitoring the damaged pavement by a multistatic GPR system YAKUMO. In Proceedings of the 2018 17th International Conference on Ground Penetrating Radar, Rapperswil, Switzerland, 18–21 June 2018. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, D.; Zou, Q.; Lin, H. 3D Laser imaging and sparse points grouping for pavement crack detection. In Proceedings of the 25th European Signal Processing Conference, Kos, Greece, 28 August–2 September 2017; pp. 2036–2040. [Google Scholar] [CrossRef]
- Medina, R.; Llamas, J.; Zalama, E.; Gomez-Garcia-Bermejo, J. Enhanced automatic detection of road surface cracks by combining 2D/3D image processing techniques. In Proceedings of the 2014 IEEE International Conference on Image Processing, Paris, France, 27–30 October 2014; pp. 778–782. [Google Scholar] [CrossRef]
- Moazzam, I.; Kamal, K.; Mathavan, S.; Usman, S.; Rahman, M. Metrology and visualization of potholes using the Microsoft Kinect sensor. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, Hague, The Netherlands, 6–9 October 2013; pp. 1284–1291. [Google Scholar] [CrossRef]
- Ul Haq, M.U.; Ashfaque, M.; Mathavan, S.; Kamal, K.; Ahmed, A. Stereo-Based 3D Reconstruction of Potholes by a Hybrid, Dense Matching Scheme. IEEE Sens. J. 2019, 19, 3807–3817. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Wang, C. 3D crack skeleton extraction from mobile LiDAR point clouds. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, QC, Canada, 13–18 July 2014; pp. 914–917. [Google Scholar] [CrossRef]
- Zhang, Z.; Cheng, M.; Chen, X.; Zhou, M.; Chen, Y.; Li, J.; Nie, H. Turning mobile laser scanning points into 2D/3D on-road object models: Current status. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 3524–3527. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, C.; Wu, Q.; Lu, Q.; Zhang, S.; Zhang, G.; Yang, Y. A kinect-based approach for 3D pavement surface reconstruction and cracking recognition. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3935–3946. [Google Scholar] [CrossRef]
- Zhang, B.; Liu, X. Intelligent Pavement Damage Monitoring Research in China. IEEE Access 2019, 7, 45891–45897. [Google Scholar] [CrossRef]
- Ziqiang, C.; Haihui, L.; Jiankang, Z. Research of the algorithm calculating the length of bridge crack based on stereo vision. In Proceedings of the 2017 4th International Conference on Systems and Informatics, Hangzhou, China, 11–13 November 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 210–214. [Google Scholar] [CrossRef]
- Fedele, R.; Della Corte, F.G.; Carotenuto, R.; Praticò, F.G. Sensing road pavement health status through acoustic signals analysis. In Proceedings of the 13th Conference on PhD Research in Microelectronics and Electronics, Giardini Naxos, Italy, 12–15 June 2017; pp. 165–168. [Google Scholar] [CrossRef]
- Uus, A.; Liatsis, P.; Nardoni, G.; Rahman, E. Optimisation of transducer positioning in air-coupled ultrasound inspection of concrete/asphalt structures. In Proceedings of the 2015 22nd International Conference on Systems, Signals and Image Processing, London, UK, 10–12 September 2015; pp. 309–312. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, X.; Cervone, G.; Yang, L. Detection of Asphalt Pavement Potholes and Cracks Based on the Unmanned Aerial Vehicle Multispectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2018, 1–12. [Google Scholar] [CrossRef]
- Choi, J.; Zhu, L.; Kurosu, H. Detection of cracks in paved road surface using laser scan image data. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences Congress (XXIII ISPRS), Prague, Czech Republic, 12–19 July 2016; Volume XLI-B1, pp. 559–562. [Google Scholar] [CrossRef]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2039–2047. [Google Scholar] [CrossRef]
- Kapela, R.; Śniatała, P.; Turkot, A.; Rybarczyk, A.; Pożarycki, A.; Rydzewski, P.; Wyczałek, M.; Błoch, A. Asphalt surfaced pavement cracks detection based on histograms of oriented gradients. In Proceedings of the 2015 22nd International Conference Mixed Design of Integrated Circuits Systems (MIXDES), Torun, Poland, 25–27 June 2015; pp. 579–584. [Google Scholar] [CrossRef]
- Wang, C.; Sha, A.; Sun, Z. Pavement Crack Classification based on Chain Code. In Proceedings of the 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2010), Yantai, China, 10–12 August 2010; pp. 593–597. [Google Scholar] [CrossRef]
- Yu, X.; Salari, E. Pavement pothole detection and severity measurement using laser imaging. In Proceedings of the IEEE International Conference on Electro Information Technology, Mankato, MN, USA, 15–17 May 2011. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep Convolutional Neural Networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man, Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P. CrackIT—An image processing toolbox for crack detection and characterization. In Proceedings of the IEEE International Conf. on Image Processing—ICIP, Paris, France, 27–30 October 2014; pp. 798–802. [Google Scholar] [CrossRef]
- Li, L.; Sun, L.; Ning, G.; Tan, S. Automatic Pavement Crack Recognition Based on BP Neural Network. Promet Traffic Transp. 2014, 26, 11–22. [Google Scholar] [CrossRef]
- Zhang, D.; Li, Q.; Chen, Y.; Cao, M.; He, L.; Zhang, B. An efficient and reliable coarse-to-fine approach for asphalt pavement crack detection. Image Vis. Comput. 2017, 57, 130–146. [Google Scholar] [CrossRef]
- Wu, G.; Sun, X.; Zhou, L.; Zhang, H.; Pu, J. Research on Morphological Wavelet Operator for Crack Detection of Asphalt Pavement. In Proceedings of the 2016 IEEE International Conference on Information and Automation, Ningbo, China, 1–3 August 2016; pp. 1573–1577. [Google Scholar] [CrossRef]
- Zalama, E.; Gómez-Garcà a-Bermejo, J.; Medina, R.; Llamas, J. Road Crack Detection Using Visual Features Extracted by Gabor Filters. Comput.-Aided Civ. Infrastruct. Eng. 2014, 29, 342–358. [Google Scholar] [CrossRef]
- Oliveira, H.; Caeiro, J.; Correia, P.L. Accelerated unsupervised filtering for the smoothing of road pavement surface imagery. In Proceedings of the 2014 22nd European Signal Processing Conference (EUSIPCO), Lisbon, Portugal, 1–5 September 2014; pp. 2465–2469. [Google Scholar]
- Quintana, M.; Torres, J.; Menéndez, J.M. A Simplified Computer Vision System for Road Surface Inspection and Maintenance. IEEE Trans. Intell. Transp. Syst. 2016, 17, 608–619. [Google Scholar] [CrossRef]
- Schlotjes, M.R.; Burrow, M.P.N.; Evdorides, H.T.; Henning, T.F.P. Using support vector machines to predict the probability of pavement failure. Proc. Inst. Civ. Eng. Transp. 2015, 168, 212–222. [Google Scholar] [CrossRef]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210, Infrastructure Computer Vision. [Google Scholar] [CrossRef]
- Doulamis, A.; Doulamis, N.; Protopapadakis, E.; Voulodimos, A. Combined Convolutional Neural Networks and Fuzzy Spectral Clustering for Real Time Crack Detection in Tunnels. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4153–4157. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2019, 1–11. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Zakeri, H.; Nejad, F.M.; Fahimifar, A.; Torshizi, A.D.; Zarandi, M.H.F. A multi-stage expert system for classification of pavement cracking. In Proceedings of the 2013 Joint IFSA World Congress and NAFIPS Annual Meeting (IFSA/NAFIPS), Edmonton, AB, Canada, 24–28 June 2013; pp. 1125–1130. [Google Scholar] [CrossRef]
- Dodge, S.; Karam, L. A Study and Comparison of Human and Deep Learning Recognition Performance under Visual Distortions. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017. [Google Scholar] [CrossRef]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Sohel, F.A.; Togneri, R. Cost-Sensitive Learning of Deep Feature Representations From Imbalanced Data. IEEE Trans. Neural Networks Learn. Syst. 2018, 29, 3573–3587. [Google Scholar] [CrossRef]
- Coenen, T.B.J.; Golroo, A. A review on automated pavement distress detection methods. Cogent Eng. 2017, 4. [Google Scholar] [CrossRef]
- Brownlee, J. Deep Learning for Computer Vision: Image Classification, Object Detection, and Face Recognition in Python; Machine Learning Mastery: Vermont, Australia, 2019. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Gordon, G., Dunson, D., Dudík, M., Eds.; Proceedings of Machine Learning Research. PMLR: Fort Lauderdale, FL, USA, 2011; Volume 15, pp. 315–323. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Available online: http://arxiv.org/abs/1409.0575v3 (accessed on 15 October 2019).
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning? IEEE Trans. Med Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [PubMed]
- Rosebrock, A. Deep Learning for Computer Vision; PyImageSearch: Columbia, SC, USA, 2017. [Google Scholar]
- Stricker, R.; Eisenbach, M.; Sesselmann, M.; Debes, K.; Gross, H. Improving Visual Road Condition Assessment by Extensive Experiments on the Extended GAPs Dataset. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Available online: http://arxiv.org/abs/1409.1556v6 (accessed on 15 October 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. Available online: http://arxiv.org/abs/1512.03385v1 (accessed on 15 October 2019).
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning. 2019. Available online: http://www.d2l.ai (accessed on 15 October 2019).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A Systematic Study of the Class Imbalance Problem in Convolutional Neural Networks. Available online: http://arxiv.org/abs/1710.05381v2 (accessed on 15 October 2019).
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. In Proceedings of the NIPS 2017 Workshop Autodiff, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Howard, J. Fastai. 2018. Available online: https://github.com/fastai/fastai (accessed on 15 October 2019).
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar] [CrossRef]
- Smith, L.N. A dIsciplined Approach to Neural Network Hyper-Parameters: Part 1—Learning Rate, Batch Size, Momentum, and Weight Decay. Available online: http://arxiv.org/abs/1803.09820v2 (accessed on 15 October 2019).
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. Available online: http://arxiv.org/abs/1801.06146v5 (accessed on 15 October 2019).
- Smith, L.N.; Topin, N. Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates. Available online: http://arxiv.org/abs/1708.07120v3 (accessed on 15 October 2019).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Available online: http://arxiv.org/abs/1412.6980v9 (accessed on 15 October 2019).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Input Data and Data Collection |
|---|---|
| [2,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34] | Image |
| [35,36,37] | Radar |
| [38,39,40,41,42,43,44,45,46] | 3D images or point clouds |
| [47,48] | Acoustic |
| Source | Method |
|---|---|
| [2,7,8,9,10,11,12,13,14] | Neural network |
| [15,17,18,19,20] | Support vector regression |
| [21,22,23,24,25] | Filtering |
| [16,26,27,28,29,30] | Thresholding |
| [31,32,33,34] | (Minimal) Path |
| Source | Type of Neural Network | Recall | Precision | Dataset | Images |
|---|---|---|---|---|---|
| [14] | Convolutional neural network | 98.00% | 99.40% | Custom | 3900 |
| [7] | Convolutional neural network | 92.46% | 82.82% | CrackForest | 117 |
| [8] | Convolutional neural network | 93.55% | 96.37% | CrackForest | 117 |
| [13] | Convolutional neural network | 93.9% | 93.5% | Custom | 2 × 30,000 |
| [10] | Recurrent convolutional neural network | 98.82% | 96.67% | Custom | 1400 |
| [11] | Convolutional neural network | 92.51% | 86.96% | Custom | 500 |
| [9] | Convolutional neural network | ≈80% | ≈75% | Custom | 9053 |
| Polyline Defect Types | Polygon Defect Types | Point Defect Types |
|---|---|---|
| narrow longitudinal crack | network cracking | pothole |
| narrow joint reflection crack | patched road | |
| patched road (line) | weathering | |
| transverse cracking | ||
| edge defect |
| Defect | Count |
|---|---|
| narrow longitudinal crack | 13,475 |
| narrow joint reflection crack | 1792 |
| patched road (line) | 4108 |
| transverse cracking | 7139 |
| edge defect | 20,877 |
| network cracking | 11,709 |
| patched road | 1036 |
| weathering | 1240 |
| pothole | 32 |
| Model | Base Learning Rate | Maximum Learning Rate for Layer L | Momentum Lower Bound | Momentum Upper Bound | Weight Decay | Batch Size |
|---|---|---|---|---|---|---|
| VGG16 | 0.85 | 0.95 | 0.01 | 32 | ||
| ResNet34 | 0.85 | 0.95 | 0.01 | 32 | ||
| ResNet101 | 0.85 | 0.95 | 0.01 | 32 |
| Model | Accuracy | Precision | Recall | MCC |
|---|---|---|---|---|
| VGG16 net fine-tuned | 0.95 | 0.90 | 0.79 | 0.82 |
| ResNet34 fine-tuned | 0.96 | 0.92 | 0.82 | 0.84 |
| ResNet101 fine-tuned * | 0.97 | 0.90 | 0.87 | 0.87 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Riid, A.; Lõuk, R.; Pihlak, R.; Tepljakov, A.; Vassiljeva, K. Pavement Distress Detection with Deep Learning Using the Orthoframes Acquired by a Mobile Mapping System. Appl. Sci. 2019, 9, 4829. https://doi.org/10.3390/app9224829
Riid A, Lõuk R, Pihlak R, Tepljakov A, Vassiljeva K. Pavement Distress Detection with Deep Learning Using the Orthoframes Acquired by a Mobile Mapping System. Applied Sciences. 2019; 9(22):4829. https://doi.org/10.3390/app9224829
Chicago/Turabian StyleRiid, Andri, Roland Lõuk, Rene Pihlak, Aleksei Tepljakov, and Kristina Vassiljeva. 2019. "Pavement Distress Detection with Deep Learning Using the Orthoframes Acquired by a Mobile Mapping System" Applied Sciences 9, no. 22: 4829. https://doi.org/10.3390/app9224829
APA StyleRiid, A., Lõuk, R., Pihlak, R., Tepljakov, A., & Vassiljeva, K. (2019). Pavement Distress Detection with Deep Learning Using the Orthoframes Acquired by a Mobile Mapping System. Applied Sciences, 9(22), 4829. https://doi.org/10.3390/app9224829